
「同期処理」と「非同期処理」という言葉は、プログラミングを学び始めると必ず出てきますが、定義だけ読んでもピンとこないことが多いです。
この記事では、まず日常生活のイメージから同期と非同期を直感的に理解し、そのあとでプログラミングではどう使い分けるのかを整理していきます。
専門用語をなるべくかみ砕きながら解説していきますので、手を動かす前の「考え方の地図」として役立ててください。
「同期処理」と「非同期処理」の基本をざっくり理解しよう
同期処理とは?
同期処理とは、ある処理が終わるまで次の処理を始めないやり方です。
1つの作業がきちんと完了してから、次の作業に進みます。
プログラミング的に言うと、1行目の処理が終わってから2行目、2行目が終わってから3行目…というように、必ず順番どおりに処理が進むイメージです。
途中で時間のかかる処理(ネットワーク通信やファイル読み込みなど)があっても、その処理が終わるまで次の行は実行されません。
非同期処理とは?
非同期処理とは、時間のかかる処理を「待っているあいだ」に、別の処理を進めるやり方です。
スタートボタンを押したあと、その処理が終わるのをじっと待つのではなく、終わるまでのあいだに他のことを進められるのがポイントです。
プログラミングでは、何かを「依頼」しておいて(サーバーへのリクエスト、ファイルの読み込みなど)、結果が返ってきたときにコールバックやPromise、async/awaitなどを使って後続の処理を行います。
処理の「開始」と「完了」が時間的に離れていて、そのあいだメインの流れは塞がれないのが非同期処理です。
同期処理と非同期処理の違いを一言でいうと
「次の処理が、前の処理の完了を待つかどうか」が違いです。
- 同期処理: 前の処理が終わるまで、次の処理は進まない
- 非同期処理: 前の処理が終わるのを待っているあいだに、別の処理を進められる
この「待っているあいだに、他のことができるかどうか」を軸に考えると、以降の例も理解しやすくなります。
同期処理を身近な例でイメージしよう
レジに一列で並ぶイメージ

レジに一列で並んでいる場面をイメージしてみてください。
店員さんは目の前のお客さんの会計が終わるまで、次のお客さんの会計を始めることはできません。
3人並んでいたら、1人目 → 2人目 → 3人目と必ず順番に処理されます。
これは同期処理そのものです。
前の処理が終わらないと、次の処理はスタートできない状態です。
待ち時間が長くなっても、列に並んでいる人たちは会計が終わるまでただ待つしかありません。
料理を一品ずつ作るイメージ
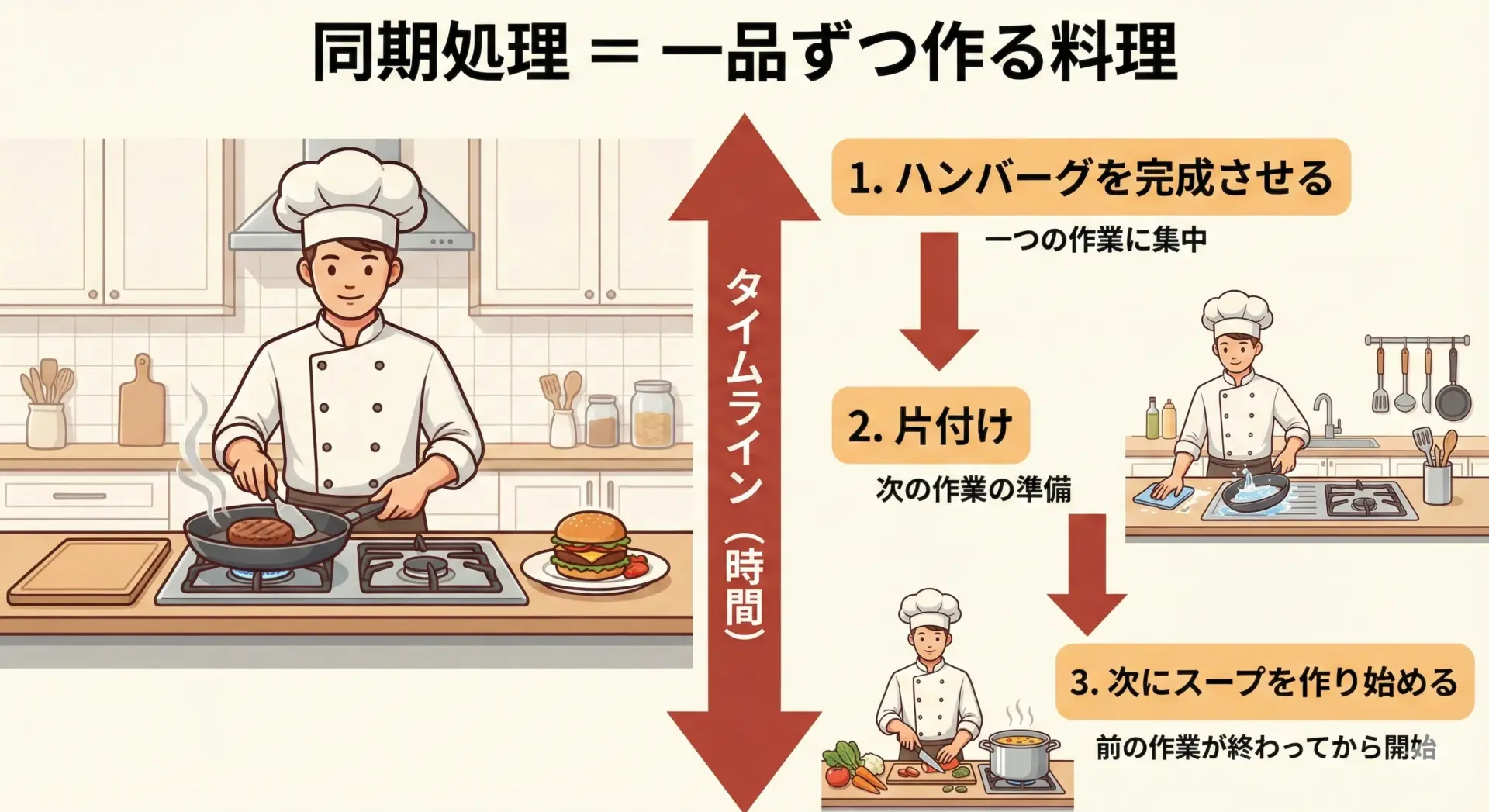
自炊のときに、ハンバーグ、スープ、サラダを作るとします。
同期的なやり方は、たとえば次のようになります。
- ハンバーグを最後まで作り切る
- キッチンを軽く片付ける
- スープを最初から最後まで作る
- 片付ける
- サラダを作る
このとき、ハンバーグを焼いているあいだ、ただフライパンの前で立って待っているなら、それも同期的な行動です。
1つの料理が完全に終わるまで次に進まず、常に「1タスクだけ」に集中している状態です。
同期処理のメリット
同期処理の一番のメリットは、流れが分かりやすく、バグを追いかけやすいことです。
処理が「上から下へ」素直に流れていくため、次のようなメリットがあります。
- プログラムの実行順序を頭の中でイメージしやすい
- どこで何が起きているか、追跡しやすい
- 共有資源(ファイルやデータ)を扱うときに、「同時アクセス」による競合を気にしなくてよいことが多い
レジの例でいうと、常に「今はこの人の会計だけ」と決まっているため、店員さんはお金の計算を間違えにくく、管理しやすい状態と言えます。
同期処理のデメリット
一方で、同期処理の最大のデメリットは「待ち時間がそのまま無駄時間になりやすい」ことです。
- ネットワーク通信やディスクアクセスのように、外部要因で時間がかかる処理を待っているあいだも、CPUや人間の手は止まってしまう
- 結果として、全体の処理時間が長くなりやすい
料理の例なら、スープが温まるのをじっと待つのではなく、その時間にサラダを切れれば効率が上がりますが、同期的に「待つだけ」にしていると、その時間は有効活用されていません。
同様に、プログラムでも「待つだけ」の時間が積み重なると、アプリ全体が重くなったり、ユーザーにとってのレスポンスが悪くなったりします。
非同期処理を身近な例でイメージしよう
洗濯機を回しながら別の家事をするイメージ
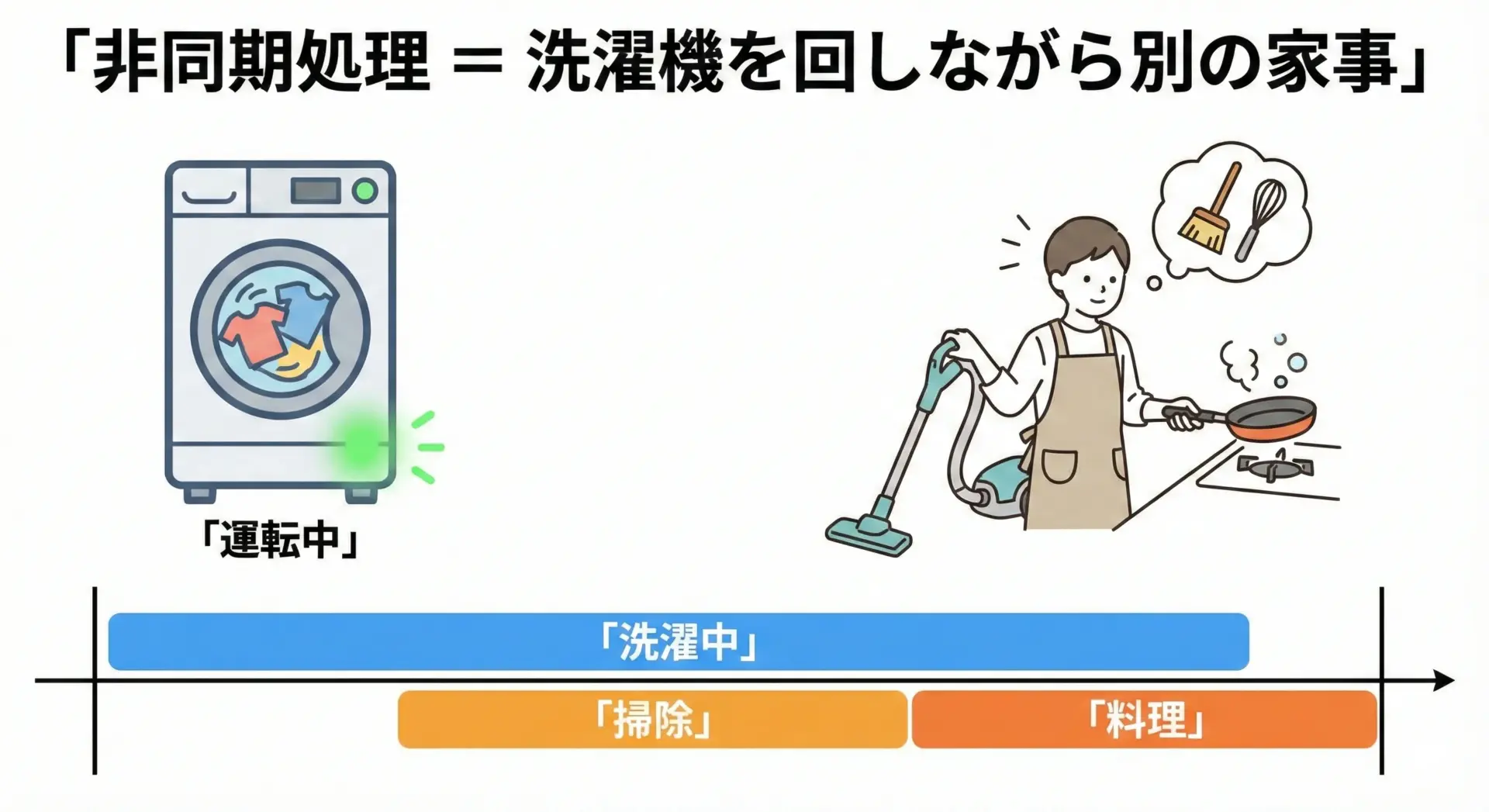
洗濯機を回しているあいだ、ずっと洗濯機の前に立って見張っている人はほとんどいません。
洗濯機のスタートボタンを押したら、洗濯が終わるまでのあいだに掃除をしたり、料理をしたりします。
これが非同期処理の発想です。
- 「洗濯を始める」という命令を洗濯機に出す
- 洗濯機が動いているあいだ、人間は別の家事をする
- 洗濯が終わったタイミングで「ピーピー」と音が鳴り、そのタイミングで洗濯物を干す
プログラミングでは、時間のかかる処理(洗濯)を「開始」だけさせておいて、その完了を待っているあいだに別のタスクを進め、終わったタイミングの通知(イベントやコールバック)を受けて後続処理を実行する、という流れになります。
レストランの注文と料理の提供のイメージ
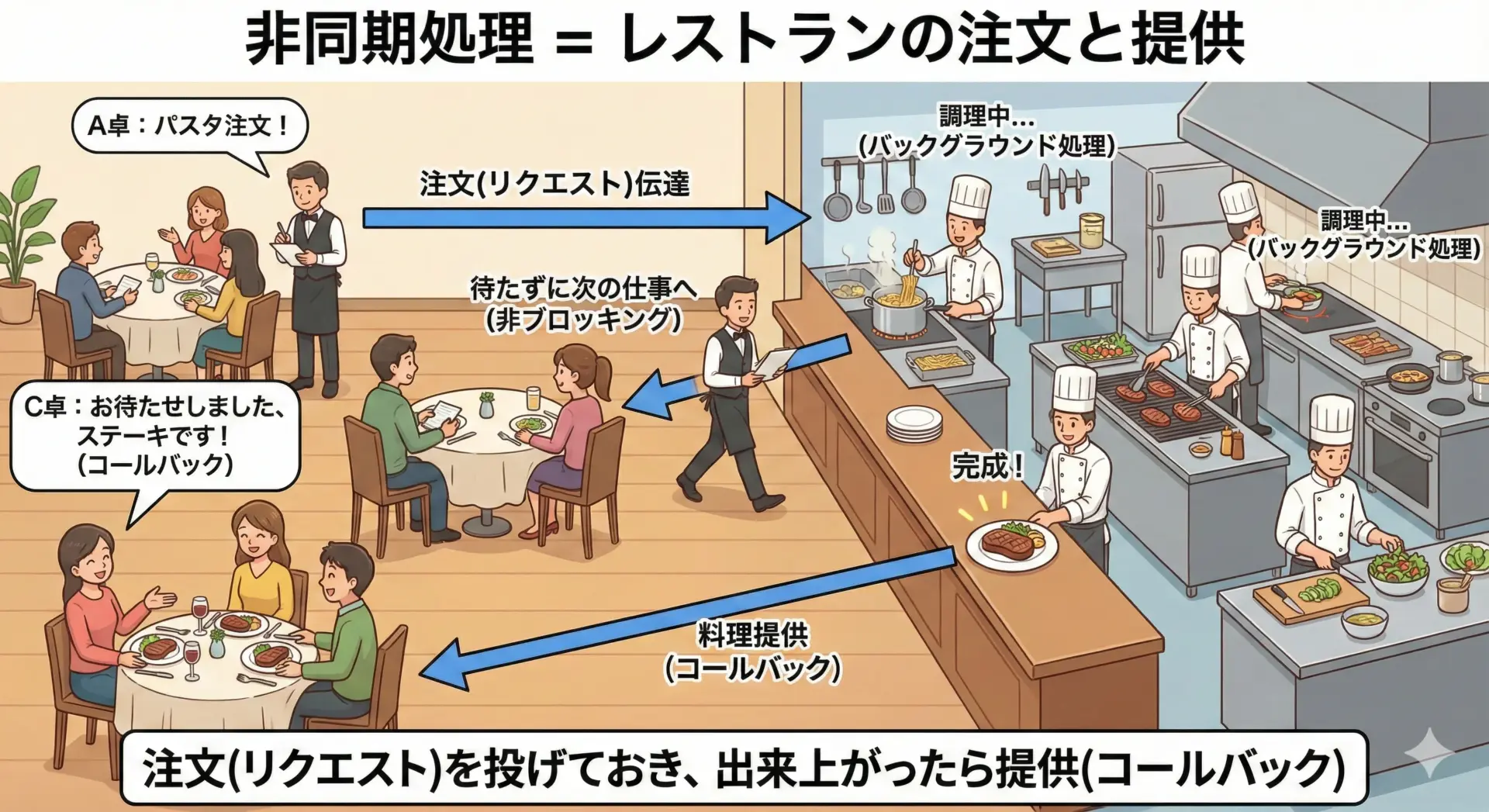
レストランでは、店員さんは1組のお客さんの料理が出てくるまでそのテーブルに張り付いているわけではありません。
次のような流れになっています。
- Aさんのテーブルで注文を聞く
- キッチンに注文を伝える
- 料理ができるまでのあいだ、Bさんの注文を取りに行く
- キッチンから「Aさんの料理ができました」と呼ばれたら、Aさんのテーブルに運ぶ
ここで重要なのは、キッチンで料理が作られているあいだ、店員さんは「待つだけ」ではなく別の仕事をしていることです。
これが非同期的な振る舞いです。
プログラミングでも同じように、ある処理を外部のサービスやOSに任せておき、その処理中に他のタスクを実行し、完了したら通知を受けて続きの処理を行います。
非同期処理のメリット
非同期処理の一番のメリットは、待ち時間を有効活用して全体の効率を高められることです。
- ネットワークアクセスやファイル読み込みのような待ち時間を、別の処理で埋められる
- 1つのスレッド(メインスレッド)しか使えない環境でも、体感の処理速度やレスポンスを大きく改善できる
- UIアプリやWebブラウザでは、画面が固まらずに操作を受け付け続けられる
洗濯機と家事の例でいえば、洗濯中も掃除や料理を進めることで、トータルの家事時間を短縮できます。
レストランの例では、店員さんが1組ずつ同期的に対応していたら待ち時間が非常に長くなりますが、非同期的に複数テーブルを回すことで店全体の回転が良くなります。
非同期処理のデメリット
非同期処理はパワフルですが、その分だけ複雑さとバグのリスクを連れてきます。
- 処理が「同時並行」で進むため、いつどの順番で結果が返ってくるかが一定ではない
- データの整合性(誰がいつデータを書き換えるのか)を意識しないと、予期しないバグが発生しやすい
- コールバック地獄、Promiseチェーンの複雑化、
async/awaitでのエラーハンドリングなど、「書き方」を理解するハードルがある
人間の直感はどうしても「上から順番に実行される」ことを前提にしてしまうため、非同期特有の「順番が前後する」世界観に慣れるまでが難所です。
プログラミングでの同期処理と非同期処理の使い分け
どんなときに同期処理が向いているか
「順番どおりにきっちり進んでほしい」「途中で割り込まれては困る」処理は、同期処理が向いています。
具体的には次のようなケースです。
- 入力 → 検証 → 保存 のように、前の結果がなければ次に進めない一連の処理
- データベースの更新やファイル書き込みなど、同時に実行すると不具合が起こりやすい処理
- スクリプトやバッチ処理のように、
実行スピードよりも処理の単純さ・確実さが重要な場面
また、学習段階では、まず同期処理でロジックを組んでから、必要なところだけ非同期化するというステップを踏むと理解しやすくなります。
すべてをいきなり非同期で書こうとすると、順番や状態管理が混乱しがちです。
どんなときに非同期処理が向いているか
「待ち時間」が長く、「待っているあいだに他の処理を進めたい」ときは非同期処理が活きてきます。
代表的な例は次のとおりです。
- ネットワーク通信(HTTPリクエスト、API呼び出しなど)
- ファイルの読み書き、大きなデータのダウンロード・アップロード
- タイマー処理(一定時間後に何かを実行したいとき)
- UIアプリやWebフロントエンドで、画面を固めずに重い処理をしたいとき
これらは、人間でいえば「洗濯機」「オーブン」「業者への依頼」のようなものです。
自分が直接作業していない時間を有効に使うために、非同期処理を使うと考えるとイメージしやすいです。
Web開発での非同期処理の具体例
Web開発、とくにJavaScriptでは非同期処理が頻出します。
代表的なパターンをいくつか挙げます。
画面をリロードせずにデータを取得する(AJAX / Fetch API)
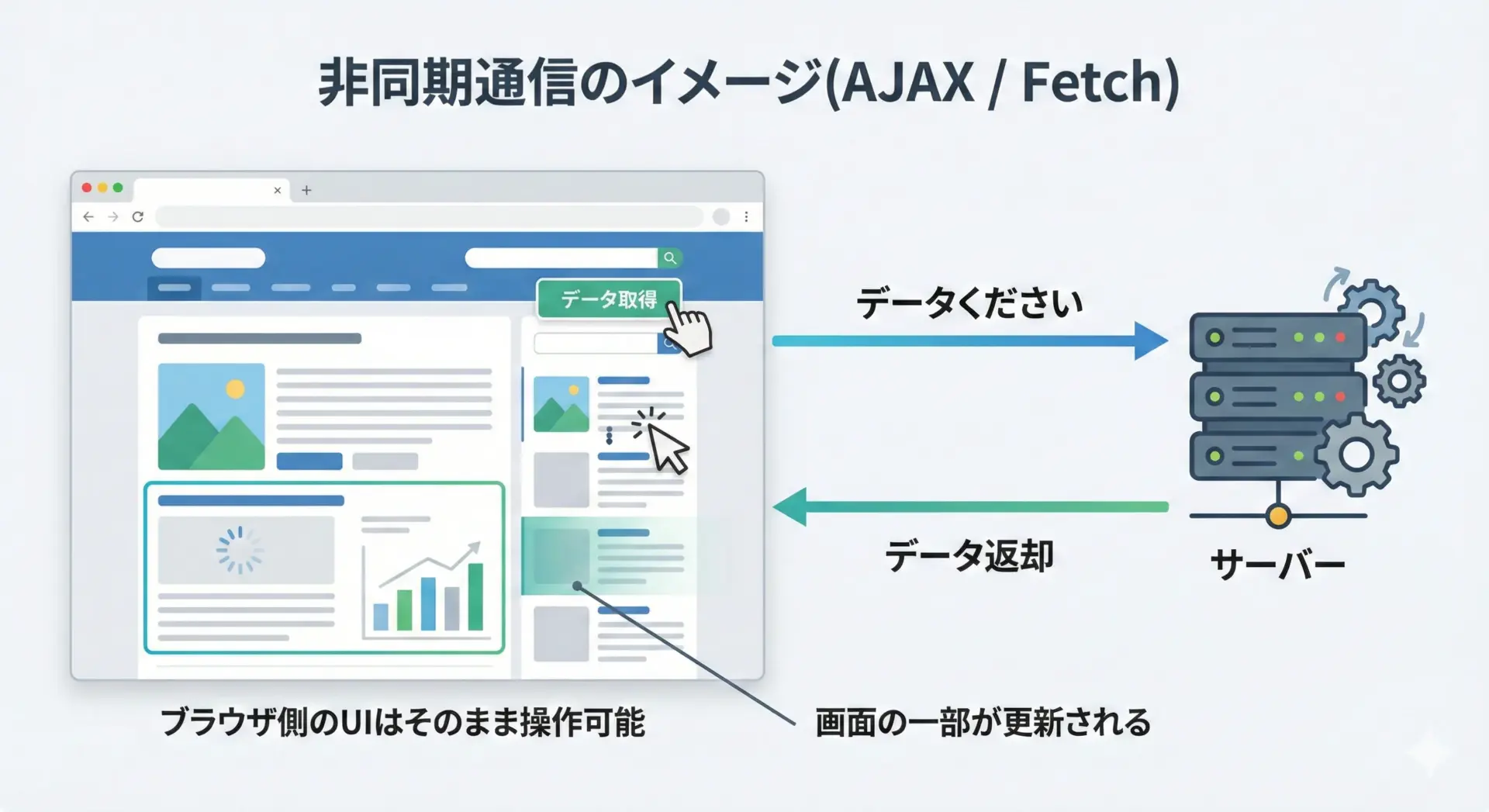
たとえば、ニュースサイトで「もっと読む」ボタンを押すと、ページ全体はリロードされず、記事一覧だけが下に追加されることがあります。
これはJavaScriptがfetchなどを使ってサーバーに非同期リクエストを送り、レスポンスが返ってきたタイミングで表示を更新しているからです。
async function loadMoreArticles() {
const res = await fetch('/api/articles?offset=10');
const data = await res.json();
// ここで画面に記事を追加
}このawait fetch(...)の間、JavaScriptは「完全に止まる」わけではなく、他のイベント(クリックやスクロールなど)を処理し続けます。
これが非同期処理の恩恵です。
フォーム送信中の「ぐるぐる」インジケーター
フォームを送信したとき、画面全体が真っ白になってしまうのではなく、ボタンの横で「読み込み中…」のインジケーターが回り続けている場面があります。
ここでも非同期処理が使われています。
- 送信ボタンが押される
- JavaScriptが非同期でサーバーにデータを送信する
- そのあいだ、「送信中…」と表示し、ボタンを無効化するなどのUI更新も続けて行う
- 結果が返ってきたら、成功メッセージやエラーメッセージを表示する
このように、「通信中だから何もできない」状態を避けるために非同期処理が使われているのです。
リアルタイム更新(チャット、通知など)
チャットアプリや通知機能では、サーバーからのメッセージを「届いたときに即座に画面に反映」する必要があります。
このとき、WebSocketやServer-Sent Eventsなどの仕組みを使って、サーバーからのイベントを非同期で受け取り、そのたびに画面を更新しています。
ここでも、メインのUIは常にユーザー操作を受け付けつつ、裏側で非同期的に新着メッセージを処理しています。
初心者がつまずきやすいポイントと理解のコツ
非同期処理は、最初のハードルが高く感じられがちです。
つまずきやすいポイントと、その乗り越え方をまとめます。
1. 「コードの順番」と「実行のタイミング」がズレる
コードの見た目の順番どおりに処理が進まないことが、最初の戸惑いポイントです。
console.log('A');
setTimeout(() => {
console.log('B');
}, 1000);
console.log('C');このコードでは、多くの人が最初「A → B → C」と出力されると想像しますが、実際にはA → C → Bの順に表示されます。
非同期処理のコールバックは、あとで実行されるからです。
理解のコツとしては、「非同期処理は予約だけしておき、実行はあとからやってくる」と意識することです。
レストランの「注文票」を出しておき、料理ができたら店員さんが持ってきてくれる、というイメージを思い出してください。
2. 値の「受け渡し方」が同期と違う
同期処理では、関数の戻り値で結果を受け取ることが多いですが、非同期処理ではそれが通用しない場面があります。
// これはうまくいかない例
function getData() {
let result;
fetch('/api/data')
.then(res => res.json())
.then(data => {
result = data;
});
return result; // ここではまだ result に値が入っていない
}非同期処理では、「結果はあとで届く」ため、戻り値に直接入れようとするとタイミングが合いません。
この違いを理解するには、「非同期の結果は、コールバックやPromise、async/awaitで受け取る」と頭を切り替えることが重要です。
3. まずは日常の例で「動き方」をイメージする
技術的な用語に飛びつく前に、日常生活の非同期パターンを意識的に観察してみると理解が早くなります。
- 洗濯機を回しながら掃除する
- 炊飯器をセットしてからお風呂に入る
- レストランで注文したあと、スマホを触りながら料理を待つ
これらはすべて「非同期的な行動」です。
プログラムでも同じように、「お願いしておいて、結果が出るまでのあいだ別のことをする」という構造を見つけることが、非同期処理の設計につながります。
まとめ
同期処理と非同期処理の違いは、「前の処理の完了を待つあいだ、何もしないか」「別の処理を進めるか」という一点に集約されます。
レジに一列で並ぶ、料理を一品ずつ作るといった例は同期処理、洗濯機を回しながら別の家事をする、レストランで注文してから別のテーブルに向かうといった例は非同期処理のイメージです。
プログラミングでは、順序と整合性が最重要なところは同期的に、待ち時間が長くて並行できるところは非同期的に、という使い分けが基本方針になります。
とくにWeb開発では、ネットワーク通信や画面更新の多くが非同期で行われており、ユーザーにとって快適な体験を実現するために欠かせない考え方です。
最初は非同期処理の「順番がズレる」感覚に戸惑いやすいですが、日常の家事やレストランでのふるまいを思い出しながら、「これは同期っぽい」「これは非同期っぽい」と分類してみると、概念がぐっと身近になります。
そのうえでPromiseやasync/awaitのコードを読むと、「何を待って」「何を並行しているのか」がクリアに見えてくるはずです。
