Unicodeは世界中の文字を1つの体系で扱うための規格ですが、実際にプログラムで扱おうとすると「思ったより複雑だった」と感じる場面が多いです。
本記事では、その中でも理解のハードルになりやすいサロゲートペア・結合文字・絵文字について、図解とサンプルコードを交えながら、実践的な観点で整理していきます。
Unicodeの基本構造をおさえる
コードポイント・コードユニット・文字の違い
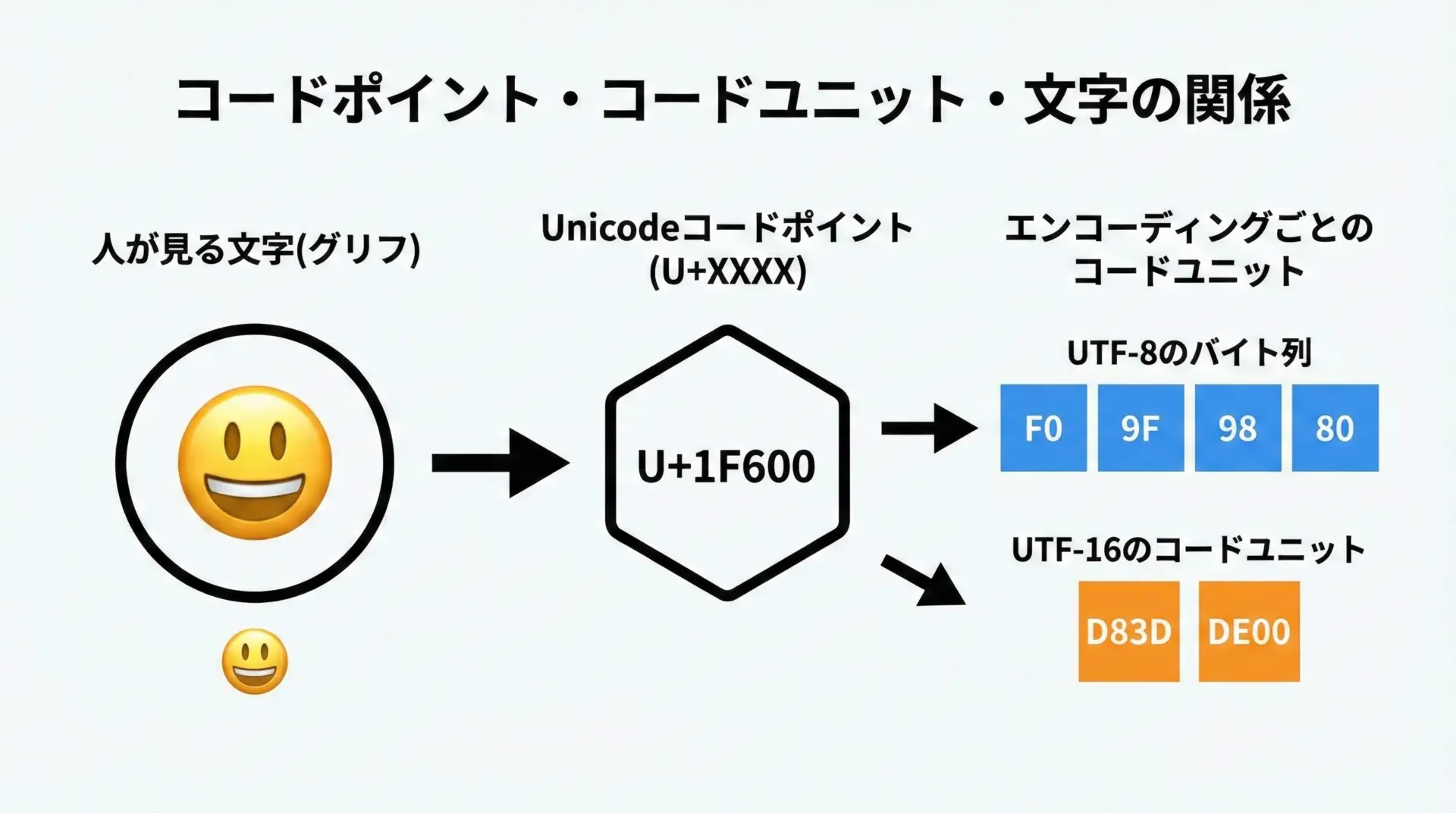
Unicodeを理解するうえで、まず区別しておきたいものが3つあります。
1つ目はコードポイントです。
これはU+1F600のように表記される「抽象的な文字番号」です。
Unicodeは0~0x10FFFFまでの番号空間を持ち、その中に世界中の文字や記号が割り当てられています。
2つ目はコードユニットです。
UTF-8やUTF-16など、具体的なエンコーディング方式ごとに「最小単位の値」が決まっています。
UTF-8では1バイト、UTF-16では16ビット(2バイト)がコードユニットです。
同じコードポイントでも、エンコーディングによって並び方が変わります。
3つ目は文字(グリフ)です。
私たち人間が画面上で見ている「1つの文字」の見た目です。
注意したいのは、人が見て1文字に見えるものが、必ずしも1つのコードポイントとは限らないという点です。
これが、後述する結合文字や絵文字の複雑さの根本にあります。
サロゲートペアとは何か
BMPとサロゲート領域
Unicodeの最初期には、0~0xFFFFまでの範囲(BMP: Basic Multilingual Plane)に文字を割り当てる想定でした。
しかし、世界中の文字や絵文字を含めていくうちに収まりきらなくなり、0x10000以上のコードポイントが必要になりました。
ところが、UTF-16ではコードユニットが16ビットのため、そのままでは0xFFFFまでしか表現できません。
そこで導入された仕組みがサロゲートペアです。
これは2つの16ビット値を組み合わせて1つのコードポイント(0x10000~0x10FFFF)を表現する仕組みです。
高位サロゲート・低位サロゲート
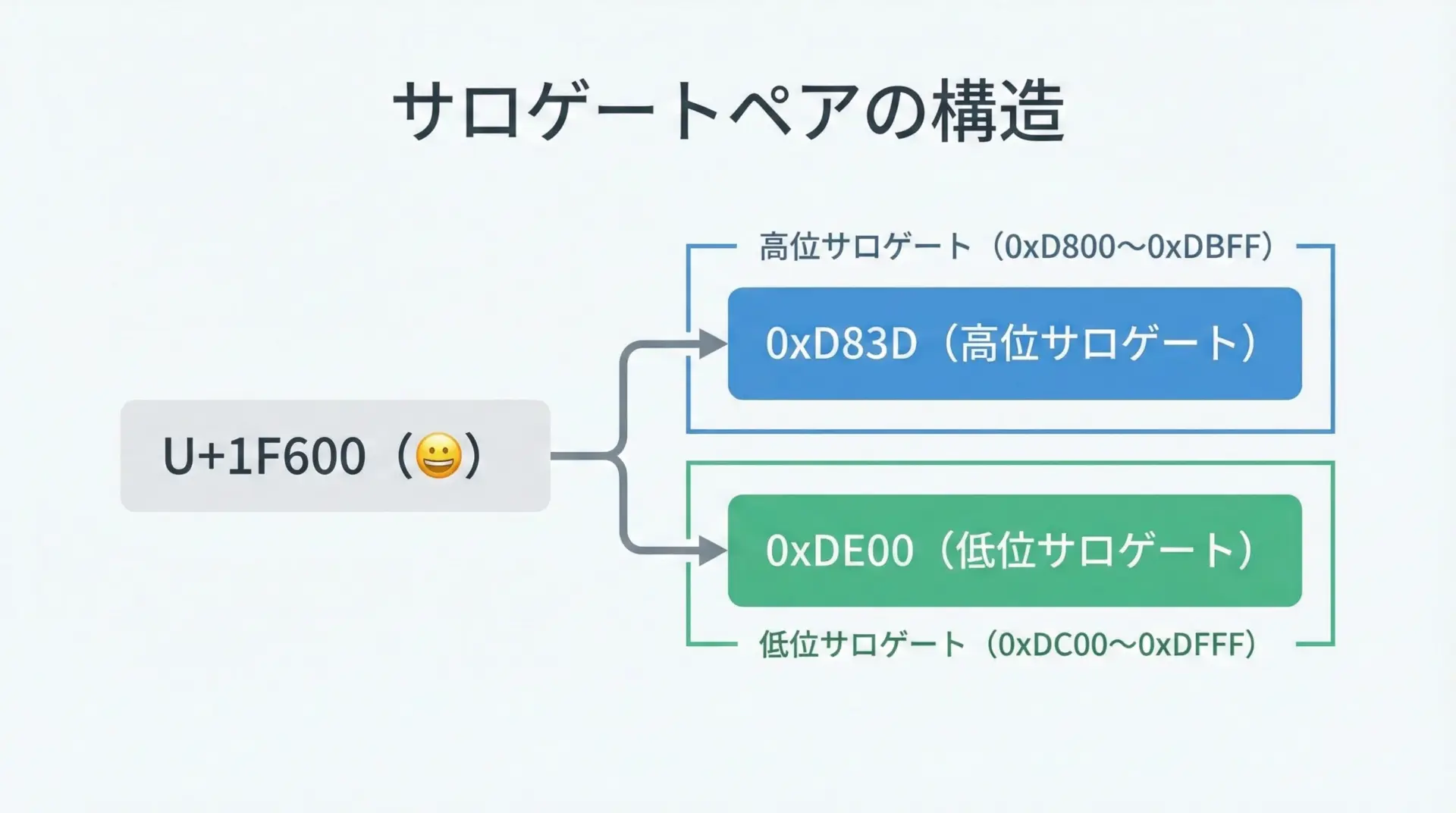
UTF-16のサロゲートペアには、次の2種類があります。
- 高位サロゲート(High Surrogate): 0xD800~0xDBFF
- 低位サロゲート(Low Surrogate): 0xDC00~0xDFFF
これらは単独では有効な文字ではなく、必ず「高位サロゲート + 低位サロゲート」の2つで1文字を構成します。
例えば絵文字😀(U+1F600)は、UTF-16では次の2つのコードユニットで表現されます。
- 0xD83D (高位サロゲート)
- 0xDE00 (低位サロゲート)
この2つを組み合わせて、はじめてU+1F600というコードポイントになります。
C言語とサロゲートペアの落とし穴
C言語でUTF-16の配列を扱うとき、「要素数」と「人間が見る文字数」が一致しないことに注意が必要です。
サロゲートペアを含む文字列では、コードユニット数のほうが多くなります。
UTF-16でのコードユニット数を数える例(C)
#include <stdio.h>
#include <wchar.h>
// この例では、Windowsなどでwchar_tがUTF-16(2バイト)の環境を想定しています。
// Linux(glibc)ではwchar_tはUTF-32の場合が多いので、その場合は挙動が異なります。
int main(void) {
// 絵文字 😀 (U+1F600) をUTF-16のサロゲートペアで定義
// 高位サロゲート 0xD83D, 低位サロゲート 0xDE00
wchar_t utf16_str[] = { 0xD83D, 0xDE00, L'A', L'\0' };
// 要素数を計算(終端のL'\0'は除く)
size_t length = 0;
while (utf16_str[length] != L'\0') {
length++;
}
wprintf(L"コードユニット数: %zu\n", length);
// ここでのlengthは「文字数」ではなく「UTF-16コードユニット数」です
return 0;
}コードユニット数: 3文字としては「😀A」の2文字ですが、UTF-16のコードユニットとしては「サロゲート2つ + ‘A’」で3ユニットあることが分かります。
この違いを意識せずに「1文字ずつ」と考えてインデックスを操作すると、サロゲートペアを分断してしまい、不正な文字列になってしまう可能性があります。
結合文字と「見かけの1文字」
結合文字とは
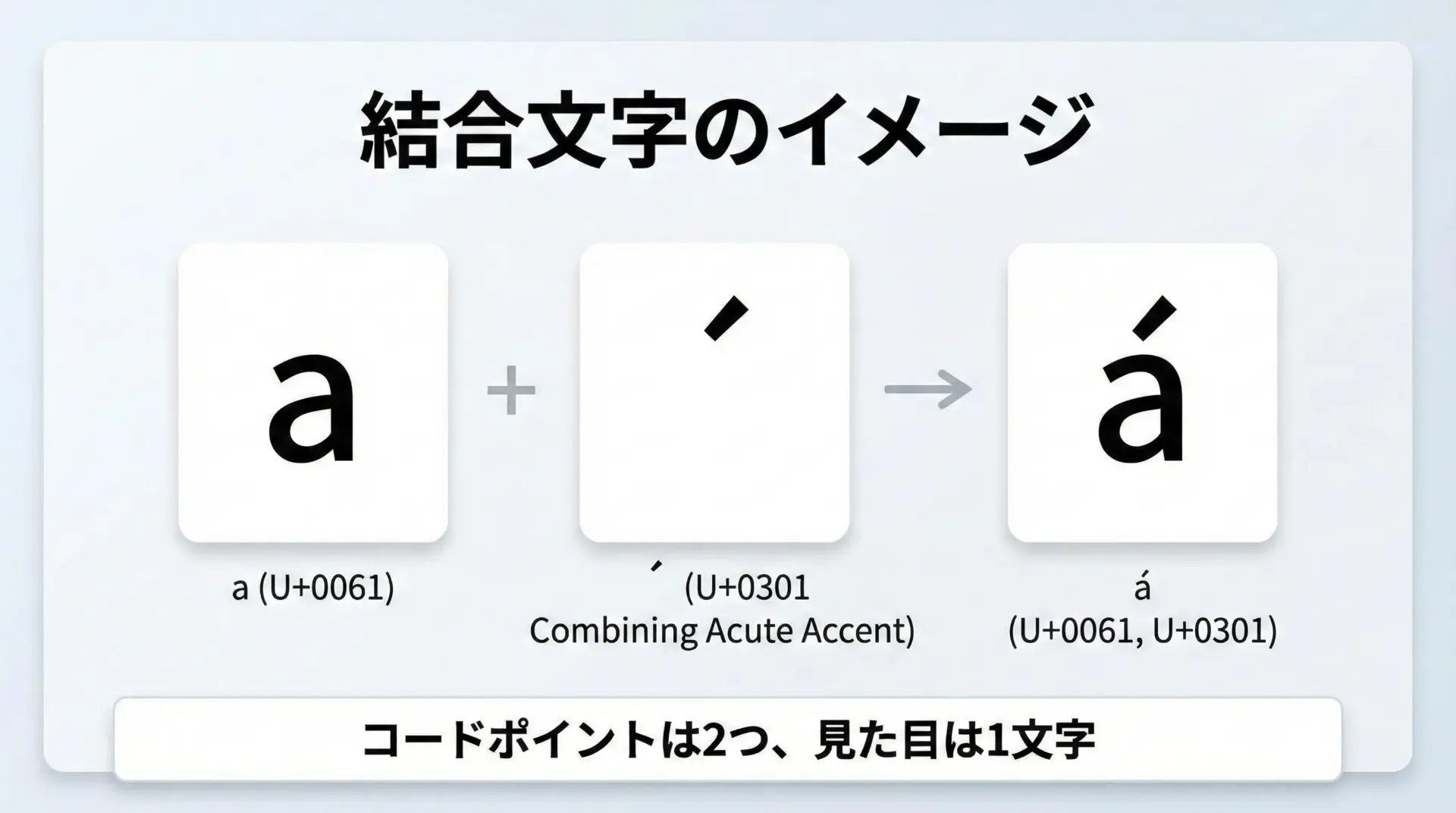
結合文字(Combining Mark)とは、直前の文字に重なって表示される修飾用の文字です。
代表的なものとして、アクセント記号やダイアクリティカルマークがあります。
例えば「á」は、次の2通りで表現できます。
- 1文字としての
U+00E1 (LATIN SMALL LETTER A WITH ACUTE) U+0061 (a)+U+0301 (Combining Acute Accent)の2コードポイント
後者のように、ベース文字 + 結合文字の組み合わせで1文字に見えるケースが、Unicodeでは多数存在します。
正規化と複数の表現
同じ「見かけの文字」でも、コードポイントの並びが複数存在することがあります。
この揺れをそろえるための仕組みが正規化(Normalization)です。
代表的な正規化形式は次のとおりです。
| 正規化形式 | 特徴 |
|---|---|
| NFC | 可能な限り単一の合成済み文字にまとめる |
| NFD | 可能な限りベース文字 + 結合文字に分解する |
文字の一致判定や検索処理を行う場合は、入力をあらかじめNFCなどの特定形式にそろえることが重要になります。
絵文字の複雑な構成
単体絵文字と絵文字シーケンス
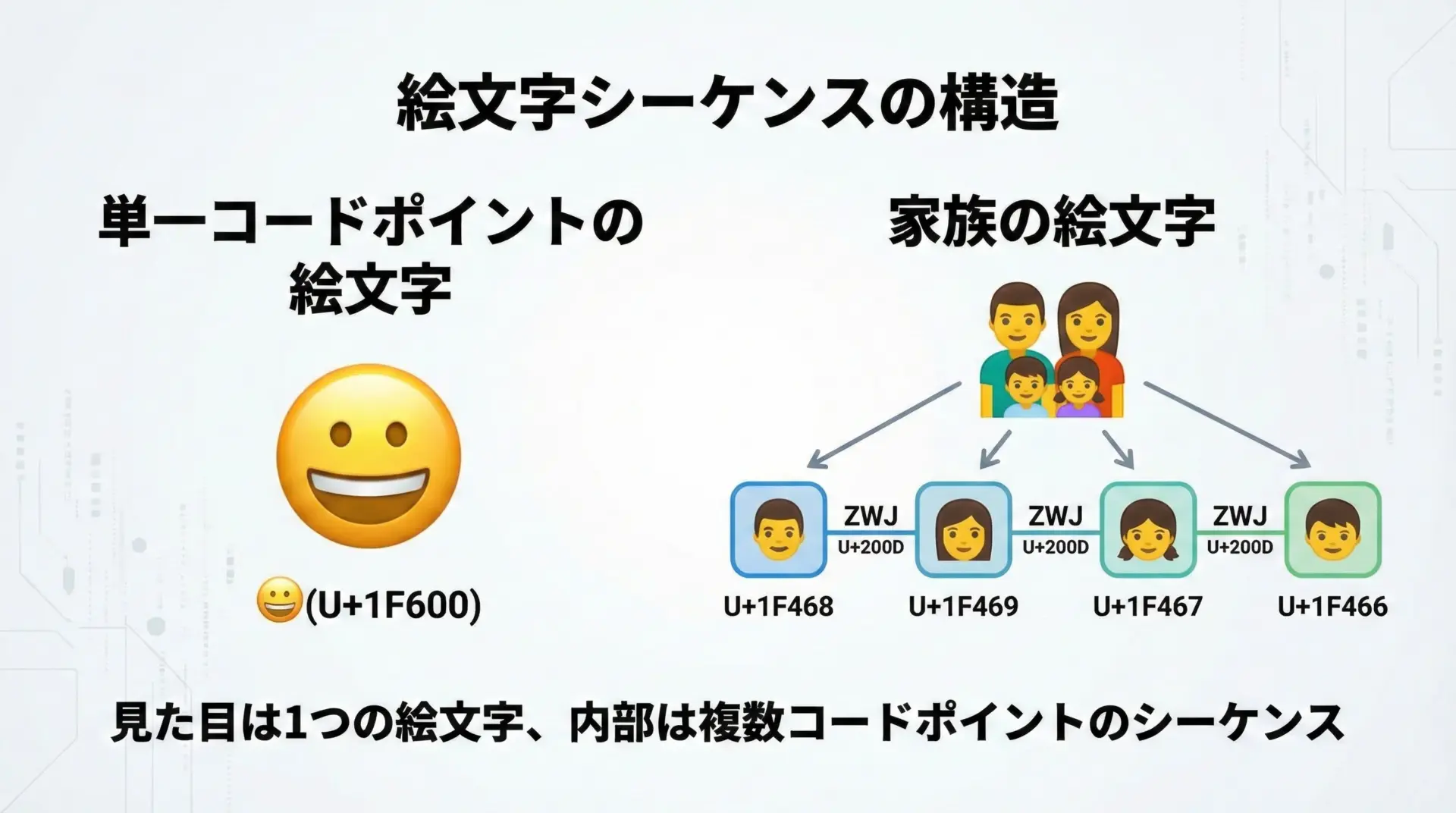
絵文字は、最初は単一のコードポイントで表されるだけのシンプルなものでした。
しかし、バリエーションを表現するニーズが高まり、次のような仕組みが追加されてきました。
- 肌の色のバリエーション
- 性別・家族構成
- 国旗の組み合わせ
- 職業やロールを表す複合的な絵文字
これらの多くは、複数のコードポイントを並べた「絵文字シーケンス」として定義されています。
特に重要なのがZWJ(Zero Width Joiner, U+200D)です。
これは「前後の絵文字を結び付けて1つの絵文字として表示する」ために使われる不可視文字です。
家族の絵文字などは、このZWJで複数の人物絵文字をつないで構成されています。
「1文字」が多数のコードポイントになる例
例えば次のような絵文字シーケンスがあります。
- 「女性医師」:
👩 (U+1F469)+ZWJ (U+200D)+⚕ (U+2695) - 「虹色の旗」:
🏳 (U+1F3F3)+ZWJ+🌈 (U+1F308)
これらは、ユーザーには1つの絵文字として見えているにもかかわらず、内部的には3つ以上のコードポイントで構成されています。
単に「char配列の長さを数えて文字数とみなす」ような処理では不正確になることが分かります。
「文字数」をどう数えるか
コードポイント数と書記素クラスタ
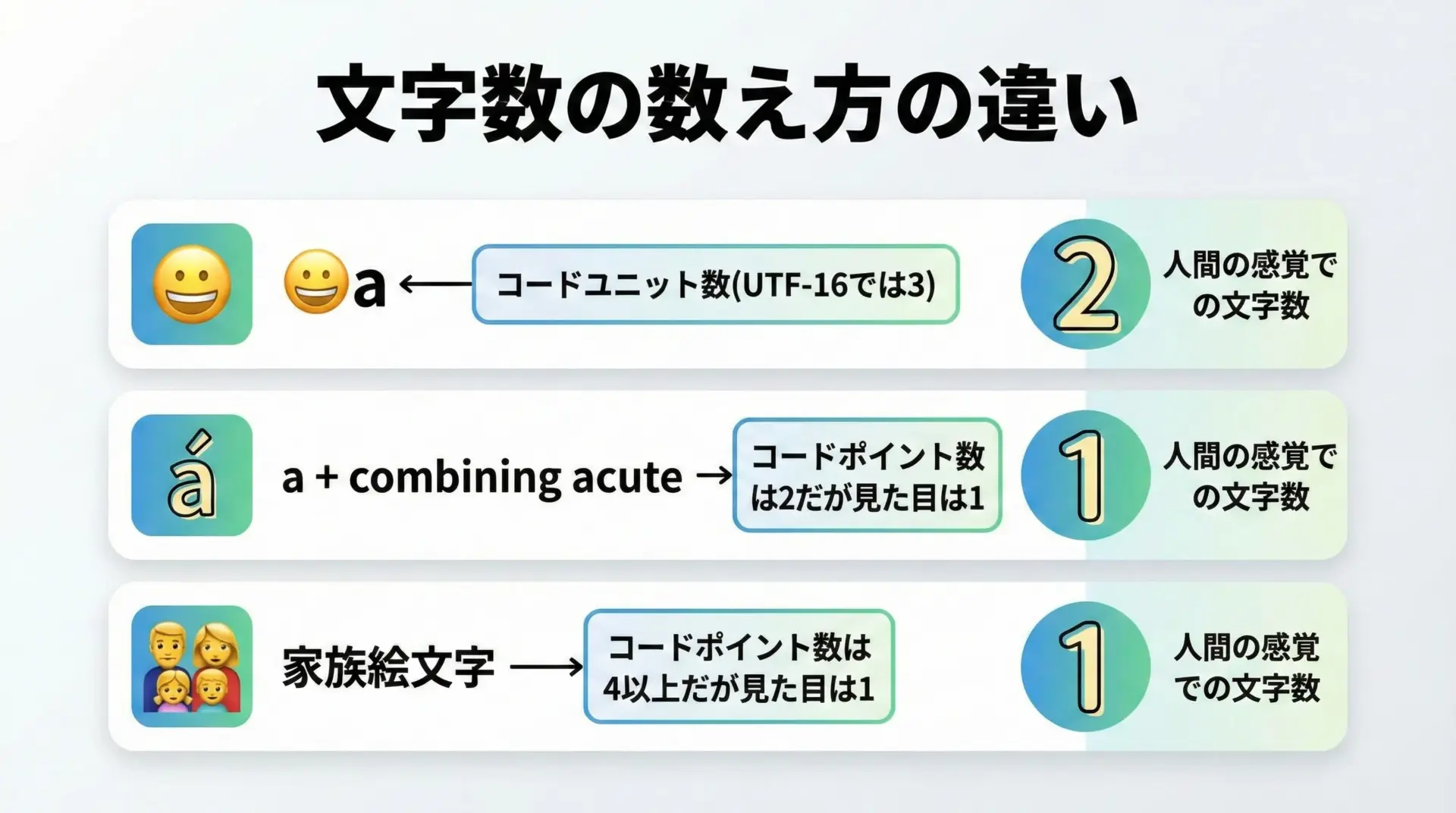
Unicodeでは、「人間が1文字と感じる単位」を「書記素クラスタ(grapheme cluster)」と呼びます。
これは概念的には次のような単位です。
- 単純な1コードポイントの文字(例: A, あ)
- ベース文字 + 結合文字のまとまり
- ZWJで結合された複数の絵文字
- 国旗のように、2つのリージョンコードを組み合わせたもの など
一方でプログラム内部では、よく次のような単位が使われます。
- コードユニット数(UTF-16の配列長など)
- コードポイント数(U+XXXXごとの数)
しかし「ユーザーにとっての1文字」として扱いたい場合は、書記素クラスタを単位に扱う必要があります。
これは、自前で完全に実装しようとすると非常に複雑です。
そのため、多くの言語やライブラリでは、Unicode対応の文字列操作APIを提供し、書記素クラスタ単位でのイテレーションや切り出しをサポートしています。
Cレベルでの安全な扱い方の考え方
C言語では、標準ライブラリだけで書記素クラスタ単位の処理を実現するのは困難です。
そのため、次のような戦略をとることが多いです。
- 可能なら上位レベルの言語やライブラリ(Python, ICU, Rustのunicode-segmentationなど)に処理を任せる
- Cで扱う場合でも、中身のバイト列を安易に1バイトずつ・1コードユニットずつ分割しない
- 入力の検証や、ライブラリ(ICUなど)を用いた正規化・分解を活用する
次のサンプルは、あくまで「UTF-8のバイト数」を数えるだけの簡易的な例ですが、バイト列と文字数が異なるという意識を持つ上で参考になります。
UTF-8でのバイト長を数える簡易例(C)
#include <stdio.h>
#include <string.h>
int main(void) {
// UTF-8で「😀A」を表現した文字列
// 😀(U+1F600)はUTF-8で4バイト、'A'は1バイト
const char *s = "😀A";
size_t byte_len = strlen(s); // バイト数を取得
printf("UTF-8バイト数: %zu\n", byte_len);
// 「人の感覚での文字数」は2ですが、この例では計算していません。
// 書記素クラスタ数を正しく数えるには、Unicode対応ライブラリが必要です。
return 0;
}UTF-8バイト数: 5このように、UTF-8では1文字が1~4バイトで表現されるため、strlenは「文字数」ではなくあくまでバイト数であることに注意しなければなりません。
文字列処理で気をつけるポイント
部分切り出し・削除・反転
サロゲートペア・結合文字・絵文字シーケンスを前提にすると、次のような操作は特に注意が必要です。
- 文字列の途中で切り出す(substr)
- 文字列の一部を削除する
- 文字列を反転させる(reverse)
例えば、絵文字シーケンスの途中で切ってしまうと、前半・後半ともに意味不明な断片になってしまうことがあります。
結合文字の途中で切っても、ベース文字だけが残ったり、結合文字だけが宙に浮いたりして、不自然な表示になります。
そのため、ユーザーに見える単位で操作したい場合は、必ずUnicode対応のライブラリを利用して「書記素クラスタ単位」で処理することが推奨されます。
長さ制限とバリデーション
データベースのフィールド長や、入力フォームの最大長を制限する場合も注意が必要です。
例えば「20文字まで」という仕様を、
- バイト数(UTF-8)
- コードユニット数(UTF-16)
- コードポイント数
- 書記素クラスタ数
のどれで測っているのかを明確にし、それに応じたカウント方法を選ぶ必要があります。
特にユーザー向けのUIでは、人間の感覚に沿った「見た目の文字数」(書記素クラスタ数)を基準にするほうが混乱が少なくなります。
まとめ
Unicodeの世界では、「1文字 = 1コードポイント = 1コードユニット」ではないことが、サロゲートペア・結合文字・絵文字の登場によってはっきりと表れています。
サロゲートペアはUTF-16で0x10000以上の文字を扱うための仕組みであり、結合文字やZWJを用いた絵文字シーケンスは、複数のコードポイントで1つの「見かけの文字」を構成します。
プログラムで文字列を扱う際には、バイト数や配列長と、人間が認識する「文字数」が異なることを常に意識し、可能な限りUnicode対応のライブラリで書記素クラスタ単位の操作を行うことが重要です。
