
データの量は増え続ける一方ですが、ストレージ容量や通信速度には限りがあります。
このギャップを埋めるのが「データ圧縮」です。
とくにプログラミングに携わる方にとって、可逆圧縮と非可逆圧縮の違いを理解しておくことは、パフォーマンスチューニングや設計判断に直結します。
本記事では、仕組みのイメージから、具体的な形式、実際のプログラミングでの活用例まで、丁寧に解説していきます。
データ圧縮とは何か
データ圧縮の基本概念
データ圧縮とは、元の情報をできるだけ保ったまま、必要なデータ量(ビット数やバイト数)を小さくする技術のことです。
たとえば、同じ内容のテキストファイルでも、圧縮前は100KB、圧縮後は20KBといった具合に、サイズを小さくできます。
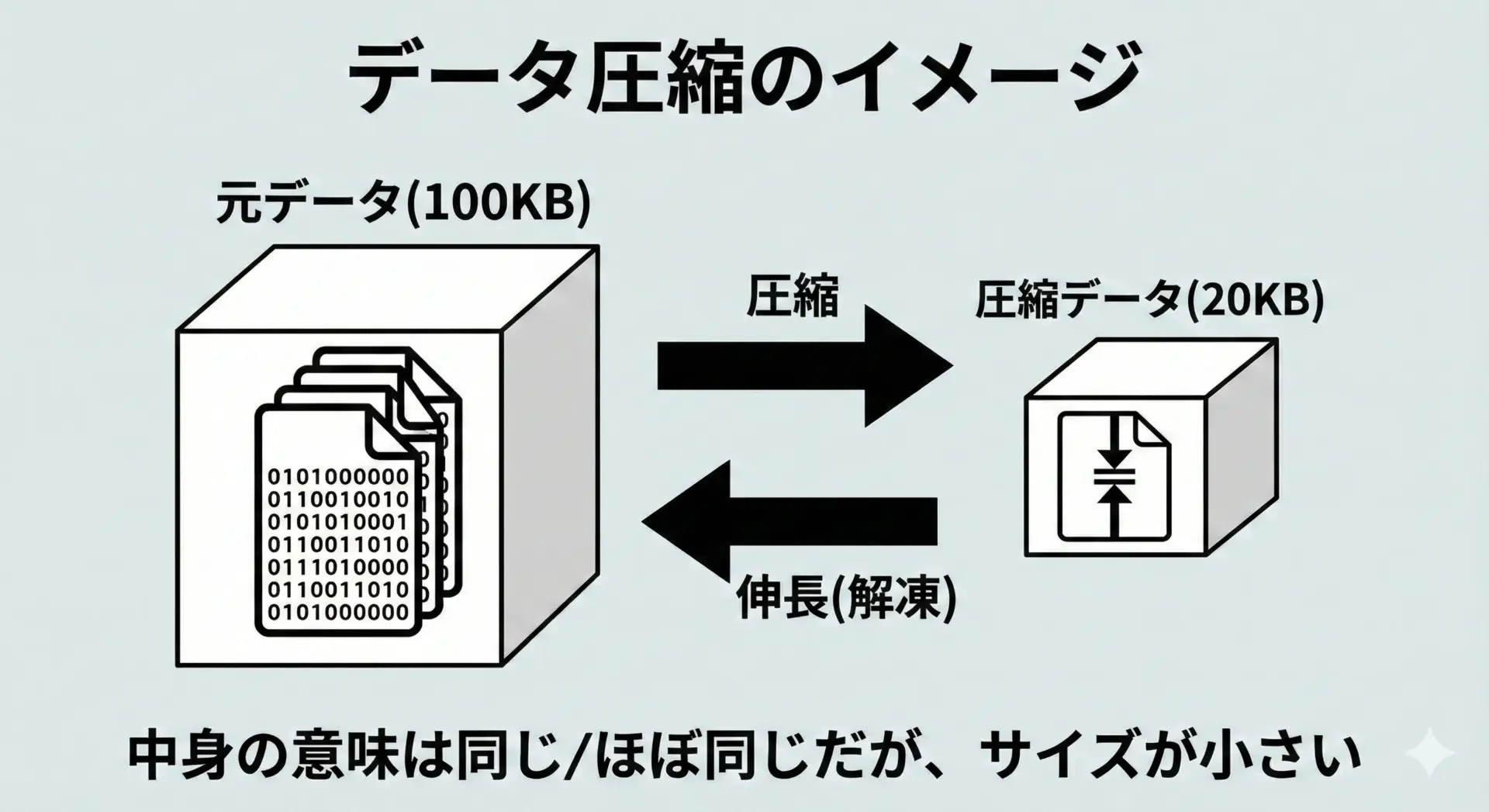
圧縮されたデータは、そのままでは人間が読んだり、多くのアプリケーションで直接扱ったりできません。
通常は圧縮 → 保存や転送 → 伸長(解凍)という流れで利用します。
このとき、伸長後のデータが圧縮前と完全に一致するかどうかによって、可逆圧縮と非可逆圧縮に分かれます。
データ圧縮が必要となる理由
データ圧縮が必要になる理由は、大きく次のように整理できます。
1. 保存コストの削減 ログ、バックアップ、画像、動画などをそのまま保存すると、ストレージを圧迫します。
圧縮することで、同じ容量でより多くのデータを保存でき、クラウドストレージやバックアップのコスト削減にもつながります。
2. 転送時間と帯域の節約 ネットワーク越しのデータ転送では、サイズが小さいほど送受信にかかる時間が短くなります。
APIレスポンス、Webページの配信、ファイルダウンロードなどで圧縮を行うと、ユーザー体験の向上と回線コストの削減に直結します。
3. キャッシュの効率化 ブラウザキャッシュやCDN、アプリ内キャッシュは容量が限られているため、圧縮データの方が多くのコンテンツを保持できます。
その結果、キャッシュヒット率が上がり、全体的なパフォーマンスが向上します。
可逆圧縮と非可逆圧縮の違いの全体像
可逆圧縮(lossless compression)は、伸長すると元のデータを1ビット単位で完全に復元できる圧縮方式です。
テキストやプログラムソース、設定ファイル、データベースバックアップなど、内容が少しでも変わると困るデータで使います。
非可逆圧縮(lossy compression)は、伸長しても元のデータを完全には復元できず、一部の情報を失う圧縮方式です。
ただし、人間の目や耳で気づきにくい部分を削ることで、大幅なサイズ削減を実現します。
画像(JPEG)、音声(MP3)、動画(H.264など)に多く使われます。
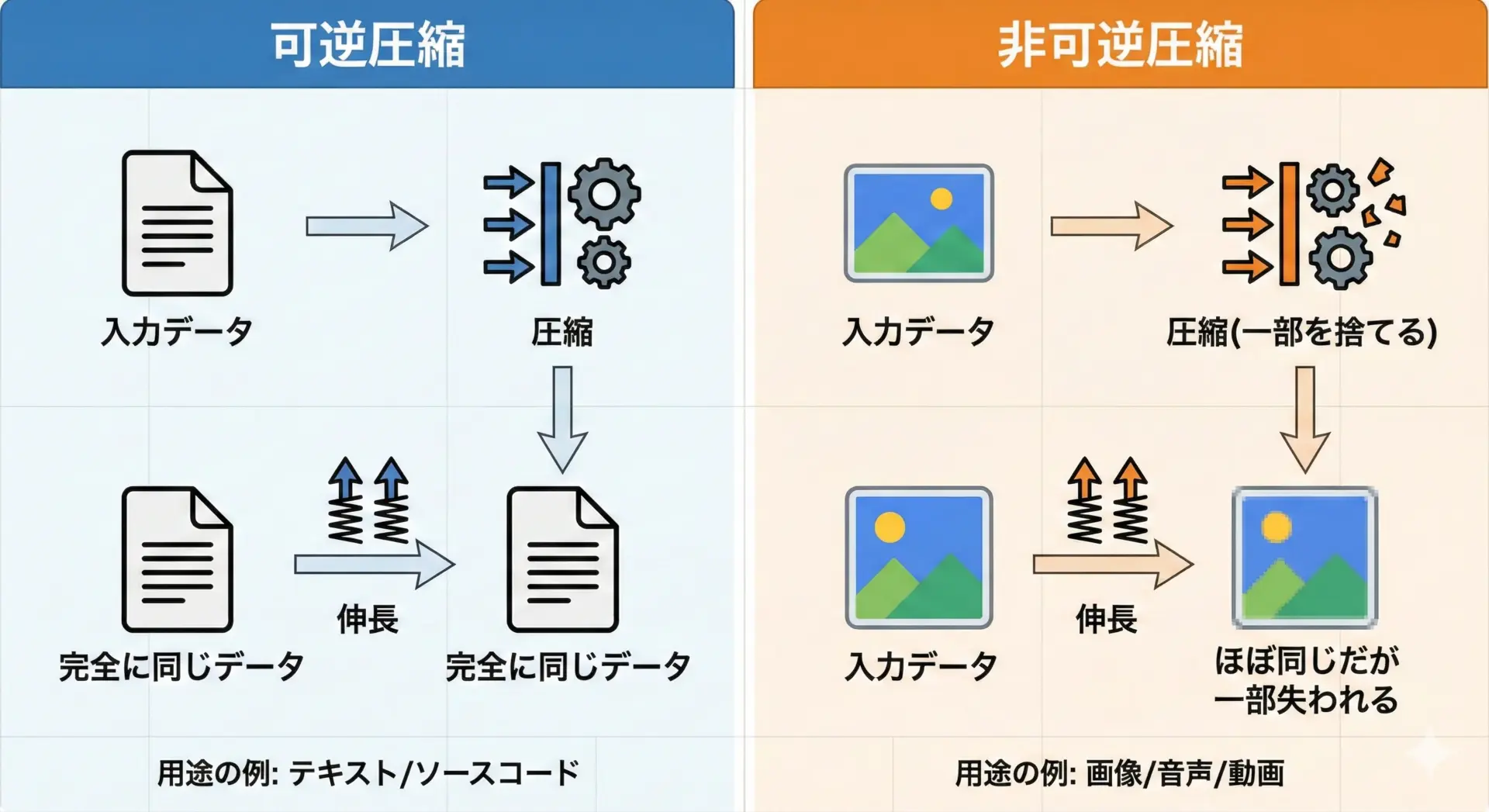
この2つの違いを理解しておくことで、システム設計時に「どのフォーマットを選ぶべきか」「どこで何を圧縮するべきか」を合理的に判断できるようになります。
可逆圧縮の基本
可逆圧縮とは何か
可逆圧縮とは、圧縮したデータを伸長したときに、元のデータをビット単位で完全に再現できる圧縮方式です。
1文字でも違ってはならないテキストや、1ビットの変化がバグにつながるプログラムコードでは、可逆圧縮が必須になります。
可逆圧縮では、データの「規則性」を見つけて、より短い表現に置き換えることが基本的な考え方です。
たとえば、同じ文字列が何度も繰り返されている場合、それをまとめて表現することで、全体を小さくできます。
可逆圧縮の代表的な形式
代表的な可逆圧縮形式には、次のようなものがあります。
| 分野 | 形式・規格 | 説明 |
|---|---|---|
| 汎用圧縮 | ZIP | ファイル圧縮で広く使われる形式。Windowsの標準機能としても使われる。 |
| 汎用圧縮 | gzip | UNIX系でよく使われる圧縮形式。HTTPレスポンスの圧縮にも利用される。 |
| 汎用圧縮 | bzip2 / xz | gzipより高圧縮率を狙う形式。圧縮・伸長速度は遅め。 |
| 画像 | PNG | 透過に対応する可逆圧縮画像形式。アイコンや図版に多用される。 |
| 画像 | WebP(losslessモード) | Googleが開発した新しめの画像形式。可逆モードも非可逆モードもある。 |
| 音声 | FLAC | 音楽の可逆圧縮形式。可逆でありながら圧縮率が比較的高い。 |
| データ構造 | zlib / Deflate | gzipやPNG内部などで使われる圧縮アルゴリズム。 |
プログラミングの現場では、「ファイル形式」と「圧縮アルゴリズム」を区別することが重要です。
たとえばZIPはファイル形式であり、その中でDeflateという圧縮アルゴリズムが使われる、といった関係があります。
可逆圧縮の仕組みのイメージ
可逆圧縮のアルゴリズムの中身は多様ですが、代表的なアイデアをイメージで説明します。
ランレングス圧縮(RLE)のイメージ
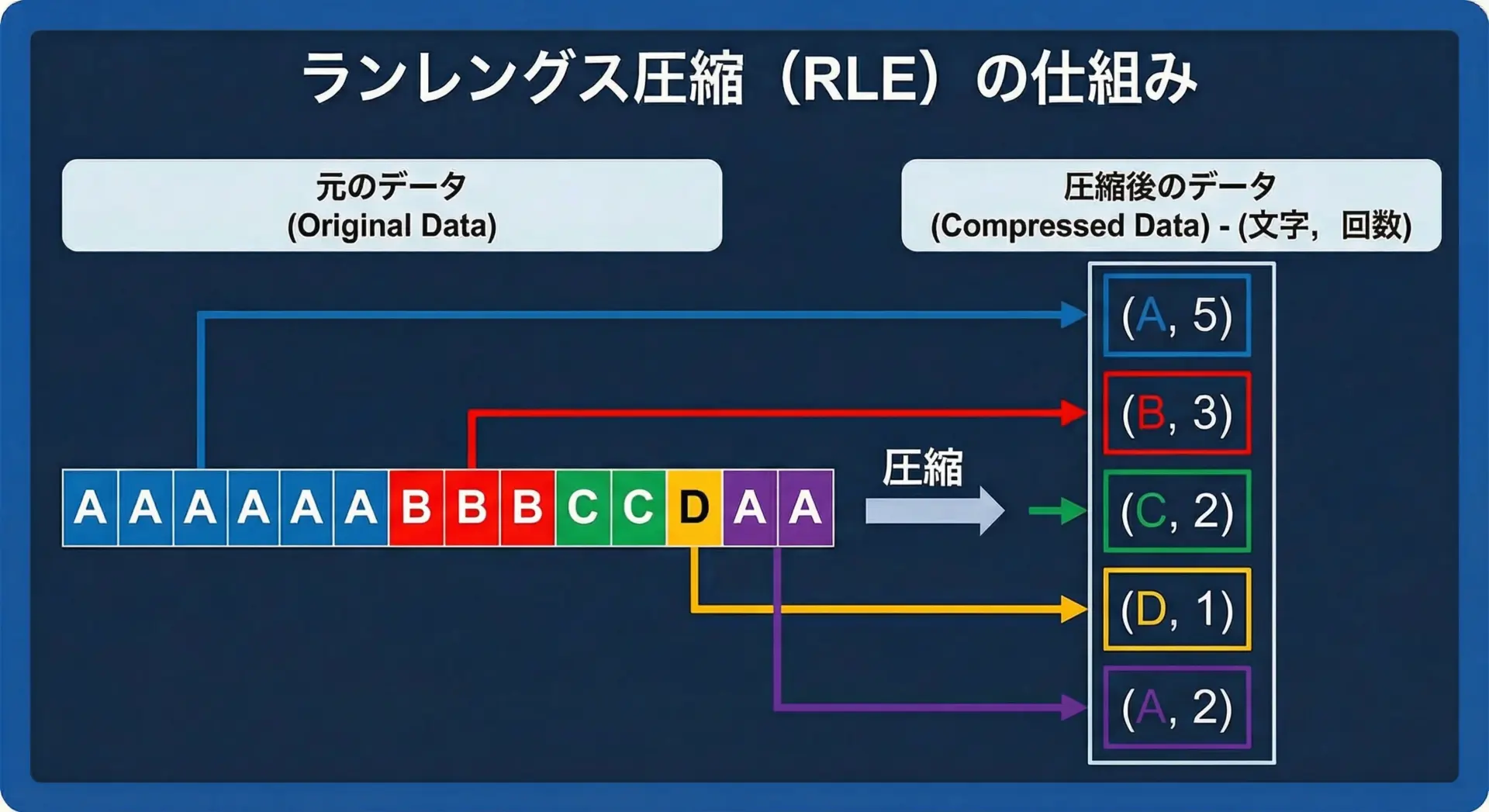
同じ文字が続く箇所を(文字, 回数)のペアに置き換えることで、繰り返し部分を短く表現します。
これは画像の単色領域などにも応用できます。
辞書ベース圧縮(LZ系)のイメージ
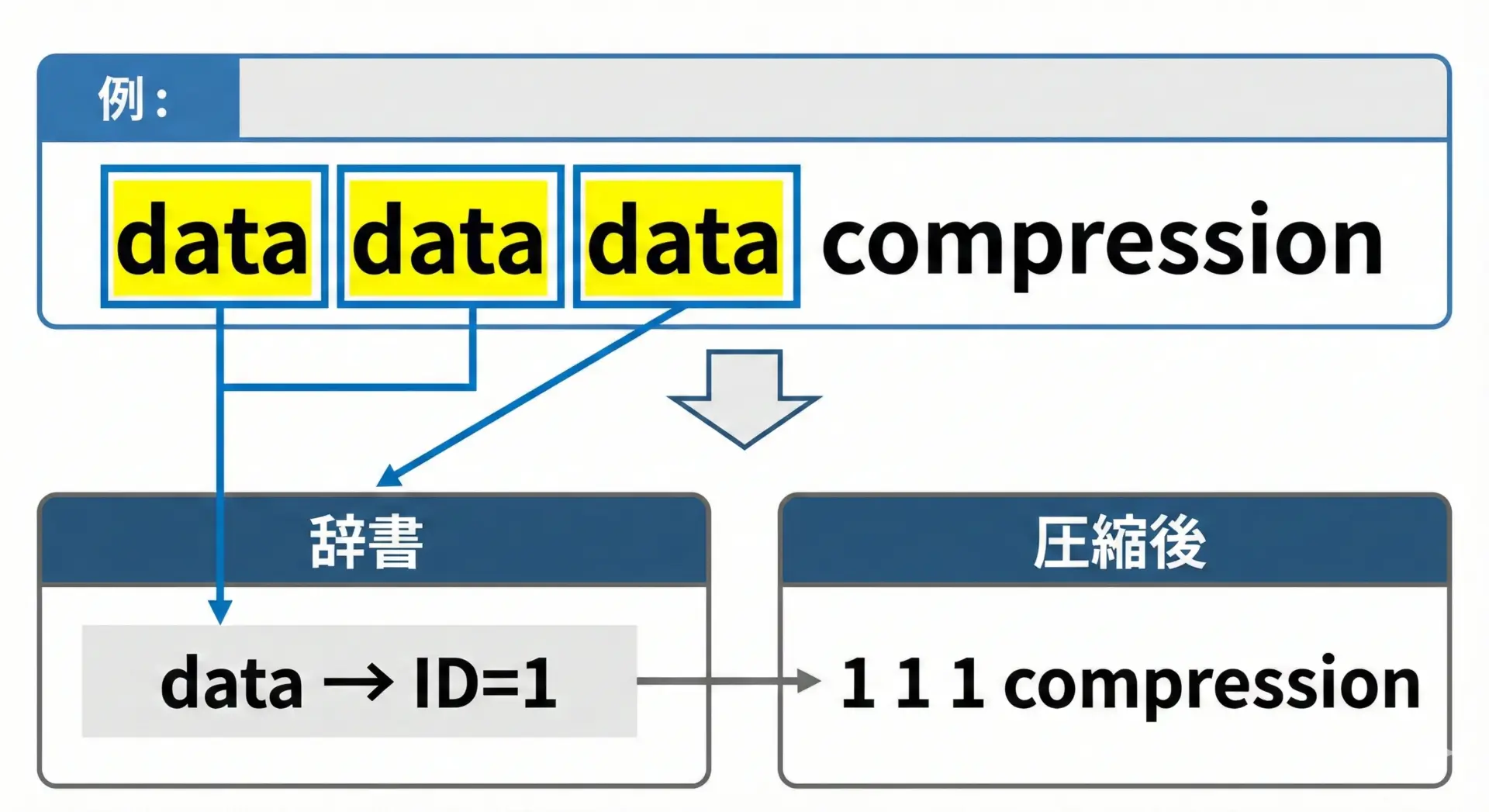
よく出現する文字列に「ID」を割り振り、そのIDで参照することで全体のサイズを減らします。
Deflate、LZ77、LZ4など、多くの実用的圧縮方式の土台になっている考え方です。
テキストデータとソースコードで可逆圧縮が必須な理由
テキストやソースコードに対して非可逆圧縮を使うのは、基本的にはNGです。
その理由は明確で、1文字でも違えば意味が変わってしまうからです。
たとえばプログラムコードで、次のような違いが生じると致命的です。
==が=に変わるifがofになる- 数値の小数点がずれる(例:
0.5→0.6)
ログや設定ファイルについても同様で、1文字の違いが解析結果の誤りやシステム障害につながります。
「再現性」「監査性」「デバッグ可能性」が求められるデータには、必ず可逆圧縮を用いるべきです。
プログラミングで使う可逆圧縮ライブラリの例
実際のプログラミングでは、言語や用途に応じて次のようなライブラリを使います。
- zlib / gzip
C/C++からの利用が多く、Python、Node.js、Javaなど多くの言語でラッパーが用意されています。HTTPレスポンスのContent-Encoding: gzipにも使われます。 - LZ4
高速な圧縮・伸長を特徴とするライブラリです。圧縮率よりも速度が重要な場面(リアルタイムログ圧縮、ゲーム、ネットワークプロトコルなど)でよく採用されます。 - zstd(Zstandard)
Facebook(現Meta)が開発した圧縮アルゴリズムで、高圧縮率と高速性の両立を狙っています。近年のバックアップツールやデータベース、アーカイブツールで採用例が増えています。 - 各言語標準ライブラリ
- Python:
gzip、zlib、bz2、lzmaモジュール - Java:
java.util.zipパッケージ - Node.js:
zlibモジュール
など、標準で可逆圧縮を扱えることが多く、外部依存を増やさずに導入できます。
- Python:
プログラムから扱う場合、基本的な流れはどのライブラリでも入力ストリームを圧縮器/伸長器でラップする、あるいはbyte列を関数に渡すという形です。
APIリファレンスやサンプルコードを一度なぞっておくと、実務でスムーズに活用できるようになります。
非可逆圧縮の基本
非可逆圧縮とは何か
非可逆圧縮とは、圧縮・伸長の過程で元データの一部情報を意図的に捨てる圧縮方式です。
伸長しても、元データを完全に復元することはできません。
ここで重要なのは、人間の知覚特性を利用して「失っても気づきにくい情報」を削る点です。
たとえば画像であれば、人間の目が感じにくい微妙な色の差をまとめてしまったり、音声であれば、人間の耳が聞き取りにくい周波数帯を間引いたりします。
非可逆圧縮の代表的な形式
非可逆圧縮は、主にマルチメディアデータで使われます。
| 分野 | 形式・規格 | 説明 |
|---|---|---|
| 画像 | JPEG | 写真などの自然画像に適した形式。高い圧縮率が得られる。 |
| 画像 | WebP(lossy) | JPEGよりも高圧縮率を目指した新しめの形式。Webでの利用が増えている。 |
| 画像 | HEIF/HEIC | スマートフォン(とくにiOS)で採用される高効率画像形式。 |
| 音声 | MP3 | 長年標準的に使われてきた音楽の圧縮形式。 |
| 音声 | AAC | MP3より効率がよいとされ、多くのストリーミングサービスで採用。 |
| 動画 | H.264/AVC | 現在もっとも広く使われている動画コーデック。 |
| 動画 | H.265/HEVC、AV1 | H.264より高圧縮率を狙う新世代動画コーデック。 |
これらは多くの場合、「コンテナ形式」(MP4、MKV、WebM など)の中で使われるコーデックです。
プログラミングで動画や音声を扱うときには、コンテナとコーデックの組み合わせを意識する必要があります。
非可逆圧縮の仕組みのイメージ
非可逆圧縮の中身はかなり数学的ですが、「大まかな流れ」をイメージで押さえることはできます。
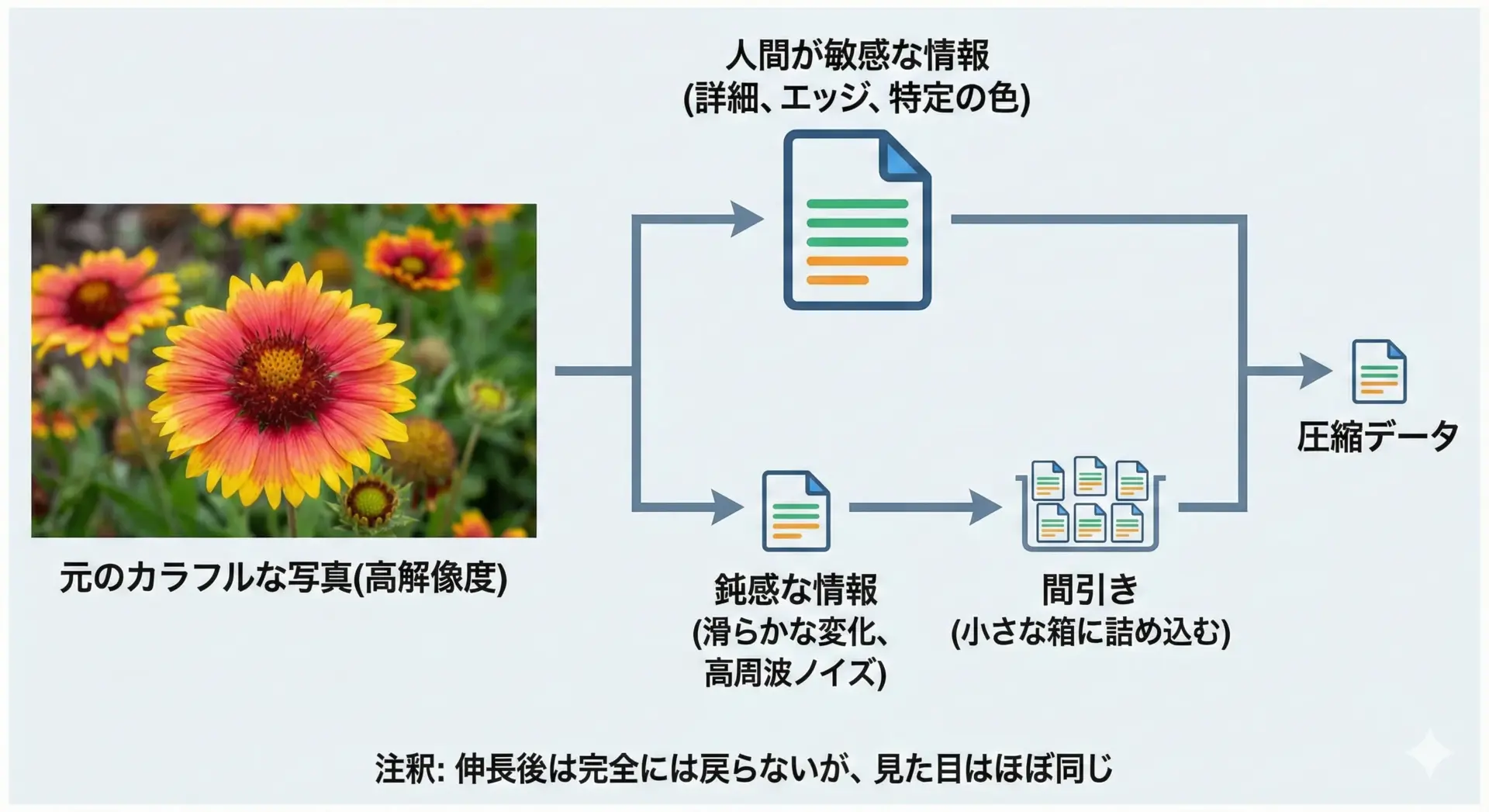
典型的なJPEGを例にすると、おおよそ次のような処理が行われています。
- 画像を小さなブロックに分割する
- 各ブロックを周波数成分に分解する(離散コサイン変換: DCT)
- 人間が感じにくい高周波成分を粗く量子化(丸め)する
- 残った成分を可逆圧縮(ハフマン符号など)でさらに小さくする
「非可逆」なのは主にステップ3の量子化の部分で、ここで細かい情報が失われます。
その後の可逆圧縮部分は、さらにサイズを減らすための追加工程です。
画像・音声・動画で非可逆圧縮が多く使われる理由
画像・音声・動画で非可逆圧縮が選ばれる理由は、次の2点に集約されます。
1. 人間の感覚には「限界」があるから 人間の目や耳は、一定以上の細かさを区別できません。
- 画像: 微小な色の差や高周波ノイズは、ほとんど気づかれない
- 音声: ごく小さな音やマスキングされる音(大きな音に隠れる音)は聞こえにくい
この「気づきにくい部分」を削ることで、情報を減らしても体感品質をあまり落とさずに済みます。
2. データ量が桁違いに大きいから 非圧縮のフルHD動画(1920×1080, 60fps, 24bitカラー)は、1秒あたり数百MBにも達します。
音声も、非圧縮のPCM(44.1kHz, 16bit, ステレオ)だと1分で約10MBです。
非可逆圧縮を使うと、これらを10分の1〜100分の1程度にまで削減できるため、ストリーミングやオンライン配信には必須の技術になっています。
非可逆圧縮の長所と短所
非可逆圧縮には、はっきりしたメリットとデメリットがあります。
長所
- 圧縮率が非常に高い
同じ品質レベルを保ちながら、可逆圧縮よりもずっと小さなサイズにできます。 - ストリーミングやオンライン配信に向く
帯域が限られた環境でも、動画や音楽をリアルタイムに届けやすくなります。
短所
- 元に完全には戻せない
一度非可逆圧縮をかけたデータから、元の完全な情報を再構成することは不可能です。 - 繰り返し再圧縮で品質が劣化する
JPEG画像を開いて再保存する、動画を再エンコードする、などを繰り返すと、「ブロックノイズ」や「モスキートノイズ」などが目立つようになってきます。 - アーカイブやバックアップには不向き
将来にわたって「正確なデータ」を残したい用途には使えません。
プログラミングでは、「ユーザーが直接見るための最終出力なのか」「将来の再利用のための保存データなのか」という観点で使い分けることが重要です。
可逆圧縮と非可逆圧縮の使い分け
どちらを選ぶかの判断基準
可逆圧縮と非可逆圧縮の使い分けは、次の観点で判断すると整理しやすくなります。
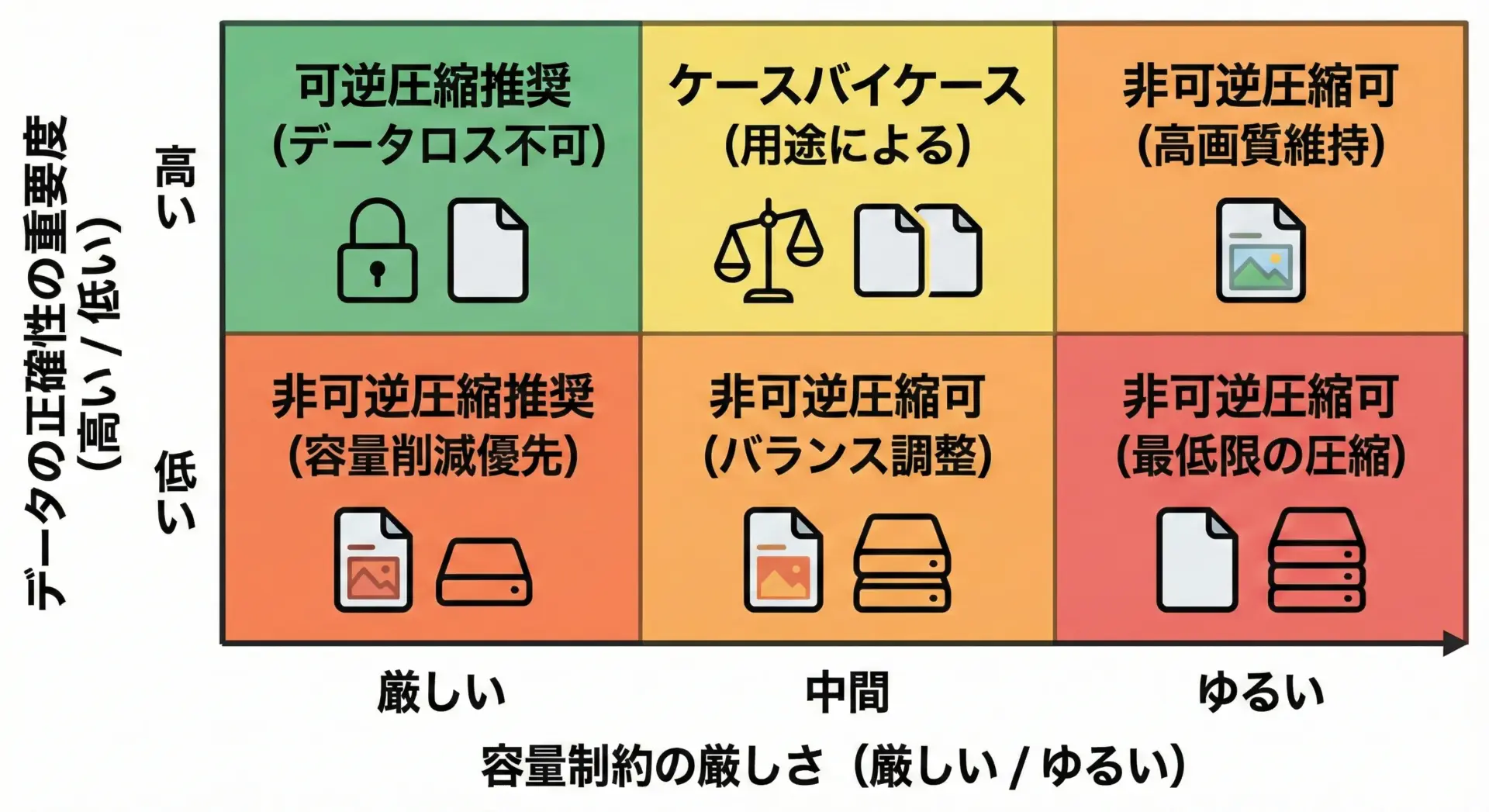
1. 正確性が最優先かどうか
- 正確性が最優先 → 可逆圧縮一択
- 多少の劣化が許容される → 非可逆圧縮も検討
2. 容量・帯域の制約がどの程度厳しいか
- 非常に厳しい(モバイルネットワーク、長期保存コストなど) → 非可逆圧縮の価値が大きい
- そこまで厳しくない → 可逆圧縮でシンプルに運用する選択肢もある
3. データのライフサイクル
- 将来、再編集や再解析の可能性が高い → 可逆圧縮
- 最終成果物で、視聴・閲覧が主な用途 → 非可逆圧縮が有力候補
このように、単に「何となく JPEG で」ではなく、要件に基づいて圧縮方式を選ぶことが、堅実なシステム設計につながります。
バックアップやログには可逆圧縮を選ぶ理由
バックアップファイルやログデータには、原則として可逆圧縮を用いるべきです。
その理由は次の通りです。
1. 復元時に正確な状態が必要だから バックアップの目的は「障害時に元の状態を忠実に戻すこと」です。
非可逆圧縮で一部の情報が欠落していた場合、データ不整合やアプリケーションエラーの原因になります。
2. ログは後からの解析・監査のための証拠だから ログは、不具合解析や不正アクセス調査などの「事後的な分析」で重要な役割を果たします。
1行でも欠落したり改変されたりすると、誤った結論に至る可能性があります。
そのため、ログ圧縮にはgzipやbzip2などの可逆圧縮を使うのが定石です。
3. 将来の再利用やマイグレーションを考慮する必要があるから バックアップデータは、将来別のシステムやフォーマットに移行する際にも利用されるかもしれません。
非可逆圧縮された状態では、移行後のシステムで意図しない動作をする可能性があるため、避けるのが無難です。
Web画像やストリーミングに非可逆圧縮を使う理由
一方で、Webページや動画配信などの分野では、非可逆圧縮が積極的に利用されます。
1. ページ表示速度・再生開始時間が重要だから ユーザーは、ページが数秒表示されないだけで離脱してしまいます。
画像サイズを削減することは、Webパフォーマンス最適化(Core Web Vitalsなど)の重要な要素です。
JPEGやWebP(lossy)を使うことで、画像の見た目を保ちつつ、ページ全体のサイズを大幅に削減できます。
動画ストリーミングでは、「再生が途切れないこと」が体験の要です。
非可逆圧縮を用いてビットレートを抑えることで、モバイル回線でも滑らかな再生が可能になります。
2. ユーザーは「完璧な原本」より「快適な視聴」を求めるから 多くのユーザーにとって、細部の画素が完全に一致しているかどうかよりも、
- ページが素早く開く
- 動画が止まらずに見られる
といった体験の方が重要です。多少の画質劣化を許容することで、体験全体の質を高められる点が、非可逆圧縮が選ばれる大きな理由です。
プログラミングでの実践例
最後に、プログラミングでの典型的な実践例をいくつか挙げます。
1. Web APIレスポンスの圧縮(gzip)
多くのWebサーバやアプリケーションフレームワークでは、HTTPレスポンスをgzipで圧縮する機能があります。
- JSONやHTML、CSS、JavaScriptなどのテキストレスポンス
- 圧縮前提のバイナリフォーマットではないが、サイズ削減したいデータ
これらには可逆圧縮(gzip)を適用するのが一般的です。
クライアントがAccept-Encoding: gzipを送っていれば、サーバ側でContent-Encoding: gzipを付与して圧縮応答します。
2. ログローテーションでのgzip圧縮
Linux環境などでは、logrotateを使ってログを一定期間ごとにローテーションし、古いログを.gzに圧縮するのがよくあるパターンです。
- ファイル:
app.log.1.gz,access.log.2024-01-01.gzなど - 圧縮形式: 可逆圧縮(gzip)
こうすることで、ディスク容量を節約しつつ、必要になったときに完全なログを復元できる運用が実現できます。
3. 画像配信でのJPEG/WebP変換
Webアプリケーションでは、ユーザーがアップロードした画像(しばしばPNGや非圧縮の状態)を、サーバ側でJPEGやWebP(lossy)に変換して配信することがあります。
- オリジナル: PNG(可逆)で保存しておく
- 配信用: JPEG/WebP(lossy)でサイズを小さくして配信
このように、オリジナルは可逆形式で保持し、ユーザー向けの配信は非可逆形式で最適化する構成は、品質とコストのバランスがよいパターンです。
4. 音声・動画のトランスコード
配信サービスやメディア変換ツールでは、入力ファイル(ときに可逆形式)を各種ビットレートの非可逆形式に変換する処理を行います。
- 入力: WAV(PCM, 可逆)やFLAC(可逆)
- 出力: MP3/AAC(音声)、H.264/H.265/AV1(動画)
この際、解析・編集用には可能な限り可逆形式を維持し、配信用には非可逆形式を使うのが定石です。
まとめ
本記事では、データ圧縮の基本から、可逆圧縮と非可逆圧縮の違い、代表的な形式、仕組みのイメージ、そしてプログラミングでの具体的な活用例までを解説しました。
可逆圧縮(lossless)は、元のデータを1ビット単位で正確に復元できる圧縮方式であり、テキスト、ソースコード、ログ、バックアップなど、正確性が最重要なデータに必須です。
ZIP、gzip、PNG、FLACなどが代表例です。
一方、非可逆圧縮(lossy)は、人間が気づきにくい情報を削ることで高い圧縮率を実現する方式で、JPEG、MP3、H.264などが代表例です。
画像・音声・動画の配信やWebページの高速化に欠かせませんが、元に完全には戻せないという制約があります。
実務では、「正確性」「容量・帯域」「データのライフサイクル」という観点から、両者を適切に使い分けることが重要です。
- バックアップやログ、プログラムコード → 可逆圧縮
- Web画像やストリーミング、最終成果物のメディア → 非可逆圧縮(必要に応じて可逆原本も保持)
これらの考え方を押さえておくと、システム設計やパフォーマンスチューニングの場面で、より納得感のある技術選択ができるようになります。
