プログラミングを続けていると、ある程度のところで「同じようなコードを何度も書いているな」と感じる瞬間がやってきます。
そんなときに威力を発揮するのが高階関数です。
聞き慣れない言葉ですが、考え方さえつかめば、むしろ初心者ほど「もっと早く知りたかった」と感じるテクニックです。
この記事では、難しい用語や数式はできるだけ避けながら、JavaScriptやPythonを例に高階関数がどうコードをラクにしてくれるのかを、メリット重視でかみくだいて紹介していきます。
高階関数とは何かを初心者向けに説明
高階関数は、ひと言でいえば「関数を受け取ったり、関数を返したりする関数」です。
いきなりこれだけ聞くとよく分からないので、まずは前提となる「関数を値として扱う」という考え方から整理していきます。
関数を「値」として扱うとはどういうことか
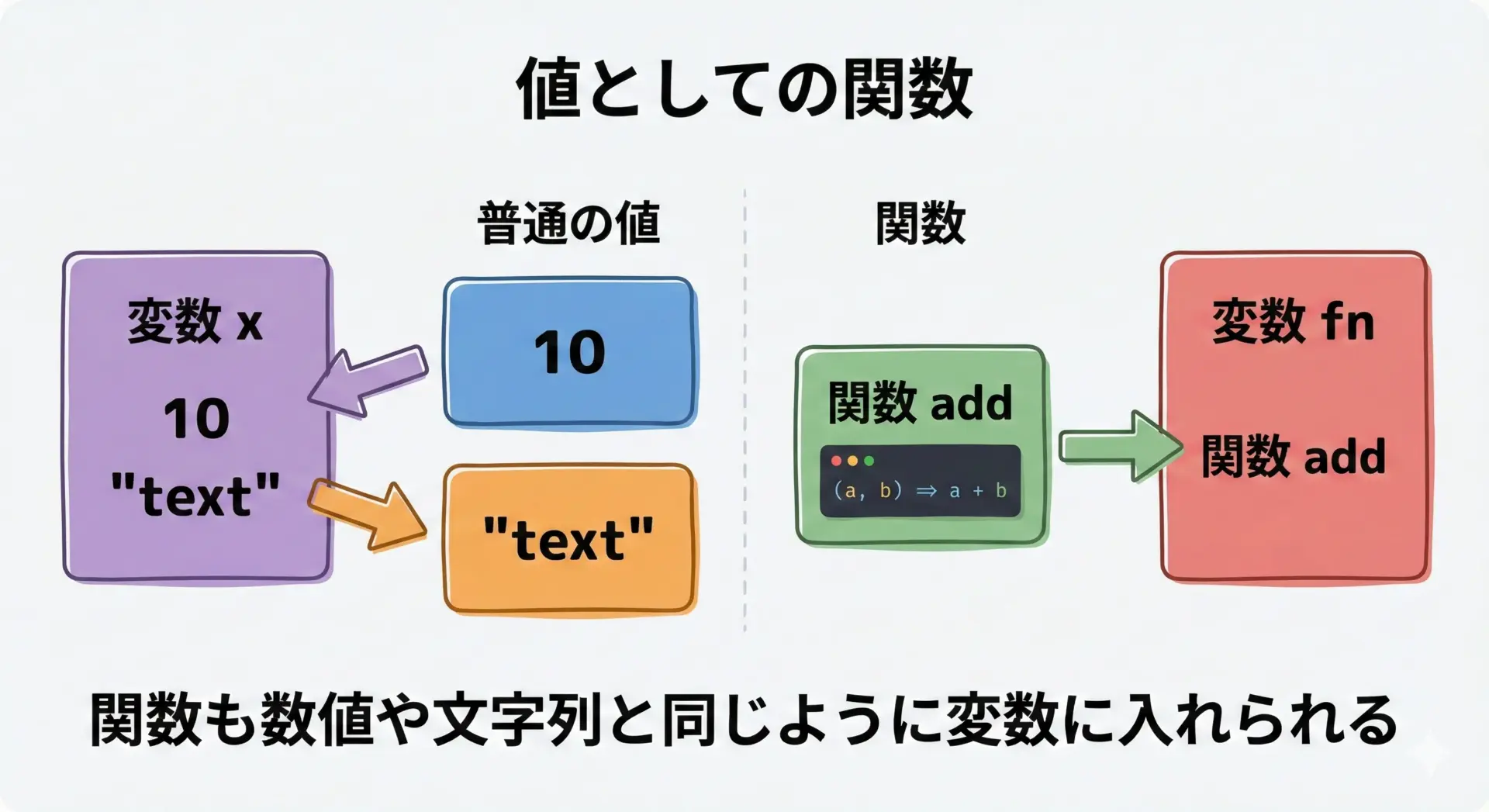
プログラミングを学び始めると、変数に数値や文字列を入れて使うことはすぐに慣れてくると思います。
// JavaScript の例
const x = 10;
const name = "Taro";ここではxやnameという変数に、数字や文字列といった「値」を入れています。
実は、関数も同じように「値」として変数に入れることができます。
function add(a, b) {
return a + b;
}
const fn = add; // 関数 add をそのまま変数 fn に代入
console.log(fn(1, 2)); // 3この例では、add という関数そのものをfnという変数に代入しています。
数値や文字列だけでなく、関数自体を「値」として扱っているわけです。
Pythonでも同じことができます。
def add(a, b):
return a + b
fn = add # 関数 add をそのまま変数 fn に代入
print(fn(1, 2)) # 3関数を変数に入れられると、次のようなことが可能になります。
- 関数を引数として別の関数に渡す
- 関数の戻り値として、関数そのものを返す
- 配列や辞書の中に、関数を要素として入れる
この「関数を値として扱う」性質を利用しているのが高階関数です。
このイメージを持っておくと、高階関数の説明がぐっと理解しやすくなります。
高階関数の定義と具体的なイメージ
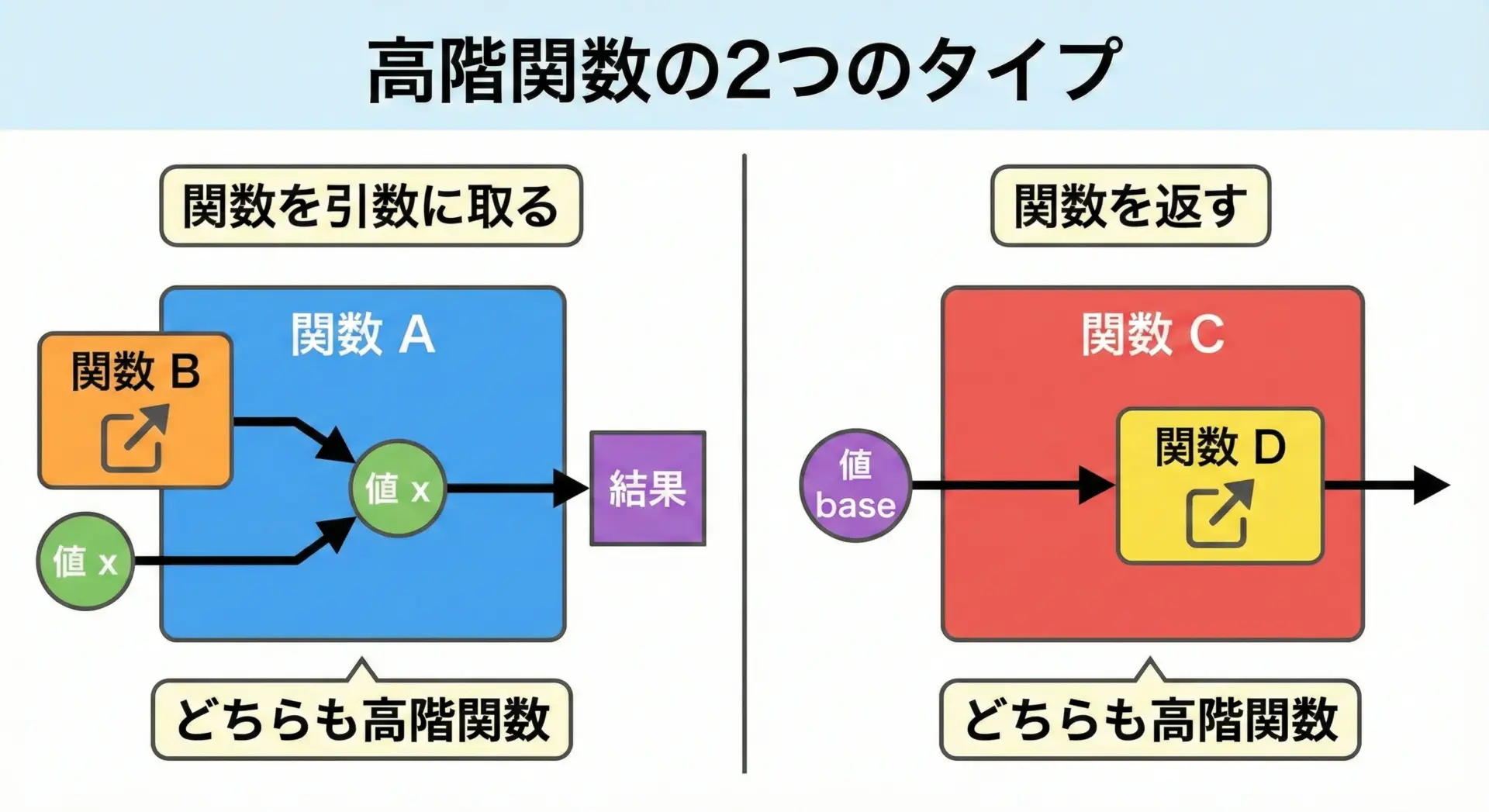
高階関数(high-order function)とは次のどちらか、または両方を満たす関数のことです。
- 関数を引数として受け取る関数
- 関数を戻り値として返す関数
定義だけだとピンと来ないので、まずは「関数を引数に取る」パターンを見てみます。
function twice(fn, x) {
return fn(fn(x));
}
function plusOne(n) {
return n + 1;
}
console.log(twice(plusOne, 3)); // 5 (3+1+1)ここでtwiceはfnという関数を引数に受け取っています。
つまりtwice は「関数を受け取る関数」なので高階関数です。
関数を返すパターンも見てみます。
function createMultiplier(base) {
return function (n) {
return n * base;
};
}
const double = createMultiplier(2);
console.log(double(5)); // 10createMultiplierは、新しく作った関数を戻り値として返しているので、これも高階関数です。
初心者視点では、「関数を“道具”として受け渡しできるようになるもの」とイメージすると理解しやすくなります。
関数型言語だけでなくJavaScriptやPythonでも使われる理由
高階関数というと「関数型言語だけの難しい概念」というイメージを持つこともありますが、実際にはJavaScriptやPythonの標準ライブラリにも当たり前に登場します。
理由はいくつかあります。
1つ目は、繰り返しや条件分岐といった「よくあるパターン」を共通化しやすいからです。
ループや絞り込みなどの処理の流れはライブラリ側にまとめ、「何をしたいか」だけを関数として渡すと、コードが短く読みやすくなります。
2つ目は、非同期処理やイベント処理と相性が良いからです。
JavaScriptではボタンをクリックしたときに実行する処理を、関数として登録します。
これも立派な高階関数の利用例です。
button.addEventListener("click", function () {
console.log("clicked!");
});3つ目は、テストや差し替えがしやすくなるという実務上のメリットです。
挙動を変えたい部分を関数として切り出しておけば、テスト時にはテスト用の関数を渡す、という形で柔軟に動作を切り替えられます。
「JavaScriptでもPythonでも、ちょっと本格的なコードを書くと自然に出てくるもの」と捉えておくとよいでしょう。
高階関数でコードがラクになる基本パターン
ここからは、具体的にどのような場面で高階関数が役立つのか、代表的なパターンを見ていきます。
特に配列の処理(map/filter/reduce)は、高階関数のメリットを体感しやすい場面です。
「繰り返し処理」をmapでスッキリ書く
まずは、配列の各要素に同じ処理をする「繰り返し」です。
ふつうに書くと次のようになります。
const nums = [1, 2, 3, 4];
const doubled = [];
for (let i = 0; i < nums.length; i++) {
doubled.push(nums[i] * 2);
}
console.log(doubled); // [2, 4, 6, 8]やりたいことは「配列の要素を2倍にした新しい配列を作る」だけなのに、インデックスの扱いやpushなど、余計なコードがたくさん出てきます。
高階関数mapを使うと、次のように書けます。
const nums = [1, 2, 3, 4];
const doubled = nums.map(n => n * 2);
console.log(doubled); // [2, 4, 6, 8]「各要素に何をするか」(n => n * 2) だけを関数として渡し、ループ自体は map に任せることで、コードが一気に短く読みやすくなります。
Pythonでも同じ発想です。
nums = [1, 2, 3, 4]
doubled = list(map(lambda n: n * 2, nums))
print(doubled) # [2, 4, 6, 8]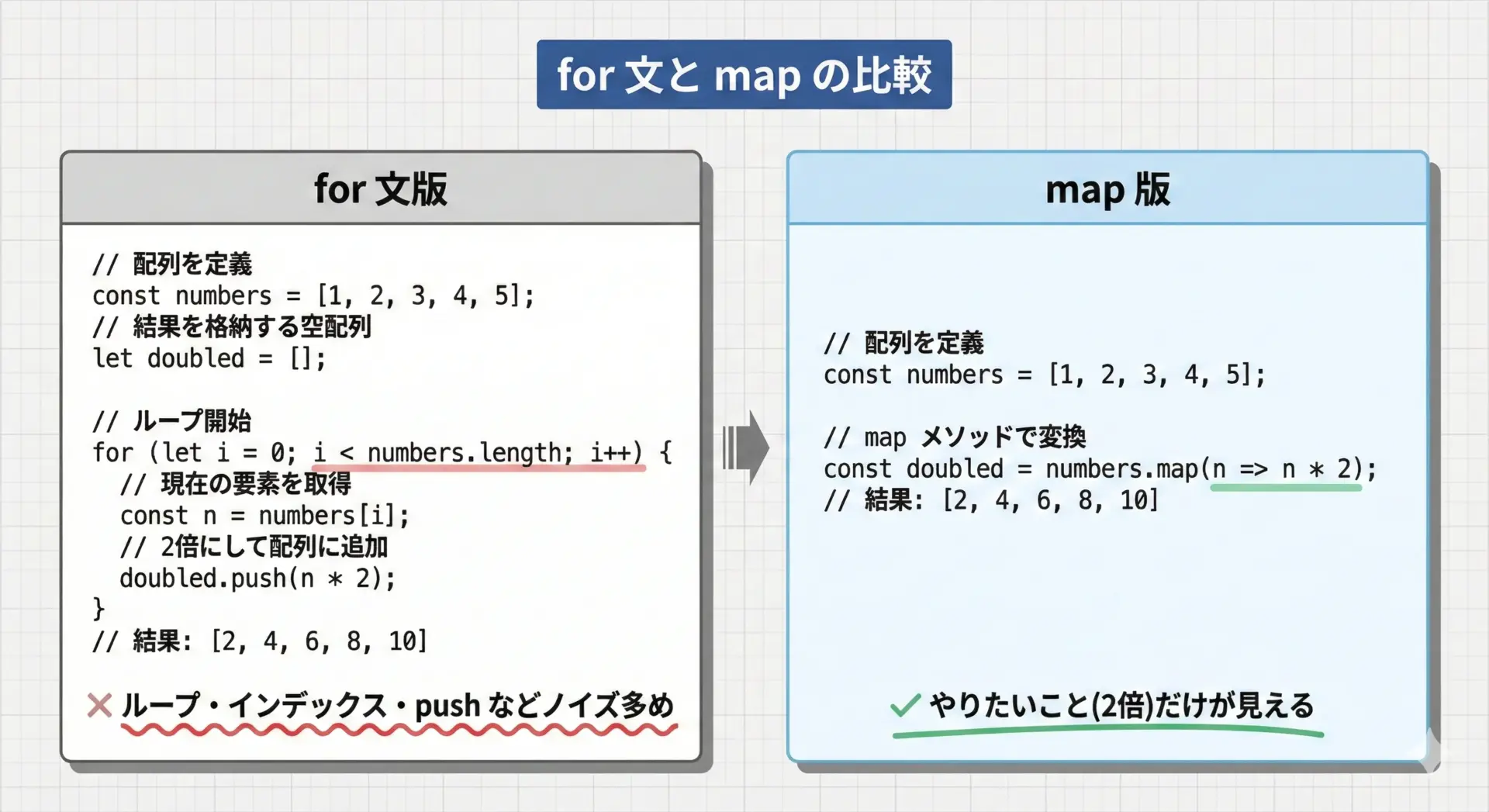
map のポイントは次の通りです。
- 「どうループするか」は map に任せる
- 「各要素に何をするか」だけを関数で指定する
- 元の配列は変更せず、新しい配列を返す
これだけでも、配列処理のコード量とノイズがかなり減ります。
絞り込みをfilterで書くメリット
次に「条件に合う要素だけを残したい」という場面です。
たとえば「偶数だけを取り出したい」場合、for 文で書くと次のようになります。
const nums = [1, 2, 3, 4, 5, 6];
const evens = [];
for (let i = 0; i < nums.length; i++) {
if (nums[i] % 2 === 0) {
evens.push(nums[i]);
}
}
console.log(evens); // [2, 4, 6]filter を使うと、こう書けます。
const nums = [1, 2, 3, 4, 5, 6];
const evens = nums.filter(n => n % 2 === 0);
console.log(evens); // [2, 4, 6]filter は「残すかどうか」を true/false で返す関数を受け取る高階関数です。
ループと if をまとめて引き受けてくれるので、コードを読むときに「何を条件に絞り込んでいるのか」だけに集中できます。
Python版も考え方は同じです。
nums = [1, 2, 3, 4, 5, 6]
evens = list(filter(lambda n: n % 2 == 0, nums))
print(evens) # [2, 4, 6]map が「変換」、filter が「絞り込み」だと整理しておくと、使い分けが直感的になります。
合計や集計をreduceでまとめる考え方
もう一歩進んで、配列から「1つの値」にまとめ上げる処理を考えてみます。
たとえば、合計値を計算するケースです。
const nums = [1, 2, 3, 4];
let sum = 0;
for (let i = 0; i < nums.length; i++) {
sum += nums[i];
}
console.log(sum); // 10高階関数reduceを使うと、次のように書けます。
const nums = [1, 2, 3, 4];
const sum = nums.reduce((acc, n) => acc + n, 0);
console.log(sum); // 10ここでのポイントは、acc(累積値)と n(現在の要素)から、新しい累積値を返す関数を渡しているところです。
reduce は配列を頭から順に見ていき、毎回その関数を呼び出して、最終的な 1 つの値を作り出します。
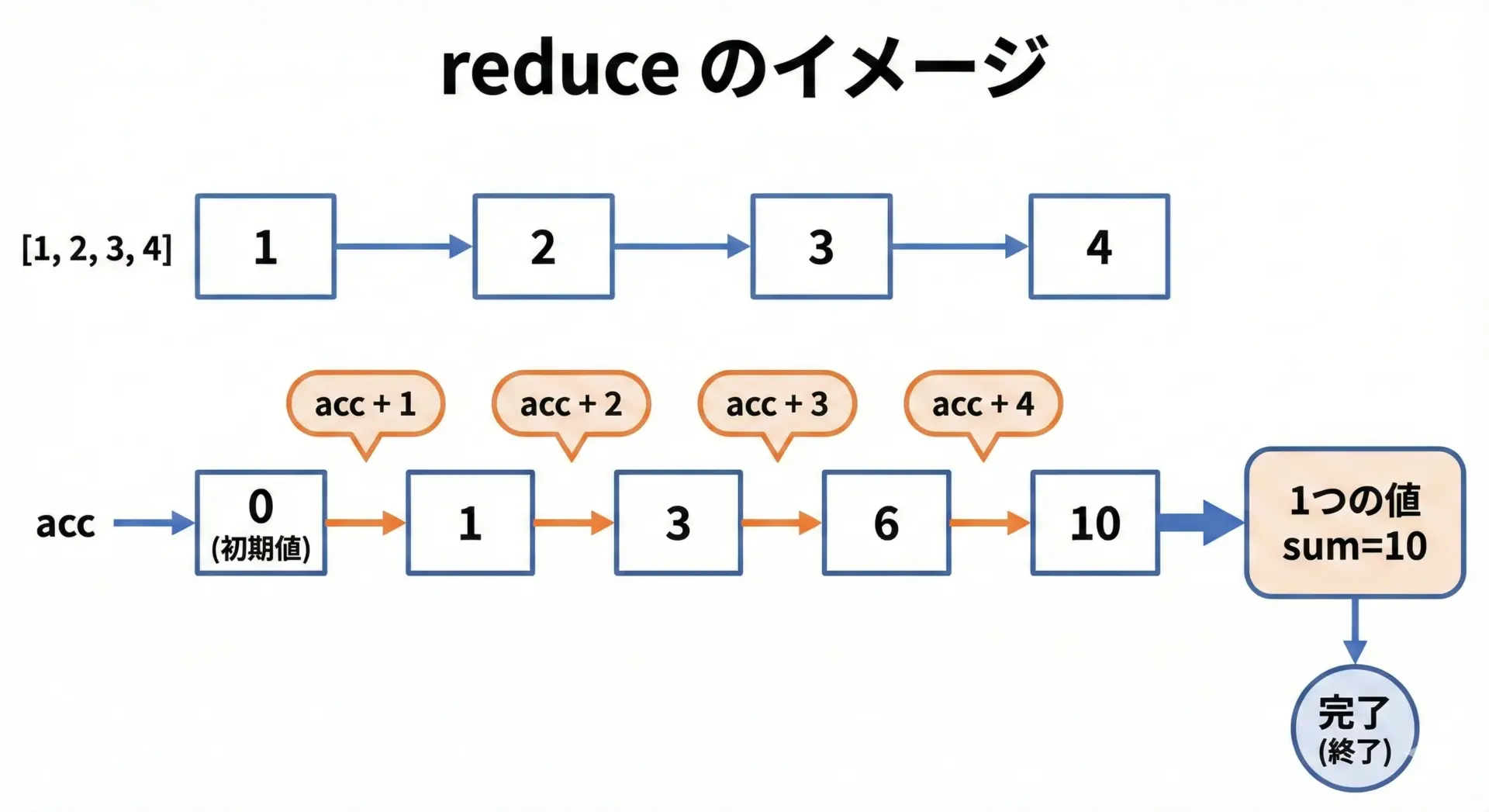
reduce は最初は少し抽象度が高く感じますが、「配列をぐるっと1周して1つの結果にまとめるもの」と理解しておくと、多くの集計処理をきれいに書けるようになります。
なお、実務では「むやみに reduce を多用しない」というスタイルもあります。
理由は、やり過ぎると何をやっているか分かりづらくなるからです。
合計・最大値・グルーピングなど「1つにまとめる」と明確に言える場面に絞って使うのがコツです。
共通処理を高階関数に切り出すリファクタリング
map / filter / reduce のように、すでに用意されている高階関数を使うだけでなく、自分で高階関数を作って共通処理をまとめることもできます。
これはリファクタリング(整理整頓)のときに特に役立ちます。
例えば、次のようなコードを考えます。
function saveUser(user) {
console.log("start");
// バリデーション
if (!user.name) throw new Error("name is required");
// 実処理
console.log("saving user", user.name);
console.log("end");
}
function deleteUser(user) {
console.log("start");
// バリデーション
if (!user.id) throw new Error("id is required");
// 実処理
console.log("deleting user", user.id);
console.log("end");
}「start/end のログ」や「バリデーションの囲い方」が重複しています。
ここで高階関数を使うと、共通処理を1か所にまとめられます。
function withLog(fn) {
return function (...args) {
console.log("start");
const result = fn(...args);
console.log("end");
return result;
};
}
function rawSaveUser(user) {
if (!user.name) throw new Error("name is required");
console.log("saving user", user.name);
}
function rawDeleteUser(user) {
if (!user.id) throw new Error("id is required");
console.log("deleting user", user.id);
}
const saveUser = withLog(rawSaveUser);
const deleteUser = withLog(rawDeleteUser);withLog が「関数を受け取り、ログ付きの新しい関数を返す高階関数」になっています。
これにより、ログの出し方を変えたいときもwithLog だけ直せばよい状態になります。
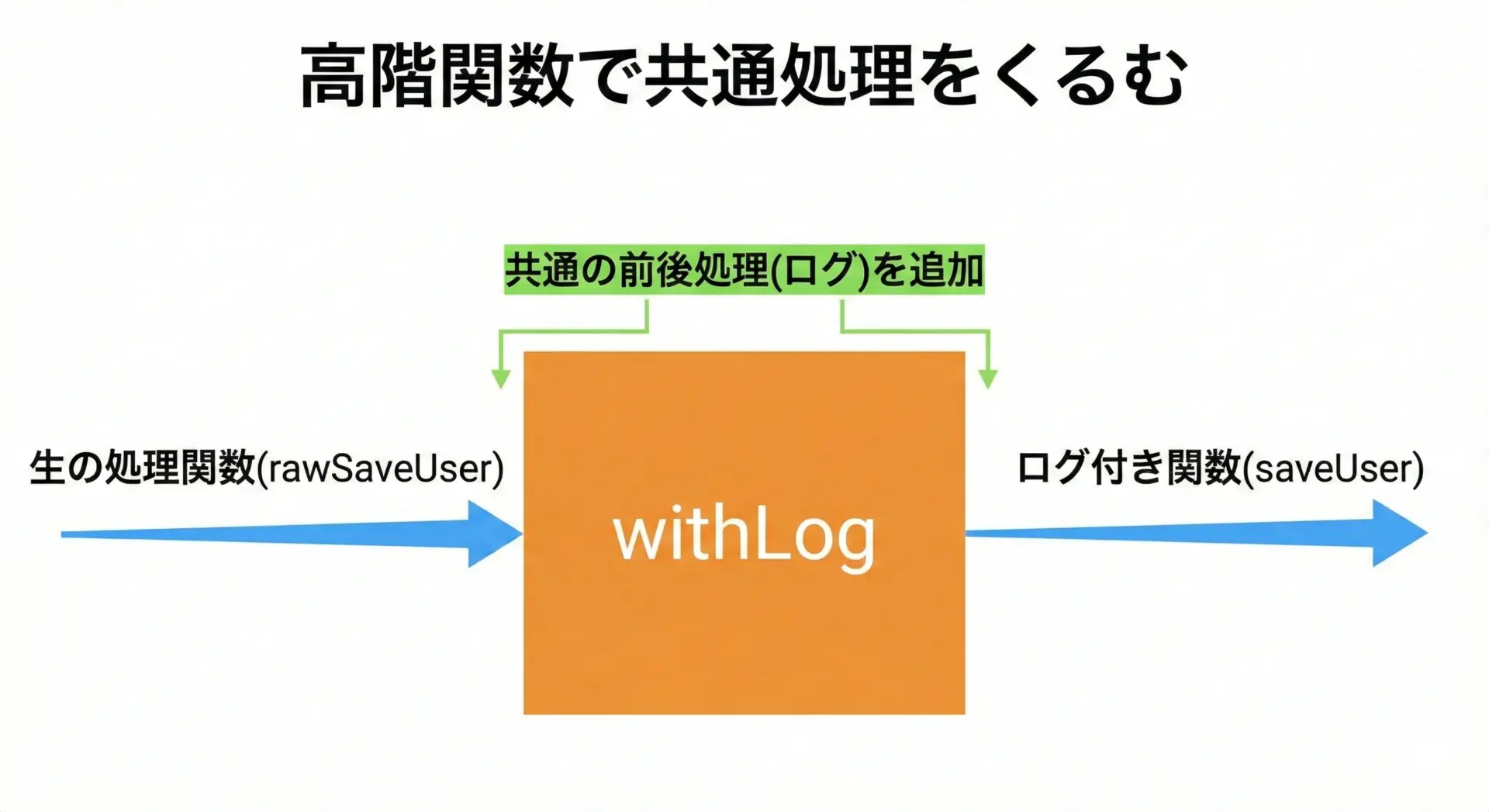
このように「○○な処理をする関数に、共通の前後処理を足したい」という場面で、自作の高階関数が威力を発揮します。
条件分岐やエラーハンドリングも高階関数で整理
高階関数のメリットは配列処理だけではありません。
if 文や try-catch が増えすぎて読みづらくなったコードも、高階関数でかなりスッキリさせることができます。
if文だらけのコードを高階関数で整理する
たとえば、ユーザーのステータスによってメッセージを変える処理を考えます。
function getMessage(status) {
if (status === "active") {
return "利用中です";
} else if (status === "inactive") {
return "停止中です";
} else if (status === "pending") {
return "確認中です";
} else {
return "不明な状態です";
}
}この程度ならまだ読めますが、条件が増えてくると if だらけになりがちです。
ここで、「ステータスごとに処理を登録する」という考え方に切り替えると、関数を値として扱うメリットが見えてきます。
const handlers = {
active: () => "利用中です",
inactive: () => "停止中です",
pending: () => "確認中です",
default: () => "不明な状態です",
};
function getMessage(status) {
const handler = handlers[status] || handlers.default;
return handler();
}ここではオブジェクトhandlersにステータスごとの処理(関数)を値として登録しています。
if 文が消え、「マッピング表」を1か所にまとめる形になりました。
これは「高階関数」という言葉を使わないことも多いですが、関数を値として扱う発想の延長線上にあるテクニックです。
条件が増えたらhandlersに項目を足すだけ、という分かりやすい構造になります。
コールバック関数で前後処理をまとめる
非同期処理や「終わったら○○をする」という流れを扱うとき、コールバック関数という形で高階関数がよく使われます。
function fetchData(callback) {
setTimeout(() => {
const data = { id: 1, name: "Taro" };
callback(data);
}, 1000);
}
fetchData(user => {
console.log("取得したユーザー:", user.name);
});fetchData は「データが取れたらこの関数を呼んでね」というコールバックを引数で受け取る高階関数になっています。
データ取得の方法は fetchData に閉じ込めておき、「データ取得後に何をするか」だけを関数として渡すわけです。
この発想は、処理の「前」と「後」を高階関数にまとめるときにも応用できます。
function withTimeLog(fn) {
return function (...args) {
console.time("time");
const result = fn(...args);
console.timeEnd("time");
return result;
};
}
const heavyTask = () => {
// 重い処理...
};
const heavyTaskWithLog = withTimeLog(heavyTask);
heavyTaskWithLog();withTimeLog が「関数を受け取り、時間計測付きの関数を返す高階関数」です。
どの処理にも同じように「前後に時間を測りたい」とき、このパターンで量産できます。
ログ出力や例外処理を高階関数で共通化する
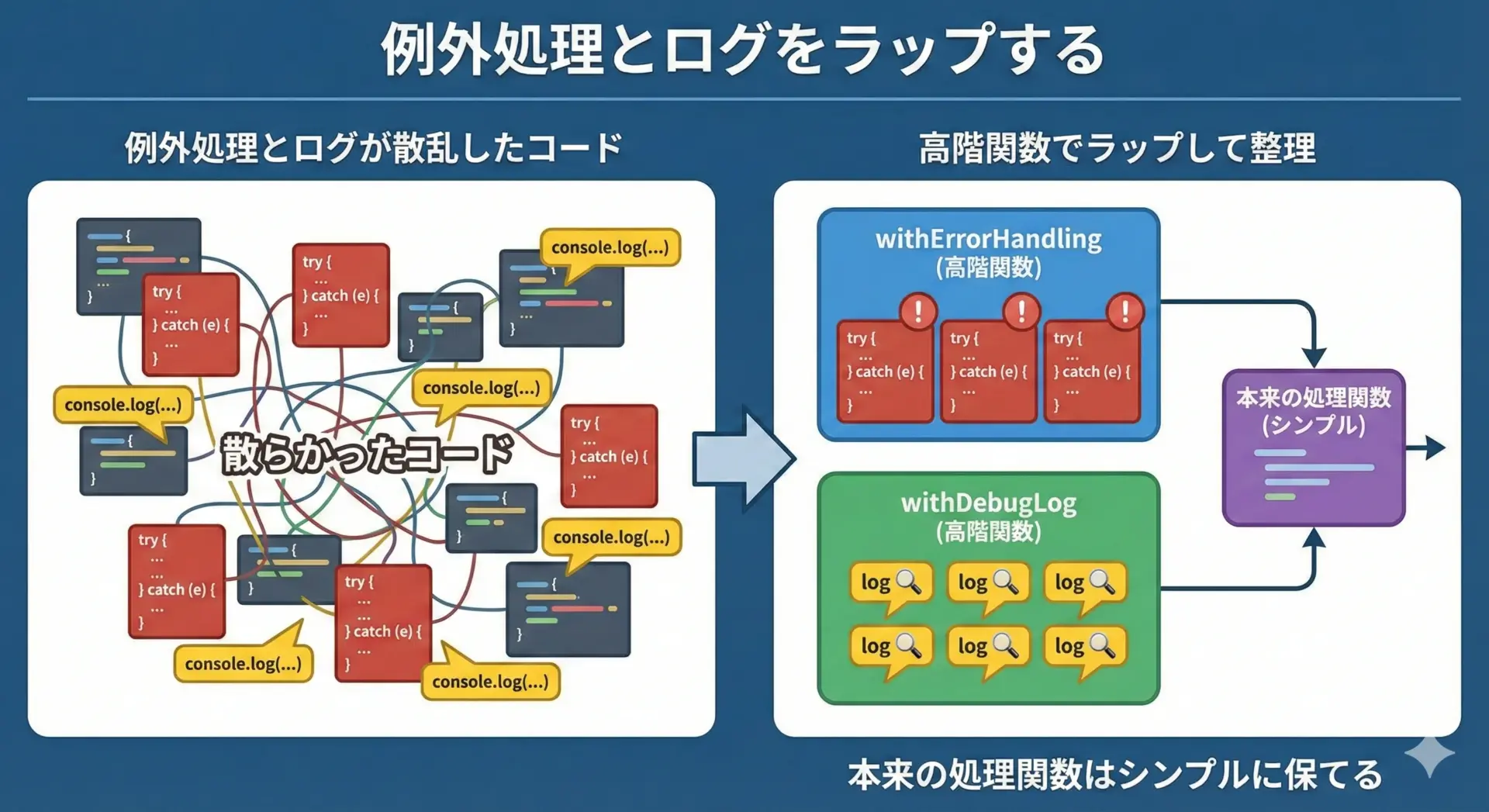
実務では、ログ出力や例外処理(try-catch)があちこちに散らばりがちです。
これも高階関数を使うと、かなり整理できます。
まず、例外処理を共通化する例です。
function withErrorHandling(fn) {
return async function (...args) {
try {
return await fn(...args);
} catch (e) {
console.error("エラー発生:", e);
throw e; // 必要に応じて再スロー
}
};
}
async function fetchUser(id) {
// どこかで例外が発生するかもしれない処理
}
const safeFetchUser = withErrorHandling(fetchUser);エラーが起きたらどう扱うか、というポリシーを withErrorHandling に1か所で集約することで、各処理関数は「本来の処理」に集中できます。
同様に、ログ出力も高階関数でくるむことができます。
function withDebugLog(fn, name) {
return function (...args) {
console.log(`[${name}] start`, args);
const result = fn(...args);
console.log(`[${name}] end`, result);
return result;
};
}
function calcTax(price) {
return price * 0.1;
}
const calcTaxWithLog = withDebugLog(calcTax, "calcTax");
calcTaxWithLog(1000);このように「あちこちに書かれがちなパターン」を高階関数にまとめると、コード全体の見通しが良くなり、修正漏れも減らせます。
高階関数のメリットを初心者目線で整理
最後に、高階関数を使うことで得られるメリットを、初心者の方にとって分かりやすい切り口で整理しておきます。
コードの重複が減りメンテナンス性が上がる
一番分かりやすいメリットは「同じようなコードを何度も書かなくてすむ」ことです。
map / filter / reduce を使うと、for 文や if 文のテンプレートを書き続ける必要がなくなります。
さらに、自分で高階関数を作って共通の前後処理(ログ・エラー処理など)を1か所に集約すれば、仕様変更があったときも「ここだけ直せば全部に反映される」状態にできます。
重複コードが多いほど、修正漏れやバグの温床になります。
高階関数は、そうした重複を減らしてくれる「整理整頓ツール」として非常に有効です。
バグが見つけやすくテストしやすいコードになる
高階関数の発想でコードを書くと、「1つの関数の役割が小さく、はっきりする」傾向があります。
たとえば次のように分割できます。
- データを取得する関数
- データを変換する関数(map などに渡す)
- 結果を表示する関数
それぞれの関数が小さくシンプルだと、単体テストがしやすくなります。
また、バグが起きたときにも「どの関数が怪しいか」を絞り込みやすくなります。
さらに、テスト用のダミー関数を差し込むといったこともしやすくなります。
たとえば、本番では本物の API を呼ぶ関数を、高階関数に渡して使い、テスト時にはテスト用の関数を渡す、といった差し替えが自然に行えます。
読みやすい抽象化でチーム開発がラクになる
高階関数を使うと、「処理の流れ」と「細かい中身」を分離して書きやすくなります。
例えば次のようにです。
const activeUsers = users
.filter(isActiveUser)
.map(toUserViewModel);このコードを読むとき、「アクティブユーザーを絞り込んで、表示用の形に変換している」という大まかな流れが一目で分かります。
isActiveUserやtoUserViewModelの中身は、必要になったときだけ具体的に追えばよい、という読み方ができます。
チーム開発では、「概要をすぐつかめるコード」がとても重要です。
細部まで読み込まないと何をしているか分からないコードは、レビューにも時間がかかり、バグも入り込みやすくなります。
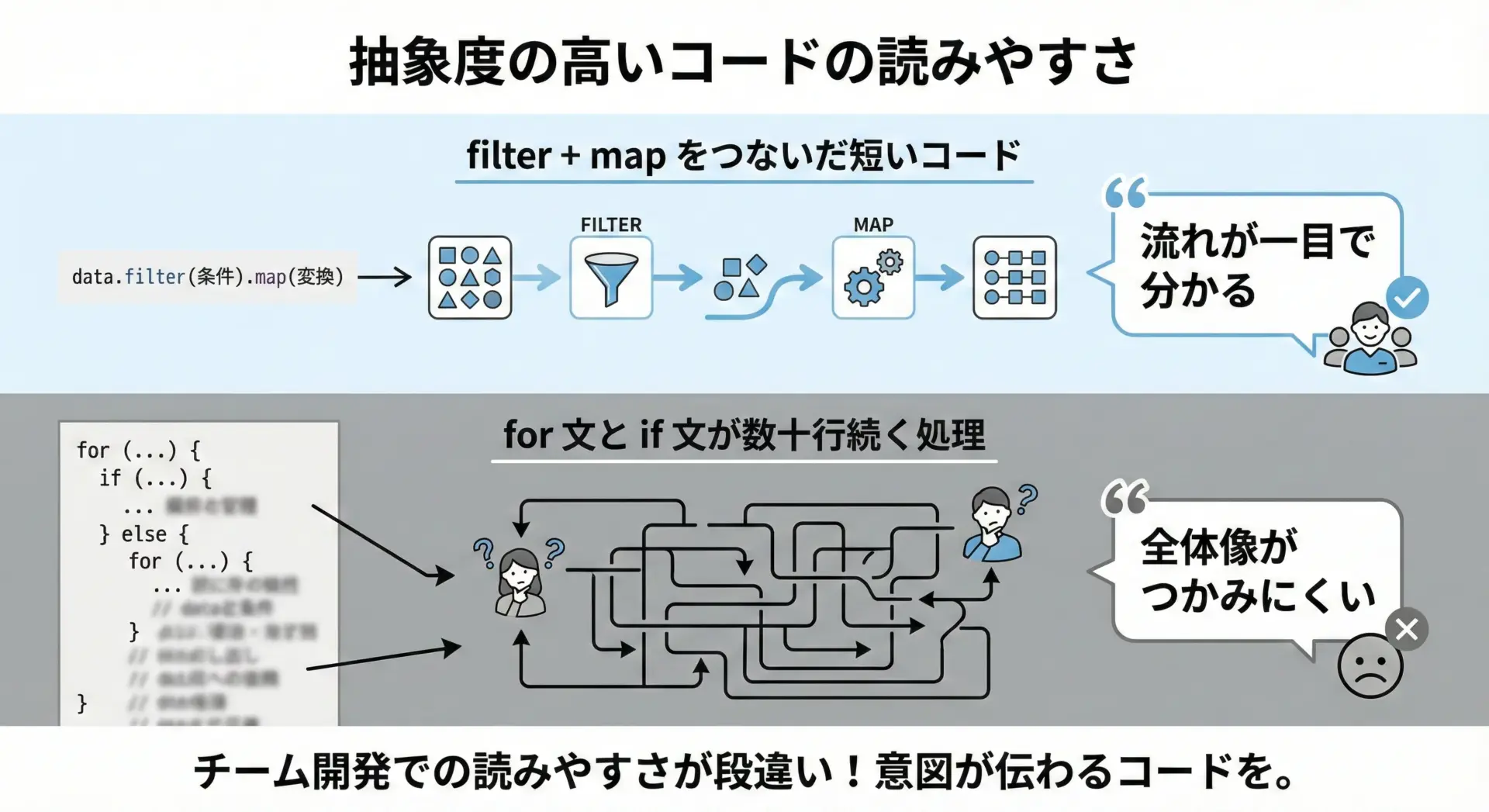
高階関数をうまく使えば、「大枠の処理の流れ」と「個々のロジック」を自然に分離できるため、コードの見通しが大幅に良くなります。
まとめ
この記事では、高階関数の仕組みと、そのメリットを初心者目線で整理してきました。
重要なポイントを振り返ると、次のようになります。
- 高階関数とは、関数を引数に取ったり、関数を返したりする関数であり、その前提として「関数を値として扱う」考え方がある
- JavaScript や Python では、map / filter / reduce といった高階関数が標準で提供されており、繰り返し・絞り込み・集計などの処理をスッキリ書ける
- 自分で高階関数を作ることで、ログ出力やエラーハンドリングなどの共通処理を1か所にまとめられ、コードの重複を減らせる
- 高階関数を活用すると、関数の役割が小さく・明確になり、テストしやすくバグを見つけやすいコードになる
- 抽象度の高い書き方ができるため、処理の「流れ」と「中身」を分離し、チーム開発での読みやすさとメンテナンス性が向上する
高階関数は、最初は少しとっつきにくく感じるかもしれませんが、「繰り返し処理はまず map と filter を思い出してみる」といった小さな一歩から取り入れていくと、自然に感覚がつかめてきます。
まずは日常的に書いている for 文や if 文の一部を、高階関数に置き換えてみるところから試してみてください。
コードが少しずつラクになっていく感覚を、きっと実感できるはずです。
