
プログラムが動くとき、メモリの中では「スタック」と「ヒープ」という2つのエリアが大きな役割を担っています。
しかし用語だけ聞いても、何がどう違うのか、なぜ分ける必要があるのかはイメージしにくいものです。
この記事では、難しい理論よりもイメージと具体例を重視して、スタックとヒープの違いをやさしく解説します。
C/C++だけでなく、JavaやPythonなどの言語にも触れながら、頭の中にメモリ構造の「地図」が描けるようになることを目指します。
スタックとヒープとは?プログラミングにおける基本用語
スタックとヒープは、どちらもプログラムがデータを一時的に置いておくためのメモリ領域です。
ただし、置き方や片づけ方、使われ方が大きく異なります。
メモリ管理やパフォーマンス、バグの原因理解に直結する概念なので、早い段階でイメージをつかんでおくと、その後の学習がかなり楽になります。
メモリ管理の全体像とスタック・ヒープの位置づけ
まずは、プログラムが利用するメモリの全体像をざっくりイメージしてみましょう。
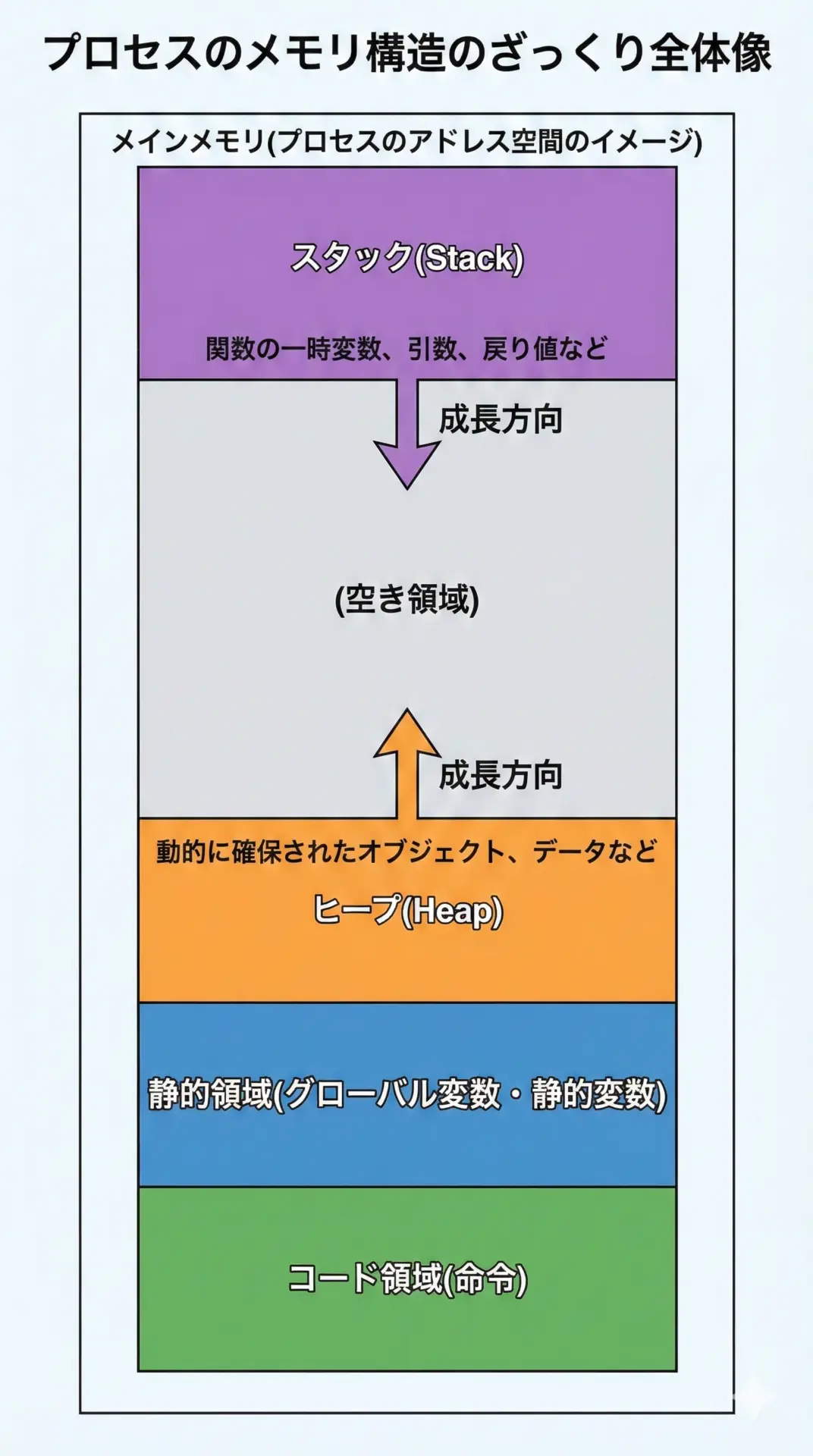
プログラムが動作するとき、1つのプロセスには上の図のようなアドレス空間が割り当てられます。
そこには、命令が入るコード領域、グローバル変数などが入る静的領域、そして一時的なデータが入るスタックとヒープがあります。
- スタック(Stack): 主に関数呼び出し時の一時データ(ローカル変数など)を置く場所
- ヒープ(Heap): 必要になったときに動的に確保するデータを置く場所
どちらも「一時的なデータ」を扱いますが、そのライフサイクル(いつ生まれて、いつ消えるか)の管理方法が決定的に異なります。
初心者が「スタック」と「ヒープ」でつまずきやすいポイント
初心者がよく混乱するポイントは次のようなものです。
- 「ローカル変数は全部スタック?ヒープとは何が違うのか」という混乱
- 「なぜ new / malloc したら free / delete が必要なのか」が腹落ちしない
- 「スタックオーバーフロー」「メモリリーク」といったエラーの意味が曖昧
- JavaやPythonでは new するけど、C++のような delete が無いのはなぜか
これらはスタックは自動で片づく・ヒープは自分で(またはランタイムが)片づけるという違いをイメージできると、一気につながって理解しやすくなります。
スタック領域とは?特徴と使われ方
スタックは、関数が呼び出されるたびに自動的に使われるメモリ領域です。
多くの処理系では、「最後に使ったものから先に片づける」LIFO(Last In, First Out)構造になっています。
スタックの基本イメージ
スタックのイメージとして定番なのが「積み重ねたお皿」や「本の山」です。
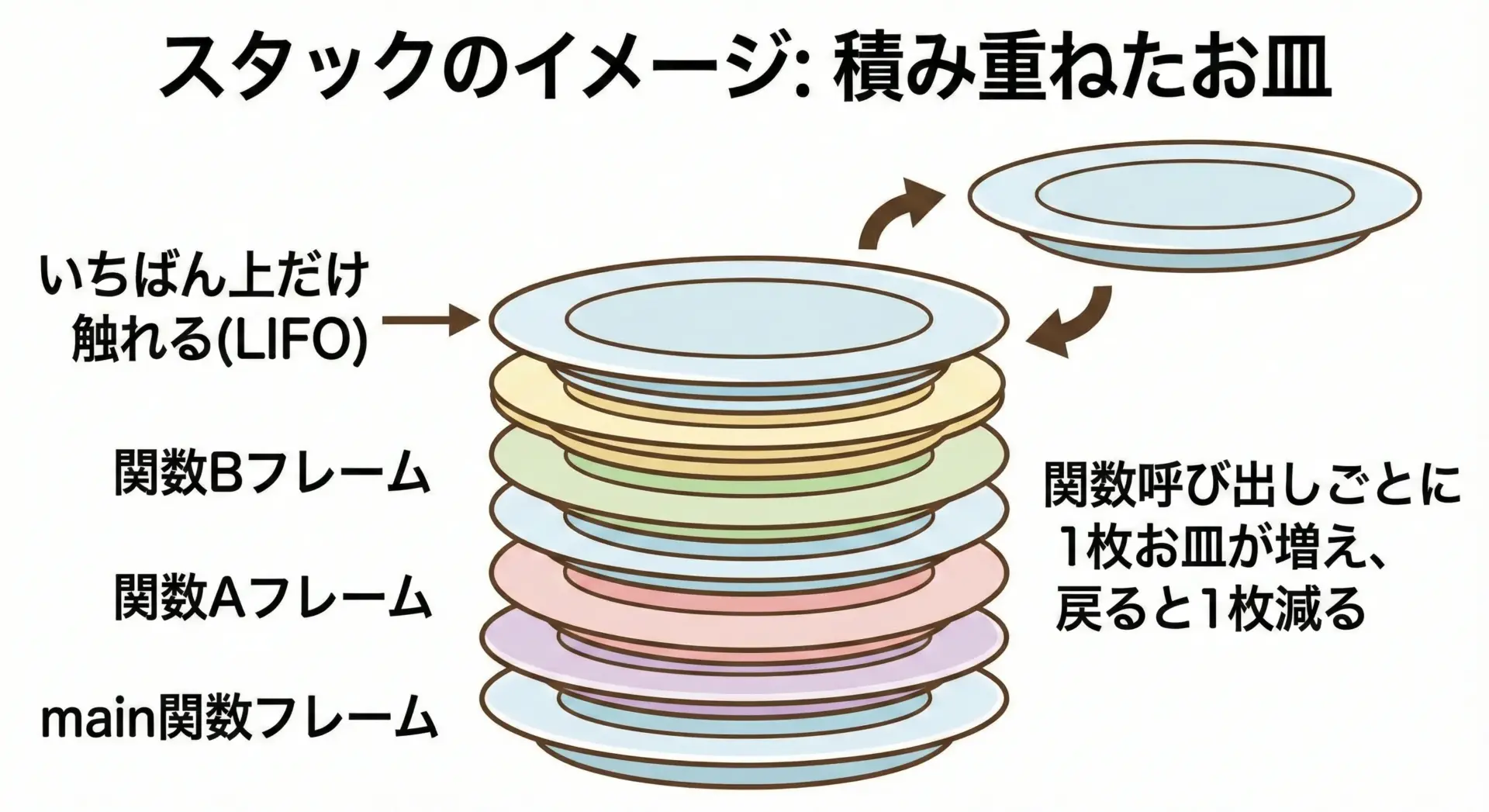
プログラムが実行されると、最初に main関数(またはエントリポイント)のスタックフレームがお皿1枚分として積み上がります。
mainの中から別の関数を呼び出すと、もう1枚お皿が増えます。
呼び出された関数が終わると、そのお皿(スタックフレーム)は丸ごと片づけられます。
このようにスタックは、関数のネスト構造に対応して自動的に積み上がり、自動的に片づく領域です。
自動変数と関数呼び出しとスタックフレーム
ローカル変数の多くは、スタックに配置されます。
Cの用語では自動変数(auto変数)と呼ばれます。
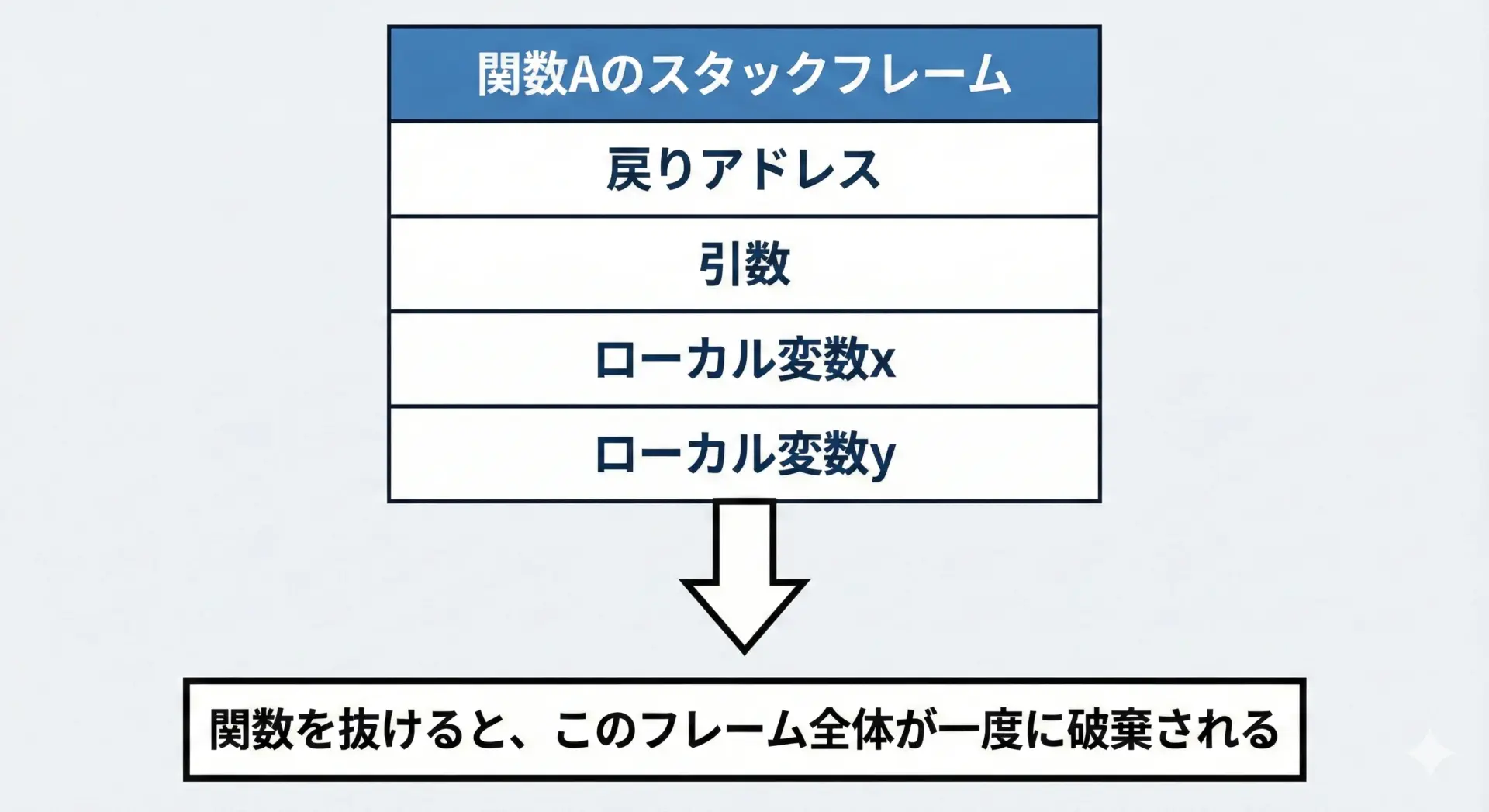
典型的な動きは次のようになります。
- 関数が呼び出される
- その関数専用の「スタックフレーム」がスタック上に確保される
- 引数やローカル変数が、そのフレームの中に配置される
- 関数処理が終わると、スタックポインタが元に戻り、フレーム全体が無効になる
このとき、プログラマはスタックフレームを明示的に確保・解放する必要はありません。
コンパイラとCPUが自動的に行ってくれます。
スタック領域のメリット
スタックには、プログラミング上うれしい特徴がいくつもあります。
1つ目は速度です。
スタックは単に「スタックポインタ」という位置情報を増減するだけで確保・解放が行えるため、非常に高速です。
動的な検索や複雑な管理を行う必要がありません。
2つ目は管理がシンプルで安全になりやすいことです。
関数を抜けるタイミングは明確なので、「いつ片づければいいか」を考える必要がありません。
そのため、メモリリークのような「解放し忘れ」のバグが起こりません。
3つ目は局所性が高く、キャッシュヒット率が良くなりやすいことです。
多くの処理系では、スタックは連続したアドレス領域で管理されるため、CPUキャッシュに載りやすく、実行効率にも寄与します。
スタック領域のデメリット
一方で、スタックには制約もあります。
1つ目はサイズの制限です。
スタックには一般的に上限サイズがあり、巨大な配列や大きな構造体をたくさん積むことには向きません。
スレッドごとにスタックサイズが決まっている場合も多く、無制限に使えるわけではありません。
2つ目は寿命(ライフタイム)が関数に束縛されることです。
ローカル変数は、関数を抜けると無効になります。
そのため、「関数を抜けた後も使い続けたいデータ」をスタックに置くことは根本的にできません。
3つ目は柔軟なサイズ変更が苦手なことです。
再帰的な呼び出しなどを除けば、スタックに置く変数のサイズはコンパイル時にある程度決まっている必要があります。
「実行してみないと必要なサイズがわからない」ケースには向きません。
スタックオーバーフローとは何か
スタックに関する代表的なエラーがスタックオーバーフローです。
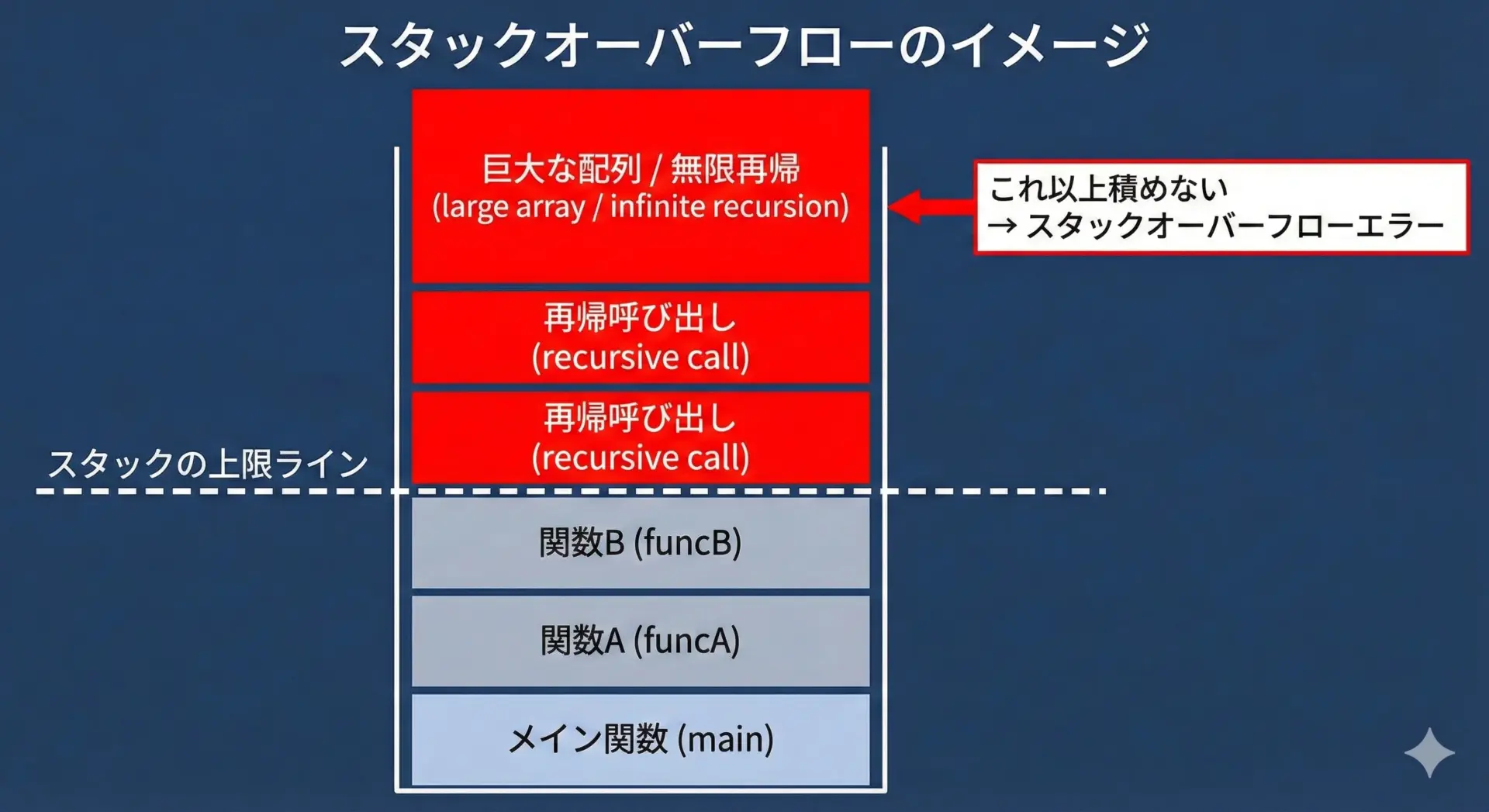
スタックオーバーフローは、次のような状況で発生します。
- 終了条件の無い再帰呼び出しで、スタックフレームが無限に積み上がる
- 1回の関数呼び出しで、あまりに大きなローカル配列を確保してしまう
- 深すぎる再帰呼び出し(たとえ終了条件があっても、深さがスタックサイズを越えてしまう)
スタックオーバーフローが起きると、多くの環境ではプログラムが異常終了します。
これは、スタックがヒープや他の領域を壊さないようにするための安全装置のようなものです。
ヒープ領域とは?特徴と使われ方
ヒープは、必要になったときに任意のサイズのメモリを確保し、必要なくなったら解放するための領域です。
スタックのような「自動片づけ」は行ってくれませんが、そのぶん柔軟に使えます。
ヒープの基本イメージ
ヒープの定番イメージは「大きな空き地に、好きな大きさのテントを建てたり壊したりする」感じです。
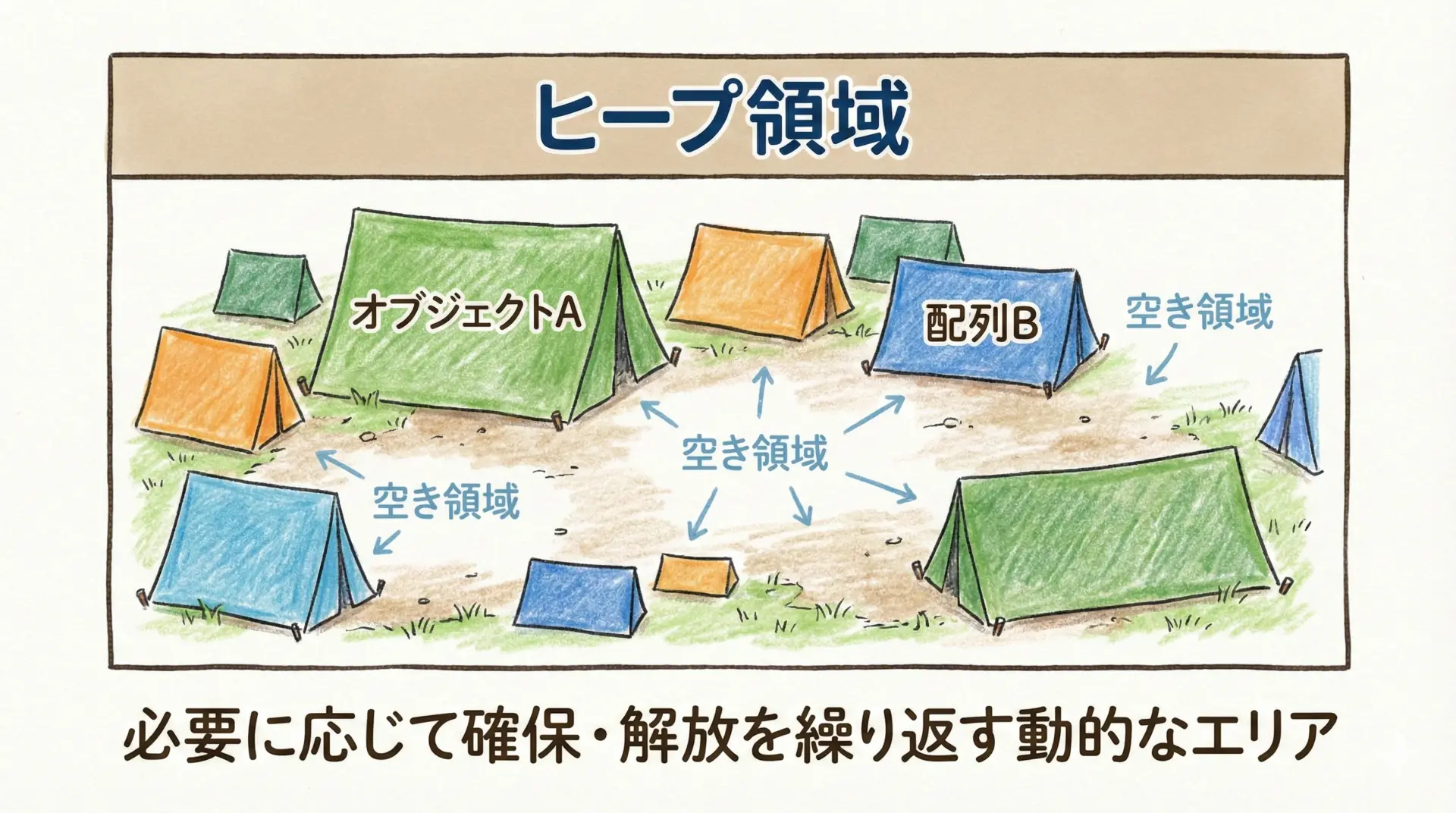
ヒープでは「今ここに 100バイトほしい」「次は 1MB ほしい」といった要求に応じて、メモリ管理システム(アロケータ)が空き領域を探して割り当てます。
解放すると、その部分はまた空き地に戻ります。
動的メモリアロケーション(malloc/new など)の役割
CやC++では、ヒープのメモリ確保には次のような関数や演算子を使います。
- C:
malloc(),calloc(),realloc(),free() - C++:
new,delete,new[],delete[]
JavaやC#、Pythonなどでは、new もしくはオブジェクト生成構文を使うと、内部的にヒープからメモリが割り当てられます。
ただし、それをいつ解放するかはガーベジコレクタ(GC)が自動的に判断します。
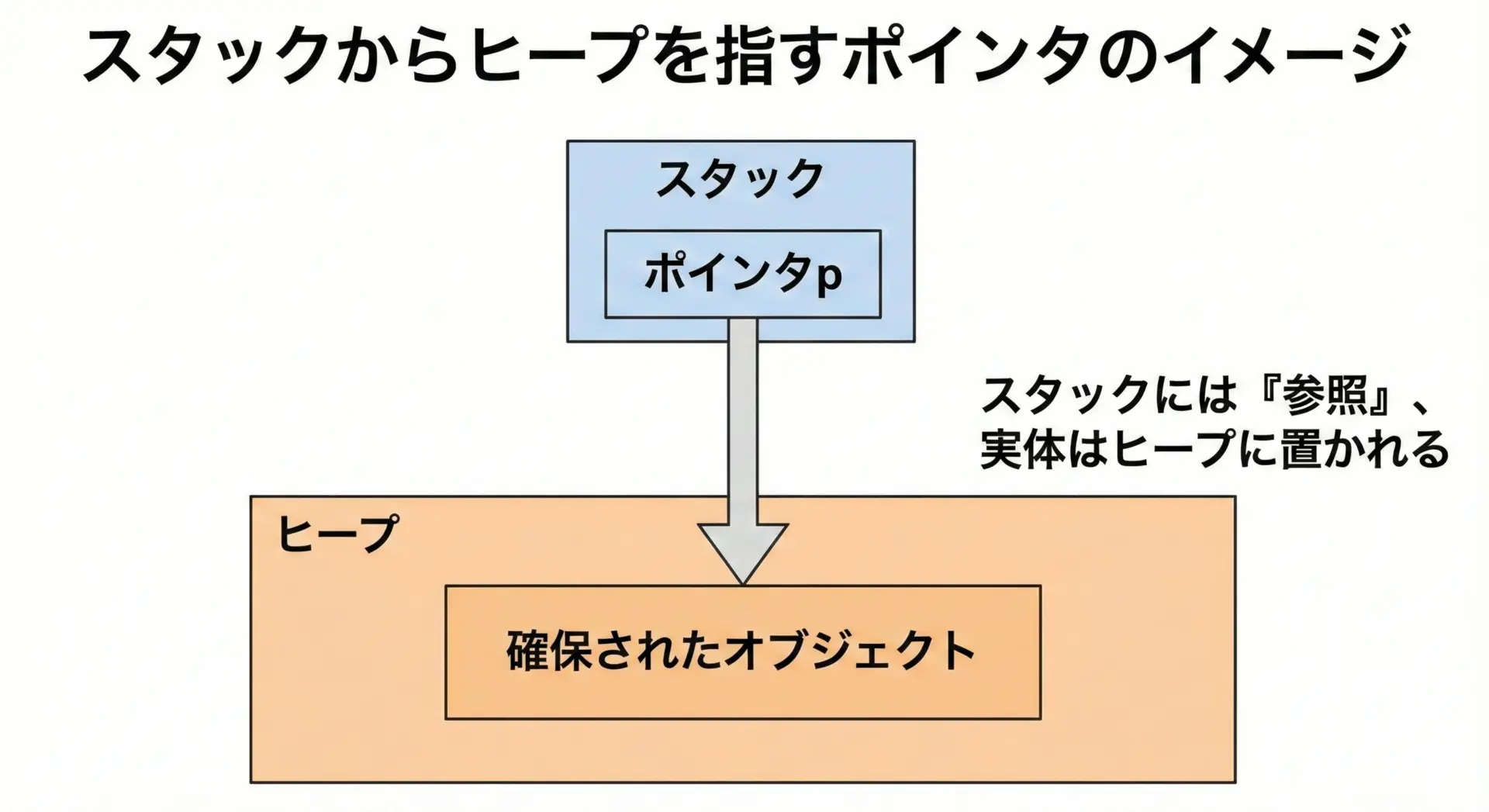
多くの場合、スタックには「ヒープ上のオブジェクトを指すポインタ(または参照)だけが置かれるという形になります。
ヒープ領域のメリット
ヒープの最大のメリットは柔軟性です。
1つ目は大きなデータを扱えることです。
スタックに乗せるには大きすぎる配列やオブジェクトでも、ヒープなら確保できる場合が多くなります。
2つ目はオブジェクトの寿命を自由に決められることです。
関数を抜けた後も保持しておきたいデータを、ヒープ上に置いてポインタや参照を渡す、という使い方が可能です。
これにより、状態を長期間維持する必要があるデータ構造(リスト、ツリー、キャッシュなど)を扱えます。
3つ目は実行時にサイズを決められることです。
「ユーザが入力したサイズに応じて配列を確保したい」といったケースで重宝します。
ヒープ領域のデメリット
一方で、ヒープにも注意すべき点があります。
1つ目は確保・解放がスタックより遅いことです。
ヒープアロケータは、空き領域を探したり、断片化を抑えようとしたりするため、スタックのように単純なポインタ操作だけでは済みません。
2つ目はメモリ管理が複雑になりやすいことです。
C/C++のように手動で free や delete を呼ぶ言語では、「どこで解放するのか」「二重解放していないか」など、ライフサイクル設計に注意が必要です。
3つ目は断片化の問題です。
大小さまざまなサイズの確保と解放を繰り返すと、ヒープ内に細かい空き領域が点在し、見かけ上の空き容量はあるのに連続した大きな領域が確保できないという状況になることがあります。
メモリリークとは何か
ヒープにまつわる有名な問題がメモリリークです。
メモリリークとは「もう使わないメモリが解放されずに残り続ける」状態を指します。
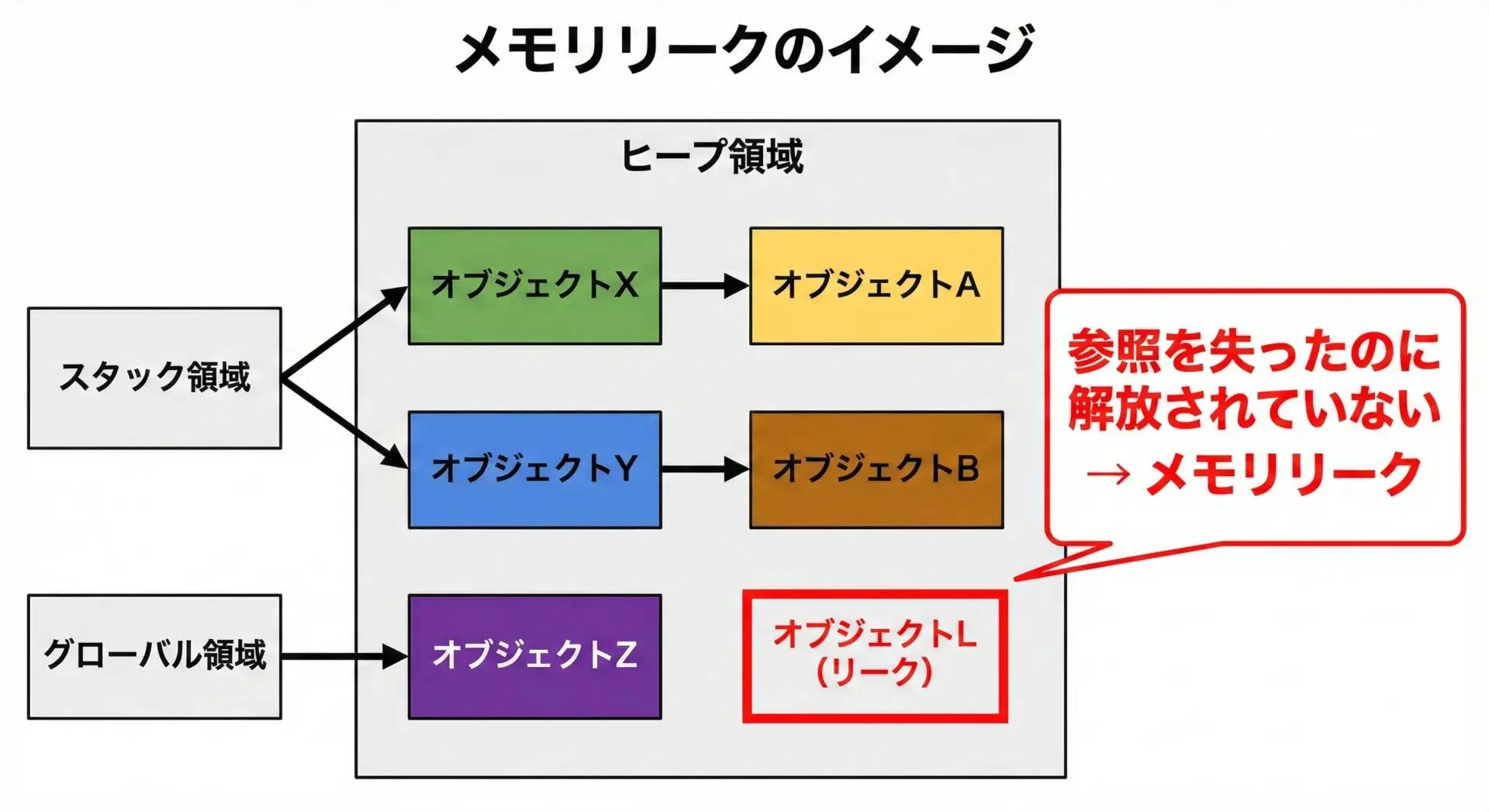
典型的なパターンは次のようなものです。
- C/C++で
malloc/newしたポインタを、free/deleteし忘れる - 参照を上書きしてしまい、元のオブジェクトへのポインタを失ってしまう(到達不能だが解放されていない)
- 長期間動作するサーバプログラムで、少しずつリークを積み重ねていき、最終的にメモリ枯渇で落ちる
ガーベジコレクションがある言語でも、論理的なリークは起こり得ます。
たとえば、もう使わないオブジェクトへの参照をどこかに持ち続けてしまうと、GCは「まだ参照されている」と判断して回収しません。
この場合も「実質的にメモリリーク」となります。
スタックとヒープの違いをイメージでつかむ
ここまでの内容を踏まえて、スタックとヒープの違いを「イメージ」と「コード例」で整理していきます。
「自動で片づくスタック」と「自分で片づけるヒープ」の違い
という比喩がよく使われます。
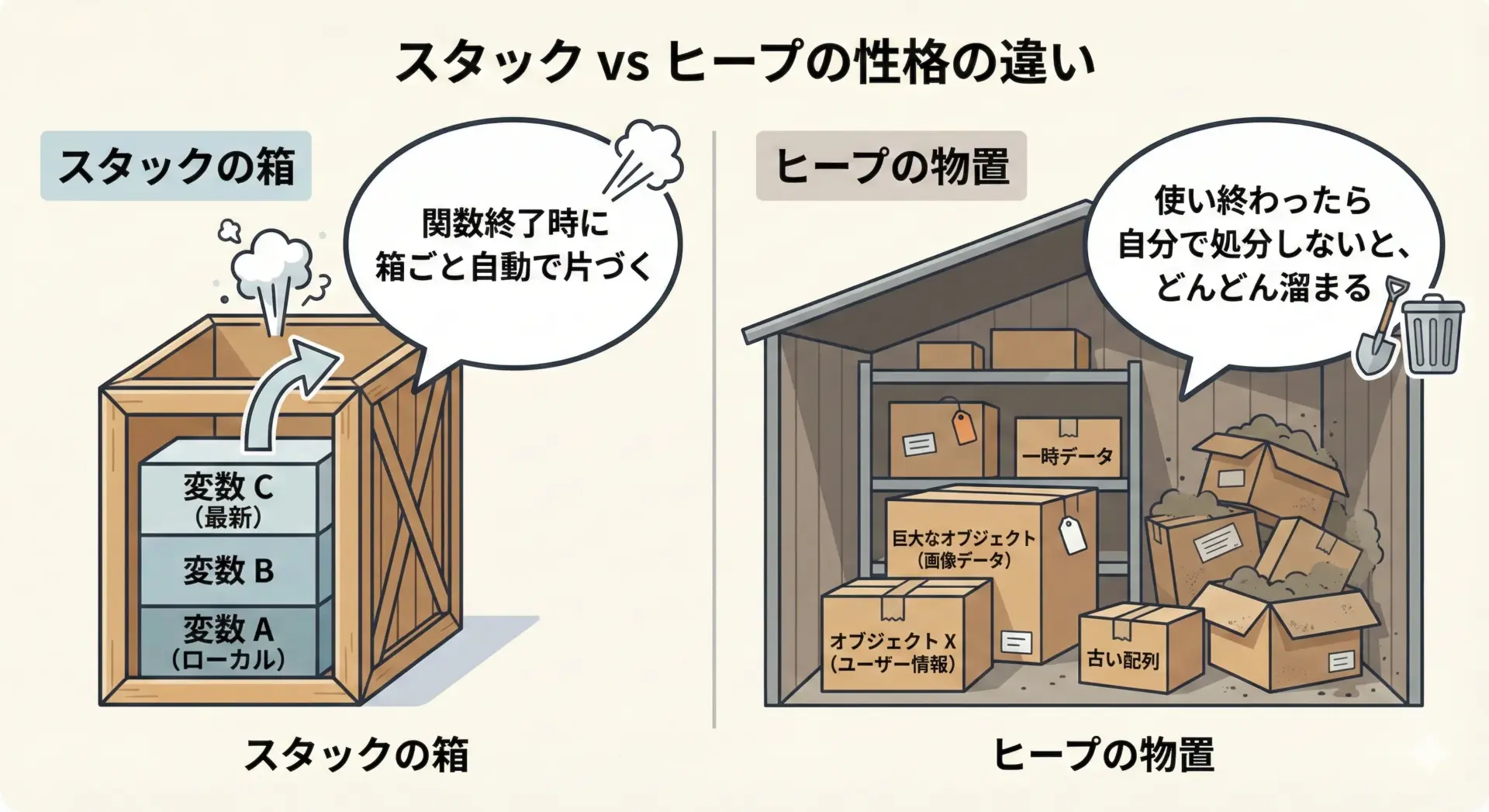
スタックの箱は、「関数が終わる」というタイミングで中身ごと自動的に片づきます。
これは非常に便利ですが、逆に言えば、そのタイミング以外で寿命をコントロールすることはできません。
一方ヒープの物置は、いつでも物を入れたり出したりできますが、片づける責任も自分(またはランタイム)にあります。
C/C++では明示的な解放が必要で、Java/PythonではGCが自動的に片づけてくれますが、どちらにせよ「どのタイミングで不要になるか」を設計する必要があります。
使用例で比べるスタック変数とヒープ変数
C言語風の擬似コードで、スタックとヒープの違いを見てみます。
void example() {
// スタック上に確保されるローカル変数
int a = 10; // 自動変数 (関数終了とともに消える)
// ヒープ上に確保される領域
int* p = malloc(sizeof(int));
*p = 20; // ヒープ上のintに代入
// ここでは a も *p も使える
free(p); // ヒープ領域を解放 (しないとメモリリーク)
// ここで *p を使うのは危険 (ダングリングポインタ)
}このコードから読み取れるポイントは次の通りです。
- a はスタック上に置かれ、example関数を抜けると自動的に無効になります
- p が指している実体はヒープ上にあり、
free(p)を呼ぶまでは残り続けます free(p)した後で*pを使うと、解放済みメモリへのアクセス(未定義動作)になります
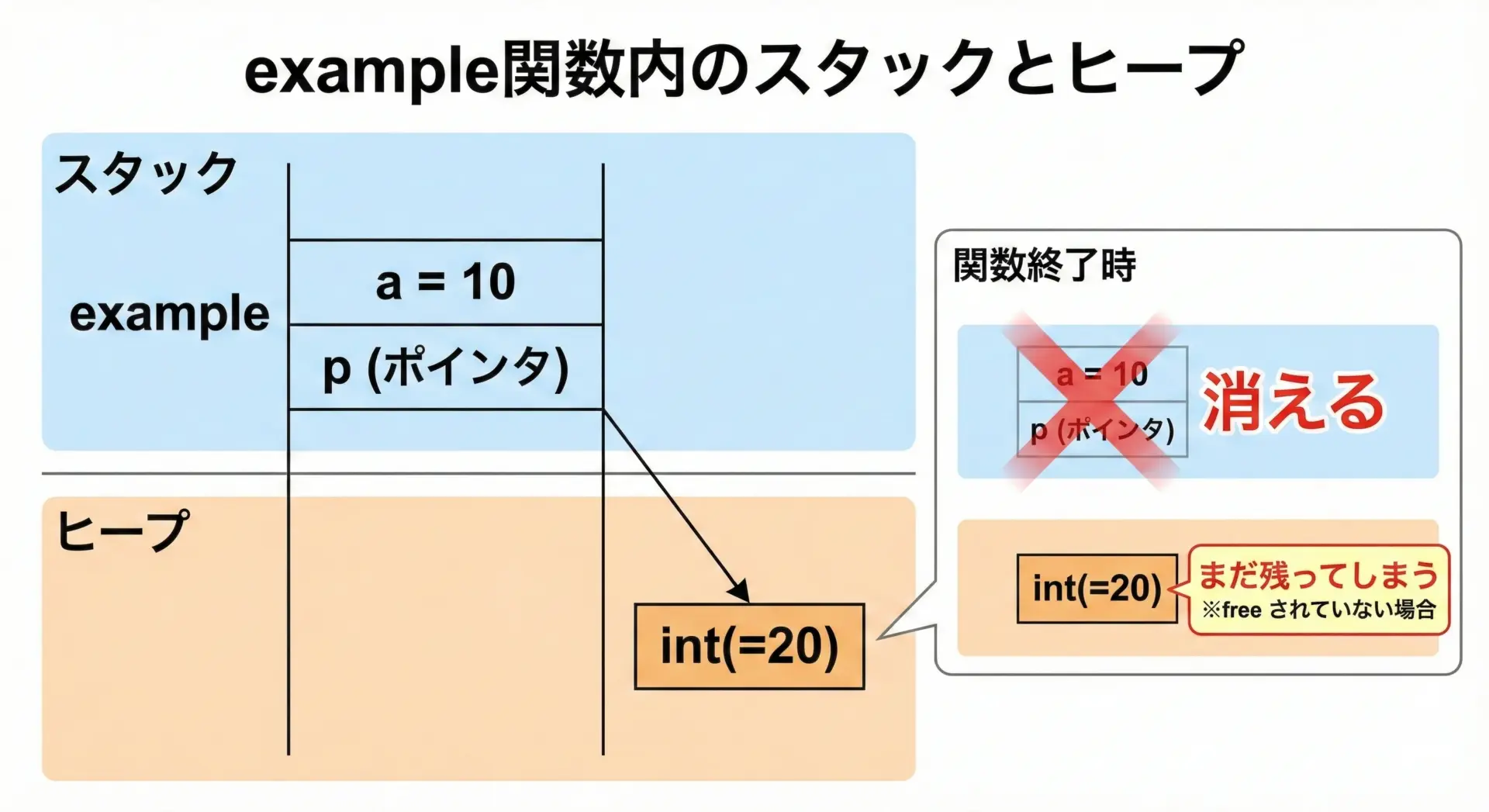
このように、「変数がどこに置かれているか」と「実際のデータがどこにあるか」は別の話という点が、スタックとヒープを理解する鍵になります。
パフォーマンスに与える影響
スタックとヒープは、パフォーマンス面でも性格がかなり異なります。
- スタック
- 確保・解放が速い(ポインタの増減のみ)
- 領域が連続しているため、CPUキャッシュと相性が良い
- サイズ上限があるため、大量の大きなデータには向かない
- ヒープ
- 確保・解放が相対的に遅い(管理構造の更新が必要)
- 断片化などでレイアウトが不規則になりやすい
- 大きなデータや長生きするオブジェクトに向く
- GC言語では、ガーベジコレクションの一時停止がパフォーマンスに影響することもある
「とりあえず全部ヒープに置けばよい」というのは、パフォーマンスやメモリ効率の観点からは必ずしも良い選択ではありません。
逆に、何でもスタックで済ませようとすると、スタックオーバーフローを招く可能性があります。
C/C++とJava/Pythonでのスタック・ヒープの考え方の違い
最後に、言語ごとの扱いの違いを整理します。
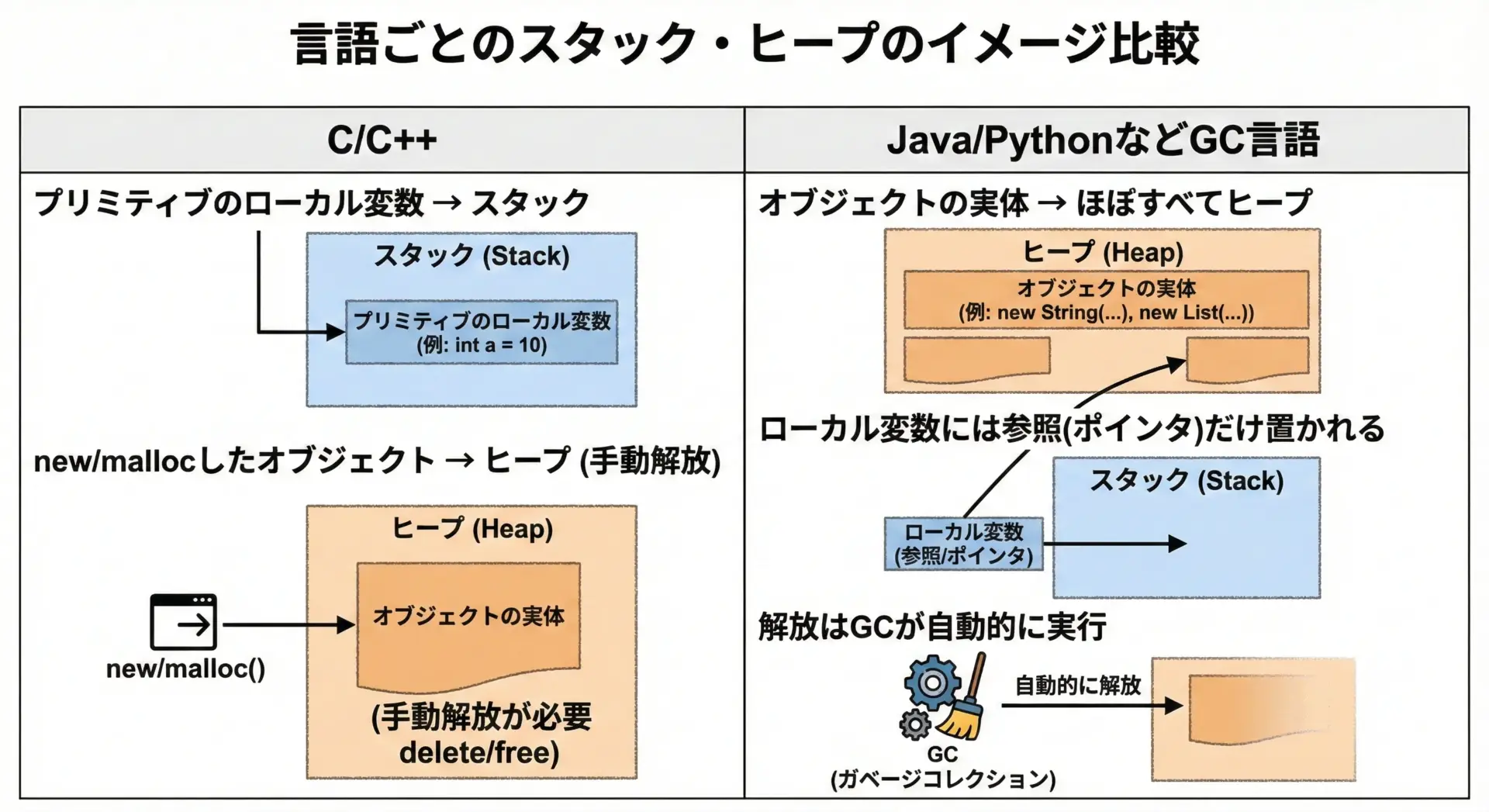
C/C++の場合
C/C++では、メモリモデルが比較的「素直」で、スタックかヒープかを自分で選ぶ場面が多くあります。
- 関数内の通常のローカル変数 → スタック
staticなローカル変数やグローバル変数 → 静的領域malloc/newで確保したもの → ヒープ(明示的な解放が必要)
そのため、スタックとヒープの違いを理解することは、C/C++プログラマにとって避けて通れない基本になります。
Java / C# / Python などGC言語の場合
JavaやC#、Pythonなどの言語では、オブジェクトの実体は基本的にすべてヒープ上に置かれます。
ローカル変数に入るのは、ヒープ上のオブジェクトへの参照(ポインタ)です。
- Java:
- プリミティブ型(int, long など)のローカル変数 → 実装依存だが、多くはスタック
- オブジェクト(
newしたもの) → ヒープ - 解放はGCが自動で実行
- Python:
- すべてがオブジェクト(整数もリストも)
- 実体はヒープ上、変数名は参照
- 参照カウント+GCで解放を自動管理
このため、アプリケーションプログラマの視点では「スタックかヒープか」を意識しなくてもコードは書けます。
しかし、パフォーマンスチューニングやGCの挙動理解、Cとの連携(FFI)などを行う段階になると、メモリモデルの理解が再び重要になってきます。
まとめ
スタックとヒープは、どちらもプログラムが一時的なデータを置くためのメモリ領域ですが、性格は大きく異なります。
- スタックは「自動で片づく、高速でシンプルな箱」で、関数呼び出しごとのローカル変数や引数が入ります。寿命は関数スコープに縛られ、巨大なデータや長寿命のデータには向きません。過剰に使うとスタックオーバーフローを引き起こします。
- ヒープは「自分で片づける(またはGCが片づける)、柔軟な物置」で、大きなデータや寿命が長いオブジェクトを置くのに向いていますが、管理が複雑で、メモリリークや断片化などの問題が発生しやすくなります。
C/C++のようにメモリ管理を自分の手で行う言語では、この違いを理解していないと、クラッシュやリークに悩まされることになります。
JavaやPythonのようなGC言語でも、オブジェクトがどこに置かれているかをイメージできると、パフォーマンスやメモリ使用量を意識した設計がしやすくなります。
「ローカル変数はスタック」「動的なオブジェクトはヒープ」「スタックは自動で片づく」「ヒープは自分(もしくはGC)で片づける」という4点を、まずはイメージとしてしっかり押さえておくとよいでしょう。
その上で、実際のコードを書きながら、「この変数は今どこにいて、いつまで生きるのか」を意識してみると、メモリモデルへの理解が一段と深まっていきます。
