C言語でテキストファイルを扱うとき、1文字ずつ読み書きできると、細かい制御やデバッグがしやすくなります。
本記事では、標準ライブラリ関数であるfgetcとfputcを中心に、基本的な使い方から、EOF(ファイル終端)やエラー処理、改行コードへの注意点、さらにファイルコピーの実例まで、丁寧に解説していきます。
fgetcとfputcとは?基本動作と特徴
fgetcとは
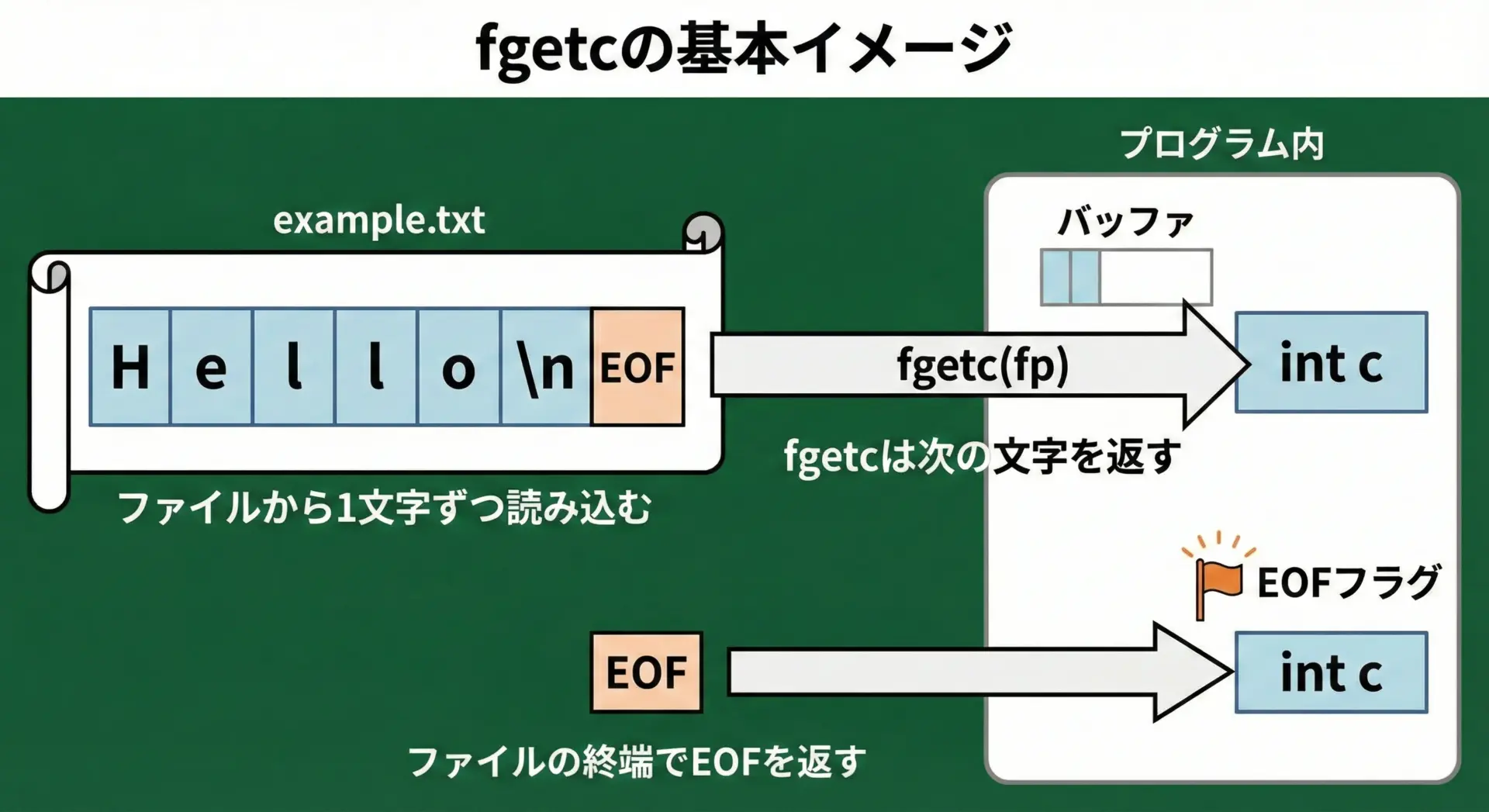
fgetcは、C言語の標準ライブラリに含まれる1文字入力用の関数です。
指定したFILE *ストリームから1文字だけ読み込み、その文字をint型として返します。
fgetcの宣言
int fgetc(FILE *stream);ここで、streamはfopenで開いたファイルポインタです。
戻り値は読み込んだ文字(のunsigned charをintに拡張した値)か、EOFが返されます。
重要なポイントとして、戻り値の型はcharではなくintです。
これは文字としての値とEOF(-1が一般的)を区別するためであり、後で説明するEOF判定にも直結します。
fputcとは
fputcは、1文字を書き込むための関数です。
指定したFILE *ストリームに対して、与えた文字を1文字だけ出力します。
fputcの宣言
int fputc(int c, FILE *stream);cには出力したい文字をunsigned charに変換可能な値として渡します。
戻り値は書き込まれた文字が返され、エラー時にはEOFが返されます。
fgetcとfputcを使うメリット・デメリット
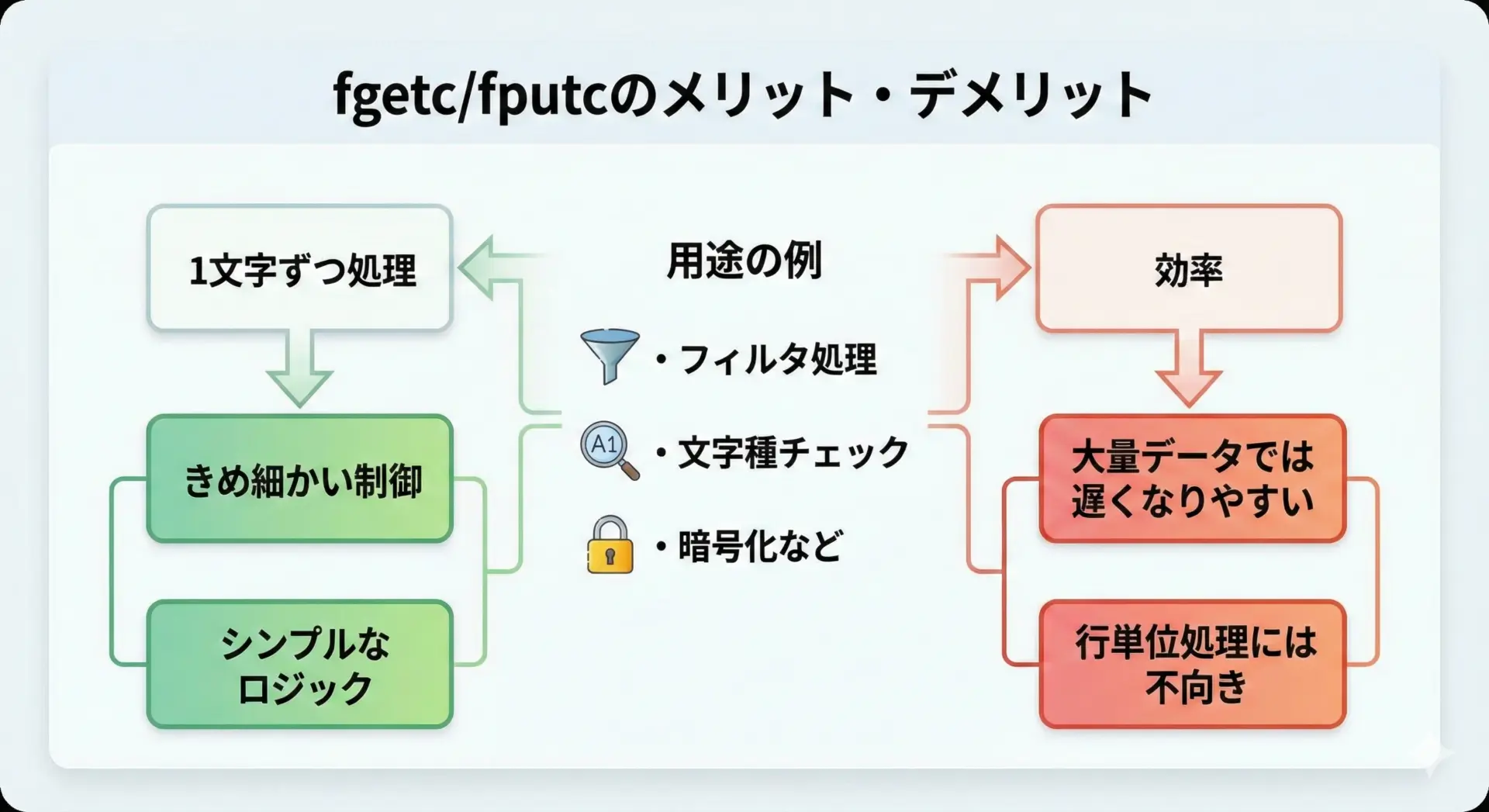
fgetc/fputcの主なメリットとしては、次のような点が挙げられます。
- 1文字単位で処理するため、細かい制御がしやすいです。たとえば、特定の文字だけを置換したり、制御文字をスキップしたりといった処理に向いています。
- 関数自体が非常にシンプルであり、
while ((c = fgetc(fp)) != EOF)のような定型的な書き方で読み取りループが組めます。 - バイナリファイルでも使用できますが、今回のテーマではテキストファイル前提で説明します。
一方で、デメリットもあります。
- 1文字ずつ関数呼び出しを行うため、大量データではオーバーヘッドが大きくなりがちです。行単位やブロック単位での処理と比べると、速度が遅くなることがあります。
- 行単位の処理や文字列処理を行いたい場合にはfgets/fputsや
fread/fwriteの方が自然な場合も多く、用途の見極めが重要です。
【読み込み】fgetcでテキストファイルを1文字ずつ読む
fgetcの基本的な使い方
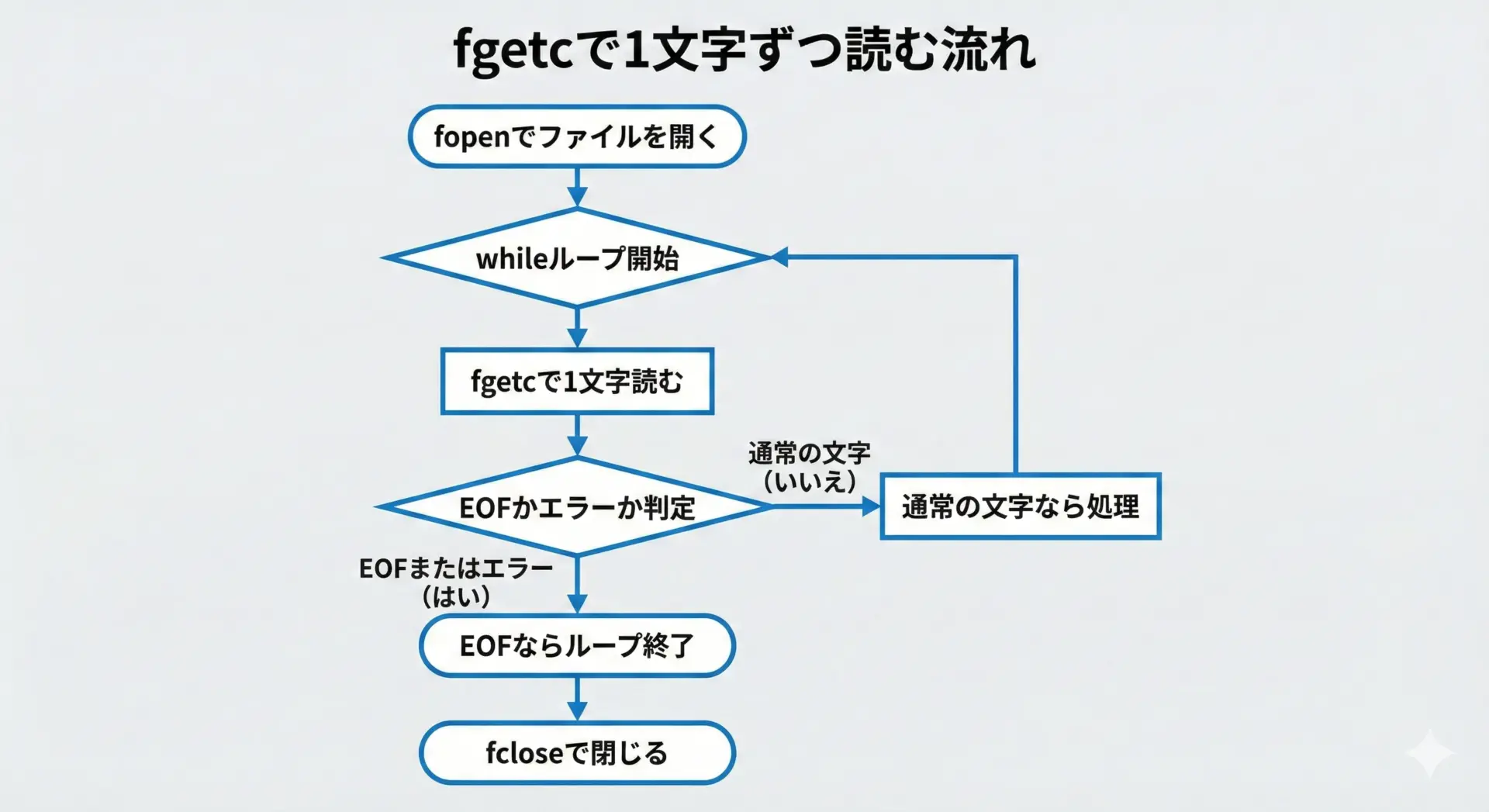
ここでは、fgetcを使ってテキストファイルを1文字ずつ読みながら表示する基本的なサンプルを示します。
#include <stdio.h>
int main(void) {
FILE *fp;
int c; // fgetcの戻り値を受けるのでint型
// ファイルを読み取りモード("r")で開く
fp = fopen("input.txt", "r");
if (fp == NULL) {
// fopenに失敗した場合のエラー処理
perror("fopen");
return 1;
}
// 1文字ずつ読み込みながら標準出力に表示する
// EOFになるまでループ
while ((c = fgetc(fp)) != EOF) {
// 読み込んだ文字をそのまま出力
putchar(c);
}
// ファイルを閉じる
if (fclose(fp) == EOF) {
perror("fclose");
return 1;
}
return 0;
}このプログラムはinput.txtの内容を1文字ずつ読み取り、画面にそのまま表示します。
文字の読み込みとEOF判定が1行にまとまっているため、とても見通しがよい書き方です。
EOF判定とエラー処理のポイント
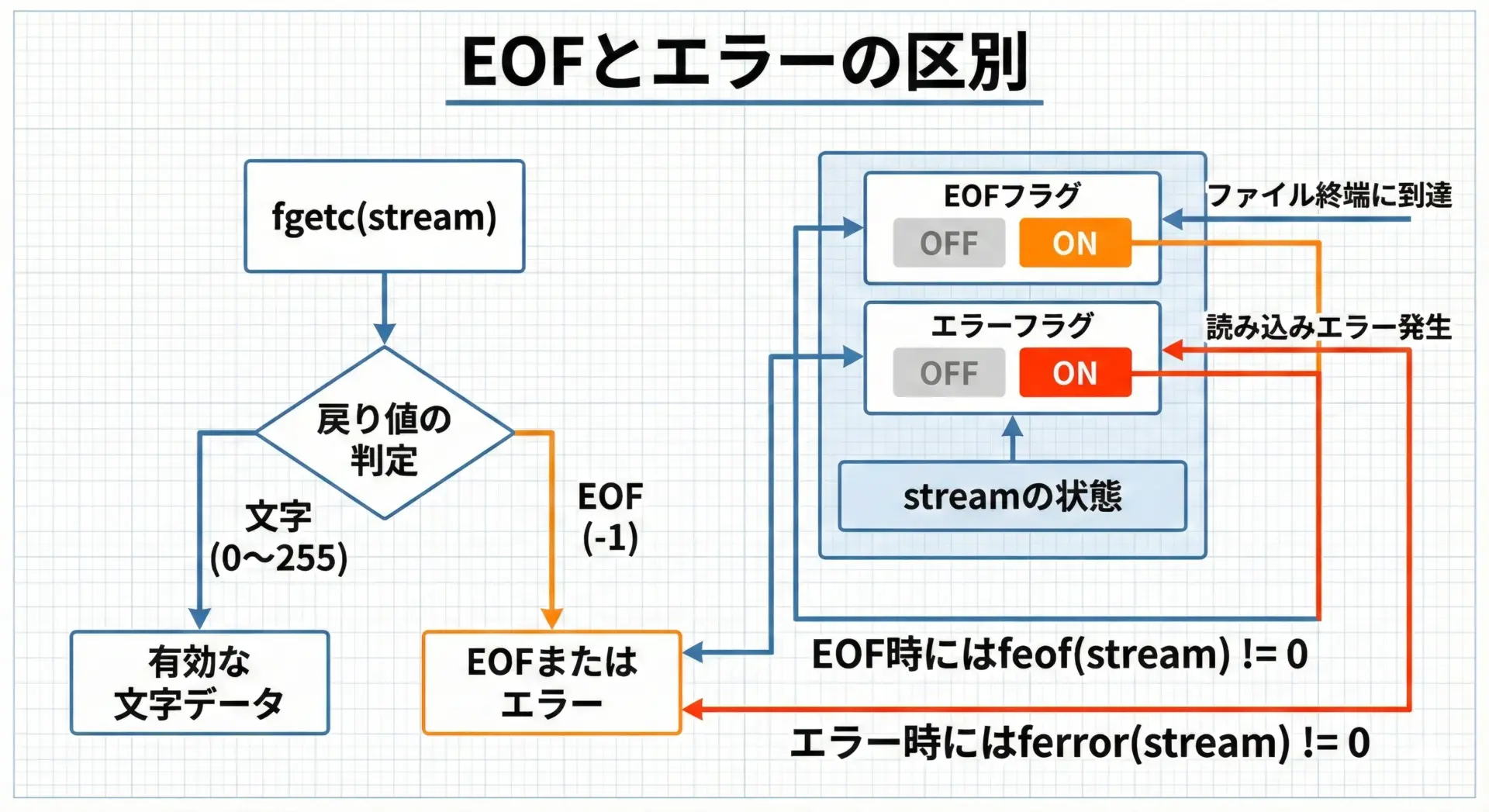
fgetcの戻り値がEOFである場合、それは必ずしも「ファイルの終わりに達した」という意味ではありません。
読み込み中にエラーが発生した場合にもEOFが返されるため、EOFとエラーを区別したいときにはfeofやferrorを使います。
EOFとエラーの区別例
#include <stdio.h>
int main(void) {
FILE *fp;
int c;
fp = fopen("input.txt", "r");
if (fp == NULL) {
perror("fopen");
return 1;
}
while ((c = fgetc(fp)) != EOF) {
putchar(c);
}
// ここに到達した時点でc == EOF
if (feof(fp)) {
// 正常にEOF(ファイル末尾)に到達した場合
printf("\n[INFO] End of file reached.\n");
} else if (ferror(fp)) {
// 読み込み中にエラーが発生した場合
perror("fgetc");
fclose(fp);
return 1;
}
if (fclose(fp) == EOF) {
perror("fclose");
return 1;
}
return 0;
}(ファイルの内容が表示されたあと)
[INFO] End of file reached.このように、ループを抜けた後でfeofとferrorの両方をチェックすることで、EOFなのかエラーなのかを確実に判定できます。
また、戻り値をchar型に代入してはいけない点にも注意が必要です。
もしchar ch = fgetc(fp);とすると、EOF(-1)がcharに変換されてしまい、ch == EOFの判定が正しく動かなくなる可能性があります。
必ずint型変数で受け取りましょう。
改行コードと文字コードに注意する点
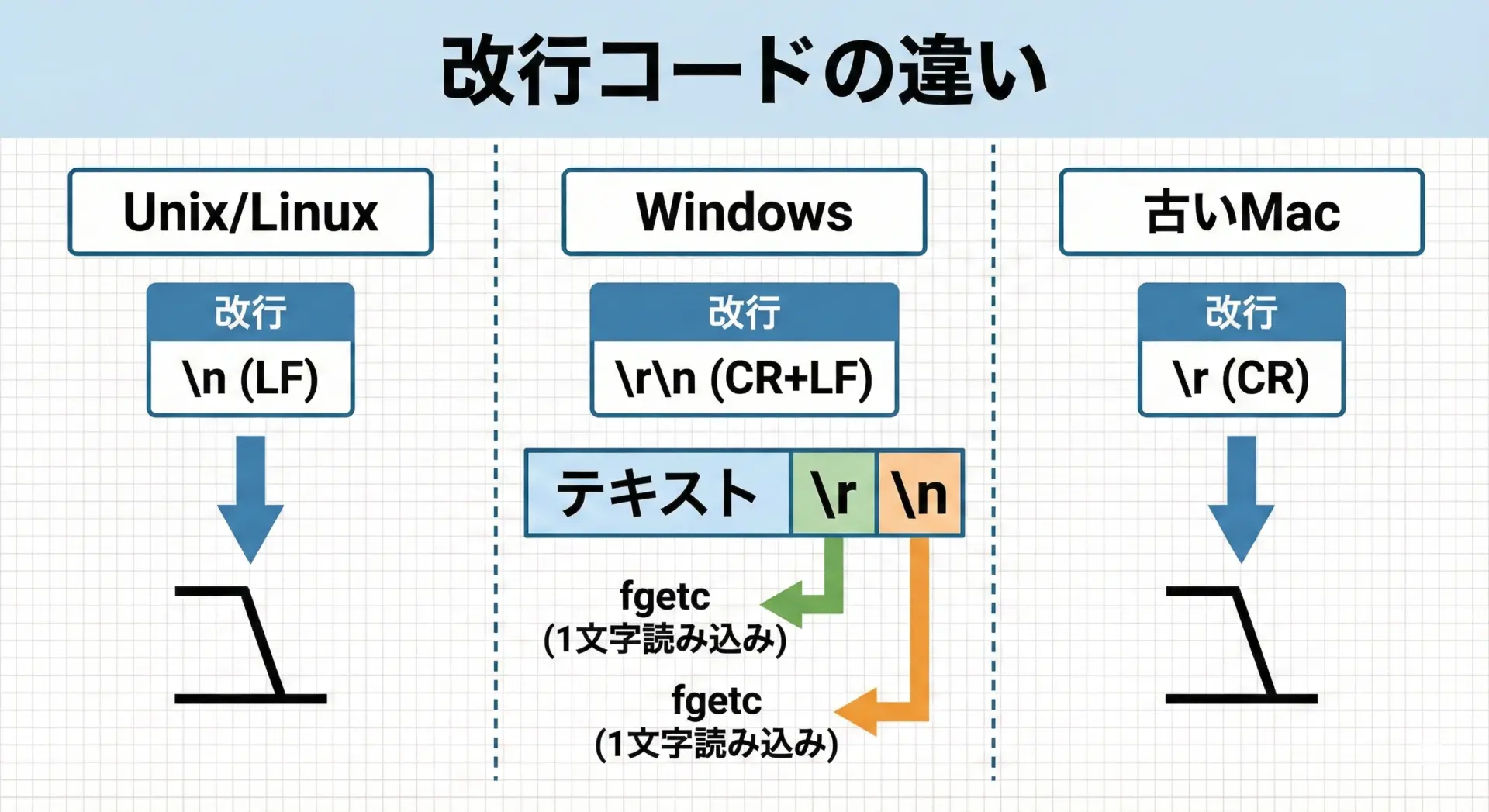
fgetcはファイルに格納されているバイト列を、そのまま1バイトずつ読み込みます(テキストモードの変換はOS依存ですが、ここでは主な注意点だけに絞ります)。
特に改行コードには注意が必要です。
- Unix/Linuxでは、改行は1文字
'\n'(LF)です。 - Windowsでは、改行は2文字
'\r'(CR) +'\n'(LF)の連続です。 - そのため、Windowsのテキストファイルをバイナリモードで読むと、fgetcで
'\r'と'\n'が別々の文字として2回読み込まれます。
たとえば、Windows環境で次のようなコードを"rb"モードで実行するとします。
#include <stdio.h>
int main(void) {
FILE *fp = fopen("win_text.txt", "rb"); // バイナリモード
int c;
if (fp == NULL) {
perror("fopen");
return 1;
}
while ((c = fgetc(fp)) != EOF) {
if (c == '\n') {
printf("\\n");
} else if (c == '\r') {
printf("\\r");
} else {
putchar(c);
}
}
fclose(fp);
return 0;
}出力例(元ファイルが「Hello(改行)World(改行)」の場合):
Hello\r\nWorld\r\nこのように、環境やモードによって改行コードがどう解釈されるかを理解しておくことは重要です。
また、文字コード(UTF-8やShift_JISなど)にも注意が必要です。
UTF-8では、日本語1文字が3バイト程度になることが多く、fgetcで1文字ずつ読むと「1文字≠1回のfgetc呼び出し」になります。
UTF-8文字を正しく扱いたい場合は、マルチバイト文字向けの関数fgetwcなどの利用も検討する必要があります。
【書き込み】fputcでテキストファイルに1文字ずつ書く
fputcの基本的な使い方
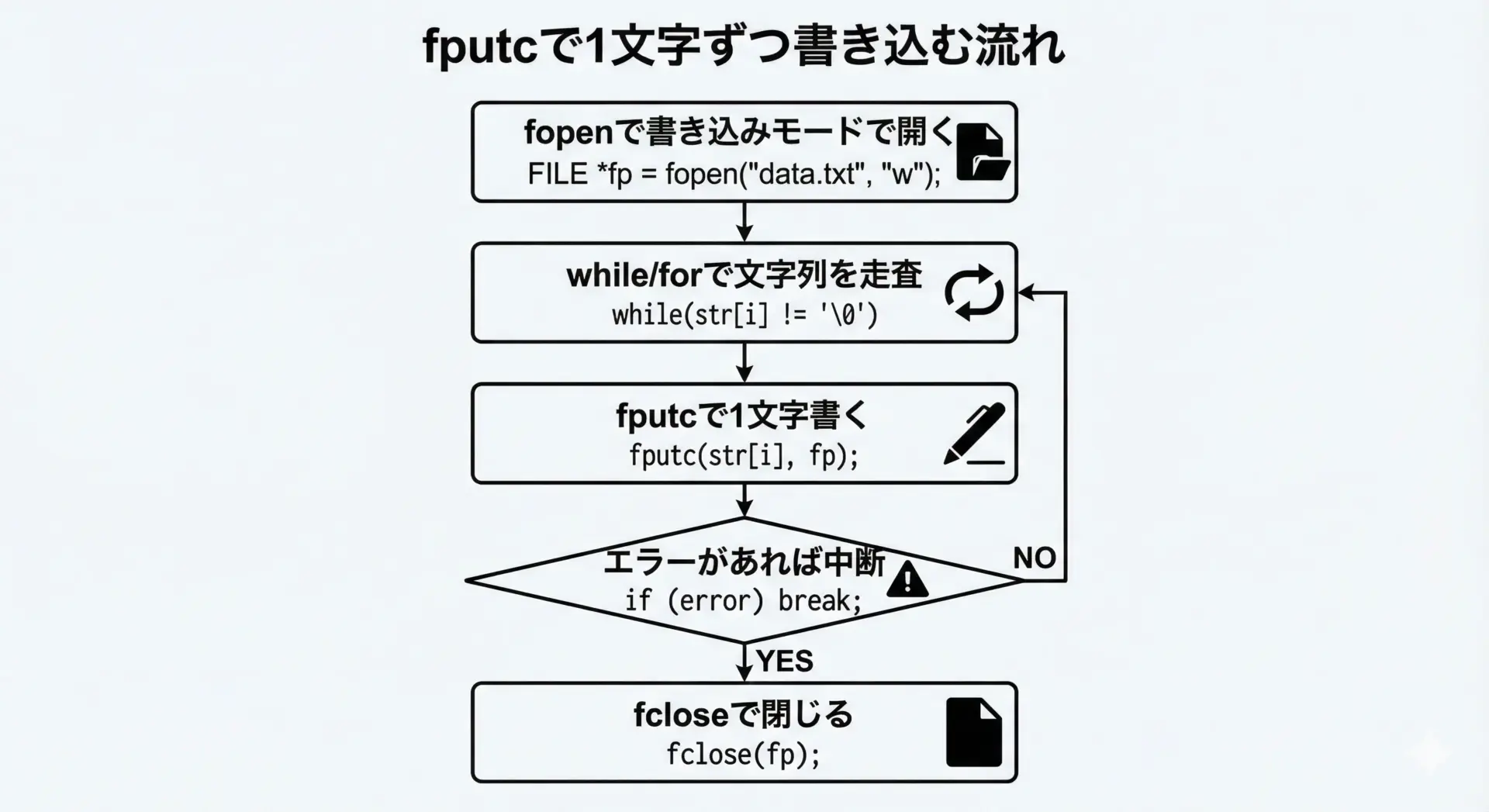
ここでは、文字列を1文字ずつfputcでファイルに書き込む簡単な例を紹介します。
#include <stdio.h>
int main(void) {
FILE *fp;
const char *text = "Hello, fputc!\n";
const char *p;
// 書き込み専用モード("w")でファイルを開く
fp = fopen("output.txt", "w");
if (fp == NULL) {
perror("fopen");
return 1;
}
// 文字列を1文字ずつファイルに書き込む
for (p = text; *p != '\0'; p++) {
if (fputc((unsigned char)*p, fp) == EOF) {
// 書き込みに失敗した場合
perror("fputc");
fclose(fp);
return 1;
}
}
// ファイルを閉じる
if (fclose(fp) == EOF) {
perror("fclose");
return 1;
}
return 0;
}このプログラムを実行すると、カレントディレクトリにoutput.txtが作成され、その内容は次のようになります。
Hello, fputc!テキスト全体を一気に出力するfputsと比べて、この方法は文字ごとに判定や変換処理を挟める点が利点です。
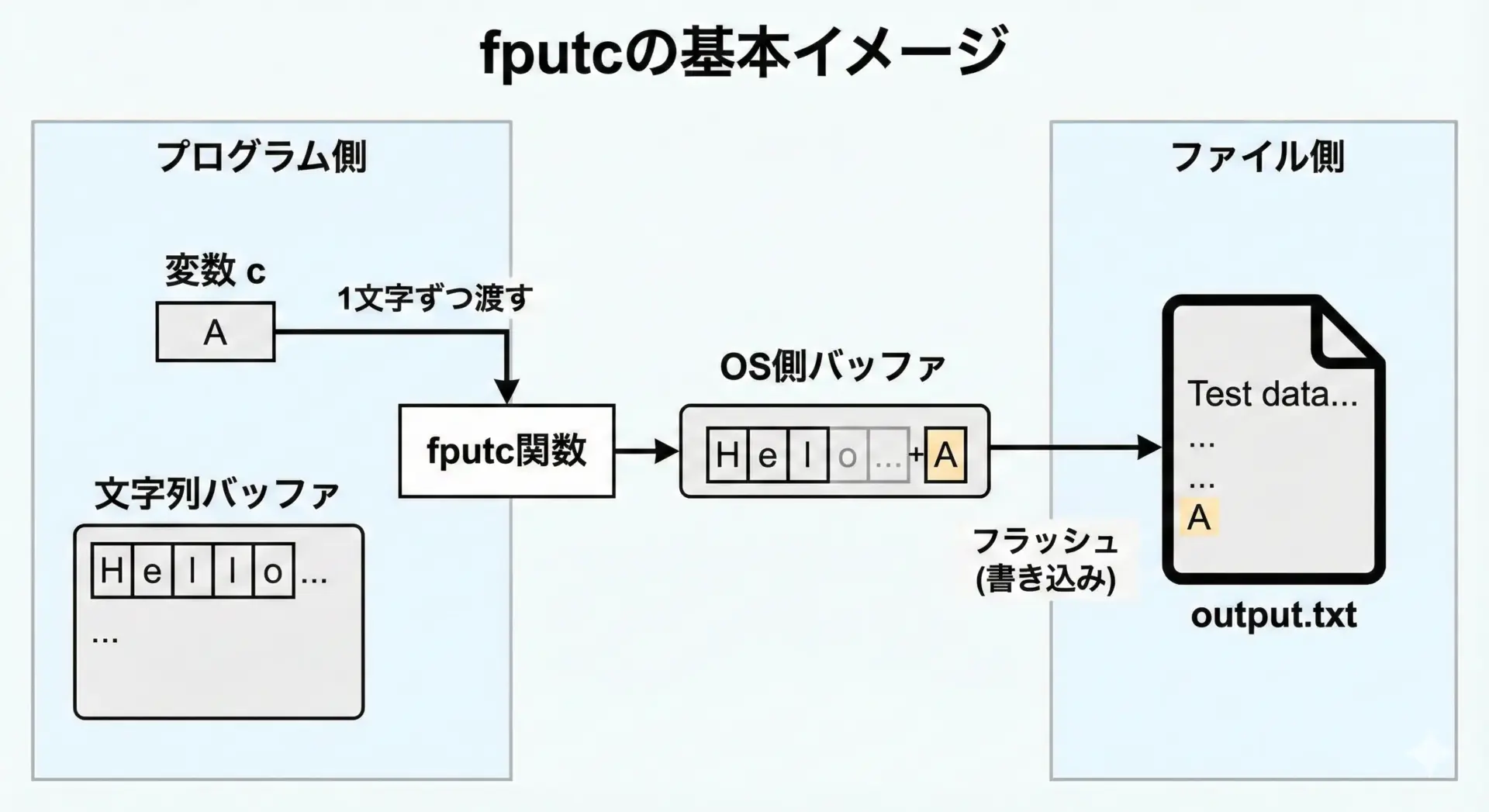
バッファリングとfflushのタイミング
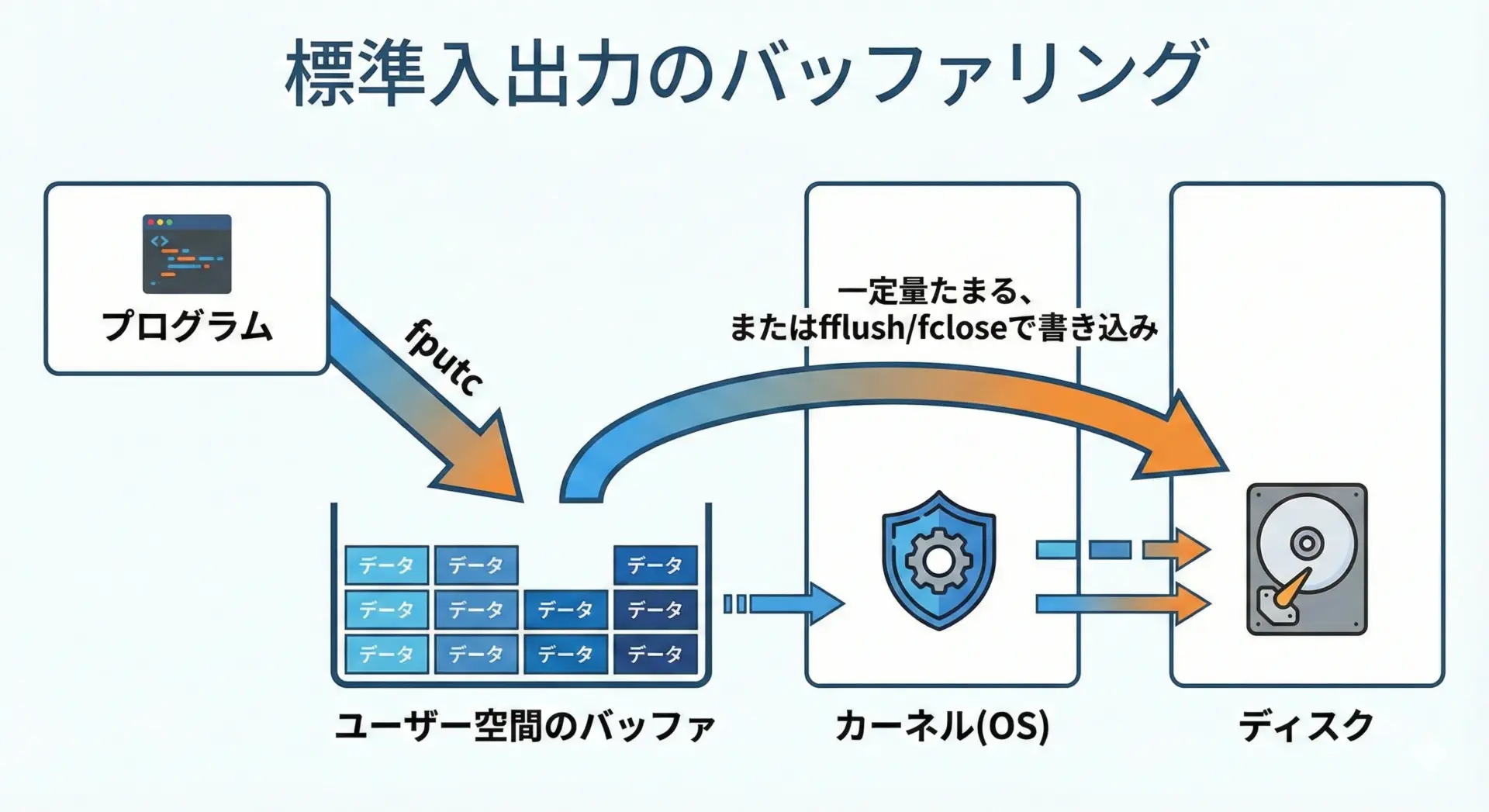
Cの標準入出力は通常バッファリングされています。
これはfputcが呼ばれた瞬間に必ずしもディスクに書き込まれるわけではないということを意味します。
具体的には、次のような動作になります。
- fputcは、まずメモリ上のバッファに1文字書き込みます。
- バッファがいっぱいになったり、
fflushやfcloseが呼ばれたり、プログラムが正常終了したりしたタイミングで、まとめてディスクに書き込まれることが多いです。
そのため、プログラムが異常終了した場合などには、まだバッファに残っていてディスクに書き込まれていないデータが失われる可能性があります。
途中までのデータを確実にディスクに反映させたい場合は、次のようにfflushを利用します。
#include <stdio.h>
int main(void) {
FILE *fp = fopen("log.txt", "w");
if (fp == NULL) {
perror("fopen");
return 1;
}
if (fputc('A', fp) == EOF) {
perror("fputc");
fclose(fp);
return 1;
}
// この時点では、まだディスクに書き込まれていない可能性がある
// 必要に応じてfflushで明示的にフラッシュする
if (fflush(fp) == EOF) {
perror("fflush");
fclose(fp);
return 1;
}
// ここまで来れば、'A'はディスクに書き込まれている可能性が高い
fclose(fp);
return 0;
}頻繁にfflushを呼ぶと、バッファリングのメリットである高速化効果が下がるため、必要な箇所(ログを逐次残したい処理など)だけに絞るのが現実的です。
追記モードや書き込みモードの指定方法

fputcを利用する際には、fopenで指定するモードがとても重要です。
代表的なモードの挙動を簡単に整理します。
| モード | 読み/書き | ファイルが存在しない場合 | すでに存在する場合 | 主な用途 |
|---|---|---|---|---|
"r" | 読み込みのみ | エラー | 先頭から読み込み | 読み専用 |
"w" | 書き込みのみ | 新規作成 | 内容を破棄して新規作成 | 上書き出力 |
"a" | 書き込みのみ | 新規作成 | 末尾に追記 | 追記ログなど |
"r+" | 読み/書き | エラー | 先頭から読み書き | 既存ファイル編集 |
"a+" | 読み/書き | 新規作成 | 末尾に追記(読みは可) | 読みもしたい追記 |
追記モード(“a”や”a+”)では、fputcで書き込む位置は常にファイルの末尾になります。
プログラム中でfseekを呼び出しても、書き込み位置は常に末尾へ移動する実装もあるため、追記専用の用途に使うのが無難です。
上書きでもよく、ファイルの内容をすべて破棄して最初から書き直したい場合は"w"を指定します。
既存の内容を保持したまま途中を書き換えたい場合には"r+"を使い、必要に応じてfseekで位置を調整しながらfgetc/fputcを組み合わせて処理する、というやり方になります。
fgetcとfputcを組み合わせたファイルコピー例
fgetcとfputcでテキストファイルをコピーするコード
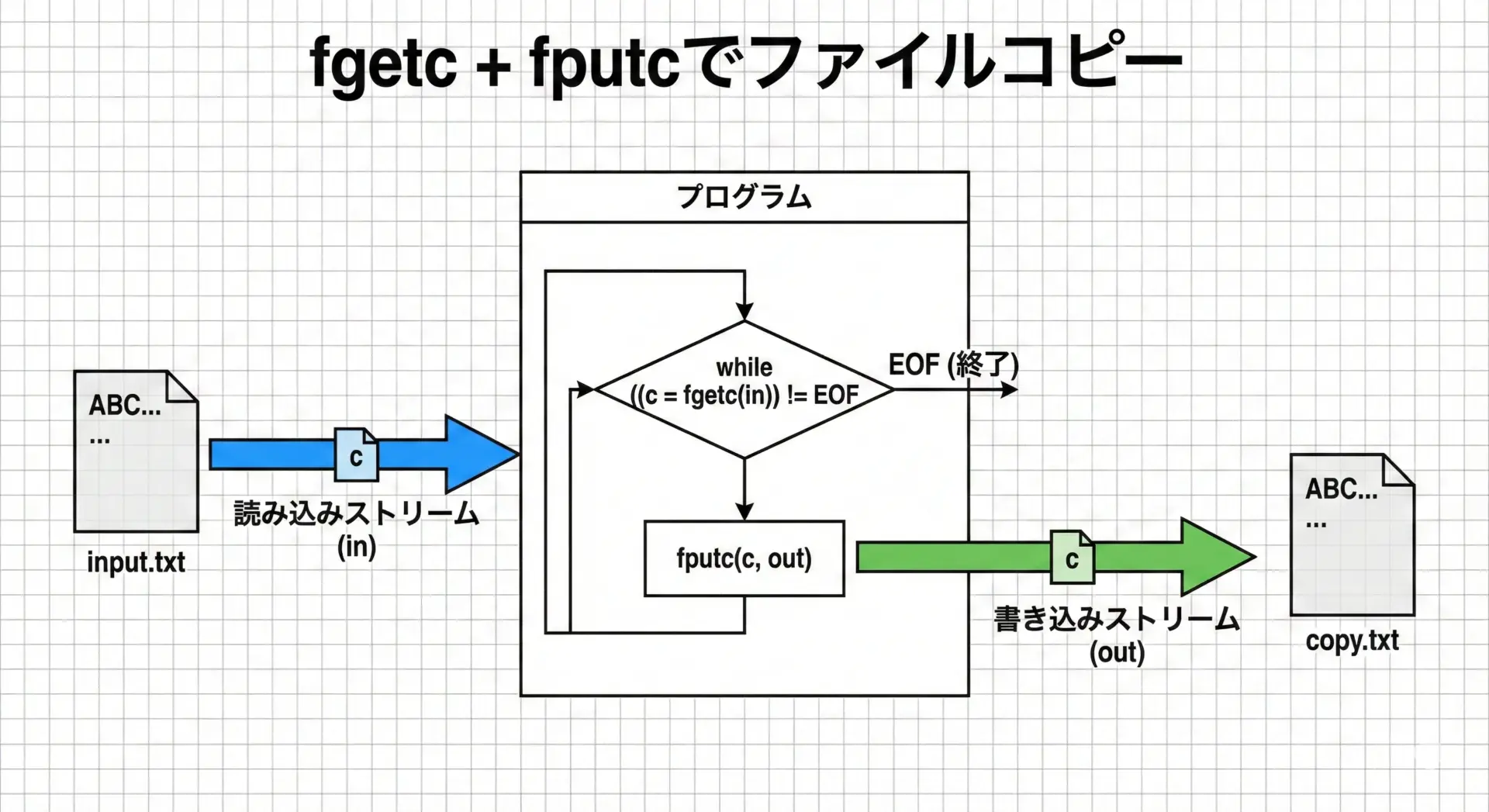
ここまでで解説したfgetcとfputcを組み合わせると、非常にシンプルなファイルコピーが実現できます。
次のサンプルでは、テキストファイルを1文字ずつ読み取り、そのまま別のファイルに書き出します。
#include <stdio.h>
int main(void) {
FILE *fin; // 入力ファイル
FILE *fout; // 出力ファイル
int c;
// 入力ファイルを読み込みモードで開く
fin = fopen("input.txt", "r");
if (fin == NULL) {
perror("fopen input");
return 1;
}
// 出力ファイルを書き込みモードで開く(既存なら内容を破棄)
fout = fopen("copy.txt", "w");
if (fout == NULL) {
perror("fopen output");
fclose(fin); // すでに開いているfinは必ず閉じる
return 1;
}
// 1文字ずつ読み込み、読み込んだら即書き込む
while ((c = fgetc(fin)) != EOF) {
if (fputc(c, fout) == EOF) {
perror("fputc");
fclose(fin);
fclose(fout);
return 1;
}
}
// ループ終了後にEOFかエラーかを判定
if (ferror(fin)) {
perror("fgetc");
fclose(fin);
fclose(fout);
return 1;
}
// ファイルを閉じる
if (fclose(fin) == EOF) {
perror("fclose input");
// ここでは続行してfoutのクローズも試みる
}
if (fclose(fout) == EOF) {
perror("fclose output");
return 1;
}
return 0;
}このプログラムを実行すると、input.txtとcopy.txtが全く同じ内容になります(テキストモードによる改行コードの変換挙動は、実行環境に依存します)。
実際のファイルサイズが大きい場合、1文字ずつのコピーは効率がよくありませんが、アルゴリズム理解やデバッグには非常に分かりやすい方法です。
エラー処理とファイルクローズの注意点
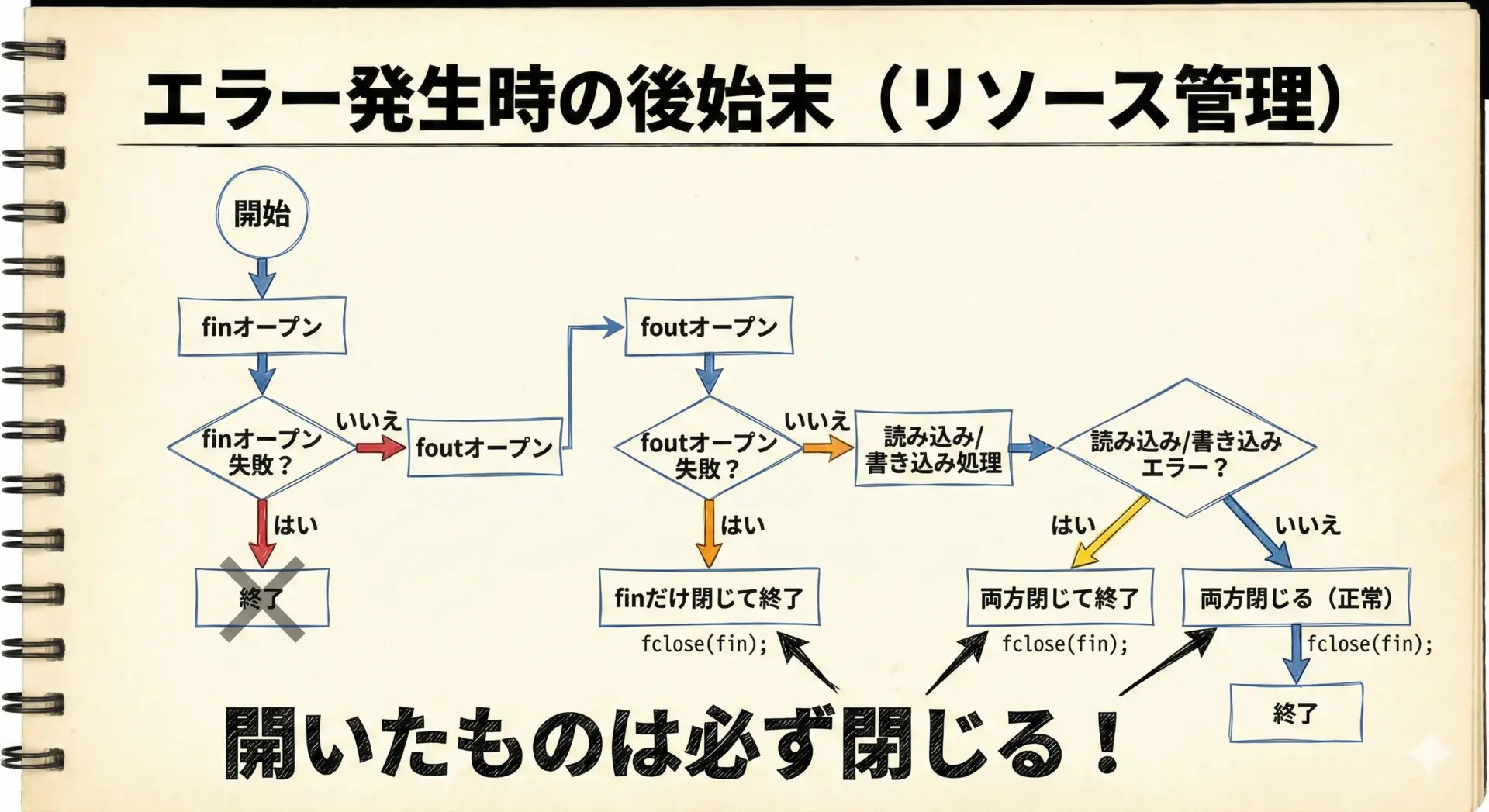
ファイルを扱うプログラムでは、エラーが起きてもリソースを必ず解放することが大切です。
特に、複数のファイルを同時に開いている場合、どこまで成功していてどこから失敗したのかを意識しないと、開いたまま閉じ忘れることになりかねません。
上記のコピー例では、次のような方針でエラー処理を行っています。
- 入力ファイル
finを開くのに失敗したら、何も開かれていないのでそのまま終了します。 - 出力ファイル
foutを開くのに失敗したら、その時点でfinだけは開かれているので、必ずfclose(fin)を呼んでから終了します。 - 読み込みや書き込みの途中でエラーが起きた場合には、両方のファイルを可能な限り
fcloseするようにしています。エラーが起きた後でも、fcloseは呼んでかまいません。
また、コピー処理のループを抜けた後でferror(fin)をチェックしているのも重要なポイントです。
EOFとエラーの区別をしない場合、途中までしかコピーできていないのに成功したかのように見えてしまう危険があります。
fgetsやfputsとの使い分けの目安
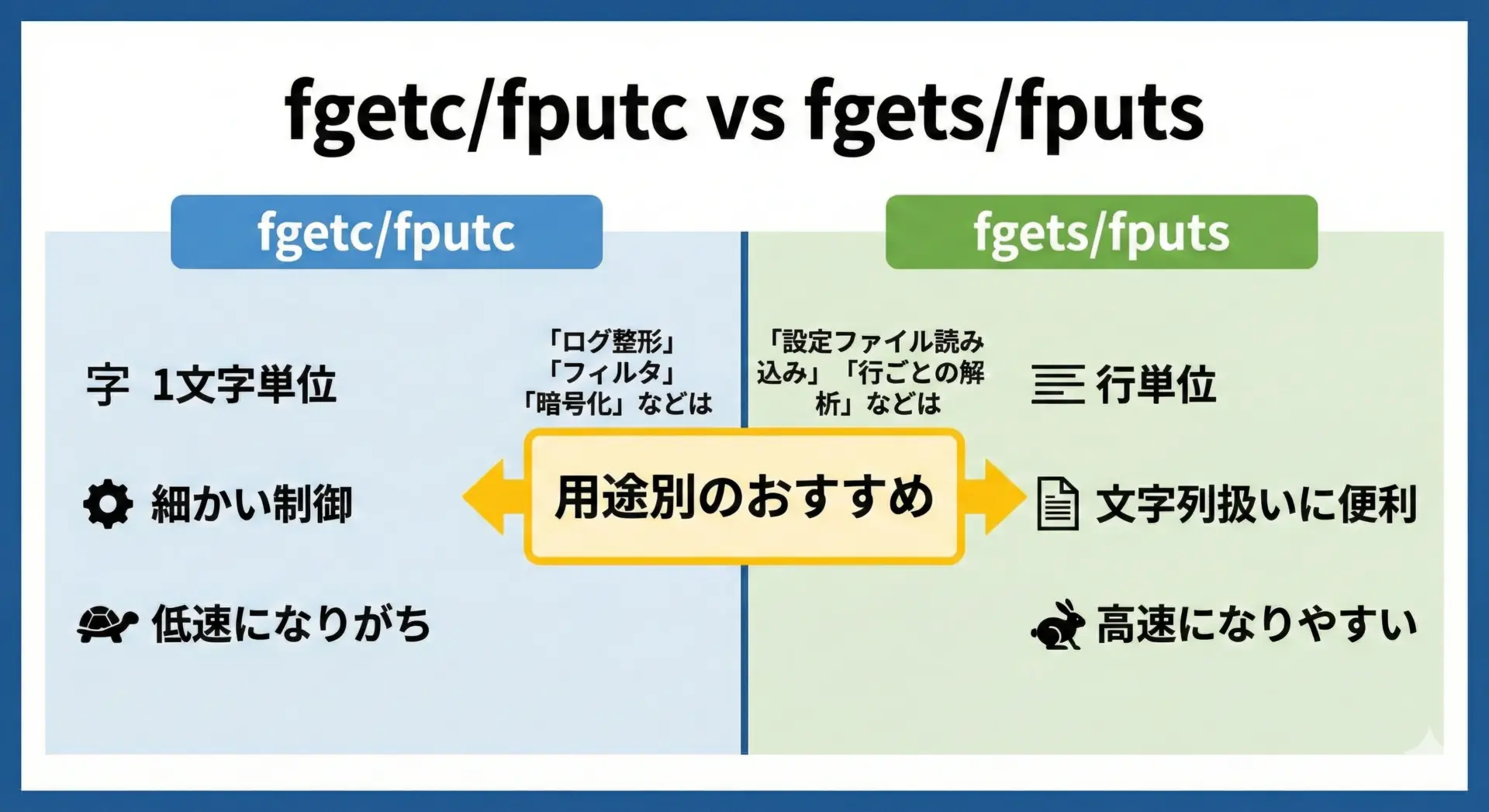
最後に、fgetc/fputcとfgets/fputsをどう使い分けるかについて整理しておきます。
どちらもテキスト向けの関数ですが、用途によって向き不向きがあります。
fgetc/fputcを選ぶとよい場面は、次のようなケースです。
- 文字ごとに個別の処理をしたいとき。たとえば、
- 特定の文字を除去・置換したい場合。
- タブをスペースに変換する場合。
- 改行や空白の扱いを細かく制御したい場合。
- シンプルなフィルタプログラム(標準入力→標準出力)を素早く書きたいとき。
- 教育目的で、ファイル入出力の基本動作を理解したいとき。
一方、fgets/fputsを選ぶとよい場面は、次のようなケースです。
- 行単位で処理したいとき。たとえば、
- 1行ごとにパースする設定ファイルやCSV。
- ログファイルを行ごとに解析するプログラム。
- 文字列関数(
strlenやstrtokなど)と組み合わせて処理したいとき。 - 性能がそれなりに重要で、できるだけ関数呼び出し回数を減らしたいとき。
表で簡単に比較すると、次のようなイメージです。
| 関数群 | 処理単位 | 主な利点 | 主な欠点 |
|---|---|---|---|
fgetc / fputc | 文字 | 細かい制御・実装が直感的 | 大量データでは遅くなりやすい |
fgets / fputs | 行(文字列) | 文字列処理と相性が良い・比較的高速 | 行の長さに制限が必要・改行処理を意識する必要 |
重要なのは「1文字ずつ処理したいのか、それとも行(文字列)単位で処理したいのか」を最初に決めることです。
そのうえで、今回紹介したfgetc/fputcは「細かい制御が必要な場面」で非常に頼りになる道具になります。
まとめ
fgetcとfputcは、C言語でテキストファイルを1文字ずつ読み書きするための最も基本的な関数です。
1文字単位の処理であるがゆえに、EOFやエラーの判定、改行コードや文字コードへの配慮といった細かな点に注意する必要がありますが、その分、処理内容を細かく制御できるという大きな利点があります。
行単位処理のfgets/fputsと上手に使い分けつつ、ログ整形やフィルタ処理、簡易コピーなど、目的に応じて適切な関数を選択することで、より柔軟で堅牢なファイル入出力プログラムを作成できるようになります。
