
プログラミングをしていると、必ずと言っていいほど登場するNULL。
なんとなく「空っぽの値」「何もないことを表すやつ」と理解していても、0や空文字との違いを明確に説明してくださいと言われると、少し自信が揺らぐのではないでしょうか。
この記事では、NULLの正体や歴史的背景、よくあるトラブル、そしてうまく付き合うための設計のコツまで、丁寧に整理していきます。
NULLとは何かをざっくり理解しよう
NULLの基本概念
NULLは「まだ値が存在しないこと」を表す特別な値です。
ここで大事なのは、単に「空っぽ」ではなく、「その変数や項目に、まだ値がセットされていない状態」を意味する点です。
たとえば、ユーザーのプロフィール情報を考えてみます。
ユーザーには誕生日の項目があるが、まだ本人が入力していない場合、その誕生日をどう表現するかという問題が出てきます。
このとき、次のような候補が考えられます。
- 0日0月0年
- 空文字(“”)
- NULL
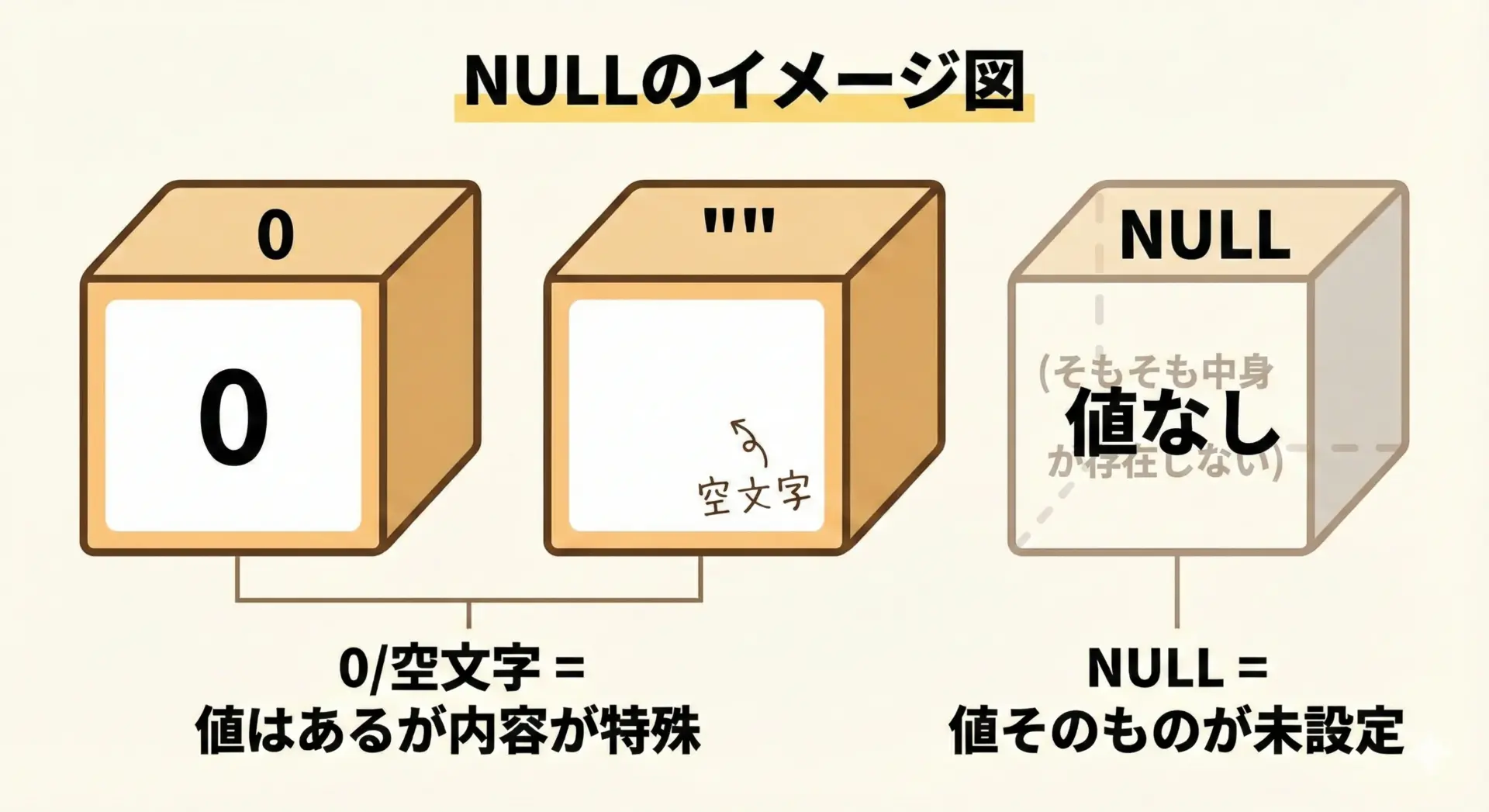
0日0月0年や空文字といった表現は、一応「何かしらの値」が入っている状態です。
一方、NULLは「まだ値そのものが存在していない状態」を示すために用意された特別なマーカーだと考えると理解しやすくなります。
NULLは多くのプログラミング言語やデータベースで登場しますが、実装や表記は言語によって少しずつ異なります。
C系の言語ではNULLやnullptr、JavaScriptではnull、SQLではNULL、PythonではNoneと書きます。
名前や記法は違っても「値がないことを特別に表す記号」という役割は共通です。
0や空文字との直感的な違い
0や空文字との違いは、次のように直感的に整理できます。
- 0は「数値として存在はしているが、その値が0である」状態
- 空文字(“”)は「文字列として存在はしているが、文字数が0である」状態
- NULLは「そもそも値が設定されておらず、存在していない」状態
たとえるなら、本棚の本をイメージするとわかりやすいです。
- 0ページの本 → そんな本は特殊だけれど「本というモノ」はある
- 空のタイトル → タイトルは空だが「タイトルという項目」は存在する
- NULL → そもそも本が棚に置かれていない、またはその棚のスペース自体が未使用
「値があるが、その内容が何かの理由で0や空になっている」のか、「値自体がまだ用意されていない」のかという違いが、後々のロジックやエラー処理に大きく関わってきます。
なぜプログラミングにNULLが導入されたのか
NULLは、1960年代にトニー・ホーア(Tony Hoare)という計算機科学者が設計したポインタの仕組みの中で登場したとされています。
彼の狙いはシンプルでした。
「ポインタが指す先が存在しない場合を表す、簡単で共通の方法がほしかった」
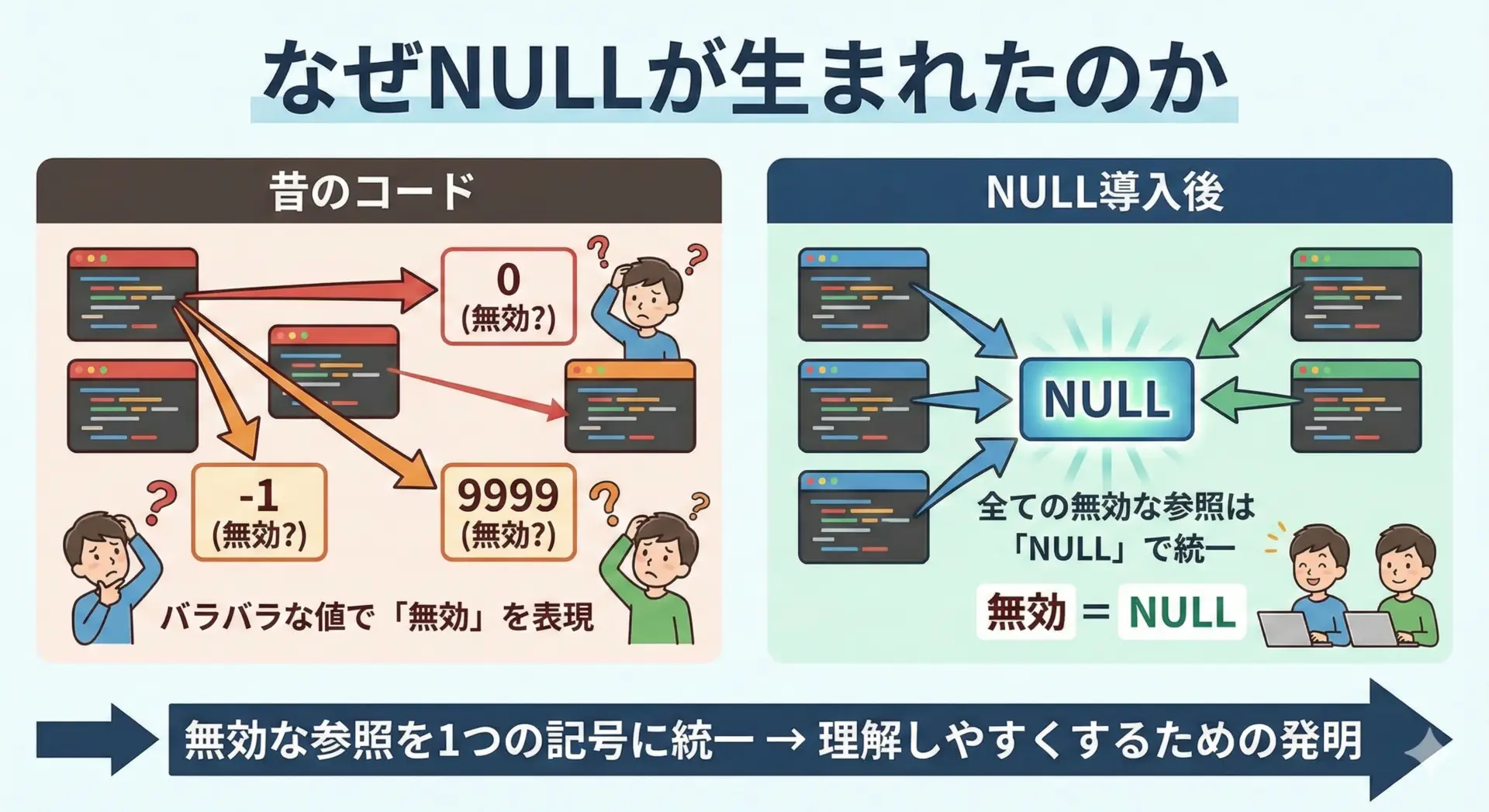
それまで、ポインタ(アドレス)が「どこも指していない」状態をどう表すかは、各プログラマーに任されていました。
その結果、コードを読む側にとっても「この0は本当に0なのか、それとも特別な意味を持つ0なのか」が不明瞭になり、バグの温床になっていました。
そこで、「有効な参照先がないことを示す特別な値」としてNULLを導入したというわけです。
このアイデア自体はとても便利で、当時としては画期的でした。
しかし、後で述べるように、このシンプルな仕組みが長年にわたり無数のバグを生み出すことになります。
NULL・0・空文字の違いを丁寧に整理する
ここからは、NULLと混同されやすい値との違いを、もう少し具体的に見ていきます。
数値の0(numberの0)とNULLの違い
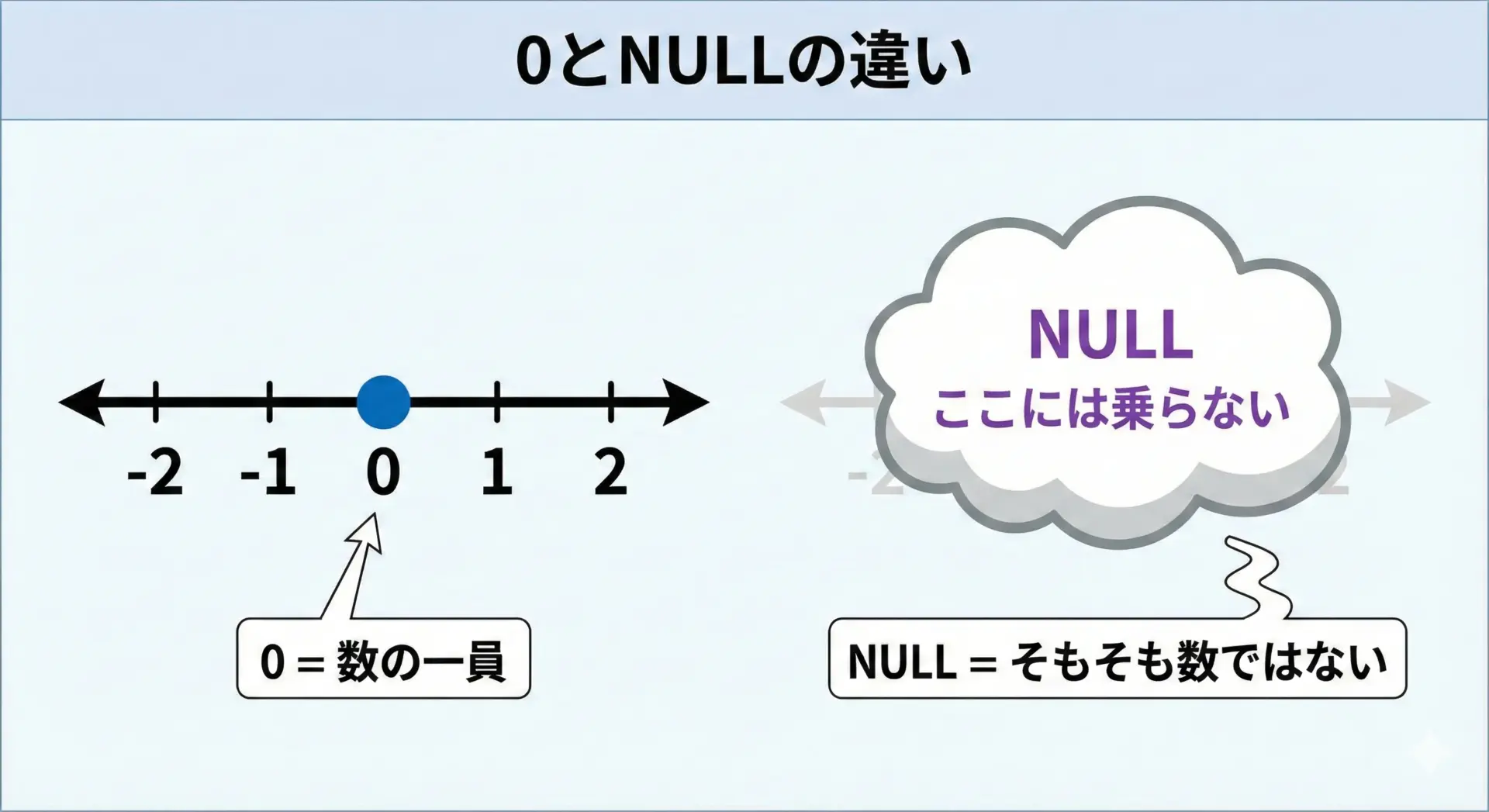
数値の0は「数としての意味を持つ、れっきとした値」です。
一方でNULLは「数値ですらない、単なる『欠損のマーカー』です。
たとえば「商品の在庫数」を考えてみましょう。
- 在庫が0個 → 「商品は存在するが、今は在庫切れ」
- 在庫がNULL → 「そもそも在庫数が登録されていない(まだ不明)」
プログラムの観点から見ると次のような違いがあります。
- 0同士の四則演算は通常どおり可能
- NULLが混ざった四則演算は、多くの言語やSQLでは「結果もNULL」になるか、エラーになる
例としてSQLを見てみます。
SELECT 0 + 5; -- 結果: 5
SELECT NULL + 5; -- 結果: NULL (多くのDBでこう振る舞う)「0は数値計算の仲間」「NULLは計算の土俵にすら上がってこない存在」という整理が役立ちます。
空文字(“”)とNULLの違い
文字列の場合も考え方は同じです。
- 空文字(“”)は「文字列としては存在しているが、長さが0の文字列」
- NULLは「文字列という値そのものが存在していない」
たとえば「ニックネーム」のフィールドで見てみましょう。
- 空文字(“”) → ユーザーが意図的に「ニックネームは空欄にする」と決めた状態
- NULL → まだユーザーがニックネーム入力画面に一度も来ていない状態、またはデータ自体が登録されていない状態
この違いはユーザー体験にも影響します。
- 空文字なら「入力済みだが空」が明確なので、「未入力のユーザーだけにリマインドメールを送る」といった処理の区別ができます。
- NULLなら「そのユーザーがニックネーム機能を知っているかすら分からない」可能性があります。
「ユーザーの意思として空にしたのか」「そもそも触っていないのか」を区別するために、NULLは重要な役割を果たします。
空配列([])とNULLの違い
配列やリストなどのコレクションでも、空配列とNULLの違いがよく登場します。
- 空配列([]) → 「コレクションは存在するが、要素が1つもない」
- NULL → 「コレクション自体が存在しない、またはまだ用意されていない」
たとえば、あるユーザーが購入した商品の一覧を表すpurchasesという変数があるとします。
[]→ 「このユーザーは、今まで1回も購入していない」NULL→ 「まだ購入履歴の取得処理を実行していない」「DBとの連携がまだ」など、履歴が不明な状態
この違いは、エラーを避けるうえでも重要です。
NULLのままpurchases.lengthやpurchases[0]にアクセスすると、多くの言語で例外エラーになります。
一方、空配列なら
- 長さは0
- 添字アクセスはエラーになるが、「配列がない」エラーではなく「範囲外」エラー
など、振る舞いが明確です。
「0件という情報」と「件数がまだ分からない状態」を区別するために、空配列とNULLを使い分けるのが理想です。
未定義(undefined)とNULLの違い

JavaScriptなど、一部の言語にはundefinedという値も存在します。
これがNULLと混ざると混乱の元になります。
よくある整理は次の通りです。
- undefined → 「変数が宣言されているが、プログラム側からまだ値を一度も代入していない状態」
- NULL → 「プログラマーが意図的に『ここには値がない(未設定)』と代入した状態」
たとえばJavaScriptでは、次のような違いがあります。
let a; // a は宣言されたが、値は代入されていない
let b = null; // b には、明示的に「値なし」が代入されている
console.log(a); // undefined
console.log(b); // nullundefinedは「システム側が用意した未初期化状態」、NULLは「人間が意味を持たせて設定した未設定状態」と理解すると整理しやすくなります。
「存在するけど中身が空」と「存在自体がない」の区別
ここまでの話を一言でまとめると、NULLは「存在自体がない」、0や空文字、空配列は「存在するけれど今は中身が空」という違いです。
これを表に整理してみます。
| 状態 | 例 | 意味 |
|---|---|---|
| 数値の0 | 在庫数 = 0 | 商品はあるが、いま在庫切れ |
| 空文字(“”) | ニックネーム = “” | ユーザーが空欄を選んだ、または消した |
| 空配列([]) | 購入履歴 = [] | 1度も購入していない |
| NULL | 誕生日 = NULL | 誕生日が未登録、またはまだ不明 |
| undefined(JavaScriptなど) | let x; → x は undefined | 変数はあるが、代入されたことがない |
プログラム設計では、この区別を意識することが重要です。
「空であること」と「不明であること」は意味が違うため、必要に応じて使い分けないと、仕様があいまいになり、バグの温床になります。
NULLが生むトラブルと「10億ドルの間違い」問題

トニーホーアが語った「10億ドルの間違い」とは
NULLを導入したトニー・ホーア本人は、後年の講演で「NULL参照を発明したことは、私の10億ドルの間違いだ」と語りました。
ここでいう10億ドルとは、NULLに起因するバグやセキュリティ問題、障害対応などに世界中で費やされたコストを象徴的に表現したものです。
彼がそう語る背景には、NULLがあまりに簡単に使え、あらゆるところに紛れ込めてしまうという問題があります。
その結果、
- NULLポインタ参照によるクラッシュ
- NULLチェック忘れによる予期せぬ動作
- 「ここはNULLにならないはず」という思い込みが崩れるバグ
などが、数え切れないほど発生してしまいました。
NULLによるバグの典型例
NULLにまつわるバグは多種多様ですが、典型的なパターンをいくつか挙げます。
1つ目はNULL参照によるクラッシュです。
// C風のイメージ例
User* user = find_user_by_id(123);
// ユーザーが存在しないとき、find_user_by_id は NULL を返す仕様だが…
printf("%s\n", user->name); // user が NULL ならクラッシュこのコードではuserがNULLかどうかを確認せずにuser->nameにアクセスしてしまっています。
もしユーザーが存在せずuserがNULLなら、プログラムは異常終了します。
2つ目は意図しないデフォルト値への変換です。
言語によっては、NULLを数値に変換したときに0になってしまうものがあります。
これは一見便利ですが、「本来は値が未設定であることを検出したかったのに、0として扱われてしまう」というバグを引き起こします。
「NULLを0だとみなして計算する」のか「NULLが混ざっていたら計算不能として扱う」のかという仕様は、言語やライブラリごとに異なり、開発者を悩ませます。
条件分岐(if)でよくあるNULL判定の落とし穴

NULLを条件分岐で扱うときの落とし穴も多くあります。
代表的なのが「ゆるい等価比較」です。
JavaScriptのように==と===がある言語では、次のような挙動になります。
null == undefined // true
null === undefined // false==は型変換を伴うゆるい比較、===は型まで含めた厳密な比較であるためです。
NULL判定を雑に==で書いてしまうと、意図しない値が「同じ」とみなされてしまうことがあります。
また、次のようなコードも要注意です。
if (value) {
// ここに来るのは、value が「真とみなされる値」のとき
}JavaScriptではnullやundefined、数値の0、空文字""などはすべてfalsy(偽とみなされる値)なので、区別がつかなくなります。
「NULLだけを特別扱いしたい」のか、「0や空文字も含めて『空っぽ』として扱いたい」のかを、条件式で明確に書き分けることが重要です。
データベース(SQL)におけるNULLのややこしさ
SQLの世界でも、NULLは非常にややこしい存在です。
代表的なポイントをいくつか挙げます。
1つ目は三値論理(真 / 偽 / 不明)です。
SQLでは、NULLを含む比較は多くの場合「不明(unknown)」になります。
SELECT 1 = 1; -- TRUE
SELECT 1 = NULL; -- UNKNOWN (真でも偽でもない)
SELECT NULL = NULL; -- UNKNOWN (NULL同士でも TRUE にならない)このため、WHERE句でNULLを比較しても、思ったように行がヒットしないという問題がよく起こります。
SELECT * FROM users WHERE nickname = NULL; -- 何も返ってこないNULLと比較すると常にUNKNOWNになり、WHERE句ではUNKNOWNは弾かれてしまうためです。
正しくは次のように書きます。
SELECT * FROM users WHERE nickname IS NULL;2つ目は、集計関数での扱いです。
多くのDBでは、COUNTやSUMなどの集計関数はNULLを無視します。
SELECT COUNT(age) FROM users; -- age が NULL の行は数えられない
SELECT COUNT(*) FROM users; -- 全行を数える意図せずNULLを含んだ状態で集計をすると、「なぜか件数が少ない」「平均値がずれている」など、原因不明の集計バグにつながります。
NULLと上手につきあうための考え方とテクニック
ここまで見てきたように、NULLは強力な表現力を持つ一方で、多くのトラブルも生みます。
では、NULLとうまく付き合うにはどうすればよいのでしょうか。
「使わなくていいNULL」はなるべく避ける設計
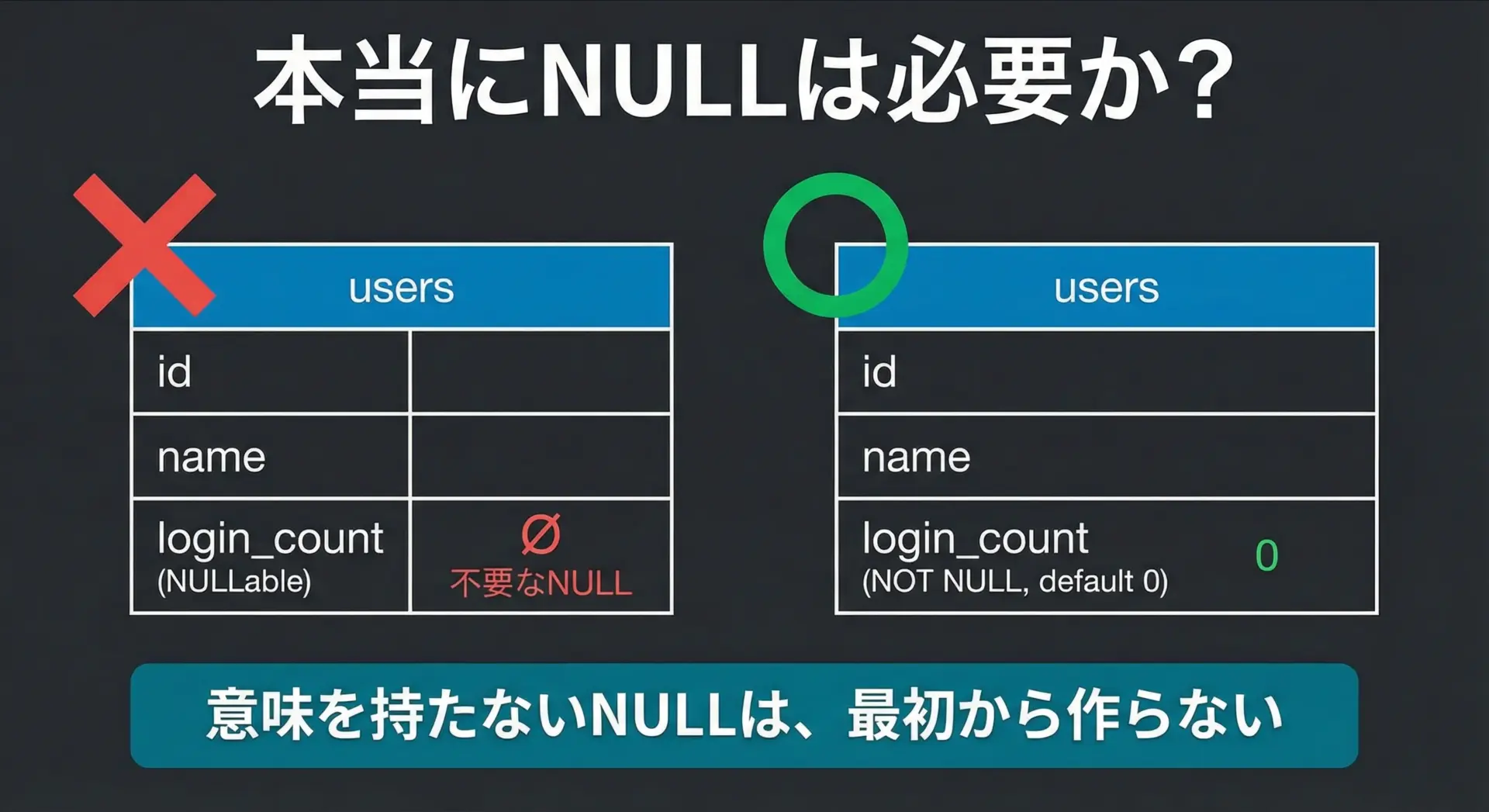
まず大切なのは、「なくてもよいNULLは、そもそも作らない」という設計方針です。
たとえば、ユーザーのログイン回数を表すlogin_countというカラムを考えます。
- 最初は0回からスタートし、ログインのたびに1ずつ増やす
- ログイン履歴がなくても「0回」として扱える
このような場合、NULLを使う必要はありません。
カラム定義でNOT NULLを指定し、デフォルト値を0にしてしまえば、NULLに悩まされることはなくなります。
逆に、NULLが意味を持つケースでは、「このフィールドがNULLだったら何を意味するのか」を仕様として明文化しておくことが重要です。
オプショナル型(optional)やMaybe型でNULLを代替する
近年の多くの言語では、オプショナル型(Optional)やMaybe型という仕組みが導入されています。
代表的な例としては次のようなものがあります。
- Swift:
String?(オプショナル) - Kotlin:
String?(nullable型) - Rust:
Option<T> - Haskell:
Maybe a
これらの型のポイントは、「値がある場合」と「値がない場合」を型レベルで区別することにあります。
たとえばKotlinでは、次のように書きます。
val name: String? = null // null を許す
val age: Int = 0 // null を許さない「nullを許すかどうか」が型として明示されるため、コンパイラが「この変数はnullかもしれないから、ちゃんとチェックしなさい」と警告してくれます。
また、RustのOptionのように、Some(value)かNoneかを明示的に扱うスタイルでは、「値なし」のケースを必ずコードに書かないとコンパイルが通らないため、NULL漏れによるバグを減らすことができます。
初期値を決めてNULLを減らすプログラミング
NULLを完全になくすことは難しくても、「どんな状態でも、なるべくNULLを残さない」という考え方は有効です。
その1つの手段が、初期値をうまく決めておくことです。
たとえば、次のような工夫が考えられます。
- 文字列: 空文字
""を初期値にしておく - 数値: 0や-1など、ビジネス的に意味のある初期値を決めておく
- 配列・リスト: 必ず空配列
[]で初期化する - オブジェクト: 必須フィールドだけでもデフォルト値を入れておく
ただし、「0や空文字をNULLの代わりに乱用する」のは逆効果です。
大事なのは、「この値は本来どういう意味を持つのか」をよく考えたうえで、妥当な初期値を選ぶことです。
NULL安全(null safety)をサポートする言語の活用方法
最近の言語は、NULLによるバグを減らすためにNULL安全(null safety)と呼ばれる仕組みを取り入れています。
代表的なのはKotlinやSwift、TypeScriptなどです。
これらの言語では、おおむね次のような機能が用意されています。
- nullable型とnon-null型の区別
- コンパイル時のnullチェック
- 安全呼び出し演算子(例: Kotlinの
?.、TypeScriptの?.) - デフォルト値演算子(例: Kotlinの
?:、JavaScriptの??)
例えばKotlinでは次のように書けます。
val length = user?.name?.length ?: 0この1行で、
userがnullならlengthは0userはあるがnameがnullならやはり0- それ以外は
name.lengthの値
というロジックを安全に表現できます。
NULL安全な言語を選び、その機能を積極的に活用することは、NULL地獄から抜け出すための近道です。
既存言語でも、静的解析ツールや型チェッカー(たとえばTypeScript、Flow、静的解析付きのJavaなど)を導入することで、似たような効果を得ることができます。
まとめ
NULLは、「値が未設定であること」を表すための強力な記号であり、0や空文字、空配列とは明確に役割が異なります。
0や空文字は「存在しているが、内容が特別な値」であり、NULLは「存在自体がまだ不明」を意味します。
一方で、その使いやすさゆえに、NULLは長年にわたって無数のバグや障害を生んできました。
トニー・ホーアが「10億ドルの間違い」と呼んだのも、NULLがもたらす負の側面の大きさを物語っています。
NULLとうまく付き合うためには、
- 意味のないNULLは設計段階で排除する
- NULLが意味を持つ箇所では、その意味を仕様としてはっきりさせる
- オプショナル型やMaybe型、null safetyといった仕組みを積極的に活用する
- 初期値やNOT NULL制約をうまく使い、NULLの登場場面を最小限にする
といった考え方が重要です。
NULLは「世紀の発明」であり、「10億ドルの間違い」でもあります。
しかし、その正体と扱い方をきちんと理解すれば、NULLの持つ表現力だけを活かし、トラブルを最小限に抑えることは十分に可能です。
日頃のコードやDB設計を見直すきっかけとして、NULLとの付き合い方を改めて意識してみてください。
