C言語で文字列を扱い始めると、文字列リテラルとchar配列の違いで混乱しやすくなります。
どちらも似たように見えますが、メモリの扱い方や寿命、書き換えの可否など、重要な違いがたくさんあります。
この記事では、C言語入門者がつまずきがちなポイントを、図解とサンプルコードを使いながら、ひとつずつ丁寧に解説していきます。
文字列リテラルとchar配列とは
C言語の文字列リテラルとは
まず、C言語における文字列リテラルとは何かを明確にしておきます。
文字列リテラルとは、プログラムのソースコード中に"Hello"のようにダブルクォーテーションで囲まれた文字列のことです。
これはコンパイル時に決まった定数データとして扱われます。
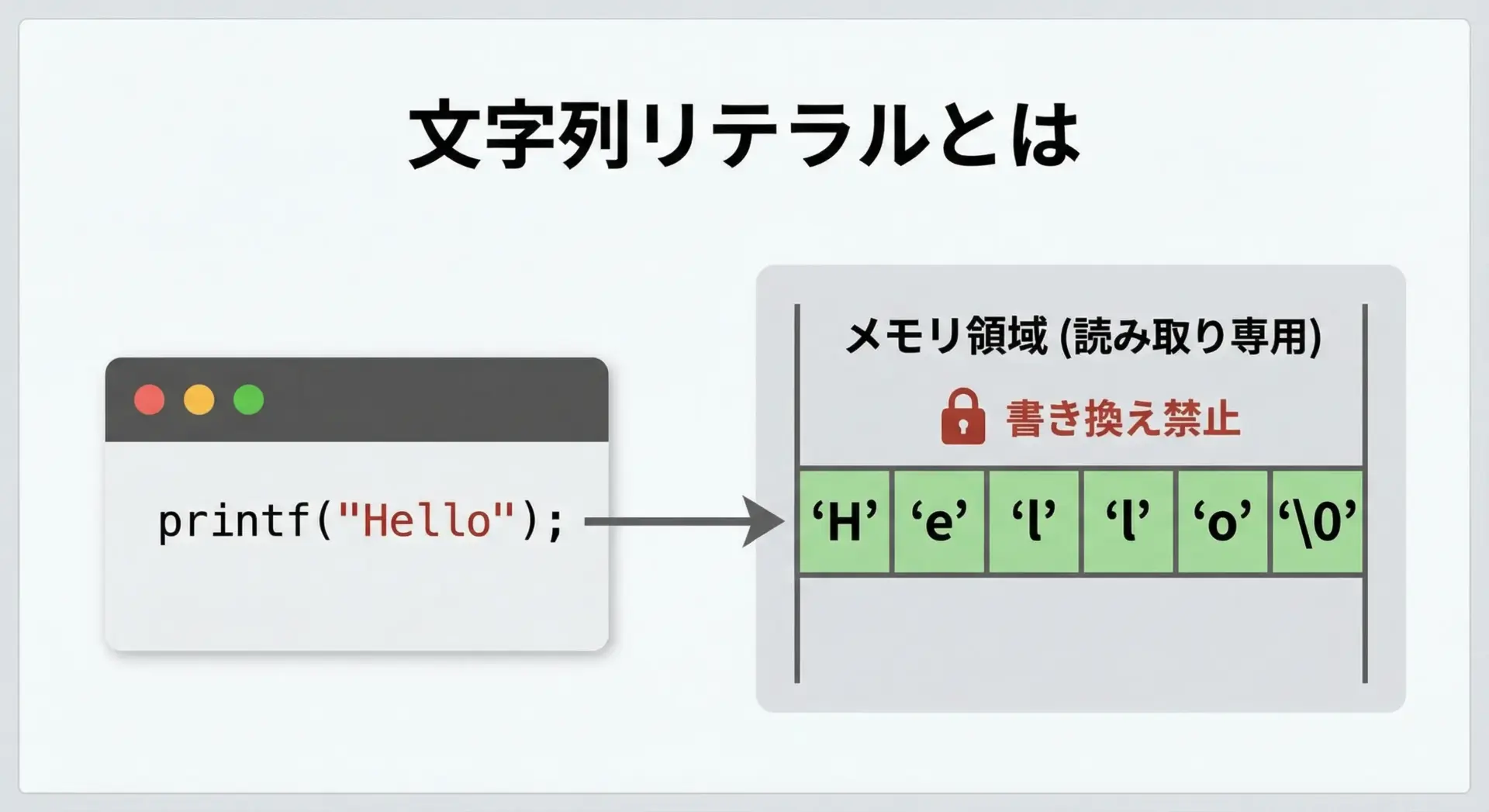
文字列リテラルには、次のような特徴があります。
- プログラム開始前にメモリに配置される
- 通常は書き換えてはいけないデータとして扱われる
- 文字列の最後に
'\0'(ナル文字、終端文字)が自動的に付く
たとえば、次のような記述があります。
#include <stdio.h>
int main(void) {
// 文字列リテラル "Hello" を printf に直接渡している例
printf("Hello\n");
return 0;
}このとき"Hello\n"は文字列リテラルであり、コンパイルされたプログラムの中に「定数データ」として埋め込まれます。
char配列とは
次に、char配列について見ていきます。
char配列は、複数の文字を連続して格納するための通常の配列です。
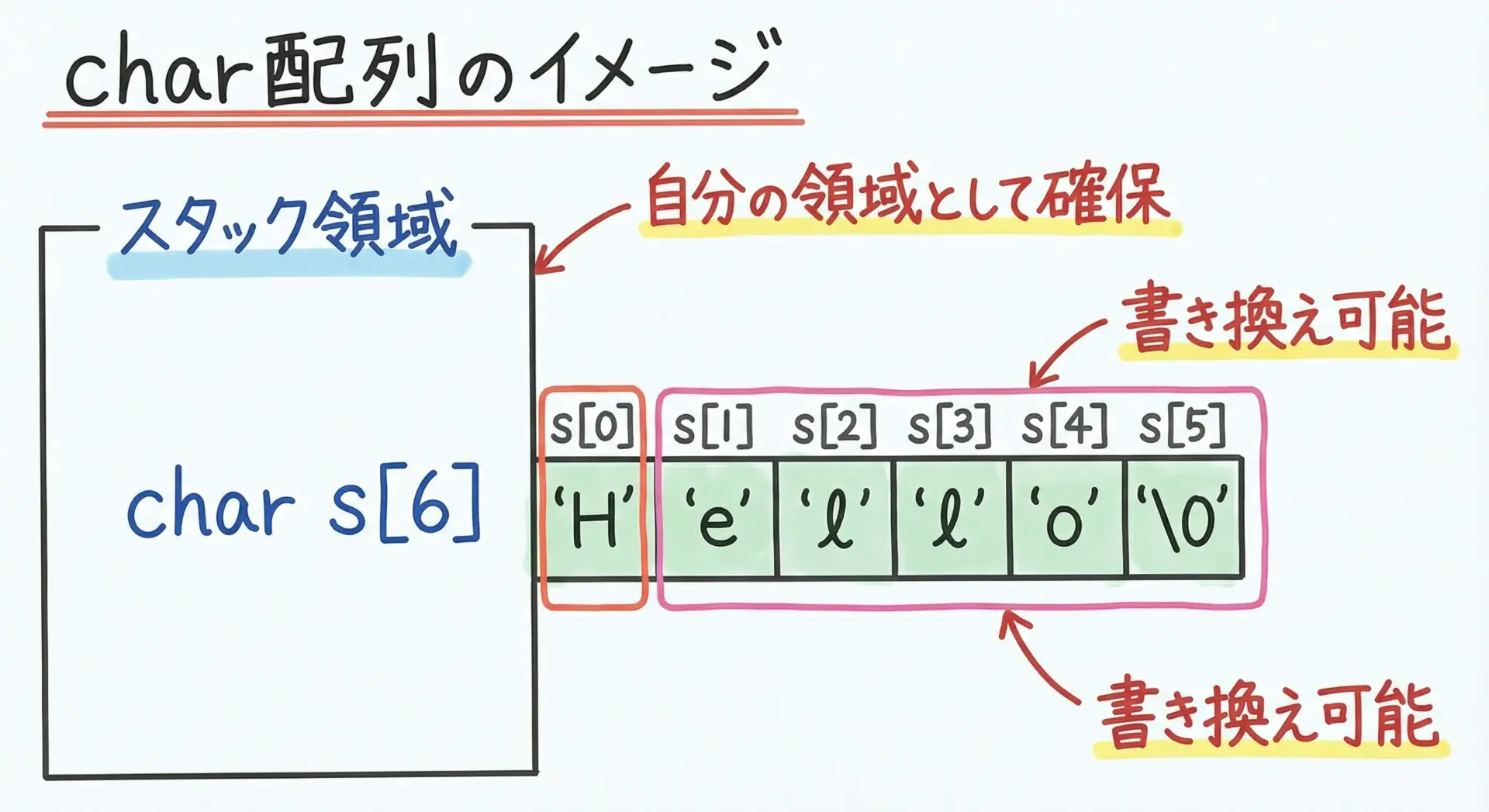
たとえば、次のように定義します。
#include <stdio.h>
int main(void) {
// 6文字分のchar配列を宣言 (Hello\0 の6文字分)
char s[6] = { 'H', 'e', 'l', 'l', 'o', '\0' };
printf("%s\n", s); // 配列sを文字列として表示
return 0;
}この配列sは、プログラムの実行時に自分専用のメモリ領域として確保され、その中に1文字ずつ格納されます。
配列ですので、必要に応じて中身を書き換えることができます。
文字列リテラルとchar配列の基本的な違い
ここまでの内容を、いったん表に整理してみます。
| 項目 | 文字列リテラル | char配列 |
|---|---|---|
| 宣言の例 | "Hello" | char s[6] = "Hello"; |
| 正体 | 定数データ | 配列(変数) |
| 配置される場所 | 実行ファイル中の静的領域 | 通常はスタック(自動変数) |
| 書き換え | 不可(してはいけない) | 可 |
終端文字'\0' | コンパイラが自動で付加 | サイズに余裕があれば自動付加、手動指定もあり |
| 寿命 | プログラム開始〜終了まで | 変数のスコープに依存 |
「見た目は似ているが、性質はかなり違う」という点を頭に入れておくことが重要です。
メモリ配置と寿命の違い
文字列リテラルとchar配列の違いを本当に理解するには、メモリ上の配置と有効期間(寿命)をセットで考える必要があります。
文字列リテラルのメモリ領域
文字列リテラルは、通常「静的領域」「読み取り専用領域」と呼ばれる場所に配置されます。
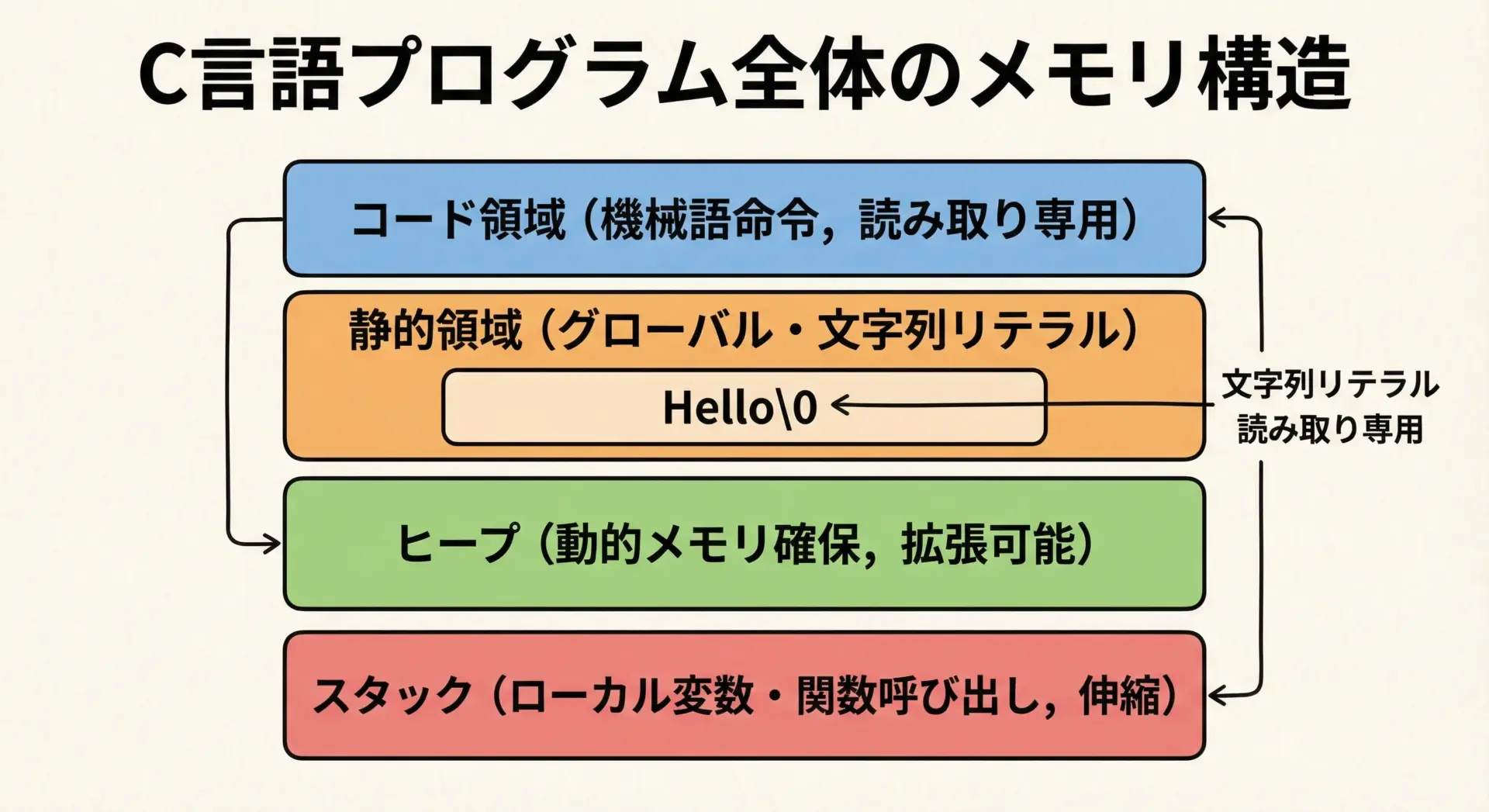
文字列リテラルの特徴を整理すると、次の通りです。
- 実行ファイルの中に定数として埋め込まれる
- プログラムの開始から終了まで、ずっと同じ場所に存在し続ける
- 通常は書き換えを行うと未定義動作になる(やってはいけない)
たとえば次のコードを見てください。
#include <stdio.h>
int main(void) {
// "Hello" という文字列リテラルへのポインタ
const char *p = "Hello";
printf("%s\n", p);
return 0;
}ここで"Hello"は静的領域にあり、変数pはスタック上にあります。
pには「文字列リテラルの先頭アドレス」が入っていますが、実体は静的領域側です。
char配列のメモリ領域
一方、char配列は定義の仕方によってメモリ領域が変わりますが、もっとも典型的なのはローカル変数として定義されるケースです。
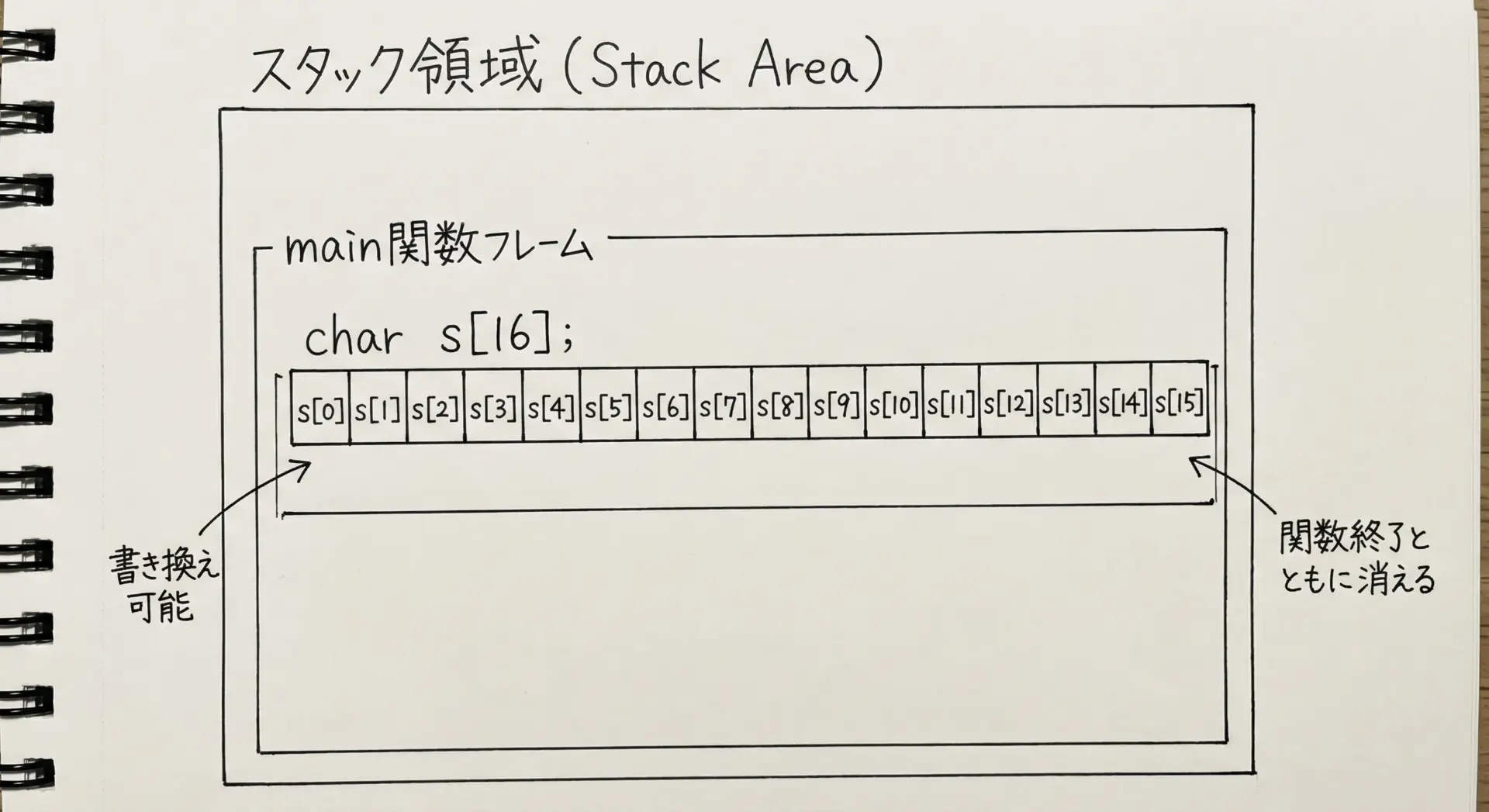
#include <stdio.h>
int main(void) {
// スタック上に16バイトのchar配列を確保
char buf[16] = "Hello";
printf("%s\n", buf); // "Hello" と表示される
return 0;
}ここでbufはスタック領域に確保され、関数mainが動いている間だけ存在します。
プログラムがreturn 0;に到達してmainを抜けると、bufの領域は無効になります。
有効期間と書き換え可否の違い
「どこに置かれるか」が違うので、「いつまで生きているか」「書き換えてよいか」も変わります。

文字列リテラル:
- プログラム開始〜終了まで存在する
- ただし書き換え禁止
char配列(ローカル変数):
- 定義されたブロック(たとえば関数)の実行中だけ存在
- その間は自由に書き換え可能
次のようなコードは、実は危険です。
#include <stdio.h>
char *make_message(void) {
char buf[16] = "Hello"; // スタック上のローカル配列
return buf; // NG: ローカル変数のアドレスを返している
}
int main(void) {
char *p = make_message(); // p はすでに無効になった領域を指す
printf("%s\n", p); // 未定義動作(たまたま動くこともある)
return 0;
}ローカルなchar配列の寿命は関数を抜けるまでなので、そのアドレスを返してはいけません。
ここが文字列リテラルとの大きな差です。
よくあるつまずきポイント
ここからは、入門者が特につまずきやすいポイントを、具体的な例とともに解説します。
const charポインタとchar配列の混同
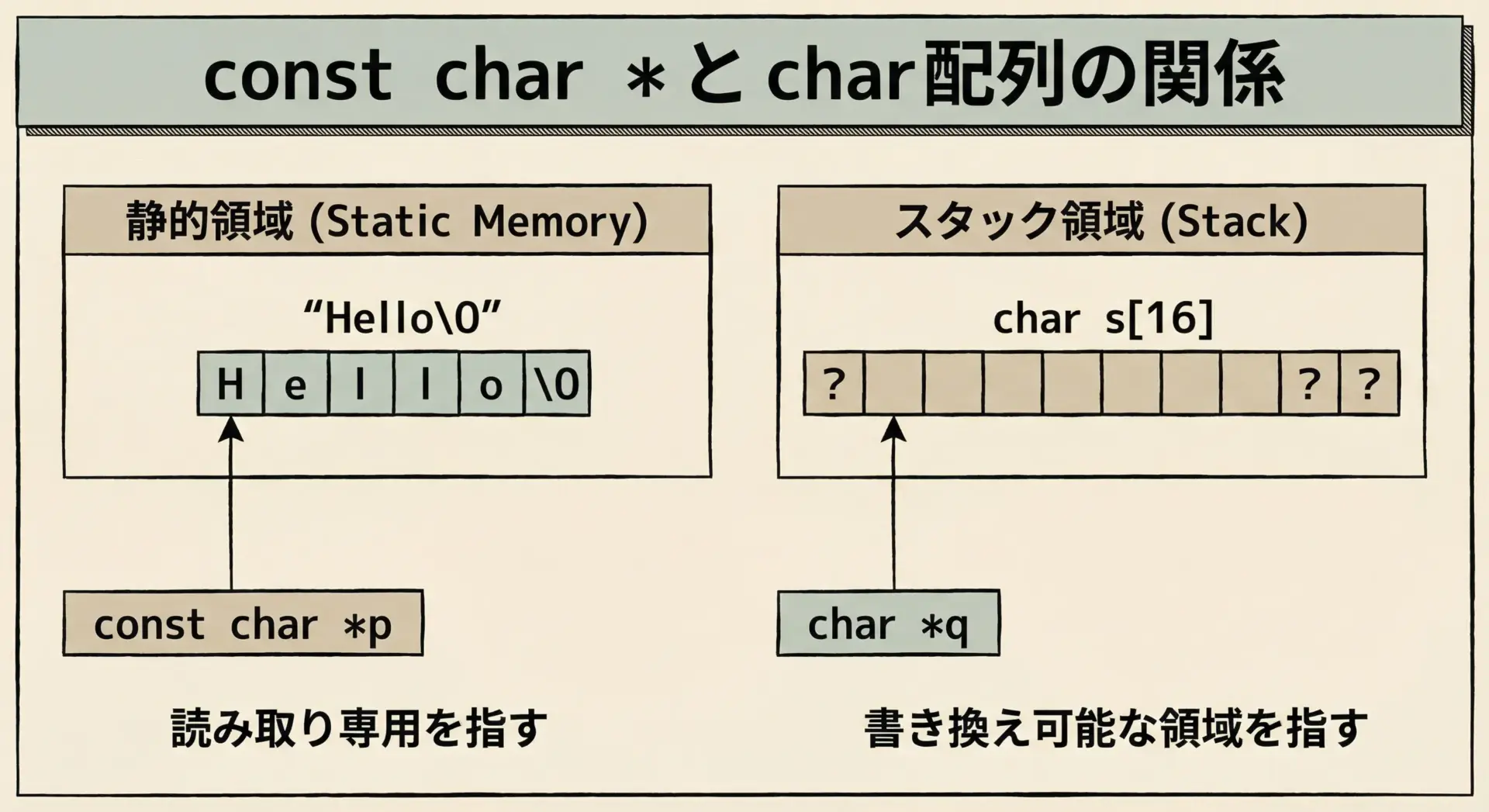
文字列リテラルを扱うときに頻出するのがconst char *という型です。
これは「書き換えてはいけない文字列を指すポインタ」という意味になります。
#include <stdio.h>
int main(void) {
const char *p = "Hello"; // 文字列リテラルへのポインタ(書き換え禁止)
char s[] = "Hello"; // 書き換え可能な配列
// p[0] = 'h'; // コンパイルエラー、または警告(書き換え禁止のため)
s[0] = 'h'; // OK: 配列sは書き換え可能
printf("p = %s\n", p);
printf("s = %s\n", s);
return 0;
}p = Hello
s = helloここで重要なのは、「pがconstなのではなく、『pが指している先の文字列がconst』」という点です。
つまりp自体には、別の文字列リテラルのアドレスを代入できますが、p[0]のように中身は変えてはいけません。
配列初期化とポインタ代入の違い
「見た目は同じように見えるが、意味がまったく違う」有名な例を見てみます。
#include <stdio.h>
int main(void) {
char a[] = "Hello"; // 配列を文字列で初期化
char *p = "Hello"; // 文字列リテラルへのポインタ
a[0] = 'h'; // OK: aは配列なので書き換え可能
// p[0] = 'h'; // NG: 文字列リテラルを書き換えようとしている(未定義動作)
printf("a = %s\n", a);
printf("p = %s\n", p);
return 0;
}a = hello
p = Hello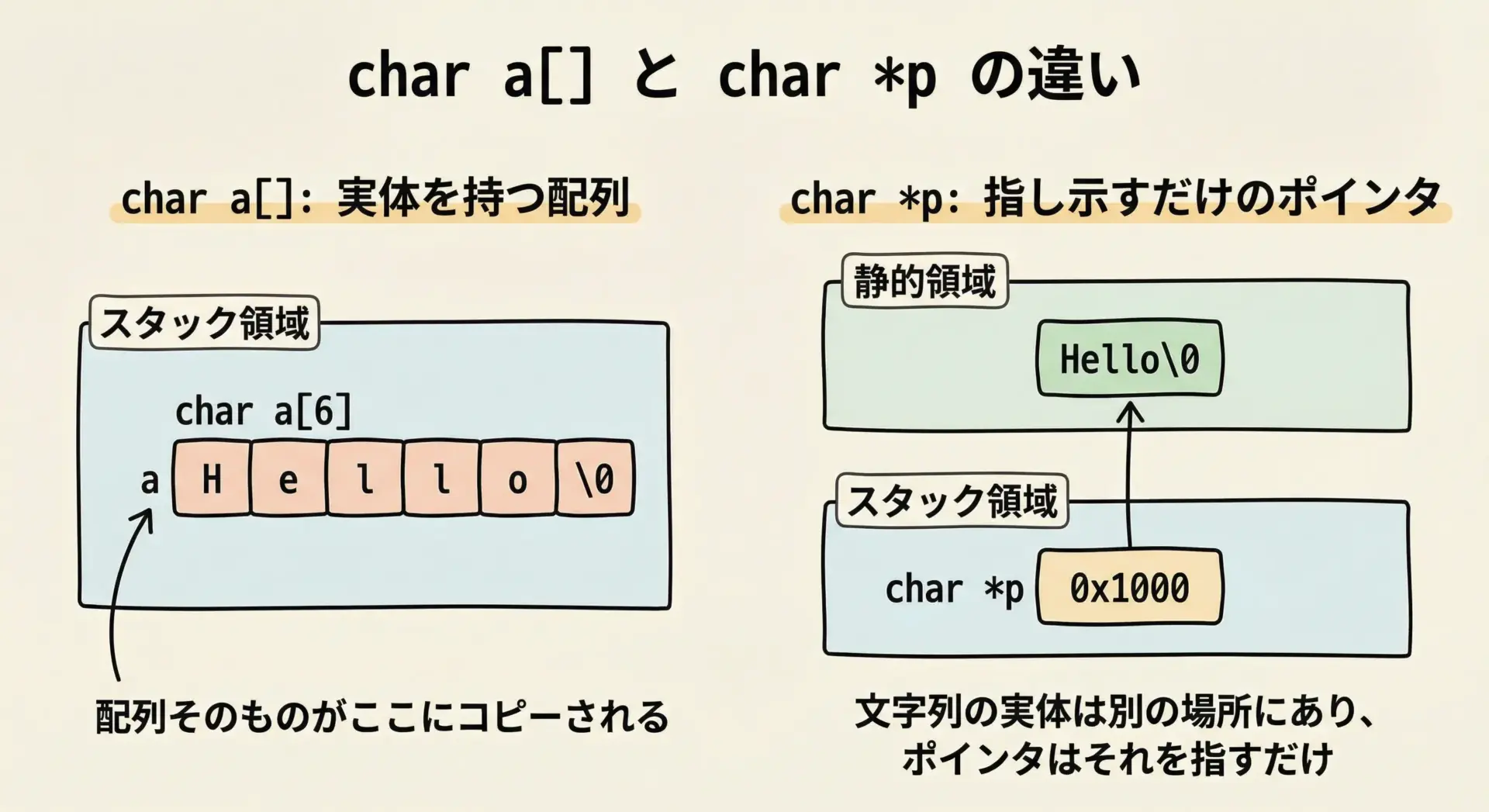
char a[] = “Hello”; は、コンパイル時に「配列aを作り、その中に’H’,’e’,’l’,’l’,’o’,’\0’を書き込む」という意味になります。
一方で、char *p = “Hello”;は、静的領域にある文字列リテラルの先頭アドレスをpに代入しているだけです。
strlenとsizeofの勘違い
文字列の長さを扱うときに混乱しやすいのが、strlenとsizeofです。
strlen:
- 引数で渡された文字列の実際の長さ(終端’\0’は含まない)を、実行時に数える関数
sizeof:
- 与えられた型や変数のバイト数を、コンパイル時に決定する演算子
#include <stdio.h>
#include <string.h>
int main(void) {
char s1[] = "Hello";
char s2[100] = "Hello";
printf("s1: strlen = %zu, sizeof = %zu\n",
strlen(s1), sizeof(s1));
printf("s2: strlen = %zu, sizeof = %zu\n",
strlen(s2), sizeof(s2));
return 0;
}s1: strlen = 5, sizeof = 6
s2: strlen = 5, sizeof = 100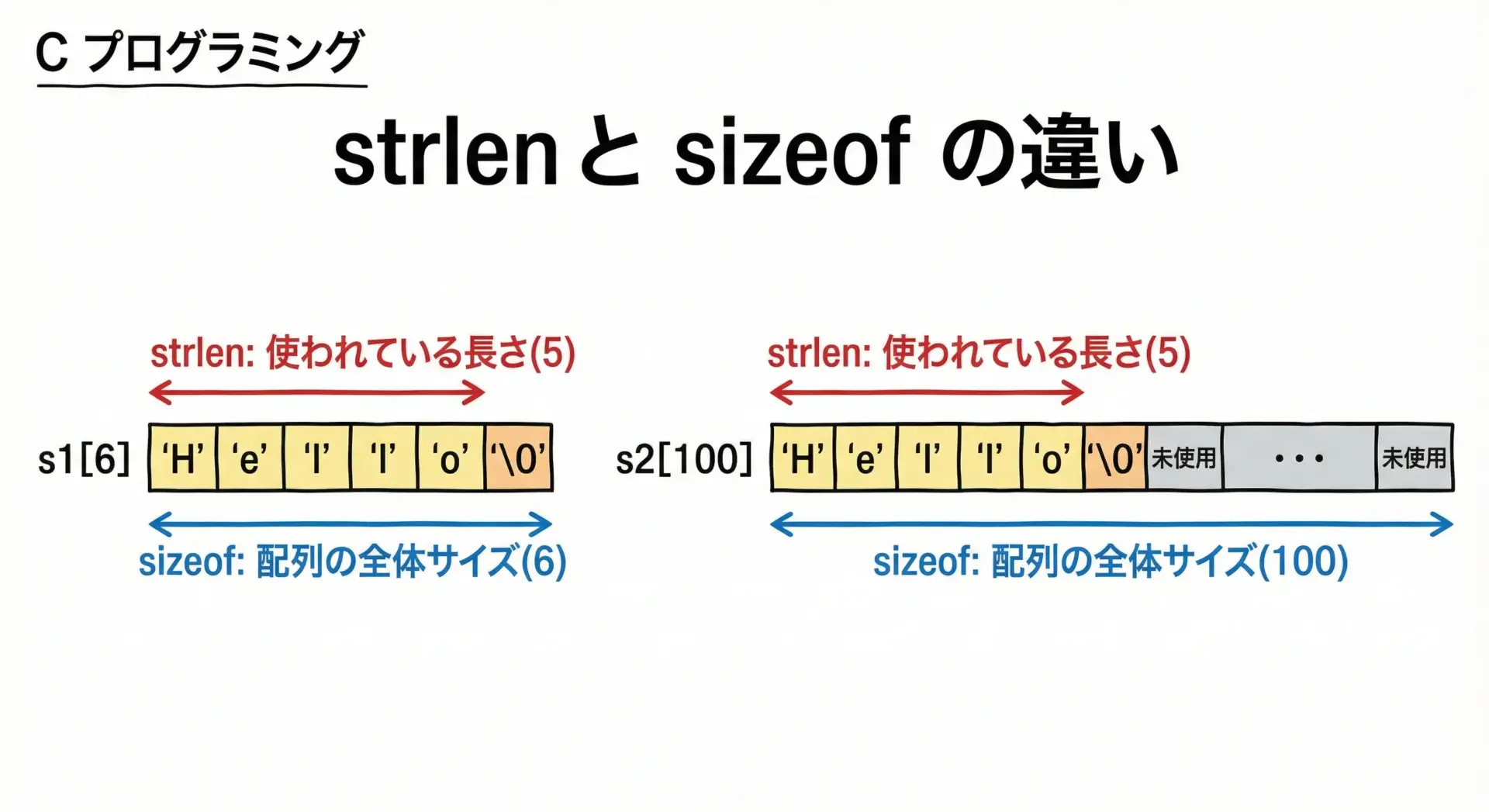
「文字列の長さが知りたいなら strlen」「領域の大きさが知りたいなら sizeof」と覚えておくとよいです。
終端文字(‘\0’)の付け忘れによるバグ
C言語の文字列は、最後に'\0'が入っていることで終わりを判定しています。
これを終端文字と呼びます。
終端文字がなかったり、誤って消してしまったりすると、strlenやprintfがメモリの先まで読み続けてしまい、バグやクラッシュの原因になります。
#include <stdio.h>
#include <string.h>
int main(void) {
char s[5]; // 5バイトしかない配列
s[0] = 'H';
s[1] = 'e';
s[2] = 'l';
s[3] = 'l';
s[4] = 'o'; // '\0' を入れる余地がない
printf("strlen(s) = %zu\n", strlen(s)); // 未定義動作
printf("%s\n", s); // どこまで出力されるかわからない
return 0;
}
自分で配列を1文字ずつ埋めるときは、必ず最後に’\0’を入れることを習慣にしてください。
正しい使い分けと実践的な書き方
ここまでの知識を踏まえて、実際にどのようにコードを書けばよいのか、具体的な方針を整理します。
文字列リテラルを使う場面と注意点
文字列リテラルが向いているのは、「固定のメッセージ」をただ表示したり、比較したりする場面です。
#include <stdio.h>
#include <string.h>
int main(void) {
// 定数メッセージの表示
printf("入力してください: ");
char cmd[16];
scanf("%15s", cmd);
// 文字列リテラルとの比較
if (strcmp(cmd, "exit") == 0) {
printf("終了します。\n");
} else {
printf("コマンド: %s\n", cmd);
}
return 0;
}
注意点として、文字列リテラル自体を変更しようとしないことが重要です。
必要なら、後述のようにchar配列へコピーしてから変更します。
char配列を使う場面と注意点
char配列が向いているのは、「中身を変更する可能性がある文字列」を扱う場面です。
たとえば、ユーザ入力を受け取るバッファや、パス名を組み立てる作業領域などが該当します。
#include <stdio.h>
int main(void) {
char name[32]; // ユーザの名前を格納するバッファ
printf("名前を入力してください: ");
scanf("%31s", name); // 最大31文字まで読み込む('\0'分を残す)
// nameを自由に加工できる
name[0] = '★'; // たとえば先頭文字を変える(例として)
printf("加工後の名前: %s\n", name);
return 0;
}
注意する点として、以下のポイントがあります。
- バッファサイズに対して読み込む最大文字数を常に意識する
- 終端文字’\0’の分を必ず残す
- 関数の外にポインタとして渡す場合は、寿命(スコープ)を意識する
安全な文字列コピーと結合の書き方
文字列を操作するとき、バッファオーバーフロー(配列の外にはみ出して書き込んでしまう)を避けることがとても重要です。
ここでは標準的なstrcpy, strcatと、その安全な使い方を解説します。
#include <stdio.h>
#include <string.h>
int main(void) {
char buf[32];
// 安全なコピー
// 1. まず空文字で初期化しておく
buf[0] = '\0';
// 2. strcatを使うときは、バッファ残量を自分でチェックする
const char *s1 = "Hello";
const char *s2 = ", world";
// s1 をコピー
if (strlen(s1) < sizeof(buf)) {
strcpy(buf, s1);
}
// s2 を後ろに結合
if (strlen(buf) + strlen(s2) < sizeof(buf)) {
strcat(buf, s2);
}
printf("%s\n", buf);
return 0;
}Hello, world
「コピーや結合の前に、必ずサイズ条件をチェックする」という習慣が、C言語で安全に文字列を扱うための基本パターンになります。
初心者が意識すべきコーディングパターン
最後に、初心者のうちから意識しておくと安全でわかりやすいおすすめパターンをいくつか挙げます。
パターン1: 「書き換えないもの」はconst char *で扱う
#include <stdio.h>
// メッセージを表示するだけの関数
void show_message(const char *msg) {
printf("%s\n", msg);
}
int main(void) {
show_message("Hello");
show_message("Goodbye");
return 0;
}関数の引数で、書き換えない文字列には必ずconstを付けると、意図が明確になり、間違った書き換えも防げます。
パターン2: 「書き換える可能性があるもの」はchar配列で確保
#include <stdio.h>
#include <string.h>
int main(void) {
char buf[64];
// 初期値をコピー
strcpy(buf, "base");
// 状況によって書き換え・追記
strcat(buf, "_v2");
printf("%s\n", buf); // base_v2
return 0;
}今後変更する可能性がある文字列は、最初から配列で用意すると、後からの修正がしやすくなります。
パターン3: sizeofは「同じスコープの配列」にだけ使う
#include <stdio.h>
void f(char s[]) {
// ここで sizeof(s) を使っても、配列のサイズはわからない
// s はポインタに「退化」しているため
printf("sizeof(s) in f = %zu\n", sizeof(s));
}
int main(void) {
char s[10];
printf("sizeof(s) in main = %zu\n", sizeof(s)); // 10
f(s); // ポインタサイズ(例: 8など)
return 0;
}出力例(64bit環境の一例):
sizeof(s) in main = 10
sizeof(s) in f = 8sizeofで配列のサイズを知りたいときは、「配列が定義されているスコープ内」だけで使うというルールを守ると、混乱を避けられます。
まとめ
文字列リテラルとchar配列は、どちらも文字列を扱うために使われますが、「定数データ」か「自分の領域を持つ変数」かという決定的な違いがあります。
文字列リテラルは静的領域に配置され、基本的に書き換え禁止で、プログラム中ずっと生きています。
一方でchar配列は、スタックなどに確保され、スコープ内でのみ有効で、自由に書き換え可能です。
strlenとsizeofの違いや終端文字'\0'の重要性を理解し、「変えないものはconst char *」「変えるものはchar配列」という基本パターンを守れば、文字列周りの多くのバグを避けられます。
実際のコードを書きながら、ここで紹介したポイントを少しずつ体に覚えさせていってください。
