
C言語で整数型を扱うとき、signedとunsignedの違いは非常に重要です。
特に境界値やオーバーフローに関する理解が不足していると、テストでは見つからない致命的なバグにつながります。
本記事では、整数型の基礎から、境界値の罠、比較時の暗黙変換、実践的な防止テクニックまでを体系的に解説します。
現場で遭遇しがちなコード例も交えながら、安心して整数型を設計・利用できるようになることを目指します。
C言語のsignedとunsignedの基本
signedとunsignedの意味と使い分け
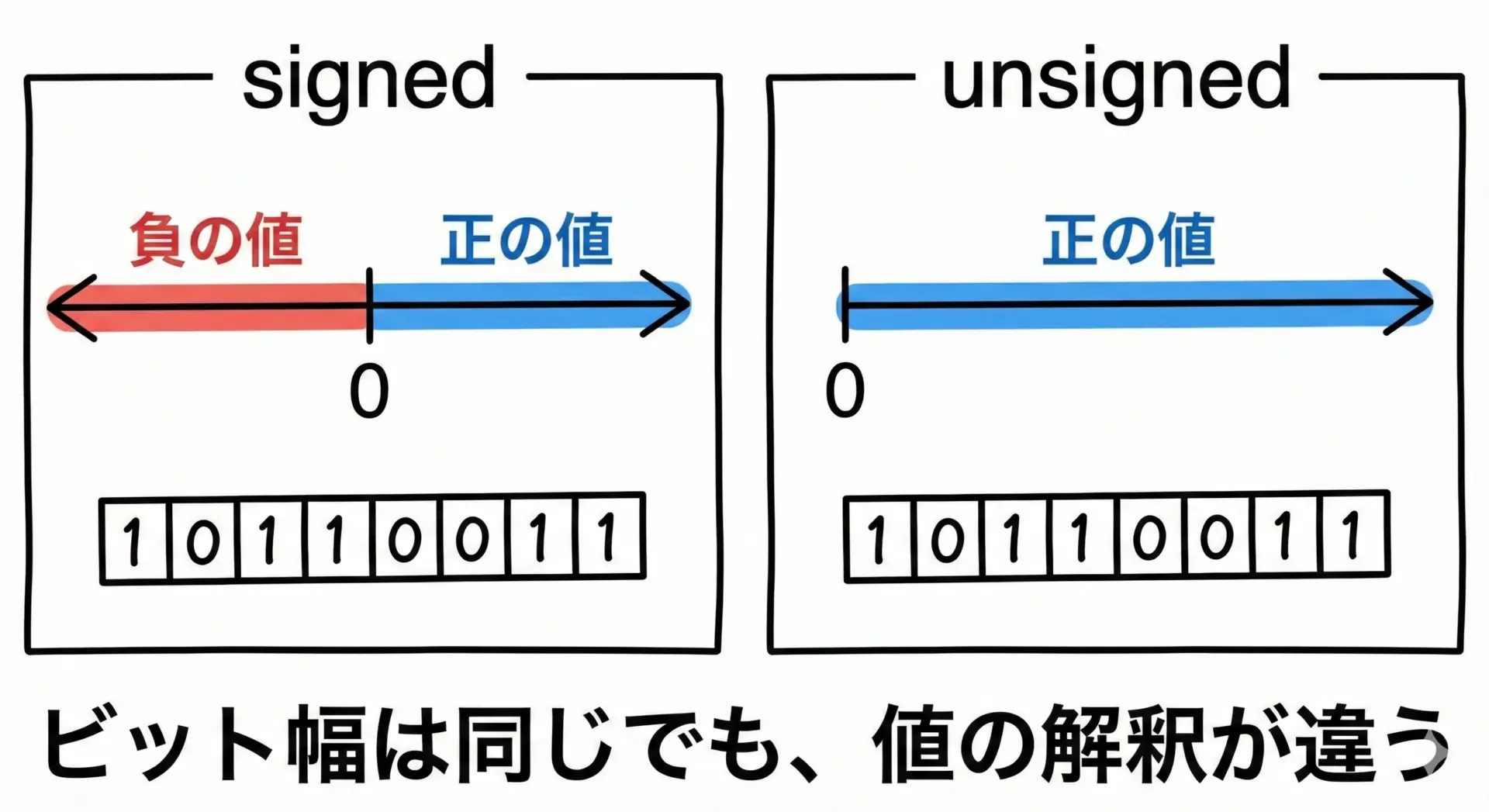
C言語におけるsignedとunsignedは、「同じビット幅をどのように数値として解釈するか」の違いを表します。
重要なのは、ビット数は変わらなくても、扱える値の範囲と意味が変わるという点です。
signedは負の値も扱える整数型であり、符号付き整数とも呼ばれます。
一方、unsignedは負の値を持たず、0以上の値だけを扱う整数型です。
たとえば、32ビットのintとunsigned intは、メモリ上のサイズとしては同じ32ビットですが、そのビット列をどう「数値として読むか」が異なります。
使い分けの基本方針としては、次のように整理できます。
- 値として負数があり得る場合や、計算途中で負値が意味を持つ場合はsignedを選ぶ
- サイズや個数、インデックスなど、論理的に負の値が存在しないものはunsignedを候補とする
- ただし、後述するようにsignedとunsignedの混在は比較バグを生みやすいため、チームのコーディング規約として「基本はsigned」「ごく一部だけunsigned」と決めることも多いです
int、short、charなど代表的な型とビット幅
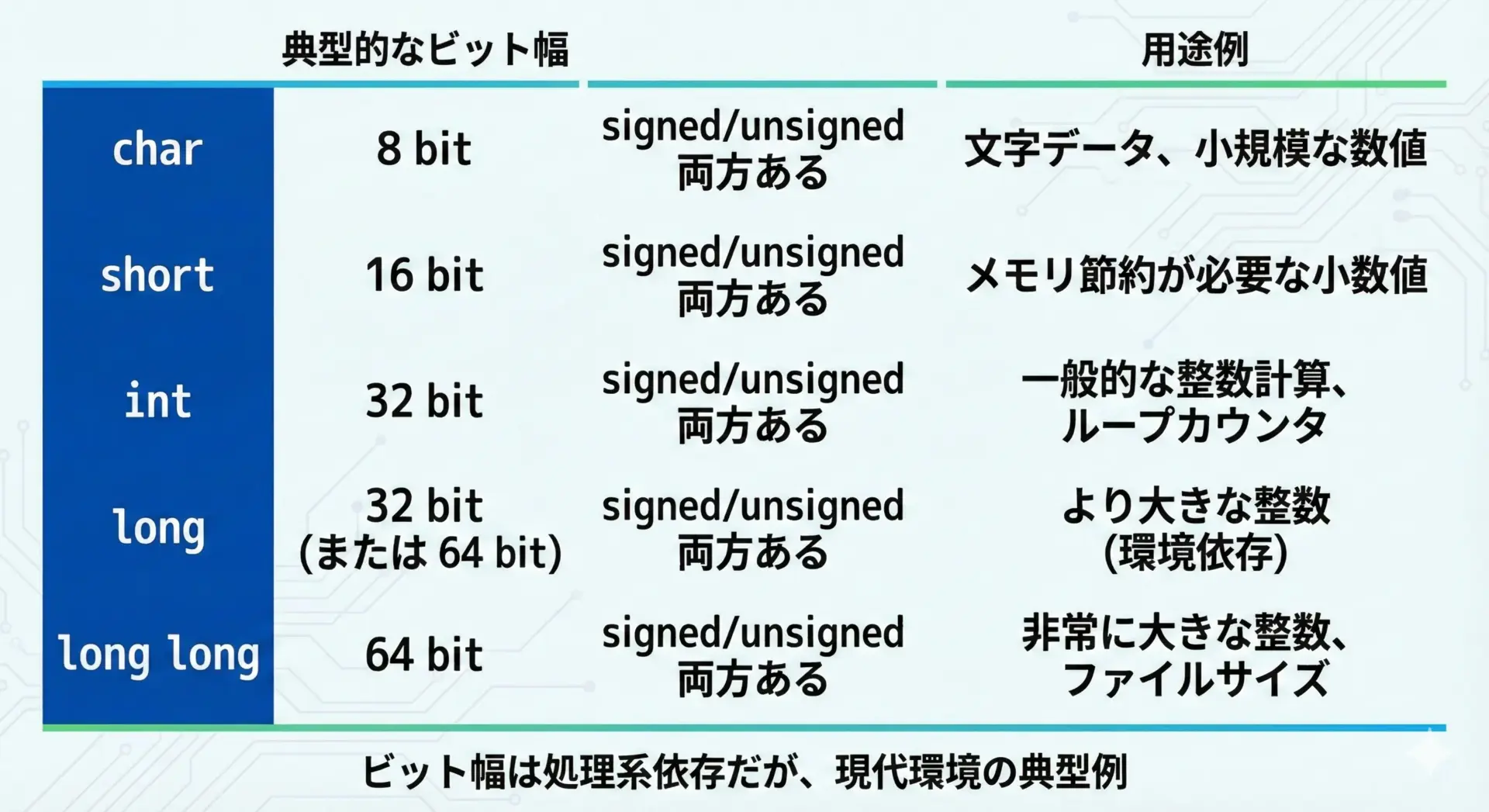
C言語の整数型は、signed/unsignedの前にcharやintなどの基本型名が付きます。
代表的な型と、現代の一般的な32ビット/64ビット環境での典型的なビット幅を、表にまとめます。
※標準ではビット幅は処理系依存ですが、現代的なPC向けコンパイラ(GCCやClangなど)では、以下がほぼデファクトスタンダードです。
| 型名 | 典型的なビット幅 | 備考 |
|---|---|---|
| signed char | 8ビット | charがsignedかunsignedかは処理系依存 |
| unsigned char | 8ビット | バイトを表すのに頻繁に使用 |
| short / short int | 16ビット | signed shortの省略形 |
| unsigned short | 16ビット | |
| int | 32ビット | signed intの省略形 |
| unsigned int | 32ビット | サイズやビットフラグなどでよく使用 |
| long | 32ビット or 64ビット | LP64環境(Unix系)では64ビット |
| unsigned long | 32ビット or 64ビット | |
| long long | 64ビット | C99以降、64ビット整数として広く利用 |
| unsigned long long | 64ビット |
標準ではsizeof(char)は常に1バイト(8ビットとは限らないが、ほとんどの環境で8ビット)であり、sizeof(short) <= sizeof(int) <= sizeof(long)という関係が保証されています。
signedとunsignedで表現できる値の範囲
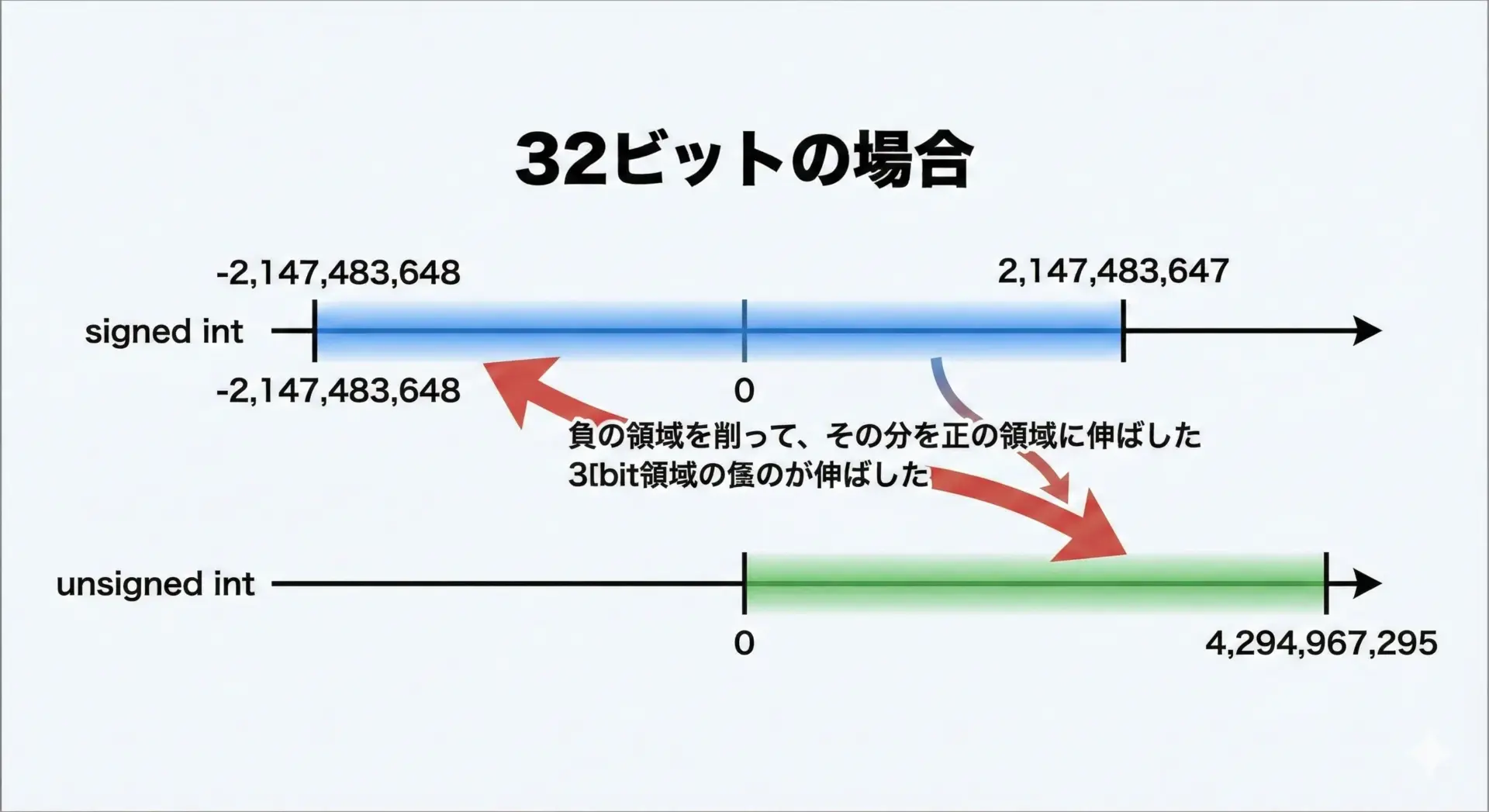
整数型の値の範囲はビット幅とsigned/unsignedによって決まります。
典型的なビット幅を前提に、代表的な型の範囲を一覧します。
| 型 | ビット幅(典型) | signedの場合の範囲 | unsignedの場合の範囲 |
|---|---|---|---|
| char | 8ビット | -128 ~ 127 | 0 ~ 255 |
| short | 16ビット | -32,768 ~ 32,767 | 0 ~ 65,535 |
| int | 32ビット | -2,147,483,648 ~ 2,147,483,647 | 0 ~ 4,294,967,295 |
| long long | 64ビット | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | 0 ~ 18,446,744,073,709,551,615 |
同じビット幅なら、unsignedのほうが2倍近く大きな正の値を扱える一方で、負の値を一切表現できなくなります。
これはメモリ上のビットパターンを2の補数表現で解釈するかどうかによる違いです。
なお、C標準ではINT_MAXINT_MINなどのマクロがlimits.hで定義されています。
実際の値は処理系依存ですが、ほぼすべての現代環境で上記のような範囲になっています。
C言語の境界値とオーバーフローの罠
最大値(INT_MAX)・最小値(INT_MIN)付近で起こるバグ
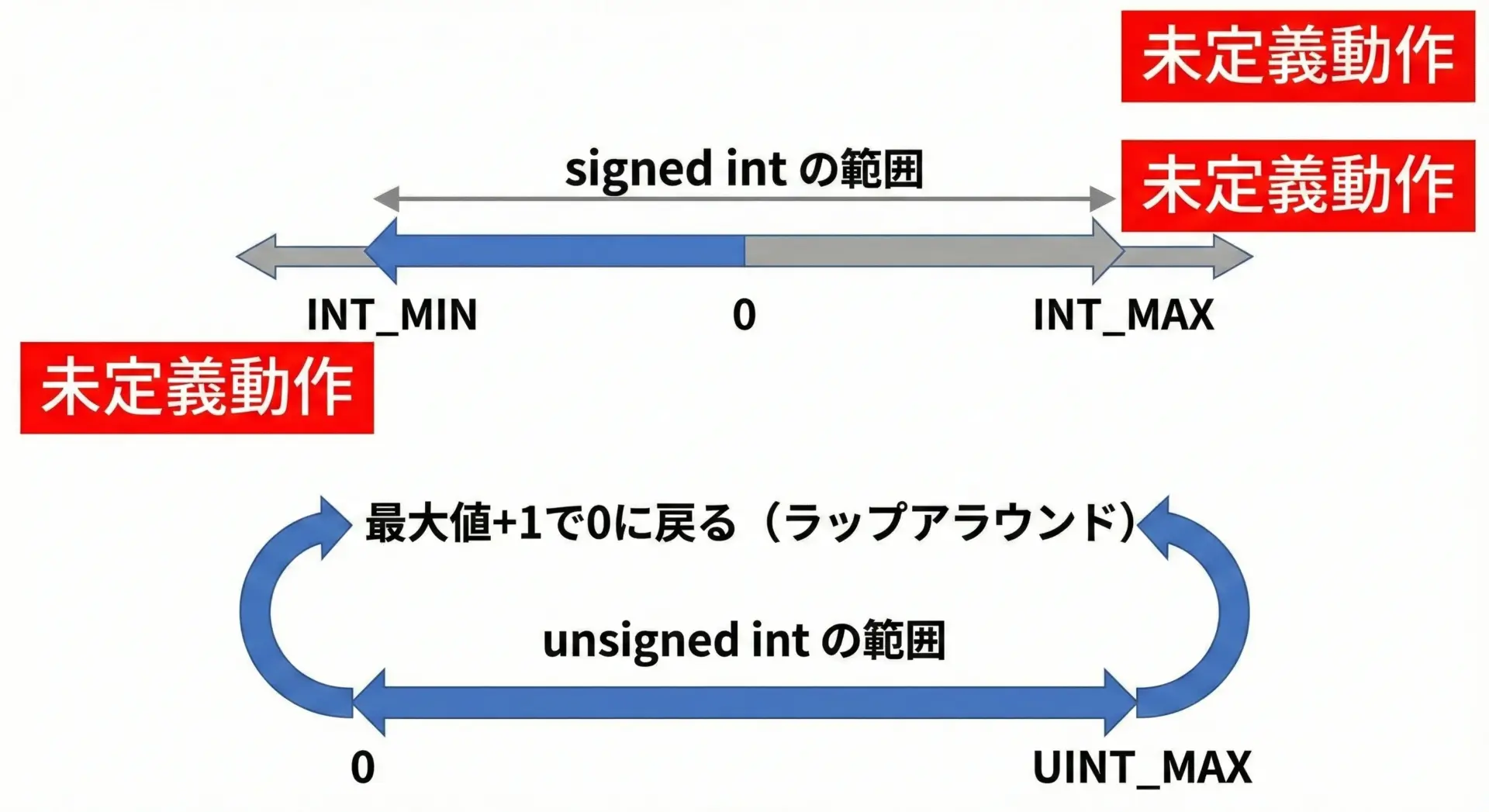
signed整数では値がINT_MAXやINT_MIN付近に達すると、少しの加減算でオーバーフローが発生します。
これが境界値バグの温床です。
例えば32ビットのintでINT_MAXはおおよそ2.1×10^9です。
単純な加算ロジックで次のようなコードを書くと、特定の条件で突然おかしな挙動になります。
#include <stdio.h>
#include <limits.h>
int main(void) {
int x = INT_MAX;
printf("INT_MAX = %d\n", INT_MAX);
// ここでオーバーフローの可能性がある
int y = x + 1;
printf("x + 1 = %d\n", y); // 何が表示されるかは処理系依存
return 0;
}INT_MAX = 2147483647
x + 1 = -2147483648このように最大値を1増やしただけで最小値にジャンプしてしまう例がよく知られています。
ただし、この挙動は後述するように未定義動作であり、必ずしもこのように振る舞うとは限りません。
signed整数オーバーフローは未定義動作
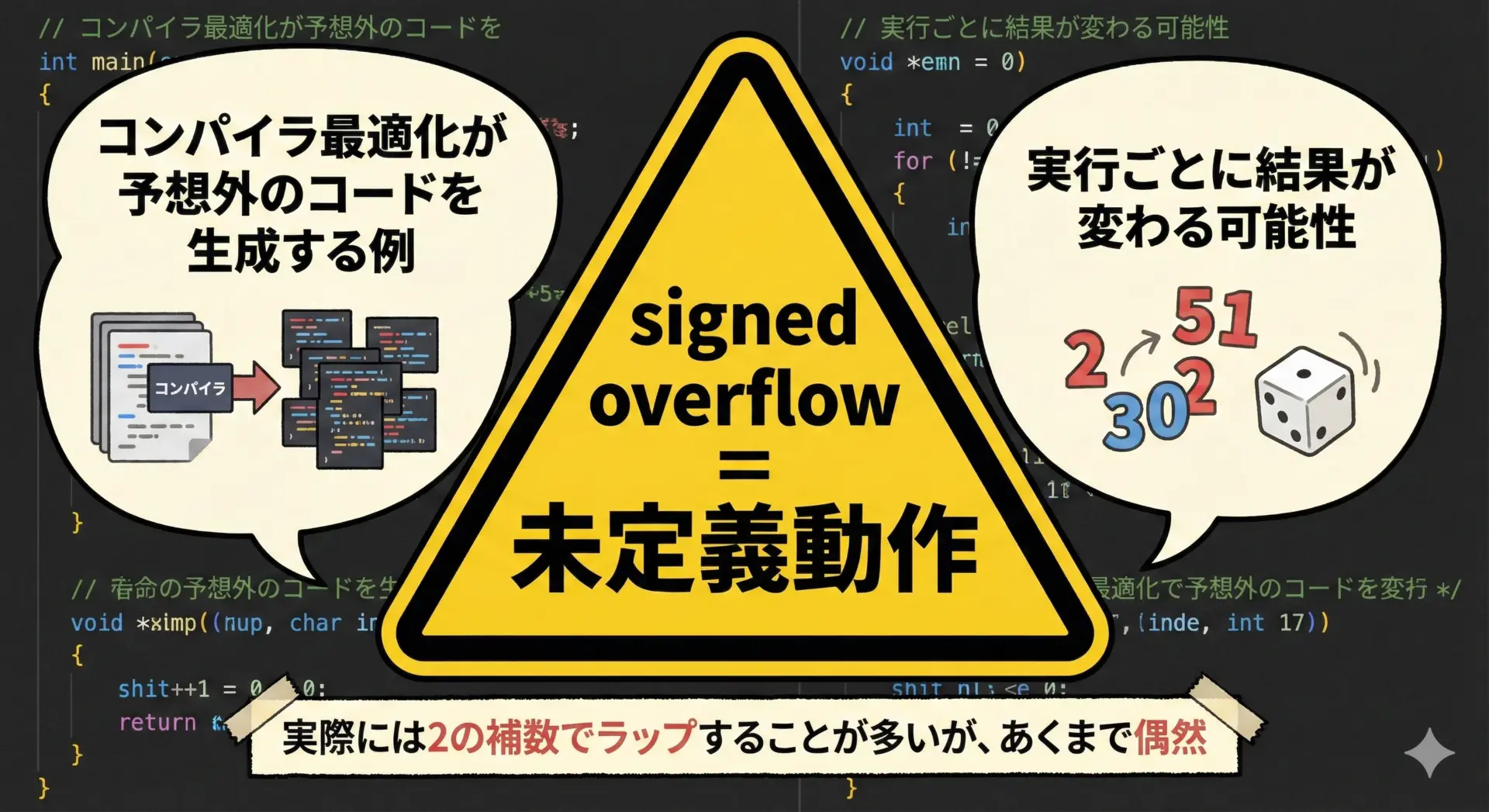
C標準では「符号付き整数型のオーバーフローは未定義動作」と明記されています。
未定義動作とは、コンパイラがどのような動作をしてもよいという意味であり、次のようなリスクがあります。
- 実行環境やコンパイラのバージョンが変わると結果が変わる
- 最適化により、意図しない形へコードが変形される
- セキュリティホール(バッファオーバーフローなど)につながる
例えば次のようなコードを考えます。
#include <stdio.h>
#include <limits.h>
#include <stdbool.h>
bool is_non_negative_after_add(int x, int y) {
// 「x + y が負にならないなら true」を期待しているつもりのコード
return x + y >= 0;
}
int main(void) {
int a = INT_MAX;
int b = 1;
printf("INT_MAX = %d\n", INT_MAX);
printf("a + b >= 0 ? %s\n",
is_non_negative_after_add(a, b) ? "true" : "false");
return 0;
}多くの処理系ではa + bが負の値になり、結果としてfalseが出力されるかもしれません。
しかし、INT_MAX + 1は未定義動作のため、コンパイラが以下のように推論してしまうことがあります。
- 前提: intの範囲でオーバーフローは発生しない(という暗黙の仮定)
- したがって
x + y >= 0が常に真になる、とみなす最適化
結果として、関数is_non_negative_after_addが常にtrueを返すように最適化されてしまう可能性があり、実際のCPU上の計算結果と矛盾した動作を引き起こします。
「実機ではラップしているから大丈夫」と考えるのは危険であり、signed整数でオーバーフローが起きる設計そのものを避ける必要があります。
unsignedオーバーフローとゼロ周りの挙動
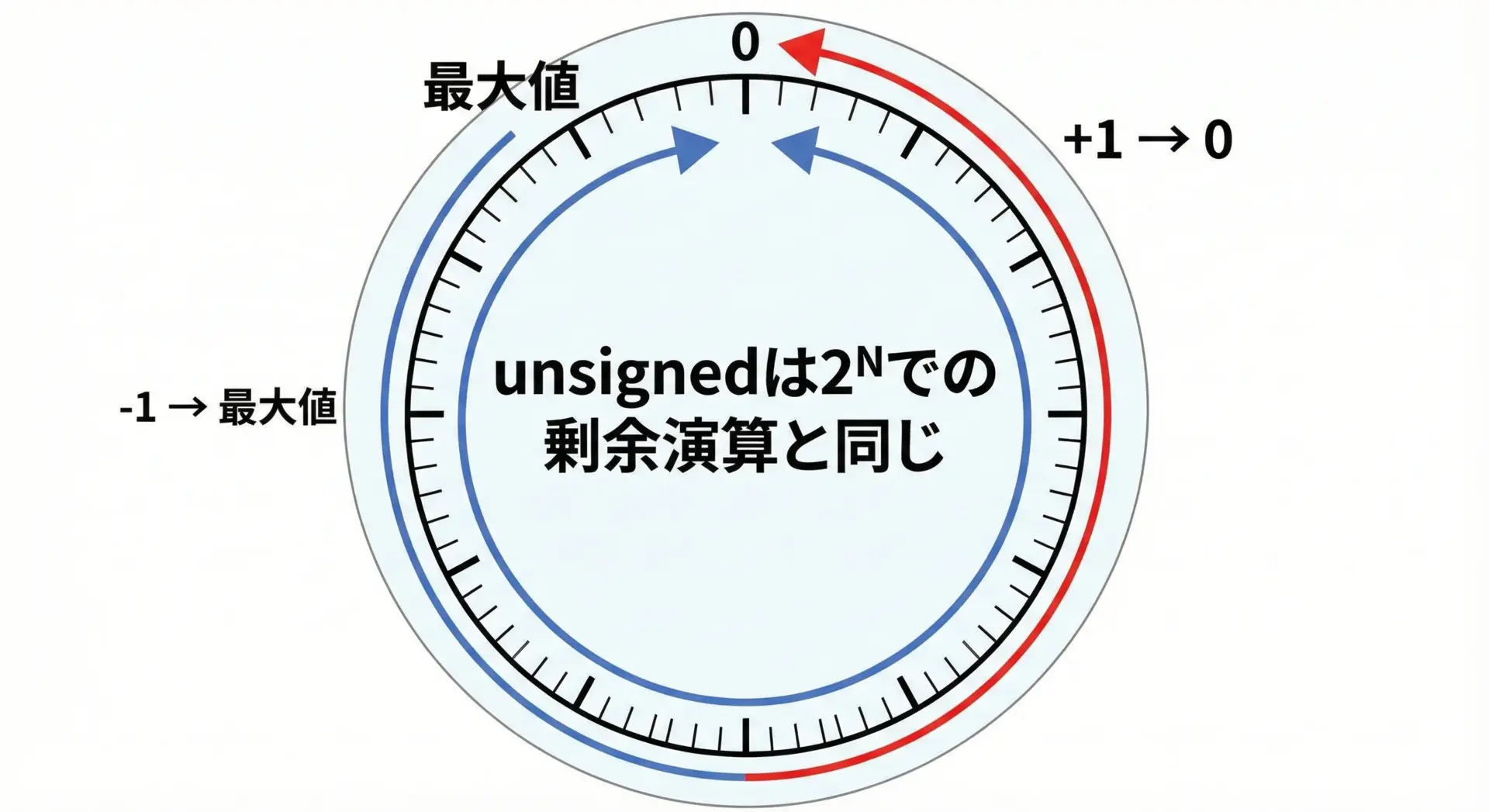
一方、unsigned整数のオーバーフローは未定義動作ではありません。
C標準では、ビット幅Nのunsigned型について、値は2^Nを法とした剰余演算として定義されています。
つまり、unsignedでは次の関係が常に成り立ちます。
- 最大値 + 1 == 0
- 0 – 1 == 最大値
これを確認する簡単なサンプルコードを示します。
#include <stdio.h>
#include <limits.h>
int main(void) {
unsigned int max = UINT_MAX;
unsigned int zero = 0;
printf("UINT_MAX = %u\n", max);
printf("UINT_MAX + 1 = %u\n", max + 1);
printf("0 - 1 (unsigned) = %u\n", zero - 1);
return 0;
}UINT_MAX = 4294967295
UINT_MAX + 1 = 0
0 - 1 (unsigned) = 4294967295このように、unsignedではオーバーフローが数学的に定義された剰余演算として扱われるため、特にビット演算やハッシュ、暗号実装などでは便利です。
ただし一般的なロジックでは、0から最大値へのラップアラウンドがバグの原因になりやすいため、安易な利用は注意が必要です。
signedとunsigned比較が生むバグ
signedとunsignedの混在比較で起きる暗黙変換
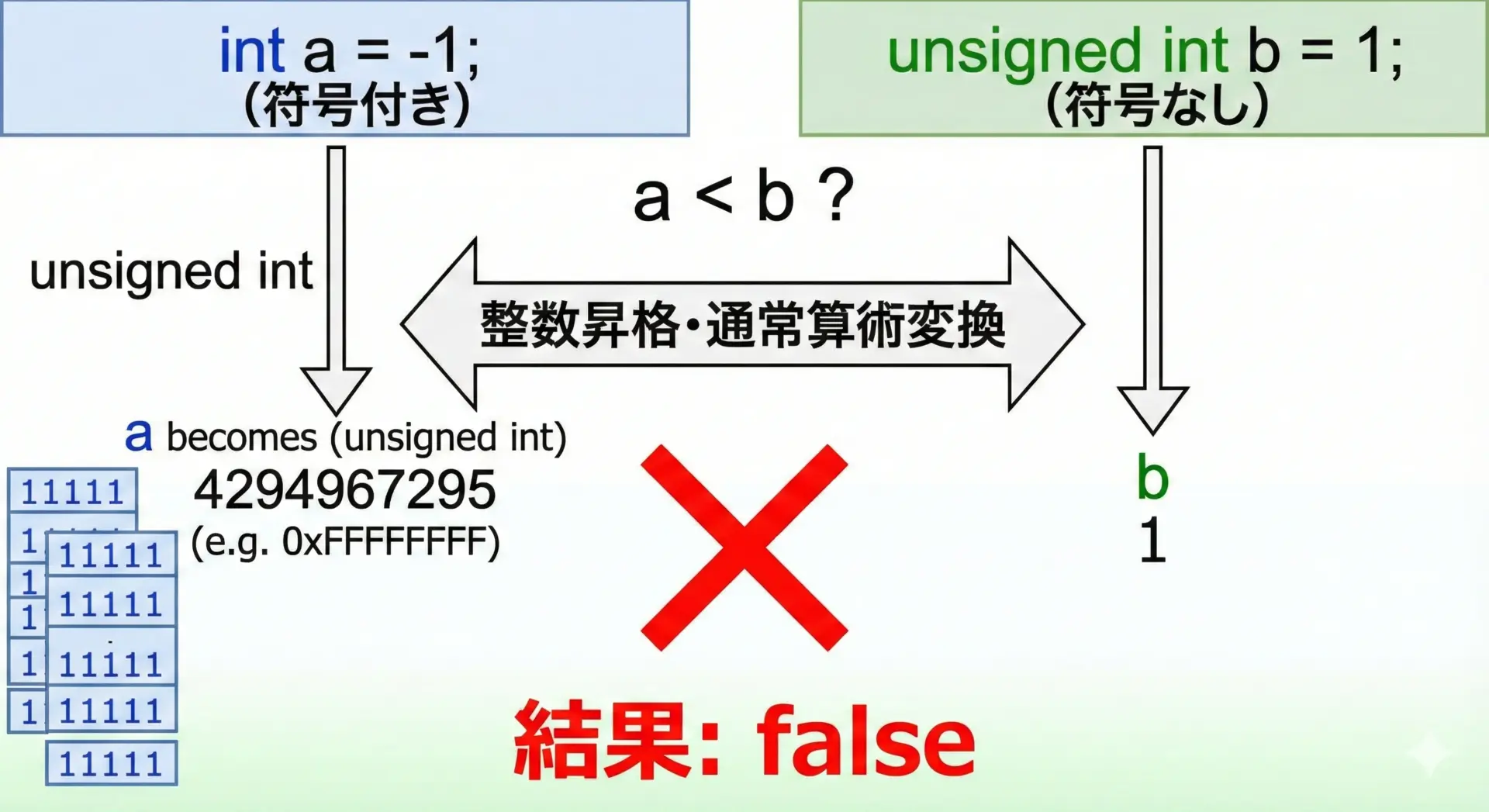
C言語では、異なる型同士を比較するときに暗黙の型変換(整数昇格、通常算術変換)が行われます。
ここでsignedとunsignedが混在すると非常に直感に反する結果が生まれます。
典型的な例を見てみます。
#include <stdio.h>
int main(void) {
int a = -1; // signed
unsigned int b = 1; // unsigned
if (a < b) {
printf("a < b\n");
} else {
printf("a >= b\n");
}
return 0;
}一見すると-1 は 1 より小さいので、a < bが真になりそうですが、多くの環境では次のような結果になります。
a >= bこれは、比較の前に次のような変換が行われるためです。
- 比較に参加する両方のオペランドは同じ型にそろえられる
- このときunsignedが優先される
- よって
aがunsigned intに変換される -1はunsignedではUINT_MAXとして解釈される(2^32 – 1など)
結果としてaは非常に大きな正の値となり、b = 1よりも大きいと判断されてしまいます。
「負数とunsignedの比較」はほぼ確実に危険であり、コンパイラの警告を最大限有効にして検出することが重要です。
size_tとの比較で発生する典型的なバグ例
実務で最も多いパターンの1つが、size_tとintの比較です。
標準ライブラリの多くの関数はsize_tを返しますが、プログラマ側が誤ってintに代入してしまう例が頻発します。
次のコードを見てください。
#include <stdio.h>
#include <string.h>
int main(void) {
char buf[8];
const char *src = "example";
// strlenはsize_tを返すが、intに代入してしまっている例
int len = strlen(src);
// sizeof(buf) は size_t 型
if (len < sizeof(buf)) {
// ここは「バッファに収まるときだけコピーする」つもり
// だが、len が負になる条件があると危険
printf("copy ok\n");
} else {
printf("too long\n");
}
return 0;
}この単純な例ではstrlenはマイナスを返さないため実害は出ませんが、より現実的なシナリオとして、エラー時に-1を返す関数を使っている場合を考えます。
#include <stdio.h>
long get_length_maybe_error(void);
int main(void) {
char buf[8];
long len = get_length_maybe_error(); // 負数でエラーを表す仕様だとする
if (len < sizeof(buf)) {
// エラー(-1)でもここに入ってしまう可能性がある
printf("do something with len = %ld\n", len);
} else {
printf("error or too long\n");
}
return 0;
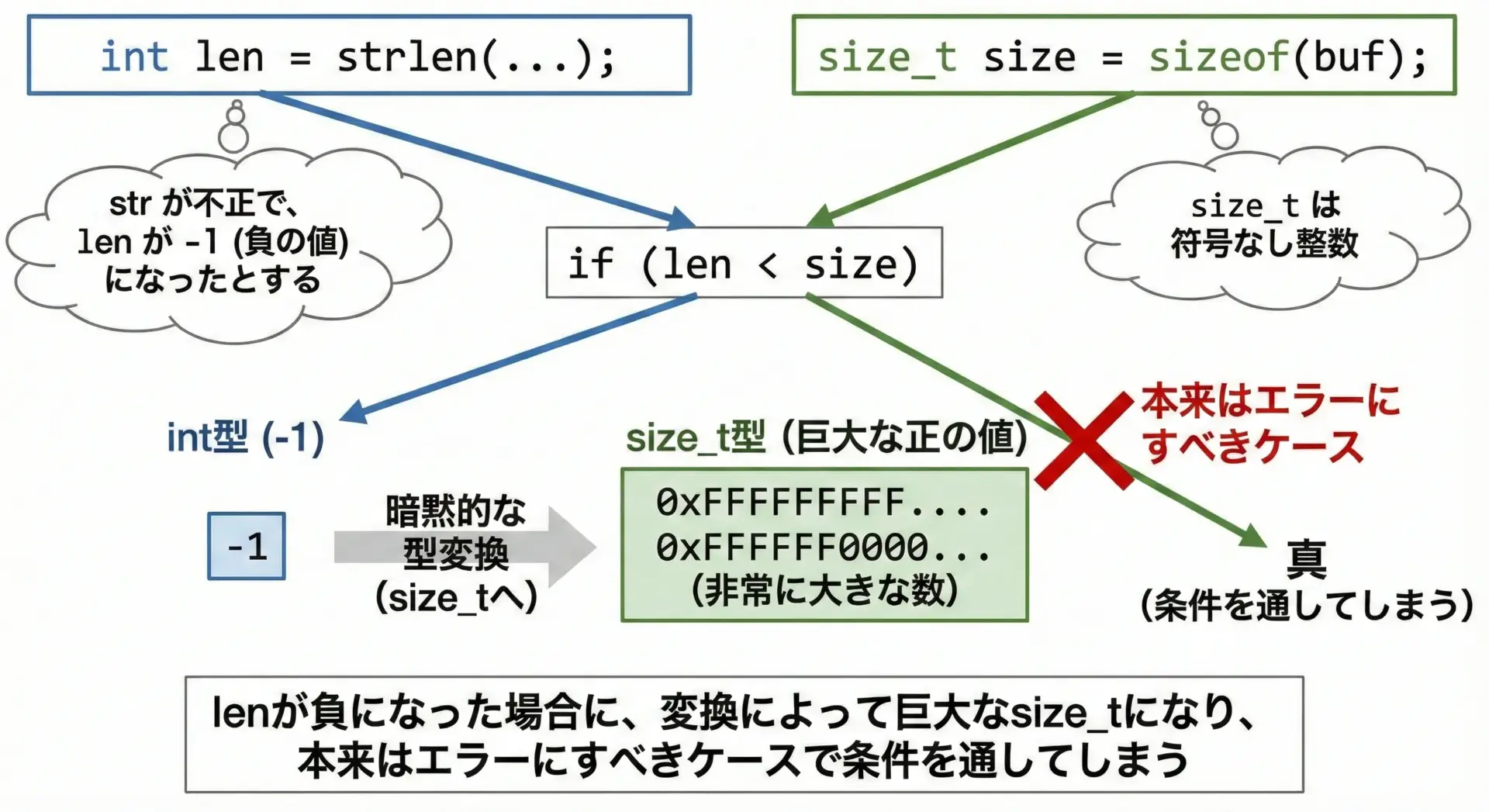
}ここでlenが負の値(-1)の場合を考えます。
- 比較
len < sizeof(buf)では、左がlong、右がsize_t(unsigned longなど) - 通常算術変換により、
lenがunsigned longに変換される - 負の値
-1は、unsignedでは非常に大きな値(2^64 – 1など)になる - 結果として
len < sizeof(buf)はfalseとなるはず…ですが、状況によっては逆方向の比較で危険になります
もっと危険なのはif (len <= sizeof(buf))のような条件より、if (len >= 0 && len < sizeof(buf))と書いたつもりが、暗黙変換により不正に評価されるケースです。
ここでは本質的な教訓として、size_tや配列長と比較するときは、比較相手もunsignedにそろえる、または明示的に境界チェック用の関数を用意することが重要になります。
forループと配列添字での境界値の罠
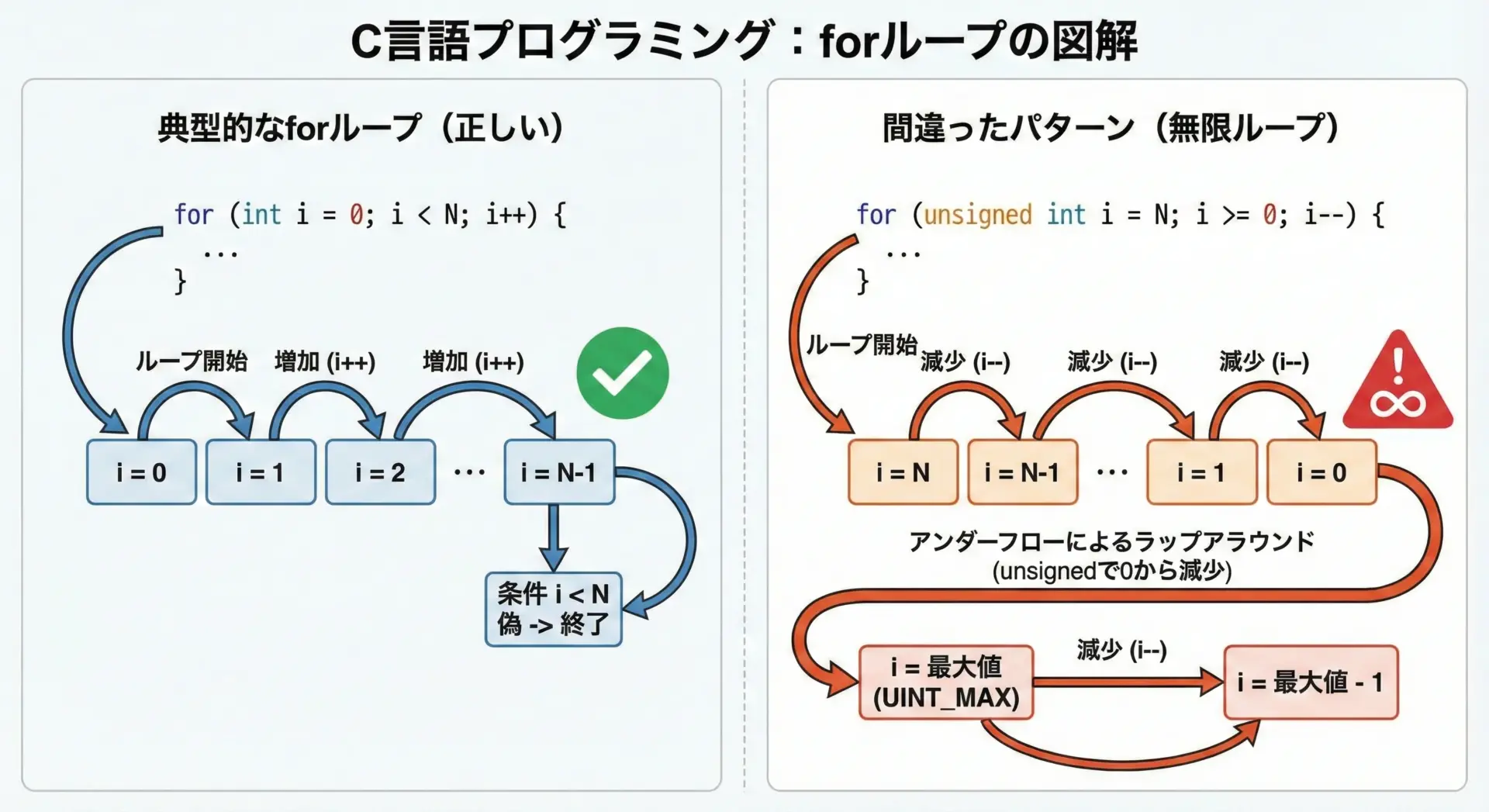
unsignedをforループのカウンタに使うと、0の直前での挙動がバグの原因になります。
次の2つのループを比較してください。
#include <stdio.h>
void forward_loop(int n) {
for (int i = 0; i < n; i++) {
printf("i = %d\n", i);
}
}
void backward_loop_wrong(unsigned int n) {
// 間違った逆順ループの例
// 「i が 0 以上の間ループする」と書いてしまっている
for (unsigned int i = n - 1; i >= 0; i--) {
printf("i = %u\n", i);
}
}
int main(void) {
forward_loop(3);
printf("---\n");
backward_loop_wrong(3);
return 0;
}i = 0
i = 1
i = 2
---
i = 2
i = 1
i = 0
i = 4294967295
i = 4294967294
... (続く)後半のループは事実上無限ループになってしまいます。
その原因は次の通りです。
iはunsigned inti--で0から1引くと、UINT_MAXへラップする- ループ条件
i >= 0はunsignedにとって常に真となる
対策としては、次のような設計方針が考えられます。
- ループ変数には原則としてsigned整数を使う
- どうしてもunsignedのサイズと比較する場合は、
size_t i = 0; i < n; i++のような増加方向のループに限定する - 減少方向のループを組みたいときは、終端条件を
i--ではなくwhile (i-- > 0)のように書き換える、あるいはfor (int i = (int)n - 1; i >= 0; i--)のようにsignedにキャストした変数を使う
signed/unsignedバグを防ぐ実践テクニック
型の設計指針とsigned/unsignedの選び方
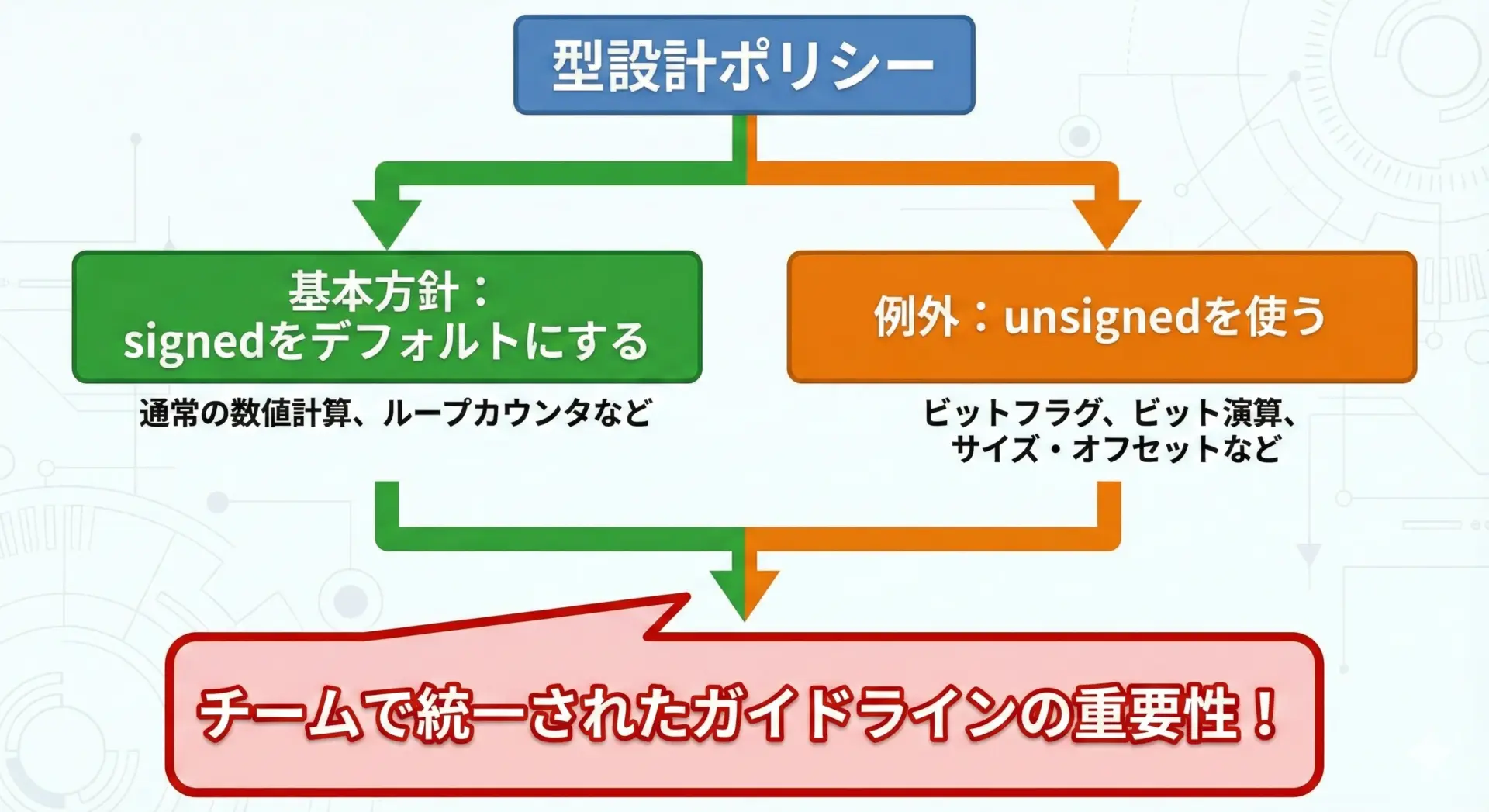
バグを減らすには、「どの場面でどの型を使うか」をあらかじめ決めておくことが非常に効果的です。
おすすめの指針をまとめます。
1つの有力な方針は「特別な理由がなければsignedを使う」というものです。
理由は次の通りです。
- 算術演算の意味が自然(負数も表現できる)
- signed同士の演算では、オーバーフローさえ避ければ比較が直感通りに動く
- signed/unsignedの混在という危険な状態を避けやすい
その上で、以下のような場面ではunsignedを検討します。
- ビットフラグやマスク(ビット単位の演算が主役)
- ハッシュ値やCRCなど、モジュロ2^Nが意味を持つアルゴリズム
- サイズやオフセット(
size_tやuintptr_tなど、ライブラリ仕様でunsignedが要求される場合)
型の選択は一度ミスすると後から修正が難しいため、API設計や構造体定義の段階で慎重に検討し、チーム内でガイドライン化しておくことが重要です。
キャストと比較時の注意点
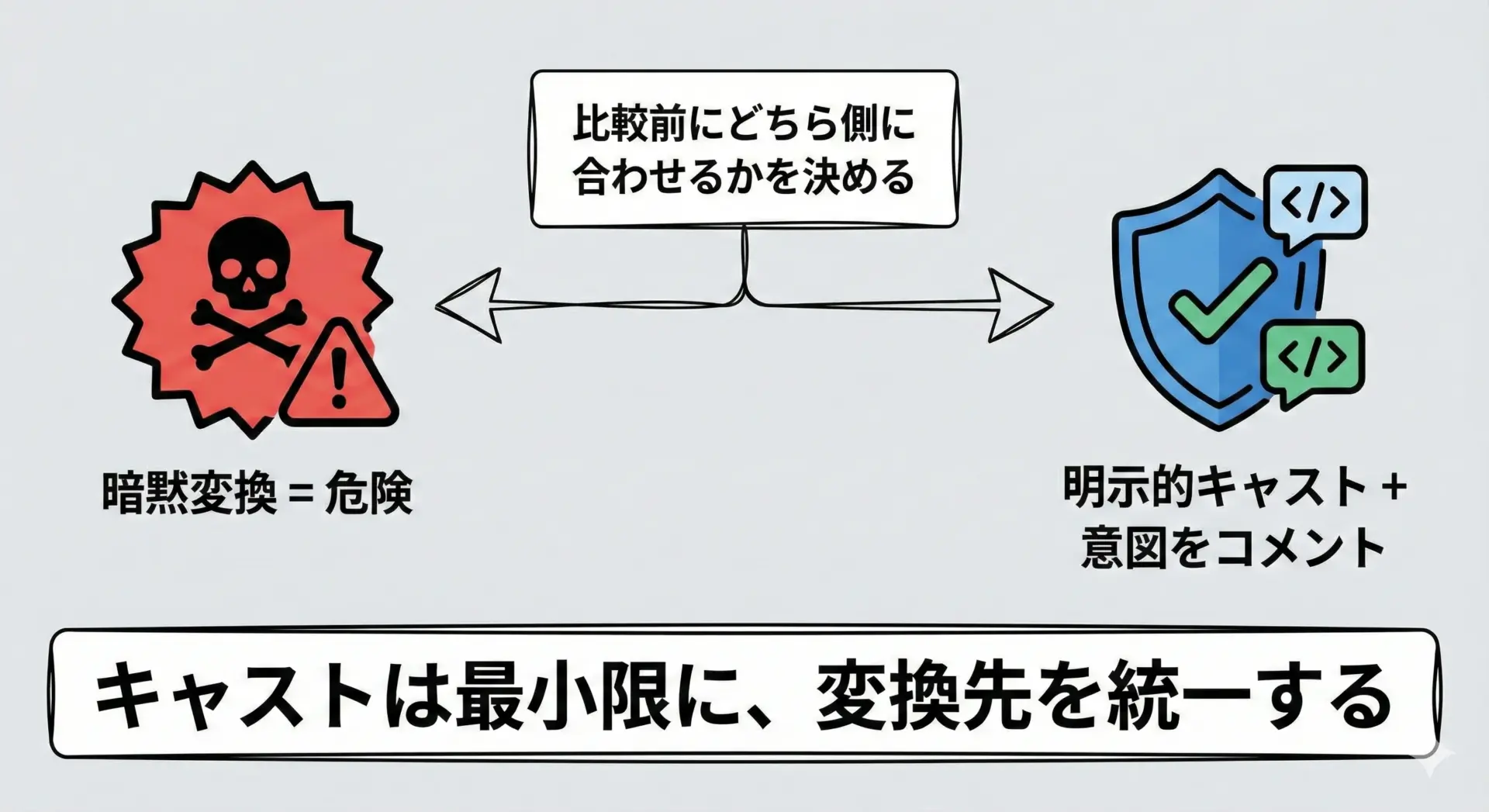
signed/unsignedの混在を完全に避けるのは難しく、どこかで型変換が必要になります。
このとき、暗黙の変換に頼るのではなく、明示的なキャストとコメントによる意図の明示が大切です。
次のようなテクニックを意識すると安全性が高まります。
- 比較のときはどちら側の型に合わせるかを最初に決める
たとえば「配列長と比較するときは常にsize_tに揃える」など、プロジェクト内でルール化します。 - 負数の可能性があるかどうかを明示的にチェックする
具体例を示します。
#include <stdbool.h>
#include <stddef.h>
// buf_size は size_t (unsigned)、len は int (signed) とする
bool can_copy(int len, size_t buf_size) {
// まず負数を除外する
if (len < 0) {
return false;
}
// ここで len は 0 以上であることが保証されたので、安全にキャストできる
return (size_t)len <= buf_size;
}このように、キャスト前に必ず値域のチェックを行ってから変換することで、意図しないラップアラウンドや比較バグを防げます。
- キャストは「狭い型への変換」を特に警戒する
例えばlongからintへのキャストは、範囲外の値を失う可能性があるため、事前チェックやコメントが必須です。
コンパイラ警告と静的解析による検出方法
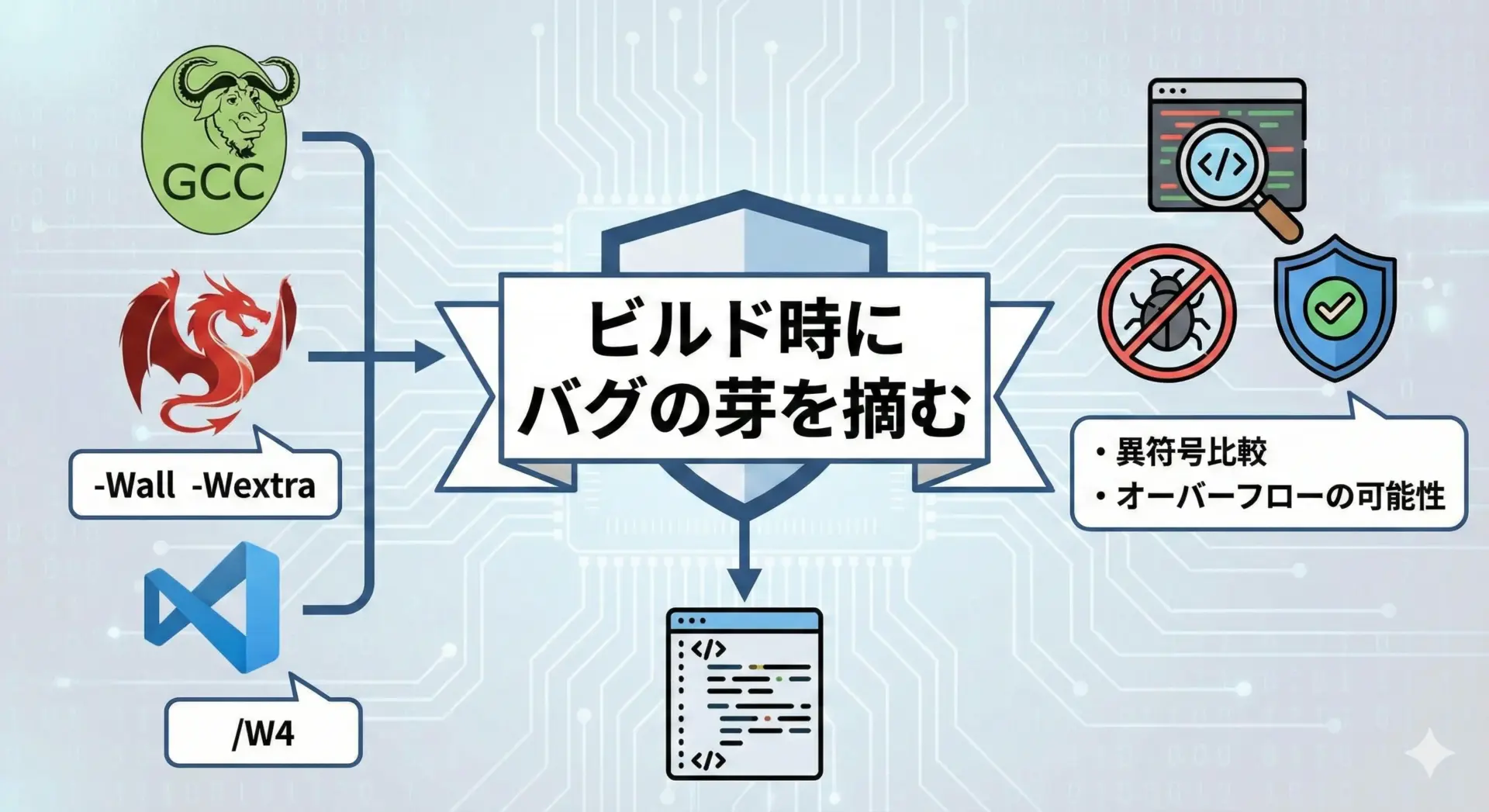
最後に、コンパイラ警告と静的解析ツールを活用してバグを早期発見する方法を紹介します。
コンパイラ警告の活用
GCCやClangなど多くのコンパイラには、signed/unsignedの比較に関する警告があります。
例えばGCC/Clangでは次のようなオプション設定が推奨されます。
-Wall -Wextra -Wsign-compare-Wall基本的な警告をすべて有効化-Wextra追加の有用な警告を有効化-Wsign-compare異なる符号の型同士の比較に警告
MSVCの場合は、プロジェクトの警告レベルを/W4に上げ、さらに/Wallを検討することで、多くの潜在バグを検出できます。
「警告ゼロ」をビルドの品質基準とする運用にしておくと、signed/unsigned関連のバグを早期に見つけやすくなります。
静的解析ツールの利用
コンパイラ警告だけでなく、静的解析ツールも非常に有効です。
代表的なものとして次のようなツールがあります。
- clang-tidy
- cppcheck
- commercialな静的解析ツール(Coverity、PVS-Studioなど)
これらのツールは、次のような問題を検出できます。
- 異符号比較による論理バグの可能性
- signed/unsigned変換でのオーバーフロー・アンダーフローの可能性
- 境界チェック漏れやバッファオーバーランのリスク
静的解析ツールをCI(継続的インテグレーション)に組み込むことで、レビューの前に機械的にバグの芽を摘むことができ、品質向上に大きく貢献します。
まとめ
本記事では、C言語におけるsignedとunsignedの違いと、それが生み出す境界値・オーバーフロー・比較バグについて詳しく解説しました。
符号付き整数のオーバーフローが未定義動作であること、unsignedでは2^Nでの剰余として定義されること、そしてsigned/unsignedの混在比較が直感に反する結果を生むことを理解することが重要です。
その上で、型の設計指針を定め、キャストと比較時に値域を慎重に扱い、コンパイラ警告や静的解析を活用することで、これらの罠を大きく減らせます。
整数型の扱いを丁寧に設計し、堅牢なCプログラムを目指していきましょう。
