C言語を学び始めると、intやshort、longの違いで必ず一度はつまずきます。
どれも「整数」を扱う型ですが、サイズや表現できる範囲、環境による違いがあるため、なんとなく選んでいるとバグの原因になります。
本記事では、初心者の方にもわかりやすいように、図解とサンプルコードを交えながら「結局どれをどう使えばよいか」まで丁寧に解説します。
C言語のint / short / longとは
整数型(integer)の基本と役割
整数型は、プログラムで数値を扱うときの「箱」のような役割を持ちます。
箱の大きさとルール(符号の有無など)によって、入れられる数値の範囲が決まります。
int / short / longの違いは、主に「箱の大きさ」と「扱う範囲」の違いだとイメージすると理解しやすくなります。
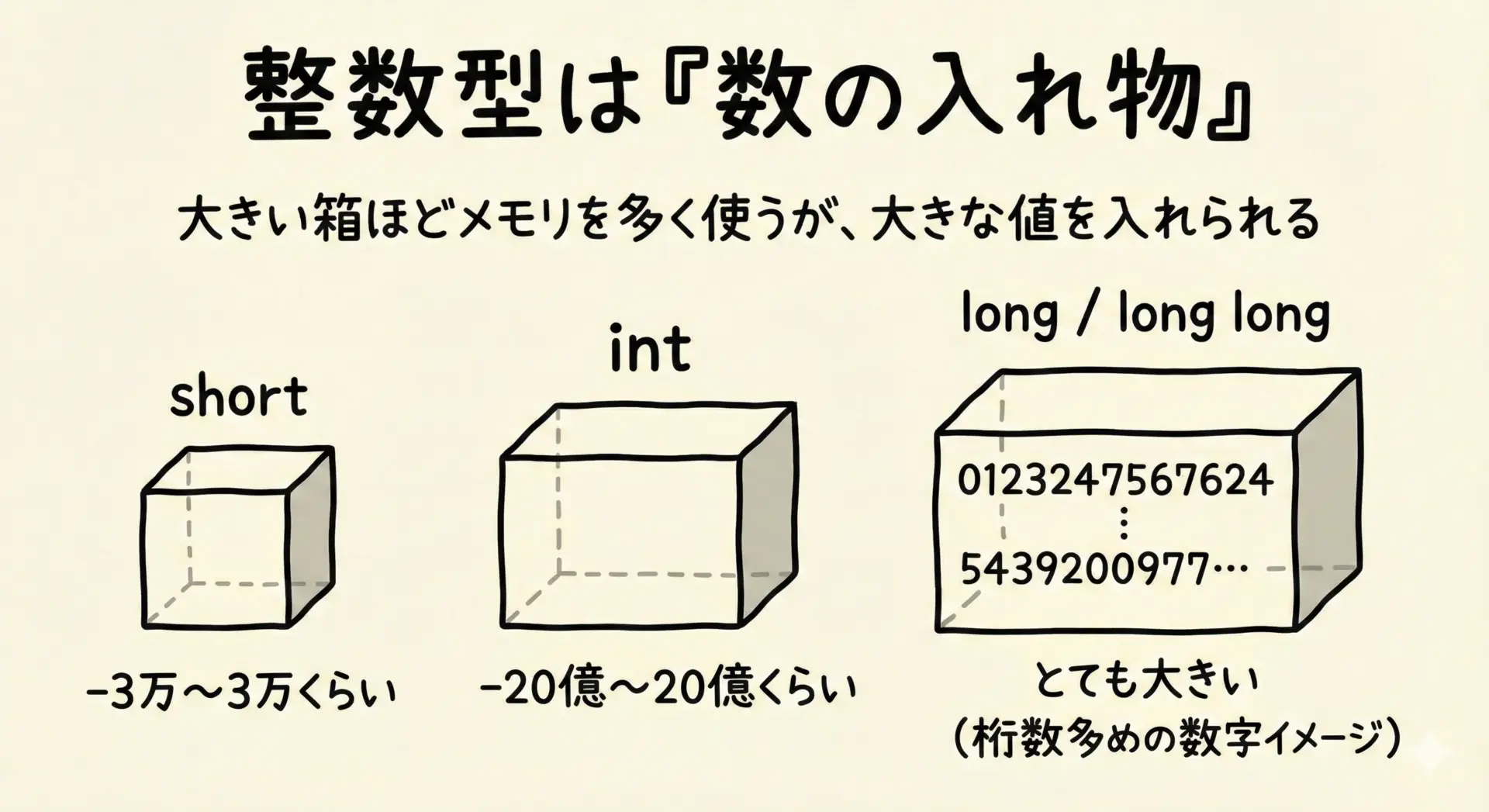
整数型の役割を整理すると、次のようになります。
- 短い範囲の整数を、少ないメモリで扱いたいときに
short - 標準的な整数型として、もっともよく使われるのが
int - より大きな値を扱いたいときに
longやlong long
ここで重要なのは、これらのサイズ(ビット数)が「どの環境でも同じ」とは限らないという点です。
これが、C言語の型をややこしくしている大きな理由です。
C言語規格で決まっていること・決まっていないこと
C言語の規格(標準仕様)では、各整数型の「最小サイズ」や「相対的な関係」は決めていますが、「何ビット」とまでは決めていません。
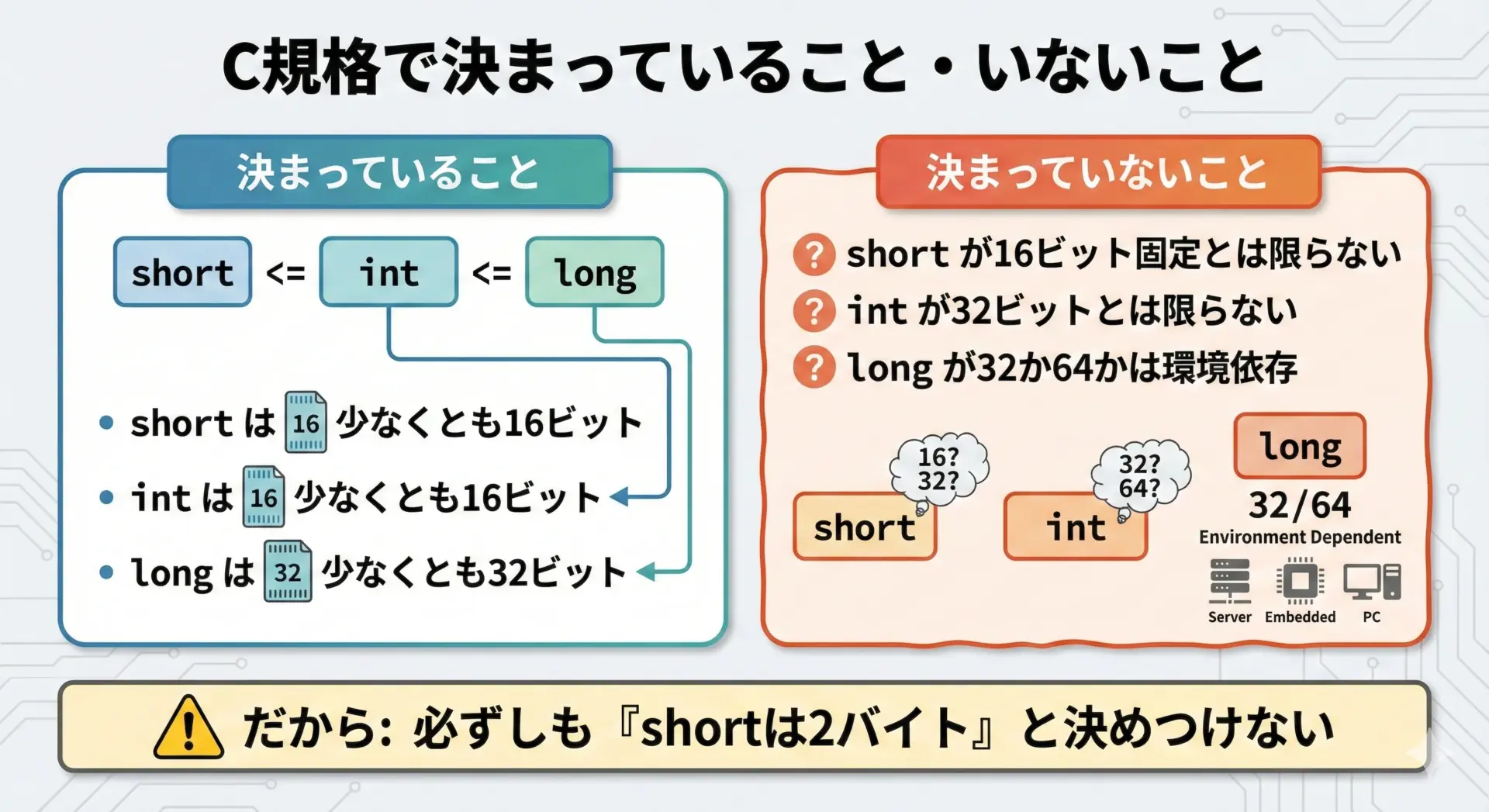
規格で決まっていることは、代表的なものだと次のようになります。
- shortのビット数 ≤ intのビット数 ≤ longのビット数
- shortは少なくとも16ビット
- intも少なくとも16ビット
- longは少なくとも32ビット
- signed型は負の数も扱える
- unsigned型は0以上のみ扱える
一方で、決まっていないことも多くあります。
intが32ビットとは限らない(16ビットや64ビットも理屈上あり得る)longが32ビットか64ビットかは環境に依存するshortのサイズも環境依存(ただし16ビット以上)
このように、C言語では「ビット数は環境依存だが、型同士の大小関係は決まっている」と覚えておくと良いです。
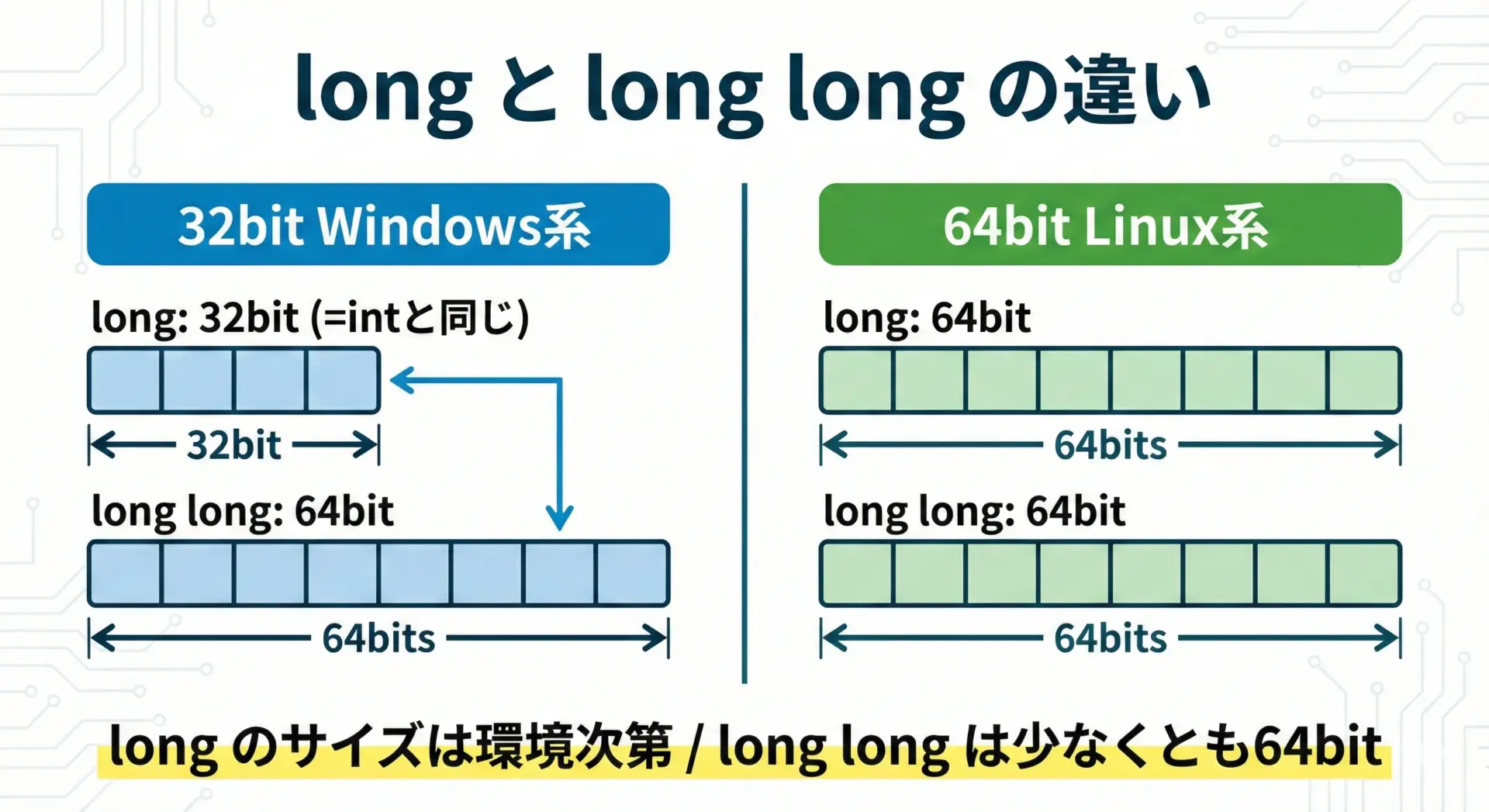
32bit環境と64bit環境での違い
現在主流のPCは64bit環境がほとんどですが、C言語の型のサイズは「OSやCPU、コンパイラの設計方針」によって変わります。
代表的な2つのモデルを比較してみます。
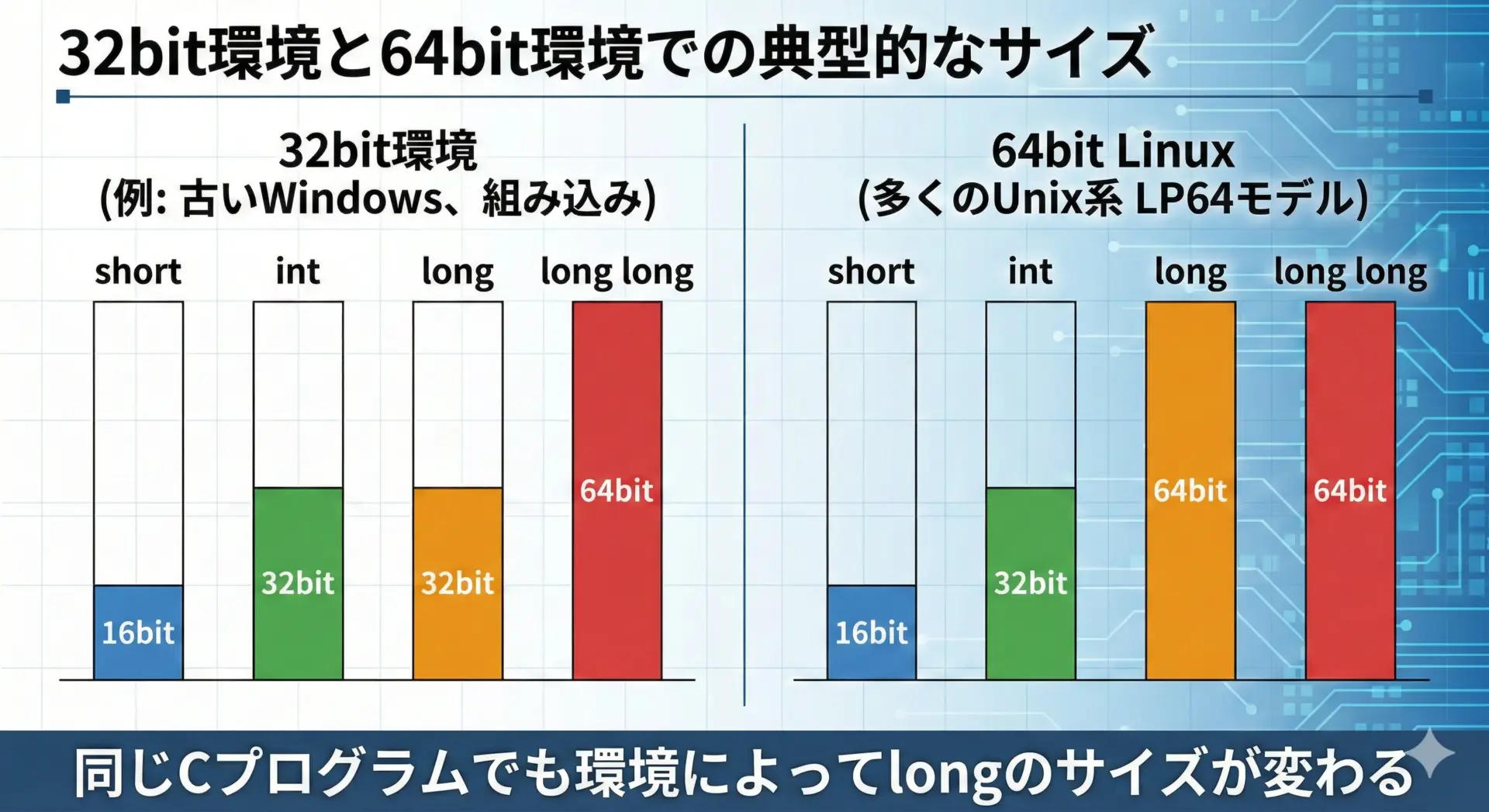
典型的なサイズは、次のような形です。
| モデル例 | short | int | long | long long |
|---|---|---|---|---|
| 32bit環境(ILP32) | 16bit | 32bit | 32bit | 64bit |
| 64bit Linux系(LP64) | 16bit | 32bit | 64bit | 64bit |
| 64bit Windows(LLP64) | 16bit | 32bit | 32bit | 64bit |
特に注意すべきは、64bit環境でもWindowsではlongが32bitのままであることです。
一方、多くのLinux系ではlongが64bitになっています。
この違いが、「同じCコードでも、OSを変えると型のサイズが変わる」というややこしさの原因です。
サイズは、プログラム中でsizeof演算子を使うことで確認できます。
#include <stdio.h>
int main(void) {
printf("short: %zu bytes\n", sizeof(short));
printf("int: %zu bytes\n", sizeof(int));
printf("long: %zu bytes\n", sizeof(long));
printf("long long: %zu bytes\n", sizeof(long long));
return 0;
}short: 2 bytes
int: 4 bytes
long: 8 bytes
long long: 8 bytes上記の出力例は、典型的な64bit Linux環境(LP64)の一例です。
実際の環境で実行して、自分の環境のサイズを確認してみると理解が深まります。
int / short / longのサイズと範囲
short型のサイズと表現できる値の範囲
short型は、小さめの整数を扱うための型です。
規格上は「少なくとも16ビット」とされており、多くの環境では16ビット(2バイト)です。
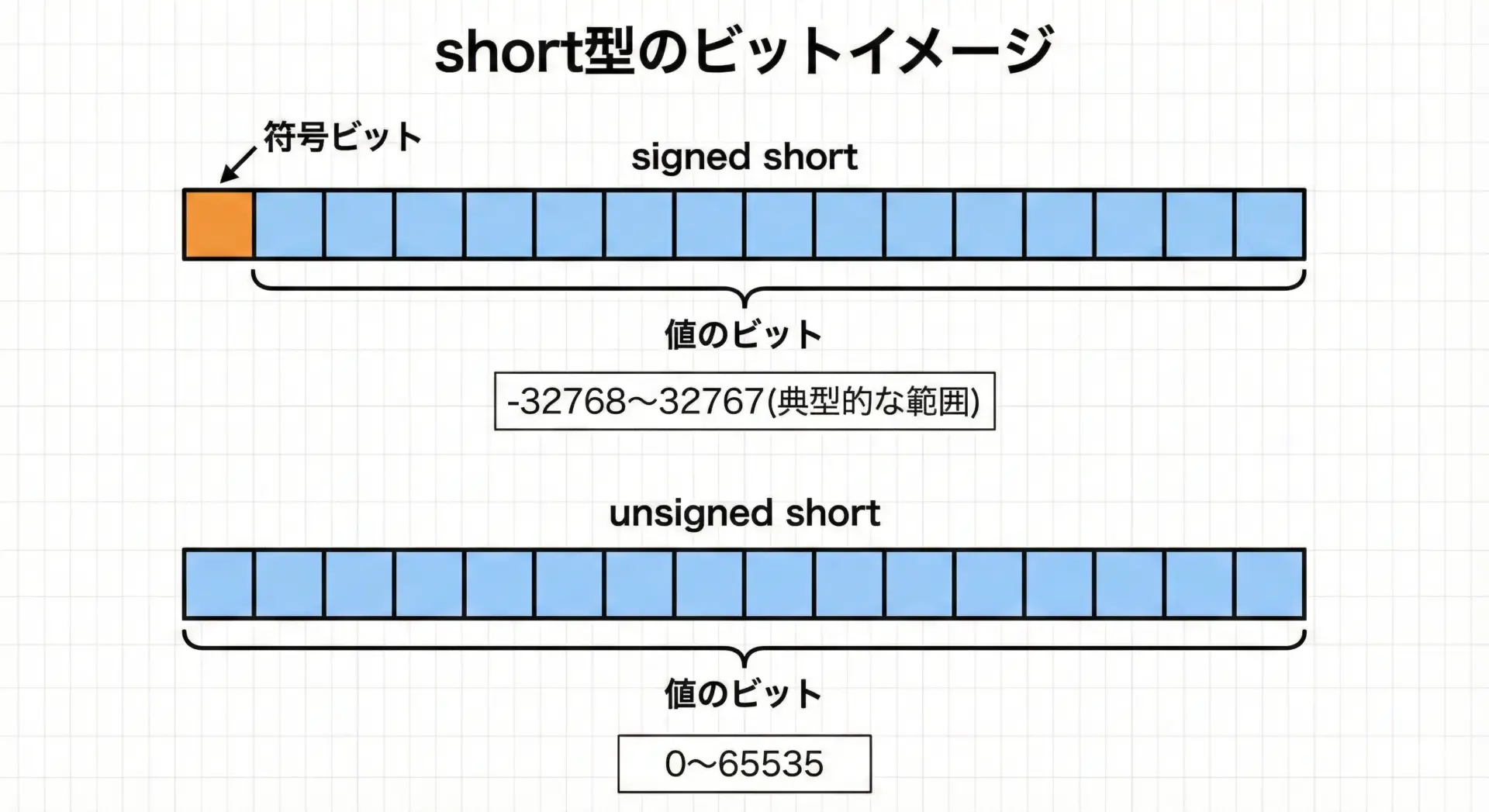
代表的な環境での値の範囲の例を示します(16ビットの場合)。
| 型 | ビット数 | 最小値 | 最大値 |
|---|---|---|---|
| signed short | 16 | -32768 | 32767 |
| unsigned short | 16 | 0 | 65535 |
signedかunsignedかで、扱える範囲が大きく変わることも重要です。
負の数が不要であれば、unsigned shortを使うことで0〜65535までの広い範囲が使えます。
int型のサイズと表現できる値の範囲
int型は、C言語で最も標準的に使われる整数型です。
サイズは環境依存ですが、現在のPC向け環境では32ビット(4バイト)であることが非常に多いです。

32ビット環境・64ビット環境問わず、多くのPCでは次のようになります。
| 型 | ビット数 | 最小値 | 最大値 |
|---|---|---|---|
| signed int | 32 | -2,147,483,648 | 2,147,483,647 |
| unsigned int | 32 | 0 | 4,294,967,295 |
環境によってはintが16ビットである場合もありますが、一般的なPC開発では32ビットと考えて問題ないケースがほとんどです。
ただし、「どんな環境でも32ビット」と思い込むのは危険なので、移植性が重要なコードではsizeof(int)などで確認したり、後述するint32_tなどの固定幅整数型を使うことが推奨されます。
long型・long long型のサイズと範囲
long型はintよりも「長い」(広い範囲を扱える)整数型として定義されています。
ただし、そのビット数は環境により32ビットだったり64ビットだったりします。
一方、long long型は「少なくとも64ビット」であることがC99以降で保証されており、大きな整数を扱いたいときに安心して使える型です。
典型的な範囲を64ビットの場合で示します。
| 型 | ビット数 | 最小値 | 最大値 |
|---|---|---|---|
| signed long (64bit環境LP64) | 64 | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
| unsigned long (64bit) | 64 | 0 | 18,446,744,073,709,551,615 |
| signed long long | 64 | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
| unsigned long long | 64 | 0 | 18,446,744,073,709,551,615 |
「とても大きな整数が必要なら、とりあえずlong long」と覚えておくと実務では安心です。
longは環境ごとにサイズが違うため、大きな値を狙って使うには少しリスキーです。
signed / unsignedの違いと注意点
整数型には、符号付き(signed)と符号なし(unsigned)があります。
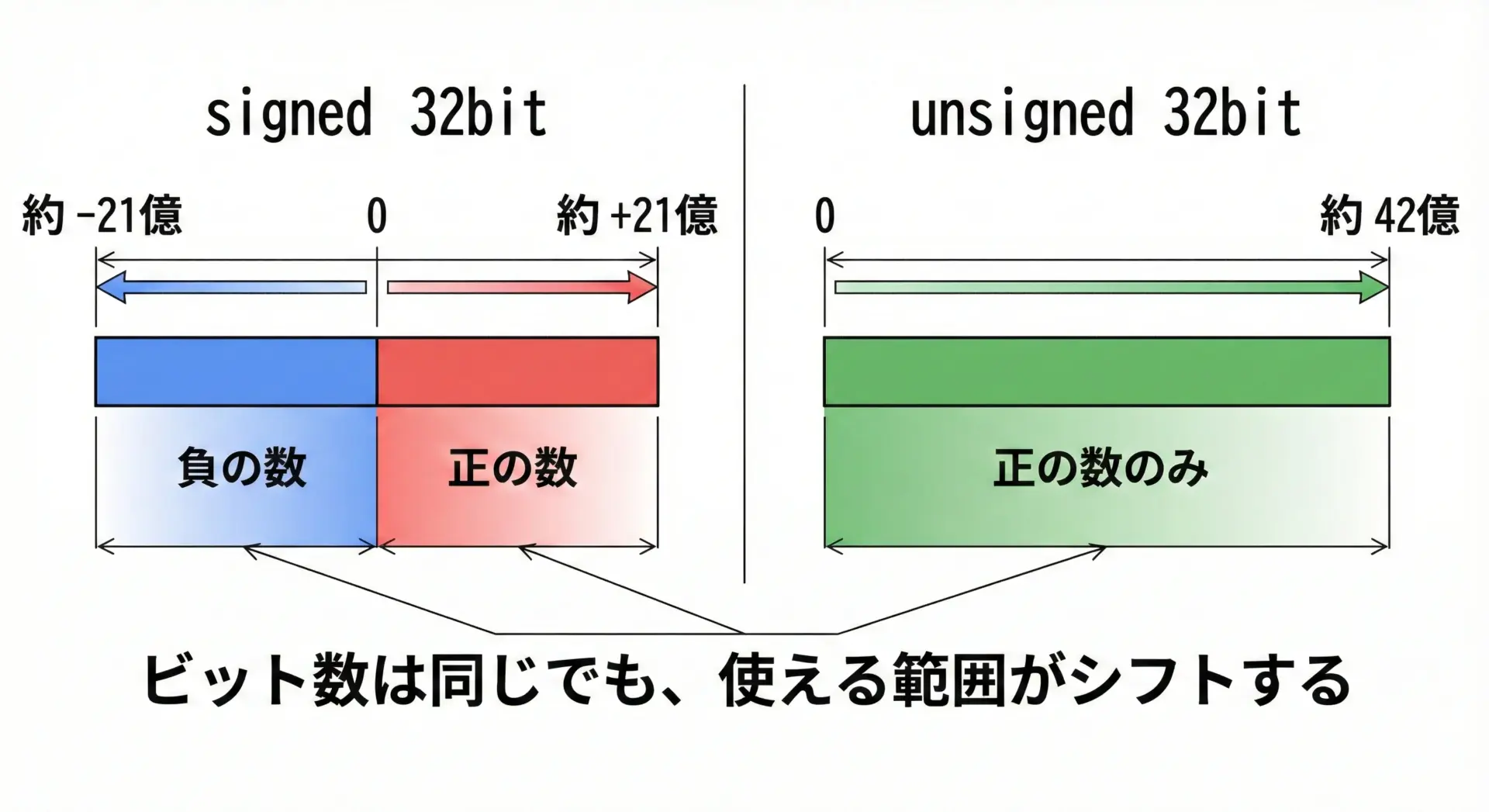
同じビット数でも、表現できる範囲は大きく異なります。
signed int(32ビットの例)- -2,147,483,648〜2,147,483,647
unsigned int(32ビットの例)- 0〜4,294,967,295
負の値が絶対に出てこない個数・インデックスなどは、unsignedを使う選択肢がありますが、初心者のうちはむやみにunsignedを多用するとバグの原因になりがちです。
特に注意したいのは、signedとunsignedを混ぜて比較・計算する場合です。
C言語では、演算時に型が暗黙に変換されるため、意図しない結果になることがあります。
int / short / longの使い分けと選び方
初心者が基本的にintを使うべき理由
初心者がまず選ぶべき整数型は、ほぼ常にintです。
理由は次の通りです。
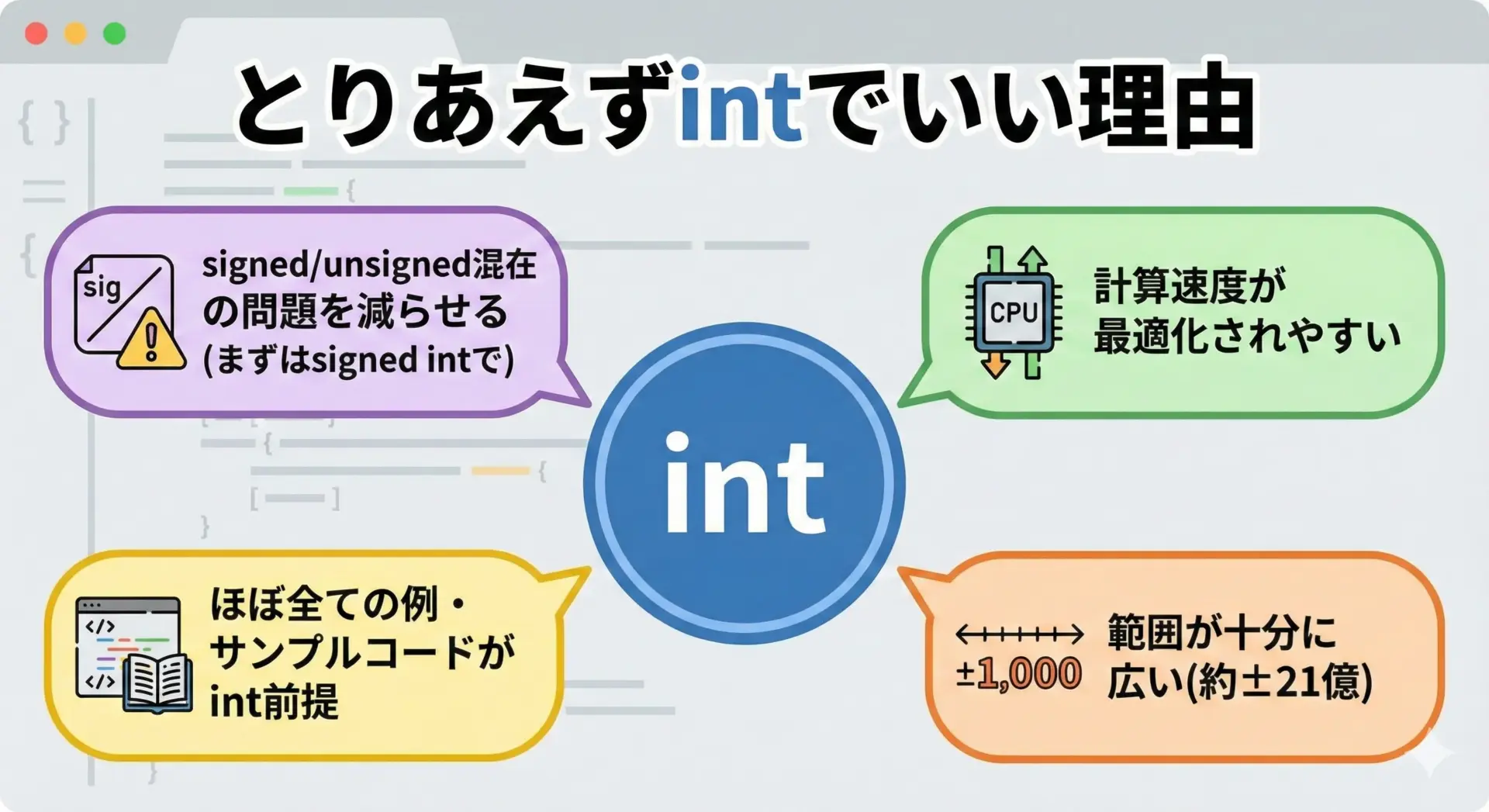
文章として整理すると、次のようになります。
- CPUが最も扱いやすいサイズであることが多く、計算が高速
- 標準ライブラリやサンプルコードがintを前提としていることが多い
- 32ビットintなら約±21億まで扱えるため、日常的な数値には十分
- まずは符号付きint(signed int)だけに絞ることで、型変換の混乱を減らせる
そのため、「特別な理由がなければ、まずint」という指針で問題ありません。
メモリ節約でshortを選ぶべきケース
short型は、メモリを極力節約したいときに検討される型です。
ただし、現代のPC開発ではメモリが潤沢なことが多く、安易にshortに切り替えるメリットは少なくなっています。
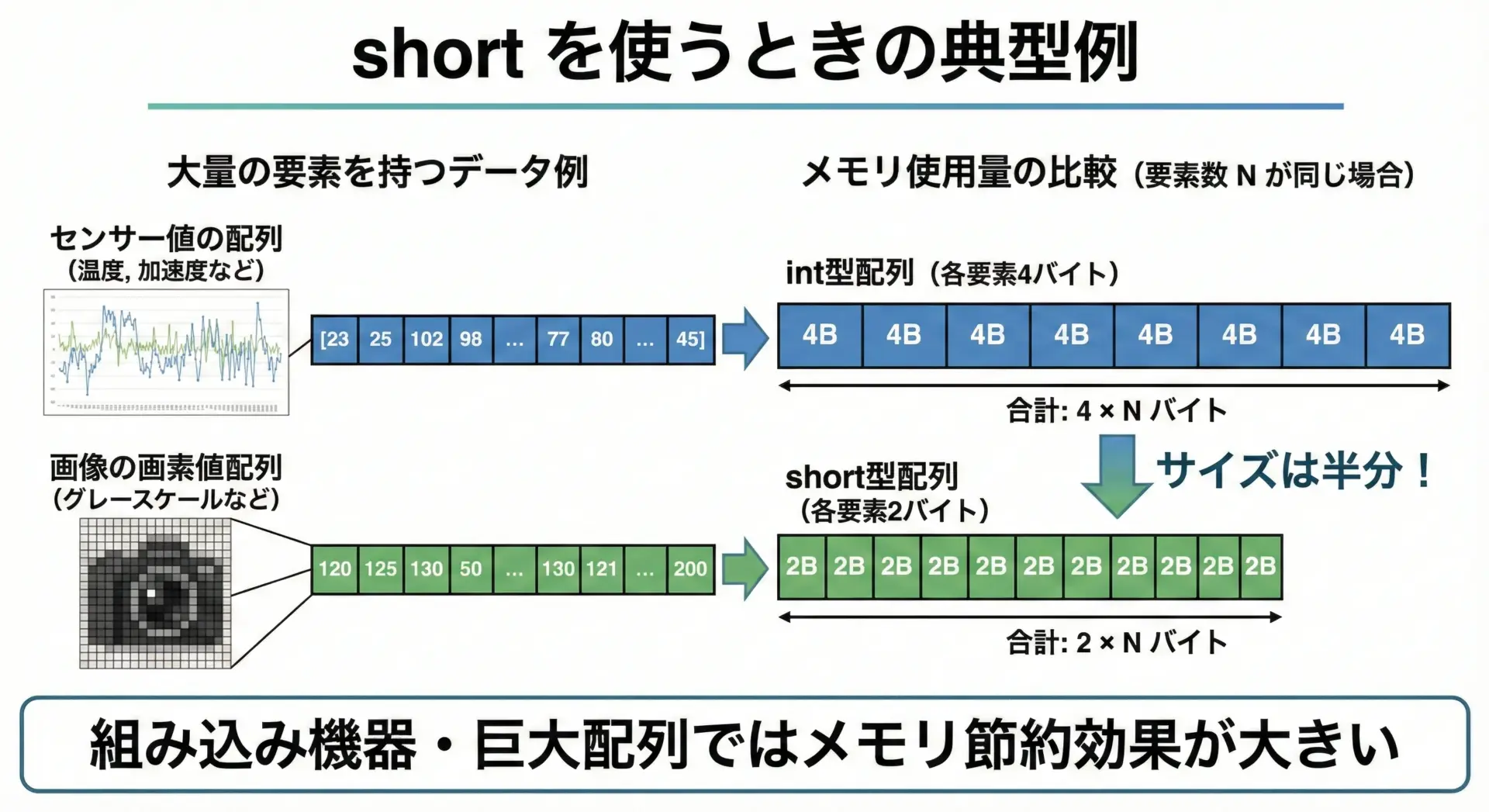
shortが有効なケースの例としては、次のような場面です。
- 組み込み機器など、メモリが数十KB〜数百KBしかない環境でのプログラム
- センサー値や画像データなど、数万〜数百万要素の配列を扱う場合
- 値の範囲が-32768〜32767(または0〜65535)に確実に収まることが分かっている場合
サンプルとして、shortとintでメモリ使用量がどう変わるか見てみます。
#include <stdio.h>
#define N 1000000 /* 要素数100万 */
int main(void) {
short a[N]; /* short配列 */
int b[N]; /* int配列 */
printf("short配列のサイズ: %zu bytes\n", sizeof(a));
printf("int配列のサイズ: %zu bytes\n", sizeof(b));
return 0;
}short配列のサイズ: 2000000 bytes
int配列のサイズ: 4000000 bytesこのように、要素数が多い配列では、shortを使うことでメモリを半分にできることがあります。
ただし、値が範囲を超えないかどうかを慎重に確認することが前提条件です。
大きな値にはlong longを使う場面
非常に大きな値(32ビットintでは足りない値)を扱うときは、long longを使います。
long longは少なくとも64ビットで、約±9.2×10^18まで扱えます。
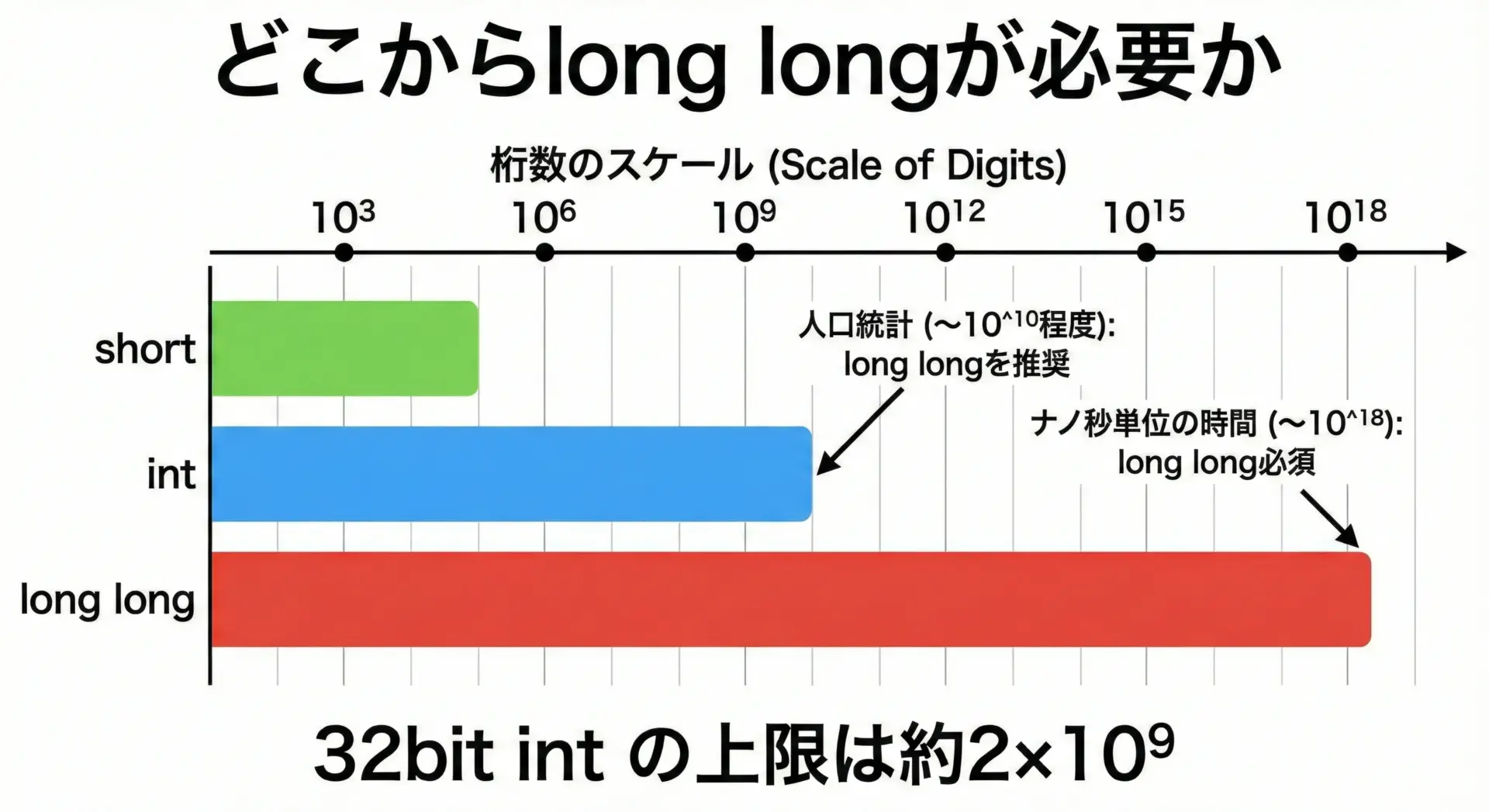
具体的な例として、階乗やべき乗計算では、intではすぐにオーバーフローしてしまいます。
#include <stdio.h>
int main(void) {
int i;
long long fact = 1; /* 64ビット整数で階乗を計算 */
for (i = 1; i <= 20; i++) {
fact *= i;
printf("%2d! = %20lld\n", i, fact);
}
return 0;
} 1! = 1
2! = 2
3! = 6
4! = 24
5! = 120
...
20! = 243290200817664000020!は約2.4×10^18で、32ビットintでは絶対に表現できません。
このような大きな値を扱う場合は、必ずlong longを使うことが必要です。
ビット幅を固定したいときのstdint.h(int32_tなど)の使い方
環境によってintやlongのビット数が変わる問題を避けるために、C99以降ではstdint.hヘッダで「ビット幅が明確な整数型」が用意されています。
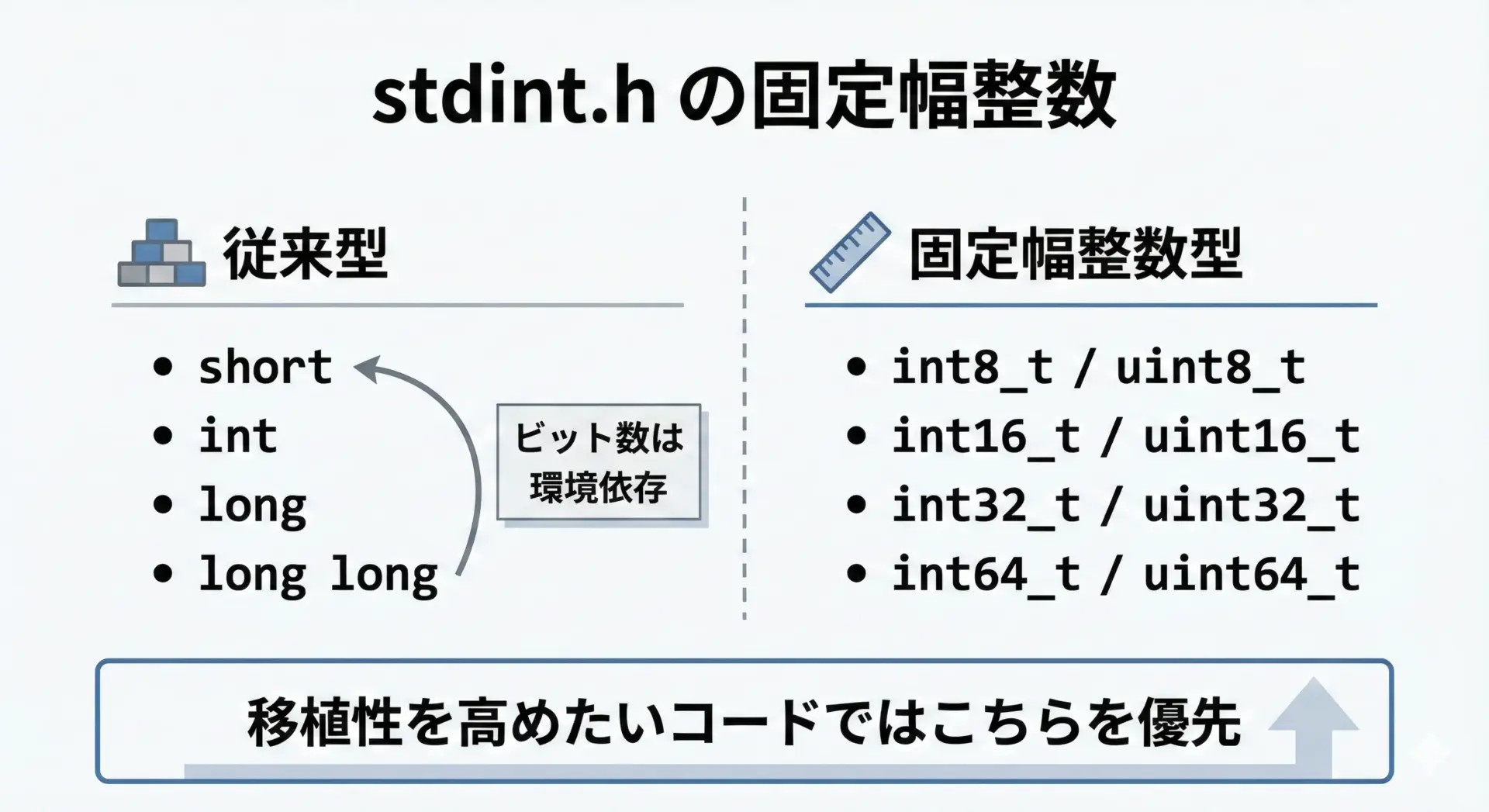
代表的な型は次の通りです。
| 型 | 意味 |
|---|---|
| int8_t | 符号付き8ビット整数 |
| uint8_t | 符号なし8ビット整数 |
| int16_t | 符号付き16ビット整数 |
| uint16_t | 符号なし16ビット整数 |
| int32_t | 符号付き32ビット整数 |
| uint32_t | 符号なし32ビット整数 |
| int64_t | 符号付き64ビット整数 |
| uint64_t | 符号なし64ビット整数 |
これらは「そのビット数で定義できる環境でのみ定義される」ため、存在する場合は常に指定通りのビット数になります。
使用例を示します。
#include <stdio.h>
#include <stdint.h> /* 固定幅整数型を使うためにインクルード */
int main(void) {
int32_t a = 100000; /* 32ビット符号付き整数 */
uint16_t b = 65000; /* 16ビット符号なし整数 */
int64_t c = 10000000000LL; /* 64ビット符号付き整数 */
printf("a(int32_t) = %d\n", a);
printf("b(uint16_t) = %u\n", b);
printf("c(int64_t) = %lld\n", c);
return 0;
}a(int32_t) = 100000
b(uint16_t) = 65000
c(int64_t) = 10000000000ネットワークプロトコルやファイルフォーマットなど、ビット単位で仕様が決まっている場面では、これらの固定幅整数型の使用がほぼ必須です。
printfやscanfでのフォーマット指定子の選び方
整数型をprintfやscanfで入出力するときは、型に合わせて正しいフォーマット指定子を使う必要があります。
ここを間違えると、正しい値が表示されなかったり、未定義動作になったりします。
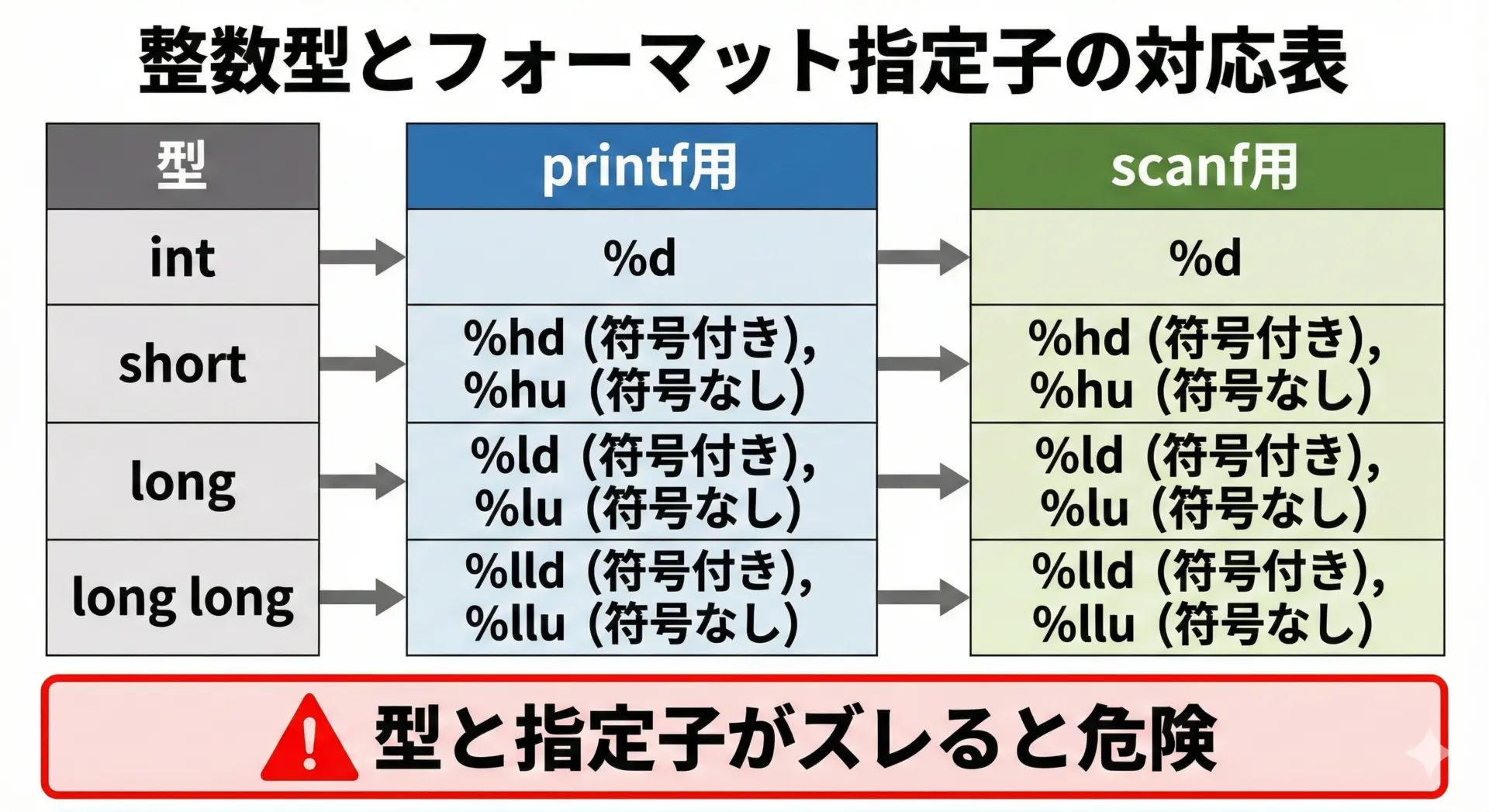
代表的な対応を表にまとめます。
| 型 | printf(符号付き) | printf(符号なし) | scanf(符号付き) | scanf(符号なし) |
|---|---|---|---|---|
| short | %hd | %hu | %hd | %hu |
| int | %d | %u | %d | %u |
| long | %ld | %lu | %ld | %lu |
| long long | %lld | %llu | %lld | %llu |
| int32_t (多くの環境) | %d | %u | %d | %u |
| int64_t (多くの環境) | %lld | %llu | %lld | %llu |
例として、各型を入力・出力してみます。
#include <stdio.h>
int main(void) {
short s;
int i;
long l;
long long ll;
printf("4つの整数を入力してください(short, int, long, long long):\n");
/* 型に合わせたフォーマット指定子を使う */
scanf("%hd %d %ld %lld", &s, &i, &l, &ll);
printf("short: %hd\n", s);
printf("int: %d\n", i);
printf("long: %ld\n", l);
printf("long long: %lld\n", ll);
return 0;
}4つの整数を入力してください(short, int, long, long long):
10 20 30 40
short: 10
int: 20
long: 30
long long: 40フォーマット指定子と変数型が一致しているかは、コンパイラの警告を有効にするとチェックしやすくなります。
-Wallオプションなどをつけてコンパイルすると、安全性が高まります。
C言語初心者がやりがちなミスと対策
桁あふれ(オーバーフロー)を防ぐint / longの選び方
オーバーフロー(桁あふれ)は、整数型の範囲を超える値を扱ったときに発生する現象です。
C言語では、符号付き整数のオーバーフローは未定義動作とされています。
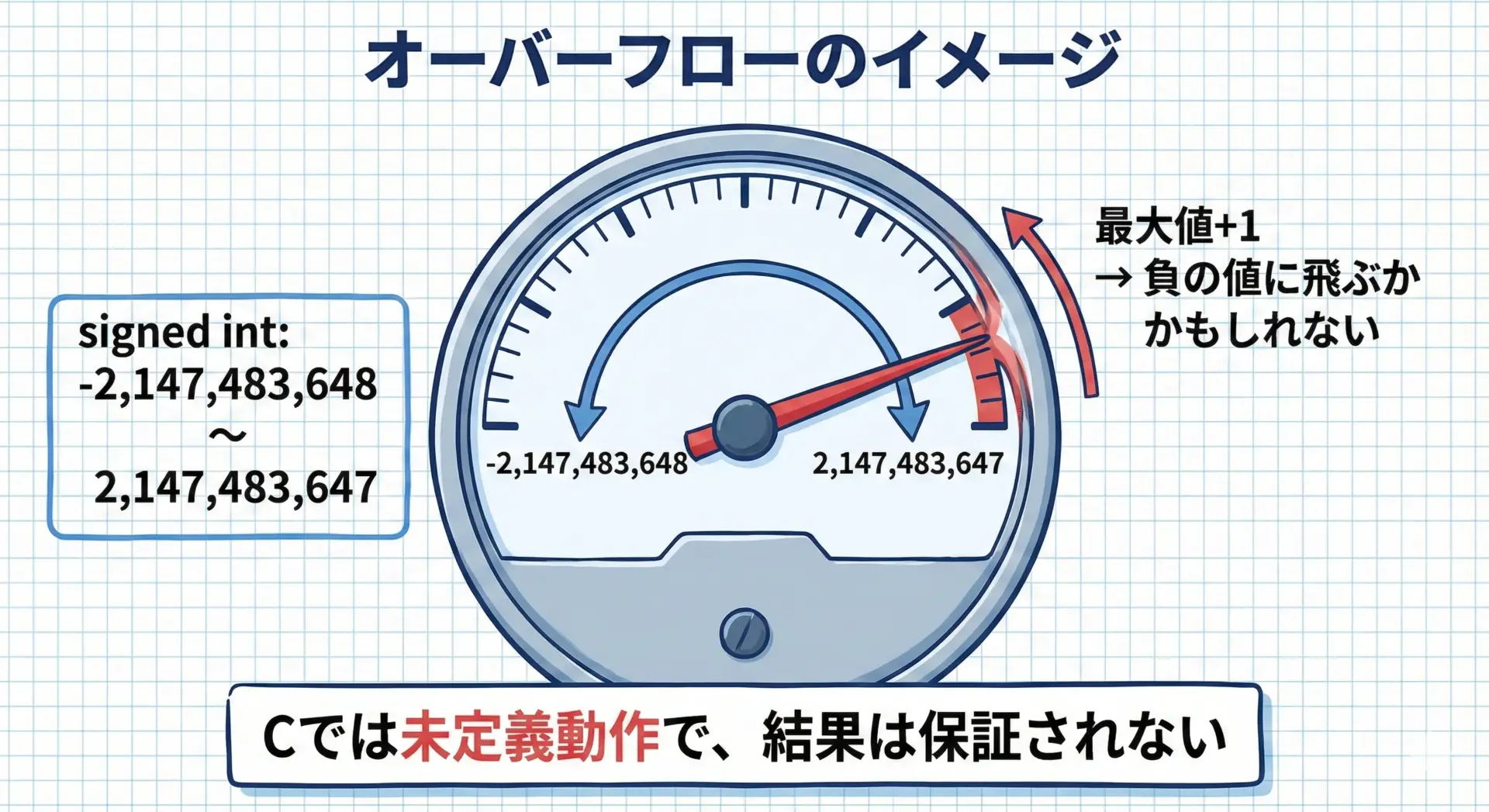
典型的な失敗例を見てみます。
#include <stdio.h>
#include <limits.h> /* INT_MAX, LONG_MAX などの定数 */
int main(void) {
int a = INT_MAX;
int b = a + 1; /* オーバーフローの可能性あり */
printf("INT_MAX: %d\n", INT_MAX);
printf("a: %d\n", a);
printf("a + 1: %d (未定義動作の可能性)\n", b);
return 0;
}INT_MAX: 2147483647
a: 2147483647
a + 1: -2147483648 (環境によって異なる可能性あり)この例では、a + 1がオーバーフローして負の値になっていますが、これはたまたまそうなっているだけで、C言語規格上は結果は保証されません。
オーバーフローを防ぐためには、次のような対策が有効です。
- 必要な最大値から逆算して、十分なビット幅の型を選ぶ
- 不安なら1つか2つ大きめの型(例: intではなくlong long)を使う
INT_MAXやLLONG_MAXなどの定数で、限界値を意識する
#include <stdio.h>
#include <limits.h>
int main(void) {
long long x = LLONG_MAX - 5; /* long long の最大値付近 */
printf("LLONG_MAX: %lld\n", LLONG_MAX);
printf("x: %lld\n", x);
if (x + 10 < x) {
printf("オーバーフローが起きた可能性があります。\n");
} else {
printf("まだオーバーフローしていません。\n");
}
return 0;
}LLONG_MAX: 9223372036854775807
x: 9223372036854775802
オーバーフローが起きた可能性があります。このように、計算前に型と最大値を意識することが、オーバーフロー対策の第一歩です。
環境依存(intのビット数が違う)への対処法
同じCコードなのに、環境を変えたらintのサイズが変わってしまう。
これが、移植性の問題の典型例です。
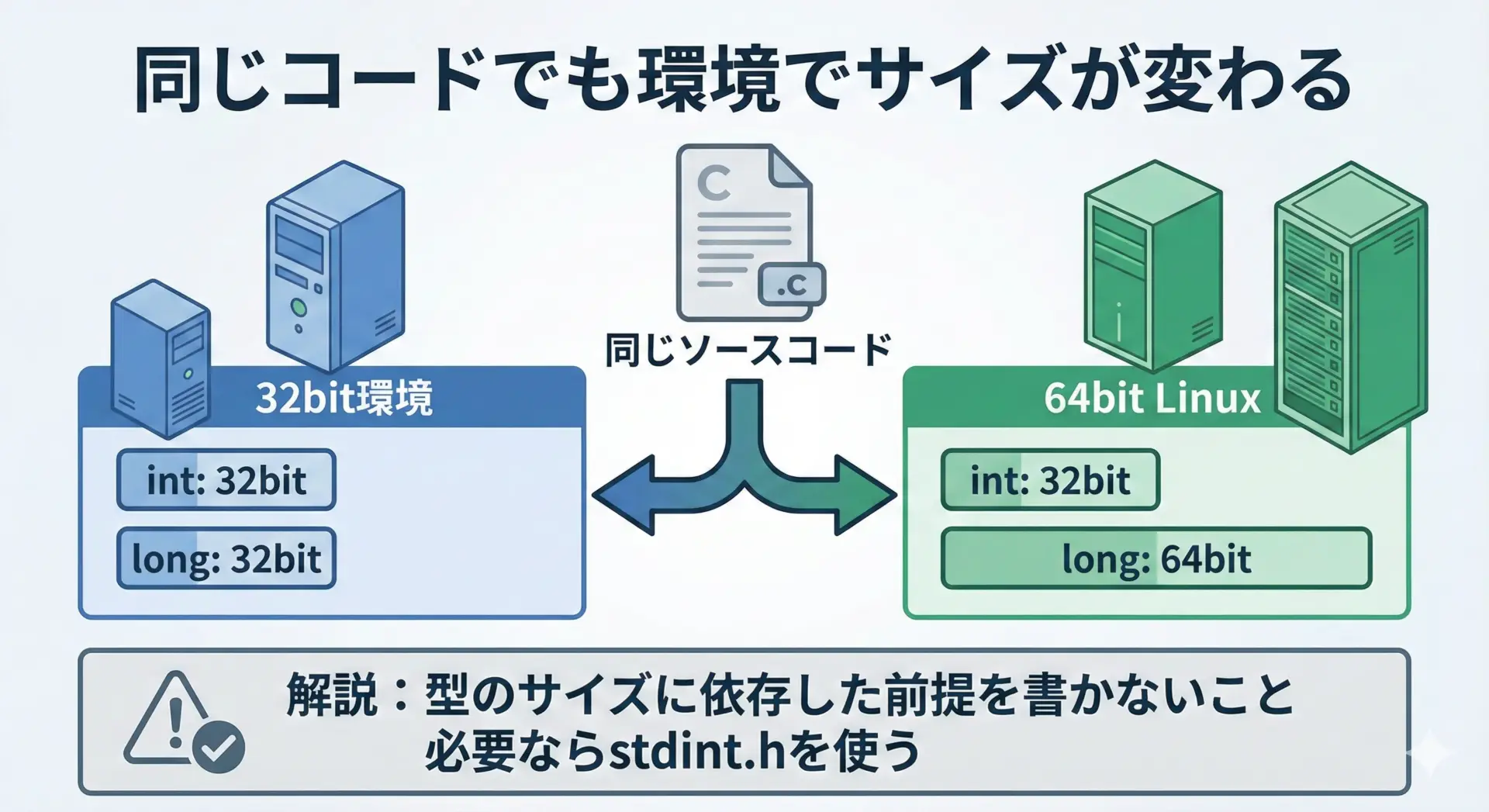
対策としては、次のような考え方が有効です。
- 「intは32ビット」と決めつけたコードを書かない
- ビット数が重要な場面では、固定幅整数型(int32_tなど)を使う
- コンパイル時に
sizeofを使って、型のサイズを確認するテストコードを仕込む
例として、環境ごとに整数型のサイズを表示するツールを書いておくと便利です。
#include <stdio.h>
int main(void) {
printf("char: %zu bytes\n", sizeof(char));
printf("short: %zu bytes\n", sizeof(short));
printf("int: %zu bytes\n", sizeof(int));
printf("long: %zu bytes\n", sizeof(long));
printf("long long: %zu bytes\n", sizeof(long long));
return 0;
}char: 1 bytes
short: 2 bytes
int: 4 bytes
long: 8 bytes
long long: 8 bytesチーム開発や長期運用されるソフトウェアでは、こうした「環境チェック用ツール」を最初に一度実行しておくと安心です。
キャストや演算での型変換ミスを避けるコツ
C言語では、異なる整数型同士を計算するときに暗黙の型変換(整数の usual arithmetic conversions)が行われます。
これが原因で、初心者が意図しないバグを生むことがよくあります。
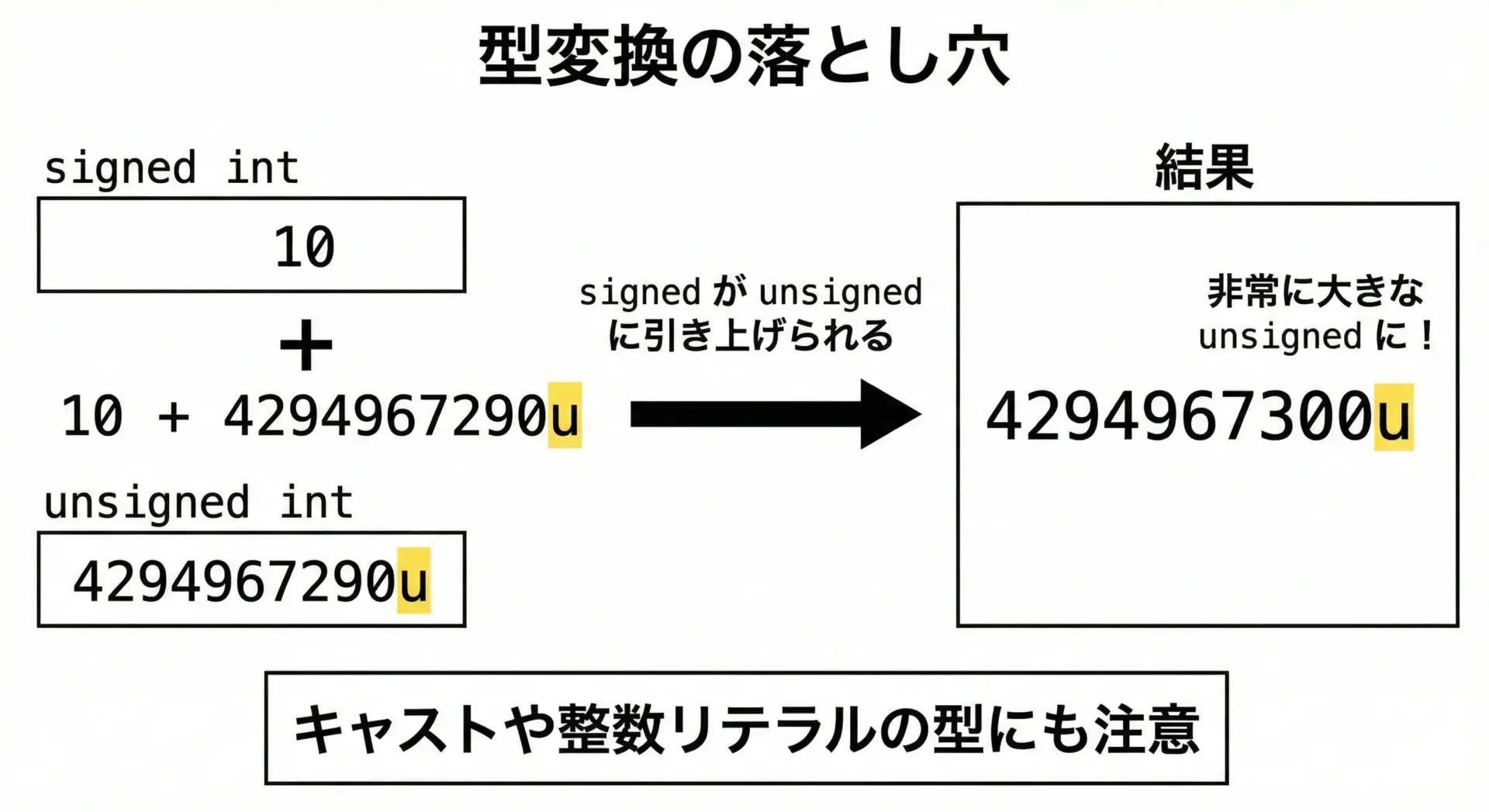
代表的な落とし穴をいくつか挙げます。
1. signed と unsigned の混在
#include <stdio.h>
int main(void) {
int a = -1; /* 符号付き */
unsigned int b = 1; /* 符号なし */
if (a < b) {
printf("a < b です\n");
} else {
printf("a >= b です\n");
}
return 0;
}a >= b です一見a = -1なのでa < bに見えますが、実際にはaがunsignedに変換されて非常に大きな値になり、条件が逆転してしまいます。
対策としては、次のようなことが挙げられます。
- signedとunsignedを混ぜないように心がける
- 比較するときは、どちらかに明示的にキャストして意図をはっきりさせる
2. 小さい型から大きい型への変換での誤解
#include <stdio.h>
int main(void) {
unsigned char c = 255; /* 0〜255の範囲 */
int i = c; /* intに拡張される */
printf("c = %u, i = %d\n", c, i);
return 0;
}c = 255, i = 255この例では問題ありませんが、signed charで負の値を扱った場合など、符号拡張のルールを理解していないと意外な結果になることがあります。
3. 明示的なキャストの乱用
#include <stdio.h>
int main(void) {
long long big = 10000000000LL;
int x = (int)big; /* 明示的にintへキャスト */
printf("big = %lld, x = %d\n", big, x);
return 0;
}big = 10000000000, x = 1410065408intの範囲を超える値を無理にキャストすると、情報が失われてしまいます。
明示的なキャストは、「間違いを隠してしまう」ことがあるため、むやみに使わず、本当に必要な箇所にだけ慎重に使うことが重要です。
まとめ
本記事では、C言語のint / short / long / long longの違いと、それぞれのサイズ・範囲・使い分けの指針を解説しました。
基本的には「特別な理由がなければint」、大きな値が必要ならlong long、ビット幅を固定したい場面ではstdint.hのint32_tなどを使う、という方針で考えると整理しやすくなります。
環境依存やオーバーフロー、型変換の落とし穴を意識しつつ、まずはintを中心に安全な整数型の扱い方に慣れていってください。
