
プログラムを書いていて「ローカルでは動いたのに、本番で結果が違う」「昨日はテストが通っていたのに、今日は落ちる」という経験はないでしょうか。
コードを変えていないのに挙動が変わると、不気味さと不信感が一気に高まります。
こうした現象の背景には、決定性(determinism)と非決定性(nondeterminism)という重要な概念があります。
本記事では、同じコードでも結果が変わる理由を、決定性・非決定性という視点から整理し、予測しやすくテストしやすいコードを書くための考え方と実践的な工夫を解説します。
決定性と非決定性とは何か
まずは、決定性と非決定性という言葉の意味を明確にします。
コンピュータは「決まった手順で処理する機械」のように思われがちですが、実際のプログラムの挙動は、必ずしも毎回同じ結果になるとは限りません。
この差を説明するキーワードが決定性です。
決定性(deterministic)なプログラムとは
決定性プログラムとは、同じ入力と同じ環境条件のもとでは、常に同じ出力を返すプログラムのことを指します。
ここでいう「同じ環境条件」とは、時刻や乱数の種、外部サービスの応答、OSやハードウェアの状態などが同一であることを含みます。
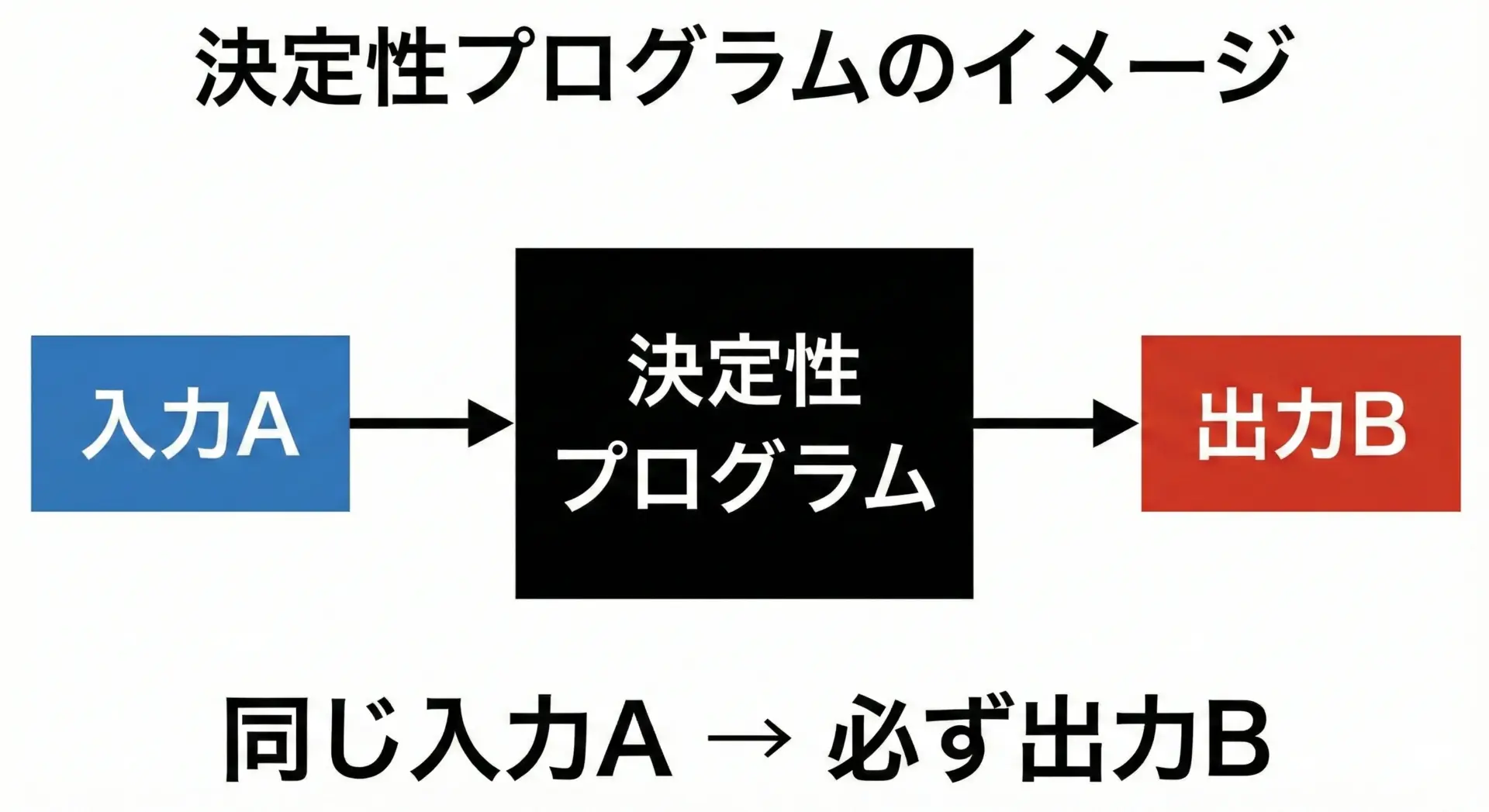
決定性プログラムの典型例は、足し算・掛け算などの算術計算や、純粋関数型プログラミングにおける副作用のない関数です。
例えば、次のような関数は決定的です。
def add(a, b):
return a + bこの関数はadd(2, 3)と呼べば、いつどこで実行しても結果は必ず5になります。
他のスレッドの状態、時刻、ネットワークなどには依存していません。
決定性は、プログラムの理解・テスト・検証を容易にする強力な性質です。
多くのライブラリやフレームワークは、非決定的な要素を内部に隠蔽し、表に見えるAPIはできるだけ決定的に振る舞うよう設計されています。
非決定性(nondeterministic)なプログラムとは
非決定性プログラムとは、同じコード・同じ入力にもかかわらず、実行のたびに結果や実行経路が変わりうるプログラムです。
ここで重要なのは「コードが同じでも結果が変わる」という点です。
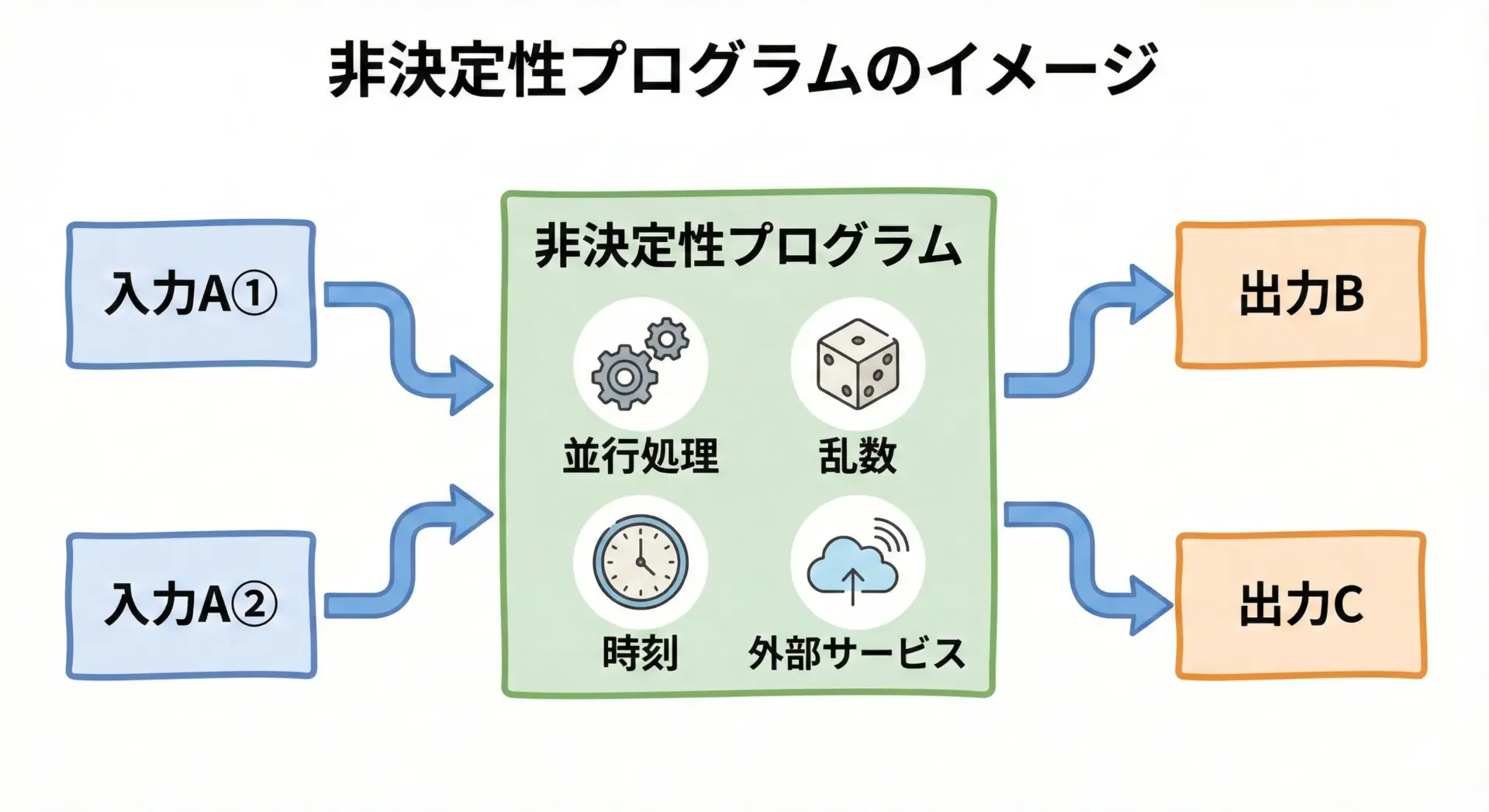
例えば、現在時刻に応じて結果を変える関数は、入力値だけを見れば非決定的です。
from datetime import datetime
def is_morning():
now = datetime.now().hour
return now < 12この関数は引数を取りませんが、呼び出すタイミングによってTrueになったりFalseになったりします。
入力は同じ(常に引数なし)でも結果が変わるため、非決定的なふるまいだといえます。
また、マルチスレッドプログラムで共有変数にアクセスする処理も、スレッドスケジューラのタイミングによって実行順序が変わり、結果が変わることがあります。
このように、非決定性は多くの場合、プログラムの外側(環境や並行性)の影響と結びついています。
「同じコードなのに結果が違う?」が起こる理由
エンジニアが現場でよく直面するのが、「コードを変えていないのに挙動が変わる」「特定の環境・タイミングだけでバグが再現する」といった現象です。
これは本質的に、非決定的な要素がプログラムに紛れ込んでいることが主な原因です。
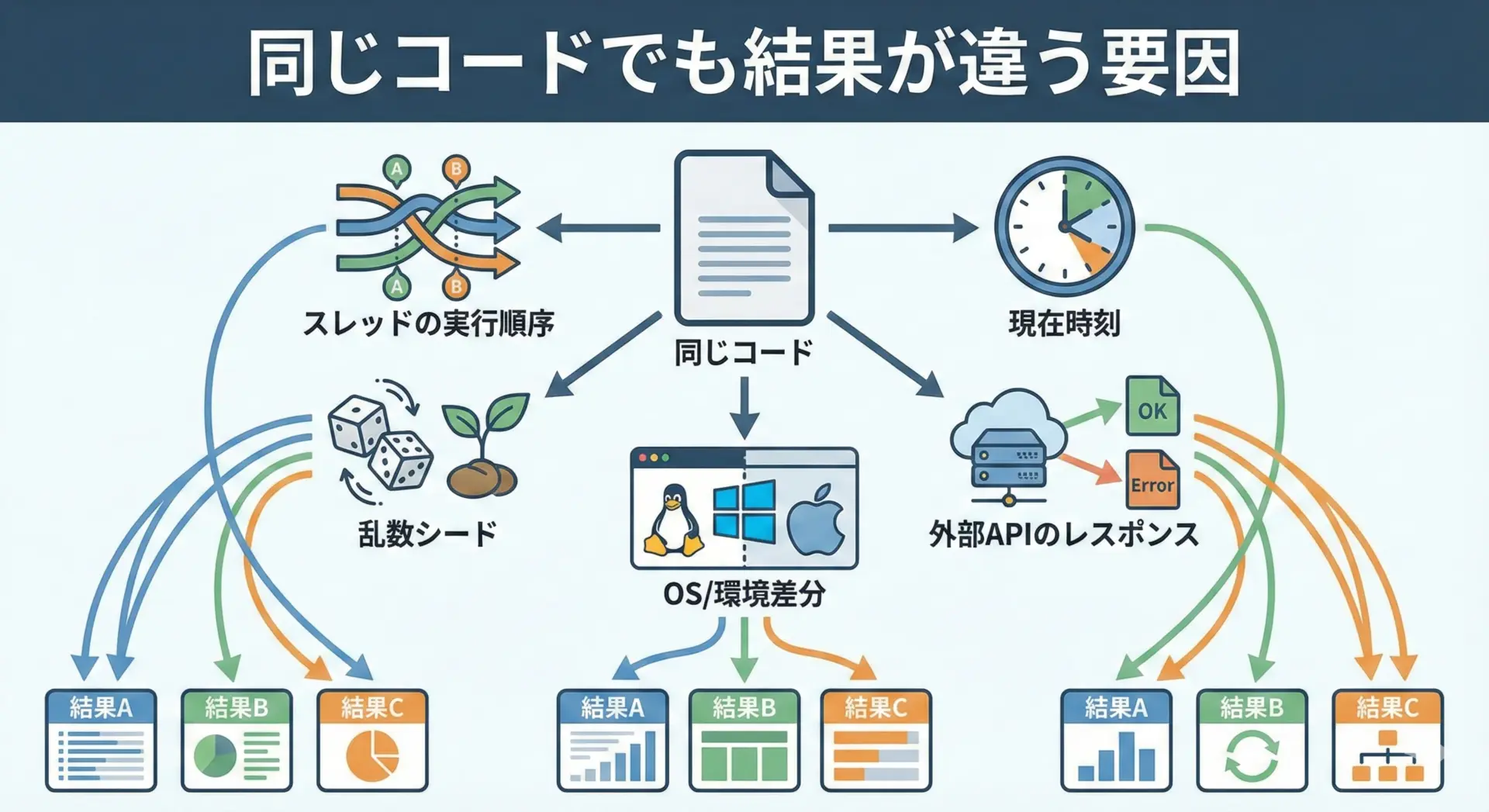
ラップトップでの単体テストでは成功するのに、CI環境や本番サーバでは失敗する場合、たとえば次のような違いが影響していることが多くあります。
- マシン性能の違いによるスレッドの実行タイミングの変化
- 乱数の種(シード)が固定されていない
- タイムゾーンやシステム時刻設定の違い
- 外部APIのレスポンスの遅延やエラー率の差
- OSやライブラリのバージョンが異なる
「コードは同じでも、それを取り巻く環境と状態が同じとは限らない」という事実が、非決定的なふるまいを生みます。
この記事の残りの部分では、この非決定性を理解し、必要に応じてコントロールする方法を解説していきます。
決定的なプログラムの特徴とメリット
ここからは、決定性のあるプログラムに焦点を当て、その特徴とメリットを整理します。
なぜ多くの場合で「決定的であること」が望まれるのかを明確にしておくと、あえて非決定性を許容する場面との対比も分かりやすくなります。
決定性プログラムの具体例
決定性プログラムの典型パターンはいくつかあります。
共通しているのは、「関数の出力が、その引数だけに依存している」という性質です。
純粋な関数的ロジック
def normalize_scores(scores):
total = sum(scores)
return [s / total for s in scores]この関数は、引数scores以外の状態に依存しません。
同じscoresを渡せば、必ず同じリストが返ってきます。
ソートや検索などのアルゴリズム
def sorted_numbers(nums):
return sorted(nums)標準ライブラリのソートアルゴリズムは、入力されたリストの内容だけに基づいて結果を返します。
ソートのアルゴリズム自体は決定的であることが多く、同じ入力なら同じ順序で出力が返ってきます(ただし、安定ソートかどうかなどの仕様は別途確認が必要です)。
シリアライズ/デシリアライズ処理
JSONやProtocol Buffersのようなフォーマットでのシリアライズ処理も、多くの場合決定的です。
同じオブジェクトをシリアライズすれば、同じバイト列や文字列が得られるように設計されています。
これはキャッシュや差分判定、ハッシュ計算などに利用されます。
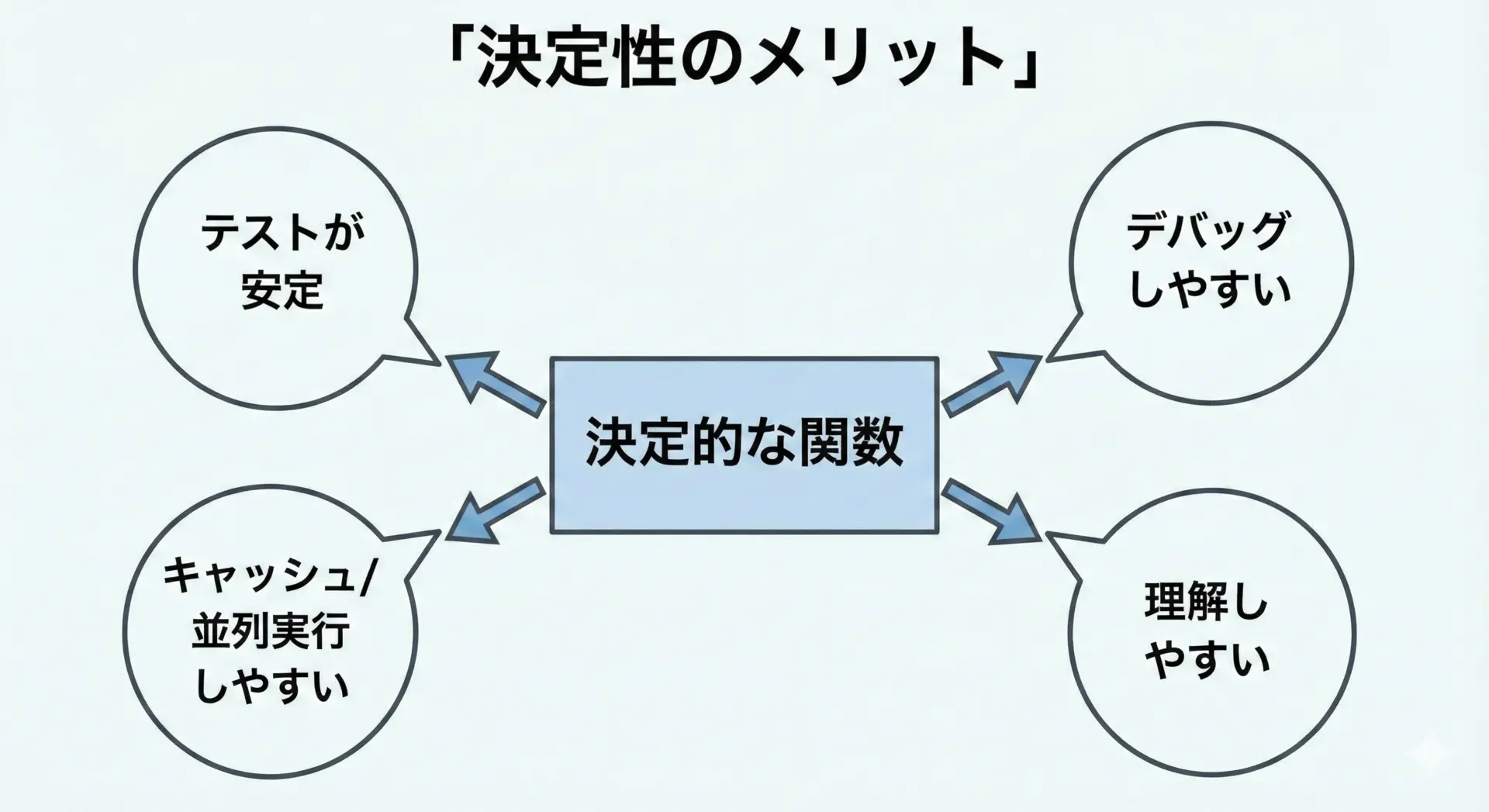
決定性のメリット
決定性はなぜ重要視されるのでしょうか。
主なメリットを整理します。
1. テストが安定し、再現性が高い 決定性プログラムでは、同じテストケースは常に同じ結果を生みます。
そのため、テストが「たまに落ちる」「環境によってだけ失敗する」といったストレスが減ります。
CI環境での自動テストや、バグ報告時の再現にも強いです。
2. デバッグがしやすい 再現性が高いため、1度見つけたバグを何度でも同じ条件で再現できます。
ログやトレースを見ながら原因箇所を特定しやすくなります。
3. 思考コストが下がる エンジニアは、コードを読むときに「この処理は何に依存しているのか」「どの状態が影響しうるのか」を常に意識しています。
決定性プログラムでは、関数の引数だけを見ればよいので、理解とレビューの負担が軽くなります。
4. 並列実行やキャッシュとの相性がよい 同じ入力なら同じ結果が得られるため、メモ化やキャッシュが自然に適用できます。
また、副作用がなければ、複数のスレッドやプロセスから同時に呼び出しても衝突しません。
決定性を保つための基本ルール
決定性を保つには、コードレベルで守るべき基本的なルールがあります。
すべてを完全に守ることは難しくても、「ここを破ると非決定要素が入る」というポイントを意識することが重要です。
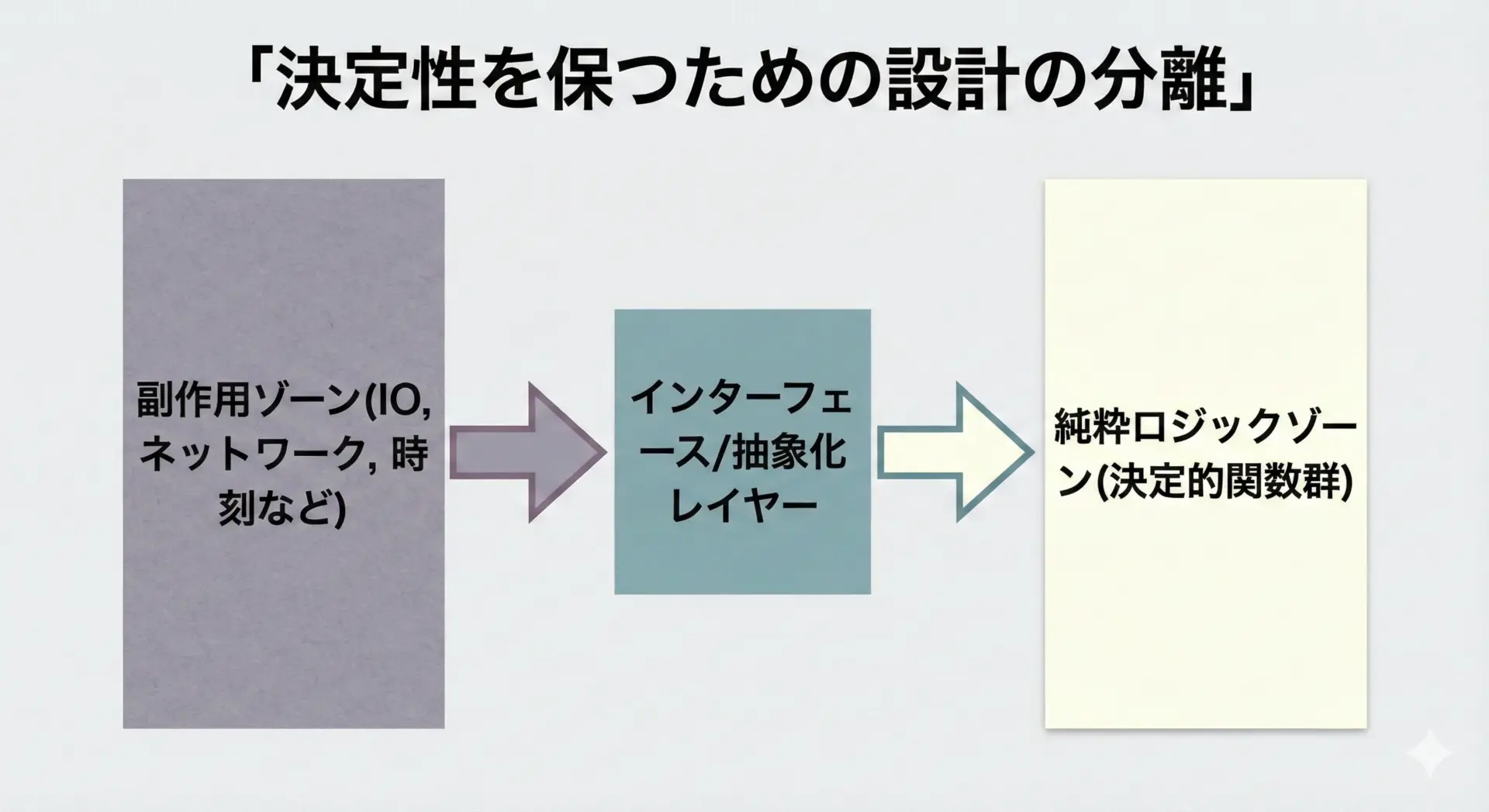
1つの目安は、関数やメソッドを次のように設計することです。
「この関数の出力は、明示的な引数と戻り値だけで説明できるか?」
そのための具体的なルールとして、次のようなものがあります。
- 隠れた入力・出力を減らす
グローバル変数、シングルトン、環境変数、現在時刻、ランダム関数などに直接依存しないようにします。それらが必要な場合は、引数として渡すか、抽象化(インターフェース)を挟むなどして明示化します。 - 副作用を局所化する
ファイルI/Oやネットワーク通信などの副作用は、ロジックとは分離し、境界層にまとめます。ビジネスロジック自体は決定的に保つと、テストしやすくなります。 - 共有可変状態を極力持たない
グローバル変数や、複数スレッドから書き込み可能なデータ構造を避けます。どうしても必要な場合は、排他制御やイミュータブルデータ構造の利用を検討します。
こうしたルールは、いわゆる「関数型プログラミング」の考え方とよく似ていますが、オブジェクト指向や手続き型のコードでも十分に応用できます。
非決定的な挙動が生まれる原因
非決定性は、常に悪いわけではありません。
しかし、どこから非決定性が入ってくるのかを理解していないと、予期せぬバグや再現の難しい不具合に悩まされます。
ここでは、典型的な原因を整理します。
並行処理・マルチスレッドでの非決定性
非決定性の代表例が、マルチスレッドや並行処理の世界です。
スレッドの実行順序やタイミングは、プログラマが完全に制御することはできません。
そのため、共有変数や共有リソースへのアクセス順序が変わり、結果が変わることがあります。
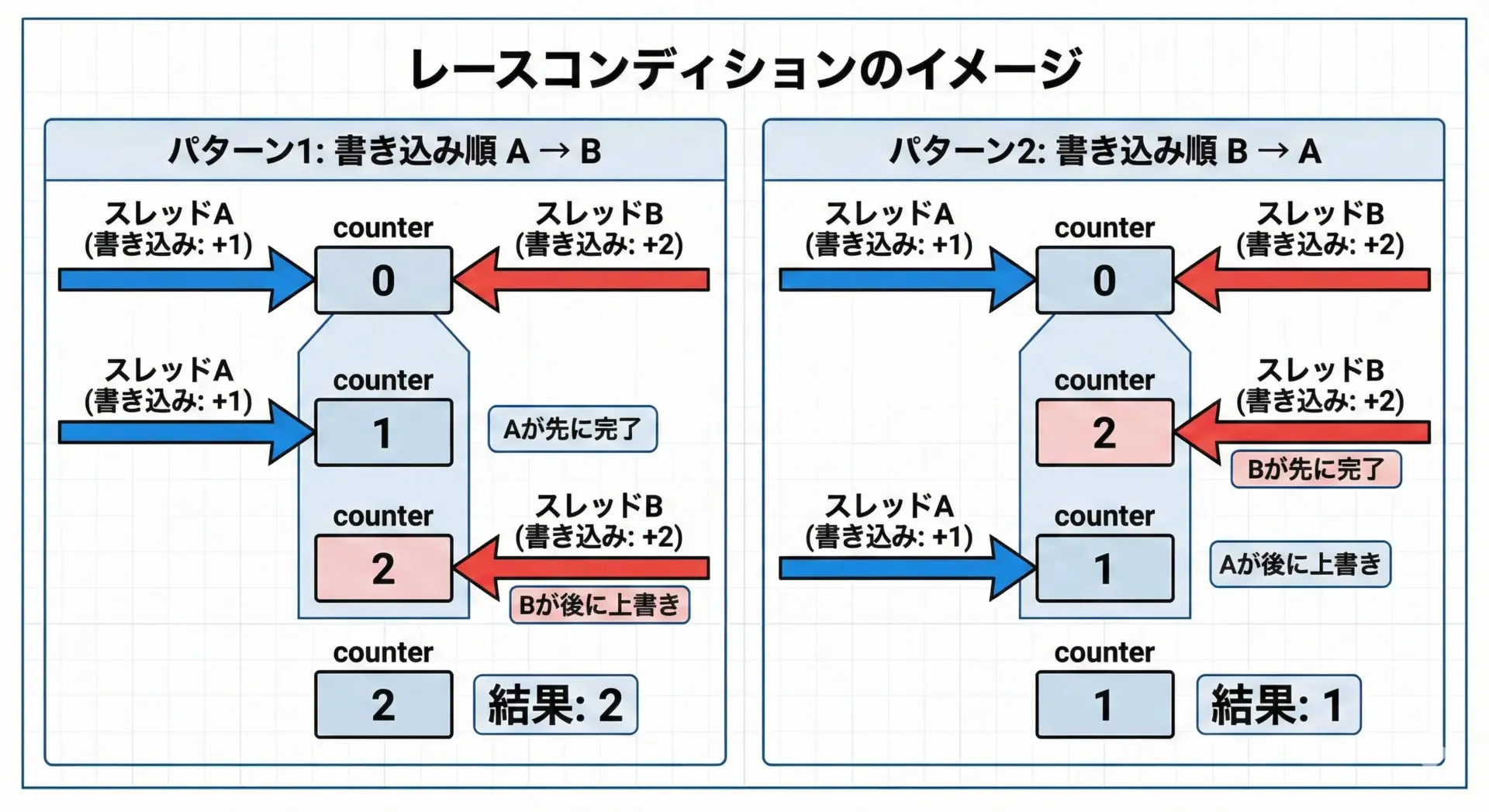
レースコンディションによる結果の揺らぎ
import threading
counter = 0
def increment():
global counter
for _ in range(100000):
counter += 1
t1 = threading.Thread(target=increment)
t2 = threading.Thread(target=increment)
t1.start()
t2.start()
t1.join()
t2.join()
print(counter)このコードは、理論上は200000を出力してほしいところですが、実際には実行するたびに異なる値が出ることがあります。
これはレースコンディションと呼ばれ、「どのスレッドがいつどの命令を実行するか」によって結果が変わる典型的な非決定的挙動です。
並行処理を行う際には、ミューテックスやロック、アトミック操作などを利用して、実行順序をある程度制御する必要があります。
それでもなお、どのスレッドが先にロックを取得するかなど、残る非決定性は存在します。
ランダム関数と乱数シードによる非決定性
乱数は、多くのプログラムで使われる非決定性の源です。
ゲームの挙動、テストデータ生成、機械学習における初期値設定など、用途は多岐にわたります。
import random
def random_choice():
return random.randint(1, 6)この関数は、呼び出すたびに1〜6のどれかを返します。
内部的には擬似乱数生成アルゴリズムを使っているため、本質的には決定的な計算の組み合わせですが、初期シード値に依存して結果が変わります。
シードを固定すると、「見かけ上非決定的な処理」を「テスト時には決定的」にできます。
import random
random.seed(42) # シードを固定
print(random.randint(1, 6)) # 毎回同じ結果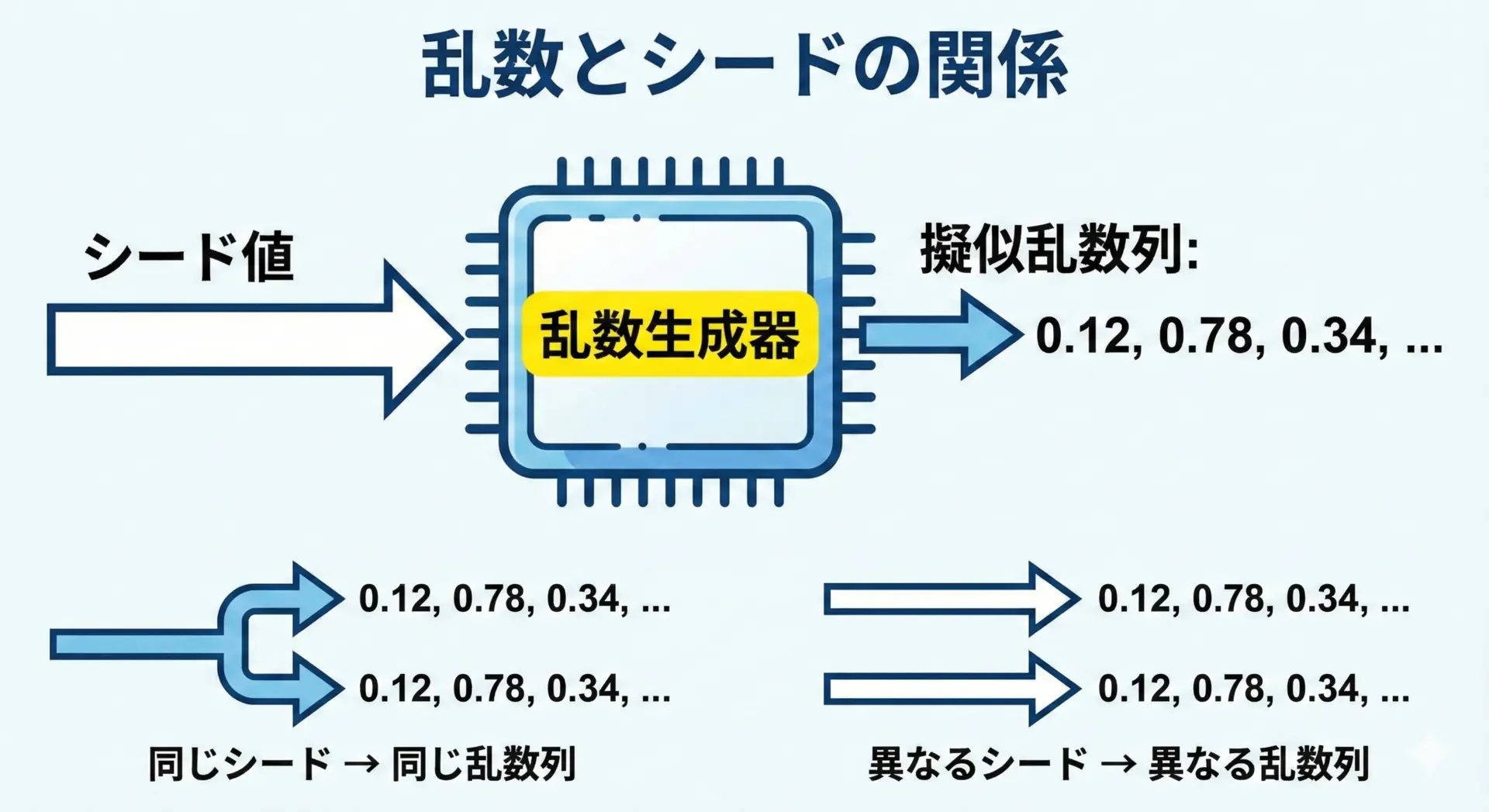
この性質を理解していないと、テストでランダムを使ったときに結果が毎回変わってしまい、テストが安定しない原因になります。
時刻・外部サービス(API)・環境依存による非決定性
プログラムは現実世界と接続して動いているため、時刻や外部サービス、環境に依存しがちです。
これらは典型的な非決定性要因です。
現在時刻・タイムゾーン
from datetime import datetime
def greeting():
hour = datetime.now().hour
if hour < 12:
return "Good morning"
else:
return "Hello"この関数は、呼び出す時刻・タイムゾーンによって結果が変わります。
テストするときには、時刻取得部分を抽象化して差し替え可能にしておくと、決定的に扱いやすくなります。
外部APIやネットワーク
外部APIのレスポンスは、ネットワークの状態、サーバ側の負荷、APIのバージョン変更などにより変わりえます。
APIが返してくるデータがランダム性を含んでいなくても、レスポンス時間やエラーレートには非決定性があります。
環境依存(OS・ロケール・ハードウェアなど)
- OSやCPUアーキテクチャの違いによる浮動小数点計算の誤差
- ロケールによる文字列ソート順の違い
- ファイルシステムの大文字小文字区別の有無
これらは、ある程度予見できますが、「同じコードなのに、Windowsでは動いてLinuxでは動かない」といった問題の原因になります。
グローバル状態・共有リソースによる非決定性
グローバル変数や、アプリケーション全体で共有される状態も、非決定性を生みやすい要因です。
config = {"mode": "prod"}
def is_prod():
return config["mode"] == "prod"この関数は一見決定的に見えますが、どこか別の場所でconfig["mode"]が書き換えられると、結果が変わってしまいます。
特に、テストコードが設定を書き換え、本番コードがそれを引き継いでしまうようなケースでは、「テストの順番によって結果が変わる」という非決定的な挙動が起きます。
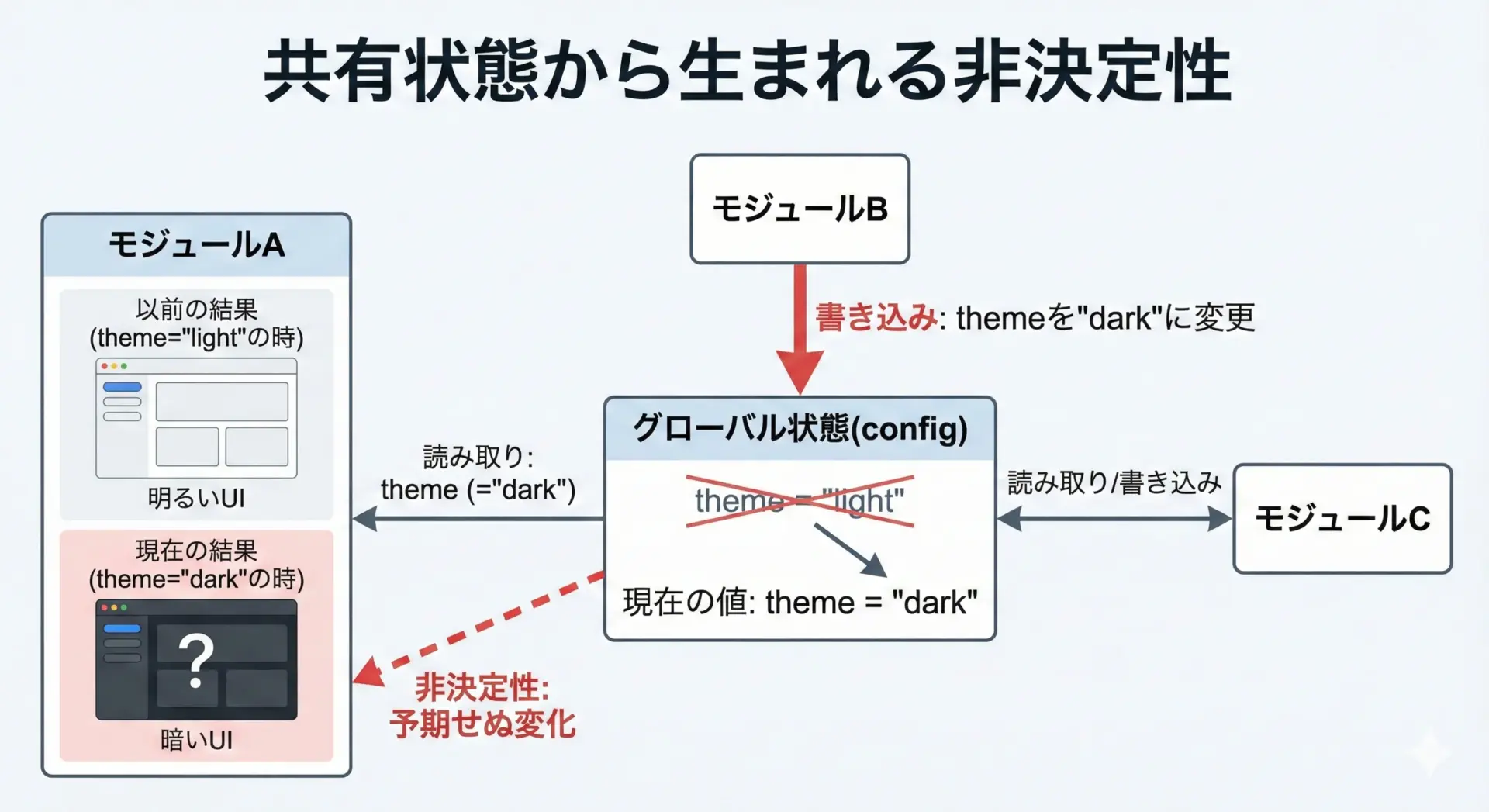
また、ファイル、データベース、キャッシュ、スレッドプールなど、プロセス内外で共有されるリソースも、アクセスタイミングやライフサイクルの違いにより非決定的なふるまいを見せることがあります。
決定性をコントロールして予測しやすいコードにする
非決定的な要素を完全になくすことは現実的ではありません。
しかし、非決定性を意識的にコントロールし、表面上のAPIやテストからは決定的に見えるように設計することは可能です。
非決定的なコードを決定的に近づける方法
非決定的な要素を「内部に閉じ込める」「明示的に渡す」という方針が有効です。
代表的なテクニックをいくつか挙げます。
1. 依存性の注入(Dependency Injection)
時刻取得、乱数生成、外部APIクライアントなどを、コンストラクタや関数引数として注入し、テスト時には決定的な実装に差し替えます。
class Greeter:
def __init__(self, clock):
self.clock = clock # 依存性を注入
def greeting(self):
hour = self.clock.now().hour
return "Good morning" if hour < 12 else "Hello"テスト時には、FakeClockを渡して、常に特定の時刻を返すようにできます。
2. ランダムシードの制御
ライブラリやアプリケーションのエントリポイントで、乱数生成器のシードを明示的に設定し、「本番ではシードを環境ごとに変えるが、テストでは固定する」といったポリシーを決めます。
def init_app(seed=None):
if seed is not None:
random.seed(seed)3. 副作用とロジックの分離
ビジネスロジックを、副作用のない決定的な関数群として書き、その周りを入出力コードでラップします。
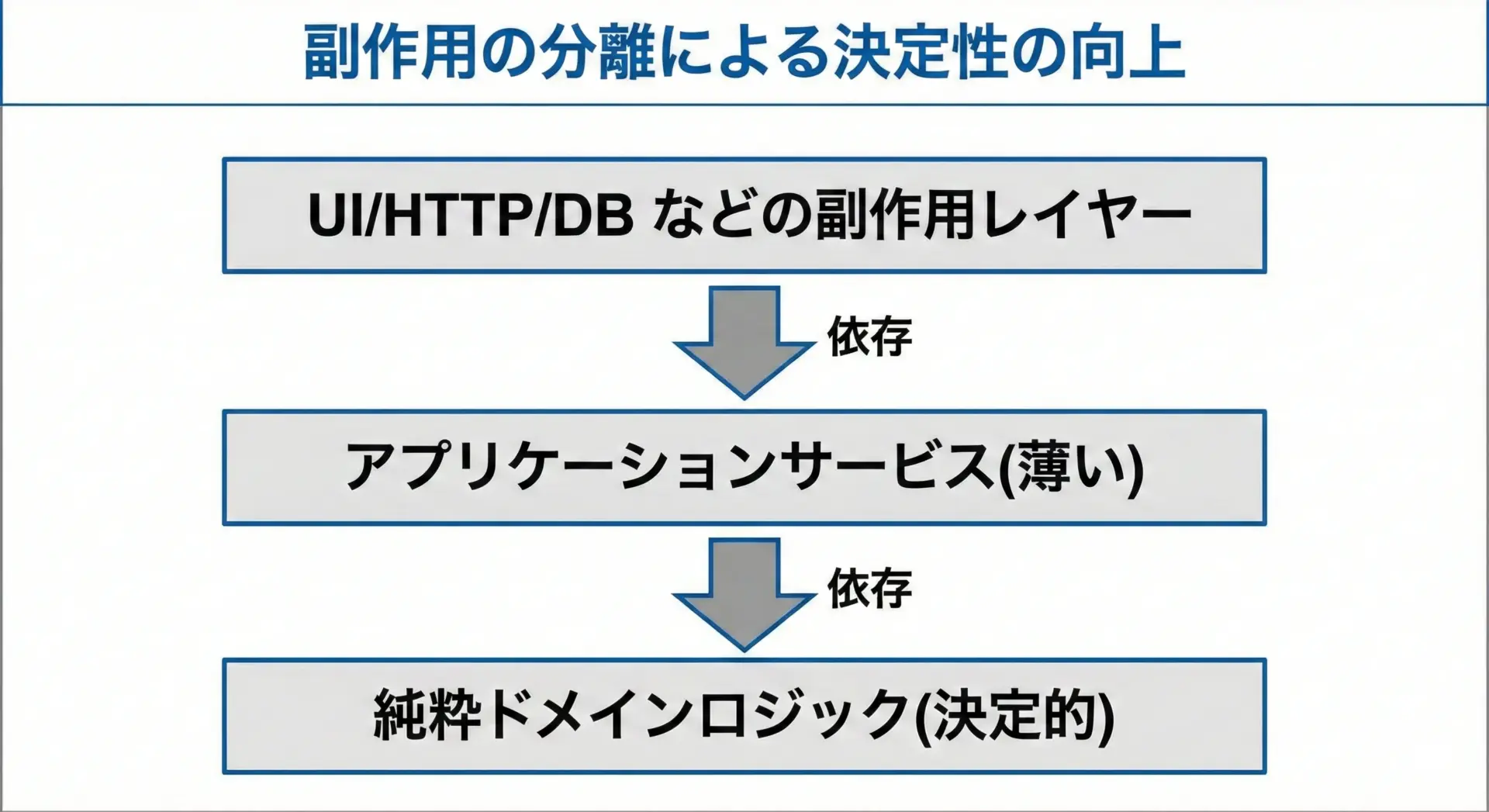
この分離により、非決定的な要素は境界部分に限定され、中心のロジックは決定的に保てます。
テストで結果を安定させるための工夫
テストの安定性は、開発体験と品質に直結します。
非決定性をうまく扱わないと、「たまに落ちるテスト」が増え、チーム全体の信頼を損ないます。
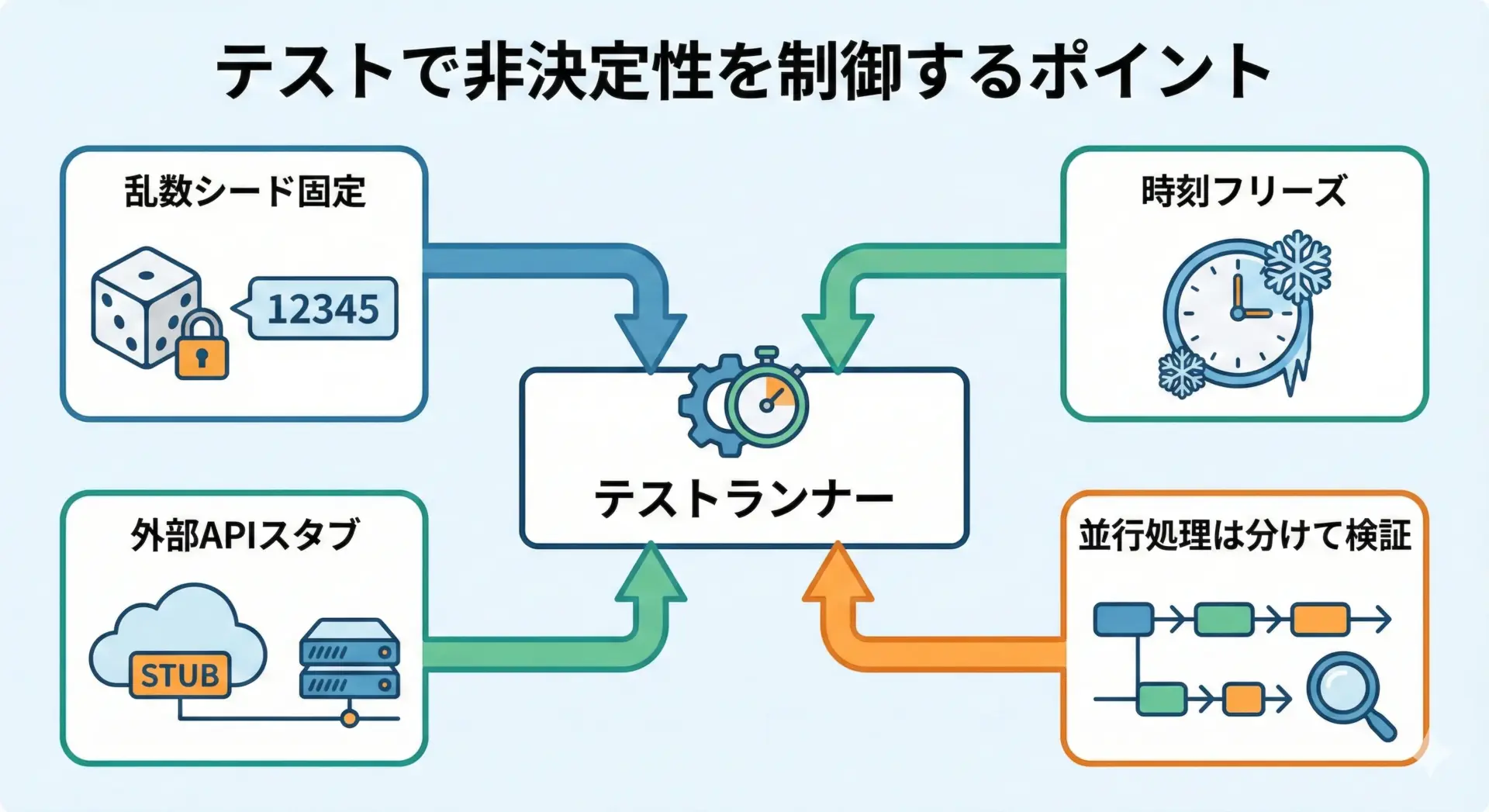
ランダム性の固定
- 乱数シードをテストセットアップで固定する
- テストごとにシードをログに残し、不具合発生時に再現に使えるようにする
時刻のモック・フリーズ
- 時刻取得をラップするユーティリティを用意し、それをモックする
- Pythonなら
freezegun、JavaScriptならsinon.useFakeTimers()などのライブラリを利用し、テスト時に時刻を固定する
外部サービスのスタブ・モック
- HTTPクライアントをインターフェース越しに呼び出し、テスト時にはスタブ実装に差し替える
- 契約テスト(Contract Test)を用いて、スタブと本物のAPIの整合性を定期的に検証する
並行処理のテスト戦略
- 並行処理のコアロジックを、できるだけ単一スレッドでテスト可能な形に分解する
- 本当にマルチスレッドでの相互作用をテストする必要がある場合は、専用のストレステストや長時間テストとして位置付ける
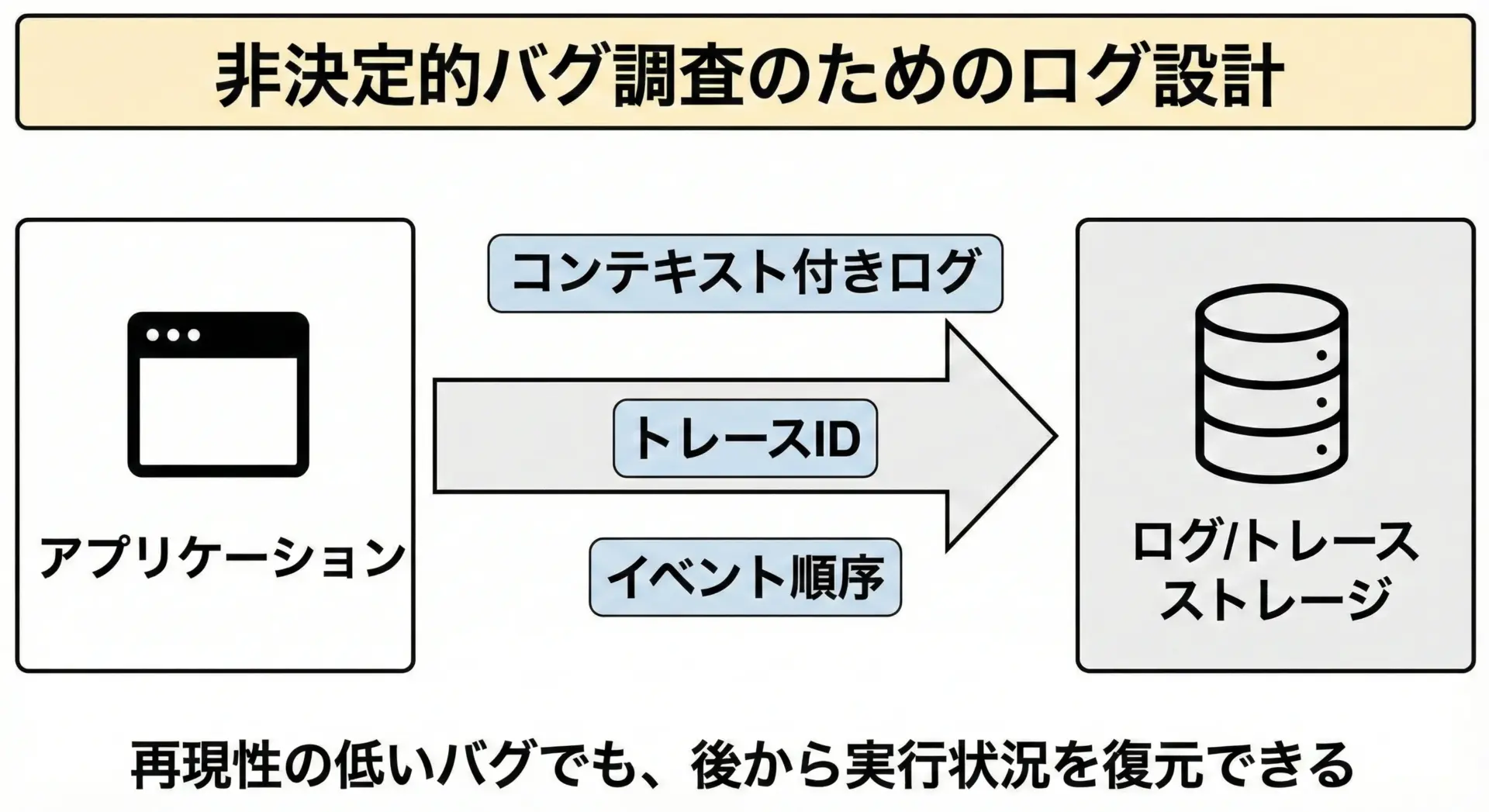
ログとトレースで非決定的なバグを追いかけるコツ
非決定的なバグを完全に防ぐのは難しく、いざ発生したときに原因を追えるようにしておくことが重要です。
そのための実践的なコツをいくつか挙げます。
1. 実行コンテキストをログに含める
- リクエストIDやトレースID
- スレッドIDやプロセスID
- 乱数シード値や設定バージョン
- 環境情報(OS, アプリケーションバージョン, コンフィグ)
「バグ報告時のログだけで、どのような環境・状態で実行されたかを再現できる情報」が重要です。
2. イベントの順序を追跡できるようにする
並行処理のバグでは、「どの順序でイベントが発生したか」がカギになります。
時刻やシーケンス番号を付与してログを出力し、後から並べ替えて検証できるようにします。
3. サンプリングと詳細ログのバランス
常に詳細なログを全件出すと、パフォーマンスとストレージを圧迫します。
異常時にだけ詳細ログやトレースを有効にする仕組みを用意しておくと、非決定的なバグの調査に役立ちます。
まとめ
本記事では、「同じコードなのに結果が違う」という現象を、決定性(determinism)と非決定性(nondeterminism)という観点から整理しました。
決定性プログラムは、同じ入力と環境条件なら常に同じ結果を返すため、テストやデバッグが容易で、理解もしやすくなります。
一方、非決定性は、並行処理、乱数、時刻、外部サービス、グローバル状態などから自然と生まれますが、多くの場合は「どこから入ってくるのか」を意識して設計すれば、制御・局所化することができます。
ポイントは次の通りです。
- 決定性を意識した設計により、ロジックをシンプルに保ち、非決定性は境界層に押し込める
- 依存性注入やシード固定、時刻モック、外部APIスタブなどを活用し、テストからは決定的に見えるよう工夫する
- ログとトレースを設計しておき、非決定的なバグが起きたときにも実行状況を再現しやすくする
プログラムのふるまいを完全に予測することは難しくても、「どこが決定的で、どこが非決定的なのか」を自覚してコントロールすることで、「たまにしか起きない謎の不具合」に振り回される時間を大きく減らすことができます。
日々の設計や実装の中で、ぜひ「これは決定的か?」と問いかける習慣を取り入れてみてください。
