
C言語を学び始めると必ずと言ってよいほど登場するのが、前置インクリメント(++i)と後置インクリメント(i++)です。
どちらも「1増やす」記号に見えますが、評価順序や戻り値の違いから思わぬバグや未定義動作を招くことがあります。
本記事では、i++と++iの違いから、なぜバグを生みやすいのか、安全な書き方・使い分け方まで、図解とコード例を交えて詳しく解説します。
C言語の前置インクリメントと後置インクリメントとは
i++(後置インクリメント)と++i(前置インクリメント)の基本
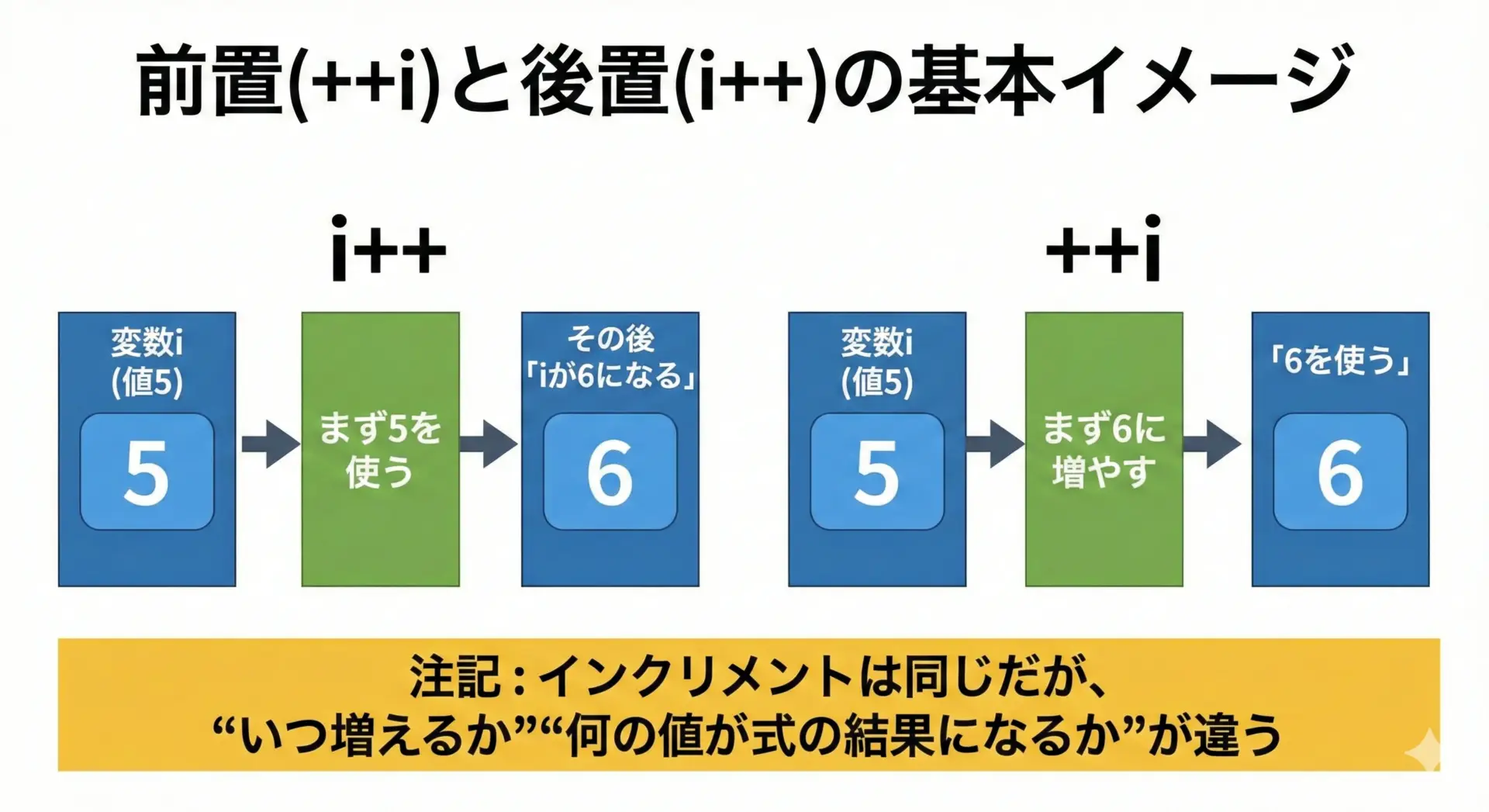
C言語では、変数の値を1増やす演算子としてインクリメント演算子が用意されています。
書き方は大きく2つあり、後置インクリメント(i++)と前置インクリメント(++i)に分かれます。
文章でまとめると次のようになります。
- i++ (後置インクリメント)は「いまの値を使ってから1増やす」という動きをします。
- ++i (前置インクリメント)は「先に1増やしてから、その新しい値を使う」という動きをします。
どちらも最終的にはiが1増えますが、「式として評価されたときに返ってくる値」が異なることが、バグの原因になりやすい重要ポイントです。
簡単なコード例で違いを確認する
#include <stdio.h>
int main(void) {
int i = 5;
// 後置インクリメント: i++ は「今の値を返してから、あとで1増える」
int a = i++; // a には 5 が入り、その後 i は 6 になる
// 前置インクリメント: ++i は「先に1増えて、その新しい値を返す」
int b = ++i; // ここに来たとき i は 6 なので、先に 7 になり b には 7 が入る
printf("a = %d\n", a);
printf("b = %d\n", b);
printf("i = %d\n", i);
return 0;
}a = 5
b = 7
i = 7この例ではaには「代入前のiの値」(5)が入り、bには「インクリメント後のiの値」(7)が入ることが確認できます。
++iとi++の評価順序と戻り値の違い
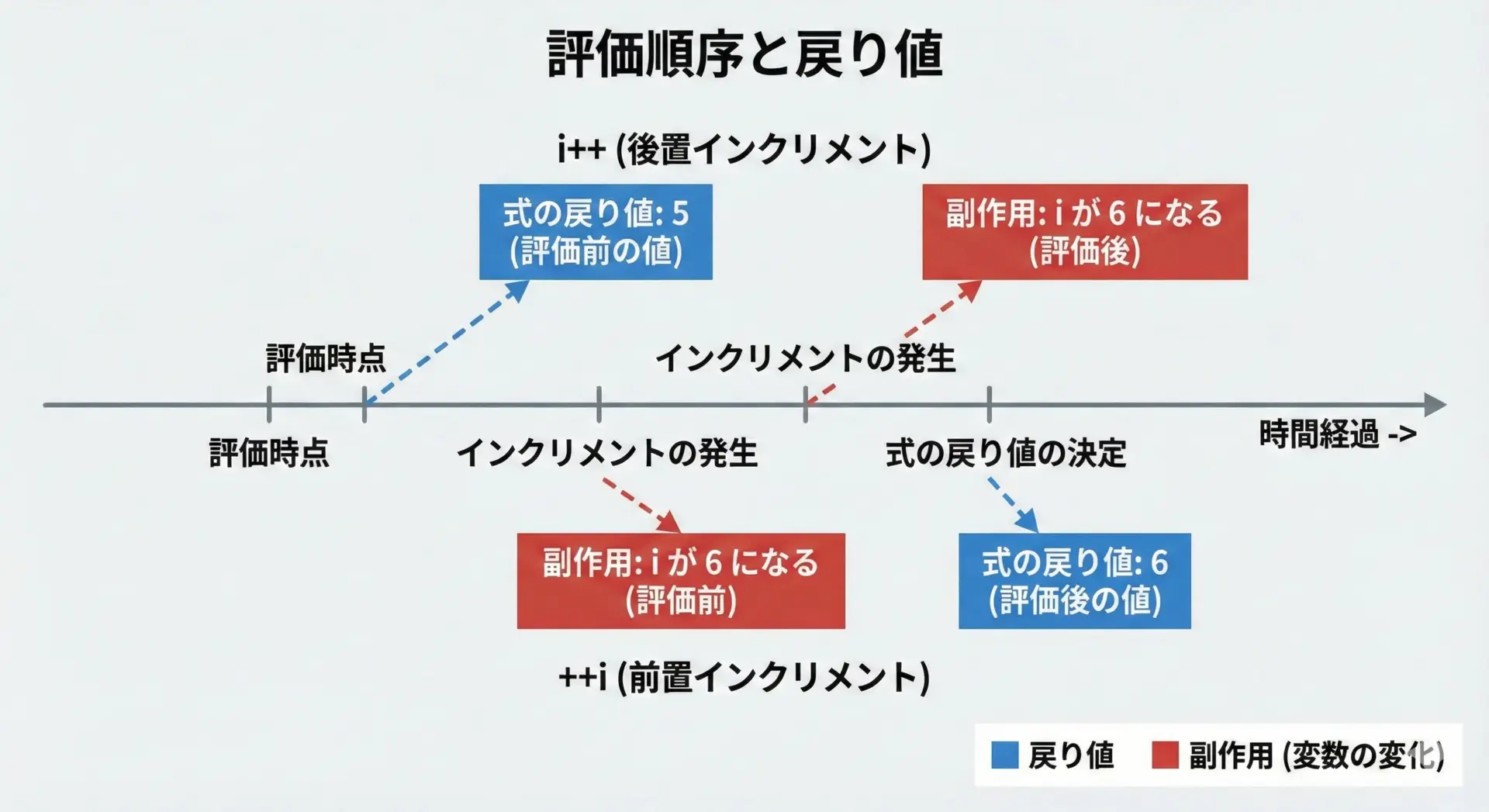
インクリメント演算子を理解するためには、「副作用」と「式の値」の違いを意識することが重要です。
ここでいう副作用とは、iという変数の中身が書き換わることを指します。
一方で式の値とは、その式が評価された結果として「次の演算に渡される値」のことです。
この観点から、i++と++iを整理すると次のようになります。
| 書き方 | 式の評価タイミングでの動き | 式としての戻り値 | 副作用が完了した後のi |
|---|---|---|---|
i++ | 現在のiの値を一旦返し、その後でiを1増やす | インクリメント前の値 | 元の値+1 |
++i | 先にiを1増やし、その新しい値を返す | インクリメント後の(新しい)値 | 元の値+1 |
どちらの場合でも最終的なiの値は「元の値+1」で同じですが、「式として他の演算に渡される値」が違うことを押さえておく必要があります。
#include <stdio.h>
int main(void) {
int i = 10;
// 後置: まず 10 が x に渡され、その後 i が 11 になる
int x = i++ * 2; // x = 10 * 2 = 20, その後 i = 11
// 前置: 先に i が 12 になり、その 12 が y に渡される
int y = ++i * 2; // y = 12 * 2 = 24, その後 i = 12
printf("x = %d\n", x);
printf("y = %d\n", y);
printf("i = %d\n", i);
return 0;
}x = 20
y = 24
i = 12このように、同じ「1増やす」演算子でも、他の演算(ここでは* 2)と組み合わさったときに結果が変わることがわかります。
デクリメント(–i / i–)との共通点と相違点
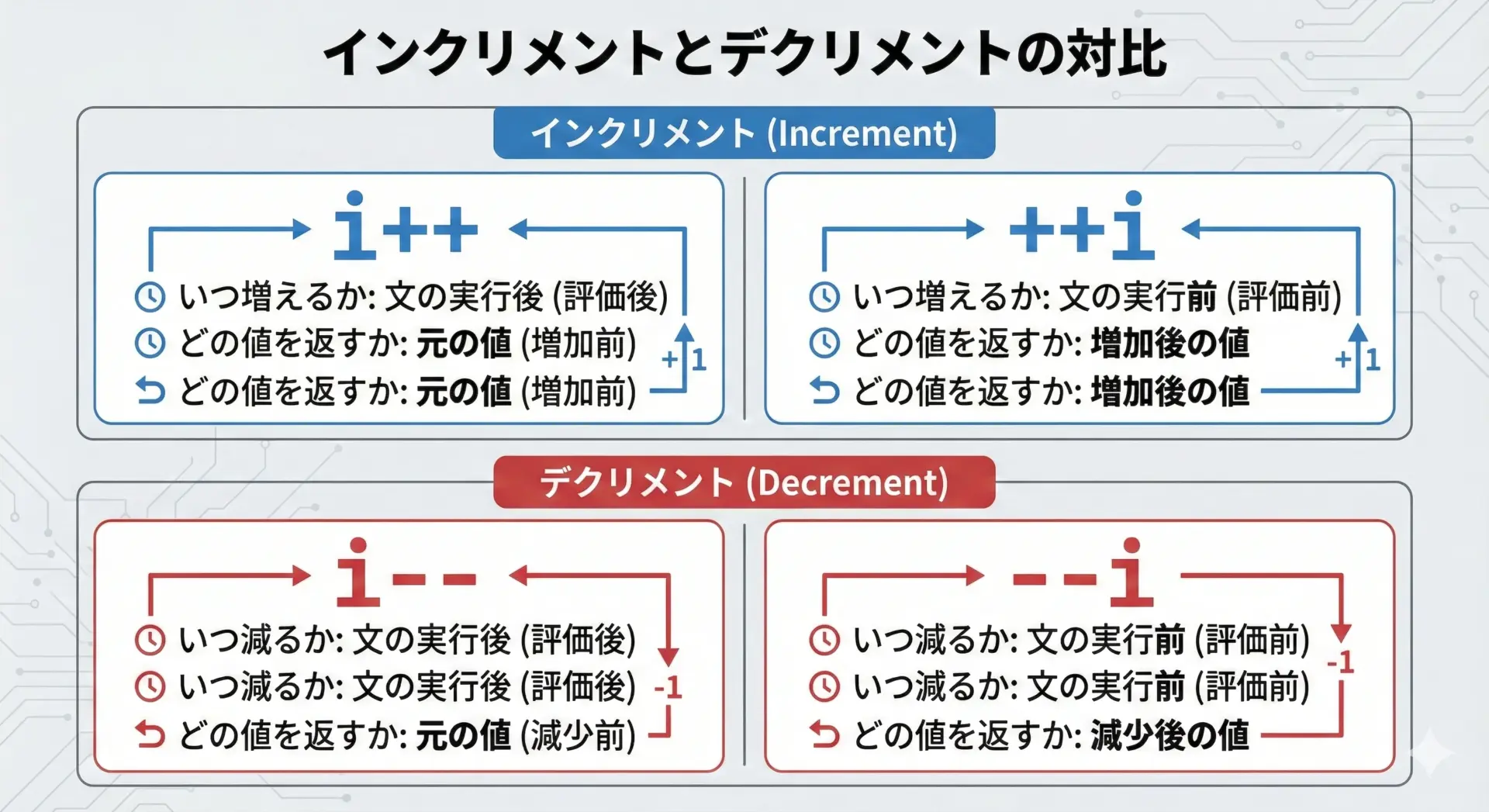
インクリメント(++演算子)に対応するのがデクリメント(–演算子)です。
こちらもインクリメントと同様に前置(–i)と後置(i–)があります。
i--は「いまの値を返してから、あとで1減らす」--iは「先に1減らしてから、その新しい値を返す」
インクリメントとデクリメントを合わせて整理すると次のようになります。
| 種類 | 記法 | 変化量 | 式の戻り値 | 副作用後のiの値 |
|---|---|---|---|---|
| インクリメント | i++ | +1 | 変更前のiの値 | 元の値+1 |
| インクリメント | ++i | +1 | 変更後(インクリメント後)の値 | 元の値+1 |
| デクリメント | i-- | -1 | 変更前のiの値 | 元の値-1 |
| デクリメント | --i | -1 | 変更後(デクリメント後)の値 | 元の値-1 |
動きの「形」はインクリメントとまったく同じで、違うのは増える(+1)か減る(-1)かだけです。
ただし、後で説明する未定義動作(Undefined Behavior)に関しては、++でも–でも同じように問題になります。
i++と++iがバグを生む理由
副作用と未定義動作(UB)が起きる典型パターン
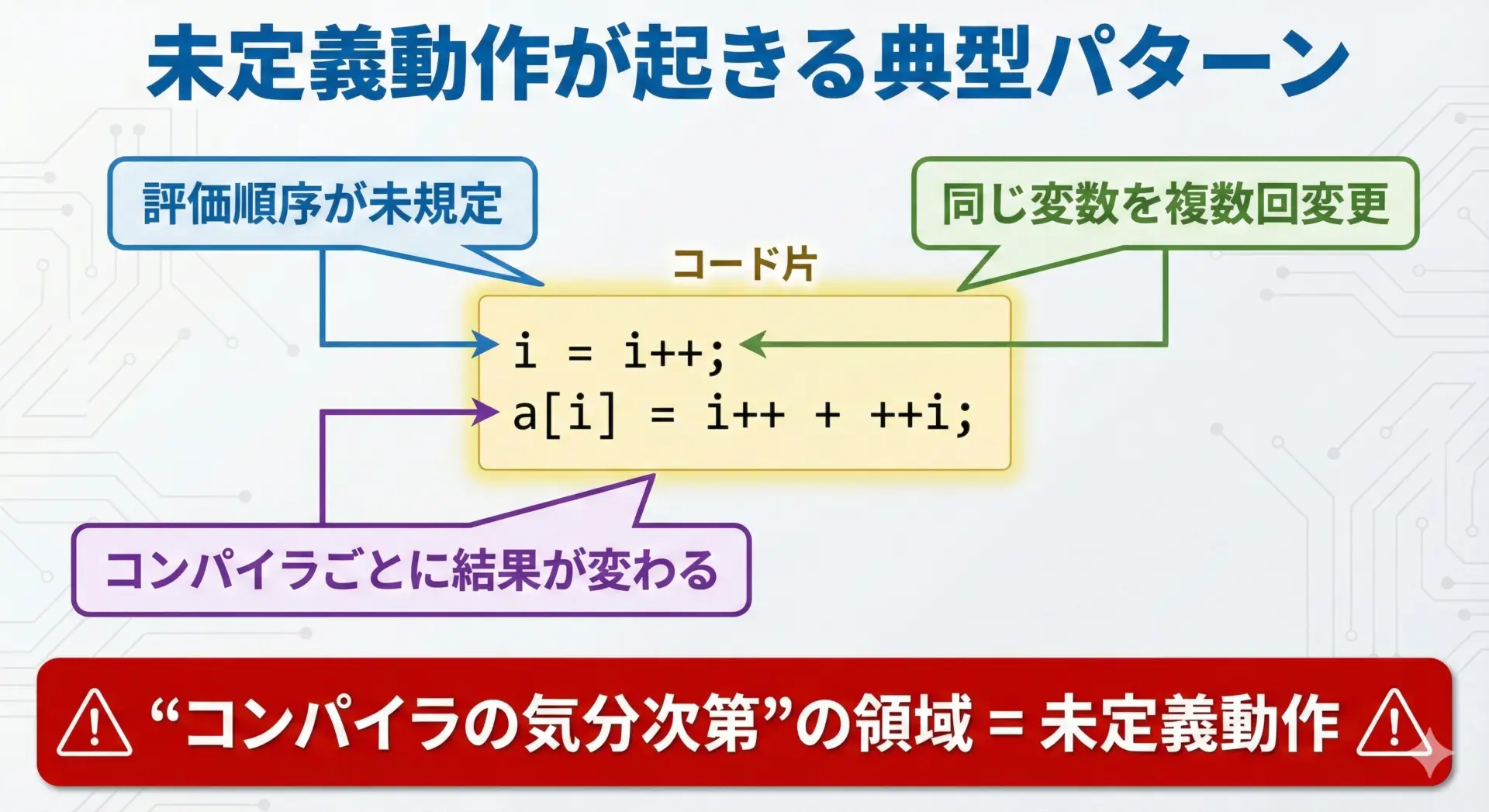
C言語では、式の評価順序が明確に決まっていない箇所が多く存在します。
そのため、「同じ変数を、1つの式の中で複数回変更し、その間に“値を読む”操作も行う」と、未定義動作(Undefined Behavior, UB)を引き起こします。
このとき問題になるのが、まさにi++や++iといった副作用を持つ演算子です。
代表的な例を挙げます。
int i = 0;
i = i++; // 典型的な未定義動作
int x = i++ + ++i; // これも未定義動作になり得るこのようなコードでは、どのタイミングでiの値が読み取られ、どの順番でインクリメントが適用されるかが規格上はっきり決まっていません。
したがってコンパイラや最適化のレベルによって結果が変わる可能性があり、正しい挙動を期待できません。
代入式でのi = i++が危険な理由
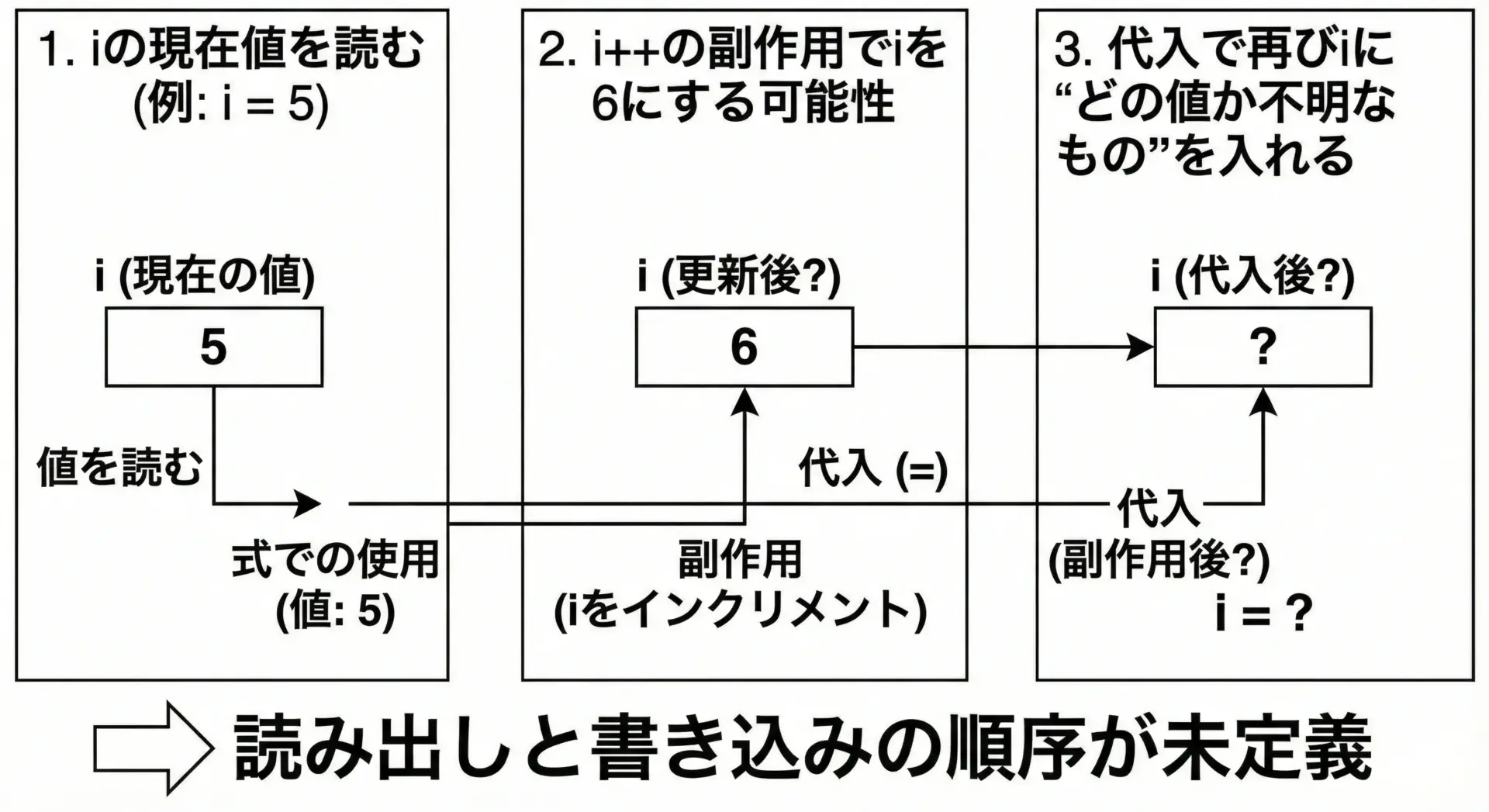
i = i++;は一見「自分自身を1増やして代入しているだけ」のようにも見えますが、実際には未定義動作です。
理由は1つの式の中でiに対する書き込み(代入)と、インクリメントによる書き込みが競合するからです。
Cの規格では、「シーケンスポイント(後述)の間に、同じオブジェクトを2回以上変更してはならない」と定められています。
i = i++;は、代入の左辺でiを書き換え、副作用としてi++でも書き換えようとするため、このルールに違反します。
#include <stdio.h>
int main(void) {
int i = 5;
// 理論的には未定義動作の例 (実際の表示結果はコンパイラ依存)
i = i++;
printf("i = %d\n", i);
return 0;
}i = 5 (と表示されることもあれば、6になることもあり得る)多くの実装では「iは5のまま」となるケースが多いですが、これは“たまたまそうなっているだけ”であり、保証された挙動ではありません。
このようなコードを書くこと自体が危険であると理解しておくことが重要です。
複雑な式中のi++ / ++iが読みにくさとバグを招く

インクリメント演算子を式の中に埋め込むと、評価順序を正確に追いかけないと意味がわからないコードになりがちです。
そのようなコードは、経験豊富なエンジニアにとってもバグの温床になります。
例を見てみます。
// 悪い例: 一見して挙動がわかりにくい
a[i++] = b[++j] + i++;この1行を理解するには、次のような点をすべて追いかけなければなりません。
- 配列
aのどのインデックスに代入しているのか - 配列
bのどのインデックスの値を読んでいるのか iとjは何回インクリメントされ、式のどの時点でどの値を取っているのか
安全で読みやすい書き方に分解すると次のようになります。
// 良い例: ステップごとに分解して、各行の意味が明確
int idx_a = i; // まず a のインデックスに使う i を保存
i++; // a 用として使った後に i をインクリメント
j++; // b のインデックス j を先にインクリメント
int value = b[j];
a[idx_a] = value + i; // ここで i の現在値を使う
i++; // 使い終わった後で再度インクリメントこのように式の中にインクリメントを埋め込まず、1つずつ順に処理を書くことで、評価順序のあいまいさを排除できます。
結果としてバグを防ぎ、他人にも自分にも読みやすいコードになります。
ループ内でのインクリメント位置によるオフバイワンエラー

ループ処理では、インクリメントのタイミングを1つ間違えるだけで「1回多い・1回少ない」といったオフバイワンエラーが起きます。
前置・後置自体は評価順序の違いですが、ループと組み合わせると混乱を生みやすくなります。
基本形を確認します。
// 0, 1, 2, 3, 4 と5回回る for 文
for (int i = 0; i < 5; i++) {
printf("%d\n", i);
}このi++の部分を、++iに変えてもループの回数は変わりません。
// 0, 1, 2, 3, 4 と5回回る (挙動は上と同じ)
for (int i = 0; i < 5; ++i) {
printf("%d\n", i);
}for文の第3式の位置では、前置・後置どちらでも結果は同じです。
しかし、次のような書き方をした場合は注意が必要です。
int i = 0;
while (i++ < 5) {
// この中に入るときの i の値は 1, 2, 3, 4, 5
printf("%d\n", i);
}int j = 0;
while (++j < 5) {
// この中に入るときの j の値は 1, 2, 3, 4
printf("%d\n", j);
}似たようなループでも、ループ内部に入るときに変数が持つ値が異なります。
その結果、配列へのインデックスとして使ったときに1つはみ出す、あるいは1つ余らせるといったエラーに直結しやすくなります。
コンパイラ最適化と挙動の違いに潜む落とし穴
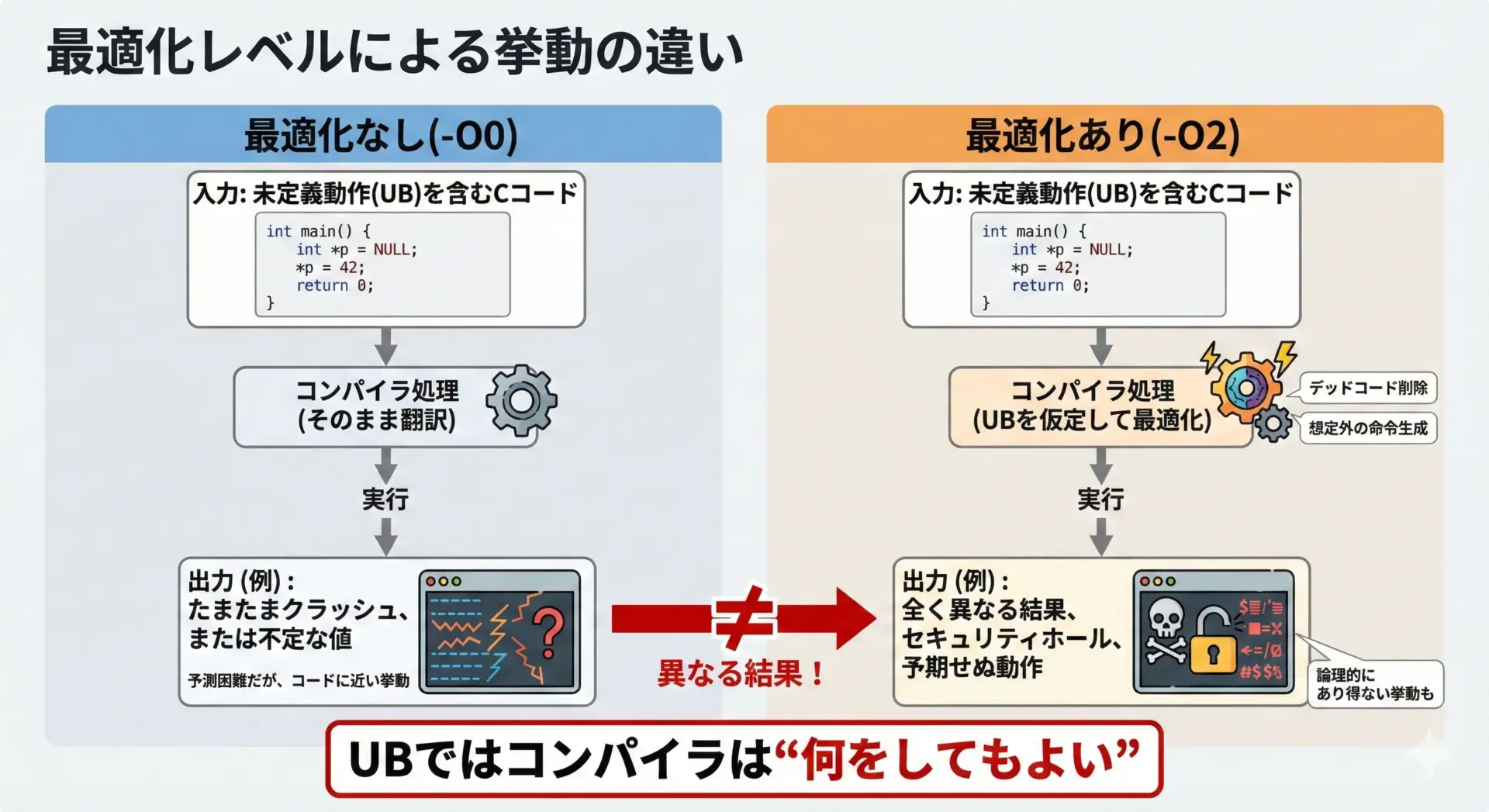
未定義動作を含むコードは、コンパイラの最適化によって挙動が大きく変わる可能性があります。
これはつまり、デバッグビルドでは“たまたま動く”のに、リリースビルドでは壊れるといった危険な状況を引き起こします。
#include <stdio.h>
int main(void) {
int i = 0;
int a = i++ + i++; // 未定義動作の例
printf("i = %d, a = %d\n", i, a);
return 0;
}このコードをコンパイルする際、-O0と-O2など、異なる最適化レベルでビルドして実行すると、違う結果が出る場合があります。
これはバグの原因を追いにくくする最大の要因の1つです。
UBが含まれていると、コンパイラは「好きなようにしてよい」とみなすため、デバッグのためのprintfでさえ、最適化時とは別のコードパスを生成することがあります。
安全なi++ / ++iの書き方と使い分け
for文でのインクリメントはどちらを使うべきか
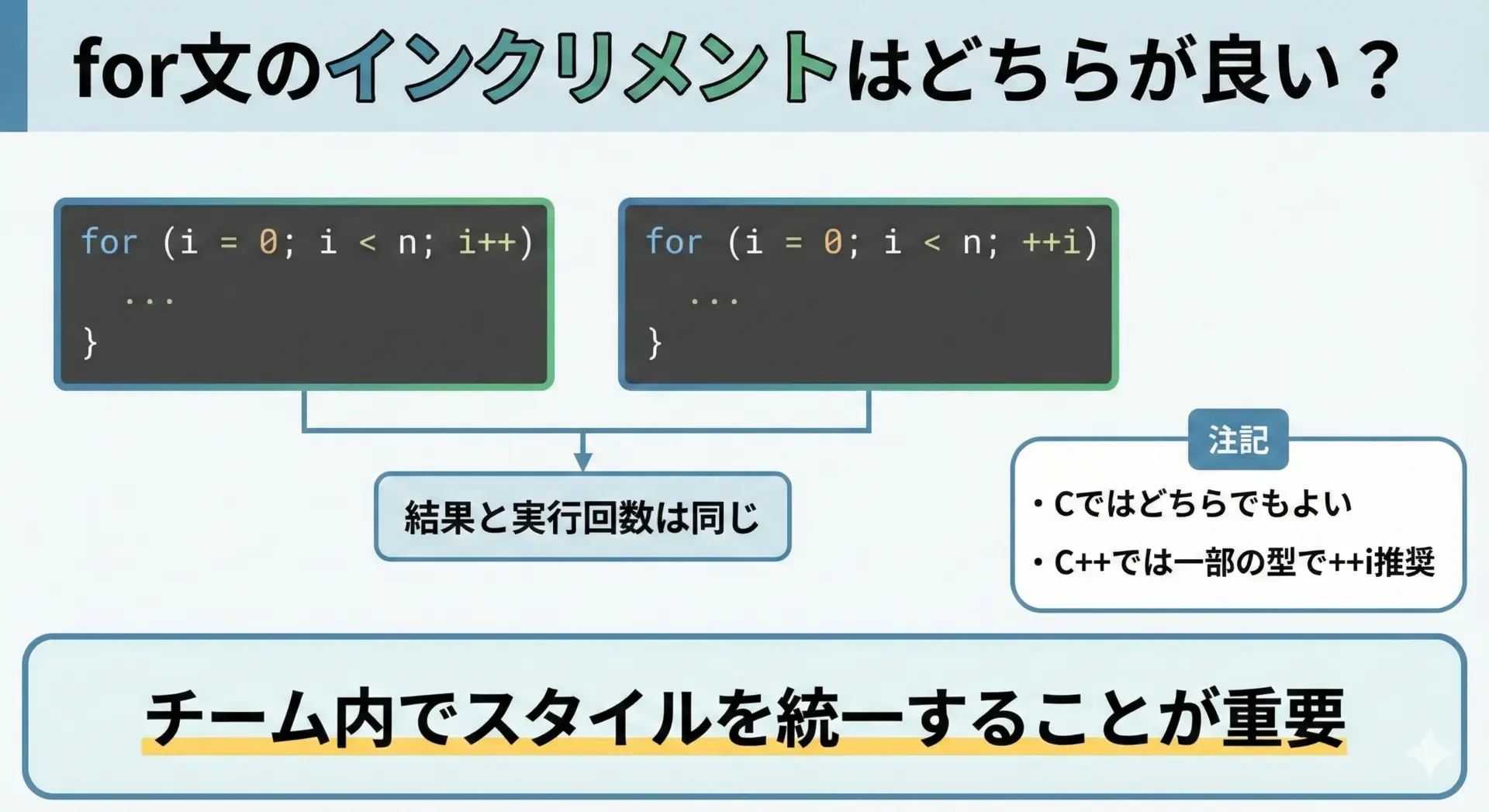
C言語において、次の2つのfor文は挙動も性能も実質的に同じです。
for (int i = 0; i < n; i++) {
// 本体
}
for (int i = 0; i < n; ++i) {
// 本体
}C++ではイテレータなどを扱う際に前置(++i)の方が多少有利という議論がありますが、C言語の単純なintに対しては差はほとんどありません。
重要なのはプロジェクト内でスタイルを統一することです。
同じファイルの中でi++と++iが混在していると、読む側が「何か意図のある違いなのか」と迷ってしまいます。
単独文としてのi++と++iの使い方
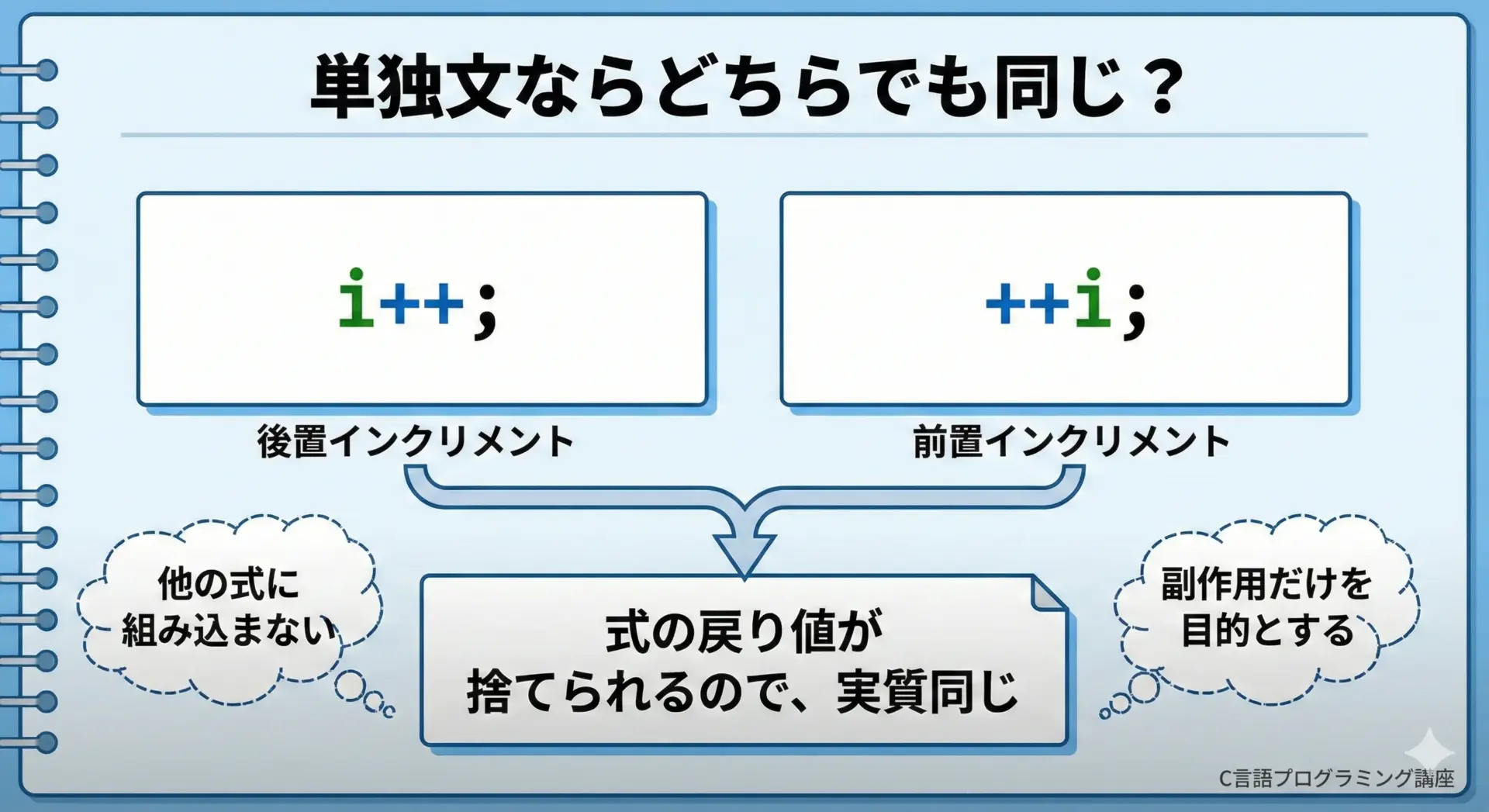
1行が単独の文として完結している場合、i++;と++i;は意味的にまったく同じです。
i++; // i を 1 増やす (戻り値は無視される)
++i; // i を 1 増やす (戻り値は無視される)この場合、どちらを書いても「iが1増える」という副作用だけが重要であり、式の戻り値は使っていません。
そのため、評価順序や戻り値の違いによるバグは起こりません。
ただし重要なのは、このように「単独文として使う」ことに徹し、他の式の一部として組み込まないというスタイルを保つことです。
返り値を利用する場合の前置・後置の選び方
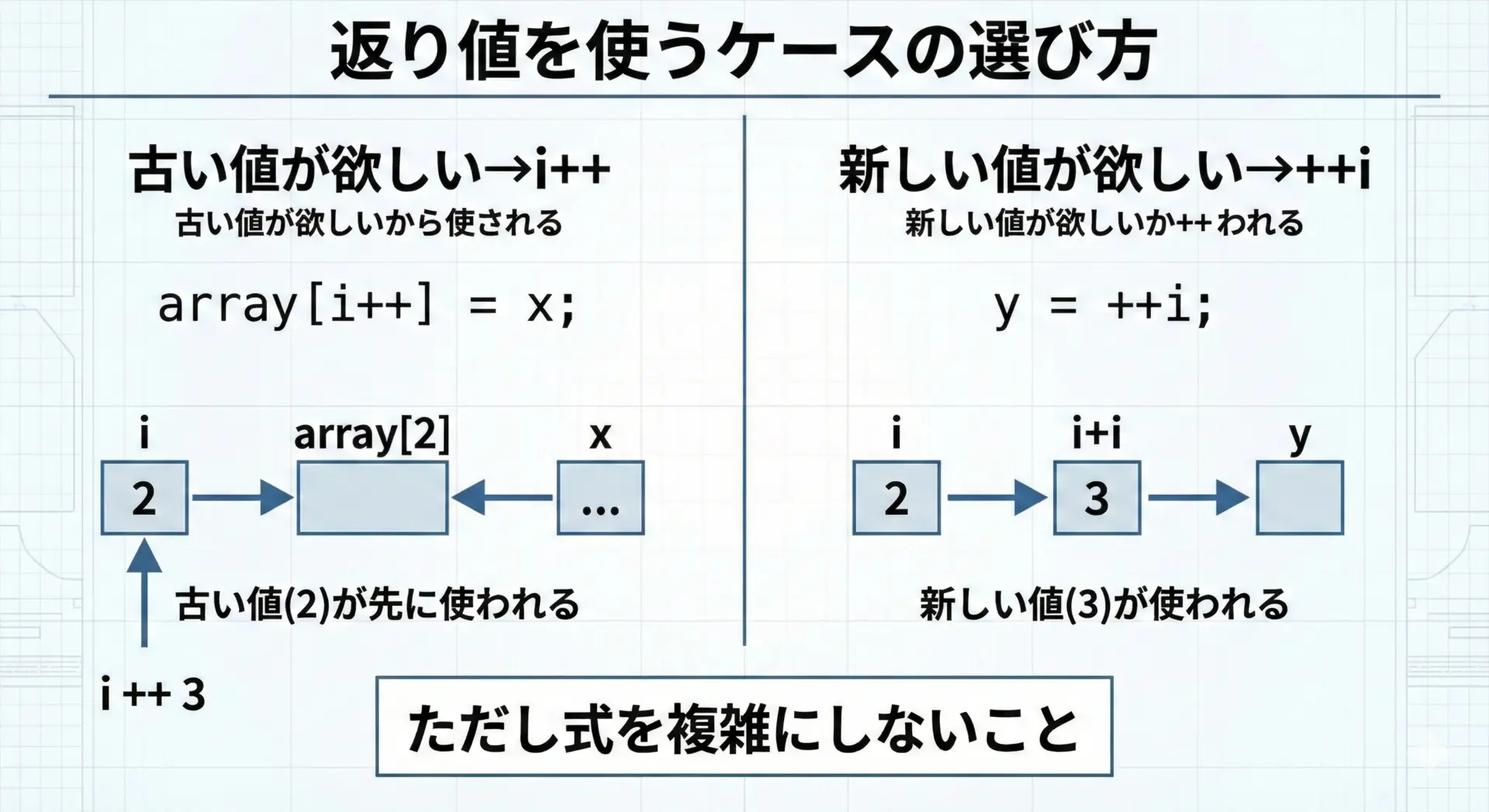
インクリメントの返り値を意識的に利用したい場合は、次のように整理すると直感的です。
- インクリメント前の値を使いたい → i++
- インクリメント後の値を使いたい → ++i
たとえば、配列に値を埋めていくときに「いまのインデックスを使ってから、次に進めたい」という場合、次のような書き方がよく使われます。
int i = 0;
int arr[3];
arr[i++] = 10; // arr[0] = 10, その後 i = 1
arr[i++] = 20; // arr[1] = 20, その後 i = 2
arr[i++] = 30; // arr[2] = 30, その後 i = 3一方、「インクリメントした結果をそのまま使いたい」という場合は++iを使います。
int i = 0;
// i を 1 にしてから、その 1 を返して printf に渡す
printf("i = %d\n", ++i); // 出力: i = 1ただし、返り値を使う場合でも式を複雑にし過ぎないことが大切です。
同じ式の中で複数回インクリメントを使うと、すぐに未定義動作の領域に入り込んでしまいます。
マクロや関数呼び出しとの組み合わせで避けるべき書き方

マクロとインクリメント演算子を組み合わせると、自分では意図していない形で同じ変数が複数回評価されることがあります。
#include <stdio.h>
#define SQR(x) ((x) * (x)) // x を2回評価してしまう危険なマクロ
int main(void) {
int i = 3;
int a = SQR(i++); // (i++) * (i++) に展開される
printf("i = %d, a = %d\n", i, a);
return 0;
}展開後のコードは次のようになります。
int a = ((i++) * (i++)); // i++ が2回登場するこれは同じ式の中でiを2回変更しているため、再び未定義動作になります。
このような問題を避けるために、次のような方針を取ると安全です。
- マクロの引数には副作用を持つ式(例えばi++や++i)を渡さない
- インクリメントを含む式をマクロの引数に入れる必要があるなら、一度変数に代入してから渡す
- 可能なら関数やインライン関数で置き換える
// 安全側の使い方: 先にインクリメントしてから別変数に保存する
int tmp = i++; // ここで副作用を完結させる
int a = SQR(tmp); // 副作用のない値をマクロに渡すコーディング規約で前置・後置を統一するメリット
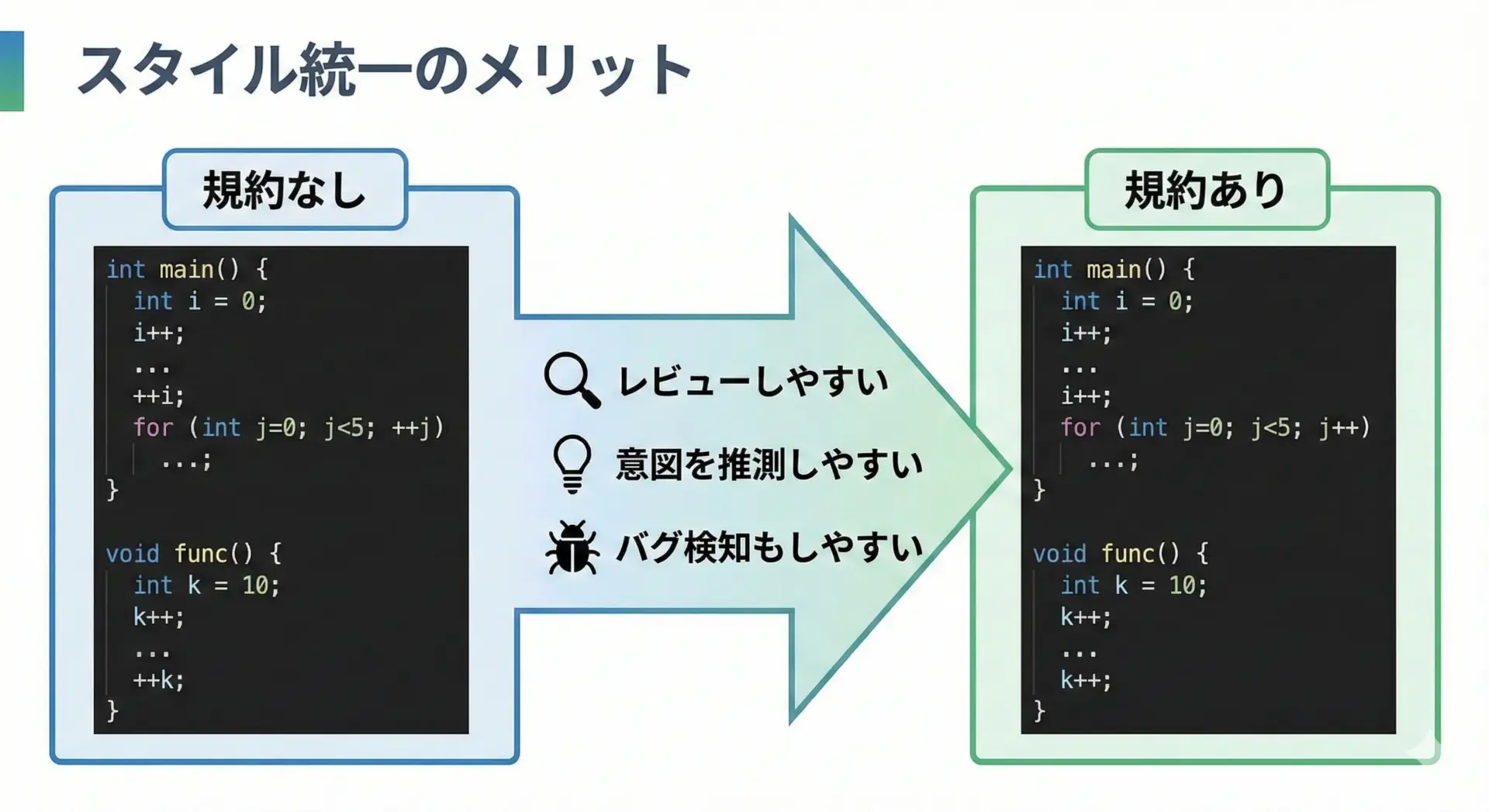
前置と後置のどちらを使うかは、プロジェクトやチームのコーディング規約で統一しておくことを強くおすすめします。
例えば、次のようなルールを決めるとわかりやすくなります。
- 単独文のインクリメント・デクリメントはすべてi++ / i–を使う
- 返り値が必要な場合だけ++i / –iを使うが、そのときも式を簡潔に保つ
- 同じ式の中で1つの変数に対してインクリメント・デクリメントは1回まで
このようにルールを明確にしておくと、コードレビューの際に「この++iには何か特別な意味があるのか?」といった余計な疑問を減らせます。
また、ルールに違反している箇所を「危険なコードの兆候」としてすぐに検出できるようになります。
C言語で前置・後置インクリメントを理解するコツ
評価順序(sequence point)の基本を押さえる
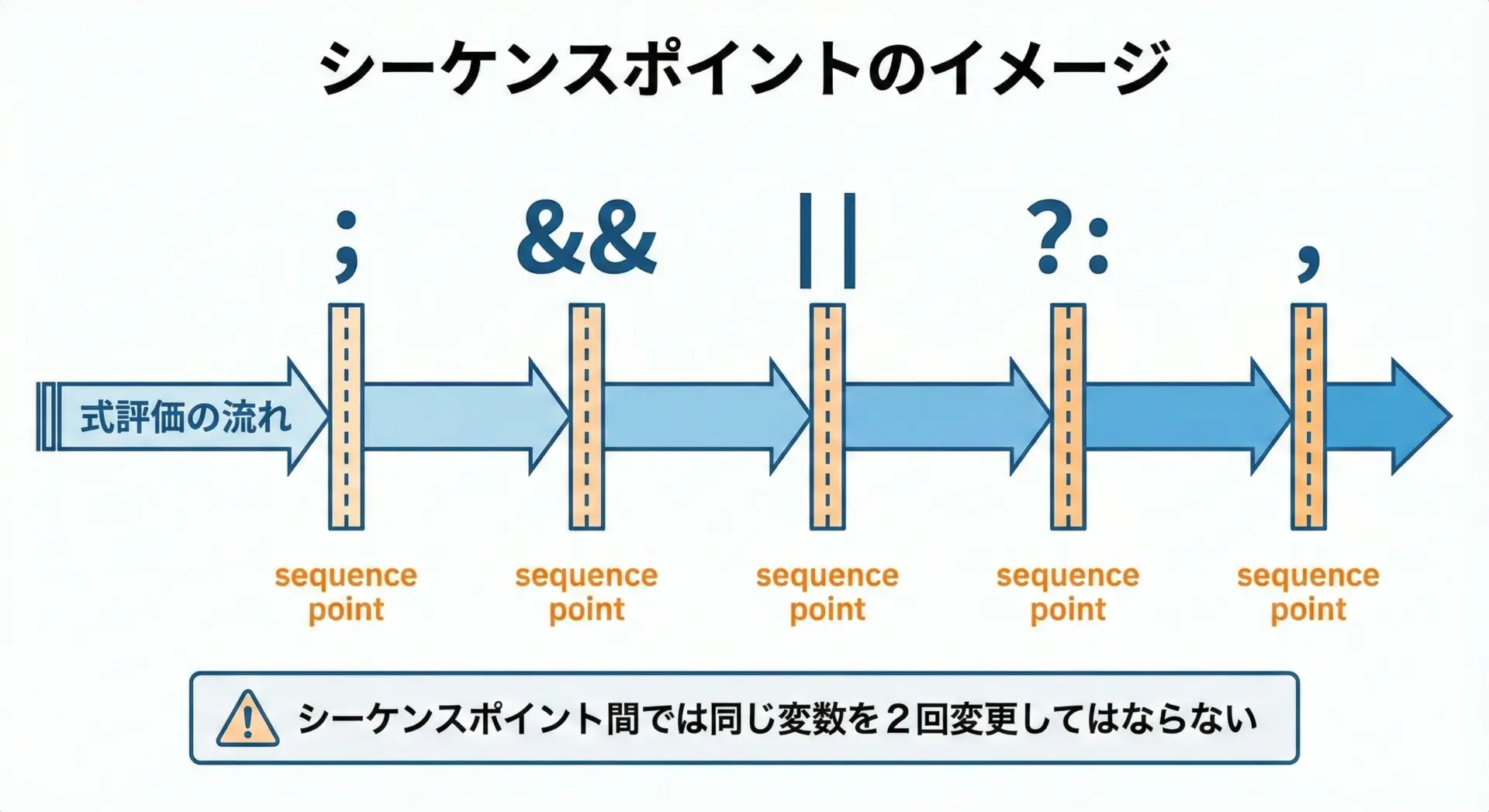
インクリメント演算子と未定義動作の関係を理解するには、シーケンスポイント(sequence point)という概念が欠かせません。
古いC規格(C89/C99など)では、次のような場所がシーケンスポイントとされていました。
- 文末の
; - 論理演算子
&&や||の評価後 - 条件演算子
? :の評価箇所 - カンマ演算子
,の評価後 など
シーケンスポイントとは「それまでに発生したすべての副作用が完了していることが保証される場所」です。
そして、シーケンスポイントの間で、同じ変数を2回以上変更してはならないというルールがあります。
次のようなコードは、このルールに違反する典型例です。
i = i++; // i への変更が2回
a[i++] = i++; // i への変更が2回現在のC11/C17規格では「シーケンスポイント」という用語は廃止され、「評価順序・副作用の完了順序」としてより厳密に定義されていますが、実務では「シーケンスポイントの間で同じ変数を何度もいじらない」という古典的な覚え方の方が理解しやすい場合も多いです。
デバッガでi++ / ++iの動きを確認する
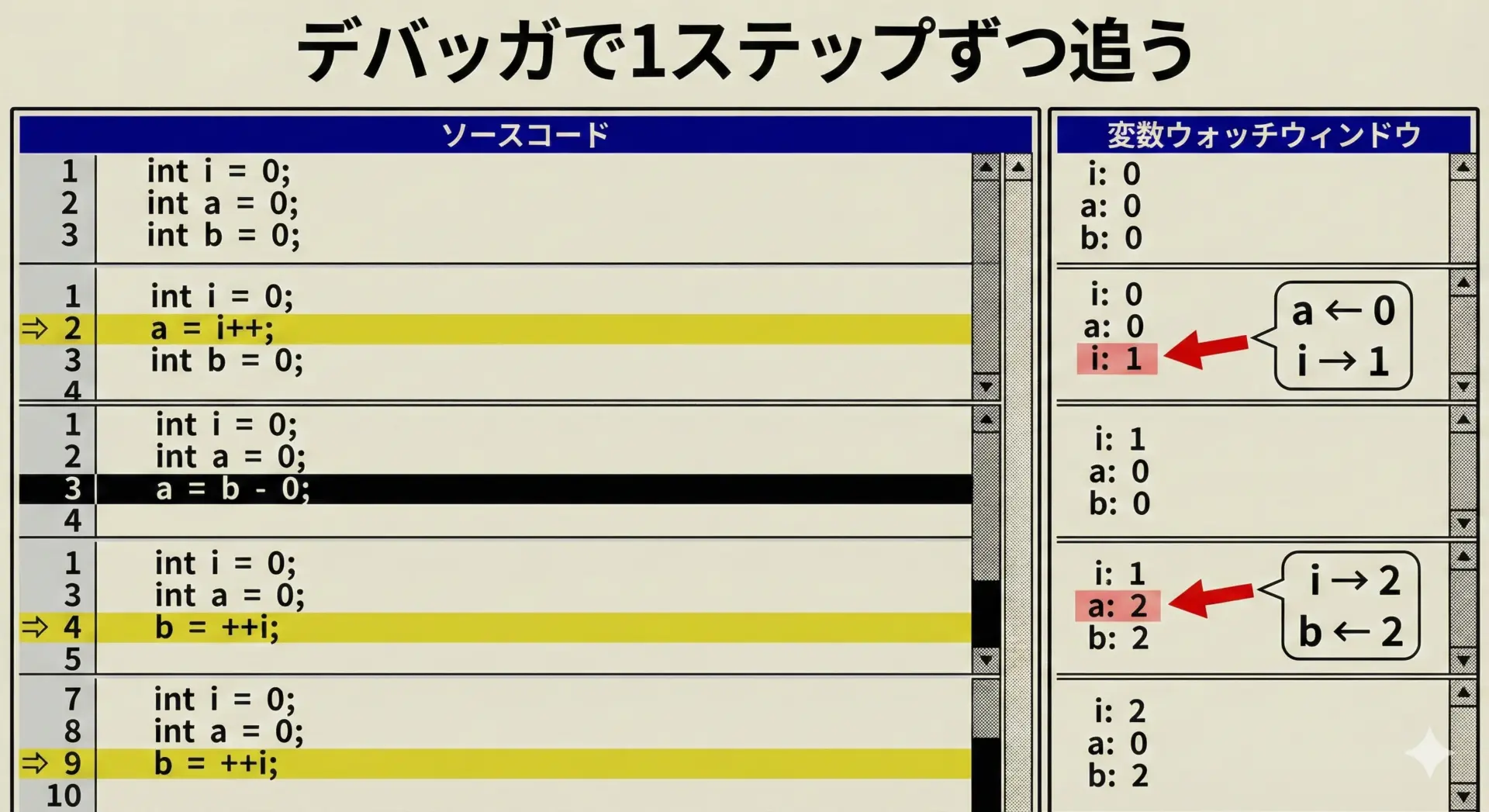
概念だけでなく実際の挙動を目で見ると、前置/後置インクリメントの理解が一段と深まります。
gdbなどのデバッガを使って、次のようなプログラムを1行ずつ追いかけてみてください。
#include <stdio.h>
int main(void) {
int i = 5;
int a = i++; // ブレークポイント1
int b = ++i; // ブレークポイント2
printf("a = %d, b = %d, i = %d\n", a, b, i); // ブレークポイント3
return 0;
}デバッガでブレークポイントを設定し、ステップ実行しながら変数i, a, bの値を観察すると、次のような変化が見られます。
| 行 | iの値の変化 | aの値 | bの値 |
|---|---|---|---|
| 初期状態 | 5 | 未定 | 未定 |
a = i++; 実行後 | 6 | 5 | 未定 |
b = ++i; 実行後 | 7 | 5 | 7 |
このように実際のメモリ上の値の変化を追いかけることで、「どのタイミングで増え、どの値が返されるのか」が感覚として掴めるようになります。
シンプルなコードでインクリメントの副作用を検証する
最後に、自分で実験しやすいように、インクリメントの副作用を確かめるための小さなテストプログラムを示します。
#include <stdio.h>
// 単独インクリメントのテスト
void test_simple_increment(void) {
int i = 5;
printf("[simple] 初期 i = %d\n", i);
i++;
printf("[simple] i++ 後 i = %d\n", i);
++i;
printf("[simple] ++i 後 i = %d\n", i);
}
// 式中での前置/後置の違い
void test_expression(void) {
int i = 5;
printf("\n[expr] 初期 i = %d\n", i);
int a = i++ * 2;
printf("[expr] a = i++ * 2 の結果: a = %d, i = %d\n", a, i);
int b = ++i * 2;
printf("[expr] b = ++i * 2 の結果: b = %d, i = %d\n", b, i);
}
// 危険なパターン(未定義動作)を確認する例
// ※ 実際にはコンパイルや実行環境によって結果が変わる可能性があります
void test_ub(void) {
int i = 0;
printf("\n[UB] 初期 i = %d\n", i);
int a = i++ + i++; // 未定義動作
printf("[UB] a = i++ + i++ の結果(未定義): i = %d, a = %d\n", i, a);
i = 0;
int b = i++ + ++i; // これも未定義動作
printf("[UB] b = i++ + ++i の結果(未定義): i = %d, b = %d\n", i, b);
}
int main(void) {
test_simple_increment();
test_expression();
test_ub(); // 理論上は未定義動作だが、教材として実行結果を観察する
return 0;
}[simple] 初期 i = 5
[simple] i++ 後 i = 6
[simple] ++i 後 i = 7
[expr] 初期 i = 5
[expr] a = i++ * 2 の結果: a = 10, i = 6
[expr] b = ++i * 2 の結果: b = 14, i = 7
[UB] 初期 i = 0
[UB] a = i++ + i++ の結果(未定義): i = 2, a = 1
[UB] b = i++ + ++i の結果(未定義): i = 2, b = 2最後のUBテストの結果は、あくまで「手元の環境ではたまたまこうなった」に過ぎません。
このように実際の実行結果がバラバラになる可能性があること自体が、未定義動作の恐ろしさです。
まとめ
この記事では、C言語における前置インクリメント(++i)と後置インクリメント(i++)の違いを、評価順序や戻り値、副作用の観点から詳しく解説しました。
どちらも「1増やす」点は同じですが、式として返す値の違いが、未定義動作やオフバイワンエラーを招きやすいことを見てきました。
安全に使うためには、単独文で使う・同じ式で同じ変数を何度も変更しない・複雑な式に埋め込まないという基本を守り、チームでスタイルを統一することが重要です。
デバッガや小さな実験コードも活用しながら、直感的に理解できるまで確認してみてください。
