コンピュータの世界では、数値はそのままの形ではなく、0と1の列としてメモリに保存されています。
このとき、複数バイトからなる数値を「どちら側から並べるか」を決めるルールがエンディアンです。
普段のプログラミングではあまり意識しないことも多いですが、ネットワーク通信やバイナリファイル処理では避けて通れない重要な概念です。
本記事では、リトルエンディアンとビッグエンディアンの違いを、図解と具体例を交えながら丁寧に解説します。
エンディアンとは?
エンディアン(Endian)の意味と由来
エンディアン(Endian)とは、複数バイトで表現されるデータ(整数など)をメモリ上に格納するときのバイトの並び順(バイトオーダー)のことを指します。
例えば、32ビット整数は4バイトで表現されますが、その4バイトをメモリ上でどの順番に並べるかのルールがエンディアンです。
エンディアンという名称は、ジョナサン・スウィフトの小説「ガリバー旅行記」に登場するBig-endianとLittle-endianという言葉に由来します。
作中では「ゆで卵のどちらの端から割るべきか」で争う人々が描かれており、コンピュータの世界でも「データをどちら側から並べるか」という対立に例えられたことから、この名称が使われるようになりました。
一般に、エンディアンには次の2種類があります。
- リトルエンディアン(Little Endian)
- ビッグエンディアン(Big Endian)
この2つの違いを理解することが、エンディアン入門の第一歩になります。
リトルエンディアンとビッグエンディアンの違い
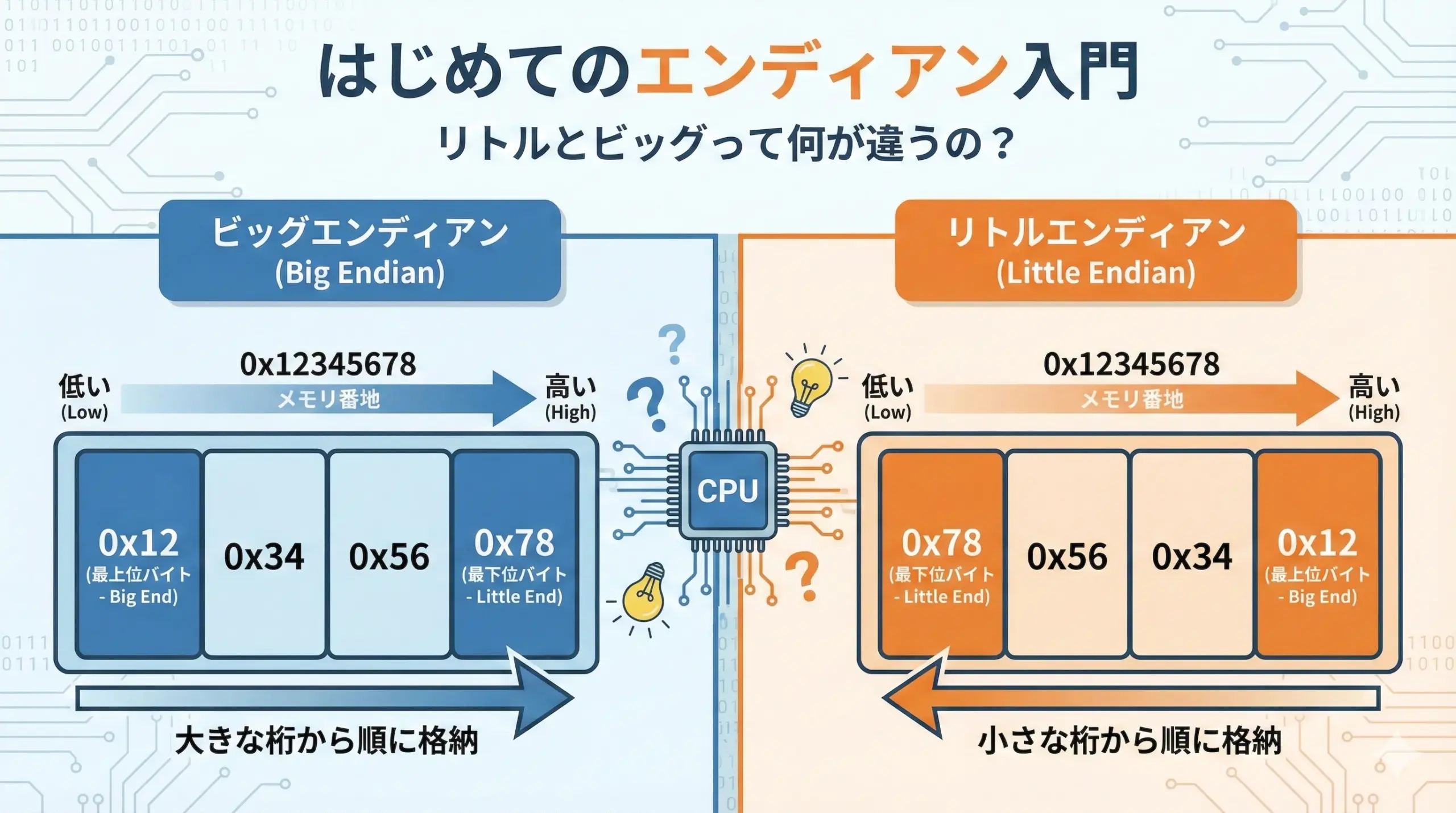
リトルエンディアンとビッグエンディアンの違いは、とてもシンプルに言えば「最下位バイト(小さい桁)を先に並べるか、最上位バイト(大きい桁)を先に並べるか」の違いです。
- リトルエンディアン: 小さい方のバイト(Least Significant Byte: LSB)を先頭に置く
- ビッグエンディアン: 大きい方のバイト(Most Significant Byte: MSB)を先頭に置く

この図のように、同じ値0x12345678であっても、メモリ上にどの順番で並ぶかがエンディアンによって変わります。
ただし、どちらのエンディアンであっても、CPU側から見れば「数値としての意味」は同じであり、異なるのはあくまでメモリ上の表現方法だけです。
バイト列とメモリの並び順をイメージする
エンディアンを理解するうえで重要なのは、「メモリアドレスが小さい側からデータが並ぶ」というイメージを持つことです。
メモリには連続したアドレスがあり、例えば4バイトの整数なら、あるアドレスAからA+3までを使って保存します。

このような図を頭の中でイメージできるようになると、「どのバイトがどのアドレスに入るのか」が直感的に理解しやすくなります。
エンディアンの違いは、数値の桁の大きさとメモリアドレスの大小の対応関係、と考えると整理しやすいです。
リトルエンディアンの仕組みと特徴
リトルエンディアンとは
リトルエンディアン(Little Endian)は、最下位バイト(最も小さい桁のバイト)をメモリの最も低いアドレスに格納する方式です。
つまり、数値の「末尾のバイト」から順番に、メモリ上の小さいアドレスに配置されていきます。
論理的なバイト列が[0x12, 0x34, 0x56, 0x78]であっても、リトルエンディアンではメモリ上では[0x78, 0x56, 0x34, 0x12]という並びになります。
この順番は一見わかりづらいように感じますが、CPU内部での計算と相性が良い面があります。
具体例で見るリトルエンディアンのメモリ配置
4バイトの符号なし整数0x12345678を、アドレス0x1000から格納するリトルエンディアンの例を見てみましょう。

このように、メモリ上では見た目が「逆順」になっていますが、CPUが4バイトまとめて読み取ると、正しい数値として扱われます。
重要なのは、「どのエンディアンで保存されているかさえ分かっていれば、正しく解釈できる」という点です。
リトルエンディアンが主流になっている理由
現在のPCやサーバで広く使われているx86やx86_64アーキテクチャは、基本的にリトルエンディアンです。
リトルエンディアンが主流になっている理由として、よく挙げられるポイントは次のようなものです。
1つ目は、下位バイトへのアクセスがしやすいという点です。
例えば、32ビット整数の下位8ビットだけを使いたい場合、リトルエンディアンでは「先頭の1バイト」だけを見ればよく、アドレス計算が単純になります。
CPUの内部実装やコンパイラの最適化において、この性質が有利になることがあります。
2つ目は、歴史的・市場的な広がりです。
インテル系CPUがリトルエンディアンを採用し、そのアーキテクチャがPC市場を席巻したことで、OSやコンパイラ、ツールチェーンなどもリトルエンディアン前提で発展してきました。
この結果、「リトルエンディアンがデファクトスタンダード」のような状況が生まれました。
3つ目に、算術演算ユニット内部の設計と相性が良い、という指摘もあります。
加算や乗算の処理では、下位ビットから計算を進めて繰り上がりを伝播させていくため、下位バイトを低アドレス側に置く方が実装しやすい、という見方もあります。
Windowsやx86(CPU)がリトルエンディアンである意味
Windowsを含む多くのデスクトップOSは、x86系CPUを前提として発展してきました。
そのため、Windows環境では「リトルエンディアンであること」が事実上の前提になっている場面が多くあります。
例えば、次のような状況です。
- C/C++で構造体をそのまま
write()してバイナリファイルに保存する - Windows固有のバイナリ形式(PE形式、DLL、EXEなど)を扱う
- Windows APIでバイト列を渡したり受け取ったりする
これらは、内部的には「リトルエンディアンである」ことに依存して設計されています。
そのため、同じコードを異なるエンディアンの環境(一部の組み込みCPUや古いRISC系CPUなど)に移植するときには、エンディアン依存の処理がないかを確認する必要があります。
一方で、.NETやJava、Pythonなどの高水準ランタイム環境では、エンディアンをある程度抽象化し、開発者が直接エンディアンを意識しなくても済むAPIを提供していることも多いです。
ビッグエンディアンの仕組みと特徴
ビッグエンディアンとは
ビッグエンディアン(Big Endian)は、最上位バイト(最も大きい桁のバイト)をメモリの最も低いアドレスに格納する方式です。
つまり、人間が16進数で数値を書くときの並びと、メモリ上の「低アドレスから高アドレスへの並び」が一致します。
論理的なバイト列が[0x12, 0x34, 0x56, 0x78]であれば、そのまま[0x12, 0x34, 0x56, 0x78]の順でアドレスが増えていきます。
そのため、人間にとって直感的に理解しやすいという特徴があります。
具体例で見るビッグエンディアンのメモリ配置
先ほどと同じく、4バイトの符号なし整数0x12345678をアドレス0x1000から格納する場合のビッグエンディアンを見てみます。

このように、ビッグエンディアンでは「左から右に読むと、そのまま数値の16進表現になる」というわかりやすさがあります。
メモリダンプを目視で確認するときなどには、ビッグエンディアンの方が楽に感じられることも多いです。
ネットワークバイトオーダーとビッグエンディアン
ネットワークの世界では、ネットワークバイトオーダー(Network Byte Order)という用語が使われます。
これは、「ネットワークでデータをやり取りするときに採用する標準的なバイトオーダー」のことを意味します。
重要なのは、ネットワークバイトオーダー = ビッグエンディアンである、という点です。
TCP/IPなどのインターネットプロトコル群では、プロトコル仕様書(RFC)において「マルチバイト整数はネットワークバイトオーダー(=ビッグエンディアン)で送受信する」と定められています。
その理由には、次のような背景があります。
- 初期のインターネット(ARPANET)で使われていたマシンの多くがビッグエンディアンだった
- 人間が読むプロトコル仕様書のビットフィールド図と、実際のバイト列の対応を直感的にしたかった
- 異なるエンディアンのマシン同士で通信する際に、共通の規約を設ける必要があった
結果として、「ネットワークではビッグエンディアンが標準」という文化が定着し、現在でも変わらず使われ続けています。
組み込み機器や通信プロトコルで使われる理由
ビッグエンディアンは、組み込み機器や各種通信プロトコルでも広く使われています。
理由はいくつかあります。
1つは、プロトコル仕様書を作る立場から見て、ビッグエンディアンの方がビット・バイト列を図で説明しやすいことです。
上位ビットから順番に左から右に並べていく図と、実際のバイト列が素直に対応するため、誤解や実装ミスを減らしやすくなります。
もう1つは、マイコンや専用プロセッサのアーキテクチャ選択の歴史です。
かつてはモトローラ系(68kなど)など、ビッグエンディアンを採用するCPUが組み込み分野で広く使われていました。
その名残として、今でもビッグエンディアン前提のプロトコルやデータフォーマットが残っています。
さらに、通信チップやセンサなどのハードウェア仕様書でも、「送信するデータはビッグエンディアンで」と明記されていることがあります。
この場合、リトルエンディアンのCPU側では「受信したバイト列を自分のエンディアンに変換する」処理が必要になります。
プログラミングでのエンディアン実践
自分の環境のエンディアンを確認する方法
プログラマとして実務でエンディアンを扱う際には、まず「自分が使っている環境がリトルエンディアンかビッグエンディアンか」を知っておくことが重要です。
多くのPC環境(x86/x86_64)はリトルエンディアンですが、組み込み機器や一部の特殊なCPUではビッグエンディアンのこともあります。
C言語でエンディアンを確認する簡単な方法の一例を示します。
#include <stdio.h>
#include <stdint.h>
int main(void) {
uint32_t x = 0x12345678;
unsigned char *p = (unsigned char *)&x;
printf("0x%02x 0x%02x 0x%02x 0x%02x\n",
p[0], p[1], p[2], p[3]);
return 0;
}このプログラムを実行して、出力が78 56 34 12であればリトルエンディアン、12 34 56 78であればビッグエンディアンです。
つまり、「先頭のバイトがLSBかMSBか」を確認すればよいことになります。
Pythonでも、sysモジュールを使ってエンディアンを確認できます。
import sys
print(sys.byteorder) # 'little' または 'big'高水準言語では、このように標準ライブラリでエンディアン情報を取得できることが多いため、積極的に活用するとよいでしょう。
エンディアン変換(バイトオーダー変換)の基本テクニック
異なるエンディアンの間でデータをやり取りするときには、エンディアン変換(バイトオーダー変換)が必要になります。
基本的な考え方は「バイトの順番を逆に並べ替える」ことです。
例えば、32ビット整数のエンディアン変換を行うCの例を示します。
#include <stdint.h>
uint32_t swap32(uint32_t x) {
return ((x & 0x000000FFu) << 24) |
((x & 0x0000FF00u) << 8) |
((x & 0x00FF0000u) >> 8) |
((x & 0xFF000000u) >> 24);
}この関数は、0x11223344を0x44332211に変換します。
つまり、バイト単位で反転しているわけです。
多くの環境では、このような処理を自前で書かなくても、標準ライブラリに専用の関数が用意されています。
Unix系環境では、ネットワークバイトオーダーとの変換用に次の関数がよく使われます。
htons(): host to network (16ビット)htonl(): host to network (32ビット)ntohs(): network to host (16ビット)ntohl(): network to host (32ビット)
ここでhostは「ホストマシンのエンディアン」、networkは「ネットワークバイトオーダー(=ビッグエンディアン)」を意味します。
つまり、どちら側がリトルエンディアンかビッグエンディアンかを意識せずに、変換を任せられる便利なAPIです。
ネットワーク通信でのエンディアン
ネットワーク通信(特にTCP/UDPソケットを直接扱う場合)では、エンディアンの扱いを誤ると、ポート番号や長さ、識別子などの値がすべて異常に見える、といった問題が起きます。

この図のように、アプリケーションは「自分の環境のエンディアン」で数値を扱い、送信時・受信時にだけネットワークバイトオーダーとの間で変換を行います。
これにより、リトルエンディアンのマシンとビッグエンディアンのマシンが混在していても、正しく通信できる仕組みになっています。
バイナリファイル処理でのエンディアン注意点
画像ファイル、音声ファイル、独自フォーマットのデータファイルなど、バイナリファイルを扱うときもエンディアンは非常に重要です。
ファイルフォーマット仕様書には、たいてい「整数値はリトルエンディアンで格納する」「ビッグエンディアンで格納する」といった記述があります。
例えば、次のような場面でエンディアンを意識する必要があります。
- ファイルヘッダ中の「マジックナンバー」「バージョン」「データ長」などの読み書き
- 各レコードのIDやタイムスタンプ、オフセット値の解析
- 他OSや他言語で作成されたバイナリファイルを読み込む場合
エンディアンを誤ると、「長さフィールドが異常な巨大値になる」「レコード数が負数になる」といった奇妙な挙動が発生し、バグの原因になります。
バイナリファイル処理では、次のような方針を取ると安全です。
- ファイル仕様書を読み、どの整数がどのエンディアンかを明確に把握する
- 言語やライブラリが提供する「エンディアン指定付きの読み書きAPI」を使う
- 例: Pythonの
struct.pack()/struct.unpack()の'<'(リトル)や'>'(ビッグ)指定
- 例: Pythonの
- 自前でバイト列を処理する場合も、エンディアン変換用の関数を1か所に集約しておく
このように設計しておけば、将来的に別のエンディアンの環境に移植する際も、変換ロジックの修正を局所化でき、保守性が高まります。
エンディアンを意識すべき場面と、気にしなくてよい場面
最後に、実務として「どの場面でエンディアンを強く意識すべきか」を整理しておきます。
すべてのコードでエンディアンを気にしていると大変なので、メリハリを付けることが大切です。
エンディアンを意識すべき典型的な場面は次の通りです。
- ソケットプログラミングで、TCP/UDPのペイロードを自前で組み立てるとき
- バイナリファイルフォーマット(画像、音声、独自フォーマットなど)を扱うとき
- 組み込み機器やセンサと、SPI/I2C/UARTなどでバイト列をやり取りするとき
- 異なるアーキテクチャ間でメモリダンプや構造体をそのまま共有するとき
- シリアライゼーション/デシリアライゼーションの実装を自作するとき
一方で、多くの場合はエンディアンを意識しなくてもよいのも事実です。
例えば次のようなケースです。
- アプリケーションコードが、整数や浮動小数点を通常の変数として扱っているだけのとき
- DBやJSON、XML、Protobufなど、高水準のデータフォーマットやライブラリがエンディアンを隠蔽しているとき
- 同一アーキテクチャ内だけで完結する処理(メモリ内での計算のみ)のとき
このような場面では、エンディアンはプラットフォームやランタイムがよしなに扱ってくれるので、過度に気にする必要はありません。
重要なのは、「どこから先は自分で責任を持つ必要があるか」を理解しておくことです。
まとめ
本記事では、エンディアンの基本から実務での扱い方までを順を追って解説しました。
エンディアンとは、複数バイトのデータをメモリに並べるときのバイト順序(バイトオーダー)のルールであり、主にリトルエンディアンとビッグエンディアンの2種類があります。
リトルエンディアンは「最下位バイトを低アドレスに置く」方式で、現在のPCやサーバ(x86/x86_64)の主流です。
一方、ビッグエンディアンは「最上位バイトを低アドレスに置く」方式で、人間にとって直感的であり、ネットワークバイトオーダーや多くの通信プロトコルで採用されています。
プログラミングにおいてエンディアンが重要になるのは、ネットワーク通信、バイナリファイル処理、組み込み機器とのデータ交換といった、異なる環境間で生のバイト列をやり取りするときです。
そのような場面では、自分の環境のエンディアンを確認し、適切なエンディアン変換(バイトオーダー変換)を行う必要があります。
逆に、通常のアプリケーション開発では、高水準のAPIやデータフォーマットがエンディアン差を吸収してくれることが多く、常に意識し続ける必要はありません。
大切なのは、「なぜ値が食い違っているのか」「なぜバイナリが読めないのか」を調査するときに、エンディアンという視点を持てることです。
エンディアンを一度しっかり理解しておけば、ネットワークプロトコルの仕様書やバイナリフォーマットのドキュメントが格段に読みやすくなります。
今後、低レイヤの処理や性能チューニングに踏み込む際にも、エンディアンの知識は必ず役に立つはずです。
