
C言語で部分文字列を探すときに活躍するのがstrstr関数です。
標準ライブラリに含まれているため、追加ライブラリなしで利用でき、検索結果の位置をポインタで返すため、応用の幅も広いです。
本記事では、strstrの基本からNULL判定、安全な使い方、実践的な応用例までを丁寧に解説し、文字列検索処理の基礎力を高めることを目指します。
strstr関数の基本と特徴
strstrとは
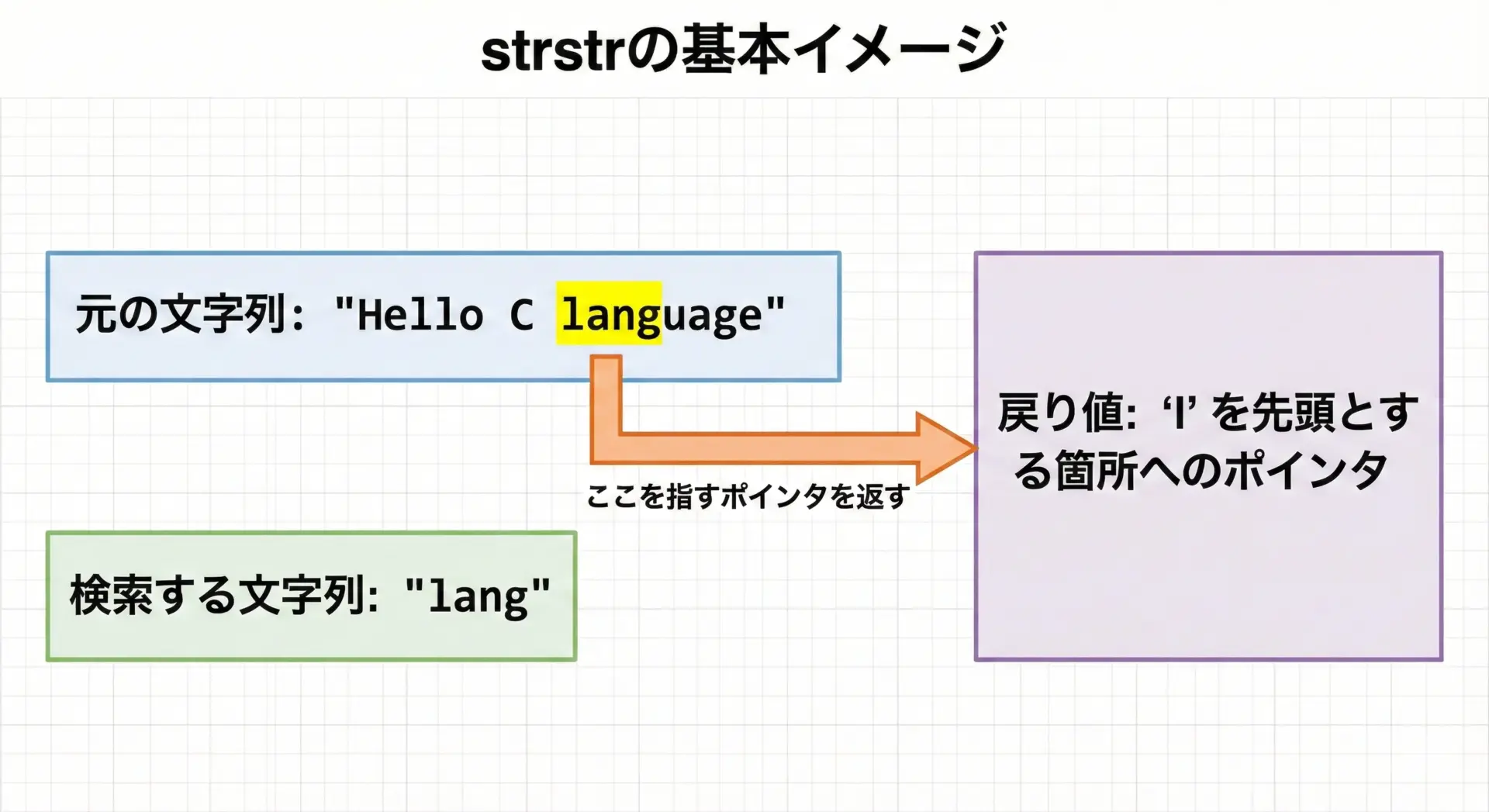
C言語のstrstr関数は、ある文字列の中から、指定した「部分文字列」が最初に現れる位置を探すための関数です。
見つかった場合は、その位置を指すポインタを返し、見つからなければNULLを返します。
イメージとしては、長い文章の中から特定の単語を探し、その単語が始まる位置を指で指し示してくれる関数だと考えると分かりやすいです。
strstrの戻り値とNULLの意味
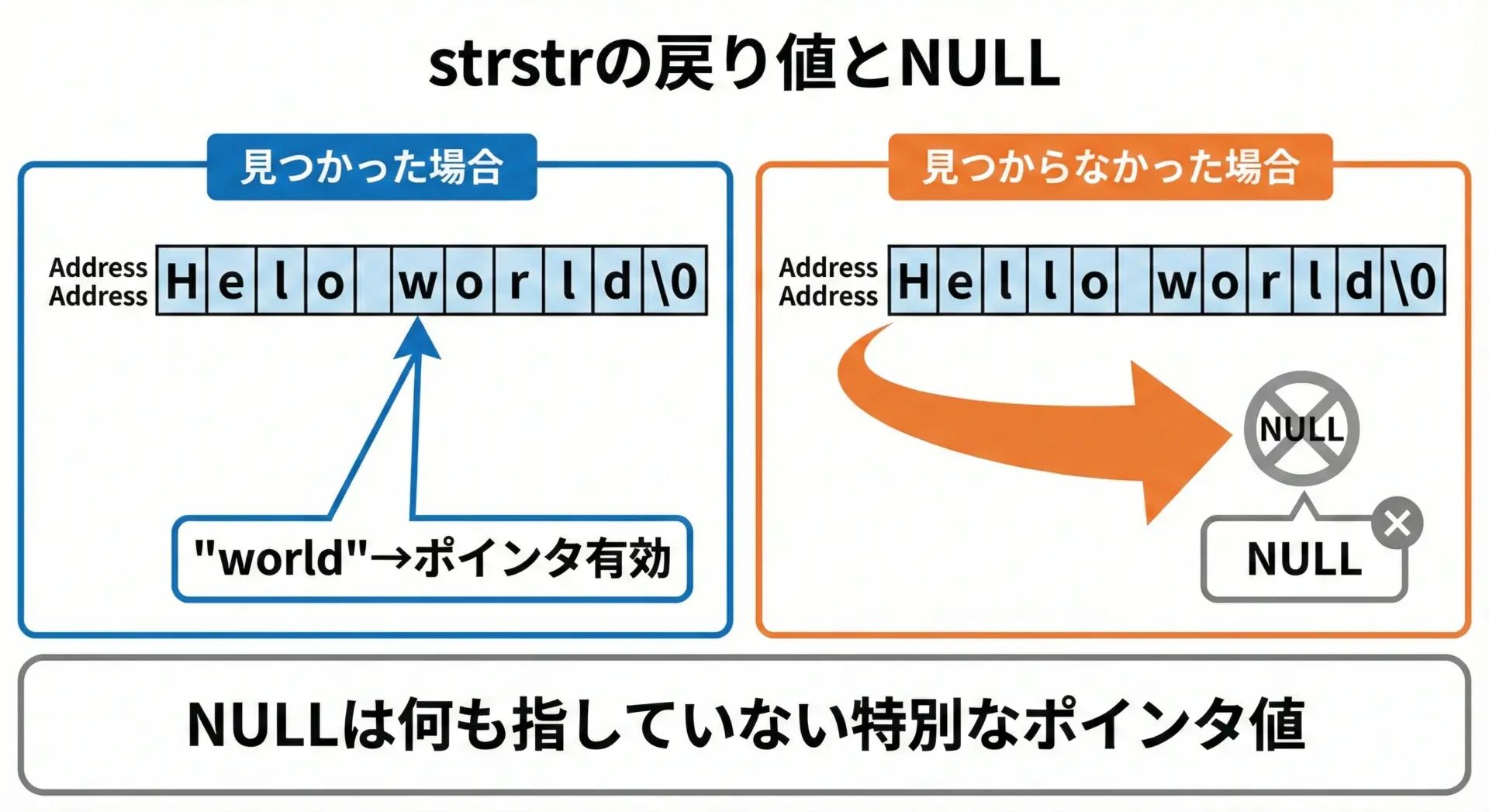
strstrの戻り値の型はchar *です。
これは「文字へのポインタ」を意味しますが、実際には「検索に成功した位置を指すポインタ」として使われます。
戻り値の意味は次の2通りです。
- 部分文字列が見つかった場合
検索対象文字列の中で最初に一致した箇所を指すchar *が返ります。 - 部分文字列が見つからなかった場合
NULLが返ります。
このNULLは「どの有効なメモリ位置も指していない」ことを示す特別なポインタ値であり、この値を使って文字列操作をしようとすると不正アクセスになります。
戻り値がNULLかどうかを必ず確認することが、安全なプログラムを書くうえで非常に重要です。
strstrとstrchrの違い
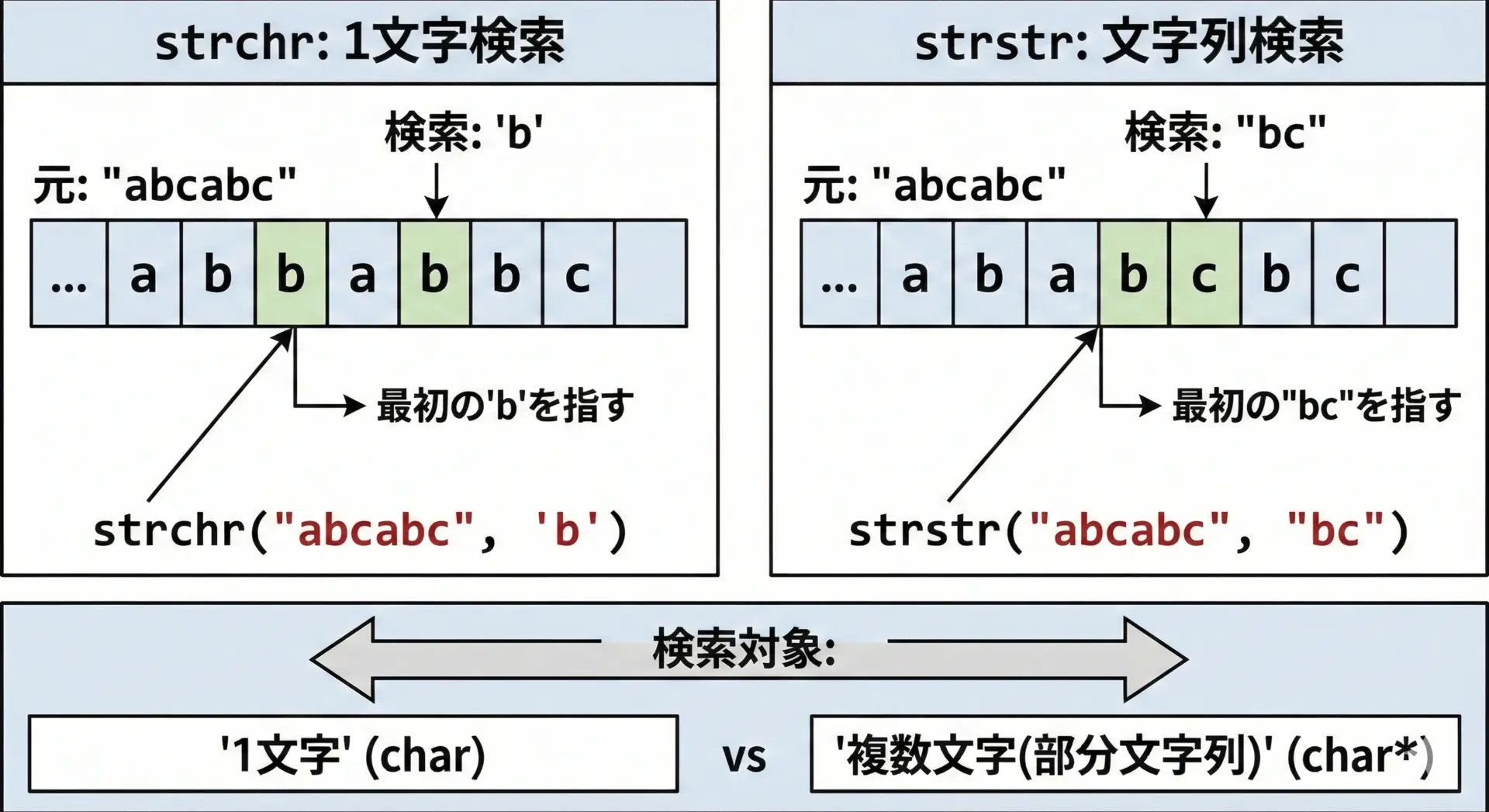
strstrとよく比較されるのがstrchrです。
両者の違いを整理すると理解が深まります。
| 関数名 | 役割 | 検索対象 | 例 |
|---|---|---|---|
| strstr | 部分文字列検索 | 複数文字(文字列) | “Hello”の中の”ll” |
| strchr | 文字検索 | 1文字 | “Hello”の中の’H’ |
strchrは「1文字を探す」関数、strstrは「文字列(複数文字)を探す」関数だと覚えておくと混乱しにくいです。
strstrの基本的な使い方
strstrの関数プロトタイプとインクルード
strstrを使用するには、標準ヘッダ<string.h>をインクルードする必要があります。
公式な関数プロトタイプは次の通りです。
/* string.h に宣言されているプロトタイプ */
char *strstr(const char *haystack, const char *needle);ここでの引数の意味は次のようになります。
haystack
探索対象となる文字列(「干し草」)です。慣習的にこう呼ばれます。needle
探したい部分文字列(「針」)です。
「干し草の山の中から針を探す」という比喩で名前が付けられているため、この2つの名前になっています。
strstrを使ったシンプルな文字列検索の例
実際にstrstrを使って文字列を検索する簡単な例を示します。
#include <stdio.h>
#include <string.h>
int main(void)
{
/* 探索対象の文字列 */
const char *text = "I like C programming.";
/* 探したい部分文字列 */
const char *keyword = "C";
/* strstrで部分文字列を検索 */
char *pos = strstr(text, keyword);
if (pos != NULL) {
/* 見つかった場合は、その位置以降を表示 */
printf("見つかりました: %s\n", pos);
/* 先頭からのオフセットも表示 */
printf("先頭からの位置: %ld 文字目\n", pos - text);
} else {
/* 見つからなかった場合 */
printf("見つかりませんでした。\n");
}
return 0;
}見つかりました: C programming.
先頭からの位置: 7 文字目このサンプルでは、strstrが"C programming."の先頭を指すポインタを返すため、posを%sで表示すると、その位置以降の文字列がそのまま出力されます。
また、pos - textというポインタの差を取ることで、「先頭から何文字目に見つかったか」も簡単に求められます。
大文字小文字の違いに注意
strstrは大文字と小文字を区別して比較する関数です。
つまり、ASCII環境では"World"と"world"は別の文字列として扱われます。
#include <stdio.h>
#include <string.h>
int main(void)
{
const char *text = "Hello World";
char *p1 = strstr(text, "World"); /* 大文字W */
char *p2 = strstr(text, "world"); /* 小文字w */
if (p1 != NULL) {
printf("\"World\" は見つかりました: %s\n", p1);
}
if (p2 == NULL) {
printf("\"world\" は見つかりませんでした。\n");
}
return 0;
}"World" は見つかりました: World
"world" は見つかりませんでした。大文字小文字を無視して検索したい場合には、後述するstrcasestrや自前の実装などを検討する必要があります。
strstrのNULL判定と安全な書き方
strstrの戻り値に対するNULLチェックの書き方
strstrを使用するときに最も重要なのが、戻り値に対するNULLチェックです。
実際のコード例で、安全な書き方を確認してみます。
#include <stdio.h>
#include <string.h>
int main(void)
{
const char *text = "Sample text";
const char *keyword = "amp";
/* strstrの戻り値をポインタ変数で受け取る */
char *pos = strstr(text, keyword);
/* まずはNULLかどうかを必ずチェックする */
if (pos == NULL) {
printf("キーワード \"%s\" は見つかりませんでした。\n", keyword);
return 0; /* ここで安全に終了 */
}
/* ここに来た時点で、posは必ず有効なポインタ */
printf("見つかりました: %s\n", pos);
return 0;
}見つかりました: ample textNULLチェックを通過した後であれば、戻り値のポインタを安心して使えるという形で、コードを「段階的」に書くと安全です。
NULL判定を忘れた場合に起こる典型的なバグ

NULL判定を忘れると、プログラムがクラッシュする危険があります。
典型的な悪い例を、あえて示します。
#include <stdio.h>
#include <string.h>
int main(void)
{
const char *text = "Hello";
const char *keyword = "XYZ";
/* この検索は失敗するので、戻り値はNULLになる */
char *pos = strstr(text, keyword);
/* ★悪い例: NULLチェックをしていない */
/* pos が NULL のまま %s で表示しようとすると未定義動作 */
printf("結果: %s\n", pos); /* 危険! */
return 0;
}このようなコードは、環境によっては何も起こらないように見える場合もありますが、C言語の規格上は完全な未定義動作となり、セグメンテーションフォルト(アクセス違反)などのクラッシュを引き起こす可能性があります。
特にありがちなパターンとしては、posがNULLかもしれないのに*posにアクセスしたり、strlen(pos)などを呼び出してしまうケースがあります。
ポインタを「使う前に」必ずNULL判定をするという習慣を身に付けることが重要です。
NULL判定を関数化してコードを分かりやすくするコツ
同じようなstrstrとNULL判定のパターンを何度も書く場合、関数として切り出しておくとコードが読みやすくなります。
#include <stdio.h>
#include <string.h>
#include <stdbool.h>
/* text の中に keyword が含まれているかどうかを判定する関数 */
bool contains_keyword(const char *text, const char *keyword)
{
/* strstr の戻り値が NULL でなければ、含まれている */
return strstr(text, keyword) != NULL;
}
int main(void)
{
const char *text = "This is a sample string.";
if (contains_keyword(text, "sample")) {
printf("\"sample\" を含みます。\n");
} else {
printf("\"sample\" を含みません。\n");
}
if (contains_keyword(text, "test")) {
printf("\"test\" を含みます。\n");
} else {
printf("\"test\" を含みません。\n");
}
return 0;
}"sample" を含みます。
"test" を含みません。このように「含まれているかどうか」という意味を持つ関数contains_keywordを用意することで、呼び出し側のコードが論理的に読みやすくなります。
また、将来検索ロジックを変更したくなった場合も、関数の中だけを修正すれば済むという利点があります。
strstrの応用例と実践テクニック
複数回の文字列検索
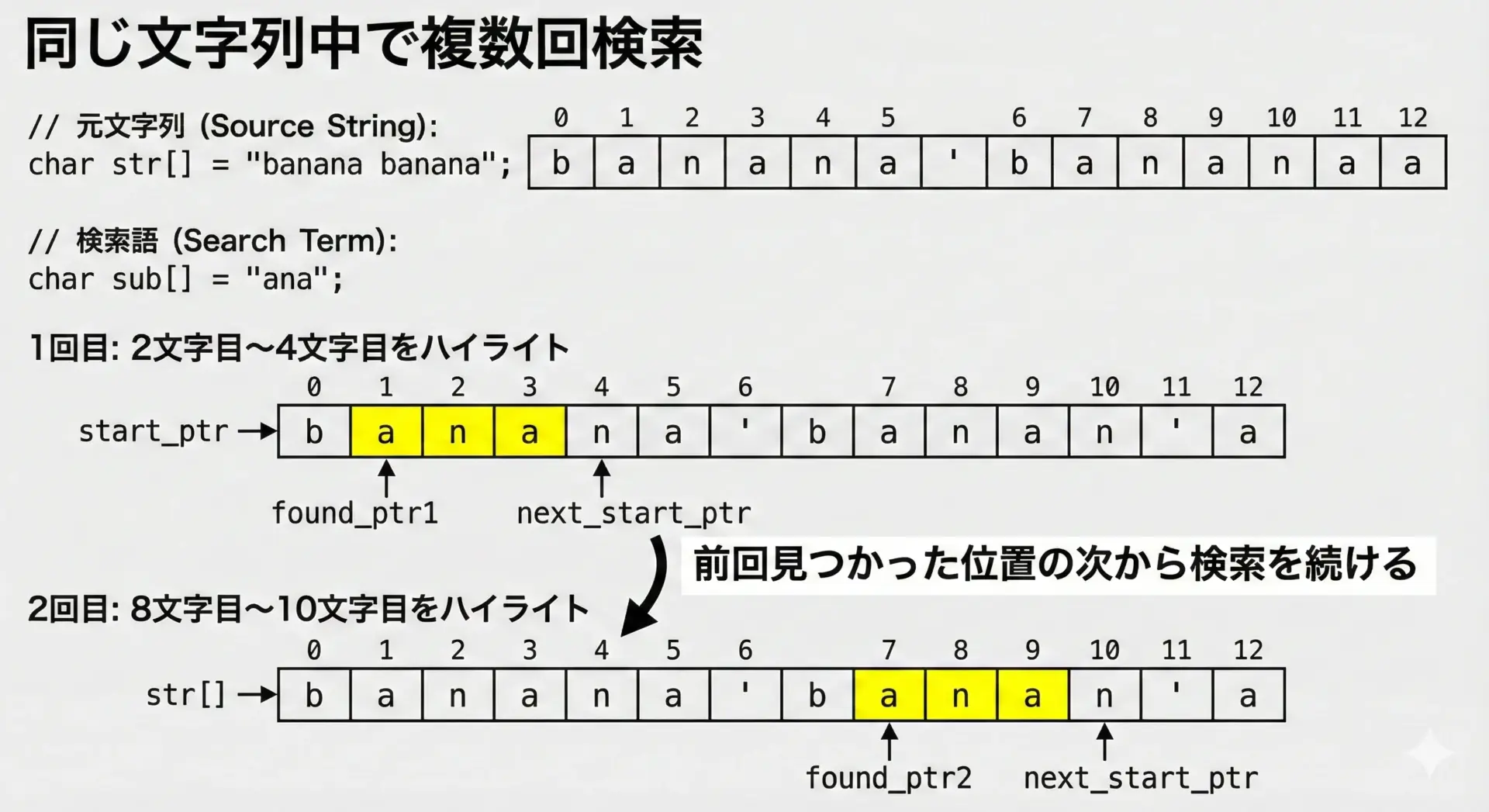
strstrは、1回呼び出して終わりではなく、繰り返し呼び出すことで「すべての出現箇所」を順番に見つけることができます。
ポイントは、「前回見つかった位置の次」から検索を続けることです。
#include <stdio.h>
#include <string.h>
int main(void)
{
const char *text = "banana banana";
const char *keyword = "ana";
const char *p = text; /* 探索開始位置 */
int count = 0;
while (1) {
/* p から keyword を検索 */
char *pos = strstr(p, keyword);
if (pos == NULL) {
/* これ以上は見つからないのでループ終了 */
break;
}
count++;
printf("%d 回目: 先頭から %ld 文字目で見つかりました。\n",
count, pos - text);
/* 次回は、今回見つかった位置の「次の文字」から検索 */
p = pos + 1;
}
printf("合計 %d 個の \"%s\" が見つかりました。\n", count, keyword);
return 0;
}1 回目: 先頭から 1 文字目で見つかりました。
2 回目: 先頭から 8 文字目で見つかりました。
合計 2 個の "ana" が見つかりました。このようにポインタを少しずつ進めながらstrstrを繰り返し呼び出すことで、同じキーワードが複数回登場する場合にもすべての位置を取得することができます。
キーワードハイライト表示への応用
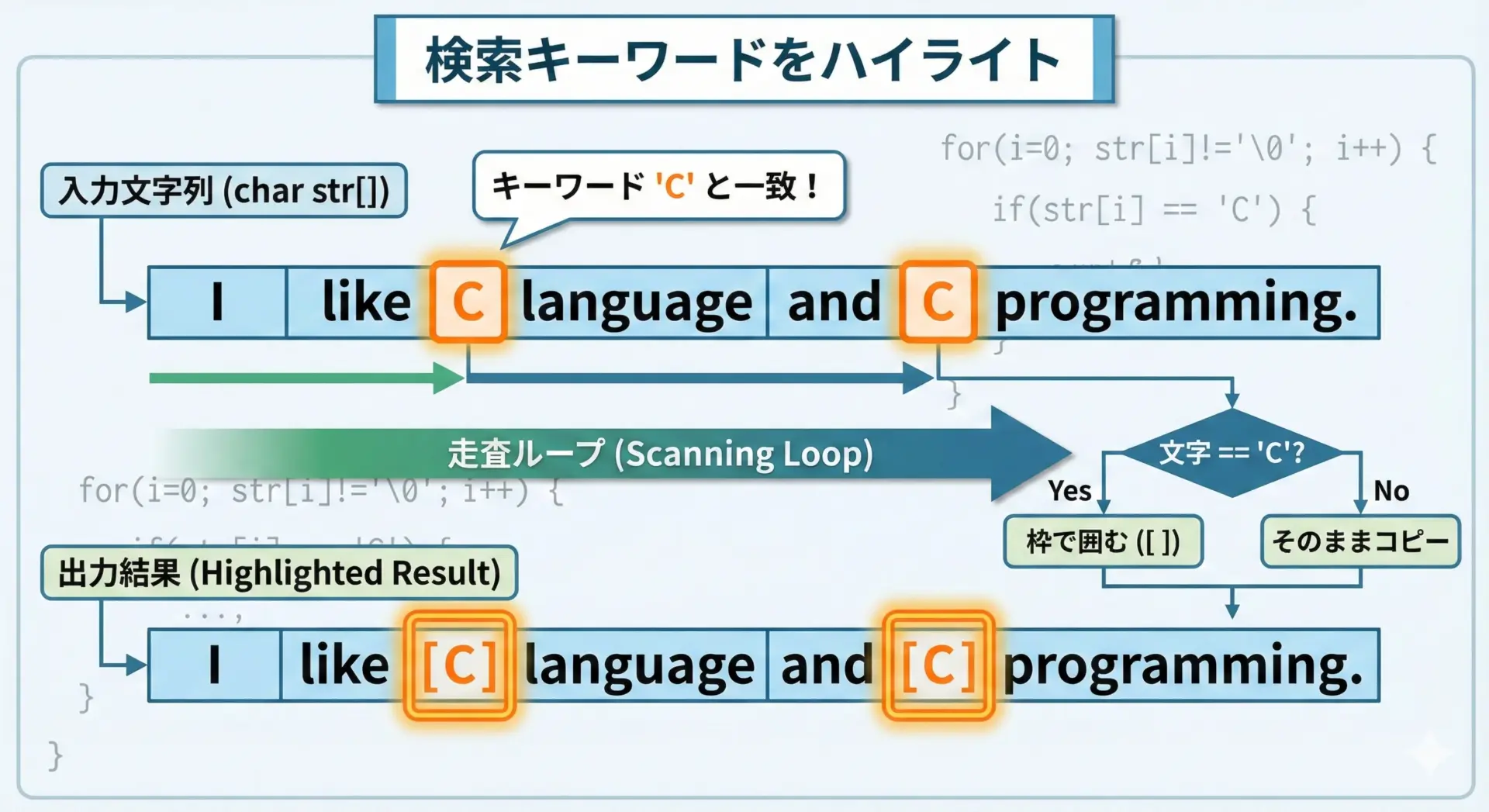
検索結果をユーザーに見せるとき、キーワードをハイライトして表示したい場面は多くあります。
strstrを使えば、比較的簡単に実現できます。
#include <stdio.h>
#include <string.h>
/* キーワードを [ ] で囲んでハイライト表示する例 */
void highlight_keyword(const char *text, const char *keyword)
{
const char *p = text;
size_t keylen = strlen(keyword);
while (1) {
/* 現在位置 p から keyword を検索 */
const char *pos = strstr(p, keyword);
if (pos == NULL) {
/* 残りをそのまま出力して終了 */
printf("%s", p);
break;
}
/* キーワードの手前までを出力 */
fwrite(p, 1, (size_t)(pos - p), stdout);
/* キーワードを [ ] で囲んで出力 */
printf("[");
fwrite(pos, 1, keylen, stdout);
printf("]");
/* 検索開始位置をキーワードの直後に進める */
p = pos + keylen;
}
}
int main(void)
{
const char *text = "I like C language and C programming.";
const char *keyword = "C";
printf("元の文字列:\n%s\n\n", text);
printf("ハイライト表示:\n");
highlight_keyword(text, keyword);
printf("\n");
return 0;
}元の文字列:
I like C language and C programming.
ハイライト表示:
I like [C] language and [C] programming.このように「見つかった文字列の前後を区切りながら表示する」というパターンは、ログビューアや検索機能付きツールなどでよく使われる実践的なテクニックです。
拡張子判定など部分一致チェックへの応用
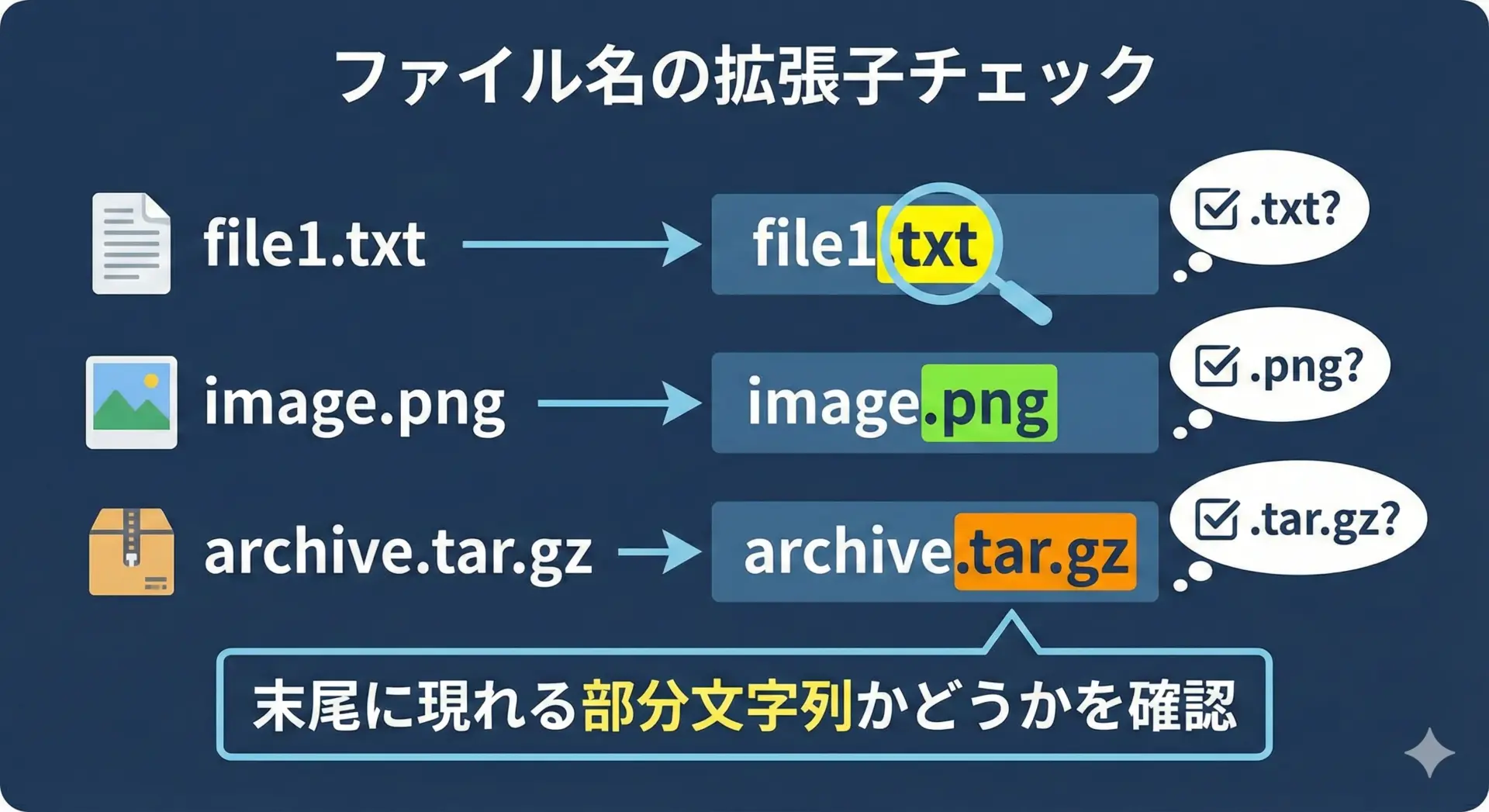
strstrは文字列の「どこかに含まれているか」を判定するだけでなく、「末尾に特定の文字列が付いているか」を確認する用途にも応用できます。
たとえば、ファイル名の拡張子判定です。
#include <stdio.h>
#include <string.h>
#include <stdbool.h>
/* file_name が ext で終わっているかを判定する関数 */
bool has_extension(const char *file_name, const char *ext)
{
size_t len_name = strlen(file_name);
size_t len_ext = strlen(ext);
if (len_name < len_ext) {
/* ファイル名が拡張子より短ければ一致しない */
return false;
}
/* ファイル名の末尾の位置を計算 */
const char *pos = file_name + (len_name - len_ext);
/* 末尾から ext と比較する */
return strstr(pos, ext) == pos;
}
int main(void)
{
const char *files[] = {
"document.txt",
"image.png",
"archive.tar.gz",
"note.TXT",
};
size_t n = sizeof(files) / sizeof(files[0]);
for (size_t i = 0; i < n; i++) {
const char *name = files[i];
printf("%s: ", name);
if (has_extension(name, ".txt")) {
printf(".txt のファイルです。\n");
} else if (has_extension(name, ".png")) {
printf(".png のファイルです。\n");
} else if (has_extension(name, ".tar.gz")) {
printf(".tar.gz のファイルです。\n");
} else {
printf("対象外の拡張子です。\n");
}
}
return 0;
}document.txt: .txt のファイルです。
image.png: .png のファイルです。
archive.tar.gz: .tar.gz のファイルです。
note.TXT: 対象外の拡張子です。この例ではstrstrだけでなくstrlenと組み合わせることで、「文字列の末尾に一致するかどうか」を判定しています。
大文字小文字を無視して判定したい場合は、tolowerなどを駆使して両方を小文字化してから比較する方法もあります。
strstrの代替(自前実装・strcasestrなど)の検討ポイント
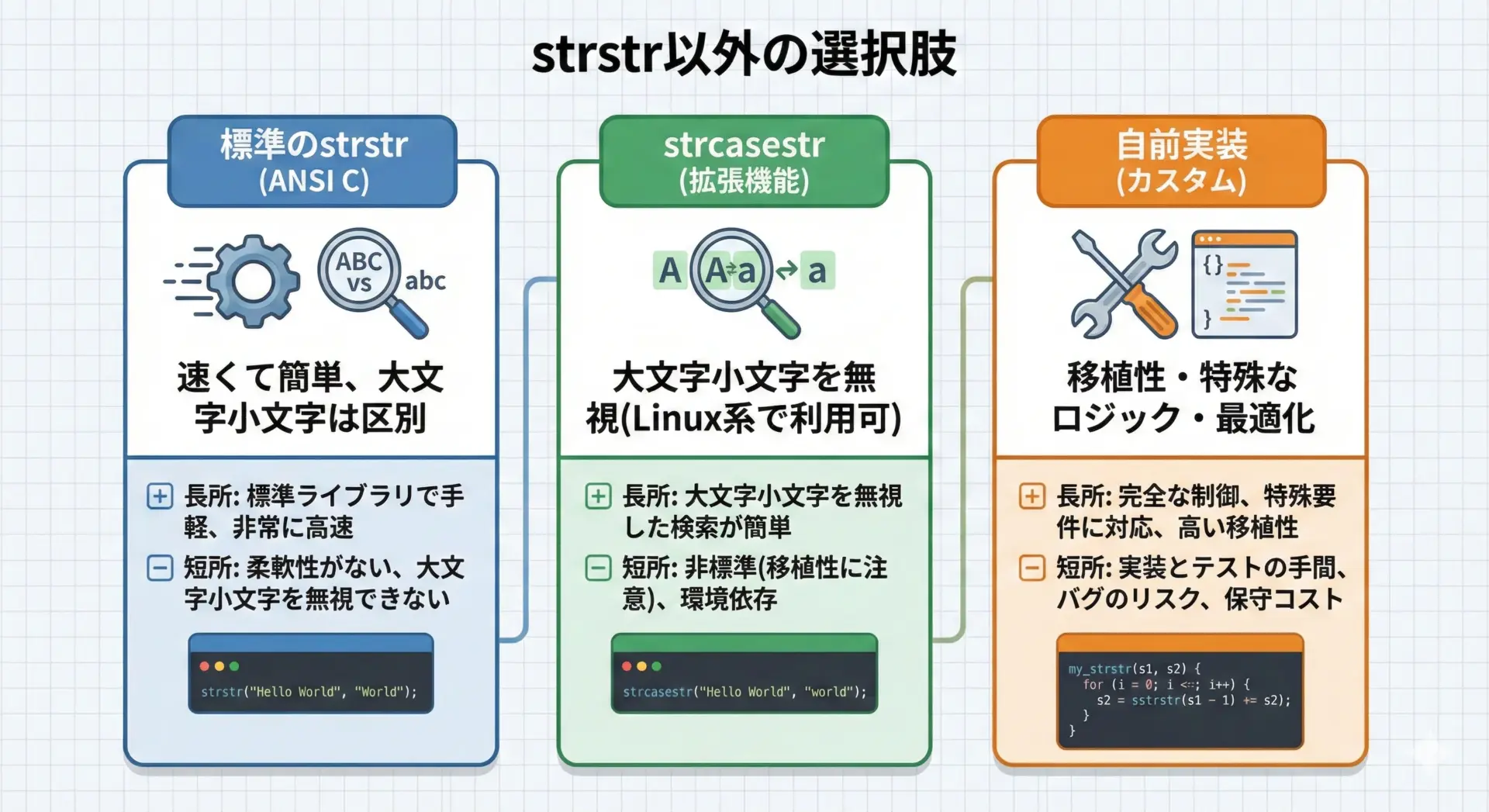
用途によっては、標準のstrstrだけでは足りない場合もあります。
そのようなときの代表的な選択肢として、strcasestrや自前実装があります。
大文字小文字を無視するstrcasestr
strcasestrは大文字小文字を無視して部分文字列を検索する関数です。
Linuxなど多くのUnix系環境には存在しますが、標準Cライブラリには含まれていません。
そのため、Windows環境などでは使えないことがあります。
#include <stdio.h>
#include <strings.h> /* POSIX: strcasestr の宣言 */
int main(void)
{
const char *text = "Hello World";
const char *keyword = "world";
/* 大文字小文字を無視して検索 */
char *pos = strcasestr(text, keyword);
if (pos != NULL) {
printf("見つかりました: %s\n", pos);
} else {
printf("見つかりませんでした。\n");
}
return 0;
}見つかりました: World移植性を重視する場合には、strcasestrが存在しない環境向けに、同等の機能を自前で実装しておく必要があります。
自前で簡易的なstrstrを実装する例
アルゴリズムの学習や、特殊な条件付き検索が必要な場合には、自分で部分文字列検索関数を実装するのも1つの方法です。
ここでは、ごく基本的な「総当たり」方式の実装例を示します。
#include <stdio.h>
#include <string.h>
#include <ctype.h>
/* 大文字小文字を無視した strstr の簡易実装例 */
char *my_strcasestr(const char *haystack, const char *needle)
{
size_t len_h = strlen(haystack);
size_t len_n = strlen(needle);
if (len_n == 0) {
/* 空文字列を探す場合は先頭を返す(標準strstrと同じ挙動) */
return (char *)haystack;
}
for (size_t i = 0; i + len_n <= len_h; i++) {
size_t j = 0;
for (; j < len_n; j++) {
/* 大文字小文字を無視して比較 */
if (tolower((unsigned char)haystack[i + j]) !=
tolower((unsigned char)needle[j])) {
break;
}
}
if (j == len_n) {
/* すべて一致した場所を返す */
return (char *)&haystack[i];
}
}
return NULL;
}
int main(void)
{
const char *text = "Hello World";
const char *keyword = "world";
char *pos = my_strcasestr(text, keyword);
if (pos != NULL) {
printf("my_strcasestr: 見つかりました: %s\n", pos);
} else {
printf("my_strcasestr: 見つかりませんでした。\n");
}
return 0;
}my_strcasestr: 見つかりました: Worldこの実装は最も単純な方法の1つで、長い文字列や大量の検索には効率が十分でない場合もあります。
しかし、処理内容を完全にコントロールしたい場合や、環境に依存しない大文字小文字無視検索を提供したい場合には有用です。
まとめ
strstr関数は、C言語における部分文字列検索の基本ツールであり、戻り値のNULL判定さえ徹底すれば、安全かつ強力に利用できます。
本記事では、基本的な使い方、NULLチェックの重要性、複数回検索やハイライト表示、拡張子判定への応用、さらにstrcasestrや自前実装まで幅広く紹介しました。
これらを理解しておけば、多くの文字列処理で迷わずに適切な検索ロジックを組めるようになります。
ぜひ実際にコードを書きながら、自分のプロジェクトで活用してみてください。
