
C言語でユーザー入力やファイルの内容を扱うと、まず文字列としてデータを受け取り、それを整数や小数に変換する場面がとても多いです。
そのとき安全かつ柔軟に文字列を数値へ変換する標準関数がstrtolとstrtodです。
本記事では、これら2つの関数の基本的な使い方から、エラー処理や実用的なサンプルまで、図解を交えて詳しく解説します。
【C言語】strtolとstrtodで文字列を数値に変換する方法
文字列を数値に変換する目的と概要
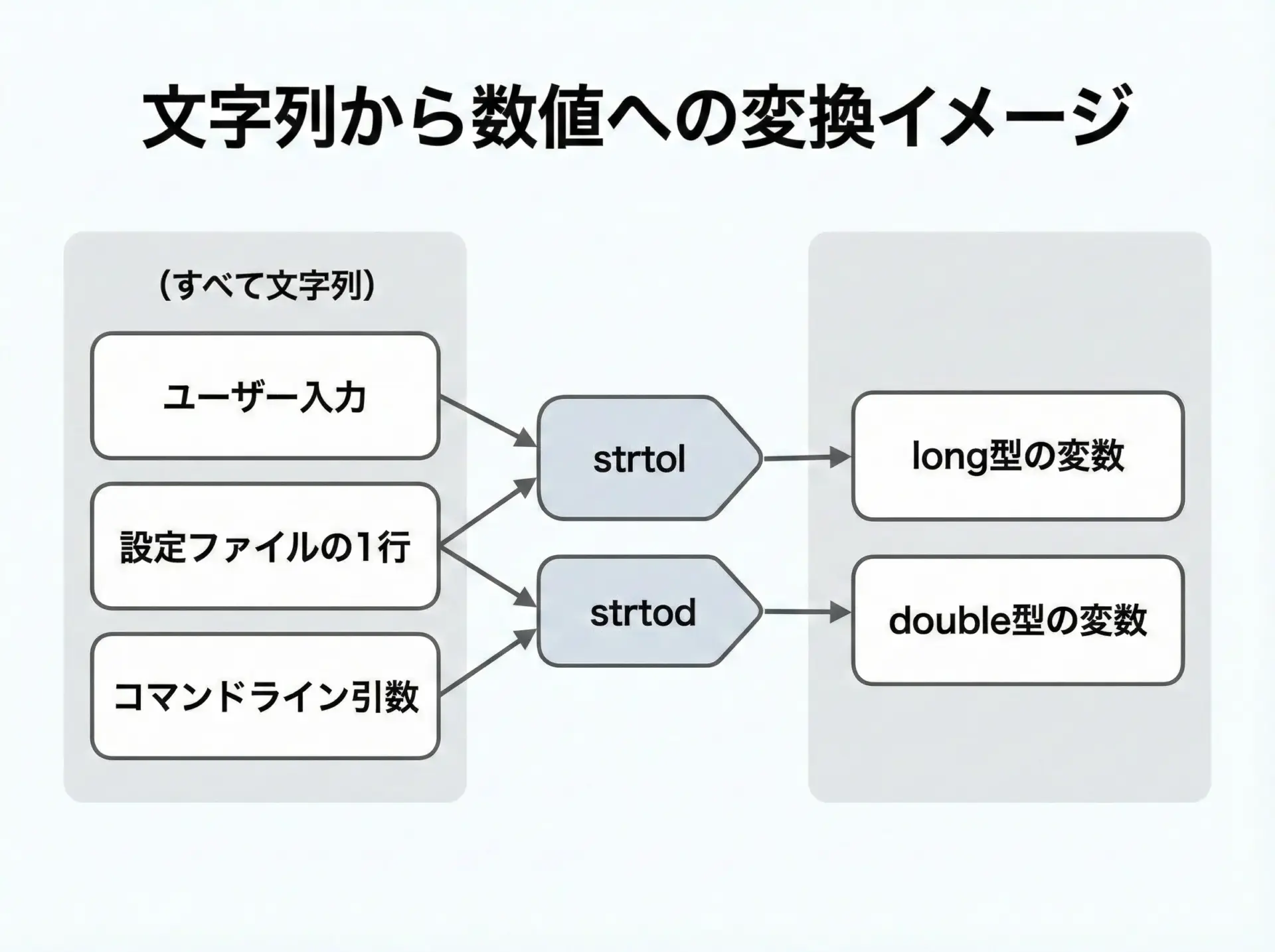
文字列から数値への変換は、次のような場面で登場します。
文章として入力した値を、そのまま計算に使うことはできません。
そこで文字列を対応する数値型に変換する必要があります。
C言語にはatoiやatofといった簡易的な変換関数もありますが、エラー検出ができない・基数(10進/16進など)を指定できないといった制約があります。
この問題を解決するのがstrtolとstrtodです。
どちらも変換に成功した位置までのポインタを返すため、文字列の途中までを数値として解釈し、その先の文字列も続けて解析するといった柔軟な処理が可能になります。
strtolの基本的な使い方
strtolの関数プロトタイプと引数
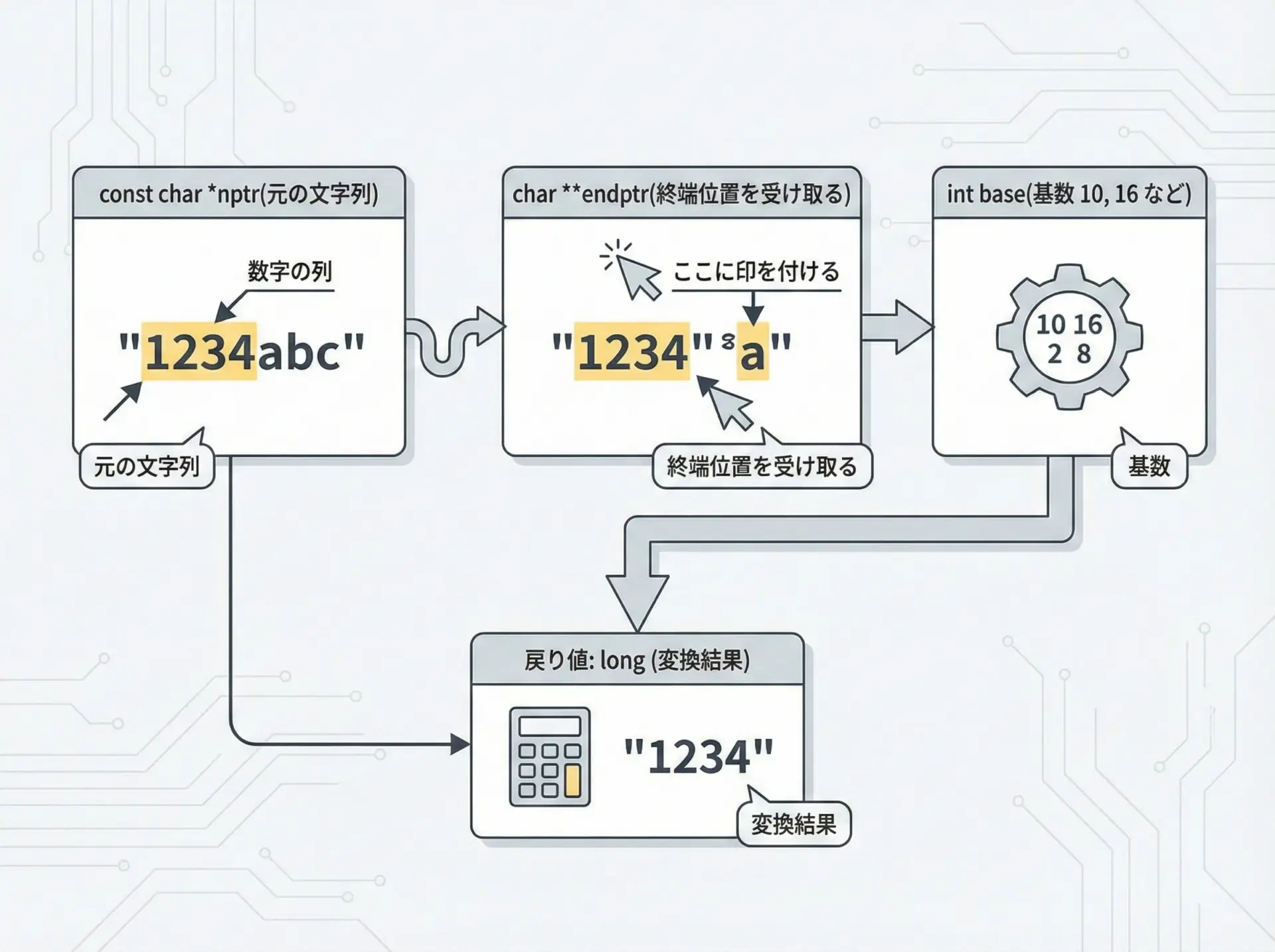
strtolは、文字列をlong型に変換する関数です。
ヘッダ<stdlib.h>で宣言されています。
#include <stdlib.h>
long strtol(const char *nptr, char **endptr, int base);各引数の意味は次のとおりです。
nptr: 変換対象となる文字列の先頭アドレスendptr: 変換が止まった位置(次の文字)へのポインタを書き込むためのポインタbase: 基数(2〜36、または0)。通常は10、16などを指定します
変換結果は戻り値のlong型として返され、同時にendptrに「どこまで数値として読めたか」が書き込まれます。
最も基本的な使用例
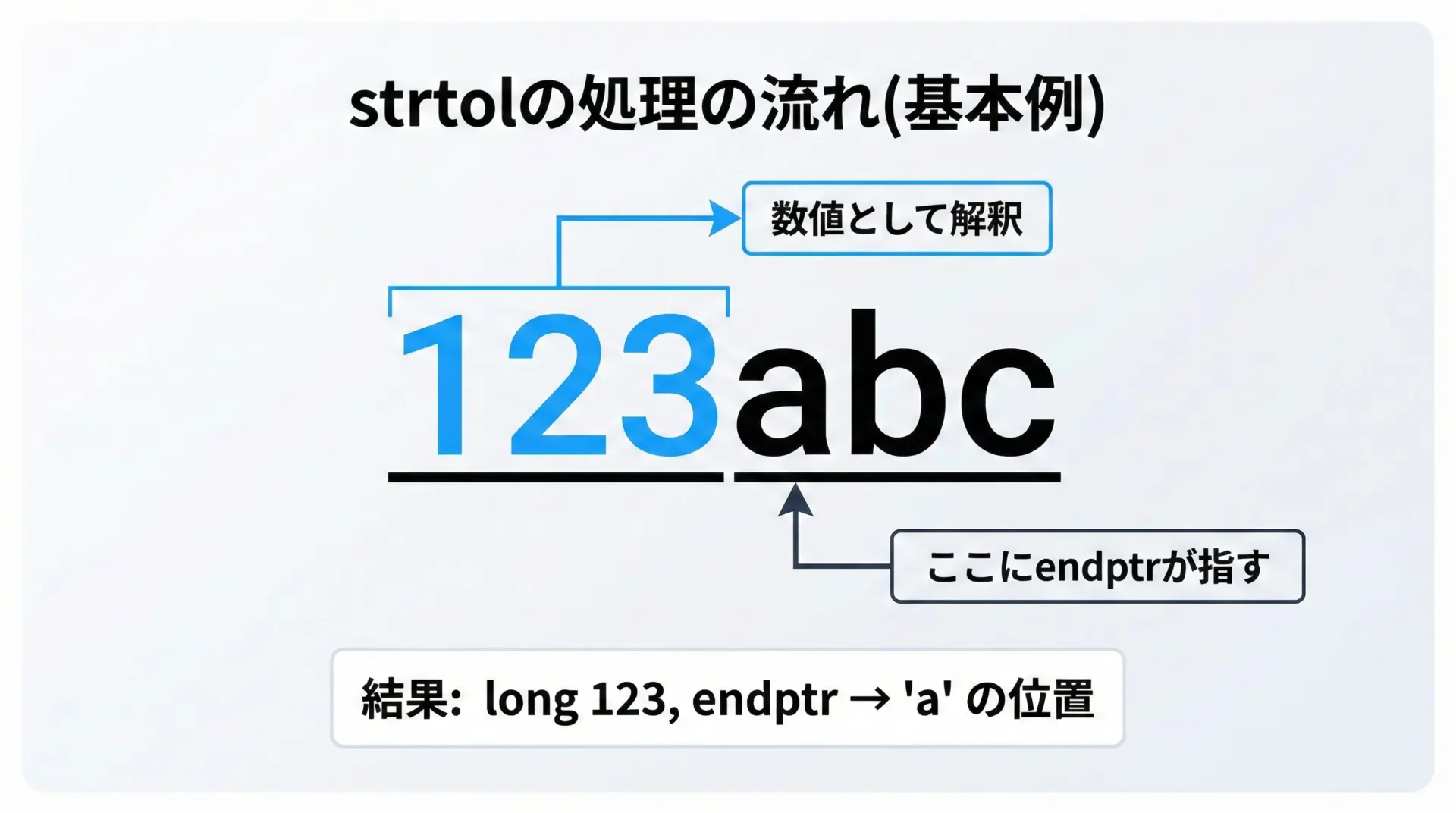
#include <stdio.h>
#include <stdlib.h>
int main(void) {
const char *text = "123abc"; /* 先頭に数字、その後に文字が続く文字列 */
char *end; /* 変換の終了位置を受け取るポインタ */
long value = strtol(text, &end, 10); /* 10進数として変換 */
printf("変換結果: %ld\n", value);
printf("未変換部分: \"%s\"\n", end); /* end 以降の文字列を表示 */
return 0;
}変換結果: 123
未変換部分: "abc"ここでは先頭から読み取れる数字123だけが数値として扱われ、その直後の'a'の位置にendが設定されます。
文字列の手前に空白があっても自動的に読み飛ばされる点も実用上便利です。
strtolのエラー処理と基数指定
エラーを検出する典型パターン
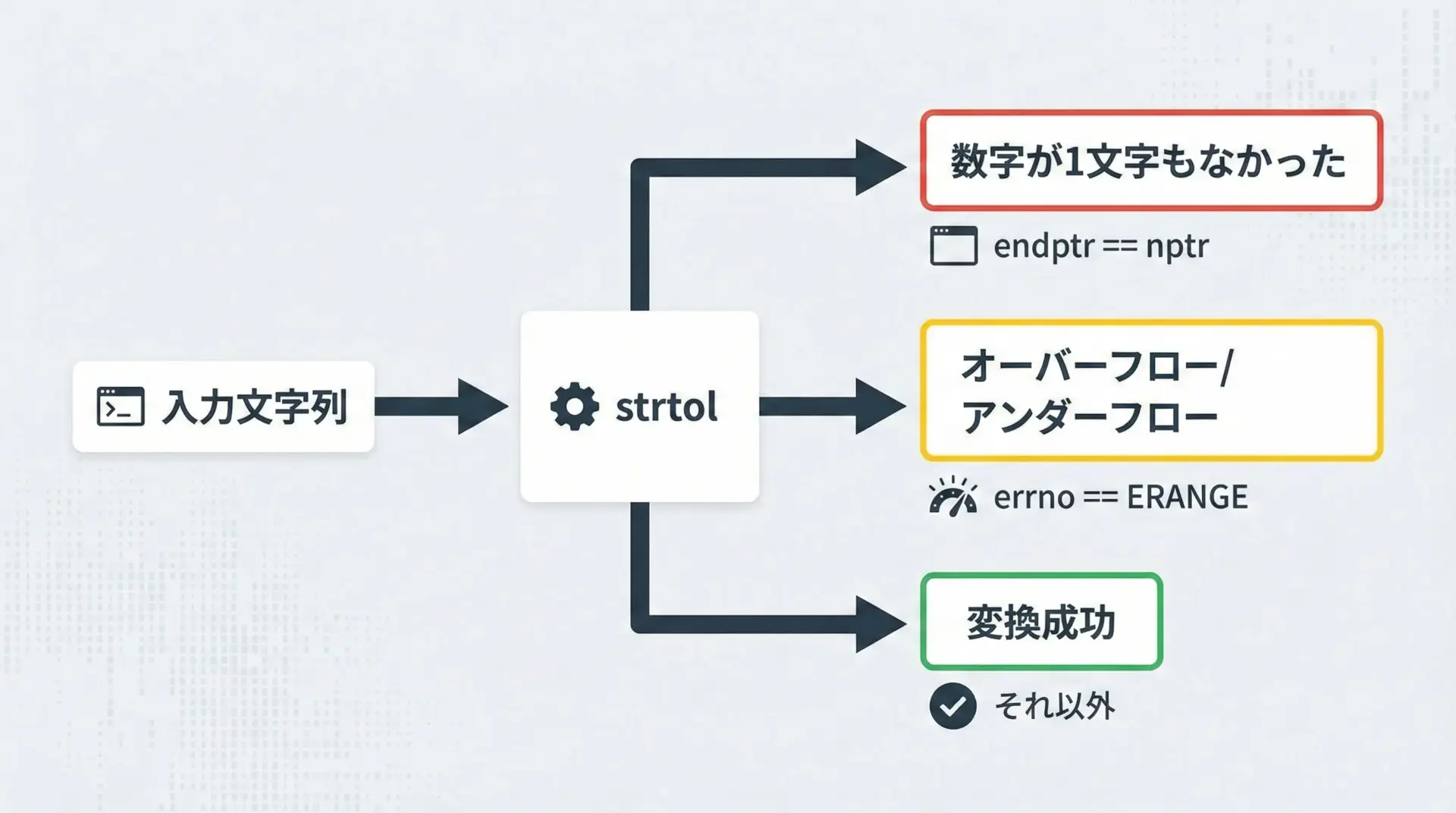
strtolで注意すべきなのは、失敗したときに単純に0を返すとは限らないことです。
0は「本当に0を変換した」場合にも使われるため、戻り値だけでは失敗と区別できません。
そこで、次の2点を組み合わせてチェックします。
endptr == nptrで「数字が1文字もなかったか」を判定errnoと戻り値の値で「オーバーフロー/アンダーフロー」を判定
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <limits.h>
int main(void) {
const char *text = "999999999999999999999999"; /* 非常に大きな値 */
char *end;
errno = 0; /* errno を必ず0で初期化してから呼び出す */
long value = strtol(text, &end, 10);
if (end == text) {
/* 1文字も数字として読めなかった */
printf("エラー: 数値として解釈できる部分がありませんでした。\n");
return 1;
}
if (errno == ERANGE && (value == LONG_MAX || value == LONG_MIN)) {
/* 値が long の表現範囲外 */
printf("エラー: オーバーフローまたはアンダーフローが発生しました。\n");
return 1;
}
printf("変換成功: %ld\n", value);
return 0;
}エラー: オーバーフローまたはアンダーフローが発生しました。信頼できる数値変換を行いたいときは、このようなエラーチェックをセットで書くのが重要です。
基数(base)の指定と自動判定
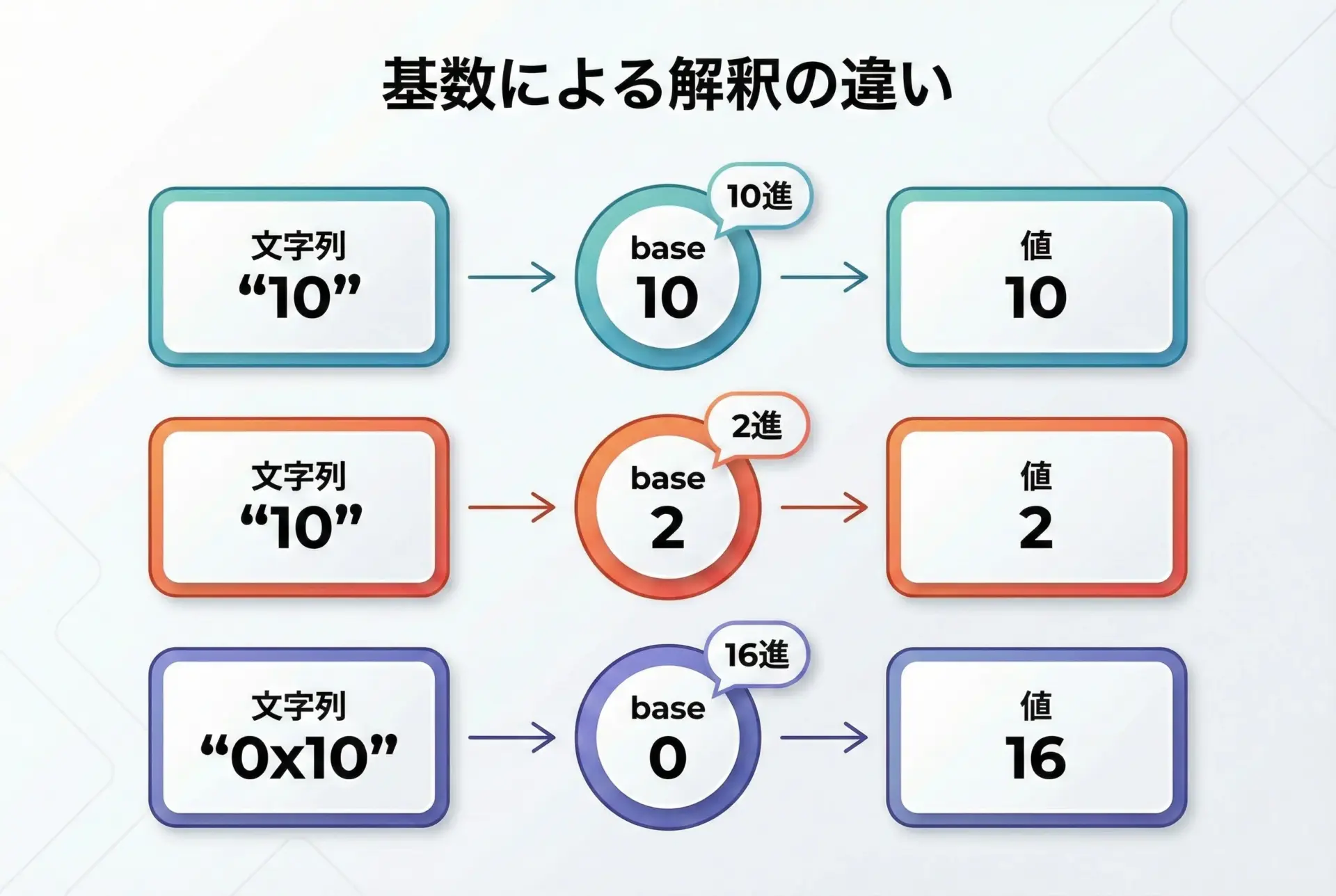
strtolの大きな特徴は、任意の基数で数値を解釈できることです。
代表的な使い方を表にまとめると、次のようになります。
| base の値 | 意味 |
|---|---|
| 10 | 常に10進数として解釈 |
| 16 | 常に16進数として解釈(接頭辞0xがあってもなくてもよい) |
| 8 | 8進数として解釈 |
| 0 | 接頭辞に応じて自動判定(0x→16進、0→8進、それ以外→10進) |
実際の例を見てみます。
#include <stdio.h>
#include <stdlib.h>
int main(void) {
const char *hex = "0x1A";
const char *oct = "077";
const char *dec = "42";
char *end;
long v1 = strtol(hex, &end, 0); /* 接頭辞から自動判定 */
long v2 = strtol(oct, &end, 0);
long v3 = strtol(dec, &end, 0);
printf("hex(0x1A) = %ld\n", v1); /* 26 */
printf("oct(077) = %ld\n", v2); /* 63 */
printf("dec(42) = %ld\n", v3); /* 42 */
return 0;
}hex(0x1A) = 26
oct(077) = 63
dec(42) = 42設定ファイルやコマンドライン引数で、利用者に16進・8進・10進の好きな表記を許したい場合は、base = 0を指定すると自然に対応できます。
strtodの基本とstrtolとの違い
strtodのプロトタイプと基本使用例

strtodは、文字列をdouble型の浮動小数点数に変換する関数です。
こちらも<stdlib.h>に宣言されています。
#include <stdlib.h>
double strtod(const char *nptr, char **endptr);strtolと同様に、変換不能な文字が現れた場所をendptrに返すため、文字列の残りを続けて解析することができます。
#include <stdio.h>
#include <stdlib.h>
int main(void) {
const char *text = "3.14159pi";
char *end;
double value = strtod(text, &end);
printf("変換結果: %f\n", value);
printf("未変換部分: \"%s\"\n", end);
return 0;
}変換結果: 3.141590
未変換部分: "pi"このように、小数点や指数表記(例: 1.23e-4)を含む実数値を安全に扱えるのがstrtodの役割です。
strtolとstrtodの使い分け
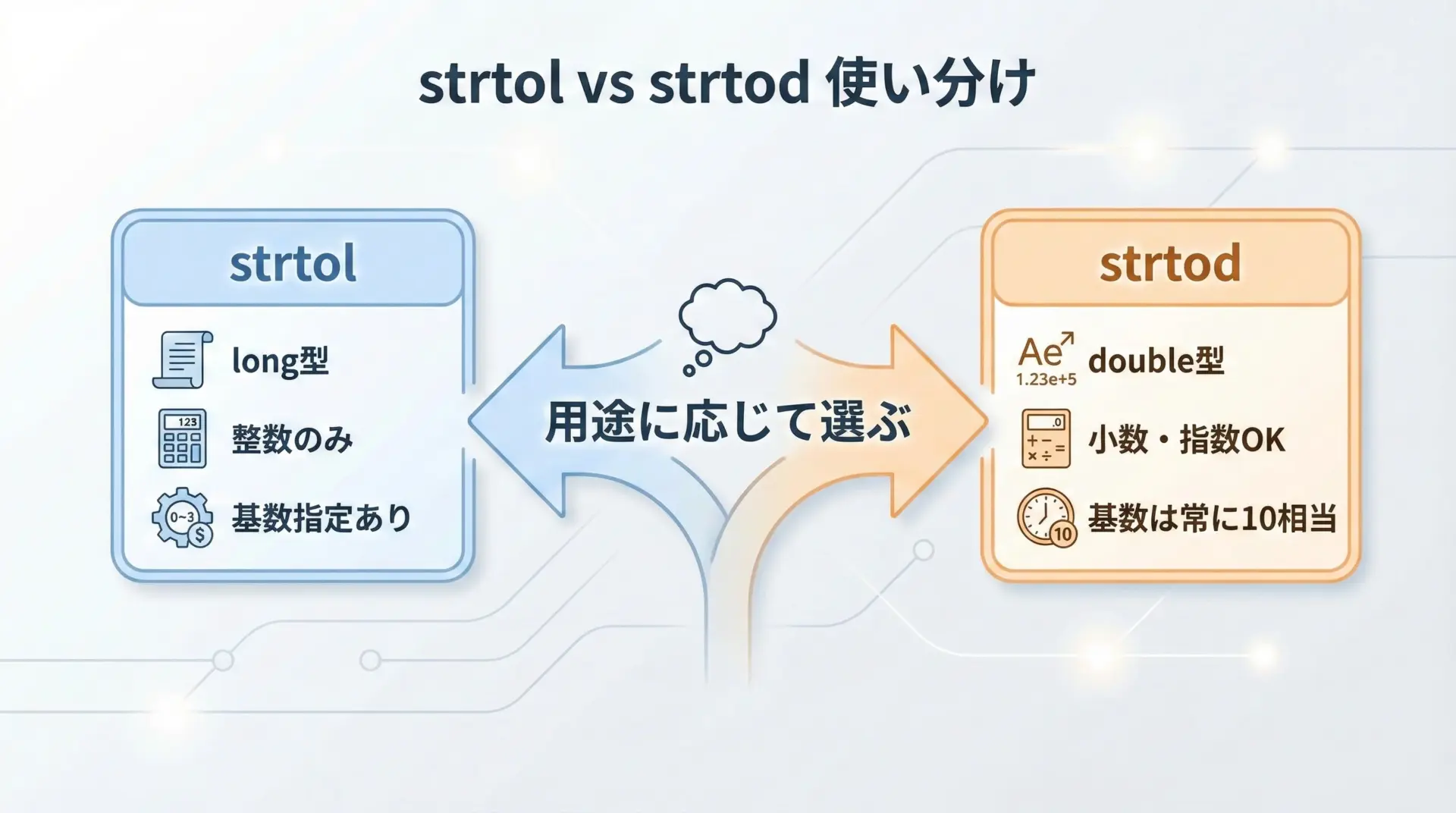
整数を扱いたい場合はstrtol、小数や実数を扱いたい場合はstrtodを選びます。
strtol: 基数を自由に指定できるため、16進のアドレス値や2進表現なども読み取り可能strtod: 10進数の浮動小数点数に特化し、小数点や指数表記を正しく解釈
用途が明確な場合は、どちらか一方に統一しておくとコードの可読性も上がります。
strtodのエラー処理と注意点
エラー検出の基本パターン
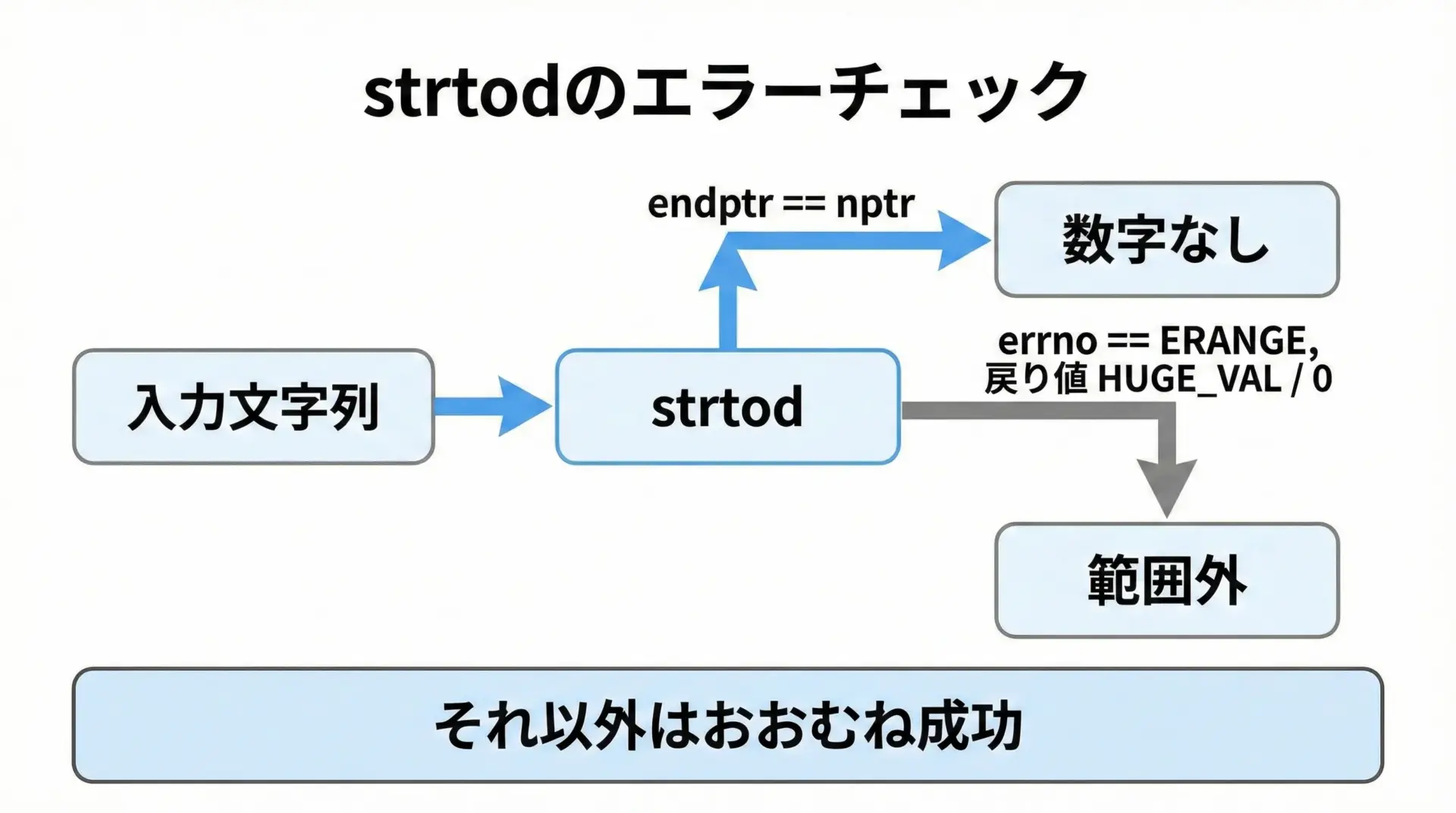
strtodもstrtolと非常によく似た形でエラーを検出します。
代表的なパターンを簡単なコードで示します。
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <math.h>
int main(void) {
const char *text = "1e5000"; /* 非常に大きな指数でオーバーフローを誘発 */
char *end;
errno = 0;
double value = strtod(text, &end);
if (end == text) {
printf("エラー: 数値として解釈できる部分がありませんでした。\n");
return 1;
}
if (errno == ERANGE && (value == HUGE_VAL || value == -HUGE_VAL)) {
printf("エラー: オーバーフローが発生しました。\n");
return 1;
}
if (errno == ERANGE && value == 0.0) {
printf("エラー: アンダーフローが発生しました。\n");
return 1;
}
printf("変換成功: %g\n", value);
return 0;
}エラー: オーバーフローが発生しました。浮動小数点数はそもそも誤差を含む表現であるため、変換後の値が厳密に元の10進数と一致するとは限りません。
そのため「0.1 などの値を変換した結果を、他の値と == で比較する」ような使い方は避けるべきです。
ロケール(小数点文字)の違いに注意

strtodは現在のロケールに依存して、小数点文字を解釈します。
通常のCロケール(C言語のデフォルト環境)では'.'が小数点ですが、言語環境によっては','が小数点として扱われる場合もあります。
国際化や多言語対応が必要な場合には、setlocaleとの組み合わせや、strtod_l(ロケール指定版、非標準の場合あり)の使用を検討する必要があります。
実用例: 1行に整数と小数が混在する入力の解析
例: 「整数 小数 文字列」の行を分解する
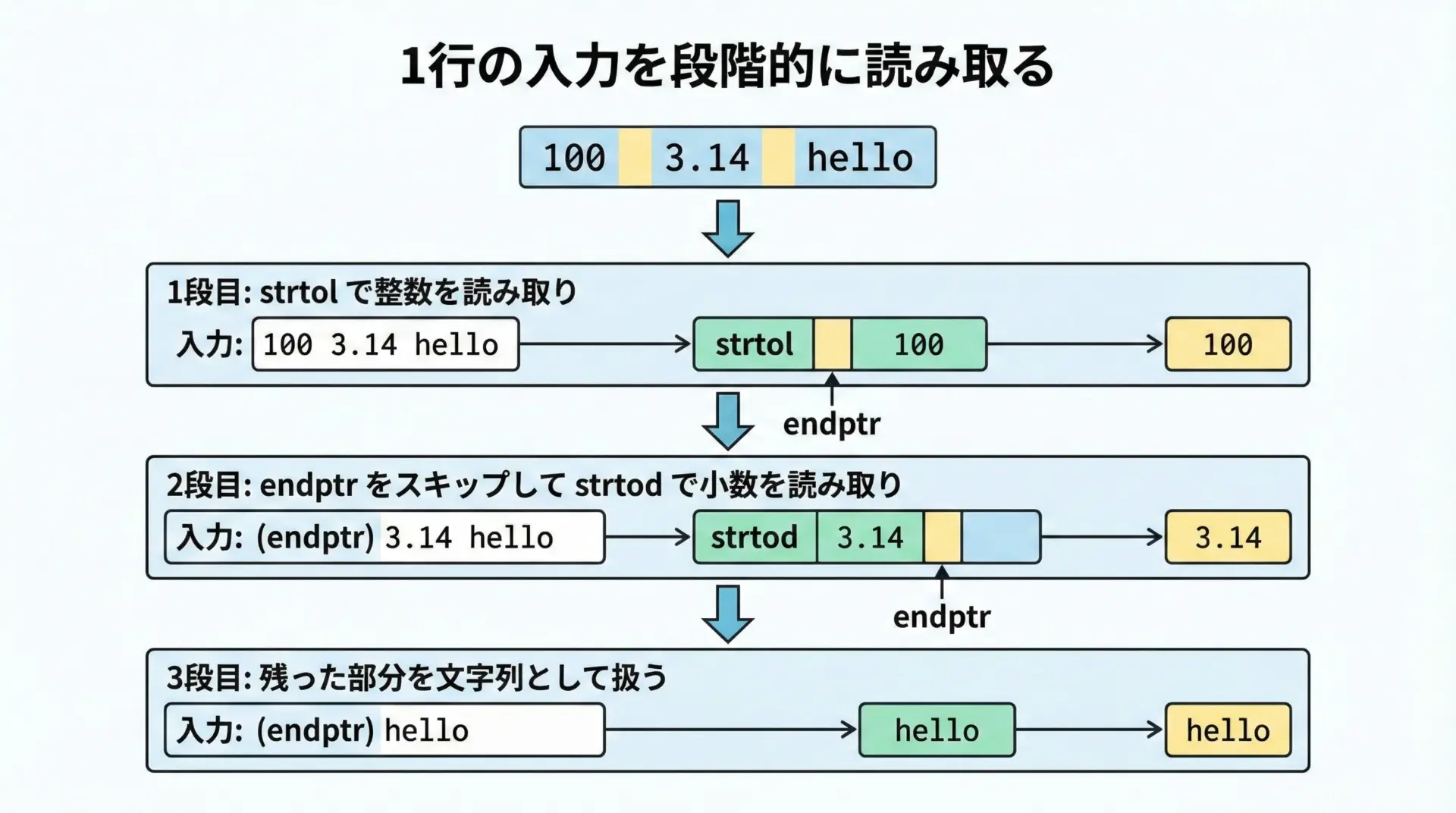
strtolとstrtodを組み合わせると、1行の文字列に複数の値が混在している形式も柔軟に解析できます。
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
int main(void) {
const char *line = "100 3.14 hello";
const char *p = line;
char *end;
/* 1つ目: 整数を読む */
long iv = strtol(p, &end, 10);
if (end == p) {
printf("エラー: 先頭に整数がありません。\n");
return 1;
}
p = end;
/* 空白を飛ばす */
while (*p != '\0' && isspace((unsigned char)*p)) {
p++;
}
/* 2つ目: 実数を読む */
double dv = strtod(p, &end);
if (end == p) {
printf("エラー: 整数の次に実数がありません。\n");
return 1;
}
p = end;
/* 再び空白を飛ばす */
while (*p != '\0' && isspace((unsigned char)*p)) {
p++;
}
/* 残りは文字列として扱う */
const char *word = p;
printf("整数: %ld\n", iv);
printf("実数: %f\n", dv);
printf("文字列: \"%s\"\n", word);
return 0;
}整数: 100
実数: 3.140000
文字列: "hello"このように1本のポインタを少しずつ進めながら、strtol/strtodで順番に値を読み取ることで、柔軟なテキストフォーマットのパーサを自作することができます。
まとめ
strtolとstrtodは、文字列を安全かつ柔軟に数値へ変換するための標準関数です。
atoiやatofに比べて、エラー検出や基数指定、部分的な解析など、多くの場面で優れた使い勝手を提供します。
整数にはstrtol、小数にはstrtodを使い分け、endptrとerrnoを活用したエラー処理をセットで覚えておくと、信頼性の高い入力処理が書けるようになります。
実際のアプリケーションでは、ここで紹介したパターンを土台に、行単位の解析や設定ファイルの読み込みなどへ応用していくとよいです。
