インターネットのサービスにログインするとき、ユーザー名とパスワードを入力しますが、そのパスワードはサービス側に「そのまま」保存されているわけではありません。
多くの場合、ハッシュ関数と呼ばれる仕組みを使って、別の形に変換してから保存されています。
本記事では、プログラミングを学び始めた方を対象に、ハッシュ関数の基本から、パスワード保存に使われる理由、実際のプログラミングでの使い方までを、できるだけイメージしやすく解説します。
ハッシュ関数とは何か
ハッシュ関数の基本的な意味
ハッシュ関数(hash function)とは、あるデータ(入力)を受け取り、一定のルールにしたがって、固定長の「ハッシュ値」と呼ばれるデータに変換する関数のことです。
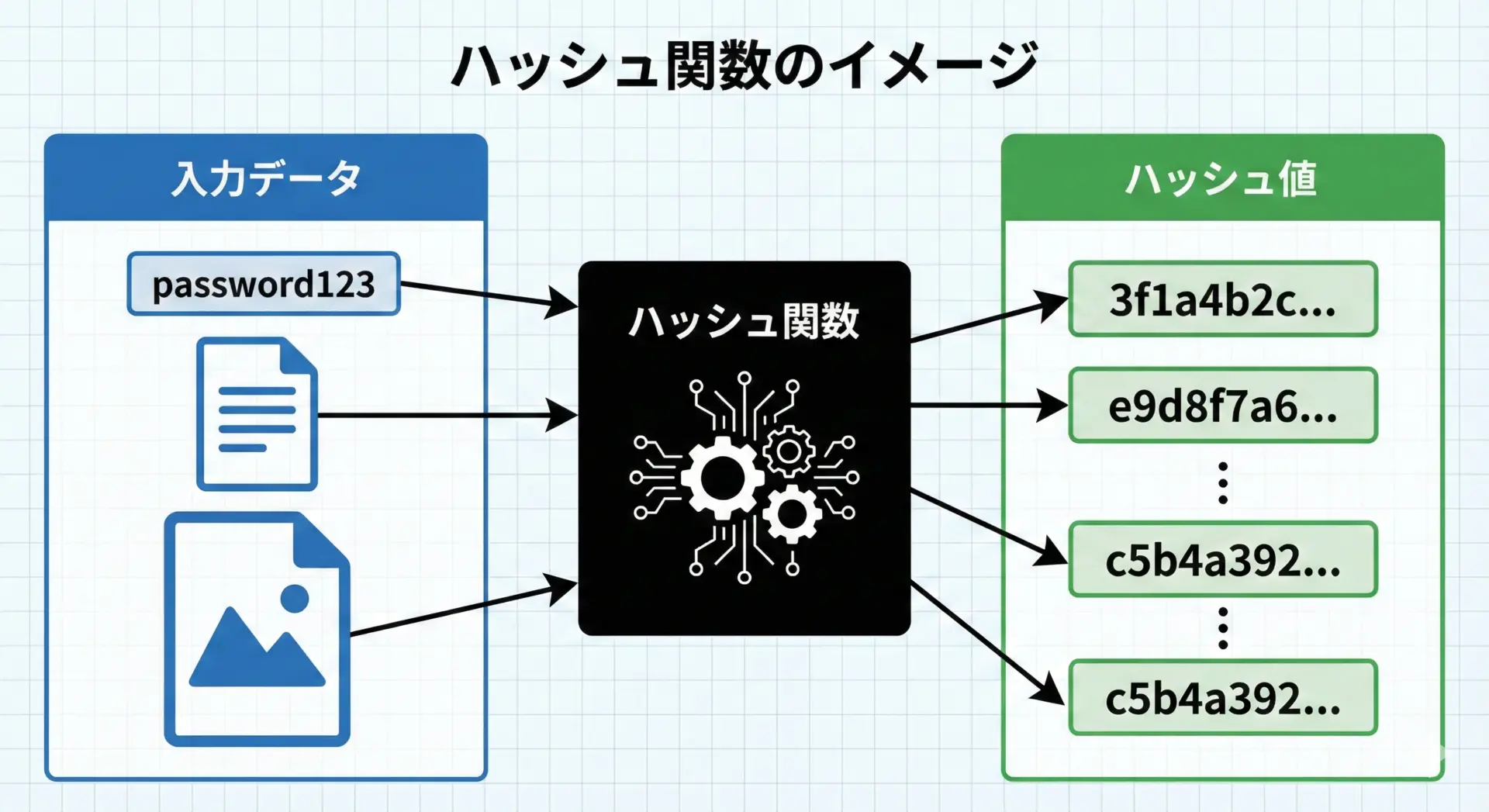
ハッシュ関数の重要なポイントは、どんな長さの入力でも、決まった長さの出力に変換することです。
1文字の文字列でも、1GBのファイルでも、ハッシュ値の長さは同じになります。
プログラミングの世界では、次のような場面で利用されています。
- パスワードの保存
- ファイルが改ざんされていないかのチェック
- データベースやハッシュテーブルでの高速な検索
- ブロックチェーンなどのセキュリティ分野
ハッシュ値とは何か
ハッシュ値(hash value)とは、ハッシュ関数の出力として得られる値のことです。
元のデータを「要約」した指紋のようなものと考えるとイメージしやすくなります。
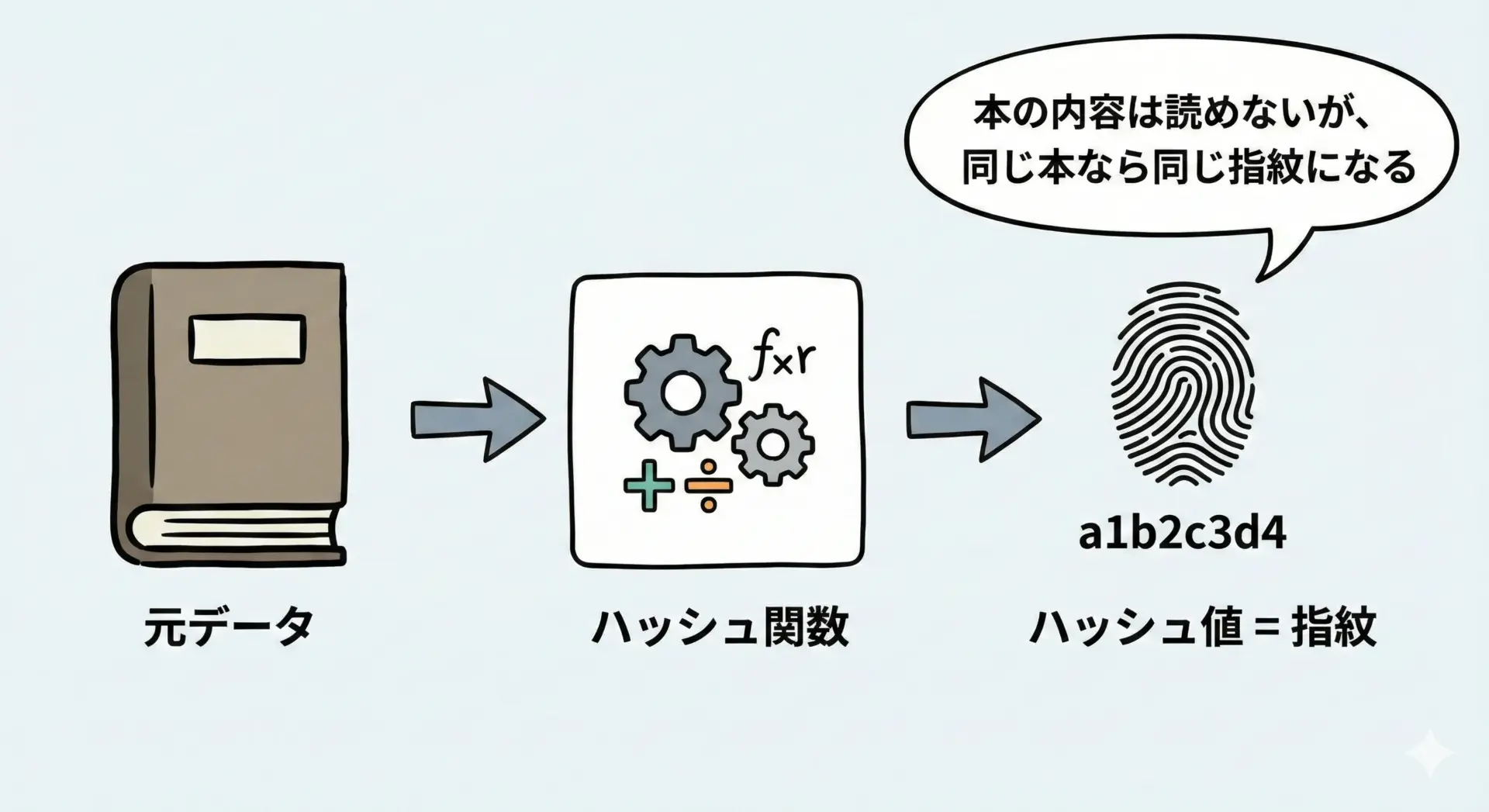
たとえば、同じ文字列をハッシュ関数に通すと、必ず同じハッシュ値が得られます。
これは、通常の関数と同じく「同じ入力からは同じ出力が得られる」という性質によるものです。
一方で、ハッシュ値から元のデータを復元することは、基本的に現実的ではありません。
この点が、暗号目的で使われるハッシュ関数の核心となる性質です。
ハッシュ関数と通常の関数の違い
数学やプログラミングで扱う「関数」と、ハッシュ関数はどこが違うのでしょうか。
両方とも「入力に対して出力を返す」という点は同じですが、セキュリティ目的で使われるハッシュ関数には特有の性質があります。
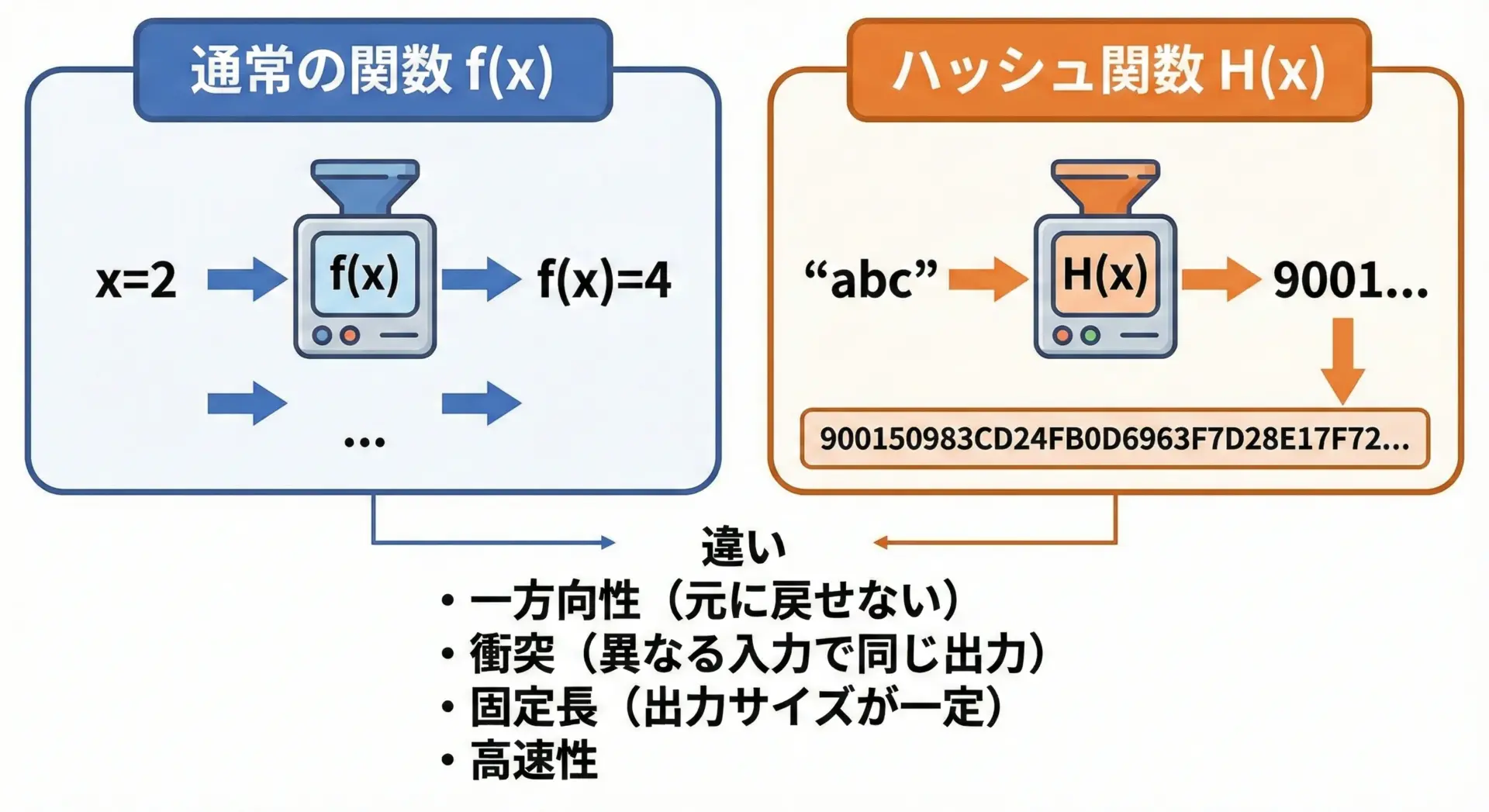
主な違いを整理すると、次のようになります。
- 通常の関数は、逆関数を持つこともあるが、ハッシュ関数は基本的に逆関数を計算できない設計になっている
- 通常の関数は数学的な性質(連続性など)が重要になることがありますが、ハッシュ関数は「予測不可能さ」「一方向性」など、セキュリティ的な性質が重視される
- ハッシュ関数は、出力の長さが固定であることが多く、入力の長さとは無関係
このように、ハッシュ関数は「ただの関数」というよりも、セキュリティ仕様を満たすように設計された特殊な関数だと捉えると理解しやすくなります。
ハッシュ関数の特徴と性質
一方向性(元のデータに戻せない)とは
ハッシュ関数の代表的な性質が一方向性(one-way)です。
これは、入力からハッシュ値を計算するのは簡単だが、その逆(ハッシュ値から入力を特定する)は非常に難しいという意味です。
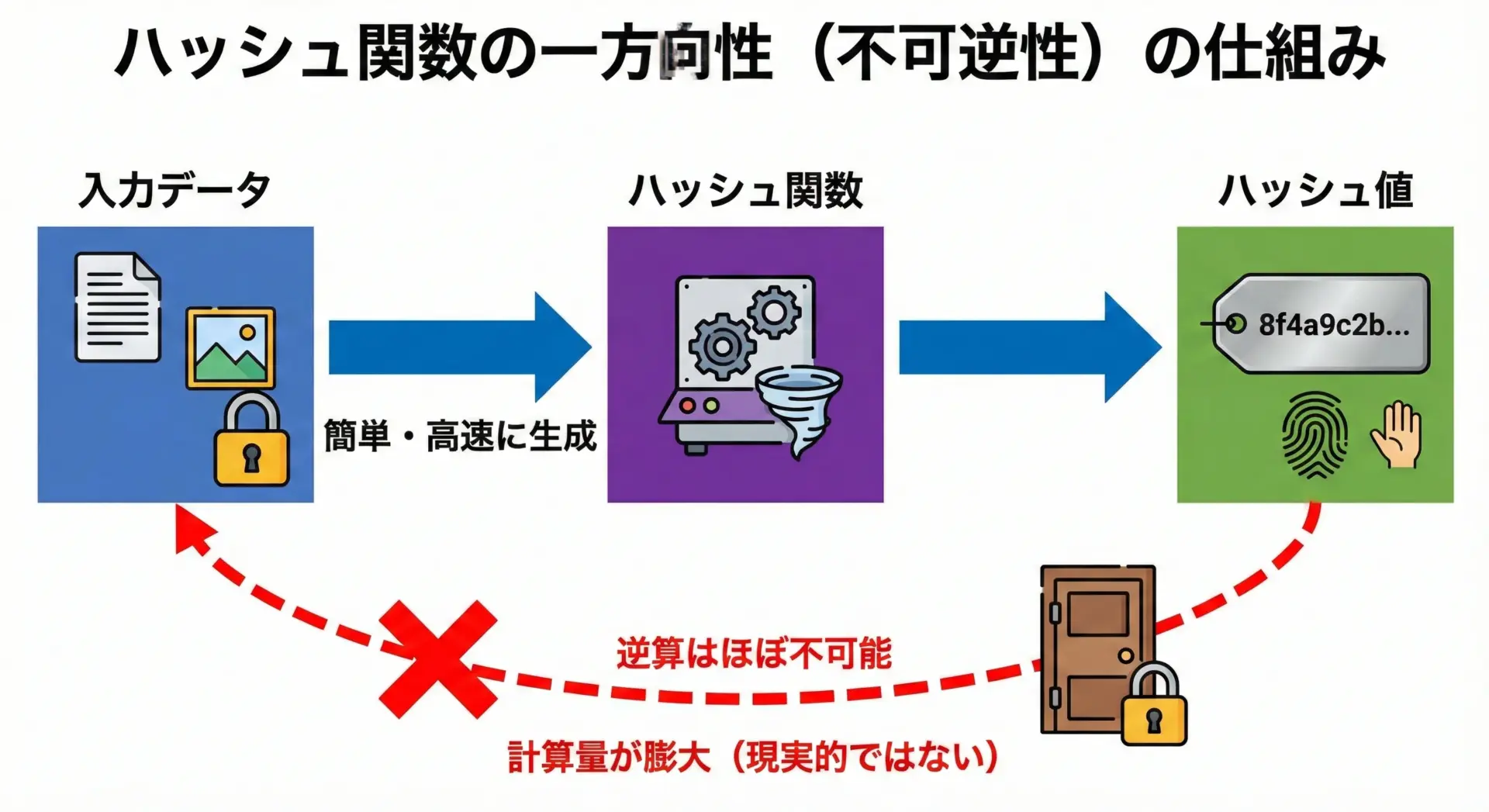
例えば、あるパスワード"password123"のハッシュ値が"abcdef..."だったとします。
この"abcdef..."だけを見て、元の文字列が “password123” だと逆算することは想定上できません。
実際には、総当たり攻撃(ブルートフォース)などで推測を試みるしかありませんが、十分に長く複雑なパスワードであれば、現実的な時間内に割り出すことは困難になります。
衝突とは何かとそのリスク
衝突(collision)とは、異なる2つの入力から同じハッシュ値が得られてしまう現象のことです。
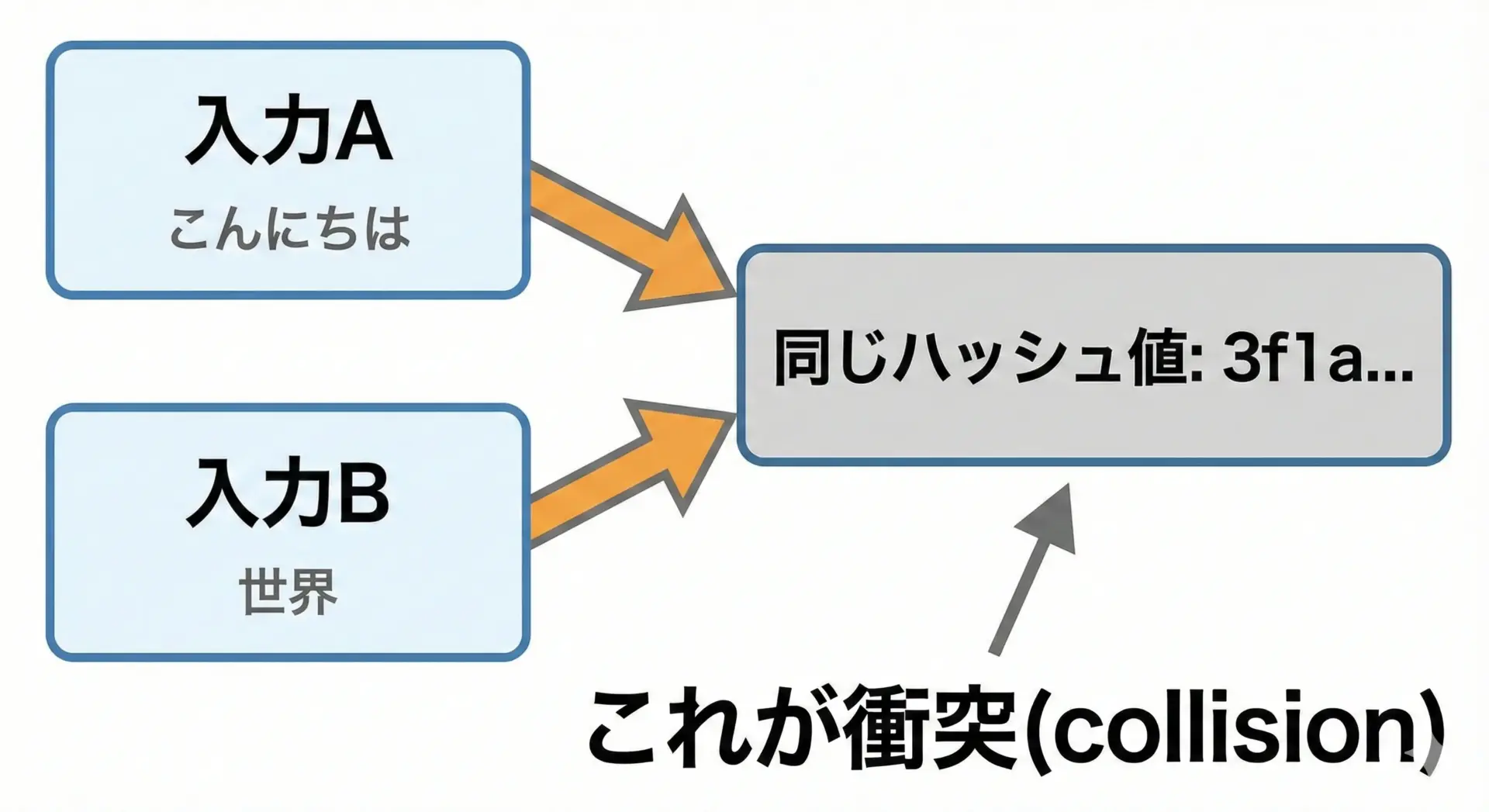
ハッシュ関数の出力は固定長で、取りうる値のパターンは有限です。
一方で、入力データのパターンは無限に近いため、理論的には必ず衝突が存在します。
問題は、その衝突がどれだけ「見つけにくいか」です。
- 衝突が見つけやすいハッシュ関数
→ 悪意ある人が、同じハッシュ値を持つ別データを作成し、改ざんや偽造に悪用できるリスクが高い - 衝突が見つけにくいハッシュ関数
→ 実用上、安全に使いやすい
古いハッシュ関数であるMD5やSHA-1は、衝突が現実的な計算量で見つけられることが判明しており、セキュリティ用途には推奨されていません。
わずかな変更で大きく変わる性質
ハッシュ関数には、入力データをほんの少し変えただけでも、ハッシュ値がまったく別物のように変わるという性質があります。
これはアバランシェ効果(avalanche effect)と呼ばれます。
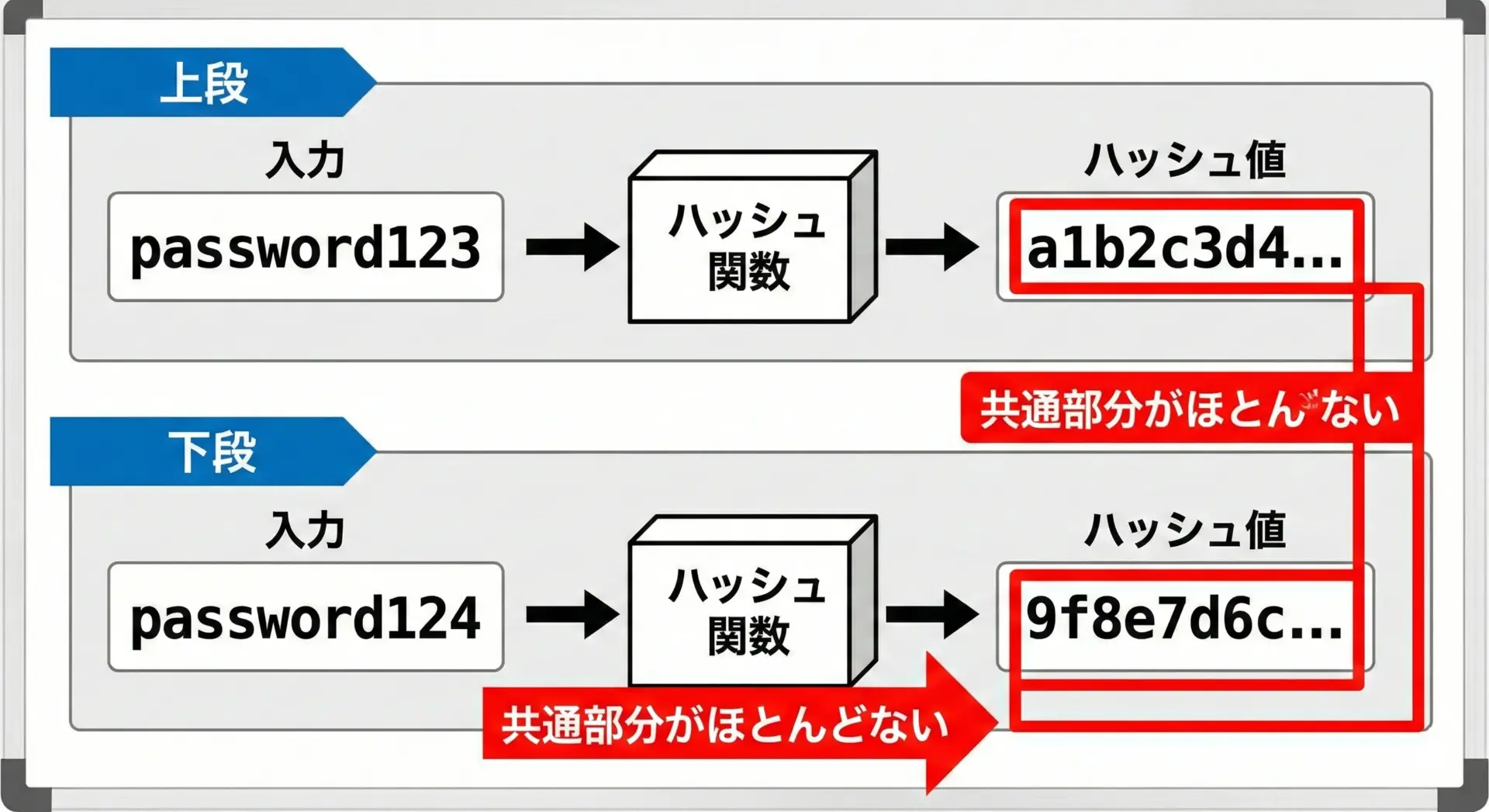
人間の感覚では、password123とpassword124は1文字しか違わないので「似たような値」になりそうですが、ハッシュ関数ではそうはなりません。
入力の1ビットの違いが、出力の多くのビットを変化させるように設計されています。
この性質により、次のようなメリットがあります。
- 少しの改ざんでも、ハッシュ値が大きく変わるため、改ざん検知に使いやすい
- ハッシュ値から、元のデータの「傾向」や「類似度」を推測しにくい
出力長が一定である理由
ハッシュ関数の出力が一定の長さであることには、いくつかの実用的な理由があります。
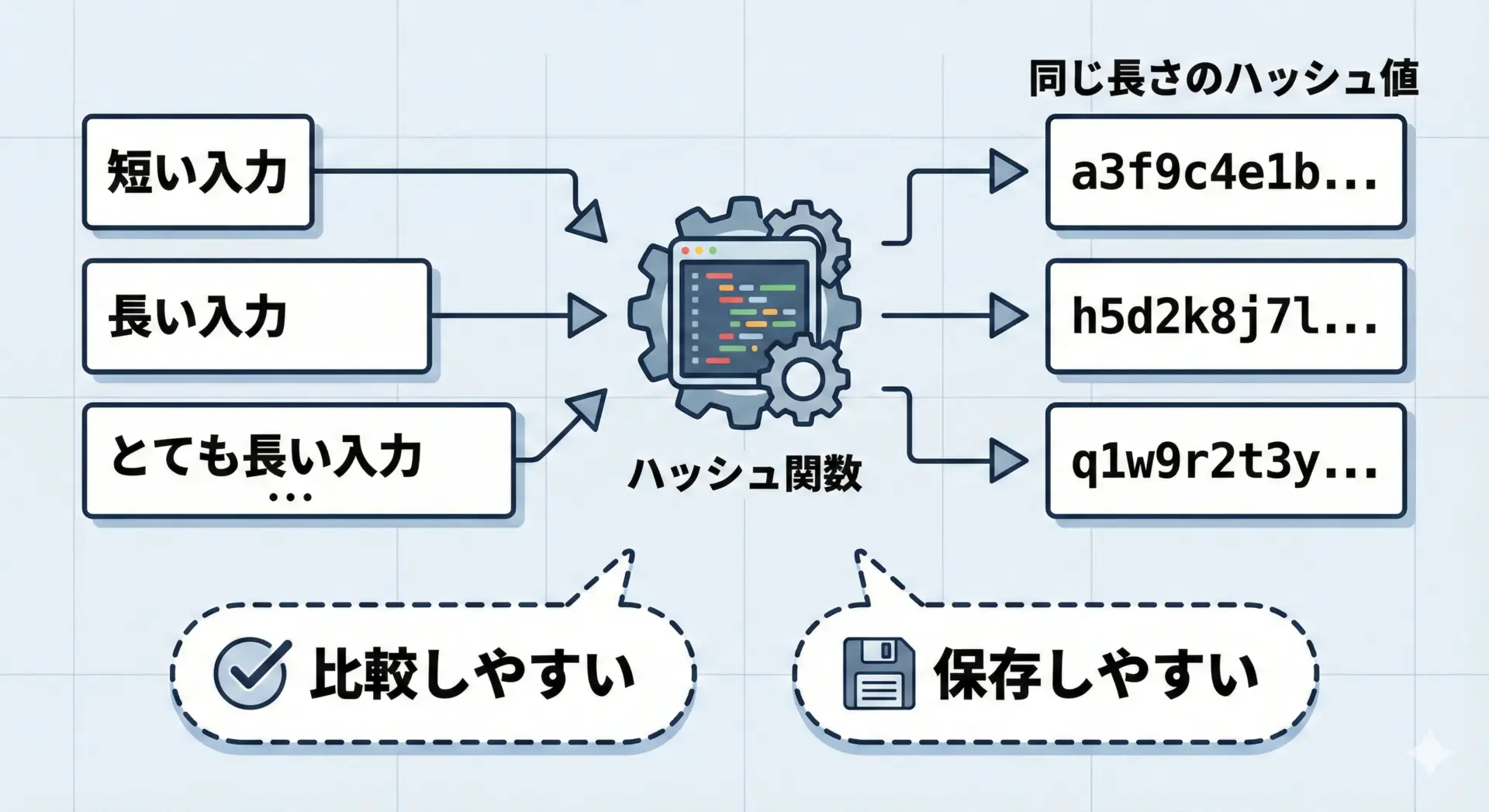
主な理由としては、次のような点が挙げられます。
- データベースに保存する際、列の長さを固定できるため扱いやすい
- ファイルの整合性チェックなどで、長さが決まっている方が比較が簡単
- 暗号設計の観点から、出力空間をコントロールしやすい
ハッシュ関数SHA-256であれば、常に256ビット(=32バイト)の出力、16進数表記にすると64文字の長さになります。
入力が1文字でも1GBでも、この長さは変わりません。
パスワード保存にハッシュ関数が使われる理由
なぜパスワードをそのまま保存してはいけないのか
Webサービスの開発では、ユーザーのパスワードを決して平文(そのままの文字列)で保存してはいけません。
理由は明確で、もしデータベースが流出した場合、すべてのユーザーのパスワードが一瞬でバレてしまうからです。

多くのユーザーは、複数のサービスで同じパスワードを使い回しているため、1つのサービスから流出すると、他のサービスのアカウントも乗っ取られる可能性があります。
そのため、開発者側には、「パスワードを直接知らなくても認証できる仕組み」を作る責任があります。
ハッシュ化して保存する仕組み
そこで登場するのがパスワードのハッシュ化です。
サービス側は、ユーザーが登録したパスワードをそのまま保存するのではなく、ハッシュ値だけを保存します。
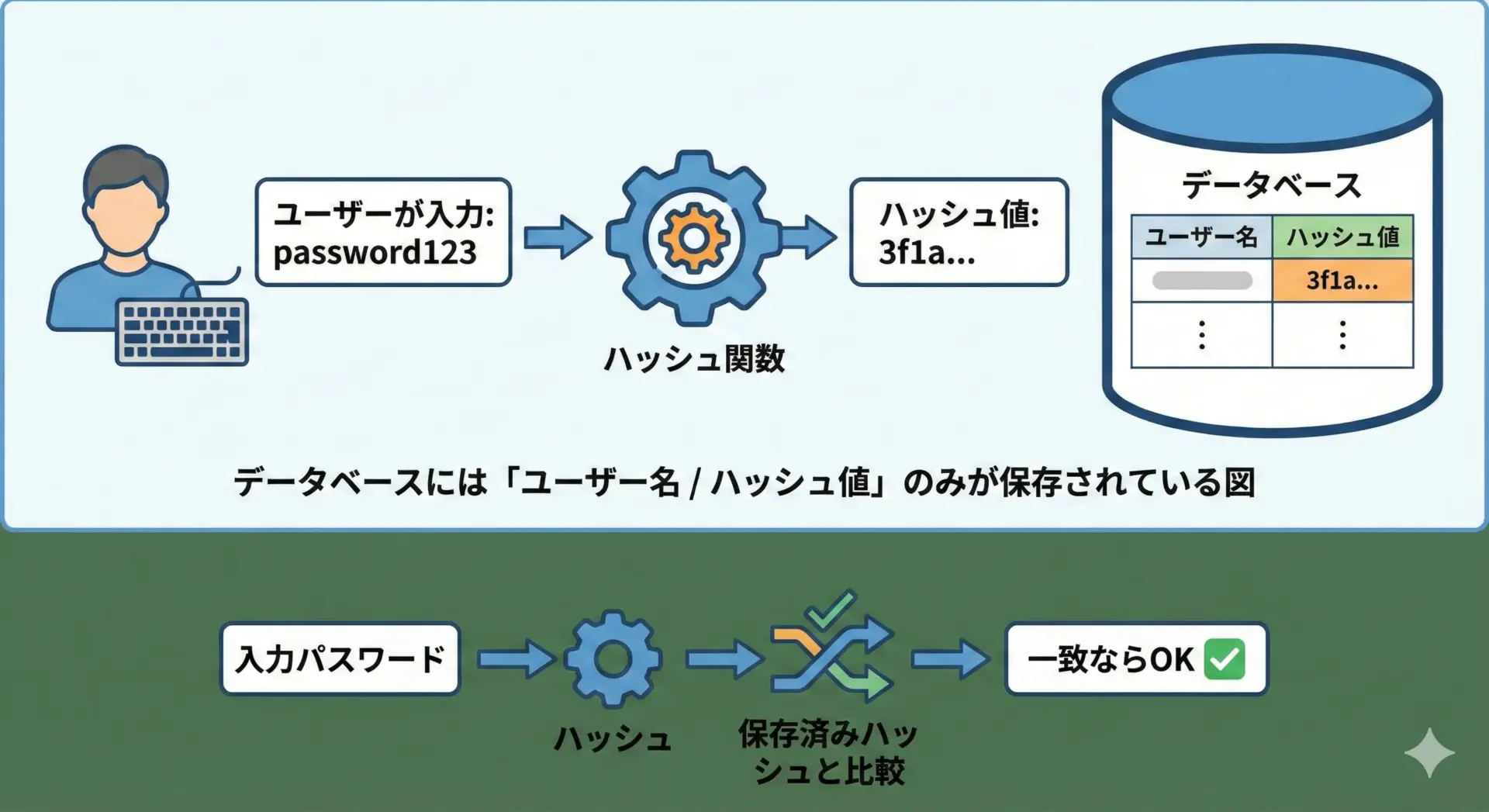
ログインの流れは次のようになります。
- ユーザーがパスワードを入力する
- サーバー側で、そのパスワードにハッシュ関数を適用する
- データベースに保存してあるハッシュ値と比較する
- 一致していれば、正しいパスワードだと判断する
この仕組みの重要な点は、サーバー側も「元のパスワード」は知らなくてよいということです。
仮にデータベースが流出しても、攻撃者が手に入れられるのはハッシュ値だけとなり、パスワードがそのまま盗まれる危険性を大きく減らせます。
ソルト(salt)とは何かとその役割
ただし、password123のようなパスワードは、多くのユーザーが使いがちです。
同じパスワードは同じハッシュ値になるため、「このハッシュ値は password123 に違いない」と推測されてしまう危険があります。
ここで登場するのがソルト(salt)です。
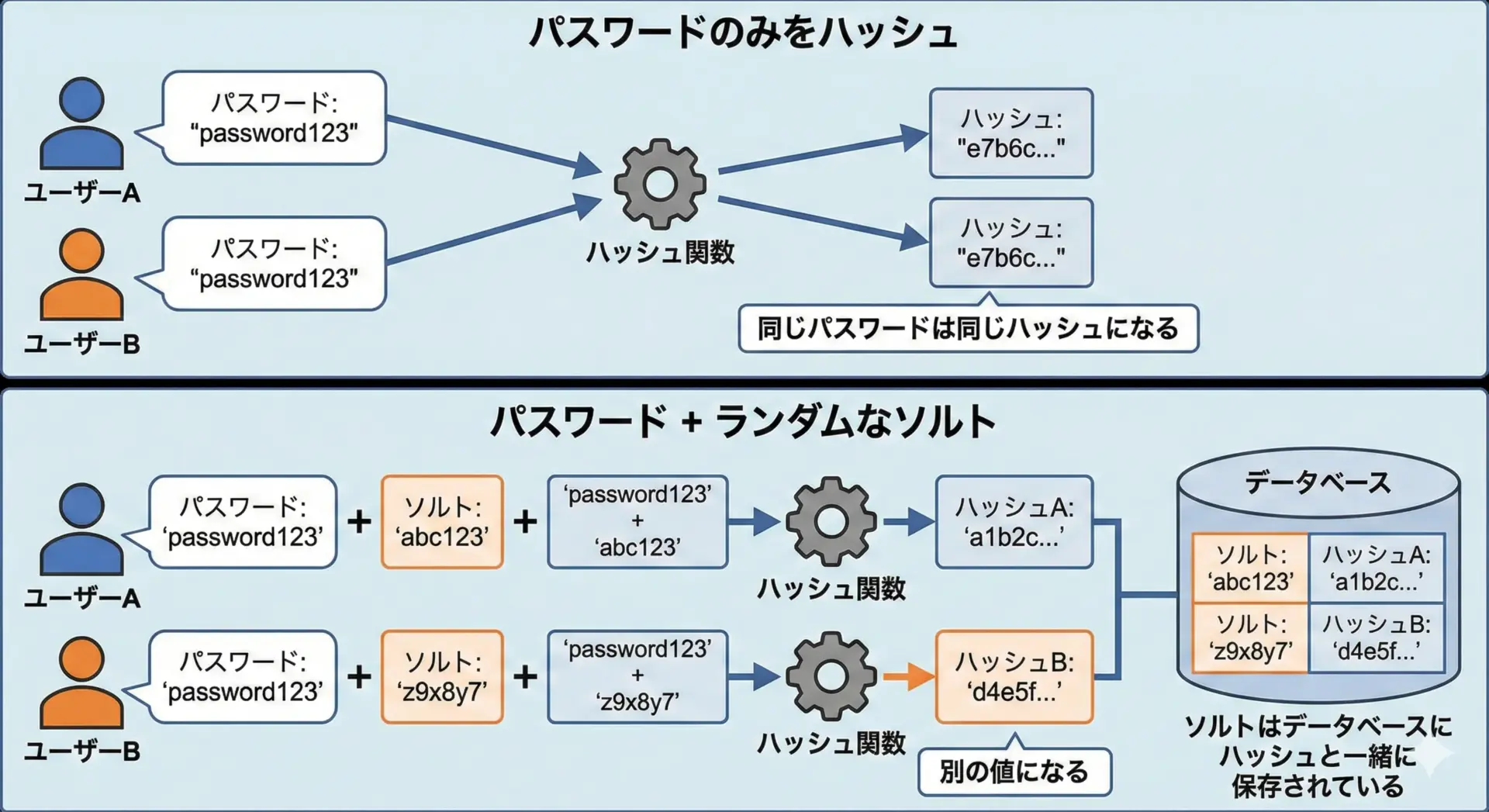
ソルトとは、各ユーザーごとにランダムに生成される追加データで、パスワードと一緒にハッシュ関数へ入力します。
- 保存されるのは、ソルトとハッシュ値
- ログイン時には、そのユーザーのソルトを取り出して、入力されたパスワードと組み合わせてハッシュを計算し、保存済みのハッシュと比較する
これにより、同じパスワードを使っていても、ユーザーごとにハッシュ値が異なるようになります。
結果として、後述するレインボーテーブル攻撃などの効率的な攻撃を困難にできます。
レインボーテーブル攻撃とその対策
レインボーテーブル攻撃とは、よく使われそうなパスワードと、そのハッシュ値をあらかじめ大量に計算・保存しておき、攻撃時に照合する手法です。
総当たり攻撃を事前に準備しておくイメージです。
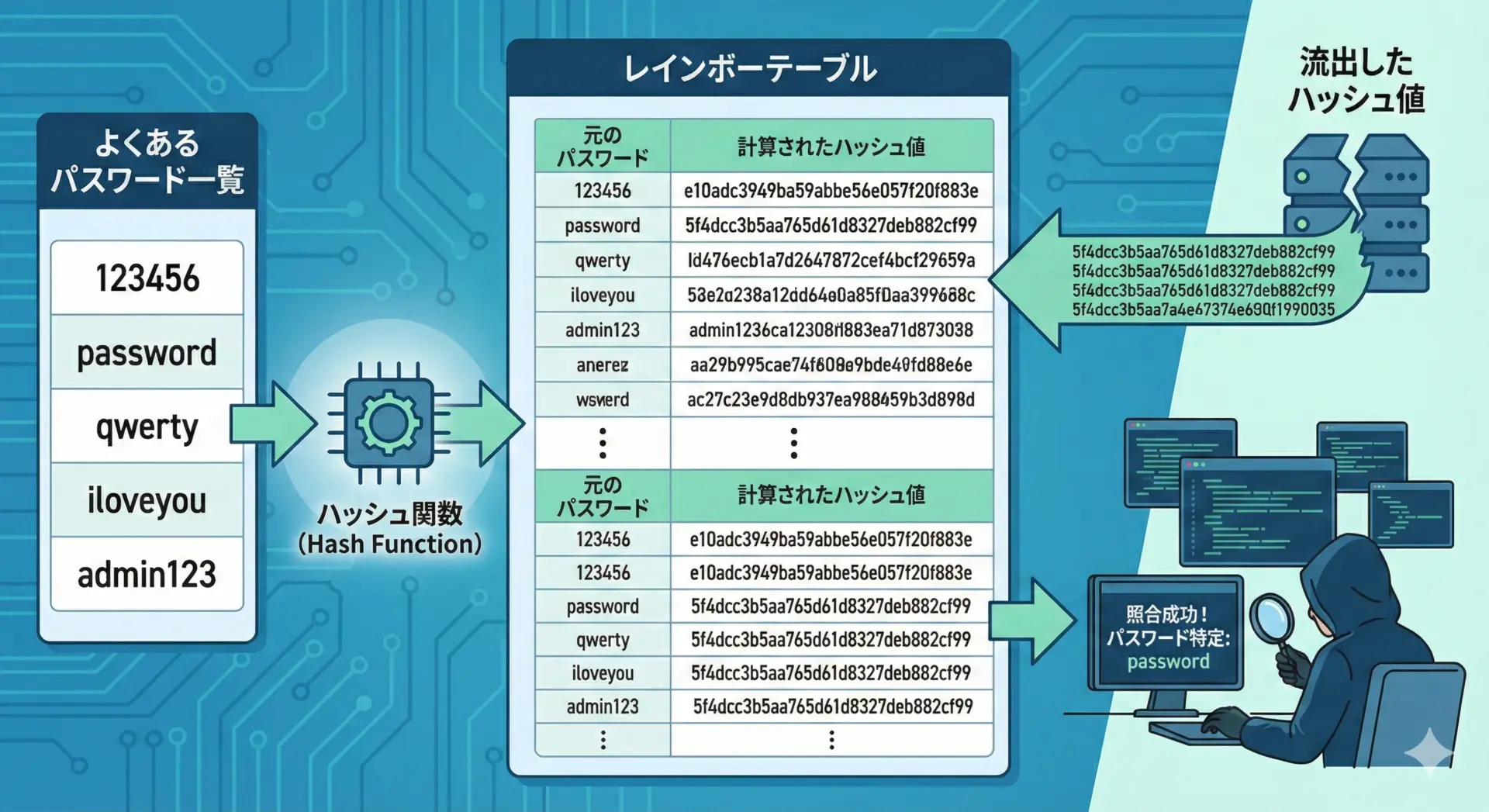
ソルトを使わず、単純にSHA-256などでハッシュ化しただけのパスワードは、レインボーテーブルで一気に解析されてしまう可能性があります。
対策としては、次のような方法があります。
- ソルトを必ず利用する
→ ユーザーごとに異なるソルトが付くため、事前計算したテーブルが使えなくなる - 専用のパスワードハッシュ関数を使う
→ 後述するbcryptやArgon2は、計算コストが高く設計されており、大量の事前計算がしづらい
実際に使われるハッシュ関数
ハッシュ関数にはさまざまな種類がありますが、用途によって適切な関数は変わります。
特に「パスワード保存」に使う場合は要注意です。

例として、代表的なハッシュ関数を整理します。
| 関数名 | 主な用途 | パスワード保存への適性 |
|---|---|---|
| MD5 | 古いチェックサム用途など | × (危険) |
| SHA-1 | 古いシステムとの互換程度 | × (危険) |
| SHA-256 | データの整合性チェックなど | △ (単体では不十分) |
| SHA-3 | 新しい標準ハッシュ | △ (単体では不十分) |
| bcrypt | パスワードハッシュ専用 | ◎ |
| scrypt | パスワードハッシュ専用 | ◎ |
| Argon2 | パスワードハッシュ専用(最新系) | ◎ |
MD5やSHA-1は衝突が見つかっており、セキュリティ用途には使うべきではありません。
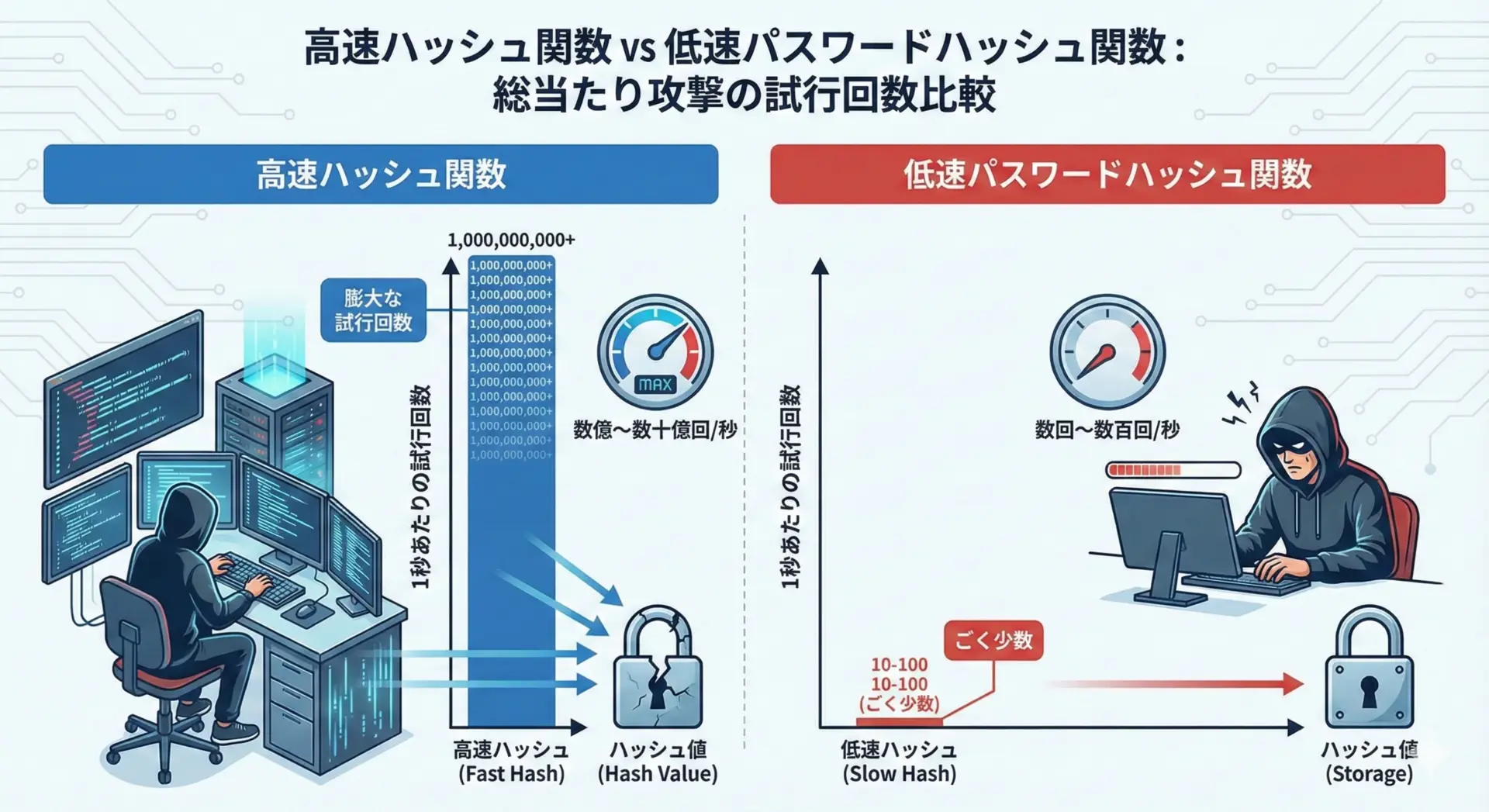
また、SHA-256のような高速なハッシュ関数も、パスワード保存に「そのまま」使うのは危険です。
パスワード保存には、計算コストをわざと重くした専用の関数を使うのが基本です。
プログラミングで学ぶハッシュ関数の使い方
まずは文字列をハッシュ化してみる
ここでは例として、Pythonを使ってSHA-256で文字列をハッシュ化する簡単なコードを見てみます。
import hashlib
text = "password123"
# バイト列にエンコードしてからハッシュを計算
hash_bytes = hashlib.sha256(text.encode("utf-8")).digest()
# 16進数文字列に変換
hash_hex = hashlib.sha256(text.encode("utf-8")).hexdigest()
print("元の文字列:", text)
print("ハッシュ値(バイト列):", hash_bytes)
print("ハッシュ値(16進数):", hash_hex)このコードでは、同じ文字列からは、いつ実行しても同じハッシュ値が得られます。
別の文字列に変えると、ハッシュ値が大きく変化することも確認できます。

このような実験を通じて、「同じ入力なら同じハッシュ」「少し変えると大きく変わる」という性質を体感しながら理解することができます。
ハッシュ関数のよくある誤用例
ハッシュ関数は便利ですが、使い方を間違えると簡単に破られることがあります。
代表的な誤用例をいくつか挙げます。
- MD5やSHA-1をパスワード保存に使う
これらは既に安全ではなく、高速すぎて総当たり攻撃に弱いため、パスワードには不適切です。 - ソルトなしで SHA-256 などを使う
ソルトを使わないと、同じパスワードは同じハッシュになり、レインボーテーブル攻撃や使い回しの検出が容易になります。 - 自作の「暗号アルゴリズム」や「独自ハッシュ」を使う
セキュリティ分野では、自作アルゴリズムはほぼ確実に脆弱とみなされます。広く検証された標準的なアルゴリズムを使うことが鉄則です。
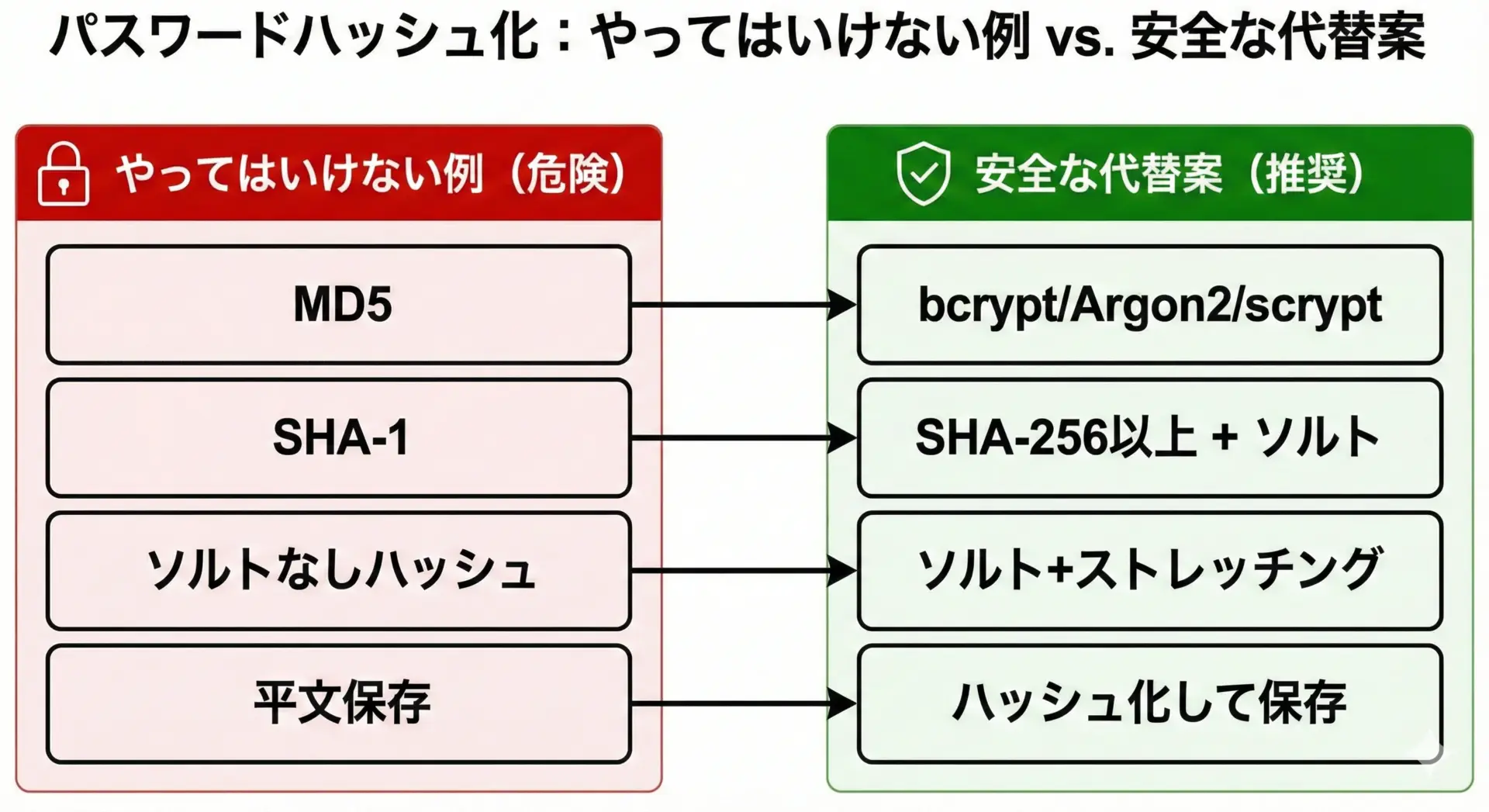
開発時には、「速くハッシュできること」ではなく「攻撃者にとって遅くなること」を重視する必要があります。
パスワード保存に適した関数(bcryptやArgon2)を選ぶポイント
パスワード保存専用のハッシュ関数として、現在よく使われているのがbcryptやArgon2です。
これらは、一般的なハッシュ関数とは異なる性質を持っています。
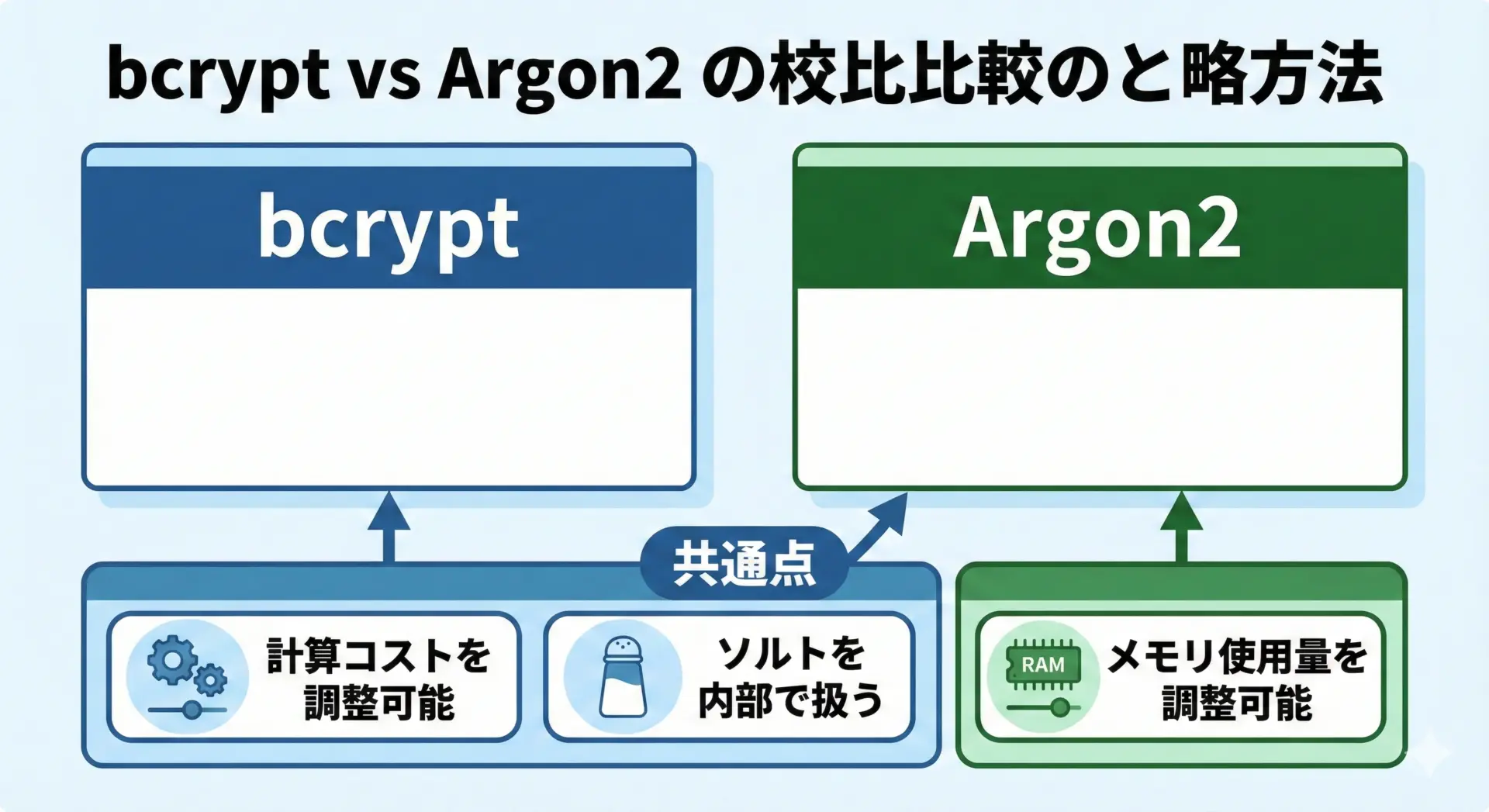
選ぶ際に意識したいポイントは次の通りです。
- 計算コスト(ストレッチング)を調整できること
bcrypt や Argon2 では、「コスト」や「ラウンド数」を設定して、ハッシュ計算をわざと重くできます。これにより、攻撃者が1秒間に試せるパスワード候補の数を大幅に減らせます。 - ソルトを自動で扱ってくれること
多くのライブラリでは、ソルトを自動生成・保存してくれるため、実装ミスのリスクを減らせます。 - 実績と標準化
- bcrypt: 長年使われており、実績が豊富
- Argon2: パスワードハッシュコンペティションで選ばれた比較的新しい方式で、メモリ量も調整でき、GPUによる攻撃にも強く設計されています。
簡単なイメージとして、「パスワードハッシュ関数は、意図的に重いロックをかける仕組み」だと捉えるとよいでしょう。
ユーザーが1回ログインする分には少し遅くても問題ありませんが、攻撃者が何億回も試すのは現実的でなくなります。
まとめ
ハッシュ関数は、一見するとただの「データを変換する関数」に見えますが、一方向性・衝突耐性・アバランシェ効果・固定長出力といった性質を備えた、非常に重要な基盤技術です。
特に、パスワードを安全に保存する仕組みにおいて、その役割は欠かせません。
本記事では、以下のポイントを中心に解説しました。
- ハッシュ関数は、入力を一定長のハッシュ値に変換する「データの指紋生成器」のようなものであること
- 一方向性やアバランシェ効果などの性質により、元データの推測や改ざん検知が難しくなること
- パスワードは決して平文で保存せず、ソルト付きのハッシュとして保存するべきであること
- レインボーテーブル攻撃などに対抗するには、ソルトと専用のパスワードハッシュ関数(bcryptやArgon2など)が重要であること
- MD5やSHA-1など古いハッシュ関数や、高速ハッシュの素朴な利用は避けるべきであること
今後、実際の開発でユーザー認証やセキュリティを扱う際には、「なぜハッシュ関数を使うのか」「どのハッシュ関数を、どのように使うべきか」を意識することが大切です。
本記事をきっかけに、パスワードハッシュのライブラリやセキュリティのベストプラクティスも、ぜひ一歩踏み込んで学んでみてください。
