
プログラムを書いていると、いつの間にか「うまく動いた」「さっきまで動いていたのに壊れた」を繰り返してしまうことがあります。
その原因の多くは、コードの中で何が「変わる」のか、どこに「記憶」がたまっていくのかをはっきり意識できていないことにあります。
本記事では、プログラムのふるまいを理解するうえで土台となる状態(state)と副作用(side effect)の考え方を、初心者の方にもわかりやすいように整理して解説します。
状態(state)とは何か
プログラムにおける「状態」の意味
日常の言葉で「状態」と聞くと、「体調がいい」「部屋が散らかっている」といった、そのときどきの様子を思い浮かべると思います。
プログラミングにおける状態(state)も、基本的な考え方は同じです。
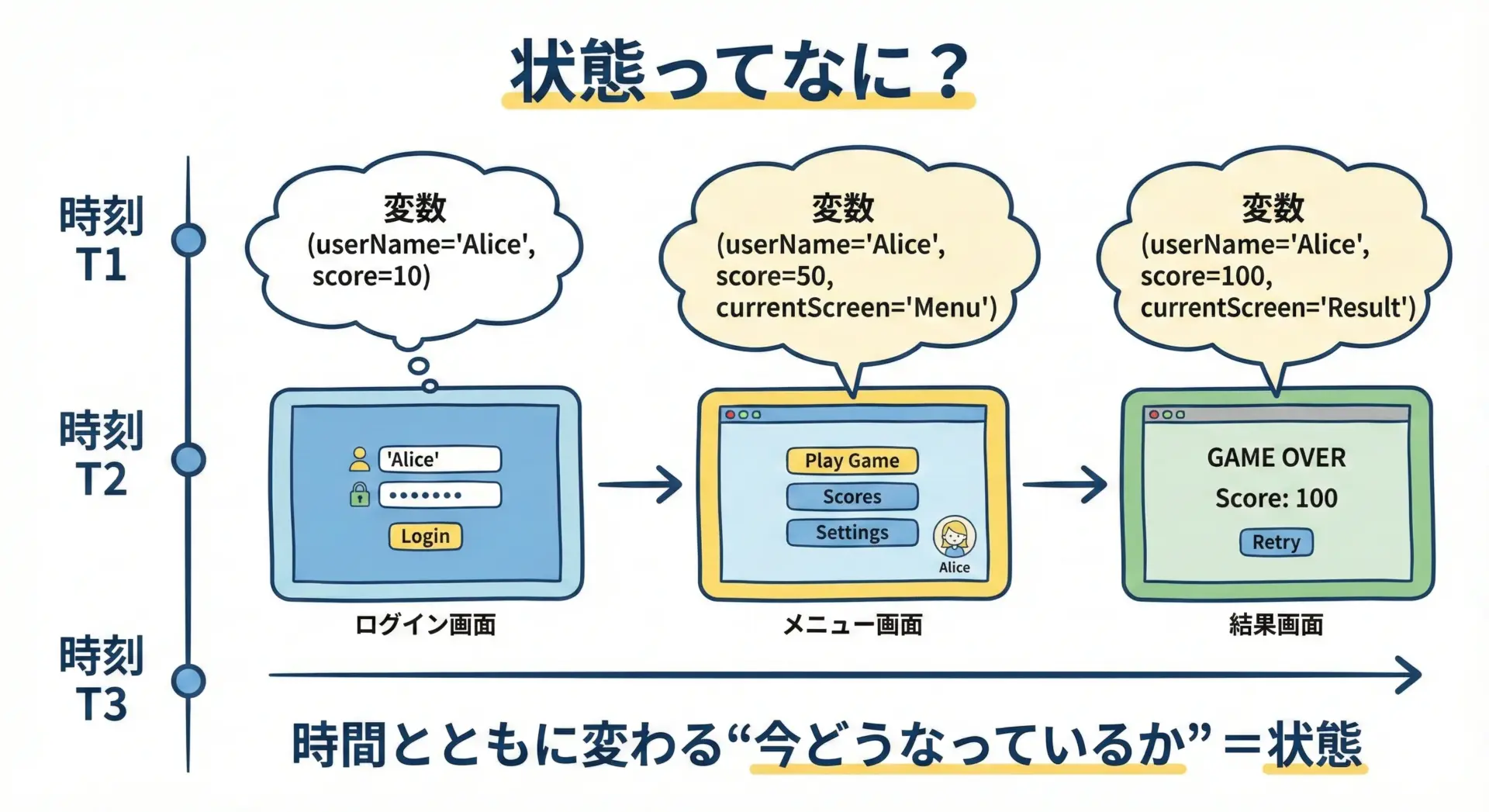
ある時点において、プログラムの内部や外部の「今どうなっているか」をまとめて表したものが状態です。
プログラムは、入力を受け取り、何らかの処理をして、結果を出力します。
この処理の途中や前後で、「どの変数にどんな値が入っているか」「画面に何が表示されているか」「ファイルにどんなデータが保存されているか」といった、さまざまな情報が移り変わります。
これらの「今現在の値たち」の集合を、プログラムの状態と呼びます。
このように、状態はいつでも「時間」とセットで考えます。
ある時刻の状態がわかると、その時刻にプログラム内部で何が起こっているかをイメージしやすくなります。
変数・オブジェクト・データ構造と状態の関係
では、プログラムの「状態」は具体的にどのようなものから構成されるのでしょうか。
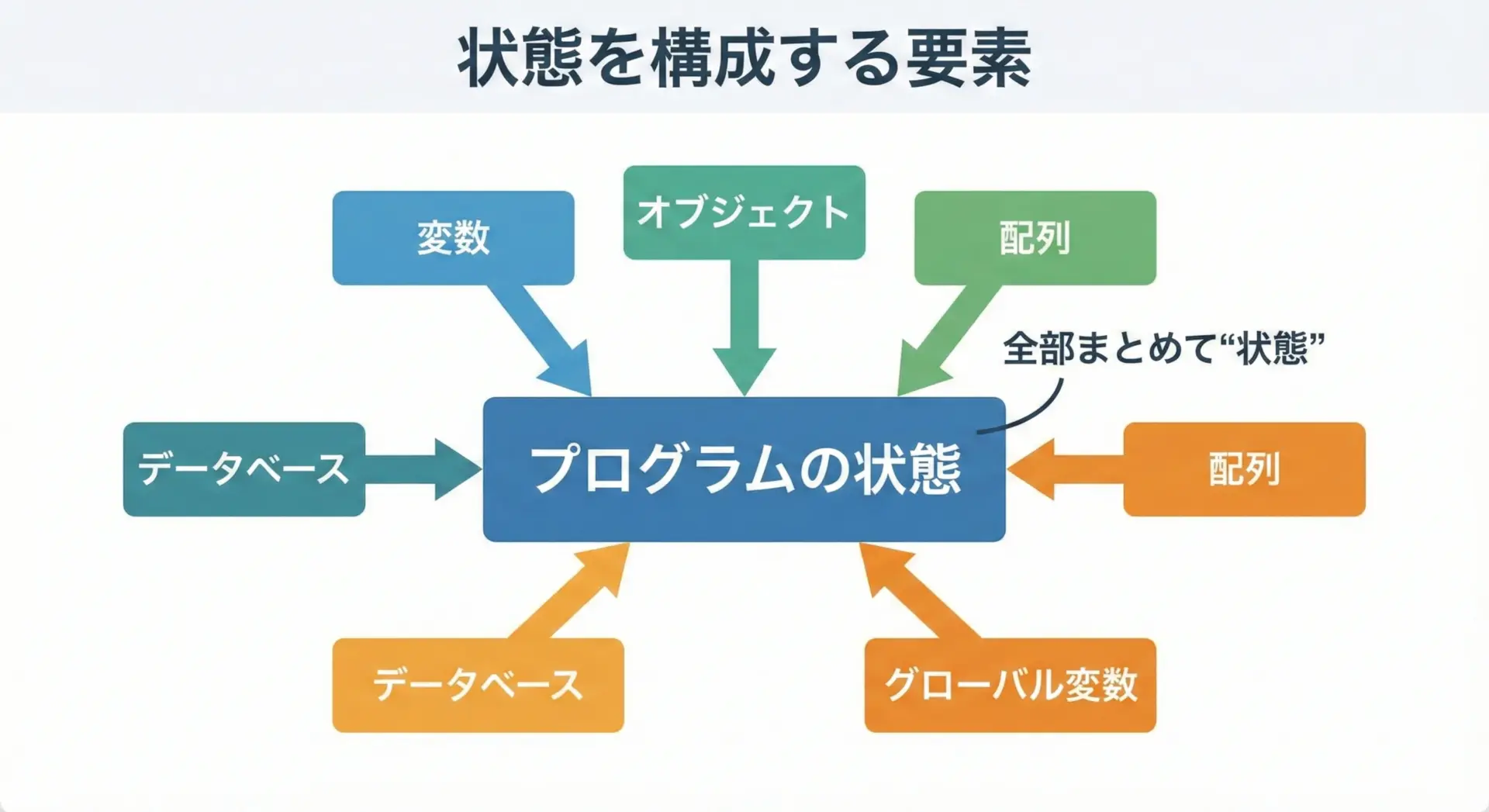
多くのプログラミング言語では、主に次のような要素が状態を形作ります。
- 変数に入っている値
- オブジェクトやインスタンスが持つプロパティやフィールド
- 配列やリスト、マップといったデータ構造の中身
- グローバル変数やシングルトンの持つ情報
- (環境によりますが)データベースのレコードの内容など外部システムの情報
これら「値を覚えておける場所」に入っている中身が、そのまま状態を構成していると考えると理解しやすくなります。
オブジェクト指向言語では、クラスから生成したオブジェクトが複数のプロパティを持ち、それぞれが値を保持します。
このオブジェクトが持つ値の集合も「オブジェクトの状態」と呼ばれます。
たとえばユーザーを表すオブジェクトなら、name、email、isActiveといったプロパティの値が、そのユーザーオブジェクトの状態です。
「今どうなっているか」を表す状態の具体例
抽象的な説明だけではイメージしづらいので、ごく簡単な例をいくつか挙げてみます。
カウンターの例
1ずつ数を増やしていくカウンターを考えます。
let count = 0;
function increment() {
count = count + 1;
}このとき、countという変数の値が、このプログラムの主要な状態です。
プログラム開始時点ではcount = 0という状態で、increment()を1回呼ぶとcount = 1、もう1回呼ぶとcount = 2というように、関数を呼ぶたびに状態が変化していきます。
ログイン状態の例
Webサービスの利用者を想像してみてください。
ログインしていないときと、ログインしているときでは、表示される内容が違います。
この「ログインしている or していない」は、プログラムにとっての重要な状態です。
- ログイン状態:
isLoggedIn = true / false - 現在のユーザー情報:
currentUser = null or { name: "Alice", id: 123 }
どの状態かによって、ボタンが押せるかどうか、見せてよい情報かどうかが変わってきます。
こうした違いを正しく制御できるように、状態を明確に意識することが重要です。
ゲームの例
ゲームプログラムでは、状態の概念が特にわかりやすく現れます。
- プレイヤーの現在位置(x, y座標)
- 所持しているアイテムのリスト
- HP、MP、スコア
- 進行中のステージ番号
これらの値が変わるたびに、ゲームの「今どうなっているか」が変化します。
ゲームのルールとは、ある状態から次の状態へどう移るかの決まりだと言い換えることもできます。
副作用(side effect)とは何か
関数の「入力と出力」と「副作用」の違い
関数を理解するとき、よく入力 → 処理 → 出力というモデルで説明されます。
たとえば、次のような関数は、まさにそのイメージ通りです。
function add(a, b) {
return a + b;
}このadd関数は、入力(a, b)から出力(a + b)を計算するだけで、他の何かを変えたり記録したりはしていません。
このような関数は副作用がないと表現されます。
では副作用(side effect)とは何かというと、関数(あるいは処理)が、引数や戻り値とは別に、外の世界に何かしらの「影響」を与えることを指します。
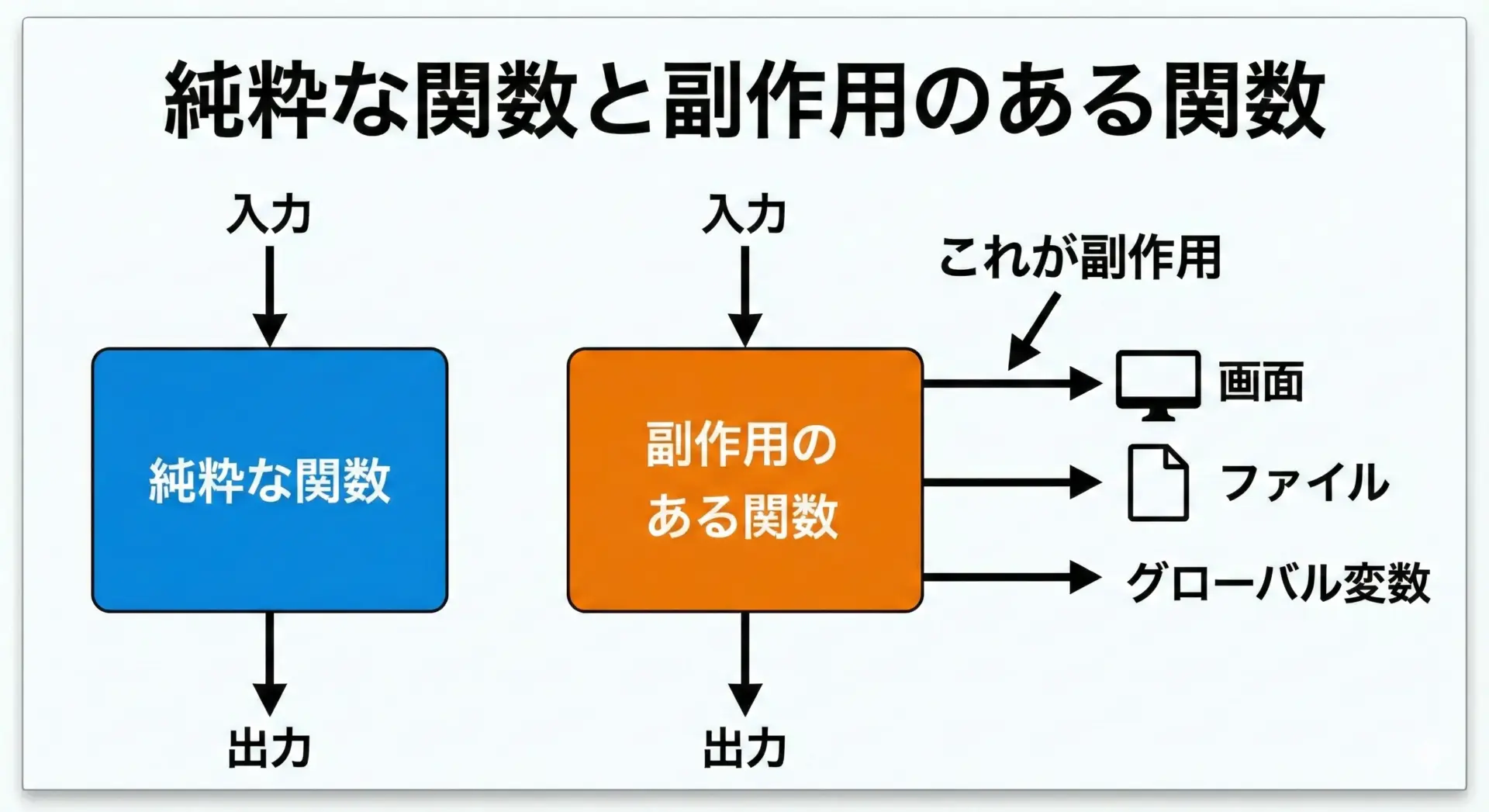
副作用は悪いものというわけではありません。
画面に結果を表示したり、ファイルに保存したり、ネットワークに送信したりといった「外とやりとりする」ためには、副作用が必ず必要だからです。
ただし、どの関数がどんな副作用を持っているかを意識しないままコードを書くと、途端に理解しにくいプログラムになってしまいます。
画面表示・ファイル書き込み・グローバル変数更新はなぜ副作用か
副作用の代表的な例として、次のようなものがあります。
- コンソールや画面に文字を表示する
- ファイルに書き込む・読み書きする
- ネットワーク通信を行う(APIコールなど)
- グローバル変数や外側のスコープの変数を更新する
- データベースのレコードを追加・更新・削除する
たとえば、次のようなJavaScriptの関数を考えます。
let totalCalls = 0;
function logMessage(message) {
console.log(message); // 画面(コンソール)への出力
totalCalls++; // グローバル変数の更新
}この関数は、呼び出されるたびに次のことを行います。
- コンソールに文字を表示する
- グローバル変数
totalCallsの値を1増やす
どちらも「関数の外側」にある何かを変えています。
この「外側」を変える動きが、まさに副作用です。
なぜ「外側を変えること」が副作用になるのかというと、その関数の影響範囲が、引数と戻り値だけにとどまらず、プログラムの別の部分にも及ぶようになるからです。
こうした影響が増えるほど、「この関数を呼ぶと、他に何が変わるのか?」を正しく追いかけるのが難しくなります。
副作用が多いコードが読みづらくなる理由
副作用は避けられないものですが、副作用だらけのコードは非常に読みづらく、バグの温床になります。
その主な理由を整理してみます。
1. 同じ呼び出しでも結果が変わる
副作用がない関数は、同じ入力に対して常に同じ出力を返します。
これを参照透明性と呼びます。
一方、副作用を持つ関数は、内部や外部の状態に依存して結果が変わることがあります。
たとえば、次のような関数を考えます。
let counter = 0;
function getNext() {
counter++;
return counter;
}getNext()は同じ引数(なし)で呼んでいるにもかかわらず、呼ぶたびに返り値が変わります。
返り値が「外部状態(counter)の現在の値」に依存しているからです。
このような関数が増えるほど、コード全体のふるまいを頭の中だけで追いかけるのが難しくなります。
2. どこで状態が変わったのか追いにくい
副作用の多いコードでは、変数やオブジェクトの値が、どこで・いつ・なぜ変わったのかを特定するのが大変になります。
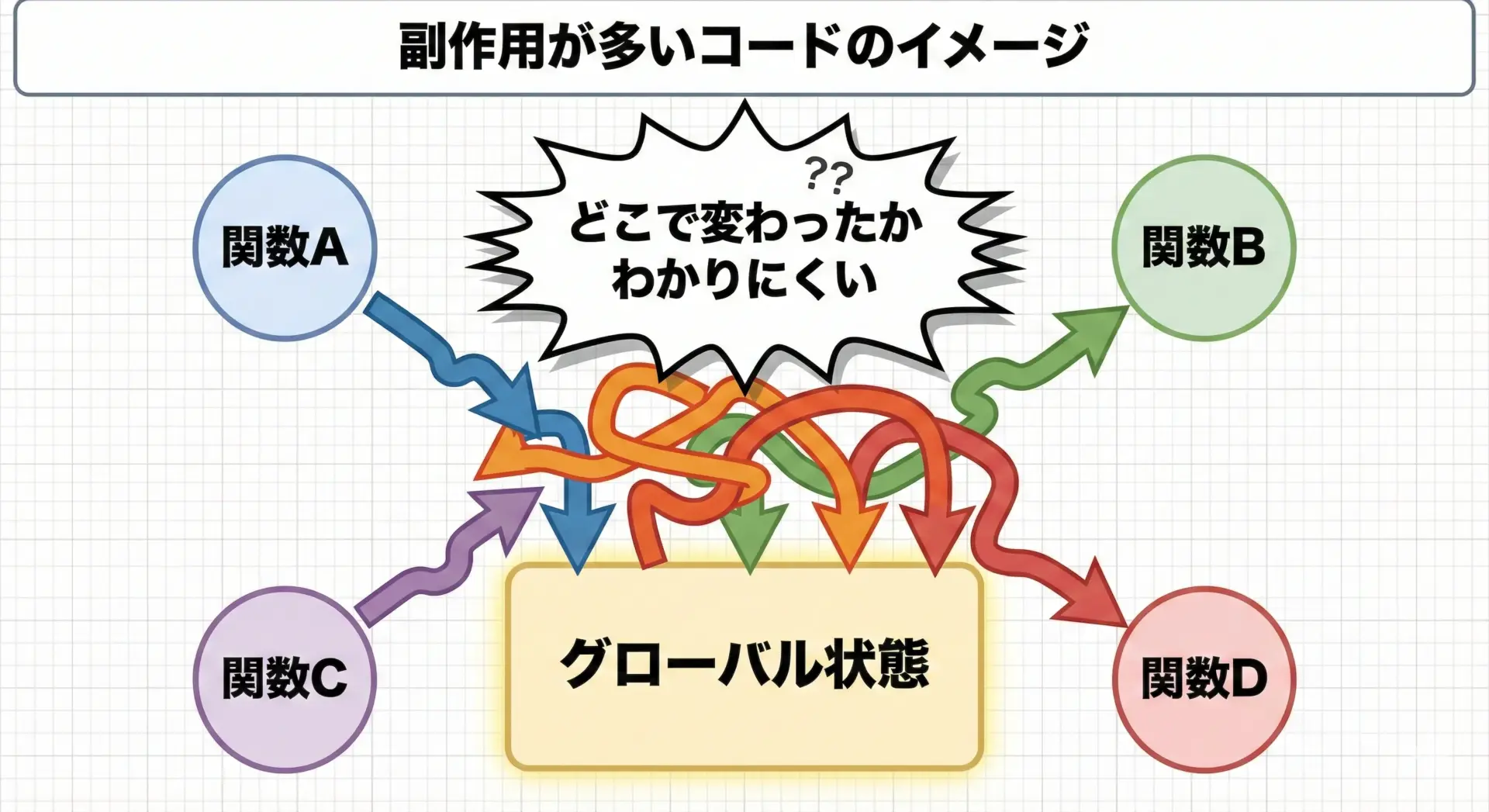
たとえば、ある画面で表示される残高がなぜマイナスになっているのか調べようとしたとき、残高を更新する可能性のある場所が関数A〜Zまで大量に存在すると、原因を絞り込むのに時間がかかります。
このような状況は、「どこからでも状態を変えられる」設計によって生まれます。
3. テストや再利用が難しくなる
副作用が多い関数は、テストも難しくなります。
たとえば、ファイルに書き込んだり、APIを叩いたり、グローバル変数を更新する関数は、テストごとに環境をきれいにしたり、モックを用意したりといった準備が必要になります。
逆に、副作用のない関数は、入力と期待される出力だけを見ればよいので、テストが圧倒的に簡単です。
状態と副作用の関係を理解する
「状態を変えること」自体が副作用になるケース
ここまでの説明からわかるように、「ある関数の外にある状態を変えること」は、基本的に副作用とみなされます。
とくに、次のようなパターンでは注意が必要です。
- グローバル変数を更新する
- 引数として渡されたオブジェクトや配列の中身を直接書き換える
- シングルトンや共有オブジェクトのフィールドを変更する
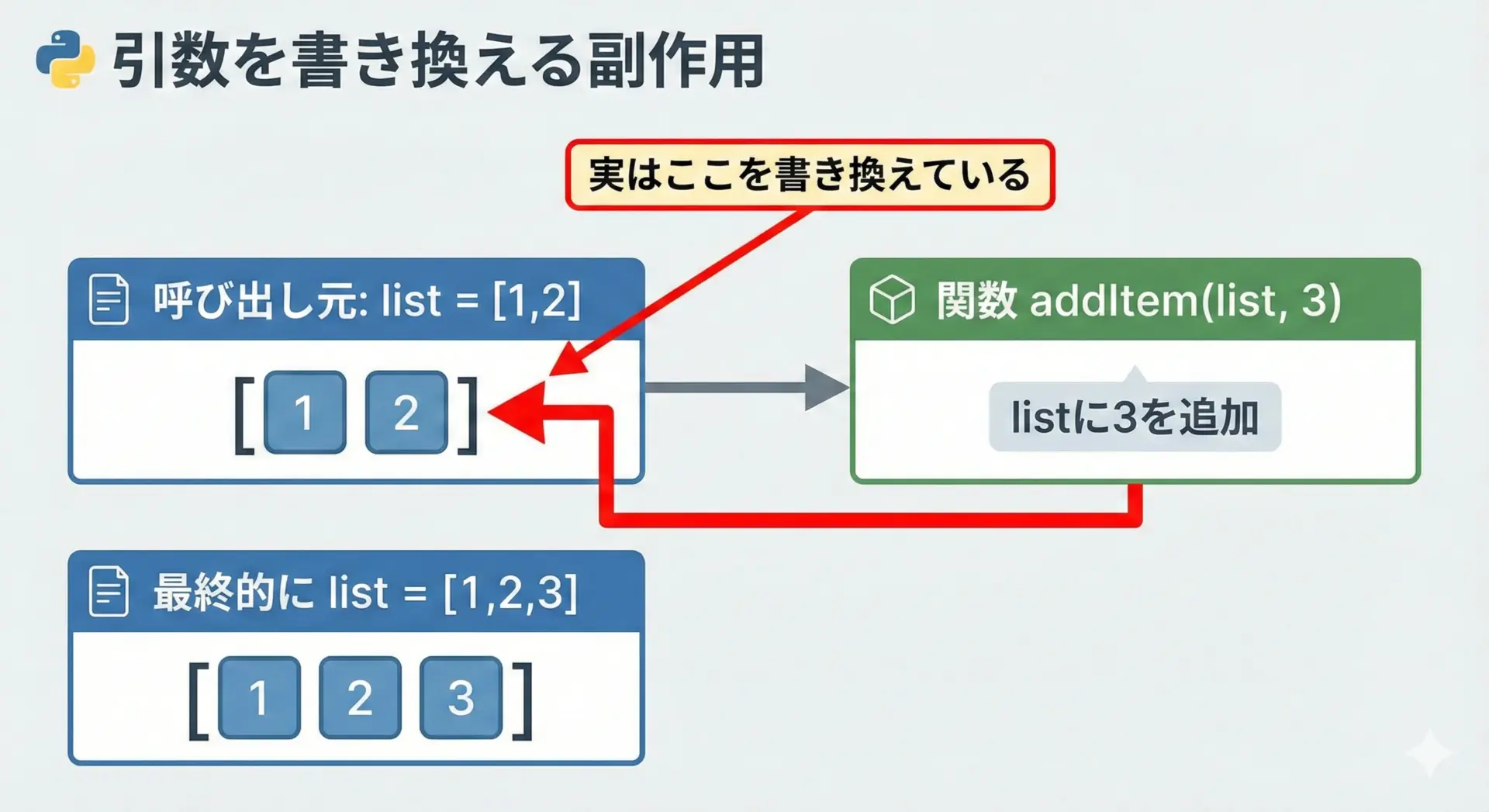
function addItem(list, item) {
list.push(item); // 引数listの中身を書き換えている
}このaddItem関数は、表向きにはlistとitemを受け取って何も返していませんが、渡されたlistの内部状態を変えるという副作用を持っています。
このような関数は、呼び出し側から見ると「いつの間にか引数の中身が変わっている」ように見えるため、バグの原因になりやすくなります。
反対に、関数の内部で完結しているローカル変数の変更は、副作用とみなさないことが多いです。
ローカル変数は外から見えず、関数の外部に影響を与えないからです。
function sum(arr) {
let total = 0; // ローカル変数
for (const v of arr) {
total += v; // ローカルな状態の変化
}
return total;
}この例では、totalというローカル変数の値は確かに変化していますが、それは関数の外側からは観測できません。
したがって、多くの場合、このような状態変化を副作用とは呼びません。
関数型プログラミングと「副作用を減らす」考え方
関数型プログラミング(functional programming)というパラダイムでは、副作用をできるだけ減らし、状態変化を局所化することが重視されます。
背景には次のような考え方があります。
- 同じ入力に対して必ず同じ結果を返す関数は、理解しやすく、テストしやすい
- 状態をむやみに書き換えないことで、バグを減らしやすい
- 並列処理や非同期処理との相性がよい
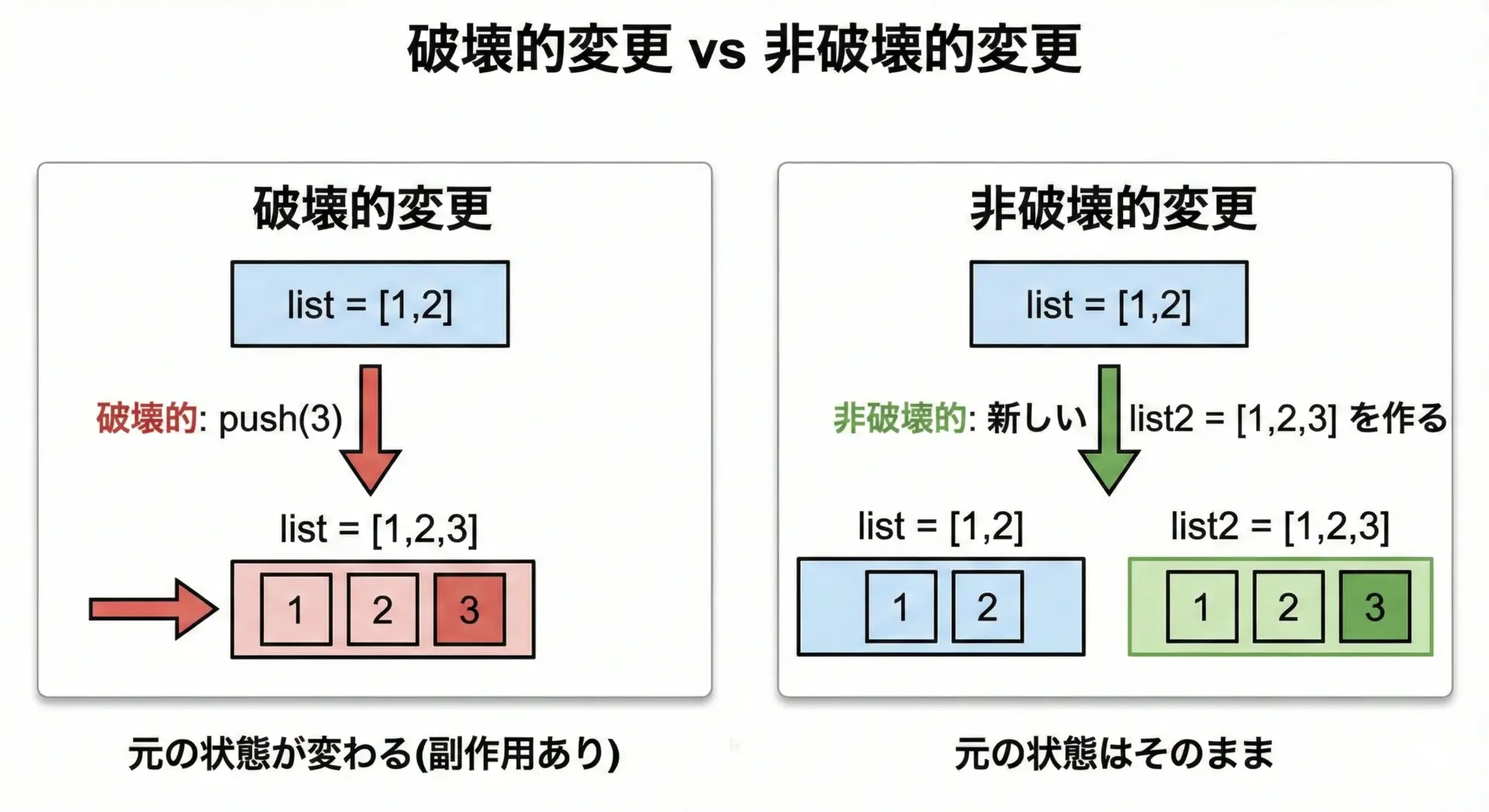
関数型スタイルの典型的な書き方として、「元のデータ構造を変更せず、新しいデータ構造を返す」というパターンがあります。
// 関数型スタイルの例
function appendItem(list, item) {
return [...list, item]; // 元のlistは変えず、新しい配列を返す
}このappendItemは、listのコピーにitemを追加し、その新しい配列を返します。
元のlistは変わらないので、関数の外側の状態を書き換える副作用がありません。
もちろん、現実のプログラムでは、まったく副作用を持たないことは不可能です。
しかし、「どの部分を副作用ありにするか」「どの部分は副作用なしに保つか」を意識的に分けることで、コードの見通しは大きく改善します。
状態管理が難しくなる典型パターン
状態と副作用の関係を理解すると、どんなときに状態管理が難しくなるのかも見えやすくなります。
いくつか典型的なパターンを挙げます。
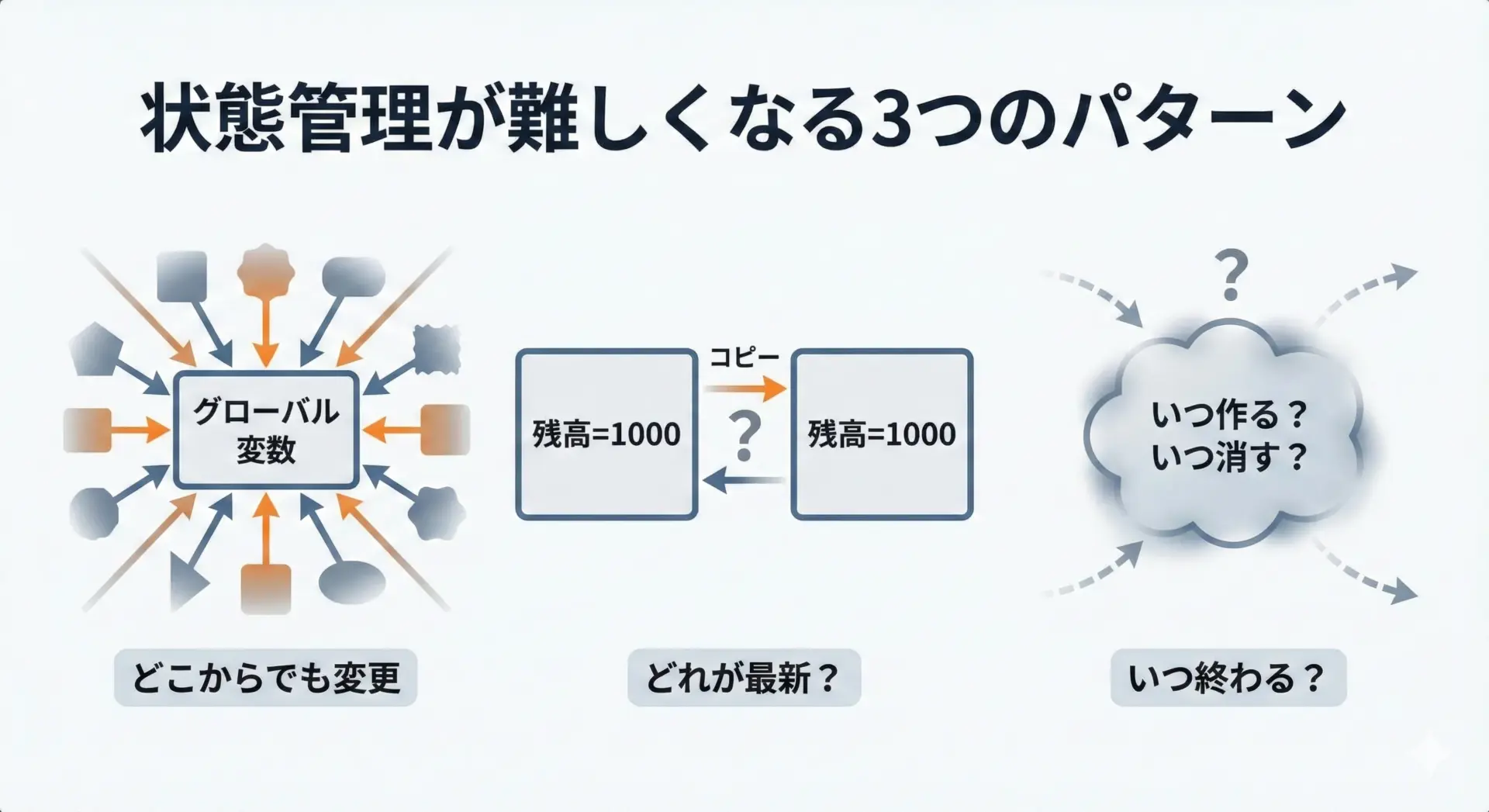
1. グローバル変数に頼りすぎる
プログラムのどこからでもアクセス・更新できるグローバル変数は、一見便利ですが、「隠れた共有状態」になりやすく、バグの原因になります。
- どこで値が変えられているのか追いづらい
- 新しく書いたコードが、既存コードと知らないうちに干渉する
- テストのたびに状態をリセットしないと、前のテストの影響を受ける
2. 同じ情報が複数の場所にコピーされている
ユーザー名や残高など、本来は1か所で管理したい情報が、複数の変数やオブジェクトにコピーされていると、「どれが最新か」がわからなくなります。
片方だけ更新してもう片方を更新し忘れると、画面表示と内部状態が食い違う、といった問題が起こります。
3. ライフサイクルがあいまいな状態
画面のコンポーネント、ゲームのシーン、Webアプリのセッションなど、いつ作られて、いつ破棄されるべきかがあいまいな状態も、管理を難しくします。
破棄されたはずのオブジェクトを参照し続けてしまったり、不要になったイベントリスナーを解除し忘れて挙動が二重になる、といったトラブルが起こりやすくなります。
初心者のための状態と副作用の扱い方
ここからは、初心者の方が実際にコードを書くときに意識すると役立つポイントを紹介します。
すべてを一度に完璧に行う必要はありませんが、頭の片隅に置いておくと、少しずつ状態と副作用の扱いが上達していきます。
副作用を行う場所を分けて整理する
副作用は必要ですが、あちこちでバラバラに起こると追いかけにくくなります。
そこで、「副作用を行う場所」を意識的に分けると、状態管理がかなり楽になります。
簡単な考え方として、次の2種類に処理を分けてみてください。
- 計算だけをする関数(副作用なし)
入力から出力を計算するだけで、画面表示やファイル書き込み、外部状態の変更は行わない。 - 外部とのやりとりをまとめる関数(副作用あり)
ユーザー入力を受け取ったり、画面に反映したり、APIを呼んだりする。必要に応じて、1の関数を呼び出して結果を使う。
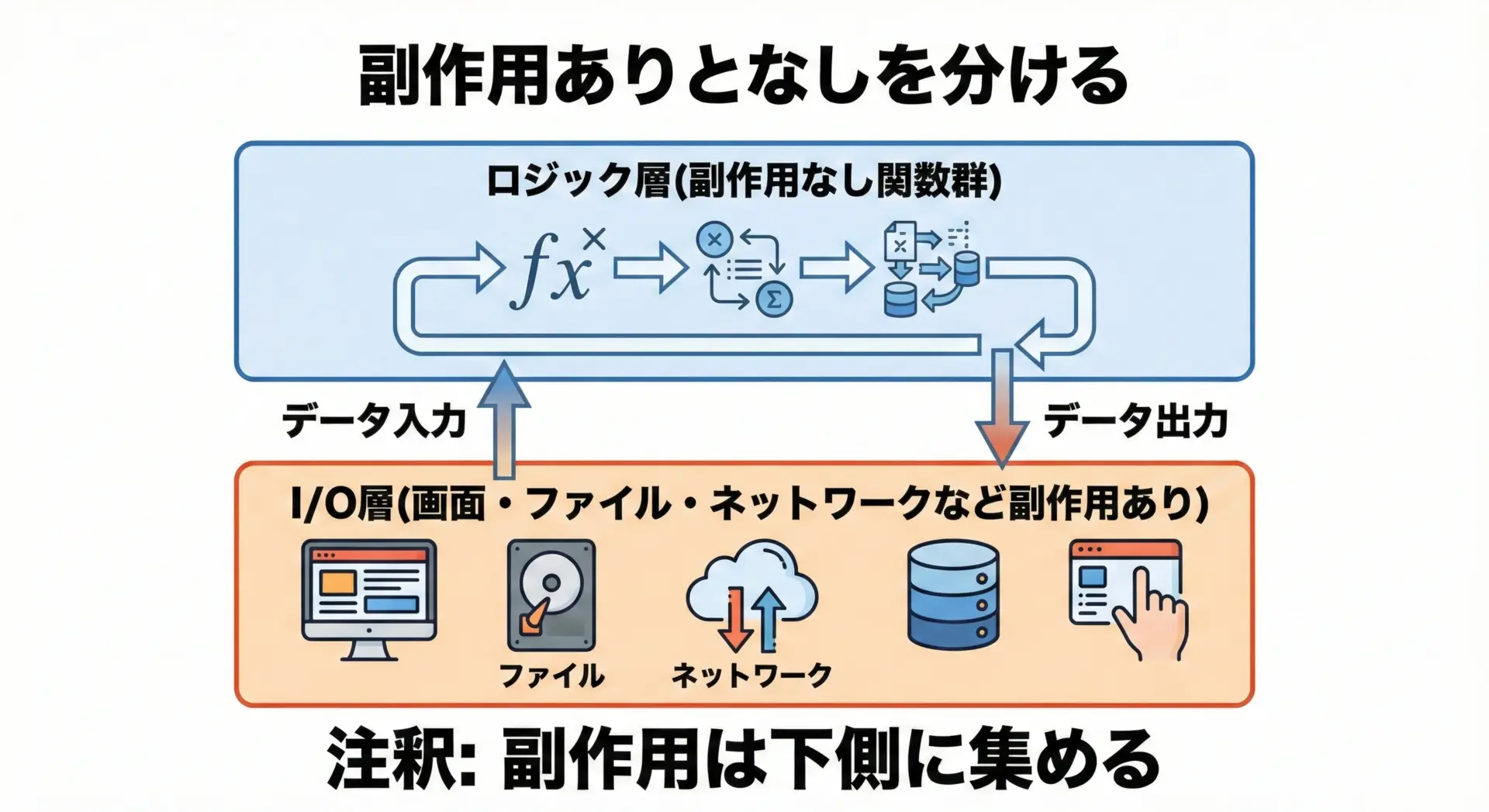
このように層を分けると、「バグっぽい挙動があったときに、どの層を疑えばよいか」を判断しやすくなります。
計算ロジックはテストしやすく、I/O部分は目視で確認しやすいという利点もあります。
小さな関数で状態の変化を追いやすくする
1つの関数の中で、状態の変更や副作用がたくさん行われていると、何がどの順番で起きているのかを理解するのが難しくなります。
そこで、「1つの関数は、できるだけ1つの責務に絞る」ことを意識してみてください。
たとえば、次のような巨大な関数があったとします。
function processOrder(order) {
// 入力チェック
// 在庫確認
// 残高確認
// 注文レコード作成
// 在庫更新
// メール送信
// 画面表示更新
}この中では、おそらくさまざまな状態変更と副作用がごちゃ混ぜになっています。
これを、次のように分解してみます。
function validateOrder(order) { ... } // ロジック
function checkStock(order) { ... } // ロジック
function checkBalance(order) { ... } // ロジック
function createOrderRecord(order) { ... } // ロジック + もしかするとDB副作用
function updateStock(order) { ... } // 副作用
function sendMail(order) { ... } // 副作用
function updateView(order) { ... } // 副作用
function processOrder(order) {
validateOrder(order);
checkStock(order);
checkBalance(order);
createOrderRecord(order);
updateStock(order);
sendMail(order);
updateView(order);
}このように小さな関数に分けることで、「どの関数がどんな副作用を持つのか」を把握しやすくなります。
また、ロジック部分だけを切り出してテストすることも容易になります。
デバッグしやすい状態管理のコツ
実際にバグと向き合う場面では、「いつ、どの状態から、どの状態に変わったのか」を追跡することが重要になります。
デバッグしやすくするための、シンプルなコツをいくつか紹介します。
1. 状態の「源泉」を明確にする
同じ情報を複数の変数にコピーする代わりに、「この情報の本当の持ち主はどこか」を1か所に決めると、整合性を保ちやすくなります。
たとえば「ログイン中のユーザー情報」はcurrentUserだけが真実の値を持ち、画面の表示は常にこれを参照して描画する、といったルールを作るとよいでしょう。
2. 「状態が変わるタイミング」を限定する
状態を変更できるのは、特定の関数やメソッドに限定し、それ以外のコードからは直接変更できないようにするのも有効です。
オブジェクト指向であれば、フィールドをprivateにして、setXxx()のようなメソッド経由だけで変更するといった方法があります。
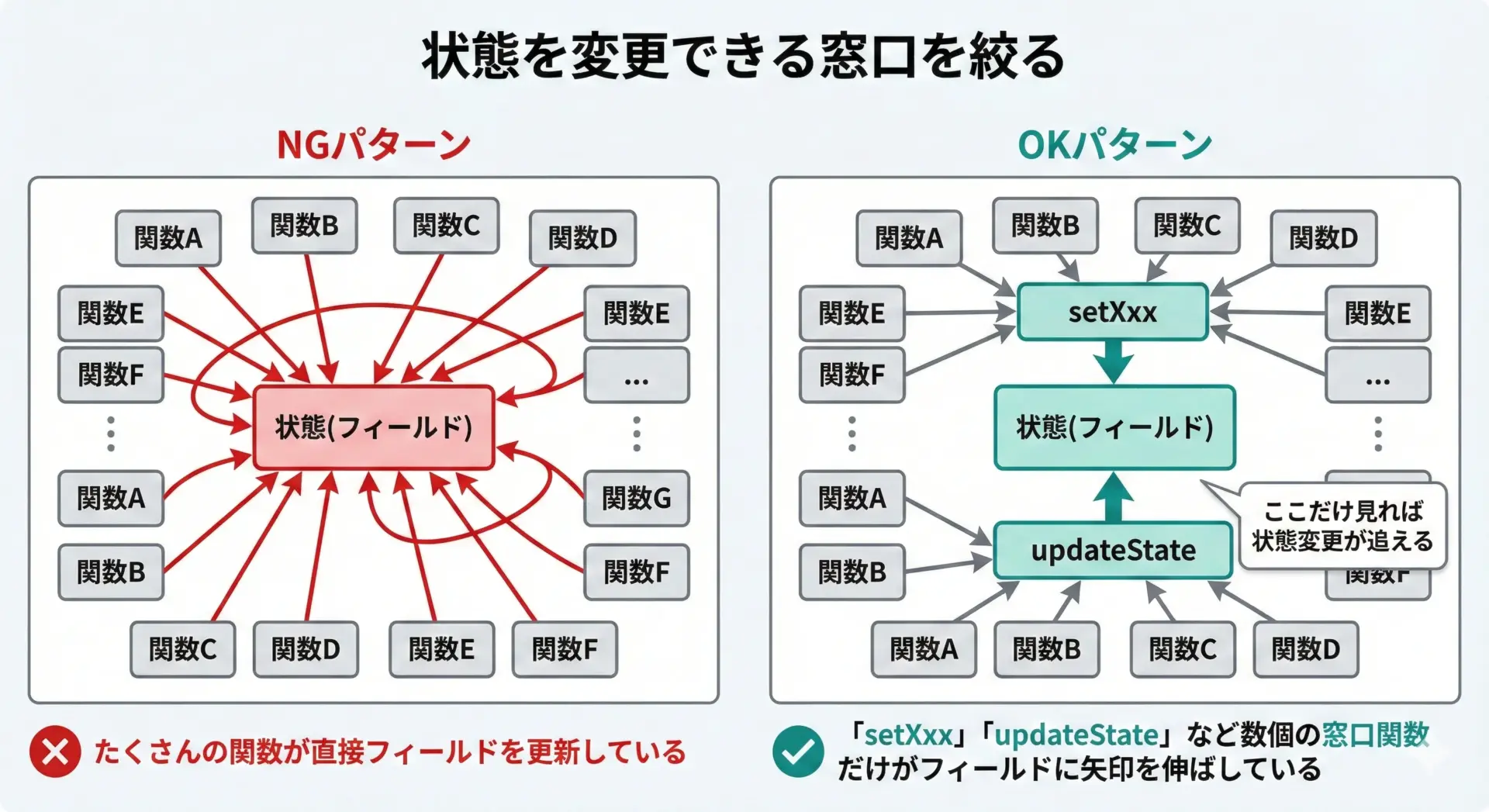
3. ログやスナップショットで状態を記録する
バグ調査のときには、状態がどう変化したかをログに記録しておくと役に立ちます。
たとえば、重要な状態を変更する直前と直後にconsole.logで値を出力するだけでも、かなり原因を絞り込めるようになります。
function updateBalance(balance, delta) {
console.log("before:", balance);
const newBalance = balance + delta;
console.log("after:", newBalance);
return newBalance;
}このように、「状態の変化」を意識してコードを書くことで、問題が起きたときにも冷静に原因を追うことができるようになります。
まとめ
本記事では、プログラムの理解と設計の土台となる状態(state)と副作用(side effect)について、基本的な考え方を整理しました。
- 状態とは、ある時点における「今どうなっているか」を表す値の集合であり、変数・オブジェクト・データ構造などがそれを構成します。
- 副作用とは、関数が引数と戻り値以外の場所(画面、ファイル、グローバル変数など)に与える影響を指し、多すぎるとコードの見通しが悪くなります。
- 「外の状態を変える」ことは基本的に副作用であり、関数型プログラミングではこれを減らし、状態変化を局所化することが重視されます。
- 状態管理が難しくなる原因として、グローバル変数の乱用、情報の重複、ライフサイクルのあいまいな状態などが挙げられます。
- 実務的な対策として、副作用を行う場所を分ける、小さな関数で責務を分割する、状態変更の窓口とログを整えるといった工夫が有効です。
状態と副作用は、どの言語・どのフレームワークでも避けて通れないテーマです。
一度に完璧に理解しようとする必要はありませんが、コードを書くたびに「これはどんな状態を変えているだろう?」「この関数にどんな副作用があるだろう?」と問いかける習慣を持つことで、少しずつプログラムの「記憶」と「変化」をコントロールできるようになっていきます。
