
C言語で文字列の長さを調べる標準関数strlenは、一見シンプルですが、マルチバイト文字やバッファ境界、sizeofとの違いなど、理解しておくべきポイントが多くあります。
本記事では「strlenとは何か」から「落とし穴と代替手段」までを丁寧に解説し、実践的なサンプルコードと図解で理解を深めます。
strlenとは
strlenの役割と返り値の型
strlenの基本的な役割を全体像として押さえる図解を表示
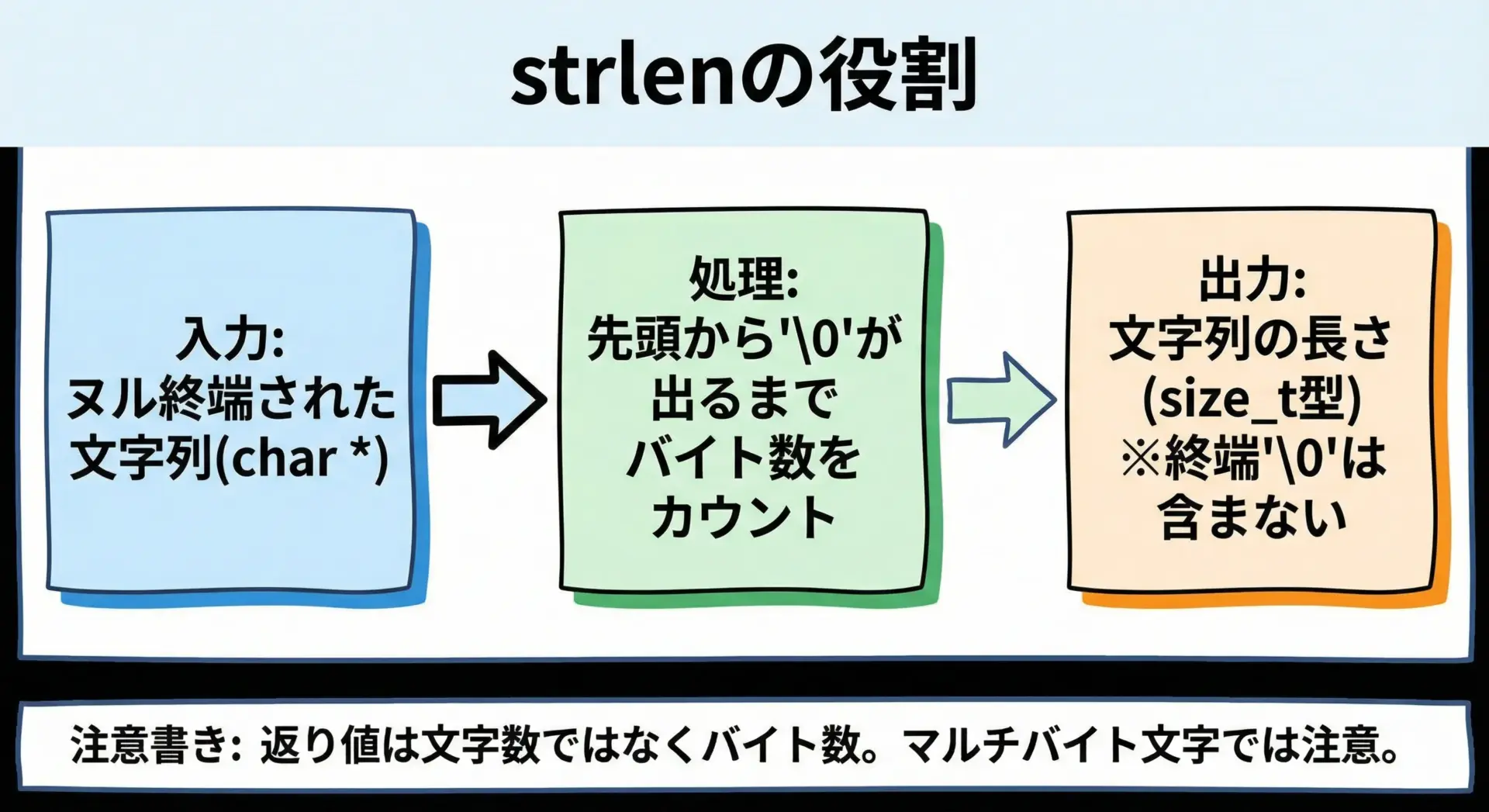
C言語のstrlen関数は、ヌル終端された文字列の「長さ(バイト数)」を返す標準ライブラリ関数です。
宣言は<string.h>で行われており、返り値の型はsize_tです。
関数プロトタイプは次のようになっています。
size_t strlen(const char *s);ここで、size_tは配列のサイズやメモリの大きさなどを表すために使われる符号なし整数型で、環境によってunsigned intやunsigned longなどに対応します。
重要なポイントとして、strlenの返り値は負の値にはならないため、戻り値を受ける変数もsize_tもしくはそれ以上の容量を持つ符号なし型を使うのが安全です。
ヌル終端文字列とstrlenの関係
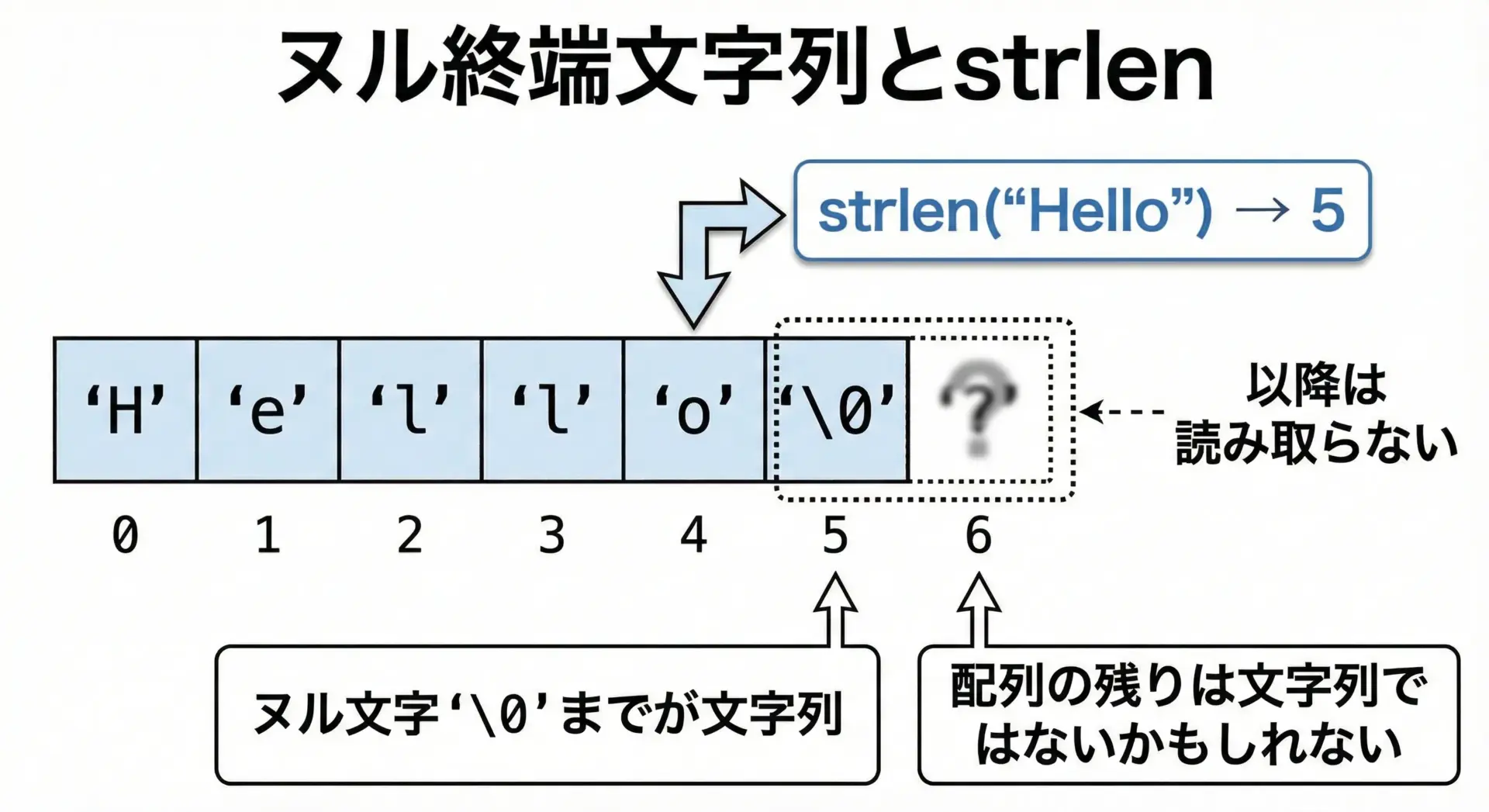
C言語では、文字列は'\0'(ヌル文字)で終端されているchar配列として表現されます。
strlenは、このヌル文字が現れる位置まで配列を順に調べて、そこまでのバイト数を数えています。
例えば、次のような配列を考えます。
char str[10] = "Hello";この場合、メモリ上の状態は概ね次のようになります。
- インデックス0〜4: ‘H’,’e’,’l’,’l’,’o’
- インデックス5: ‘\0’
- インデックス6〜9: 不定値(初期化されていない)
strlen(str)はインデックス5の'\0'までをカウントするので返り値は5になります。
インデックス6以降にどのような値が入っていてもstrlenは関知しません。
このことから、「正しくヌル終端された文字列」を渡すことがstrlenの大前提であると理解できます。
strlenがカウントするのは「バイト数」
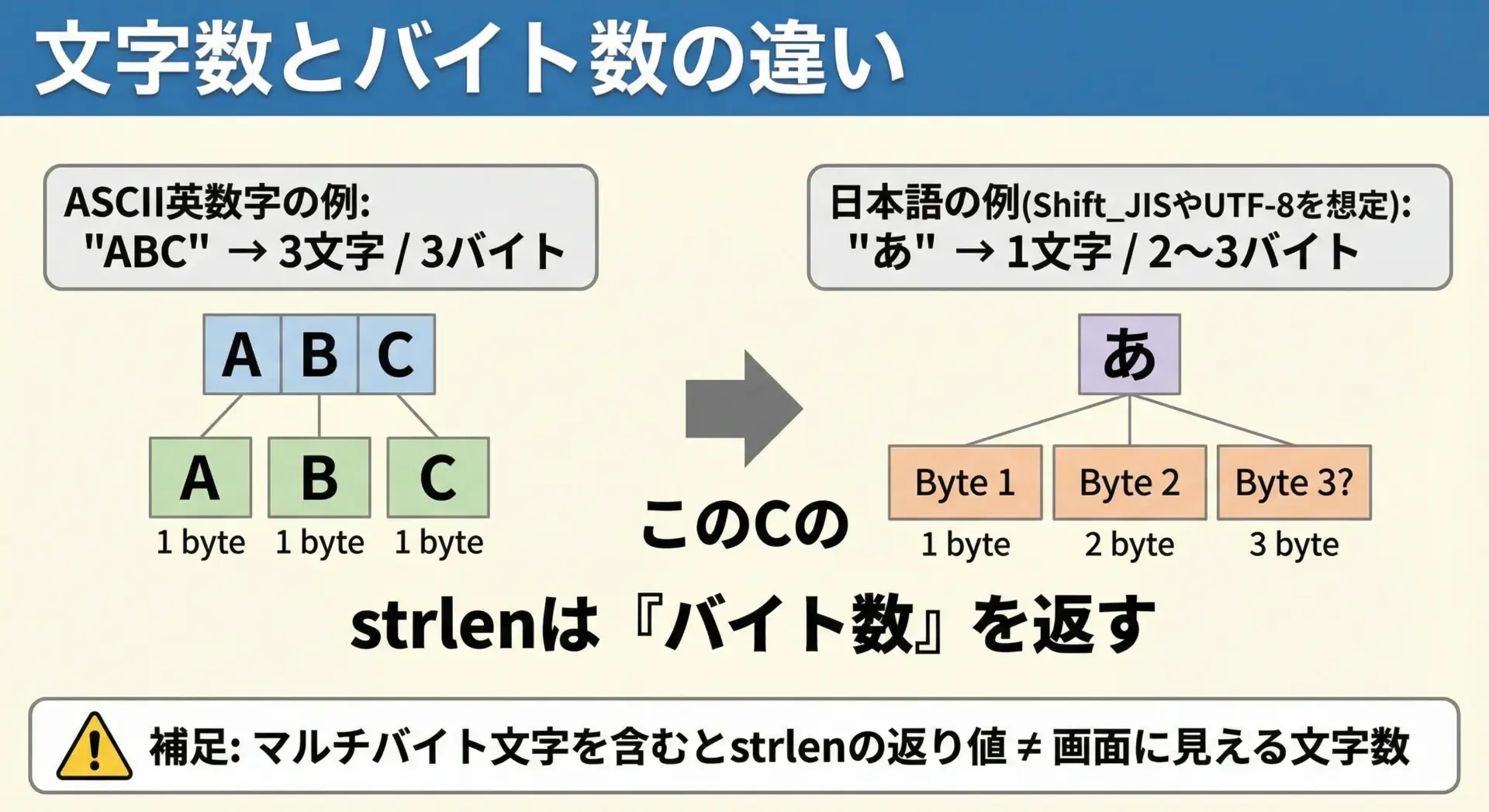
strlenが返すのは「ヌル文字までのバイト数」であり、「目に見える文字数」ではない点に注意が必要です。
英数字のみのASCII文字列の場合は、1文字1バイトで表現されるため、strlenの返り値と文字数が一致します。
しかし、日本語などのマルチバイト文字(Shift_JIS, EUC-JP, UTF-8など)を含む場合、1文字が2バイト以上で表現されるため、strlenの値は「画面の文字数より大きく」なります。
この違いは、後述するマルチバイト文字列処理やUI上の文字数制限などで特に重要になります。
strlenの基本的な使い方
C言語でのstrlenの書き方とインクルードファイル
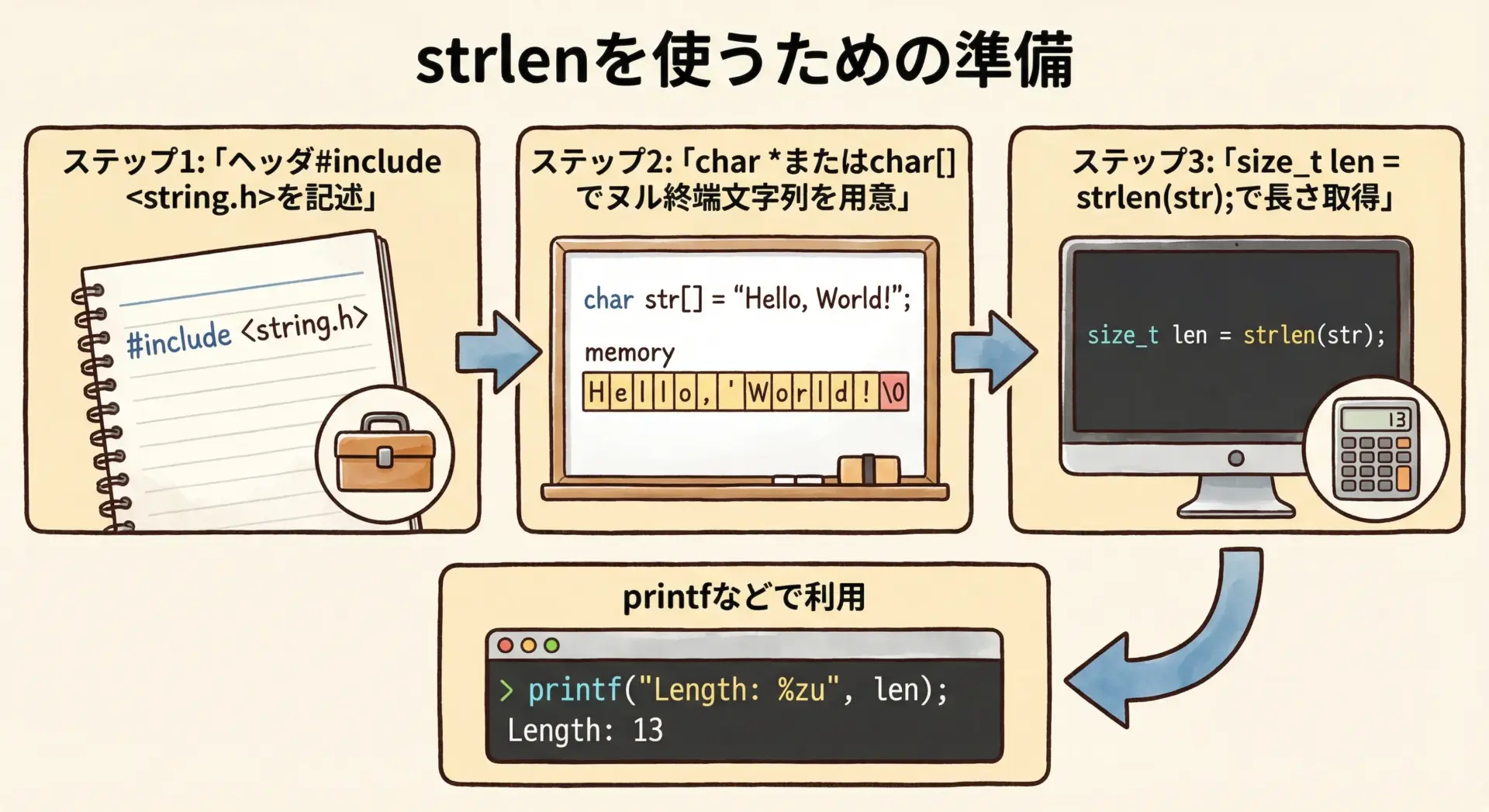
strlenを使用するには、プログラムの先頭で<string.h>ヘッダをインクルードする必要があります。
基本的な書き方は次のようになります。
#include <stdio.h>
#include <string.h> // strlenを使うために必要
int main(void) {
char str[] = "Hello, world!";
// strlenの戻り値はsize_t型
size_t len = strlen(str);
printf("文字列: %s\n", str);
printf("長さ: %zu\n", len); // size_tを表示するときは%zuが推奨
return 0;
}この例では、文字列"Hello, world!"の長さがstrlenで取得され、%zu書式指定子を用いてprintfで表示しています。
文字列リテラルとstrlenの使用例

文字列リテラルは、コンパイル時に自動的に末尾に'\0'が付加されるため、そのままstrlenに渡すことができます。
#include <stdio.h>
#include <string.h>
int main(void) {
// 文字列リテラルを直接strlenに渡す
size_t len1 = strlen("Hello");
// ポインタに文字列リテラルを代入
const char *msg = "C言語";
size_t len2 = strlen(msg);
printf("\"Hello\" の長さ: %zu\n", len1);
printf("\"C言語\" の長さ(バイト数): %zu\n", len2);
return 0;
}"Hello" の長さ: 5
"C言語" の長さ(バイト数): 6 ← 例: UTF-8環境の場合(各2〜3バイト)注意点として、文字列リテラルは通常const char[]として扱われるため、msg[0] = 'c';のような書き換えは未定義動作になりますが、strlenで長さを調べるだけなら問題ありません。
配列とポインタでのstrlenの使い方
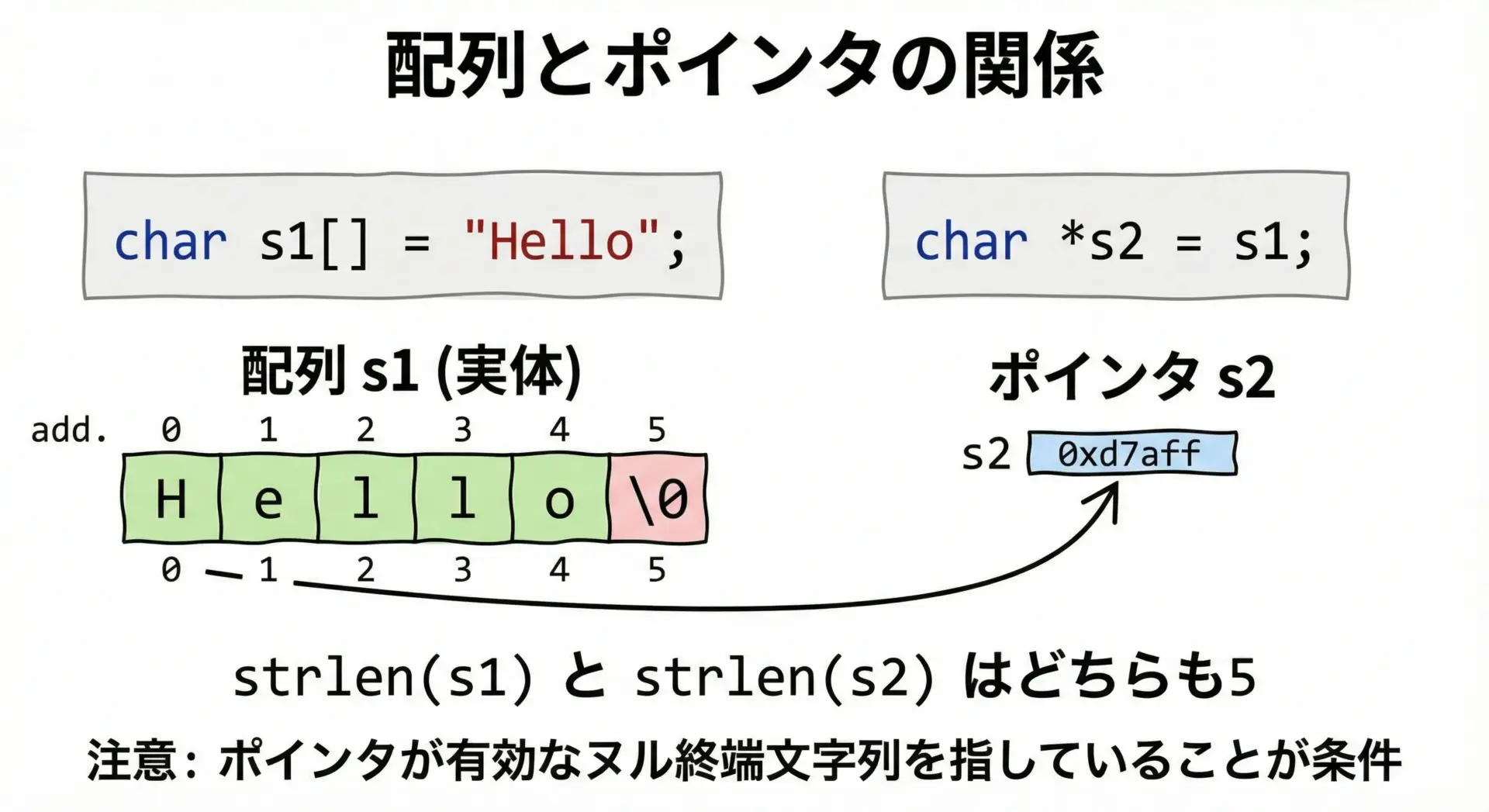
strlenはconst char *を受け取るので、配列名でもポインタ変数でも同じように使用できます。
#include <stdio.h>
#include <string.h>
int main(void) {
char arr[] = "Array"; // 配列
char *ptr = arr; // 配列の先頭要素を指すポインタ
size_t len_arr = strlen(arr); // 配列名は先頭要素へのポインタに暗黙変換される
size_t len_ptr = strlen(ptr); // ポインタもそのまま渡せる
printf("arr の長さ: %zu\n", len_arr);
printf("ptr の長さ: %zu\n", len_ptr);
return 0;
}arr の長さ: 5
ptr の長さ: 5ここで重要なのは、ポインタptrが必ずヌル終端された文字列を指している必要があるという点です。
後述の「ヌル終端されていない文字列に対する危険性」で詳しく解説します。
printfと組み合わせた文字数表示の例
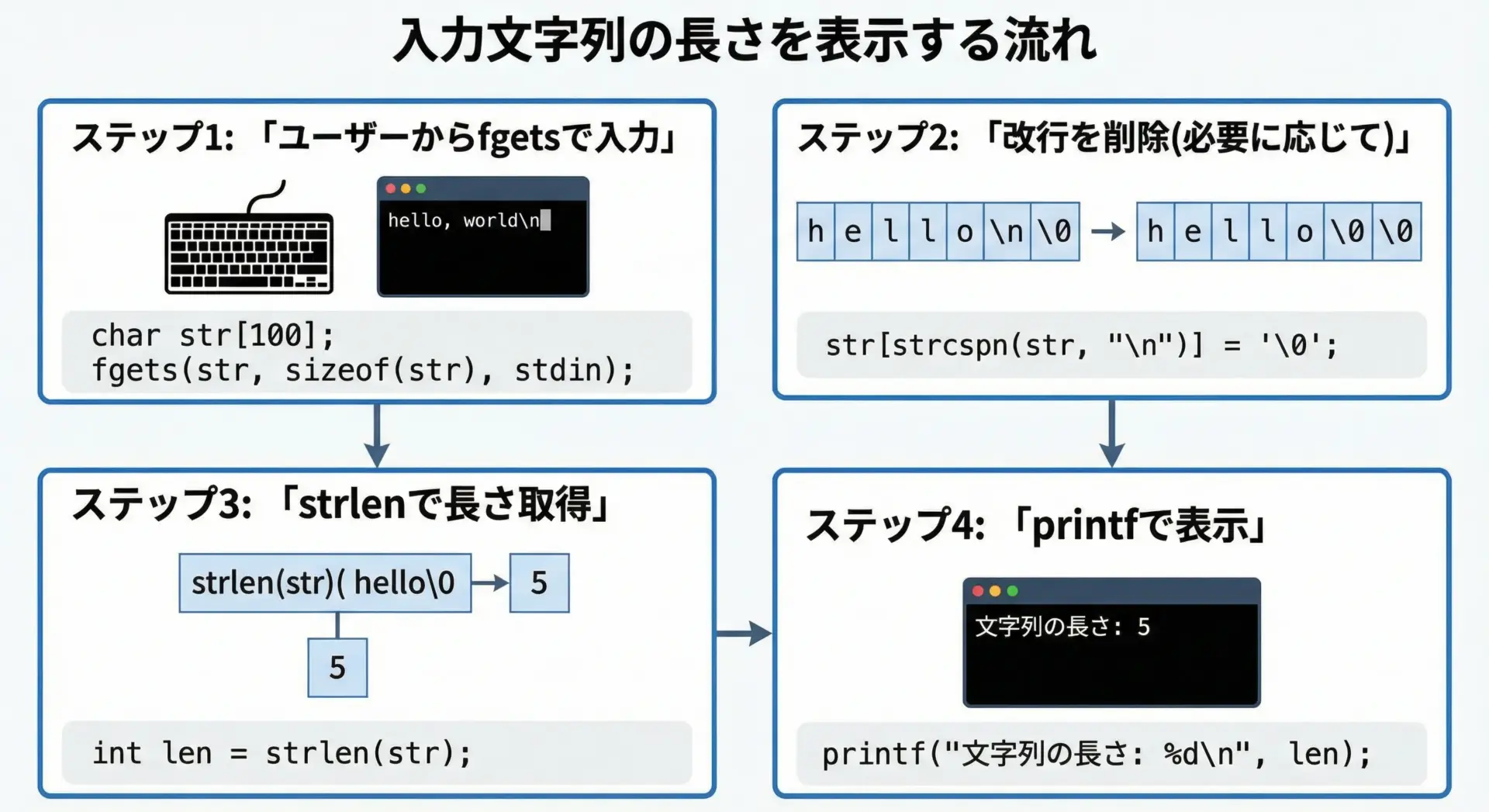
strlenは、ユーザー入力の確認やログ出力など文字列の長さを動的に扱いたい場面でよく使われます。
#include <stdio.h>
#include <string.h>
int main(void) {
char buf[100];
printf("文字列を入力してください: ");
// 標準入力から1行読み込む(最大99文字+終端)
if (fgets(buf, sizeof(buf), stdin) == NULL) {
printf("入力エラーです。\n");
return 1;
}
// 末尾の改行を取り除く(あれば)
size_t len = strlen(buf);
if (len > 0 && buf[len - 1] == '\n') {
buf[len - 1] = '\0';
len--; // 長さを1つ減らす
}
printf("入力された文字列: \"%s\"\n", buf);
printf("長さ(バイト数): %zu\n", len);
return 0;
}文字列を入力してください: Hello
入力された文字列: "Hello"
長さ(バイト数): 5このようにstrlenとprintfを組み合わせることで、任意の文字列の長さを柔軟に表示できます。
strlenの落とし穴と注意点
strlenとマルチバイト文字(日本語)の注意点
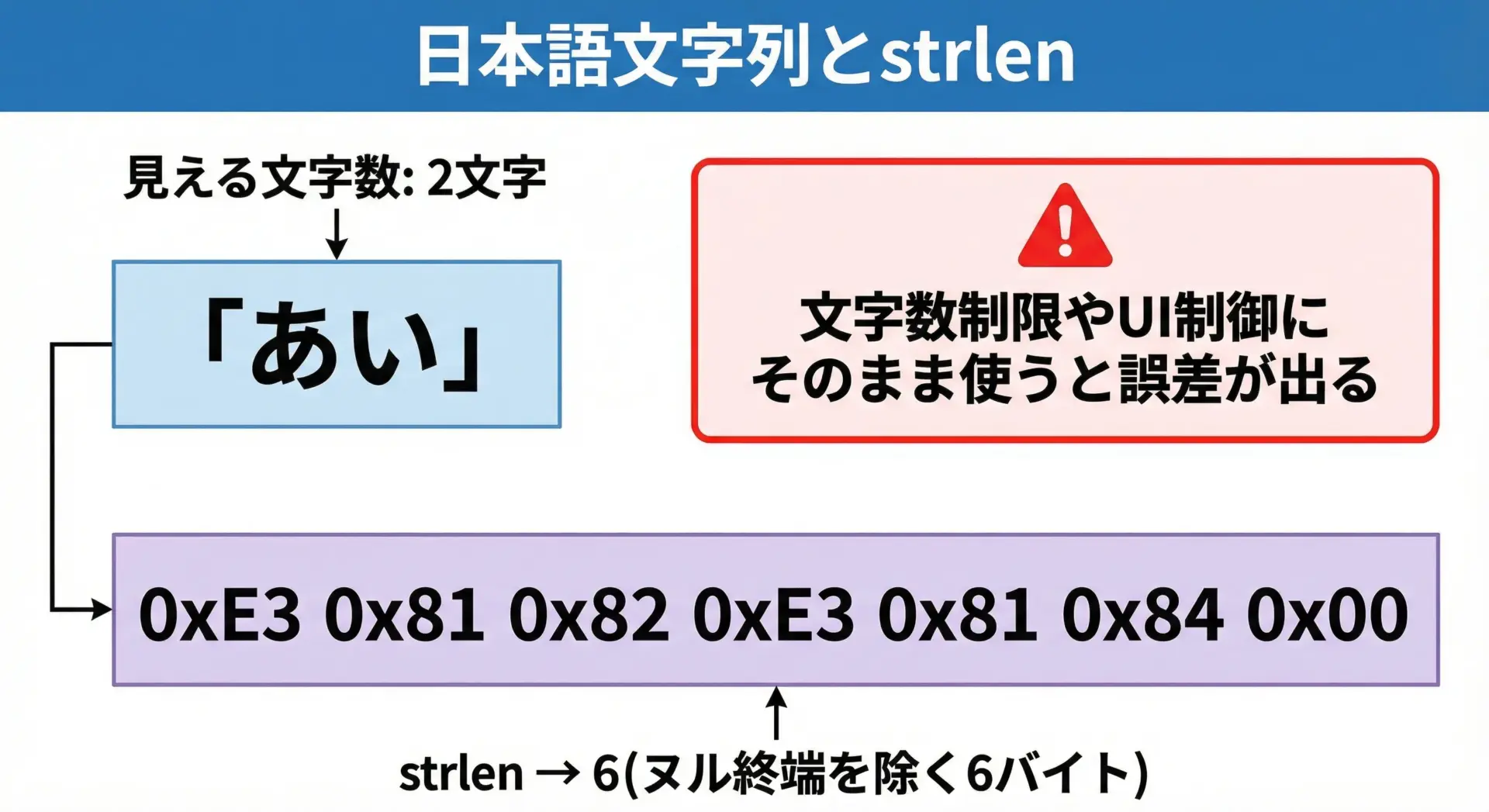
日本語などのマルチバイト文字を含む文字列では、「画面に見える文字数」とstrlenの結果が一致しないことがほとんどです。
例えば、UTF-8環境で次のようなコードを考えます。
#include <stdio.h>
#include <string.h>
int main(void) {
const char *s = "あい"; // UTF-8を仮定(1文字3バイト)
size_t len = strlen(s);
printf("文字列: \"%s\"\n", s);
printf("strlenの結果(バイト数): %zu\n", len);
printf("見た目の文字数(目視): 2\n");
return 0;
}文字列: "あい"
strlenの結果(バイト数): 6
見た目の文字数(目視): 2このように、strlenは「あ」も「い」もそれぞれ3バイトとして数えるため、結果は6になります。
文字数制限やレイアウト制御で「10文字まで」などのルールを実装したい場合にstrlenだけで判断すると誤差が発生します。
そのような場面では、後述するマルチバイト文字列用関数(例: mbstowcsやmblen)やワイド文字列wchar_tを利用する必要があります。
strlenとsizeofの違いと使い分け
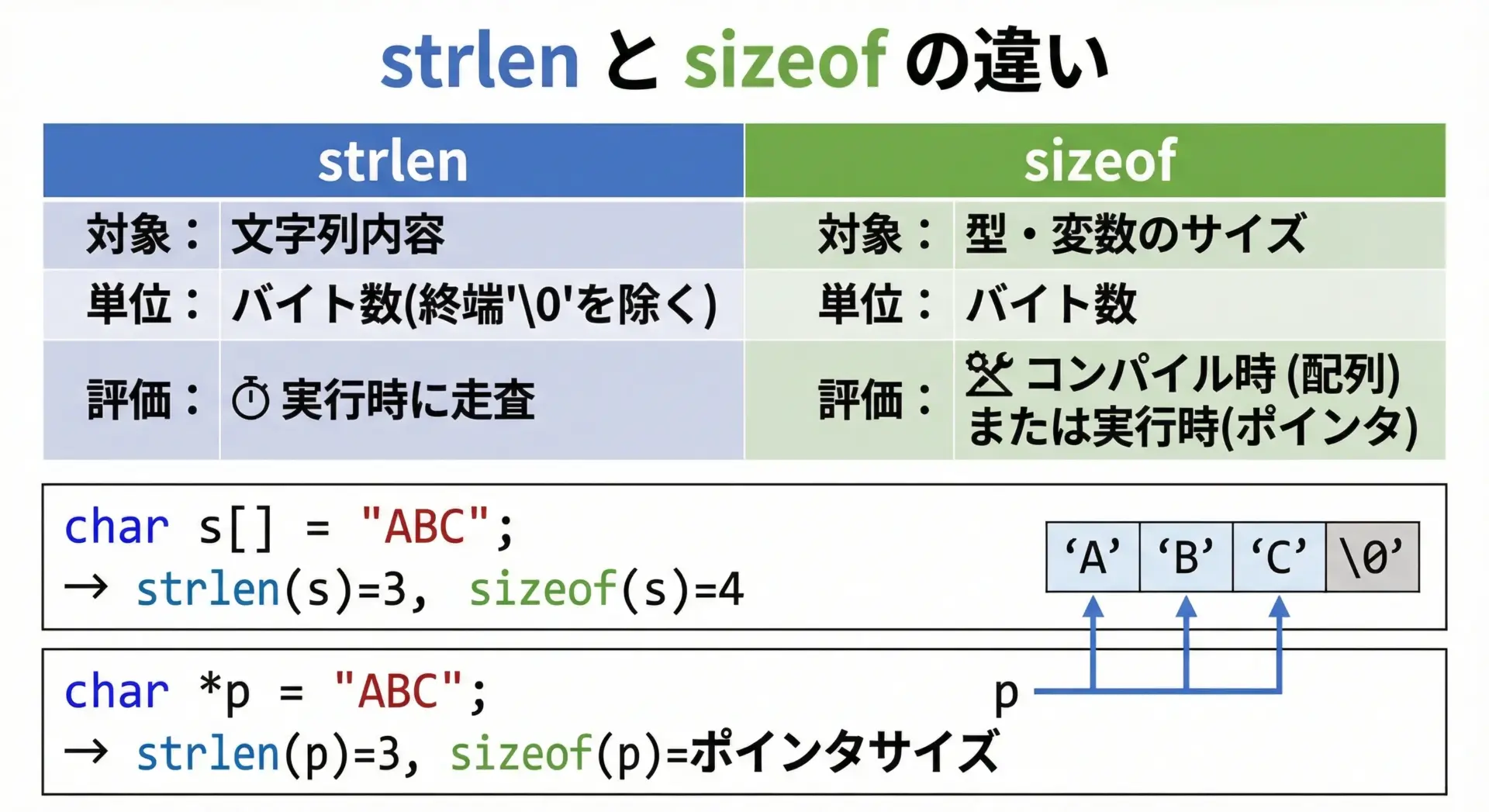
strlenとsizeofはどちらも「サイズ」に関わるため混同されがちですが、役割が大きく異なります。
| 項目 | strlen | sizeof |
|---|---|---|
| 対象 | ヌル終端文字列の内容 | 型・変数そのもの |
| 単位 | バイト数(終端'\0'を除く) | バイト数 |
| 判定 | 実行時に'\0'まで走査 | コンパイル時(配列)または実行時(ポインタ) |
| 引数の型 | const char * | 任意の式(型情報に基づく) |
代表的な例を見てみます。
#include <stdio.h>
#include <string.h>
int main(void) {
char s1[] = "ABC"; // 配列(要素数4: 'A','B','C','\0')
char *s2 = "ABC"; // ポインタ(アドレスを保持)
printf("s1: strlen=%zu, sizeof=%zu\n", strlen(s1), sizeof(s1));
printf("s2: strlen=%zu, sizeof=%zu\n", strlen(s2), sizeof(s2));
return 0;
}s1: strlen=3, sizeof=4
s2: strlen=3, sizeof=8 ← 例: 64bit環境でポインタが8バイトの場合重要な使い分けとして、
strlen: 文字列の長さを知りたいとき(ヌル終端前まで)sizeof: 配列や型そのもののサイズ(バッファの最大サイズなど)を知りたいとき
というように目的に応じて使い分ける必要があります。
ヌル終端されていない文字列に対する危険性

strlenは、文字列が必ずヌル終端されていることを前提として設計されています。
したがって、末尾に'\0'がない配列や、偶然にヌル終端が消えてしまった文字列に対してstrlenを呼び出すと、未定義動作になります。
次のコードは典型的な危険な例です。
#include <stdio.h>
#include <string.h>
int main(void) {
char buf[4];
// ヌル終端を付けずに4バイト書き込む
buf[0] = 'T';
buf[1] = 'E';
buf[2] = 'S';
buf[3] = 'T'; // '\0' がない!
// 非常に危険: '\0'を求めてバッファ外まで読み続ける可能性がある
size_t len = strlen(buf);
printf("len = %zu\n", len); // 挙動は未定義(クラッシュするかもしれない)
return 0;
}このようなコードでは、strlenが配列境界を越えてメモリを読み続ける可能性があり、クラッシュや情報漏えいの原因となります。
常に'\0'が付いているかを確認することが重要です。
部分文字列やバッファ境界でのstrlenの誤用
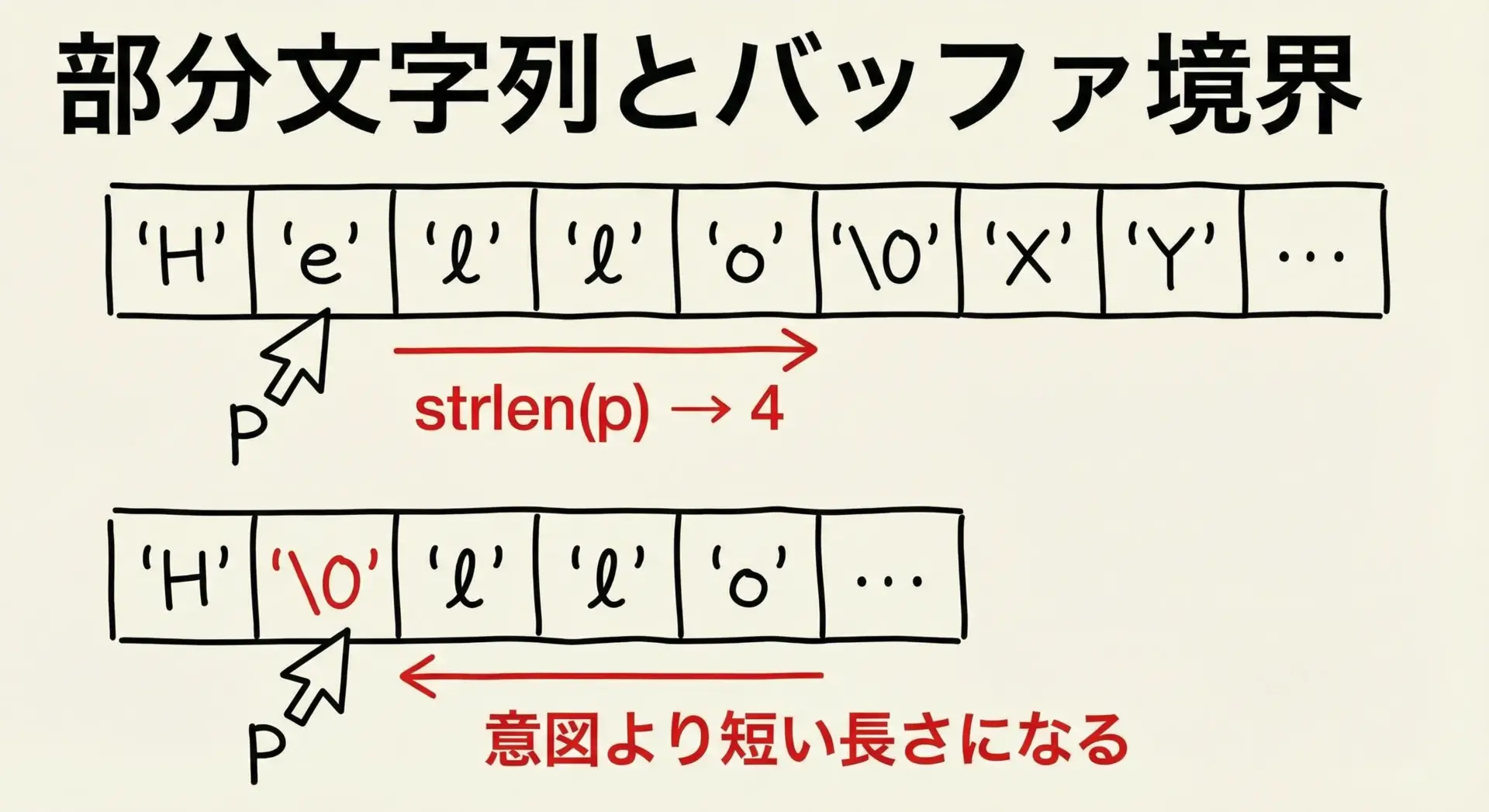
部分文字列や固定長バッファを扱うときにも注意が必要です。
例えば、次のようなコードを考えます。
#include <stdio.h>
#include <string.h>
int main(void) {
char str[] = "Hello, world!";
char *sub = &str[7]; // "world!" を指す
printf("元の文字列: %s\n", str);
printf("部分文字列(sub): %s\n", sub);
printf("strlen(sub) = %zu\n", strlen(sub));
return 0;
}元の文字列: Hello, world!
部分文字列(sub): world!
strlen(sub) = 6この例のように、部分文字列が元の文字列中でヌル終端まで続いている場合は問題ありません。
しかし、途中で意図的に'\0'を挿入していたり、別のバッファとの境目に重なっていたりすると、strlenが意図した長さより短く/長く数えてしまうことがあります。
特に固定長バッファでは、
- バッファ全体のサイズは
sizeof(buf)で管理 - 実際の文字列長は
strlen(buf)で管理
というように、役割を明確に分けて設計することが重要です。
また、文字数ではなく「最大何バイトまで」を意識した関数(例: strnlen)の利用を検討することも有効です。
パフォーマンス面の注意
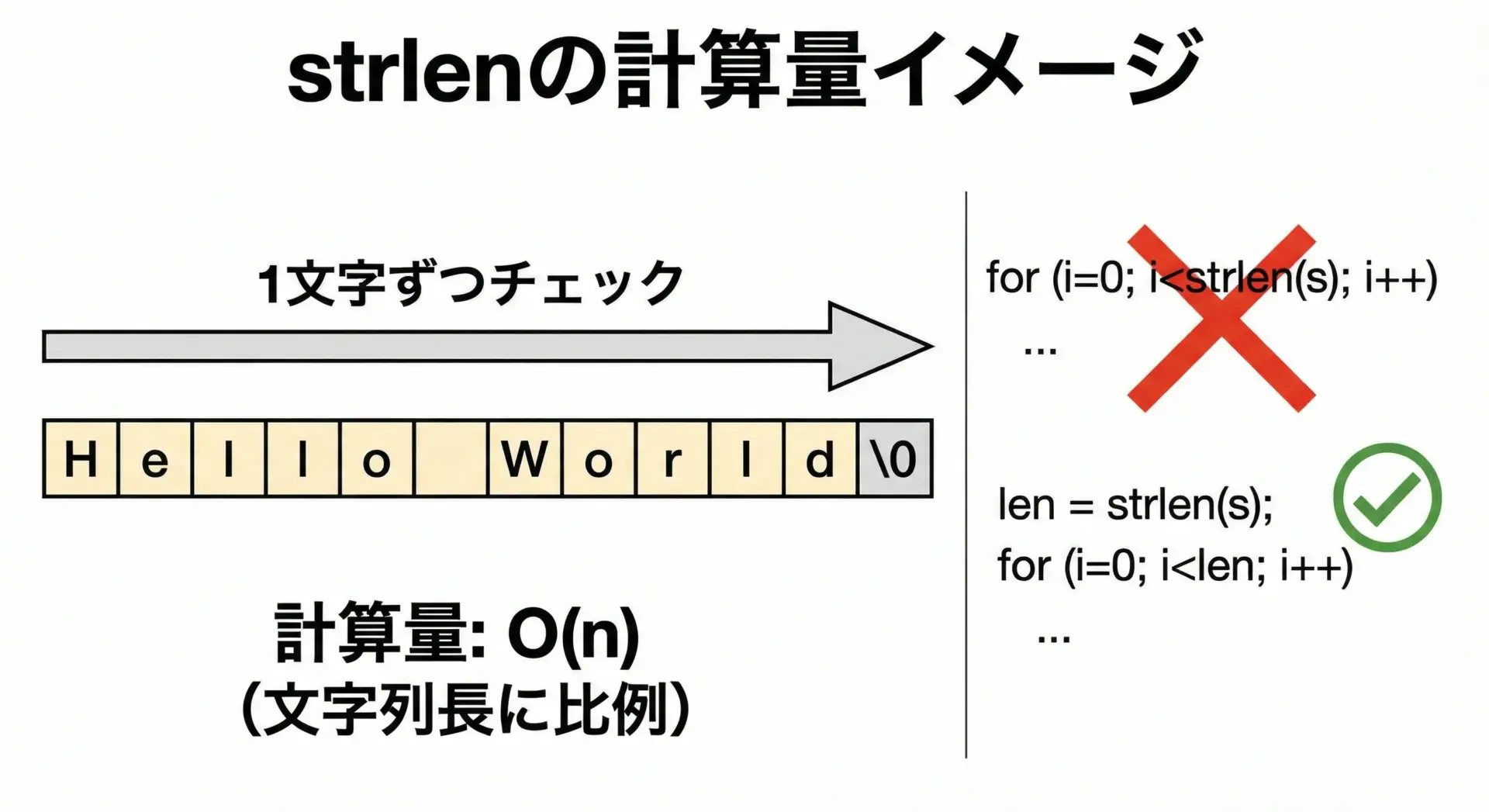
strlenは先頭から'\0'まで1文字ずつ走査するため、処理時間は文字列長に比例して増加します。
通常の短い文字列では問題になりませんが、非常に長い文字列や頻繁に呼び出されるループ内部ではパフォーマンスに影響することがあります。
典型的なアンチパターンとして、次のようなコードが挙げられます。
#include <string.h>
void func(char *s) {
// 悪い例: strlenを毎回呼び出している
for (size_t i = 0; i < strlen(s); i++) {
// 何らかの処理
}
}この書き方では、ループのたびにstrlenが呼び出され、文字列全体を毎回走査することになります。
改善版は次のようになります。
#include <string.h>
void func(char *s) {
// 良い例: 長さを事前に1回だけ計算して使い回す
size_t len = strlen(s);
for (size_t i = 0; i < len; i++) {
// 何らかの処理
}
}文字列長が変わらない場面では、strlenの結果を事前に保存して再利用することで、不要な処理を減らすことができます。
strlen以外の文字数カウント方法
マルチバイト文字列の文字数カウント関数
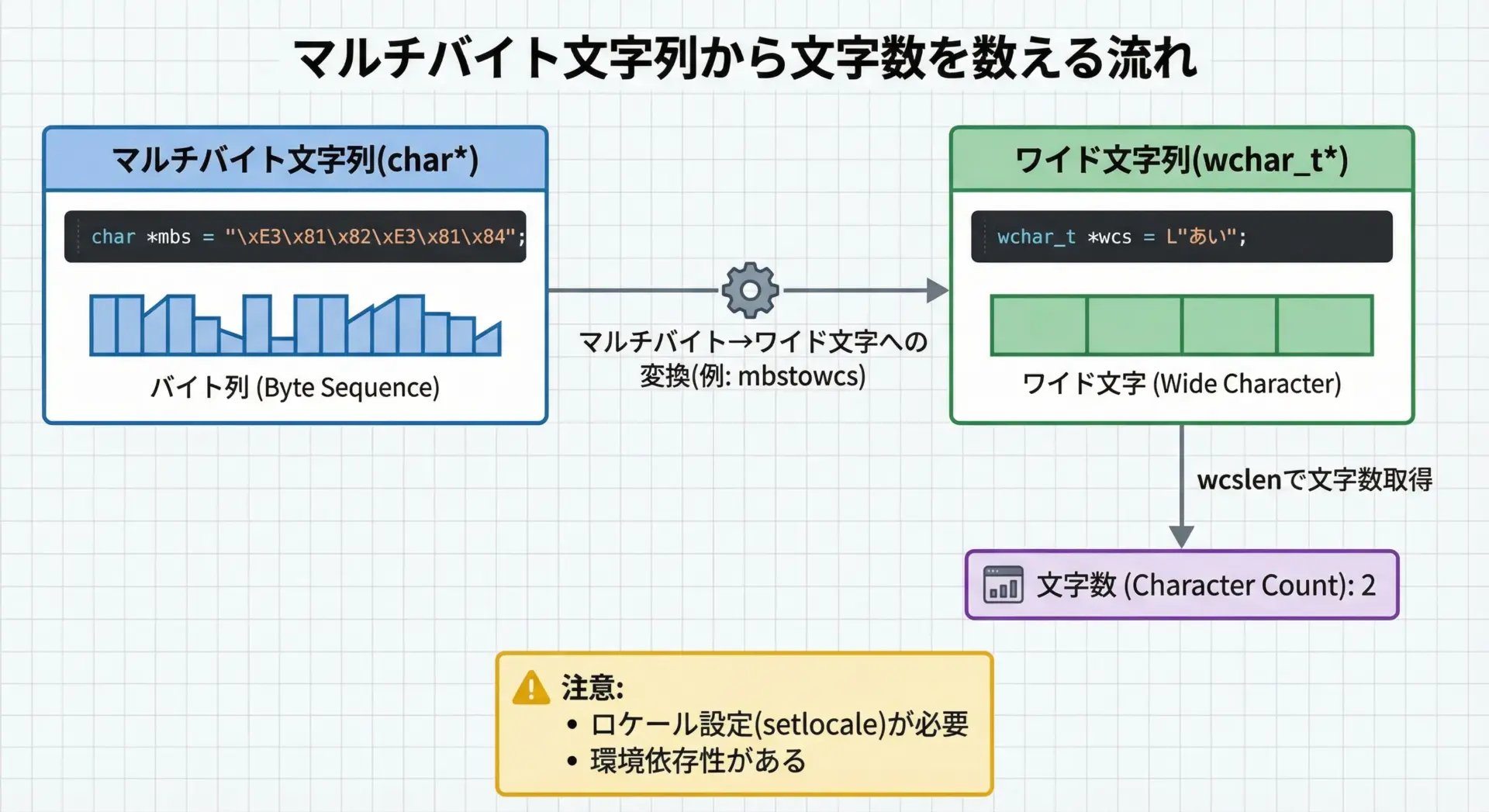
日本語などのマルチバイト文字を「文字数」として数えたい場合は、マルチバイト文字用のライブラリ関数を利用するのが一般的です。
代表的なアプローチとして、mbstowcsを使ってcharのマルチバイト文字列をwchar_tのワイド文字列に変換し、その後wcslenで文字数を数える方法があります。
#include <stdio.h>
#include <string.h>
#include <wchar.h>
#include <locale.h>
int main(void) {
// ロケールを日本語環境に設定(環境に応じて変更)
setlocale(LC_CTYPE, "");
const char *mbs = "あい"; // マルチバイト文字列(UTF-8などを想定)
wchar_t wbuf[100];
// マルチバイト文字列をワイド文字列に変換
size_t n = mbstowcs(wbuf, mbs, sizeof(wbuf) / sizeof(wbuf[0]));
if (n == (size_t)-1) {
printf("変換エラー\n");
return 1;
}
// wcslenで「文字単位」の長さを取得
size_t char_count = wcslen(wbuf);
printf("マルチバイト文字列: \"%s\"\n", mbs);
printf("文字数(ワイド文字としての長さ): %zu\n", char_count);
return 0;
}マルチバイト文字列: "あい"
文字数(ワイド文字としての長さ): 2この方法では、画面に見える「文字数」に近い値を得ることができます。
ただし、
- ロケール
setlocaleの設定が必須 - エンコーディングや環境に依存する
などの注意点があります。
ワイド文字列(wchar_t)と文字数カウント
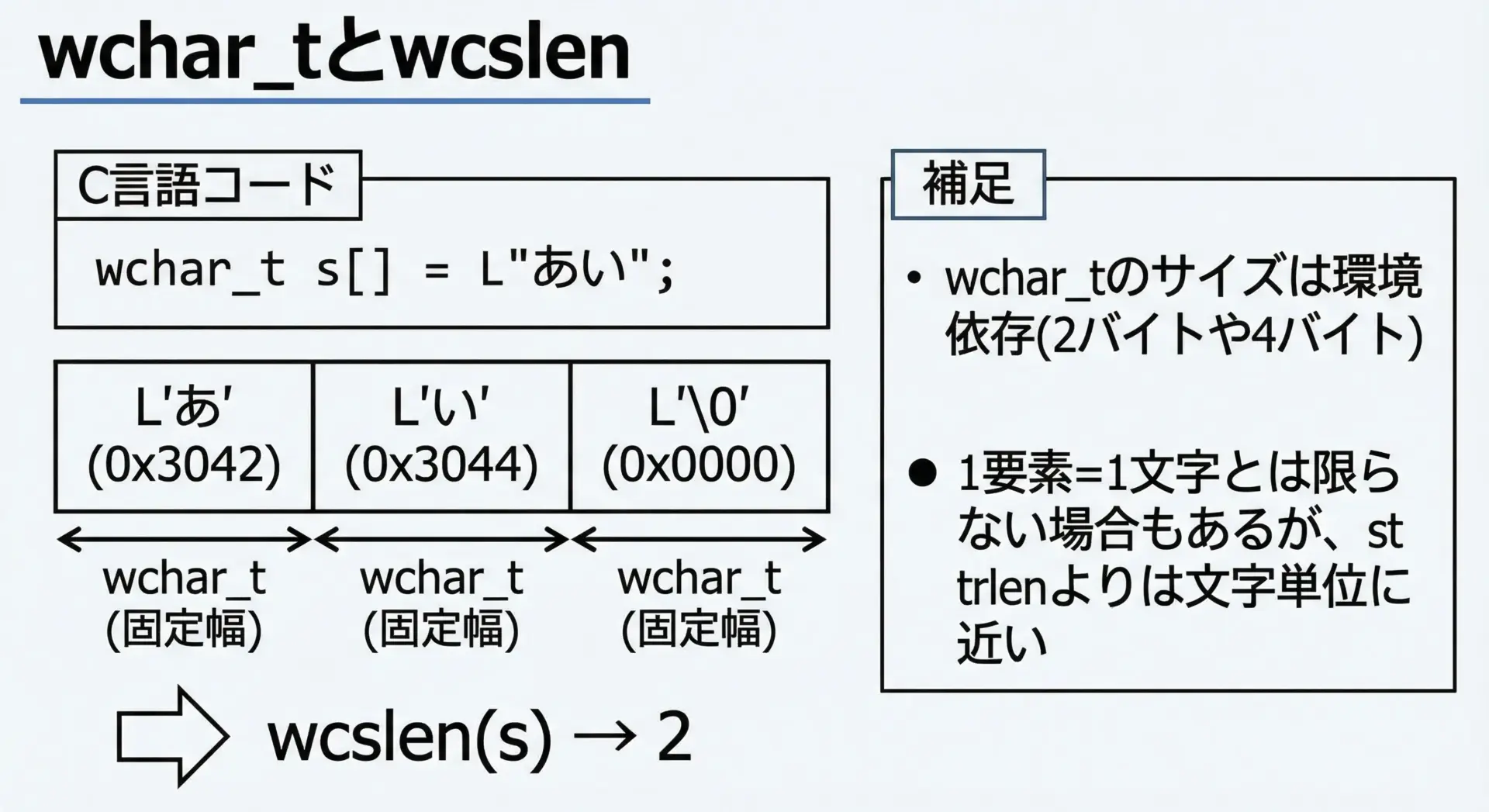
wchar_tは、より広い文字集合を扱うための型で、多くの環境ではUTF-16またはUTF-32に対応する幅を持ちます。
ワイド文字列の長さを数えるにはwcslen関数を使います。
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int main(void) {
// ワイド文字列を正しく表示するためにロケールを設定
setlocale(LC_CTYPE, "");
// ワイド文字列リテラルは先頭に L を付ける
wchar_t ws[] = L"あい";
size_t len = wcslen(ws);
wprintf(L"ワイド文字列: \"%ls\"\n", ws);
wprintf(L"文字数(wcslenの結果): %zu\n", len);
return 0;
}ワイド文字列: "あい"
文字数(wcslenの結果): 2wchar_t + wcslenは、strlenよりも「文字単位」に近い扱いができますが、
- 完全に「1要素=1文字」になるとは限らない(サロゲートペアや結合文字など)
- 実装やプラットフォームによって
wchar_tのサイズが異なる
といった点は押さえておく必要があります。
UTF-8文字列の文字数カウントの考え方

UTF-8では、1文字が1〜4バイトで表現されるため、単純なstrlenでは「文字数」を求めることができません。
UTF-8の文字数を数える基本的な考え方は、各コードポイントの先頭バイトを検出し、その数をカウントするというものです。
ここでは、厳密性よりも「UTF-8の概念理解」を目的とした簡易的なカウンタの例を示します。
(実務ではICUなどの信頼できるライブラリの利用を強く推奨します。)
#include <stdio.h>
#include <string.h>
// 簡易的なUTF-8文字数カウンタ
// ※ エラー処理や不正なシーケンスの扱いは最小限であり、実務用途には不十分です。
size_t utf8_char_count(const char *s) {
size_t count = 0;
const unsigned char *p = (const unsigned char *)s;
while (*p != '\0') {
// 先頭バイトのビットパターンで文字のバイト数を判定
if ((*p & 0x80) == 0x00) {
// 0xxxxxxx (ASCII, 1バイト文字)
p += 1;
} else if ((*p & 0xE0) == 0xC0) {
// 110xxxxx (2バイト文字の先頭)
p += 2;
} else if ((*p & 0xF0) == 0xE0) {
// 1110xxxx (3バイト文字の先頭)
p += 3;
} else if ((*p & 0xF8) == 0xF0) {
// 11110xxx (4バイト文字の先頭)
p += 4;
} else {
// 不正なバイト(本来は厳密なチェックが必要)
p += 1;
}
count++;
}
return count;
}
int main(void) {
const char *s1 = "ABC";
const char *s2 = "あい";
const char *s3 = "Aあ🙂"; // 絵文字を含む例(環境によっては文字化けする場合があります)
printf("s1: \"%s\" strlen=%zu utf8_char_count=%zu\n",
s1, strlen(s1), utf8_char_count(s1));
printf("s2: \"%s\" strlen=%zu utf8_char_count=%zu\n",
s2, strlen(s2), utf8_char_count(s2));
printf("s3: \"%s\" strlen=%zu utf8_char_count=%zu\n",
s3, strlen(s3), utf8_char_count(s3));
return 0;
}s1: "ABC" strlen=3 utf8_char_count=3
s2: "あい" strlen=6 utf8_char_count=2
s3: "Aあ🙂" strlen=?? utf8_char_count=3 ← 文字コードによりstrlen結果は変化このような関数を使うことで、UTF-8文字列の「ざっくりとした文字数」を知ることはできますが、実際には、
- 結合文字(濁点・半濁点など)をどう扱うか
- 絵文字のバリエーション(肌の色、性別など)をどう数えるか
といった問題があり、「ユーザーに見える1文字」の定義は非常に複雑です。
そのため、本格的な国際化対応アプリケーションでは、ICUライブラリなどの専門ライブラリを利用することが一般的です。
まとめ
strlenは「ヌル終端されたchar配列のバイト数を返す、シンプルかつ強力な標準関数」です。
一方で、マルチバイト文字における「文字数」との違いや、ヌル終端の有無、sizeofとの混同、パフォーマンスなど、注意すべき点も多く存在します。
日本語やUTF-8を正しく扱うにはwchar_tやマルチバイト関数、さらには専用ライブラリの利用が不可欠です。
用途に応じて「バイト数」と「文字数」を明確に区別し、適切な関数を選択することが、安全で読みやすいC言語プログラムへの第一歩になります。
