「同期処理」と「非同期処理」は、プログラミングの学習を進めると必ず出てくるキーワードです。
しかし、いきなりコードの話から入ると、イメージがつかめずにモヤモヤしやすい概念でもあります。
この記事では、まず日常生活の例からイメージを固めてから、プログラミングの話に少しずつ橋渡ししていきます。
コードを書く前に、頭の中に「動き方のイメージ」をしっかり作っておきましょう。
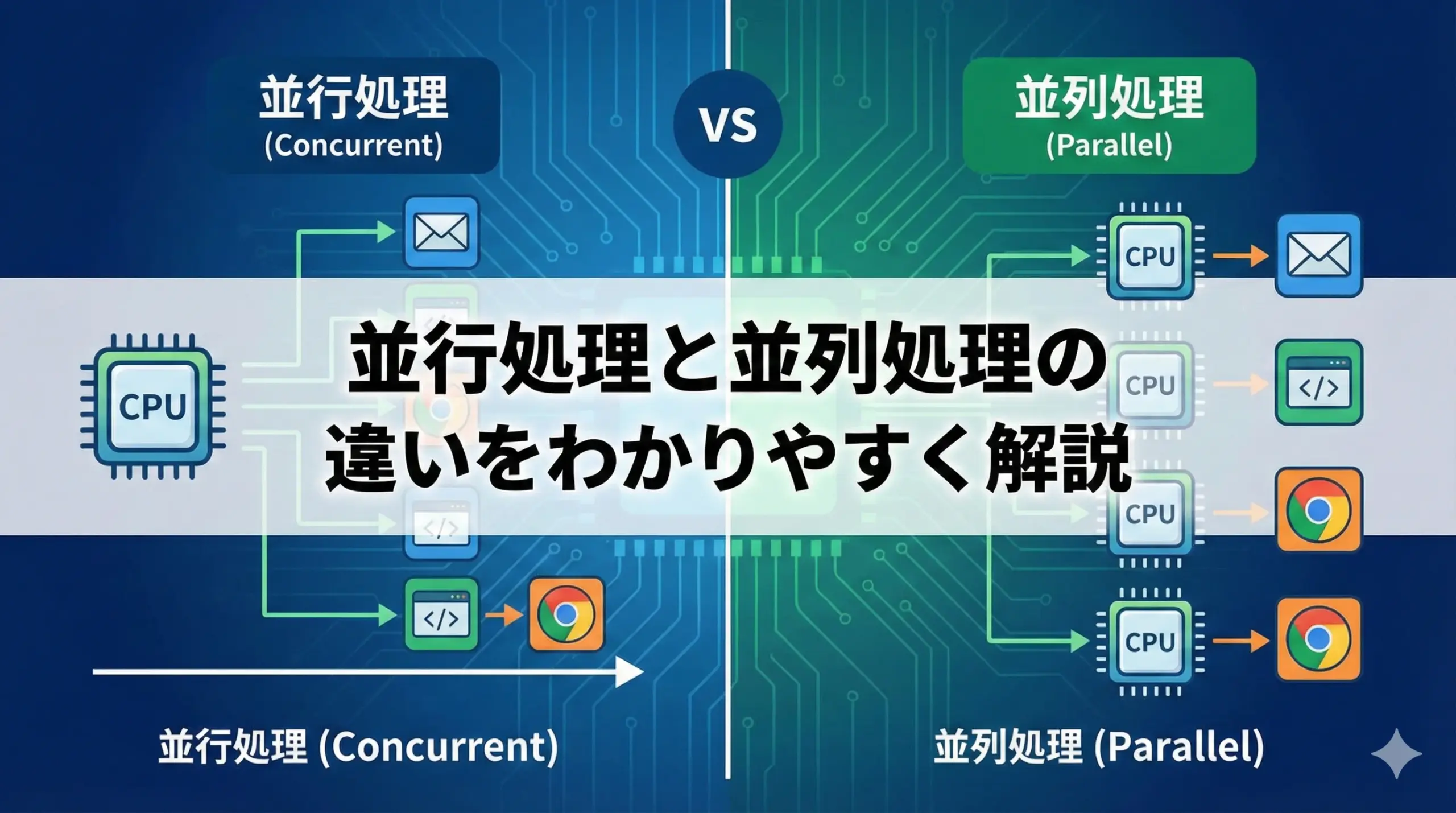
「同期処理」と「非同期処理」の基本をざっくり理解しよう
同期処理とは?
同期処理とは、「1つの処理が終わるまで、次の処理を始めないやり方」のことです。
処理が順番に、1本の線のように流れていきます。
プログラミング的に言うと、ある命令が完了するまで、次の命令が待たされる状態です。
例えば1 + 1を計算して、結果を画面に表示して、それが終わったら次にファイルを読む、というように常に「今やっている処理」が1つだけ存在します。
処理の流れは、上から順番に追いかければよいので理解しやすく、デバッグしやすいという特徴があります。
非同期処理とは?
非同期処理とは、「ある処理の完了を待っているあいだに、別の処理も進めるやり方」です。
1本の線ではなく、ところどころで枝分かれして、複数の流れが同時進行しているイメージです。
たとえば、サーバーにデータを取りにいく処理は時間がかかることがあります。
このとき、結果をずっと待ち続けて画面が固まってしまうと困るので、リクエストを送っておいて、返事が来るまでのあいだに別の処理を進める、というのが典型的な非同期処理です。
プログラムの世界では、コールバック関数やPromise、async/awaitなどを使って「終わったタイミングで通知を受け取る」という書き方をします。
同期処理と非同期処理の違いを一言でいうと
一言でいうと、「待つか、待たないか」の違いです。
- 同期処理: 前の処理が終わるまで待ってから次に進む
- 非同期処理: 前の処理の完了を待たずに、進められるところを先に進む
ただし、「待たない」といっても、結果がいらないわけではありません。
「結果が必要になる瞬間」まで、うまく待ち時間を隠しておくのが、非同期処理の肝になります。
同期処理を身近な例でイメージしよう
レジに一列で並ぶイメージ
同期処理は「レジに一列で並ぶ」ときの流れにたとえるとイメージしやすくなります。
1つのレジに、お客さんが1列に並んでいる状況を考えてみてください。
レジ係は、先頭の人の会計が完全に終わるまで、次の人の対応を始められません。
これはまさに同期処理です。
- 1人目の会計が終わるまで、2人目は待つ
- 2人目が終わるまで、3人目は待つ
「前の人の処理が終わらないと、自分の番が来ない」というルールが、同期処理の本質と同じです。
このように、処理が1列に並び、順番に1つずつ片付いていく様子を思い浮かべると、コードの実行順序もイメージしやすくなります。
料理を一品ずつ作るイメージ
もう1つ、「料理を一品ずつ作る」という例も同期処理のイメージにぴったりです。
たとえば、以下のような流れを考えます。
- 味噌汁を作る(だしを取る、具材を切る、煮る)
- 味噌汁が完全にできてから、次に焼き魚を焼き始める
- 焼き魚が終わってから、サラダを作り始める
この場合、常に「今作っている料理」は1品だけです。
味噌汁の煮込み中も、焼き魚の下ごしらえは始めません。
火にかけている時間もずっとコンロの前で待ち続けるイメージです。
同期処理では、このように「ひと仕事が終わるまで、次に手を付けない」ため、全体の完了まで時間がかかりますが、状態を把握しやすく、ミスも少なくなります。
同期処理のメリット
同期処理には、日常生活でもプログラミングでも、共通するメリットがあります。
1つ目は、「理解しやすさ」です。
処理が上から順番にしか進まないので、「次に何が起きるか」が直感的に分かります。
レジの例でも、「自分の番は、目の前の人が終わってから」と誰でも理解できますし、料理でも「味噌汁が終わったら焼き魚」という流れは追いやすいです。
2つ目は、「状態管理のしやすさ」です。
同時進行しているタスクが1つだけなので、「今システムが何をしているか」を追いやすく、バグの原因を特定しやすいという利点があります。
プログラムに置き換えると、同期処理は「実行の流れをトレースしやすい」という大きなメリットがあります。
特に初心者にとっては、動作のイメージが付きやすいので学びやすいスタイルと言えます。
同期処理のデメリット
一方で、同期処理にははっきりとしたデメリットもあります。
代表的なのは「待ち時間がそのままロスになる」ことです。
料理の例で言えば、煮込み時間のあいだ、何もしないでコンロの前で立ち尽くしている状態です。
その時間にサラダを切るなど、他の作業を進められるはずなのに、ルール上それができません。
プログラムの世界でも同じです。
ネットワーク通信やファイル読み込みなどの「時間のかかる処理」を待っているあいだ、CPUがほとんど何もせずに止まってしまうことがあります。
その結果、画面が固まったように見えたり、アプリの反応が悪く感じられたりします。
「シンプルだが、効率が悪くなりやすい」というのが同期処理の弱点です。
非同期処理を身近な例でイメージしよう
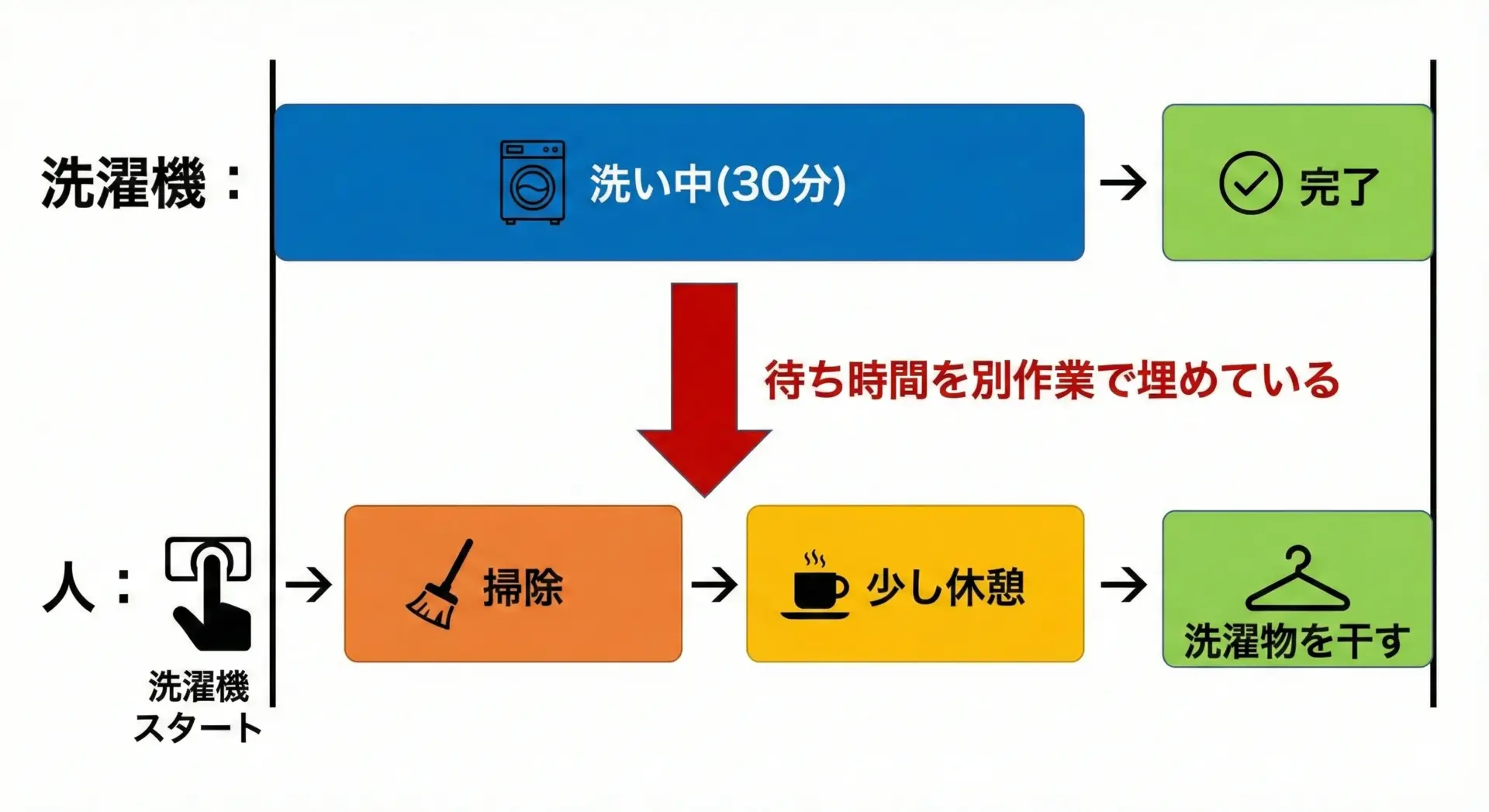
洗濯機を回しながら別の家事をするイメージ
非同期処理のイメージとして最も分かりやすいのが「洗濯機を回しながら、別の家事をする」というシーンです。
- 洗濯物を洗濯機に入れて、スイッチを押す
- 洗濯機が動いているあいだに、掃除機をかける
- 掃除が終わるころに洗濯も終わり、洗濯物を干す
ここで重要なのは、「洗濯機が終わるのを、じっと見て待っていない」という点です。
洗濯が終わるまでの30分間、その場に立ち尽くす必要はありません。
別の家事を進めることで、家事全体の完了時間を短縮できます。
非同期処理もこれと同じで、時間のかかる処理(洗濯)を機械に任せているあいだに、CPUは他の処理(掃除)を進めることができます。
レストランの注文と料理の提供のイメージ
もう1つの分かりやすい例が「レストランの注文と料理の提供」です。
- お客さんが注文をする
- 店員さんは注文をキッチンに伝える
- 料理ができあがるまでのあいだ、別のテーブルの注文を取ったり、片付けをしたりする
- 料理が完成したら、呼び出しがあり、該当テーブルに運ぶ
ここでも同じく、「料理ができるまで、そのお客さんの横に張り付いて待ち続ける」ことはしません。
キッチンから「完成しました」という通知が来たタイミングで、必要な行動(料理を運ぶ)を行います。
プログラムの非同期処理でも、「リクエストを投げておいて、結果が返ってきたタイミングでコールバックを実行する」というパターンが頻出します。
これはちょうど、「料理が完成したらベルが鳴るので、そのときに取りに行く」のとよく似ています。
非同期処理のメリット
非同期処理の最大のメリットは「待ち時間を有効活用できる」ことです。
洗濯機の例では、洗濯中に掃除や料理の下ごしらえを進めることで、トータルの家事時間を短縮できます。
レストランの例では、複数のテーブルを同時に回すことで、より多くのお客さんに効率よく対応できます。
プログラムで言い換えると、「I/O待ち(ネットワーク通信やディスクアクセスなど)でCPUを遊ばせず、その間に別の仕事をさせる」ということです。
これにより、以下のようなメリットが得られます。
- アプリのレスポンスがよくなる
- 画面が固まりにくくなる
- サーバーが多くのリクエストをさばけるようになる
特にWebアプリやスマホアプリの体験を良くするうえで、非同期処理は欠かせない技術です。
非同期処理のデメリット
メリットが大きい一方で、非同期処理には学習コストと設計の難しさというデメリットもあります。
最初にぶつかる壁は、「処理の順序が直感的でなくなる」ことです。
コード上では上から順番に書かれていても、実際の実行順序は「途中で別の処理が割り込んだり」「結果が返ってくるタイミングによって前後したり」します。
その結果として、以下のような難しさが生まれます。
- 「どのタイミングでこの変数は値が入るのか」が分かりにくい
- 結果を使う処理を、どこに書けばよいか迷う
- 複数の非同期処理を組み合わせると、処理の流れを追えなくなる
さらに、エラー処理や例外処理も複雑になりがちです。
同期処理ならtry ... catchで一括して扱えたものが、非同期の世界では.catch()やasync/awaitと組み合わせて考える必要があります。
「効率はよくなるが、頭の中のモデルが難しくなる」というのが、非同期処理の大きなトレードオフです。
プログラミングでの同期処理と非同期処理の使い分け
ここまでの例を、実際のプログラミングにどう結びつけるかを見ていきます。
どんなときに同期処理が向いているか
基本的な方針として、「待ち時間がほとんどない処理」や「順番がとても重要な処理」は同期処理のほうが向いています。
例えば、以下のようなケースです。
- 単純な計算処理(足し算・掛け算など)
- メモリ上のデータを少し書き換えるだけの処理
- 前の結果がないと次の処理が成立しないような、きっちりしたステップが必要な処理
「常に1列に並んでも、待ち時間が無視できるレベルなら、同期でシンプルに書いたほうがよい」と考えると分かりやすいです。
また、小規模なスクリプトやツール、バッチ処理など、ユーザーの操作に対してリアルタイムな応答性をそこまで要求しない場合も、同期処理をメインにした設計で十分なことが多いです。
どんなときに非同期処理が向いているか
非同期処理は、「待ち時間が長い処理」と「同時にたくさんのことをしたい処理」に向いています。
具体的には、次のような場面です。
- ネットワーク通信(APIリクエスト、ファイルのダウンロード、データベースアクセスなど)
- ディスクへの読み書き(大きなファイルの読み込み・保存)
- ユーザーインターフェースの操作を止めたくない処理(ボタンを押してからの処理など)
- 複数の外部サービスから同時にデータを取得したい場合
これらはすべて「洗濯機が回っている時間」や「料理ができあがるまでの時間」に相当します。
その待ち時間を、他の処理で埋めることで全体の速度を上げるのが非同期処理の役割です。
Web開発での非同期処理の具体例
Web開発、とくにフロントエンド(JavaScript)の世界では、非同期処理は日常茶飯事です。
いくつか典型的なパターンを見てみましょう。
例1: APIからデータを取得して画面に表示する
ブラウザでサーバーからデータを取得するとき、fetch()やaxiosなどは非同期で動作します。
例えば次のようなコードです。
async function loadUser() {
const response = await fetch("/api/user");
const user = await response.json();
console.log(user.name);
}ここではサーバーのレスポンスを待っているあいだも、ブラウザは固まらずに他の処理を続けられます。
ユーザーはスクロールしたり、別のボタンを押したりできます。
例2: ボタンを押したときの処理
ボタンのクリックイベントも、コールバックの形で非同期的に処理されます。
button.addEventListener("click", () => {
console.log("ボタンがクリックされました");
});プログラムは常に「ボタンが押されるまで待っている」わけではなく、イベントが発生したときにだけ、この処理が呼ばれます。
これも「通知が来たタイミングで動く」という意味で、非同期処理の一種です。
例3: 複数のデータを同時に取得する
非同期処理の強みを活かしたパターンとして、複数のAPIを同時に呼び出すというものがあります。
async function loadInitialData() {
const [userRes, articlesRes] = await Promise.all([
fetch("/api/user"),
fetch("/api/articles"),
]);
const user = await userRes.json();
const articles = await articlesRes.json();
console.log(user, articles);
}これは、レストランで複数のテーブルの注文を同時進行でキッチンに回し、料理ができたものから順に運ぶイメージです。
順番に1つずつ待つより、全体の待ち時間を大きく短縮できます。
初心者がつまずきやすいポイントと理解のコツ
非同期処理は便利ですが、初心者がつまずきやすいポイントがいくつかあります。
それぞれに対して、理解のコツもあわせて見ていきます。
つまずきポイント1: 「変数にまだ値が入っていない」問題
非同期処理では、以下のようなことがよく起きます。
let user;
fetch("/api/user").then(response => response.json()).then(data => {
user = data;
});
console.log(user); // ここではまだundefinedこのように、「値が入る前に変数を使ってしまう」問題が頻発します。
洗濯の例で言えば、「洗濯が終わる前に、まだ濡れている洗濯物を取り出そうとしている」ようなものです。
理解のコツは、「結果が必要な処理は、結果が届いた場所に一緒に書く」ことです。
Promiseなら.then()の中、async/awaitならawaitの後に書く、と意識すると整理しやすくなります。
つまずきポイント2: コールバック地獄・Promiseチェーンの混乱
複数の非同期処理を順番に行いたいとき、コールバックを入れ子にしすぎると、コードが右側にどんどんズレていき、「コールバック地獄」と呼ばれる状態になります。
doA(resultA => {
doB(resultA, resultB => {
doC(resultB, resultC => {
// ...
});
});
});これでは、処理の流れを追うだけで一苦労です。
理解と回避のコツは、「非同期処理を1つの直線に戻す」ことです。
Promiseやasync/awaitを使うと、見た目は同期処理のような書き方に近づけられます。
async function main() {
const resultA = await doA();
const resultB = await doB(resultA);
const resultC = await doC(resultB);
}これは、「実際は洗濯機やキッチンが裏で動いているけれど、表のレシピは1行ずつ順番に読める」状態だと考えるとイメージしやすいです。
つまずきポイント3: 「同期」と「非同期」が混じったコード
実際のアプリケーションでは、同期処理と非同期処理が混ざって存在します。
このとき、どこまでが同期で、どこからが非同期なのかが分からなくなりがちです。
理解のコツは、「待ち時間が発生しそうな場所にマーカーを付ける」意識を持つことです。
具体的には、以下のような関数は「たぶん非同期」と目星を付けておきます。
- ネットワーク関連の関数(
fetch、axios.getなど) - ファイル読み書き(
fs.readFileなど、言語や環境による) - タイマー(
setTimeout、setInterval) - イベントリスナー(クリック、入力、スクロールなど)
「これは洗濯機タイプの処理だな」とラベル付けする習慣をつけると、コードの理解がぐっと楽になります。
まとめ
同期処理と非同期処理の違いは、突き詰めると「前の処理を待つか、待たずに他の処理を進めるか」というシンプルなものです。
- 同期処理は、レジに一列で並ぶ、料理を一品ずつ作るイメージ。理解しやすく、状態管理もしやすい反面、待ち時間がそのままロスになります。
- 非同期処理は、洗濯機を回しながら別の家事をする、レストランで複数のテーブルを同時に回すイメージ。待ち時間を有効活用でき、アプリのレスポンスやスループットを向上させられる一方で、処理の流れやエラー処理が難しくなります。
プログラミングでは、「どちらが偉い」ということではなく、用途に応じて使い分けることが重要です。
待ち時間がほとんどなく、順番が重要な処理は同期でシンプルに書き、ネットワーク通信やファイルアクセスのように時間がかかる部分は非同期で並行して進める、というのがよくある設計パターンです。
最初は非同期処理の挙動に戸惑うかもしれませんが、日常生活の「待ち時間をどう使うか」という視点で考えると、一気に理解しやすくなります。
レジ、料理、洗濯機、レストランといった身近なイメージを頭の中に置きながら、実際のコードと結びつけていくと、徐々に「同期」と「非同期」が自然な感覚として身についていくはずです。
