C言語で数値計算を行うとき、ユーザー入力やファイル内の数値は多くの場合「文字列」として扱われます。
そのままでは計算に使えないため、数値型への変換が必要になります。
本記事では、その中でも非常によく使われる文字列をdouble型に変換する関数atofの使い方と注意点について、図解と具体例を交えながら丁寧に解説します。
C言語のatofとは
atofの役割と基本概要
atof関数は、文字列で表現された数値をdouble型に変換する標準ライブラリ関数です。
英語では「ASCII to floating point」の略と覚えておくと分かりやすいです。
代表的な利用場面としては、次のようなケースがあります。
ユーザーがキーボードから入力した「3.14」や、ファイルから読み込んだ「-1.23e-4」といった文字列を、実際に計算に利用できる実数値に変換したいときに使用します。
atofの宣言とヘッダファイル
atofを利用するためには、標準ライブラリstdlib.hをインクルードする必要があります。
宣言は次のようになっています。
double atof(const char *nptr);ここでnptrは、数値として解釈したい文字列(ヌル終端文字列)へのポインタを指します。
戻り値は、文字列から変換されたdouble型の値です。
どんな文字列を変換できるか
atofは、基本的に次のような形式の文字列を変換できます。
- 整数形式: 「”123″」「”-45″」
- 少数形式: 「”3.14″」「”-0.001″」
- 指数形式: 「”1.23e4″」「”-2.5E-3″」
- 前後に空白がある文字列: 「” 3.14″」「”42 “」
文字列全体が完全に数値でなくても、先頭から読める範囲までを数値として解釈するという挙動を持つ点が、後ほど説明する注意点につながります。
atofの基本的な使い方
最小限のサンプルコード
まずはもっともシンプルなatofの使用例です。
#include <stdio.h>
#include <stdlib.h> // atofを使うために必要
int main(void) {
const char *str = "3.14159"; // 文字列としての数値
double value;
// 文字列をdoubleに変換
value = atof(str);
// 結果を表示
printf("文字列: %s\n", str);
printf("double値: %f\n", value);
return 0;
}文字列: 3.14159
double値: 3.141590このように、"3.14159"という文字列がdouble型に変換され、printfで数値として出力できていることが分かります。
標準入力から読み取ってatofで変換する
実際のプログラムでは、ユーザーから入力された文字列を変換する場面が多くあります。
次のサンプルでは、fgetsを使って1行分の文字列を読み取り、atofでdoubleに変換しています。
#include <stdio.h>
#include <stdlib.h> // atof
#include <string.h> // strcspn
int main(void) {
char buf[100]; // 入力用バッファ
double num;
printf("数値を入力してください: ");
// 安全に1行読み込む
if (fgets(buf, sizeof(buf), stdin) == NULL) {
printf("入力エラーが発生しました。\n");
return 1;
}
// 末尾の改行文字を削除
buf[strcspn(buf, "\n")] = '\0';
// 文字列からdoubleに変換
num = atof(buf);
printf("入力された文字列: %s\n", buf);
printf("変換結果(double): %f\n", num);
return 0;
}数値を入力してください: 12.34
入力された文字列: 12.34
変換結果(double): 12.340000このようにfgetsと組み合わせることで、数値以外の文字が含まれる可能性がある行入力にも柔軟に対応できます。
atofの変換ルールと挙動を詳しく理解する
先頭の空白・符号・小数・指数
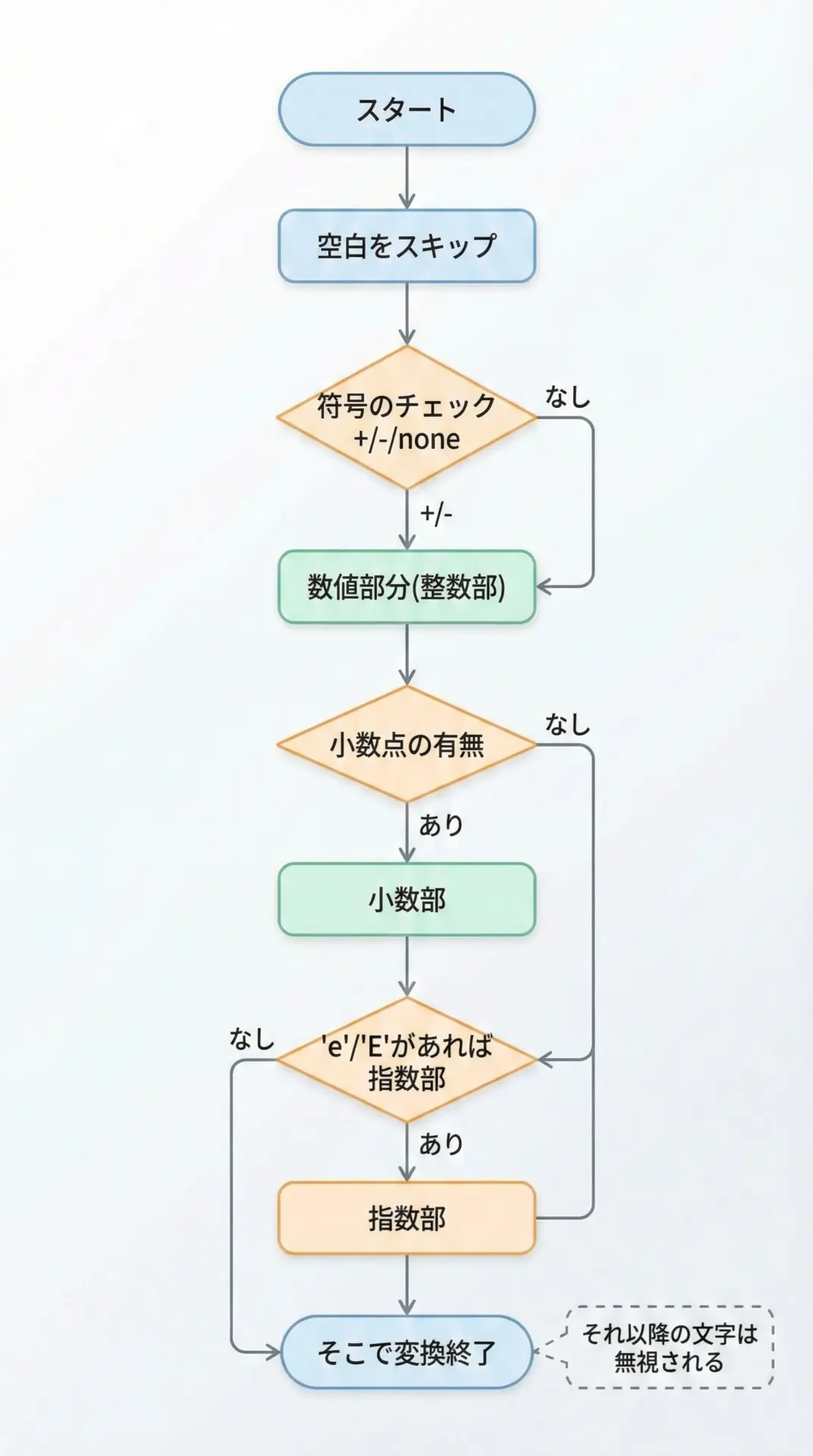
atofは、文字列の先頭から順番に文字を読み取り、次のようなルールで数値を解析します。
- 先頭の空白(スペースやタブなど)は読み飛ばします。
- 続いて
'+'または'-'があれば符号として解釈します。 - その後に続く数字列を整数部として読み取ります。
- 小数点
'.'があれば、それ以降の数字を小数部として読み取ります。 'e'または'E'が続く場合は指数部として扱い、その後の符号付き整数を指数として解釈します。- 読み取り可能な部分が終わったところで変換を終了します。
数値以降の文字がある場合の挙動
atofは、文字列の途中に数値以外の文字が現れた時点で変換を打ち切り、それまでに読み取った部分だけを数値として返します。
このため、文字列の後ろに単位やメモが書かれていても、先頭がきちんと数値形式であれば変換されてしまいます。
次のサンプルで確認してみます。
#include <stdio.h>
#include <stdlib.h>
int main(void) {
const char *s1 = "123abc";
const char *s2 = " -45.6xyz";
const char *s3 = "abc123"; // 先頭が数字ではない例
double v1 = atof(s1);
double v2 = atof(s2);
double v3 = atof(s3);
printf("s1: \"%s\" → %f\n", s1, v1);
printf("s2: \"%s\" → %f\n", s2, v2);
printf("s3: \"%s\" → %f\n", s3, v3);
return 0;
}s1: "123abc" → 123.000000
s2: " -45.6xyz" → -45.600000
s3: "abc123" → 0.000000ここで重要なのは、先頭が数字でない"abc123"は変換できず、0.0が返っている点です。
しかし、エラーなのか、本当に「0」が入力されたのか、atofの戻り値だけでは区別できないという問題があります。
この点がatof最大の注意点につながります。
atofを使うときの注意点と問題点
エラー検出ができないという問題
atofは変換エラーを検出する仕組みを提供していません。
たとえば、次の2つのケースを考えます。
- ユーザーが「0」と正しく入力した場合
- ユーザーが「abc」と誤って入力した場合
どちらもatofの戻り値は0.0になります。
戻り値だけでは、入力が正しく0だったのか、変換に失敗して0になったのかが判断できません。
このため、入力の妥当性を厳密にチェックしたいプログラムではatofは適していません。
代わりにstrtod関数を使うことが推奨されます。
オーバーフローや範囲外の値
非常に大きな値や小さすぎる値(絶対値が極端に小さい)を与えた場合、atofは内部的にはstrtodを使っている実装が多く、オーバーフローやアンダーフローが発生する可能性があります。
しかしながら、atof自体はerrnoを見てエラーを判断することもできず、どのようなエラーが起きたのかを知る公式な手段がありません。
atofよりもstrtodを推奨する理由
strtodの基本的な特徴
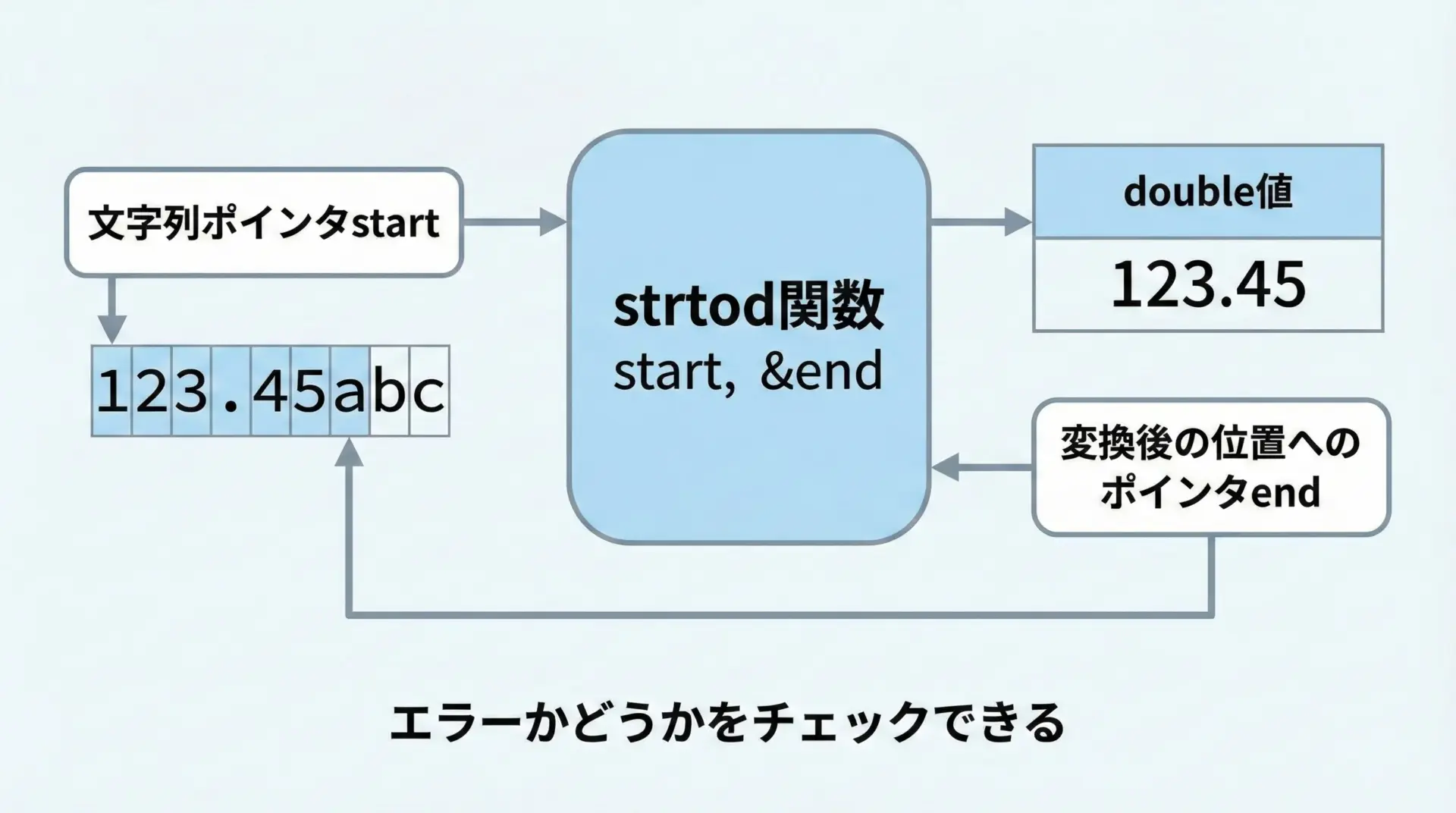
実務的なC言語プログラミングでは、atofよりもstrtodの使用が推奨されます。
strtodは次のような宣言を持つ関数です。
double strtod(const char *restrict nptr, char **restrict endptr);第1引数nptrは文字列へのポインタでatofと同じですが、第2引数endptrにより「どこまで数値として解釈できたか」を知ることができます。
また、オーバーフローなどが発生した場合にはerrnoを利用してエラーを検出することもできます。
atof相当の処理をstrtodで書く
atofは、しばしばstrtod(nptr, NULL)とほぼ同等と言われます。
しかし、実際に使う際にはendptrを活用して、入力チェックをきちんと行うほうが安全です。
次のサンプルは、strtodを使ってatofの代替としつつ、文字列全体が正しい数値かどうかも確認する例です。
#include <stdio.h>
#include <stdlib.h> // strtod
#include <errno.h> // errno
#include <math.h> // HUGE_VAL
int main(void) {
const char *str = "123.45abc"; // わざと余分な文字を含める
char *endptr;
errno = 0; // errnoをリセット
double val = strtod(str, &endptr);
printf("元の文字列: \"%s\"\n", str);
printf("変換結果: %f\n", val);
printf("未処理の部分: \"%s\"\n", endptr);
// 全体が数値かどうかのチェック例
if (str == endptr) {
printf("数値として解釈できる部分がありません。\n");
} else if (*endptr != '\0') {
printf("数値の後ろに余分な文字があります。\n");
} else {
printf("文字列全体が正しい数値です。\n");
}
// オーバーフロー検出の例
if ((val == HUGE_VAL || val == -HUGE_VAL) && errno == ERANGE) {
printf("オーバーフローが発生しました。\n");
}
return 0;
}元の文字列: "123.45abc"
変換結果: 123.450000
未処理の部分: "abc"
数値の後ろに余分な文字があります。このようにstrtodを使うと、変換に成功したのか、どこまでが数値だったのかを明確に判断できるため、堅牢なプログラムを作成しやすくなります。
atofとstrtodの比較表
以下にatofとstrtodの違いを簡単な表にまとめます。
| 項目 | atof | strtod |
|---|---|---|
| ヘッダファイル | stdlib.h | stdlib.h |
| 戻り値の型 | double | double |
| エラー検出 | できない | 可能(戻り値・endptr・errnoで判定) |
| 数値の終了位置の取得 | 不可能 | endptrで取得可能 |
| オーバーフロー検出 | 公式には不可 | errnoとHUGE_VALで判定可能 |
| 使い勝手 | 呼び出しが簡単 | やや複雑だが情報量が多い |
| 実務での推奨度 | 低い(学習用・簡易用途向け) | 高い(実務・本番コード向け) |
本格的な入力処理や数値解析を行う場合はstrtod、簡単なサンプルコードや学習用であればatofでもよいという位置づけで考えるとよいです。
実践的な例: 入力チェック付きの変換処理
ユーザー入力を厳密にチェックするパターン
ここでは、fgetsで読み込んだ文字列をstrtodで変換し、文字列全体が正しい数値だった場合だけ受け付ける例を紹介します。
表題はatofですが、実際に「正しく」扱うための発展形として理解してください。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <math.h>
int main(void) {
char buf[100];
char *endptr;
double val;
printf("数値を入力してください: ");
if (fgets(buf, sizeof(buf), stdin) == NULL) {
printf("入力エラーです。\n");
return 1;
}
// 改行文字を削除
buf[strcspn(buf, "\n")] = '\0';
errno = 0;
val = strtod(buf, &endptr);
// 1文字も変換されなかった場合
if (buf == endptr) {
printf("数値として解釈できません: \"%s\"\n", buf);
return 1;
}
// 余分な文字が残っている場合(前後の空白はOKとしたいなら調整が必要)
if (*endptr != '\0') {
printf("数値の後ろに余計な文字があります: \"%s\"\n", endptr);
return 1;
}
// 範囲エラー(オーバーフロー・アンダーフロー)のチェック例
if ((val == HUGE_VAL || val == -HUGE_VAL) && errno == ERANGE) {
printf("数値が大きすぎます(オーバーフロー)。\n");
return 1;
}
printf("正しい数値として受け付けました: %f\n", val);
return 0;
}数値を入力してください: 123.45xyz
数値の後ろに余計な文字があります: "xyz"このようにstrtodを用いれば、ユーザーの誤入力を検知し、わかりやすいエラーメッセージを出す堅牢なプログラムを作ることができます。
同じことをatofだけで実現するのは難しいという点を、あらためて意識しておくとよいでしょう。
まとめ
atofは「文字列をdoubleに変換する」簡便な関数で、学習用や簡易なツールでは手軽に利用できます。
しかし変換エラーを検出できないという致命的な欠点があるため、実務的なコードではstrtodの利用が強く推奨されます。
この記事で紹介したように、strtodとendptrを組み合わせることで、入力の妥当性チェックやオーバーフロー検出が可能になります。
C言語で文字列から実数値を扱う際には、「atofは簡単だが危険」「本番コードではstrtod」という方針を意識して、より安全で信頼性の高いプログラムを書くようにしてください。
