
プログラムを勉強していると必ず出てくるのが「プロセス」と「スレッド」という用語です。
なんとなく「同時に動く何か」というイメージはあっても、2つの違いを説明しようとすると途端にあいまいになってしまう人は少なくありません。
この記事では、専門用語だけで押し切るのではなく、家や会社、ブラウザのタブといった身近な例を通して、プロセスとスレッドの違いを直感的にイメージできるようになることを目指します。
プロセスとスレッドの基本を押さえよう
まずは用語の定義から押さえておきましょう。
ここをあいまいにしたまま進んでしまうと、後半の話がすべてぼんやりしたままになってしまいます。
プロセスとは何か
プロセスとは「実行中のプログラムの単位」です。
もう少し噛み砕くと、OSから見たときに独立して動き、独立して終了できる作業のかたまりがプロセスだと言えます。
WindowsでもmacOSでもLinuxでも、アプリケーションを起動するとOSはそのアプリのために次のようなものを用意します。
- そのアプリ専用のメモリ空間
- 必要な資源(ファイルハンドル、ネットワークソケットなど)
- 実行状態を管理する情報(プロセスID、優先度など)
これらすべてをひっくるめた「動いている実体」がプロセスです。
プロセスは互いにメモリを直接共有しないのが基本ルールで、あるプロセスが間違って別のプロセスのメモリを書き換えてしまう、ということは通常は起きません(起きないようにOSが守っています)。
タスクマネージャやアクティビティモニタに並んでいる1行1行が、そのまま1つ1つのプロセスだとイメージすると分かりやすいです。
スレッドとは何か
スレッドとは「プロセスの中で動く処理の流れの単位」です。
ひとつのプロセスの中に、1本だけスレッドがあることもあれば、数十本、数百本のスレッドが動いていることもあります。
スレッドは、同じプロセス内のほかのスレッドと次のものを共有します。
- プロセスのメモリ空間(グローバル変数やヒープなど)
- 開いているファイルやソケットなどの資源
- 設定やキャッシュなど、プロセスに紐づいたデータ
一方で、スレッド固有の情報(実行中の位置、スタック領域、レジスタの内容など)はスレッドごとに分かれています。
同じプロセスのスレッド同士は、同じメモリを直接読み書きできるという点が、プロセスとの大きな違いです。
プロセスとスレッドを区別する3つのポイント
プロセスとスレッドを区別するときは、次の3点を意識すると整理しやすくなります。
1つ目はメモリ空間が独立か共有かです。
プロセスは基本的に他プロセスとメモリを共有しませんが、スレッドは同じプロセス内でメモリを共有します。
2つ目は影響範囲です。
あるプロセスがクラッシュしても、通常は他のプロセスには直接影響しません。
一方、あるスレッドが共有メモリを壊してしまうと、同じプロセス内の他のスレッドも巻き込まれてクラッシュすることがあります。
3つ目は作成や切り替えにかかるコストです。
プロセスを新しく作るには、独立したメモリ空間や資源を用意する必要があり、スレッドに比べてコストが高くなります。
スレッドは同じプロセス内で軽量に作成でき、切り替え(コンテキストスイッチ)も比較的低コストです。
この3点を頭の片隅に置いたまま、次の「身近な例」に進んでみてください。
身近な例でプロセスとスレッドをイメージする
抽象的な話だけだとイメージしづらいので、ここからは身近なものにたとえて感覚的に理解していきます。
「家と部屋」の例でプロセスとスレッドを理解する
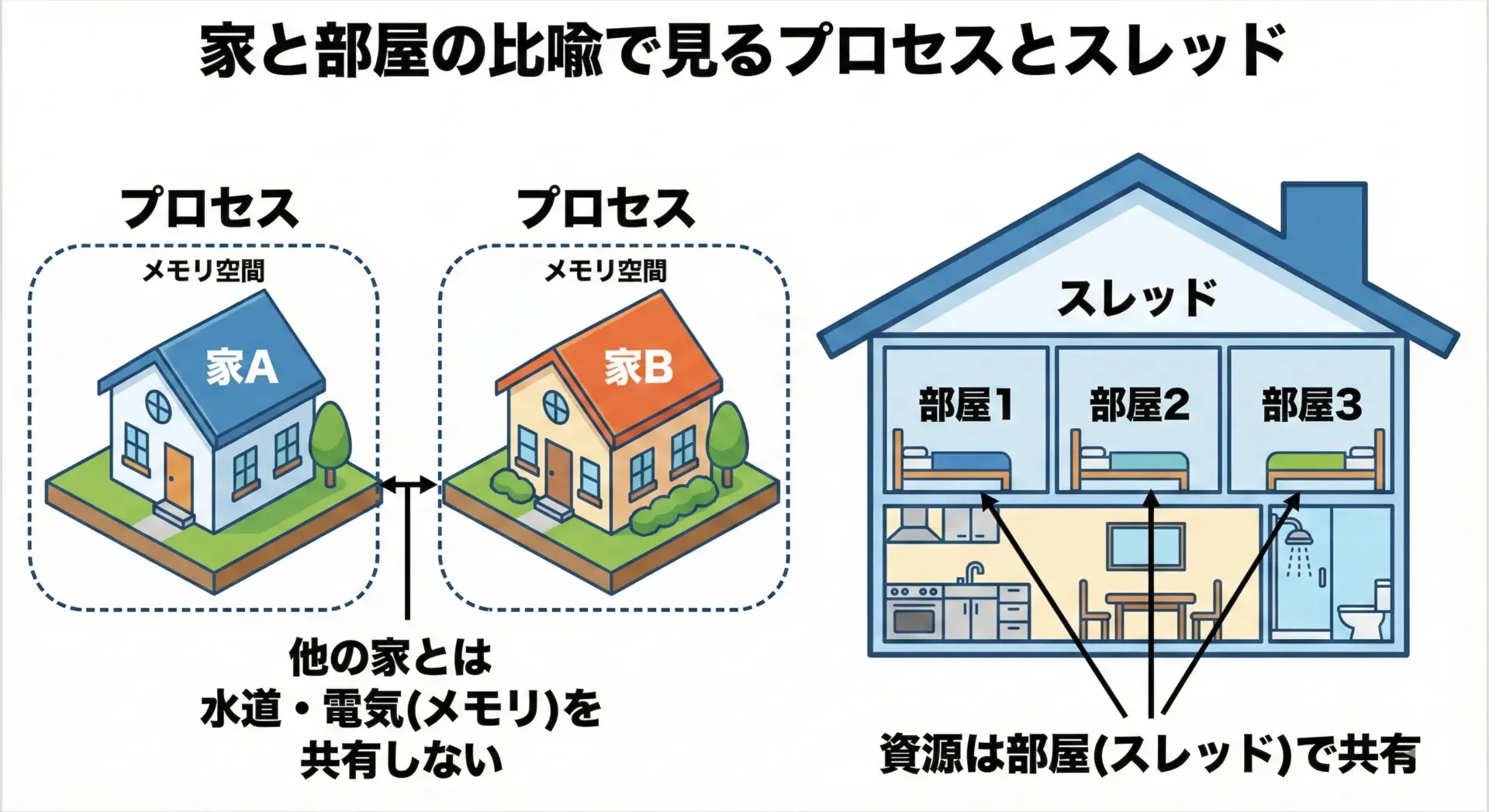
プロセスとスレッドの関係を「家と部屋」にたとえてみましょう。
- 家 = プロセス
- 部屋 = スレッド
- 家の敷地・インフラ(水道・電気・ガス) = プロセスが持つメモリや資源
1軒の家に部屋が1つだけある場合、その家には1つのスレッドしかありません。
部屋が増えると、その家の住人は複数の部屋を使い分けることができます。
この状態が、1プロセスの中で複数スレッドが動いているイメージに近いです。
同じ家の中の部屋は、キッチンやお風呂、電気などを共有しています。
スレッド同士も同じように、同じメモリやファイルなどの資源を共有しています。
誰かがブレーカーを落とすと、家全体が停電してしまうように、1つのスレッドが共有メモリを壊すとプロセス全体に影響します。
一方、隣の家(別プロセス)とは、水道や電気の契約は完全に別です。
ある家のトラブルは、直接隣の家には影響しません。
これが「プロセスが互いのメモリ空間を共有しない」ことのイメージです。
「会社と社員」の例で並行処理をイメージする
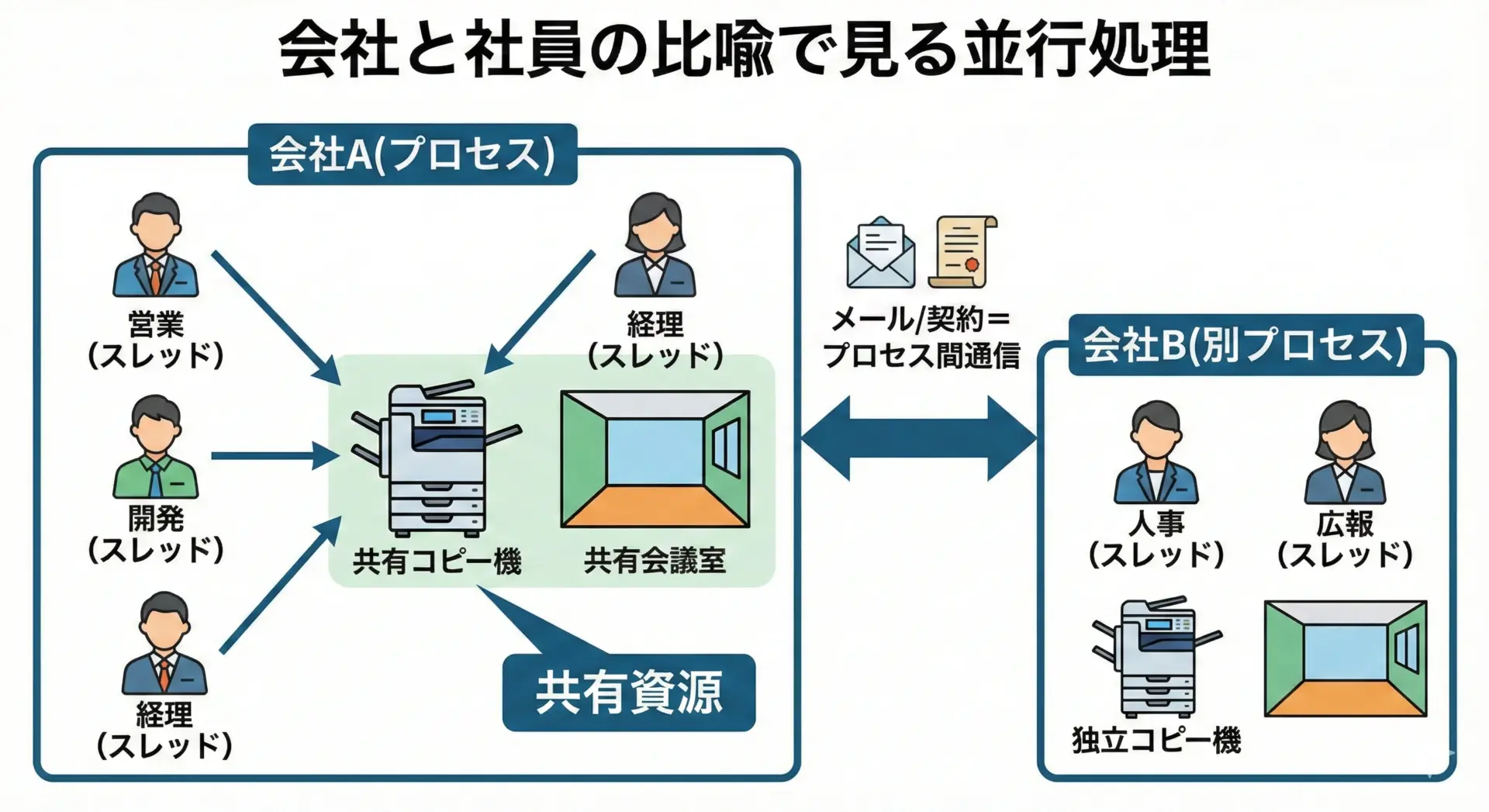
次に、「同時にいろいろな作業を進める」という観点から、会社を例に考えてみます。
- 会社 = プロセス
- 社員 = スレッド
- 会社の設備(コピー機、会議室、共有ファイルサーバ) = プロセスの資源
1人しか社員がいない会社では、営業も開発も事務処理も、その1人が順番にこなさなければなりません。
これはシングルスレッドのプログラムと同じ状態です。
社員が増えると、営業担当、開発担当、経理担当と役割を分けて同時に仕事を進められます。
これがマルチスレッドです。
ただし、社員同士は同じ会議室やコピー機を使うため、使う順番を調整しないとトラブルになります。
プログラムでも、共有資源へのアクセスを適切に制御しないとデータ競合が起きてしまいます。
一方、別の会社(別プロセス)は、自分たちの社員と設備だけで仕事を進めます。
A社の社員が、直接B社の社内サーバに勝手にアクセスすることは通常ありません。
プロセス間でデータをやり取りしたい場合は、メールや契約に相当する明示的な「プロセス間通信(IPC)」を行う必要があります。
「アプリとタブ」の例
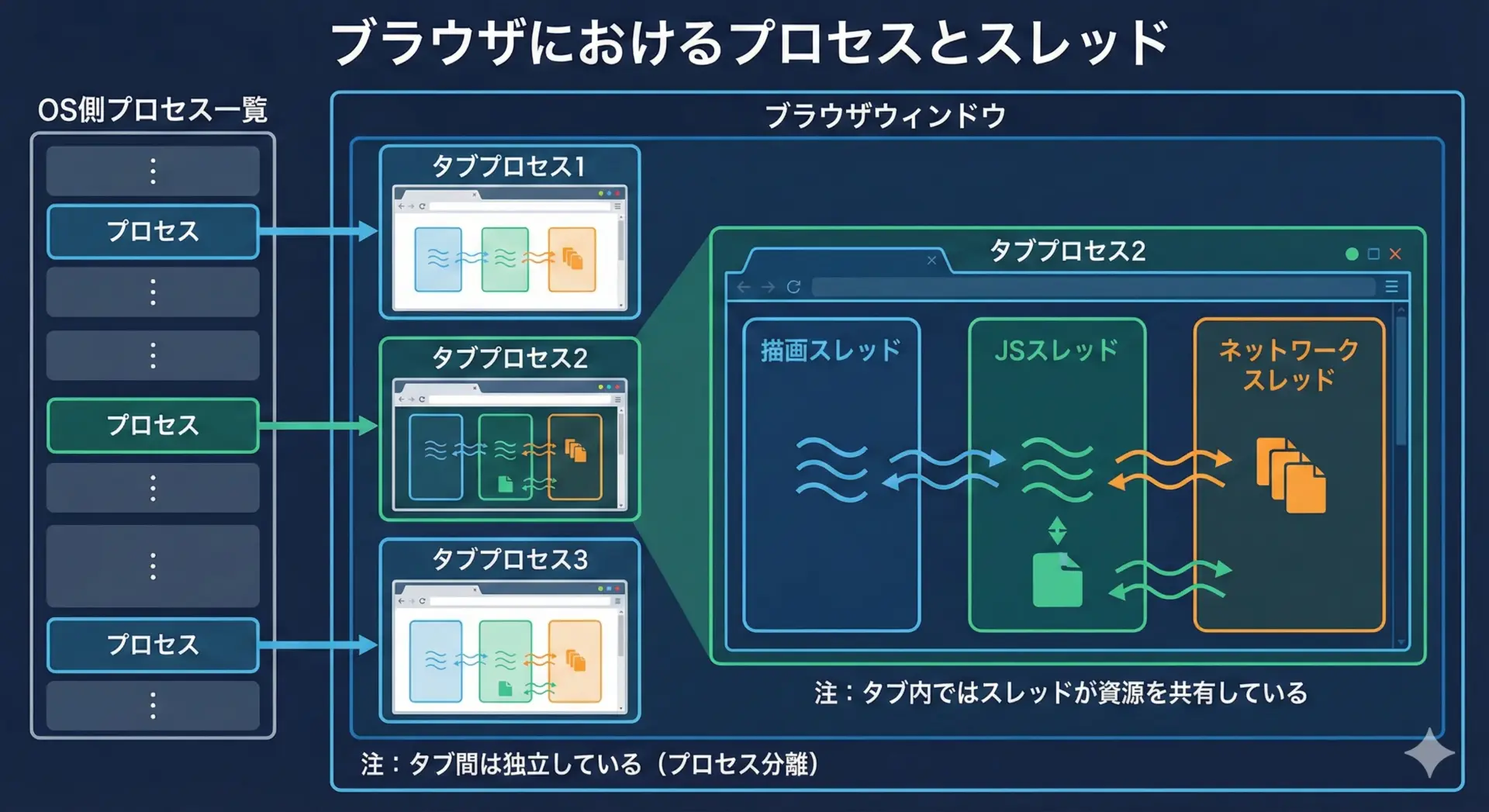
現代的な例として、ブラウザとタブを考えてみましょう。
多くのブラウザは、タブごとにプロセスを分ける方式を採用しています。
あるタブが重い処理で固まってしまっても、他のタブやブラウザ全体が巻き込まれにくくするためです。
この場合、タブ1つ1つがプロセスに近い役割を持っています。
一方、1つのタブの中では、描画処理、JavaScriptの実行、ネットワーク通信などが別々のスレッドで動いていることが多いです。
ユーザーがスクロールしても描画がスムーズなのは、描画専用スレッドが裏側で頑張っているからです。
このように、実際のアプリケーションでは「プロセス」と「スレッド」を組み合わせて、安全性と性能のバランスをとっています。
プロセスとスレッドの具体的な違い
ここまでのイメージをもとに、技術的にもう一歩踏み込んで違いを整理してみます。
メモリの使い方の違い
プロセスは、OSから完全に分離されたメモリ空間を与えられます。
他のプロセスとアドレス空間が重なって見えることはあっても、実際には別々の物理メモリに紐づいており、相手の中身を直接読んだり書き換えたりすることはできません。
これにより、1つのアプリが暴走しても、他のアプリのメモリを壊しにくくなります。
スレッドは、同じプロセス内のメモリ空間を共有します。
グローバル変数やヒープ上のオブジェクトなどは、どのスレッドからもアクセスできます。
その代わり、スタック領域やレジスタの内容など、そのスレッド固有の情報はスレッドごとに別々に管理されます。
この違いを整理すると、次のようになります。
| 項目 | プロセス | スレッド |
|---|---|---|
| メモリ空間 | 他プロセスと分離 | 同一プロセス内で共有 |
| グローバル変数 | プロセスごとに独立 | プロセス内の全スレッドで共有 |
| スタック | プロセス内の各スレッドで別々 | スレッドごとに独立 |
「共有されるもの」と「分離されるもの」を取り違えるとバグの原因になります。
特にスレッドプログラミングでは、「これはスレッド間で共有されるデータか?」と常に意識することが重要です。
安全性と影響範囲の違い
安全性という観点では、プロセスとスレッドには次のような違いがあります。
プロセスは「サンドボックス」のような保護領域として働きます。
あるプロセスがメモリ破壊や無限ループを起こしても、原則としてそのプロセスだけが終了し、他のプロセスには直接影響しません。
最近のブラウザがタブごとにプロセスを分けるのは、この特性を活かすためです。
一方、スレッドは安全性より効率を重視した仕組みです。
共有メモリに対するアクセスを適切に制御しないと、次のような問題が起こり得ます。
- データ競合(2つのスレッドが同時に同じ値を書き換え、結果が壊れる)
- デッドロック(お互いが相手のロック解除を待ち続けて処理が止まる)
- ライブロックや優先度逆転などのタイミング依存バグ
スレッド同士は「同じ会社の社員」のように、お互いの仕事に直接影響し合います。
便利な一方で、きちんとルール(ロックや同期)を決めて運用しないと問題が起きやすいのです。
作成コストと速度の違い
性能面では、次の2点が重要です。
1つ目は作成や終了のコストです。
プロセスを作るとき、OSは新しいメモリ空間や資源を準備しなければならず、そこそこ重い処理になります。
スレッドは既存のプロセス内に作るだけなので、比較的軽量です。
そのため、大量の同時実行単位が必要なときは、スレッドの方が向いていることが多くなります。
2つ目はコンテキストスイッチのコストです。
CPUが実行する対象を切り替えるとき、プロセスごと切り替えるよりスレッド同士を切り替える方が一般的に低コストです。
とはいえ、最近のOSでは最適化が進んでおり、その差は昔ほど極端ではありません。
このため、「性能だけ」を見るとスレッドの方が有利に見えますが、安全性や実装の複雑さとのトレードオフで考える必要があります。
マルチプロセスとマルチスレッドの特徴比較
ここまでの話を踏まえて、マルチプロセスとマルチスレッドを簡単に比較してみます。
| 観点 | マルチプロセス | マルチスレッド |
|---|---|---|
| メモリ共有 | 原則なし(IPCが必要) | 自然に共有される |
| 安全性 | 高い(他プロセスを巻き込みにくい) | 低め(共有メモリ破壊のリスク) |
| 作成・切替コスト | 高い | 低い |
| 実装の複雑さ | IPC設計が必要 | 同期制御が必要 |
| 向いている用途 | 独立性重視、異なる言語・ランタイムの組合せ | 高速な共有、軽量な並行処理 |
どちらが「優れている」かではなく、「どの性質を優先したいか」で選ぶのがポイントです。
プログラミングでどう使い分けるか
では、実際にプログラムを書くとき、どのような場面でプロセスやスレッドを選ぶべきでしょうか。
いつプロセスを使うべきか
次のようなケースでは、プロセスを使うことがよくあります。
1つ目は安全性や独立性を重視したいときです。
例えば、ブラウザのレンダリングエンジンやプラグイン、サンドボックスされた実行環境などは、バグが起きても他に影響を与えにくいようプロセスとして分離されることが多いです。
2つ目は異なる言語・ランタイム同士を組み合わせたいときです。
PythonとNode.js、あるいは異なるバージョンのランタイムを安全に共存させたい場合、プロセスを分けてHTTPやgRPC、標準入出力などで通信する構成がよく採用されます。
3つ目はメモリリークやクラッシュの影響を限定したいときです。
例えばワーカー型のサーバーで、処理を一定回数こなしたらプロセスごと終了・再起動することで、メモリリークをリセットする、といった設計も可能です。
このような場面では、多少のオーバーヘッドを受け入れてでも、プロセス境界による「壊れにくさ」を優先する価値があります。
いつスレッドを使うべきか
スレッドが効果的なのは、次のようなケースです。
1つ目は同じデータを共有しながら高速に処理したいときです。
例えば、メモリ上の大きなデータ構造を複数のタスクで並列に処理したい場合、プロセス間でデータをコピーするより、スレッドで共有した方が効率的です。
2つ目は大量の待ち時間(IO待ち)を伴う処理です。
ネットワーク通信やディスクIOを多用するアプリケーションでは、1つのスレッドが待機している間に別のスレッドで処理を進めることで、CPUの無駄を減らせます。
もっとも、最近はasync/awaitなどの非同期処理でスレッドを増やさずに対応するケースも増えています。
3つ目はGUIアプリでのバックグラウンド処理です。
メインスレッドは画面の描画とユーザー操作の受付に専念させ、重い計算や通信を別スレッドに任せることで、アプリを「固まりにくく」できます。
ただし、スレッド数を増やせば必ず速くなるわけではない点には注意が必要です。
同期やロックが増えすぎると、逆に性能が落ちることもあります。
初心者が最初に気をつけたいポイント
マルチプロセスやマルチスレッドに手を出すとき、初心者が特につまずきやすいポイントを挙げておきます。
1つ目は「共有されるデータ」と「共有されないデータ」の区別です。
プロセス間でメモリが共有されないこと、スレッド間ではグローバル変数やヒープが共有されることを、常に意識する必要があります。
これを誤解すると、「なぜか値が変わっている」「なぜか反映されない」といった不可解な挙動に悩まされます。
2つ目は同期とロックです。
複数スレッドが同じデータを更新する場合、mutexやlockなどを使って、排他制御を行う必要があります。
とはいえ、ロックを増やしすぎるとデッドロックの原因にもなるため、設計段階から「どのデータを誰がいつ触るか」を意識することが大切です。
3つ目はデバッグの難しさです。
並行処理のバグは、同じ手順を踏んでも毎回は再現しない「タイミング依存バグ」になりやすく、原因特定が難しくなります。
最初のうちは、できるだけシンプルな設計にとどめること、そしてテストコードやログ出力を積極的に使うことをおすすめします。
また、多くの高レベル言語やフレームワークは、スレッドやプロセスを直接意識せずに並行処理を書ける抽象化(スレッドプール、タスク、非同期関数など)を提供しています。
最初から生のスレッド操作に飛び込むのではなく、こうした抽象レイヤーを上手に活用するのも1つの戦略です。
まとめ
プロセスとスレッドの違いは、一言で言えば「独立した家」か「家の中の部屋」かだと整理できます。
プロセスは互いにメモリを共有せず、安全性や独立性が高い一方で、作成や切替にはそれなりのコストがかかります。
スレッドは同じプロセス内でメモリを共有し、軽量かつ高速に並行処理を行えますが、その分、共有データの扱いや同期制御が難しくなります。
身近な例で考えると、会社と社員の関係や、ブラウザのタブと内部処理の関係が、プロセスとスレッドのイメージに近いと言えるでしょう。
実際のプログラミングでは、安全性を重視する部分をプロセスで分け、性能が重要な部分をスレッドや非同期処理で並行化するといった組み合わせがよく使われます。
まずは、この記事で紹介した3つの視点――メモリの共有範囲、安全性と影響範囲、コストと速度――を意識しながら、身近なアプリがどのようにプロセスとスレッドを使い分けているか観察してみてください。
それだけでも、OSやプログラムの動きが、今までより一段クリアに見えてくるはずです。
