
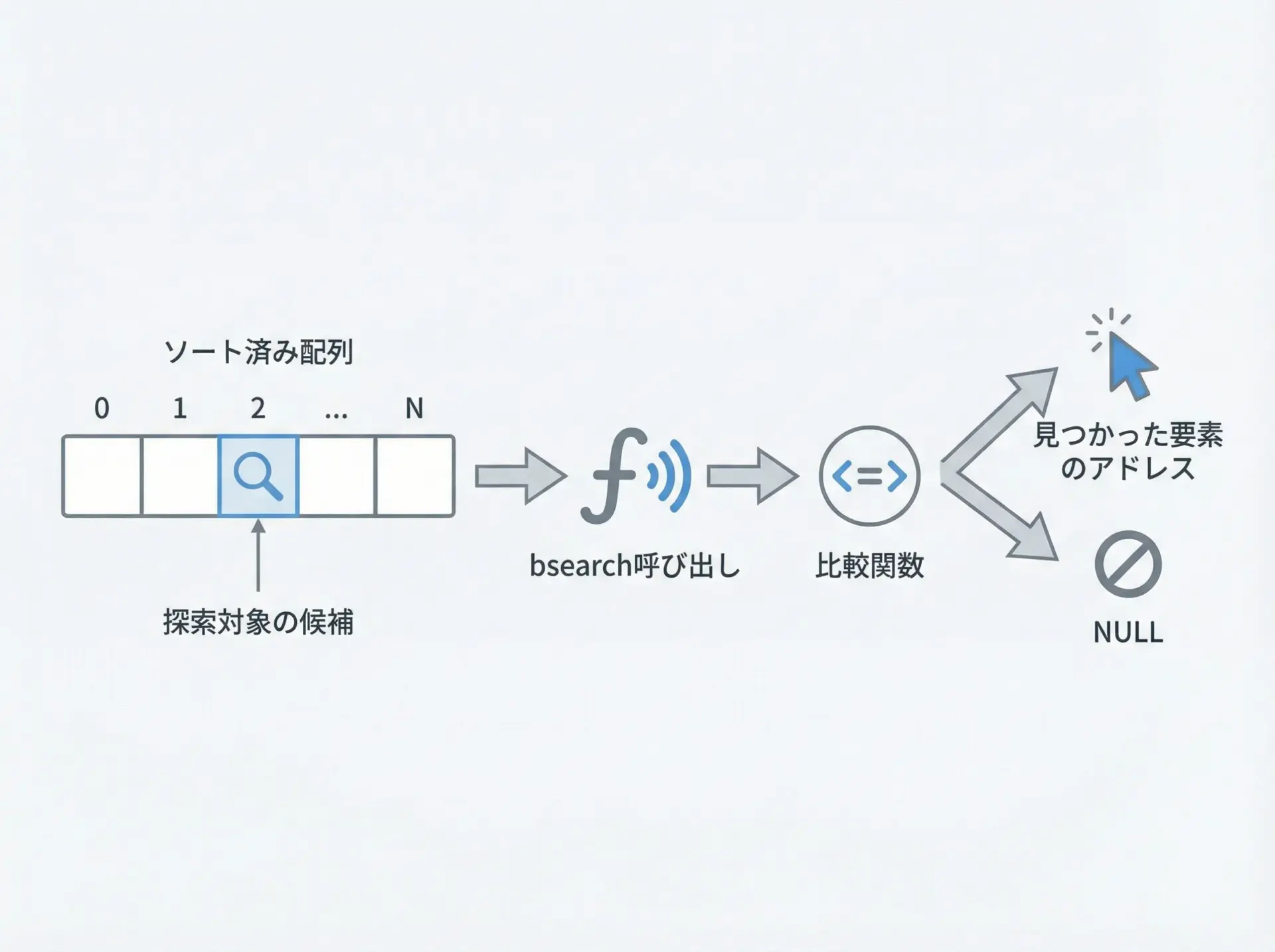
C言語で大量のデータから素早く値を探すとき、毎回for文で先頭から順番に探していては効率が悪くなります。
標準ライブラリには、こうした検索処理を高速に行うための二分探索関数<b>bsearch</b>が用意されています。
本記事では、配列の基礎的な使い方から、構造体配列に対しての検索方法まで、順を追って丁寧に解説します。
サンプルコードも豊富に用意しますので、そのままコピペして試せる内容になっています。
【C言語】bsearchとは何か
bsearchの概要
bsearchは、C言語の標準ライブラリに含まれている二分探索(バイナリサーチ)用の関数です。
事前にソートされた配列の中から、指定したキーと等しい要素を、高速に探すことができます。
重要なポイントとして、bsearchを使うためには「配列がソート済み」である必要があります。
未ソートの配列に対してbsearchを呼び出しても、正しい結果は得られません。
どのヘッダーファイルか・プロトタイプ
bsearchを使うには、標準ヘッダstdlib.hをインクルードします。
プロトタイプは次のように定義されています。
void *bsearch(
const void *key, // 探したいキー(検索対象の値)
const void *base, // 先頭要素へのポインタ(配列の先頭)
size_t nmemb, // 配列の要素数
size_t size, // 各要素のサイズ(バイト数)
int (*compar)( // 比較関数へのポインタ
const void *a,
const void *b
)
);戻り値はvoid *型であり、見つかった要素へのポインタが返されます。
もし要素が見つからなければNULLが返されます。
bsearchが向いている場面・特徴
線形探索との違い
配列を先頭から1つずつ調べる方法は線形探索と呼ばれます。
要素数がNのとき、最大でN回の比較が必要になります。
それに対して、bsearchが内部で行う二分探索では、約log2(N)回の比較で済みます。
例えば、要素数が以下のような場合の比較回数のおおよその目安を表にまとめると次のようになります。
| 要素数N | 線形探索の比較回数(最大) | 二分探索のおおよその比較回数 |
|---|---|---|
| 10 | 10 | 4以下 |
| 1,000 | 1,000 | 約10 |
| 1,000,000 | 1,000,000 | 約20 |
このように、要素数が大きくなるほど、二分探索の効果は劇的に大きくなります。
bsearchを使う前提条件
bsearchを使う上での前提条件は、次の2点です。
1つ目は、配列が比較関数に従ってソート済みであることです。
整列されていない配列では、二分探索の前提が崩れるため、結果は保証されません。
2つ目は、比較関数comparの実装が、ソートに使用した順序と一致していることです。
qsortで昇順ソートしたのであれば、bsearchにも同じ昇順ルールの比較関数を渡す必要があります。
bsearchの基本的な使い方(整数配列)
まずは、最もシンプルな例として、int型配列に対してbsearchを使うパターンを見ていきます。
サンプルコード: int配列でのbsearch
次のプログラムは、ソートされたint配列から、指定した値を探す例です。
#include <stdio.h>
#include <stdlib.h>
// int用の比較関数
// a < b のとき負の値、a == b のとき0、a > b のとき正の値を返す
int compare_int(const void *a, const void *b) {
// voidポインタをintポインタにキャストしてから中身を参照
int ia = *(const int *)a;
int ib = *(const int *)b;
if (ia < ib) return -1;
if (ia > ib) return 1;
return 0;
}
int main(void) {
// 昇順にソート済みの配列とする
int arr[] = {1, 3, 5, 7, 9, 11, 13};
int n = (int)(sizeof(arr) / sizeof(arr[0]));
int key = 7; // 探したい値
// bsearch呼び出し
// key: &key
// base: arr
// nmemb: n
// size: sizeof(int)
// compar: compare_int
int *found = bsearch(
&key,
arr,
(size_t)n,
sizeof(int),
compare_int
);
if (found != NULL) {
int index = (int)(found - arr); // 見つかった要素のインデックス計算
printf("値%dがインデックス%dで見つかりました。\n", key, index);
} else {
printf("値%dは配列内に存在しません。\n", key);
}
return 0;
}値7がインデックス3で見つかりました。コードのポイント解説
このサンプルの中で特に重要な箇所は、比較関数compare_intの実装と、戻り値の扱いです。
比較関数では、const void *として渡されるポインタをconst int *にキャストし、中身の値を取り出して比較しています。
戻り値は負・ゼロ・正の3通りで意味が決まっています。
この比較関数の規約を守らないと、bsearchは正しく動作しません。
また、bsearchの結果はint *として受け取り、配列先頭ポインタarrとの差分を取ることでインデックスを求めています。
このように、ポインタ差分でインデックスを計算するのが一般的です。
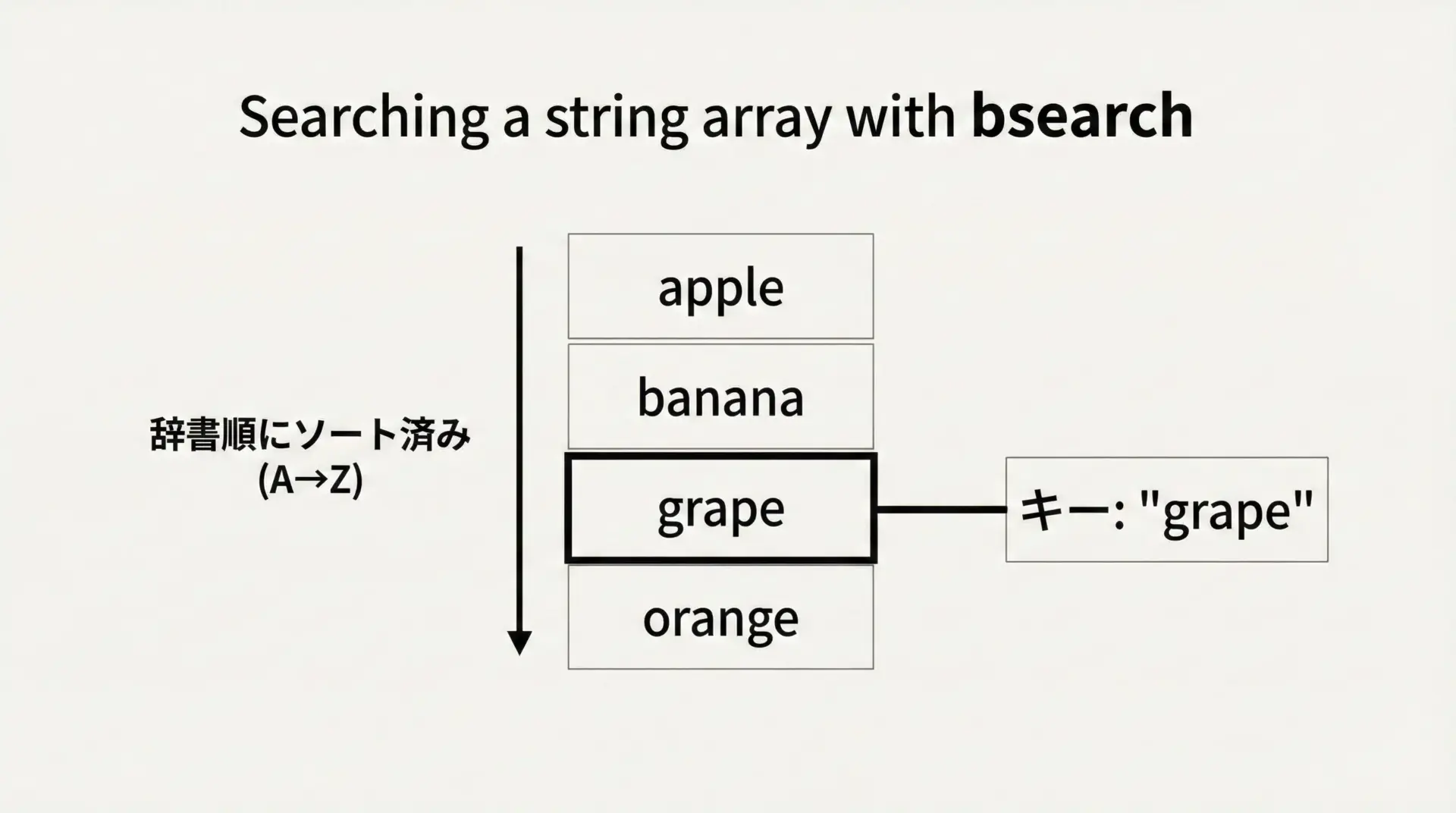
文字列配列でのbsearch(文字列比較)
次に、文字列配列に対してbsearchを使う場面を見ていきます。
文字列同士の比較には、標準ライブラリ関数strcmpを利用するのが基本です。
サンプルコード: 文字列をbsearchで検索
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 文字列(チャーポインタ)用の比較関数
int compare_str(const void *a, const void *b) {
// a, b は「char *」へのポインタ、すなわち「char **」として扱う
const char *sa = *(const char * const *)a;
const char *sb = *(const char * const *)b;
// strcmpの返り値をそのまま使う
return strcmp(sa, sb);
}
int main(void) {
// 辞書順(ASCII順)にソート済みとする
const char *words[] = {
"apple",
"banana",
"grape",
"orange",
"peach"
};
int n = (int)(sizeof(words) / sizeof(words[0]));
const char *key = "grape";
// bsearchで文字列を探索
const char **found = bsearch(
&key, // keyも「char *」へのポインタなので「&key」
words, // 配列の先頭
(size_t)n,
sizeof(char *), // 要素は「char *」なのでそのサイズ
compare_str
);
if (found != NULL) {
int index = (int)(found - words);
printf("%s はインデックス%dで見つかりました。\n", key, index);
} else {
printf("%s は配列内に存在しません。\n", key);
}
return 0;
}grape はインデックス2で見つかりました。文字列版の注意点
文字列配列では、各要素がchar *であるため、比較関数ではconst void *をconst char * const *にキャストしています。
1段階ポインタが増える点が整数配列との違いです。
比較そのものはstrcmpに任せることで、安全かつ簡潔に実装できます。
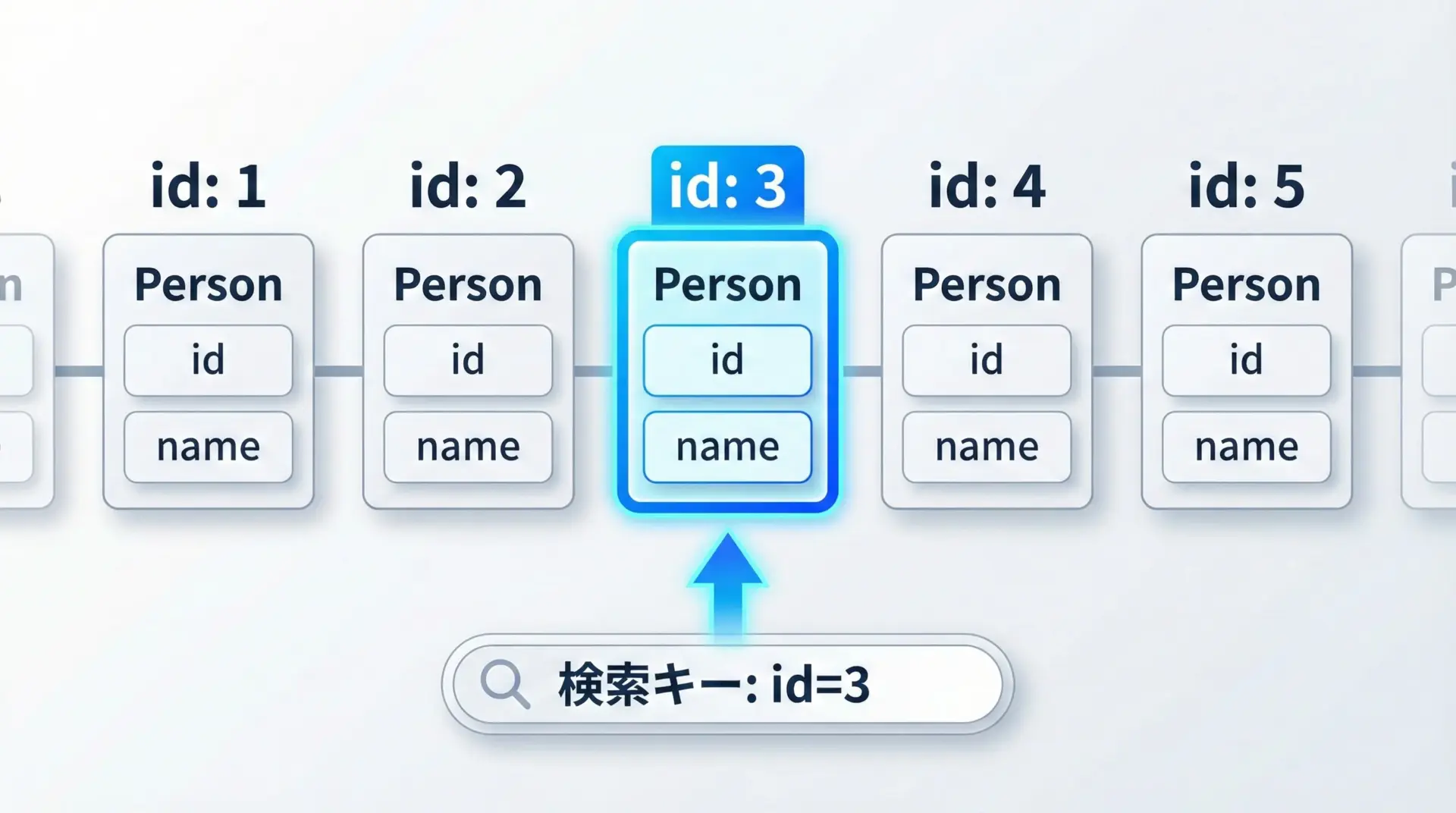
構造体配列でのbsearch(よくあるパターン)
実務でbsearchが活躍するのは、多くの場合、構造体配列を検索するときです。
例えば、IDと名前のペアを保持したレコード配列から、IDをキーに1件を素早く探したいケースなどです。
サンプル構造体
例として、IDと名前を持つPerson構造体を定義し、その配列をbsearchで検索してみます。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
int id;
char name[32];
} Person;
// Person構造体をidで比較する関数
int compare_person_by_id(const void *a, const void *b) {
const Person *pa = (const Person *)a;
const Person *pb = (const Person *)b;
if (pa->id < pb->id) return -1;
if (pa->id > pb->id) return 1;
return 0;
}
int main(void) {
// idの昇順にソート済みの配列とする
Person people[] = {
{1, "Alice"},
{3, "Bob"},
{5, "Charlie"},
{7, "Diana"}
};
int n = (int)(sizeof(people) / sizeof(people[0]));
// 「idだけ」が入った一時的なキー用構造体を作る
Person key;
key.id = 5;
// bsearch呼び出し
Person *found = bsearch(
&key, // key構造体
people, // 配列先頭
(size_t)n,
sizeof(Person), // 要素サイズ
compare_person_by_id // idで比較
);
if (found != NULL) {
int index = (int)(found - people);
printf("id=%d の人物は %s (インデックス%d) です。\n",
key.id, found->name, index);
} else {
printf("id=%d の人物は見つかりませんでした。\n", key.id);
}
return 0;
}id=5 の人物は Charlie (インデックス2) です。なぜ「キー用の構造体」を作るのか
構造体配列を検索するとき、bsearchのkey引数には、比較に必要なフィールドだけを設定したダミーの構造体を渡すのが一般的です。
この例では、idで比較するので、nameフィールドは特に使われていません。
比較関数は、「keyとして受け取る構造体」と「配列の要素として受け取る構造体」を同じ型として扱えるため、実装がシンプルになります。
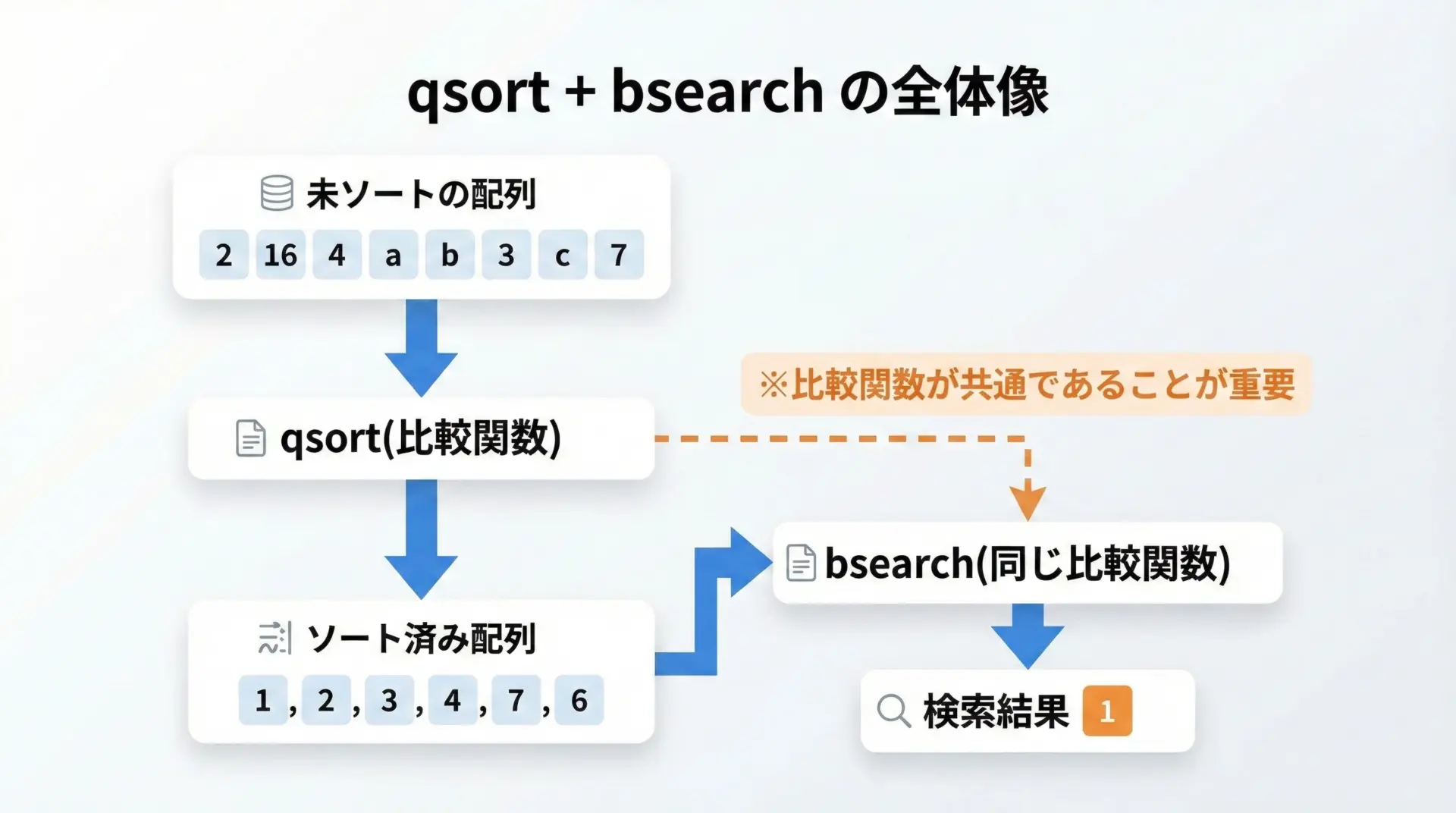
qsortとセットで使う流れ
ここまでの例では「すでにソート済みの配列」を前提にしていました。
しかし実際には、事前にqsortでソートしてから、その順序に従ってbsearchで検索することが多くなります。
サンプルコード: qsortでソートしてからbsearch
#include <stdio.h>
#include <stdlib.h>
// int用の比較関数(前と同じ)
int compare_int(const void *a, const void *b) {
int ia = *(const int *)a;
int ib = *(const int *)b;
if (ia < ib) return -1;
if (ia > ib) return 1;
return 0;
}
int main(void) {
int arr[] = {42, 7, 13, 99, 5, 28};
int n = (int)(sizeof(arr) / sizeof(arr[0]));
// まずqsortで昇順にソート
qsort(
arr,
(size_t)n,
sizeof(int),
compare_int
);
// ソート結果を表示
printf("ソート後の配列: ");
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
int key = 28;
// ソートに使ったのと同じ比較関数でbsearchを呼ぶ
int *found = bsearch(
&key,
arr,
(size_t)n,
sizeof(int),
compare_int
);
if (found != NULL) {
int index = (int)(found - arr);
printf("値%dがインデックス%dで見つかりました。\n", key, index);
} else {
printf("値%dは配列内に存在しません。\n", key);
}
return 0;
}ソート後の配列: 5 7 13 28 42 99
値28がインデックス3で見つかりました。比較関数を共有する利点
qsortとbsearchで同じ比較関数を共有することで、ソートと検索の順序が常に一致します。
これにより、「昇順と降順が食い違って結果がおかしくなる」といったバグを防ぐことができます。
bsearch使用時によくある失敗例と注意点
配列がソートされていない
最も多いのが、未ソートの配列に対してbsearchを適用してしまうパターンです。
この場合、プログラムはクラッシュこそしないものの、結果は全く信用できません。
配列を変更する可能性があるコードでは、「ソート済みである」ことを明示的にコメントや命名で残す、あるいは、検索前に毎回qsortを呼び出す設計にしておくとよいです。
比較関数の戻り値が規約通りでない
比較関数が、単にa - bのように実装されている場合、オーバーフローで不正な結果になる可能性があります。
特に大きな整数や符号付き整数では注意が必要です。
負・ゼロ・正の3値を明確に分岐して返す実装にしておくと、安全に動作します。
構造体の一部フィールドだけを比較しているのに、ソートでは別の順序を使っている
例えば、qsortではidとnameの両方で順序付けしているのに、bsearchではidだけで比較しているようなケースです。
このような比較ルールの不一致があると、検索結果は未定義になります。
qsortとbsearchの比較関数部分は、基本的に同じロジックを共有するように設計することが重要です。
まとめ
本記事では、C言語の<b>bsearch</b>関数について、整数配列・文字列配列・構造体配列を例に、使い方と注意点を解説しました。
bsearchは「ソート済み配列」+「規約通りに実装された比較関数」という2つの条件を満たせば、非常に高速で安全な検索を提供してくれます。
特に大規模なデータや頻繁な検索が必要な場面では、qsortと組み合わせて積極的に活用することで、パフォーマンス向上とコードの簡潔化が期待できます。
まずは小さな配列で動作を確認しながら、自身のプロジェクトに合わせた比較関数の実装を試してみてください。
