
C#で配列やListを扱うとき、for文よりも簡潔で安全に要素を順番に処理できる構文がforeach文です。
本記事では、配列とListを中心に、foreach文の基本から注意点、よくあるミスまでを丁寧に解説します。
初心者の方でも「毎回forを書くよりforeachのほうが楽で安全」と実感できる内容を目指します。
【C#】foreach文とは?基本の書き方
foreach文の役割と特徴
foreach文は、配列やListなどのコレクションの要素を先頭から順番に取り出して処理するための構文です。
インデックス番号を自分で管理する必要がないため、範囲外アクセスなどのミスを減らせます。
基本構文
foreach (要素の型 変数名 in コレクション)の形で記述します。
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
// 配列を定義
int[] numbers = { 1, 2, 3, 4, 5 };
// foreachで配列の中身を順番に表示
foreach (int n in numbers)
{
Console.WriteLine(n);
}
}
}1
2
3
4
5このように、インデックス(iやindex)を一切書かなくても、全要素を漏れなく処理できる点が特徴です。
foreachが向いている場面
文章でまとめると、foreachは次のような場面で特に有効です。
- 配列やListの全要素を最初から最後まで順に処理したいとき
- 要素数を意識したくない、または意識する必要がないとき
- 読みやすさや安全性を優先したいとき
逆に、「何番目の要素か」を意識して処理したい場合は、通常のfor文のほうが適しています。
配列をforeachでループする
配列 + foreachの典型パターン
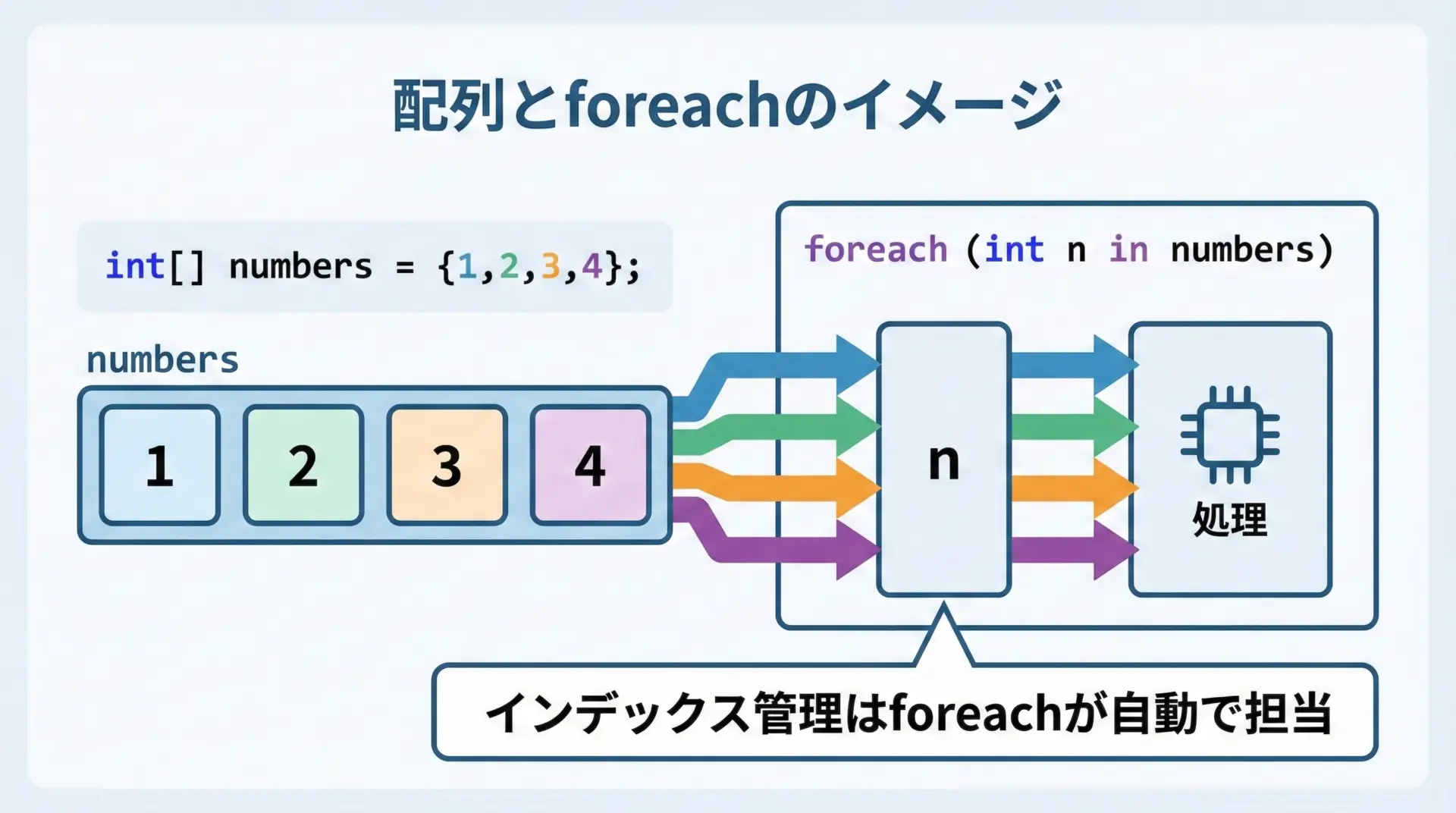
上の図のように、配列numbersの各要素が、順番にnへ入って処理されていきます。
文字列配列の例
using System;
class Program
{
static void Main()
{
// 文字列の配列を定義
string[] fruits = { "Apple", "Banana", "Cherry" };
// foreachで配列の中身を表示
foreach (string fruit in fruits)
{
// fruitには配列の要素が順番に入る
Console.WriteLine(fruit);
}
}
}Apple
Banana
Cherry配列の型とforeachの要素型を一致させることが重要です。
上の例ではstring[]なので、foreachの要素型はstringを使っています。
値型・参照型どちらもOK
配列の要素がintなどの値型でも、stringや自作クラスなどの参照型でも、foreachの使い方は同じです。
型の部分だけ書き換えればよいので、コードのパターンを覚えやすいです。
using System;
class User
{
public string Name;
}
class Program
{
static void Main()
{
// User型の配列
User[] users =
{
new User { Name = "Taro" },
new User { Name = "Hanako" }
};
foreach (User u in users)
{
Console.WriteLine(u.Name);
}
}
}Taro
HanakoListをforeachでループする
Listとforeachの基本
Listは「要素数が変動可能な配列のようなコレクション」で、実務でも頻繁に使われます。
Listも配列と同じようにforeachでループできます。
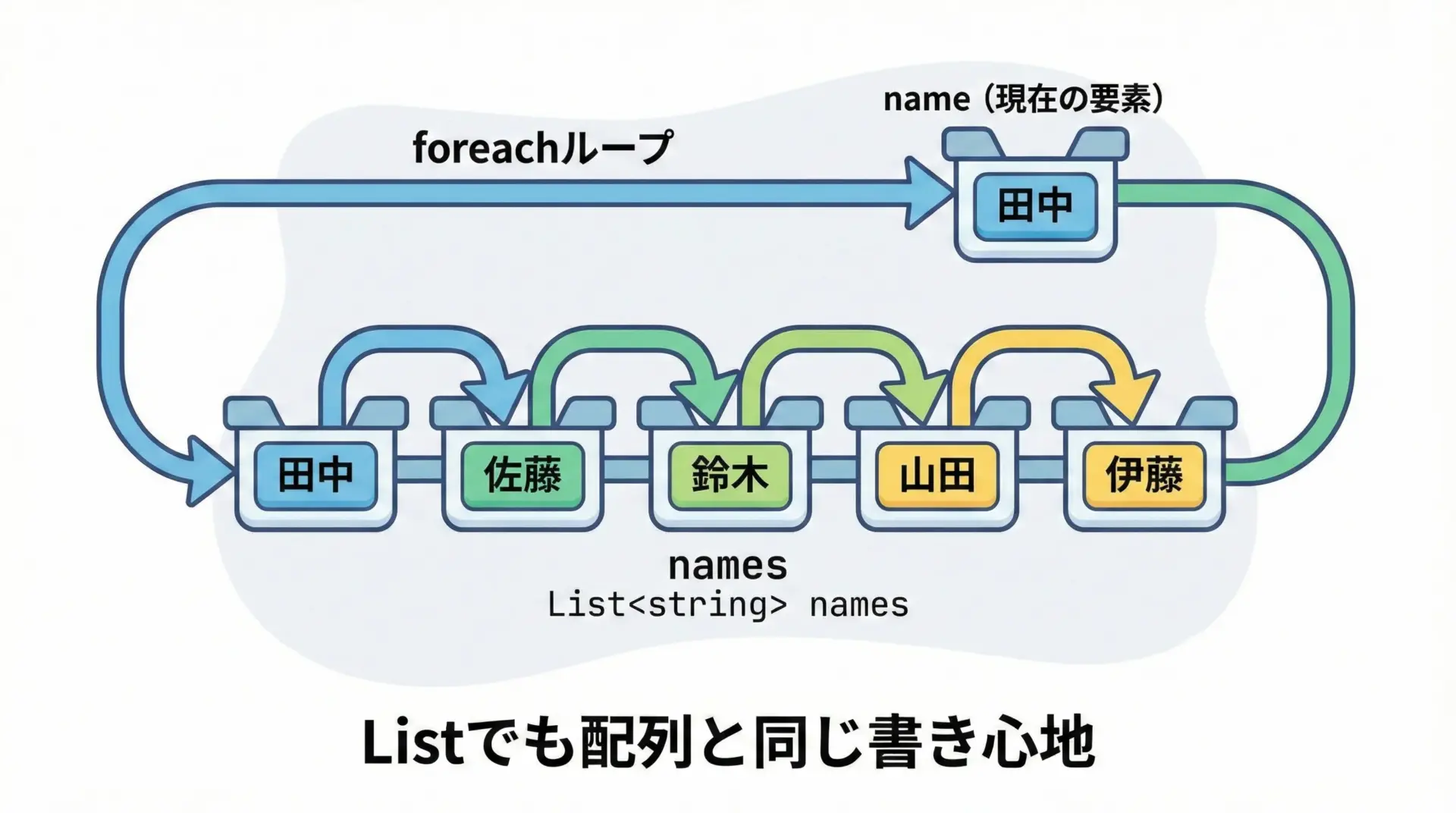
List<string>をforeachで回す例
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
// List<string>を作成して要素を追加
List<string> names = new List<string>();
names.Add("Suzuki");
names.Add("Sato");
names.Add("Tanaka");
// foreachでListの要素を順に出力
foreach (string name in names)
{
Console.WriteLine(name);
}
}
}Suzuki
Sato
Tanaka配列と書き方がほぼ同じであることが分かると思います。
コレクションの種類が変わっても、foreachのスタイルを統一して書けるのが利点です。
varを使ったforeach
C#ではvarを使って、要素型を自動推論させることもできます。
foreach (var name in names)
{
Console.WriteLine(name);
}要素の型が長い場合や、ジェネリック型で複雑なときに役立ちます。
ただし、コードの読み手が型をイメージしづらくなる場合は、明示的に型を書いたほうが親切です。
foreachが「安全」と言える理由
インデックス範囲外アクセスを防げる
for文で配列やListを扱う場合、次のようなミスがよく起こります。
int[] nums = { 1, 2, 3 };
// 間違い例: <= にしてしまっている
for (int i = 0; i <= nums.Length; i++)
{
// i == nums.Length のときに例外が発生する
Console.WriteLine(nums[i]);
}このコードはIndexOutOfRangeExceptionを引き起こします。
条件式を<にすべきところを<=にしてしまう、よくあるパターンです。
foreachを使えば、次のように境界条件のミス自体が存在しなくなるため、安全です。
int[] nums = { 1, 2, 3 };
foreach (int n in nums)
{
Console.WriteLine(n);
}読みやすさ・意図の明確さ
foreachを見るだけで、「この処理はコレクションの全要素を順に処理している」と分かります。
インデックス操作の細かいロジックがない分、意図がコードに直接現れるので、保守やレビューがしやすくなります。
foreach使用時の注意点とよくある誤解
foreach内で要素を書き換えられるか?
「foreachの変数そのもの」には代入できません。
次のようなコードはコンパイルエラーになります。
int[] numbers = { 1, 2, 3 };
// コンパイルエラーの例
foreach (int n in numbers)
{
// n = n + 1; // ここはエラーになる(読み取り専用)
}ただし、要素が参照型(クラスなど)の場合は、そのオブジェクトのプロパティを書き換えることは可能です。
using System;
class User
{
public string Name;
}
class Program
{
static void Main()
{
User[] users =
{
new User { Name = "Taro" },
new User { Name = "Hanako" }
};
foreach (User u in users)
{
// u自体を別のインスタンスに代入することはできないが、
// プロパティの変更は可能
u.Name = u.Name.ToUpper();
}
foreach (User u in users)
{
Console.WriteLine(u.Name);
}
}
}TARO
HANAKOこの挙動は「foreachでは一切変更できない」と誤解されがちなので注意が必要です。
変数そのものの再代入は不可、参照先オブジェクトの中身変更は可能と覚えるとよいです。
ループ中にコレクションを変更しない
Listなどのコレクションをforeachで回している最中にAddやRemoveを行うと、多くの場合InvalidOperationExceptionになります。
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
List<int> list = new List<int> { 1, 2, 3 };
try
{
foreach (int n in list)
{
Console.WriteLine(n);
// ループ中に要素を追加(よくない例)
list.Add(99);
}
}
catch (InvalidOperationException ex)
{
Console.WriteLine("例外発生: " + ex.Message);
}
}
}1
例外発生: コレクションが変更されました。列挙操作は実行されない可能性があります。ループ中にコレクションを変更したい場合は、次のような工夫が必要になります。
- for文を使い、インデックスで制御する
- 先に「削除・追加対象のリスト」を別に作り、ループ終了後にまとめて変更する
foreachとforの比較と使い分け
コードの比較
配列の全要素を合計する処理を、forとforeachで書き比べてみます。
int[] nums = { 1, 2, 3, 4, 5 };
// for版
int sumFor = 0;
for (int i = 0; i < nums.Length; i++)
{
sumFor += nums[i];
}
// foreach版
int sumForeach = 0;
foreach (int n in nums)
{
sumForeach += n;
}どちらも同じ結果になりますが、foreach版のほうが「やりたいこと」に集中したコードになっていることが分かります。
どちらを選べばよいかの目安
文章で整理すると次のようになります。
- foreachを選ぶとよい場面
- 全要素を順番に処理したいだけのとき
- 配列やListの中身を読み取るだけのとき
- コードの読みやすさを重視したいとき
- forを選ぶとよい場面
- 「何番目の要素か」を意識した処理が必要なとき
- インデックスを飛ばして処理したいとき(例: 2つおき)
- ループ中に要素の追加や削除、入れ替えなどの更新が必要なとき
基本的にはforeachを標準にし、インデックスが必要になったときにforを使う、という方針にするとバグを減らしやすくなります。
応用: インデックスも欲しいときのforeachテクニック
Select((value, index))との組み合わせ
LINQを使える環境であれば、Select((value, index))を使って、foreachでもインデックス相当の値を扱うことができます。
using System;
using System.Linq;
class Program
{
static void Main()
{
string[] fruits = { "Apple", "Banana", "Cherry" };
// valueが要素、indexがインデックス
foreach (var pair in fruits.Select((value, index) => new { value, index }))
{
Console.WriteLine($"{pair.index}: {pair.value}");
}
}
}0: Apple
1: Banana
2: Cherryforほどシンプルではありませんが、「読みやすさ」と「インデックス利用」の両方をバランスよく満たしたいときに便利な書き方です。
まとめ
foreach文は、配列やListなどのコレクションを簡潔かつ安全にループ処理できる構文です。
要素数やインデックスの境界を自分で管理せずに済むため、コードの見通しが良くなり、バグも減らせます。
一方で、ループ中のコレクション変更や値の再代入などには制約があるため、その特性を理解したうえで、for文と適切に使い分けることが大切です。
まずは「全要素を順番に処理するときはforeach」を基本の選択肢として、日常的なコードで活用してみてください。
