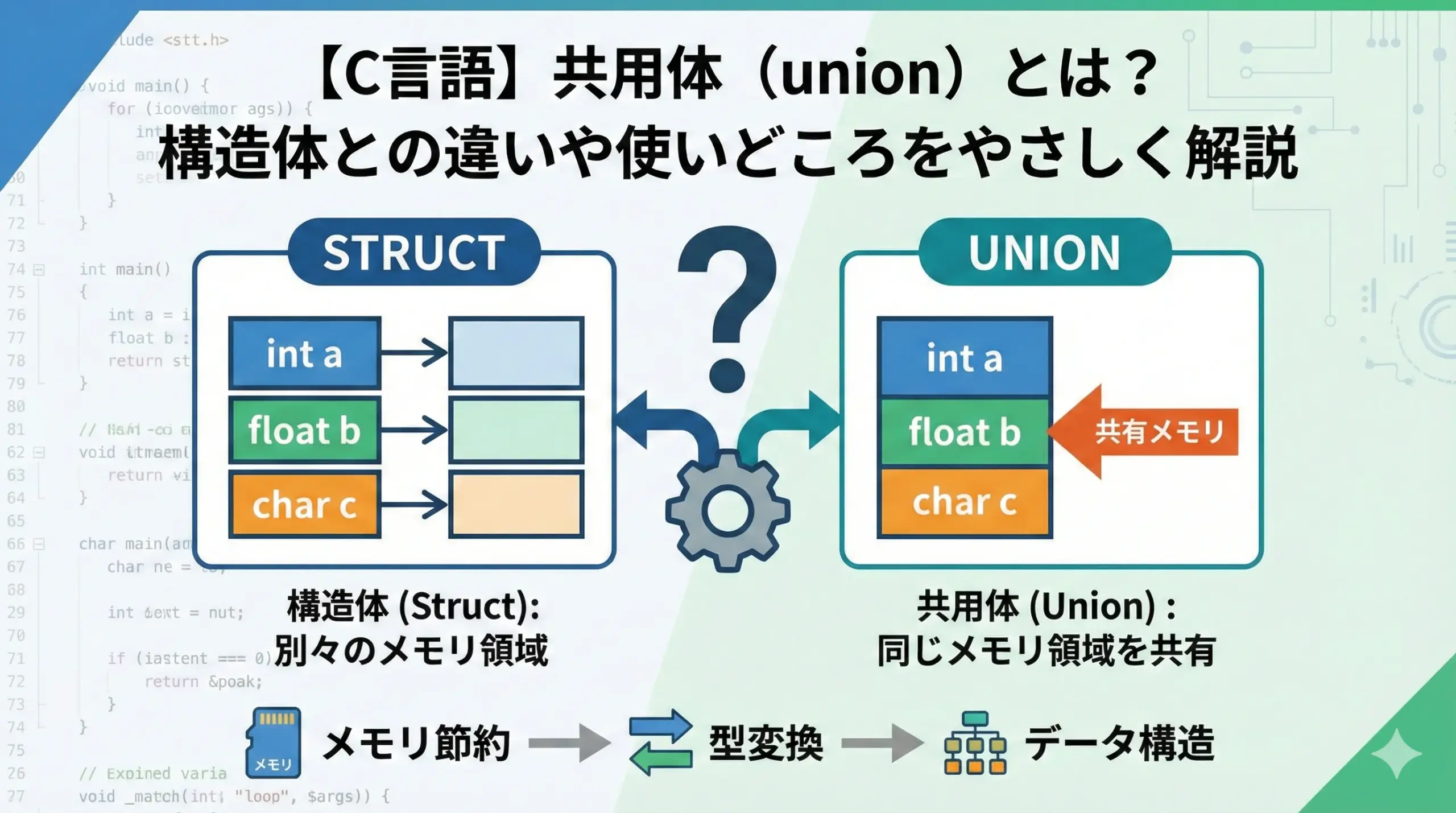
C言語の共用体(union)は、ひとつのメモリ領域を複数の型として扱える強力な機能です。
上手く使うとメモリ効率を高めたり、ビット列操作をわかりやすく書けますが、使い方を誤ると未定義動作を招きます。
本記事では、構造体との違いから書き方、実用サンプル、注意点まで、図解とコード付きで詳しく解説します。
C言語の共用体(union)とは
共用体(union)の基本概念と構造体との違い
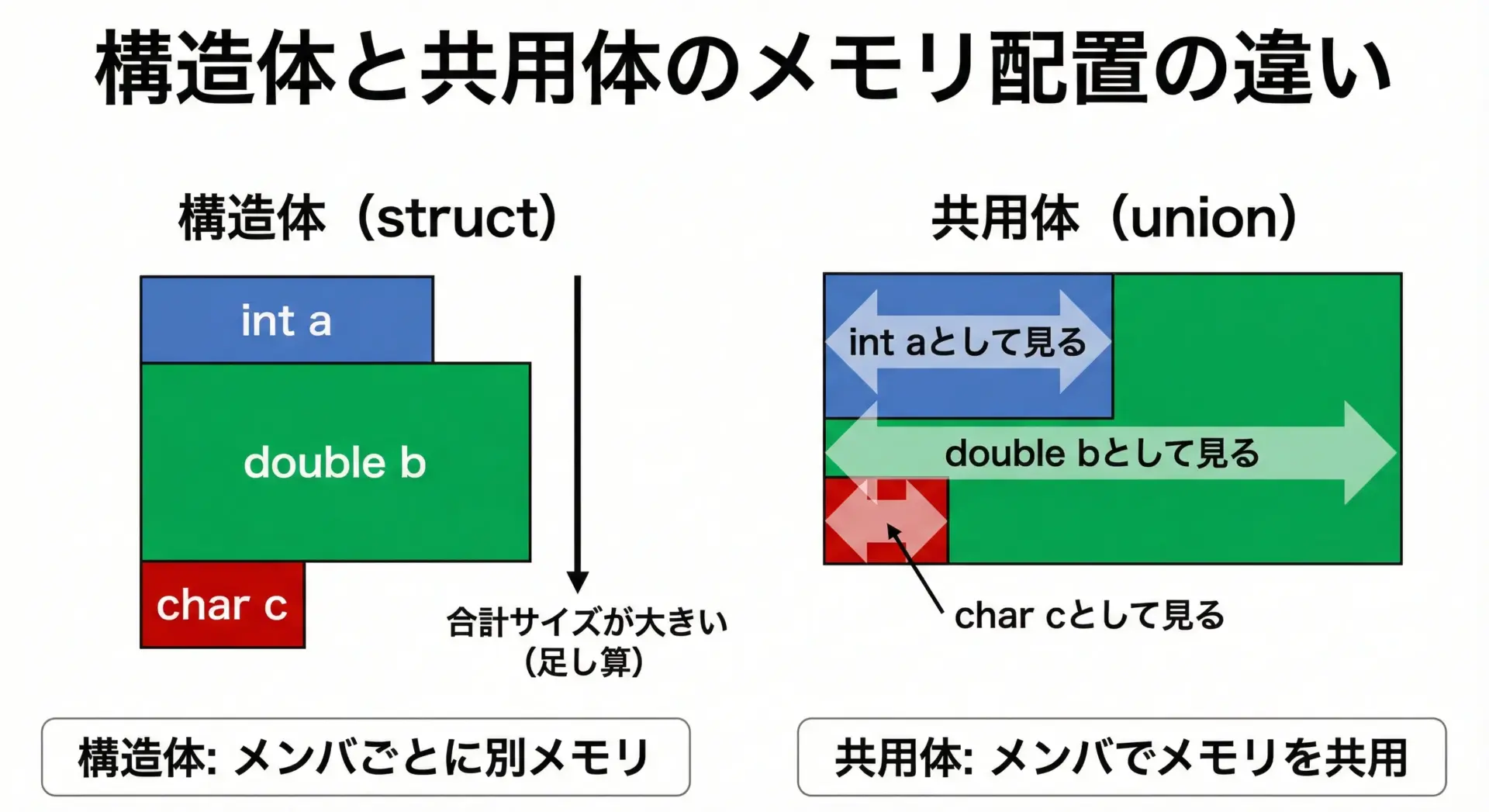
共用体(union)は、複数のメンバが同じ物理メモリ領域を共有している型です。
C言語では、構造体(struct)と非常によく似た文法で定義しますが、振る舞いが大きく異なります。
構造体と共用体の最も本質的な違いは、メモリを「足し算する」のか「共用する」のかという点です。
- 構造体(struct): 各メンバが別々のメモリ領域を持ちます。
- 共用体(union): すべてのメンバが同じメモリ領域を共有します。
構造体のイメージ
構造体では次のような定義をするとします。
struct Point {
int x;
int y;
};この場合、Point型の変数はint2つ分(+アラインメントによるパディング)のサイズを持ち、x と y は完全に別のメモリです。
共用体のイメージ
共用体では、例えば次のように定義します。
union Number {
int i;
float f;
};このとき、i と f は同じアドレスを指すようなイメージになります。
片方に値を書き込むと、同じメモリを別の型として読むことができます。
サイズは 「メンバの中で最大のサイズ」になります。
共用体がメモリ効率に優れる理由
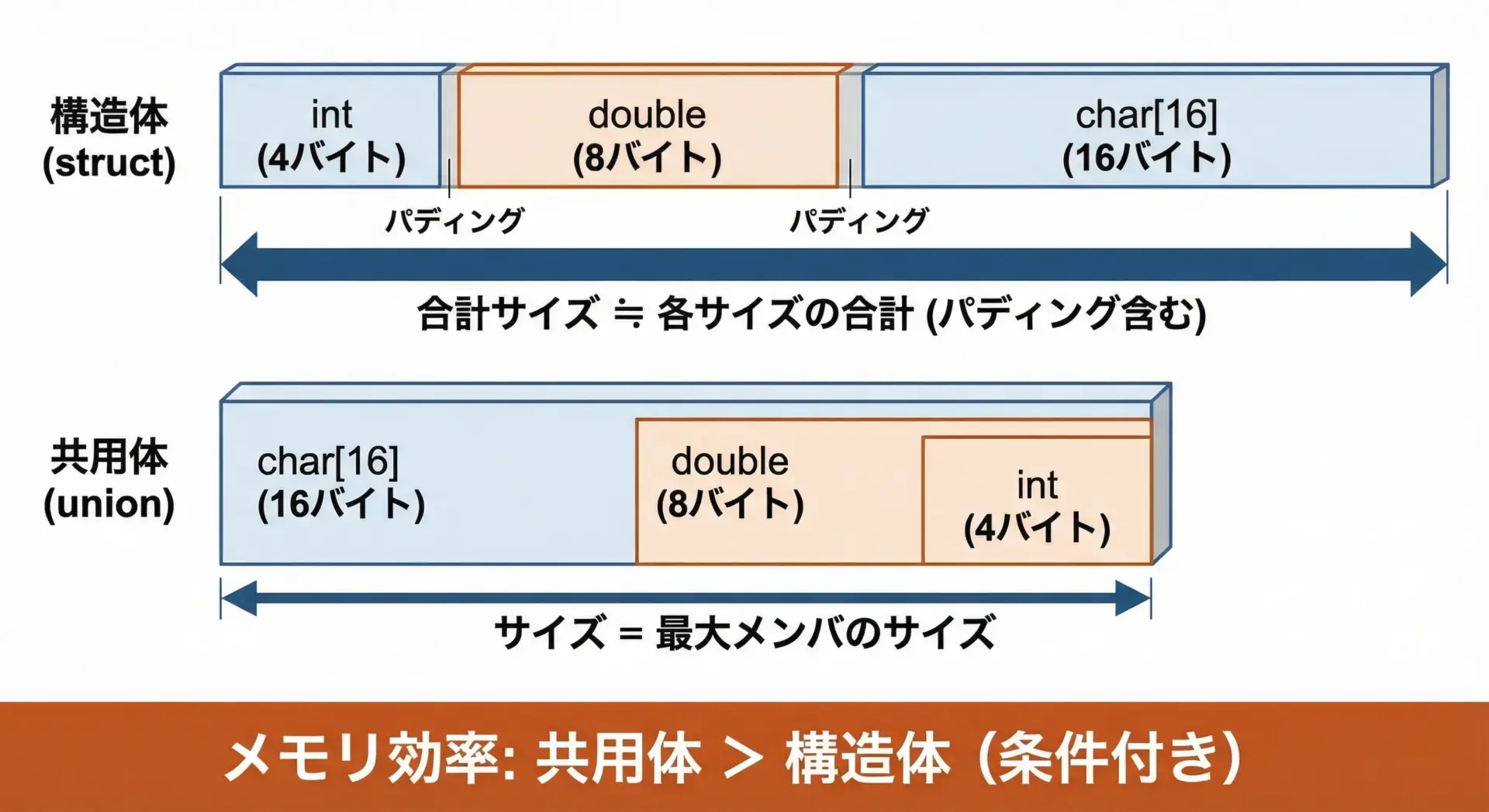
共用体がメモリ効率に優れる理由は、メンバが同時に有効である必要がない場合に、1つ分のメモリだけを確保すればよいからです。
例として、次のような定義を考えます。
struct S {
int i; // 4バイト想定
double d; // 8バイト想定
char text[16];// 16バイト
};
union U {
int i; // 4バイト想定
double d; // 8バイト想定
char text[16];// 16バイト
};典型的な環境では次のようになります。
| 型 | 想定サイズ(おおよそ) |
|---|---|
| struct S | 4 + 8 + 16 = 28バイト(+パディングで32バイトなど) |
| union U | 最大メンバの16バイト(+アラインメント調整) |
構造体は「全部載せ」、共用体は「どれか1つだけ載せ」というイメージです。
そのため、メモリが限られる組み込み開発などで特に有効です。
C言語で共用体を使うメリット・デメリット
共用体には、明確なメリットと注意すべきデメリットがあります。
共用体の主なメリット
- メモリ効率が良い
同時に使わない値を1つのメモリにまとめられます。 - ビット列・バイト列の解釈を変えやすい
例えば、同じ4バイトをintとして見たりfloatとして見たりできます。 - ハードウェア寄りの処理で便利
レジスタやプロトコルのヘッダを表現するときに、ビット単位・バイト単位の解釈を切り替えられます。
共用体の主なデメリット
- 一歩間違えると未定義動作
規格上「どのメンバが最後に格納されたか」を理解して使わないと未定義動作になります。 - コードの可読性が下がりやすい
どのメンバが有効なのかをコードから読み取りにくく、バグを生みやすいです。 - ポータビリティに弱い場合がある
エンディアンやアラインメント、実装依存の挙動に依存しがちです。
そのため、「メモリ効率」や「ビット列操作」が本当に必要な場面に限定して使うのがよい設計です。
共用体の基本的な書き方と使い方
共用体(union)の宣言と定義の書き方
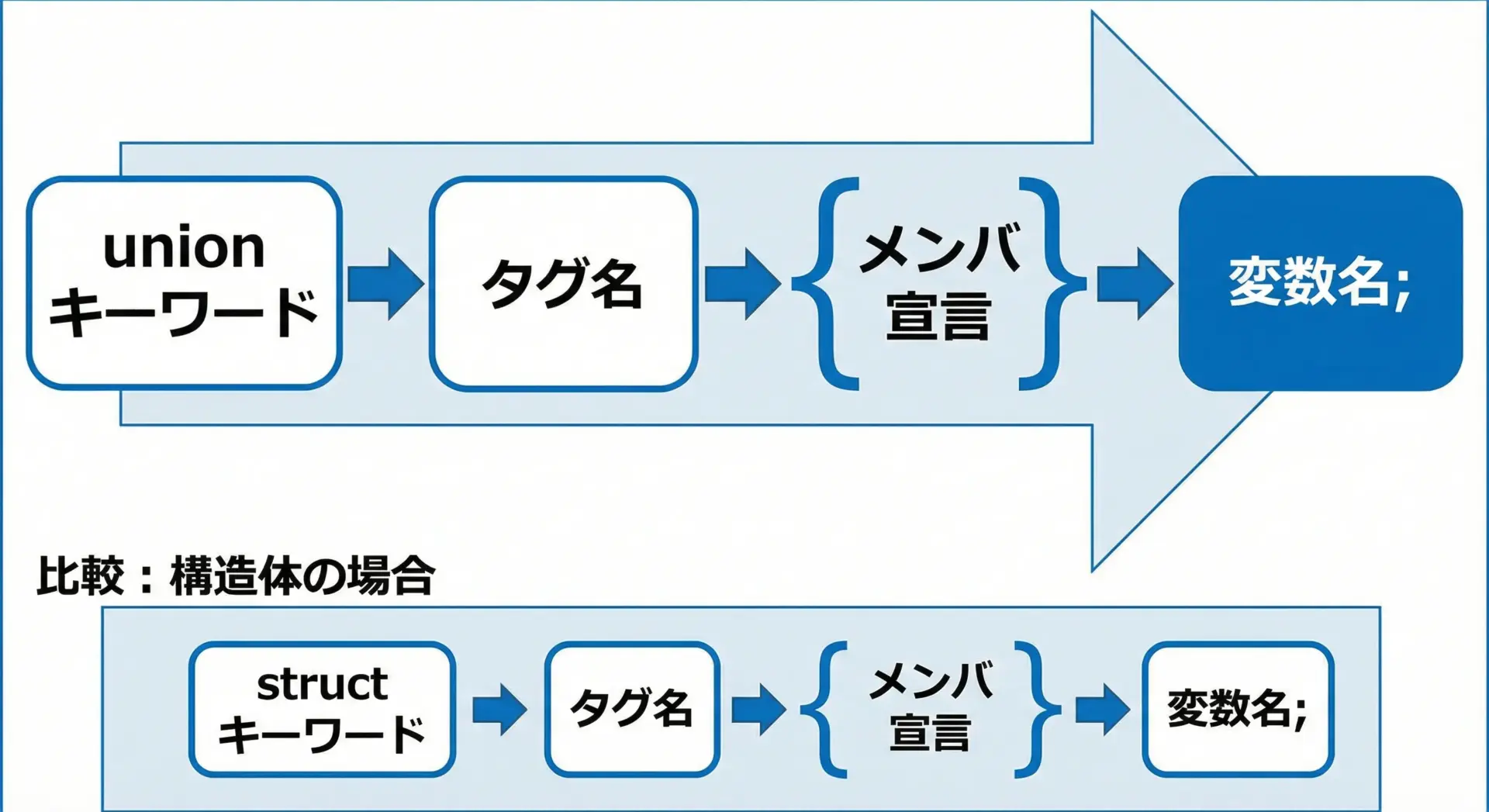
共用体の基本的な定義方法は、構造体とほとんど同じです。
違いはstructではなくunionを使う点だけです。
基本構文
union タグ名 {
型1 メンバ名1;
型2 メンバ名2;
/* ... */
} 変数名1, 変数名2;具体例
#include <stdio.h>
union Data {
int i; // 整数としてのメンバ
float f; // 浮動小数点としてのメンバ
char c; // 1文字としてのメンバ
};
int main(void) {
// union Data 型の変数を宣言
union Data d;
// int として代入
d.i = 100;
printf("d.i = %d\n", d.i);
// float として代入
d.f = 3.14f;
printf("d.f = %f\n", d.f);
// char として代入
d.c = 'A';
printf("d.c = %c\n", d.c);
return 0;
}d.i = 100
d.f = 3.140000
d.c = Aここでは「たまたま」各代入直後のメンバを読んでいるので問題はありません。
ただし、どのメンバが現在有効かを意識しない読み出しは危険になります(後述)。
メンバへのアクセス方法とドット演算子の使い方
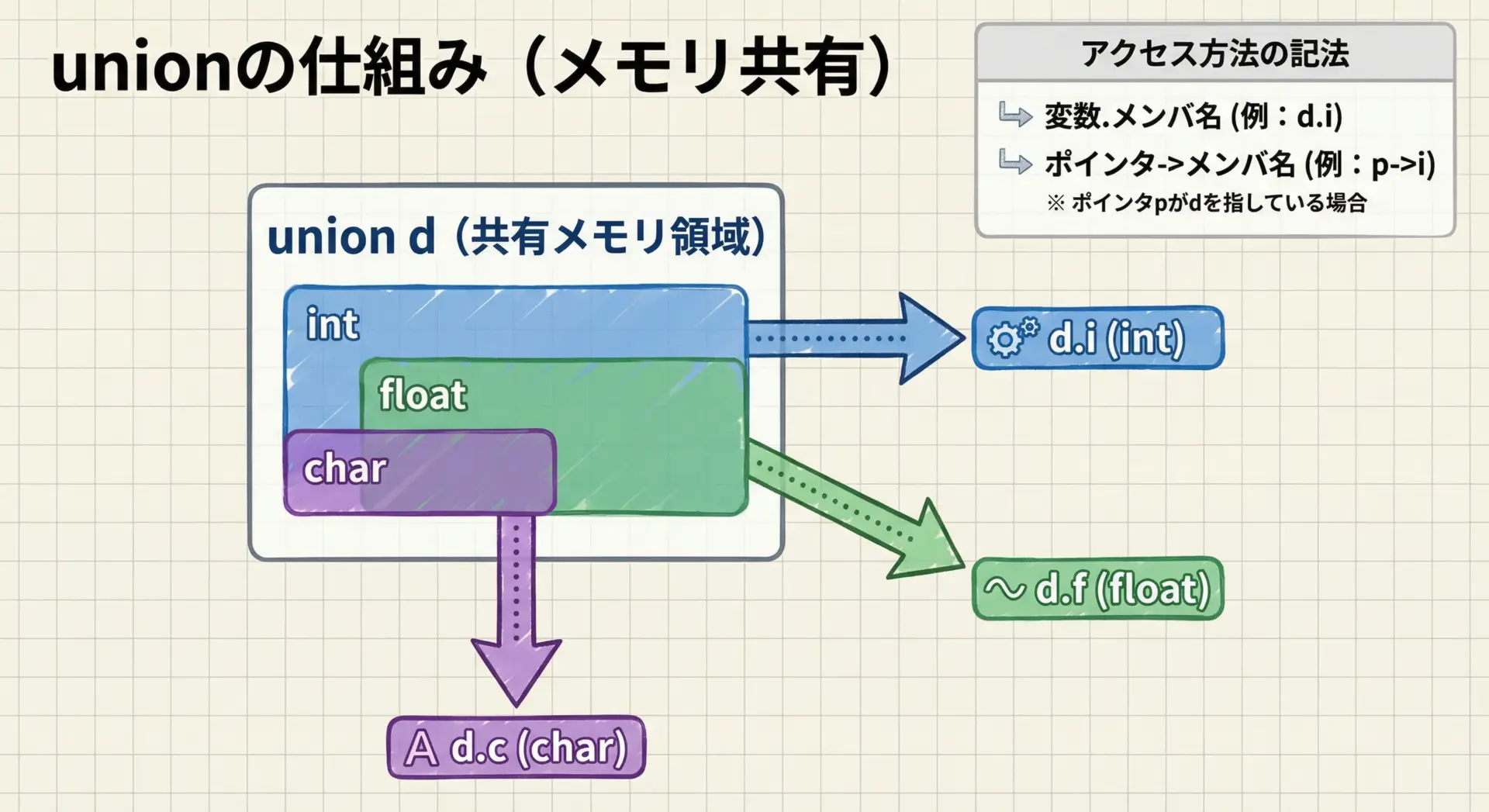
共用体のメンバへのアクセス方法は構造体とまったく同じです。
- 変数からアクセス:
変数名.メンバ名 - ポインタからアクセス:
ポインタ->メンバ名
#include <stdio.h>
union Value {
int i;
float f;
};
int main(void) {
union Value v; // 値そのもの
union Value *pv = &v;// ポインタ
v.i = 42; // ドット演算子でアクセス
printf("v.i = %d\n", v.i);
pv->f = 1.5f; // アロー演算子でアクセス
printf("v.f = %f\n", pv->f);
return 0;
}v.i = 42
v.f = 1.500000ドット(.)とアロー(->)は構造体と統一されたルールなので、そのまま覚えておくとよいです。
typedefを使った共用体型の定義
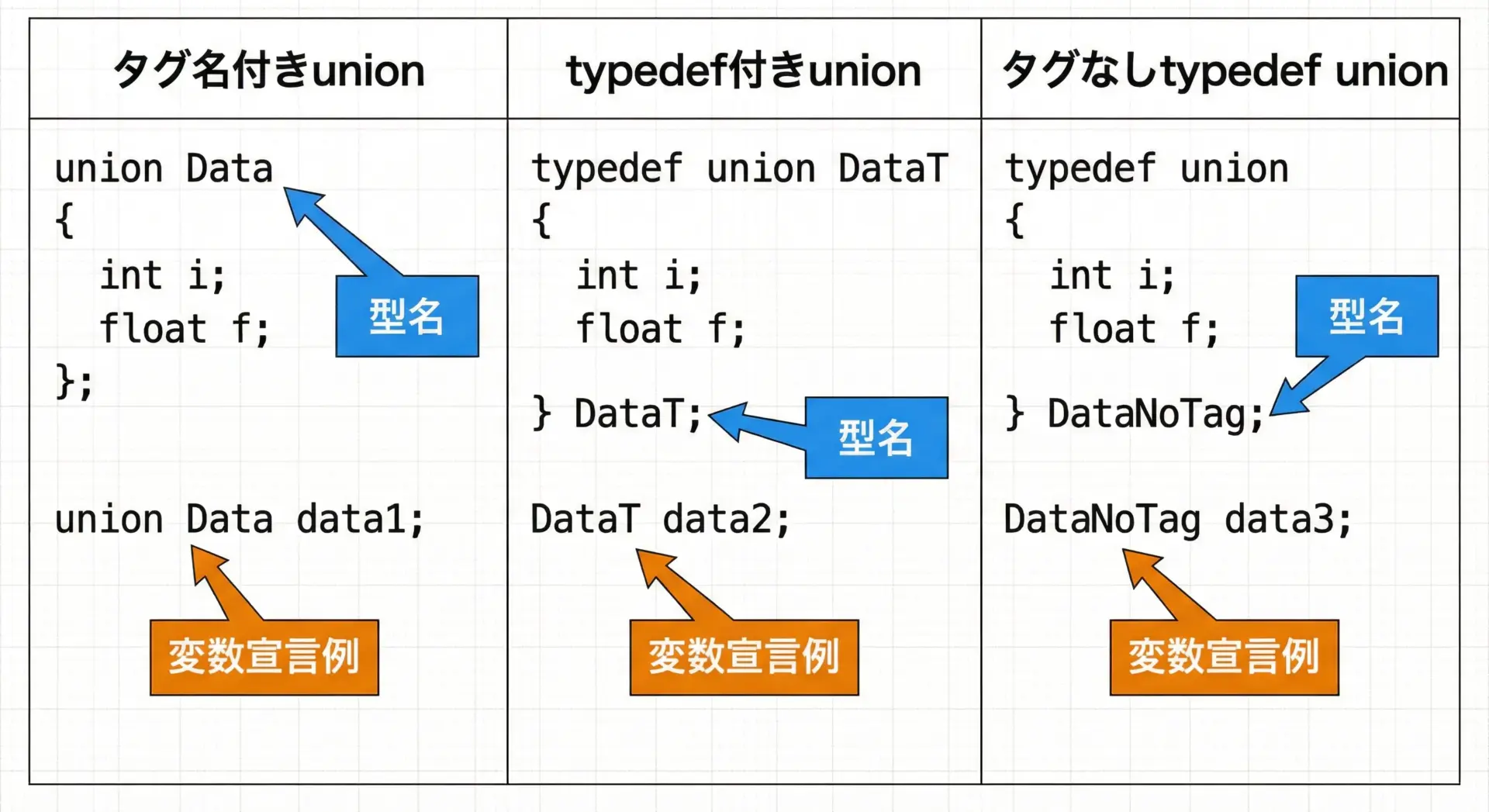
共用体も構造体と同じくtypedefで扱いやすい型名を付けることができます。
よく使うパターン
// パターン1: タグ名 + typedef名
typedef union Number {
int i;
float f;
} Number;
// パターン2: タグなし、typedefのみ
typedef union {
int i;
float f;
} Number2;使い方は通常の型と同じです。
#include <stdio.h>
typedef union {
int i;
float f;
} Number;
int main(void) {
Number n; // unionを意識せずに使える
n.i = 10;
printf("n.i = %d\n", n.i);
n.f = 2.5f;
printf("n.f = %f\n", n.f);
return 0;
}n.i = 10
n.f = 2.500000typedefで型名を与えると、ヘッダファイルやAPIの設計がすっきりします。
共用体と構造体を組み合わせて使う例
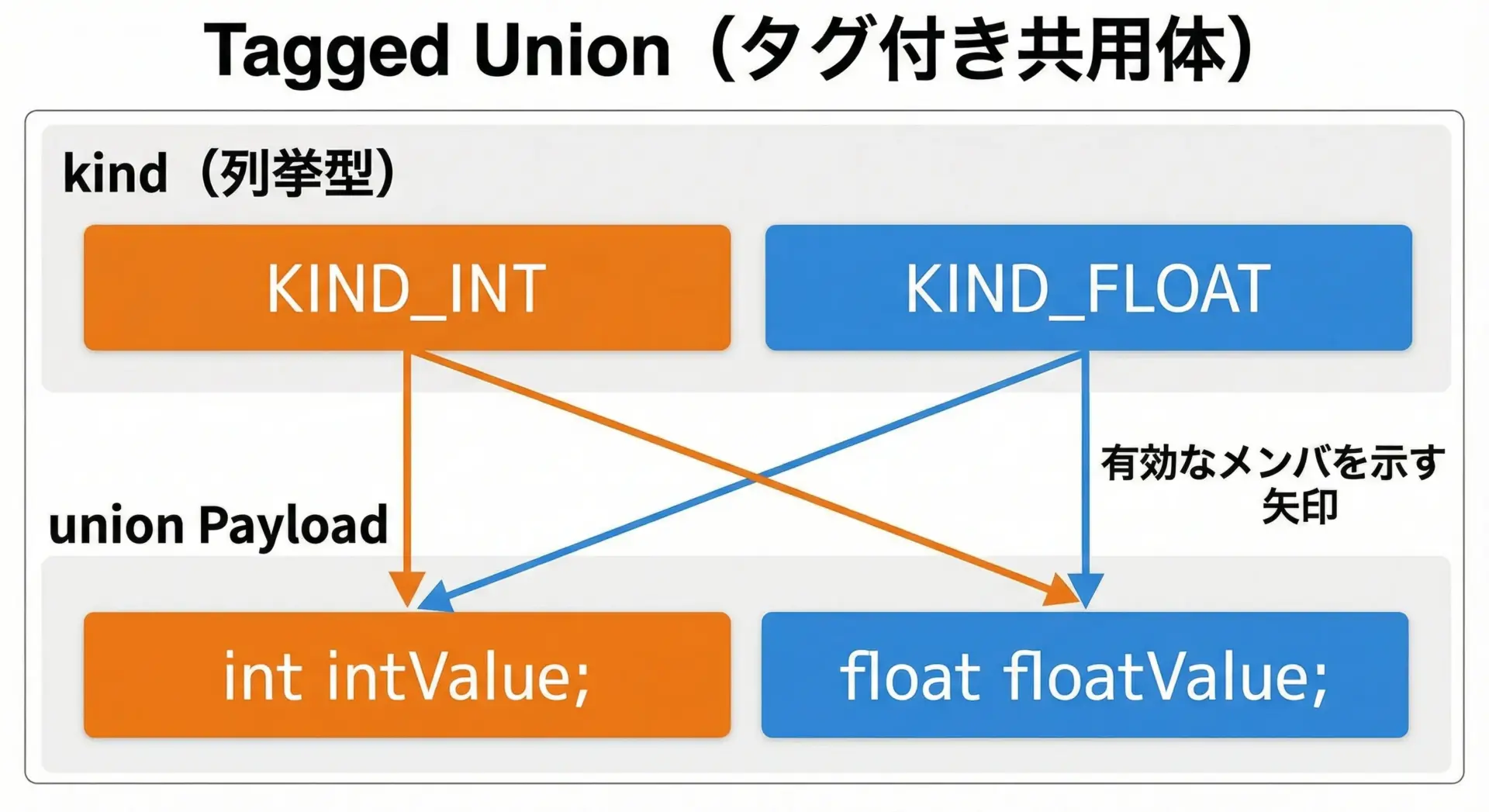
共用体は、「どのメンバが有効か」を示す情報とセットにして使うことで、安全性と可読性が大きく向上します。
このようなパターンはタグ付き共用体(tagged union)と呼ばれます。
#include <stdio.h>
typedef enum {
VALUE_INT,
VALUE_FLOAT,
VALUE_CHAR
} ValueKind;
// データ本体は共用体で表現
typedef union {
int i;
float f;
char c;
} ValueData;
// どのメンバが有効かを示すタグ付き構造体
typedef struct {
ValueKind kind; // 有効な型の情報
ValueData data; // 実際の値(共用体)
} TaggedValue;
void print_value(TaggedValue v) {
switch (v.kind) {
case VALUE_INT:
printf("INT: %d\n", v.data.i);
break;
case VALUE_FLOAT:
printf("FLOAT: %f\n", v.data.f);
break;
case VALUE_CHAR:
printf("CHAR: %c\n", v.data.c);
break;
default:
printf("UNKNOWN\n");
break;
}
}
int main(void) {
TaggedValue v1 = { VALUE_INT, { .i = 123 } };
TaggedValue v2 = { VALUE_FLOAT, { .f = 4.56f } };
TaggedValue v3 = { VALUE_CHAR, { .c = 'X' } };
print_value(v1);
print_value(v2);
print_value(v3);
return 0;
}INT: 123
FLOAT: 4.560000
CHAR: Xタグ(列挙型など)と共用体を組み合わせるのは、実践で非常によく使われる安全なパターンです。
共用体を使った実用サンプルコード
整数と浮動小数点を共用体で参照するサンプル
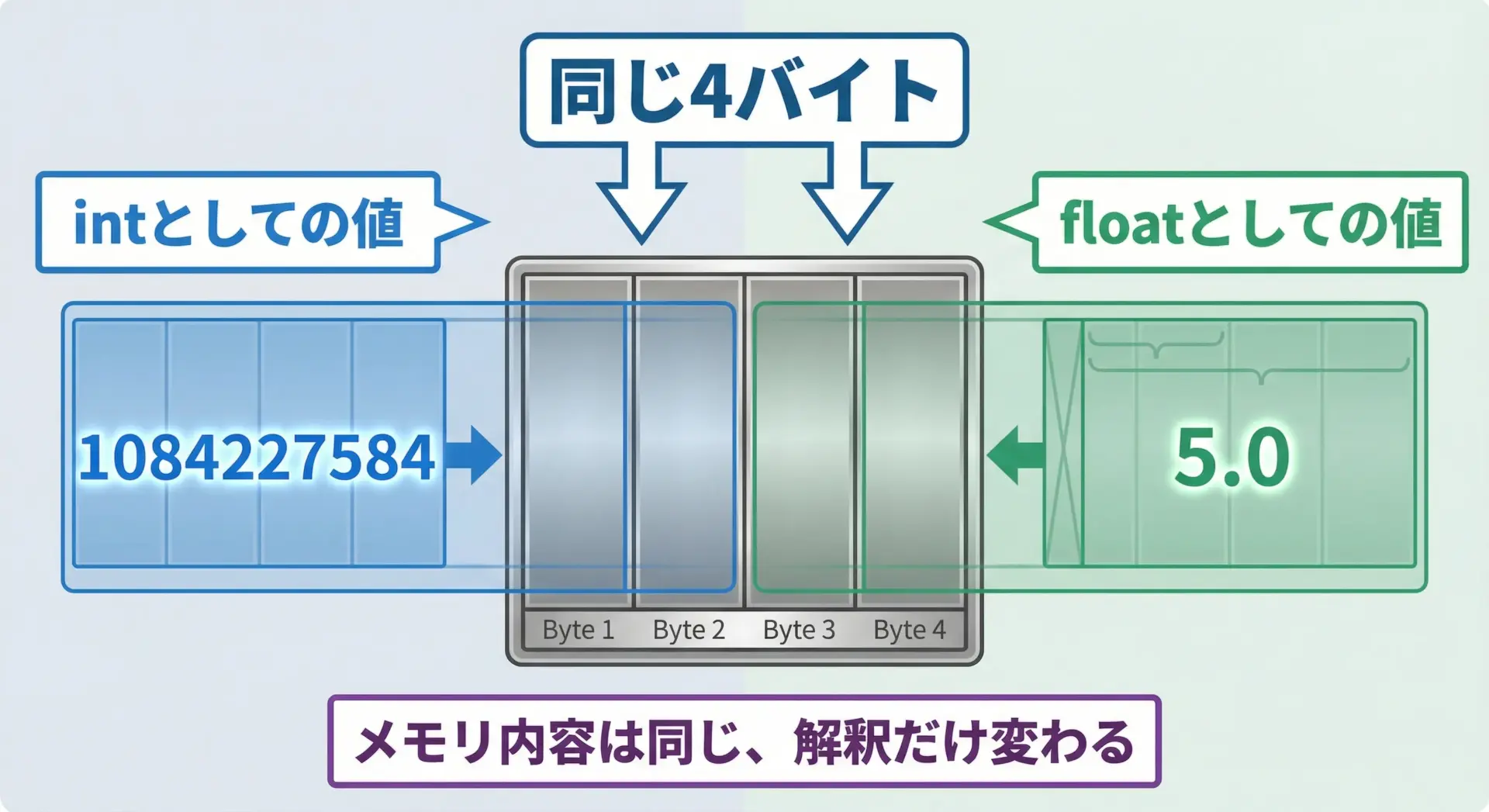
共用体を使うと、同じビット列を別の型として参照できます。
例えば、intとfloatのビット表現を比較するデモです。
#include <stdio.h>
#include <stdint.h>
// int と float のビット表現を比較するための共用体
typedef union {
int32_t i;
float f;
uint8_t bytes[4]; // 1バイト単位でも見られる
} IntFloatUnion;
void print_bits(const uint8_t *bytes, size_t size) {
for (size_t i = 0; i < size; ++i) {
// 上位ビットから順に出力
for (int bit = 7; bit >= 0; --bit) {
putchar( (bytes[i] & (1u << bit)) ? '1' : '0' );
}
putchar(' ');
}
putchar('\n');
}
int main(void) {
IntFloatUnion u;
u.f = 1.0f; // float として代入
printf("u.f = %f\n", u.f);
printf("u.i = %d\n", u.i);
printf("bytes : ");
print_bits(u.bytes, sizeof(u.bytes));
u.i = 0x3f800000; // IEEE754 で 1.0f に対応するビット列
printf("u.i = 0x%08x\n", u.i);
printf("u.f = %f\n", u.f);
printf("bytes : ");
print_bits(u.bytes, sizeof(u.bytes));
return 0;
}u.f = 1.000000
u.i = 1065353216
bytes : 00111111 10000000 00000000 00000000
u.i = 0x3f800000
u.f = 1.000000
bytes : 00111111 10000000 00000000 00000000IEEE754形式を前提としたこのような使い方は、規格上は実装依存・未定義動作に関わる可能性があります。
調査・デバッグ用途にとどめるのが安全です。
ビット列アクセスに共用体を使う方法
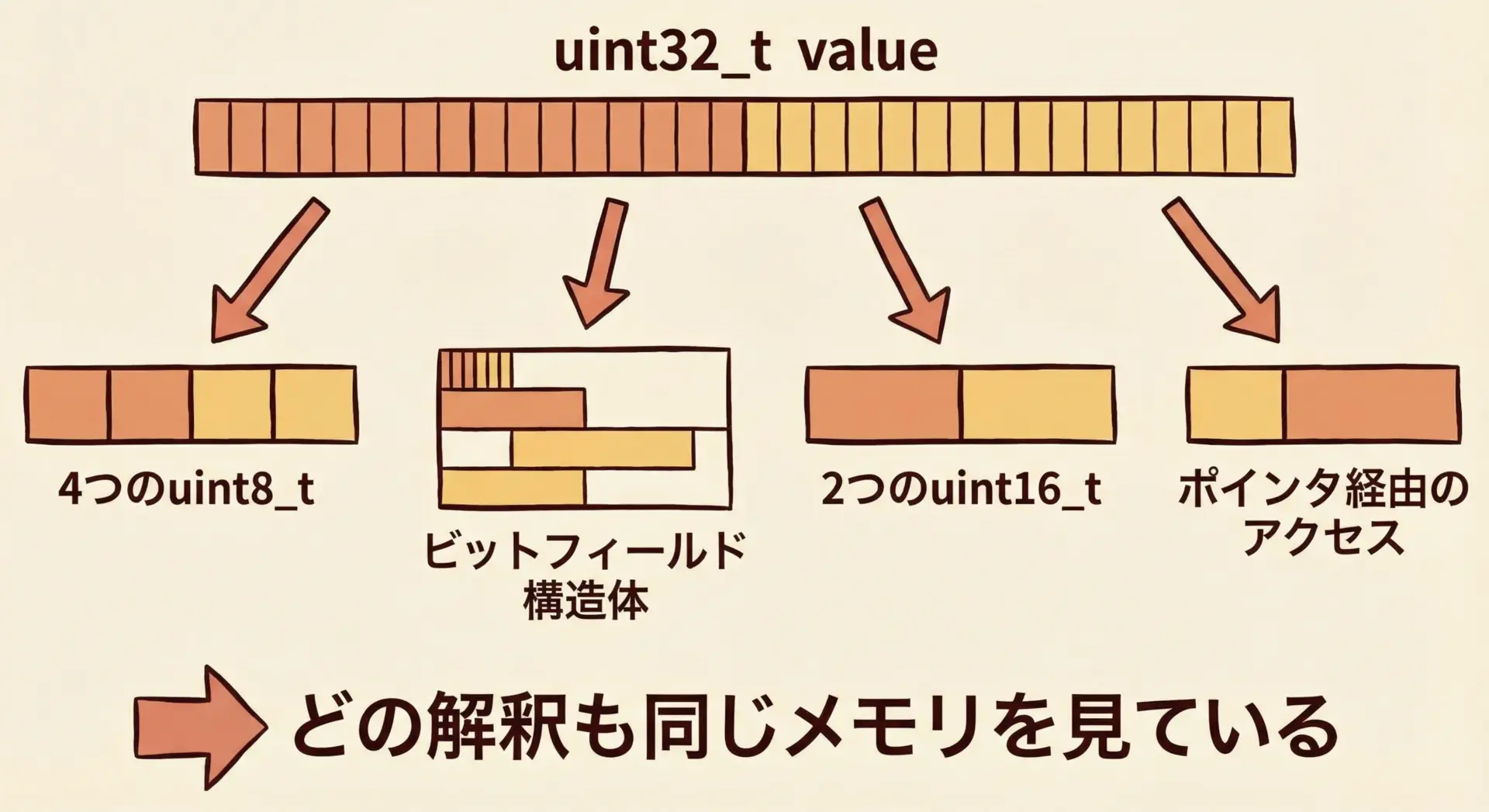
共用体は、1つの値をビットフィールド構造体やバイト配列として同時に扱うのに役立ちます。
ただし、ビットフィールドと共用体の組み合わせも実装依存が多いため、仕様に依存しない範囲で活用することが重要です。
#include <stdio.h>
#include <stdint.h>
// 32ビットレジスタを、ビット/バイト/整数として見る共用体
typedef union {
uint32_t value; // 32ビット値としてアクセス
struct {
uint32_t flag0 : 1;
uint32_t flag1 : 1;
uint32_t flag2 : 1;
uint32_t flag3 : 1;
uint32_t reserved : 28;
} bits; // フラグとしてアクセス(ビットフィールド)
uint8_t bytes[4];// バイト配列としてアクセス
} Reg32;
int main(void) {
Reg32 reg = { 0 };
// ビットフィールドでフラグを設定
reg.bits.flag0 = 1;
reg.bits.flag2 = 1;
printf("value = 0x%08x\n", reg.value);
printf("bytes = %02x %02x %02x %02x\n",
reg.bytes[0], reg.bytes[1],
reg.bytes[2], reg.bytes[3]);
// 直接 value に書き込む
reg.value = 0x0000000f;
printf("flag0 = %u\n", reg.bits.flag0);
printf("flag1 = %u\n", reg.bits.flag1);
printf("flag2 = %u\n", reg.bits.flag2);
printf("flag3 = %u\n", reg.bits.flag3);
return 0;
}value = 0x00000005
bytes = 05 00 00 00
flag0 = 1
flag1 = 1
flag2 = 1
flag3 = 1ビットフィールドのビット順や配置は実装依存です。
ハードウェア仕様に合わせて厳密に制御したい場合は、ビット演算を使う方が移植性が高いことが多いです。
エンディアン確認に共用体を使うサンプル
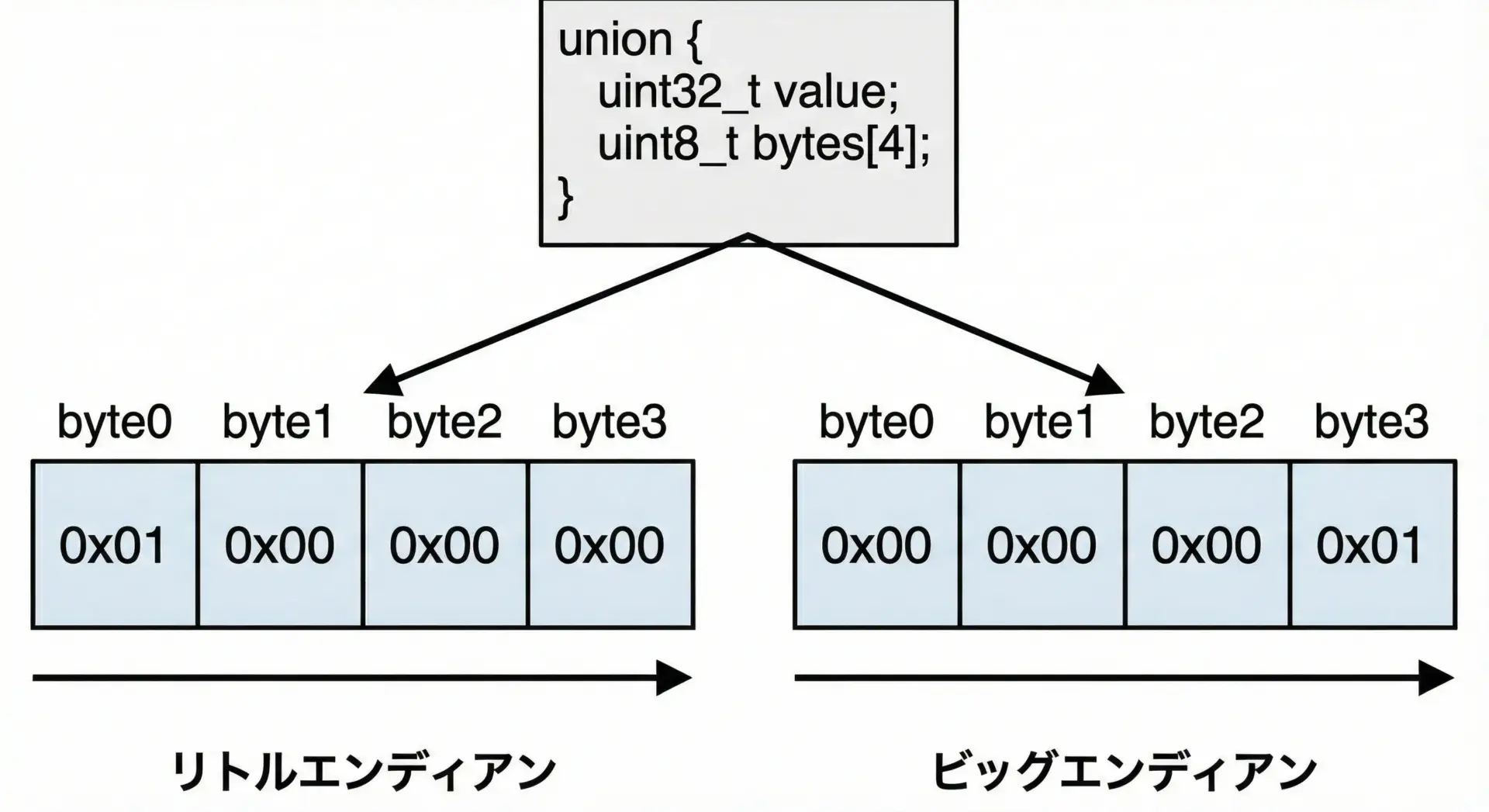
共用体は、エンディアン(バイトオーダー)を簡易的に調べる用途にも使えます。
#include <stdio.h>
#include <stdint.h>
typedef union {
uint32_t value;
uint8_t bytes[4];
} EndianCheck;
int main(void) {
EndianCheck e;
e.value = 0x01020304;
printf("value = 0x%08x\n", e.value);
printf("bytes = %02x %02x %02x %02x\n",
e.bytes[0], e.bytes[1],
e.bytes[2], e.bytes[3]);
if (e.bytes[0] == 0x04) {
printf("Little endian\n");
} else if (e.bytes[0] == 0x01) {
printf("Big endian\n");
} else {
printf("Unknown endian\n");
}
return 0;
}value = 0x01020304
bytes = 04 03 02 01
Little endianC標準規格上、このような「別のメンバから読む」操作は厳密には未定義動作の可能性があります。
ただし、実務でもよくある実装依存テクニックとして広く使われているのが実情です。
移植性がシビアなコードでは、memcpyなどを使う方法がより安全です。
構造体と共用体の違いが分かる比較サンプル
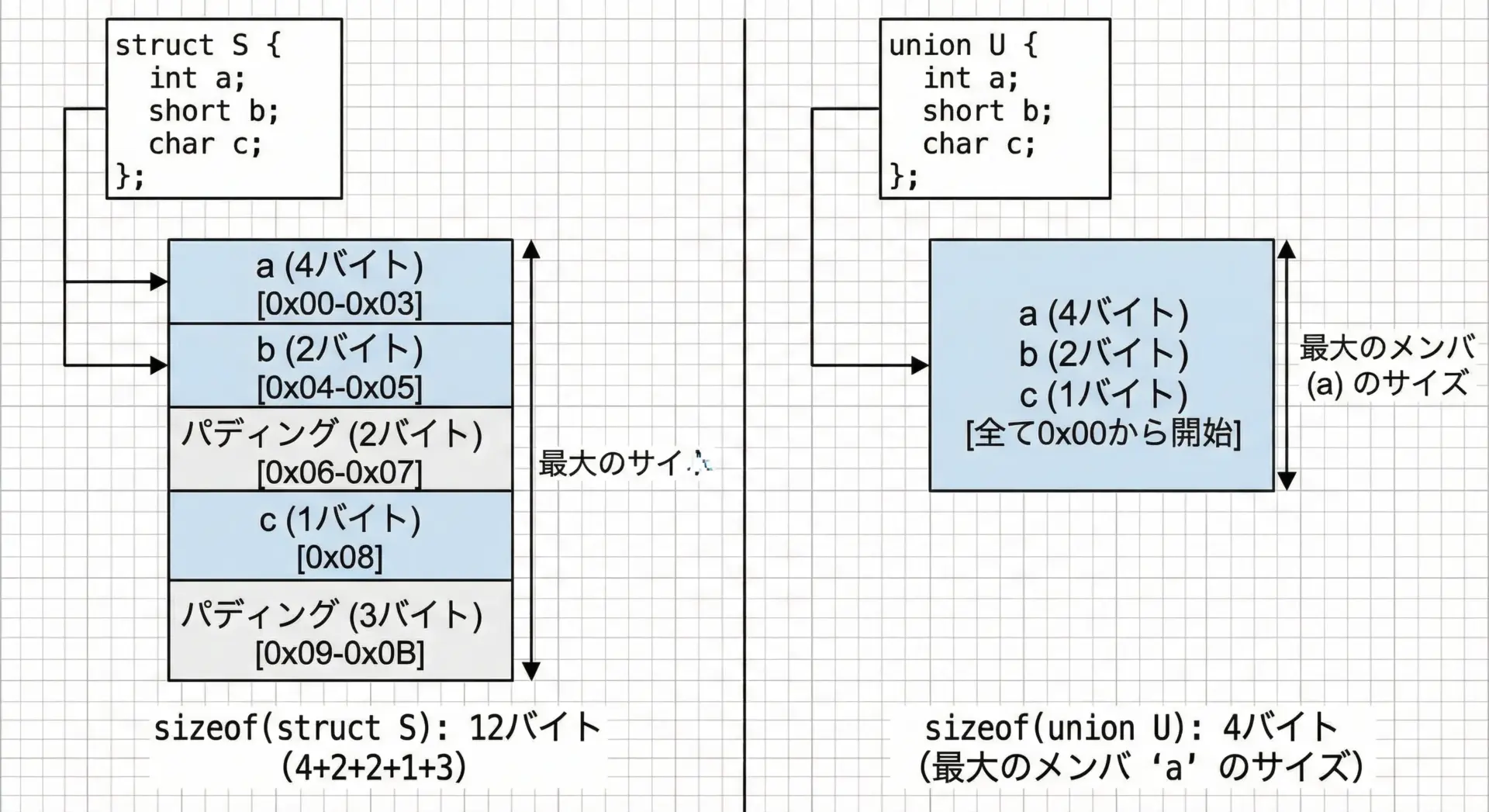
構造体と共用体の違いを、実際のサイズと動作で比べてみます。
#include <stdio.h>
#include <stdint.h>
typedef struct {
uint8_t a;
uint8_t b;
uint8_t c;
} SStruct;
typedef union {
uint8_t a;
uint8_t b;
uint8_t c;
} SUnion;
int main(void) {
printf("sizeof(SStruct) = %zu\n", sizeof(SStruct));
printf("sizeof(SUnion) = %zu\n", sizeof(SUnion));
SStruct s = { .a = 1, .b = 2, .c = 3 };
SUnion u = { .a = 1 };
printf("Struct: a=%u, b=%u, c=%u\n", s.a, s.b, s.c);
printf("Union(before): a=%u, b=%u, c=%u\n", u.a, u.b, u.c);
u.b = 5; // 同じ1バイトを上書き
printf("Union(after b=5): a=%u, b=%u, c=%u\n", u.a, u.b, u.c);
return 0;
}sizeof(SStruct) = 3
sizeof(SUnion) = 1
Struct: a=1, b=2, c=3
Union(before): a=1, b=1, c=1
Union(after b=5): a=5, b=5, c=5この結果からわかることを整理します。
- 構造体は、各メンバが独立したメモリを持つため、値も独立している。
- 共用体は、すべてのメンバが同じ1バイトを共有しているため、どのメンバから読んでも同じ内容になる。
「メンバが独立しているならstruct」「同じデータを別の型として扱うならunion」と覚えると整理しやすいです。
共用体の注意点と設計のコツ
未定義動作に注意すべき共用体の使い方
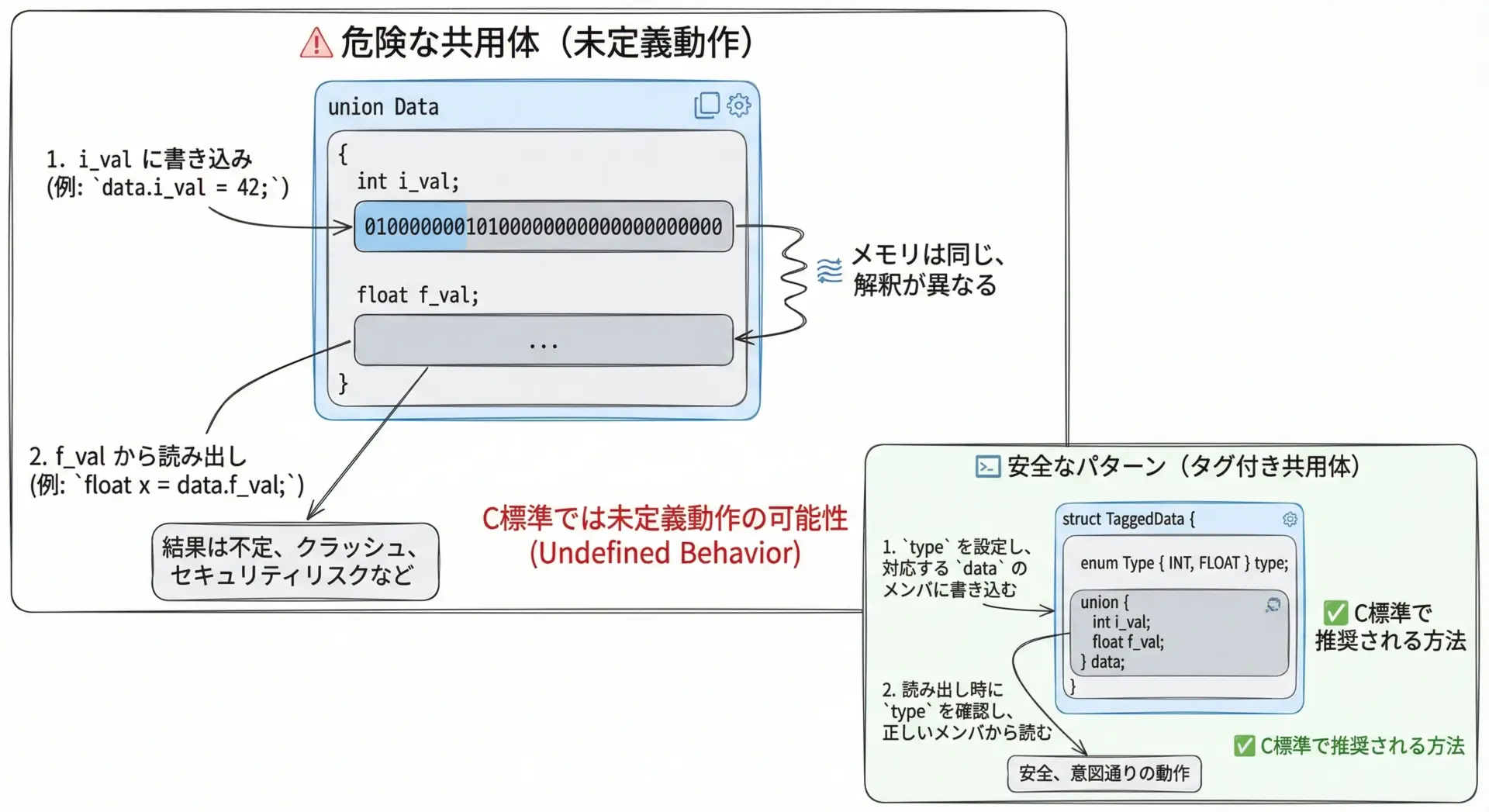
共用体は、未定義動作(undefined behavior)を招きやすい機能です。
特に注意したいパターンを整理します。
代表的な危険パターン
union U {
int i;
float f;
};
union U u;
u.i = 123;
printf("%f\n", u.f); // 規格上は未定義動作C標準(特にC11以降)では、最後に書き込んだメンバとは異なるメンバから読み取ることは未定義動作とされています(ただし一部の特殊なケースを除く実装定義などの扱いもあり、コンパイラ依存です)。
未定義動作になると、次のような問題が起こり得ます。
- コンパイラが想定外の最適化を行い、結果が変わったりクラッシュしたりする。
- 開発環境が変わると挙動が変わる。
- デバッグが非常に難しくなる。
回避の基本方針
- 「どのメンバが有効か」を明示するタグ付き共用体にする。
- 「別の型として解釈したい」だけなら、
memcpyでビット列をコピーして扱う。 - CPUやコンパイラに依存する低レベルコードは、対象環境を明確にしたうえで限定的に使う。
共用体とメモリアラインメント・パディング
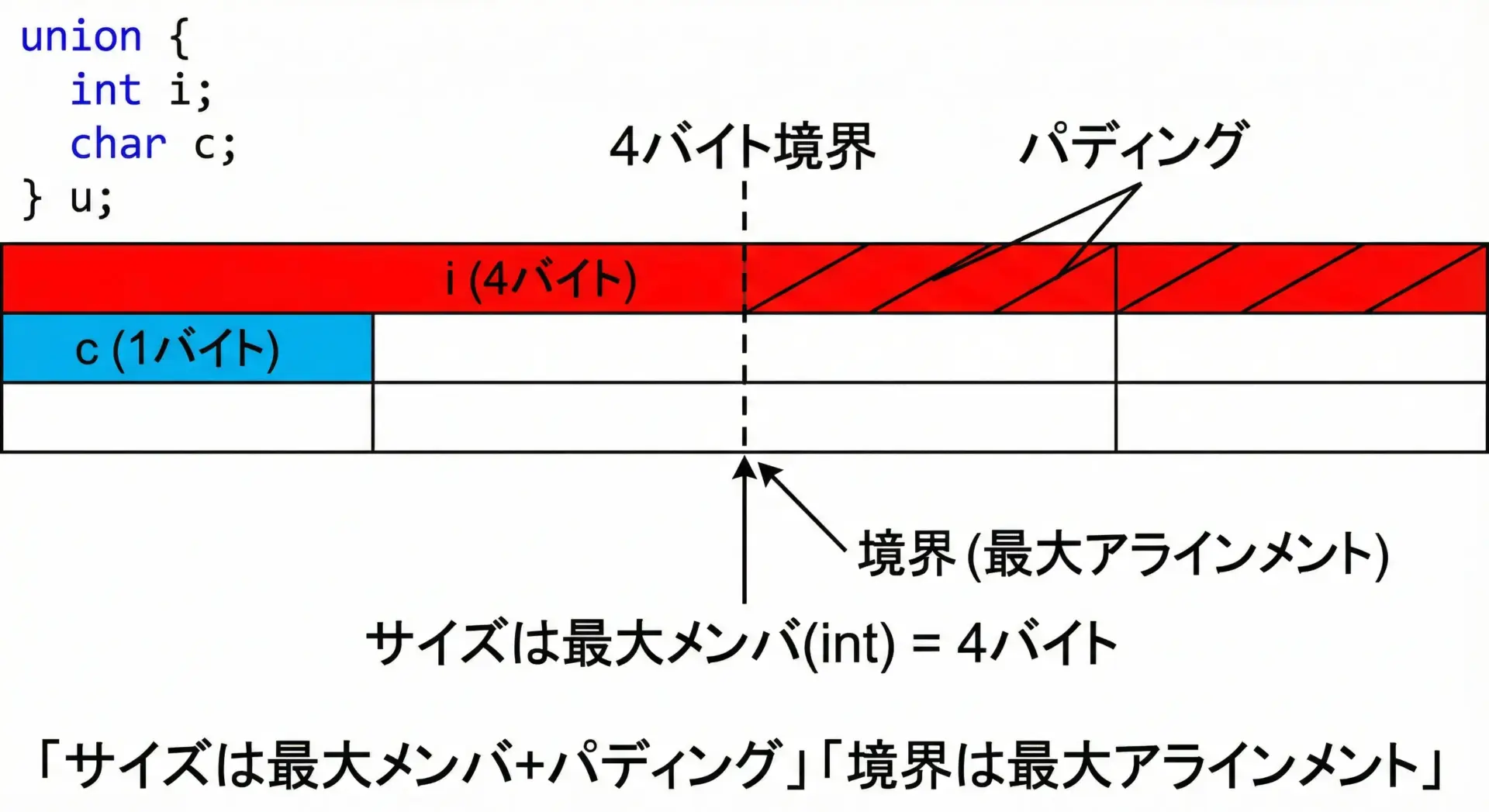
共用体のサイズやアラインメントは、中に含まれるメンバの中で最も厳しい制約を持つものに合わせられます。
共用体のサイズとアラインメントの一般的なルール
- サイズ: メンバのうち最大サイズ以上(+パディング)。
- アラインメント: メンバのうち最も厳しいアラインメント要求に従う。
#include <stdio.h>
union AlignTest {
char c; // 通常は1バイト境界
int i; // 多くの環境で4バイト境界
float f; // 多くの環境で4バイト境界
};
int main(void) {
printf("sizeof(AlignTest) = %zu\n", sizeof(union AlignTest));
return 0;
}sizeof(AlignTest) = 4多くの環境では上記のように4バイトになります。
共用体は「すべてのメンバを安全に格納できるように」アラインメントを選ぶ必要があるためです。
構造体の中に共用体を入れる場合は、構造体全体のアラインメントやサイズにも影響します。
メモリレイアウトを厳密に管理したい場合は、
sizeofやoffsetofで確認する。- パディングを避けるためにメンバの順序を工夫する。
といった工夫が必要になります。
ポータビリティを意識した共用体設計のポイント
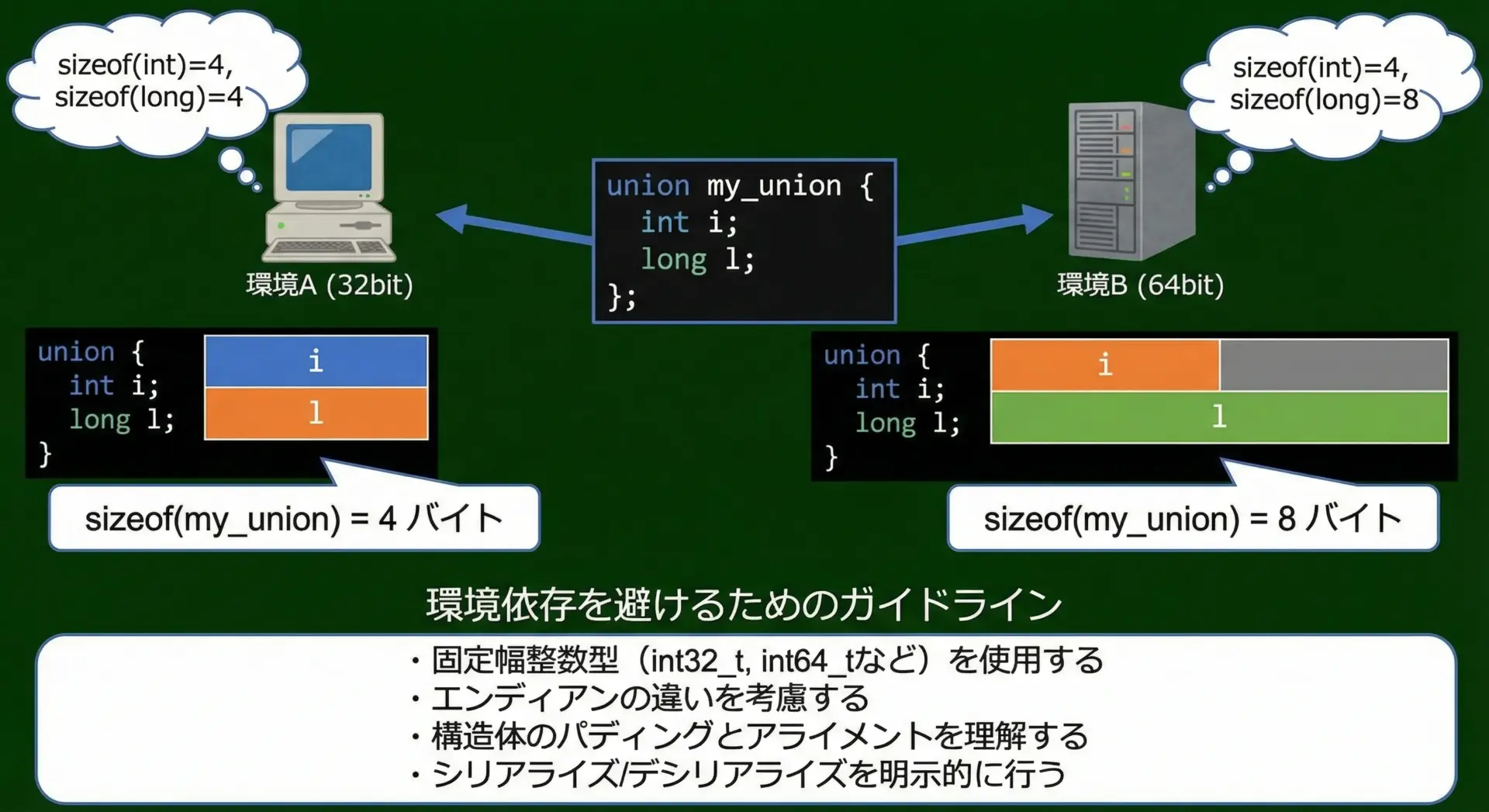
- 2つの環境(A: 32bit, B: 64bit)のアイコンを描き、それぞれに同じunion定義が矢印でつながっている図。
- しかしサイズやビット配置が異なることを示す(例: sizeofが違う吹き出し)。
- 下に「環境依存を避けるためのガイドライン」を箇条書き。
ポータビリティ(移植性)を高めるためには、共用体の使い方をかなり慎重に設計する必要があります。
できるだけ避けるべきこと
- 異なるメンバ間での読み書きに依存するロジック(未定義動作の可能性)。
- ビットフィールドと共用体を組み合わせて、ビット配置を前提にすること。
- エンディアンや整数サイズ(32bit/64bit)に依存した共用体設計。
比較的安全な使い方
- タグ付き共用体で、「有効なメンバを切り替える単なるコンテナ」として使う。
- 1つのメンバだけを読み書きし、他のメンバはデバッグ用・可視化用に限定する。
- 仕様書やコメントで「対象とする環境」「依存している前提(エンディアンなど)」を明示する。
ライブラリや公開APIとして共用体を露出させる場合は特に慎重に設計してください。
共用体を使うべきケース・避けるべきケース
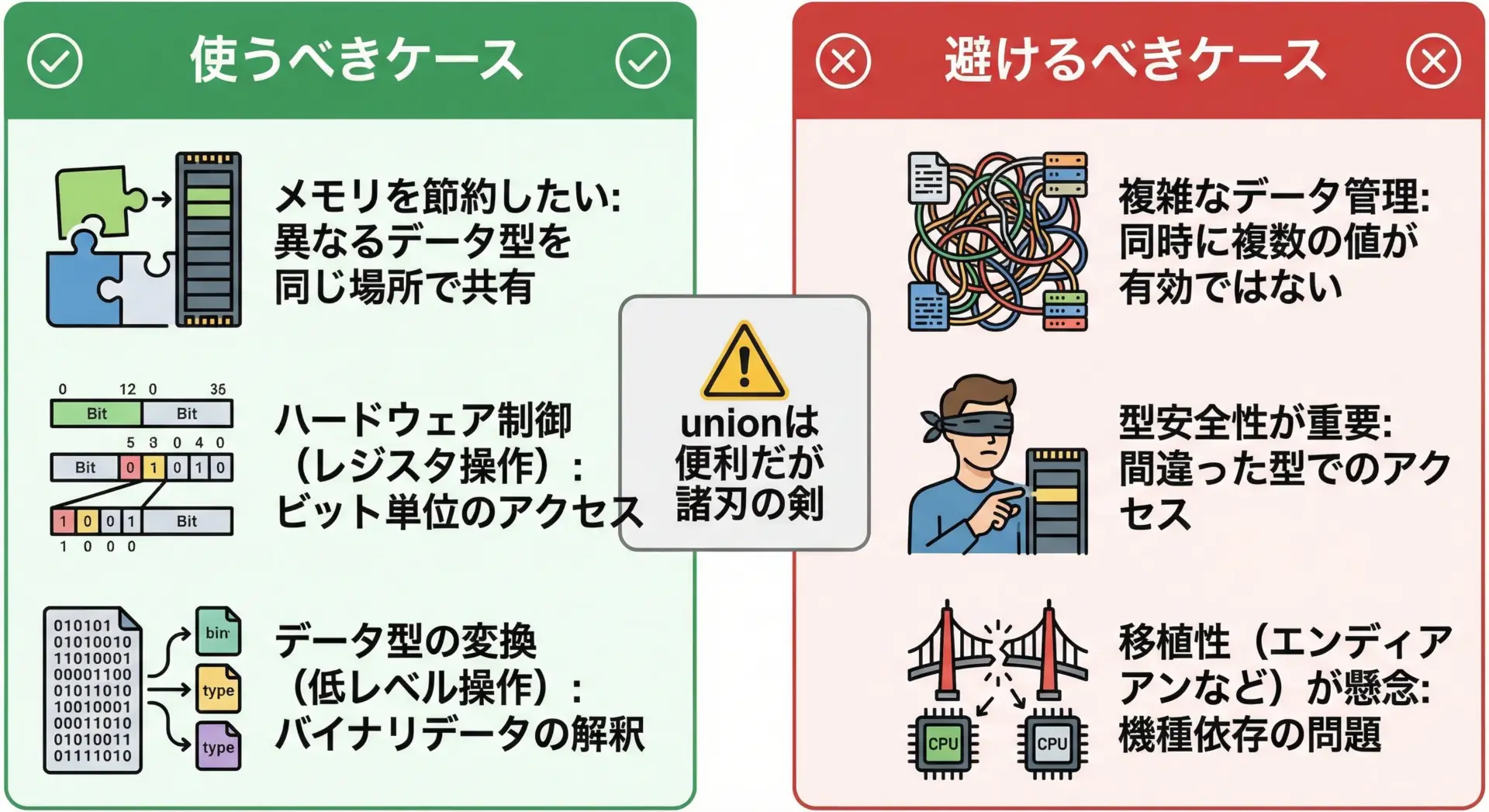
最後に、共用体を実際に使うかどうかの判断基準を整理します。
共用体を使うべき典型的なケース
- メモリが極めて制限されている環境
組み込み機器やマイコンなど、数バイト単位でメモリを節約したい場合。 - プロトコルヘッダやハードウェアレジスタの表現
同じデータを「整数として」「ビット列として」「フィールド構造体として」見たい場合。
ただし、ビット配置・エンディアンを仕様でしっかり固定しておく必要があります。 - タグ付き共用体による多態的な値の表現
JSON値のように「数値か文字列かブールか」など、型が可変なデータを表現するときに便利です。
共用体を避けるべき典型的なケース
- 一般的な業務アプリケーション
PC上で動く通常のアプリケーションでは、メモリ節約よりも可読性・保守性がはるかに重要です。まず構造体や通常の型で実装し、必要なら後から最適化を検討する方が安全です。 - 移植性・保守性が特に重要なコード
ライブラリ、フレームワーク、長期運用される製品などでは、共用体依存のトリッキーな実装は避けた方がよい場合が多いです。 - 未定義動作を回避する自信がない場合
共用体特有の落とし穴(未定義動作・実装依存)をきちんと理解し、コメントやテストでカバーできる状態になるまでは、むやみに使わない方が安全です。
まとめ
共用体(union)は、「同じメモリ領域を複数の型として扱う」ためのC言語の機能です。
構造体との大きな違いは、メモリをメンバ間で共有する点にあり、これによりメモリ効率やビット列操作の柔軟性が得られます。
一方で、異なるメンバ間での読み書きは未定義動作の原因になりやすく、エンディアンやアラインメントにも影響を受けます。
実用では、タグ付き共用体で安全性を高めつつ、組み込みやプロトコル処理など必要な場面に絞って使うことが重要です。
共用体の特徴と注意点を理解して、適切な場面で効果的に活用してください。
