
文字列をBase64エンコードすると、突然「英数字と記号がごちゃまぜになった謎の記号列」に見えて驚くことがあります。
しかし、その正体はとても規則正しく、コンピュータにとって扱いやすい形に変換しただけのデータです。
この記事では、Base64エンコーディングの基本概念から仕組み、そして実際のプログラミングでの使い方まで、段階を追ってわかりやすく解説していきます。
Base64エンコーディングとは
Base64エンコーディングの基本概念
Base64エンコーディングとは、バイナリデータ(0と1の列)を、限定された64種類の文字だけを使って表現するためのルールです。
ここで使われる「64」という数字が、そのまま名前の由来になっています。
通常、コンピュータの世界ではデータはすべてビット(0か1)の組み合わせで表されます。
しかし、人間が読むテキストやメール、あるいは一部のプロトコルでは、バイナリのままでは扱いにくい、あるいは壊れてしまうことがあります。
そこで、どんなバイナリデータでも「印字可能な文字」だけで表現できるようにする中間形式として、Base64が広く使われています。
Base64は暗号ではなく、あくまで「エンコード(符号化)」であり、意味を変えずに表現方法を変えるだけという点が重要です。
エンコードした文字列をルールに従ってデコードすれば、必ず元のデータを復元できます。
文字列が謎の記号に見える理由
Base64でエンコードされた文字列は、たとえば次のような見た目になります。
SGVsbG8gd29ybGQ=aHR0cHM6Ly9leGFtcGxlLmNvbS8=
これらは一見すると意味のない記号の羅列のように見えますが、実際には「バイト列を6ビットずつ区切り、それぞれを特定の文字に対応させた結果」です。
人間が日常的に見るテキストは、文字コード表に沿って1文字ごとに意味を持ちます。
しかしBase64文字列は、1文字ごとに完結した意味を持つのではなく、複数文字がまとまることで元のバイト列を構成しています。
「謎の記号」に見える主な理由は、次の2点です。
- 英数字と記号を混ぜて使っているため、自然言語らしさがまったくない
- 人間が読むことを前提としていないため、意味のある単語やパターンがほとんど現れない
このため、暗号のように感じられますが、ルールさえ知っていれば機械的に元のデータを取り出せます。
Base64が使われる主な用途とメリット
Base64は、さまざまな場面で利用されています。
代表的な用途として、次のようなものがあります。
- メール(特に古い仕様のSMTP)で、添付ファイルなどのバイナリデータを送るとき
- HTTPヘッダー(例: Basic認証の認証情報)で情報を安全に運ぶとき
- JSONやXMLの中に画像やバイナリを埋め込みたいとき
- データURIスキームで、画像をHTMLやCSSに直接埋め込むとき
Base64を使うメリットとしては、以下の点が挙げられます。
1つ目は、非テキストデータを「壊れにくい形」でテキストとして扱えることです。
ネットワークやシステムによっては、特定のバイト値をうまく扱えなかったり、途中で勝手に改行や変換が入ってしまうことがあります。
Base64は印字可能な文字のみを使うため、こうしたトラブルを回避しやすくなります。
2つ目は、多くのプログラミング言語やライブラリで標準的にサポートされており、相互運用性が高いことです。
どの言語でもほぼ同じ結果が得られるため、異なるシステム間でデータをやり取りする際に便利です。
一方で、Base64はデータ量が約1.33倍(4/3倍)に膨らむというデメリットもあります。
そのため、サイズが重要な場面では使いどころに注意が必要です。
Base64エンコーディングの仕組みを分解
ビットとバイトの基礎知識
Base64の仕組みを理解するには、まずビット(bit)とバイト(byte)の関係を押さえる必要があります。
- 1ビット: 0 または 1 のどちらか一方
- 1バイト: 8ビット(例:
01000001)
通常、テキストファイルの1文字(ASCIIの場合)は1バイトで表現されます。
たとえばアルファベットのAは、ASCIIコードだと10進数で65、2進数だと01000001です。
Base64では、この「8ビットごとのグループ」をそのまま使うのではなく、6ビット単位に区切り直して別の文字に対応させるというアイデアを使います。
6ビットで表現できる値の範囲は0〜63なので、ちょうど64種類の文字に割り当てられる、というわけです。
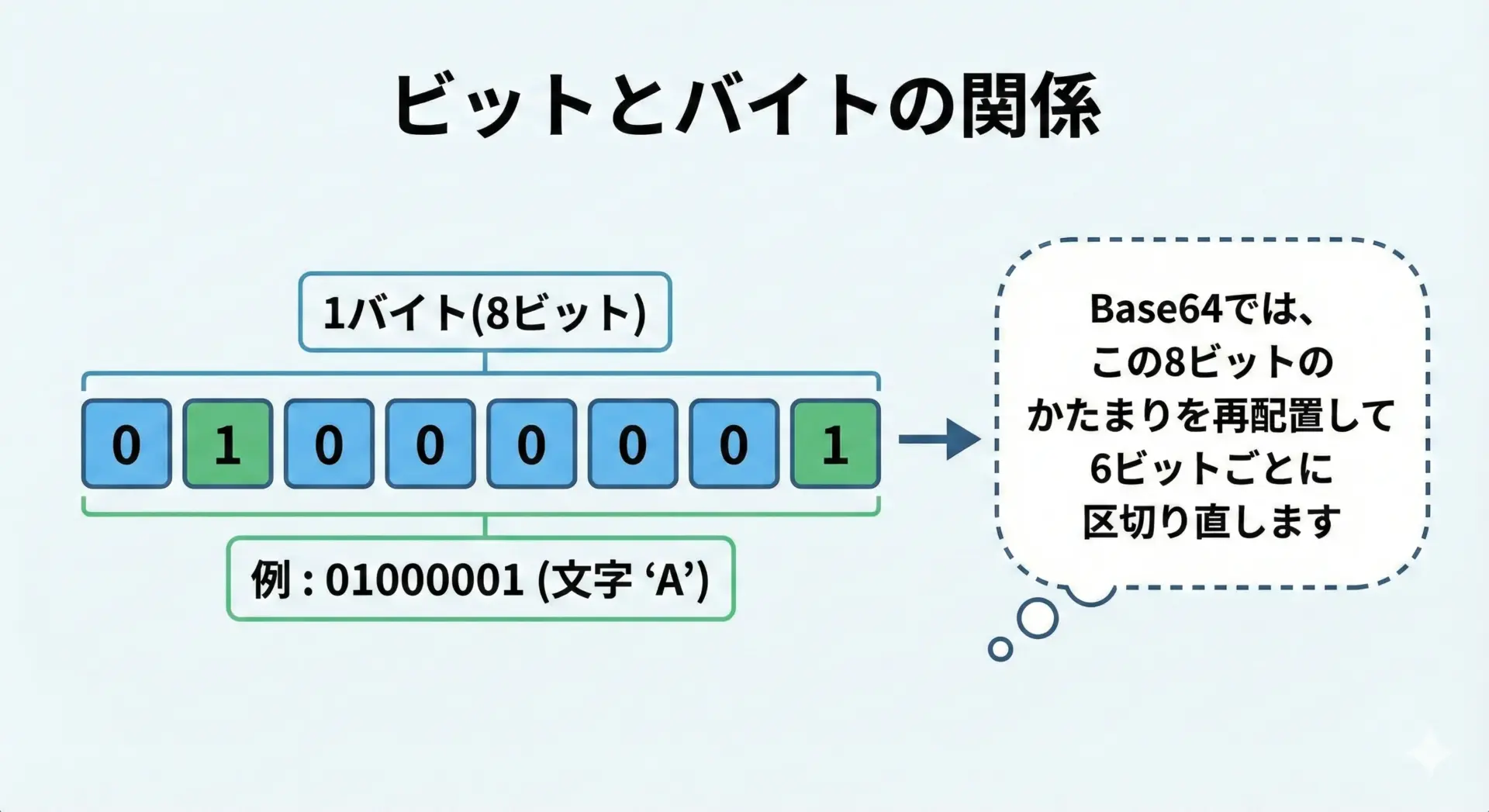
このように、Base64はビット列の「見方」を変えることで、別の文字集合へマッピングしているだけです。
3バイトを4つの数値に分割する流れ
Base64のコアとなる処理は、元のデータを3バイト(24ビット)ずつ取り出し、それを4つの6ビット(合計24ビット)に分割するという流れです。
流れを順番に見ていきます。
- まず、元データから3バイト(=24ビット)を取り出します。
- 24ビットを連結して1本のビット列として扱います。
- そのビット列を左から順に6ビットずつ、4つのグループに分割します。
- 各6ビットを0〜63の数値とみなし、その数値をBase64の文字一覧表から対応する文字に変換します。
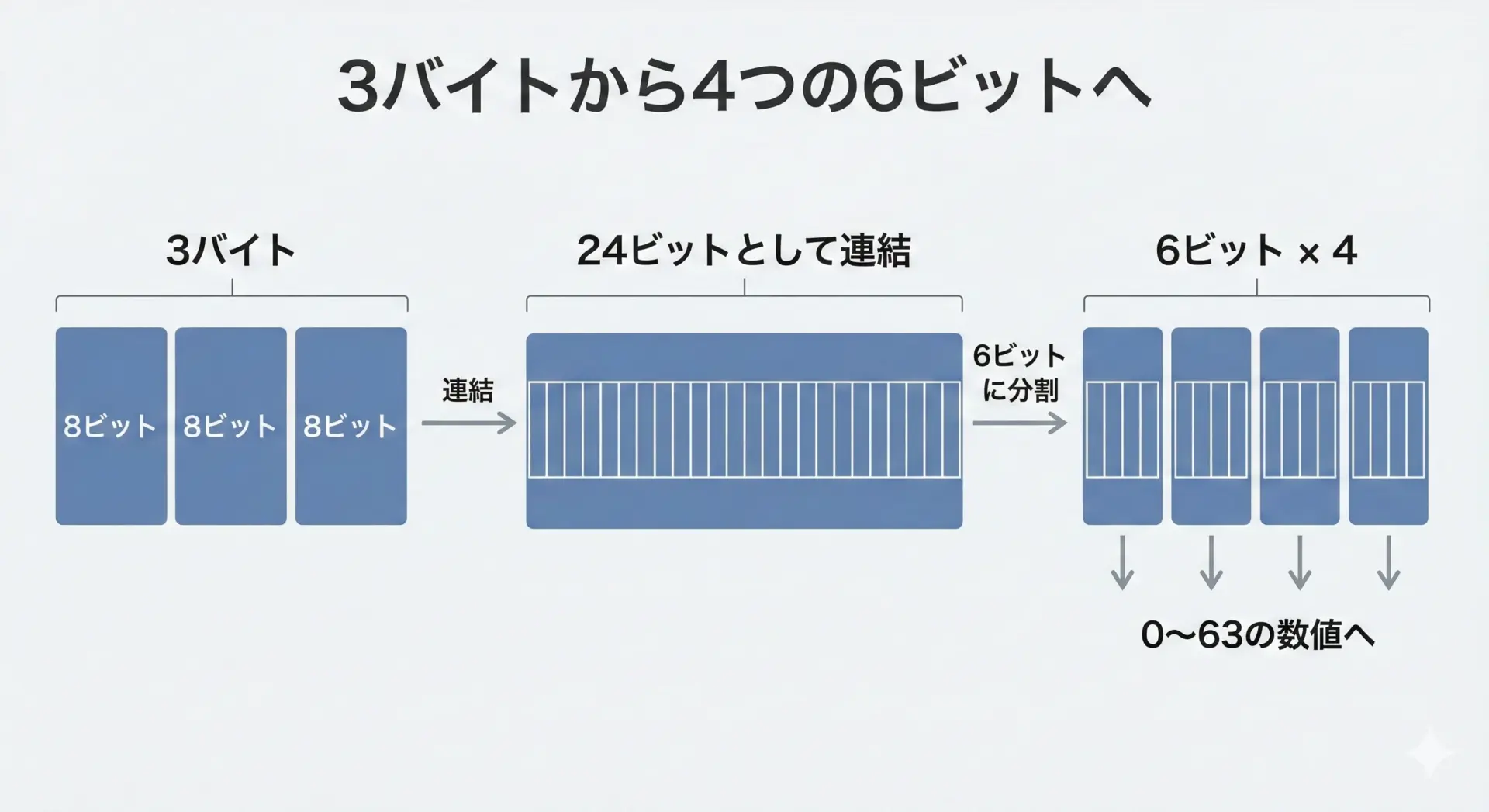
この変換によって、もともと3バイト(8ビット × 3 = 24ビット)だったデータが、4文字のBase64文字列(6ビット × 4 = 24ビット)として表現されることになります。
ビット数は変わっていないので、情報としては完全に等価です。
6ビットごとに区切って64種類の文字に対応させる
6ビットで表現できるパターンは2の6乗 = 64通りあります。
つまり、0〜63までの整数をすべてカバーできます。
Base64では、この0〜63の値を次のような文字に割り当てています。
- 0〜25: アルファベット大文字
A〜Z - 26〜51: アルファベット小文字
a〜z - 52〜61: 数字
0〜9 - 62: 記号
+ - 63: 記号
/
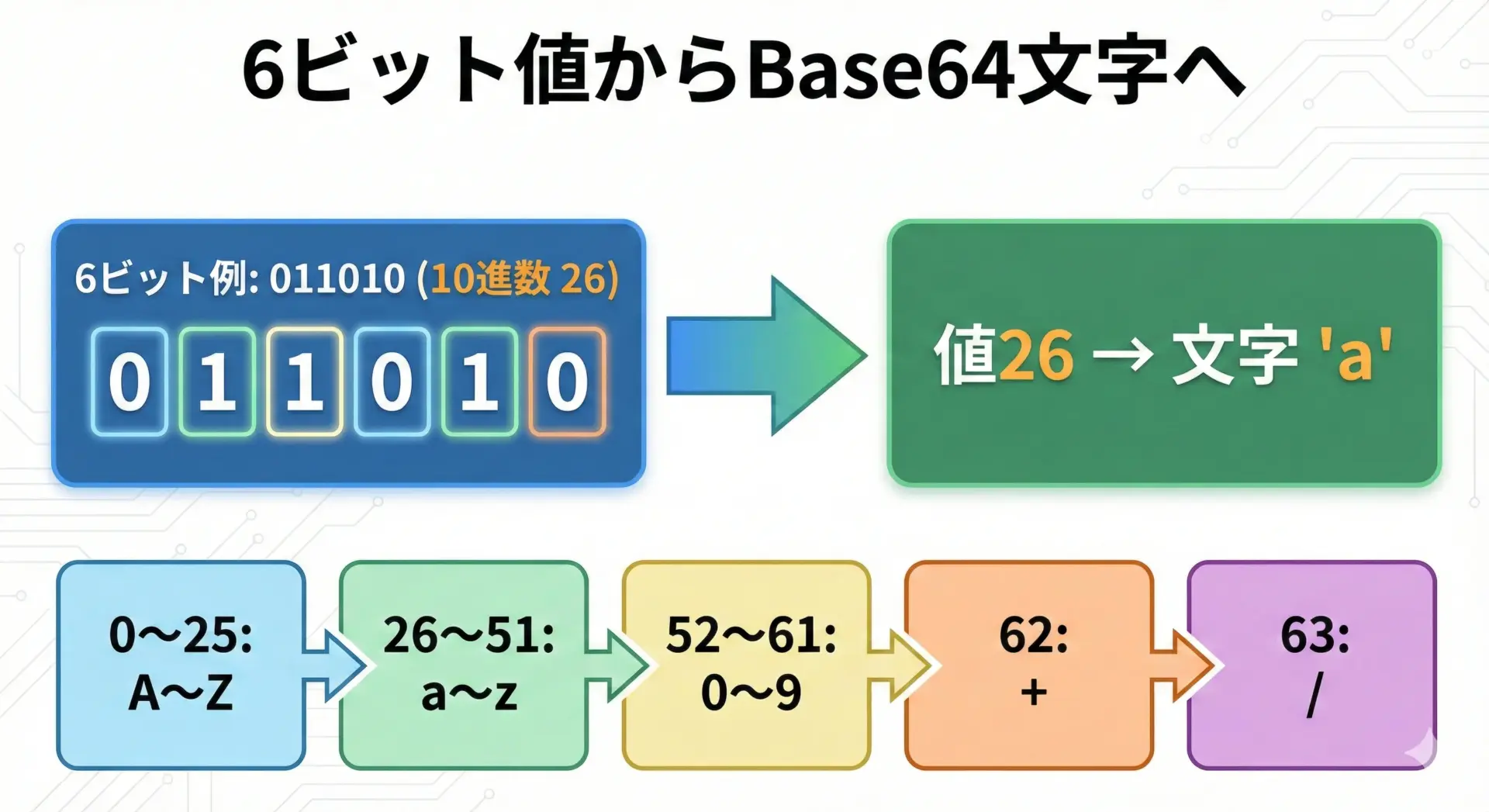
この対応によって、どんなバイト列であっても、必ず「A〜Z」「a〜z」「0〜9」「+」「/」「=」だけを使った文字列として表現できるようになります。
ここで'='は特別な役割(パディング)を持つので、次のセクションで説明します。
Base64の文字一覧
Base64で使われる64個の文字は、標準仕様で次の順番に定義されています。
この順番が、先ほどの0〜63の値にそのまま対応します。
| 値(10進数) | Base64文字 | 範囲の説明 |
|---|---|---|
| 0〜25 | A〜Z | 英大文字 |
| 26〜51 | a〜z | 英小文字 |
| 52〜61 | 0〜9 | 数字 |
| 62 | + | 記号 |
| 63 | / | 記号 |
具体的な一覧は、次のような並びになります。
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
この並び順がBase64の「辞書」のような役割を果たしており、エンコード時もデコード時も、この順番に基づいて変換が行われます。
たとえば、6ビット値が19であれば、上の文字列の19番目(0始まり)の文字であるTになります。
同じように、Base64文字eを見たときは、それが文字一覧の中で何番目かを数えることで、元の6ビット値を復元できます。
パディング記号(=)の役割
ここまでの説明では、元データが3バイトの倍数でぴったり分割できることを前提にしてきました。
しかし、実際のデータサイズは3バイトきっちりとは限りません。
そこで登場するのが、パディング記号'='です。
Base64では、次のように余りバイト数に応じて'='を付け加えます。
- 元データの長さが 3の倍数 → パディングなし
- 余り1バイト → Base64文字列の末尾に
==を付ける - 余り2バイト → Base64文字列の末尾に
=を付ける
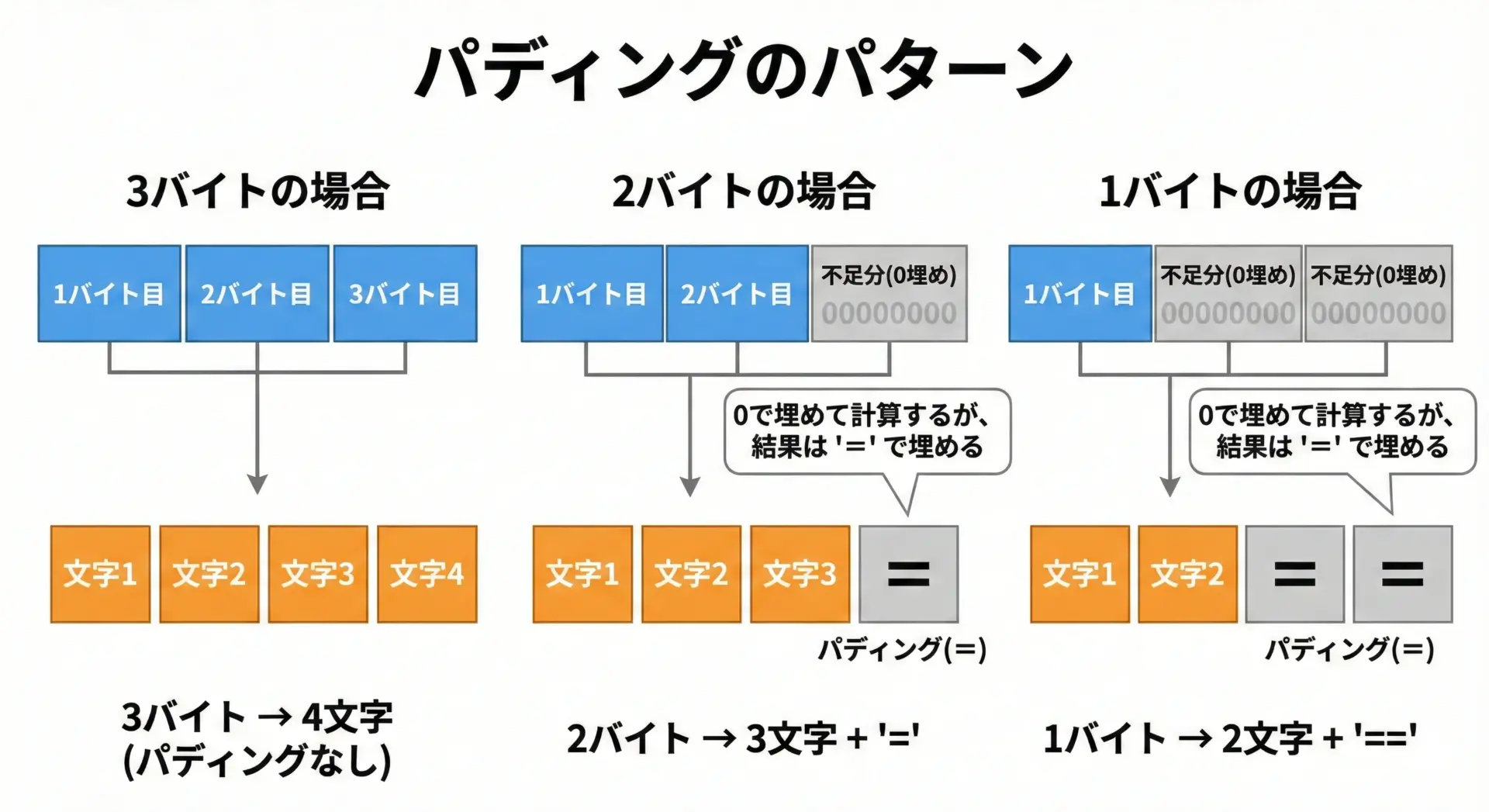
パディングは「本来のデータではないことを示すための目印」です。
エンコード時には、不足分のビットを0で埋めて計算しますが、デコード時には'='を見て「ここから先は本来のデータではない」と判断し、元のバイト数だけを復元します。
具体例で学ぶBase64エンコード
短い文字列(abc)のBase64エンコードを手計算する
ここからは、具体的な例として"abc"という文字列がどのようにBase64に変換されるかを手計算で確認してみます。
ASCIIを前提とします。
まず、各文字のASCIIコードと2進数表現を確認します。
| 文字 | 10進数(ASCII) | 2進数(8ビット) |
|---|---|---|
| a | 97 | 01100001 |
| b | 98 | 01100010 |
| c | 99 | 01100011 |
- 3文字分のビットを連結します。
01100001 01100010 01100011
- これを6ビットずつ区切ります。
011000 010110 001001 100011
- 各6ビットを10進数に変換します。
011000→ 24010110→ 22001001→ 9100011→ 35
- それぞれをBase64文字一覧から対応する文字に変換します。
- 24番目 →
Y - 22番目 →
W - 9番目 →
J - 35番目 →
j
したがって、"abc"をBase64エンコードすると"YWJj"になります。
3バイトぴったりなので、パディング'='は付きません。
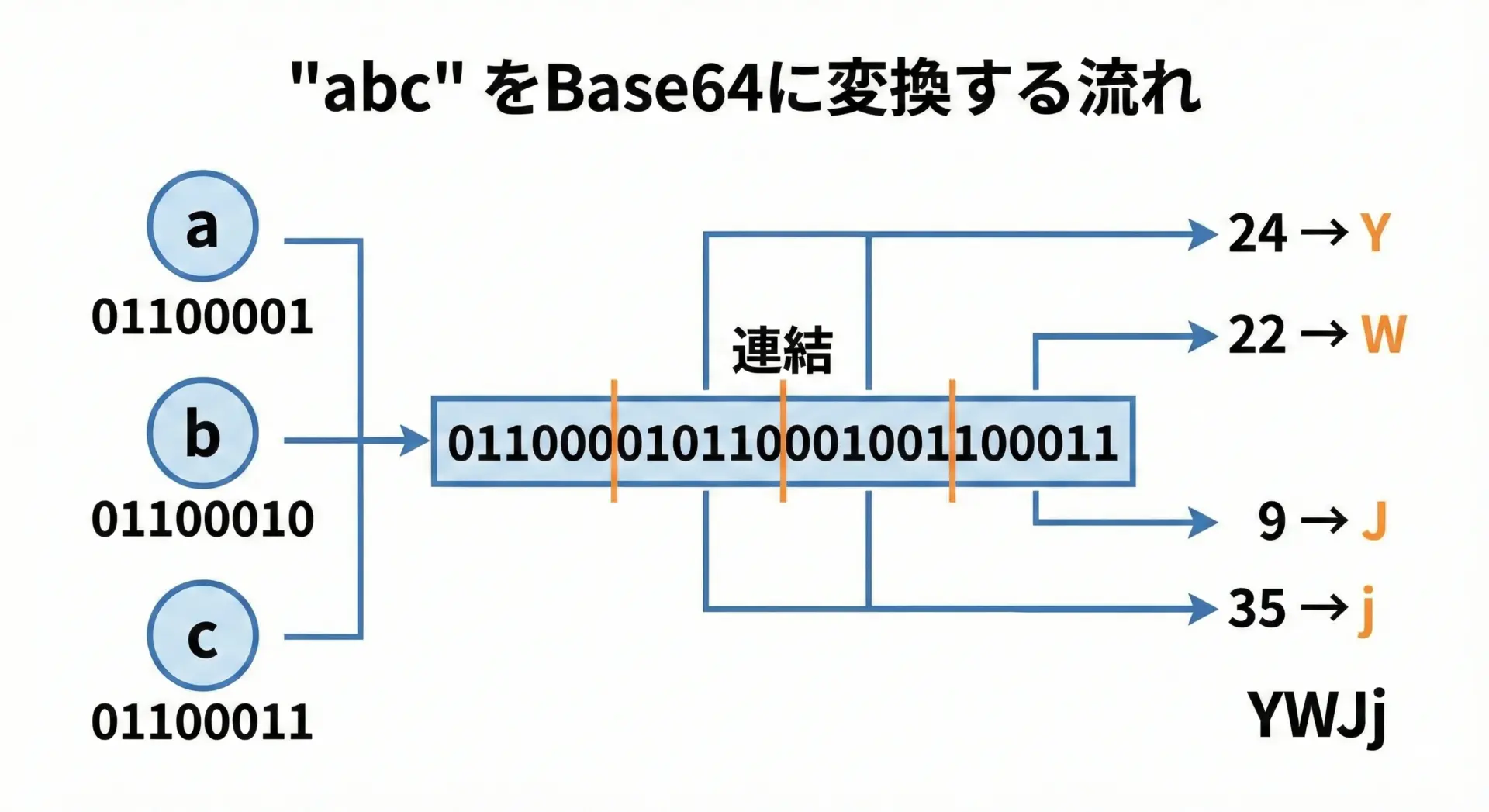
このように、実際に手で追ってみると「3バイト → 24ビット → 6ビット × 4 → 4文字」というパターンがはっきりイメージできるようになります。
日本語文字列をBase64エンコードする際の注意点
ここまでの例はASCII文字(1文字 = 1バイト)を前提にしていました。
しかし、日本語文字列はUTF-8などの文字コードでは1文字が複数バイトになります。
たとえば"あ"という文字は、UTF-8では次のように3バイトで表されます。
"あ"→ 16進数でE3 81 82→ 2進数で11100011 10000001 10000010
Base64はあくまで「バイナリ(バイト列)」を扱う仕組みなので、エンコード前にどの文字コードで文字列をバイト列に変換するかが重要になります。
多くのプログラミング言語やWebの世界ではUTF-8が標準なので、基本的には「UTF-8のバイト列をBase64エンコードする」と考えて問題ありません。
注意すべきポイントは以下の通りです。
- 同じ見た目の文字列でも、文字コードが違うとBase64結果も変わる
- フロントエンド(JavaScript)とバックエンド(他言語)で文字コード設定がずれていると、デコード時に文字化けする
- API仕様などでは「UTF-8でエンコードしたうえでBase64化する」と明示されることが多い
つまり、日本語を扱うときは「文字列 → 文字コード(例: UTF-8) → バイト列 → Base64」という二段階の変換を意識することが大切です。
改行やスペースはどう扱われるか
Base64エンコードの対象は、元のデータ中に含まれる改行やスペースも含めた「生のバイト列」です。
そのため、次の2つを区別する必要があります。
- 元データに含まれている改行・スペース
- Base64エンコード後の文字列を表示・送信する際に挿入される改行
1については、改行コードもスペースも他の文字と同じようにバイト列として処理され、そのままBase64化されます。
たとえば"a\nb"(a、改行、b)と"ab"は、もちろん異なるBase64文字列になります。
一方で2について、古いメール仕様などではBase64文字列を76文字ごとに改行するといったルールがありました。
現代の実装では、URL-safe Base64やAPIのやり取りなどでは、改行を一切入れずに1行で送ることが多いです。
実務上のポイントとしては、次のようなものがあります。
- ライブラリが自動で改行を挿入する/しない設定を持っている場合がある
- デコード側の実装によっては、改行やスペースを無視してくれる場合と、エラーになる場合がある
- Base64をURLやCookieに載せる場合は、改行を含めず1行で扱うのが一般的
このように、「どのレイヤーで挿入された改行なのか」を意識して扱うことが重要です。
プログラミングで使うBase64エンコード
よくある利用シーン
プログラミングの現場で、Base64は日常的に登場します。
代表的なシーンをいくつか挙げてみます。
1つ目は、HTTP Basic認証の認証情報です。
username:passwordという文字列をBase64でエンコードし、Authorizationヘッダーに載せて送信します。
このとき、Base64はあくまでフォーマット上の要件を満たすためであり、セキュリティ強化のための暗号ではありません。
2つ目は、JSONやXMLなどテキストベースのフォーマットにバイナリデータを埋め込む場合です。
画像ファイルのバイト列や、暗号化されたデータなど、そのままではテキスト形式に載せにくいデータをBase64に変換して文字列として扱います。
3つ目は、データURIスキームです。
HTMLやCSSの中に、data:image/png;base64,...という形で画像ファイルを直接埋め込むことができます。
これにより、外部ファイルを別途読み込まずにリソースを1つのファイルにまとめることができます。
このほか、JWT(Json Web Token)などのトークン形式でも、ヘッダーやペイロード部分をBase64URLというバリエーションでエンコードして利用しています。
代表的なプログラミング言語でのBase64エンコード例
多くのプログラミング言語は、標準ライブラリとしてBase64のエンコード/デコード機能を提供しています。
ここでは、いくつかの言語での典型的な使い方を簡単に紹介します。
Python
import base64
text = "Hello, world!"
# 文字列をUTF-8でバイト列にしてからBase64エンコード
encoded = base64.b64encode(text.encode("utf-8"))
print(encoded) # b'SGVsbG8sIHdvcmxkIQ=='
print(encoded.decode()) # 'SGVsbG8sIHdvcmxkIQ=='JavaScript(ブラウザ環境)
const text = "Hello, world!";
// btoa は基本的にASCIIを前提にしているため、日本語には注意が必要
const encoded = btoa(unescape(encodeURIComponent(text)));
console.log(encoded); // SGVsbG8sIHdvcmxkIQ==Node.js
const text = "Hello, world!";
const encoded = Buffer.from(text, "utf8").toString("base64");
console.log(encoded); // SGVsbG8sIHdvcmxkIQ==Java
import java.util.Base64;
String text = "Hello, world!";
String encoded = Base64.getEncoder().encodeToString(text.getBytes("UTF-8"));
System.out.println(encoded); // SGVsbG8sIHdvcmxkIQ==どの言語でも共通しているのは、「文字列 → バイト列(文字コード指定) → Base64」という流れを辿っている点です。
デコード時はその逆になります。
セキュリティ上の注意点
Base64は、セキュリティを高めるための技術ではありません。
これを理解しておかないと、意図せず弱い実装になってしまうことがあります。
Base64は「読みにくくする」ことはできますが、「守る」ことはできません。
ルールさえ知っていれば誰でも簡単にデコードできるため、次のような誤用は避けるべきです。
- APIキーやパスワードをBase64エンコードしただけで保存し、「暗号化したから安全」と考える
- URLパラメータをBase64化して、「中身を隠せた」と誤解する
- 機密情報をBase64のままログに書き出し、「一見わからないから大丈夫」と判断する
機密性が必要な場面では、暗号化(AESなど)とBase64を組み合わせるのが一般的です。
具体的には、「(平文 → 暗号化 → バイナリ) → Base64」という順番で処理します。
Base64は、暗号化結果のようなバイナリを文字列として安全に運ぶための「ラッパー」の役割を果たします。
また、JWTなどでBase64URLを使う場合も、Base64部分は単にエンコードされているだけであって、署名検証や暗号化を行わなければ改ざんや盗み見に対しては無防備であることを意識する必要があります。
まとめ
Base64エンコーディングは、一見すると「謎の記号の列」を生み出す不思議な仕組みのように見えますが、その中身は3バイトを24ビットとして扱い、6ビットごとに64種類の文字へマッピングするだけの、非常にシンプルで規則的な変換です。
パディング'='の役割も、本来のデータ長を正確に復元するための目印にすぎません。
プログラミングの世界では、メール、HTTPヘッダー、JSONやXMLへのバイナリ埋め込み、データURI、JWTなど、実に多くの場面でBase64が使われています。
その際には、文字コード(特に日本語でのUTF-8)や改行の扱いに注意しながら実装することが重要です。
そして何より押さえておきたいのは、Base64は暗号ではなく、あくまで表現形式を変換するためのエンコードであるという点です。
セキュリティが必要な場面では、暗号化と組み合わせることを前提に設計する必要があります。
Base64の仕組みをビットレベルで理解しておけば、エンコード結果を見たときに「なぜこうなるのか」を自信を持って説明できるようになりますし、トラブルシューティングや他者とのコミュニケーションでも大きな助けになります。
今回の内容を土台に、実際のコードやツールでエンコード・デコードを試しながら理解を深めてみてください。
