
Web APIやマイクロサービス、スマホアプリなどを作り始めると、データを「どういう形式でやり取りするか」という問題に必ずぶつかります。
代表的なのがJSONとProtocol Buffers(Protocol Buffers、略してProtobuf)です。
どちらもよく名前を聞く一方で、違いがあいまいなまま「なんとなくJSONを使っている」というケースも多いのではないでしょうか。
本記事では、プログラミング初心者の方に向けて、Protocol BuffersとJSONの基本的な特徴・メリット・デメリット・選び方を丁寧に解説します。
Protocol Buffers と JSON の基本を理解しよう
まずは、Protocol BuffersとJSONそれぞれの概要を押さえた上で、2つのフォーマットの主な違いを整理します。
Protocol Buffersとは
Protocol Buffersは、Googleが開発したデータのシリアライズ(直列化)フォーマットです。
シリアライズとは、プログラム内のオブジェクトを、ネットワークで送信したり、ファイルに保存したりできるようにコンパクトな形式に変換することを指します。
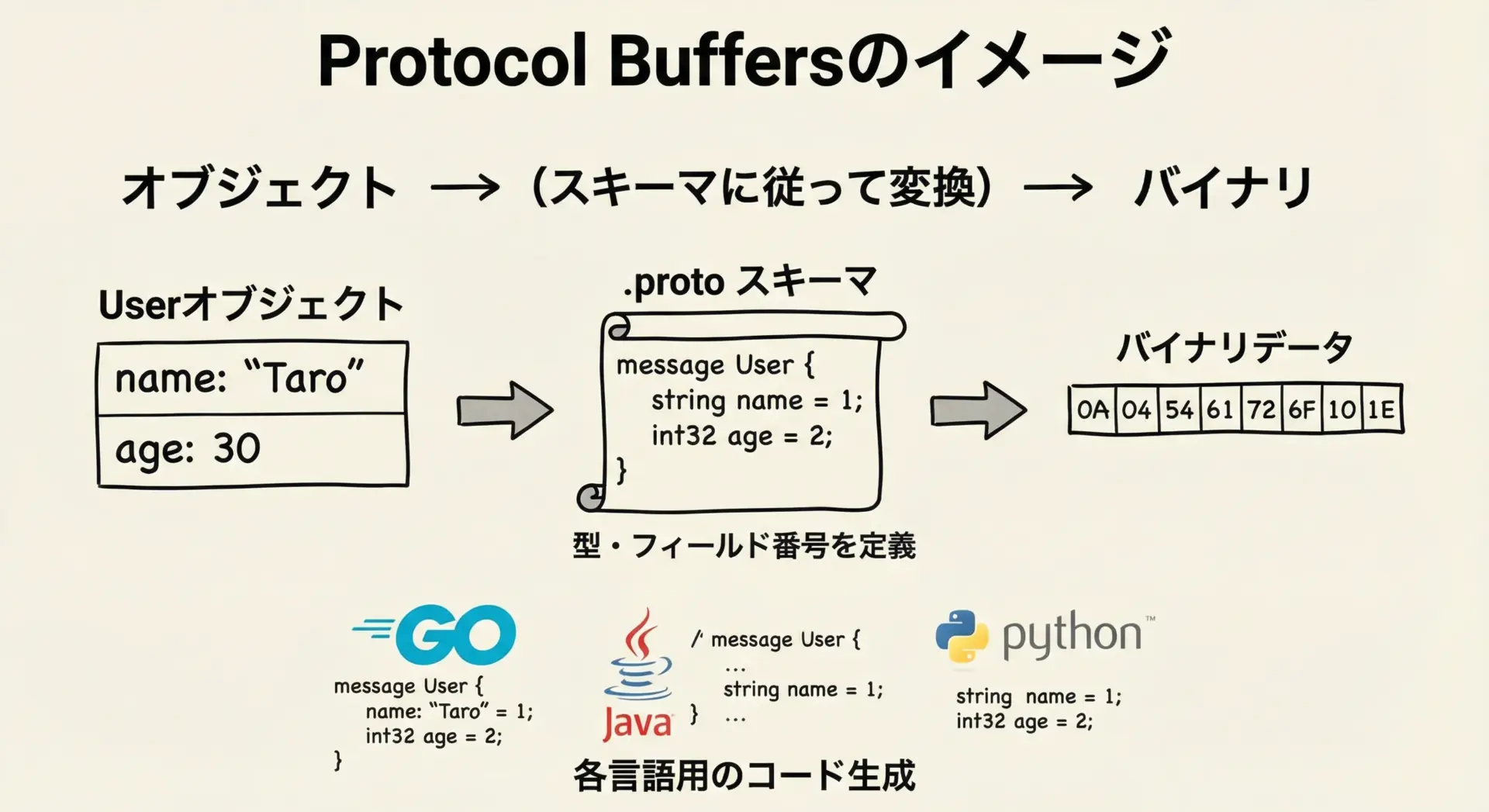
Protocol Buffersでは、まず.protoファイル(スキーマ定義ファイル)に、どのようなフィールドを持つメッセージを扱うかを記述します。
そのスキーマを元に、公式ツールprotocを使って各プログラミング言語向けのクラスや構造体が自動生成されます。
アプリケーションはその生成コードを使い、オブジェクトをバイナリ形式にシリアライズしたり、逆にバイナリから復元(デシリアライズ)したりします。
主な特徴としては、次のような点が挙げられます。
- コンパクトなバイナリ形式であるため、データサイズが小さい
- バイナリ形式のため人間には読みづらい
- 事前にスキーマ定義(.proto)が必要
- スキーマから各言語向けのコードを自動生成できる
- フィールド番号に基づく設計により、後方互換性を保ちやすい
JSONとは
JSON(JavaScript Object Notation)は、テキストベースのデータ表現形式です。
JavaScriptに由来する構文を持ちますが、現在では多くのプログラミング言語で標準的に扱える形式になっています。
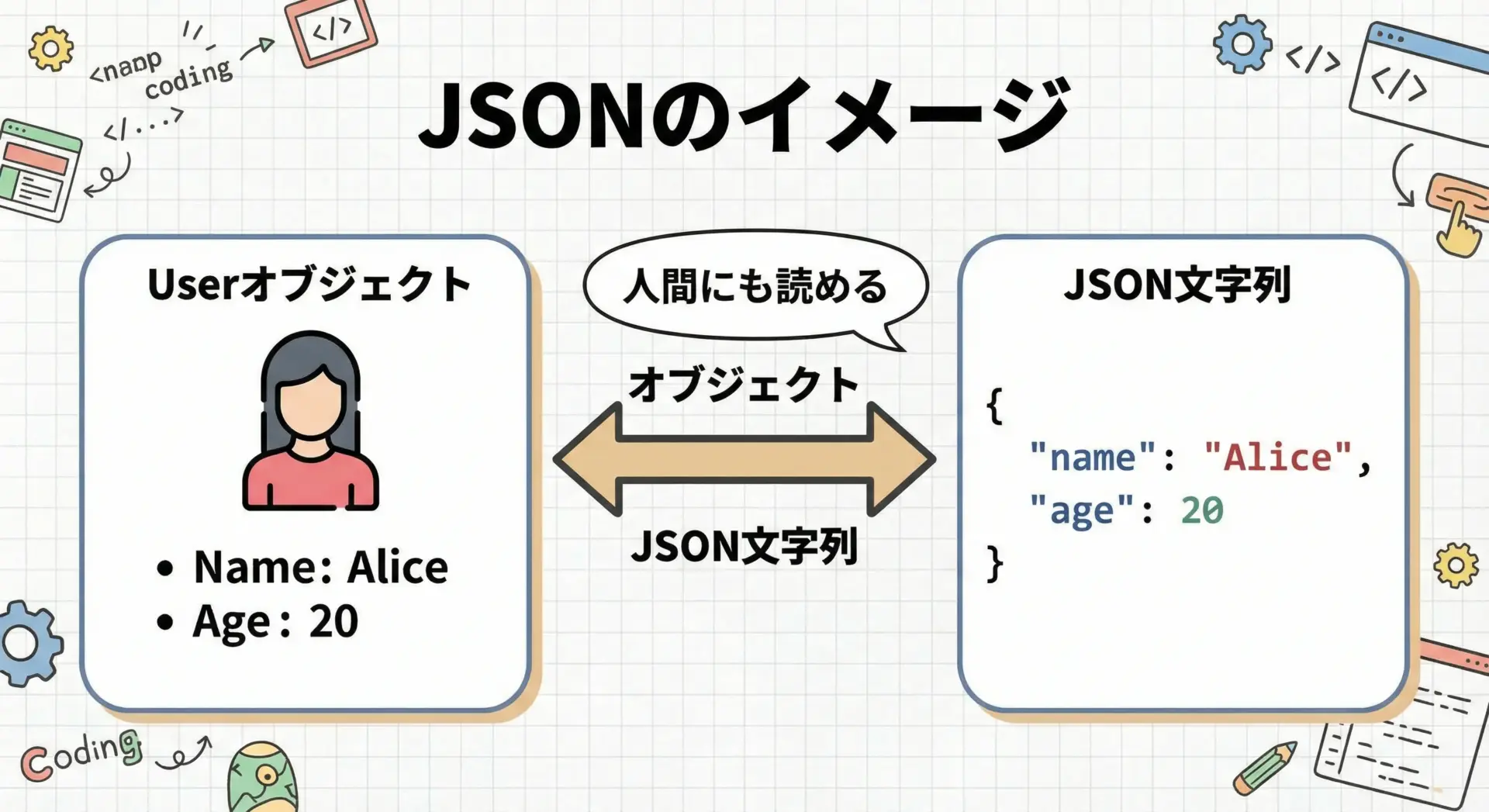
JSONは人間が読み書きしやすいことが大きな特徴です。
キーと値の組み合わせや配列を、{} や [] を用いて表現します。
Web APIのレスポンスや、設定ファイルなど、さまざまな場面で利用されています。
主な特徴は次の通りです。
- テキスト形式で、人間が容易に読める・編集できる
- 多くの言語の標準ライブラリでそのまま利用可能
- スキーマ定義がなくても扱える一方、型の厳密さには欠ける
- パース(解析)や変換が比較的簡単
Protocol BuffersとJSONの主な違い
ここまでの説明を踏まえて、両者の主な違いを整理します。
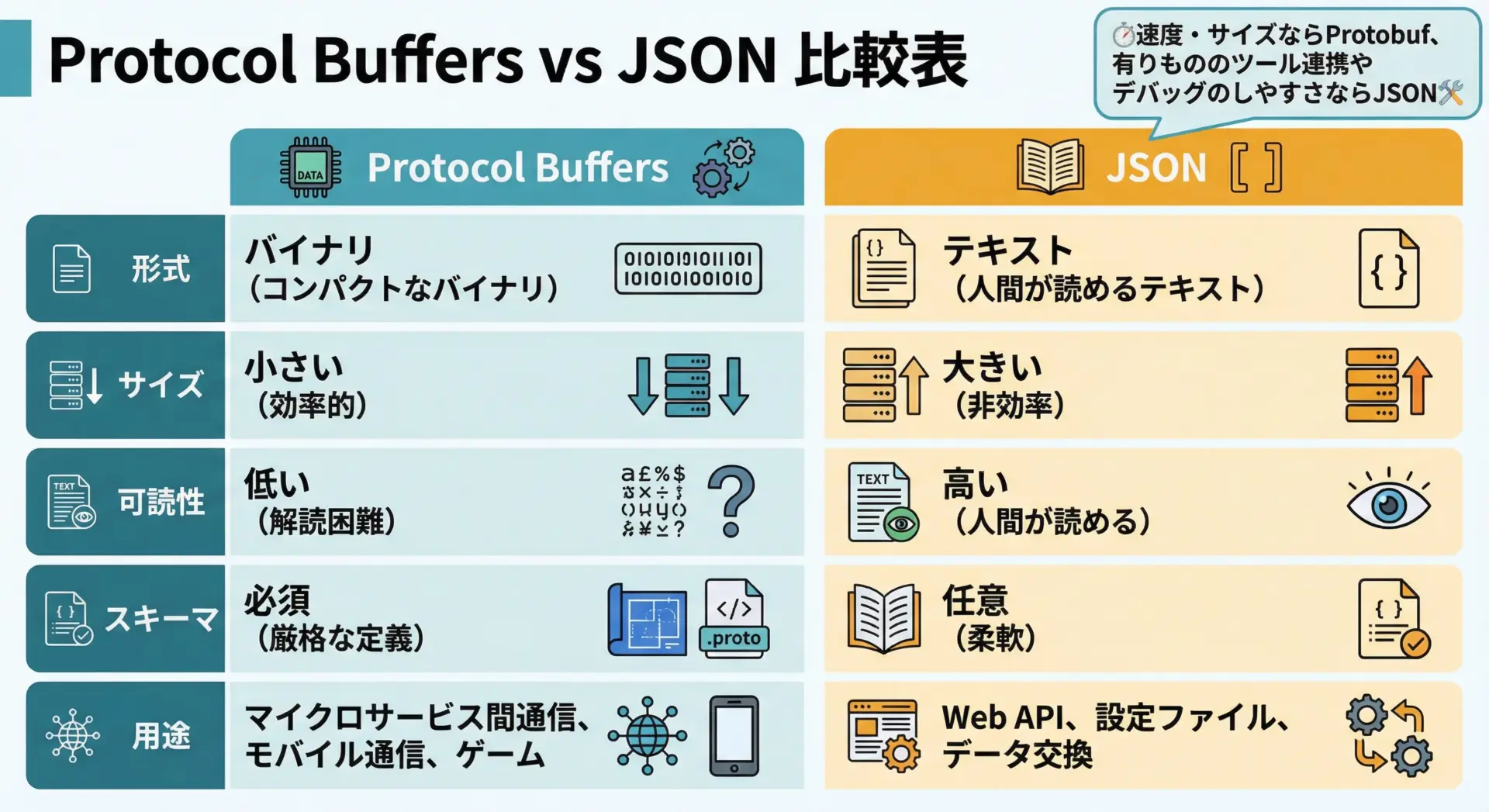
代表的な違いを表にまとめると次のようになります。
| 項目 | Protocol Buffers | JSON |
|---|---|---|
| データ形式 | バイナリ | テキスト |
| データサイズ | 小さい | 比較的大きい |
| 可読性 | 人間には読みにくい | 人間にとって読みやすい |
| スキーマ | 必須(.protoが必要) | 任意(なくても使える) |
| 型安全性 | 高い(コンパイル時にチェック) | 低め(実行時エラーになりやすい) |
| 主な用途 | 内部通信、マイクロサービス間通信、モバイルバックエンドなど | Web API、フロントエンドとの通信、設定ファイルなど |
Protocol Buffersは性能と効率を重視した「機械向け」、JSONは可読性と手軽さを重視した「人間にもやさしい」フォーマットというイメージを持つと理解しやすくなります。
Protocol Buffersのメリット・デメリット
続いて、Protocol Buffersを採用する場合の具体的なメリット・デメリットを整理していきます。
Protocol Buffersのメリット
Protocol Buffersの最大のメリットは、高速・省サイズ・型安全の3点です。
メリット1: データサイズが小さく高速
Protocol Buffersはバイナリ形式でフィールド番号を使ってデータを表現するため、同じ内容をJSONで表現した場合と比べて、データサイズが小さくなります。
また、構造が機械向けに最適化されているため、シリアライズ・デシリアライズも高速です。
大量のデータを頻繁にやり取りするマイクロサービス間通信や、限られた帯域しかないモバイル回線での通信などにおいて、トラフィック削減やレスポンス改善に直接効いてくる点は大きな利点です。
メリット2: スキーマに基づく型安全性と自動生成
Protocol Buffersは、あらかじめ.protoファイルでスキーマを定義する必要がありますが、そのおかげで次のようなメリットが得られます。
- スキーマから各言語向けのクラス/構造体を自動生成できる
- コンパイル時にフィールドの有無や型の不一致を検出できる
- APIの仕様が明示的な契約(Contract)として残る
スキーマが「1つの真実のソース」として振る舞うため、バックエンドとフロントエンド、複数サービス間での仕様のズレを防ぎやすい点も見逃せません。
メリット3: 後方互換性を保ちやすい設計
Protocol Buffersは、フィールド番号を意識した設計になっており、既存のメッセージ構造に対してフィールドの追加・一部変更を行っても、古いクライアントを壊しにくいという特徴があります。
- 新しいフィールドを新しいフィールド番号で追加する
- 古いクライアントはそのフィールドを無視して処理できる
- 新しいクライアントは、古いクライアントが送る「フィールドの少ないメッセージ」も扱える
このように、ロングライフなAPIを設計する上で、後方互換性を保ちやすいことは、実運用では非常に大きな利点になります。
Protocol Buffersのデメリット
メリットが多い一方で、Protocol Buffersには初心者にとってのハードルや、ユースケースによってはデメリットとなる点も存在します。
デメリット1: 人間にとって読みづらい
Protocol Buffersはバイナリ形式であるため、そのままでは中身を目視で確認しづらいという問題があります。
もちろんprotocや各種ツールを利用してデコードすることは可能ですが、JSONのようにすぐにテキストエディタで中身を眺めてデバッグするといった使い方はできません。
ログや一時的なデバッグのために人間にとっての可読性が重要な場面では不向きと言えます。
デメリット2: スキーマとツールの学習コスト
Protocol Buffersを使うには、少なくとも以下のようなステップが必要です。
- .protoファイルの記法やフィールド番号の考え方を学ぶ
protocコンパイラの使い方を覚える- 言語ごとのバインディングやライブラリを理解する
JSONであればJSON.parse()やJSON.stringify()のように、すぐに使い始められるのに対して、Protocol Buffersは導入にひと手間かかるのが現実です。
デメリット3: ブラウザやフロントエンドとの直接連携はひと工夫必要
ブラウザは標準でJSONとの相性がよく、fetchやXMLHttpRequestとresponse.json()の組み合わせなど、JSON前提のAPIが豊富です。
一方で、ブラウザがProtocol Buffersを直接扱うには、専用のJavaScriptライブラリを読み込んだり、ビルド設定を整えたりと、やや工夫が必要になります。
フロントエンド中心の小規模プロジェクトでは、その手間がコストに見合わない場合も多くあります。
初心者がつまずきやすいポイント
初心者がProtocol Buffersを学ぶときに、特につまずきがちなポイントをいくつか挙げます。
よくあるつまずき1: フィールド番号の扱い
Protocol Buffersでは、各フィールドに一意のフィールド番号を割り当てます。
最初は「名前があれば十分では?」と感じるかもしれませんが、この番号が後方互換性や内部表現に直結する重要な要素です。
- フィールド番号を勝手に変更してはいけない
- 削除した番号を再利用しない方が安全
といったルールを理解していないと、バージョンアップ時に予期しない不具合が生じることがあります。
よくあるつまずき2: スキーマ変更時の互換性
スキーマを変更する際、「何をしてはいけないか」を意識しないと、古いクライアントとの互換性が壊れてしまうことがあります。
例えば、フィールドの型を互換性のないものに変更したり、重要な必須フィールドを安易に削除したりすると、古いクライアントでデシリアライズが失敗します。
初心者のうちは、新しいフィールドを追加する方向で進化させることを基本とし、既存フィールドの削除・大幅変更には慎重になることが重要です。
JSONのメリット・デメリット
続いて、JSONのメリット・デメリットを整理し、どのような点が初心者にとって魅力的で、どのような落とし穴があるのかを見ていきます。
JSONのメリット
JSONの最大の魅力は、シンプルさとエコシステムの豊かさです。
メリット1: 人間にとって読み書きしやすい
JSONはテキスト形式であり、構造もシンプルなため、エディタで開いてそのまま読めるという強い利点があります。
- APIレスポンスをブラウザの開発者ツールでそのまま確認
- 設定ファイルをテキストエディタでちょっとだけ書き換え
- ログにJSONを出力し、人間が目で追いながらデバッグ
といった作業は、Protocol Buffersよりも圧倒的にやりやすくなります。
メリット2: 多くの言語・ツールで標準対応
JSONは今や事実上の標準データフォーマットと言っても良く、多くのプログラミング言語が標準ライブラリまたはデファクトライブラリとしてJSONサポートを提供しています。
- JavaScriptの
JSON.parse()/JSON.stringify() - Pythonの
jsonモジュール - Goの
encoding/jsonパッケージ
など、追加ツールなしですぐに使い始められる点は、初心者にとって非常に大きなメリットです。
メリット3: スキーマなしでも始められる柔軟さ
JSONは、事前のスキーマ定義がなくてもデータをやり取りできます。
プロトタイプや小規模なツールで「とりあえず動くものを作りたい」というときに、スキーマ設計に時間をかけずに済むのは大きな利点です。
また、構造が多少変わっても、受け手側がうまく条件分岐を入れたり、デフォルト値で補ったりすれば、柔軟に対応できる余地もあります。
JSONのデメリット
一方で、JSONの手軽さは中長期的な運用や大規模化の場面でデメリットに転じることもあります。
デメリット1: データサイズと速度の面で不利
JSONはテキスト形式であり、キー名を毎回文字列として書く必要があるため、同じ情報量であればバイナリ形式よりサイズが大きくなりがちです。
また、文字列のパースが必要になるため、CPU負荷やパース時間の面でもProtocol Buffersより不利になるケースが多くあります。
大量データや高頻度通信が発生するシステムでは、パフォーマンスのボトルネックになりうる点に注意が必要です。
デメリット2: 型の曖昧さとスキーマ不在
JSONはスキーマを必須としないため、一見すると自由度が高く便利に見えますが、その分型や構造の保証が弱いと言えます。
- あるフィールドが文字列のはずが、いつの間にか数値として扱われている
- 必須だと思っていたフィールドが抜け落ちていて、実行時にエラーになる
- フロントとバックエンドで期待するJSON構造が微妙に違う
といった問題が起きやすくなります。
JSON Schemaなどでスキーマを補う方法もありますが、スキーマと実体が自然に同期するProtocol Buffersと比べると一体感が弱いことは否めません。
デメリット3: 進化するAPIの管理が難しくなりがち
JSONベースのAPIを長期運用していると、バージョンによってフィールドが増えたり減ったり、意味が変わったりします。
スキーマが明確でないまま進化を続けると、ある時点の仕様がどこにもちゃんと書かれていないという状態になりがちです。
結果として、新しい開発者が仕様を理解するコストや、互換性を保ちながらリファクタリングするコストが高くなってしまうことがあります。
初心者が誤解しやすいJSONの使いどころ
JSONは手軽さゆえに「とりあえず全部JSONでよい」と考えてしまいがちですが、これは誤解を生みやすいポイントです。
誤解1: どんな規模でもJSONだけで十分
小規模なアプリや社内ツールであれば、JSONだけで困らないことも多いですが、数十・数百のサービスが連携するマイクロサービス環境や、数千万件レベルのデータ転送となると、サイズやパフォーマンスの問題が現れてきます。
こうした場面では、内部通信はProtocol Buffersで効率化し、外部公開APIではJSONを採用するといったハイブリッドな構成を検討すべきです。
誤解2: スキーマを定義しなくてよい = 仕様を考えなくてよい
JSONだからといって、APIの仕様設計が不要になるわけではありません。
むしろスキーマファイルがない分、別の形でドキュメントをしっかり書かないと仕様が分からなくなる危険があります。
初心者ほど、「まずJSONの構造をちゃんと文章や図で定義してから実装する」習慣を身につけることが重要です。
Protocol Buffers vs JSONの選び方
ここまでの特徴を踏まえ、実際の開発プロジェクトでどのような基準でProtocol BuffersとJSONを選ぶかを整理します。
どんなときにProtocol Buffersを選ぶか
Protocol Buffersは、次のような条件に当てはまる場合に特に威力を発揮します。
- 高トラフィックなマイクロサービス間通信
- モバイルアプリやIoTデバイスなど、帯域が限られた環境
- 複数のサービス・言語・チームが関わる大規模システム
- API仕様の長期的な保守・進化が重要な場合
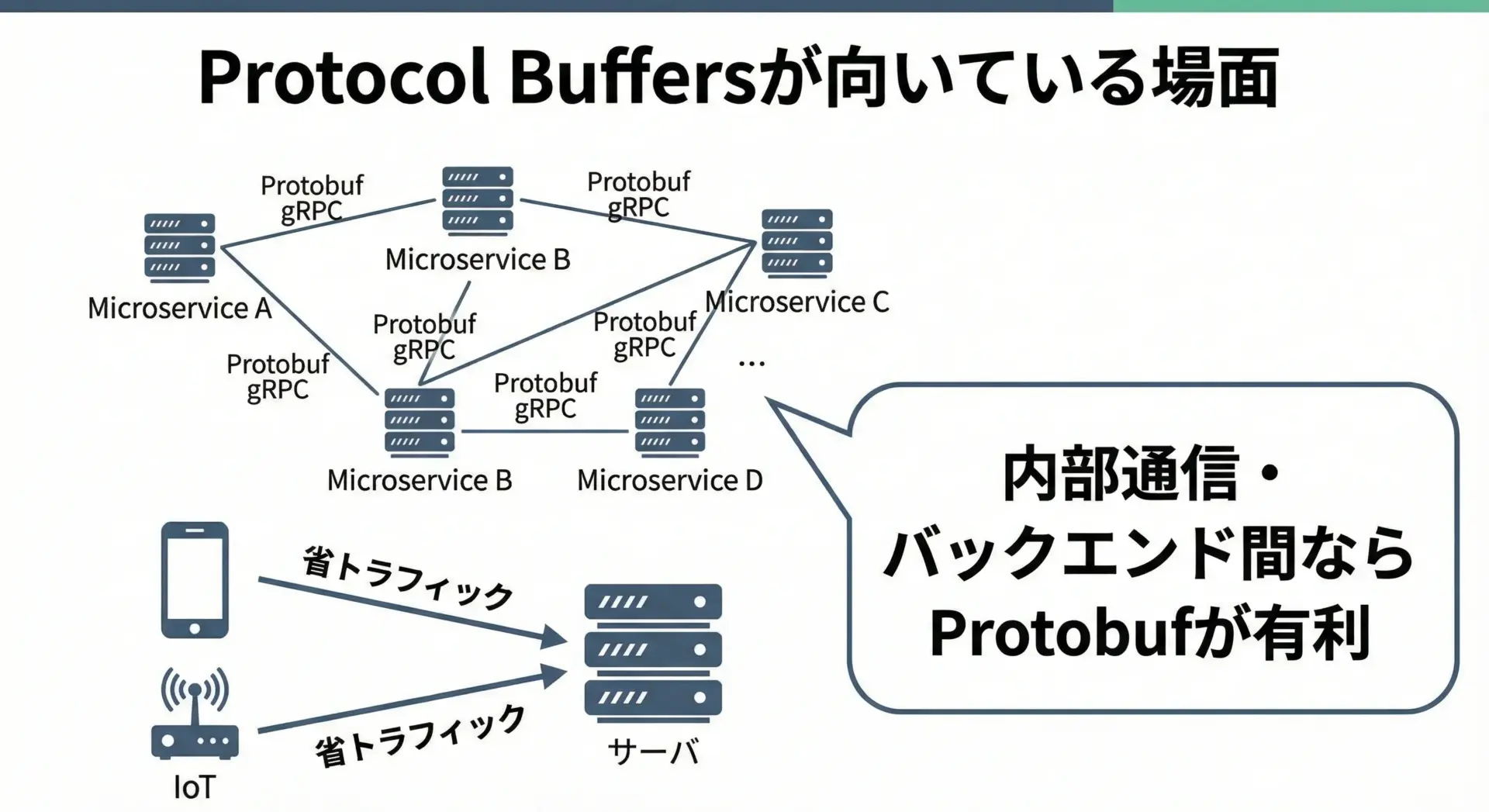
特に、gRPCのようなRPCフレームワークと組み合わせると、IDL(Interface Definition Language)としての.protoを中心に、API定義・通信・型チェックが一体化するため、中〜大規模バックエンドの基盤技術として非常に有力な選択肢となります。
どんなときにJSONを選ぶか
一方で、JSONは次のような場面で引き続き第一候補になります。
- ブラウザやフロントエンドとの通信が中心のWebアプリケーション
- 外部公開API(SaaSのREST APIなど)を提供する場合
- 小規模・短期のプロトタイプやPoC
- インフラやアプリケーションの設定ファイル
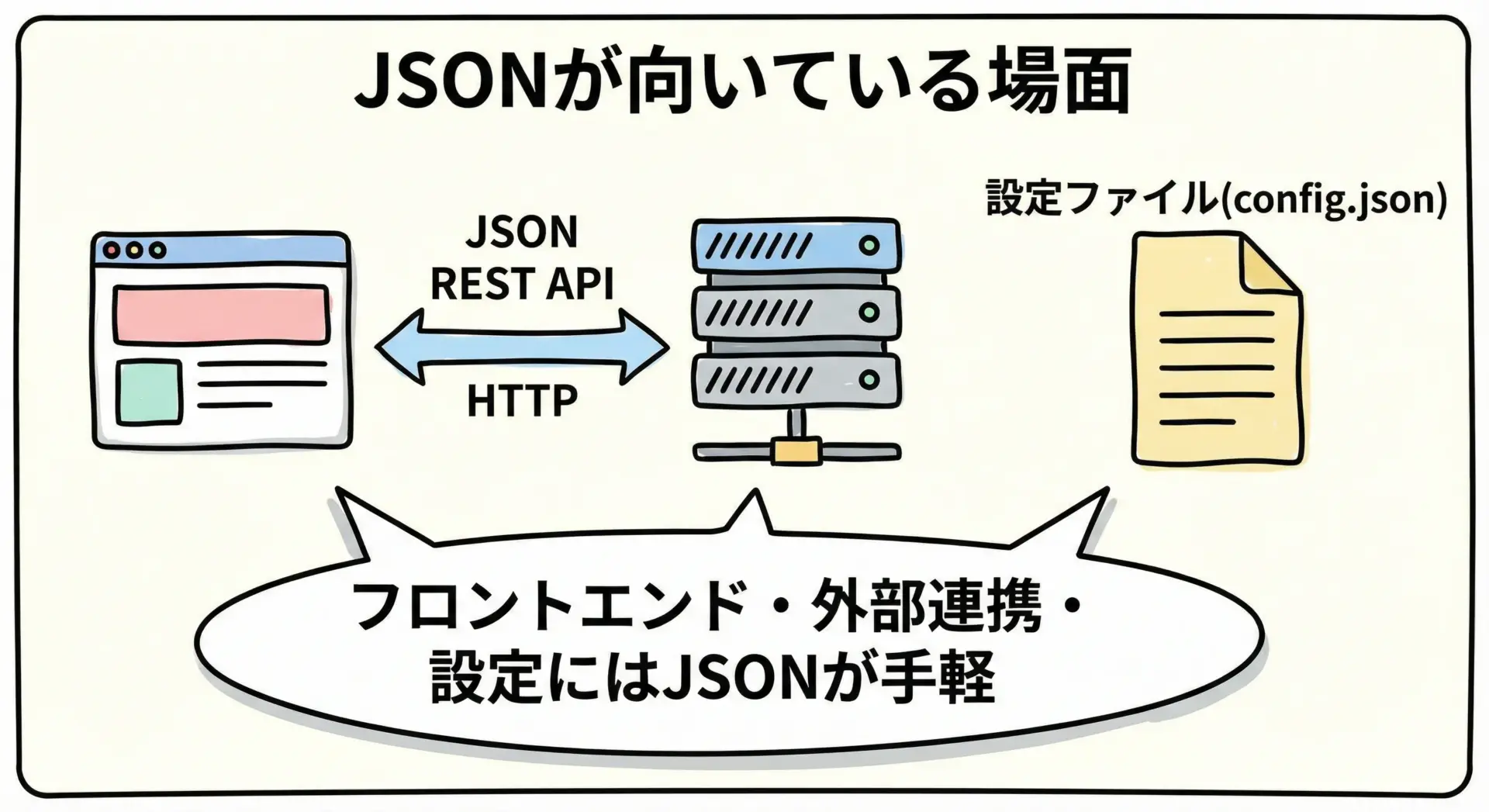
特に、フロントエンド開発者が日常的に扱うデータや、外部の開発者にも理解してもらいたいAPIでは、JSONの可読性と普及度合いが大きなアドバンテージになります。
Protocol BuffersとJSONを併用するパターン
現実のシステムでは、Protocol BuffersとJSONを併用する構成がよく見られます。
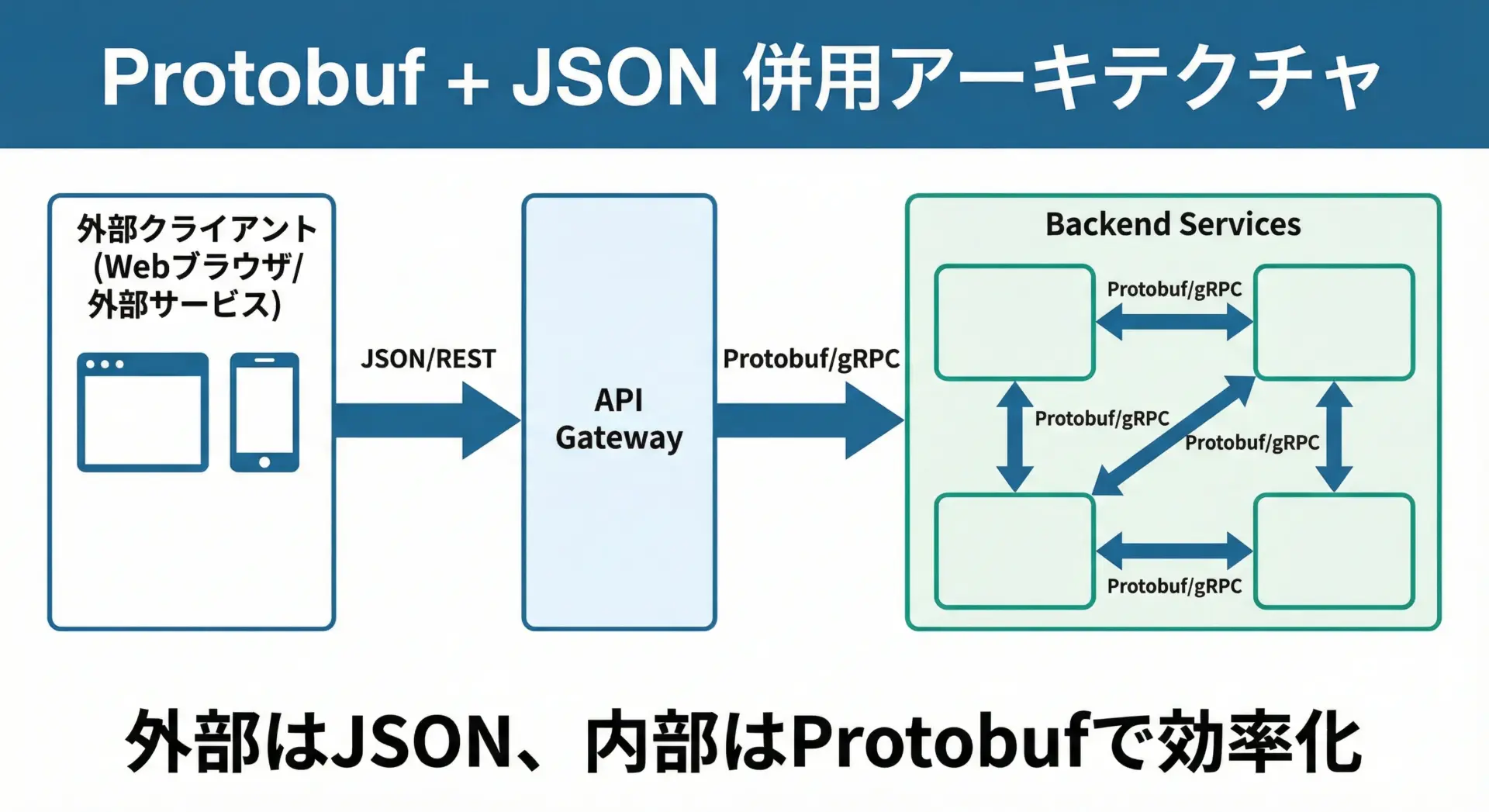
典型的なパターンは次の通りです。
- 外部公開APIはJSON + RESTで提供し、開発者体験と互換性を優先
- 内部のマイクロサービス間はProtocol Buffers + gRPCで、性能と型安全性を追求
このように層によってフォーマットを使い分けることで、外部との連携のしやすさと内部の効率性を両立させることができます。
初心者向けロードマップ
最後に、これからProtocol BuffersとJSONを学び始める初心者に向けて、どの順番で学ぶと理解しやすいかのロードマップを示します。
ステップ1: JSONをしっかり使いこなす
まずは、JSONを不自由なく扱える状態を目指すと良いです。
- 自分の得意な言語で、JSONのパースと生成を練習する
- 簡単なREST APIを叩いて、JSONレスポンスを扱う
- 設定ファイルをJSONで書いて読み込む小さなツールを作る
この段階で、オブジェクトとJSON文字列の相互変換のイメージをしっかり持っておくと、次のステップでの理解がスムーズになります。
ステップ2: Protocol Buffersの基本概念を押さえる
次に、Protocol Buffersについて、まずは概念とワークフローだけを押さえます。
- .protoファイルの基本的な書き方
- protocコンパイラでコードを生成する手順
- 生成されたクラスを使ってシリアライズ/デシリアライズする流れ
最初は小さなメッセージ定義から始めて、JSONと同じデータをProtobufでも表現してみると、違いがつかみやすくなります。
ステップ3: 実運用のイメージを持つ
ある程度慣れてきたら、実際のシステム構成でどう使われるかを学びます。
- gRPCのようなフレームワークと組み合わせたサンプルを試す
- 内部通信をProtobuf、外部通信をJSONにする小さなデモアプリを作る
- スキーマ変更時の互換性の扱いを、バージョン違いクライアントで試してみる
この段階まで進めば、自分のプロジェクトでどちらを採用すべきか判断できる基礎体力が身についているはずです。
まとめ
Protocol BuffersとJSONは、どちらが一方的に優れているという関係ではなく、異なる強みと弱みを持つデータフォーマットです。
- Protocol Buffersは、高速・省サイズ・型安全・後方互換性といった点で優れ、特に内部通信や大規模分散システムで力を発揮します。
- JSONは、人間が読みやすく、ツールや言語の対応が豊富で、導入が簡単であり、フロントエンドとの通信や外部公開API、設定ファイルといった場面で定番の選択肢です。
初心者のうちは、まずJSONでデータシリアライズの基本を身につけ、その後Protocol Buffersを学ぶことで、性能・保守性・スケーラビリティを意識した設計にステップアップできます。
また、実際の現場では両者を併用するアーキテクチャも一般的であり、状況に応じて使い分けるスキルが重要になります。
本記事の内容を踏まえて、自身のプロジェクトの規模や要件を見直し、「どこでJSONを使い、どこでProtocol Buffersを導入するか」を意識して設計できるようになると、より実践的なエンジニアリング力が身についていきます。
