
Pythonでの定期実行は、ちょっとした自動化やバッチ処理を作るうえで非常に便利です。
本記事では、軽量ライブラリ「schedule」を使って、毎日・毎時・平日だけ、などの定期実行をシンプルなコードで実現する方法を詳しく解説します。
cronよりわかりやすく、初心者でも扱いやすい方法を中心に紹介します。
Python×scheduleとは
scheduleライブラリの概要
scheduleは、Python用の軽量なジョブスケジューラーです。
バックグラウンドで常駐する巨大な仕組みではなく、1つのPythonスクリプトの中で「何を」「いつ」実行するかをシンプルに書けるライブラリです。
特徴として、次のような点があります。
- cronのような難しい書式を覚える必要がない
- Pythonのコードだけで完結する
- 毎日・毎時・毎分・平日だけなどの指定が簡単
- プロセスとして動いている間だけスケジュールが有効
どんな用途に向いているか
たとえば次のような用途で活躍します。
- 毎日決まった時間にAPIからデータを取得しファイル保存する
- 5分おきにWebサイトをチェックして異常を検知する
- 平日9:00にSlackへリマインドメッセージを送る
- 1時間ごとにログを集計してレポートを作る
「サーバを常時動かしておける」「Pythonスクリプトを動かしっぱなしにできる」環境であれば、scheduleはとても扱いやすい選択肢になります。
インストールと基本的な使い方
インストール方法
まずはpipでscheduleをインストールします。
pip install schedule仮想環境を使っている場合は、仮想環境をアクティブにしてから実行してください。
最小構成のサンプル
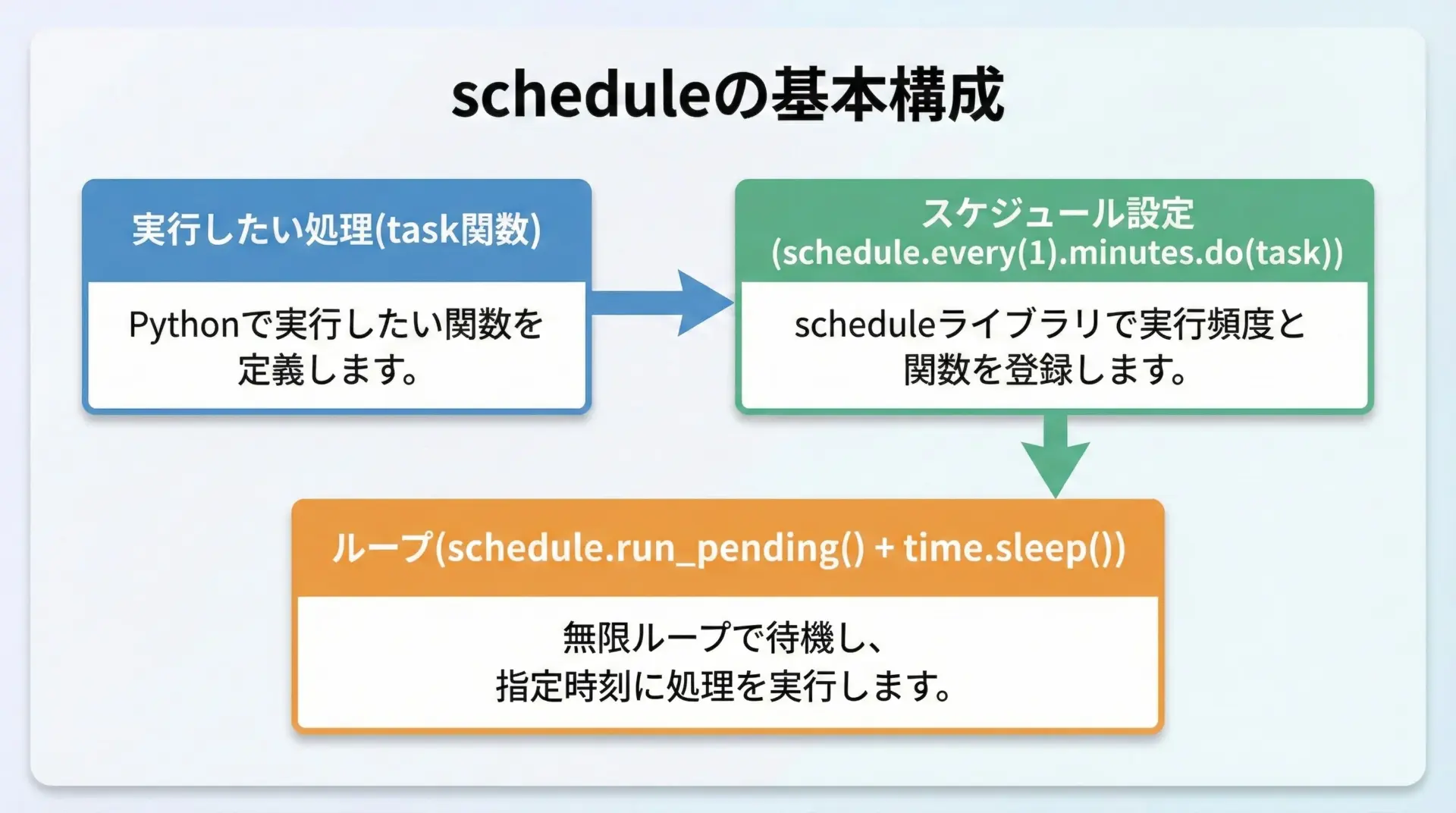
「1分ごとにメッセージを表示する」最小構成のサンプルです。
import schedule
import time
# 実行したい処理を関数として定義します
def job():
# 実際の処理の代わりに、ここではメッセージを表示します
print("1分ごとに実行されています")
# スケジュールの設定を行います
# every(1).minutes で「1分ごと」を意味します
schedule.every(1).minutes.do(job)
# 永久ループでスケジュールされたジョブを監視・実行します
while True:
# 実行時刻になっているジョブがあれば実行します
schedule.run_pending()
# CPUを占有しないように1秒スリープします
time.sleep(1)上のコードを実行すると、1分ごとにメッセージが出力され続けます。
このサンプルからわかるように、scheduleの基本構成は「関数定義」「スケジュール設定」「無限ループ」の3要素です。
毎日・毎時・毎分の定期実行
毎日決まった時刻に実行する
「毎日◯時◯分」の実行は、最もよく使われるパターンの1つです。
たとえば毎日23:30にバックアップ処理を実行するコードは次のようになります。

import schedule
import time
from datetime import datetime
def backup():
# ここにバックアップ処理を書くイメージです
print(f"バックアップ実行: {datetime.now()}")
# 毎日23:30にbackup関数を実行します
schedule.every().day.at("23:30").do(backup)
while True:
schedule.run_pending()
time.sleep(1)ポイントはevery().day.at("HH:MM")という書き方です。
24時間表記で、”08:00″ や “19:45” のように指定できます。
毎時決まったタイミングで実行する
毎時ちょうど(例: 10:00, 11:00, 12:00, …)に処理したい場合は次のように書けます。
import schedule
import time
from datetime import datetime
def hourly_job():
print(f"毎時ちょうどの処理: {datetime.now()}")
# 毎時0分に実行するイメージ
schedule.every().hour.at(":00").do(hourly_job)
while True:
schedule.run_pending()
time.sleep(1)every().hour.at(":00")のように、分だけを指定する書き方が可能です。
“:30” とすれば「毎時30分」に実行することもできます。
毎分・数分おき・数時間おきの実行
時間間隔ベースでの定期実行はさらに簡単です。
毎分実行、5分ごと、2時間ごとなどは次のように書きます。
import schedule
import time
from datetime import datetime
def check_status():
print(f"システム状態チェック: {datetime.now()}")
def report():
print(f"簡易レポート出力: {datetime.now()}")
# 1分ごとに状態チェック
schedule.every(1).minutes.do(check_status)
# 5分ごとにレポート出力
schedule.every(5).minutes.do(report)
# 2時間ごとにレポート出力(例)
# schedule.every(2).hours.do(report)
while True:
schedule.run_pending()
time.sleep(1)every(n).minutesやevery(n).hoursのように、数字を変えるだけで簡単に間隔を調整できます。
平日だけ/特定曜日だけの定期実行
平日のみ実行する
業務でよくあるケースとして「平日のみ定期実行したい」というニーズがあります。
scheduleでは曜日指定がそのままメソッド名で用意されているため、直感的に記述できます。

import schedule
import time
from datetime import datetime
def weekday_task():
print(f"平日タスク実行: {datetime.now()}")
# 月曜から金曜の9:30に実行します
schedule.every().monday.at("09:30").do(weekday_task)
schedule.every().tuesday.at("09:30").do(weekday_task)
schedule.every().wednesday.at("09:30").do(weekday_task)
schedule.every().thursday.at("09:30").do(weekday_task)
schedule.every().friday.at("09:30").do(weekday_task)
while True:
schedule.run_pending()
time.sleep(1)少し冗長に見えますが、「平日だけ」のような抽象的な指定はscheduleにはないため、曜日ごとに設定するのが基本です。
特定の曜日だけ実行する
特定の曜日だけでよければ、1行でシンプルに書けます。
import schedule
import time
from datetime import datetime
def weekly_report():
print(f"週次レポート作成: {datetime.now()}")
# 毎週月曜日の10:00に実行
schedule.every().monday.at("10:00").do(weekly_report)
while True:
schedule.run_pending()
time.sleep(1)利用できる曜日メソッドは次の通りです。
| 曜日 | メソッド名の例 |
|---|---|
| 月曜 | every().monday |
| 火曜 | every().tuesday |
| 水曜 | every().wednesday |
| 木曜 | every().thursday |
| 金曜 | every().friday |
| 土曜 | every().saturday |
| 日曜 | every().sunday |
複数ジョブの同時スケジュール
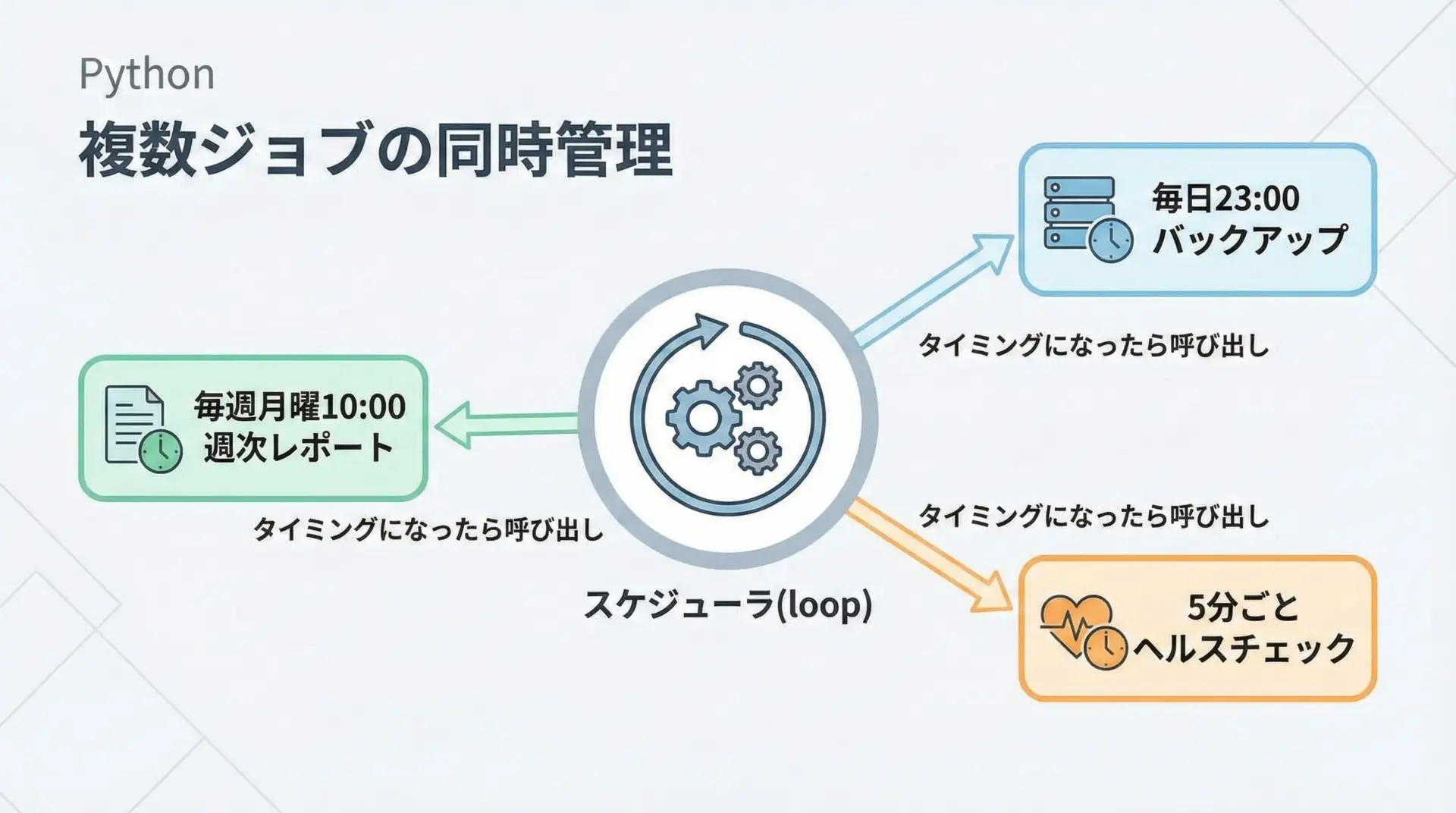
1つのスクリプトで複数タスクを管理する
scheduleは、1つのスクリプト内で複数のジョブをまとめて管理できます。
たとえば次のような構成が可能です。
import schedule
import time
from datetime import datetime
def backup():
print(f"[バックアップ] {datetime.now()}")
def health_check():
print(f"[ヘルスチェック] {datetime.now()}")
def weekly_report():
print(f"[週次レポート] {datetime.now()}")
# 毎日23:00にバックアップ
schedule.every().day.at("23:00").do(backup)
# 5分ごとにヘルスチェック
schedule.every(5).minutes.do(health_check)
# 毎週月曜10:00に週次レポート
schedule.every().monday.at("10:00").do(weekly_report)
while True:
schedule.run_pending()
time.sleep(1)ループは1つだけでよく、すべてのジョブは共通のschedule.run_pending()によって管理されます。
ジョブに引数を渡す
実行する関数に引数を渡すことも可能です。
たとえば、メール送信先や処理モードを引数で切り替えるような場合です。
import schedule
import time
from datetime import datetime
def send_report(report_type, to):
print(f"[{report_type}] を {to} に送信: {datetime.now()}")
# 引数付きでジョブ登録
schedule.every().day.at("09:00").do(
send_report,
report_type="日次レポート",
to="team@example.com",
)
schedule.every().monday.at("09:30").do(
send_report,
report_type="週次レポート",
to="boss@example.com",
)
while True:
schedule.run_pending()
time.sleep(1)キーワード引数もそのまま指定できるため、読みやすく保ったまま柔軟なジョブを組み立てられます。
scheduleを使う際の注意点と工夫
スクリプトを動かし続ける必要がある
scheduleは「OSレベルの常駐サービス」ではありません。
あくまで「実行中のPythonプロセス内」でスケジューリングされるため、次の点に注意が必要です。
- Pythonスクリプトが終了すると、スケジュールも止まる
- サーバ再起動後は、スクリプトを再度起動し直す必要がある
実運用では、以下のような方法でスクリプトを常駐させます。
- Linuxなら
systemdやsupervisorでPythonスクリプトを常時起動 - 開発中であれば、ターミナルで実行したままにする
「cronの代替」として完全に置き換えるというより、cronなどと組み合わせて「cronがPythonを起動する」「中でscheduleが細かいスケジュールを管理する」構成にするケースも多いです。
長時間かかる処理とブロッキング
1つのジョブが長時間ブロックすると、他のジョブの実行タイミングがずれます。
schedule自体はシングルスレッドで、run_pending()の中で順にジョブを呼び出します。
そのため、10分かかる処理があると、その10分間は他のジョブが実行されません。
対策としては次のようなパターンがあります。
- ジョブ内でスレッドやプロセスを立てて非同期実行する
- ジョブの処理時間を短く保ち、重い処理は別のワーカーに委譲する
たとえば簡易的にスレッドで非同期実行するコードは次のようになります。
import schedule
import time
import threading
from datetime import datetime
def heavy_task():
print(f"[heavy_task start] {datetime.now()}")
time.sleep(10) # 重い処理をシミュレート
print(f"[heavy_task end] {datetime.now()}")
def run_in_thread(job_func):
# ジョブを別スレッドで実行するラッパーです
job_thread = threading.Thread(target=job_func)
job_thread.start()
# heavy_task をスレッドで実行するようにスケジュール
schedule.every(1).minutes.do(run_in_thread, heavy_task)
while True:
schedule.run_pending()
time.sleep(1)このようにすることで、スケジューラーのメインループは軽量なまま保ちつつ、重い処理は別スレッドに逃がすことができます。
タイムゾーンと時刻のずれ
scheduleは基本的に実行環境のローカルタイムを前提に動きます。
サーバのタイムゾーン設定や夏時間(DST)の影響を受けるため、次の点に注意してください。
- サーバの時刻・タイムゾーン設定が適切か確認する
- UTCベースで運用したい場合は、サーバ自体をUTCにしておく
- タイムゾーンを厳密に扱いたい場合は、cronやAirflowなどの他ツールも検討
schedule単体ではタイムゾーン指定などの高度な制御はできない点は、設計時に意識しておきましょう。
まとめ
Pythonのscheduleライブラリを使うと、毎日・毎時・平日だけといった定期実行を、直感的なPythonコードだけで実現できます。
「関数で処理を定義し、every()やday.at()でスケジュールを指定し、while True: run_pending()で回し続ける」だけのシンプルな構成です。
一方で、スクリプトを常時起動しておく必要があることや、長時間処理をどう扱うかといった注意点もあります。
小規模な自動化やバッチ処理であれば、まずscheduleで試し、その限界を感じてからcronや専用ジョブ管理ツールへの移行を検討するのが現実的な進め方です。
