Unicodeは世界中の文字を統一的に扱うための仕組みですが、そのまま使うと「見た目は同じなのにバイト列が違う」という問題が頻繁に発生します。
この記事では、Unicodeの正規化の基本からNFC/NFD/NFKC/NFKDの違いと使い分けまでを、実務で迷わないレベルまで整理して解説します。
Unicodeの正規化とは何か
正規化が必要になる背景
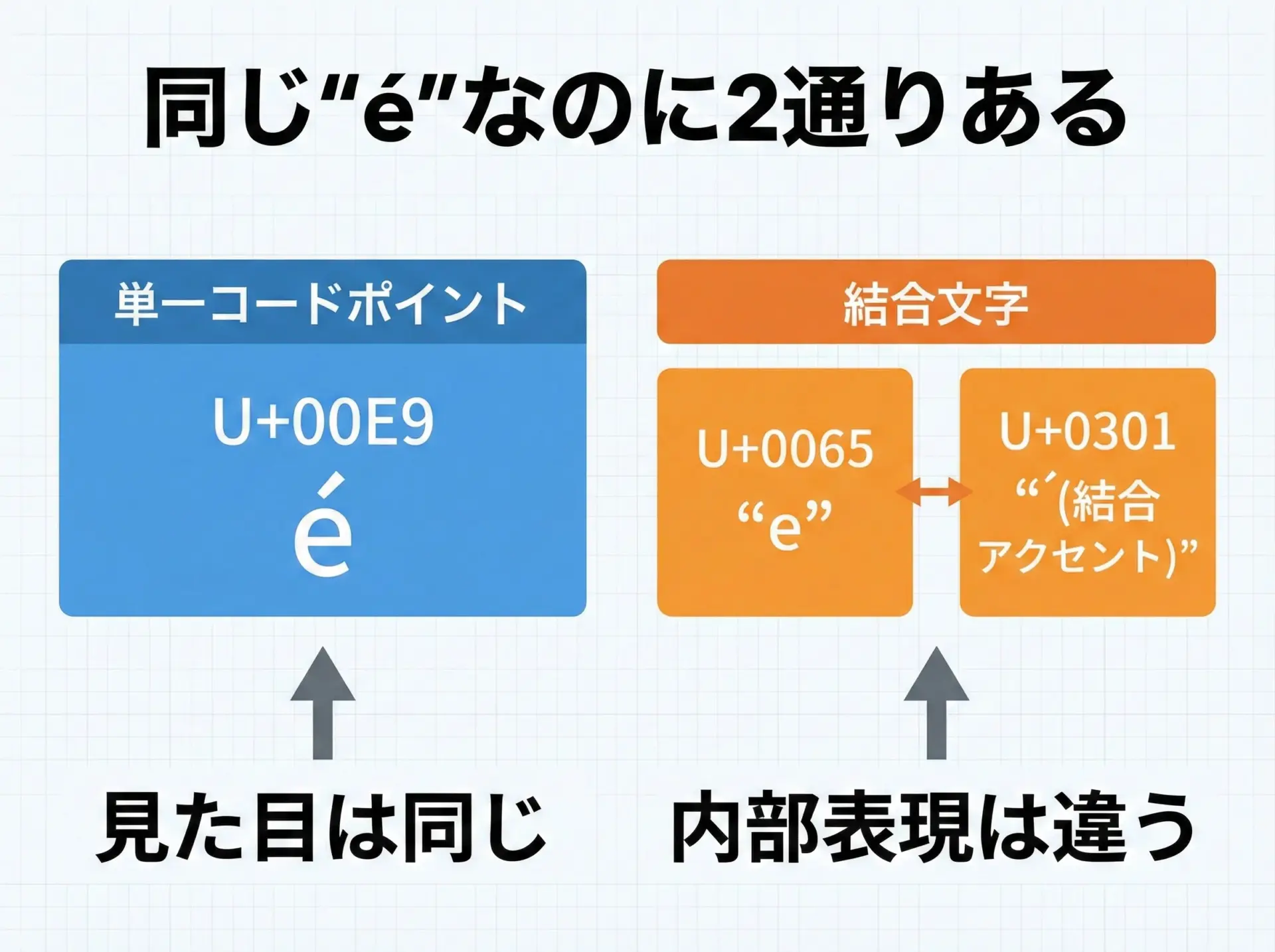
Unicodeでは、同じ見た目の文字に対して複数の表現方法が存在します。
例えば、ラテン小文字の「é」は次の2通りで表現できます。
- 単一文字: U+00E9 (LATIN SMALL LETTER E WITH ACUTE)
- 結合文字列: U+0065 (e) + U+0301 (COMBINING ACUTE ACCENT)
ユーザーから見るとどちらも同じ「é」に見えますが、バイト列が異なるため、そのまま比較すると「違う文字列」と判定されてしまいます。
このような見た目とバイト列の不一致を解消するためのルールが「Unicodeの正規化」です。
正規化の基本的な考え方
Unicode正規化は、あるテキスト列に対して一意な標準表現を与える変換処理です。
これにより、もともと別々の表現をしていた文字列を、比較可能な状態に揃えます。
正規化のポイントは次の2つです。
- 合成文字と分解文字をどう扱うか
- 互換文字をどう扱うか
この2つの観点の組み合わせで、NFC/NFD/NFKC/NFKDという4種類の正規化形式が定義されています。
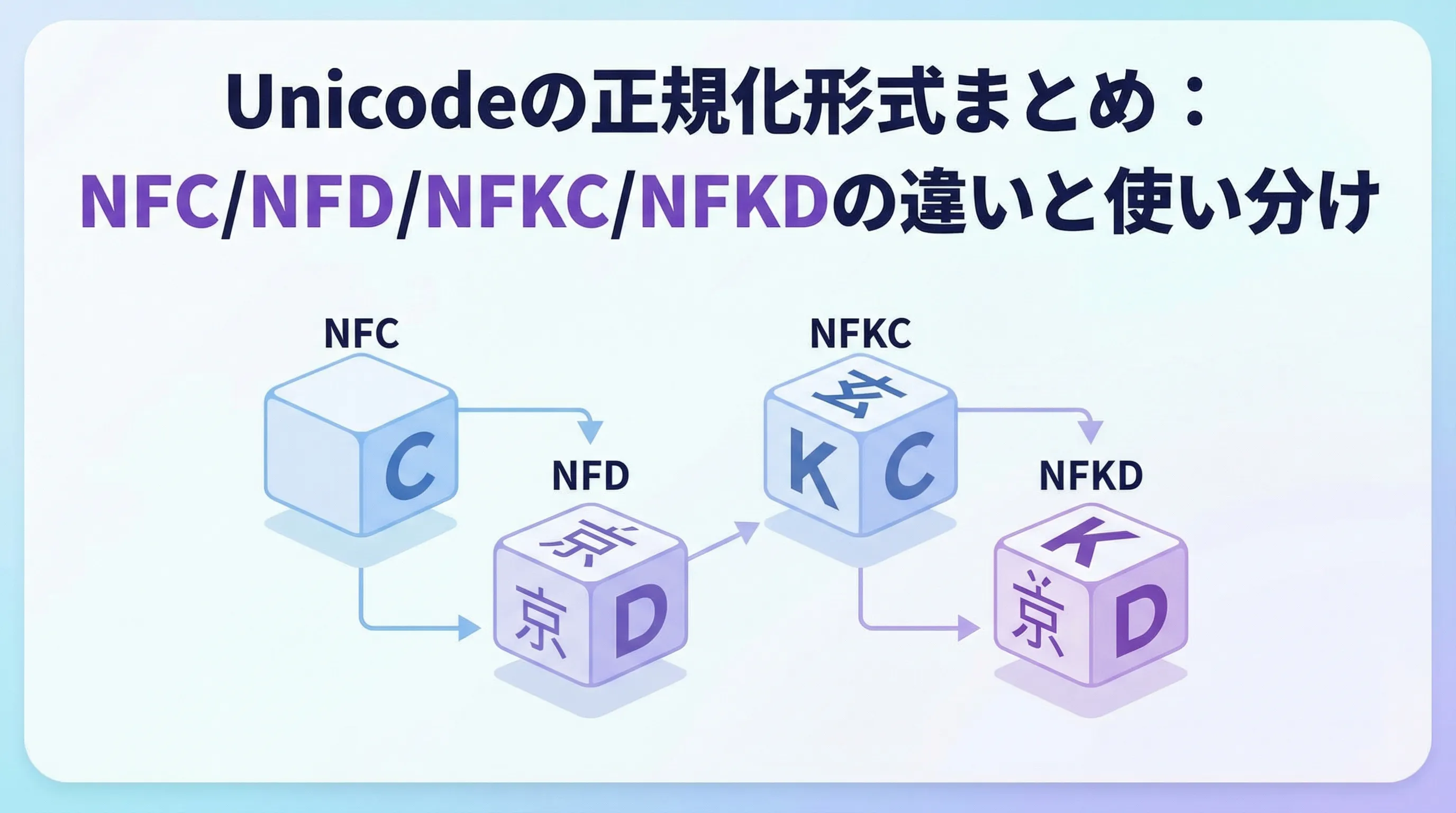
Unicode正規化の4形式の概要
4形式の一覧と分類
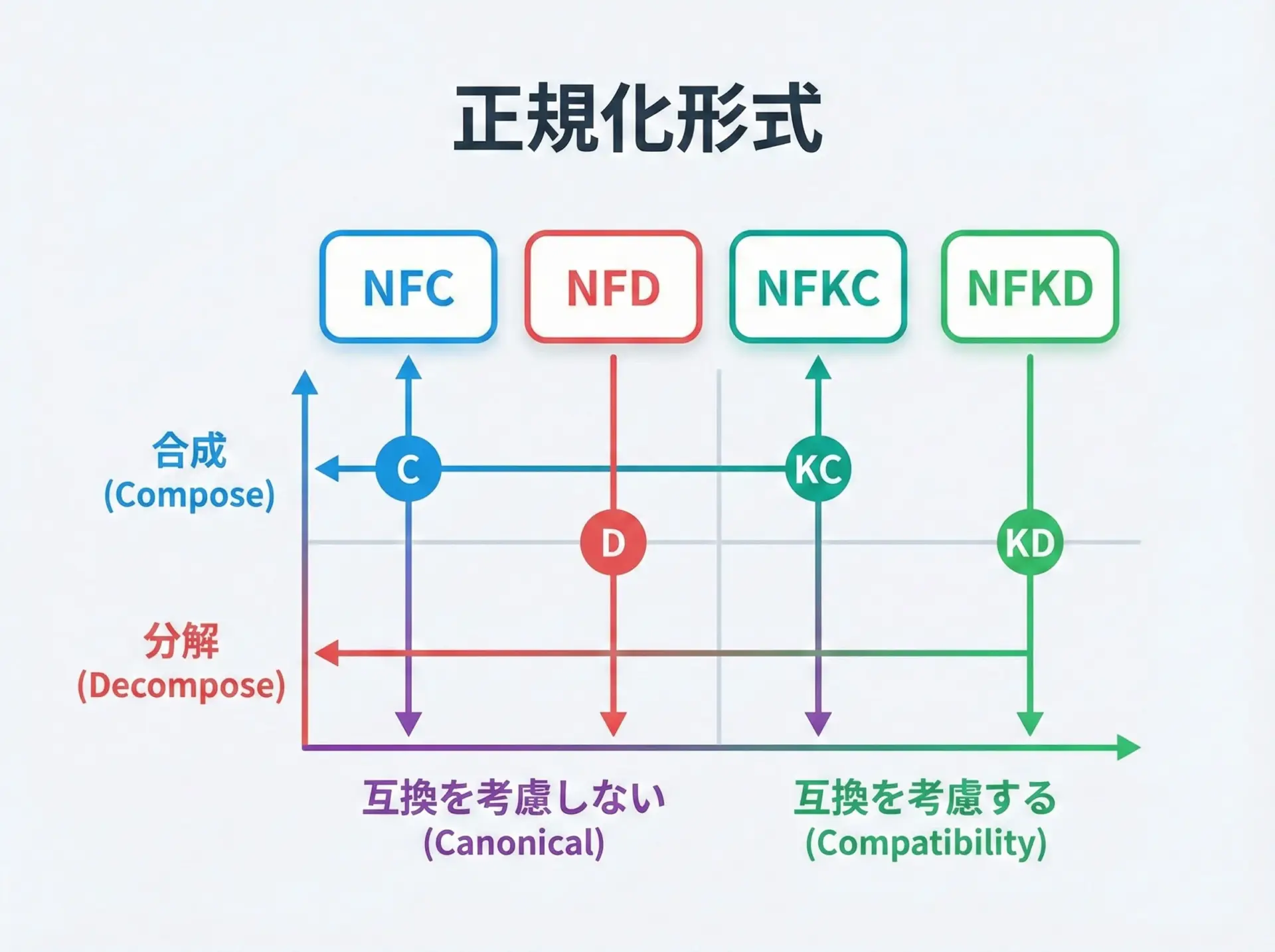
Unicode正規化は、次の2軸で分類されます。
- 合成か分解か
- C(Compose): できるだけ1文字に合成する
- D(Decompose): できるだけ分解して表現する
- 互換分解をするかどうか
- N(Non-Compatibility): 文字の意味や区別を保つ
- NK(Compatibility): 見た目は近いが意味の違う文字もまとめる
この組み合わせから、次の4形式が定義されています。
| 形式 | 合成/分解 | 互換性考慮 | 特徴の要約 |
|---|---|---|---|
| NFC | 合成(Compose) | しない | 実務で最もよく使われる「標準形」 |
| NFD | 分解(Decompose) | しない | アクセントなどを分離した形。検索・解析向き |
| NFKC | 合成(Compose) | する | 見た目が近い文字を1つに寄せる。照合・検索特化 |
| NFKD | 分解(Decompose) | する | 最も「バラバラ」にする形。高度な正規化・解析用 |
通常のテキスト保存や比較ではNFC、検索エンジンや照合ロジックではNFKCがよく利用されます。
NFCとNFDの違い
NFC(Normalization Form C)の特徴
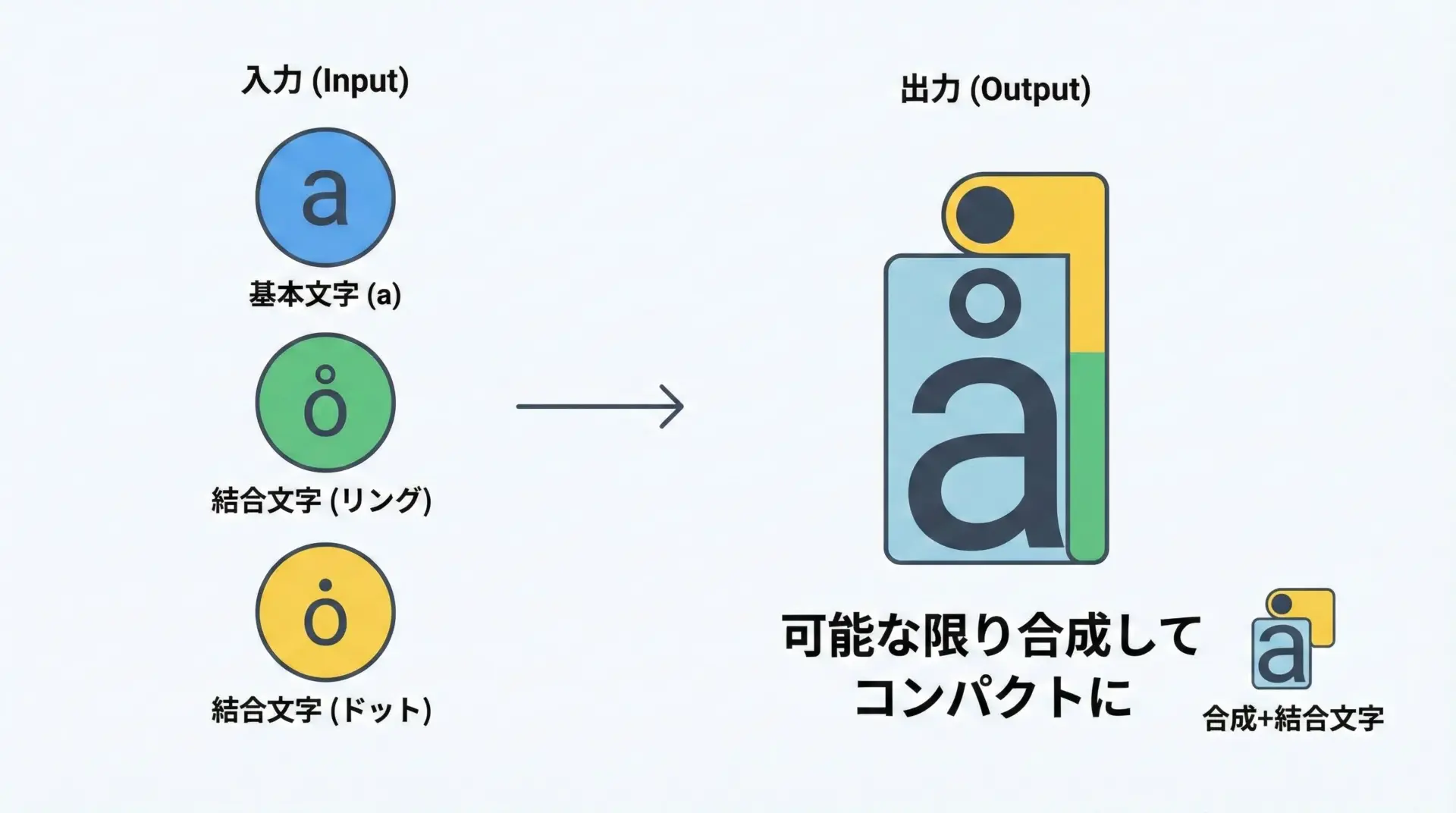
NFCは正規等価(Canonical Equivalence)だけを考慮して、可能な限り合成した形式です。
実務的には「保存するならとりあえずNFC」と覚えて問題ありません。
特徴としては次のようになります。
- 組み合わせ可能な文字は、できるだけ1文字にまとめる
- 互換文字は区別を保つ(例: 上付き「1」と通常の「1」は別)
- 多くのOS・ファイルシステム・フォントがNFC前提で設計されている
NFCの具体例
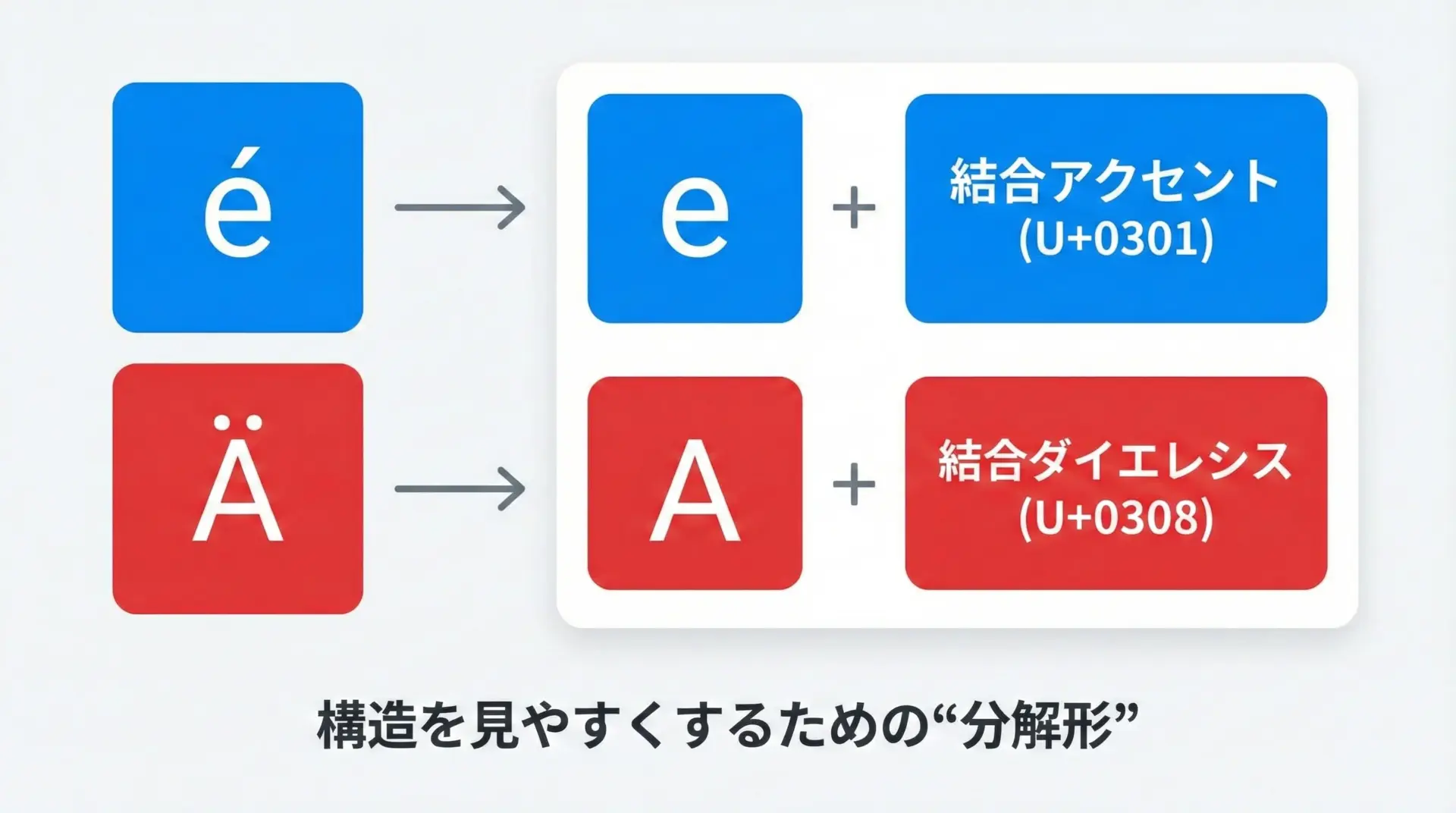
- U+0065 (e) + U+0301 (´) → NFC → U+00E9 (é)
- U+0041 (A) + U+0308 (¨) → NFC → U+00C4 (Ä)
NFD(Normalization Form D)の特徴
NFDは正規等価のみを考慮しつつ、可能な限り分解した形式です。
文字の構造を明示したいときに使います。
特徴は次の通りです。
- アクセント・ダイアクリティカルマークを分離する
- 検索・索引・形態素解析など、文字構造を扱いたい処理に向く
- ファイルシステム(HFS+のmacOSなど)が内部的にNFD風表現を使うことがある
NFDの具体例
- U+00E9 (é) → NFD → U+0065 (e) + U+0301 (´)
- U+00C4 (Ä) → NFD → U+0041 (A) + U+0308 (¨)
NFKCとNFKDの「互換」正規化
互換分解とは何か
互換正規化の核となるのが互換分解(Compatibility Decomposition)です。
これは次のような変換を行います。
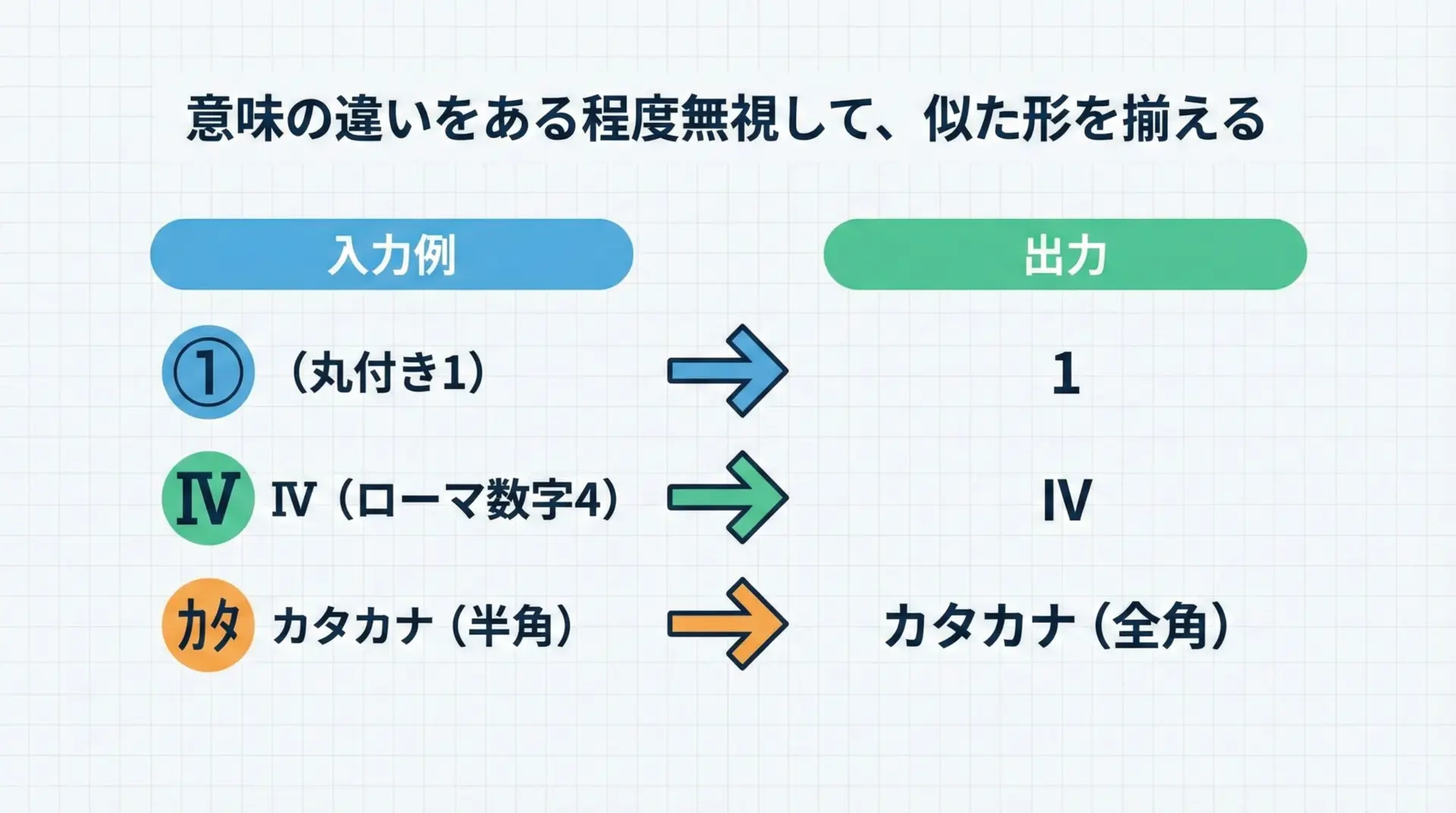
- 丸付き数字「①」→ 「1」
- ローマ数字「Ⅳ」→ 「IV」
- 半角カタカナ「カタカナ」→ 全角「カタカナ」
つまり「意味や用途の違いをある程度無視して、見た目が近いものを同じにする」処理です。
このため、互換正規化の結果は元のテキストを完全には再現できない可能性があります。
NFKC(Normalization Form KC)
NFKCは、互換分解のあとに可能な限り合成した形式です。
検索・照合・入力正規化など、「同じような見た目を同一視したい」用途に適しています。
NFKCの特徴
- 半角・全角・一部の記号を統一する
- Rôle のように、互換な書き方を可能な限り同じ形に寄せる
- ログインIDやタグ名など、比較時に差異を減らしたいケースで有効
NFKCの例
- U+FF71 (ア) → NFKC → U+30A2 (ア)
- U+217C (ⅼ) → NFKC → U+0078 (x) + U+0076 (v) = “xv” といった分解を伴う場合もある
NFKD(Normalization Form KD)
NFKDは、互換分解した上で可能な限り分解する形式です。
「とにかく文字種のばらつきをならして、構造を露出したい」場合に用いられます。
特徴としては次があります。
- 丸付き、ローマ数字、全角/半角などをすべて分解
- さらにアクセントやダイアクリティカルマークも分ける
- 検索インデックスの作成や高度なテキスト分析、正規化前処理に利用
NFC/NFD/NFKC/NFKDの使い分け
代表的な利用シーン別のおすすめ
利用シーンごとのおすすめは次のようになります。
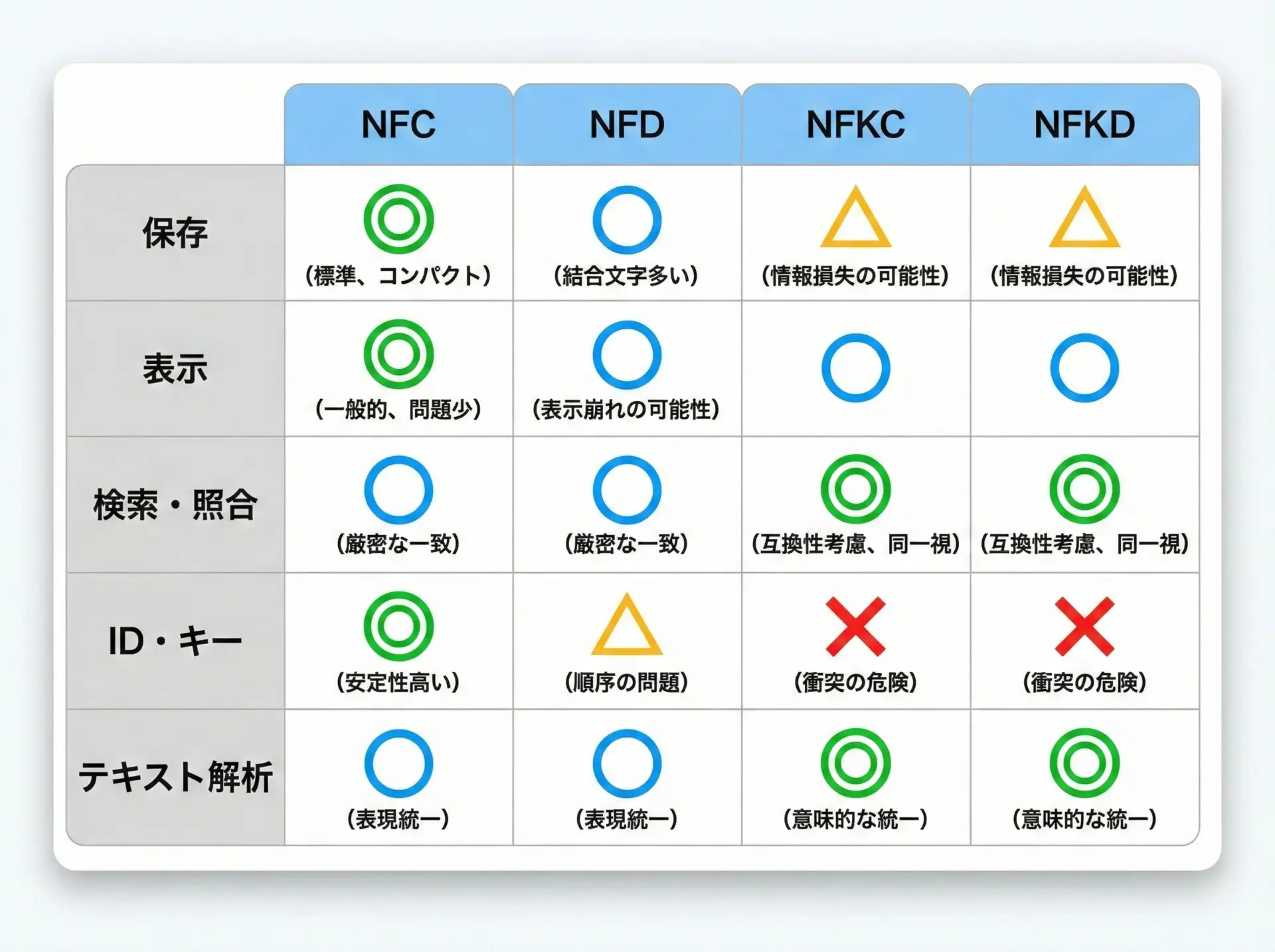
| 用途 | おすすめ形式 | 補足説明 |
|---|---|---|
| データベース保存 | NFC | 多くのシステムが前提とする標準形。互換分解はしない |
| ファイル名(一般用途) | NFC | OSやツールとの相性が良い |
| 検索・全文検索 | NFKC + 独自ルール | 半角/全角や丸付き数字などを揃えたい |
| ログインID・ユーザー名 | NFKC | 入力ゆらぎを減らす。ただし禁止文字もあわせて定義する |
| 形態素解析・NLP | NFD または NFKD | アクセントや記号を分けて扱いたい場合に有効 |
| 暗号学的ハッシュ、署名 | NFC | 比較対象をNFCに揃えてからハッシュする |
「保存はNFC、検索はNFKCベース」という運用パターンが多いです。
実務での具体的な判断ポイント
実装者としては、次のように判断すると実務で迷いにくくなります。
- 元の文字をできるだけ忠実に保持したい場合
→NFC または NFDを使い、互換正規化(NFK*)は避ける - ユーザー入力のブレ(半角/全角/丸付きなど)を吸収したい場合
→NFKCで正規化してから比較する - NLPなどで文字構造を分析したい場合
→NFD/NFKDにしてから処理し、必要に応じて再合成
C言語でのUnicode正規化サンプル(ICU利用)
ICUを用いた正規化の基本コード
C言語でUnicode正規化を行う際は、ICU(International Components for Unicode)ライブラリを利用するのが一般的です。
ここでは、NFCとNFKCに正規化する簡単な例を示します。
// コンパイル例: gcc normalize.c -o normalize `pkg-config --cflags --libs icu-uc`
#include <stdio.h>
#include <string.h>
#include <unicode/utypes.h>
#include <unicode/unorm2.h>
#include <unicode/ustring.h>
// ユーティリティ: UTF-8文字列を指定の正規化形式に変換する関数
int normalize_utf8(
const char *input_utf8,
char *output_utf8,
int output_capacity,
const char *norm_form_name // 例: "nfc", "nfkc" など
) {
UErrorCode status = U_ZERO_ERROR;
// 1. 正規化インスタンスを取得
const UNormalizer2 *norm = unorm2_getInstance(
NULL, // デフォルトのルート
norm_form_name,// "nfc" / "nfd" / "nfkc" / "nfkd"
UNORM2_COMPOSE,// COMPOSE or DECOMPOSE (形式ごとにICUが解釈)
&status
);
if (U_FAILURE(status)) {
fprintf(stderr, "unorm2_getInstance error: %s\n", u_errorName(status));
return -1;
}
// 2. UTF-8 → UTF-16(UChar) に変換
UChar u_input[256];
int32_t u_input_len = 0;
u_strFromUTF8(
u_input, sizeof(u_input) / sizeof(UChar),
&u_input_len,
input_utf8, (int32_t)strlen(input_utf8),
&status
);
if (U_FAILURE(status)) {
fprintf(stderr, "u_strFromUTF8 error: %s\n", u_errorName(status));
return -1;
}
// 3. UTF-16で正規化
UChar u_output[256];
int32_t u_output_len = unorm2_normalize(
norm,
u_input, u_input_len,
u_output, sizeof(u_output) / sizeof(UChar),
&status
);
if (U_FAILURE(status)) {
fprintf(stderr, "unorm2_normalize error: %s\n", u_errorName(status));
return -1;
}
// 4. UTF-16 → UTF-8 に再変換
int32_t utf8_len = 0;
u_strToUTF8(
output_utf8, output_capacity,
&utf8_len,
u_output, u_output_len,
&status
);
if (U_FAILURE(status)) {
fprintf(stderr, "u_strToUTF8 error: %s\n", u_errorName(status));
return -1;
}
return utf8_len; // 正規化後のUTF-8長
}
int main(void) {
// 例: e + 結合アキュートで構成された "é"
const char *src = "e\u0301"; // コンパイラ設定により直接は使えない場合があります
// 実際には、ソースをUTF-8ファイルとして保存しておく前提
char nfc[256];
char nfkc[256];
// NFCに正規化
int len_nfc = normalize_utf8(src, nfc, sizeof(nfc), "nfc");
// NFKCに正規化
int len_nfkc = normalize_utf8(src, nfkc, sizeof(nfkc), "nfkc");
if (len_nfc >= 0 && len_nfkc >= 0) {
printf("Original: %s\n", src);
printf("NFC : %s (len=%d)\n", nfc, len_nfc);
printf("NFKC : %s (len=%d)\n", nfkc, len_nfkc);
}
return 0;
}Original: é
NFC : é (len=2)
NFKC : é (len=2)上記は簡略化した例ですが、ICUを使うと形式名(NFC/NFD/NFKC/NFKD)を指定するだけで正規化が実行できることが分かります。
なぜ「必ずどこかで正規化」すべきなのか
正規化しない場合に起こる問題
正規化を行わないと、実務では次のようなトラブルがよく発生します。
- 同じ文字列が、入力方法やOSによって微妙に異なる内部表現になる
- データベースのユニーク制約がすり抜けて、同名ユーザーが複数登録される
- ファイルシステムや言語処理系による比較結果が想定と変わる
- ハッシュ値が一致しないため、キャッシュや署名の検証が失敗する
「目で見て同じに見えるなら同じと扱いたい」のに、それができない状態が継続してしまいます。
正規化戦略の基本指針
システム設計では、少なくとも次の2点を明確にしておく必要があります。
- 保存時の標準形式を決める(例: DBに入れる前にNFCに統一)
- 比較・検索時にどこまで互換正規化するかを決める(例: 検索クエリはNFKCしてから照合)
特に、ユーザー名やメールアドレス、タグ名など「識別子として使う文字列」は、入力時にどこまで正規化・制限するかを設計段階でルール化しておくことが重要です。
まとめ
Unicodeの正規化は、見た目は同じなのに内部表現が異なる文字列を一意な標準表現に揃えるための仕組みです。
NFC/NFDは意味の区別を保ちながら合成・分解を行い、NFKC/NFKDは互換文字も含めて形を揃えます。
保存や署名、ハッシュなどではNFC、検索や照合ではNFKCを使うのが定番です。
システム全体で「どのタイミングでどの形式に正規化するか」をあらかじめ決めておくことで、思わぬバグやデータ不整合を大きく減らすことができます。
