C言語を学ぶと必ず登場するのが「ポインタ」と「配列」です。
この2つはよく似た書き方をする部分が多いため、初学者にとって混乱の原因になりやすいテーマです。
本記事では、ポインタと配列の本質的な違いと実際のコードでの挙動を、図解とサンプルコードを交えながら丁寧に解説していきます。
ポインタと配列とは
ポインタとは何か
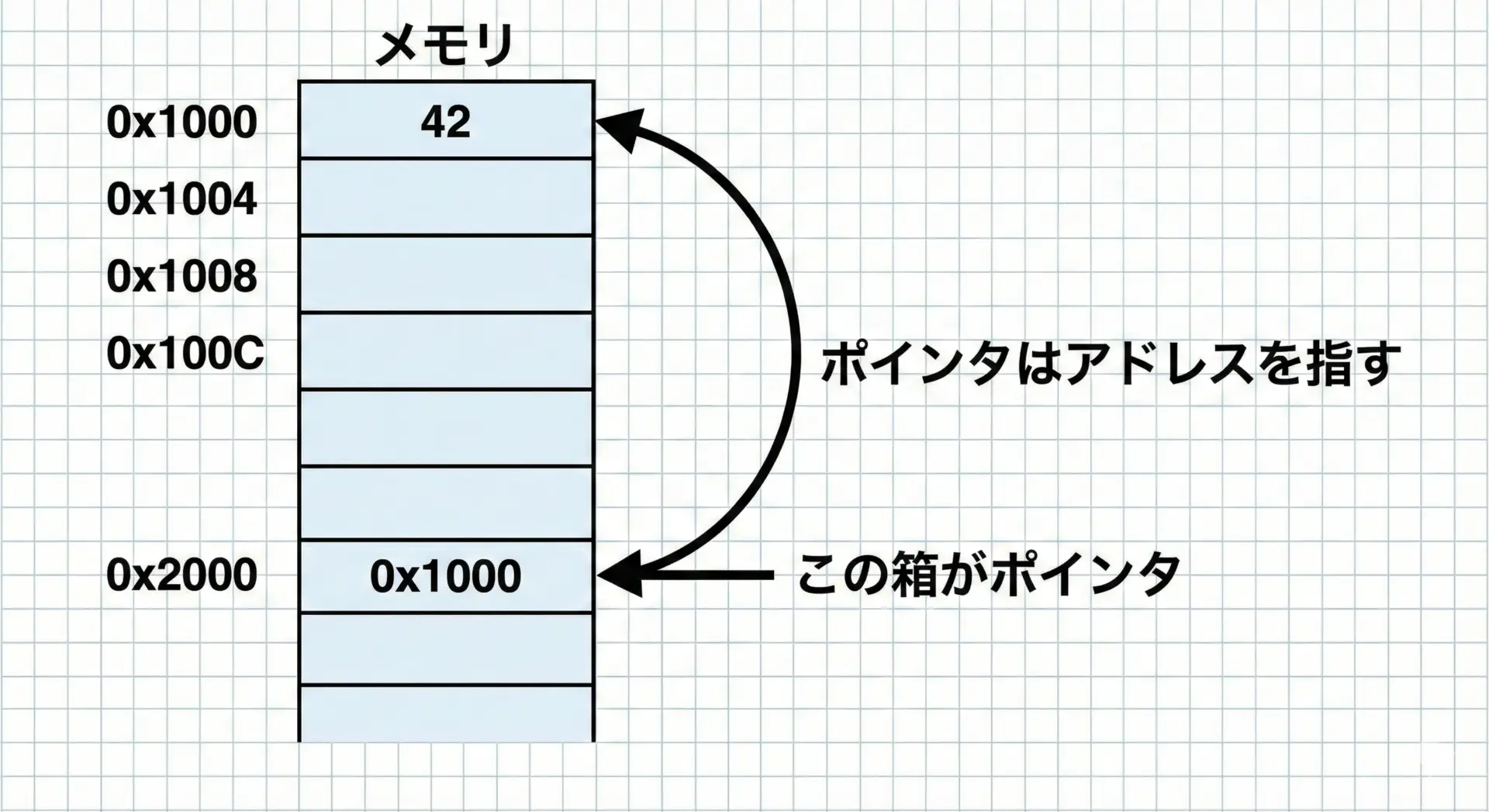
ポインタとは、「変数が格納されているメモリ上の住所(アドレス)を保存するための変数」のことです。
通常の変数は数値や文字などの値そのものを格納しますが、ポインタ変数はアドレス(場所)の情報を持ちます。
C言語では、ポインタは*を使って宣言し、対象とする型を指定します。
例えばint *p;は「int型の値が置かれている場所を指すポインタ」を意味します。
ポインタの基本例
#include <stdio.h>
int main(void) {
int x = 10; // 整数変数xを定義し、10で初期化
int *p = &x; // xのアドレスを取得し、ポインタpに代入
printf("xの値: %d\n", x);
printf("xのアドレス: %p\n", (void *)&x);
printf("pの値(指しているアドレス): %p\n", (void *)p);
printf("*pの値(ポインタ経由で参照した値): %d\n", *p);
return 0;
}xの値: 10
xのアドレス: 0x7ffee3b1c874 (例)
pの値(指しているアドレス): 0x7ffee3b1c874 (例)
*pの値(ポインタ経由で参照した値): 10このように、ポインタそのものの値は「アドレス」であり、*pと書くことで、そのアドレス先に格納されている値を参照します。
配列とは何か
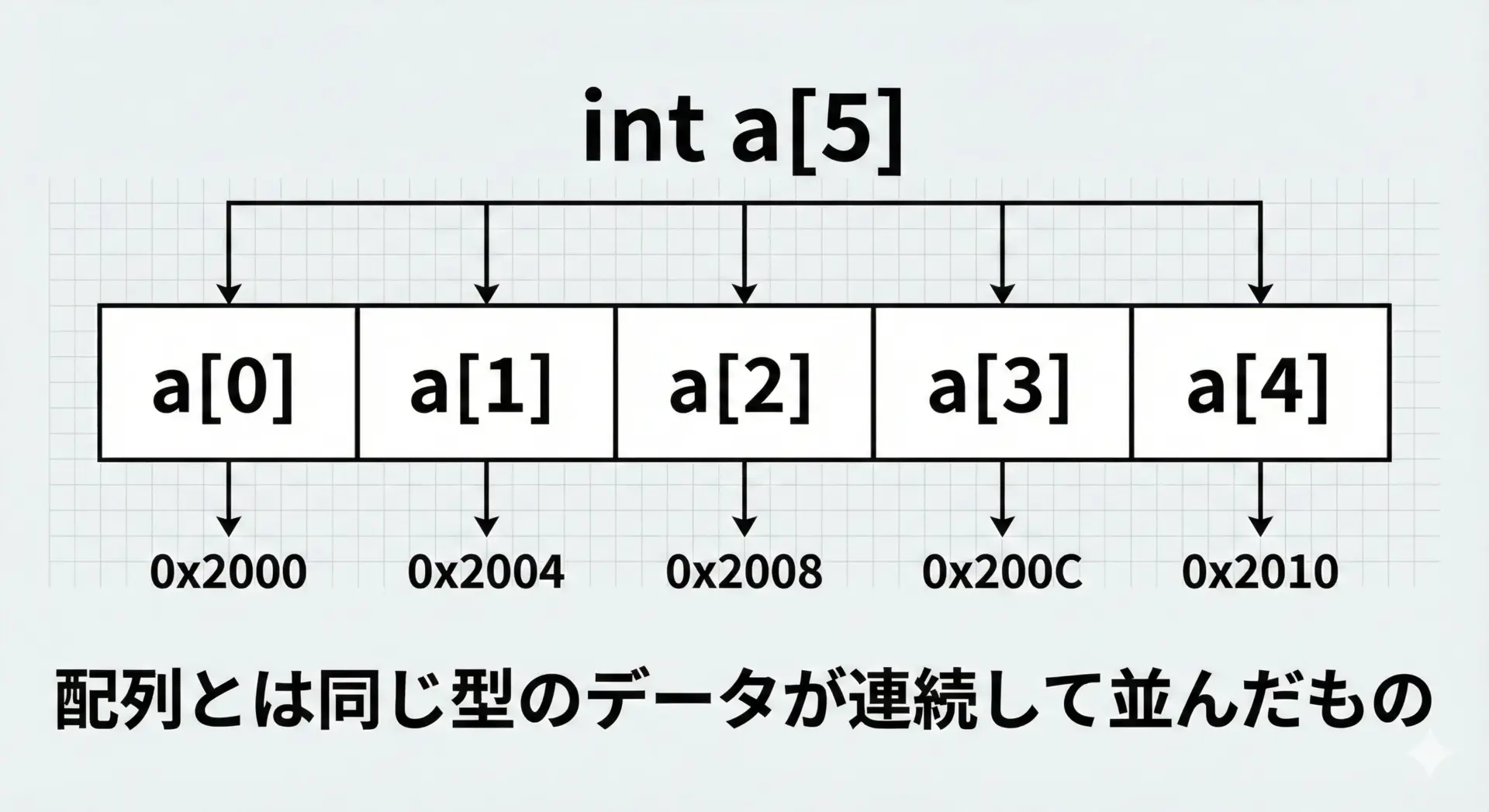
配列とは、同じ型の要素がメモリ上に連続して並んだデータ構造です。
例えばint a[5];と宣言すると、int型の領域が5個、連続して確保されます。
配列の各要素はa[0]、a[1]のようにインデックスでアクセスします。
インデックスは0から始まることに注意が必要です。
配列の基本例
#include <stdio.h>
int main(void) {
int a[5] = {10, 20, 30, 40, 50}; // 要素数5の配列を初期化
// 各要素の値とアドレスを表示
for (int i = 0; i < 5; i++) {
printf("a[%d]の値: %d, アドレス: %p\n", i, a[i], (void *)&a[i]);
}
return 0;
}a[0]の値: 10, アドレス: 0x7ffee3b1c880 (例)
a[1]の値: 20, アドレス: 0x7ffee3b1c884 (例)
a[2]の値: 30, アドレス: 0x7ffee3b1c888 (例)
a[3]の値: 40, アドレス: 0x7ffee3b1c88c (例)
a[4]の値: 50, アドレス: 0x7ffee3b1c890 (例)アドレスの差が4ずつ増えているのは、intのサイズが4バイトであり、配列が連続領域に確保されているためです。
ポインタと配列の基本的な関係
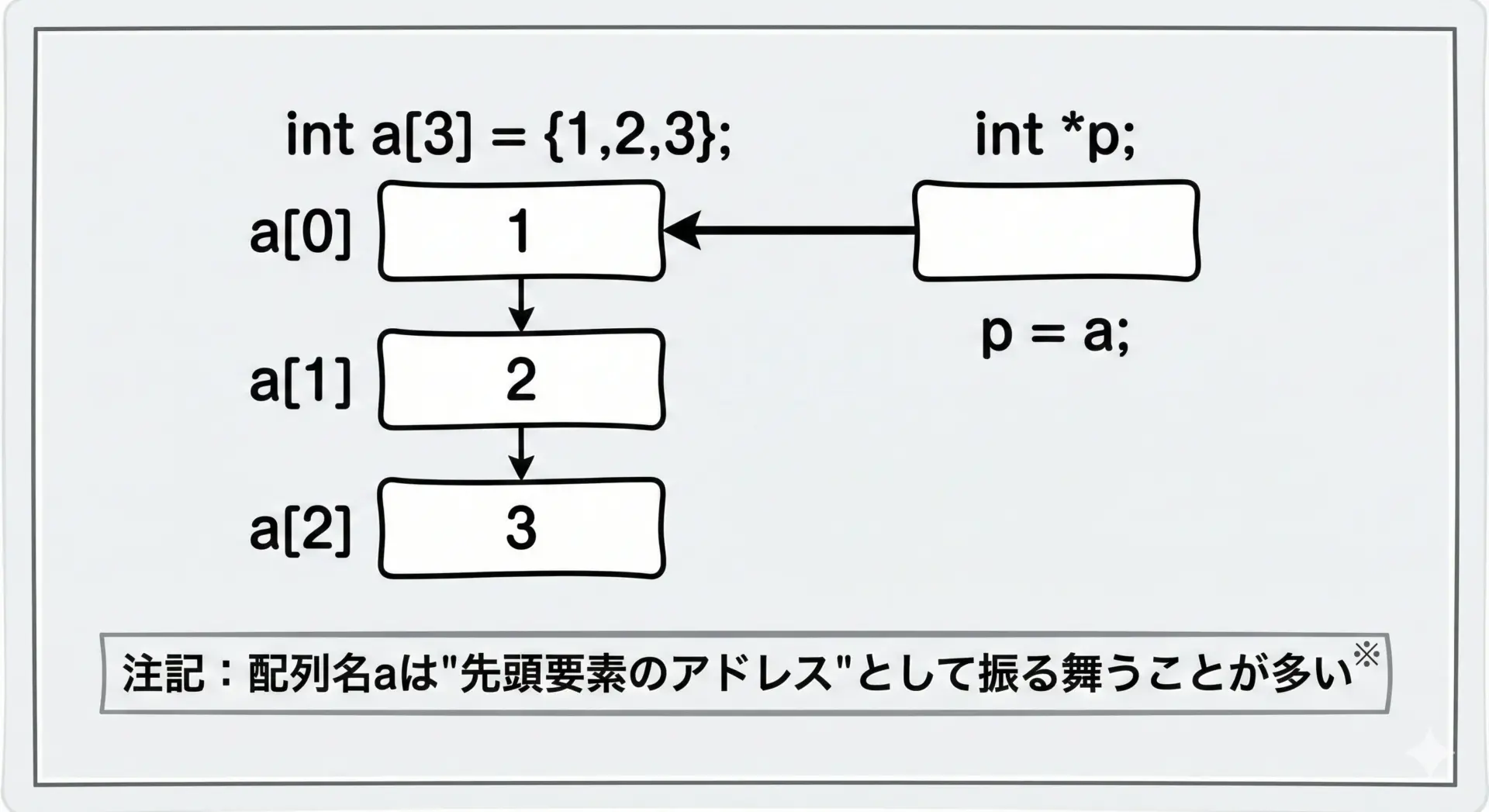
C言語では、「配列名」は多くの場面で「配列の先頭要素を指すポインタ」のように振る舞います。
この性質が、ポインタと配列を混同しやすくする原因です。
#include <stdio.h>
int main(void) {
int a[3] = {1, 2, 3};
int *p = a; // 実は「a」は「&a[0]」に暗黙変換される
printf("a の値(先頭アドレス): %p\n", (void *)a);
printf("&a[0] の値 : %p\n", (void *)&a[0]);
printf("p の値 : %p\n", (void *)p);
printf("p[0] = %d, p[1] = %d, p[2] = %d\n", p[0], p[1], p[2]);
return 0;
}a の値(先頭アドレス): 0x7ffee3b1c880 (例)
&a[0] の値 : 0x7ffee3b1c880 (例)
p の値 : 0x7ffee3b1c880 (例)
p[0] = 1, p[1] = 2, p[2] = 3配列名aは、多くの場合&a[0]と同じアドレスになります。
そのためint *p = a;と書くと、pはa[0]を指すようになります。
ただし、「配列名そのもの」と「ポインタ変数」は同じではないことを、この後しっかり確認していきます。
ポインタと配列の書き方の違い
宣言の違い

配列とポインタは、宣言の書き方からして意味が異なります。
代表的な違いを表にまとめます。
| 種類 | 宣言例 | メモリに確保されるもの |
|---|---|---|
| 配列 | int a[5]; | int型5個分の実データ領域 |
| ポインタ | int *p; | 「intのある場所」を指し示すアドレス1個分の領域 |
配列の宣言は「実データの塊」を用意し、ポインタの宣言は「どこかを指す矢印」を用意する、というイメージを持つと理解しやすくなります。
&演算子と配列名の扱い
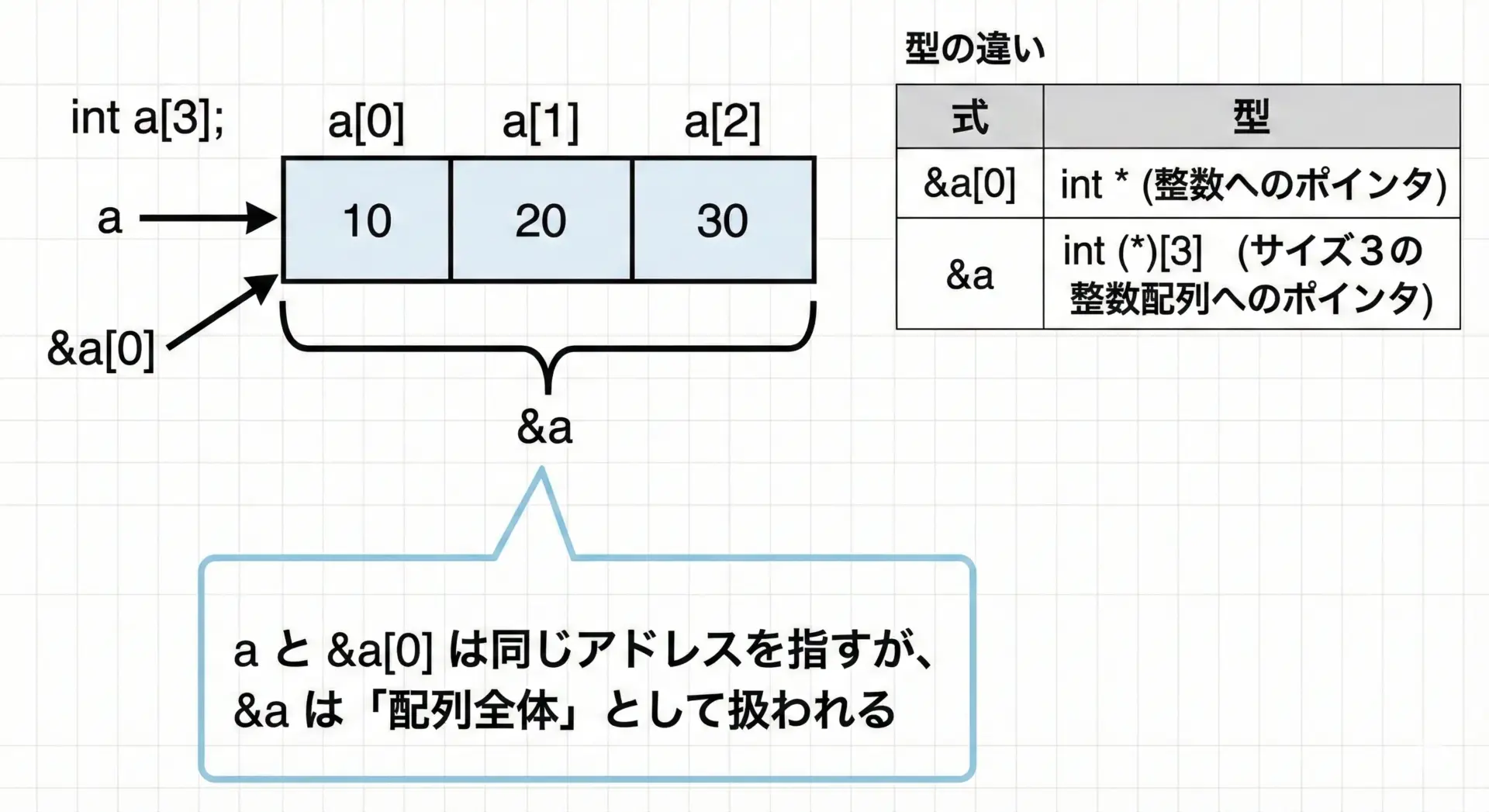
&演算子は「変数のアドレスを取得する」演算子です。
しかし、配列ではa、&a、&a[0]が微妙に異なる挙動を示します。
#include <stdio.h>
int main(void) {
int a[3] = {1, 2, 3};
printf("a の値 : %p\n", (void *)a);
printf("&a[0] の値 : %p\n", (void *)&a[0]);
printf("&a の値 : %p\n", (void *)&a);
return 0;
}a の値 : 0x7ffee3b1c880 (例)
&a[0] の値 : 0x7ffee3b1c880 (例)
&a の値 : 0x7ffee3b1c880 (例)アドレスの値は同じに見えますが、型が異なります。
aの型 …int[3]ですが、多くの式ではint *に変換されます&a[0]の型 …int *&aの型 …int (*)[3](「要素数3のint配列」を指すポインタ)
見た目は同じアドレスでも、「何を指しているポインタか」という型情報が違うため、ポインタ演算を行ったときの動きが変わる点に注意が必要です。
この違いは、後半の2次元配列の解説で重要になります。
sizeofによるポインタと配列の違い
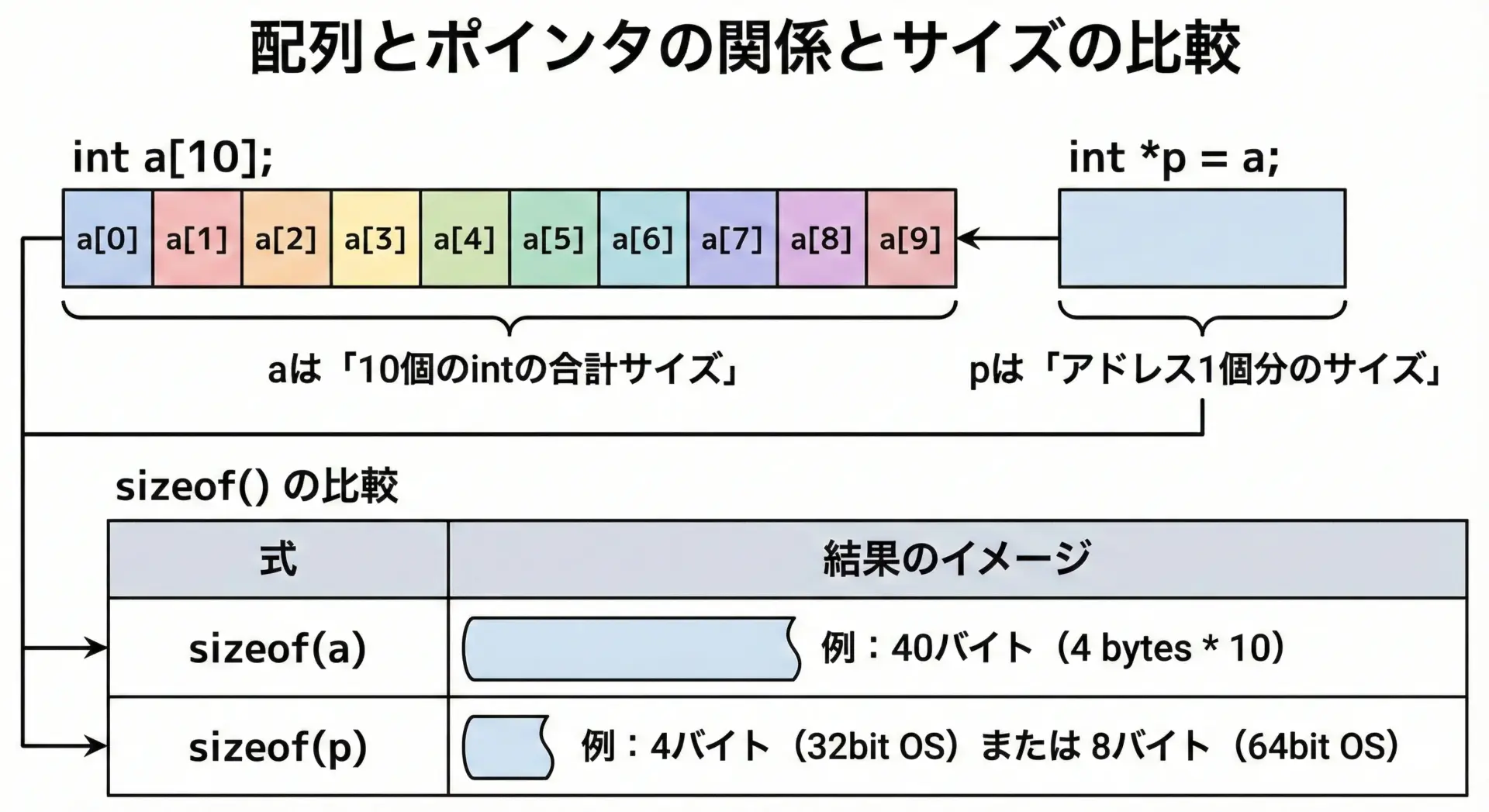
sizeof演算子を使うと、配列とポインタの「本質的な違い」がはっきり現れます。
#include <stdio.h>
int main(void) {
int a[10];
int *p = a;
printf("sizeof(a) = %zu\n", sizeof(a));
printf("sizeof(p) = %zu\n", sizeof(p));
printf("要素数(配列) = %zu\n", sizeof(a) / sizeof(a[0]));
return 0;
}sizeof(a) = 40 (例: intが4バイトの場合)
sizeof(p) = 8 (例: 64ビット環境の場合)
要素数(配列) = 10この結果から、次のように理解できます。
- 配列
aは、要素数分の実データの塊であり、sizeof(a)は配列全体のバイト数になります。 - ポインタ
pは、アドレス1個分の情報しか持たず、sizeof(p)はアドレスのサイズ(環境依存)になります。
関数の引数として配列を渡した場合、sizeofの結果に注意が必要です。
この点は後ほど詳しく説明します。
ポインタと配列の使い分け
配列をポインタとして扱うケース
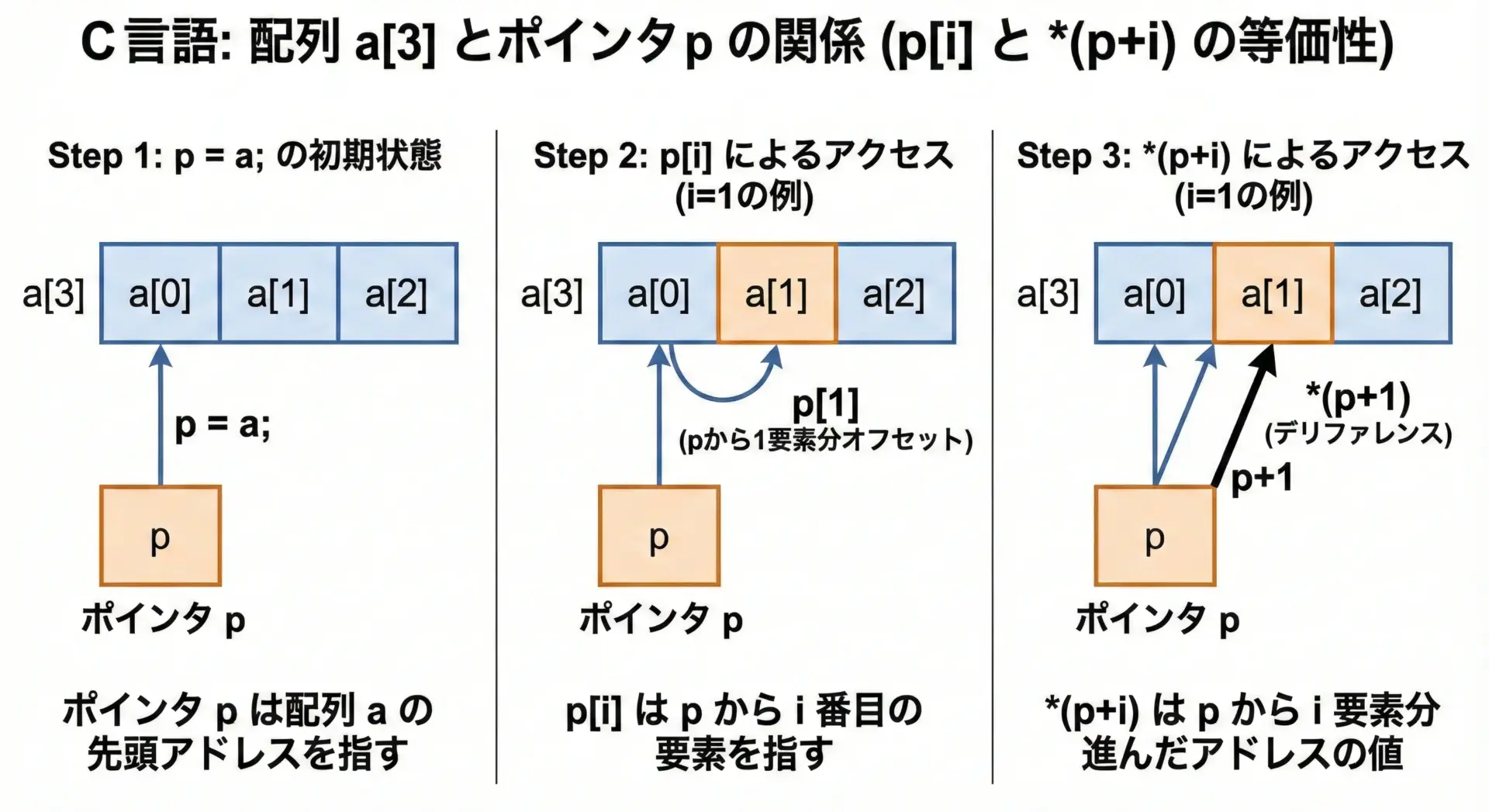
配列名は多くの文脈で「先頭要素へのポインタ」に自動変換されます。
代表的なケースは次のようなものです。
#include <stdio.h>
int main(void) {
int a[3] = {10, 20, 30};
int *p = a; // pはa[0]を指す
// 配列インデックス風の書き方
printf("p[0] = %d, p[1] = %d, p[2] = %d\n", p[0], p[1], p[2]);
// ポインタ演算風の書き方
printf("*p = %d\n", *p); // a[0]
printf("*(p + 1) = %d\n", *(p + 1)); // a[1]
printf("*(p + 2) = %d\n", *(p + 2)); // a[2]
return 0;
}p[0] = 10, p[1] = 20, p[2] = 30
*p = 10
*(p + 1) = 20
*(p + 2) = 30ここで重要なのは、配列のインデックス演算a[i]は、実は*(a + i)というポインタ演算の糖衣構文だということです。
関数引数での配列とポインタの違い
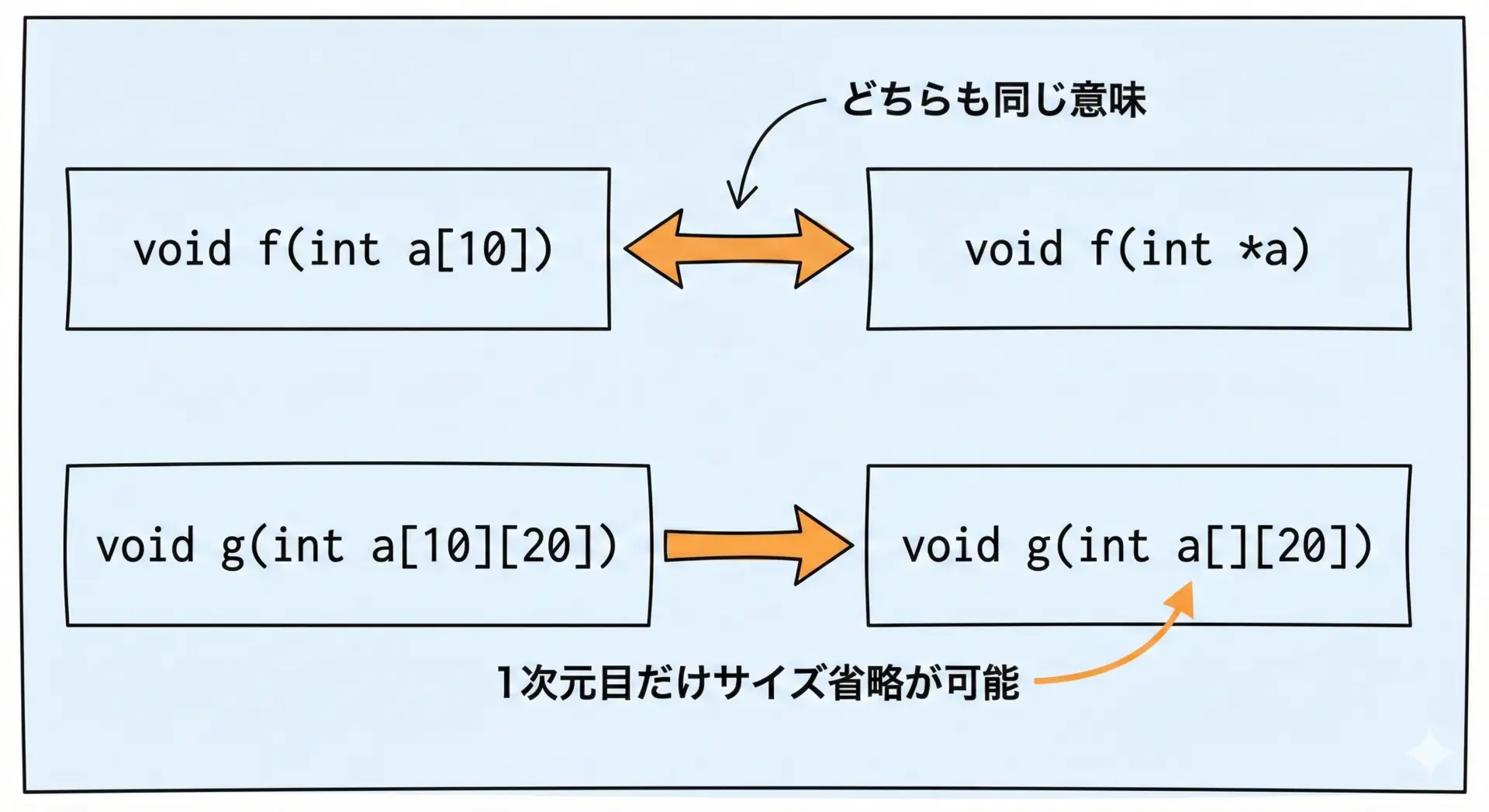
関数の引数として配列を渡すとき、次の2つは実質的に同じ意味になります。
void func1(int a[10]);
void func2(int *a);どちらも、「intへのポインタを受け取る関数」として扱われます。
実際にsizeofの挙動を確かめてみます。
#include <stdio.h>
// 配列で書かれた引数(内部的にはポインタ)
void show_size_array_param(int a[10]) {
printf("関数内 sizeof(a) (配列形式引数): %zu\n", sizeof(a));
}
// 明示的にポインタで書かれた引数
void show_size_pointer_param(int *a) {
printf("関数内 sizeof(a) (ポインタ引数): %zu\n", sizeof(a));
}
int main(void) {
int a[10];
printf("main内 sizeof(a) : %zu\n", sizeof(a));
show_size_array_param(a);
show_size_pointer_param(a);
return 0;
}main内 sizeof(a) : 40 (例: intが4バイト)
関数内 sizeof(a) (配列形式引数): 8 (例: ポインタサイズ)
関数内 sizeof(a) (ポインタ引数): 8このように、関数の引数に書かれた配列は、実際にはポインタとして扱われ、sizeofの結果もポインタのサイズになる点が重要です。
「配列引数の中で要素数を求めようとしてsizeof(a)/sizeof(a[0])と書くとバグになる」のは、このためです。
ポインタ演算で配列を走査する方法
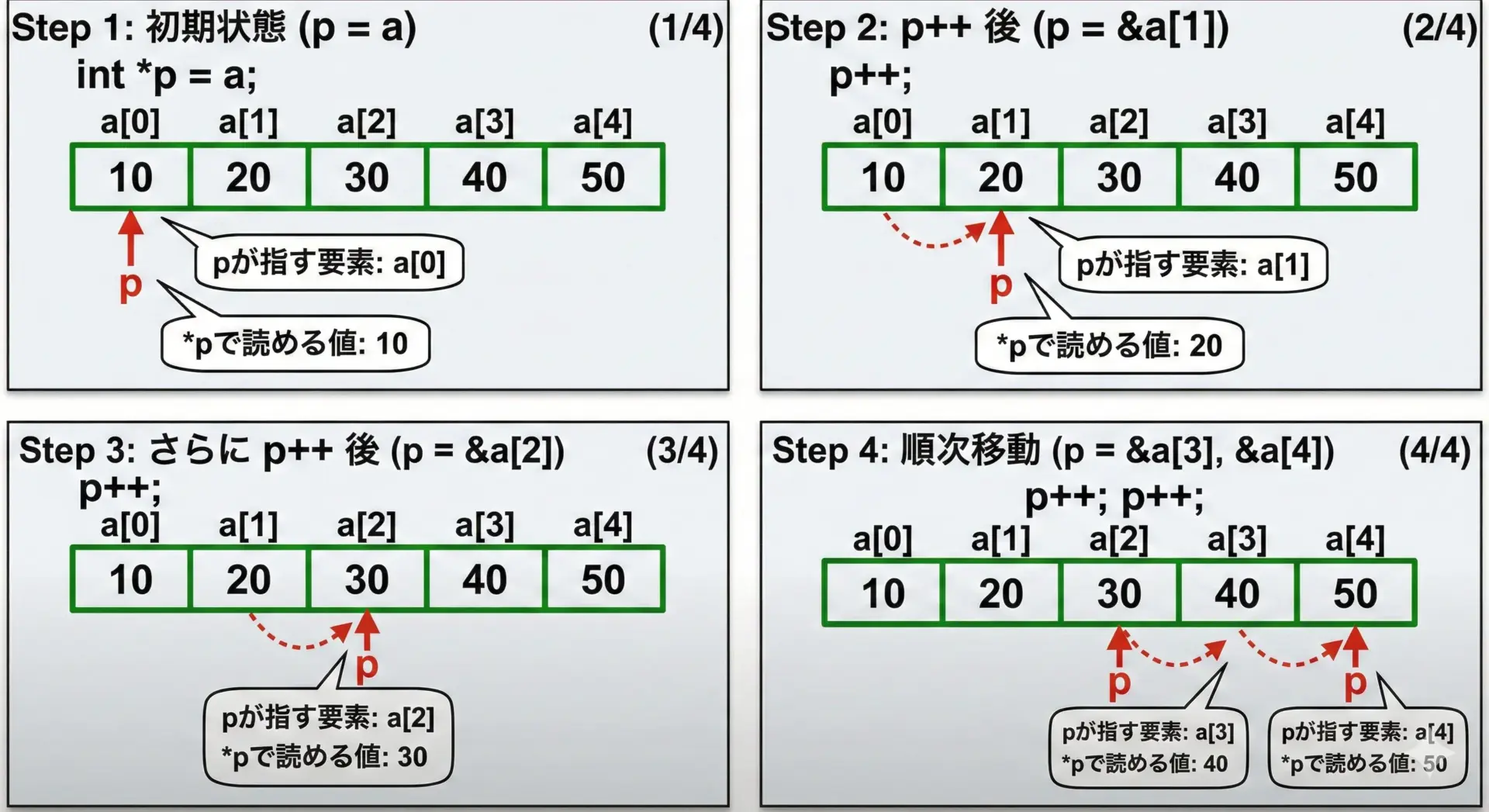
配列の要素を順番に処理するには、普通はインデックスを使いますが、ポインタ演算を使って走査することもできます。
#include <stdio.h>
int main(void) {
int a[5] = {1, 2, 3, 4, 5};
int *p = a; // pはa[0]を指す
int *end = a + 5; // 配列の「終端の次」を指すポインタ
while (p < end) { // pが終端に達するまでループ
printf("%d ", *p); // 現在の要素を出力
p++; // 次の要素へ進む
}
printf("\n");
return 0;
}1 2 3 4 5ポインタを1増やす(cst-code>p++)と、「1バイト増える」のではなく「ポインタの対象型1個分だけアドレスが進む」点がポイントです。
int *なら4バイト、double *なら8バイト(環境依存)進みます。
注意すべき典型的なバグと落とし穴
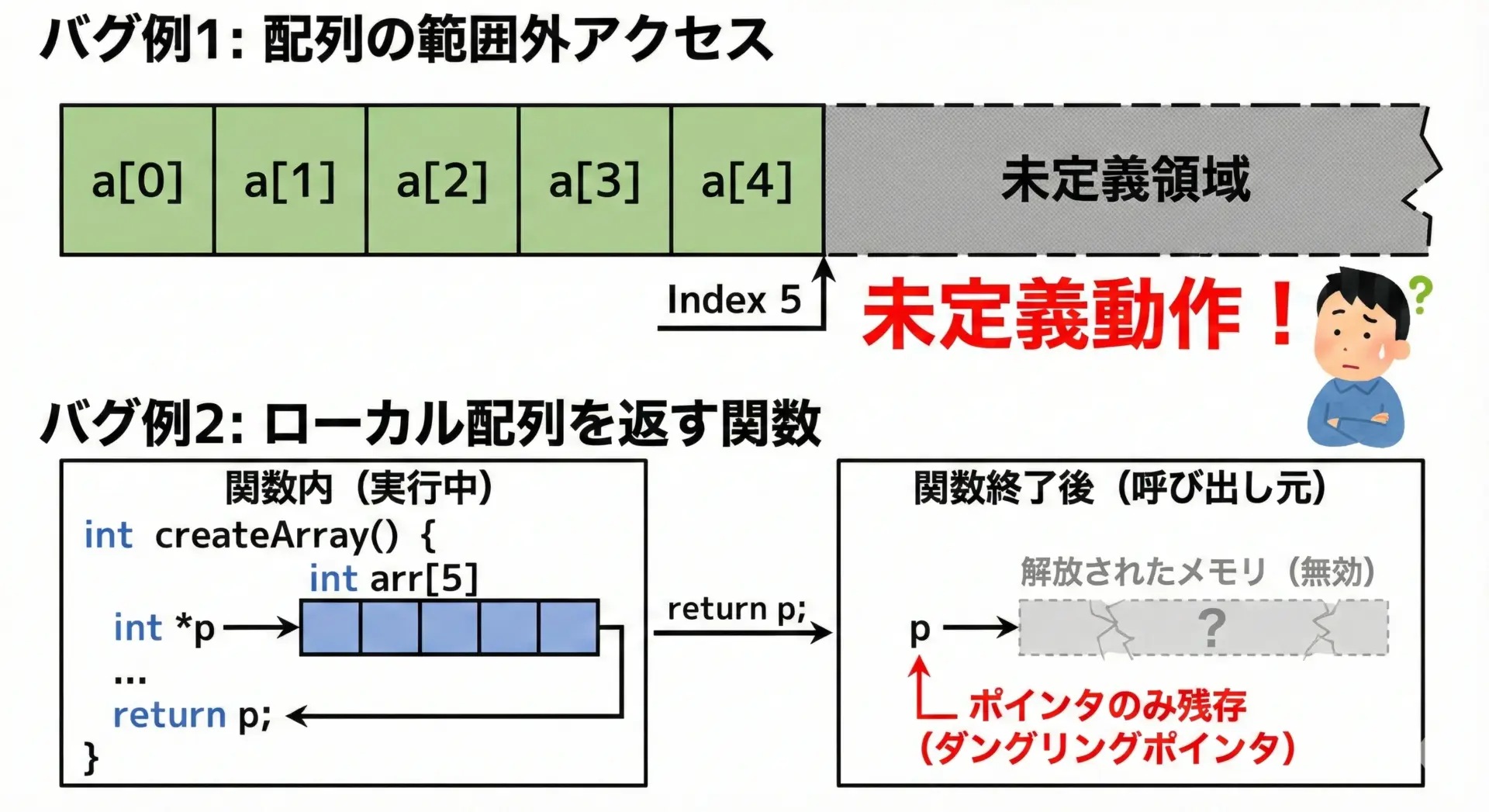
ポインタと配列に関して、よくあるバグと落とし穴をいくつか挙げます。
配列の範囲外アクセス
#include <stdio.h>
int main(void) {
int a[5] = {0, 1, 2, 3, 4};
// 誤り: 範囲外アクセス (未定義動作)
for (int i = 0; i <= 5; i++) { // 正しくは i < 5
printf("%d\n", a[i]);
}
return 0;
}このコードはコンパイルは通りますが、配列の範囲外a[5]を読み込んでしまい、未定義動作になります。
ポインタ演算でも同様に、配列の外を指すポインタを参照すると危険です。
ローカル配列のアドレスを返す
#include <stdio.h>
// 危険な関数の例
int *bad_func(void) {
int a[3] = {1, 2, 3}; // ローカル配列(関数終了とともに破棄される)
return a; // 破棄される領域の先頭アドレスを返してしまう
}
int main(void) {
int *p = bad_func();
// pは既に無効になったメモリを指している可能性がある
printf("%d\n", p[0]); // 未定義動作
return 0;
}関数内のローカル配列は、関数終了とともに無効になる領域です。
そのアドレスを返して使うと、非常に危険な未定義動作になります。
sizeofの誤用
先ほど触れたように、sizeofは「関数引数としての配列」ではポインタサイズになってしまいます。
要素数を求める意図でsizeofを使うのは、配列がスコープ内で実体として存在している場合に限定する必要があります。
実例で学ぶポインタと配列
文字列とchar配列
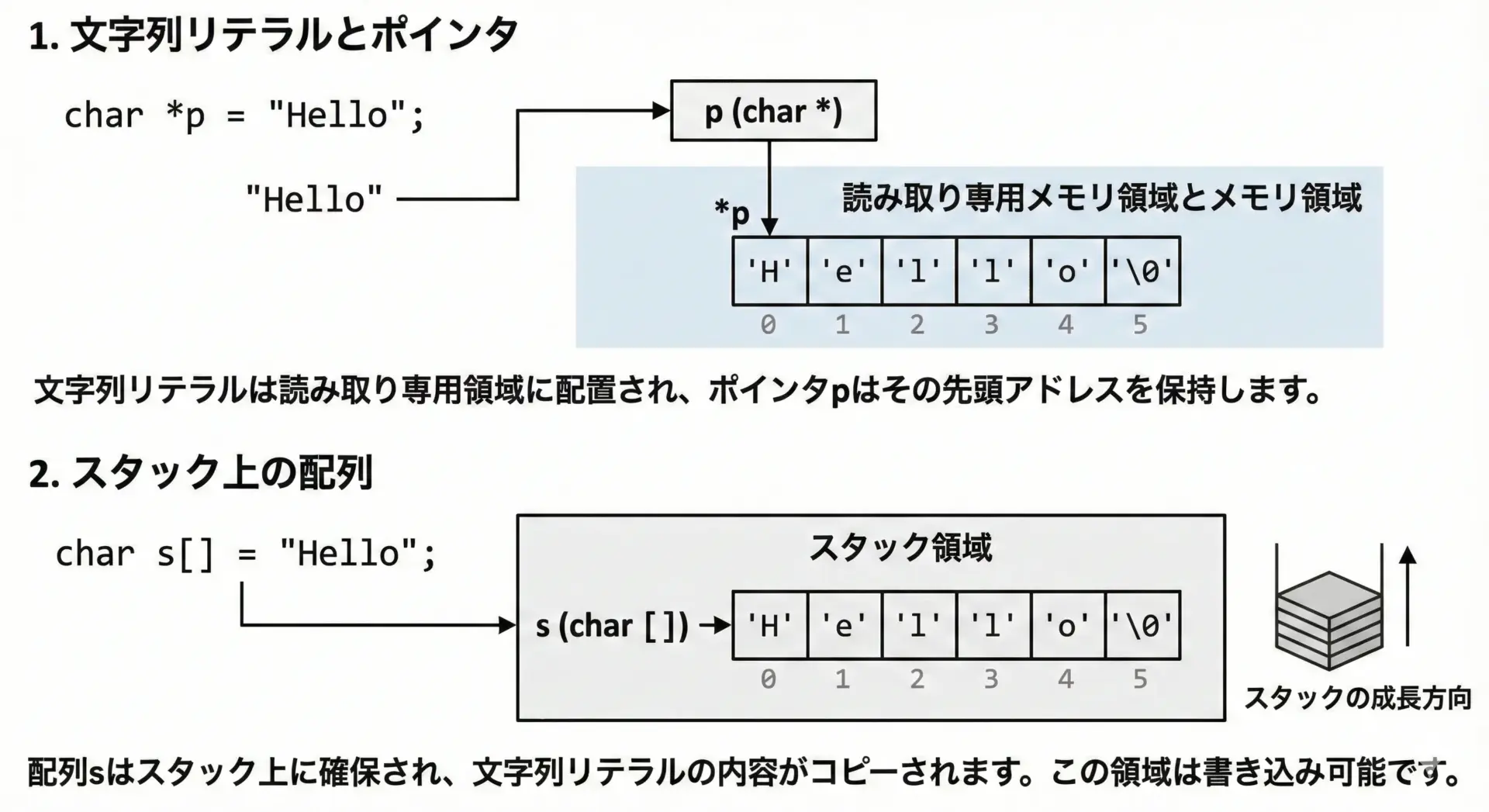
C言語の文字列は、末尾にヌル文字'\0'を持つchar配列として表現されます。
#include <stdio.h>
int main(void) {
char s1[] = "Hello"; // 配列: 要素数6 ('H','e','l','l','o','\0')
char *s2 = "World"; // ポインタ: 文字列リテラルを指す
printf("s1: %s\n", s1);
printf("s2: %s\n", s2);
printf("sizeof(s1) = %zu\n", sizeof(s1));
printf("sizeof(s2) = %zu\n", sizeof(s2));
return 0;
}s1: Hello
s2: World
sizeof(s1) = 6
sizeof(s2) = 8 (例: ポインタサイズ)ここでのポイントは、次の通りです。
char s1[] = "Hello";は、書き換え可能な配列です。例えばs1[0] = 'h';のように変更できます。char *s2 = "World";は、文字列リテラルを指すポインタであり、リテラルは通常読み取り専用領域に置かれるため、s2[0] = 'w';のように書き換えると未定義動作になります。
2次元配列とポインタの関係
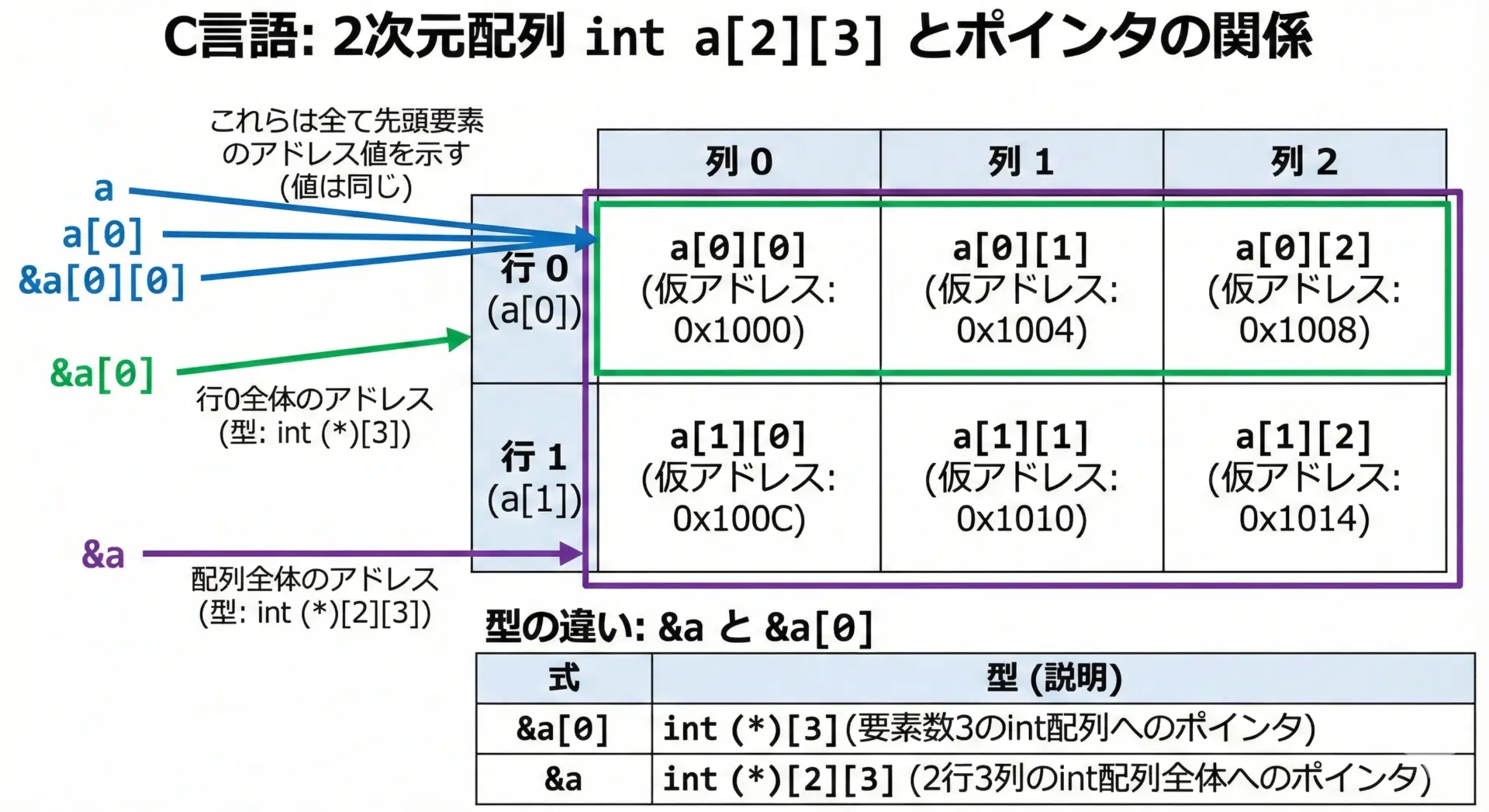
2次元配列は、「配列の配列」として実装されています。
例えばint a[2][3];は、「要素数3のint配列」が2つ分並んでいるイメージです。
#include <stdio.h>
int main(void) {
int a[2][3] = {
{1, 2, 3},
{4, 5, 6}
};
printf("a : %p\n", (void *)a);
printf("a[0] : %p\n", (void *)a[0]);
printf("&a[0][0] : %p\n", (void *)&a[0][0]);
printf("&a[0] : %p\n", (void *)&a[0]);
printf("&a : %p\n", (void *)&a);
return 0;
}a : 0x7ffee3b1c860 (例)
a[0] : 0x7ffee3b1c860 (例)
&a[0][0] : 0x7ffee3b1c860 (例)
&a[0] : 0x7ffee3b1c860 (例)
&a : 0x7ffee3b1c860 (例)アドレスは同じですが、型は次のように異なります。
| 式 | 型 | 意味 |
|---|---|---|
| a | int[2][3] | 多くの式で int (*)[3] に変換される |
| a[0] | int[3] | 多くの式で int * に変換される |
| &a[0][0] | int * | 最初の要素そのものを指すポインタ |
| &a[0] | int (*)[3] | 「要素数3のint配列」を指すポインタ |
| &a | int (*)[2][3] | 「要素数2、各要素がint[3]の配列」を指すポインタ |
2次元配列を関数に渡すときは「第2次元以降のサイズ情報」が必要になります。
#include <stdio.h>
// 第2次元のサイズ3は必須
void print_matrix(int a[2][3]) {
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 3; j++) {
printf("%d ", a[i][j]);
}
printf("\n");
}
}
int main(void) {
int m[2][3] = {
{1, 2, 3},
{4, 5, 6}
};
print_matrix(m);
return 0;
}1 2 3
4 5 6このような2次元配列は、ポインタで書き直すと次のようになります。
#include <stdio.h>
// 「要素数3のint配列」を指すポインタとして受け取る
void print_matrix(int (*p)[3], int rows) {
for (int i = 0; i < rows; i++) {
// p[i] は「i行目の配列(int[3])」
for (int j = 0; j < 3; j++) {
printf("%d ", p[i][j]); // p[i][j] は (*(p + i))[j] と同じ
}
printf("\n");
}
}
int main(void) {
int m[2][3] = {
{1, 2, 3},
{4, 5, 6}
};
print_matrix(m, 2); // mはint (*)[3]に変換されて渡る
return 0;
}1 2 3
4 5 6第2次元以降のサイズが必要なのは、ポインタ演算で「次の行」へ正しく移動するためです。
1行が3 * sizeof(int)バイトだと分かって初めて、「1行分進める」が計算できます。
サンプルコードで確認するポインタと配列の挙動
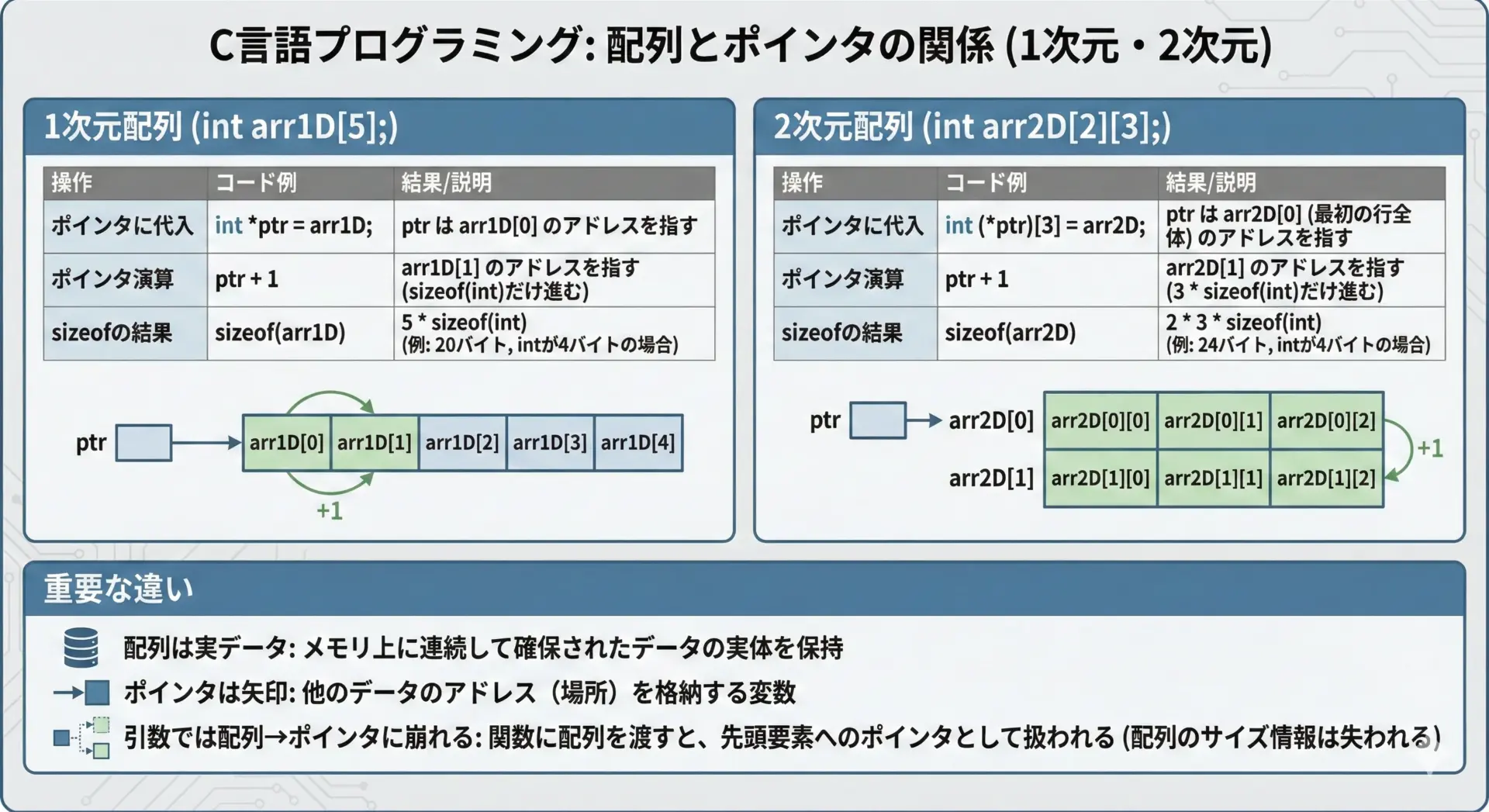
最後に、ポインタと配列の関係をまとめて確認できるサンプルコードを示します。
#include <stdio.h>
void inspect_array_and_pointer(void) {
int a[4] = {10, 20, 30, 40};
int *p = a; // 先頭要素のアドレス
printf("=== 1次元配列とポインタ ===\n");
printf("配列aのサイズ : %zu\n", sizeof(a));
printf("ポインタpのサイズ : %zu\n", sizeof(p));
printf("配列aの要素数 : %zu\n", sizeof(a) / sizeof(a[0]));
printf("&a[0]のアドレス : %p\n", (void *)&a[0]);
printf("a(先頭)のアドレス : %p\n", (void *)a);
printf("p(指しているアドレス) : %p\n", (void *)p);
printf("p[0]=%d, *(p+1)=%d, a[2]=%d\n", p[0], *(p + 1), a[2]);
}
void inspect_2d_array(void) {
int a[2][2] = {
{1, 2},
{3, 4}
};
printf("\n=== 2次元配列 ===\n");
printf("sizeof(a) : %zu\n", sizeof(a));
printf("sizeof(a[0]) : %zu\n", sizeof(a[0]));
printf("行数 (sizeof(a)/sizeof(a[0])) : %zu\n", sizeof(a) / sizeof(a[0]));
printf("a : %p\n", (void *)a);
printf("a[0] : %p\n", (void *)a[0]);
printf("&a[0][0] : %p\n", (void *)&a[0][0]);
// ポインタで2次元配列を走査
int (*p)[2] = a; // 要素数2のint配列を指すポインタ
printf("\n2次元配列の要素(ポインタ経由):\n");
for (int i = 0; i < 2; i++) {
// p+i は「i行目の配列」を指す
for (int j = 0; j < 2; j++) {
// *(*(p + i) + j) は a[i][j] と同じ
printf("%d ", *(*(p + i) + j));
}
printf("\n");
}
}
int main(void) {
inspect_array_and_pointer();
inspect_2d_array();
return 0;
}=== 1次元配列とポインタ ===
配列aのサイズ : 16 (例: intが4バイト)
ポインタpのサイズ : 8 (例: ポインタサイズ)
配列aの要素数 : 4
&a[0]のアドレス : 0x7ffee3b1c880 (例)
a(先頭)のアドレス : 0x7ffee3b1c880 (例)
p(指しているアドレス) : 0x7ffee3b1c880 (例)
p[0]=10, *(p+1)=20, a[2]=30
=== 2次元配列 ===
sizeof(a) : 16
sizeof(a[0]) : 8
行数 (sizeof(a)/sizeof(a[0])) : 2
a : 0x7ffee3b1c870 (例)
a[0] : 0x7ffee3b1c870 (例)
&a[0][0] : 0x7ffee3b1c870 (例)
2次元配列の要素(ポインタ経由):
1 2
3 4このサンプルを実行しながら、「どこに実データがあって」「ポインタは何を指しており」「sizeofは何を測っているか」を意識して追いかけていくと、ポインタと配列の関係がかなりクリアになります。
まとめ
ポインタと配列は記法が似ているため混乱しやすいですが、配列は「実データが連続して並んだ塊」、ポインタは「どこかを指す矢印」という本質を押さえれば整理しやすくなります。
配列名が多くの場面で「先頭要素へのポインタ」に自動的に変換されること、関数引数では配列がポインタに崩れること、sizeofや2次元配列での型の違いを理解しておくと、実務でのバグを大幅に減らせます。
この記事で示した図解やサンプルコードを手元で動かしながら、ポインタと配列の関係を体で覚えていくことをおすすめします。
