
C言語でプログラムの処理時間を測りたい場合、最初に出てくるのがclock関数です。
コンパイラ標準で使えて、導入がとても簡単な一方で、精度や意味を誤解しやすい関数でもあります。
本記事では、clock関数の基本から実践的なサンプルコード、注意点や他の関数との比較までを、図解とコードを交えながら詳しく解説します。
clock関数とは
clock関数でできることと用途
clock関数は「プログラムが動作していたCPU時間」を取得するための関数です。
標準ヘッダtime.hで定義されていて、ほとんどのCコンパイラで利用できます。
主な用途としては、以下のような場面が挙げられます。
- アルゴリズムの処理時間をおおまかに比較したいとき
- 処理時間の長いループや関数の「目安の時間」を知りたいとき
- デバッグ時に「どこで時間がかかっているか」をざっくり確認したいとき
開発中の性能測定や学習用途には非常に便利です。
一方で、リアルタイム性が重要な場面や、高精度な計測をしたい場面では注意が必要です。
この点は後半の「精度と限界」で詳しく説明します。
C言語で処理時間を測る基本の仕組み
処理時間を測る基本の考え方は、とてもシンプルです。
「計測したい処理の前後で時刻を取得し、その差を取る」だけです。
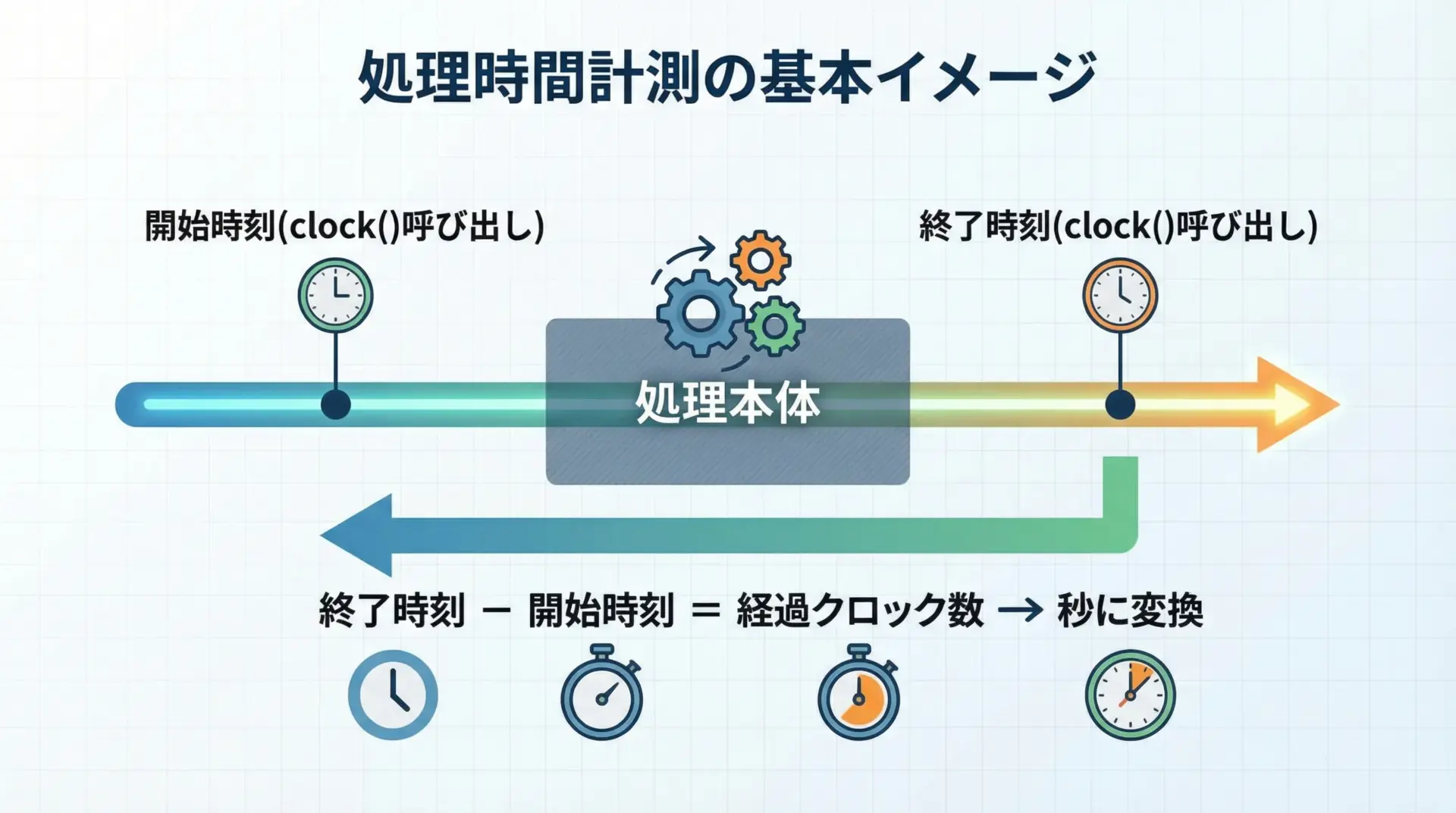
この図のように、clock関数では次の手順で処理時間を求めます。
- 計測したい処理の直前で
clock()を呼び、開始時刻を記録する。 - 計測したい処理(ループ、関数呼び出しなど)を実行する。
- 処理が終わった直後に再び
clock()を呼び、終了時刻を記録する。 - 終了時刻 − 開始時刻 を計算して、
CLOCKS_PER_SECで割ることで「秒」に変換する。
このCLOCKS_PER_SECが何を意味しているのかは、次の章で詳しく説明します。
clock関数の基本的な使い方
clock_t型とCLOCKS_PER_SECの意味
clock関数を理解するためには、clock_t型とCLOCKS_PER_SECマクロの意味を押さえることが重要です。
clock_t型とは
clock_t型は「clock関数が返す時間値の型」です。
実体は環境依存で、longであったりlong longであったりしますが、利用側からは「クロック数を入れるための型」として扱います。
代表的な定義イメージは、次のようになります。
// 実際の環境によって異なりますが、イメージとして
typedef long clock_t;ポイントは、clock_tは整数型であり、「生の時刻」ではなく「クロック数」であることです。
CLOCKS_PER_SECとは
CLOCKS_PER_SECは「1秒あたりのクロック数」を表すマクロです。
つまり、
clock()が返した値 ÷ CLOCKS_PER_SEC = 経過秒数
という関係になります。
多くの環境ではCLOCKS_PER_SECは1000または1000000などの値になっています。
ただし値は処理系依存であり、コード中では必ずマクロから取得して計算する必要があります。
clock関数で処理時間を測る手順
基本の手順は常に同じです。
重要なポイントだけ、流れとともに整理しておきます。
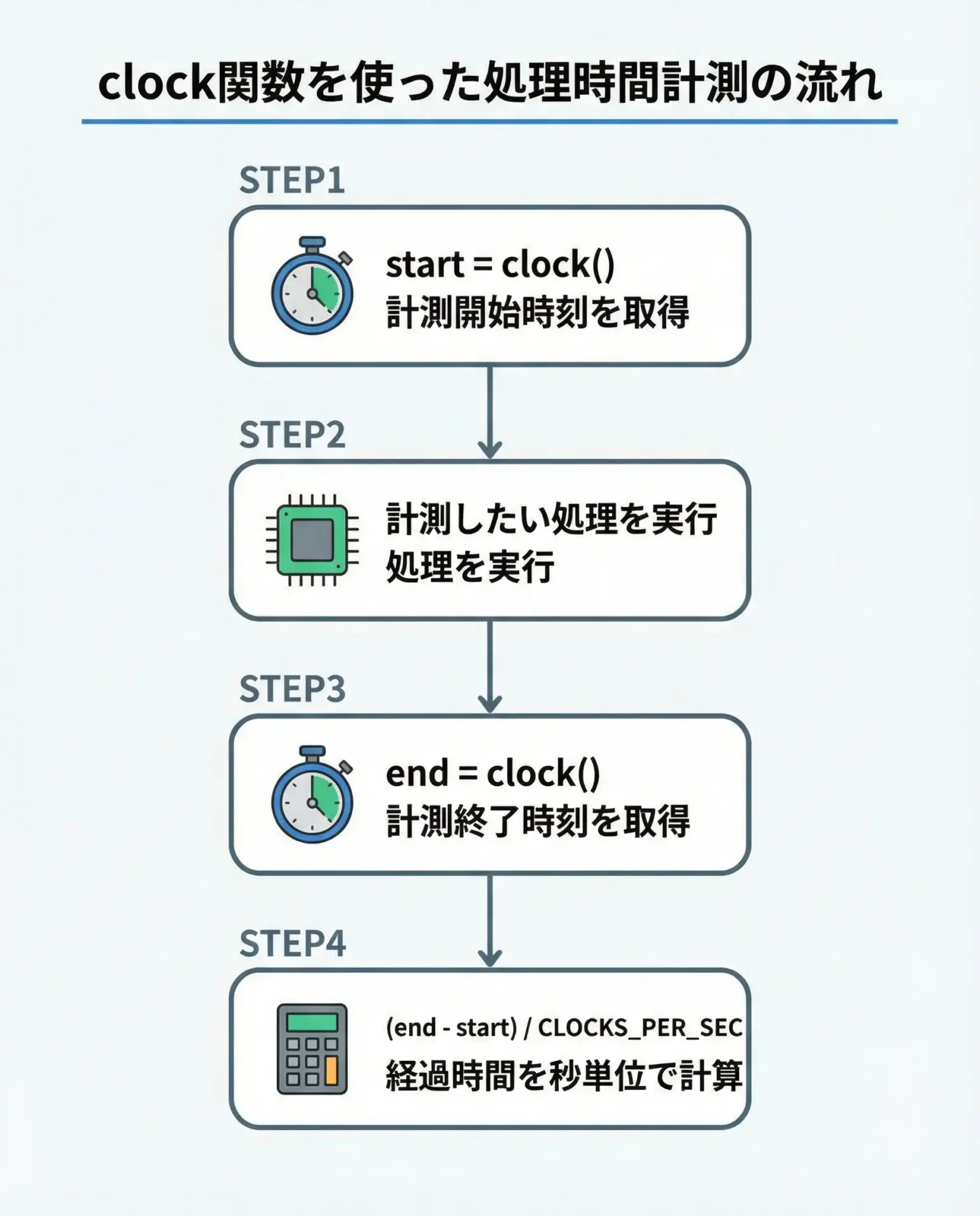
手順の詳細
- 開始時刻を取得する
計測したい処理の直前でclock()を呼び、その戻り値をclock_t型の変数に格納します。 - 計測対象の処理を実行する
ループや関数など、時間を測りたい処理をここで実行します。 - 終了時刻を取得する
処理終了直後に再びclock()を呼び、別のclock_t変数に格納します。 - 差分を秒に変換する
(end - start)でクロック差を求め、それをCLOCKS_PER_SECで割って秒数に直します。浮動小数で扱いたい場合はdoubleにキャストします。
処理時間計測のサンプルコード
ここでは、単純な待ちループの処理時間を計測するベーシックなサンプルコードを示します。
#include <stdio.h> // printf
#include <time.h> // clock, clock_t, CLOCKS_PER_SEC
int main(void) {
clock_t start, end; // 開始と終了のクロック値
double elapsed; // 経過時間(秒)
// 1. 計測開始時刻を取得
start = clock();
// 2. 計測したい処理(ここではダミーのループ)
// 実際には、重い計算やアルゴリズム処理などをここに書きます。
volatile long long sum = 0; // volatileは最適化で削除されないようにするため
for (long long i = 0; i < 100000000; i++) {
sum += i;
}
// 3. 計測終了時刻を取得
end = clock();
// 4. 差分を秒に変換
// (end - start) は clock_t なので、double にキャストしてから割る
elapsed = (double)(end - start) / CLOCKS_PER_SEC;
printf("sum = %lld\n", sum); // ダミー出力(最適化防止にも役立つ)
printf("経過時間: %f 秒\n", elapsed); // 経過時間を表示
return 0;
}(実行例)
sum = 4999999950000000
経過時間: 0.850000 秒ポイントは、必ず(double)(end - start) / CLOCKS_PER_SECのように型変換を行い、小数点付きの秒数として表示することです。
整数同士の割り算をしてしまうと、精度が大きく落ちてしまいます。
実践的なclock関数サンプルコード
ループ処理の処理時間を測るサンプルコード
多くの場面で「このループにどれくらい時間がかかっているのか」を知りたいことがよくあります。
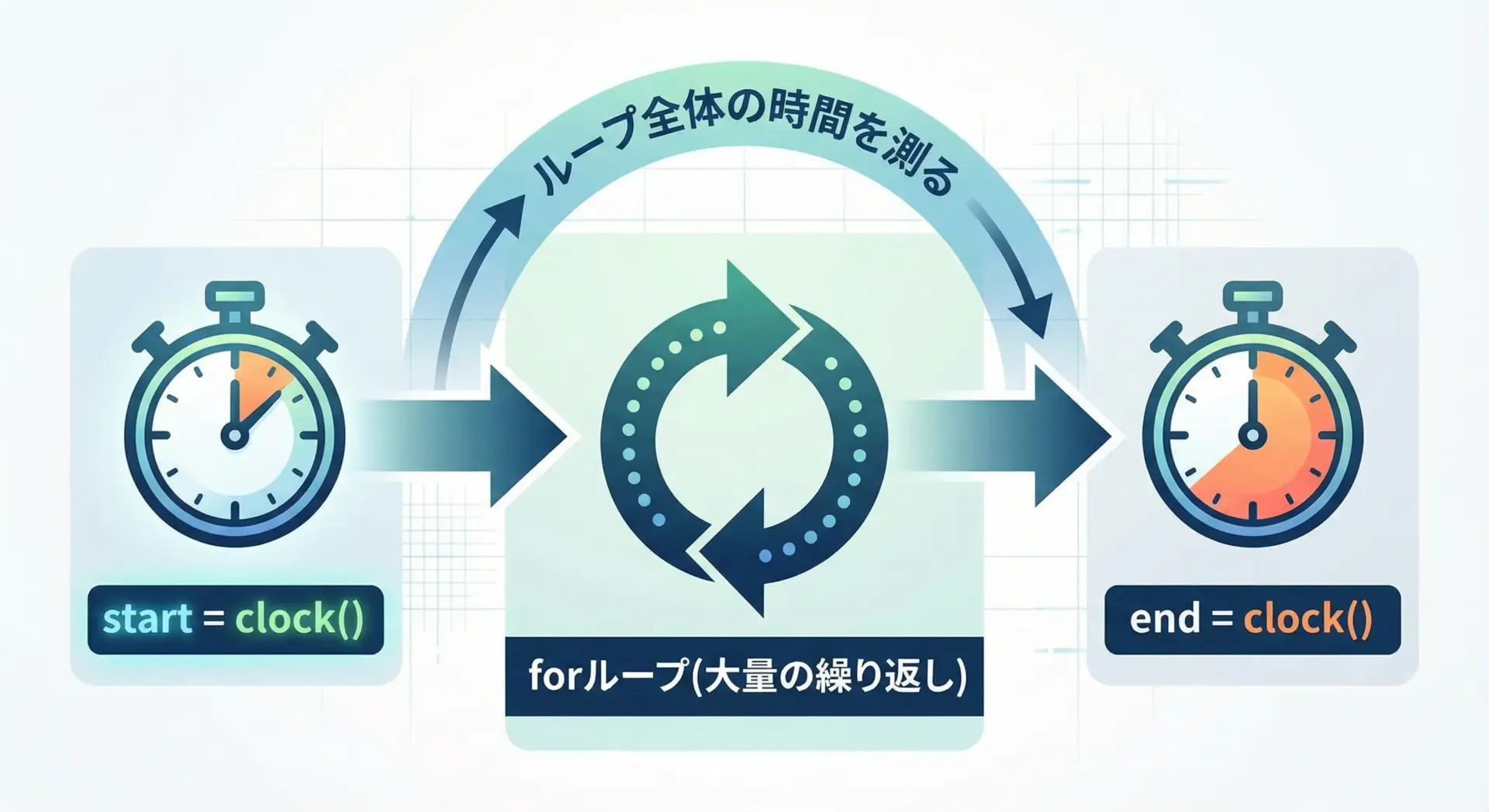
以下は、ループ全体の処理時間を測るサンプルです。
#include <stdio.h>
#include <time.h>
int main(void) {
const int N = 100000000; // 1億回ループ
clock_t start, end;
double elapsed;
volatile long long sum = 0; // 最適化で消されないようにvolatileを付ける
// 計測開始
start = clock();
// 計測対象: 1億回のループ処理
for (int i = 0; i < N; i++) {
sum += i;
}
// 計測終了
end = clock();
// 経過時間を秒に変換
elapsed = (double)(end - start) / CLOCKS_PER_SEC;
printf("ループ結果 sum = %lld\n", sum);
printf("ループ処理の経過時間: %f 秒\n", elapsed);
return 0;
}(実行例)
ループ結果 sum = 4999999950000000
ループ処理の経過時間: 0.830000 秒このように、ループの前後でclockを呼び、差分を求めるだけで、ループ全体の処理時間を簡単に測定できます。
関数ごとの処理時間を測るサンプルコード
より実践的には、個々の関数がどれくらい時間を使っているかを知りたい場面が多くなります。
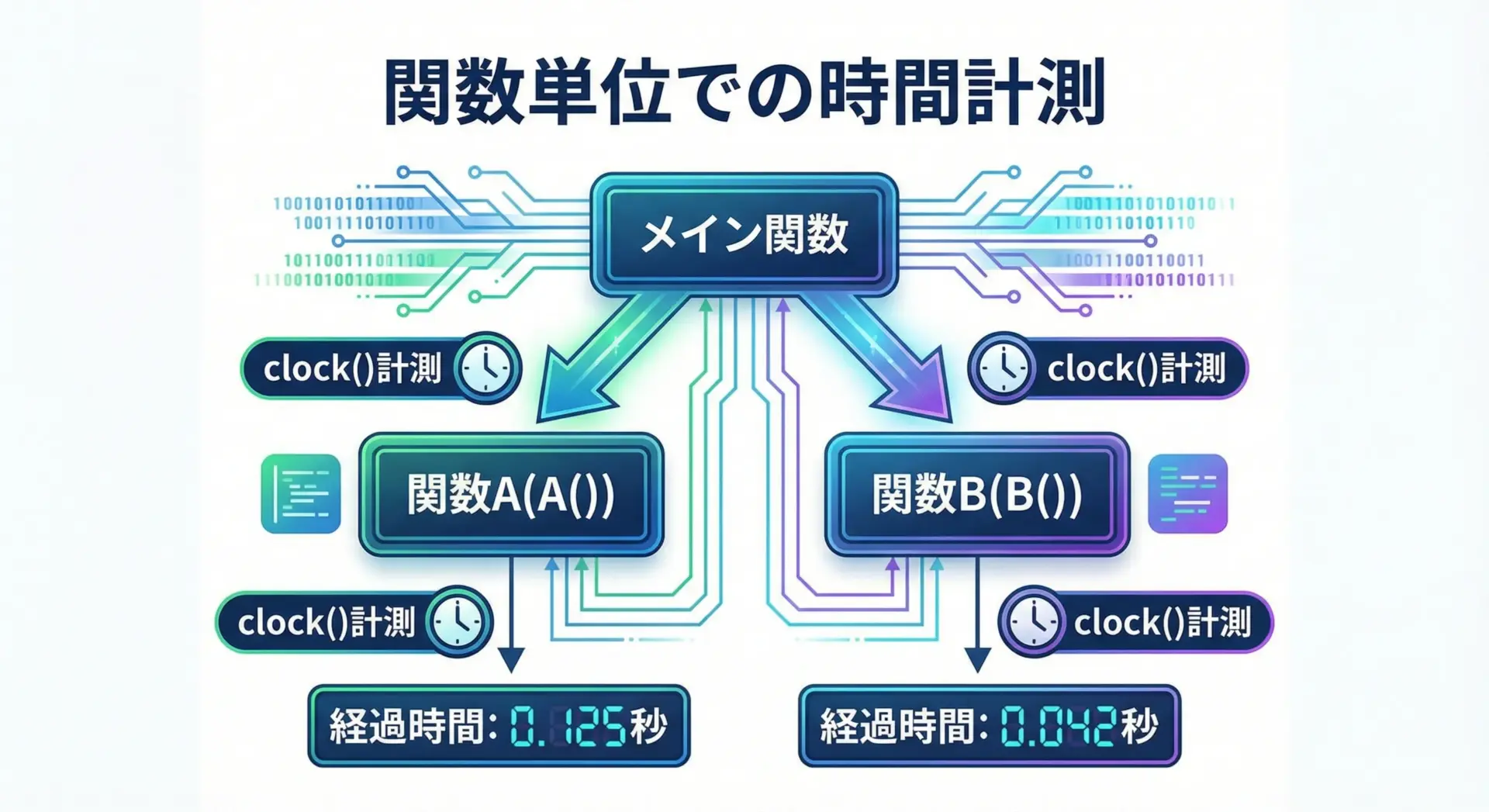
以下は、関数ごとに処理時間を測定するサンプルです。
#include <stdio.h>
#include <time.h>
void heavy_task1(void) {
volatile long long sum = 0;
for (long long i = 0; i < 50000000; i++) { // 5,000万回
sum += i;
}
// 結果を使わないと最適化で消される可能性があるので、printfなどで利用する
printf("[heavy_task1] sum = %lld\n", sum);
}
void heavy_task2(void) {
volatile long long product = 1;
for (long long i = 1; i < 20000000; i++) { // 2,000万回
product *= (i % 10 + 1); // 適当な計算処理
product %= 1000000007; // オーバーフロー防止用に絞る
}
printf("[heavy_task2] product = %lld\n", product);
}
double measure_function_time(void (*func)(void)) {
clock_t start, end;
// 測定開始
start = clock();
// 測定対象の関数を呼び出す
func();
// 測定終了
end = clock();
// 経過秒数を返す
return (double)(end - start) / CLOCKS_PER_SEC;
}
int main(void) {
double t1, t2;
// heavy_task1 の処理時間を測定
t1 = measure_function_time(heavy_task1);
// heavy_task2 の処理時間を測定
t2 = measure_function_time(heavy_task2);
printf("heavy_task1 の処理時間: %f 秒\n", t1);
printf("heavy_task2 の処理時間: %f 秒\n", t2);
return 0;
}(実行例)
[heavy_task1] sum = 1249999975000000
[heavy_task2] product = 650434721
heavy_task1 の処理時間: 0.450000 秒
heavy_task2 の処理時間: 0.320000 秒このように、関数ポインタを使って「何かの関数の処理時間を測る汎用関数」を作っておくと、さまざまな処理の計測が簡単になります。
複数回計測して平均処理時間を出すサンプルコード
処理時間は、一回だけ測るとブレが大きくなることがあります。
OSのスケジューリングや他プロセスの影響などで、実行ごとに少しずつ時間が変動するためです。
そこで、同じ処理を複数回計測し、その平均値を取ると、より安定した目安を得られます。
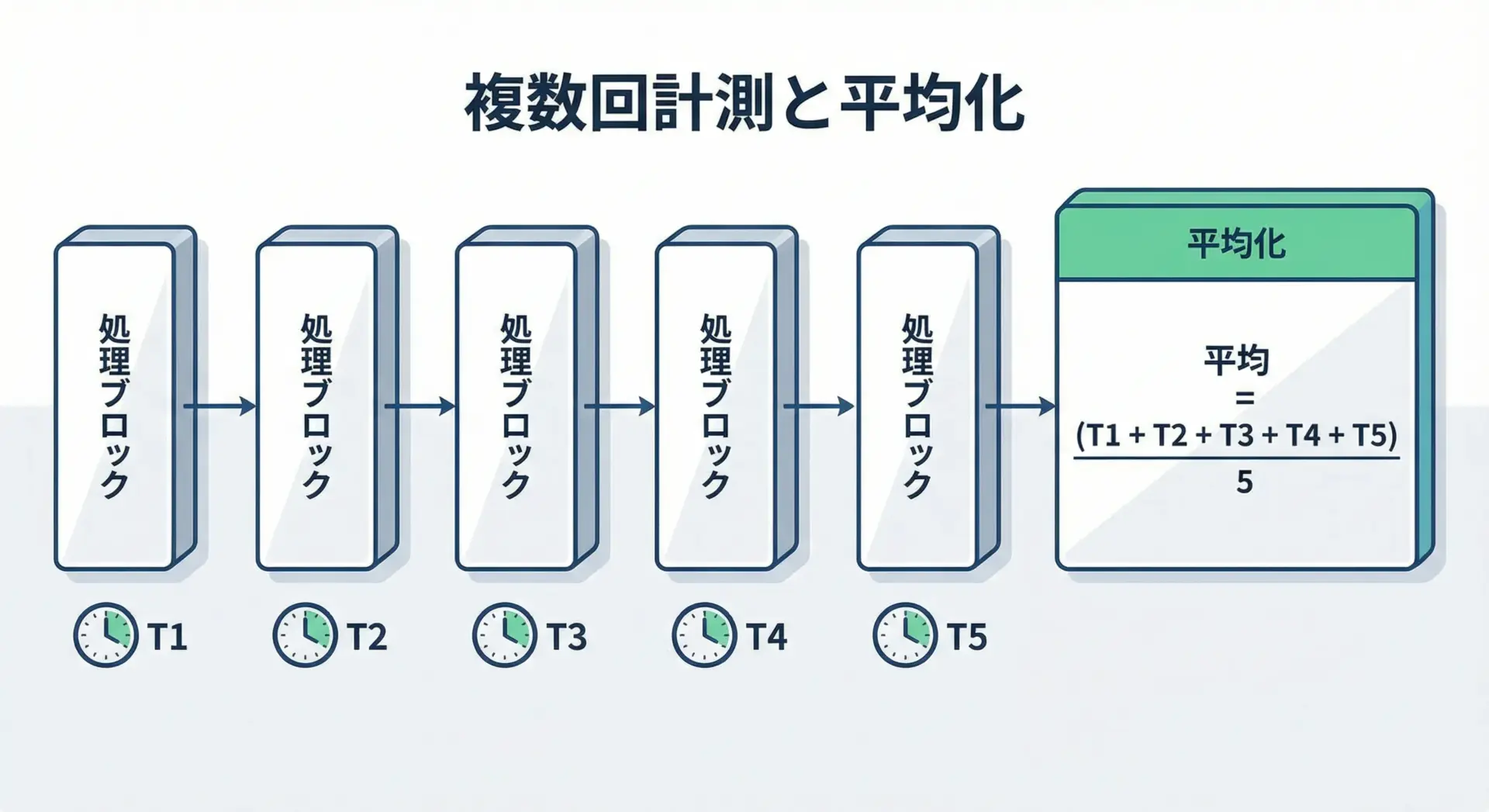
以下は、同じ関数を複数回呼び出して平均時間を計算するサンプルです。
#include <stdio.h>
#include <time.h>
void target_task(void) {
// 計測対象とする処理(ここでは単純なループ)
volatile long long sum = 0;
for (long long i = 0; i < 30000000; i++) {
sum += i;
}
}
double measure_once(void) {
clock_t start, end;
start = clock();
target_task();
end = clock();
return (double)(end - start) / CLOCKS_PER_SEC;
}
int main(void) {
const int NUM_TRY = 5; // 計測回数
double times[NUM_TRY]; // 各回の計測結果を保存
double total = 0.0;
// 複数回計測
for (int i = 0; i < NUM_TRY; i++) {
times[i] = measure_once();
total += times[i];
printf("%d回目の計測時間: %f 秒\n", i + 1, times[i]);
}
// 平均時間を計算
double avg = total / NUM_TRY;
printf("------------------------------\n");
printf("平均処理時間: %f 秒 (計測回数: %d)\n", avg, NUM_TRY);
return 0;
}(実行例)
1回目の計測時間: 0.280000 秒
2回目の計測時間: 0.270000 秒
3回目の計測時間: 0.275000 秒
4回目の計測時間: 0.272000 秒
5回目の計測時間: 0.273000 秒
------------------------------
平均処理時間: 0.274000 秒 (計測回数: 5)このように、複数回の計測結果を配列に保存し、平均値を取ることで、ばらつきの少ない目安時間を得ることができます。
必要に応じて、最大値・最小値・標準偏差などを計算すれば、より詳細な性能評価も可能です。
clock関数利用時の注意点と応用
clock関数の精度と限界
clock関数は手軽な一方で、いくつかの制約と限界があります。
これを理解していないと、「ミリ秒単位の精度が出ている」と誤解して使ってしまう危険があります。
精度(分解能)の限界
精度はCLOCKS_PER_SECと実装に依存します。
例えばCLOCKS_PER_SEC = 1000なら、理論上は1ミリ秒単位で刻まれますが、実際にはOSやライブラリの実装により、もっと荒い刻みになることがあります。
そのため、非常に短い処理(数マイクロ秒〜数十マイクロ秒程度)の計測には向きません。
このような場合は、後述する高精度タイマや、OS依存の関数の利用を検討します。
測れるのは「CPU時間」である点
多くの実装でclock関数は「経過した実時間」ではなく「プロセスが実際にCPUを使っていた時間」を返します。
つまり、I/O待ちやスリープ中の時間は含まれない場合があります。
表にまとめると次のようなイメージです。
| 種類 | clockで増えるか | 説明 |
|---|---|---|
| CPUでの計算時間 | 増える | ループ計算・関数計算など |
| ディスクI/O待ち | 実装依存 | 含まれない場合が多い |
| ネットワーク待ち | 実装依存 | 同上 |
| スリープ時間 | 含まれないことが多い | sleep中はCPUを使っていない |
「実際の経過時間」を測りたいのか、「CPUがどれだけ忙しかったか」を測りたいのかで、clock関数が適切かどうかが変わります。
オーバーフローの問題
clock関数の戻り値であるclock_tは有限のサイズしかありません。
そのため、長時間動かし続けると値がオーバーフローする可能性があります。
標準では、(clock_t)-1は「取得失敗」を表すことになっており、取得結果が(clock_t)-1かどうかをチェックする処理を入れておくのが安全です。
マルチスレッド環境でのclock関数の注意点
マルチスレッド環境では、clock関数を使うときに追加の注意が必要になります。
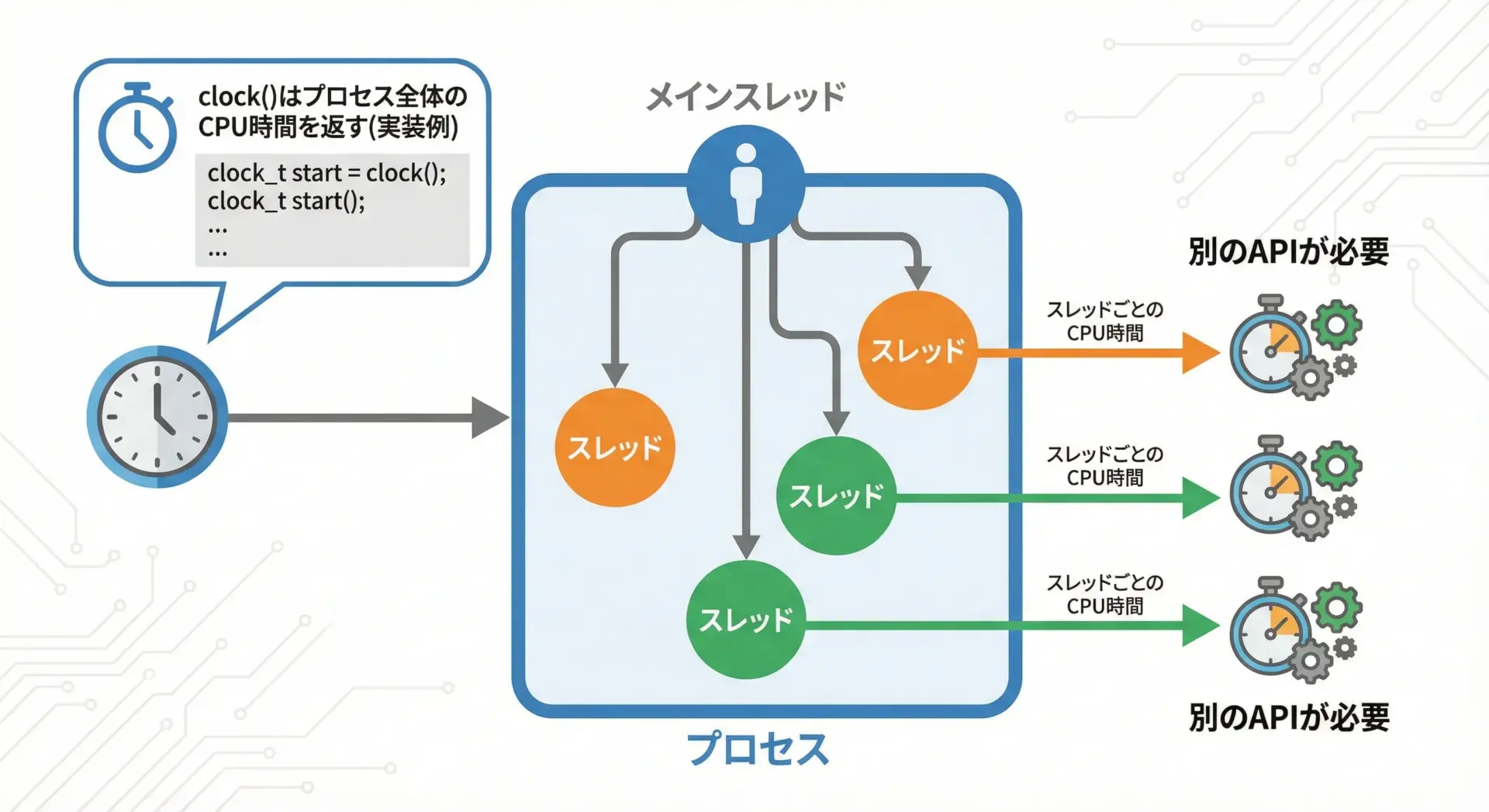
プロセス全体か、スレッド単位か
多くの処理系では、clock関数は「プロセス全体のCPU時間」を返すように実装されています。
そのため、複数スレッドが同時に動いている場合、ある1つのスレッドだけの時間を正確に測れないことがあります。
例えば、スレッドAでclockを呼んだとしても、その間にスレッドBがCPUを使っていれば、その時間も含めて増えてしまうケースがあります。
スレッド単位の計測が必要な場合
スレッドごとのCPU時間を正確に測りたい場合、OSごとの専用API(例: Linuxのclock_gettimeでCLOCK_THREAD_CPUTIME_IDを使う、など)を利用する必要があります。
これはPOSIXや各OSのドキュメントを確認する必要があります。
マルチスレッド環境でclockを使う場合は、「目安の時間を知るための簡易計測」と割り切るのが現実的です。
他の時間計測関数との比較
clock関数は標準Cの一部として手軽に使えますが、用途によってはより適した関数があります。
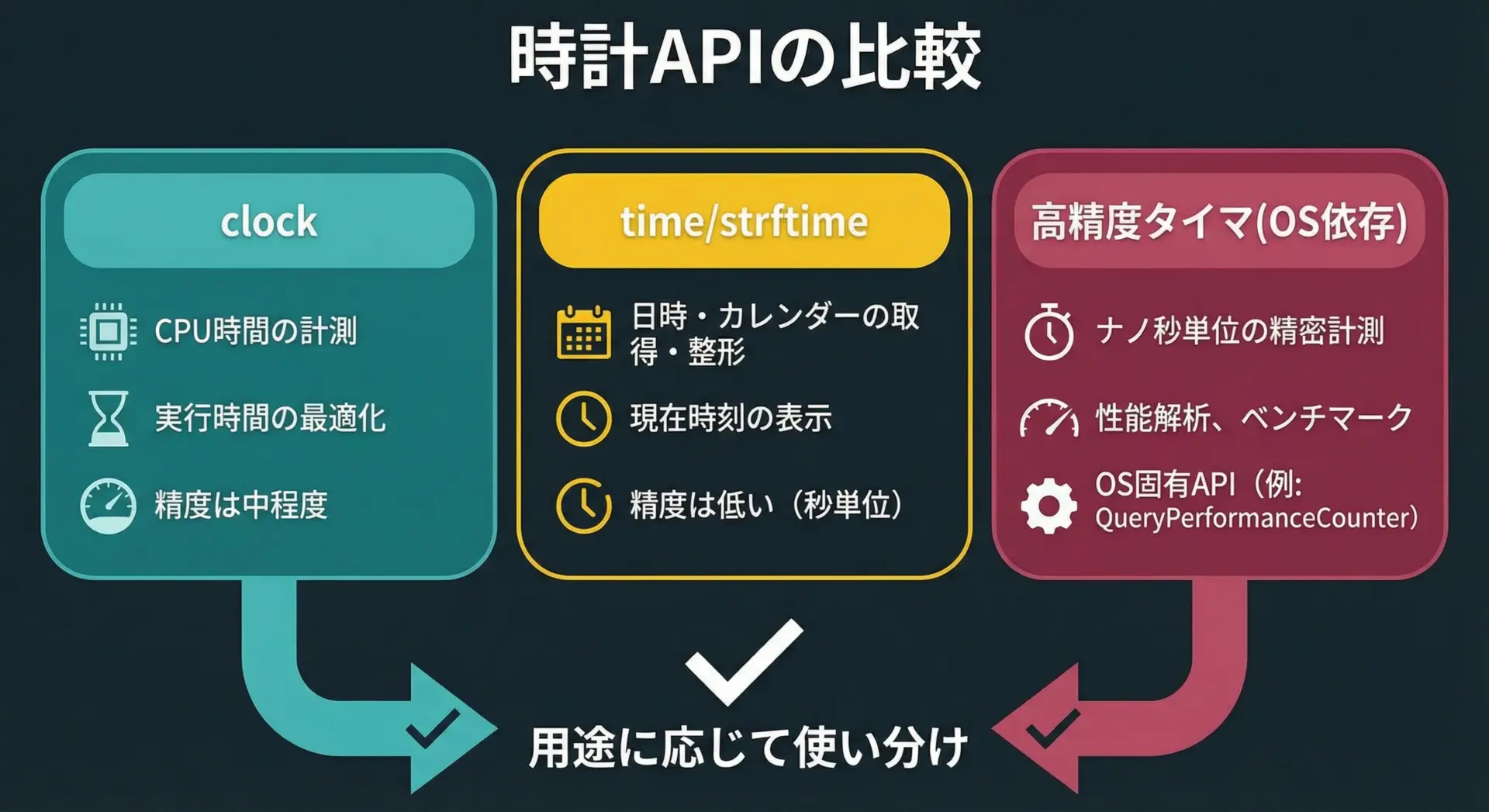
代表的な関数との簡単な比較を表にまとめます。
| 関数名・API | 主な用途 | 精度・単位 | 備考 |
|---|---|---|---|
clock | CPU時間の測定(おおまか) | 実装依存(ミリ秒程度) | 標準C。CPU使用時間が主な対象 |
time | 現在時刻(カレンダー時刻) | 秒 | 日時の表示やログ用 |
difftime | 2つのtime_tの差分 | 秒(倍精度浮動小数) | 「何秒経過したか」のざっくり計測 |
clock_gettime | 高精度な時刻取得 | ナノ秒(実際は数十ns~) | POSIX。モノトニック時計などを使える |
| Windows API(QueryPerformanceCounter) | 高精度な時刻取得 | マイクロ秒〜ナノ秒 | Windows固有の高精度タイマ |
実時間を測りたいとき
「プログラム開始から何秒経ったか」「2つのイベントの間の実時間」を測りたい場合には、POSIX環境であればclock_gettimeのCLOCK_MONOTONICを使うのが一般的です。
WindowsではQueryPerformanceCounterなどのAPIが利用できます。
日時がほしいとき
単にログのタイムスタンプが欲しい場合や、「現在年月日・時刻」を扱いたい場合は、timeとlocaltime / strftimeなどを使います。
これは処理時間計測というより時計・カレンダー用途です。
clock関数の位置づけ
このように比較すると、clock関数は「標準Cだけで、CPU時間のおおまかな目安を知りたいとき」の選択肢だと位置付けられます。
高精度計測や実時間計測が必要であれば、OSやライブラリ固有のAPIの利用を検討してください。
まとめ
clock関数は標準Cだけで利用できる、シンプルな処理時間計測の道具です。
開始時刻と終了時刻をclock()で取得し、その差をCLOCKS_PER_SECで割るという基本さえ押さえれば、ループや関数の処理時間を簡単に測ることができます。
一方で、精度には限界があり、CPU時間である点やマルチスレッドでの挙動には注意が必要です。
開発中の性能確認やアルゴリズム比較の第一歩としてclock関数を使い、より高精度な計測が必要になった段階で、OS依存の高精度タイマなどへステップアップしていくと良いでしょう。
