
プログラムを書いていると、同じように「関数に値を渡している」のに、あるときは元の変数が変わらず、別のときは勝手に書き変わってしまうことがあります。
この不思議な挙動の正体が値渡しと参照渡しです。
本記事では、難しい言語仕様の話に入る前に、日常の身近な例えから直感的なイメージをつかみ、そのうえでコード上でどう違いが出るのかを丁寧に整理していきます。
値渡しと参照渡しとは何か
最初に、プログラミング言語における値渡し(pass by value)と参照渡し(pass by reference)のざっくりしたイメージを押さえます。
ここでの理解は厳密さよりも、直感的に「何が起きているか」をつかむことを目的とします。
値渡しとは
値渡しは、「中身のコピーを渡す」イメージです。
関数に変数を渡すとき、元の値をそのまま使うのではなく複製を作って関数に渡すという考え方です。
関数の中でそのコピーを書き換えても、元の変数は変わりません。
なぜなら、元の変数と関数の中の変数は別物だからです。
- コピーを渡す
- 関数の中だけで変更が完結する
- 元の値は安全に守られる
この3点を押さえると、値渡しの基本イメージは十分です。
参照渡しとは
参照渡しは、「元の場所へのアクセス権を渡す」イメージです。
関数に渡しているのは値そのものではなく、「その値が置かれている場所」への参照(ポインタ・アドレス・ハンドルなど)です。
そのため、関数の中で値を変更すると、元の変数も一緒に変わります。
同じ場所を見ているので、どこから変更しても影響が共有されます。
- 場所(参照)を渡す
- 関数の中の変更が呼び出し元にも伝播する
- 意図せず共有状態を壊す可能性もある
という特徴があります。
値渡しと参照渡しが重要になる場面
値渡しと参照渡しの違いは、次のような場面で特に重要になります。
1つ目はバグの原因としてです。
自分では「関数の中でちょっと値をいじっただけ」のつもりが、参照渡しによって元のオブジェクトまで変わってしまい、予期せぬ動作を招くことがあります。
2つ目はパフォーマンスです。
巨大なデータ構造を丸ごと値渡しすると、毎回コピーが発生して処理が重くなります。
その場合は、参照渡しや、それに類する仕組みを使ったほうが効率的です。
3つ目はAPI設計です。
関数やメソッドが「引数を変更する意図があるのか」「結果は戻り値で返すのか」を、値渡し/参照渡しの設計を通じて明確にする必要があります。
身近な例えでイメージする値渡しと参照渡し
定義だけではイメージしづらいので、ここからは日常的な例えで理解を深めていきます。
プログラムの話はいったん忘れて、「物」や「情報」の受け渡しとして考えてみましょう。
メモのコピーと原本の貸し借りで考える値渡しと参照渡し
まずは最もシンプルな例えとして、メモ用紙をイメージします。
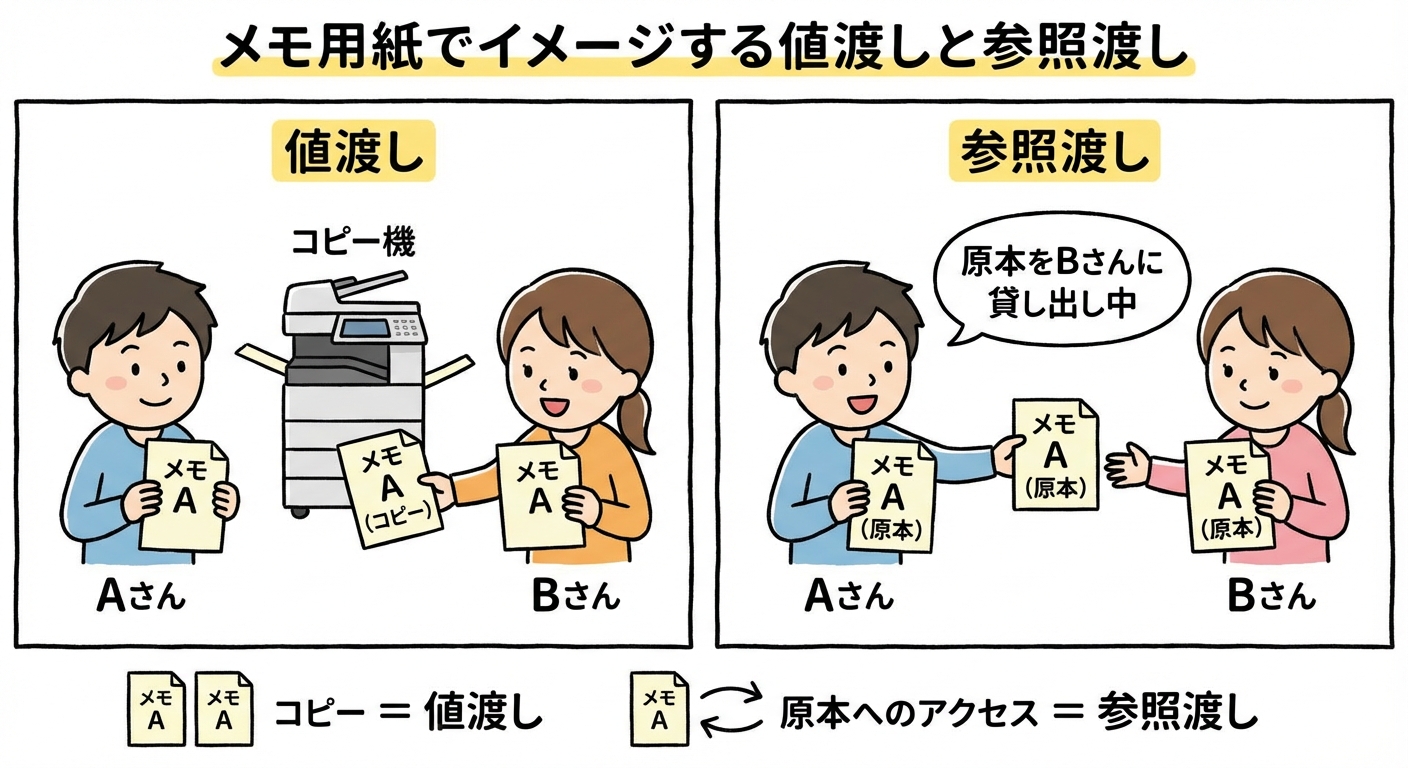
値渡しは、メモのコピーを取ってから相手に渡すイメージです。
自分の手元には元のメモが残るので、相手がコピーに書き足したり、ぐしゃぐしゃに丸めて捨てても、自分のメモには影響がありません。
参照渡しは、原本をそのまま相手に貸すイメージです。
相手が書き込みをしたり、内容を消しゴムで消したりすると、その変更は原本に対して行われるので、後で自分が見ても書き換わっています。
この例えから、次のように整理できます。
- 値渡し = コピーを渡す → 自分の手元は安全
- 参照渡し = 原本へのアクセスを渡す → 変更は共有される
料理のレシピと完成料理で考える値渡しと参照渡し
次は料理で考えてみましょう。
ここでは、「レシピ」と「完成した料理」を2種類の「情報」として扱います。
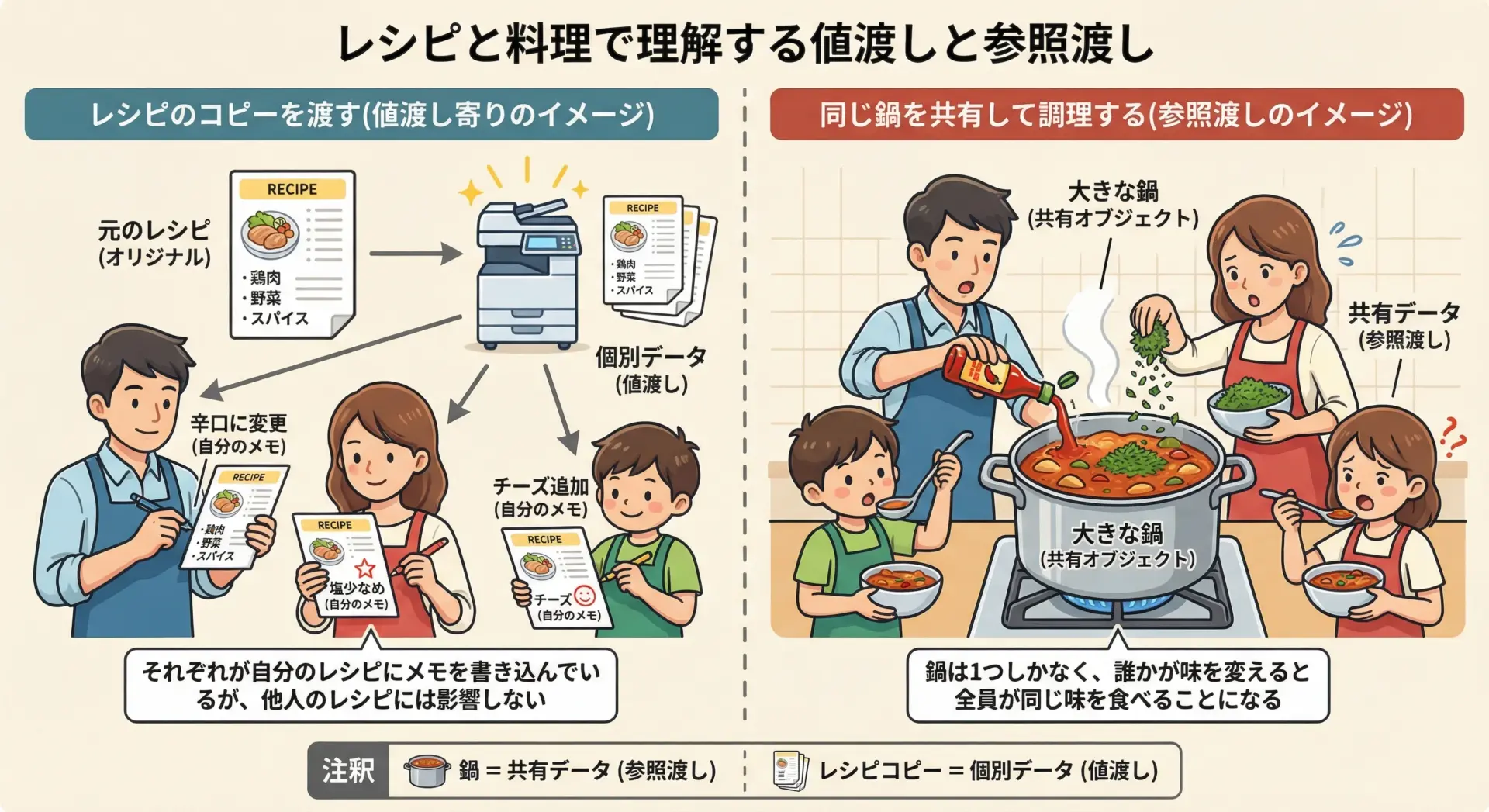
レシピのコピーを配る状況は、値渡しに近いイメージです。
各自が同じ内容のレシピを持っていますが、自分の手元のレシピにメモを書き込んでも、他の人のレシピには影響しません。
一方で、大きな鍋で作った料理をみんなで味見しながら調整する場面を想像してください。
鍋そのものは1つしかないので、誰かが塩を入れれば、全員がその味の変化を共有することになります。
これは参照渡しのイメージに近く、「鍋」という1つのデータをみんなで参照し、更新している状態です。
写真データのコピーと共有リンクで考える値渡しと参照渡し
現代的な例えとして、スマホの写真データでも考えてみましょう。
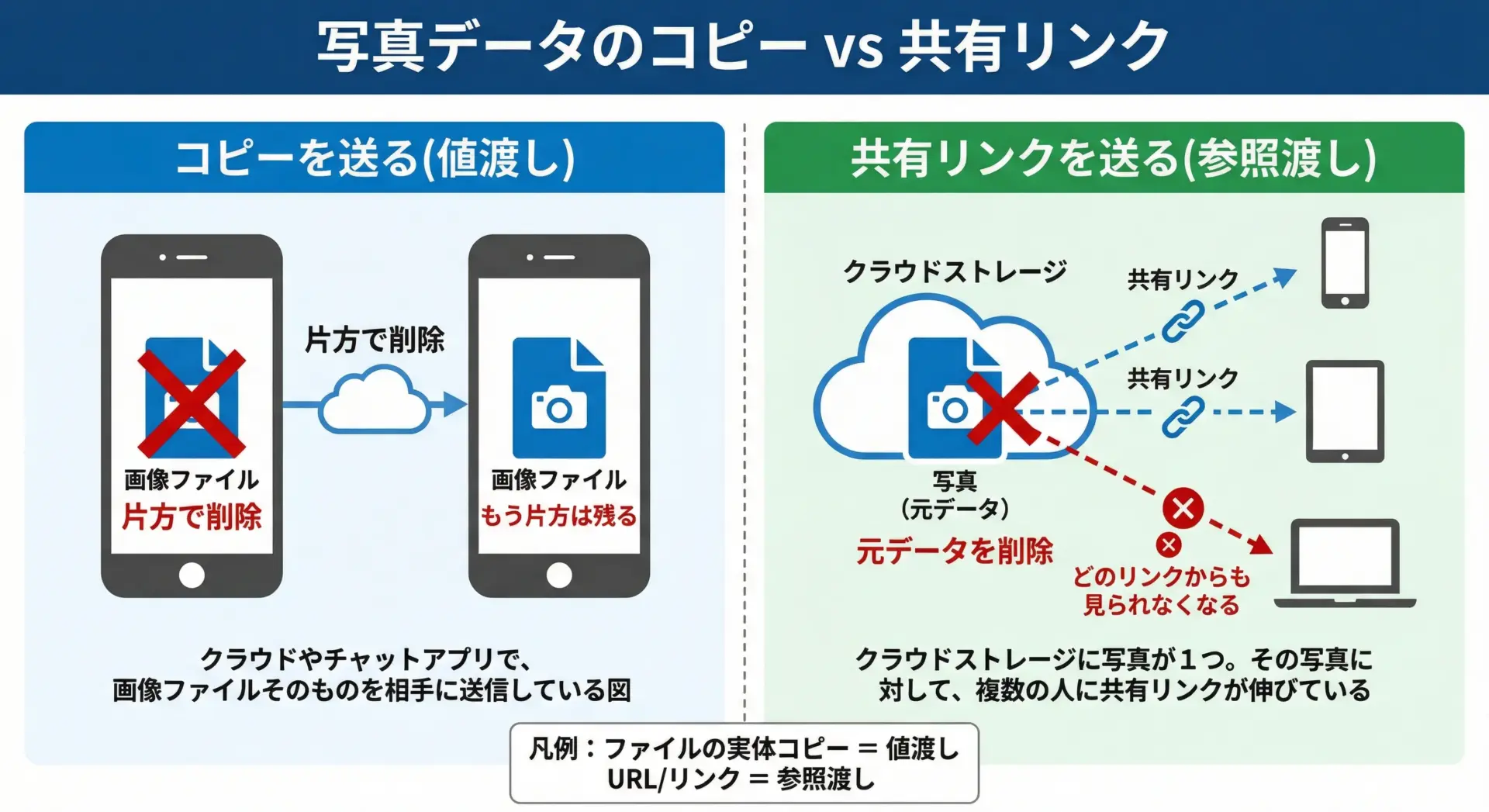
写真を相手に送りたいとき、次の2通りがあります。
- 写真データそのものを送る(ファイルコピー)
- クラウド上の写真の共有リンク(URL)を送る
1は値渡しです。
相手のスマホには写真のコピーが保存されます。
あなたが自分のスマホの写真を削除しても、相手の写真は残ったままです。
2は参照渡しです。
リンクはあくまで「そこにある写真を見に行くための道順」にすぎません。
元の写真をクラウドから削除すると、共有リンクは一斉に無効になり、みんなが同じ影響を受けます。
この例えは、後で出てくるオブジェクトや配列を「参照」で受け渡しするイメージにも直結します。
プログラムでの値渡しと参照渡しの違い
身近なイメージができたところで、ここからは実際のプログラムでどのような違いとして現れるのかを見ていきます。
ここでは、擬似コードや一般的な言語の例を用いて説明します。
関数に値を渡すときの値渡し
まずは、典型的な値渡しの例です。
ここでは整数のような「小さくてシンプルな値」を扱います。
function addOne(x) {
x = x + 1
}
a = 10
addOne(a)
print(a) // 10 のままこの例では、a の値(10)のコピーが関数addOneに渡されています。
関数内のxはローカルなコピーなので、x = x + 1としても、aは変わりません。
多くの言語で、整数・浮動小数・ブーリアン・文字などのプリミティブ型は、このような値渡しの動作をします。
関数にオブジェクトを渡すときの参照渡し
次に、オブジェクトや配列のような複合データを関数に渡した場合を考えます。
ここでは「参照」を渡すスタイルに近い挙動を例示します。
function addItem(list) {
list.append(100)
}
nums = [1, 2, 3]
addItem(nums)
print(nums) // [1, 2, 3, 100]この場合、numsという配列(リスト)そのもののコピーを渡しているわけではなく、nums が指している配列オブジェクトへの参照が渡されています。
そのため、関数内でlist.append(100)とすると、元の配列オブジェクト自体が変更され、呼び出し元から見ても要素が増えています。
ここが、値渡しとの最も大きな違いです。
値を変更したときの挙動の違い
もう少し踏み込んで、「変数に代入する」のと「中身を変更する」の違いも見ておきましょう。
ここでは JavaScript 風の疑似コードを使います。
function changePrimitive(x) {
x = 999
}
function changeObject(o) {
o.value = 999
}
let n = 10
changePrimitive(n)
console.log(n) // 10 のまま (コピーに代入しただけ)
let obj = { value: 10 }
changeObject(obj)
console.log(obj.value) // 999 に変化 (同じオブジェクトを書き換えた)この例で起きていることを整理すると、次のようになります。
changePrimitive:nの値10 のコピーがxに渡される- 関数内で
xに999を代入しても、それはコピー側だけの話 - 元の
nは10のまま
changeObject:objが指しているオブジェクトへの参照のコピーがoに渡されるo.value = 999は同じオブジェクトの中身を書き換える操作- 結果として、元の
objから見てもvalueが999になる
ここで重要なのは、「参照そのものを別のものに差し替える」のと「参照先の中身を書き換える」の違いです。
この違いは、次のような誤解を生みやすいポイントにもつながります。
配列やリストで起きやすい参照渡しの勘違い
配列やリストを引数に渡したとき、「どこまで変更が呼び出し元に影響するのか」で混乱しやすくなります。
典型的には、次のような2パターンがあります。
function resetArray(a) {
a = [] // 別の新しい配列を割り当てる
}
function clearArray(a) {
a.length = 0 // 同じ配列オブジェクトの中身を空にする
}
let nums = [1, 2, 3]
resetArray(nums)
console.log(nums) // [1, 2, 3] のまま
clearArray(nums)
console.log(nums) // [] に変化違いを言葉で整理すると、こうなります。
a = []は参照を別のオブジェクトに差し替えるだけなので、呼び出し元の変数が持つ参照は変わらないa.length = 0は今見ている配列オブジェクトの中身を変更するので、共有している全員に影響する
このように、「引数として参照を受け取っている」状況では、関数の中で「何を書き換えているか」が非常に重要になります。
言語ごとの値渡しと参照渡しの違い
実際には、プログラミング言語ごとに、値渡しと参照渡しの扱いは少しずつ異なります。
代表的な言語をざっくりと比較してみましょう。
| 言語 | 基本方針 | 補足説明 |
|---|---|---|
| C/C++ | 値渡しが基本。ポインタを使うと参照渡しに近いことができる | ポインタ演算や参照型(&)で柔軟に制御可能 |
| Java | すべて「値渡し」。ただしオブジェクトを指す「参照の値」を渡す | 参照のコピーを値渡ししている、と説明されることが多い |
| C# | 値渡しが基本。ref, outで参照渡し風にできる | 値型と参照型の区別も重要 |
| JavaScript | すべて値渡し。ただしオブジェクトや配列は参照を値として渡す | プリミティブとオブジェクトで挙動が分かれる |
| Python | 「名前をオブジェクトに束縛する」モデル。実質的には参照の値渡し | ミュータブル/イミュータブルの違いが効いてくる |
| Go | 値渡しが基本。ポインタやスライス、マップなどは参照的な性質 | コピーされるものと共有されるものを意識する必要あり |
多くのモダン言語は「すべて値渡しだが、その値の中に参照を含む型がある」という設計を取っています。
このため、「この言語は参照渡しだ/値渡しだ」とひと言で決めつけないことも大切です。
値渡し・参照渡しを正しく使うための考え方
ここまでで概念と具体的な挙動を見てきました。
最後に、実際の開発でどちらを選ぶべきか、そしてどのような点に注意すればバグを防げるかを整理します。
値渡しを選ぶべきケース
値渡しは、「安全性」や「予測しやすさ」を重視したいときに向いています。
具体的には次のようなケースです。
1つ目は関数の外側の状態を絶対に変えたくないときです。
並行処理やマルチスレッド環境では、共有データをむやみに書き換えると、予測不能なバグにつながります。
値渡しにしておけば、関数内の変更が呼び出し元に影響しないので、安全性が高まります。
2つ目は小さくて単純な値を扱うときです。
整数や真偽値などはコピーコストがほとんど無視できるため、シンプルに値渡しとして扱うのが一般的です。
多くの言語の標準的な挙動もこれに沿っています。
3つ目は「入力は変更せず、結果だけを返す」スタイルを徹底したいときです。
関数型プログラミングやテスト容易性を重視する設計では、引数を変更せずreturnで結果を返すことが推奨されます。
このときは、値渡しのイメージにそった使い方になります。
参照渡しを選ぶべきケース
一方、参照渡し(あるいはそれに近いスタイル)を選ぶべきケースもあります。
特に次のような場面です。
1つ目は巨大なデータ構造を扱うときです。
数万件の要素を持つ配列や大きなツリー構造を毎回コピーしていたら、メモリも時間も足りなくなってしまいます。
こうした場合は、参照を渡して同じデータを共有するほうが効率的です。
2つ目は関数の主な役割が「引数を更新すること」である場合です。
たとえば、ゲームの状態を更新する処理や、設定オブジェクトにデフォルト値を埋め込むような関数では、引数として渡したオブジェクトを中で書き換えること自体が目的になります。
このようなときは参照渡しが自然です。
3つ目は複数の場所から同じ状態を共有したいときです。
キャッシュ、接続プール、設定情報など、アプリケーション全体で一貫した状態を保ちたい場合には、同じオブジェクトを共有することになります。
これも広い意味で、参照渡しの世界観の中にあります。
バグを防ぐための値渡し・参照渡しのチェックポイント
最後に、実務で特に重要になるチェックポイントをいくつか挙げます。
コードを書く前後に、次の観点を確認するとバグを減らしやすくなります。
1つ目は「この引数は関数内で変更される可能性があるか」を意識することです。
もし変更されるのであれば、関数名やドキュメント、コメントでそれを明示するべきです。
可能であれば、変更するための専用メソッドに切り出し、読み手がすぐに「状態を書き換える関数だ」とわかるようにします。
2つ目は「ミュータブル(書き換え可能)かイミュータブル(書き換え不可)か」を区別することです。
イミュータブルなオブジェクトであれば、実質的に「値渡し」と同じような安全性を享受できます。
反対に、ミュータブルなオブジェクトは、参照が残っているかぎりどこからでも書き換え可能です。
この性質を意識して設計しましょう。
3つ目は「コピーなのか共有参照なのか」を明示することです。
たとえば、配列を受け取って内部でcopy()する関数なら、関数名やコメントに「コピーを作る」と書いておくと、利用者は「この関数を呼んでも元の配列は変わらない」と安心できます。
4つ目はインターフェースの一貫性です。
似た名前の関数が、片方は引数を変更し、もう片方は変更しない、といった状態は避けるべきです。
たとえばupdateX()という名前の関数群は、すべて「何かを更新する」責務を持たせ、getX()は状態を変更しない、といったルールを徹底すると、参照渡しによる副作用が予測しやすくなります。
まとめ
値渡しと参照渡しは、一見すると「関数に値を渡すか、参照を渡すか」という技術的な違いに見えます。
しかし本質的には、「データをコピーして扱うのか、それとも共有して扱うのか」という設計上の選択です。
メモのコピーと原本の貸し借り、レシピと鍋料理、写真データと共有リンクといった身近な例えで見てきたように、値渡しは「自分の手元を安全に保つ」方向、参照渡しは「効率よく共有し、変更を伝播させる」方向に向いています。
プログラムの世界では、整数や真偽値のようなプリミティブは多くの言語で値渡しとなり、オブジェクトや配列は参照を通じて共有されることが一般的です。
その結果、「関数の中で何を変更しているのか」を意識しないと、思わぬ副作用によるバグが発生します。
これからコードを書くときは、次の3点を意識してみてください。
- これはコピーを渡してもよい値か、それとも共有すべき状態か
- 関数は「入力を変える」のか「結果だけ返す」のか、どちらを意図しているのか
- 言語仕様として、いま扱っている型は値型なのか参照型なのか
この3つを押さえておけば、値渡しと参照渡しの挙動に惑わされることは大きく減ります。
身近なイメージを思い出しながら、実際のコードで少しずつ試してみることで、より直感的に理解できるようになっていきます。
