
C言語での大文字小文字変換は、単にtoupperやtolowerを呼び出すだけでなく、ASCIIコードの仕組みやマルチバイト文字の扱いを理解しておくと、バグを避けつつ短くて読みやすいコードを書けます。
本記事では、C言語での大文字小文字変換の基本から最短テクニック、実践的な応用までを、サンプルコードと図解でまとめて解説します。
C言語の大文字小文字変換の基本
C言語での大文字小文字変換とASCIIコードの関係
ASCIIコードでは、英字の大文字と小文字のコード値には一定の差分があります。
これが、C言語での大文字小文字変換ロジックをシンプルにしてくれる重要なポイントです。
まず、代表的な文字のASCIIコードを確認します。
| 文字 | 種別 | 10進数コード | 16進数コード |
|---|---|---|---|
| A | 大文字 | 65 | 0x41 |
| Z | 大文字 | 90 | 0x5A |
| a | 小文字 | 97 | 0x61 |
| z | 小文字 | 122 | 0x7A |
上の表から、次の関係が成り立ちます。
- A(65) と a(97) の差は 32
- Z(90) と z(122) の差も 32
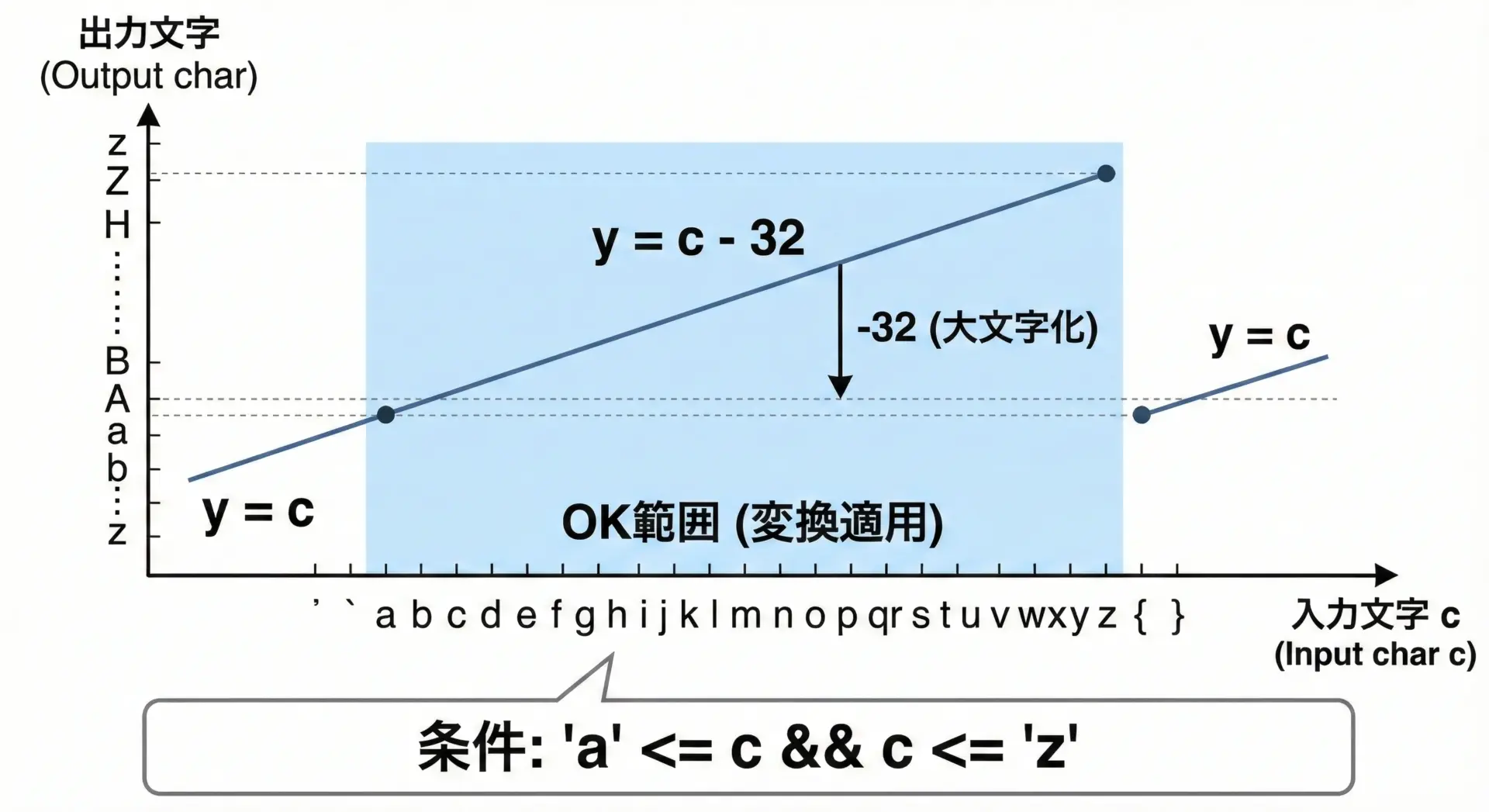
つまり、英字の大文字と小文字はASCIIコード上で「32(0x20)だけ離れている」という規則性があります。
この性質から、英字に限定すれば次のような変換が可能です。
- 大文字を小文字へ: その文字コードに 32 を足す
- 小文字を大文字へ: その文字コードから 32 を引く
ただし、この方法が安全に使えるのはASCII英字(a〜z, A〜Z)に限定される点に注意が必要です。
日本語などのマルチバイト文字や、ロケール依存の特殊文字では使えません。
tolower・toupper関数の基本的な使い方
C言語標準ライブラリには、ctype.hで提供されるtolowerとtoupperが用意されています。
これらは単一の文字を1つだけ変換する関数です。
関数の宣言
#include <ctype.h>
int tolower(int c);
int toupper(int c);どちらの関数も、引数cにunsigned charに変換可能な値、またはEOFを渡す必要があります。
戻り値はint型で、変換後の文字コードが返されます。
基本的な使用例
#include <stdio.h>
#include <ctype.h>
int main(void) {
char ch1 = 'A';
char ch2 = 'b';
// toupperで大文字に変換
char upper = (char)toupper((unsigned char)ch2); // 'b' -> 'B'
// tolowerで小文字に変換
char lower = (char)tolower((unsigned char)ch1); // 'A' -> 'a'
printf("ch1 = %c, tolower(ch1) = %c\n", ch1, lower);
printf("ch2 = %c, toupper(ch2) = %c\n", ch2, upper);
return 0;
}ch1 = A, tolower(ch1) = a
ch2 = b, toupper(ch2) = Bここではキャストの順番が重要です。
必ず(unsigned char)にキャストしてからtoupper/tolowerに渡すことが推奨されます。
この理由は後述のctype.hの注意点で説明します。
ctype.hを使うメリットと注意点
ctype.hには、tolower/toupper以外にもさまざまな文字判定・変換関数が定義されています。
代表的なものを簡単に整理します。
| 関数名 | 役割 |
|---|---|
isalpha | 英字かどうか判定 |
isdigit | 数字かどうか判定 |
isalnum | 英数字かどうか判定 |
isspace | 空白文字かどうか判定 |
tolower | 小文字に変換 |
toupper | 大文字に変換 |
メリット
もっとも大きなメリットは、ロケールに応じた変換や判定を行ってくれる可能性があることです。
ASCII前提の自前実装とは違い、環境に応じて正しい挙動をしてくれる場合があります。
また、isalphaなどと組み合わせることで、コードの可読性を高めることもできます。
注意点1: 引数はunsigned charに変換可能な値を渡す
ctype.hの関数は未定義動作に厳しく、負の値(EOF除く)を渡すと未定義動作になります。
これは日本語などを扱うときにハマりがちなポイントです。
安全な呼び出し方の例です。
#include <ctype.h>
char safe_to_upper(char ch) {
// chをunsigned charに変換してからtoupperに渡す
return (char)toupper((unsigned char)ch);
}注意点2: マルチバイト文字は1文字ずつ正しく扱えない
char単位での変換なので、UTF-8やShift_JISのようなマルチバイト文字列に対しては、日本語1文字を分割してしまい、正しく扱えません。
後述の「日本語を含む文字列での注意点」で詳しく触れますが、ctype.hは基本的に「バイト列としての英字」だけを見るものだと理解しておくと安全です。
最短で書ける大文字小文字変換テクニック
ここからは、できるだけ短く、かつ読みやすさもある大文字小文字変換のテクニックを紹介します。
いずれもASCII英字専用である点を理解した上で使うことが重要です。
if文を使わないシンプルな大文字変換ロジック
通常、大文字変換は次のようにif文で書かれます。
char to_upper_if(char c) {
if ('a' <= c && c <= 'z') {
c = c - ('a' - 'A'); // または c -= 32;
}
return c;
}これを、見た目のif文なしで書くこともできます。
ここではビット演算を用いたテクニックを紹介します。
ビット演算を使った大文字変換
ASCII英字の小文字は、文字コードのビット構造上第5ビット(0x20)が1になっています。
大文字はこのビットが0です。
したがって、0x20ビットを強制的に0にすることで大文字に変換できます。
#include <stdio.h>
char to_upper_bit(char c) {
// 'a'〜'z'のときだけ変換する安全版
if ('a' <= c && c <= 'z') {
// 0x20ビットを落とす(ANDでマスク)
c &= ~0x20;
}
return c;
}
int main(void) {
char a = 'a';
char z = 'z';
char ex = '!';
printf("%c -> %c\n", a, to_upper_bit(a));
printf("%c -> %c\n", z, to_upper_bit(z));
printf("%c -> %c\n", ex, to_upper_bit(ex)); // 変わらない
return 0;
}a -> A
z -> Z
! -> !本当にif文を1行も書かない形にしたい場合、ややトリッキーですが次のような書き方もあります。
char to_upper_no_if(char c) {
// 条件式が真なら1、偽なら0になることを利用してマスクを作る
unsigned char is_lower = (unsigned char)('a' <= c && c <= 'z');
// is_lowerが1のときだけ 0x20ビットを落とす
// is_lowerは0か1なので、-is_lowerは0か0xFF(全ビット1)になる
c &= (char)~(is_lower * 0x20);
return c;
}ただし、この種のコードは読みやすさを大きく損なう可能性があります。
「最短で書ける」ことより「後から読んで理解できること」を優先した方が実用面では有利です。
三項演算子で書くコンパクトな小文字変換
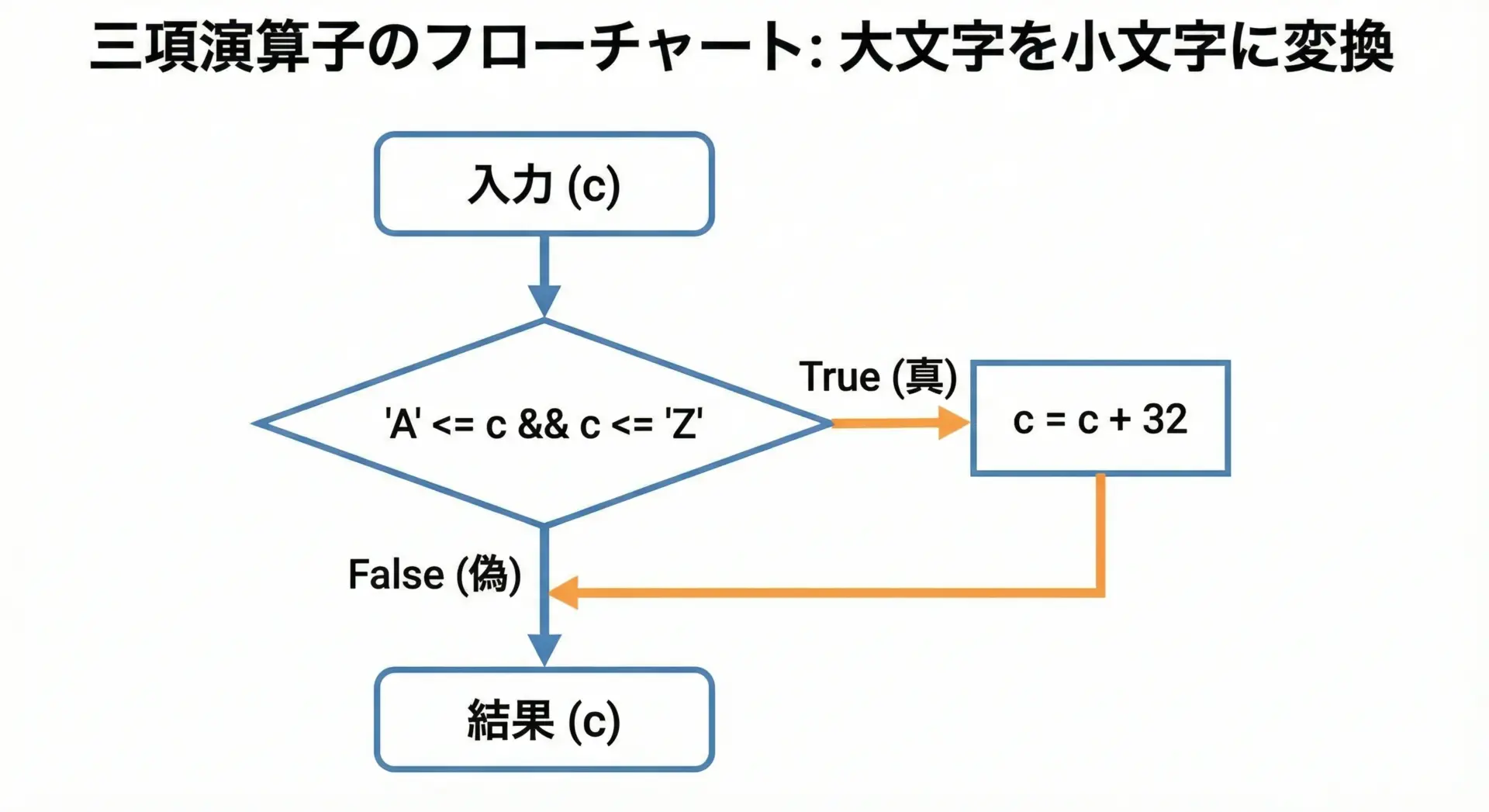
三項演算子?:を使えば、if文よりも行数を抑えつつ、条件分岐を表現できます。
#include <stdio.h>
char to_lower_ternary(char c) {
// 'A'〜'Z'なら32を足して小文字に、それ以外はそのまま返す
return ('A' <= c && c <= 'Z') ? (char)(c + ('a' - 'A')) : c;
}
int main(void) {
printf("%c\n", to_lower_ternary('A')); // a
printf("%c\n", to_lower_ternary('Z')); // z
printf("%c\n", to_lower_ternary('!')); // !
return 0;
}a
z
!この書き方は、「1行で条件付き変換を書きたい」ときに有効です。
ただし、条件式が長くなりすぎないように注意し、可読性とバランスをとることが大切です。
マクロを使った最短大文字小文字変換

マクロを使うと、関数呼び出しのオーバーヘッドなしで変換ロジックを埋め込むことができます。
短いコードで書くことも可能です。
大文字変換マクロ
#include <stdio.h>
#define TO_UPPER(c) \
( ((c) >= 'a' && (c) <= 'z') ? (char)((c) - ('a' - 'A')) : (c) )
#define TO_LOWER(c) \
( ((c) >= 'A' && (c) <= 'Z') ? (char)((c) + ('a' - 'A')) : (c) )
int main(void) {
char s[] = "AbC!zZ";
for (int i = 0; s[i] != '\0'; i++) {
char u = TO_UPPER(s[i]);
char l = TO_LOWER(s[i]);
printf("src:%c upper:%c lower:%c\n", s[i], u, l);
}
return 0;
}src:A upper:A lower:a
src:b upper:B lower:b
src:C upper:C lower:c
src:! upper:! lower:!
src:z upper:Z lower:z
src:Z upper:Z lower:zマクロを使う際の注意点として、引数cが副作用を持つ式、例えばs[i++]のような式を渡すと、マクロ展開によってi++が複数回評価される危険があります。
そのため、マクロには「単純な変数」や「配列要素の参照」だけを渡すのが安全です。
文字列全体の大文字小文字変換実装
ここまでのテクニックは1文字単位でしたが、実用上は文字列全体を変換したい場面が多くあります。
この章では、char配列とポインタを使った実装や、日本語を含む場合の注意点を解説します。
char配列とポインタで書く大文字変換関数
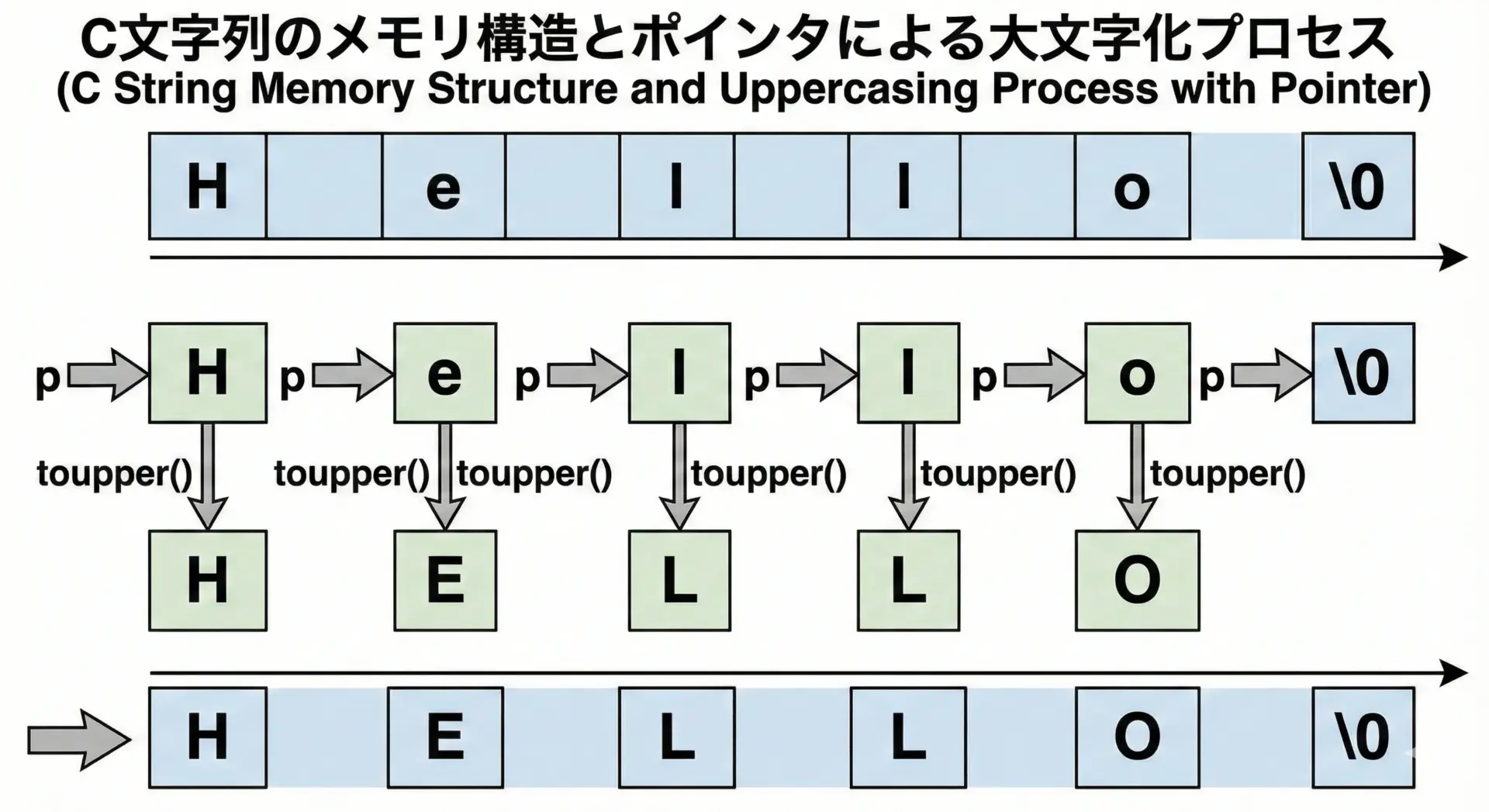
インデックスを使う実装
まずはforループとインデックスで書く素直な方法です。
#include <stdio.h>
#include <ctype.h>
// 文字列sをインプレースで大文字に変換する関数
void str_to_upper_index(char *s) {
if (s == NULL) {
return;
}
for (int i = 0; s[i] != '\0'; i++) {
// unsigned charにキャストしてからtoupperに渡すのが安全
s[i] = (char)toupper((unsigned char)s[i]);
}
}
int main(void) {
char str[] = "Abc123!xyz";
str_to_upper_index(str);
printf("UPPER: %s\n", str);
return 0;
}UPPER: ABC123!XYZポインタを使う実装(最短寄り)
同じ処理をポインタで書くと、よりC言語らしく、場合によっては短いコードになりやすいです。
#include <stdio.h>
#include <ctype.h>
// ポインタで文字列を走査しながら大文字に変換する関数
void str_to_upper_ptr(char *s) {
if (s == NULL) {
return;
}
for (unsigned char *p = (unsigned char *)s; *p != '\0'; p++) {
// pはunsigned char*なので、そのままtoupperに渡してOK
*p = (unsigned char)toupper(*p);
}
}
int main(void) {
char str[] = "Hello, World!";
str_to_upper_ptr(str);
printf("UPPER: %s\n", str);
return 0;
}UPPER: HELLO, WORLD!コツはループ変数をunsigned char*にしてしまうことです。
こうすることで、毎回(unsigned char)にキャストする手間を省けます。
小文字変換関数を最短コードで実装するコツ
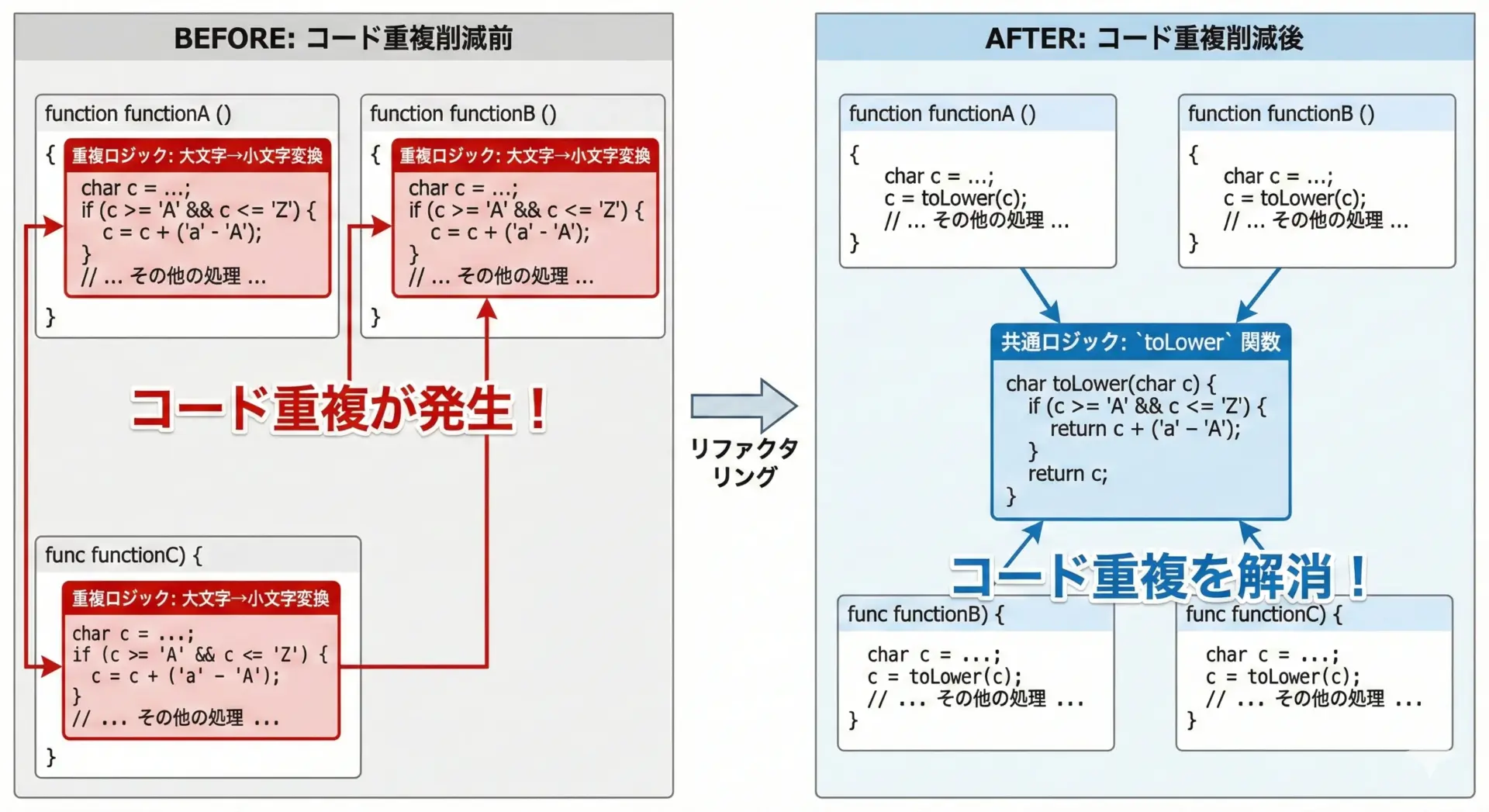
「最短コード」を目指すときでも、ロジックの重複を避けることが重要です。
先ほどのstr_to_upper_ptrと対になる小文字変換は、ほぼ同じ書き方で実装できます。
#include <stdio.h>
#include <ctype.h>
// 文字列をインプレースで小文字に変換
void str_to_lower_ptr(char *s) {
if (s == NULL) {
return;
}
for (unsigned char *p = (unsigned char *)s; *p; p++) {
*p = (unsigned char)tolower(*p);
}
}
int main(void) {
char str[] = "Hello, World!";
str_to_lower_ptr(str);
printf("lower: %s\n", str);
return 0;
}lower: hello, world!ここではfor文の条件を*pのみにして、文字列終端'\0'まで進むというCスタイルの書き方にしています。
さらにコードをまとめたい場合、toupper/tolowerのどちらを使うかをint (*func)(int)という関数ポインタで渡す方法もあります。
#include <stdio.h>
#include <ctype.h>
// 共通の変換関数: convにtoupperまたはtolowerを渡す
void str_convert(char *s, int (*conv)(int)) {
if (s == NULL || conv == NULL) {
return;
}
for (unsigned char *p = (unsigned char *)s; *p; p++) {
*p = (unsigned char)conv(*p);
}
}
int main(void) {
char str1[] = "AbC123";
char str2[] = "AbC123";
str_convert(str1, toupper);
str_convert(str2, tolower);
printf("UPPER: %s\n", str1);
printf("lower: %s\n", str2);
return 0;
}UPPER: ABC123
lower: abc123関数ポインタを使うと、大文字変換と小文字変換でコードを共有できるため、保守性が高くなります。
日本語を含む文字列での注意点と限界
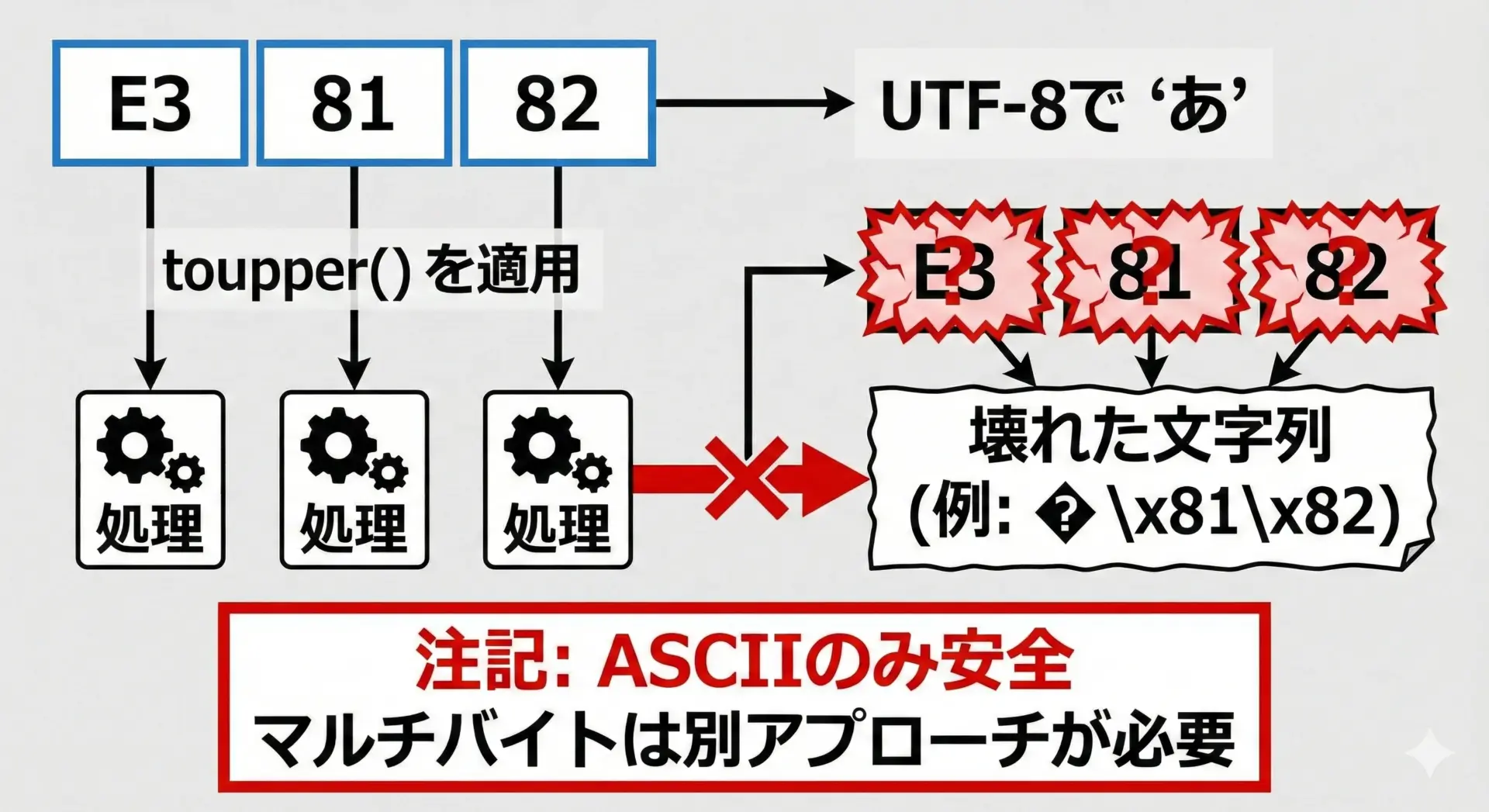
もっとも重要な注意点は、C言語標準のchar単位の処理では、日本語などのマルチバイト文字を正しく扱えないという事実です。
UTF-8やShift_JISでは、日本語1文字が複数バイトで表現されます。
英字の部分だけを変換したいつもりでも、文字列全体に対して機械的にtoupper/tolowerを適用すると、マルチバイト文字の中間バイトに誤って手を出してしまい、文字化けを引き起こします。
日本語を含む文字列で安全に大文字小文字変換を行うには、次のような方針をとる必要があります。
- 文字コードごとのマルチバイトAPIを使う(例: Windowsの
CharUpperBuffWなど) - C標準ライブラリの
wchar_tとワイド文字関数(例:towupper)を使う - そもそもC単体ではなく、ICUなどの外部ライブラリを使う
本記事の範囲では、ASCII英字に限定した変換テクニックを扱っていることを意識しておいてください。
実践的な大文字小文字変換の応用
ここからは、大文字小文字変換を応用した実践的なテクニックを紹介します。
特に、大文字小文字を無視した文字列比較はよく使われるパターンです。
大文字小文字を無視した文字列比較

C標準ライブラリには大文字小文字を無視して比較するstrcmp互換関数は含まれていません(Windowsなど一部環境には_stricmpなどがあります)。
ポータブルに実装するには、自前で比較関数を書きます。
逐文字でtolowerして比較する実装
#include <stdio.h>
#include <ctype.h>
// 0: 等しい, <0: s1 < s2, >0: s1 > s2 (strcmpと同じ意味)
int strcasecmp_ascii(const char *s1, const char *s2) {
unsigned char c1, c2;
while (*s1 != '\0' || *s2 != '\0') {
c1 = (unsigned char)*s1;
c2 = (unsigned char)*s2;
// 大文字小文字を無視するため、小文字にそろえてから比較
c1 = (unsigned char)tolower(c1);
c2 = (unsigned char)tolower(c2);
if (c1 != c2) {
// 差分を返す(符号付きintにキャスト)
return (int)c1 - (int)c2;
}
if (*s1 != '\0') {
s1++;
}
if (*s2 != '\0') {
s2++;
}
}
return 0;
}
int main(void) {
const char *a = "Hello";
const char *b = "hELLo";
const char *c = "Help";
printf("a vs b = %d\n", strcasecmp_ascii(a, b)); // 0
printf("a vs c = %d\n", strcasecmp_ascii(a, c)); // 負の値になるはず
return 0;
}a vs b = 0
a vs c = -4ここでは、逐文字でtolowerをかけながら比較しています。
そのため、追加のバッファを確保せずに済むメリットがあります。
先にコピーしてから一括変換して比較する方法
文字列が短い場合は、一度バッファにコピーして上下どちらかに統一してからstrcmpする方が理解しやすい場合もあります。
実装例は省略しますが、考え方として押さえておくとよいです。
大文字小文字変換のパフォーマンス最適化

大量の文字列を変換する場合、パフォーマンスを意識する必要があります。
現代の環境ではtoupper/tolowerは十分高速なことが多いですが、さらに微調整したい場合の考え方を紹介します。
1. 変換テーブルを使う(ルックアップテーブル)
ASCII(または拡張ASCII)だけを対象にするなら、256要素のテーブルを用意しておき、unsigned charをインデックスにして変換する方法があります。
#include <stdio.h>
// 256要素の小文字化テーブルをあらかじめ作っておく(例として手動定義の一部)
unsigned char lower_table[256];
// テーブルを初期化する関数
void init_lower_table(void) {
for (int i = 0; i < 256; i++) {
if ('A' <= i && i <= 'Z') {
lower_table[i] = (unsigned char)(i + ('a' - 'A'));
} else {
lower_table[i] = (unsigned char)i;
}
}
}
// テーブル参照で小文字変換
void str_to_lower_table(char *s) {
if (!s) {
return;
}
for (unsigned char *p = (unsigned char *)s; *p; p++) {
*p = lower_table[*p];
}
}
int main(void) {
char str[] = "AbC123!XYZ";
init_lower_table();
str_to_lower_table(str);
printf("%s\n", str);
return 0;
}abc123!xyzテーブル参照は、分岐予測ミスを減らせる、キャッシュヒットしやすいといった利点があり、大量データ処理では速度向上が期待できます。
ただし、実際の効果はコンパイラや環境に左右されるため、プロファイラを使って測定することが重要です。
2. 分岐の少ないロジックを選ぶ
前述のビット演算による変換など、条件分岐を減らすことで、特定のCPUアーキテクチャで高速化できる場合があります。
しかし、最近のコンパイラは非常に賢いため、可読性を犠牲にしてまでトリッキーな書き方をするメリットは小さいことも多いです。
マルチバイト・Unicode環境での大文字小文字変換の考え方
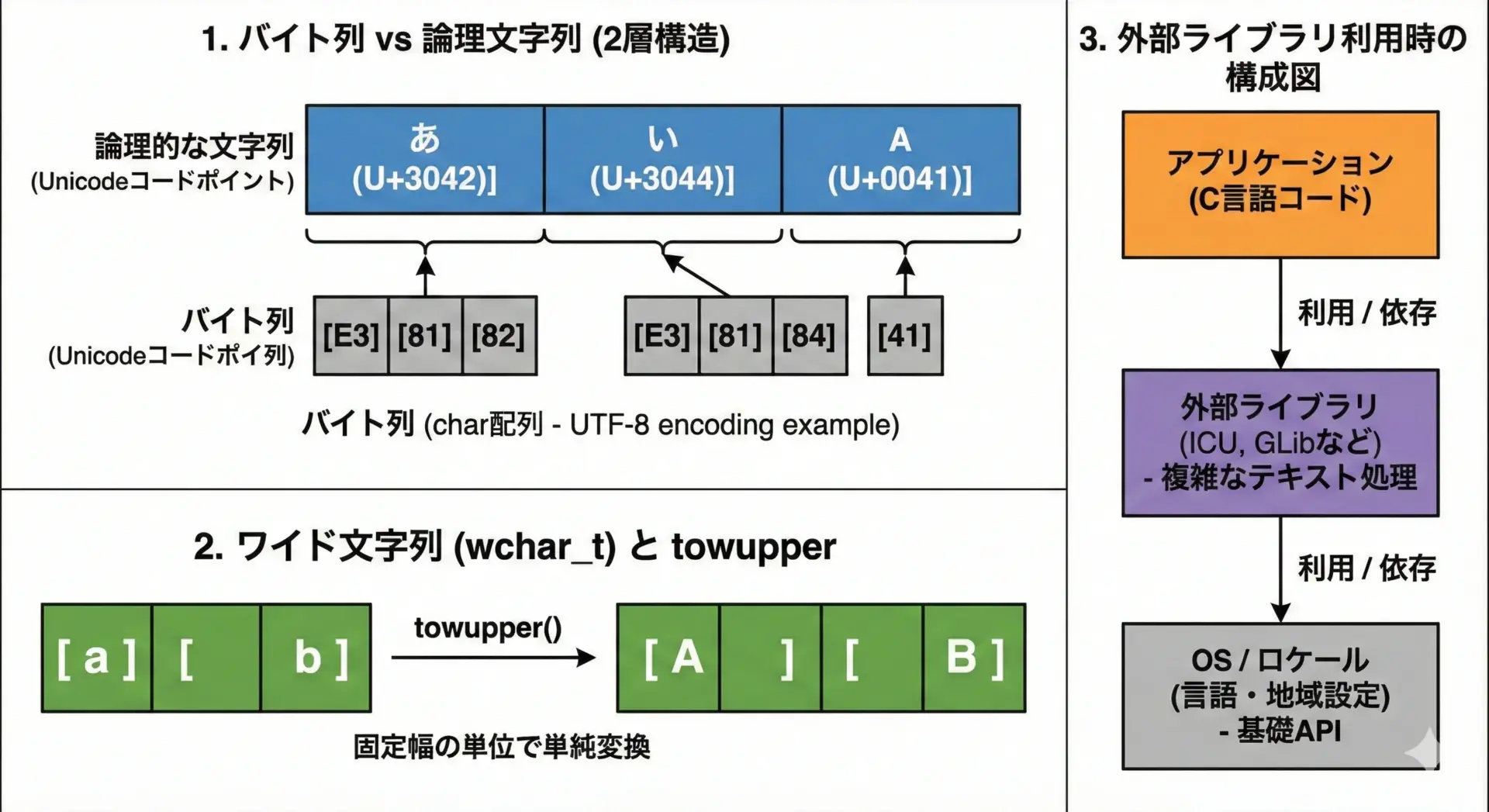
Unicode(特にUTF-8)が前提の環境では、「1バイト=1文字」という前提は成り立ちません。
この場合の大文字小文字変換は、次のようなレイヤで考える必要があります。
- バイト列(
char*)を論理的な文字列(コードポイントの列)にデコードする - 各コードポイントをUnicodeの大文字小文字ルールに基づいて変換する
- 再びターゲットのエンコーディング(UTF-8など)にエンコードする
C標準だけでは完全なUnicode処理は難しいため、現実的には次のようなアプローチをとります。
- Windowsなら
MultiByteToWideCharでwchar_t文字列に変換し、CharUpperBuffWや_wcsicmpを利用する - POSIX環境なら
wchar_tとtowupper/towlowerを組み合わせる - ICUやBoost.Localeなどの外部ライブラリを利用する
ASCII専用の自前ロジックを、そのまま多言語環境に持ち込まないことが重要です。
要件として「ASCIIの英字しか入力されない」ことが保証されている場合に限り、本記事で紹介した最短テクニックを安心して使えます。
まとめ
C言語での大文字小文字変換は、ASCIIコードの規則性を理解すると、最短で書けるシンプルなロジックから、汎用的なctype.hベースの実装まで自在に使い分けられます。
1文字の変換にはtoupper/tolower、文字列全体にはポインタループや関数ポインタを使った共通化、さらに応用として大文字小文字無視の比較やテーブル参照による高速化が可能です。
一方で、日本語を含むマルチバイト・Unicode環境ではchar単位の変換は危険であり、ワイド文字や外部ライブラリの利用といった別アプローチが必要になります。
用途と前提を明確にし、最適な手法を選んで実装してください。
