
C言語で実用的なプログラムを書くためには、複数のデータをひとまとめに扱える「構造体」を避けて通ることはできません。
本記事では、構造体の基本概念から宣言・初期化・ポインタ・アロー演算子(->)・mallocによる動的確保までを、図解とサンプルコード付きで丁寧に解説します。
初心者の方でも読み進めるだけで、構造体の「使いどころ」までイメージできることを目指します。
C言語の構造体とは?基本とメリット
構造体(struct)とは何かを図解で理解する
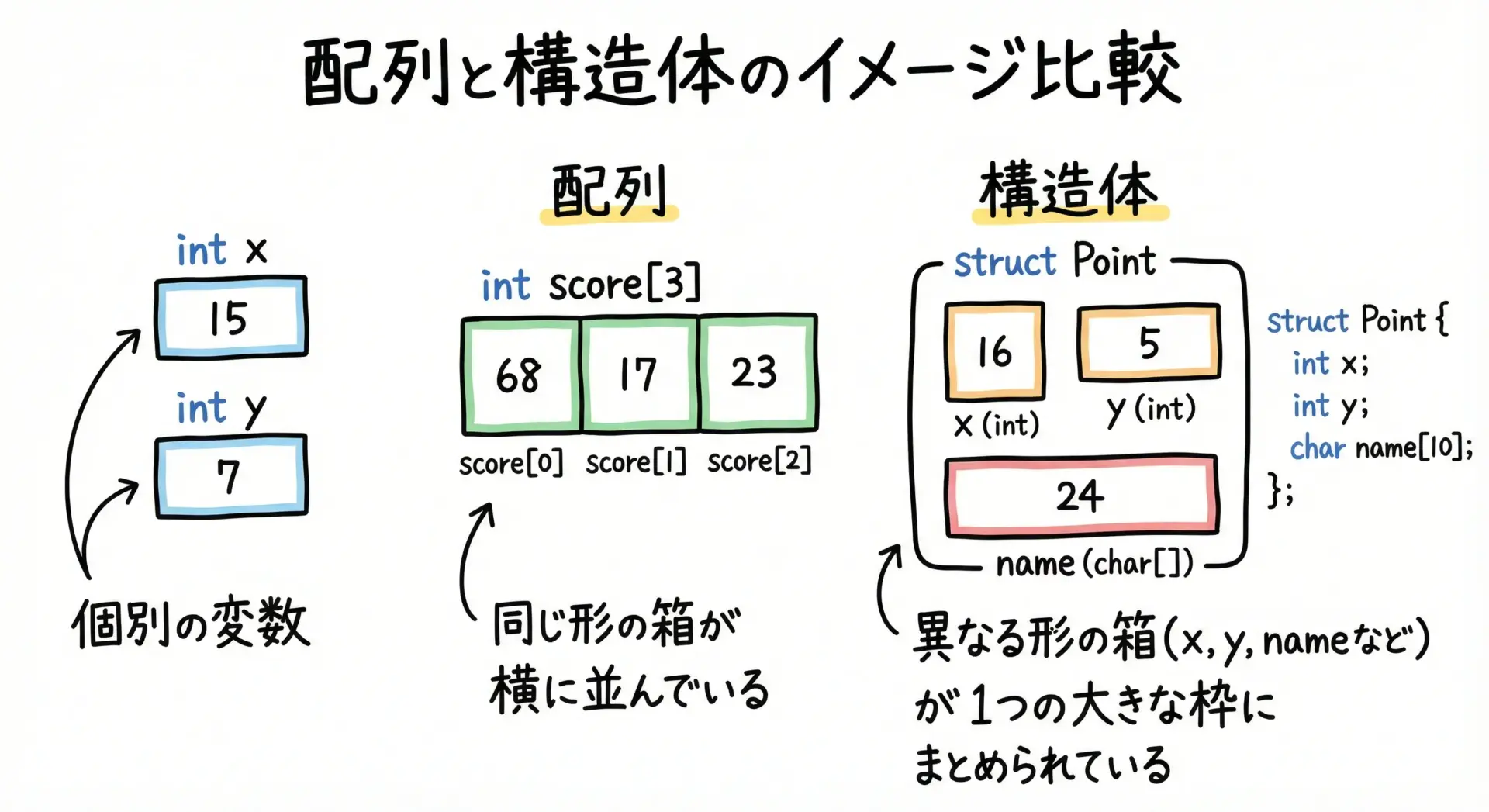
C言語の構造体(struct)は、異なる種類のデータをひとまとまりの「1つの型」として定義できる仕組みです。
整数や浮動小数点数、文字列など、関連する情報をまとめて扱うことができます。
たとえば、2次元座標を扱いたいとき、普通に変数を宣言すると次のようになります。
int x;
int y;しかし、「座標」そのものを1つのまとまりとして扱いたい場合、構造体を使って次のように書けます。
#include <stdio.h>
// 座標を表す構造体型 Point を定義
struct Point {
int x; // x座標
int y; // y座標
};
int main(void) {
struct Point p; // Point型の変数pを宣言
p.x = 10; // メンバxに代入
p.y = 20; // メンバyに代入
printf("x = %d, y = %d\n", p.x, p.y);
return 0;
}x = 10, y = 20このように構造体は、関連するデータをひとかたまりにし、「座標」や「社員情報」といった概念を型として表現するために使われます。
構造体と配列・列挙体との違い
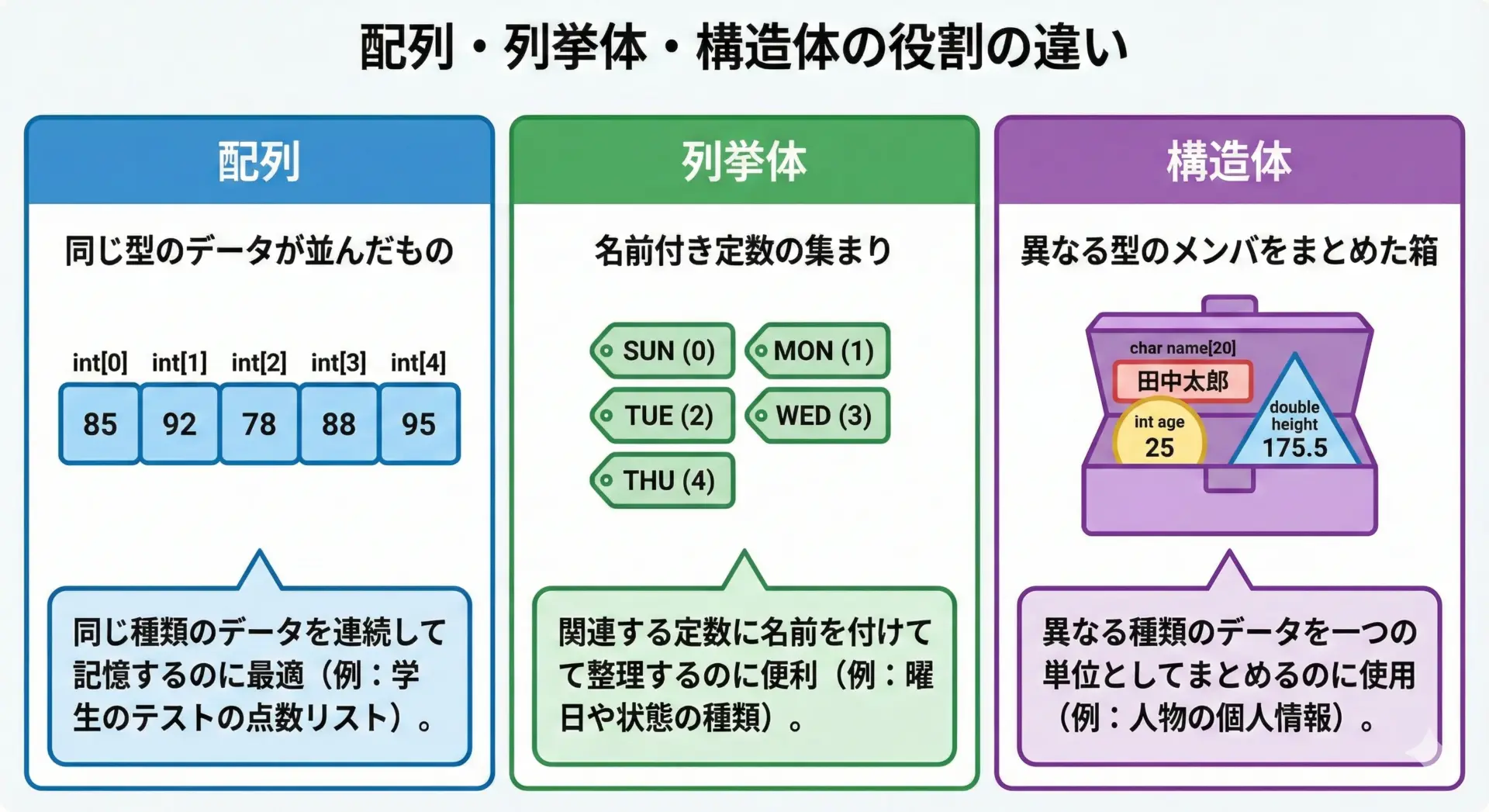
C言語には、複数の値を扱うための仕組みとして配列と列挙体(enum)もあります。
それぞれ役割が異なるので、違いを押さえておくと構造体の立ち位置が明確になります。
配列・列挙体・構造体を整理すると、次のようになります。
| 種類 | まとめ方の特徴 | 典型的な用途 |
|---|---|---|
| 配列 | 同じ型の値が並ぶ | 点数一覧、温度の記録、IDリストなど |
| 列挙体 | 整数定数に名前を付けた集合 | 状態フラグ、モード指定、曜日など |
| 構造体 | 異なる型の値をひとまとめ | 座標、社員情報、ゲームキャラ情報など |
配列は「同じ型がたくさん」、列挙体は「意味のある定数に名前を付ける」、構造体は「関連する複数の情報をパックする」、とイメージすると理解しやすくなります。
構造体でコードの保守性が上がる理由
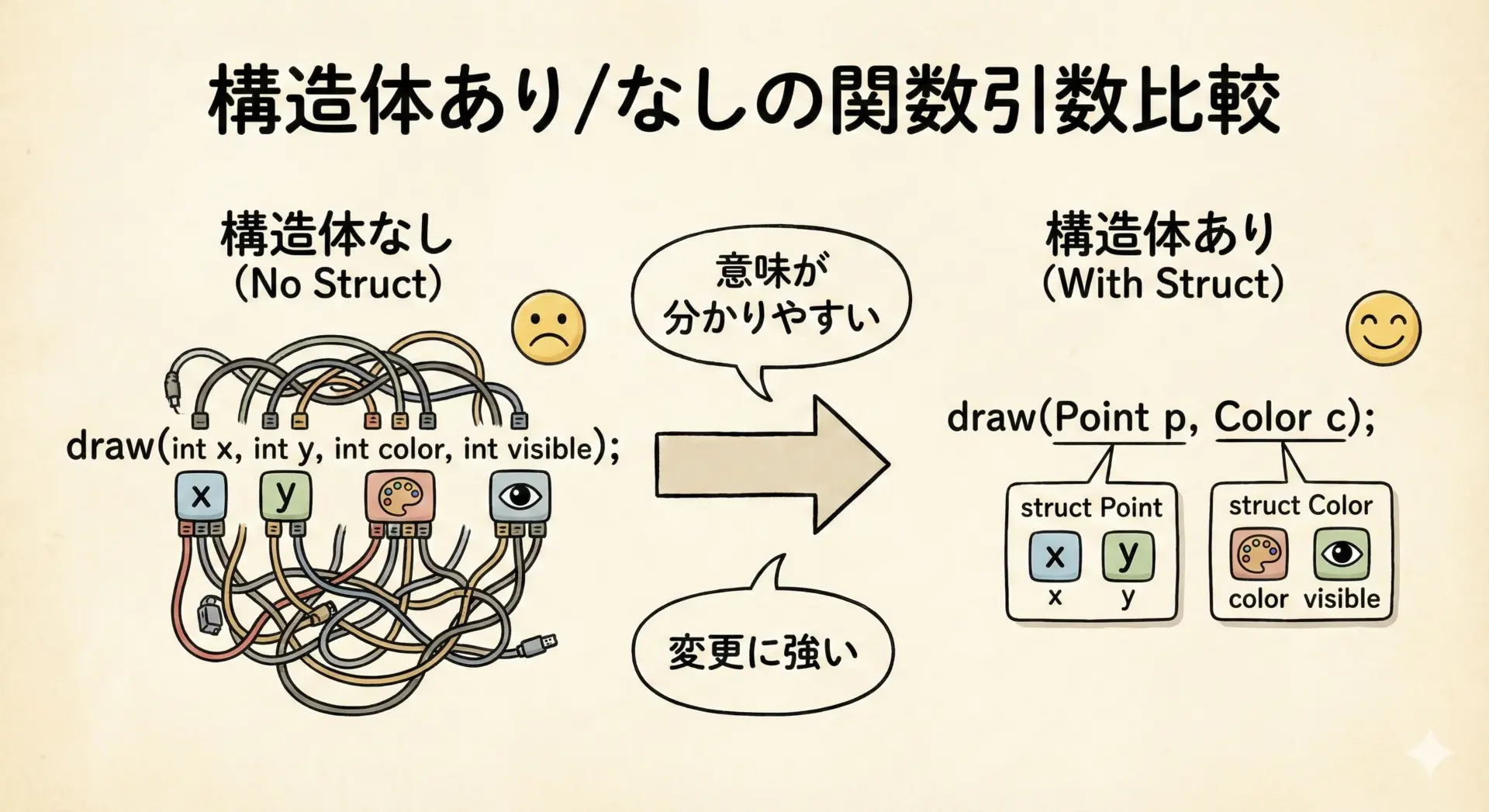
構造体を使うと、コードの保守性(読みやすさ・変更への強さ)が大きく向上します。
その理由を具体的に見てみます。
1. 引数の意味が明確になり、順番ミスを防げる
たとえば、社員情報を関数に渡したい場合、構造体を使わないと次のようになります。
void print_employee(int id, int age, double salary, const char *name);呼び出す側では、引数の順番を間違える危険があります。
構造体を使えば、次のようにまとめることができます。
// 社員情報の構造体
struct Employee {
int id;
int age;
double salary;
const char *name;
};
// Employee型を引数に取る関数
void print_employee(struct Employee e);このようにすれば、関数は「Employeeという意味のある1つのデータ」を受け取ることになり、引数の並びなどを気にする必要が減ります。
2. 情報追加・変更に強い
社員情報に部署名や入社年を追加したい場合、構造体を使っていれば構造体定義を変更するだけで、関数の引数リストの大きな変更を避けられます。
構造体なしの場合は、関数宣言も呼び出し元もすべて修正する必要がありますが、構造体なら構造体のメンバを増やせば、将来的な拡張にも自然に対応できます。
構造体の宣言と定義の書き方
structによる構造体タグとメンバの書き方
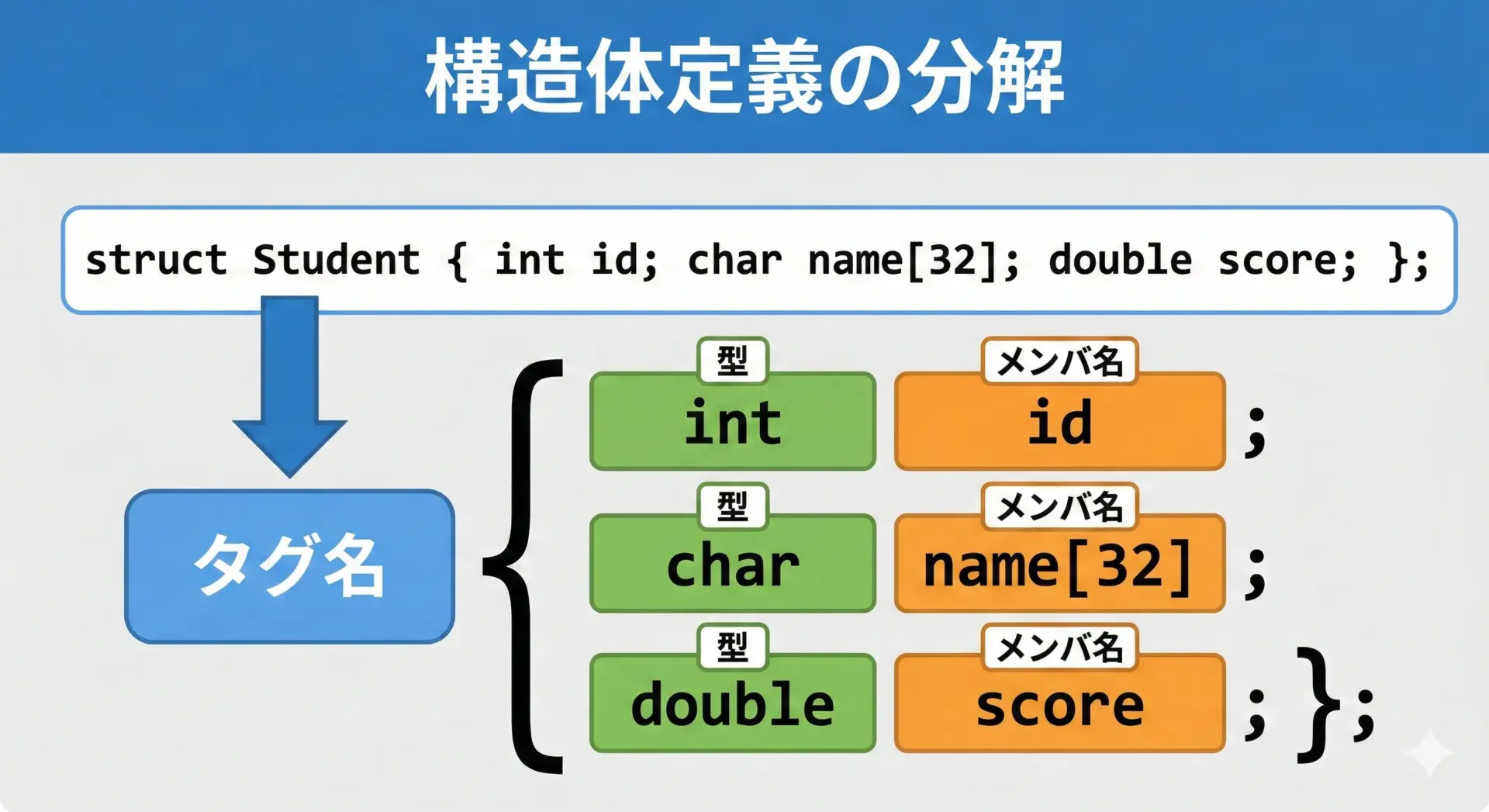
構造体を使うには、まず構造体型の定義を行います。
もっとも基本的な書き方は次のとおりです。
#include <stdio.h>
// 構造体の定義
struct Student {
int id; // 学籍番号
char name[32]; // 名前(文字列)
double score; // 点数
};
int main(void) {
// 構造体型 Student の変数 s1 を宣言
struct Student s1;
s1.id = 1;
s1.score = 92.5;
// 文字配列への代入には strcpy などを用いるのが一般的
// (ここでは説明の都合上、簡易的な代入方法は示さない)
printf("ID: %d, Score: %.1f\n", s1.id, s1.score);
return 0;
}ID: 1, Score: 92.5このうち、次の部分が構造体型の定義です。
struct Student {
int id;
char name[32];
double score;
};ここで押さえておきたいポイントは次の通りです。
- struct Student は「構造体タグ」と呼ばれる名前です。
- id, name, score が構造体のメンバです。
- 構造体定義の末尾には
;が必要です。
構造体を使うときは、struct Student s1; のように、必ずstructキーワード+タグ名で変数を宣言する必要があります(後述のtypedefを使わない場合)。
typedefを使った構造体の型定義
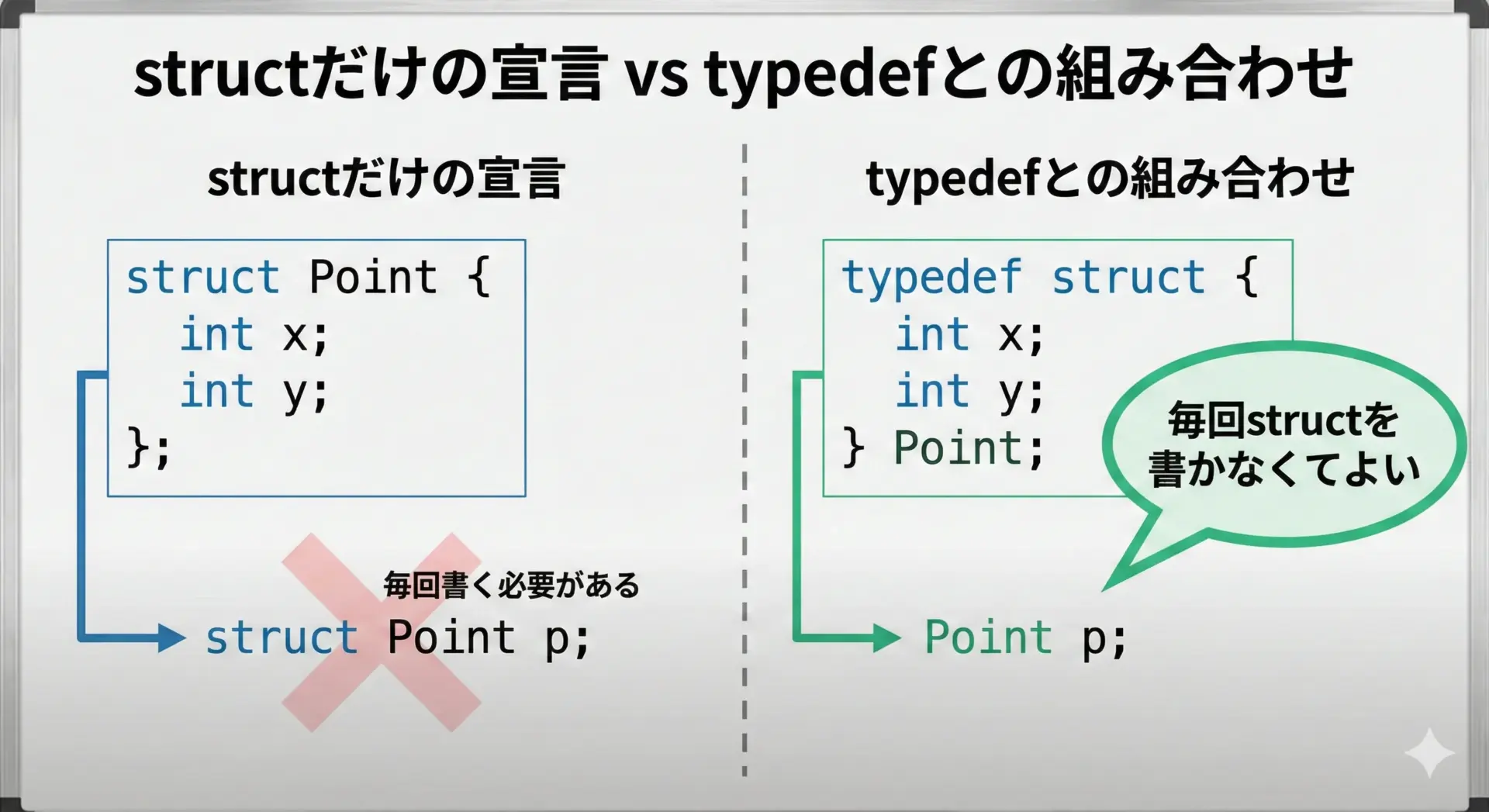
毎回struct Studentと書くのは少し長く感じるかもしれません。
その場合はtypedefを使って、構造体に別名の型名を付けるのが一般的です。
#include <stdio.h>
// typedef を用いた構造体の型定義
typedef struct {
int x; // x座標
int y; // y座標
} Point; // ここで Point という型名を定義
int main(void) {
// typedef によって struct を書かずに宣言できる
Point p1;
Point p2;
p1.x = 5;
p1.y = 10;
p2.x = -3;
p2.y = 7;
printf("p1 = (%d, %d)\n", p1.x, p1.y);
printf("p2 = (%d, %d)\n", p2.x, p2.y);
return 0;
}p1 = (5, 10)
p2 = (-3, 7)このようにtypedefを組み合わせると、構造体も通常の型(int や double など)と同じ感覚で扱えるようになります。
よく使われるパターンとして、タグ名とtypedef名を両方付ける書き方もあります。
// タグ名: struct Student
// 型名: Student
typedef struct Student {
int id;
char name[32];
double score;
} Student;この書き方を使うと、struct Studentというタグ名を構造体の再定義などに利用しつつ、Studentという短い型名で変数を宣言できます。
構造体とスコープ
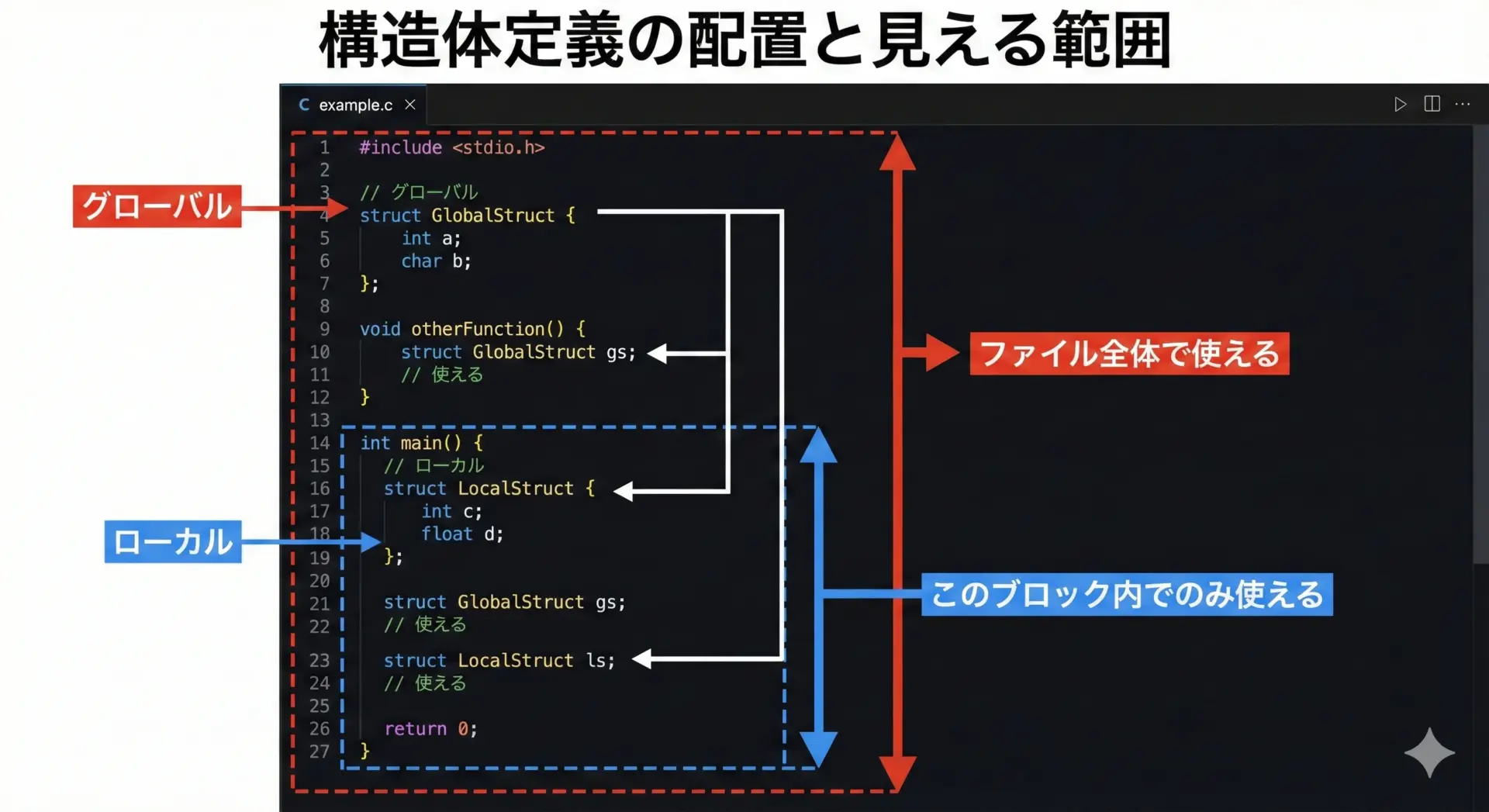
構造体の定義には、スコープ(有効範囲)があります。
どこに定義を書くかによって、使える範囲が変わります。
ファイル全体で使う構造体
プログラム全体で共通して使いたい構造体は、関数の外(グローバル領域)に定義します。
#include <stdio.h>
// ファイル全体から参照できる構造体定義
typedef struct {
int year;
int month;
int day;
} Date;
void print_date(Date d) {
printf("%04d-%02d-%02d\n", d.year, d.month, d.day);
}
int main(void) {
Date today = {2025, 12, 6};
print_date(today); // mainの外で定義した Date が使える
return 0;
}関数の中だけで使う構造体
一方、その関数の中だけで使えればよい一時的な構造体は、関数の中に定義しても構いません。
#include <stdio.h>
int main(void) {
// main関数の中だけで有効な構造体定義
struct LocalPoint {
int x;
int y;
};
struct LocalPoint p = {1, 2};
printf("(%d, %d)\n", p.x, p.y);
return 0;
}このstruct LocalPointはmain関数の外からは参照できません。
スコープの考え方は通常の変数と同じですが、構造体の定義自体にもスコープがあるという点を意識しておくとよいです。
構造体の初期化と代入の基本
構造体変数の宣言とメンバへの代入
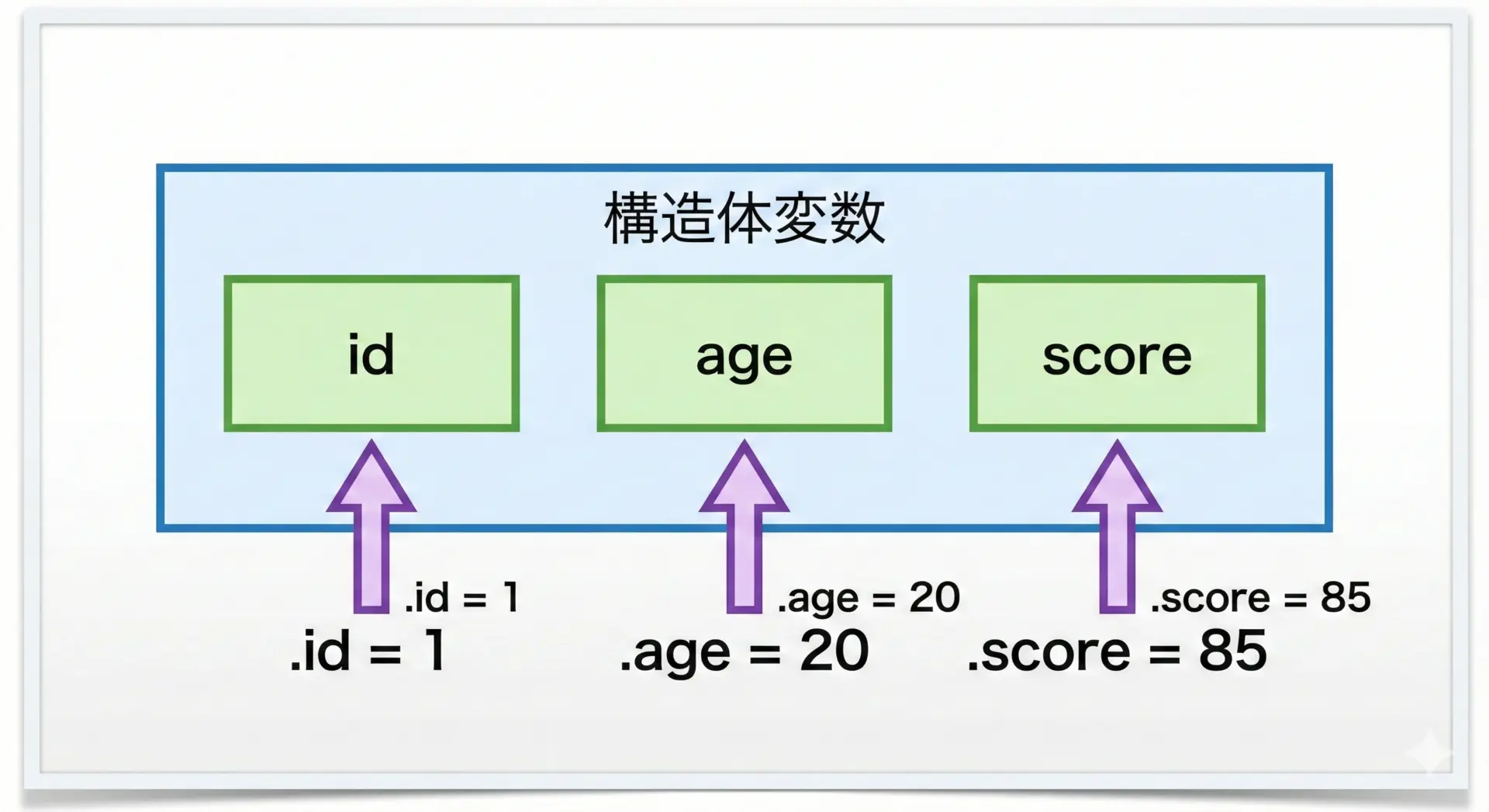
構造体型を定義したら、その型の変数を宣言し、メンバに値を代入していきます。
#include <stdio.h>
typedef struct {
int id;
int age;
double score;
} Student;
int main(void) {
Student s; // Student型の変数 s を宣言
// メンバへの代入
s.id = 1001;
s.age = 20;
s.score = 88.5;
printf("ID: %d\n", s.id);
printf("Age: %d\n", s.age);
printf("Score: %.1f\n", s.score);
return 0;
}ID: 1001
Age: 20
Score: 88.5ここで使っている.がメンバアクセス演算子(ドット演算子)です。
変数名.メンバ名という形で、構造体の中の各メンバにアクセスします。
構造体の初期化子(波括弧)の使い方
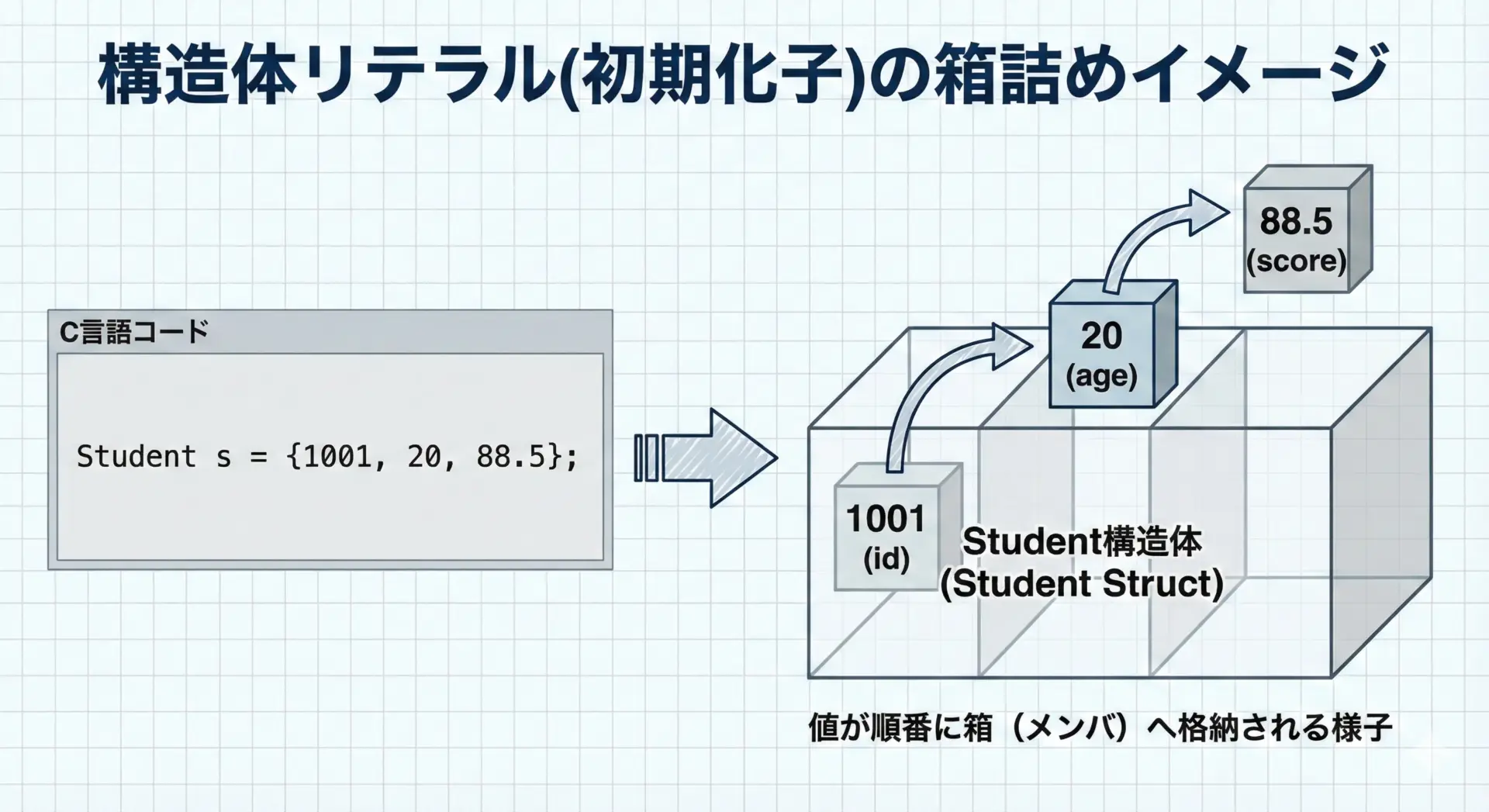
構造体変数は、宣言と同時に初期化子(波括弧 {…})を使って初期化できます。
#include <stdio.h>
typedef struct {
int id;
int age;
double score;
} Student;
int main(void) {
// 順番に従った初期化
Student s1 = {1001, 20, 88.5};
// メンバ名を明示する初期化(C99以降)
Student s2 = {
.id = 1002,
.score = 91.0,
.age = 19 // 順番は前後してもよい
};
printf("s1: id=%d age=%d score=%.1f\n", s1.id, s1.age, s1.score);
printf("s2: id=%d age=%d score=%.1f\n", s2.id, s2.age, s2.score);
return 0;
}s1: id=1001 age=20 score=88.5
s2: id=1002 age=19 score=91.0メンバ名を明示して初期化する方法は、代入忘れや順番間違いを防げるため、コードの安全性を高めるのに役立ちます。
メンバアクセス演算子(ドット演算子)の使い方
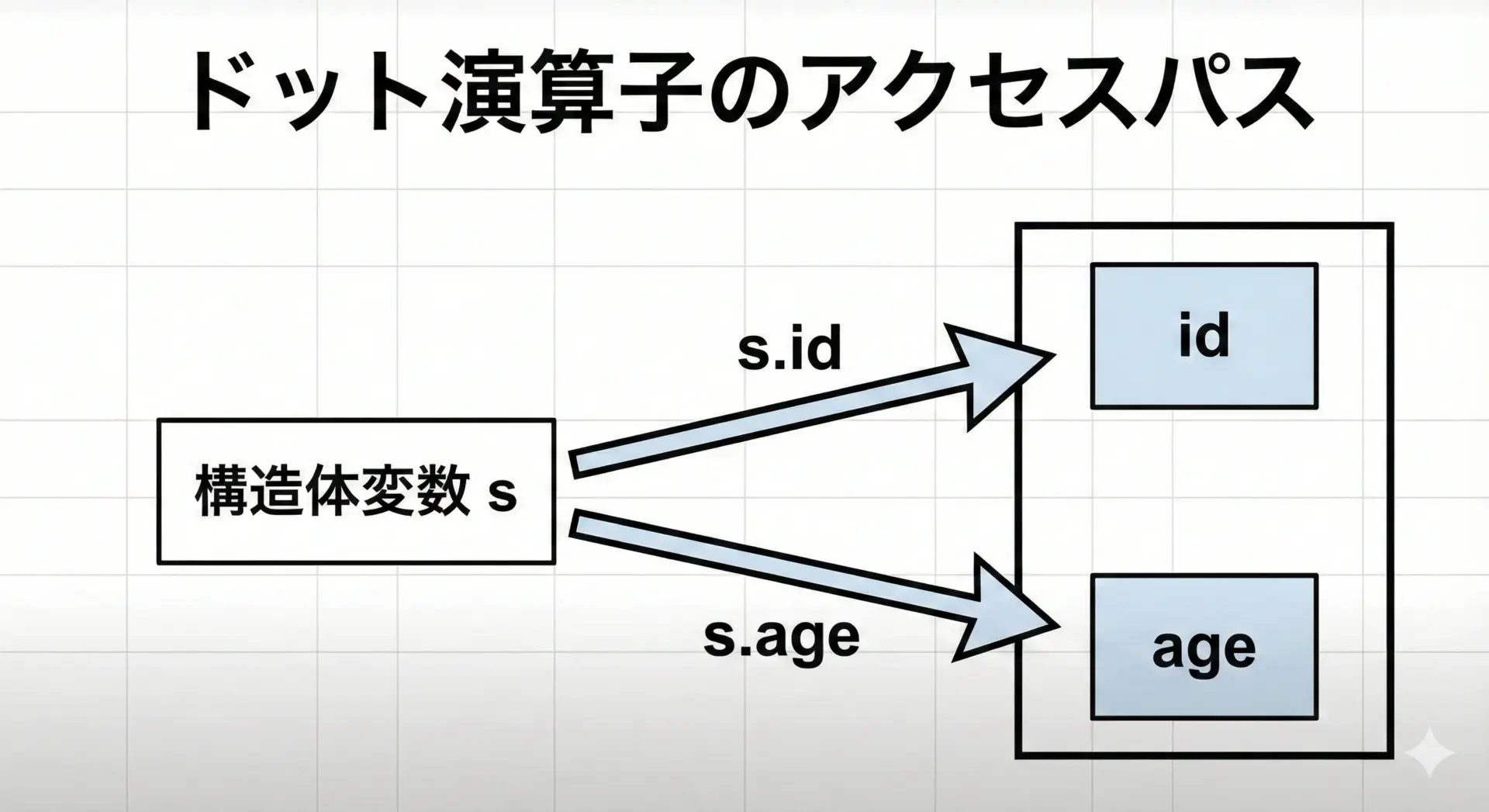
構造体変数からメンバにアクセスするには、ドット演算子.を使います。
#include <stdio.h>
typedef struct {
int id;
int age;
double score;
} Student;
int main(void) {
Student s = {1001, 21, 75.0};
// 読み取り
int id = s.id;
int age = s.age;
double sc = s.score;
// 書き込み
s.score = 80.0; // 点数を上書き
printf("id=%d age=%d score=%.1f\n", s.id, s.age, s.score);
return 0;
}id=1001 age=21 score=80.0構造体変数そのものが「塊」であり、ドット演算子でその中身の各メンバにアクセスする、というイメージを持つとわかりやすくなります。
構造体配列の宣言と初期化
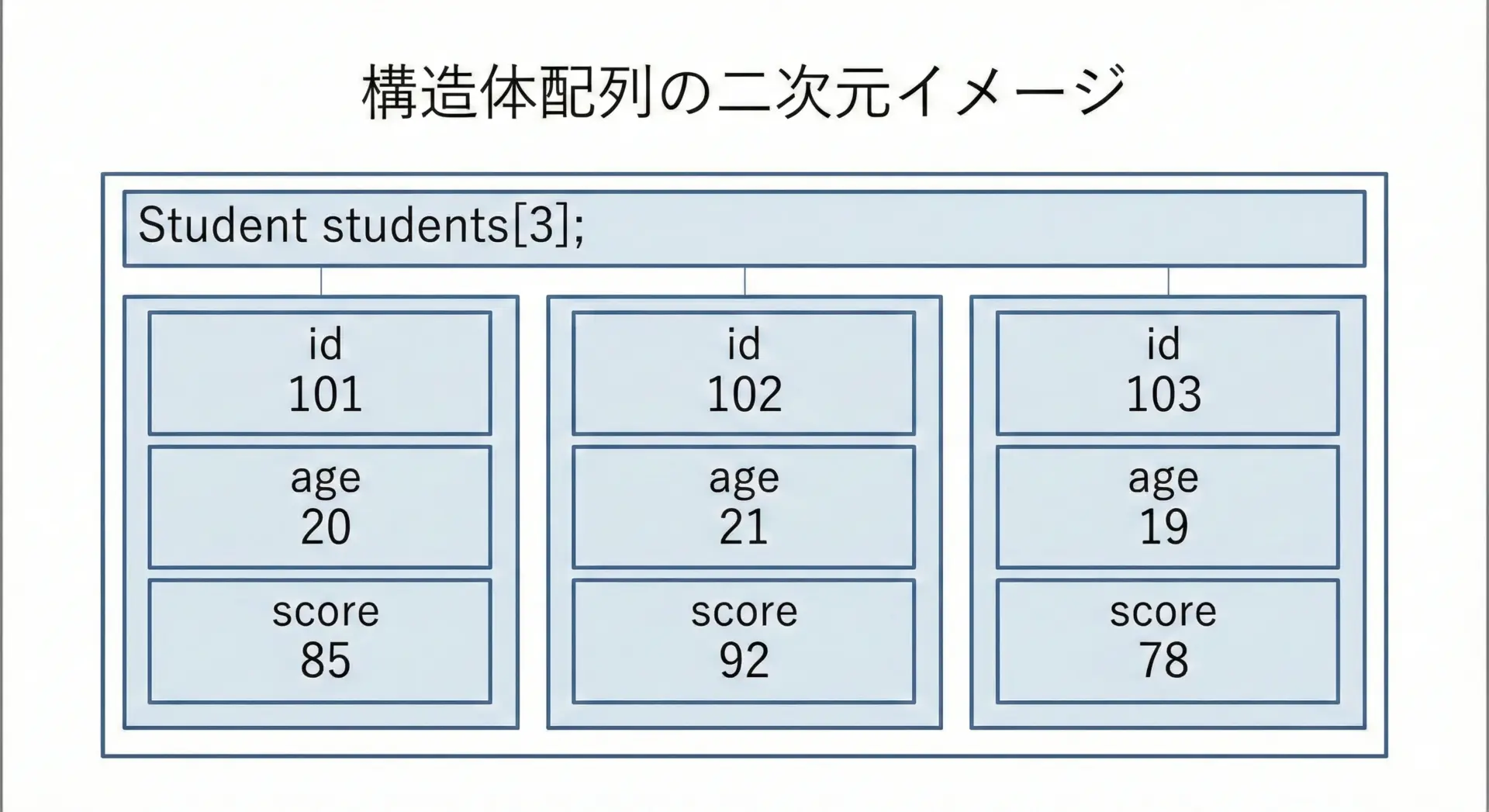
構造体は、通常の型と同様に配列として扱うこともできます。
多くの実用的なプログラムでは、構造体配列を使って「複数の社員」「複数の座標」などをまとめて扱います。
#include <stdio.h>
typedef struct {
int id;
int age;
double score;
} Student;
int main(void) {
// 構造体配列の宣言と初期化
Student students[] = {
{1001, 20, 85.0},
{1002, 19, 90.5},
{1003, 21, 78.0}
};
int size = (int)(sizeof(students) / sizeof(students[0]));
for (int i = 0; i < size; i++) {
printf("Student %d: id=%d age=%d score=%.1f\n",
i, students[i].id, students[i].age, students[i].score);
}
return 0;
}Student 0: id=1001 age=20 score=85.0
Student 1: id=1002 age=19 score=90.5
Student 2: id=1003 age=21 score=78.0ここではstudents[i].idのように、配列の要素を取り出した後にドット演算子でメンバにアクセスしています。
このパターンは非常によく登場するので、しっかり慣れておきましょう。
構造体ポインタとアロー演算子の使い方
構造体ポインタの宣言とアドレス演算子
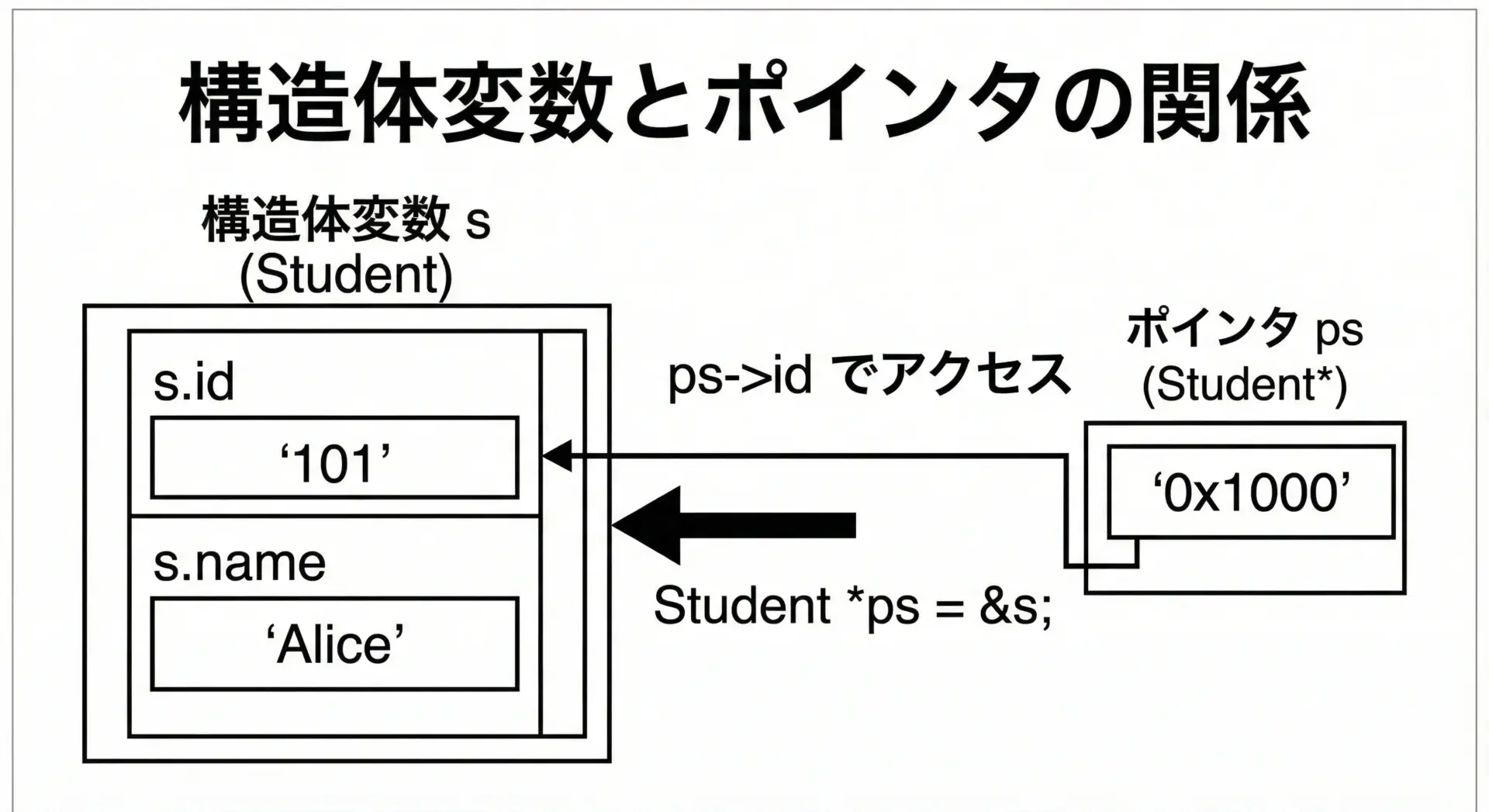
構造体も他の型と同じようにポインタを扱うことができます。
ポインタを使うと、関数間で構造体を共有したり、動的メモリ確保と組み合わせたりできます。
#include <stdio.h>
typedef struct {
int x;
int y;
} Point;
int main(void) {
Point p = {10, 20};
// Point型へのポインタ
Point *pp; // ポインタ変数の宣言
pp = &p; // p のアドレスを代入
// ポインタ経由でメンバにアクセス(いったんデリファレンスしてからドット)
(*pp).x = 30; // p.x に代入される
(*pp).y = 40; // p.y に代入される
printf("p = (%d, %d)\n", p.x, p.y);
return 0;
}p = (30, 40)ここで使っている&pがアドレス演算子で、構造体変数pのアドレス(場所)を表しています。
ポインタppは、そのアドレスを保持する変数です。
なお、(*pp).xのような書き方はやや読みづらいため、C言語では専用のアロー演算子->が用意されています。
これについては次の節で詳しく説明します。
アロー演算子(->)とドット演算子の違い
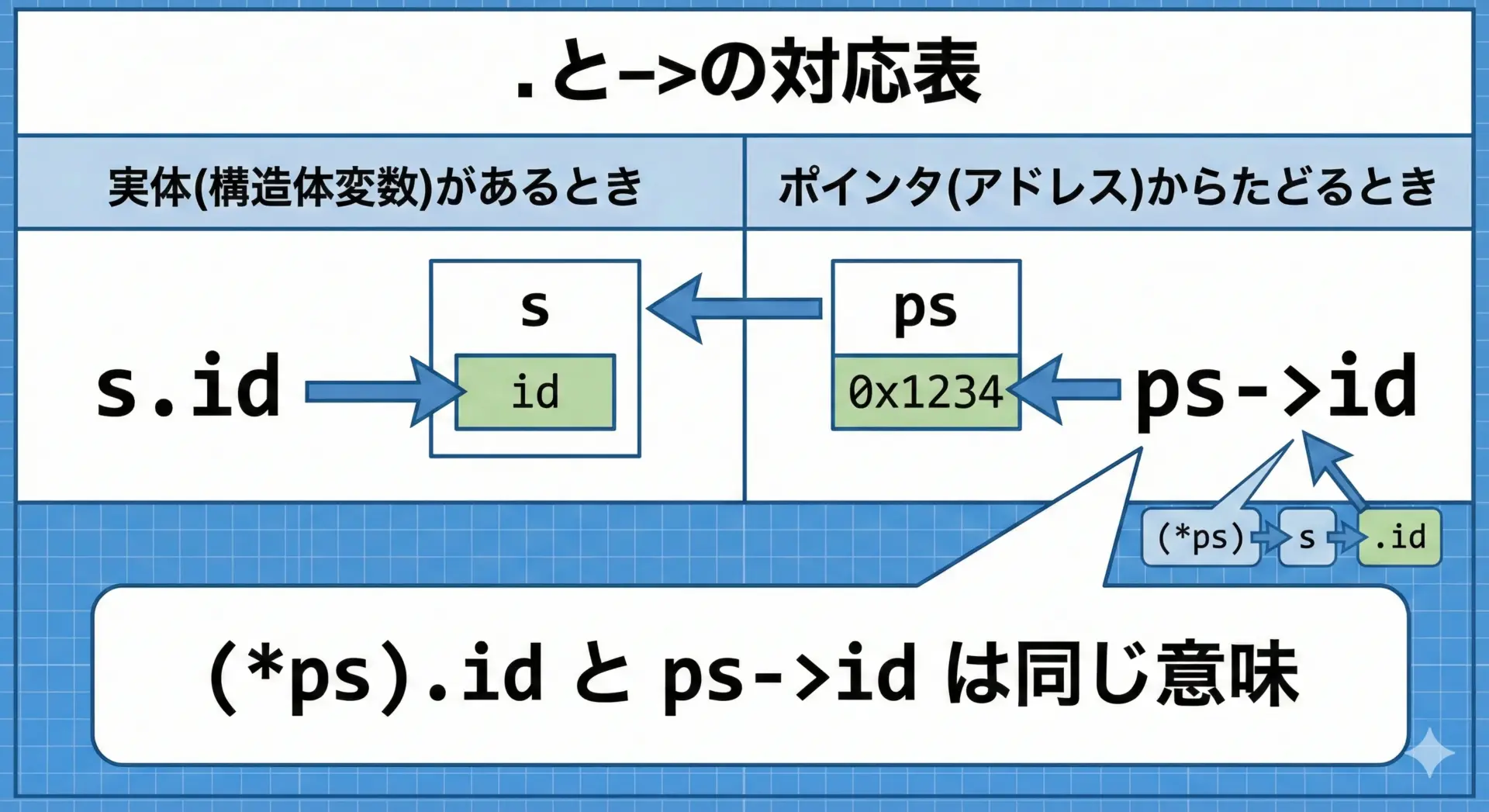
構造体ポインタからメンバにアクセスするときによく使われるのが、アロー演算子->です。
#include <stdio.h>
typedef struct {
int x;
int y;
} Point;
int main(void) {
Point p = {10, 20};
Point *pp = &p; // p へのポインタ
// ドット演算子: 構造体変数からメンバへ
printf("p.x = %d\n", p.x);
// アロー演算子: ポインタからメンバへ
printf("pp->x = %d\n", pp->x);
// (*pp).x と pp->x は同じ意味
(*pp).x = 100;
pp->y = 200;
printf("p = (%d, %d)\n", p.x, p.y);
return 0;
}p.x = 10
pp->x = 10
p = (100, 200)「実体(構造体変数)にはドット.」「ポインタにはアロー->」と覚えると整理しやすくなります。
関数に構造体を渡す方法
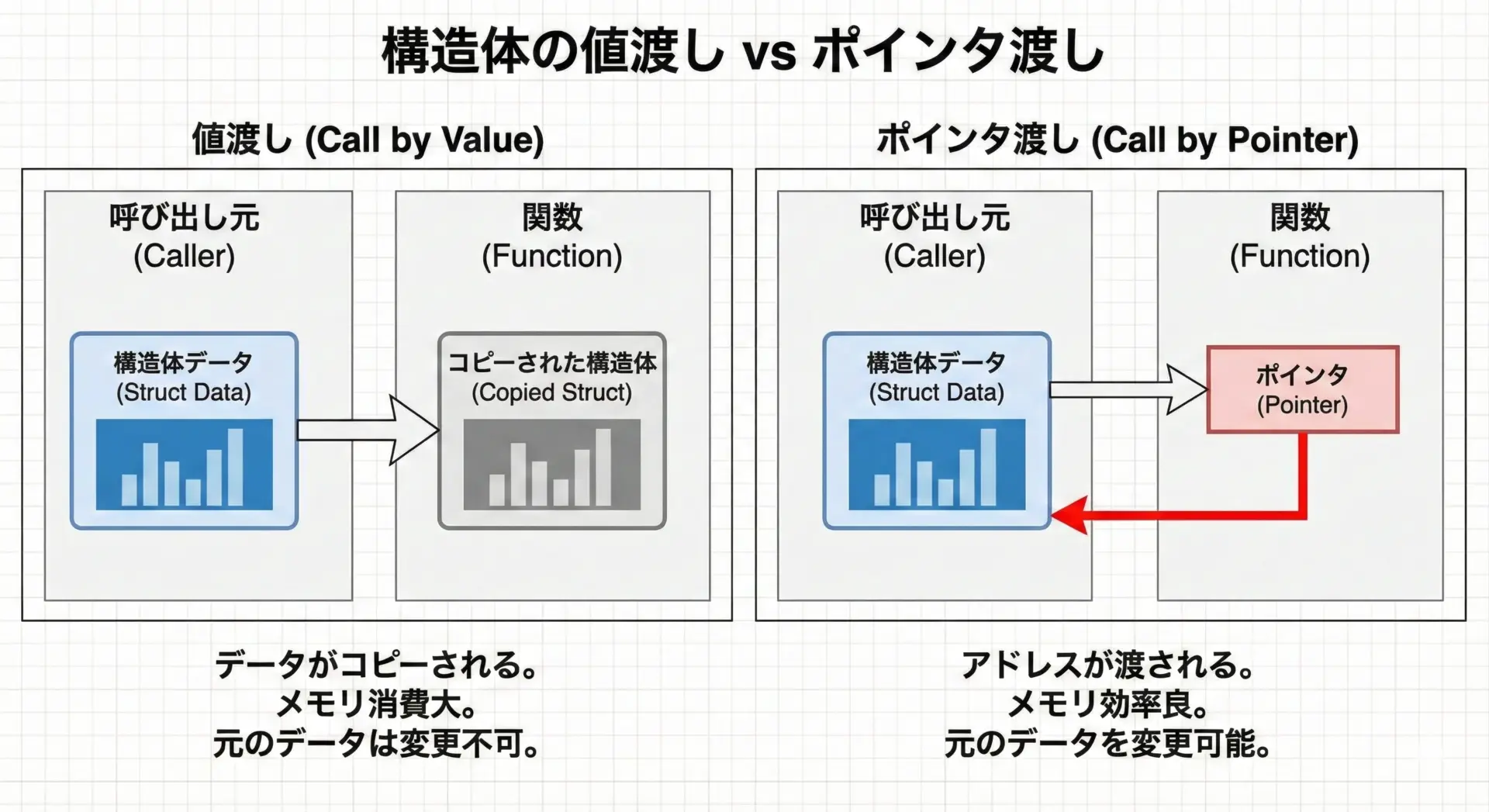
関数に構造体を渡す方法には、大きく2つあります。
- 値渡し…構造体をそのまま引数に渡す方法
- ポインタ渡し…構造体へのポインタを渡す方法
1. 構造体を値渡しする
構造体をそのまま関数に渡すと、構造体全体がコピーされます。
#include <stdio.h>
typedef struct {
int x;
int y;
} Point;
// 値渡し: 引数 p は呼び出し元のコピー
void print_point(Point p) {
printf("Point: (%d, %d)\n", p.x, p.y);
}
int main(void) {
Point p = {10, 20};
print_point(p); // p がコピーされて渡される
return 0;
}Point: (10, 20)この場合、関数内でp.xを書き換えても、呼び出し元のpには影響しません。
2. 構造体ポインタを渡す
構造体の内容を関数内で変更したい場合、またはサイズの大きな構造体を効率よく渡したい場合は、ポインタ渡しを使います。
#include <stdio.h>
typedef struct {
int x;
int y;
} Point;
// ポインタ渡し: 関数内から元のPointを書き換えられる
void move_point(Point *p, int dx, int dy) {
// p->x, p->y は呼び出し元の変数を指している
p->x += dx;
p->y += dy;
}
int main(void) {
Point p = {0, 0};
move_point(&p, 5, 3); // &p でアドレスを渡す
printf("After move: (%d, %d)\n", p.x, p.y);
return 0;
}After move: (5, 3)このように「関数側で元の構造体を更新したいときはポインタ渡し」というのが定石です。
構造体と動的メモリ確保(malloc)の基本使用例
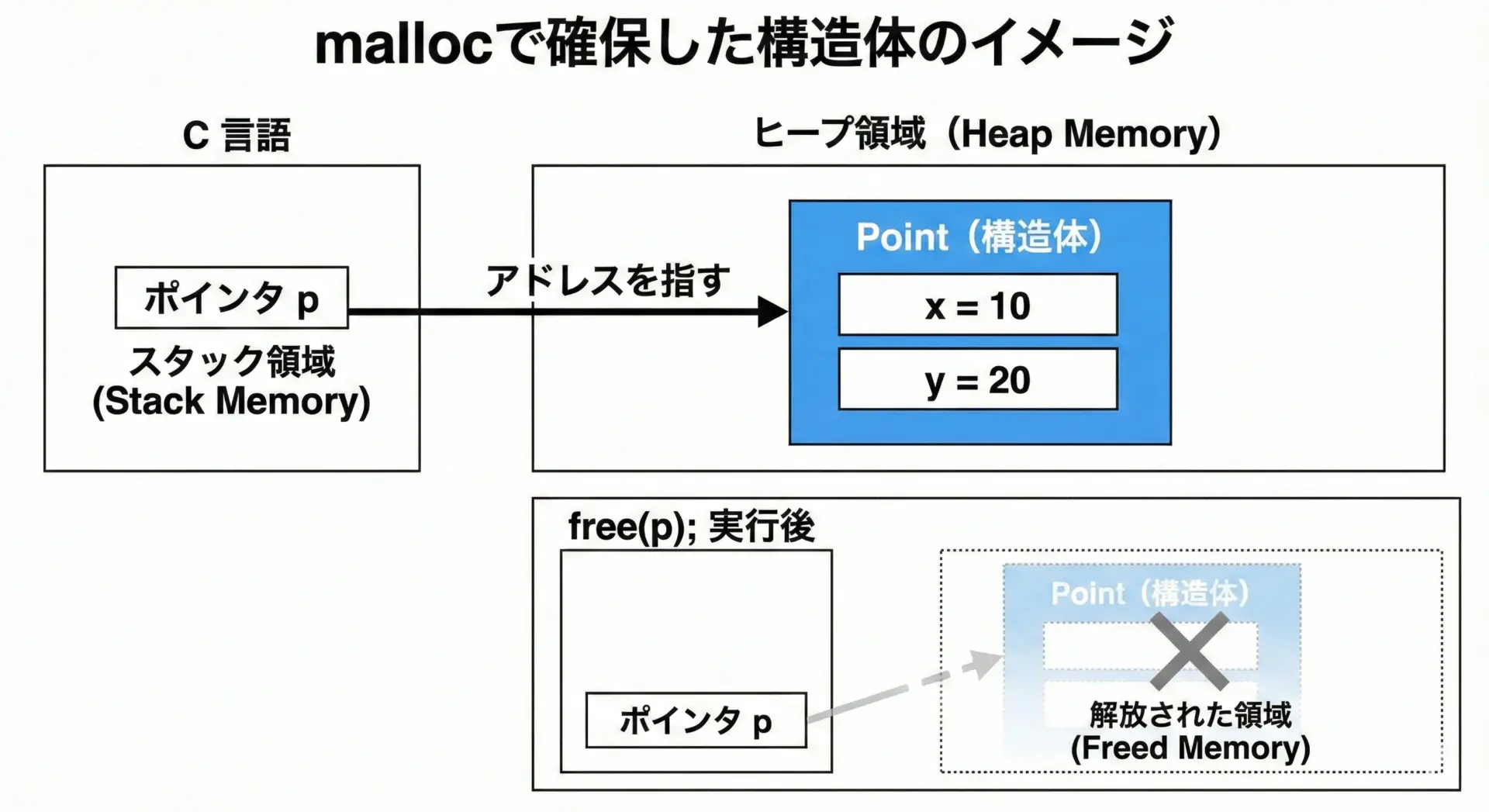
構造体はmallocを使って動的にメモリを確保することもできます。
動的確保を使うと、必要な数だけ構造体を作ったり、実行時にサイズが決まるデータ構造を扱えるようになります。
#include <stdio.h>
#include <stdlib.h> // malloc, free を使うために必要
typedef struct {
int x;
int y;
} Point;
int main(void) {
// Point型1個分のメモリを動的に確保
Point *p = (Point *)malloc(sizeof(Point));
if (p == NULL) {
// メモリ確保に失敗した場合のチェック
fprintf(stderr, "メモリの確保に失敗しました。\n");
return 1;
}
// アロー演算子でメンバにアクセス
p->x = 100;
p->y = 200;
printf("Dynamic point: (%d, %d)\n", p->x, p->y);
// 使い終わったら必ず解放する
free(p);
return 0;
}Dynamic point: (100, 200)ここで重要なのは、mallocで確保したメモリはfreeで解放しなければならないという点です。
特に構造体を多数動的に確保するような場面では、解放忘れがメモリリークの原因になります。
また、構造体配列を動的に確保することもできます。
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int id;
double score;
} Student;
int main(void) {
int n = 3;
// Student構造体をn個分まとめて確保
Student *students = (Student *)malloc(sizeof(Student) * n);
if (students == NULL) {
fprintf(stderr, "メモリの確保に失敗しました。\n");
return 1;
}
// アロー演算子と配列を組み合わせてアクセス
for (int i = 0; i < n; i++) {
students[i].id = 1000 + i;
students[i].score = 80.0 + i;
}
for (int i = 0; i < n; i++) {
printf("Student %d: id=%d score=%.1f\n",
i, students[i].id, students[i].score);
}
// 確保した配列を解放
free(students);
return 0;
}Student 0: id=1000 score=80.0
Student 1: id=1001 score=81.0
Student 2: id=1002 score=82.0このように構造体+ポインタ+mallocを組み合わせることで、実用的なデータ構造を柔軟に扱えるようになります。
まとめ
構造体は、C言語で意味のある「ひとかたまりのデータ型」を自分で作るための基本機能です。
配列や列挙体との違いを押さえつつ、structによる定義、typedefによる型名付け、初期化子やドット演算子によるメンバ操作を理解すると、コードがぐっと読みやすくなります。
さらに、構造体ポインタとアロー演算子、関数への値渡しとポインタ渡し、mallocによる動的確保まで使いこなせれば、実用的なプログラムの多くを自然に表現できるようになります。
この記事のサンプルを手元で動かしながら、自分の用途に合った構造体設計を試してみてください。
