
コンピュータの世界では、私たちが見ている「文字」は、そのままの姿で保存されているわけではありません。
実は、すべての文字は数字に置き換えられ、その数字をコンピュータが処理しています。
その「文字と数字の対応表」のひとつがASCIIコード表です。
この記事では、初学者でもイメージしやすいように、ASCIIコード表の意味や読み方、プログラミングでの具体的な使い方まで、ゆっくり丁寧に解説していきます。
ASCIIコード表とは何か
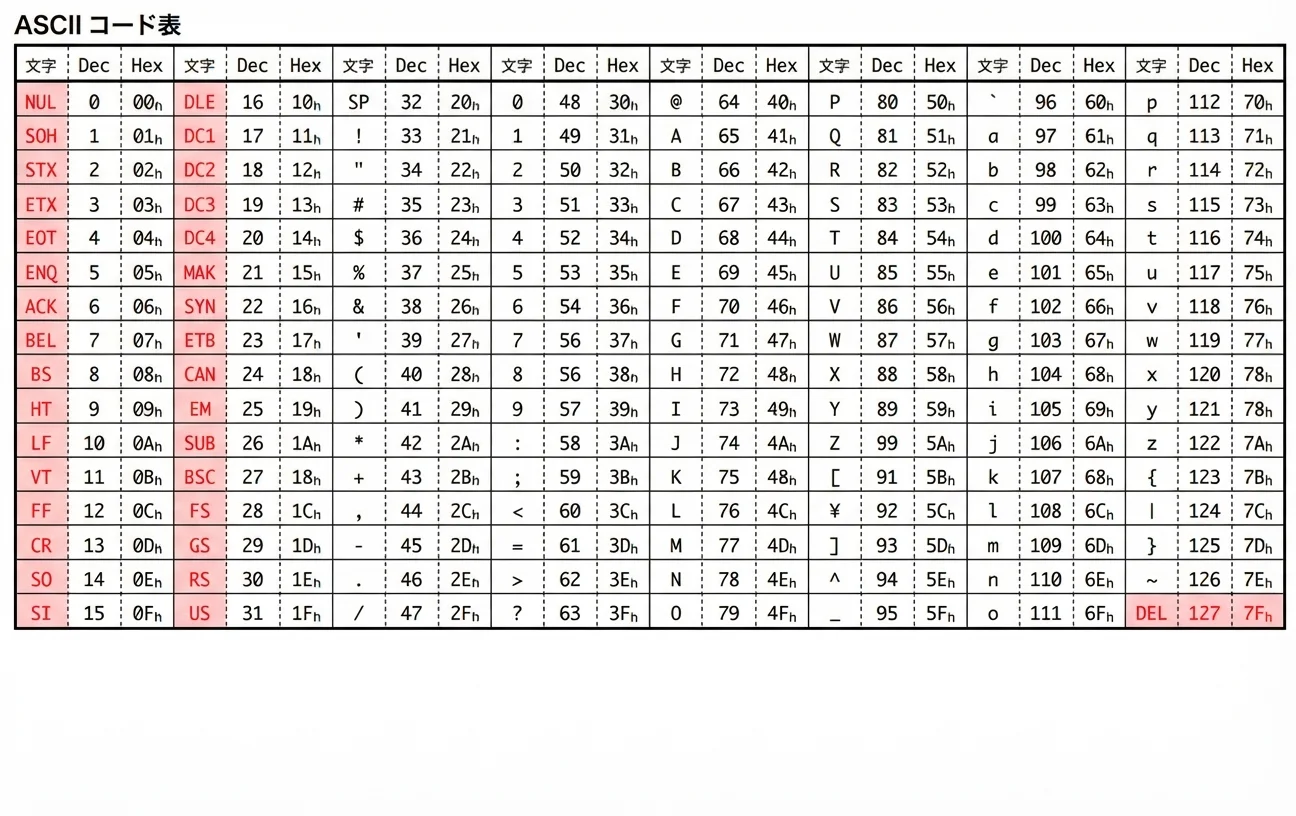
ASCIIコードとは
ASCII(アスキー)コードとは、英語の文字や記号を数字に対応づけた約束ごと(文字コード)のひとつです。
たとえば、次のような対応があります。
- 文字
A→ 数字 65 - 文字
a→ 数字 97 - 文字
0→ 数字 48
このように、「どの文字をどの番号で表すか」を決めたルールがASCIIコードです。
プログラムの内部では、文字列も最終的にはこのような数字の列として扱われています。
ASCIIコード表の全体像
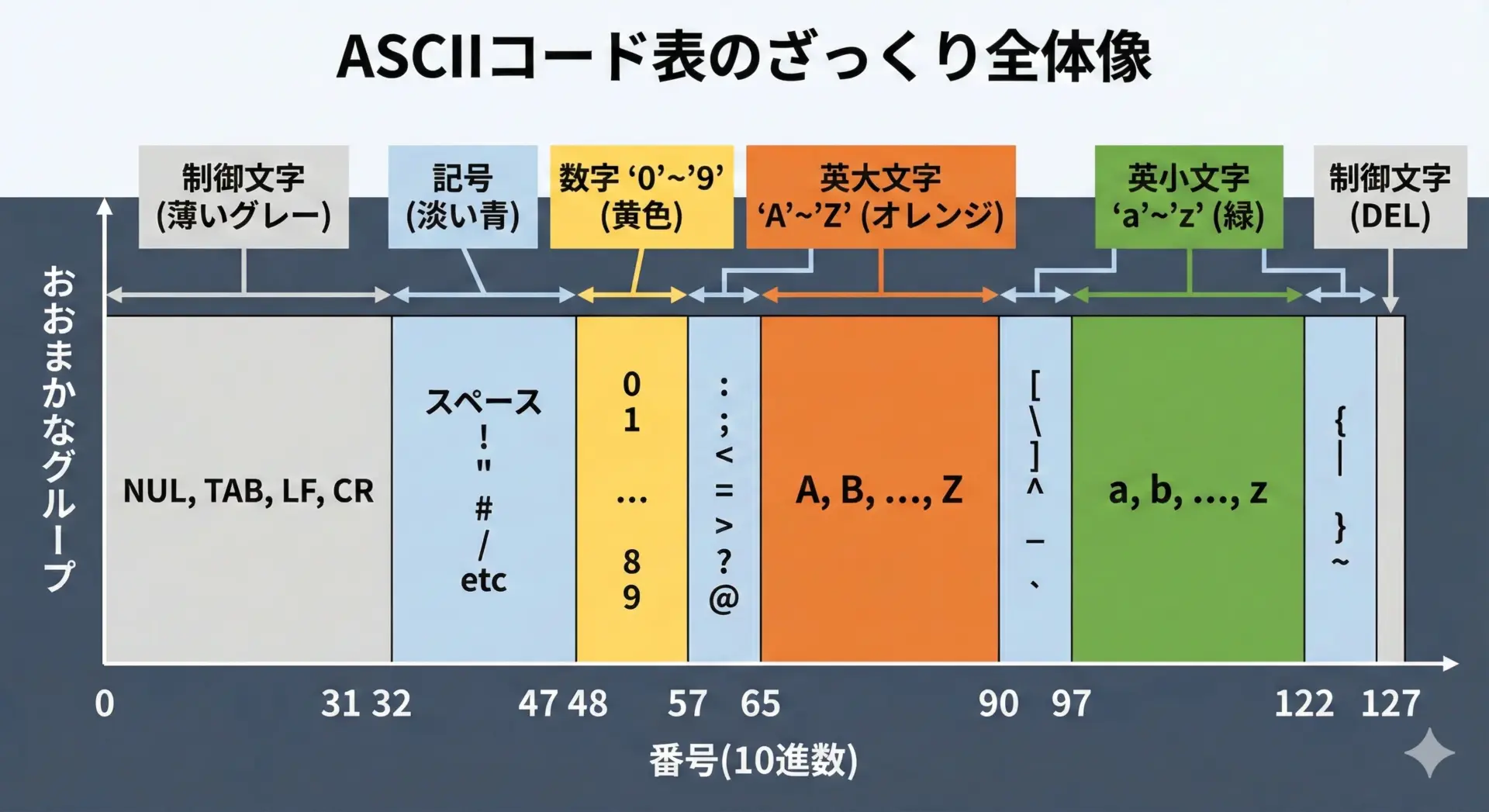
ASCIIコードは本来0〜127までの128個のコードからなります。
そのうち前半(0〜31)は特殊な制御用のコード、後半(32〜127)に、空白や数字、アルファベット、記号などの「目に見える文字」が並んでいます。
まずは、「文字は0〜127の数字に対応している」という大まかなイメージを持つところから始めてみてください。
なぜプログラミングでASCIIコード表が必要なのか
プログラミングでは、文字列を扱う場面が非常に多くあります。
ファイル名、ログ出力、ユーザーの入力、ネットワーク通信など、ほとんどすべてが文字列に関係しています。
文字列をきちんと扱うには、その裏側にある「数字としての表現」を理解しておくことが大きな助けになります。
たとえば次のような場面でASCIIコード表の知識が役立ちます。
- 文字の並び順を理解したいとき(辞書順ソートや比較)
- 大文字と小文字を変換したいとき
- 簡単な暗号化やマスク処理を行いたいとき
- 文字化けやエンコーディングの問題を説明したいとき
ASCIIコード表自体を丸暗記する必要はありませんが、「どの文字がどのあたりの番号帯にいるか」を知っておくと、コードを書いたり他人のコードを読んだりするときの理解がぐっと楽になります。
文字と数字の対応関係のイメージをつかむ
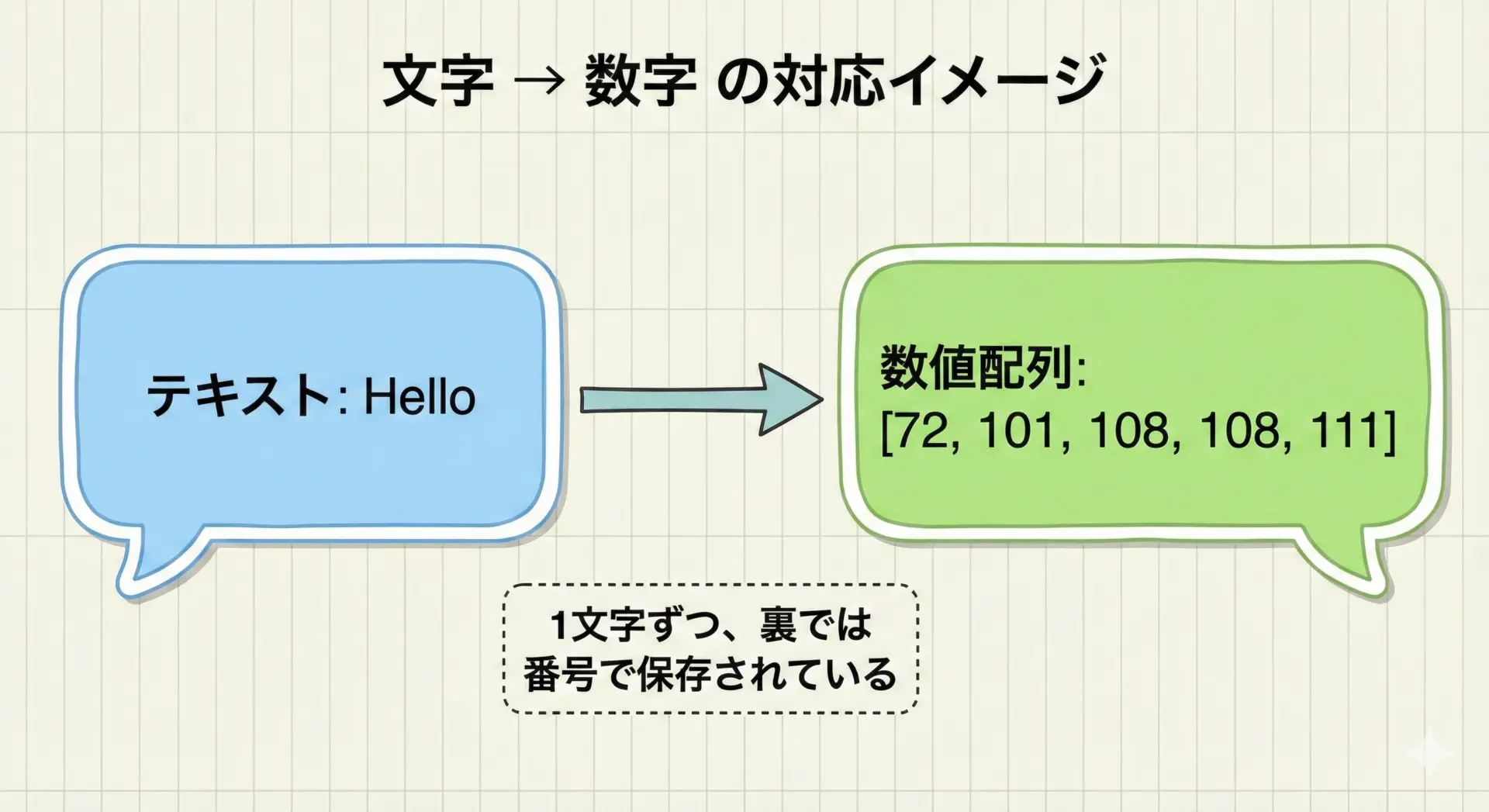
文字と数字の関係をシンプルに言うと、「文字列 = 文字のならび」ではなく「文字列 = 数字のならび」であるということです。
たとえば Hello という文字列は、ASCII的には次のような数字の列として扱われます。
H→ 72e→ 101l→ 108l→ 108o→ 111
このように、同じ文字列でも、その正体は「ASCIIコードの配列」になっています。
この感覚をつかんでおくと、これから出てくる説明も理解しやすくなります。
ASCIIコード表の読み方
10進数と16進数
ASCIIコード表を見ると、多くの場合「10進数」と「16進数」の両方が載っています。
たとえば、こんな書き方です。
- 10進数 65 = 16進数 0x41 = 文字
A
コンピュータの内部では16進数表記がよく使われますが、人間にとって直感的なのは10進数です。
そのため、ASCIIコード表では両方を併記していることが多いのです。
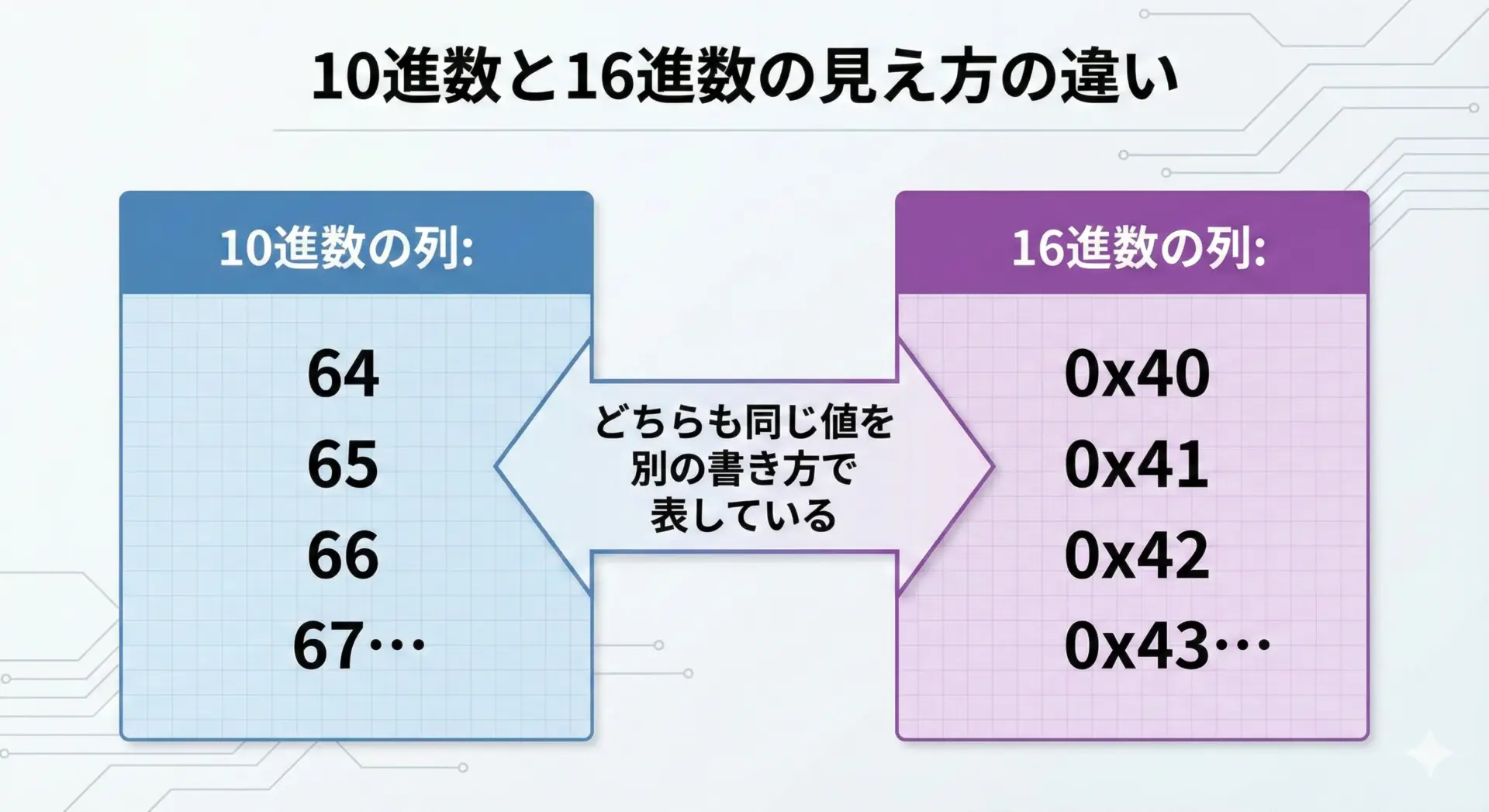
10進数と16進数の関係そのものは数学の話ですが、ASCIIコード表をざっくり読むうえでは、「よく使う文字だけ、10進数をなんとなく覚える」くらいで問題ありません。
16進数は「0x41のような見慣れない書き方が出てきたら、別の表記なんだな」くらいに捉えておけば十分です。
制御文字(表示されない文字)とは
ASCIIコードの0〜31番、そして127番は、画面にそのまま表示されない制御文字です。
もともとは、テレタイプ端末やプリンタなどを制御するために使われていました。
有名なものだけ挙げると、次のような制御文字があります。
- 9 : TAB(水平タブ)
- 10 : LF(改行)
- 13 : CR(復帰)
- 27 : ESC(エスケープ)
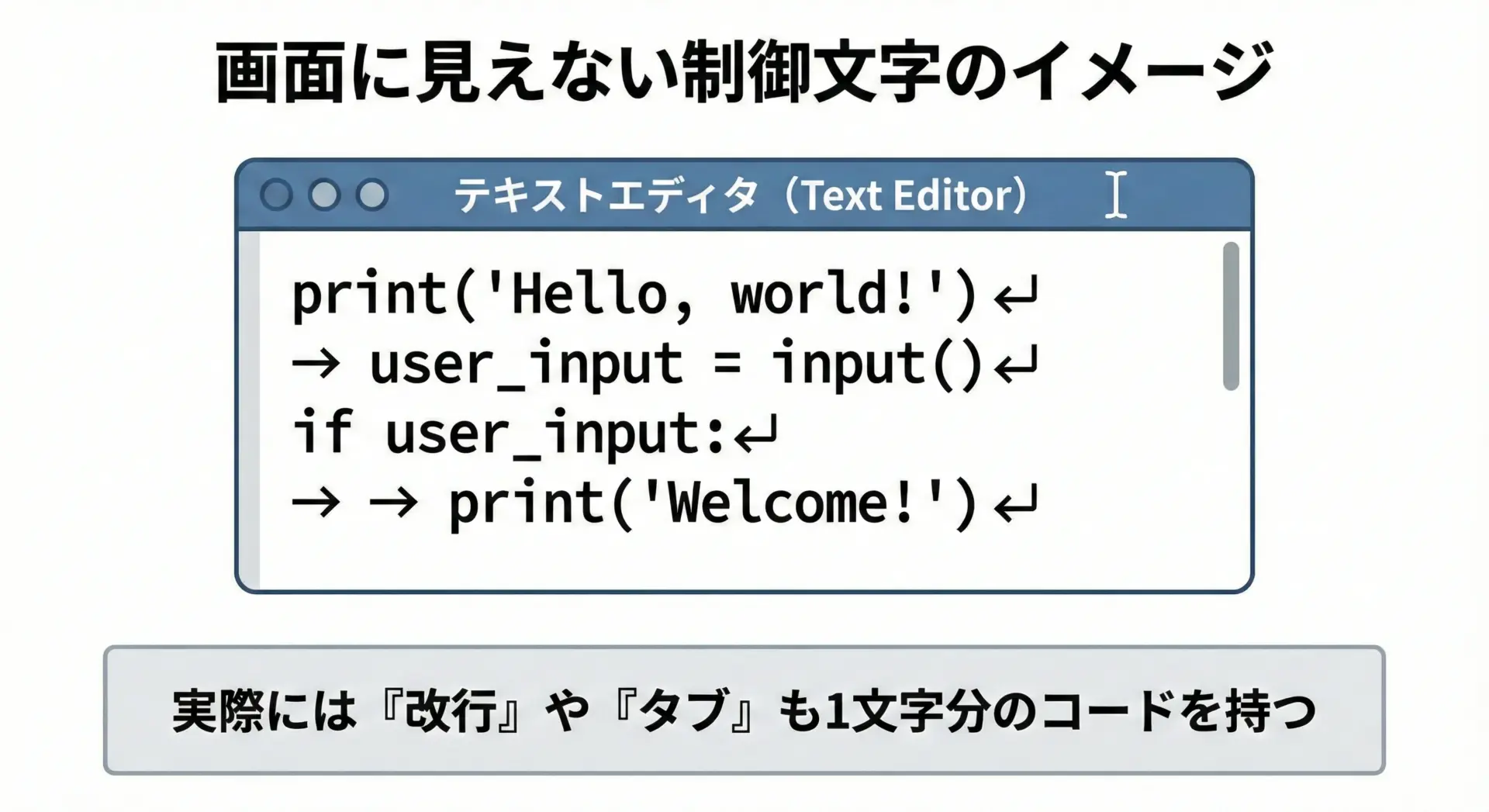
これらは表示されないため、普段は意識しにくいのですが、改行コードの違いによる文字化けや、ファイルのフォーマット問題などで必ず登場する重要な存在です。
今は「見えない文字もASCIIコードに含まれている」という理解だけでも十分です。
英字・数字・記号のASCIIコードの範囲を覚えるコツ
ASCIIコードをすべて覚える必要はありませんが、英字・数字の大まかな範囲を「ざっくり」覚えておくとプログラミングがとても楽になります。
代表的な範囲は次のとおりです。
| 種類 | 文字の例 | 10進数の範囲 |
|---|---|---|
| 数字 | ‘0’〜’9′ | 48〜57 |
| 英大文字 | ‘A’〜’Z’ | 65〜90 |
| 英小文字 | ‘a’〜’z’ | 97〜122 |
覚えやすいコツとしては、次のようなものがあります。
- 数字の’0’は48
→ 50前後と覚えておくと計算しやすいです。 - 大文字の’A’は65
→ こちらも「だいたい60代」と覚えれば十分です。 - 小文字の’a’は97
→ ちょうど大文字’A’より32大きい(詳しくは後述)という特徴があります。
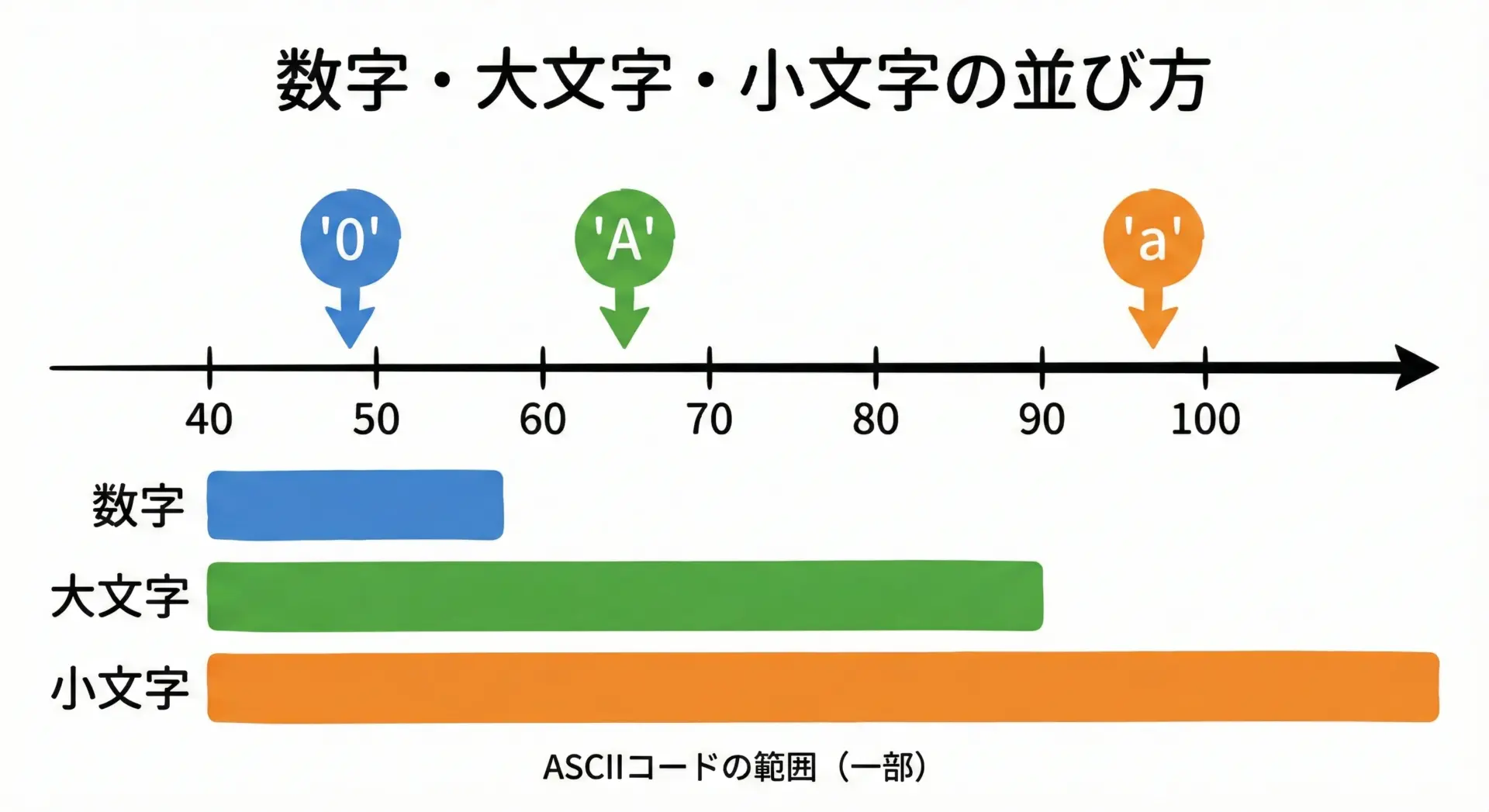
「数字は50前後から」「大文字は60台」「小文字は100前後」というラフな感覚を持てれば、ASCIIコード表を見たときに一気に理解しやすくなります。
具体例で学ぶASCIIコード
文字からASCIIコードへ変換する例
ここからは、実際に文字とASCIIコードを行き来する具体例を見ていきましょう。
まず、文字からASCIIコードに変換するイメージです。
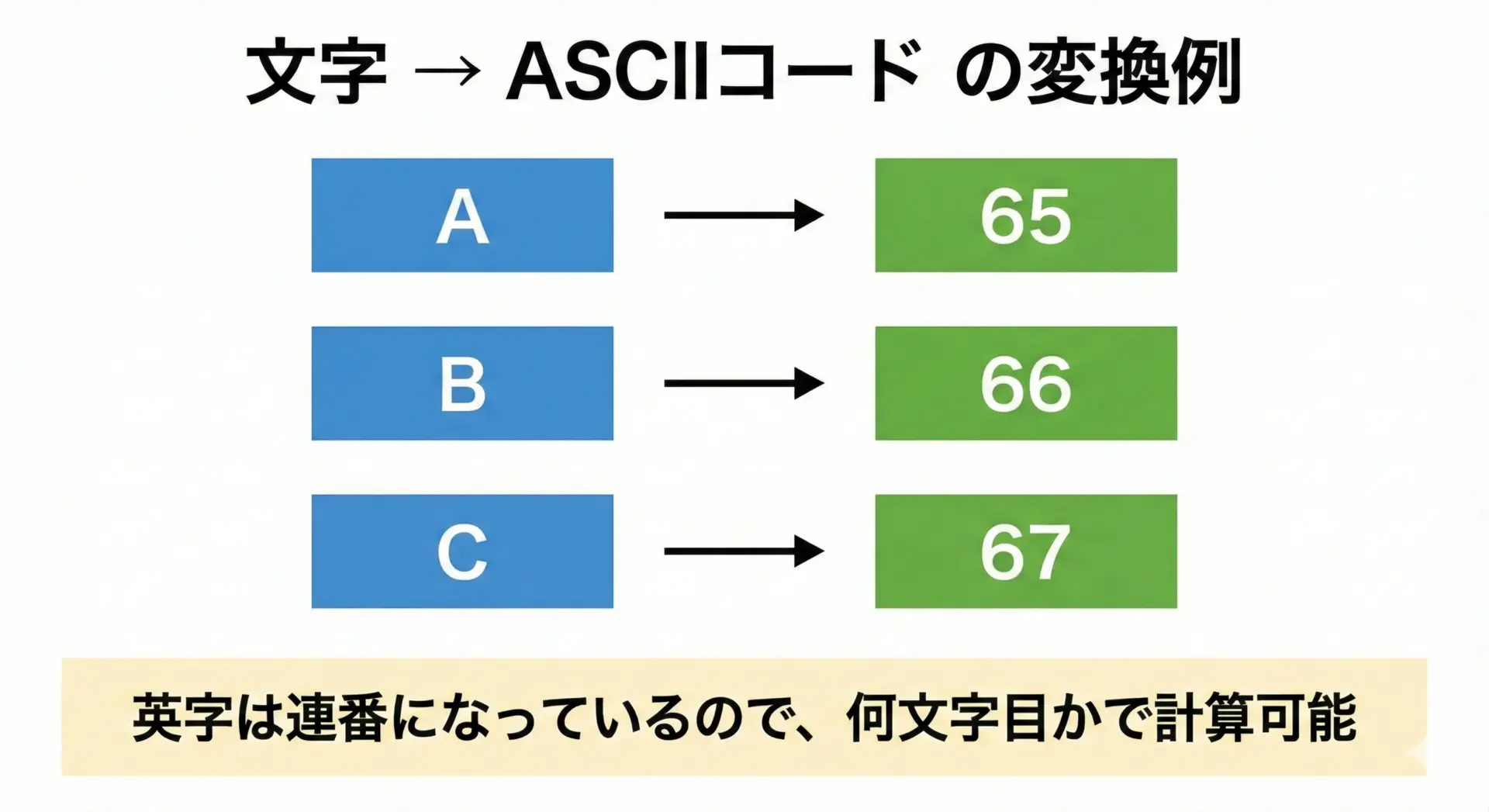
たとえば、文字 C のASCIIコードは次のようになります。
Aが 65Bが 66Cが 67
つまり、アルファベットは「Aから順番に1ずつ増えていく」形で番号が振られています。
多くのプログラミング言語では、文字からASCIIコードを取得する関数や演算があります。
たとえばPythonでは、次のように書けます。
ord('A') # 結果: 65
ord('C') # 結果: 67ここでord()は、1文字を「順序を表す数値」に変換する関数だと考えてください。
ASCIIコードから文字へ変換する例
逆に、ASCIIコードから文字へ変換することもできます。
Pythonでは次のように書きます。
chr(65) # 結果: 'A'
chr(67) # 結果: 'C'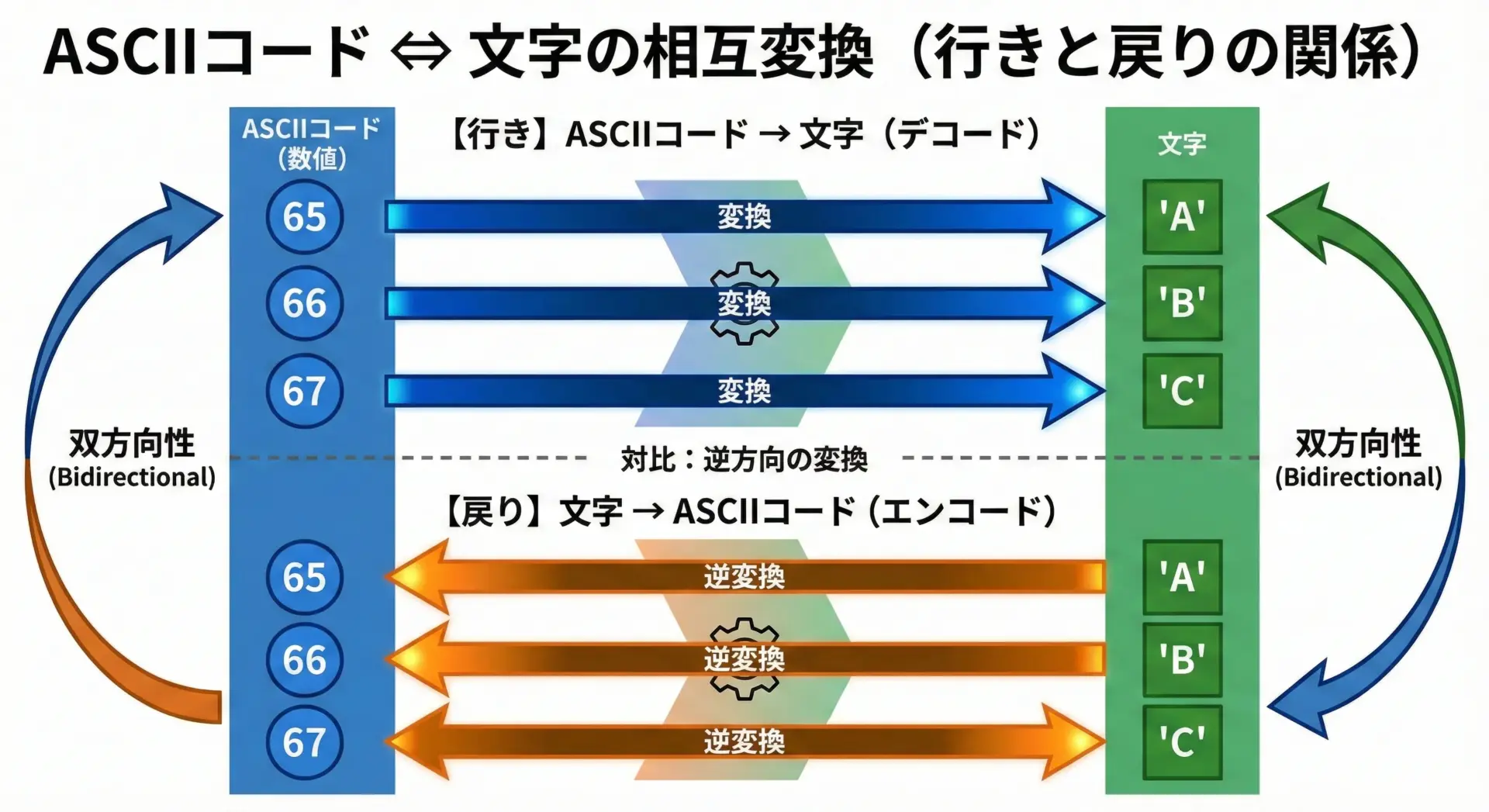
文字とASCIIコードは、このように「行ったり来たり」できる関係になっています。
これを利用して、暗号化や文字の種別判定など、さまざまな処理が可能になります。
大文字と小文字のASCIIコードの違い
英字の大文字と小文字のASCIIコードは、実はきれいな規則に従っています。
それは「同じアルファベットの大文字と小文字の差は常に32」というものです。
たとえば次のようになります。
| 文字 | ASCIIコード(10進数) |
|---|---|
| ‘A’ | 65 |
| ‘a’ | 97 |
| ‘B’ | 66 |
| ‘b’ | 98 |
‘A'(65)と’a'(97)の差は32、’B'(66)と’b'(98)の差も32です。
この規則はアルファベット全体に当てはまります。
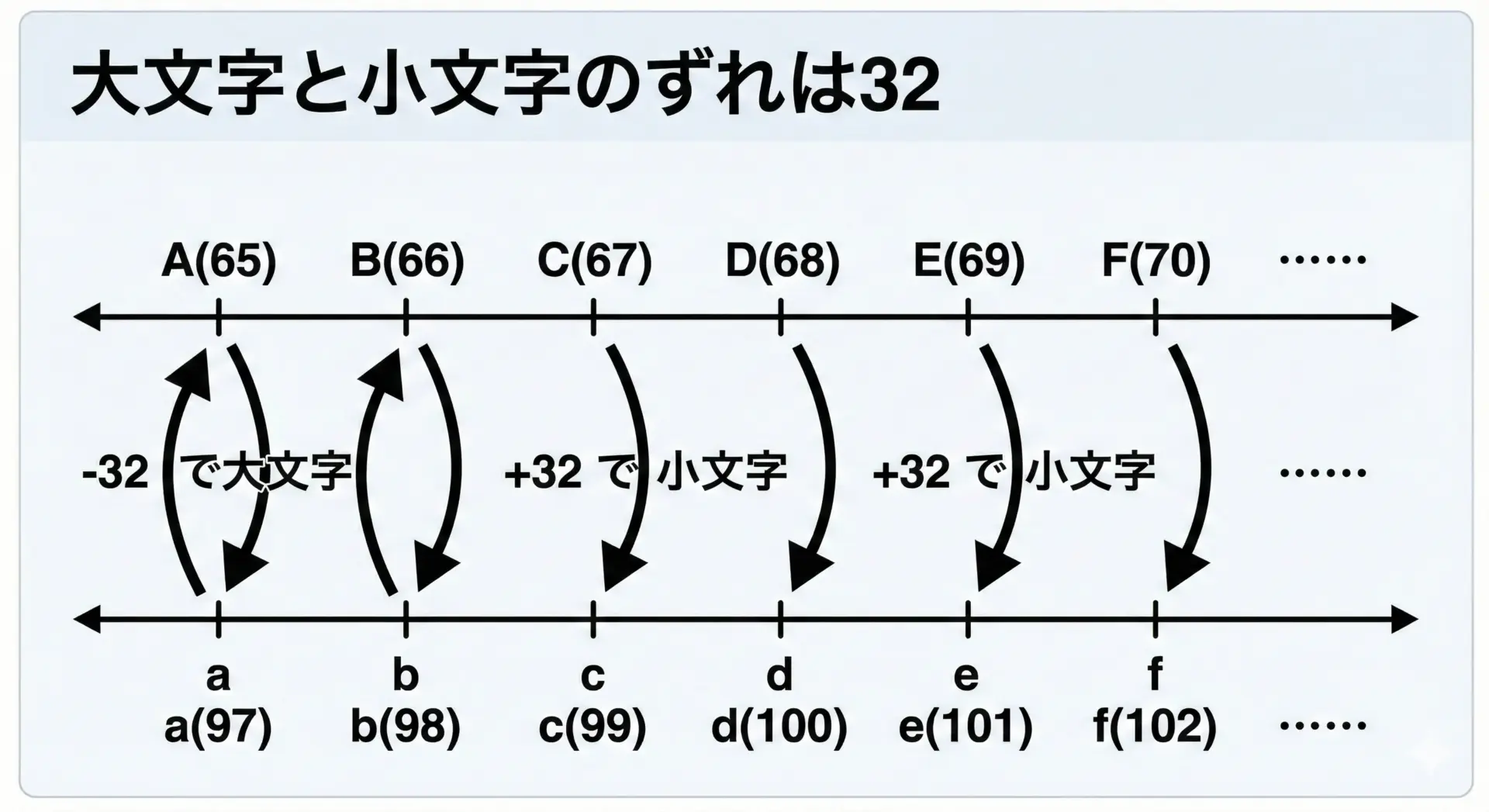
この性質を使うと、プログラムで次のような処理ができます。
- 文字が大文字なら32を足して小文字にする
- 文字が小文字なら32を引いて大文字にする
言語によっては専用の関数(toUpper()やtoLower()など)が用意されていますが、裏側ではこうしたASCIIコードの差をうまく利用していると考えると理解しやすくなります。
数字文字と数値データの違い
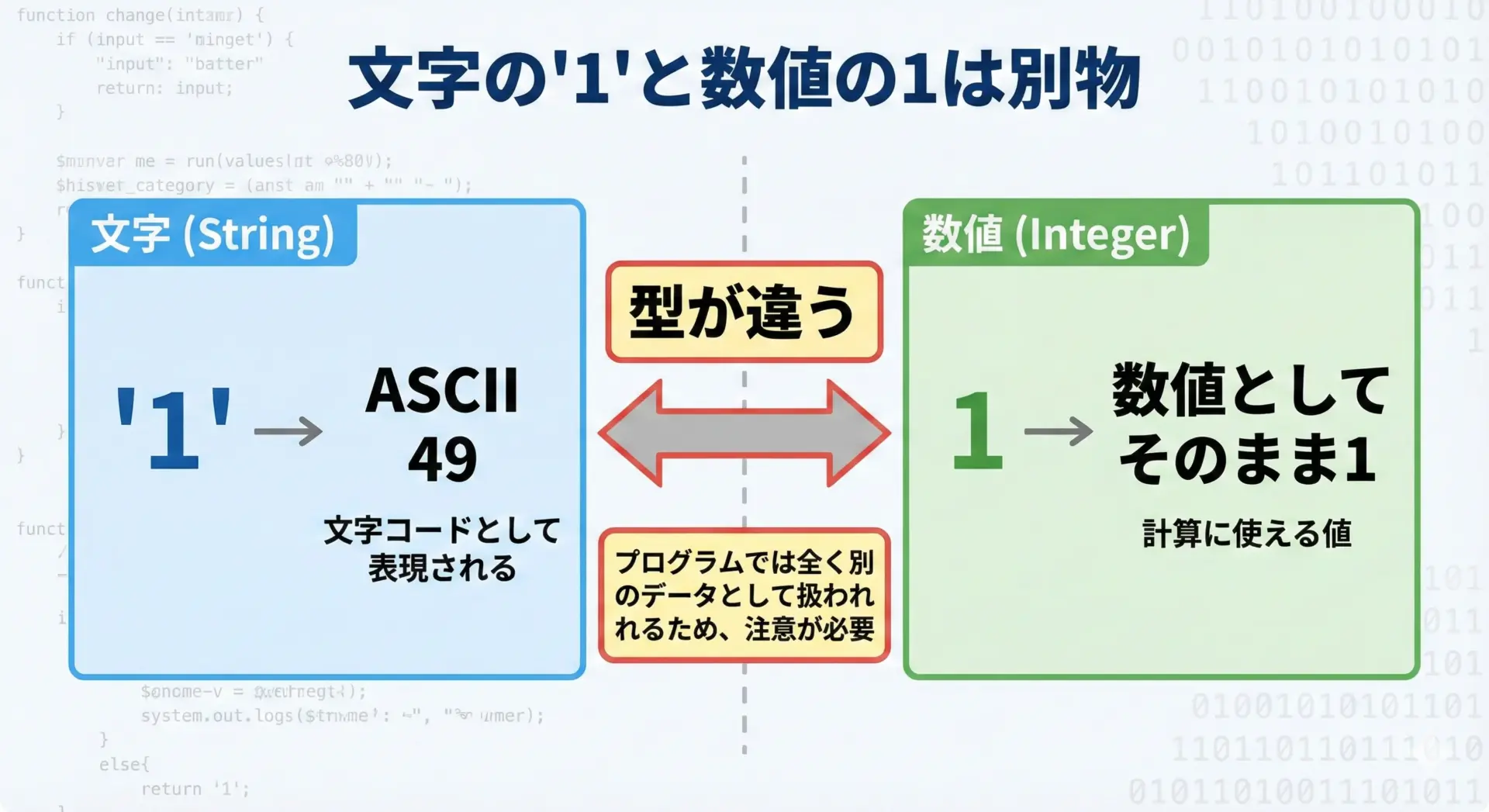
ASCIIコードを理解するときに混乱しやすいのが、「数字の文字」と「数値データ」の違いです。
- 数字の文字:
'0','1','9'など - 数値データ: 0, 1, 9 などの数値そのもの
見た目はよく似ていますが、プログラムの中ではまったく別物として扱われます。
たとえば、ASCIIコードでは次のようになります。
- 文字
'0'のコードは 48 - 文字
'1'のコードは 49 - 文字
'9'のコードは 57
Pythonでの動きを簡単に示すと、次のようになります。
ord('1') # 結果: 49 (文字 '1' のASCIIコード)
int('1') # 結果: 1 (文字列を数値に変換)「見た目が同じでも、『文字』と『数値』は別の型として扱われる」こと、そして「文字としての’1’はASCIIコード49である」ことを意識しておくと、バグを減らしやすくなります。
プログラミングで使うASCIIコードの基本テクニック
文字コードを使った簡単な暗号化の例
ASCIIコードを扱えるようになると、ちょっとした暗号化やマスク処理を自分で実装できるようになります。
最もシンプルな例として、文字のASCIIコードを一定量ずらす方法を見てみましょう。
たとえば、文字列の各文字のASCIIコードを「3だけ増やす」処理をするとします。
message = "ABC"
encoded = "".join(chr(ord(ch) + 3) for ch in message)
print(encoded) # 結果の例: "DEF"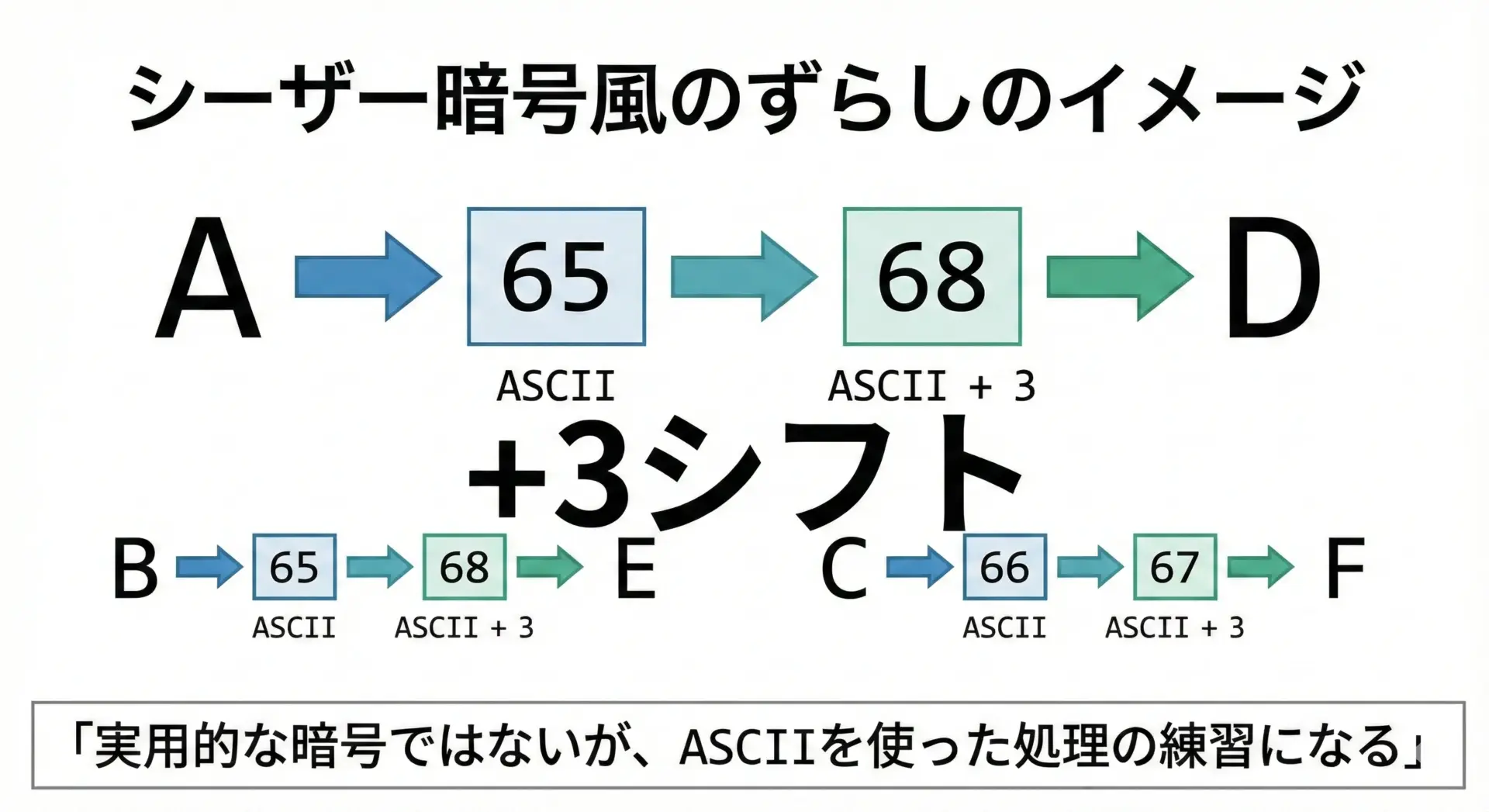
この仕組みは「シーザー暗号」と呼ばれる古典的な手法に似ています。
もちろん、実務で使うには暗号として脆弱ですが、「文字をASCIIコードに変換して計算し、また文字に戻す」という一連の流れを体感するには最適な題材です。
文字列処理でASCIIコード表を意識するポイント
文字列処理の多くは、高水準なライブラリを使えばASCIIコードを意識せずに書くことができます。
しかし、以下のような処理では、ASCIIコード表の知識があると理解しやすく、実装もしやすくなります。
- 文字が英小文字かどうか、大文字かどうかを判定する
- 英字だけを抽出するフィルタ処理
- 大文字・小文字の変換を自前で実装する
- 文字の並び順(辞書順)を説明・理解する
たとえば、自力で「英小文字かどうか」を判定する場合、ASCIIコードの範囲を使って次のように書くことができます。
ch = 'g'
code = ord(ch)
is_lower = (97 <= code <= 122) # 'a'(97)〜'z'(122)
print(is_lower) # True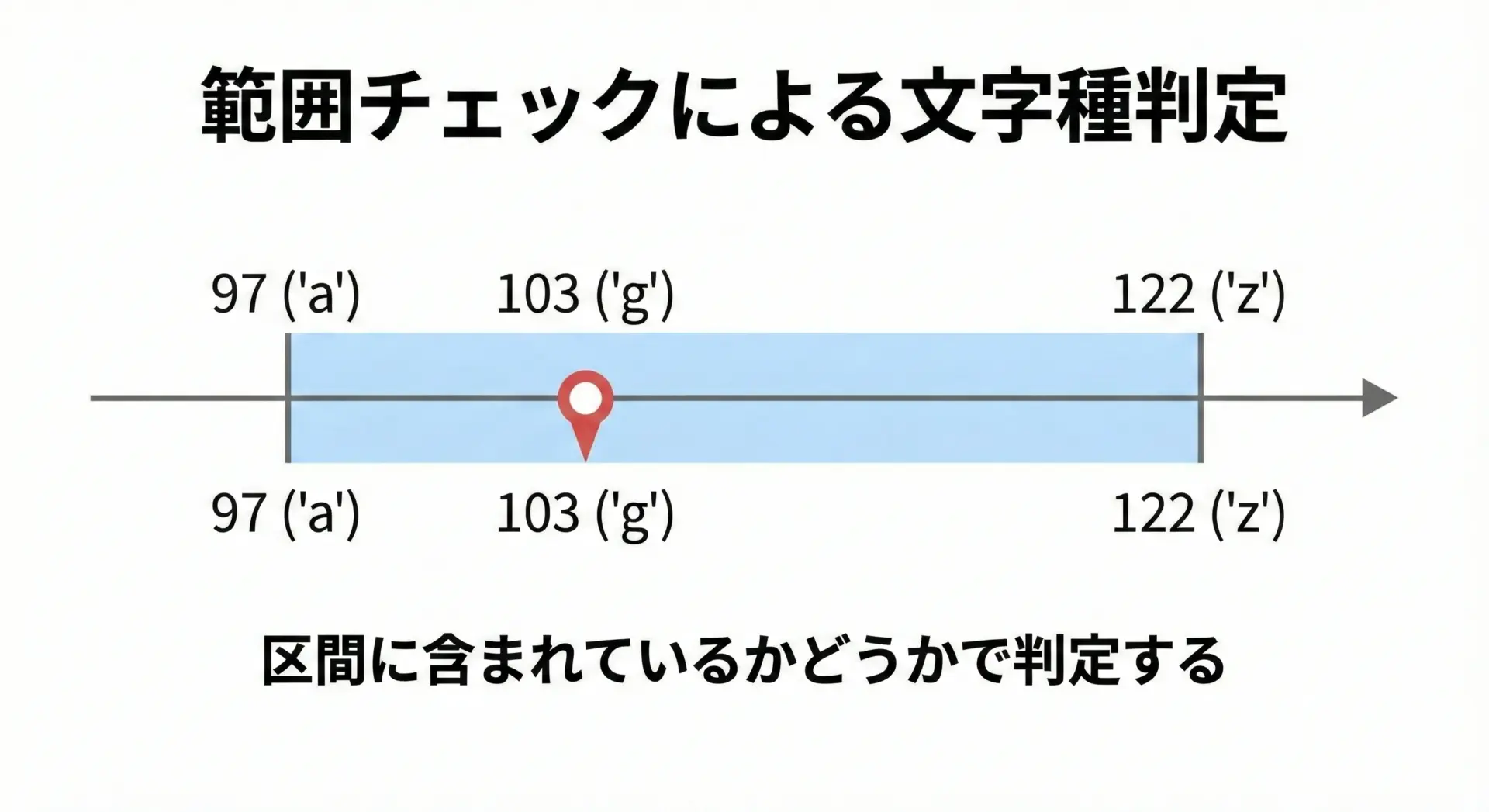
実際の開発では、言語組み込みのisalpha()やislower()といった関数を使うことが一般的ですが、その裏側にASCIIコード表の範囲判定があると理解しておくと、動作を正確にイメージしやすくなります。
他の文字コード(UTF-8など)との違いを知る足がかり
最後に、ASCIIコード表が他の文字コードを理解するための入り口になる、という話をしておきます。
現代のプログラミングでは、日本語や絵文字をはじめとするさまざまな文字を扱う必要があります。
そのために使われるのが、次のような文字コードです。
- UTF-8
- UTF-16
- Shift_JIS など
これらはすべて、「文字を数字に対応づける」という考え方を、ASCIIよりも大きな範囲で拡張したものです。
たとえばUTF-8は、世界中の文字を表現するために、1文字を1バイト〜4バイトの可変長で表現しますが、0〜127の範囲についてはASCIIと同じ値を使います。
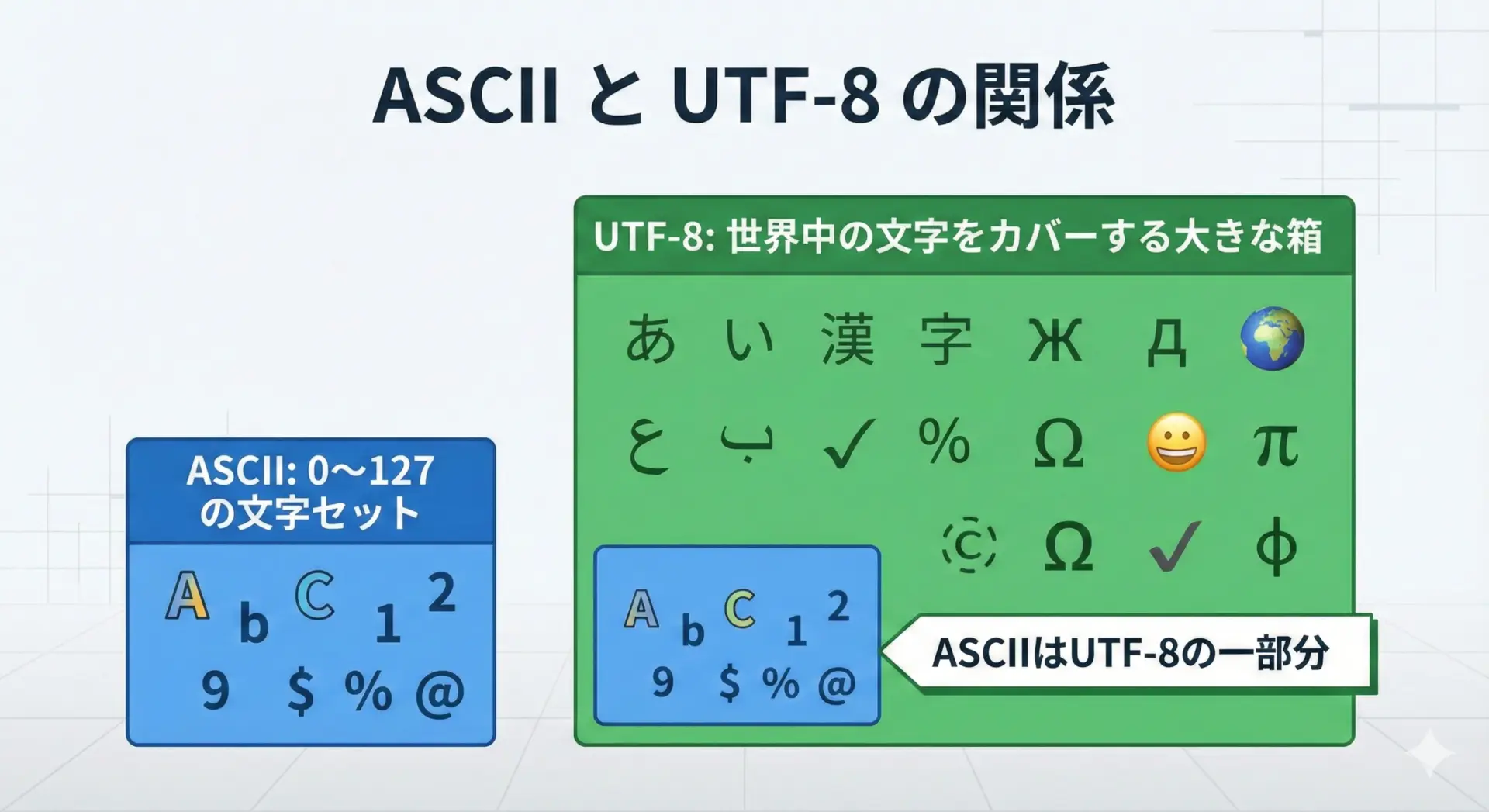
このように、ASCIIを理解することは、UTF-8などのより複雑な文字コードを理解する第一歩になります。
いきなりUTF-8のバイト列やエンコード/デコードの話に飛び込むよりも、まずASCIIで「文字と数字の対応」の感覚を身につけておくほうが、学習はずっとスムーズです。
まとめ
ASCIIコード表は、文字と数字のつながりを具体的に示した、プログラミングの基礎中の基礎です。
0〜127の範囲で、英数字や記号、見えない制御文字がどのように並んでいるかを知ることで、文字列処理の多くが「実は単なる数値処理の応用」であることが見えてきます。
特に、次のポイントを押さえておくと役立ちます。
- 英数字のざっくりした範囲
- ‘0’〜’9′ は 48〜57
- ‘A’〜’Z’ は 65〜90
- ‘a’〜’z’ は 97〜122
- 大文字と小文字の差は常に32
- 数字の文字と数値データは別物
- 文字列は、裏側ではASCIIコード(数字)の並びとして扱われる
この土台があれば、改行コードや文字化けの問題、UTF-8などの別の文字コード、さらにはテキストファイルの構造など、より発展的なテーマにも落ち着いて取り組むことができます。
これからコードを書くときは、画面に表示される文字の背後にある「数字としての姿」にも意識を向けてみてください。
文字列の扱い方が、今までより一段クリアに見えてくるはずです。
