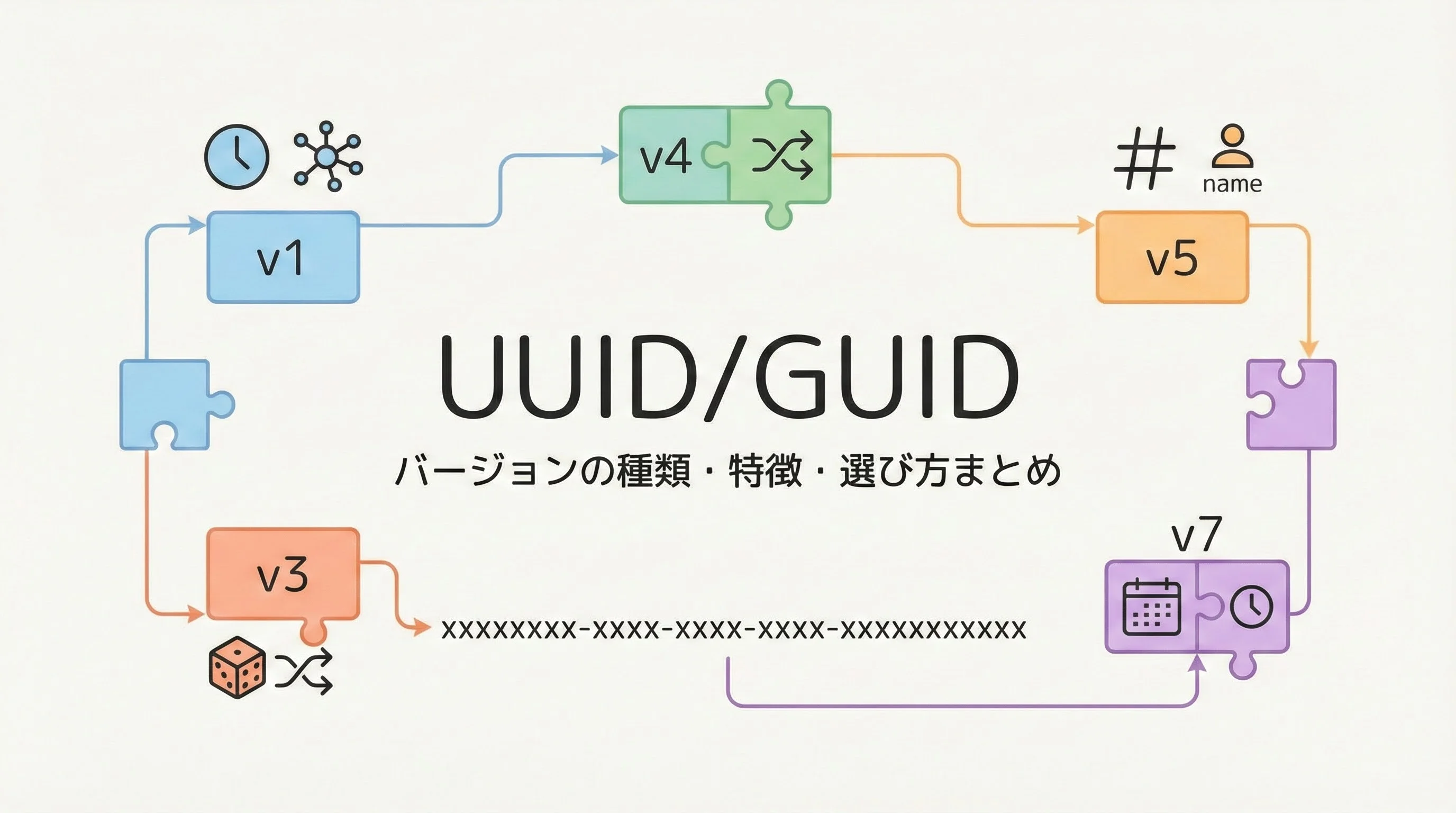
システム開発の現場で一度は目にするUUIDやGUIDですが、「とりあえずv4を使っておけばOK」となんとなく選んでいる方も多いのではないでしょうか。
UUIDには複数のバージョンがあり、用途に応じて適切なバージョンを選ぶことで、性能・衝突リスク・推測耐性などのバランスを最適化できます。
本記事では、UUID/GUIDの基本からバージョンごとの特徴、実務での選び方までを整理して解説します。
UUID/GUIDとは何か
UUID(Universally Unique Identifier)は、128ビット長の「ほぼ重複しない識別子」を生成するための標準規格です。
多くのプログラミング言語やデータベース、フレームワークでサポートされており、分散システムやマイクロサービスなど、集中管理なしに一意なIDを発行したい場面で広く利用されています。
GUID(Globally Unique Identifier)という用語もありますが、実質的にはMicrosoft系技術で使われるUUIDの別名と考えて問題ありません。
フォーマットや用途もほぼ同じであり、本記事ではUUIDとGUIDを区別せずに扱います。
UUIDは一般的に、以下のような文字列表現で利用されます。
- 例:
550e8400-e29b-41d4-a716-446655440000
この文字列は、内部的には128ビットの値であり、16進数32文字を5つのブロックに分割してハイフンで区切った形式です。

UUIDの標準仕様は、IETFのRFC 4122およびその後続のRFCで定義されています。
バージョン番号はUUID内部に埋め込まれており、どの方式で生成されたかを機械的に判別できる点が特徴です。
UUIDのバージョン一覧と概要
UUIDには複数のバージョンが定義されており、それぞれ生成方法と特徴が異なります。
主なバージョンを、用途と特徴の観点から整理します。
代表的なバージョンと特徴は次の通りです。
- v1: 時刻とMACアドレスベースのUUID
- v3: 名前空間付きハッシュ(MD5)ベースのUUID
- v4: 乱数ベースのUUID
- v5: 名前空間付きハッシュ(SHA-1)ベースのUUID
- v6: 時系列ソートしやすく再設計されたUUID(RFC 4122bis系)
- v7: UNIX時刻と乱数を組み合わせたモダンなUUID(RFC 9562)
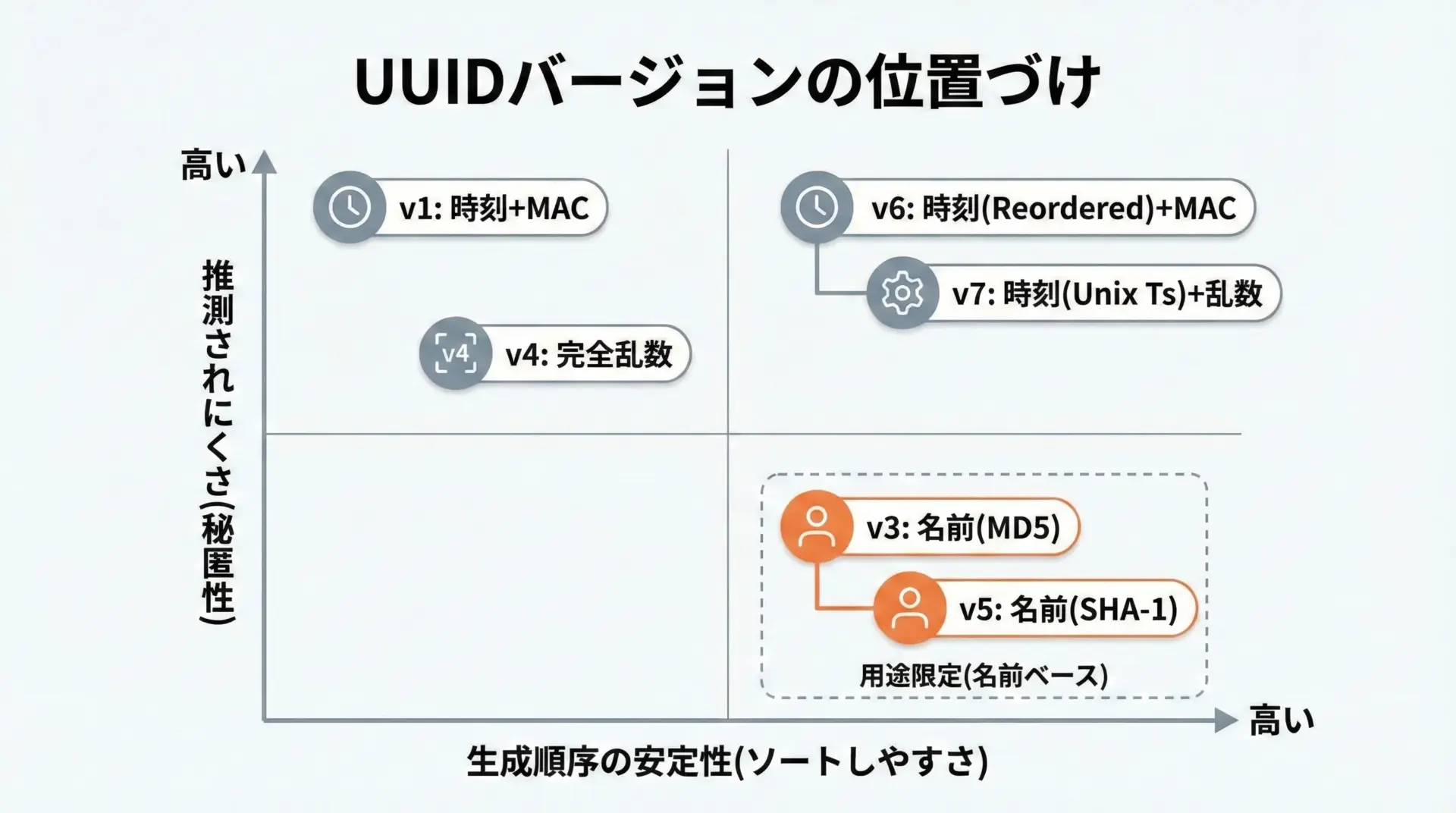
このうち、実務で頻繁に登場するのは主にv1・v4・v7(およびv6)です。
v3とv5は用途がかなり限定されます。
各バージョンの生成方式と特徴
v1: 時刻+MACアドレスベース(UUIDv1)
v1は、「時刻」「ノード(MACアドレス)」「カウンタ」を組み合わせて生成されるUUIDです。
古くから広く使われてきた方式であり、現在でも一部のシステムやミドルウェアで標準として採用されています。
特徴
- 時刻情報を含むため、おおよそ生成順に並ぶ
- ネットワークインターフェースのMACアドレスを取り込むため、生成元マシンを推測されるリスクがある
- 物理マシンが異なっても、時刻とカウンタの組み合わせにより重複しにくい設計
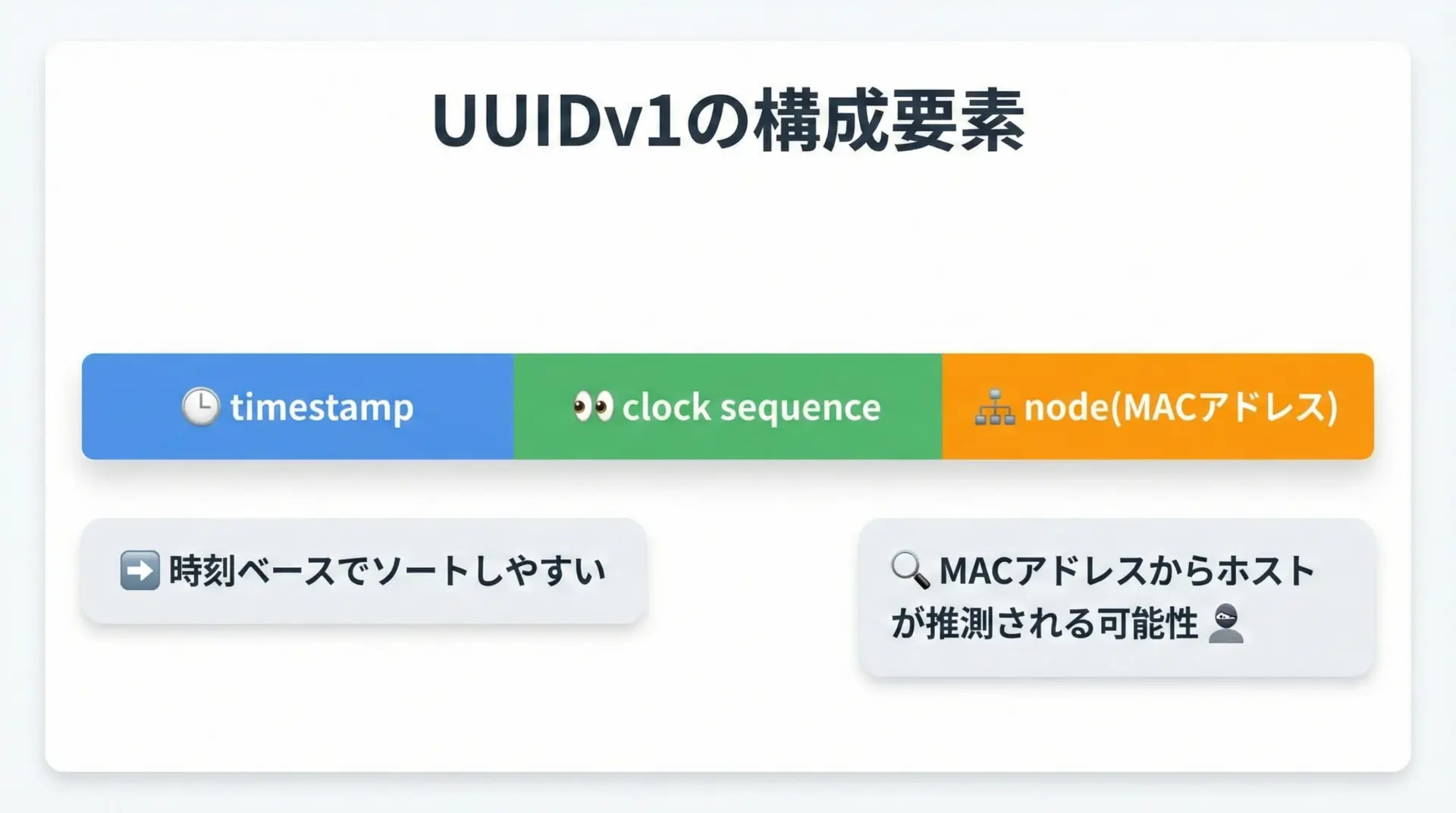
この性質から、挿入順に近い並びでデータベースに格納されるため、インデックスの断片化をある程度抑えられるメリットがあります。
一方で、MACアドレスなどの情報が外部に露出することを嫌うケースでは、v1は避けられることが多くなっています。
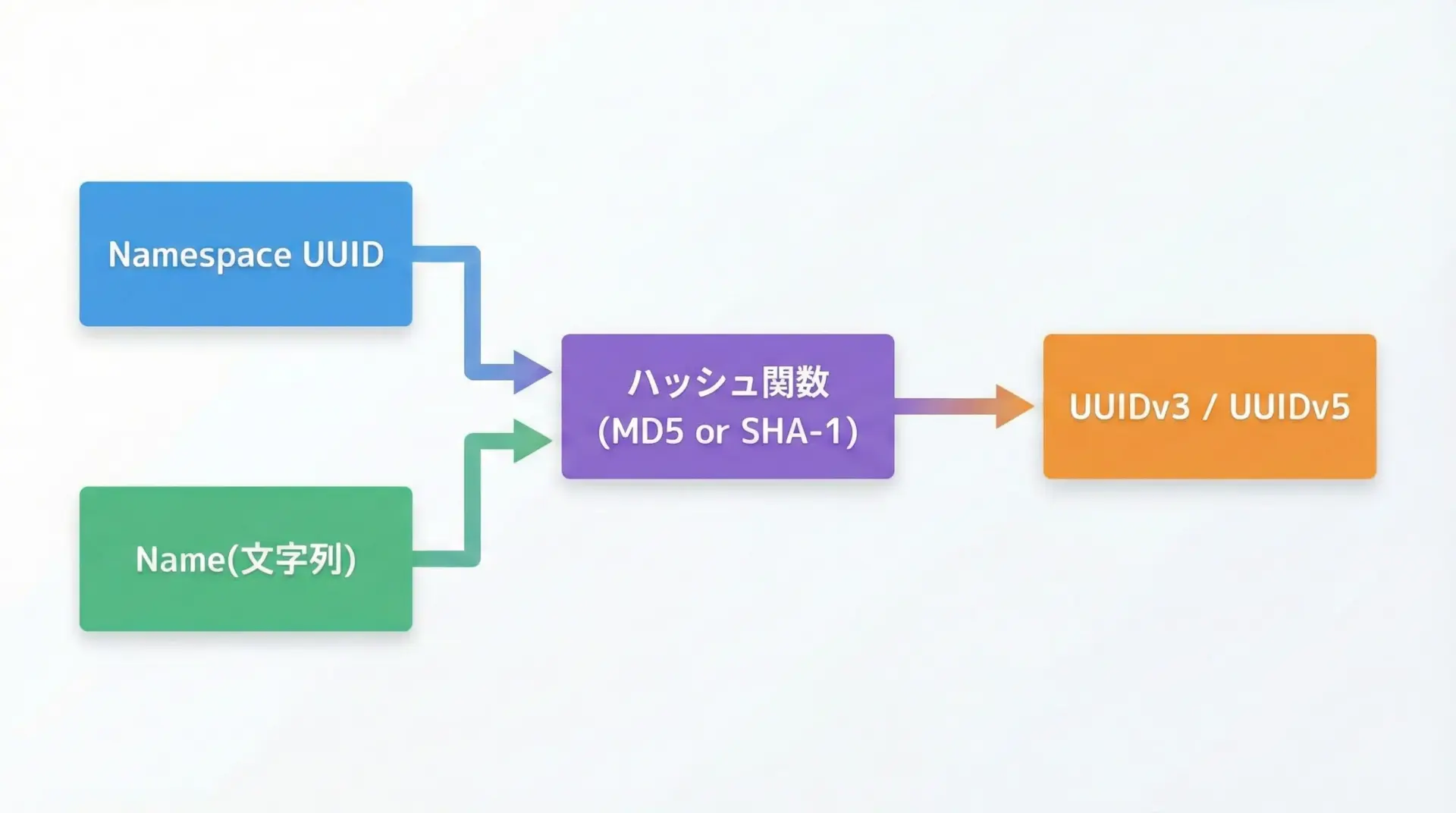
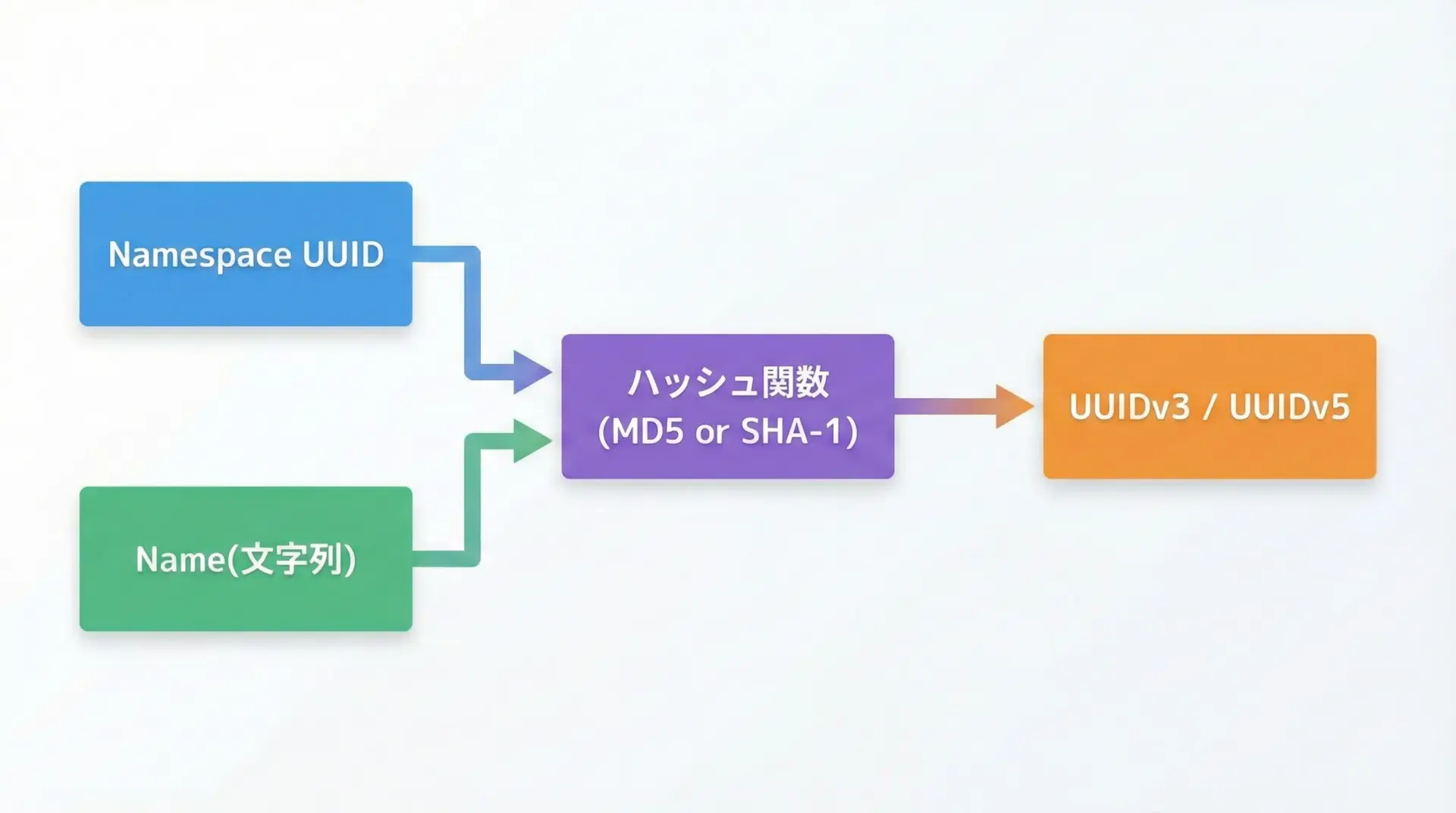
v3 / v5: 名前空間付きハッシュベース(UUIDv3, v5)
v3とv5は、「名前空間UUID」と「任意の文字列」から決定論的にUUIDを生成する仕組みです。
アルゴリズムが異なり、v3はMD5、v5はSHA-1を利用します。
特徴
- 同じ名前空間UUIDと同じ文字列からは、必ず同じUUIDが生成される
- 同じ文字列でも名前空間が違えば別のUUIDになる
- 暗号学的ハッシュを利用するため、入力文字列からUUIDを逆算することは基本的に困難
- v3(MD5)よりも、v5(SHA-1)の方がより好ましい選択肢
v3/v5は、「同じ実体を表す識別子なら、どこで生成しても同じ値になってほしい」という用途に向きます。
例えば以下のようなケースが典型です。
- URLやメールアドレスなどから一意なIDを生成したい場合
- スキーマの名前空間とテーブル名から、安定した識別子をつけたい場合
一方で、生成時刻によるソート性もなければ、乱数による推測耐性という意味でもv4に劣るため、汎用的なIDとしてはあまり使われません。
用途が明確な場面に限定して選ぶバージョンです。
v4: 乱数ベース(UUIDv4)
v4は、ほぼ純粋な乱数から構成されるUUIDです。
現在、ライブラリのデフォルト実装や多くのチュートリアルで採用されているのがこのv4であり、「UUIDと言えばv4」という認識も一般的です。
特徴
- 128ビットのうち、ほとんどがランダムビットで構成される
- 時刻情報を持たないため、生成順にソートすることはできない
- 暗号学的に安全な乱数源(CSPRNG)と組み合わせれば、推測や総当たり攻撃に強い
- 衝突確率は極めて低く、実用上無視できるレベル
データベースの主キーやトークン、APIキーなどにもよく利用されますが、「生成時刻順で並べたい」「インデックスの局所性を確保したい」といった要件には不向きです。
インデックスに乱数キーを挿入し続けるとB-treeのバランスが崩れやすく、パフォーマンスやストレージ効率に悪影響が出る可能性があります。
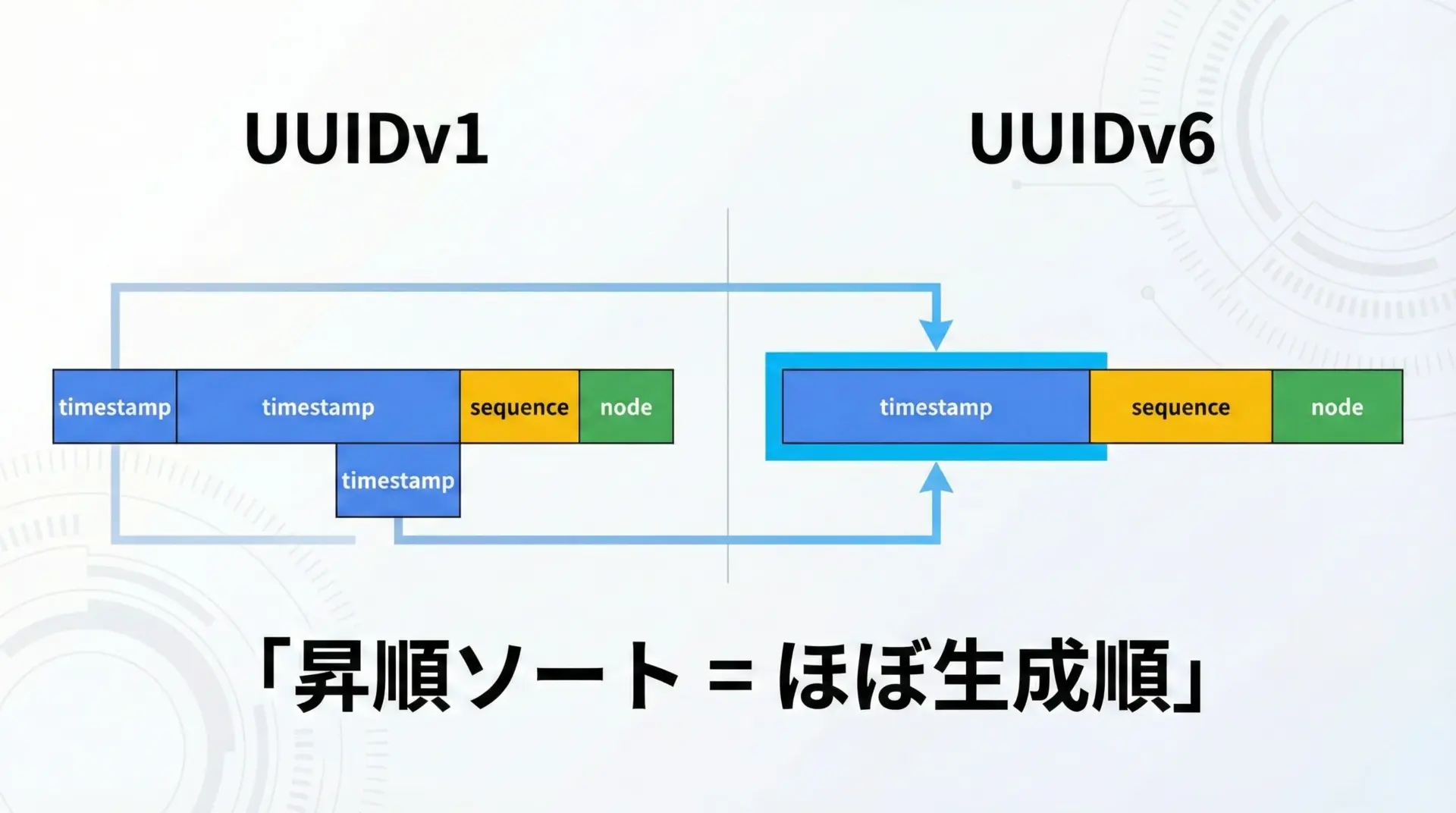
v6: 時系列ソートに最適化されたUUID(UUIDv6)
v6は、従来からあるv1の欠点を補う目的で提案され、時刻情報を先頭に持ってくることでソート性を高めたバージョンです。
RFC 4122bis系の仕様で議論されてきた経緯があります。
特徴
- v1同様、時刻情報を含み、生成時刻順に並びやすい
- ビット配置が変更され、数値としてソートしたときに時刻順に近くなる
- v1と同じく、ノード識別子(MACアドレス相当)を含む構造
v6は実装やサポート状況がまだ限定的な場合もありますが、「ソート性は欲しいが、v1/v4の欠点を避けたい」という要望に応える選択肢として注目されています。
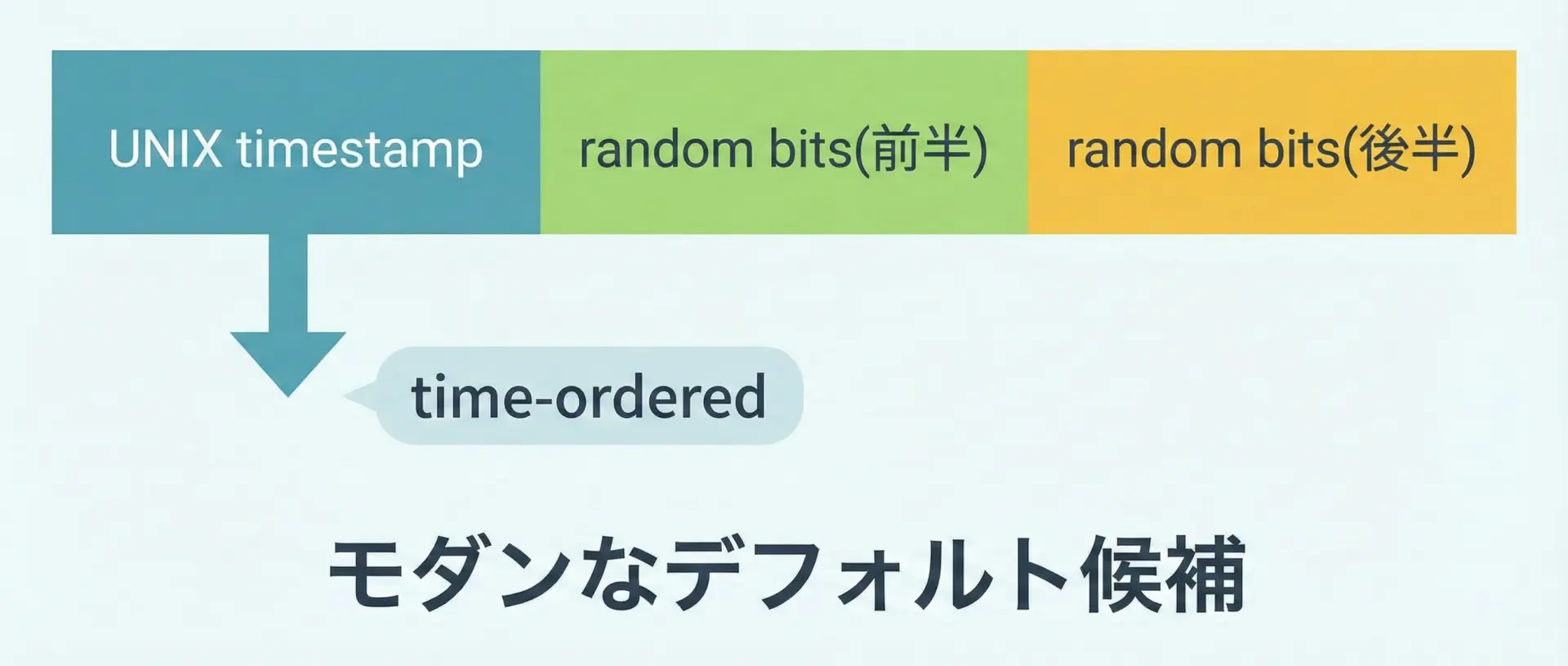
v7: UNIX時刻+乱数ベース(UUIDv7)
v7は新しい仕様で、UNIXエポック時刻(ミリ秒またはナノ秒)と乱数を組み合わせたUUIDです。
2024年時点では、RFC 9562で定義されており、「今から新規で設計するならv7を使おう」という動きが強まっています。
特徴
- 先頭部分にUNIX時刻が入り、生成順にソートしやすい
- 後半は十分な量の乱数を含み、推測されにくさと衝突回避を両立
- v1のようなMACアドレスなどのノード情報は含まないため、プライバシー上の懸念が少ない
v7は、「時系列でソートできて、かつ推測耐性も欲しい」という現代のニーズをバランス良く満たすバージョンです。
そのため、今後は多くのライブラリでデフォルトになっていくと考えられています。
UUIDバージョン選定の観点
実装レベルでは、「とりあえずライブラリのデフォルトに従う」という選び方でも動作はします。
しかし、システム規模が大きくなるほど、バージョン選定が性能やセキュリティ、運用性に影響します。
ここでは、バージョンを選ぶ際の主な観点を整理します。
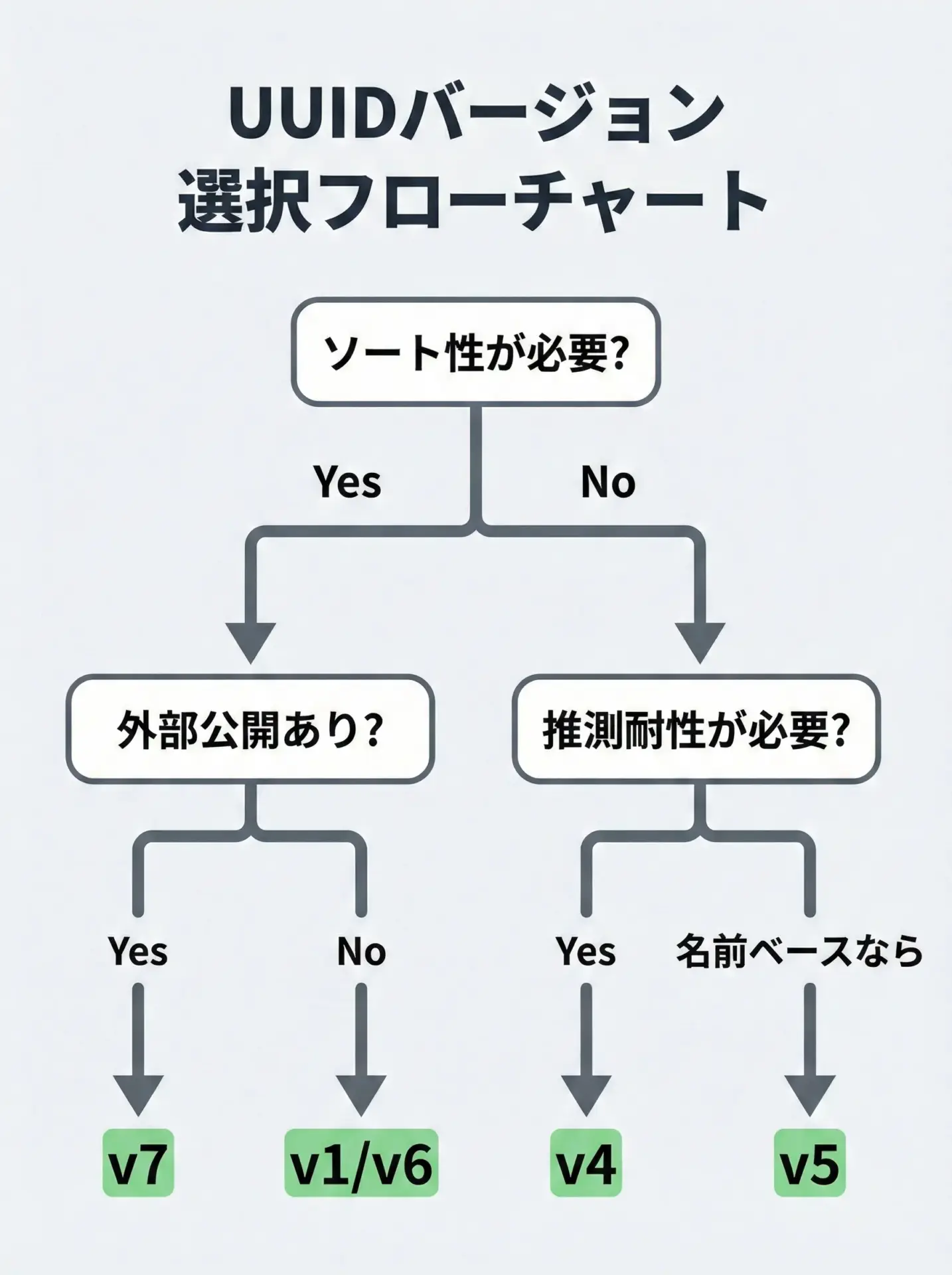
1. ソート性・時系列性
「生成時刻順に並ぶかどうか」は、データベース設計やログ解析で特に重要です。
- ソート性が欲しい → v1 / v6 / v7
- ソート性は不要 → v4 / v3 / v5 も候補
データベースの主キーにランダムなv4を使うと、インデックスのノードがランダムに更新され、挿入性能の劣化やストレージ消費の増加につながる場合があります。
一方、v7のような時刻順に並ぶIDを使えば、新規レコードが常にインデックスの末尾近くに追加されるため、B-treeインデックスと相性が良くなります。
2. 秘匿性・推測耐性
IDが外部に露出する場合、「そのIDから内部構造や他のIDが推測されないか」も重要な観点です。
- MACアドレスや内部情報を含む → v1 / v6
- 原則として内部構造が少ない → v4 / v7
- ハッシュベースで入力が秘匿される → v3 / v5(ただし名称から推測は可能)
特に、MACアドレスやホスト情報の露出を許容できない場合、v1やv6は避けるべきです。
公開APIのリソースID、ダウンロードURLのトークン、セッション識別子など、外部の攻撃者に見られる可能性があるIDには、v4またはv7が適しています。
3. 衝突リスク
UUIDは128ビットの空間を持つため、どのバージョンであっても、実用的な規模では衝突確率はほぼゼロとみなせます。
ただし、生成方法にバグがある、乱数源が貧弱、時刻の単位が荒く同時生成が多いなどの条件が重なると、理論より高い衝突リスクが生じることもあります。
- 適切なCSPRNGを利用したv4 / v7 → 非常に低い衝突リスク
- 時刻とカウンタ管理が適切なv1 / v6 → 低い衝突リスク
- 同じ(名前空間, 名前)ペアでv3 / v5を使う → 設計上そもそも衝突しない
実装ライブラリを信頼できるか、分散システムで時刻同期がどの程度とれているかといった点も、衝突リスクの実効値に影響します。
4. 実装・サポート状況
現実的には、利用する言語やフレームワークがどのバージョンをサポートしているかも選定の大きな要因です。
- v1 / v4: ほとんどの環境で標準サポート
- v3 / v5: 主要ライブラリでサポートされているが、利用頻度は低め
- v6 / v7: 比較的新しく、まだ未対応のライブラリやDBも存在
新プロジェクトでv7を採用したい場合は、使用予定のライブラリがv7を安全・正しく実装しているかを確認し、足りなければ自前実装や外部ライブラリの導入を検討する必要があります。
代表的なユースケースとおすすめバージョン
ここまでの観点を踏まえ、よくあるユースケースごとに、どのバージョンを選ぶとよいかを整理します。
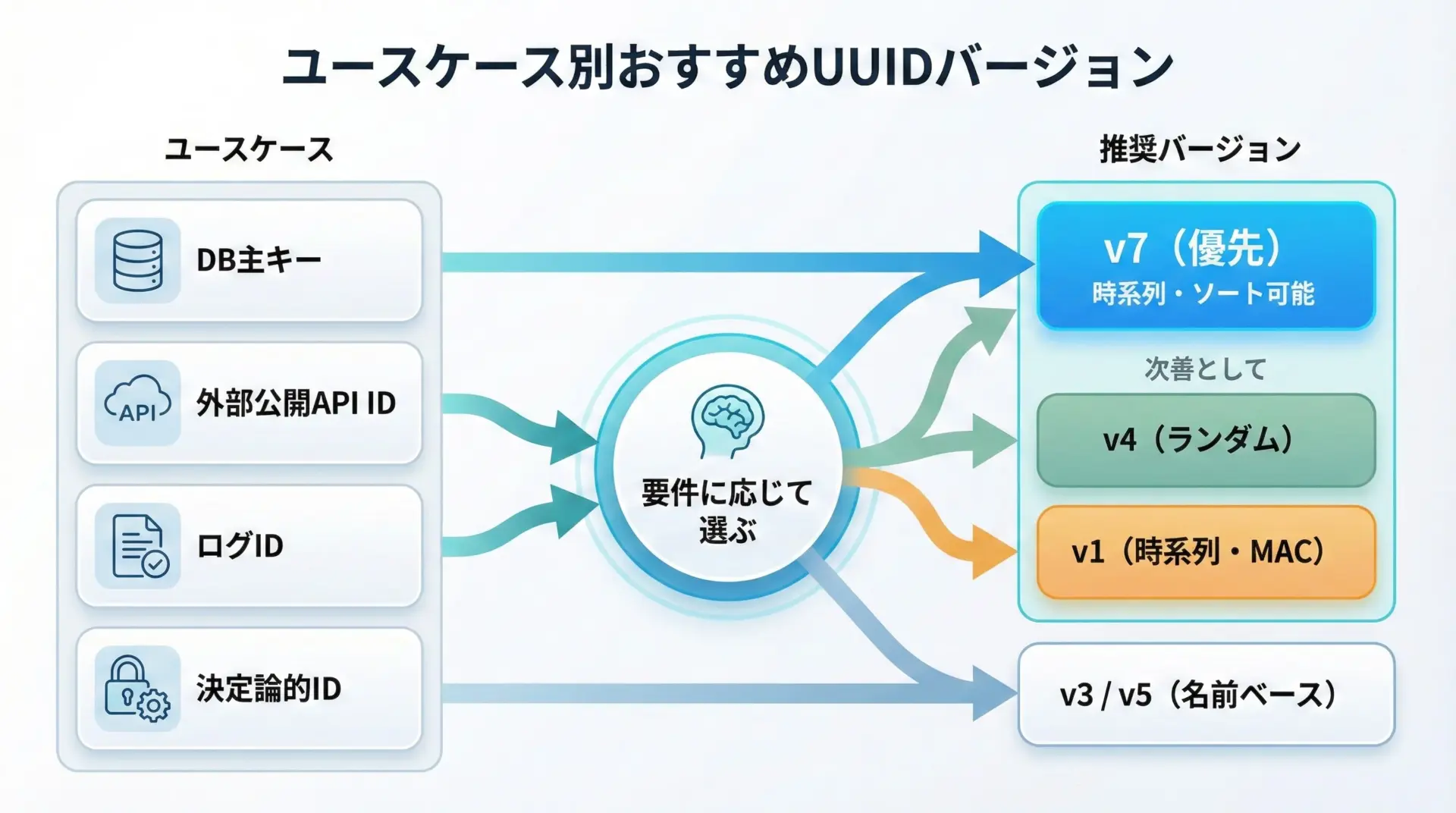
データベースの主キー(ID列)
- 要件: 挿入性能、インデックス効率、時系列でのおおまかな並び
- おすすめ:
- 新規設計なら: v7
- v7未対応の場合: v1 または v6
- プライバシー懸念が強ければ、v1/v6よりもv7導入を優先して検討
v4を主キーに使うことも技術的には可能ですが、高トラフィックなテーブルではインデックス断片化やキャッシュ効率の低下を招きやすいため、意識的に選択する必要があります。
外部に公開されるリソースIDやトークン
- 要件: 推測されにくさ、プライバシー保護
- おすすめ:
- v4 または v7
どちらも乱数を多く含み、MACアドレス等の露出もありません。
時系列性が必要ならv7、不要ならv4という選び方が妥当です。
セキュリティトークンやワンタイムURLであれば、乱数強度に気を配ったv4かv7を選びましょう。
ログIDやトレースID
- 要件: 時系列での関連付け、分散トレーシング
- おすすめ:
- v7 (または対応状況に応じてv1/v6)
ログの時系列解析やトレース相関を考えると、IDに時刻成分を含んでいると後処理がしやすくなります。
外部公開が限定される場合はv1でも実務上問題ないケースが多いですが、新規ではv7を前提に考えるのが良いでしょう。
決定論的なIDが欲しい場合(名前ベース)
- 要件: 同じ入力から常に同じUUIDを得たい
- おすすめ:
- v5(名前空間+SHA-1)
- レガシー互換が必要な場合のみv3
例えば「メールアドレスからユーザーIDを導きたい」「同じパスのリソースには同じIDを割り当てたい」といったケースでは、v5を使った名前空間付きUUID生成が有力候補です。
ただし、入力値そのものの秘匿性は保証されないため、「メールアドレスを直接ハッシュしてIDにする」ような用途では、前処理としてソルトやキー付きハッシュを組み合わせる検討も必要になります。
実務での選び方の指針
ここまでの内容を踏まえ、新しくシステムを設計する際のシンプルな指針をまとめます。
- 「ソート性が必要か」を最初に決める
- 必要 → v7(なければv1/v6)
- 不要 → v4 または用途限定でv3/v5
- 「外部に露出するか」「プライバシー懸念があるか」を確認する
- ある → v4 / v7を優先し、v1/v6は避ける
- ない → v1/v6も選択肢に入る
- 利用する言語・ライブラリのサポート状況を調べる
- v7が安定実装されていれば、モダンなデフォルトとして採用
- レガシー環境であれば、実績豊富なv4やv1を使いつつ、将来の移行も検討
このような観点をチーム内で共有し、プロジェクト標準として「原則このバージョンを使う」とガイドライン化しておくことで、後からの再設計コストを減らせます。
まとめ
UUID/GUIDは一見どれも同じ128ビットのランダムな文字列に見えますが、バージョンごとに「何を優先した設計か」が明確に異なります。
本記事で解説したポイントを整理すると、次のようにまとめられます。
- v1: 時刻+MACアドレスベース。時系列ソートしやすいが、プライバシー懸念あり。
- v3/v5: 名前空間+文字列からのハッシュ。決定論的IDが欲しい特殊用途向け。通常はv5を選ぶ。
- v4: 乱数ベース。実装が簡単で推測されにくく、多くの環境での事実上の標準。
- v6: v1を時系列ソート向けに再設計した形。実装・採用はまだ限定的。
- v7: UNIX時刻+乱数で、ソート性と推測耐性のバランスが良いモダンな候補。
新規システムであれば、まずはv7を第一候補にし、要件やサポート状況に応じてv4やv1/v6を使い分けるのが、現時点での現実的なアプローチです。
UUIDのバージョン選択をきちんと設計に組み込むことで、性能やセキュリティの面で後悔しないアーキテクチャを構築できるはずです。
