
C言語で複数の状態や種類を定数で表したい場面はとても多いです。
色、曜日、エラーコード、状態フラグなどを#defineで並べていくと、だんだんコードが読みにくく、ミスもしやすくなります。
そこで役に立つのが列挙型(enum)です。
本記事では、C言語の列挙型について、基本構文から実践的な使い方、#defineやconstとの違い、設計のコツまでを詳しく解説します。
C言語の列挙型(enum)とは何か
列挙型(enum)のイメージ
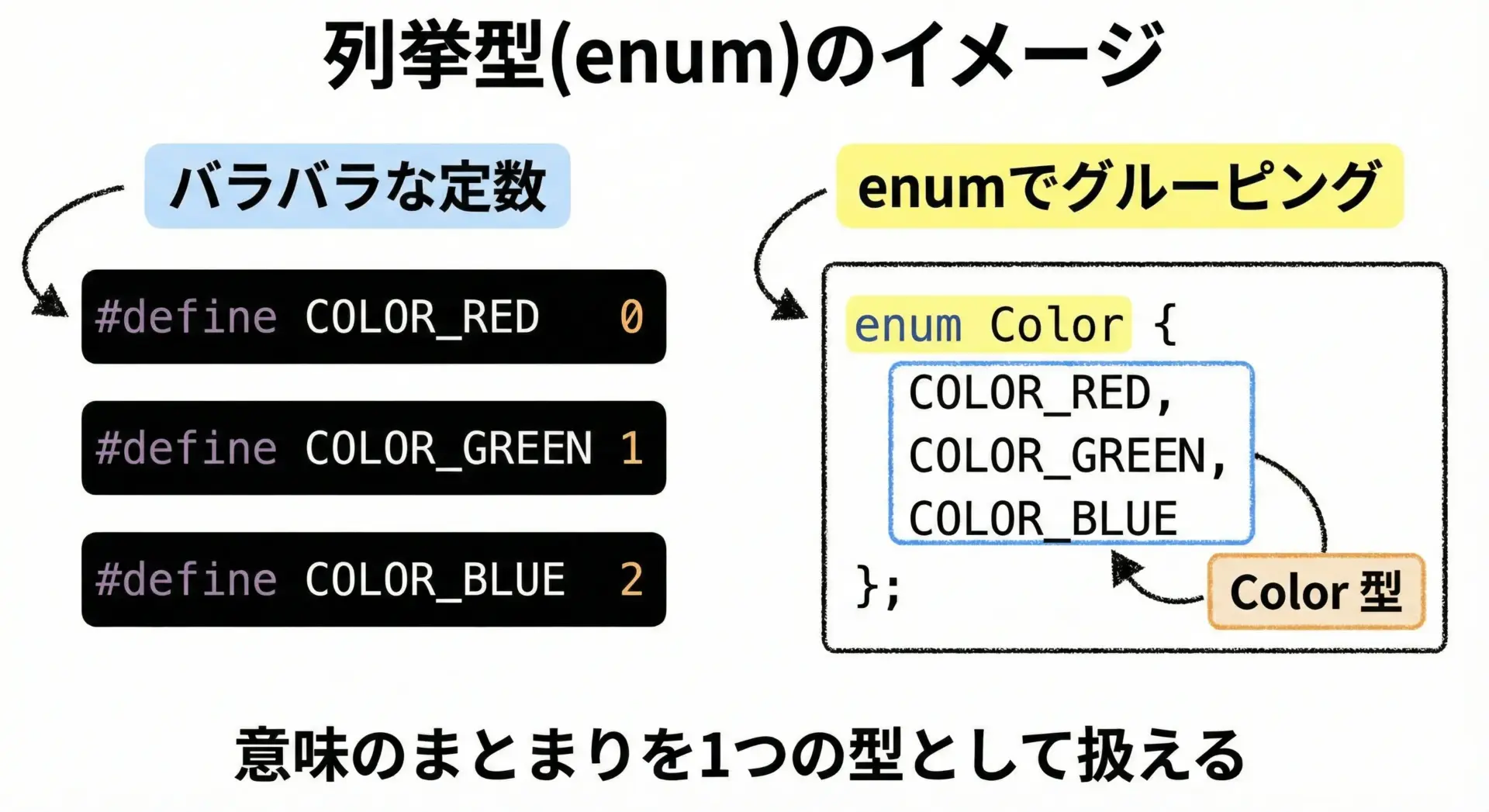
列挙型(enum)とは、関連する整数定数の集合に「名前付きの型」を与える仕組みです。
例えば、色を表す整数を0,1,2…と決めるのではなく、COLOR_RED、COLOR_GREENのように意味のある識別子で表現できます。
列挙型を使うと、コード中に0や1といった「謎の数字」(マジックナンバー)を書かずに済み、可読性と保守性が大きく向上します。
列挙型(enum)の基本構文と宣言方法
基本構文
列挙型の基本的な構文は次のようになります。
// 列挙型の宣言
enum 列挙型名 {
列挙子1, // 0
列挙子2, // 1
列挙子3 // 2
};列挙子とは、列挙型の各値につける識別子のことです。
上の例では列挙子1などが該当します。
もう少し実例に近づけたコードを見てみます。
#include <stdio.h>
// 曜日を表す列挙型の宣言
enum Weekday {
WEEKDAY_SUN, // 0
WEEKDAY_MON, // 1
WEEKDAY_TUE, // 2
WEEKDAY_WED, // 3
WEEKDAY_THU, // 4
WEEKDAY_FRI, // 5
WEEKDAY_SAT // 6
};
int main(void) {
// enum Weekday 型の変数を宣言
enum Weekday today;
// 今日は水曜日という設定
today = WEEKDAY_WED;
// 整数として出力してみる
printf("today = %d\n", today); // 期待値: 3
return 0;
}today = 3このように、列挙型は整数の別名として振る舞いますが、列挙子を通じて意味を持たせることができます。
宣言と同時に変数定義を行う形
列挙型は、宣言と同時に変数定義もできます。
#include <stdio.h>
// 宣言と同時に変数定義も行う例
enum Color {
COLOR_RED,
COLOR_GREEN,
COLOR_BLUE
} favorite_color; // ここで favorite_color という変数も定義
int main(void) {
favorite_color = COLOR_GREEN;
printf("favorite_color = %d\n", favorite_color);
return 0;
}favorite_color = 1このスタイルは短いプログラムでは便利ですが、ヘッダファイルで型だけ定義したい場合には、変数定義は分けて書くことが多いです。
typedef と組み合わせて使う
C言語ではtypedefを使って、列挙型に別名を与えるのがよくあるパターンです。
#include <stdio.h>
// typedef を使って enum Color 型に Color という別名をつける
typedef enum Color {
COLOR_RED,
COLOR_GREEN,
COLOR_BLUE
} Color;
int main(void) {
// enum Color の代わりに、単に Color と書ける
Color c = COLOR_BLUE;
printf("c = %d\n", c);
return 0;
}c = 2APIとして公開する型や状態を表す列挙型では、typedef enum {...} 型名;という書き方が一般的です。
enumで定義できる値と識別子のルール
識別子の命名ルール
列挙子も通常の変数名と同じく、次のルールに従います。
- 先頭は英字または
_で始める - 2文字目以降は英数字または
_を使える - 大文字・小文字は区別される
- キーワード(cst-code>int、
ifなど)は使えない
慣例として、列挙子はすべて大文字のスネークケース(例: FILE_MODE_READ)で書くことが多いです。
また、プレフィックス(接頭辞)をつけてグループを見分けやすくするのもよくあるスタイルです。
// 良い例: プレフィックスでどの enum か分かる
typedef enum {
FILE_MODE_READ,
FILE_MODE_WRITE,
FILE_MODE_APPEND
} FileMode;列挙子の名前の衝突に注意
列挙子は同じスコープ内で一意である必要があります。
別々のenumであっても、同じスコープに同名の列挙子を定義するとコンパイルエラーになります。
// NG 例: 同じスコープで列挙子が重複している
enum Color {
COLOR_RED,
COLOR_GREEN
};
enum Light {
COLOR_RED, // エラーになる可能性大
COLOR_BLUE
};これを避けるには、列挙型ごとに異なるプレフィックスを付けるか、名前空間風に工夫します。
// OK 例: プレフィックスで区別
enum Color {
COLOR_RED,
COLOR_GREEN
};
enum LightState {
LIGHT_RED,
LIGHT_BLUE
};列挙定数の暗黙的な値(int型)と自動採番の仕組み
暗黙的な整数値と自動採番
Cの列挙型では、列挙子に明示的な値を指定しない場合、最初の列挙子は0、以降は1ずつ増加した値が自動的に割り当てられます。
enum Example {
EX_A, // 0
EX_B, // 1
EX_C // 2
};この自動採番のルールは、途中で値を指定した場合にも適用されます。
enum Example2 {
EX2_A = 10, // 10
EX2_B, // 11 (直前の 10 + 1)
EX2_C = 5, // 5
EX2_D // 6 (直前の 5 + 1)
};列挙子の型は実質的に整数型
C標準では、列挙型は整数型として扱われます。
多くの処理系ではint型と同じサイズで実装されていますが、必ずしもintと同じとは限らない点には注意が必要です(詳しくは後述します)。
#include <stdio.h>
typedef enum {
STATUS_OK, // 0
STATUS_ERROR, // 1
STATUS_TIMEOUT // 2
} Status;
int main(void) {
Status s = STATUS_ERROR;
// int に代入することも可能 (暗黙の変換)
int value = s;
printf("Status as int = %d\n", value);
return 0;
}Status as int = 1列挙型はあくまで「整数値に名前をつけたもの」という位置づけですが、型名があることが読みやすさと安全性につながります。
enumの使い方と実例
switch文でのenum活用
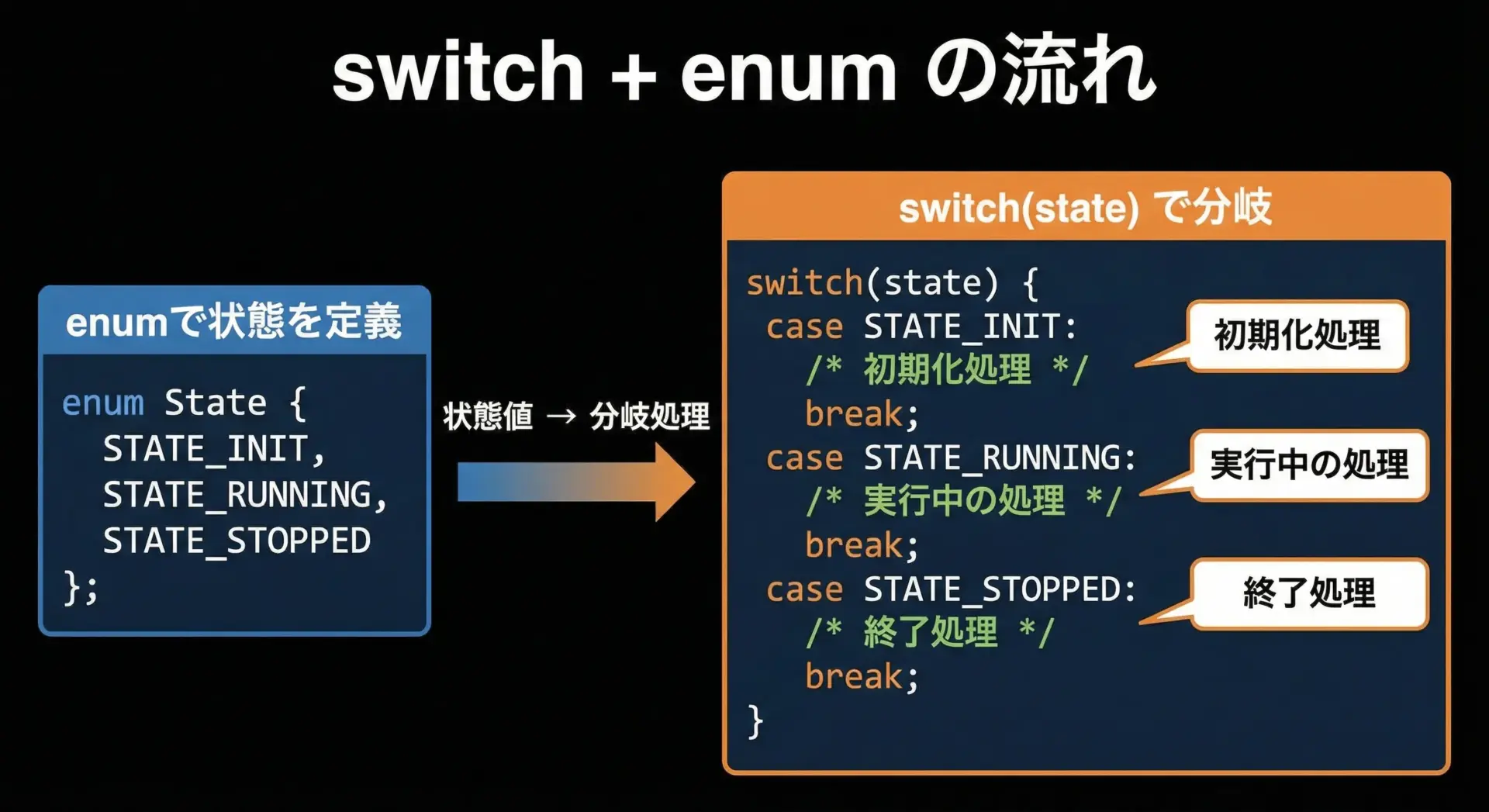
列挙型とswitch文は非常に相性が良いです。
状態遷移やモード分岐を読みやすく書けます。
#include <stdio.h>
// プログラムの状態を表す列挙型
typedef enum {
STATE_INIT, // 初期化中
STATE_RUNNING, // 実行中
STATE_STOPPED // 停止中
} State;
void handle_state(State s) {
switch (s) {
case STATE_INIT:
printf("Initializing...\n");
break;
case STATE_RUNNING:
printf("Running...\n");
break;
case STATE_STOPPED:
printf("Stopped.\n");
break;
default:
// 想定外の値に対する安全策
printf("Unknown state!\n");
break;
}
}
int main(void) {
State s;
s = STATE_INIT;
handle_state(s);
s = STATE_RUNNING;
handle_state(s);
s = STATE_STOPPED;
handle_state(s);
return 0;
}Initializing...
Running...
Stopped.このように、状態をenumで表し、switchで分岐すると、コードが自己文書化されるため、後から読んでも意図が分かりやすくなります。
default節を書くかどうか
列挙型をswitchで使うときに悩むポイントとしてdefault節をどうするかがあります。
- ライブラリの公開APIなどでは、将来の拡張に備えてdefault節で「不明な値」をハンドリングするのが安全です。
- 静的解析ツールなどを使う場合、わざとdefault節を置かず、新しい列挙子を追加したときに「未処理のcaseがある」と警告を出させる戦略もあります。
用途に応じて方針を決めるとよいです。
ビットフラグ以外の定数にenumを使うパターン
ビットフラグ(ビット単位のOR演算など)には#defineやconstを使う場面も多いですが、「同時に1つだけ成立する値」にはenumが向いています。
具体的には次のようなパターンです。
エラーコードをenumで表す
#include <stdio.h>
typedef enum {
ERR_OK = 0, // エラーなし
ERR_INVALID_ARG, // 引数不正
ERR_TIMEOUT, // タイムアウト
ERR_IO // 入出力エラー
} ErrorCode;
ErrorCode do_something(int x) {
if (x < 0) {
return ERR_INVALID_ARG;
}
if (x == 0) {
return ERR_TIMEOUT;
}
// ここでは単純に OK を返すことにする
return ERR_OK;
}
int main(void) {
ErrorCode err = do_something(0);
if (err != ERR_OK) {
printf("Error occurred: %d\n", err);
}
return 0;
}Error occurred: 2戻り値としてenumを返すことで、呼び出し側がERR_TIMEOUTのような意味のある名前を使えます。
種類やモードをenumで表す
typedef enum {
MODE_TEXT,
MODE_BINARY
} FileOpenMode;
void open_file(const char *path, FileOpenMode mode);このように関数引数の型としてenumを使うと、APIの使い方がかなり明確になります。
ヘッダファイルでのenum宣言とスコープの考え方
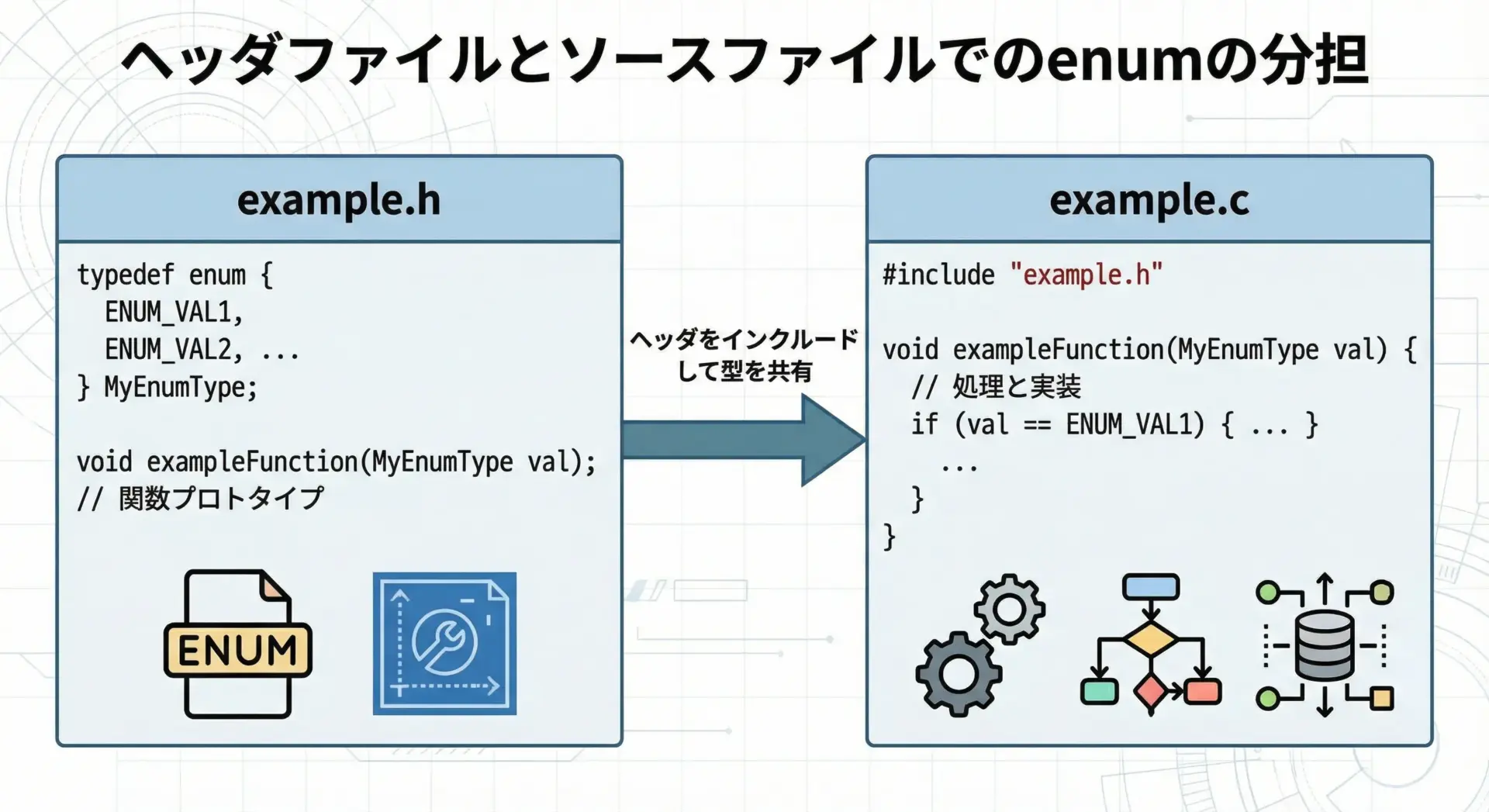
複数のソースファイルから同じ列挙型を使いたいときには、ヘッダファイルにenumの宣言を置くのが基本です。
ヘッダファイルでの宣言例
/* file: status.h */
#ifndef STATUS_H
#define STATUS_H
// ライブラリの公開用ステータス列挙型
typedef enum {
STATUS_OK = 0,
STATUS_BUSY,
STATUS_ERROR
} Status;
// Status を返す関数のプロトタイプ宣言
Status get_status(void);
#endif /* STATUS_H */実装ファイル側の例
/* file: status.c */
#include "status.h"
static Status current_status = STATUS_OK;
// Status を返す関数の定義
Status get_status(void) {
return current_status;
}/* file: main.c */
#include <stdio.h>
#include "status.h"
int main(void) {
Status s = get_status();
if (s == STATUS_OK) {
printf("OK\n");
} else {
printf("NOT OK: %d\n", s);
}
return 0;
}OKこのようにすることで、ヘッダをインクルードした全てのソースファイルで同じenum型を安全に共有できます。
スコープの基本
列挙型は宣言した位置に応じてスコープが決まります。
- ファイルスコープ(関数の外)で宣言すると、そのファイル全体で有効
- 関数の中で宣言すると、その関数のローカルな型になる
関数内だけで使う一時的なenumであれば、ローカルに宣言しても構いませんが、再利用したい型はヘッダに切り出すのが設計の基本です。
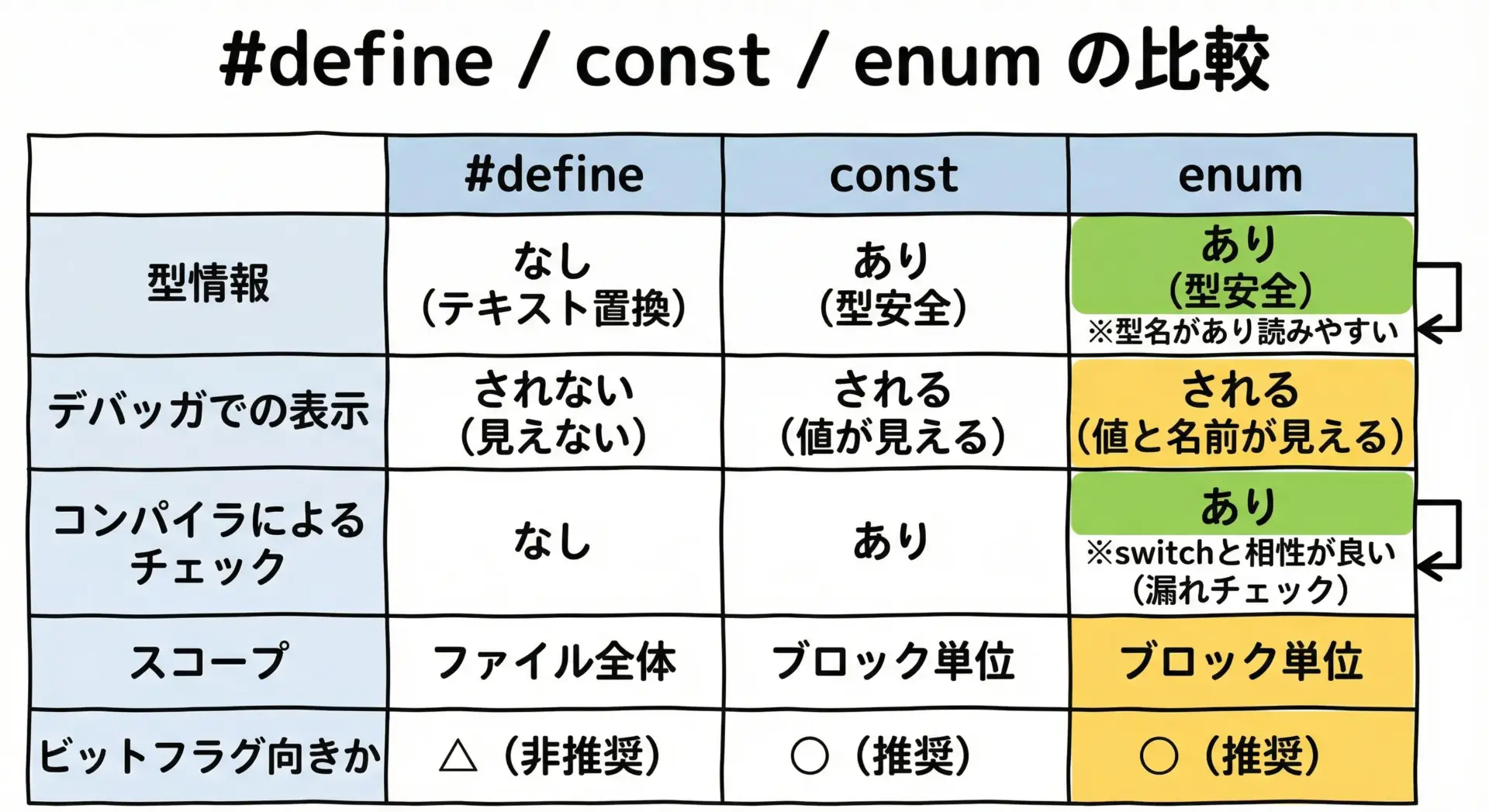
定数(#define,const)と列挙型(enum)の違い
#define定数とenumの違い
#defineはプリプロセッサによる単純な置換です。
一方でenumは型情報を持った整数定数です。
代表的な違いを表にまとめます。
| 項目 | #define | enum |
|---|---|---|
| 型情報 | なし(生のテキスト置換) | あり(整数型として扱われる) |
| デバッガ表示 | 展開後の数値のみ | 列挙子として意味が分かる場合が多い |
| スコープ | 基本的にファイル全体(マクロ) | 宣言位置に応じてCのスコープルールに従う |
| 名前空間 | 衝突しやすい | 列挙子名の付け方で整理しやすい |
| 自動採番 | なし(自分で値を書く) | あり(0から連番で割り当て) |
| switchとの相性 | 普通 | 意味が明確で読みやすい |
#defineを使った場合の例
#define MODE_TEXT 0
#define MODE_BINARY 1
void open_file(const char *path, int mode);この定義でも動作はしますが、関数プロトタイプだけからはmode引数にどんな値を渡してよいか分かりにくいです。
enumを使った場合の例
typedef enum {
MODE_TEXT,
MODE_BINARY
} OpenMode;
void open_file(const char *path, OpenMode mode);こちらは引数の型だけで渡せる値の範囲や意味が読み取れるため、設計として優れています。
const変数とenumの違い
constは「書き換えできない変数」を定義します。
一方、enumは「整数定数の集合に名前をつけた型」です。
| 項目 | const | enum |
|---|---|---|
| 実体 | 変数(読み取り専用を意図) | 定数(コンパイル時に決まる) |
| メモリ配置 | 最適化により変わるが、変数として扱われることもある | 多くの場合、即値(リテラル)として扱われる |
| 集合表現 | 値1つごとに変数を用意 | 関連する値をまとめて1つの型として表現 |
| switchとの組み合わせ | 可能だが値の一覧性は低い | 全てのケースを網羅しやすい |
constで定義した場合の例
const int MODE_TEXT = 0;
const int MODE_BINARY = 1;enumで定義した場合の例
typedef enum {
MODE_TEXT = 0,
MODE_BINARY = 1
} OpenMode;どちらも実行時の挙動は似ていますが、「関連する値を1つの型としてまとめられる」という点でenumの方が強力です。
enumを使うと読みやすくなる場面・使わない方がよい場面
enumを使うべき典型的な場面
次のような場面ではenumを積極的に使うと読みやすくなります。
- 状態遷移(State machine)の状態
- エラーコード、戻り値の種別
- モード・オプション(テキスト/バイナリ、同期/非同期など)
- プロトコル上の定義済みコード(メッセージ種別など)
- switch文で網羅的に処理したいパターン
これらはいずれも「同時に1つだけ選ばれる値」であり、enumの構造に自然に対応します。
enumを使わない方がよい場面
一方、次のような場面ではenumだけで表現しようとしない方がよいことがあります。
- ビットフラグ(複数のフラグをORして同時に立てる場合)
- 値の範囲が広く、単なる上限・下限を表現したいだけのとき
- ライブラリやABIで
sizeof(enum)に依存するバイナリ互換性が重要なとき
ビットフラグは、#defineやconstでビットマスクとして定義し、unsigned intやuint32_tなどの整数型と組み合わせた方が明確な場合が多いです。
列挙型(enum)を選ぶ理由と設計のコツ
型安全性と可読性がenumを選ぶ最大の理由
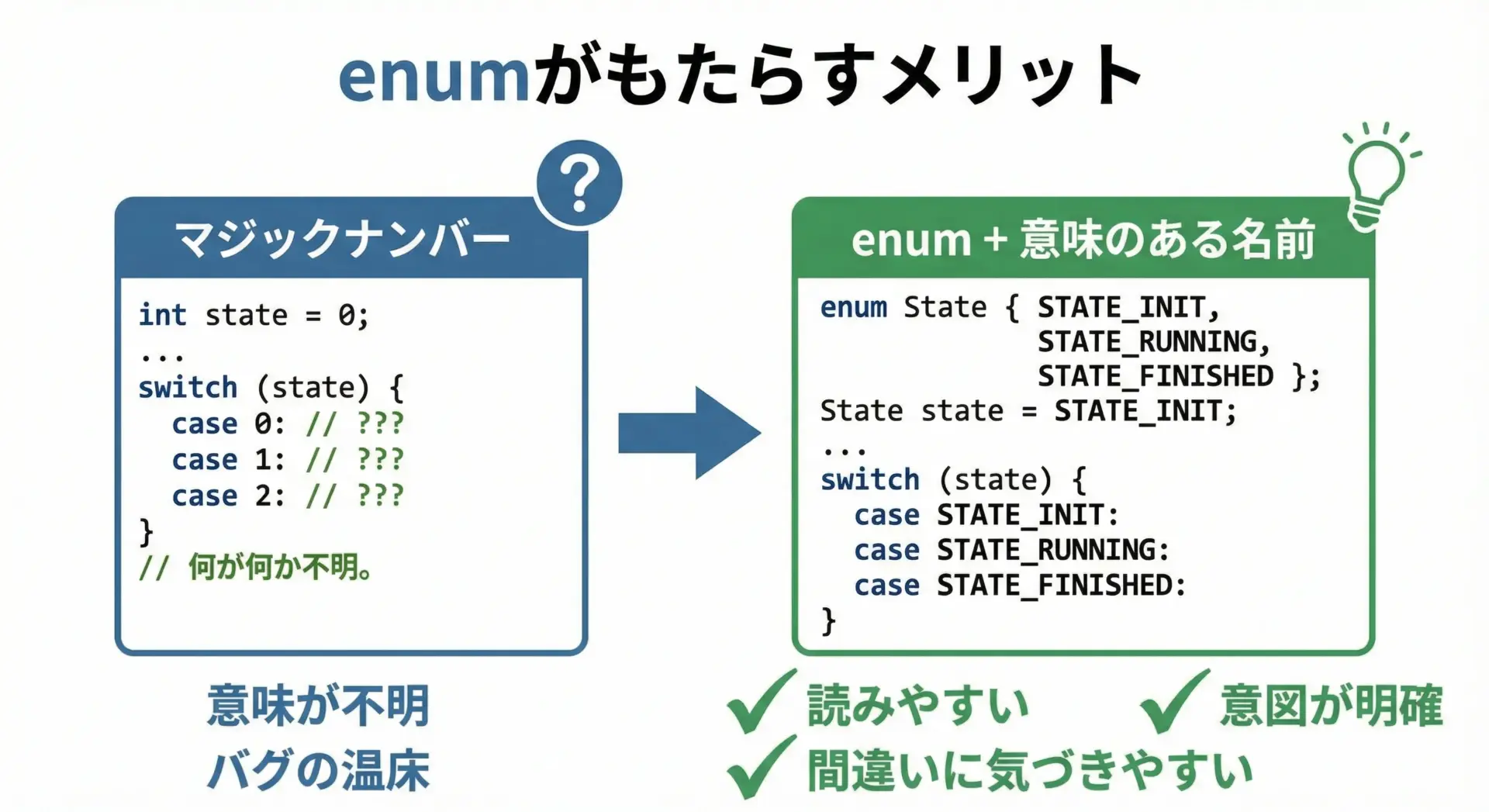
列挙型を使う最大の理由は可読性とある程度の型安全性です。
可読性の向上
// マジックナンバーを使ったコード
if (status == 2) {
// ここで何を意味しているか一見わからない
}// enum を使ったコード
if (status == STATUS_TIMEOUT) {
// タイムアウト時の処理であることがすぐ分かる
}このように、数字から意味を推測しなくてもよくなるので、レビューや保守が格段に楽になります。
擬似的な型安全性
C言語自体は強い型安全性を持つ言語ではありませんが、列挙型を使うことで「この変数にはこの種別の値しか入れない」という設計意図を示せます。
typedef enum {
LOG_DEBUG,
LOG_INFO,
LOG_WARN,
LOG_ERROR
} LogLevel;
void set_log_level(LogLevel level);この関数を呼び出すとき、set_log_level(123);のようなコードは明らかにおかしいと気づきやすくなります。
C言語とオブジェクト指向言語におけるenumの意義
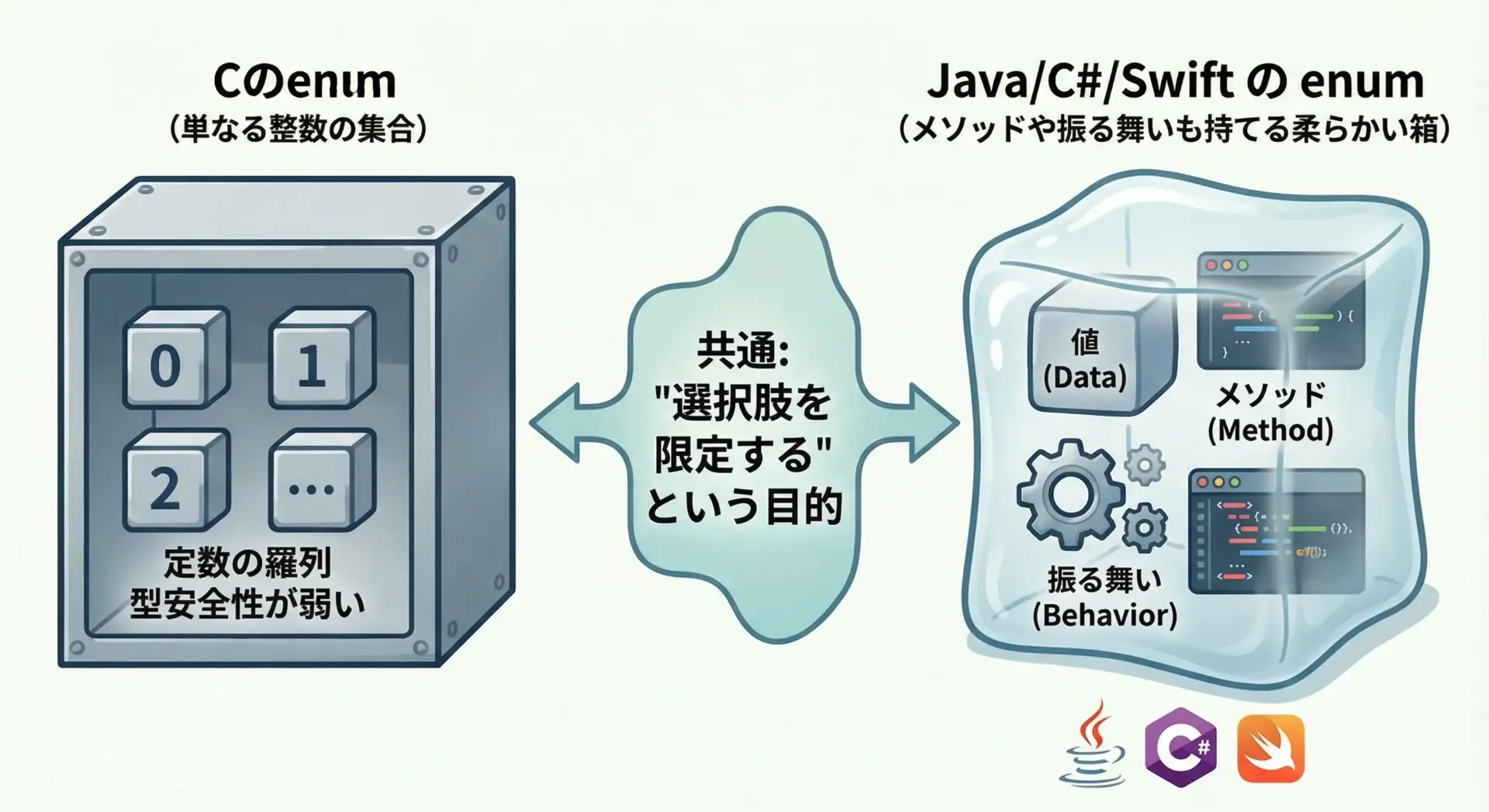
C言語のenumは、JavaやC#、Swiftなどのオブジェクト指向言語のenumと比べると機能はかなりシンプルです。
Cでは「整数値に名前をつける」ことに特化しており、メソッドや振る舞いを持ちません。
しかし、「取りうる値を限定する」という目的は共通しています。
- Cのenum:
- 整数ベース
- メモリ効率がよい
- デバイス制御やプロトコルなど、低レベルの値定義に向いている
- オブジェクト指向言語のenum:
- 場合によっては各列挙子がメソッドやプロパティを持つ
- 状態と振る舞いをまとめられる
- ドメインモデル(業務概念)の表現に向いている
Cでのenumはあくまで「軽量なタグ付け」ですが、構造化されていない#defineの列に比べると、設計レベルでの表現力が大きく向上します。
enumのサイズ(int型との関係)と実装依存性の注意点
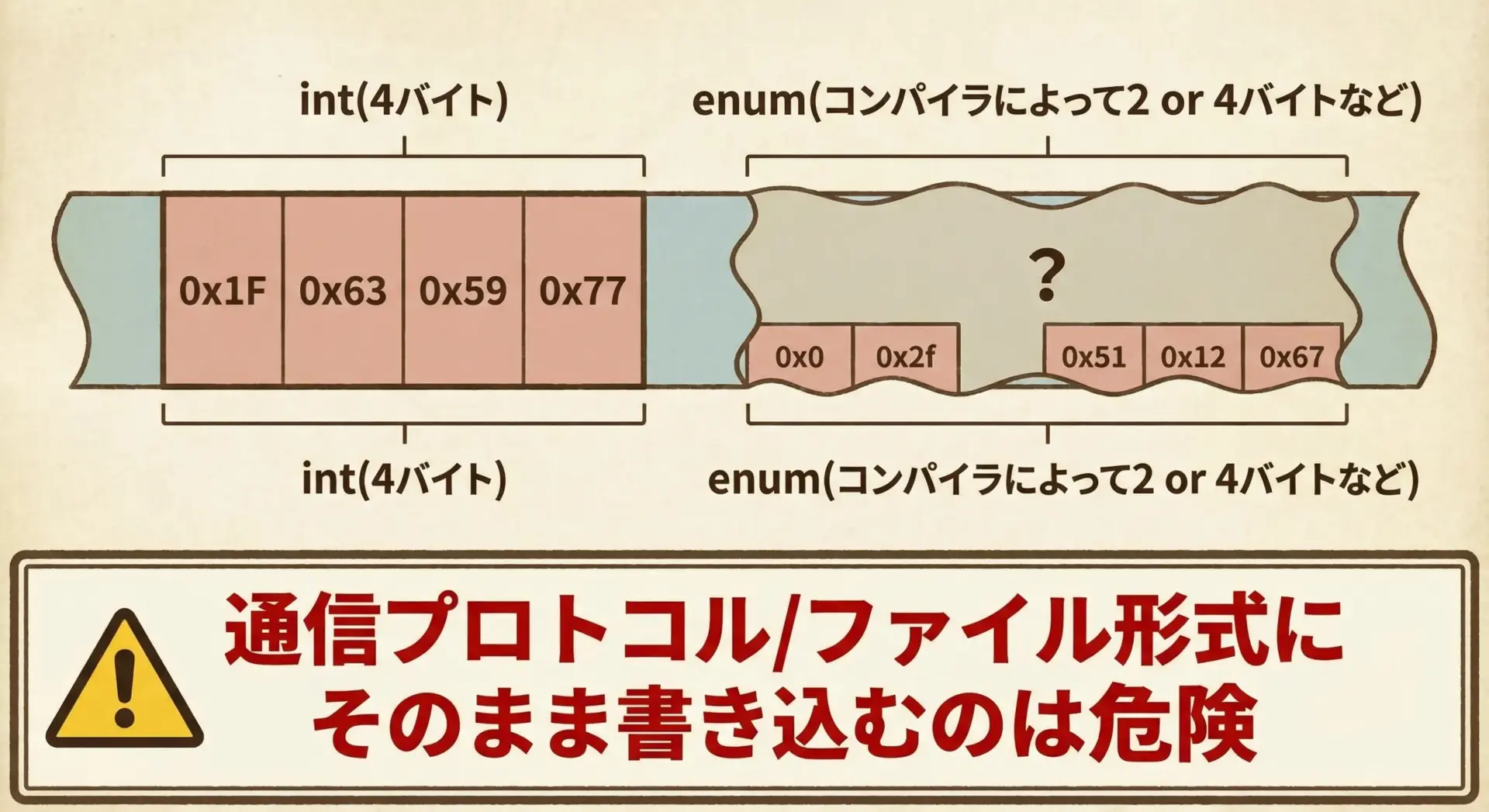
多くの処理系ではenumのサイズはintと同じですが、これはC標準で保証されているわけではありません。
sizeof(enum) は実装依存
#include <stdio.h>
typedef enum {
SMALL_A,
SMALL_B,
SMALL_C
} SmallEnum;
typedef enum {
BIG_A = 0,
BIG_B = 1000000, // 大きな値を持つenum
BIG_C
} BigEnum;
int main(void) {
printf("sizeof(SmallEnum) = %zu\n", sizeof(SmallEnum));
printf("sizeof(BigEnum) = %zu\n", sizeof(BigEnum));
printf("sizeof(int) = %zu\n", sizeof(int));
return 0;
}このプログラムの出力は処理系によって変わる可能性があります。
多くの環境では次のような出力になるでしょう。
sizeof(SmallEnum) = 4
sizeof(BigEnum) = 4
sizeof(int) = 4しかし、組み込み環境などではSmallEnumが2バイト、BigEnumが4バイトというように最適化されることもあります。
バイナリ互換性に注意
この実装依存性のため、通信プロトコルやファイル形式でenumの値をそのままバイナリとして送受信・保存する設計は危険です。
- プロトコルやファイル形式では、明示的に
uint8_tやuint16_tなどの固定幅整数型を使う - その値とenumの間を変換するラッパ関数を用意する
といった設計にすると、移植性と将来の拡張性が高まります。
拡張に強いenum設計のコツ
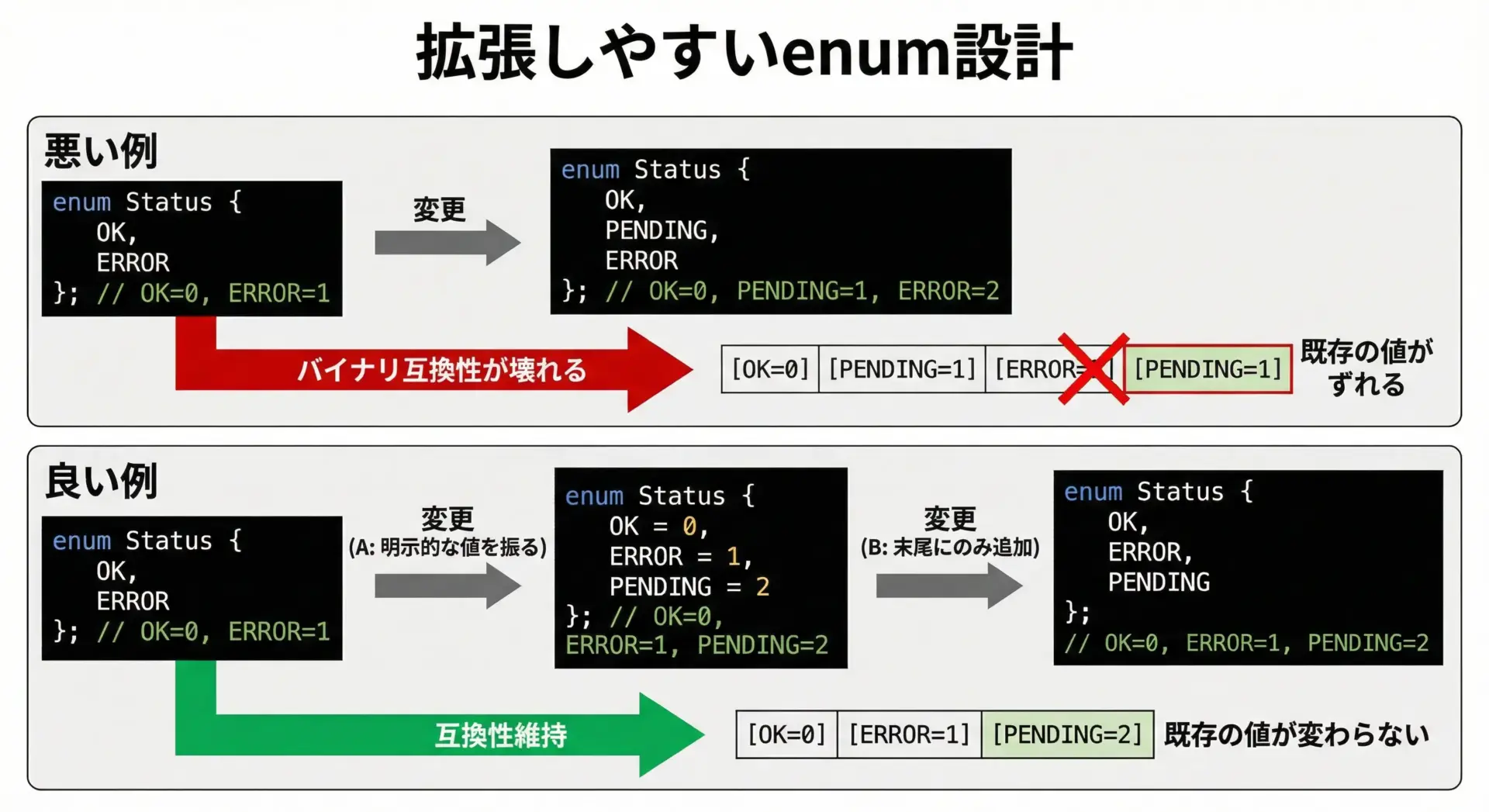
拡張に強いenum設計のために、いくつかのポイントを押さえておきます。
1. 値を明示的に指定するかどうかを目的で使い分ける
- 内部専用のenum:
- 自動採番(0,1,2,…)で十分
- 新しい値は基本的に末尾に追加する
- 外部とのインターフェースに関わるenum:
- 明示的に値を指定しておくと安心
- 真ん中に新しい値を入れても既存の数値が変わらないようにする
// プロトコルのメッセージ種別を表す enum (値を固定)
typedef enum {
MSG_TYPE_REQUEST = 1,
MSG_TYPE_RESPONSE = 2,
MSG_TYPE_ERROR = 3
} MessageType;2. 終端用のダミー値を入れるパターン
列挙子の数を表すために、末尾にカウンタ用のダミー値を入れるパターンもよく使われます。
typedef enum {
FRUIT_APPLE,
FRUIT_ORANGE,
FRUIT_GRAPE,
FRUIT_NUM // フルーツの種類数を表すダミー
} Fruit;
int main(void) {
// FRUIT_NUM を使って配列サイズを決める
const char *fruit_names[FRUIT_NUM] = {
"Apple",
"Orange",
"Grape"
};
for (int i = 0; i < FRUIT_NUM; i++) {
printf("%s\n", fruit_names[i]);
}
return 0;
}Apple
Orange
Grapeこの方法を使うと、新しい列挙子をFRUIT_NUMの前に追加するだけで配列のサイズやループの上限が自動的に調整されます。
3. 予約値を残しておく
将来の拡張を見越して意図的に未使用の値を空けておく場合もあります。
typedef enum {
CODE_A = 0,
CODE_B = 1,
// 2 は将来用に予約
CODE_C = 3
} Code;こうしておくと、後からCODE_NEW = 2;のように追加しやすくなります。
まとめ
列挙型(enum)は、C言語において関連する整数定数に意味のある名前と型を与えるための、シンプルながら強力な仕組みです。
#defineやconstと異なり、値の集合を1つの型として扱えるため、状態やモード、エラーコードなどを読みやすく、安全に表現できます。
一方で、sizeof(enum)が実装依存である点や、ビットフラグには向かない場合があるなどの注意も必要です。
用途に応じてenum・#define・constを適切に使い分け、拡張しやすい設計(末尾追加、値の固定、終端のダミー値など)を意識することで、Cのコードはぐっと整理され、保守性も向上します。
