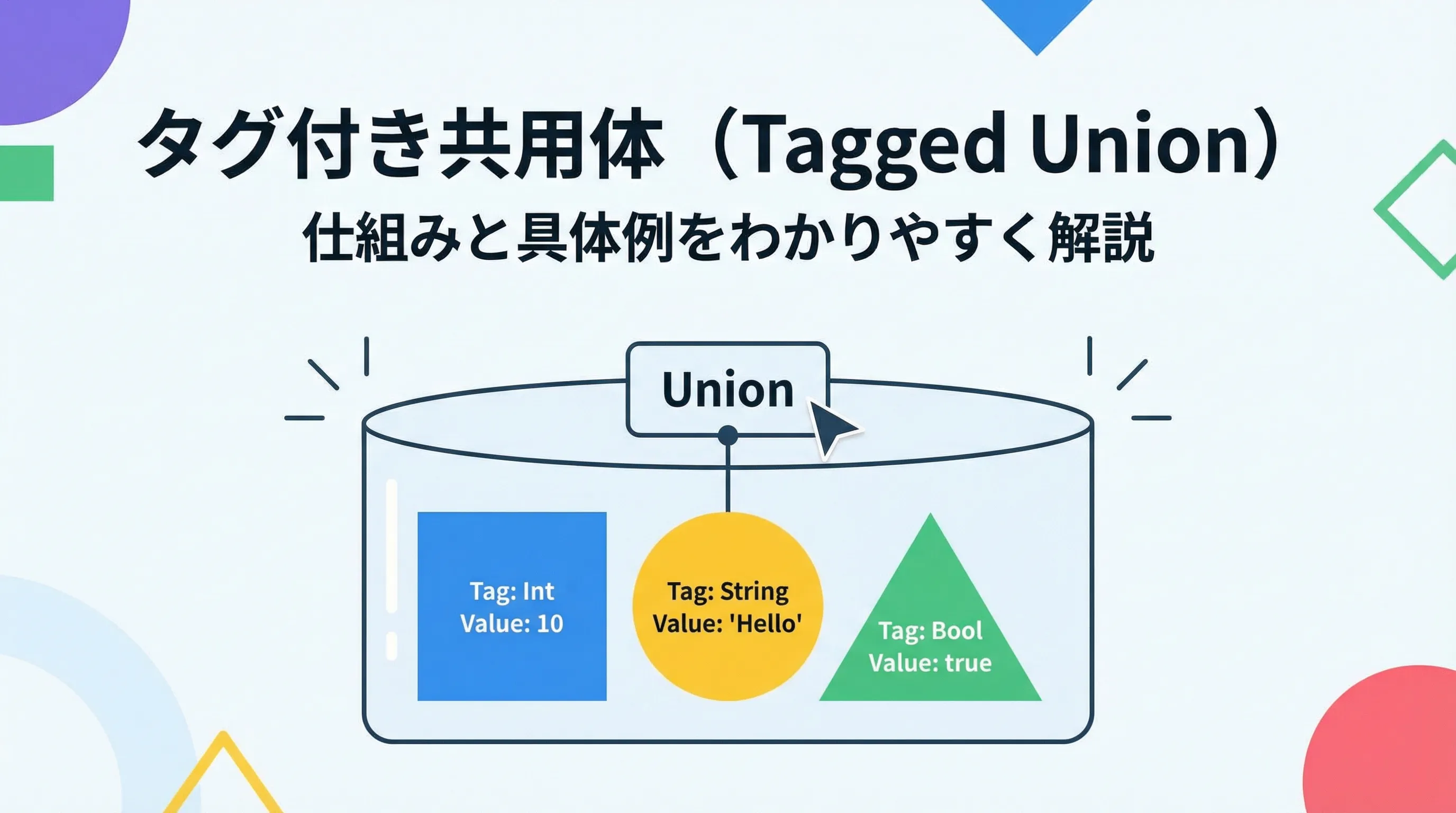
タグ付き共用体(tagged union)は、1つの変数が複数の型のどれか1つを状況に応じて扱えるようにするための仕組みです。
本記事では、C言語のunionを軸にしながら、タグ付き共用体の基本概念、なぜ必要なのか、どのように実装し、安全に使うのかを、図解と具体例を交えて詳しく解説します。
タグ付き共用体(tagged union)とは?
共用体(union)とタグの組み合わせ
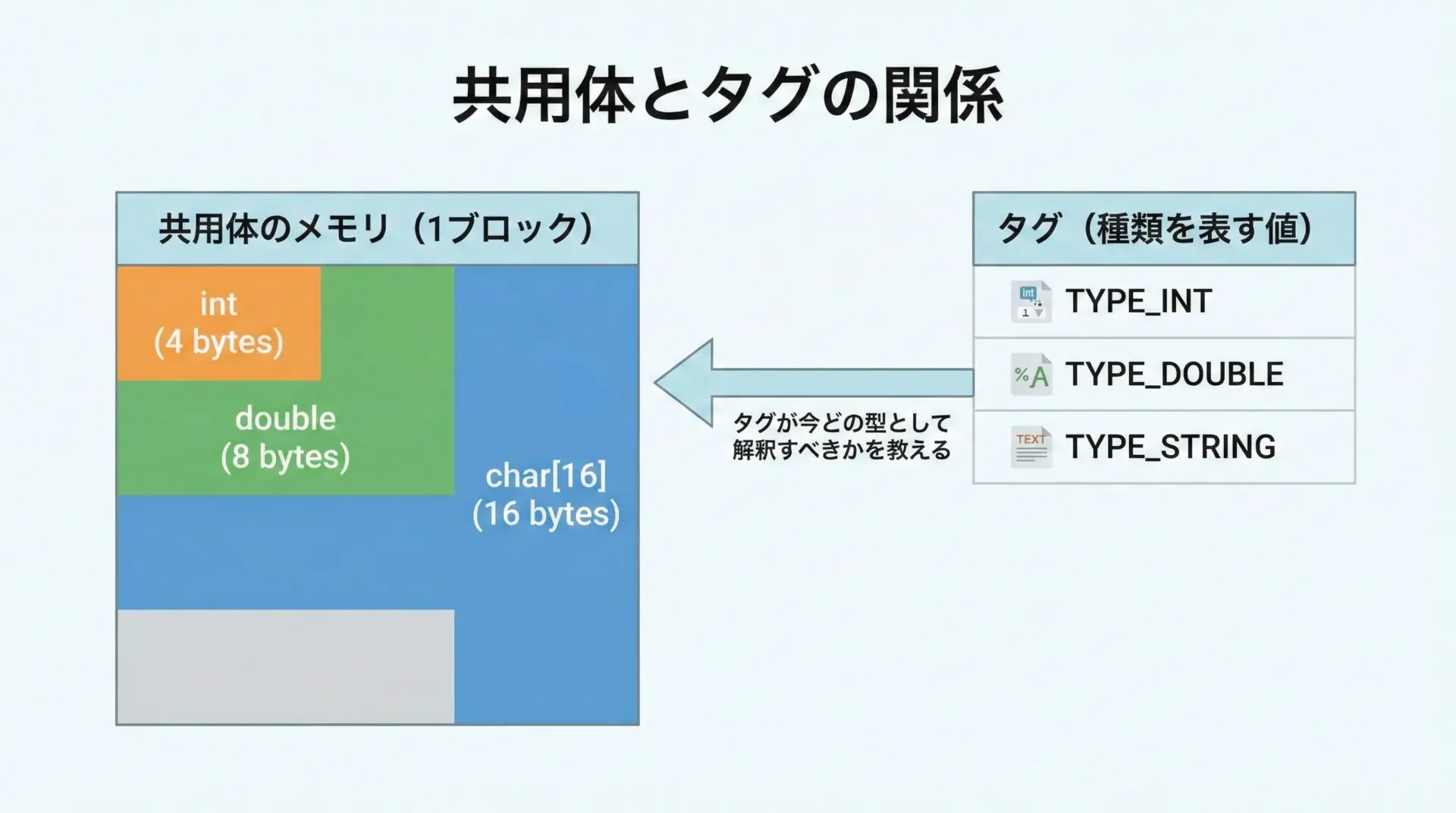
タグ付き共用体(tagged union)とは、共用体(union)と「今どの型が有効なのか」を表すタグ(種類を示す変数)をセットにしたデータ構造のことです。
C言語には「そのままの形」でタグ付き共用体が組み込まれているわけではないため、次のように構造体(struct)の中に「タグ」と「共用体」を一緒に持たせる形で表現します。
// 値の種類を表すタグ(列挙型)
typedef enum {
VALUE_INT,
VALUE_DOUBLE,
VALUE_STRING
} ValueType;
// 実際のデータを格納する共用体
typedef union {
int i;
double d;
char s[32];
} ValueData;
// タグ付き共用体
typedef struct {
ValueType type; // どのメンバが有効かを示すタグ
ValueData data; // 実際のデータ(共用体)
} TaggedValue;このように定義すると、1つのTaggedValue変数で「int か double か文字列のどれか1つ」を扱うことができます。
なぜタグ付き共用体が必要なのか
共用体だけを使うと、どのメンバが有効なのかをプログラマが覚えておく必要があります。
これはバグを生みやすく危険です。
タグ付き共用体は、タグによって「有効なメンバ」をプログラム上で明示することで、次のようなメリットを生みます。
- 読みやすく、意図が明確になる
- 誤ったメンバ読み取りを防ぎやすい(条件分岐でチェックできる)
- 将来型を増やしたい場合に拡張しやすい
共用体(union)の基本と問題点
共用体は「同じメモリを共有」する
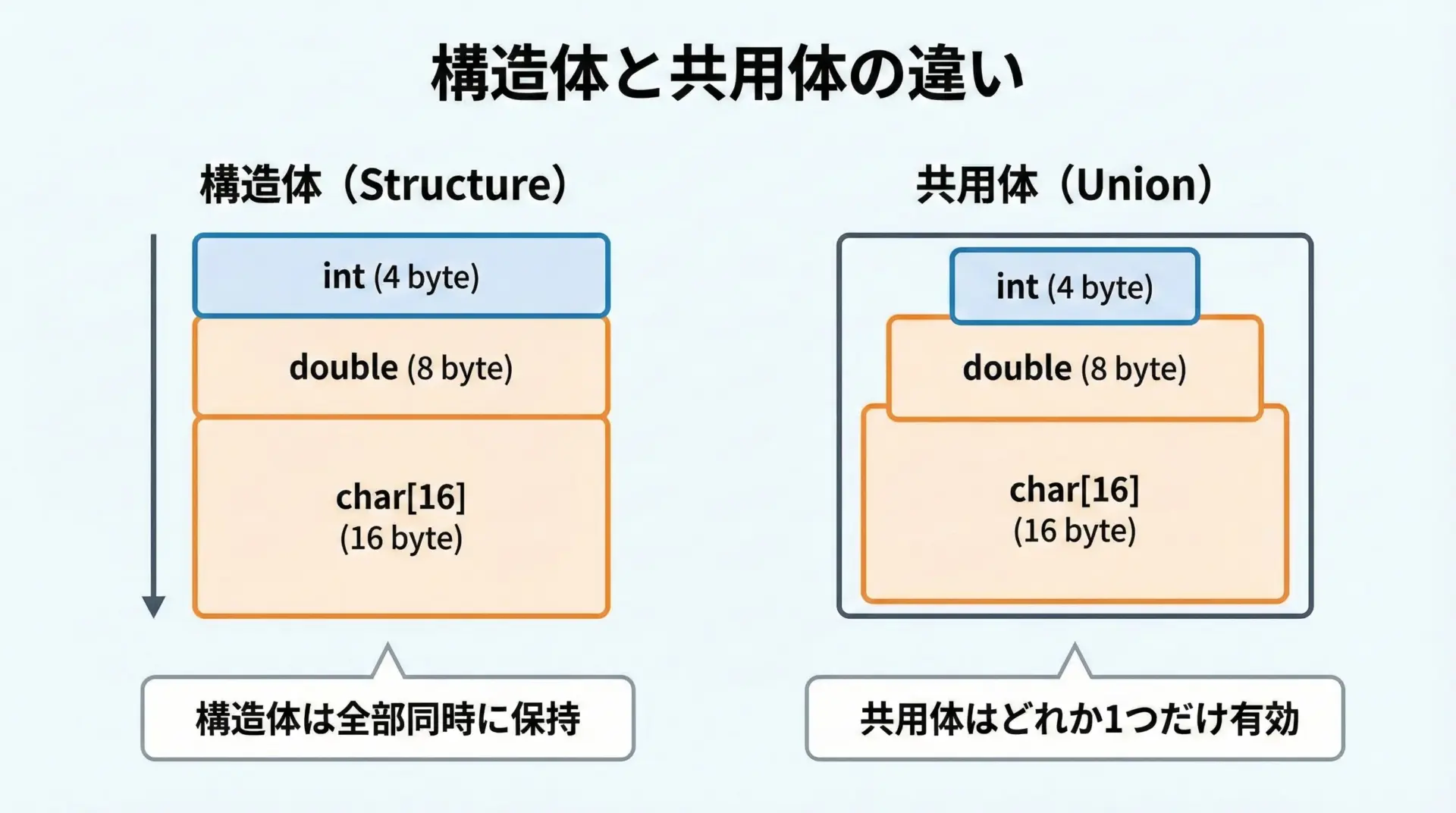
共用体unionは、複数のメンバが同じメモリ領域を共有する型です。
どのメンバを使うかによって、同じメモリを別の型として解釈します。
#include <stdio.h>
typedef union {
int i;
float f;
} IntOrFloat;
int main(void) {
IntOrFloat v;
v.i = 10; // int として格納
printf("as int : %d\n", v.i);
printf("as float : %f\n", v.f); // 同じメモリを float として読む(意味不明な値になる可能性)
v.f = 3.14f; // float として格納
printf("as int : %d\n", v.i); // 今度は逆に int として読む
return 0;
}出力例(実行環境により異なります):
as int : 10
as float : 0.000000 // 意味のある値ではない可能性
as int : 1078523331 // 3.14f のビット列を int として読んだ値このように、どのメンバが「いま有効なのか」を管理しないと、共用体は簡単に危険なコードになってしまいます。
問題点: 型がわからないまま読み書きされる
共用体単体の問題点は、「今どのメンバが正しいのか」が型システムでは表現されていないことです。
- 直前に
v.iを書いたか、v.fを書いたかを、人間が覚えていなければなりません - 別の関数に共用体を渡すと、その関数の側では「どのメンバが有効か不明」になります
ここを解決するのが「タグ付き共用体」です。
タグ付き共用体の基本構造
タグ(enum)と共用体(union)をセットにする
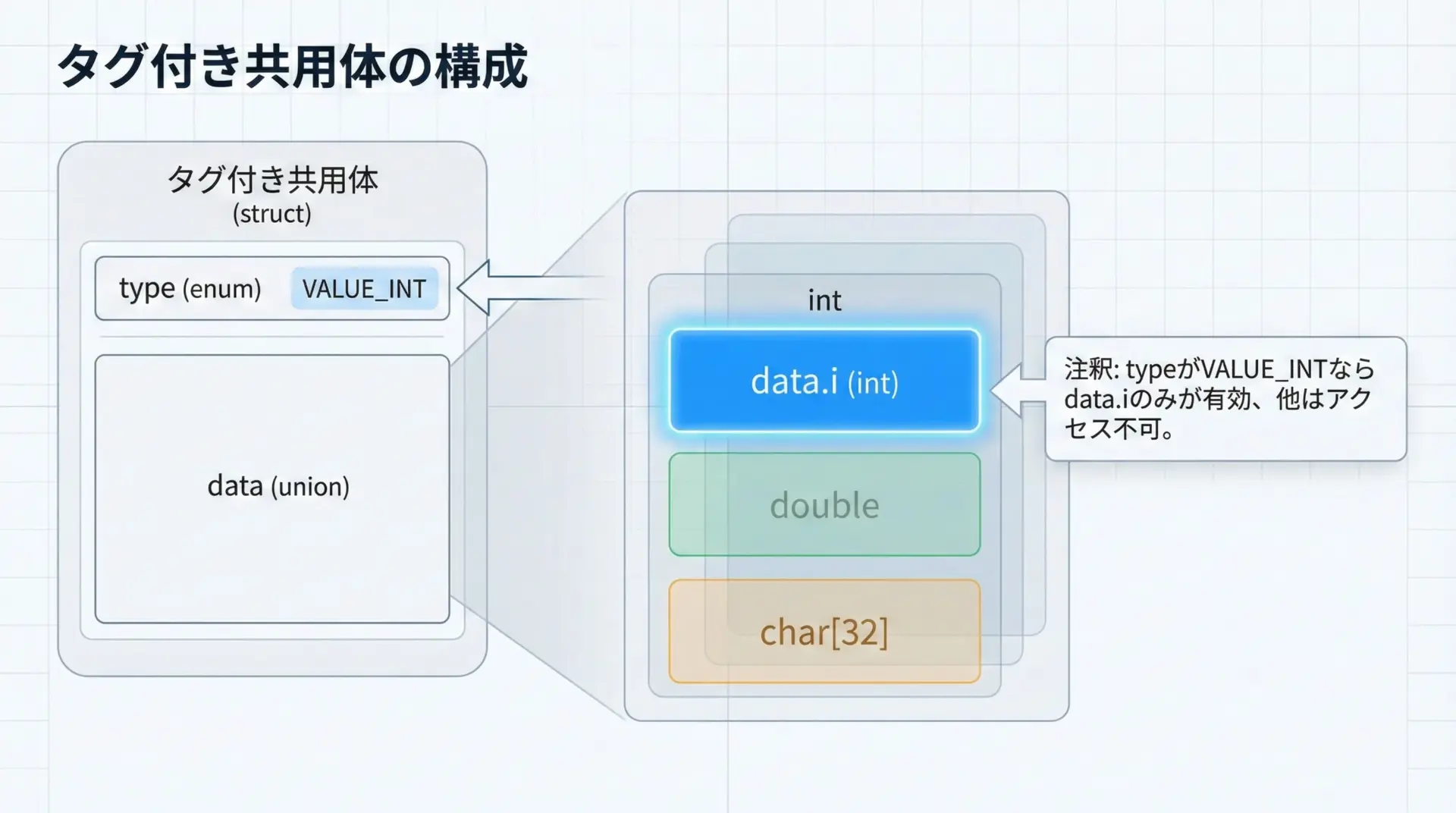
タグ付き共用体では、次の3つを組み合わせます。
- タグを表す列挙型(enum)
- 実データを格納する共用体(union)
- それらを1つにまとめる構造体(struct)
先ほどの例を改めて示します。
#include <stdio.h>
#include <string.h>
// 値の種類(タグ)を表す列挙型
typedef enum {
VALUE_INT,
VALUE_DOUBLE,
VALUE_STRING
} ValueType;
// 実データを格納する共用体
typedef union {
int i;
double d;
char s[32];
} ValueData;
// タグ付き共用体
typedef struct {
ValueType type; // どのメンバが有効か
ValueData data;
} TaggedValue;このTaggedValueを使うことで、「値の種類を意識した安全な取り扱い」が可能になります。
使い方の流れ
タグ付き共用体を使うときは、次の流れを守ります。
- 値を設定するときに、必ず
typeを正しくセットする - 値を読むときに、必ず
typeを確認してから対応するメンバを読む
// int 値を設定する関数
void set_int(TaggedValue *v, int x) {
v->type = VALUE_INT; // タグを設定
v->data.i = x; // 実データを設定
}
// double 値を設定する関数
void set_double(TaggedValue *v, double x) {
v->type = VALUE_DOUBLE;
v->data.d = x;
}
// 文字列を設定する関数
void set_string(TaggedValue *v, const char *s) {
v->type = VALUE_STRING;
strncpy(v->data.s, s, sizeof(v->data.s) - 1);
v->data.s[sizeof(v->data.s) - 1] = '\0'; // 終端を保証
}タグ付き共用体の具体例
例1: 値を表示する関数
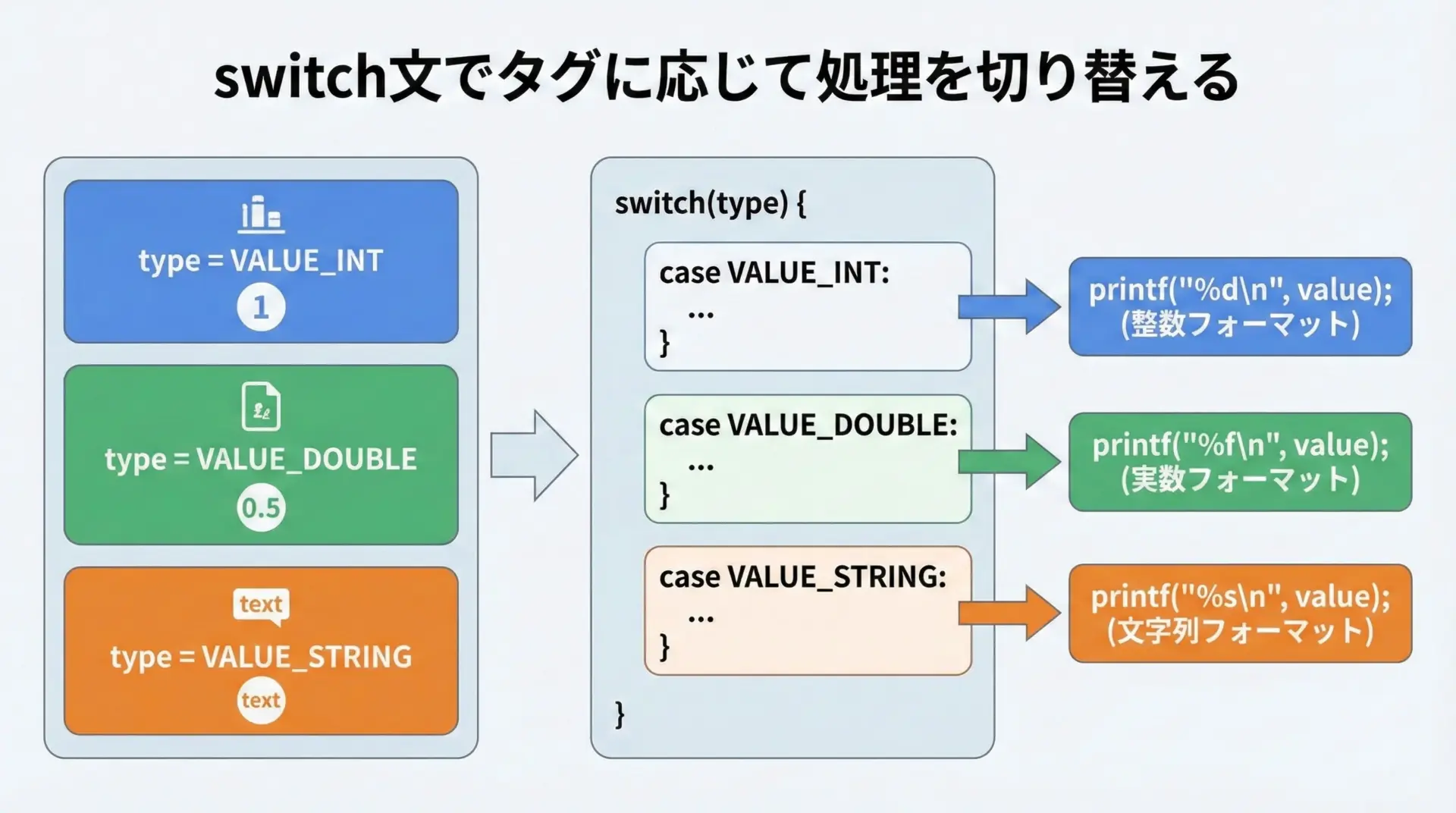
タグ付き共用体の代表的な使い方として、タグに応じて処理を切り替えるパターンがあります。
#include <stdio.h>
#include <string.h>
typedef enum {
VALUE_INT,
VALUE_DOUBLE,
VALUE_STRING
} ValueType;
typedef union {
int i;
double d;
char s[32];
} ValueData;
typedef struct {
ValueType type;
ValueData data;
} TaggedValue;
void print_value(const TaggedValue *v) {
switch (v->type) {
case VALUE_INT:
printf("INT: %d\n", v->data.i);
break;
case VALUE_DOUBLE:
printf("DOUBLE: %f\n", v->data.d);
break;
case VALUE_STRING:
printf("STRING: %s\n", v->data.s);
break;
default:
printf("UNKNOWN TYPE\n");
break;
}
}
int main(void) {
TaggedValue a, b, c;
// int を設定
a.type = VALUE_INT;
a.data.i = 42;
// double を設定
b.type = VALUE_DOUBLE;
b.data.d = 3.14159;
// 文字列を設定
b.type = VALUE_DOUBLE;
b.data.d = 3.14159;
c.type = VALUE_STRING;
strncpy(c.data.s, "Hello", sizeof(c.data.s) - 1);
c.data.s[sizeof(c.data.s) - 1] = '\0';
print_value(&a);
print_value(&b);
print_value(&c);
return 0;
}INT: 42
DOUBLE: 3.141590
STRING: Helloこのように1つの関数で複数の型に対応できるのが、タグ付き共用体の大きな利点です。
例2: 計算結果の「成功」と「エラー」を1つの型で表す
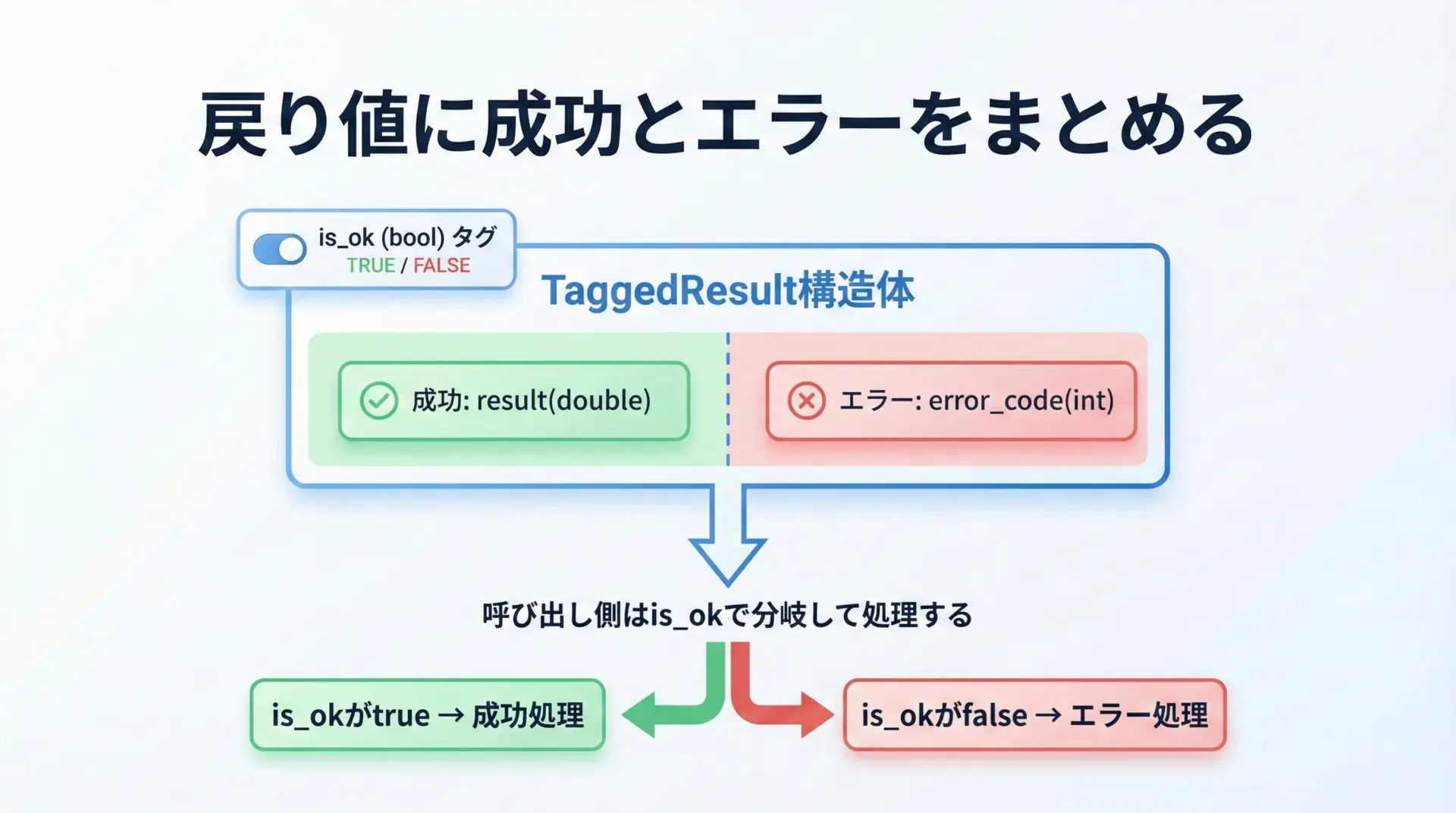
タグ付き共用体は、一方だけが有効になるような2択(または多択)のデータを表すのにも適しています。
たとえば、計算の結果として「成功時の値」か「エラー情報」のどちらかを返したい場合です。
#include <stdio.h>
#include <math.h>
typedef enum {
RESULT_OK,
RESULT_ERROR
} ResultTag;
typedef union {
double value; // 成功時の結果
int error_code; // 失敗時のエラーコード
} ResultData;
typedef struct {
ResultTag tag;
ResultData data;
} TaggedResult;
// 正の数の平方根を計算し、負の数ならエラーにする
TaggedResult safe_sqrt(double x) {
TaggedResult r;
if (x < 0.0) {
r.tag = RESULT_ERROR;
r.data.error_code = -1; // 負の数エラー
} else {
r.tag = RESULT_OK;
r.data.value = sqrt(x);
}
return r;
}
int main(void) {
TaggedResult r1 = safe_sqrt(4.0);
TaggedResult r2 = safe_sqrt(-1.0);
if (r1.tag == RESULT_OK) {
printf("sqrt(4.0) = %f\n", r1.data.value);
} else {
printf("sqrt(4.0) error: %d\n", r1.data.error_code);
}
if (r2.tag == RESULT_OK) {
printf("sqrt(-1.0) = %f\n", r2.data.value);
} else {
printf("sqrt(-1.0) error: %d\n", r2.data.error_code);
}
return 0;
}sqrt(4.0) = 2.000000
sqrt(-1.0) error: -1このようなパターンは、他の言語では「Result型」「Either型」「Option/Maybe型」などとしてライブラリや言語仕様に組み込まれていることが多く、C言語ではそれをタグ付き共用体で表現できます。
メリットと注意点
メリット: メモリ効率と柔軟なデータ表現
タグ付き共用体には次のようなメリットがあります。
- メモリ効率が良い
- 共用体部分は「最大のメンバサイズ」だけを確保すればよく、複数のメンバを同時に持つ構造体より小さくなります。
- 柔軟なデータ表現ができる
- 1つの変数で「いくつかの候補のどれか1つ」を表現するのに適しています。
- 処理をタグ基準で明確に分岐できる
switchやifでタグを見て処理を書くため、ソースコードとしても意図が読み取りやすくなります。
注意点: タグとデータの整合性を守る
一方で、タグ付き共用体には注意点もあります。
- タグと実データがずれると危険
- 例:
type = VALUE_INTなのにdata.sを読む、など。
- 例:
- 関数で値を設定する際、タグを更新し忘れるとバグになります。
- ポインタで扱う場合、生存期間や解放タイミングにも注意が必要です(特に共用体の中にポインタやヒープ領域を持つ場合)。
タグとデータの整合性を守るためには、次のような工夫が有効です。
- 値の設定は、必ず専用の関数経由にする
- 値を読むときは、必ず
switchでタグを確認する - デバッグ時に、デフォルト分岐で「不正なタグ」を検出する
void print_value_safe(const TaggedValue *v) {
switch (v->type) {
case VALUE_INT:
printf("INT: %d\n", v->data.i);
break;
case VALUE_DOUBLE:
printf("DOUBLE: %f\n", v->data.d);
break;
case VALUE_STRING:
printf("STRING: %s\n", v->data.s);
break;
default:
// ここに来るのはおかしいのでデバッグ用メッセージ
printf("ERROR: invalid tag (%d)\n", v->type);
break;
}
}他言語との比較イメージ
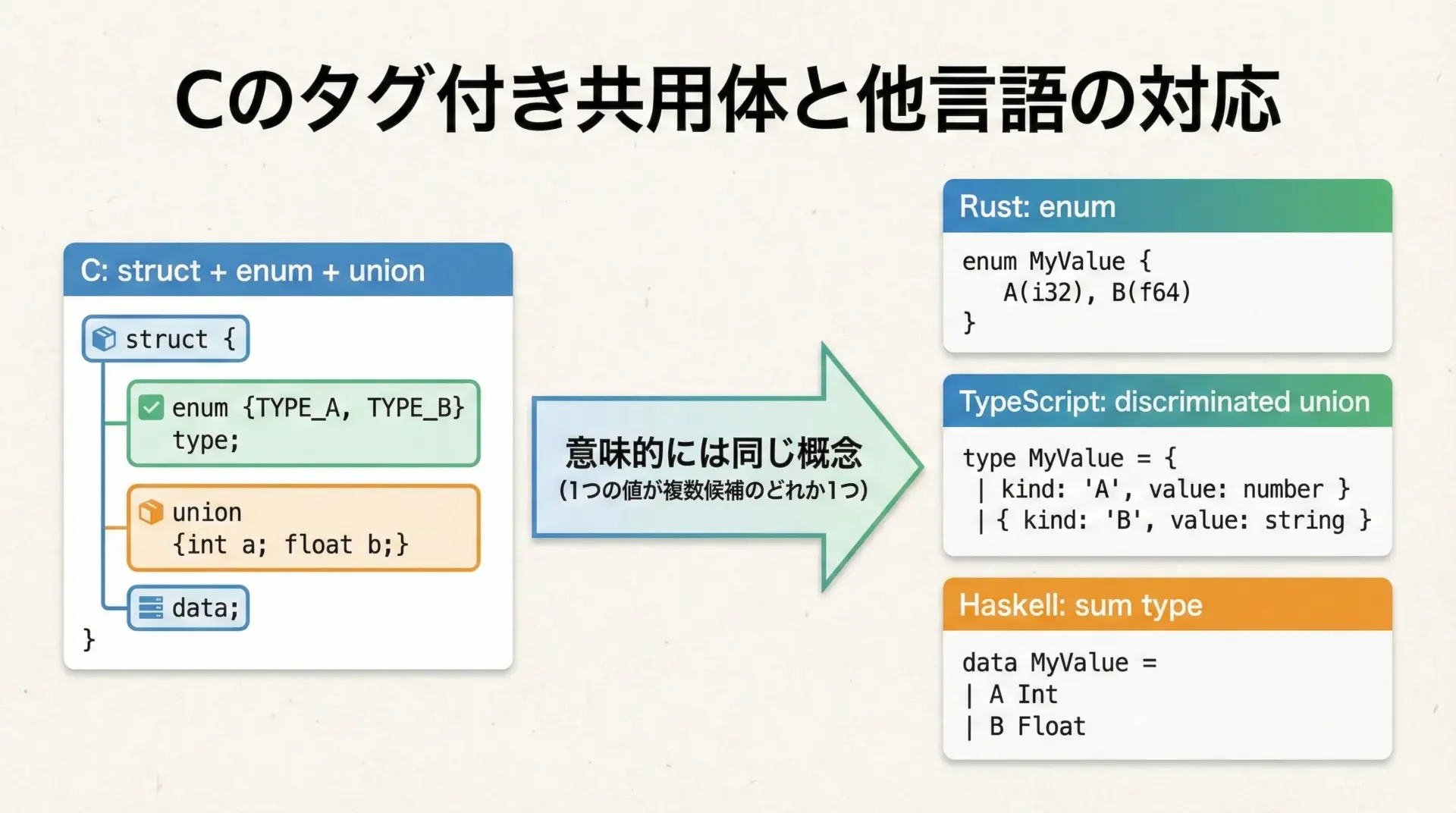
タグ付き共用体は、他の多くの言語で次のような概念に対応します。
- Rust:
enumのバリアント付き列挙体 - TypeScript: discriminated union(判別可能共用体)
- Haskell: 代数的データ型(sum type)
- OCaml/F#: 判別共用体(discriminated union)
Cにはこれらが言語仕様として直接は存在しないため、struct + enum + union を組み合わせて「自作」するというイメージです。
まとめ
タグ付き共用体(tagged union)とは、enumで表現した「タグ」と、unionで表現した「実データ」を1つのstructにまとめたデータ構造です。
共用体単体では「今どのメンバが有効か」がわからず危険ですが、タグとセットにすることで型の切り替えを安全かつ明示的に扱えるようになります。
メモリ効率や表現力にも優れ、エラーか成功のどちらかを返す関数の戻り値など、現代的な多くの言語機能の土台になる考え方です。
Cで安全に複数の型を扱いたいときには、タグ付き共用体のパターンを積極的に活用するとよいでしょう。
