
PythonでWebスクレイピングを始めると、JavaScriptで動くサイトにぶつかり、データがうまく取れずに困ることがあります。
そうしたときに頼りになるのがrequests-htmlです。
本記事では、インストール方法から基本文法、JavaScript対応のスクレイピング、ログイン処理、エラー対策まで、requests-htmlの実践的な使い方を一通り解説します。
requests-htmlとは
requests-htmlでできること

requests-htmlは、Pythonの人気HTTPライブラリであるrequestsをベースにしつつ、HTML解析機能やJavaScript実行機能を統合した高機能スクレイピング用ライブラリです。
単にHTMLを取得するだけでなく、次のような処理を1つのライブラリで行える点が特徴です。
1つのSessionオブジェクトで以下をまとめて扱えます。
- HTTPリクエスト(GET、POSTなど)
- HTML解析(CSSセレクタ、XPath)
- テキスト抽出、属性値の取得
- JavaScriptの実行(render機能)
- Cookieやセッションの管理
「requests + BeautifulSoup + Seleniumの一部」をまとめて使えるようなイメージを持つと理解しやすいです。
requestsとの違いとメリット
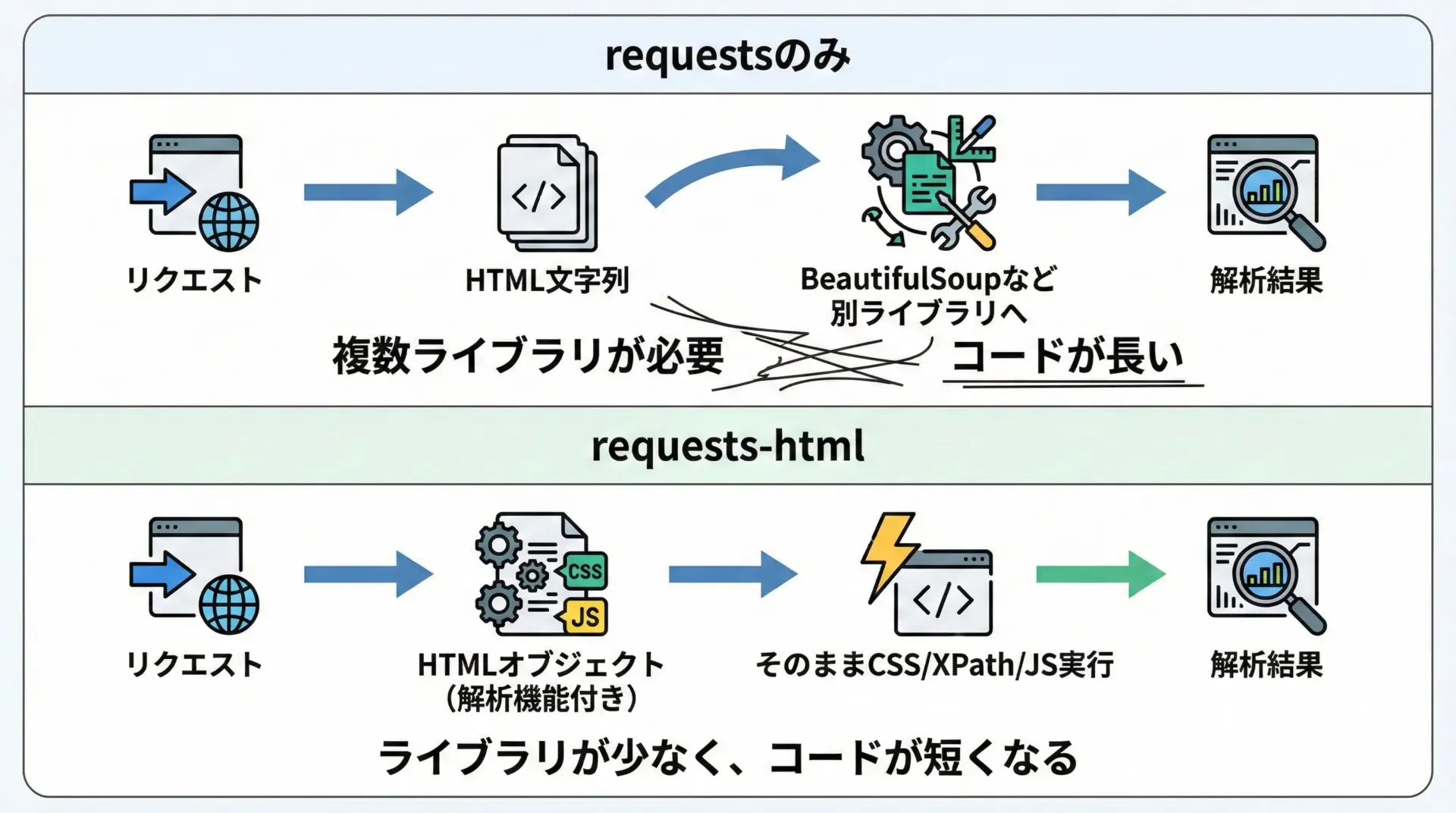
requestsとrequests-htmlの主な違いとメリットを表にまとめます。
| 項目 | requests | requests-html |
|---|---|---|
| HTML取得 | 対応 | 対応 |
| HTML解析 | 非対応(別ライブラリ必要) | 標準対応(CSS、XPath) |
| JavaScript実行 | 非対応 | renderで実行可能 |
| 依存ライブラリ | 少ない | やや多い(HTML解析・JS用) |
| コード量 | やや多くなりがち | 1つにまとまりスッキリ |
requests-htmlを使う最大のメリットは「JavaScriptで生成されるコンテンツも、Pythonから比較的簡単に取得できる」ことです。
また、文字コードの扱いなども比較的自動でよしなにやってくれるため、初学者にも扱いやすいライブラリです。
requests-htmlのインストール
pipでのインストール手順
requests-htmlはpipでインストールできます。
基本的なインストールコマンドは次の通りです。
pip install requests-htmlあるいは、Python3環境が複数ある場合には次のようにpip3を指定すると安全です。
pip3 install requests-htmlインストール後に、Pythonの対話シェルで次のようにimportできれば成功です。
from requests_html import HTMLSession
session = HTMLSession()
print("OK")OKWindowsとMacでの注意点
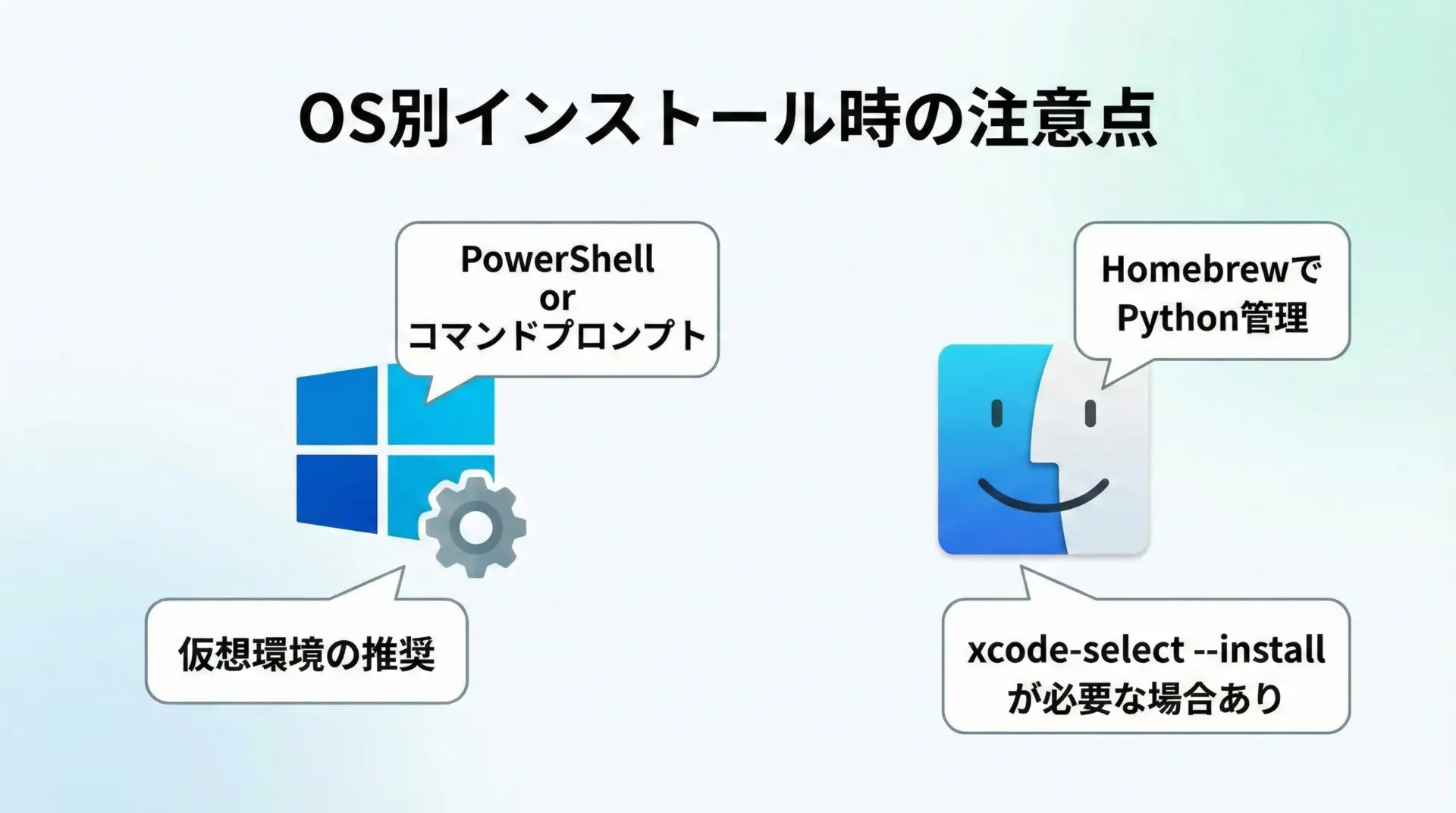
requests-htmlは内部でpyppeteerなどを利用してJavaScriptを実行します。
そのため、OSによっては追加の環境準備が必要になることがあります。
Windowsでの注意点
Windowsでは、以下の点を意識するとトラブルを減らせます。
- Pythonは公式サイトから最新版をインストールするか、Anaconda/Minicondaを利用します。
- 「アプリと機能」からPythonのバージョンを確認し、64bit版を使うと依存ライブラリの相性が良くなります。
- 可能であれば
venvやcondaなどで仮想環境を作成し、その中にrequests-htmlを入れると環境が汚れません。
仮想環境の例:
python -m venv venv
venv\Scripts\activate
pip install -U pip
pip install requests-htmlMacでの注意点
Macでは、システムPythonではなく、HomebrewでインストールしたPythonを使うことをおすすめします。
brew install python
python3 -m venv venv
source venv/bin/activate
pip install -U pip
pip install requests-htmlJavaScript実行時にpyppeteerがブラウザ(Chromium)をダウンロードするため、初回のrender呼び出しで時間がかかる場合があります。
また、Xcode Command Line Toolsが未インストールの場合、ビルドに関連するエラーが出ることがあるため、その際は次のコマンドでインストールしてください。
xcode-select --install基本的な使い方
シンプルなGETリクエストの書き方
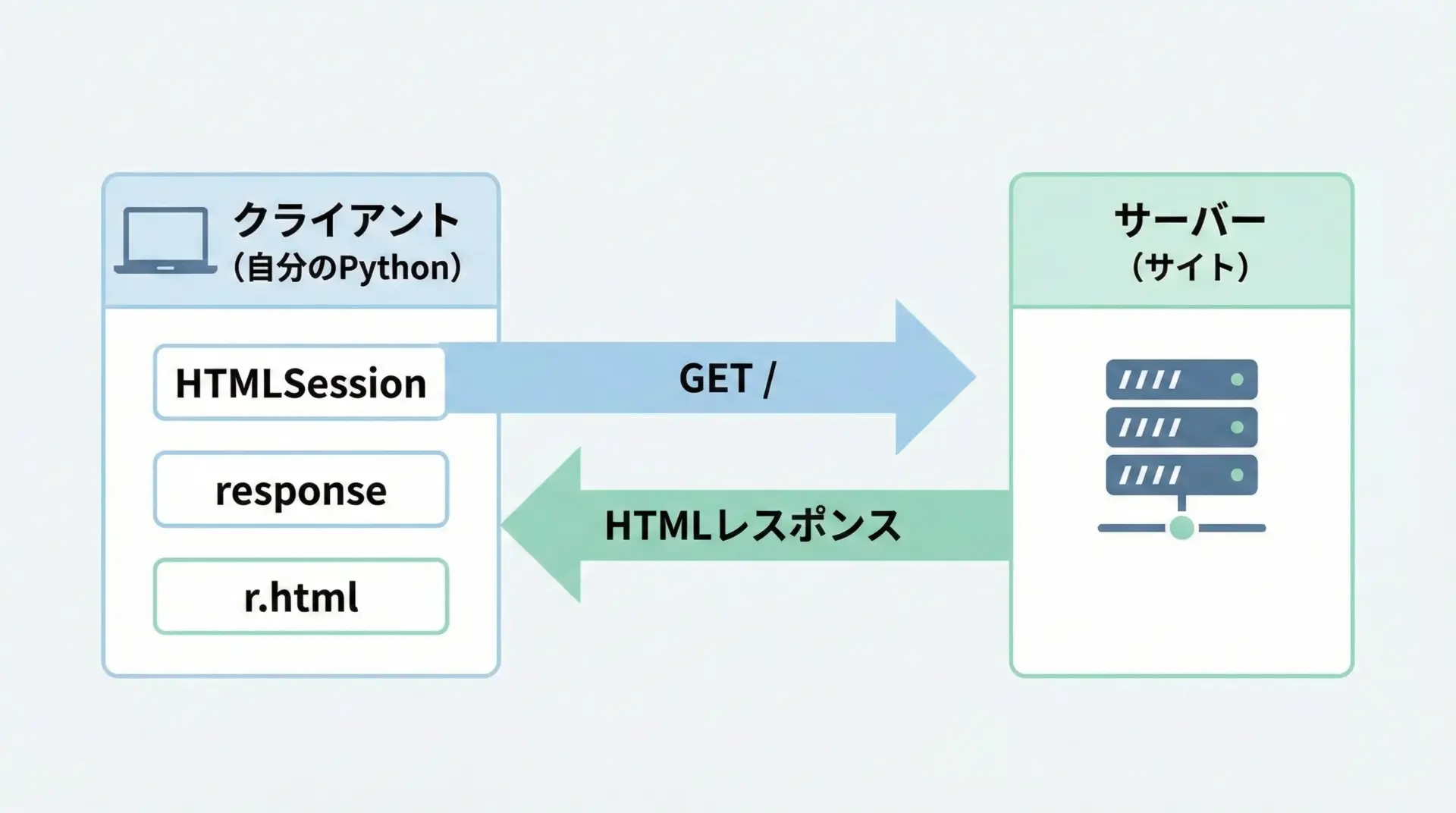
requests-htmlでは、まずHTMLSessionを作り、そこからgetメソッドを使ってリクエストを送ります。
# basic_get.py
from requests_html import HTMLSession
# セッションオブジェクトを作成
session = HTMLSession()
# シンプルなGETリクエスト
url = "https://httpbin.org/get"
r = session.get(url)
# レスポンスの一部を表示
print("URL:", r.url)
print("ステータスコード:", r.status_code)
# 生のレスポンスボディ(文字列)
print("レスポンス本文(先頭200文字):")
print(r.text[:200])URL: https://httpbin.org/get
ステータスコード: 200
レスポンス本文(先頭200文字):
{
"args": {},
"headers": {
...重要なポイントは、requestsと同様にr.textで文字列として本文を取得できるだけでなく、r.htmlでHTML解析用のオブジェクトにすぐアクセスできることです。
このHTMLオブジェクトを使って、次の章で要素の抽出を行います。
ステータスコードとエンコーディングの扱い

レスポンスを扱う際には、まずステータスコードと文字コード(エンコーディング)を確認する癖をつけるとトラブルが減ります。
# status_and_encoding.py
from requests_html import HTMLSession
session = HTMLSession()
url = "https://www.example.com"
r = session.get(url)
print("ステータスコード:", r.status_code)
# エラーなら例外を投げて止める
try:
r.raise_for_status()
print("リクエスト成功")
except Exception as e:
print("エラーが発生しました:", e)
# 推定されたエンコーディング
print("推定エンコーディング:", r.encoding)
# 必要に応じて手動でエンコーディングを指定
r.encoding = "utf-8" # 例えばUTF-8に固定したい場合
# 文字コードを反映したテキスト
print("本文(先頭100文字):", r.text[:100])ステータスコード: 200
リクエスト成功
推定エンコーディング: utf-8
本文(先頭100文字): <!doctype html>...日本語サイトでは、Shift_JISやEUC-JPなどUTF-8以外のエンコーディングもよく使われます。
文字化けしているように見えたら、r.encodingを疑ってください。
HTML解析の基本
CSSセレクタでの要素取得
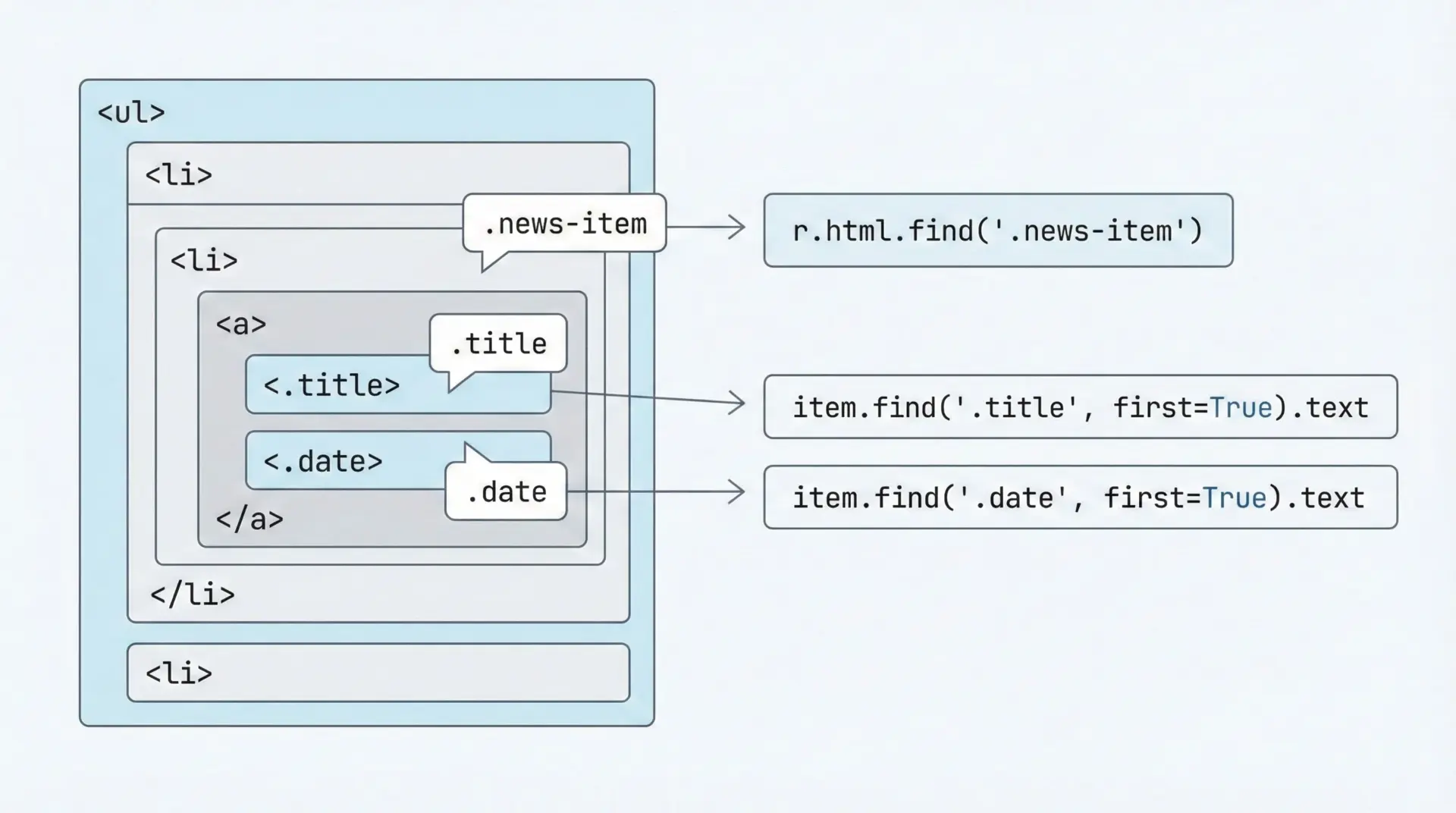
requests-htmlでは、CSSセレクタを使ってHTMLから要素を取り出せます。
これは、ブラウザの開発者ツールで使うセレクタとほぼ同じです。
# css_select.py
from requests_html import HTMLSession
html = """
<ul class="news-list">
<li class="news-item">
<a href="/news/1" class="title">Pythonの記事</a>
<span class="date">2025-01-01</span>
</li>
<li class="news-item">
<a href="/news/2" class="title">スクレイピング入門</a>
<span class="date">2025-01-02</span>
</li>
</ul>
"""
session = HTMLSession()
r = session.post("https://httpbin.org/post", data={"html": html}) # ダミー送信(例示用)
# 実際には自前のHTMLをHTMLクラスに変換して使う
from requests_html import HTML
doc = HTML(html=html)
# li.news-item をすべて取得
items = doc.find("li.news-item")
for item in items:
title_el = item.find("a.title", first=True) # 先頭1件だけ欲しいのでfirst=True
date_el = item.find("span.date", first=True)
print("タイトル:", title_el.text)
print("日付:", date_el.text)
print("---")タイトル: Pythonの記事
日付: 2025-01-01
---
タイトル: スクレイピング入門
日付: 2025-01-02
---.find(selector, first=True/False)というシンプルなAPIで、複数要素を簡単に扱えます。
CSSセレクタの例としては、次のようなパターンがよく使われます。
| セレクタ | 意味 |
|---|---|
div | divタグすべて |
.class-name | class属性にclass-nameを持つ要素 |
#main | id=”main”の要素 |
ul li | ulの中にあるliすべて |
a.title | aタグかつclass=”title” |
XPathでの要素取得
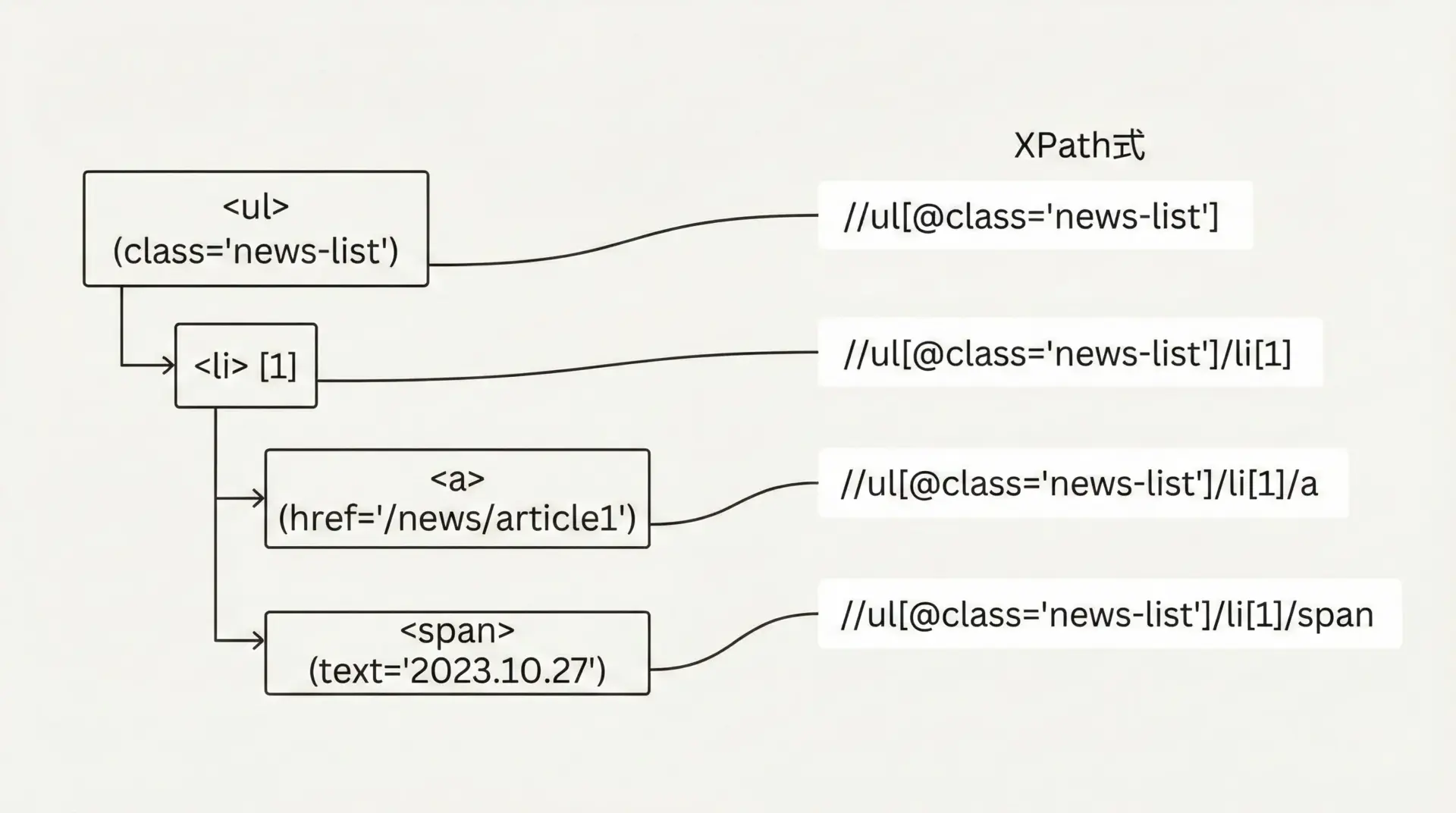
XPathは、HTML/XMLの要素をツリー構造として辿るための強力な言語です。
CSSセレクタだけでは指定しにくい場合に役立ちます。
# xpath_select.py
from requests_html import HTML
html = """
<div id="content">
<h1>ニュース一覧</h1>
<ul class="news-list">
<li class="news-item">
<a href="/news/1" class="title">Pythonの記事</a>
<span class="date">2025-01-01</span>
</li>
</ul>
</div>
"""
doc = HTML(html=html)
# XPathでh1要素を取得
h1 = doc.xpath("//div[@id='content']/h1", first=True)
print("見出し:", h1.text)
# XPathでニュースのタイトルを取得
title = doc.xpath("//ul[@class='news-list']/li/a[@class='title']", first=True)
print("タイトル:", title.text)
print("URL:", title.attrs.get("href"))見出し: ニュース一覧
タイトル: Pythonの記事
URL: /news/1XPathは柔軟ですが、記法がやや難しいため、まずはCSSセレクタで書けないかを試し、それでも難しい場合にXPathを使うというスタイルが扱いやすいです。
テキストと属性値の取り出し方
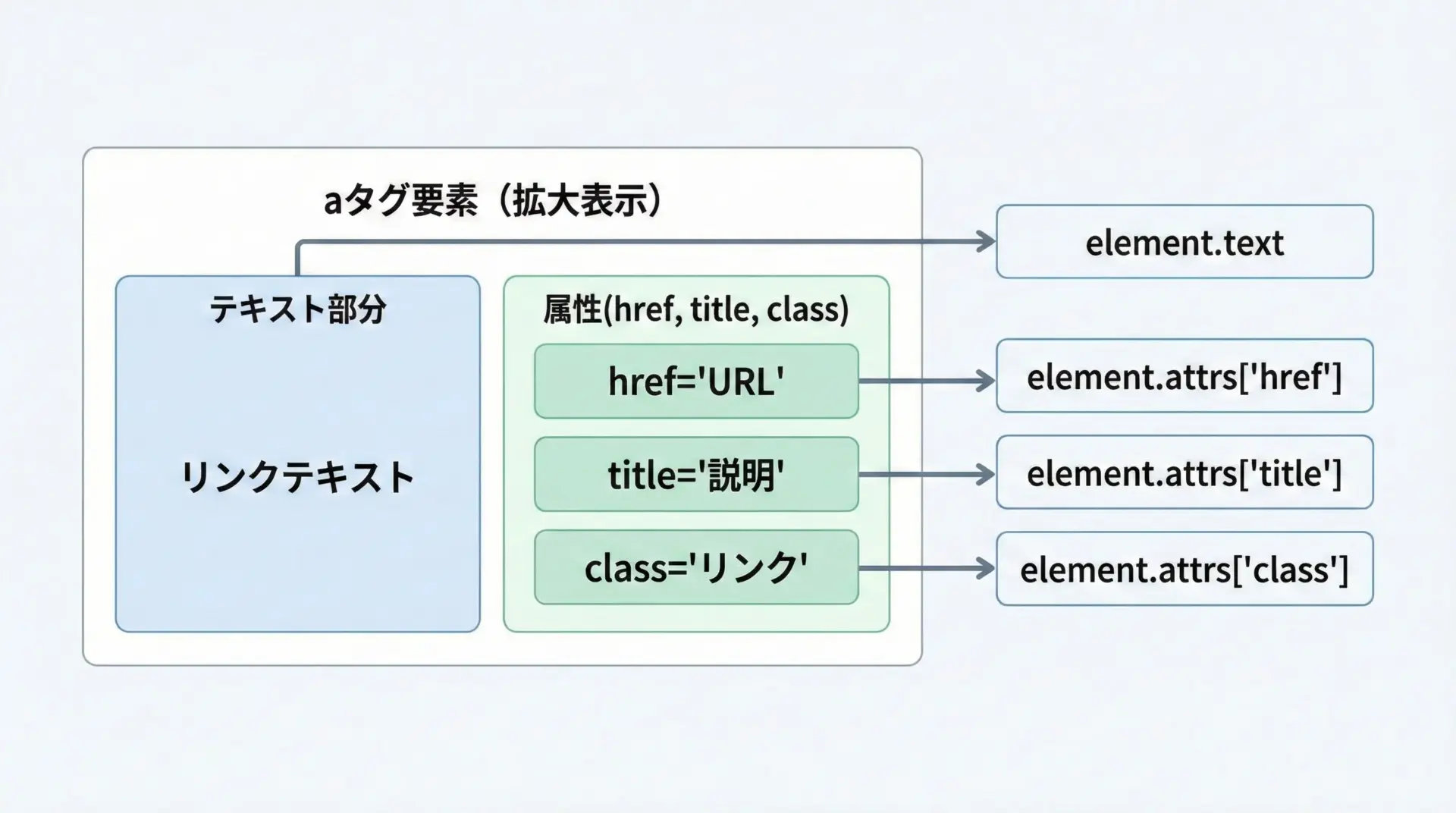
requests-htmlの要素オブジェクトからは、.textと.attrsを使って情報を取り出します。
# text_and_attrs.py
from requests_html import HTML
html = """
<a href="/news/1" class="title" title="Python入門記事">
Pythonの記事
</a>
"""
doc = HTML(html=html)
a = doc.find("a.title", first=True)
# テキスト部分(タグに挟まれた文字)
print("テキスト:", a.text.strip())
# 属性値(辞書形式)
print("href属性:", a.attrs.get("href"))
print("class属性:", a.attrs.get("class"))
print("title属性:", a.attrs.get("title"))テキスト: Pythonの記事
href属性: /news/1
class属性: title
title属性: Python入門記事.textは人間向けの表示文言、.attrsはリンク先URLやクラス名などの機械的な情報を扱うときに使い分けます。
リンク一覧を作りたいときはhref、商品IDを取りたいときはdata-*属性などを参照するとよいでしょう。
JavaScript対応スクレイピングの基本
renderでJavaScriptを実行する方法
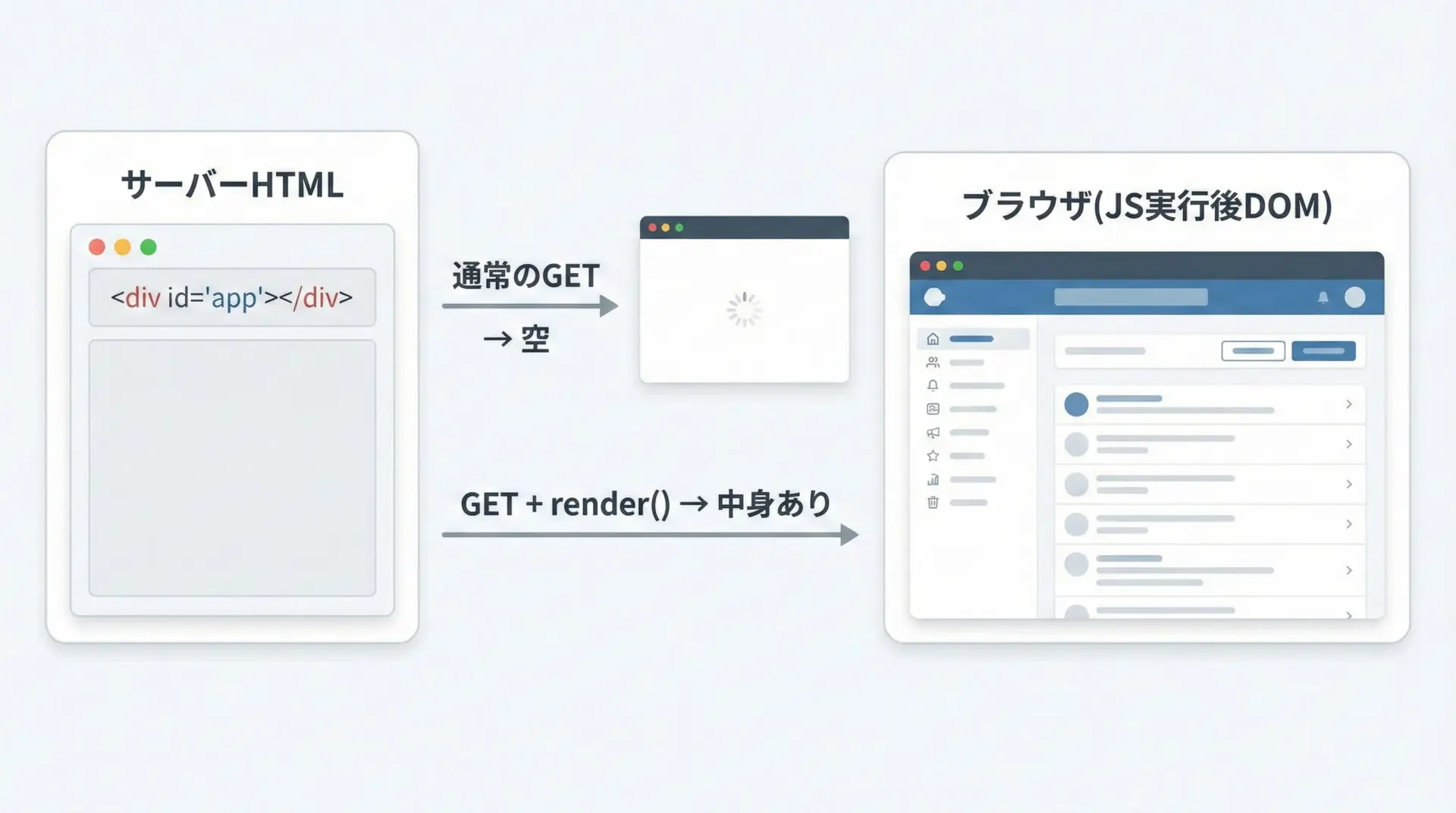
多くのモダンなWebサイトは、初回レスポンス時にはほとんどHTMLがなく、JavaScriptでコンテンツを動的に生成します。
このような場合、render()を使うと、JavaScriptを実行した後のHTMLを取得できます。
# js_render_basic.py
from requests_html import HTMLSession
session = HTMLSession()
url = "https://httpbin.org/html" # 実際にはJSで動くサイトに変える
r = session.get(url)
print("レンダリング前のHTML(先頭200文字):")
print(r.html.html[:200])
# JavaScriptを実行してレンダリング
r.html.render() # ここで時間がかかる場合があります
print("\nレンダリング後のHTML(先頭200文字):")
print(r.html.html[:200])レンダリング前のHTML(先頭200文字):
<!DOCTYPE html>
<html>
<head>
...
レンダリング後のHTML(先頭200文字):
<!DOCTYPE html>
<html>
<head>
...例ではわかりやすさのためにhttpbinを使っていますが、実際には「初回HTMLはスカスカだが、ブラウザで見ると中身が表示されている」ようなサイトで効果を発揮します。
待ち時間(timeout)と遅延ロード対策
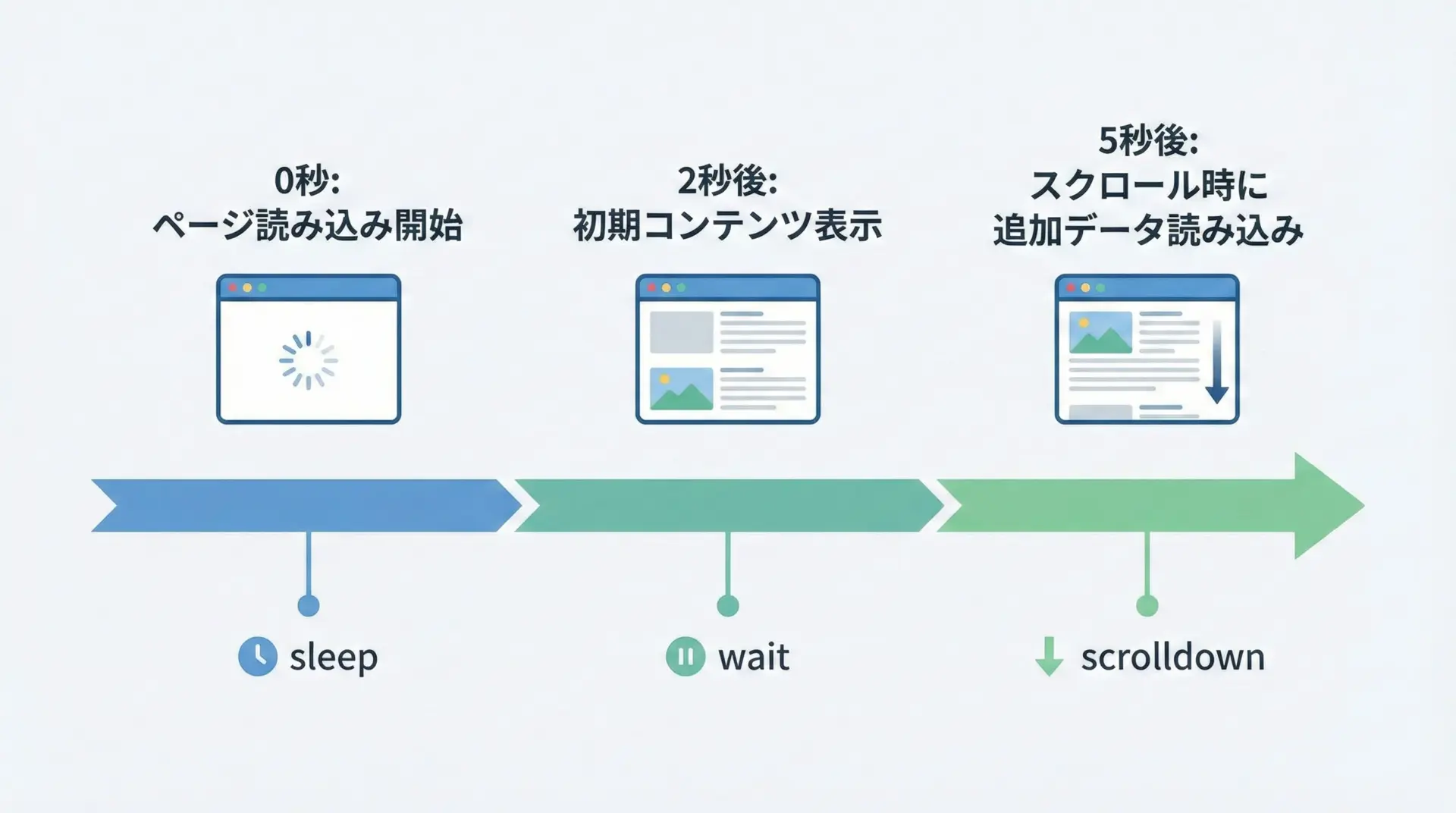
JavaScript実行には時間がかかるため、render()のオプションで待ち時間などを調整します。
# render_options.py
from requests_html import HTMLSession
session = HTMLSession()
url = "https://example.com"
r = session.get(url)
# renderのオプション例
r.html.render(
timeout=20, # JS実行のタイムアウト(秒)
sleep=3, # JS実行後、何秒待ってからHTMLを取得するか
keep_page=False, # レンダリング後にブラウザタブを閉じるかどうか
scrolldown=2 # 何回スクロールするか(遅延ロード対策)
)
print(r.html.html[:500])<!doctype html>...スクロールしないと表示されないコンテンツ(無限スクロールのリストなど)に対しては、scrolldownを増やすことで、下の方の要素までロードさせられます。
ただし、値を大きくしすぎると時間がかかるため、対象サイトに応じて調整することが重要です。
SPAサイトからデータを取得する手順
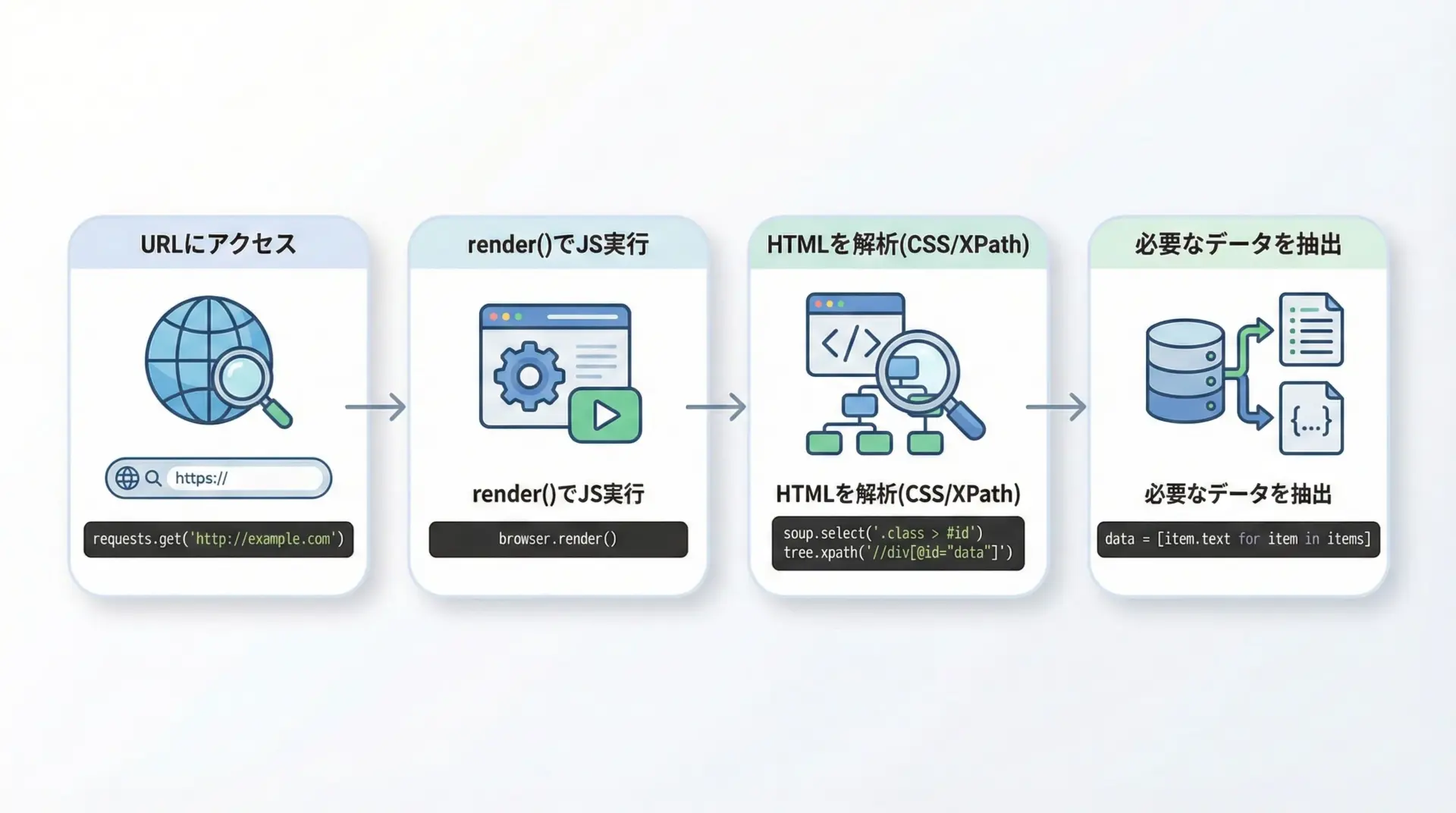
SPA(Single Page Application)サイトからデータを取得する一般的な手順は次の通りです。
- 対象ページのURLにアクセスし、
session.get()でレスポンスを取得する。 - render()を呼び出してJavaScriptを実行し、DOMを構築する。
- r.html.find()やr.html.xpath()で、必要な要素を特定する。
- .textや.attrsでデータを取り出し、リストや辞書などにまとめる。
簡単なサンプルコードを示します。
# spa_scraping_example.py
from requests_html import HTMLSession
session = HTMLSession()
url = "https://example.com/spa-page"
# 1. ページ取得
r = session.get(url)
# 2. JS実行
r.html.render(timeout=30, sleep=3, scrolldown=1)
# 3. 要素をCSSセレクタで取得(例: 商品カード)
items = r.html.find("div.product-card")
results = []
# 4. データ抽出
for item in items:
name_el = item.find(".product-name", first=True)
price_el = item.find(".product-price", first=True)
name = name_el.text if name_el else ""
price = price_el.text if price_el else ""
results.append({"name": name, "price": price})
# 結果表示
for r in results:
print(r){'name': '商品A', 'price': '1,000円'}
{'name': '商品B', 'price': '2,500円'}
...開発者ツールで実際のHTML構造を確認しながらCSSセレクタを決めることが成功のポイントです。
セッション管理とログイン処理
Cookieとセッションの使い方
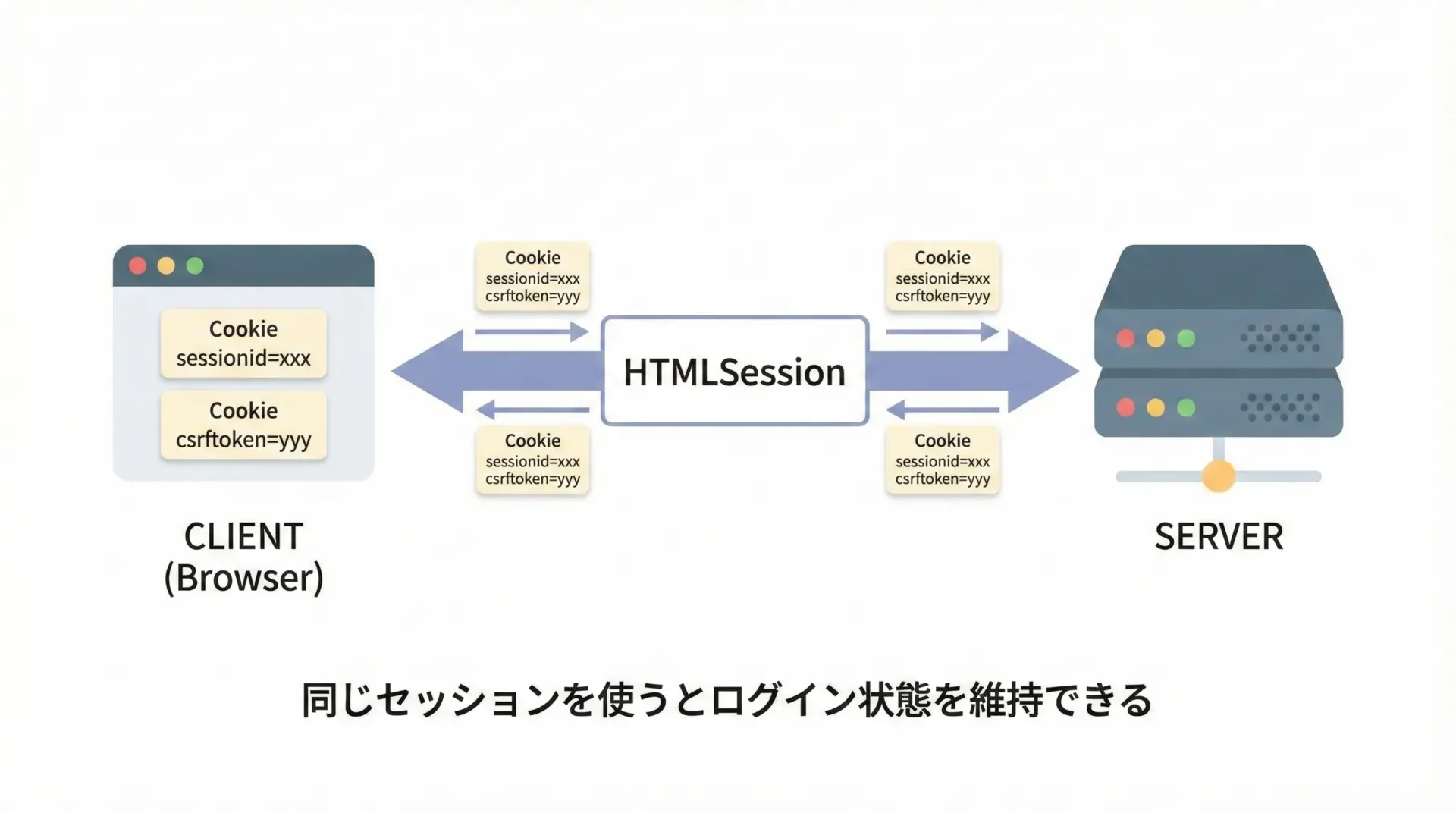
ログインが必要なサイトをスクレイピングする場合、セッションとCookieを正しく扱う必要があります。
requests-htmlのHTMLSessionは、内部にCookieを保持してくれるため、同じセッションオブジェクトを使い回すだけでログイン状態を維持できます。
# session_and_cookies.py
from requests_html import HTMLSession
session = HTMLSession()
# 1. ログインページやトップページにアクセス(サーバからCookieが渡される)
resp1 = session.get("https://example.com/")
print("初回Cookie:", session.cookies)
# 2. 何度か別ページにアクセスしても、同じセッションなのでCookieは維持される
resp2 = session.get("https://example.com/mypage")
print("マイページステータス:", resp2.status_code)
print("現在のCookie:", session.cookies)初回Cookie: <RequestsCookieJar[...]>
マイページステータス: 200
現在のCookie: <RequestsCookieJar[...]>ポイントは「毎回HTMLSession()を作り直さない」ことです。
ログイン後も同じセッションオブジェクトを使い続けることで、ログイン状態を維持できます。
フォーム送信でログインする方法
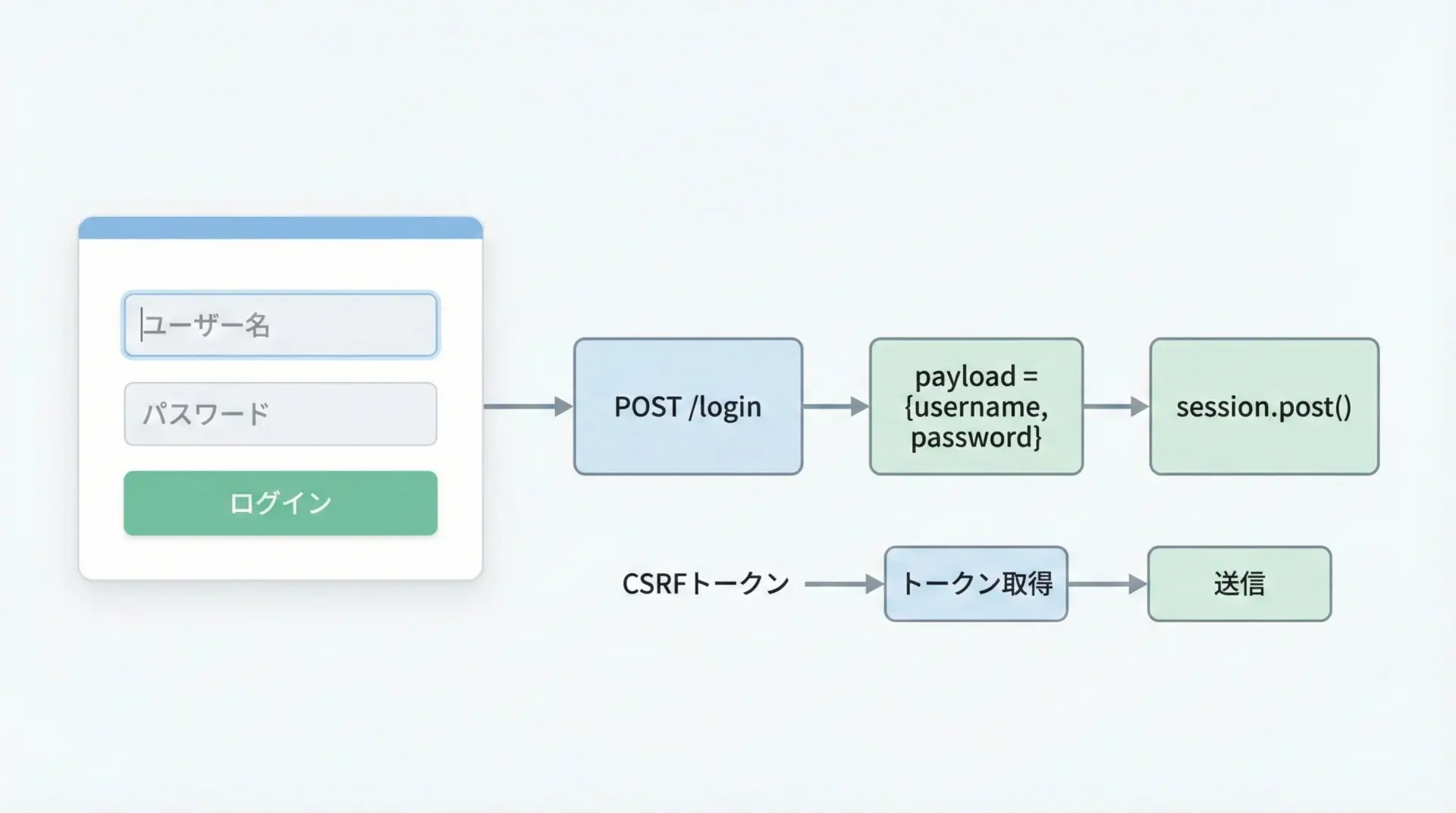
フォームログインを行うには、ブラウザで行う操作をHTTPレベルで再現します。
一般的な流れは次の通りです。
- ログインページをGETし、必要なトークン(CSRFなど)があれば取得する。
- ログイン情報(ユーザー名、パスワード、トークン)を含むデータをPOSTする。
- レスポンスを確認し、ログイン成功かどうかを判定する。
- 同じセッションでマイページなどにアクセスする。
簡略化した例を示します。
# login_example.py
from requests_html import HTMLSession
session = HTMLSession()
login_page_url = "https://example.com/login"
login_url = "https://example.com/login/post"
# 1. ログインページにアクセスしてCSRFトークンなどを取得
r = session.get(login_page_url)
# ここでは例として、input[name='csrf_token']から値を取る想定
token_el = r.html.find("input[name='csrf_token']", first=True)
csrf_token = token_el.attrs.get("value") if token_el else ""
# 2. ログイン情報を組み立ててPOST
payload = {
"username": "your_username",
"password": "your_password",
"csrf_token": csrf_token,
}
r2 = session.post(login_url, data=payload)
# 3. ログイン成功かを簡易チェック(例: URLや本文に特定の文字があるか)
if "マイページ" in r2.text or r2.url.endswith("/mypage"):
print("ログイン成功")
else:
print("ログイン失敗の可能性があります")
# 4. 同じセッションでマイページにアクセス
mypage = session.get("https://example.com/mypage")
print("マイページステータス:", mypage.status_code)ログイン成功
マイページステータス: 200実際のサイトでは、ログインフォームのname属性やCSRFトークンの有無などが異なるため、ブラウザの開発者ツールでフォームの構造を確認してからコードを書きます。
実践サンプルコード集
ニュースサイトをスクレイピングする例

ここでは、静的なHTMLで構成されたシンプルなニュース一覧ページを想定し、タイトルとURL、日付を取得する例を示します。
# news_scraping_example.py
from requests_html import HTMLSession
from urllib.parse import urljoin
session = HTMLSession()
BASE_URL = "https://example.com"
NEWS_URL = "https://example.com/news"
r = session.get(NEWS_URL)
r.raise_for_status() # エラーなら例外
# 各ニュース記事のブロックを取得(例: li.news-item)
items = r.html.find("li.news-item")
news_list = []
for item in items:
title_el = item.find("a.title", first=True)
date_el = item.find(".date", first=True)
if not title_el:
continue
title = title_el.text.strip()
# 相対パスを絶対URLに変換
link = urljoin(BASE_URL, title_el.attrs.get("href", ""))
date = date_el.text.strip() if date_el else ""
news_list.append({
"title": title,
"url": link,
"date": date,
})
# 結果表示
for n in news_list:
print(n["date"], "-", n["title"], "=>", n["url"])2025-01-01 - Pythonの記事 => https://example.com/news/1
2025-01-02 - スクレイピング入門 => https://example.com/news/2
...実運用では、この結果をCSVに保存したり、データベースに格納したりすることで、ニュースの自動収集システムを構築できます。
JSで生成される商品リストを取得する例
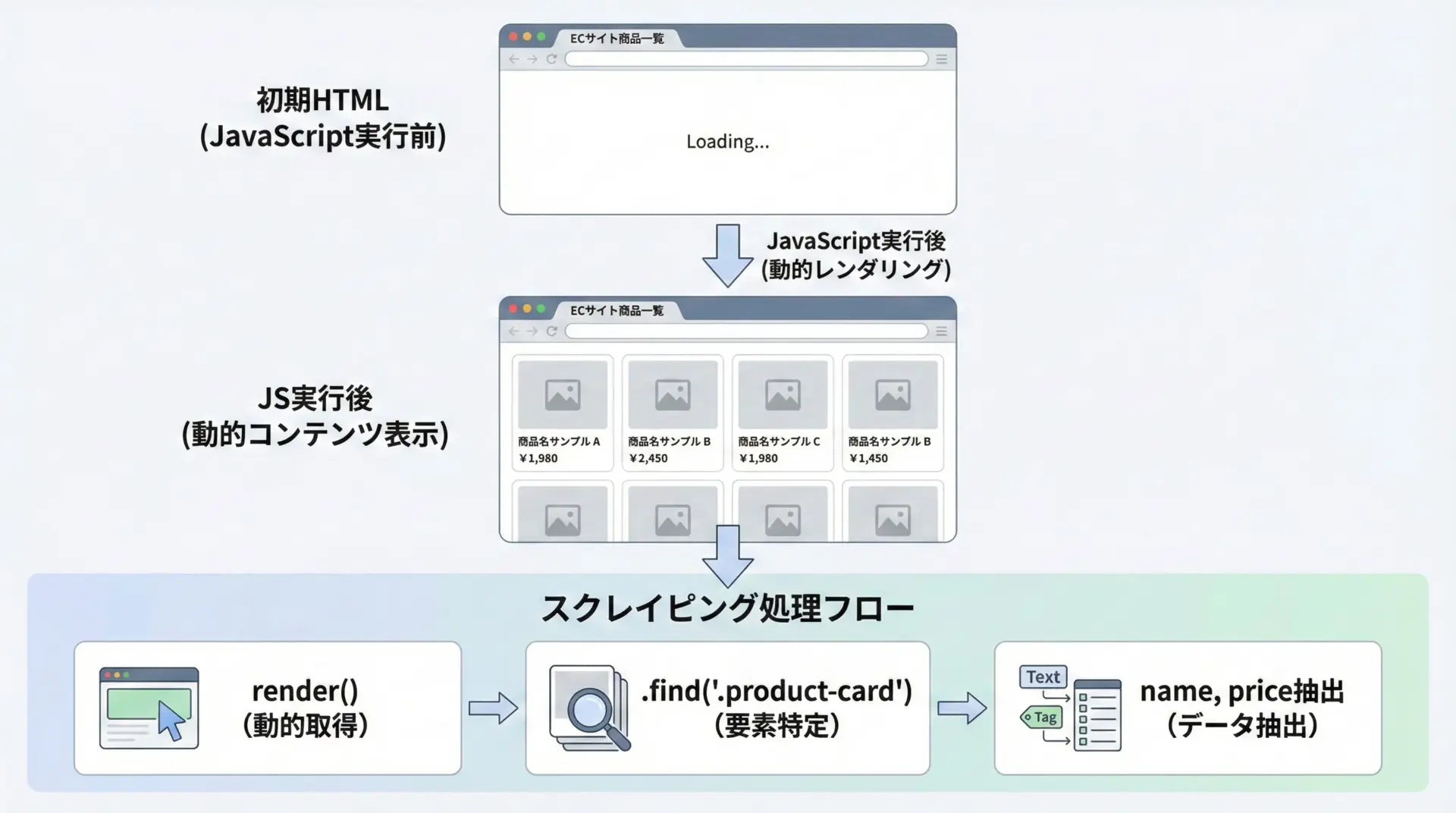
次に、JavaScriptで生成される商品一覧を取得するサンプルです。
実際のサイトによって構造は異なりますが、典型的なパターンとして参考になります。
# js_product_list_example.py
from requests_html import HTMLSession
session = HTMLSession()
url = "https://example.com/products"
# 1. ページ取得
r = session.get(url)
# 2. JS実行して商品リストが描画されるまで待つ
r.html.render(timeout=30, sleep=5, scrolldown=2)
# 3. 商品カードを取得
items = r.html.find("div.product-card")
products = []
for item in items:
name_el = item.find(".product-name", first=True)
price_el = item.find(".product-price", first=True)
link_el = item.find("a", first=True)
name = name_el.text.strip() if name_el else ""
price = price_el.text.strip() if price_el else ""
url = link_el.attrs.get("href") if link_el else ""
products.append({
"name": name,
"price": price,
"url": url,
})
# 4. 結果表示
for p in products:
print(p["name"], p["price"], p["url"])商品A 1,000円 /products/1
商品B 2,500円 /products/2
...JSで生成されるリストは、実は裏でAPI(JSON)を叩いているケースが多いです。
ブラウザのネットワークタブを観察し、JSON APIが直接叩ける場合は、そちらを使う方が高速で安定します。
requests-htmlのrenderは、そうしたAPIが見つからないときの「最後の手段」として覚えておくとよいです。
エラー対策とデバッグのコツ
よくあるエラーと原因
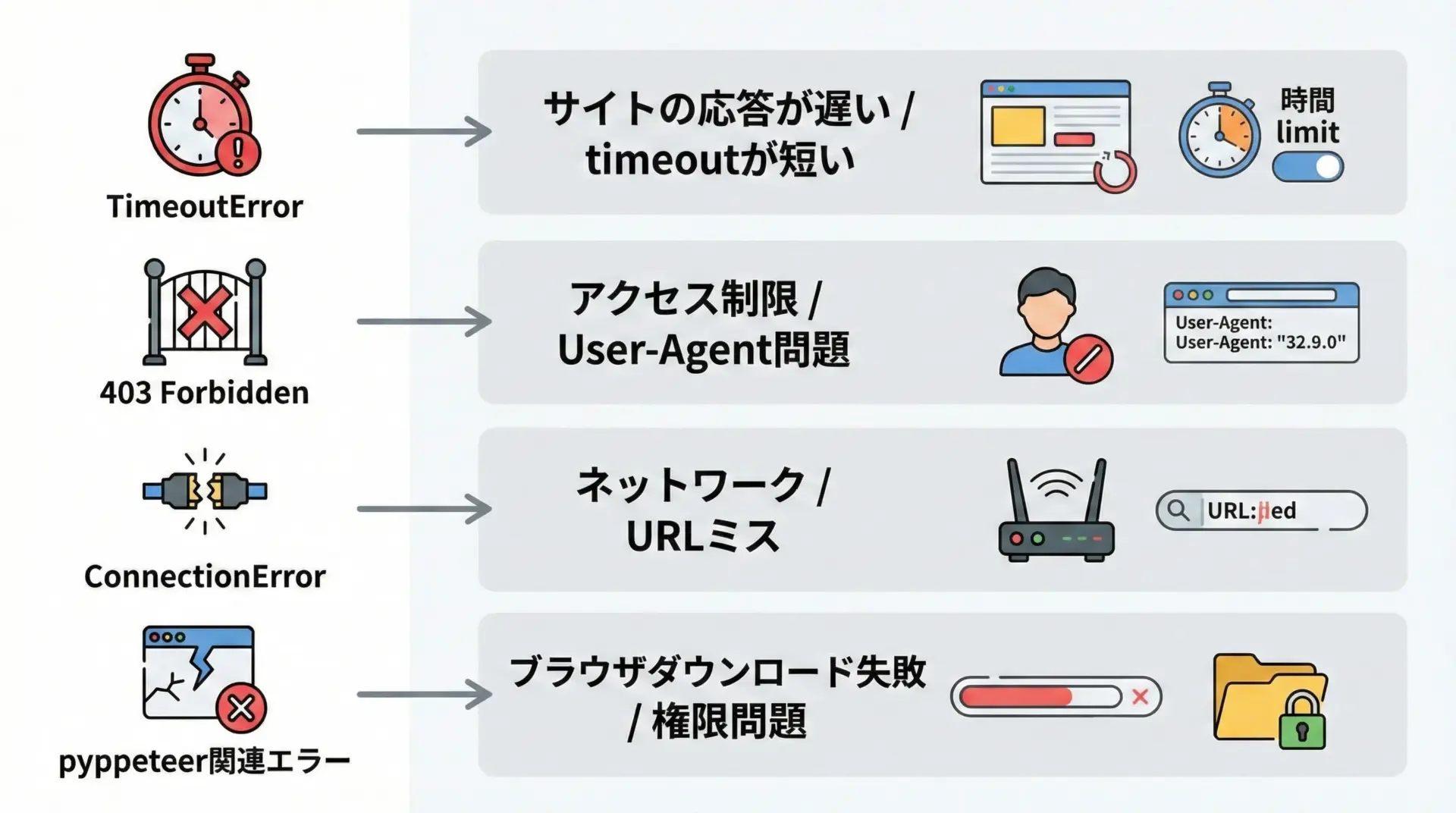
requests-htmlを使っていると、いくつか典型的なエラーに遭遇します。
代表的なものと対策を簡潔にまとめます。
| エラー例 | 主な原因 | 対策の方向性 |
|---|---|---|
| TimeoutError | サイトが重い / timeoutが短い | timeout値を伸ばす、リトライ処理 |
| 403 Forbidden | アクセス拒否 / Bot対策 | User-Agentヘッダを設定、アクセス頻度を下げる |
| ConnectionError | URL間違い / ネットワーク問題 | URLやプロキシ設定を確認 |
| pyppeteer系エラー | Chromiumダウンロード失敗など | ネットワークと権限、ディスク容量を確認 |
ヘッダ設定の例を示します。
# headers_example.py
from requests_html import HTMLSession
session = HTMLSession()
headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)
}
r = session.get("https://example.com", headers=headers, timeout=15)
print(r.status_code)200特に403エラーが出る場合、User-Agentを設定するだけで解消することも多いので、最初に試す価値があります。
HTML構造を確認する方法
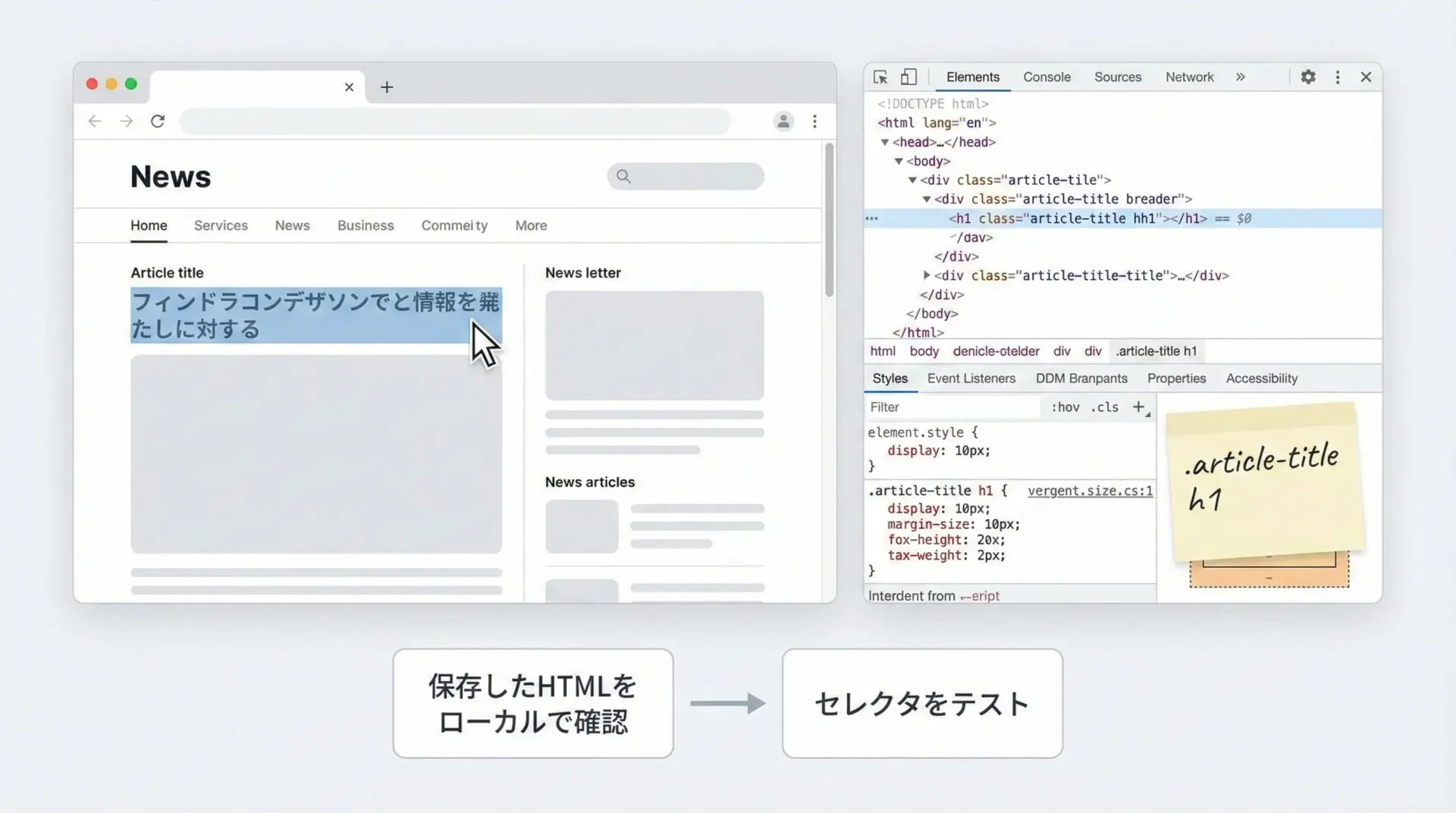
スクレイピングがうまくいかないときの多くは、想定したHTML構造と実際のHTML構造が違うことが原因です。
そのため、次のような方法でHTMLをしっかり確認することが重要です。
- ブラウザの開発者ツールで要素の構造とCSSセレクタを確認する。
- requests-htmlが取得したHTMLをファイルに保存し、ローカルでじっくり眺める。
- JS実行前と後のHTMLを比較して、どのタイミングで要素が生成されるかを把握する。
HTMLを保存する簡単なコード例です。
# save_html_for_debug.py
from requests_html import HTMLSession
session = HTMLSession()
url = "https://example.com"
r = session.get(url)
# JS実行前のHTMLを保存
with open("before_render.html", "w", encoding="utf-8") as f:
f.write(r.html.html)
# JS実行
r.html.render(timeout=30, sleep=3)
# JS実行後のHTMLを保存
with open("after_render.html", "w", encoding="utf-8") as f:
f.write(r.html.html)
print("HTMLを保存しました。エディタやブラウザで開いて確認してください。")HTMLを保存しました。エディタやブラウザで開いて確認してください。ローカルに保存したHTMLをテキストエディタやブラウザで開いてから、CSSセレクタやXPathを設計すると、精度の高いスクレイピングコードを作りやすくなります。
まとめ
requests-htmlは、HTTPリクエスト、HTML解析、JavaScript実行を1つにまとめた「オールインワン型」のスクレイピングライブラリです。
requestsに近いシンプルな書き心地で、CSSセレクタやXPathによる要素取得、renderによるJS実行、セッションを使ったログイン処理まで扱えます。
静的ページだけでなく、SPAやJS生成コンテンツにも対応したい場合に非常に心強い選択肢です。
まずは小さなページから試し、HTML保存や開発者ツールで構造を確認しながら、少しずつ実践的なスクレイピングへ発展させてみてください。
