SIMDは、同じ計算を大量のデータに対して繰り返し行う場面で、CPUの中にある「並列処理の専用回路」を使って一気に処理を進める仕組みです。
画像処理やゲーム、AI処理など、多くのアプリケーションの高速化に深く関わっています。
本記事では、SIMDの基本概念から、どのように命令とデータが扱われるのか、また簡単なサンプルコードや具体的な活用イメージまで、順を追って丁寧に解説していきます。
SIMDとは何か
単一命令で複数データを処理するという考え方
SIMD(Single Instruction, Multiple Data)とは「1つの命令で、複数のデータを同時に処理する仕組み」です。
通常のプログラムでは、1つの命令が1つのデータに対して処理を行います。
これを「スカラ演算」と呼びます。
それに対してSIMDでは、1つの命令で配列の要素をまとめて処理できるため、特定の種類の処理を大幅に高速化できます。
例えば、次のような処理を考えます。
- 画像の全ピクセルの明るさを一律に10だけ上げる
- ベクトル(配列)同士の要素ごとの加算を行う
- 音声データの各サンプル値に同じフィルタを適用する
これらは「同じ種類の演算を、たくさんの要素に対して繰り返す」処理です。
このような処理にSIMDは特に適しています。
スカラ処理とのイメージ比較
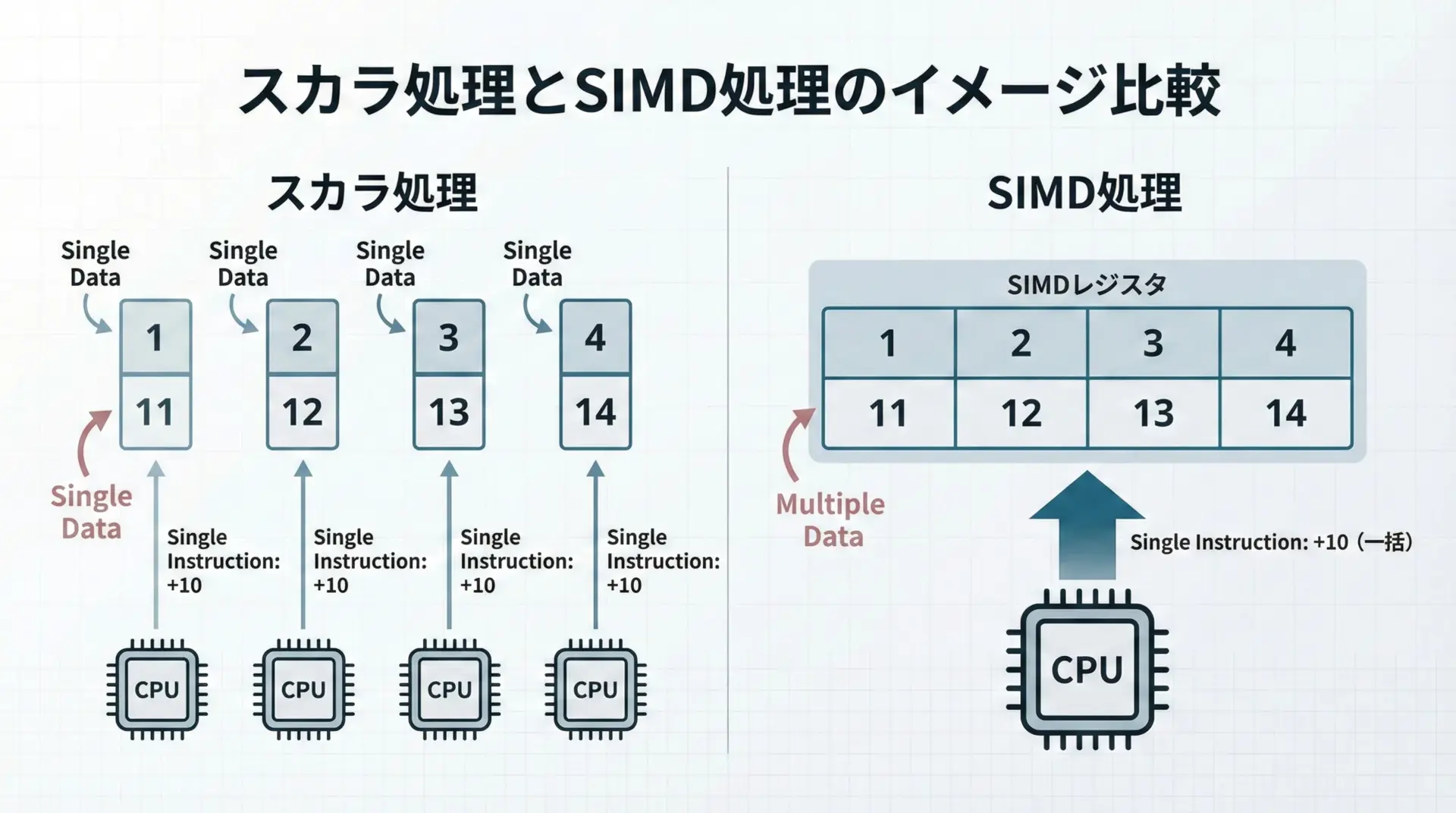
スカラ処理では、例えば4つの整数に対して加算する場合、加算命令が4回必要になります。
一方、SIMD処理では4つの整数をまとめて格納できる「ベクトルレジスタ」に入れ、1回の命令で4つ同時に加算します。
この違いが、処理速度の差につながります。
SIMDが生まれた背景と用途
なぜSIMDが求められるのか
CPUのクロック周波数の向上には限界があり、近年では「並列処理で性能を稼ぐ」方向に発展してきました。
マルチコア化もその一つですが、同じコアの中でも、より効率的に命令を実行するためにSIMDが導入されています。
とくに次のような領域では、SIMDの効果が出やすいです。
- 画像処理(フィルタ、エフェクト、変換)
- 音声・信号処理
- 物理シミュレーションやゲームのベクトル計算
- 機械学習や統計処理における行列・ベクトル演算
これらの処理は、大量のデータに同じ処理を繰り返し適用する特徴があります。
そのため、SIMDでまとめて処理することがしやすくなります。
CPUアーキテクチャとSIMD拡張
多くのCPUには、SIMDのための命令セット拡張が用意されています。
代表的な例を表にまとめます。
| CPUアーキテクチャ | SIMD拡張の例 | 概要 |
|---|---|---|
| x86 / x86_64 | SSE, AVX, AVX2, AVX-512 など | PC向けCPUで広く利用されるSIMD拡張です。浮動小数点演算や整数演算を並列化します。 |
| ARM | NEON | スマホや組み込み機器などで利用されるSIMD拡張です。省電力CPUでも並列演算が可能です。 |
| RISC-V | V拡張(Vector Extension) | RISC-V向けのベクトル拡張で、柔軟なベクトル長を扱えます。 |
これらのSIMD拡張は、CPU内部に「ベクトルレジスタ」と専用の演算器を用意することで実現されています。
SIMDの基本構造と動作原理
ベクトルレジスタとは何か
SIMDを理解するうえで重要なのがベクトルレジスタです。
通常のレジスタは1つの値(例: 32ビット整数)を保持しますが、ベクトルレジスタは複数の値を一つのまとまりとして保持します。
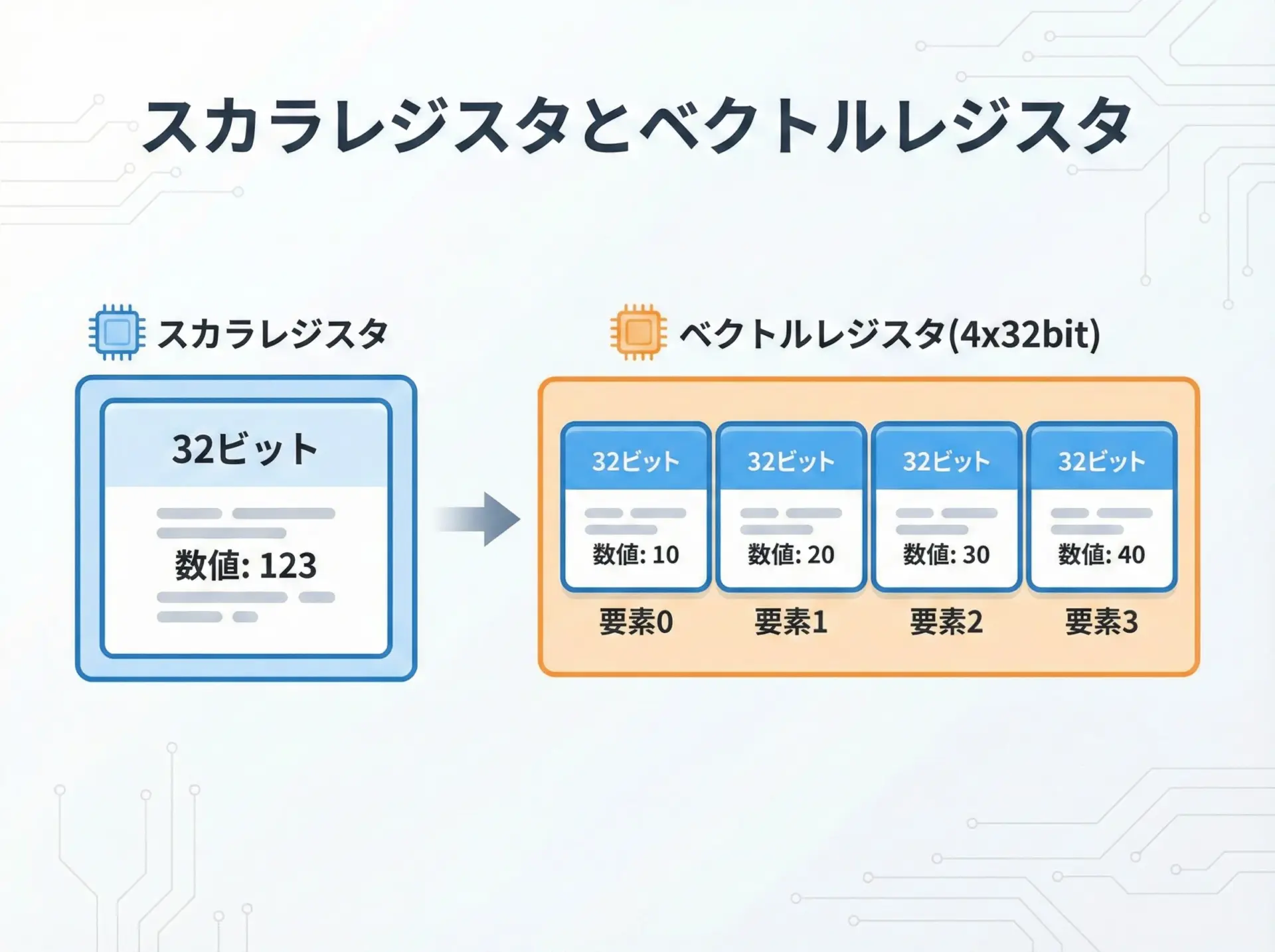
例えば、128ビット幅のSIMDレジスタであれば、32ビット整数を4つ、16ビット整数を8つ、8ビット整数を16個といった形で格納できます。
命令はこのベクトルレジスタに対して動作し、すべての要素に同時に同じ操作を行います。
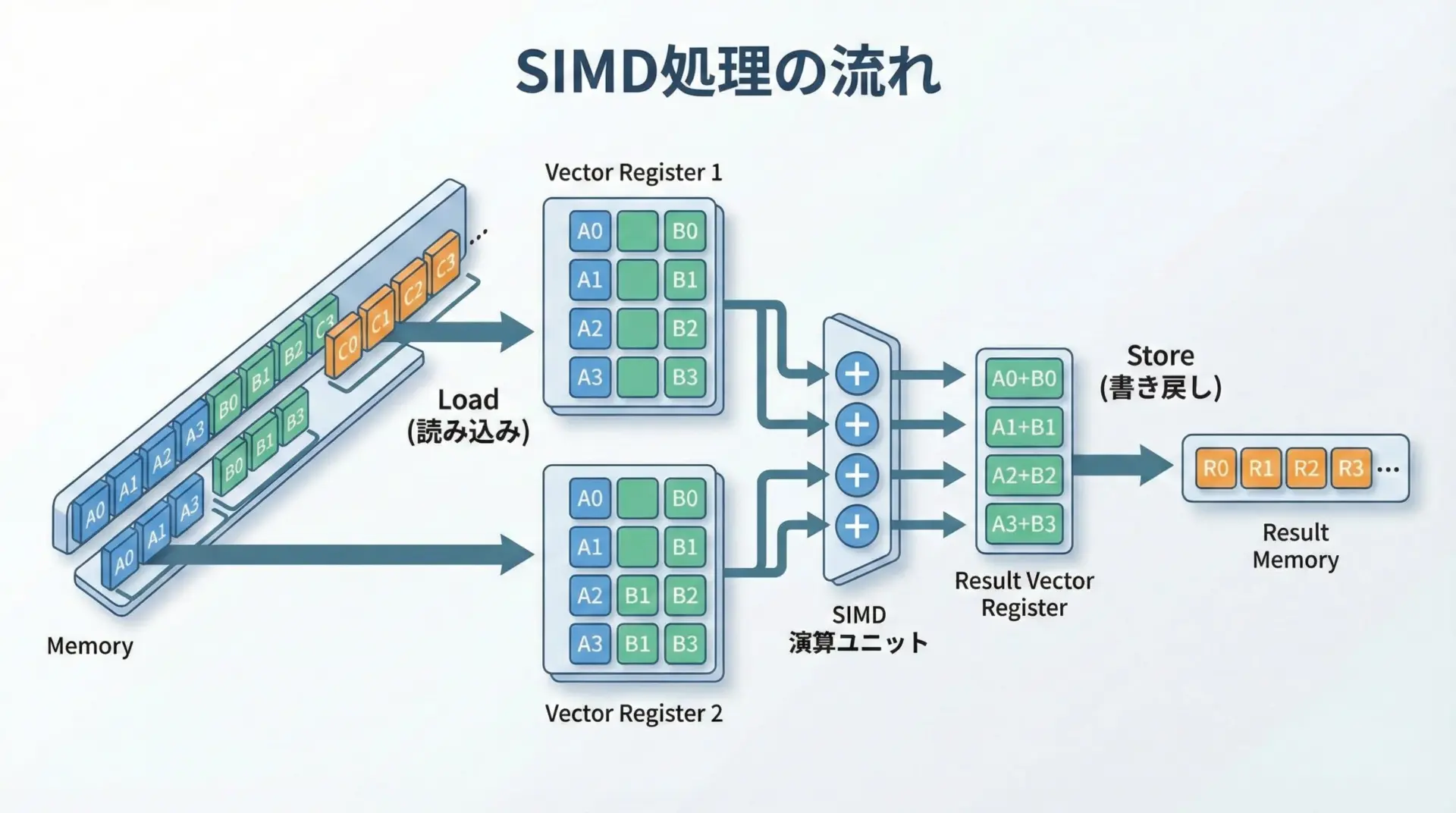
単一命令・複数データの具体的な流れ
- メモリから複数のデータを読み込み、ベクトルレジスタにまとめて格納する。
- ベクトルレジスタ同士に対して、加算や乗算などのSIMD命令を実行する。
- 結果をまたメモリにまとめて書き戻す。
この一連の流れを繰り返すことで、ループ処理を大幅に効率化できます。
スカラ処理とSIMD処理のコード比較
ここではC言語風のコードを用いて、SIMDを使わない場合と、SIMDを使った場合の違いをイメージで説明します。
環境依存の命令やヘッダは簡略化した疑似コードに近い例です。
スカラ処理の例(配列同士の加算)
#include <stdio.h>
int main(void) {
// 長さ8の整数配列を用意
int a[8] = {1, 2, 3, 4, 5, 6, 7, 8};
int b[8] = {10, 20, 30, 40, 50, 60, 70, 80};
int c[8]; // 結果を格納する配列
// スカラ(通常)処理: 要素を1つずつ順番に足していく
for (int i = 0; i < 8; i++) {
c[i] = a[i] + b[i]; // ここでは1回のループで1つの加算
}
// 結果を表示
for (int i = 0; i < 8; i++) {
printf("%d ", c[i]);
}
printf("\n");
return 0;
}11 22 33 44 55 66 77 88この場合、配列要素が8つなので、加算命令は8回実行されるイメージになります。
SIMD処理の例(概念的なコード)
実際には<x86のSSE/AVX>などの具体的な命令セットを使う必要がありますが、ここでは理解しやすいように、抽象的なSIMD APIを仮定した例を示します。
#include <stdio.h>
// 仮想的なSIMD型とAPIの例(実在のAPIとは異なります)
// 実際にはコンパイラやCPUアーキテクチャごとのヘッダを使います。
typedef struct {
int value[4]; // 4要素の整数ベクトル(128ビット相当のイメージ)
} vec4i;
// 2つのvec4iを要素ごとに加算する関数(ベクトル演算)
vec4i vec4i_add(vec4i x, vec4i y) {
vec4i r;
// 実際のSIMD命令では、これが「1命令」で4要素分行われるイメージです。
for (int i = 0; i < 4; i++) {
r.value[i] = x.value[i] + y.value[i];
}
return r;
}
int main(void) {
int a[8] = {1, 2, 3, 4, 5, 6, 7, 8};
int b[8] = {10, 20, 30, 40, 50, 60, 70, 80};
int c[8];
// 長さ8の配列を、vec4i単位(4要素ずつ)で処理する
for (int i = 0; i < 8; i += 4) {
vec4i va, vb, vc;
// メモリから4要素まとめてベクトルに読み込むイメージ
for (int k = 0; k < 4; k++) {
va.value[k] = a[i + k];
vb.value[k] = b[i + k];
}
// ベクトル同士を要素ごとに加算
vc = vec4i_add(va, vb);
// 結果をメモリに4要素まとめて書き戻すイメージ
for (int k = 0; k < 4; k++) {
c[i + k] = vc.value[k];
}
}
// 結果を表示
for (int i = 0; i < 8; i++) {
printf("%d ", c[i]);
}
printf("\n");
return 0;
}11 22 33 44 55 66 77 88このコードは内部的にはループでシミュレートしていますが、本来のSIMD命令であれば、vec4i_addの中身は「1命令で4要素同時に加算」されます。
そのため、配列長が大きくなればなるほど、SIMD命令による並列性の恩恵が大きくなります。
SIMDが得意な処理と不得意な処理
得意な処理
SIMDは「同じ操作を、たくさんのデータに対して繰り返す」場面で力を発揮します。
具体例を挙げると次のようになります。
- 画像処理
各ピクセルに対して同じフィルタ(ぼかし、シャープ、色変換など)を適用する。ピクセルをRGBそれぞれの成分で並列処理可能です。 - 音声・信号処理
サンプルごとのゲイン調整、フィルタ処理、畳み込み演算など、連続した数値列に同じ演算を行う処理で有効です。 - 数値計算(線形代数)
ベクトルの足し算、内積計算、行列演算など、多数の要素を持つ配列の計算を一気に進めることができます。
不得意な処理
一方で、SIMDがあまり向かない処理もあります。
- 各要素で違う分岐が発生する処理
例えば「要素ごとに条件が違い、その条件に応じて全く別の処理をする」ような場合、単一命令でまとめて処理しにくくなります。 - データがバラバラの場所にある処理
メモリ上でデータが連続していない(配列ではなく、ポインタでつながったリスト構造など)場合、ベクトルレジスタに効率よく読み込むのが難しくなります。
このような理由から、SIMDはデータ構造やアルゴリズムの設計段階から意識しておくと、最大限の効果を引き出しやすくなります。
コンパイラと自動ベクトル化
自動ベクトル化とは
最近のコンパイラ(GCCやClangなど)は、通常のC/C++コードでも、パターンを認識して自動的にSIMD命令に置き換える(自動ベクトル化)機能を持っています。
例えば、次のような単純なforループは、自動ベクトル化の良い候補になります。
for (int i = 0; i < n; i++) {
c[i] = a[i] + b[i];
}コンパイラは、ループ内でデータ依存がなく、安全に並列化できることを確認すると、バックエンドでSSEやAVXなどのSIMD命令を使ったコードに変換してくれます。
自動ベクトル化が効きにくいケース
ただし、次のような場合には自動ベクトル化が難しくなります。
- ループ内で複雑な条件分岐がある
- 配列同士の依存関係(1つの要素の計算に別の要素の結果が必要)がある
- ポインタエイリアシング(異なるポインタが同じメモリを指す可能性)のため、安全かどうか判断できない
このような場合、開発者がアルゴリズムやデータ構造を整理し、SIMDに向いた形へと書き換えることで、自動ベクトル化を助けることができます。
また、必要であれば、明示的にSIMD命令を呼び出すための「イントリンシック関数」を使う方法もあります。
SIMDと他の並列化技術との違い
マルチスレッドとの比較
SIMDと混同されやすいのがマルチスレッド(マルチコア)による並列処理です。
- マルチスレッド: コア(CPU)を複数使い、異なる命令列を同時に実行する。
- SIMD: 1つの命令で、同じ演算を複数データに対して同時に実行する。
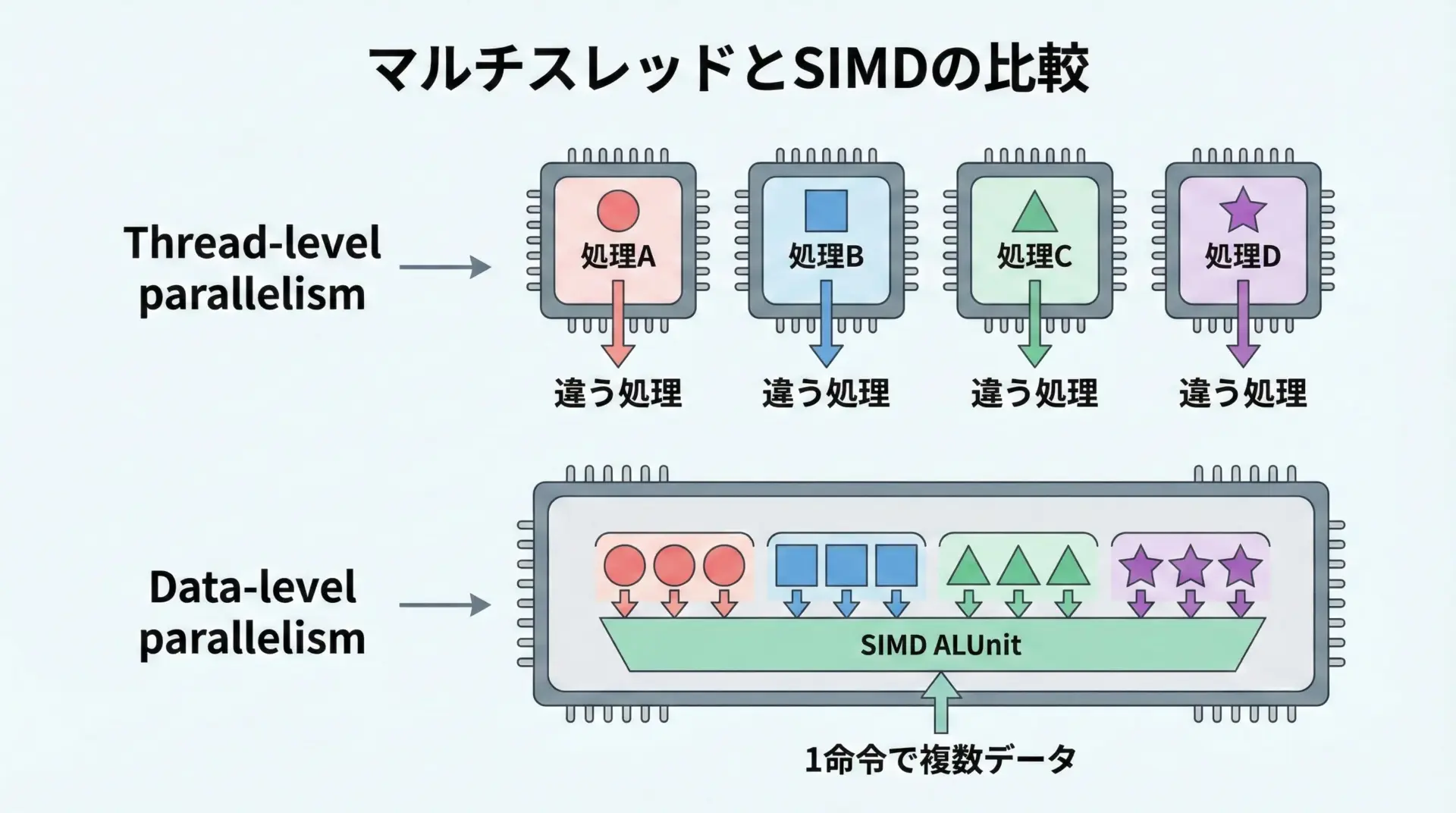
マルチスレッドは「スレッド単位」の並列性、SIMDは「データ単位」の並列性と考えると理解しやすいです。
実際には、両者を組み合わせて、コアごとにSIMDを使うことで、より大きな並列度を実現することも一般的です。
まとめ
SIMD(Single Instruction, Multiple Data)は、1つの命令で複数のデータを同時に処理することで、同種の計算を大量に行う処理を高速化する仕組みです。
CPU内部のベクトルレジスタと専用命令を活用し、配列や画像、音声など連続したデータに対する演算を効率良く進めます。
自動ベクトル化により、通常のコードからでも恩恵を受けられますが、データ構造やアルゴリズムをSIMD向けに設計すると、より大きな効果が期待できます。
マルチスレッドによる並列化とは異なり、SIMDはデータ並列性に特化した技術であり、両者を組み合わせることで現代の高性能なアプリケーションが成り立っています。
