C言語での文字列入力では、予期しないバグやセキュリティ問題を避けつつ、ユーザーの入力を安全に扱うことがとても重要です。
この記事では、その代表的な手段であるfgets関数について、scanfとの違いや使い分け、安全な書き方を実行例とともに丁寧に解説します。
初心者の方でも理解しやすいよう、図解やサンプルコードを交えながら進めていきます。
C言語のfgetsとは?基本仕様と特徴
fgetsの役割とscanfとの違い
fgetsは、ストリームから文字列を「まとめて」読み込むための関数です。
C言語では標準入力(stdin)だけでなく、ファイルからの入力などにも利用できますが、ここでは主に標準入力からの文字列読み取りとして説明します。
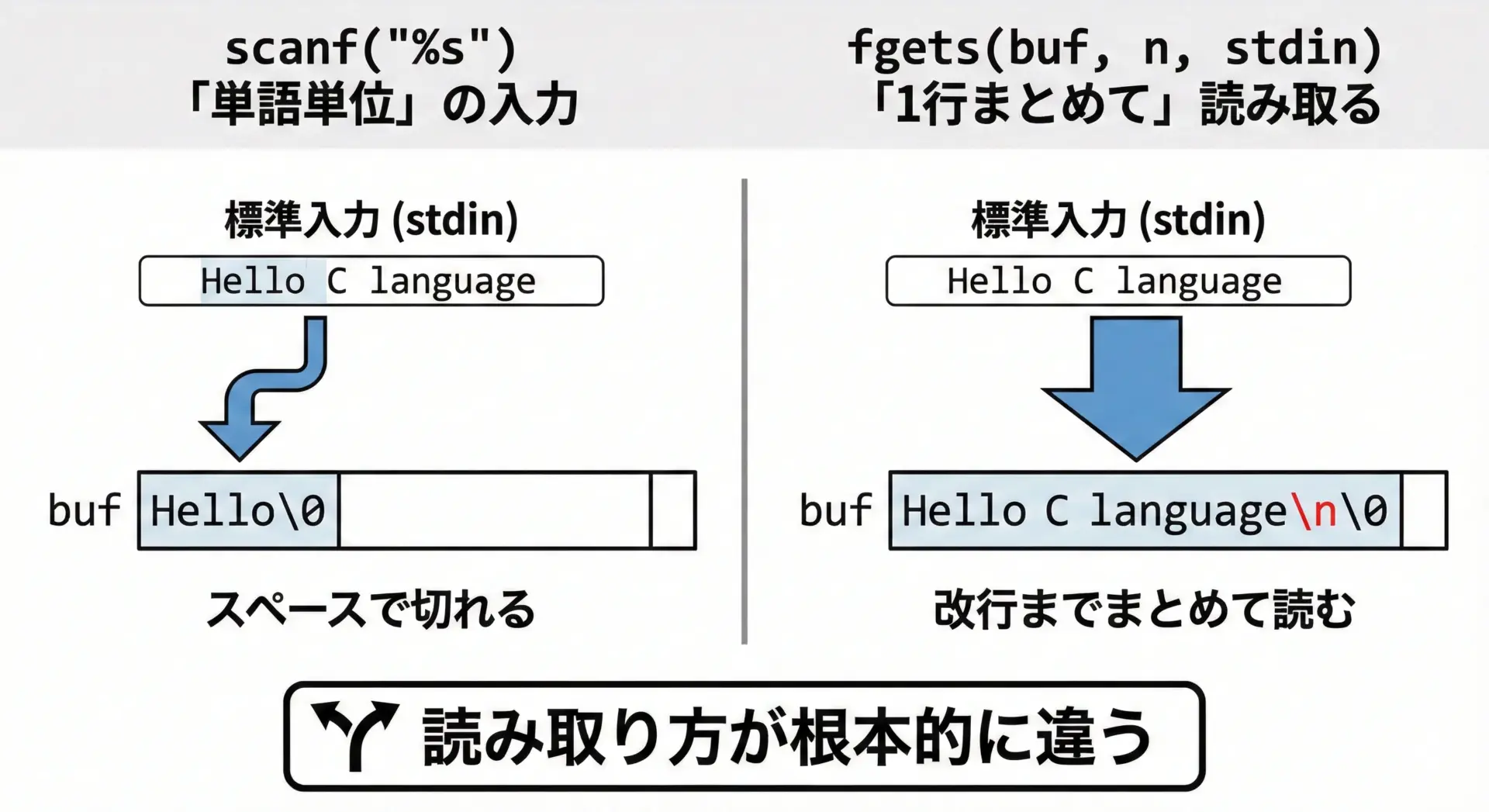
fgetsとscanfには、次のような違いがあります。
1つ目の違いは「どこまで読み込むか」です。
scanf("%s", buf);は空白(スペースやタブ、改行)で入力を区切ります。
そのため、「山田 太郎」のような名前を入力しても、最初の「山田」しか読み込みません。
一方でfgets(buf, size, stdin);は、改行がくるか、指定したサイズに達するまで読み続けるため、空白を含む1行全体を取得できます。
2つ目の違いは「安全性」です。
scanf("%s")は、読み込める最大文字数を指定しない書き方が多く、その場合バッファオーバーフローを起こしやすいという問題があります。
fgetsは「何文字まで読み込む」を明示的に指定する仕様になっているため、安全性が高い関数といえます。
3つ目の違いは「改行文字の扱い」です。
scanfは通常、入力の改行を無視して次の読み込みに進みますが、fgetsは改行文字も含めてバッファに格納します。
この挙動が、後で改行の削除処理を行う理由にもなります。
標準入力(stdin)からの文字列読み取りの仕組み
標準入力(stdin)とは、通常はキーボードからの入力を表すストリームです。
ユーザーがキーボードから文字を打ち込み、Enterキーを押すと、その1行分がOSによってバッファに蓄えられます。
fgetsやscanfは、このバッファからデータを読み取ります。
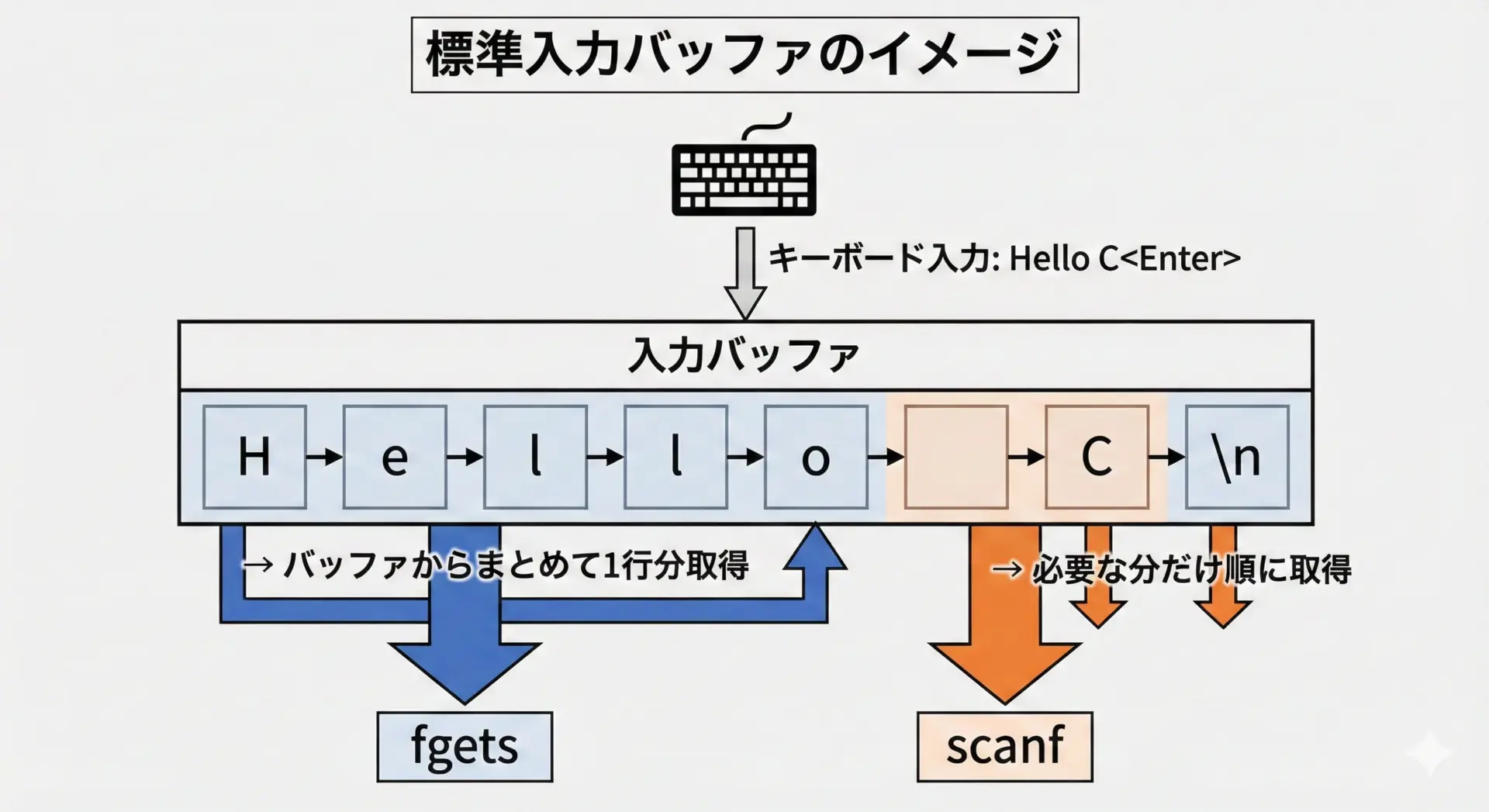
ユーザーがHello Cと入力してEnterを押すと、OSの管理するバッファには'H','e','l','l','o',' ','C','\n'といった文字列が入ります。
fgetsやscanfは、このバッファから順番に文字を取り出していき、必要な分だけ消費します。
このとき「どこまでを消費するのか」が、関数の性質の違いとして表面化します。
fgetsが改行文字を含む理由
fgetsは「行単位」で入力を扱うために設計された関数です。
そのため、改行文字も文字列の一部として取り込むのが基本動作になっています。
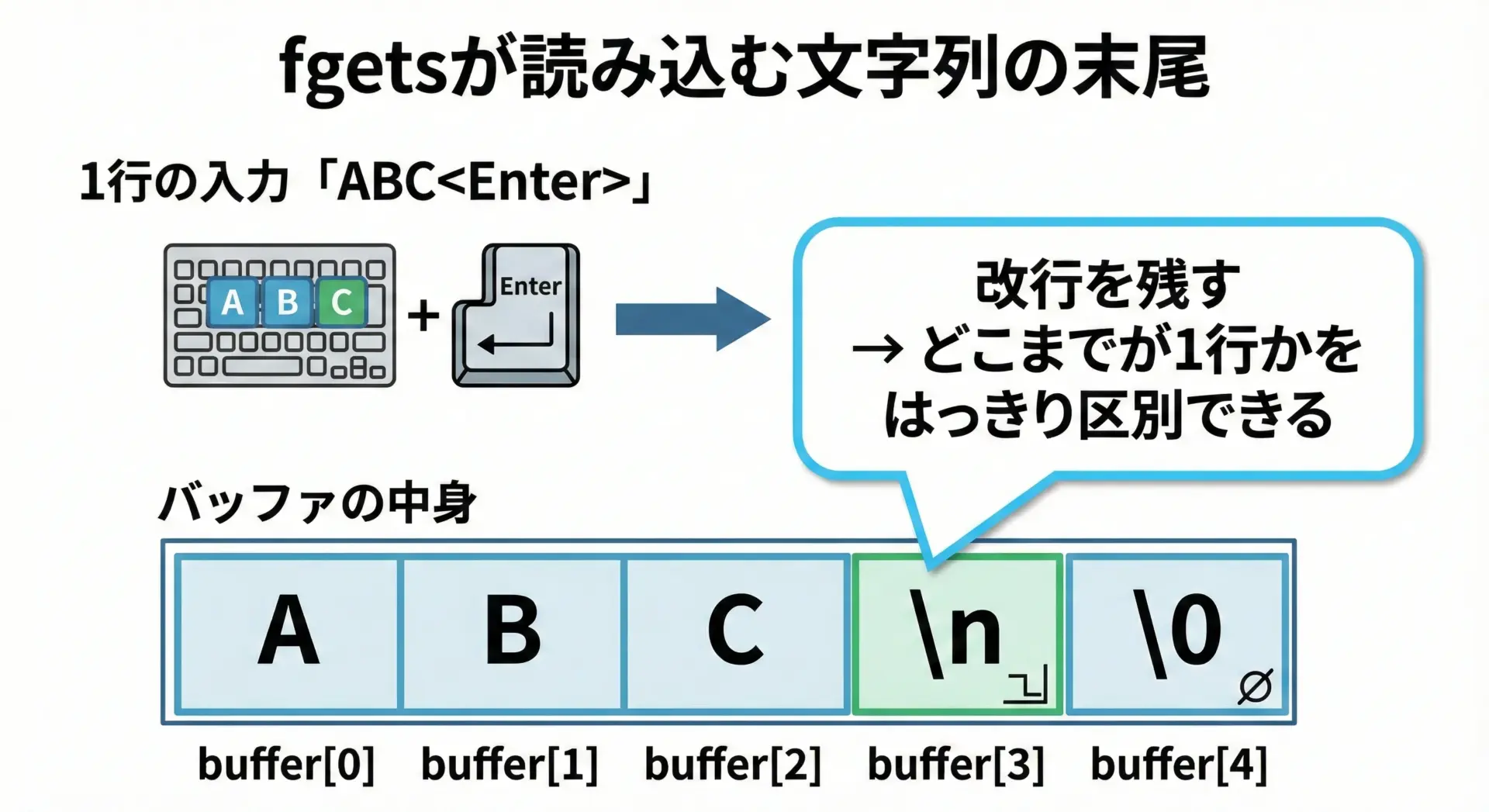
改行文字を残しておくことで、「ここまでが1行分」という境界が明確になる利点があります。
しかし、多くの場面では文字列処理の都合上、改行を削除して使いたくなることが多いです。
このため、現場のコードではfgetsで読み込んだ直後に改行を取り除くという処理が、半ばお約束のように書かれます。
この改行削除の方法については、後半の章で具体的なテクニックを紹介します。
fgetsの基本的な使い方
fgetsの関数プロトタイプと引数
まずはfgetsの公式な関数プロトタイプを確認します。
char *fgets(char *s, int n, FILE *stream);各引数の意味は次の通りです。
s: 読み込んだ文字列を格納するためのバッファ(文字配列)の先頭アドレスn: 読み込む最大の文字数。実際には最大でn-1文字まで読み込み、最後に必ず'\0'を付ける仕様ですstream: 入力元のストリーム。標準入力から読む場合はstdinを指定します
戻り値は正常に読み込めたときはs、エラーやEOF(ファイル終端)に達した場合はNULLになります。
この戻り値を利用して、入力の成否を判定できます。
文字配列(バッファ)の宣言とサイズ指定
fgetsを使う前には、文字列を格納するための十分な大きさのバッファを用意する必要があります。
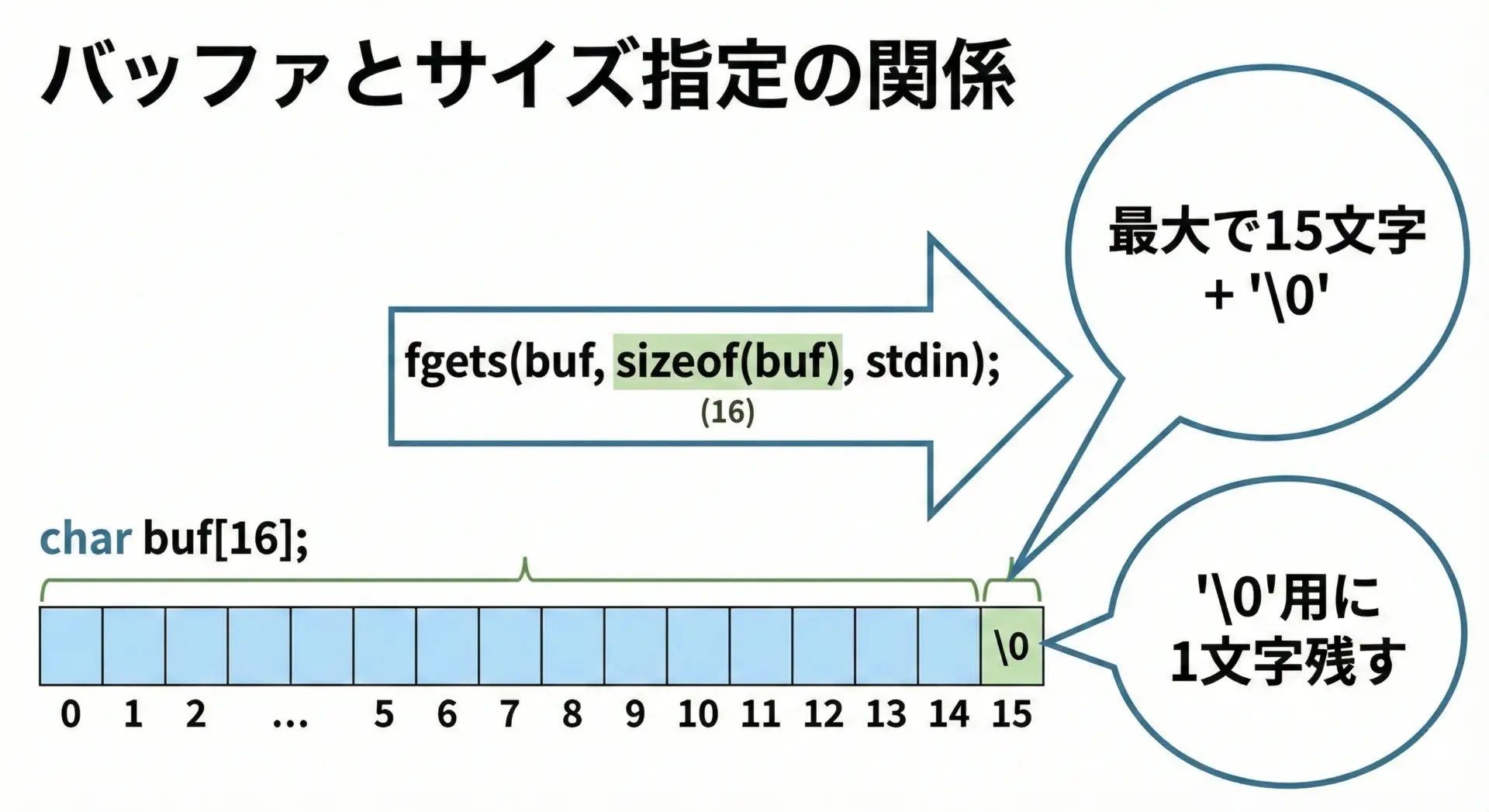
典型的な宣言と呼び出しは次のようになります。
#include <stdio.h>
int main(void) {
char buf[16]; // 長さ16のバッファ(最大15文字 + 終端文字)
printf("文字列を入力してください: ");
// sizeof(buf) でバッファ全体のサイズ(16)を渡す
if (fgets(buf, sizeof(buf), stdin) != NULL) {
printf("入力された文字列は: %s", buf);
} else {
printf("入力に失敗しました。\n");
}
return 0;
}このときfgetsは最大で15文字まで読み込み、16バイト目には必ず'\0'を設定します。
そのため、サイズ指定を誤らない限り、バッファ末尾を越えて書き込まれることはありません。
実行例で見るfgetsの挙動
実際にどのような文字列がバッファに入るのかを、具体例で確認してみます。
次のプログラムでは、バッファの中身をインデックスと一緒に可視化してみます。
#include <stdio.h>
int main(void) {
char buf[8]; // 最大7文字 + 終端
printf("文字列を入力してください(最大7文字まで読み込み): ");
if (fgets(buf, sizeof(buf), stdin) == NULL) {
printf("fgetsに失敗しました。\n");
return 1;
}
printf("fgetsで読み込んだ文字列: %s", buf);
// 各インデックスの中身を表示
printf("\nバッファ内容(インデックスと文字コード):\n");
for (int i = 0; i < (int)sizeof(buf); i++) {
// 表示しにくい文字はエスケープして表示
unsigned char ch = (unsigned char)buf[i];
printf("buf[%d] = %3d ", i, ch);
if (ch == '\0') {
printf("(\\0)");
} else if (ch == '\n') {
printf("(\\n)");
} else {
printf("('%c')", ch);
}
printf("\n");
}
return 0;
}上記のプログラムを実行し、例えば次のように入力します。
- 入力1:
ABC<Enter> - 入力2:
ABCDEFGH IJK<Enter>
出力例は概ね次のようになります。
文字列を入力してください(最大7文字まで読み込み): ABC
fgetsで読み込んだ文字列: ABC
バッファ内容(インデックスと文字コード):
buf[0] = 65 ('A')
buf[1] = 66 ('B')
buf[2] = 67 ('C')
buf[3] = 10 (\n)
buf[4] = 0 (\0)
buf[5] = 0 (\0)
buf[6] = 0 (\0)
buf[7] = 0 (\0)文字列を入力してください(最大7文字まで読み込み): ABCDEFGH IJK
fgetsで読み込んだ文字列: ABCDEFG
バッファ内容(インデックスと文字コード):
buf[0] = 65 ('A')
buf[1] = 66 ('B')
buf[2] = 67 ('C')
buf[3] = 68 ('D')
buf[4] = 69 ('E')
buf[5] = 70 ('F')
buf[6] = 71 ('G')
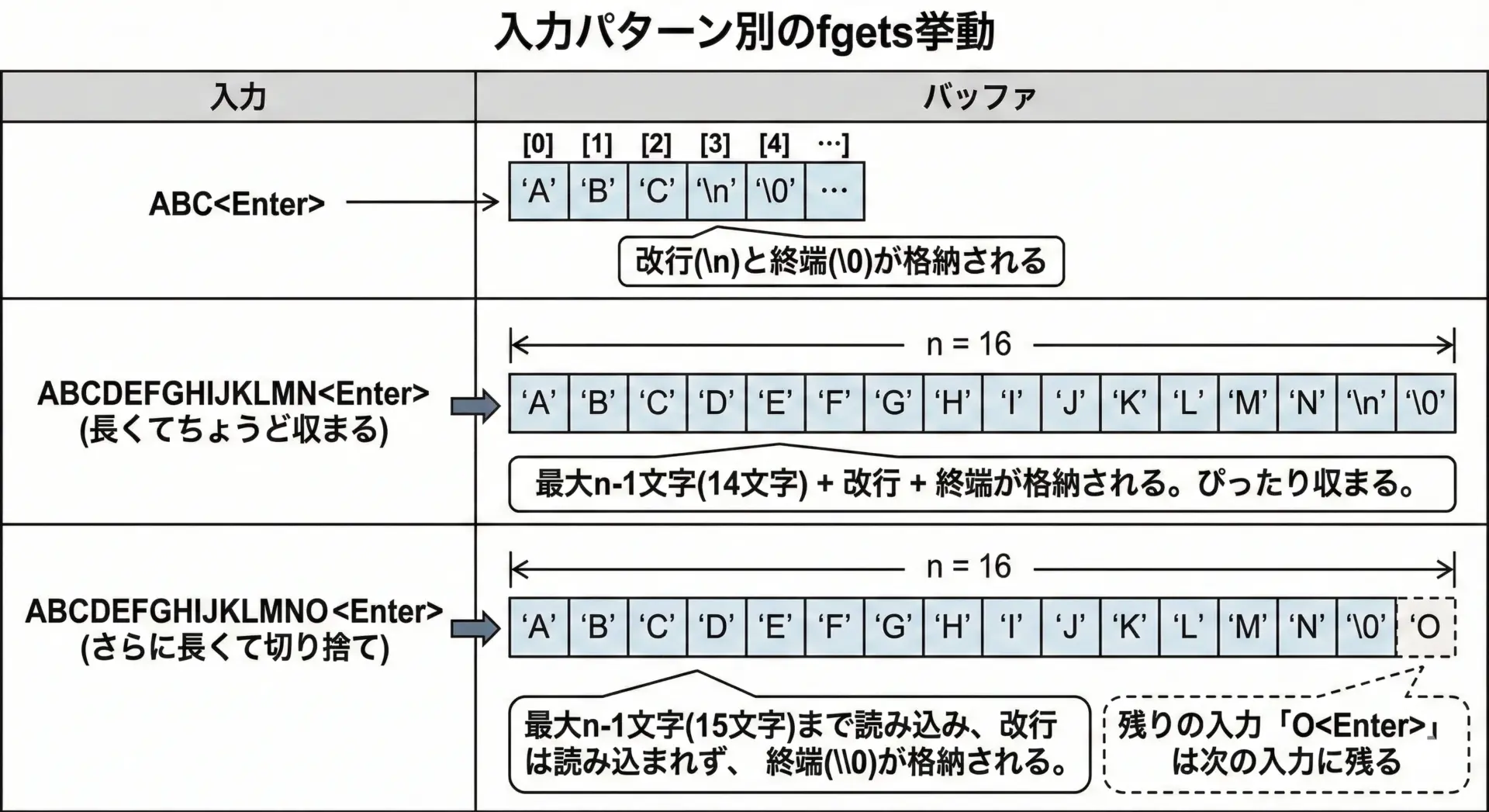
buf[7] = 0 (\0)この例から、バッファサイズが8のとき、最大7文字までしか読み込まれないこと、また長い入力は途中で切られ、改行も入らない状況があることが分かります。
残りの文字列と改行は入力バッファに残るため、このあと別の入力処理を行うときには注意が必要です。
fgetsの戻り値とエラーチェック方法
fgetsは失敗時やEOFのときにNULLを返すため、戻り値をそのまま条件式に使うと便利です。
#include <stdio.h>
int main(void) {
char buf[32];
printf("何か入力してください(EOFで終了):\n");
while (1) {
printf("> ");
// 戻り値を直接if文で判定
if (fgets(buf, sizeof(buf), stdin) == NULL) {
// EOF(Ctrl+D, Ctrl+Zなど)かエラー
printf("\nfgetsがNULLを返しました。終了します。\n");
break;
}
printf("あなたの入力: %s", buf);
}
return 0;
}何か入力してください(EOFで終了):
> hello
あなたの入力: hello
> world
あなたの入力: world
> ^D
fgetsがNULLを返しました。終了します。ファイルから読み込む場合も同様で、NULLが返ってきたらfeofやferrorでEOFとエラーを判別するのが典型的です。
標準入力では、EOFかどうかだけ分かればよいケースが多いので、上記のような簡易チェックでも実用上は十分です。
fgetsとscanfの違いと使い分け
scanf(“%s”)が危険と言われる理由
scanf("%s")は一見シンプルで便利ですが、安全性の面で問題をはらんだ書き方です。
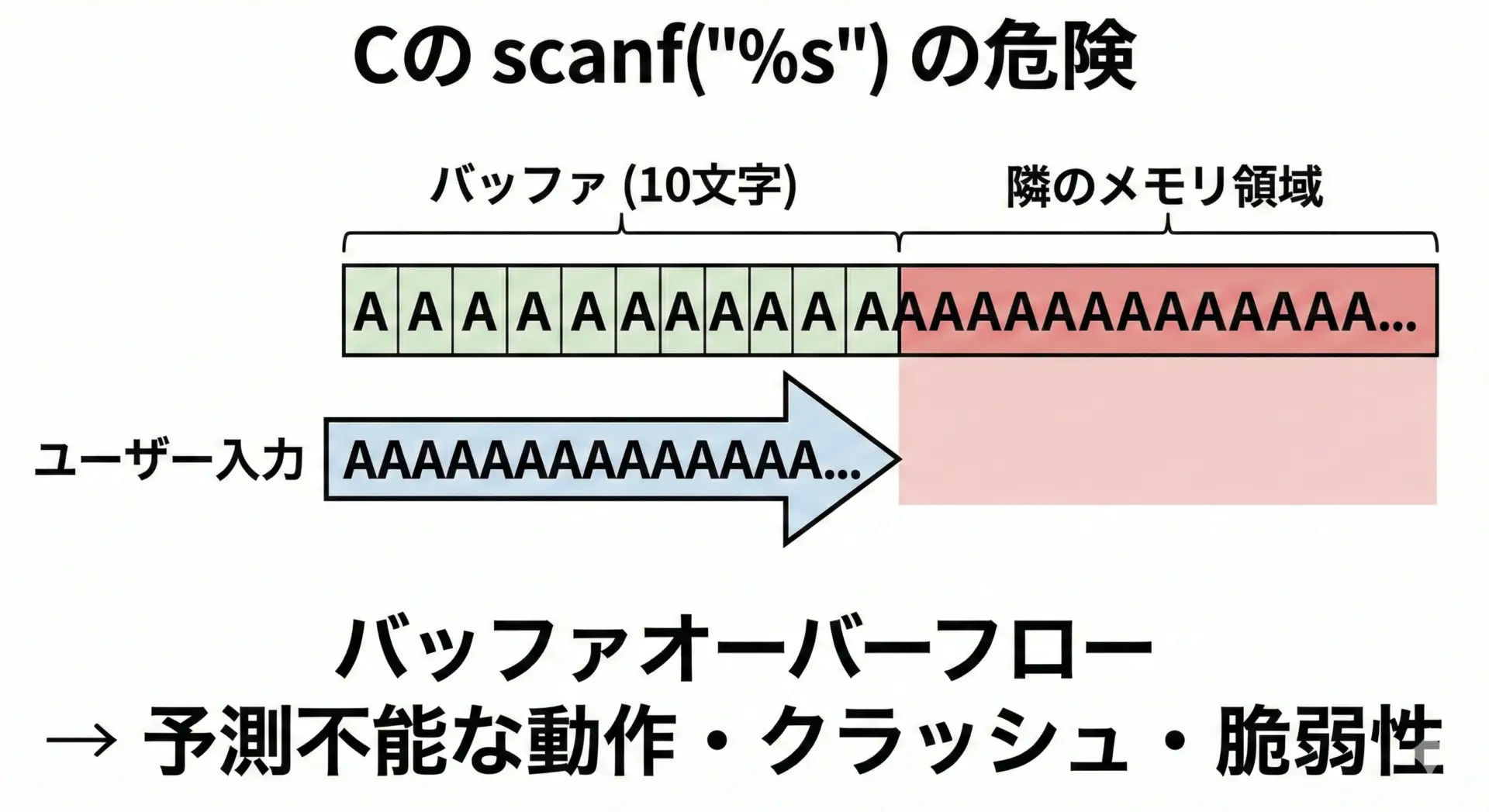
scanf("%s", buf);には「最大何文字まで読み込んでよいか」の指定がありません。
そのため、ユーザーがバッファサイズを超える長さの文字列を入力すると、簡単にバッファオーバーフローを引き起こします。
対策としては、scanf("%9s", buf);のようにフォーマット文字列側で最大文字数を指定する方法がありますが、これを常に正しく運用するのは意外と難しく、コードの見通しも悪くなりがちです。
一方でfgetsは、引数で明確に「最大サイズ」を指定し、かつ終端'\0'を必ず付与する仕様になっているため、安全な文字列入力に向いているといえます。
fgetsとscanfの入力バッファの扱いの違い
fgetsとscanfは、どちらも同じ標準入力バッファを利用しますが、消費の仕方が異なります。
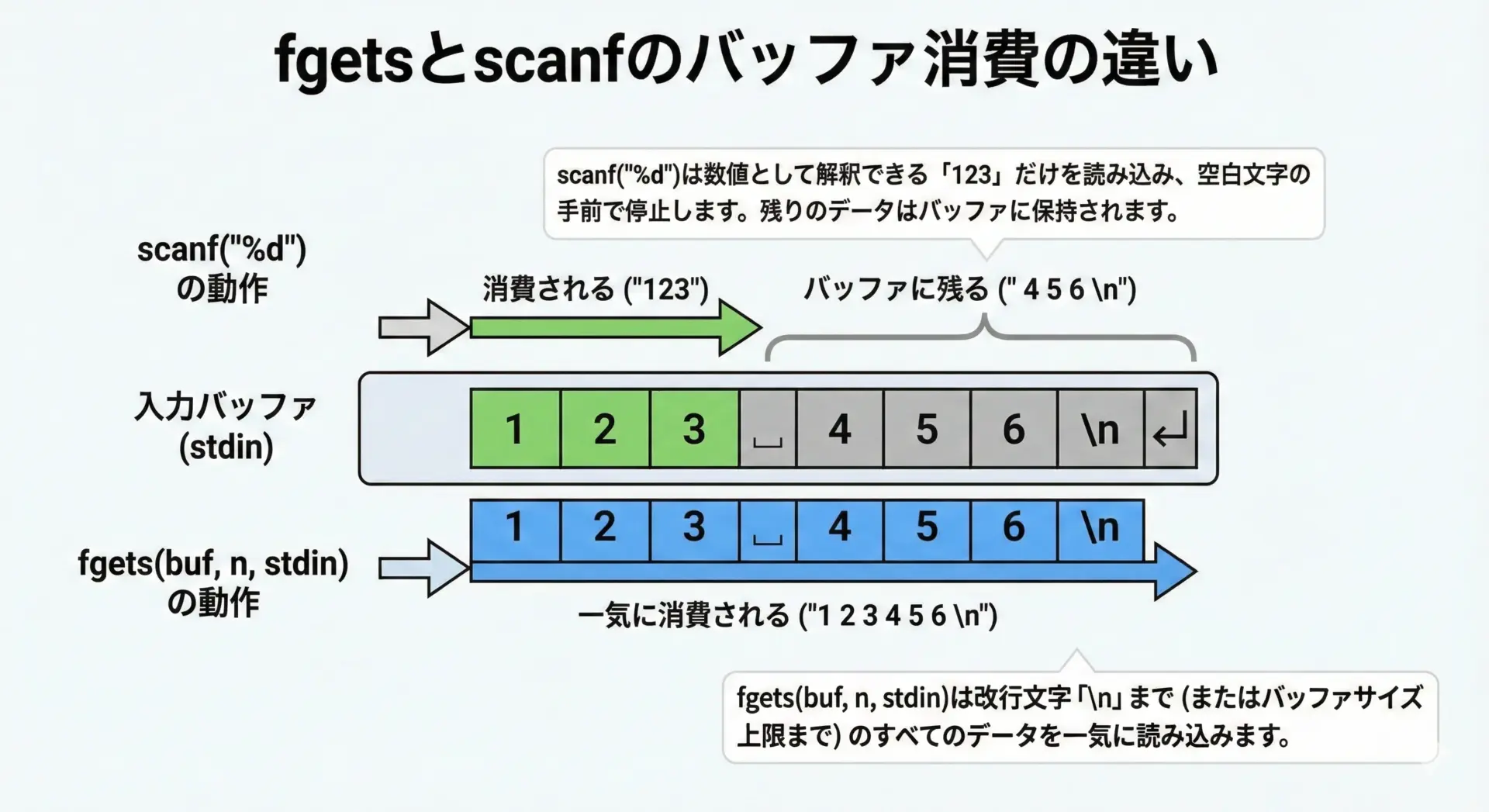
例えば、ユーザーが123 456<Enter>と入力したとき、以下のような違いが生じます。
scanf("%d", &x);
入力バッファから"123"だけを整数として読み取り、空白 "456\n"は次の入力のために残します。fgets(buf, sizeof(buf), stdin);
入力バッファから改行までの1行すべて、つまり"123 456\n"を読み取ります。
この性質の違いにより、fgetsとscanfを混在させたコードでは「読み残し」が原因のバグが発生しやすくなります。
例えば、整数をscanfで読み取った直後にfgetsで文字列を読み込もうとすると、scanfが残した改行'\n'だけがfgetsに渡されてしまい、空行を読み込んだような状態になります。
空白を含む文字列入力にはfgetsが有利
スペースを含む文字列、たとえばフルネームや住所、メッセージ本文のような入力では、fgetsが特に有利です。
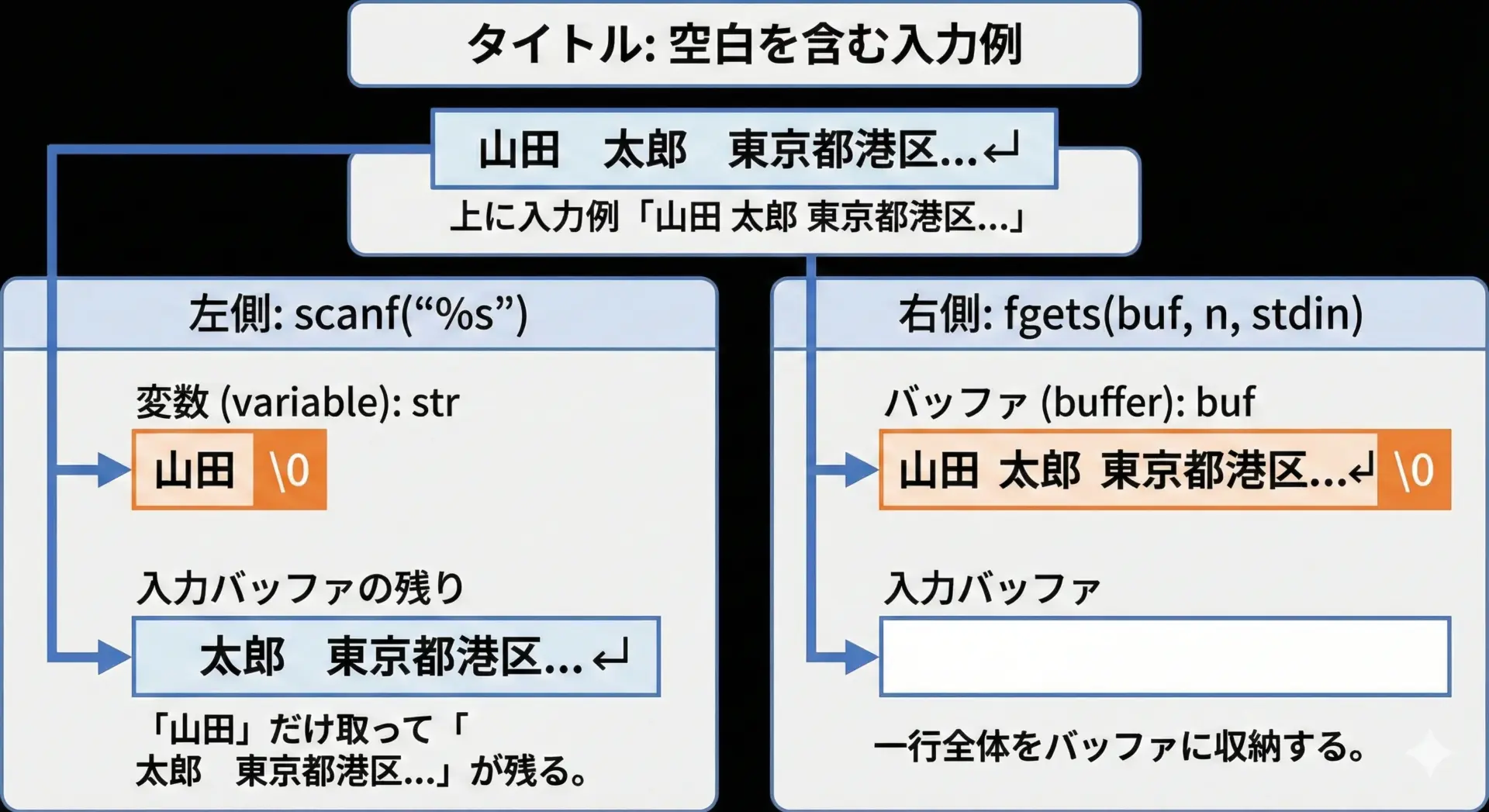
scanf("%s")は空白で入力が途切れるため、「山田 太郎」と入力すると「山田」しか取得できません。
これに対してfgetsは、空白を含む1行全体を読み込むことができるので、姓名や文などを扱う場合に非常に扱いやすくなります。
このように、「数字や単語単位」ならscanf、「行単位の文字列」ならfgetsという使い分けを意識するとよいです。
fgetsとsscanfを組み合わせた入力処理
fgetsとscanfを混在させるとバッファ問題が起きやすいことはすでに述べました。
そこで実務では、「入力はすべてfgetsで行い、そのあと必要に応じてsscanfなどで解析する」というスタイルがよく採用されます。
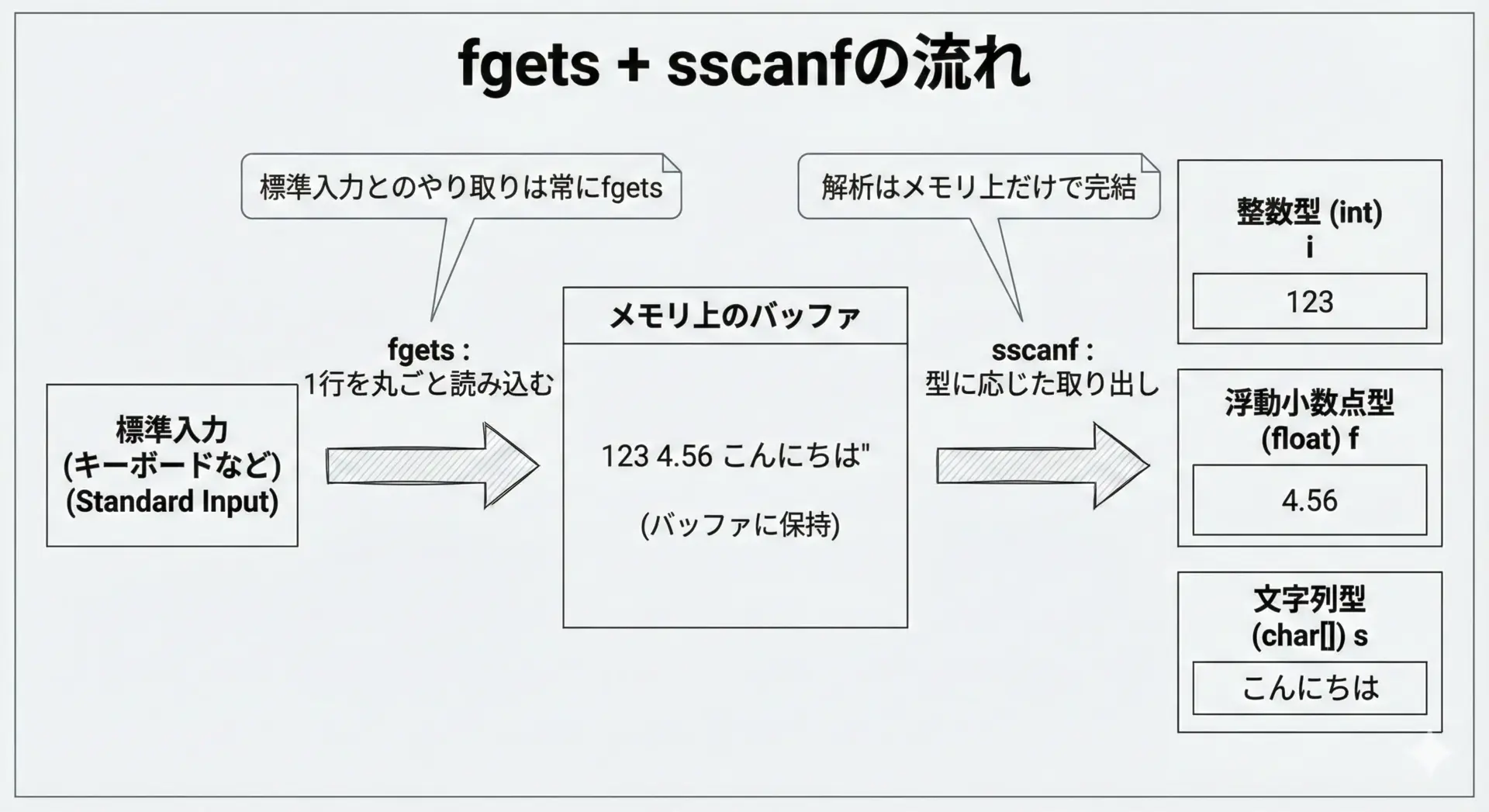
次のサンプルは、整数2つと文字列1つを安全に読み取る例です。
#include <stdio.h>
int main(void) {
char line[64]; // 一行分の入力を受けるバッファ
int a, b;
char name[32];
printf("整数2つと名前を入力してください (例: 10 20 Yamada):\n");
printf("> ");
// まずは1行まるごと取得
if (fgets(line, sizeof(line), stdin) == NULL) {
printf("入力エラーまたはEOFです。\n");
return 1;
}
// 入力行から整数2つと名前を解析
// 戻り値として「成功した項目数」が返る
int n = sscanf(line, "%d %d %31s", &a, &b, name);
if (n != 3) {
printf("入力形式が正しくありません。(解析できた項目数: %d)\n", n);
return 1;
}
printf("a = %d, b = %d, name = %s\n", a, b, name);
return 0;
}整数2つと名前を入力してください (例: 10 20 Yamada):
> 10 20 Yamada
a = 10, b = 20, name = Yamadaこのように、標準入力からは常にfgetsを使い、内部でsscanfやstrtolなどを用いて解析すると、読み残し問題を避けつつ、柔軟な入力処理ができます。
安全な文字列入力のための実践テクニック
改行文字の削除と文字列終端処理
fgetsは改行文字を含めて読み込みますが、多くの場面では末尾の'\n'を取り除いて扱う必要があります。

典型的な改行削除のコードは次のようになります。
#include <stdio.h>
#include <string.h>
int main(void) {
char buf[32];
printf("名前を入力してください: ");
if (fgets(buf, sizeof(buf), stdin) == NULL) {
printf("入力に失敗しました。\n");
return 1;
}
// 改行文字を取り除く処理
size_t len = strlen(buf);
if (len > 0 && buf[len - 1] == '\n') {
buf[len - 1] = '\0'; // '\n' を終端文字に置き換える
}
printf("こんにちは、%sさん!\n", buf);
return 0;
}名前を入力してください: Tanaka
こんにちは、Tanakaさん!このように、fgets直後に「末尾が改行なら終端文字に置き換える」というひと手間を加えておくと、その後の文字列処理が非常に扱いやすくなります。
バッファオーバーフローを防ぐサイズ設計
安全な入力のためには、バッファサイズの設計も重要です。
fgetsそのものは安全ですが、想定より短すぎるバッファを用意してしまうと、ユーザーの入力が途中で切れてしまい、期待通りの仕様になりません。

設計の際には、次の点を意識するとよいです。
- 想定する最大文字数に終端文字
'\0'の1文字を必ず加える - ユーザー入力は多少長くなることを見込み、ある程度余裕を持ったサイズにする
- 実際にfgetsを呼び出すときは、
sizeof(buf)を使ってバッファとサイズ指定を一致させる
#include <stdio.h>
#define NAME_MAX_LEN 20 // 想定する最大文字数(終端は含まない)
int main(void) {
// 終端文字分として +1、さらに余裕を持たせて +10 してみる例
char name[NAME_MAX_LEN + 1 + 10];
printf("名前を入力してください(最大% d文字程度を想定): ", NAME_MAX_LEN);
if (fgets(name, sizeof(name), stdin) == NULL) {
printf("入力エラーです。\n");
return 1;
}
// 末尾改行を削除(簡略化のため関数化は省略)
for (int i = 0; name[i] != '\0'; i++) {
if (name[i] == '\n') {
name[i] = '\0';
break;
}
}
printf("入力された名前: %s\n", name);
return 0;
}このように、サイズ指定には常にsizeofを使うと、配列サイズを間違えるリスクを減らすことができます。
入力エラー時の再入力と例外処理
実用的なプログラムでは、ユーザーが誤った形式で入力した場合に再入力を促す必要があります。
fgetsとsscanfを組み合わせることで、こうした再入力処理も比較的簡単に実装できます。
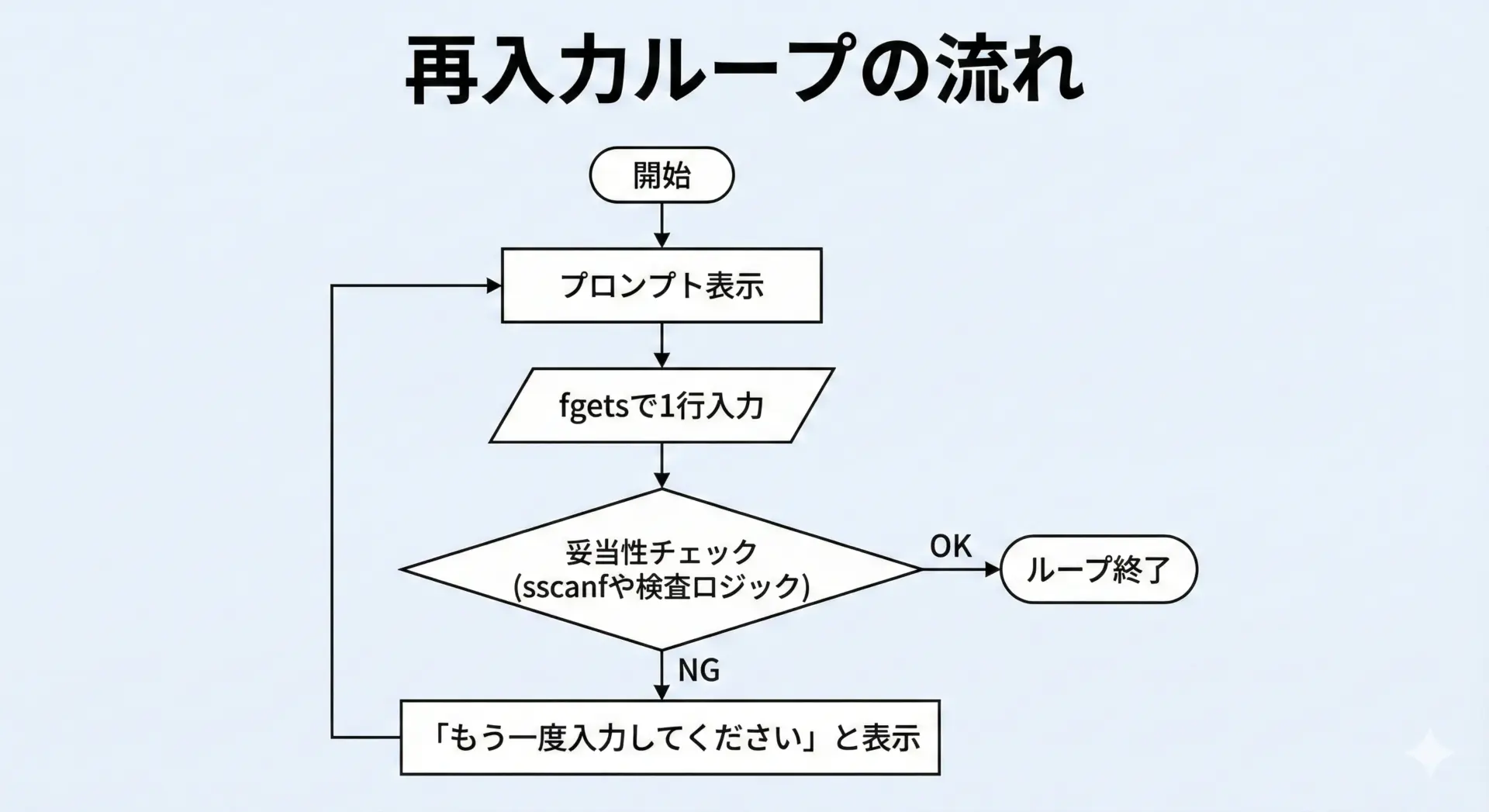
次の例では、1〜100までの整数を安全に入力させます。
#include <stdio.h>
int main(void) {
char line[64];
int value;
while (1) {
printf("1〜100の整数を入力してください: ");
if (fgets(line, sizeof(line), stdin) == NULL) {
printf("\n入力ストリームのエラーまたはEOFです。終了します。\n");
return 1;
}
// 改行を削除(なくても動作には支障ないが、見た目のために実施)
for (int i = 0; line[i] != '\0'; i++) {
if (line[i] == '\n') {
line[i] = '\0';
break;
}
}
// 整数1つだけを読み取る。余計な文字があればエラーとみなす
char extra;
int n = sscanf(line, "%d %c", &value, &extra);
if (n == 1 && value >= 1 && value <= 100) {
// 正常な整数が1つだけ読み取れた
break;
}
printf("入力が不正です。もう一度入力してください。\n");
}
printf("入力された値: %d\n", value);
return 0;
}1〜100の整数を入力してください: abc
入力が不正です。もう一度入力してください。
1〜100の整数を入力してください: 150
入力が不正です。もう一度入力してください。
1〜100の整数を入力してください: 42xyz
入力が不正です。もう一度入力してください。
1〜100の整数を入力してください: 42
入力された値: 42このように、入力自体はfgetsで安全に行い、その内容が期待どおりかどうかをsscanfなどで検査することで、堅牢な入力処理が実現できます。
fgetsが失敗したときの安全なハンドリング方法
fgetsがNULLを返すケースは、大きく分けてEOFと入力エラーの2つがあります。
ファイル入力ではfeofやferrorを使って詳しく原因を調べられますが、標準入力の場合は、「これ以上入力を続行できない」と判断して、安全に終了する方針が無難です。
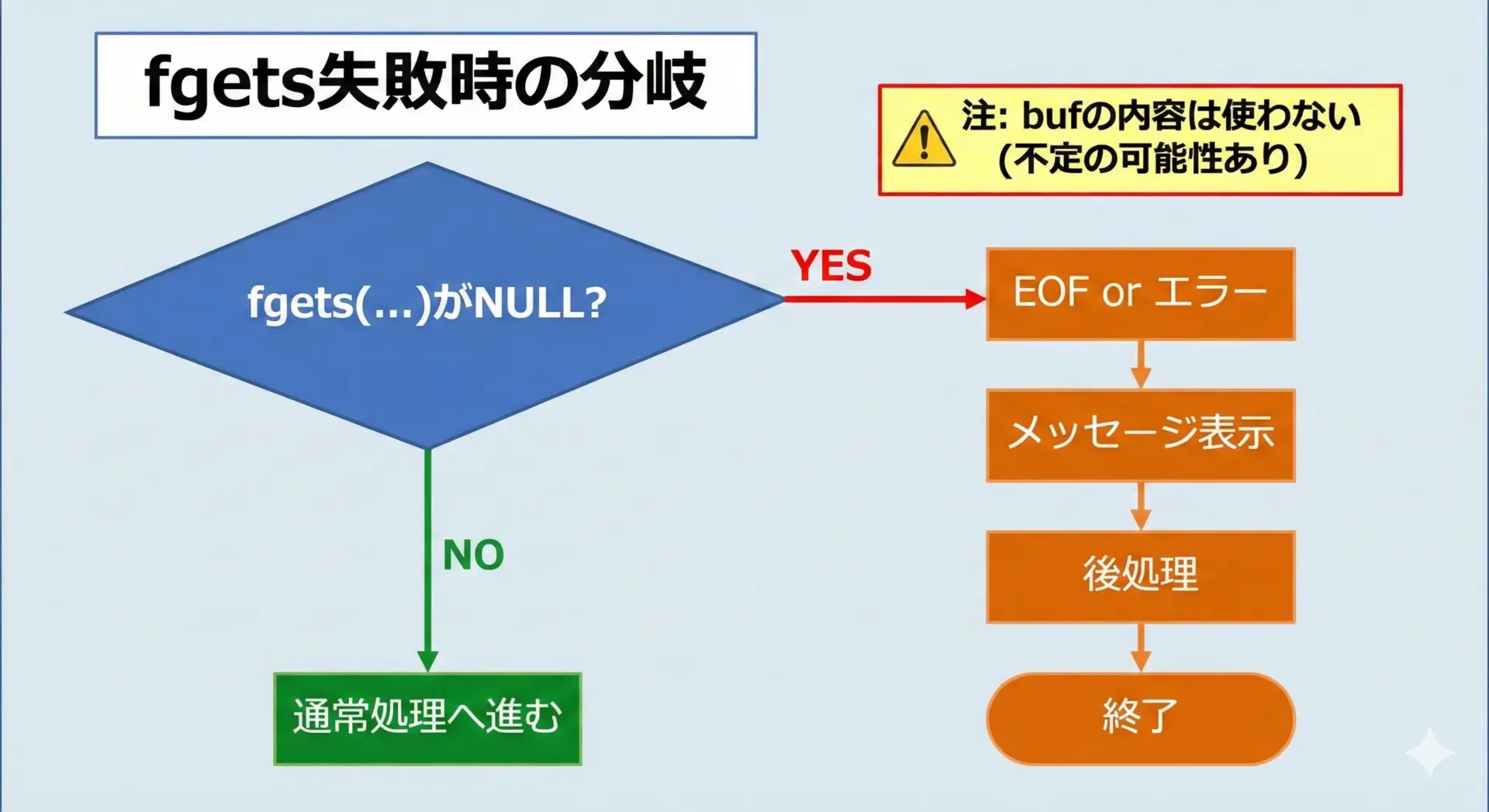
次のコードは、ループ入力の中でfgetsがNULLを返した場合に、安全に終了する例です。
#include <stdio.h>
int main(void) {
char buf[32];
printf("Ctrl+D(Ctrl+Z)で終了します。\n");
while (1) {
printf("> ");
char *ret = fgets(buf, sizeof(buf), stdin);
if (ret == NULL) {
// EOFまたはエラー
printf("\nfgetsがNULLを返しました。入力を終了します。\n");
break;
}
// 正常に読み込めた場合のみbufを使用する
printf("入力: %s", buf);
}
// ここで必要に応じてリソース解放などの後処理を行う
printf("プログラムを終了します。\n");
return 0;
}Ctrl+D(Ctrl+Z)で終了します。
> hello
入力: hello
> ^D
fgetsがNULLを返しました。入力を終了します。
プログラムを終了します。このように、fgetsの戻り値を必ずチェックし、NULLだった場合はバッファを使わないというルールを守ることが、安全なコードを書くうえでとても重要です。
まとめ
fgetsは、C言語において安全に文字列を入力するための基本となる関数です。
scanfと比べて、行単位で読み込めること、最大文字数を必ず指定すること、改行文字を含めて格納することなどの特徴を持ちます。
この記事では、fgetsの仕様から、scanfとの違い、改行削除やバッファ設計、fgetsとsscanfの組み合わせによる再入力処理まで、一連の実践的なテクニックを解説しました。
今後は「入力はまずfgetsで安全に行い、その後で必要な解析を行う」というスタイルを意識して、堅牢で読みやすいCプログラムを構築してみてください。
