
PythonでWebサイトから情報を収集したいと考えたとき、手作業でコードを書くよりもクローラーフレームワークを使うと、開発スピードも安定性も大きく向上します。
その代表格がScrapyです。
この記事では、Python初心者でも最速で実用的なクローラーを作れることをゴールに、インストールから実践的なクローラー構築、エラー対策まで、図解とサンプルコードを交えながら丁寧に解説していきます。
Scrapyとは?Pythonで高速クローラーを作る理由
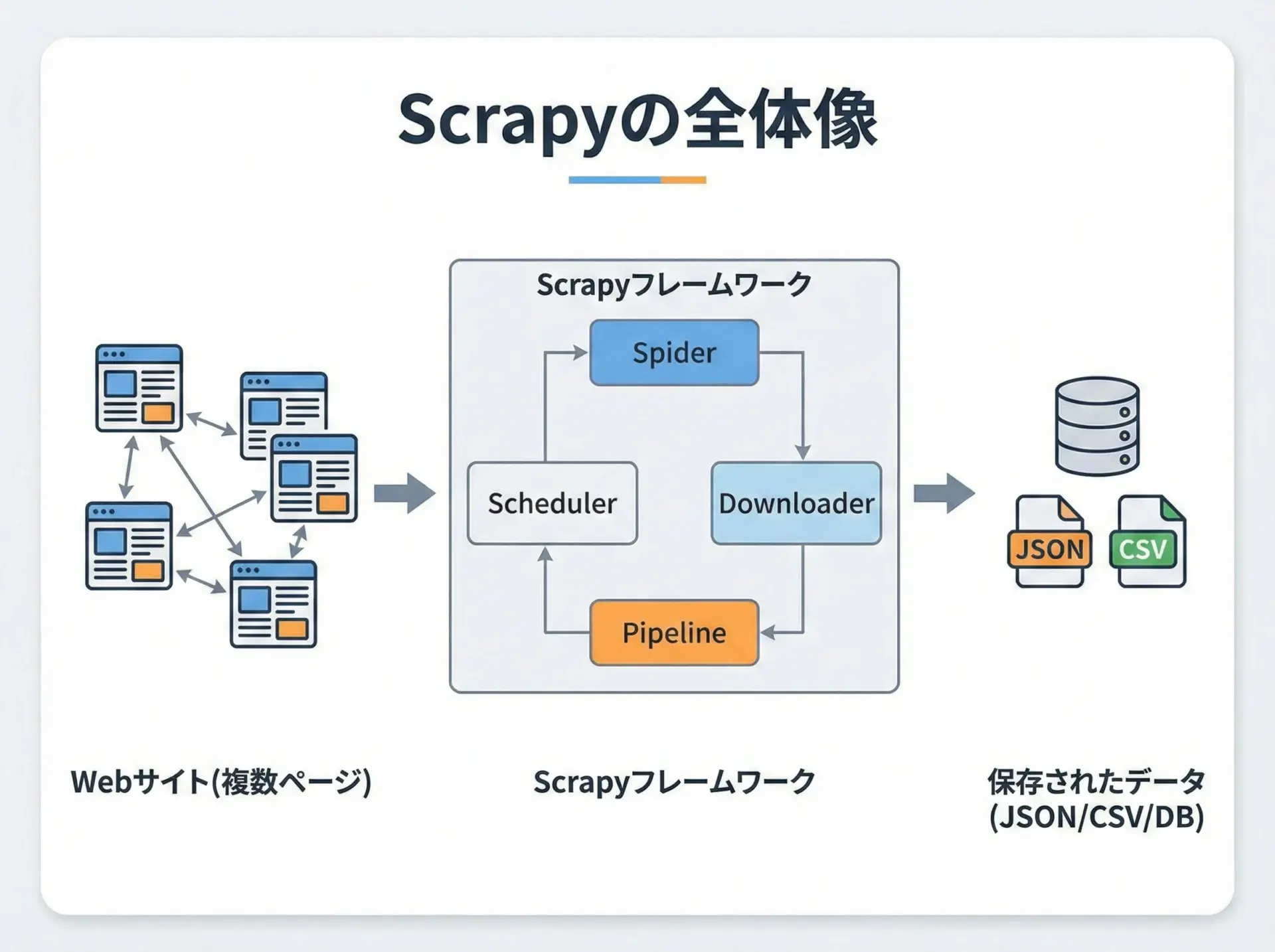
ScrapyはPythonで書かれた高速なクローラー/スクレイピング専用フレームワークです。
HTTPアクセス、HTML解析、リンクをたどる処理、データ保存など、クローラーで必要になる機能がひとまとめになっており、設定と少量のコードを書くことで効率よくクローラーを構築できます。
一般的なrequests + BeautifulSoupによる自作クローラーと比べても、Scrapyは非同期処理による高速な並列取得、再利用性の高い構造、豊富な設定項目を備えているため、大規模なクローリングでも扱いやすいのが特徴です。
Pythonのクローラー開発にScrapyを使うメリット
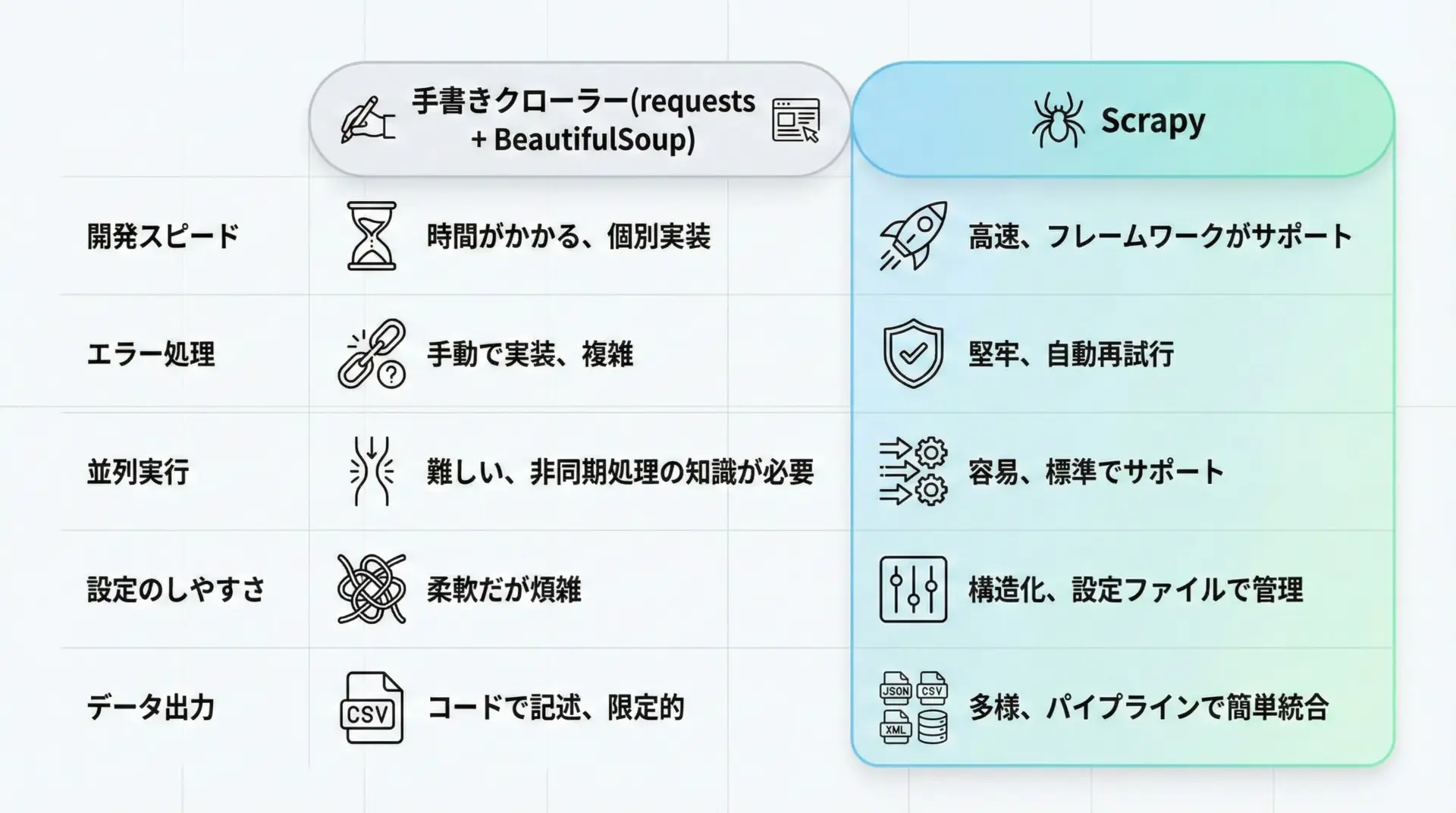
Scrapyを使う最大のメリットは、クローラーに必要な要素をフレームワーク側がほとんど用意してくれている点です。
具体的には、次のような利点があります。
1つ目は、非同期処理による高速なクローリング性能です。
Scrapyは内部でTwistedという非同期ネットワークライブラリを使用しており、複数のページに対するHTTPリクエストを同時に処理できます。
自分でスレッド管理や非同期処理を書かなくても、設定だけで並列数を調整できるため、大量ページのクロールに向いています。
2つ目は、構造化されたプロジェクトと拡張性です。
Spider、Pipeline、Middlewareなどの役割がファイルやクラスとして整理されているため、コードが肥大化しても管理しやすく、機能ごとの差し替えや共通化も簡単に行えます。
3つ目は、データ出力機能の充実です。
JSON、CSV、XMLといった形式への書き出しを設定ファイルだけで切り替えられます。
さらにPipelineを使えば、データベース(SQLite、MySQLなど)への保存処理も容易です。
最後に、堅牢なエラー処理とリトライ機構も見逃せません。
HTTPエラー、タイムアウト、リダイレクトなどに対して、Scrapyは標準で多くの対策機能を持っており、これらを設定で制御できます。
これにより、現場レベルのクローラーを短時間で構築できます。
スクレイピングとクローリングの違い
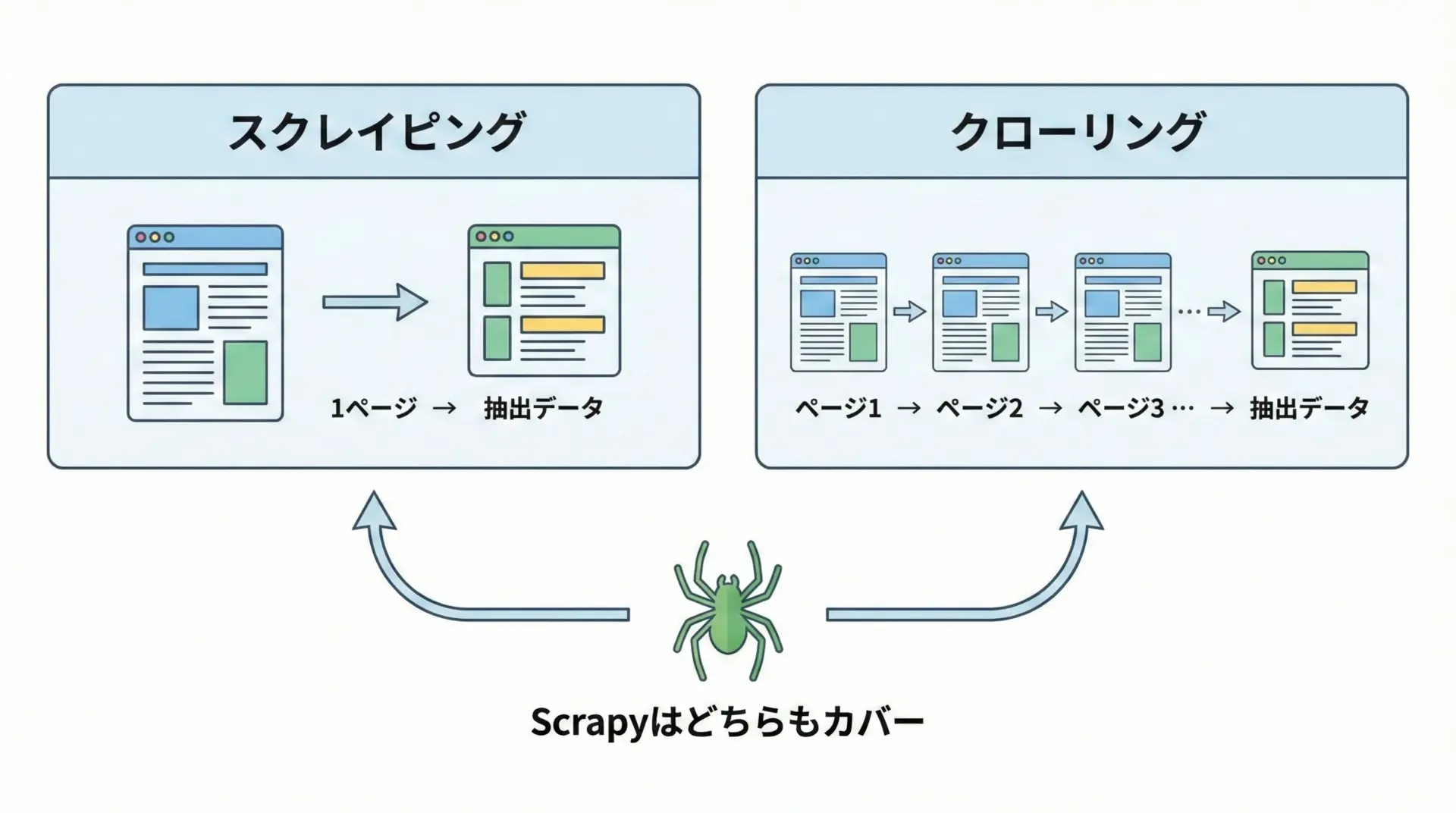
Web関連の処理では、スクレイピングとクローリングという似た用語が出てきますが、意味は少し異なります。
スクレイピング(scraping)は、特定のWebページから必要な情報を抜き出す処理を指します。
例えば、1つのニュース記事ページからタイトルや本文、日付を取得する行為はスクレイピングです。
一方で、クローリング(crawling)は、ページ内のリンクをたどりながら複数ページを巡回して情報を集める処理を指します。
検索エンジンのロボットが、サイト全体を回って情報を集めるイメージが近いです。
Scrapyは両方の役割をカバーするフレームワークであり、1ページからのデータ抽出にも、大量のリンクをたどるクローリングにも向いています。
本記事では、両者を合わせて「クローラー」として扱いながら解説していきます。
Scrapyのインストールと環境構築
PythonでScrapyをインストールする手順
Scrapyを利用するには、まずPython環境が必要です。
一般的にはPython 3.8以降を利用することをおすすめします。
すでにPythonがインストールされている前提で、pipからScrapyをインストールします。
# Scrapyをインストール
pip install scrapy
# インストール確認
scrapy versionインストールが成功すると、scrapy versionでバージョン情報が表示されます。
もしコマンドが見つからない場合は、PATHの設定や仮想環境の有効化を確認してください。
Windows環境での注意点
Windowsの場合、環境によってはビルドツールが必要になることがあります。
ビルドエラーが発生したときは、次のような対策が有効です。
- Microsoft C++ Build Toolsをインストールする
- 可能であれば、Windows向けのPythonディストリビューション(Anacondaなど)を利用し、conda経由でScrapyをインストールする
# Condaを利用する場合の例
conda install -c conda-forge scrapy仮想環境(venv)でScrapyプロジェクトを分離する
Pythonでは、プロジェクトごとにライブラリのバージョンを分けるため、仮想環境(venv)の利用がほぼ必須です。
Scrapyも例外ではなく、プロジェクトごとに仮想環境を作成するのが安全です。
次の手順で仮想環境を作成し、有効化します。
# プロジェクト用ディレクトリを作成して移動
mkdir scrapy-tutorial
cd scrapy-tutorial
# 仮想環境を作成(venvという名前で作成)
python -m venv venv
# 仮想環境を有効化 (Windows)
venv\Scripts\activate
# 仮想環境を有効化 (macOS / Linux)
/bin/bash
source venv/bin/activate仮想環境が有効化されたら、その中にScrapyをインストールします。
(venv) pip install scrapy仮想環境を使うことで、他のプロジェクトとScrapyや依存ライブラリのバージョンが衝突することを防げます。
特にScrapyはバージョン間で挙動やAPIが変わることもあるため、プロジェクト単位で環境を固定しておくと安心です。
Scrapyプロジェクトの基本構造
scrapy startprojectでプロジェクトを作成する

Scrapyでは、プロジェクトとしてクローラー一式を管理します。
まずはscrapy startprojectコマンドを使ってプロジェクトを作成します。
# プロジェクトを作成(myprojectは任意の名前)
scrapy startproject myproject
# ディレクトリへ移動
cd myproject
# プロジェクト内の構造を確認
ls実際に作成されるディレクトリ構造の例は次のようになります。
myproject/
scrapy.cfg
myproject/
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
spiders/
__init__.pyこの構造について簡単に説明します。
scrapy.cfg
プロジェクト全体の設定ファイルです。複数プロジェクトを扱うときのエントリポイントにもなります。myproject/
実際のScrapyモジュール群が入るPythonパッケージです。この中にSpiderやPipelineなどのコードを書いていきます。items.py
取得するデータの項目を定義する場所です。小規模なら必須ではありませんが、構造化して扱いたいときに利用します。middlewares.py
ダウンローダミドルウェアやSpiderミドルウェアを定義します。リクエストやレスポンスに対する共通処理を入れたい場合に使います。pipelines.py
抽出したデータを加工・保存する処理を定義します。データベース保存や重複チェックなどを実装できます。settings.py
プロジェクト全体の設定ファイルです。並列数、ダウンロード間隔、出力形式などをここで変更します。spiders/
実際のクローラー(Spiderクラス)を定義するファイルを置くディレクトリです。
spidersディレクトリとクローラーファイルの役割
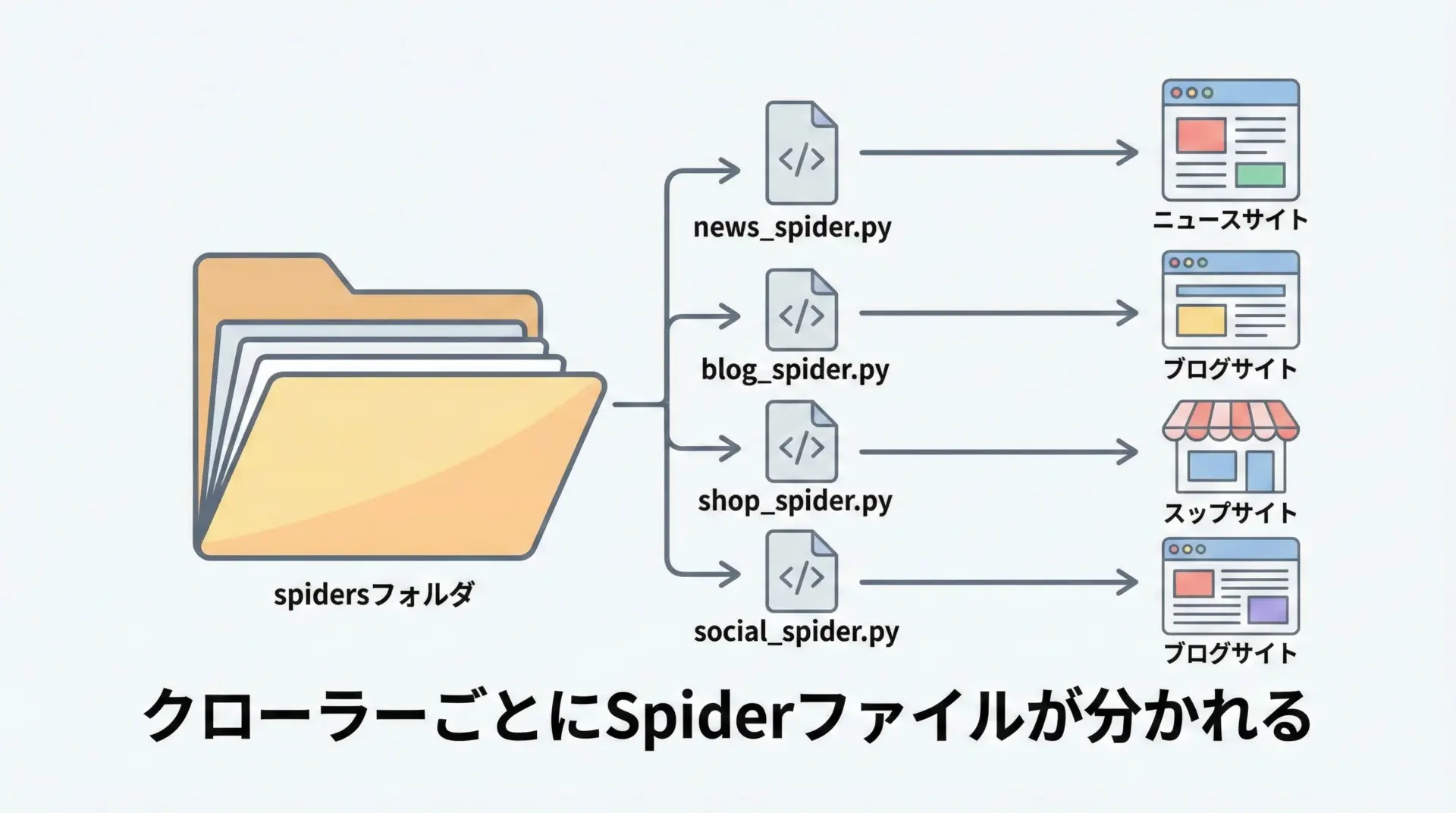
ScrapyにおいてSpiderクラスは「どのURLをどうやって巡回し、どの情報を抜き出すか」を定義する中心的な存在です。
Spiderクラスは通常spidersディレクトリ内のPythonファイルに1クラスずつ定義します。
例えば、ニュースサイト用のクローラーとブログサイト用のクローラーを別々に作る場合、news_spider.pyとblog_spider.pyのようにファイルを分け、それぞれに対応するSpiderクラスを書きます。
Scrapyはscrapy crawlコマンドを実行したときに、spiders以下を自動的に探索し、指定した名前のSpiderクラスを起動します。
そのため、Spiderクラスのname属性はプロジェクト内で一意である必要があります。
最初のScrapyクローラーを作成する
Spiderクラスの基本
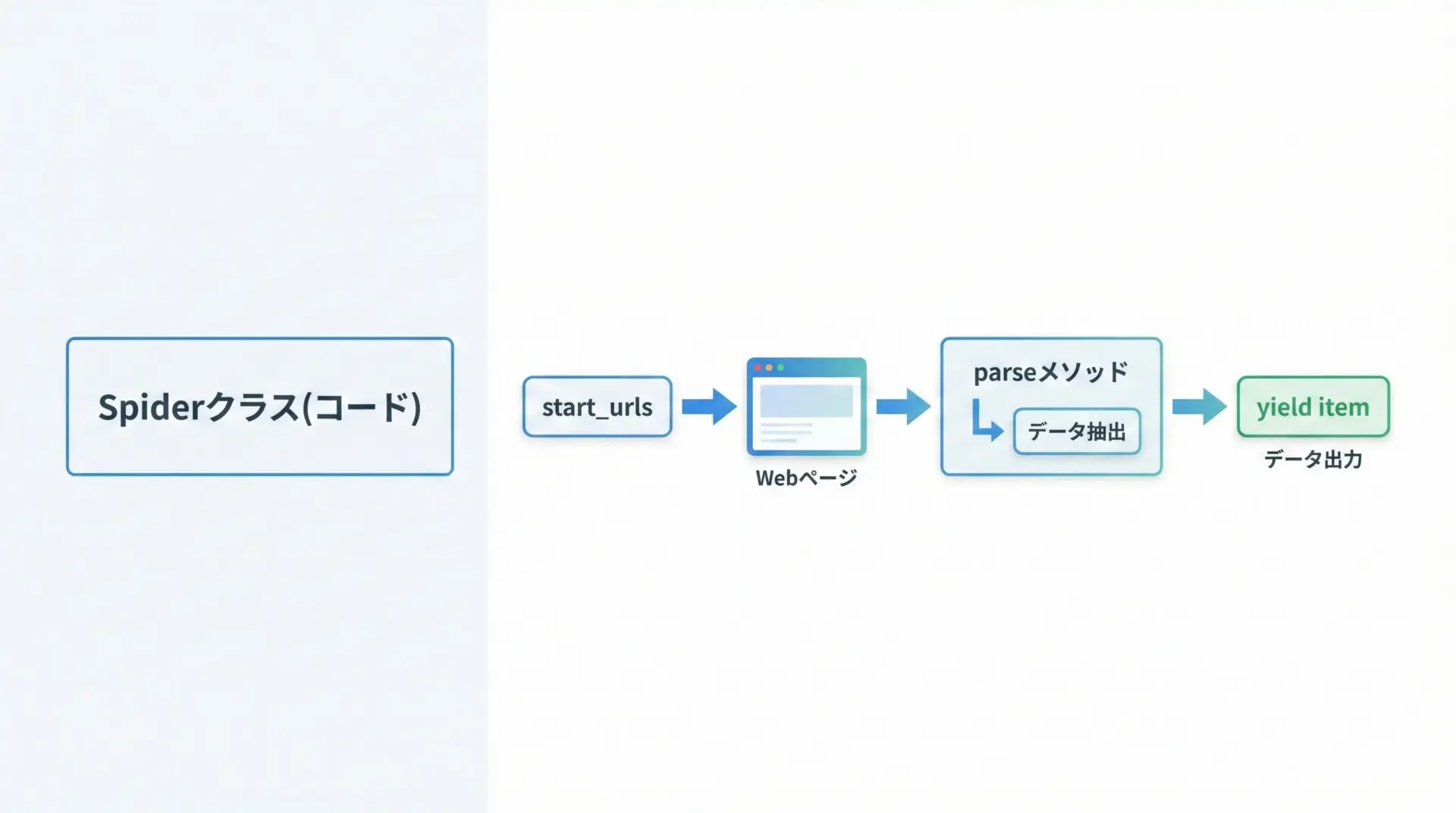
ここでは、シンプルなWebページからタイトルと見出しを取得する最初のSpiderを作成してみます。
例として、ドキュメントやテスト用に使える任意のサイトを対象とすると理解しやすいです。
手順としては、spidersディレクトリに新しいSpiderファイルを作成し、Spiderクラスを定義するだけです。
# spidersディレクトリへ移動
cd myproject
cd myproject/spiders
# 好きなエディタでsample_spider.pyを作成以下は最小限のSpiderクラスの例です。
# myproject/myproject/spiders/sample_spider.py
import scrapy # Scrapyフレームワーク本体をインポートします
class SampleSpider(scrapy.Spider):
# Spiderの一意な名前です。scrapy crawl の引数で指定します
name = "sample"
# クロールを開始するURLのリストです
start_urls = [
"https://example.com/"
]
def parse(self, response):
"""
レスポンスを受け取って、必要なデータを抽出するメソッドです。
このメソッド名はデフォルトで 'parse' が呼ばれます。
"""
# ページタイトルを取得します
title = response.xpath("//title/text()").get()
# 抽出したデータを辞書としてyieldします
# yieldすることで、Scrapyのパイプラインや出力処理に渡されます
yield {
"url": response.url,
"title": title,
}作成したSpiderを実行するには、プロジェクトのルートディレクトリ(最初にscrapy.cfgがある場所)に戻ってからscrapy crawlコマンドを使います。
cd ../.. # myproject/に戻る
# sampleという名前のSpiderを実行
scrapy crawl sampleこの段階では標準出力にJSON形式のような辞書が表示されるだけですが、ScrapyがHTTPリクエストを発行し、parseメソッドでデータが抽出されていることが確認できます。
実行結果のイメージ
2025-01-01 12:00:00 [scrapy.core.engine] INFO: Spider opened
2025-01-01 12:00:01 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://example.com/> (referer: None)
{'url': 'https://example.com/', 'title': 'Example Domain'}
2025-01-01 12:00:01 [scrapy.core.engine] INFO: Spider closed (finished)XPathとCSSセレクタでHTML要素を抽出する
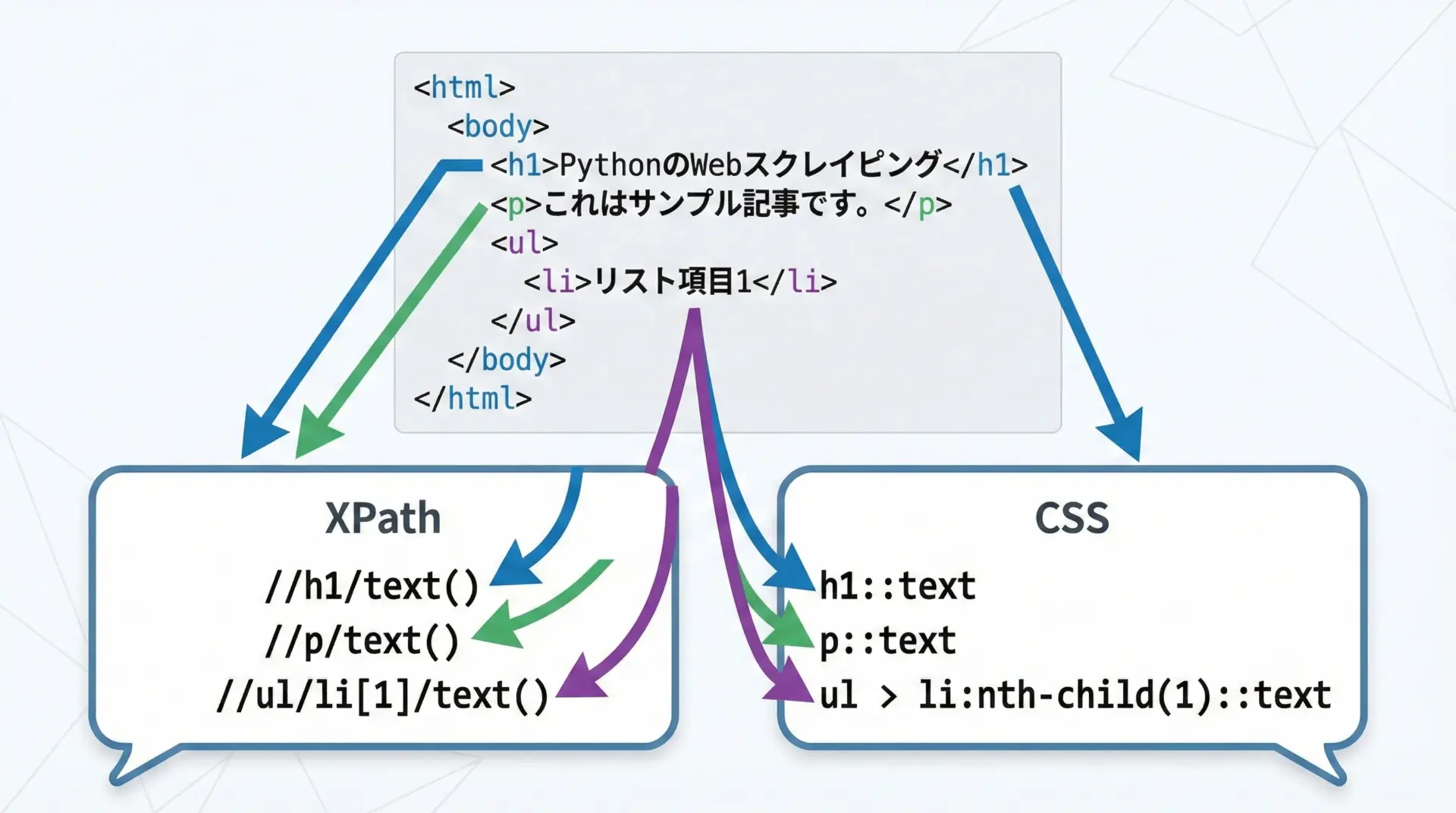
Scrapyでは、HTMLから要素を抽出するためにXPathとCSSセレクタの両方が利用できます。
どちらもresponseオブジェクトのxpathメソッド、cssメソッドを通して使います。
例えば、次のようなHTMLを考えます。
<html>
<body>
<h1>記事タイトル</h1>
<p class="summary">これは概要です。</p>
<a href="/next-page">次のページへ</a>
</body>
</html>このHTMLからタイトルや概要を抜き出す例を見てみましょう。
# myproject/myproject/spiders/selector_example_spider.py
import scrapy
class SelectorExampleSpider(scrapy.Spider):
name = "selector_example"
start_urls = [
"https://example.com/sample.html"
]
def parse(self, response):
# XPathを使って<h1>要素のテキストを取得
title_xpath = response.xpath("//h1/text()").get()
# CSSセレクタを使って<p class="summary">のテキストを取得
summary_css = response.css("p.summary::text").get()
# a要素のhref属性をXPathで取得
next_link_xpath = response.xpath("//a/@href").get()
# a要素のhref属性をCSSセレクタで取得(同じ結果になります)
next_link_css = response.css("a::attr(href)").get()
yield {
"title_xpath": title_xpath,
"summary_css": summary_css,
"next_link_xpath": next_link_xpath,
"next_link_css": next_link_css,
}実行結果のイメージ
{
"title_xpath": "記事タイトル",
"summary_css": "これは概要です。",
"next_link_xpath": "/next-page",
"next_link_css": "/next-page"
}XPathは複雑な階層指定や条件指定に強く、CSSセレクタはシンプルで直感的です。
Scrapyでは両方を併用できるため、ページ構造に応じて使い分けるとよいでしょう。
Scrapyでデータを保存する方法
JSON・CSV・SQLiteにスクレイピング結果を書き出す
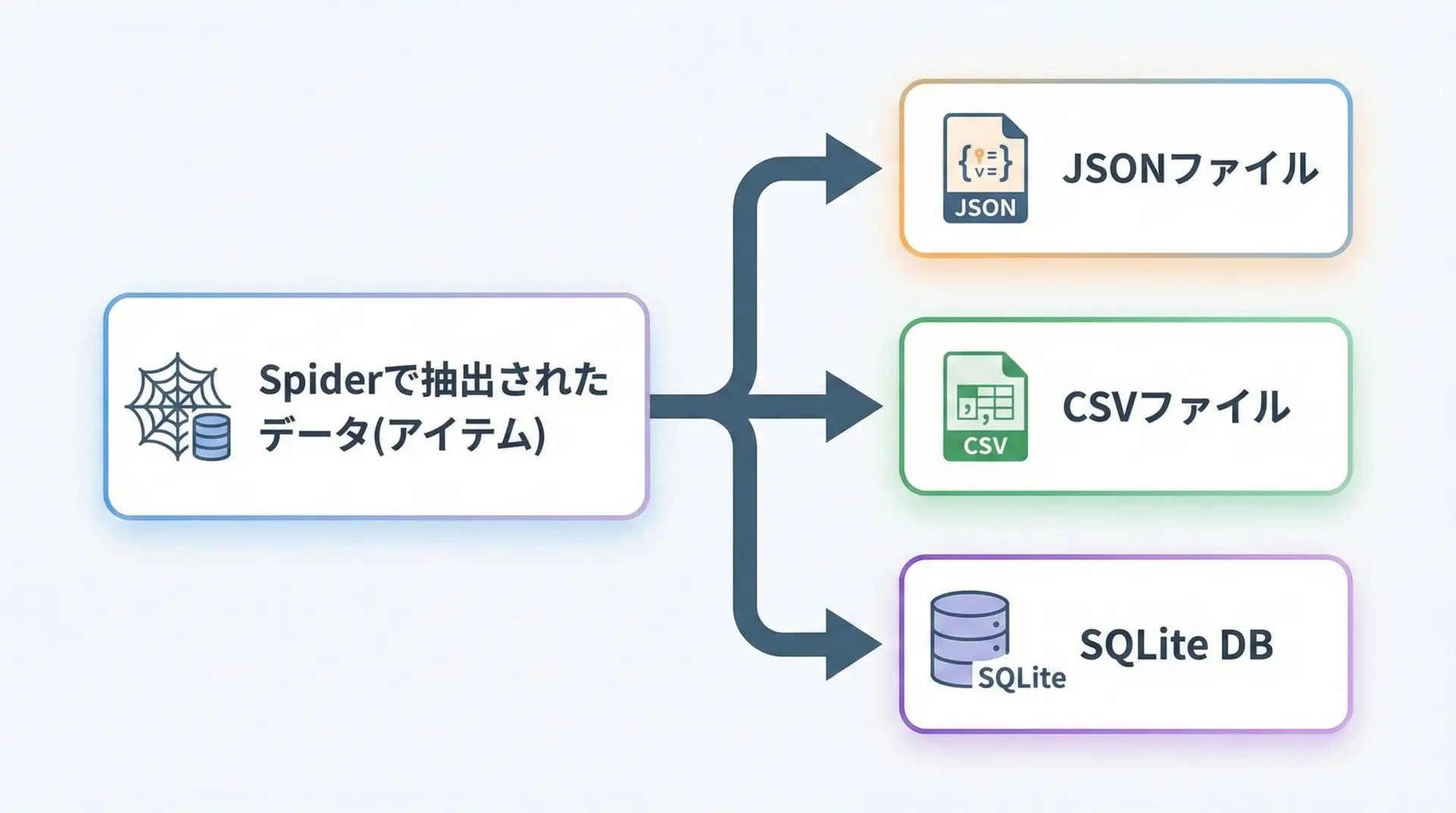
Scrapyで抽出したデータは、コマンドラインオプションを使うことで簡単にファイルへ保存できます。
-oオプションを使うだけで、JSONやCSV形式に出力できるため、最初はこの方法から始めると良いです。
次のようなSpiderを例にします。
# myproject/myproject/spiders/books_spider.py
import scrapy
class BooksSpider(scrapy.Spider):
name = "books"
start_urls = [
"https://example.com/books"
]
def parse(self, response):
# 書籍リストをループで回して情報を抽出するイメージです
for book in response.css("div.book"):
title = book.css("h2.title::text").get()
price = book.css("span.price::text").get()
yield {
"title": title,
"price": price,
}このSpiderを実行しつつ、結果をJSONファイルに保存する場合は次のようにします。
# JSON形式で保存
scrapy crawl books -o books.json
# CSV形式で保存
scrapy crawl books -o books.csvこのとき、Scrapyは出力ファイルの拡張子を見て自動的にフォーマットを判断します。
特別な設定を書かなくても、Spider側でyieldされた辞書がそのまま行やレコードとして保存されます。
SQLiteなどのデータベースに保存したい場合は、Pipelineを使って自分でINSERT処理を書くのが一般的です。
簡単な例を示します。
# myproject/myproject/pipelines.py
import sqlite3
class SQLitePipeline:
def open_spider(self, spider):
"""Spider開始時に呼ばれ、DB接続を開きます。"""
self.connection = sqlite3.connect("books.db")
self.cursor = self.connection.cursor()
# テーブルがなければ作成します
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS books (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
price TEXT
)
""")
def close_spider(self, spider):
"""Spider終了時に呼ばれ、DB接続を閉じます。"""
self.connection.commit()
self.connection.close()
def process_item(self, item, spider):
"""各アイテムごとに呼ばれ、DBに保存します。"""
self.cursor.execute(
"INSERT INTO books (title, price) VALUES (?, ?)",
(item.get("title"), item.get("price"))
)
# 他のPipelineに渡すためにitemを返します
return itemこのPipelineを有効にするには、settings.pyに追記します。
# myproject/myproject/settings.py
ITEM_PIPELINES = {
"myproject.pipelines.SQLitePipeline": 300,
}これで、booksSpiderを実行すると、抽出したデータがbooks.dbというSQLiteファイルに自動で蓄積されます。
FEEDS設定で出力フォーマットを切り替える
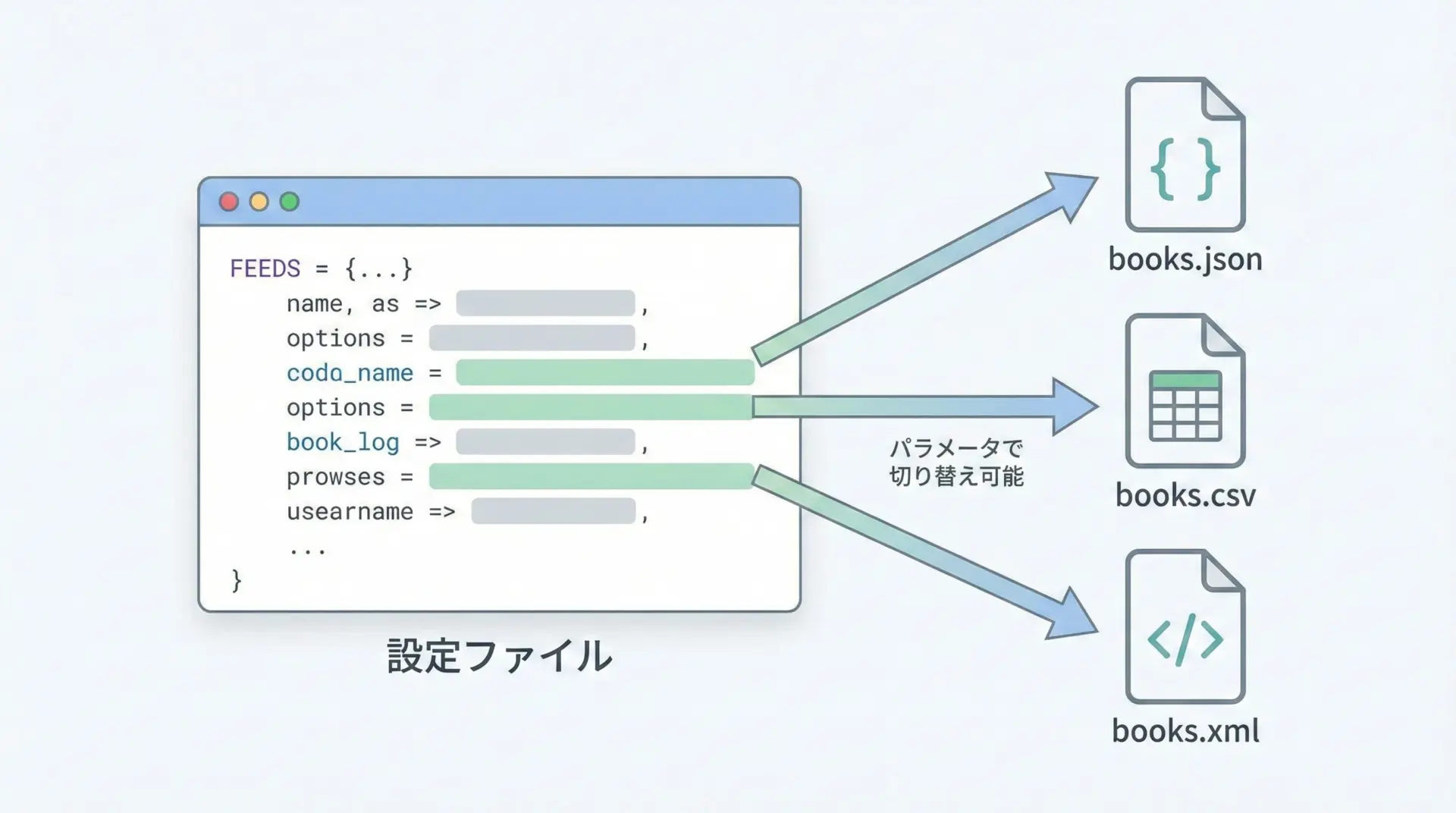
Scrapy 2.x以降では、FEEDS設定を使うことで柔軟な出力制御が可能になりました。
settings.pyにFEEDS辞書を設定することで、どのSpiderを実行しても特定のフォーマット・パスへ出力できるようになります。
例えば、プロジェクト全体でJSON Lines形式のファイルに毎回出力する設定は次のように書けます。
# myproject/myproject/settings.py
FEEDS = {
"output/items.jsonl": {
"format": "jsonlines", # 1行1JSONの形式です
"encoding": "utf8",
"store_empty": False,
"indent": 4,
"overwrite": True, # 実行のたびに上書きします
},
}この状態で通常どおりSpiderを実行すると、output/items.jsonlに自動的に出力されます。
scrapy crawl books複数フォーマットへ同時出力したい場合は、FEEDSに複数のキーを指定します。
FEEDS = {
"output/books.json": {
"format": "json",
"encoding": "utf8",
"indent": 2,
},
"output/books.csv": {
"format": "csv",
"encoding": "utf8",
},
}FEEDS設定を使うと、コマンドラインオプション-oを毎回指定しなくても、一定のルールで結果が保存されるため、運用面での負担を減らすことができます。
実践的なScrapyクローラーの作り方
ページネーションを辿るクローリング処理
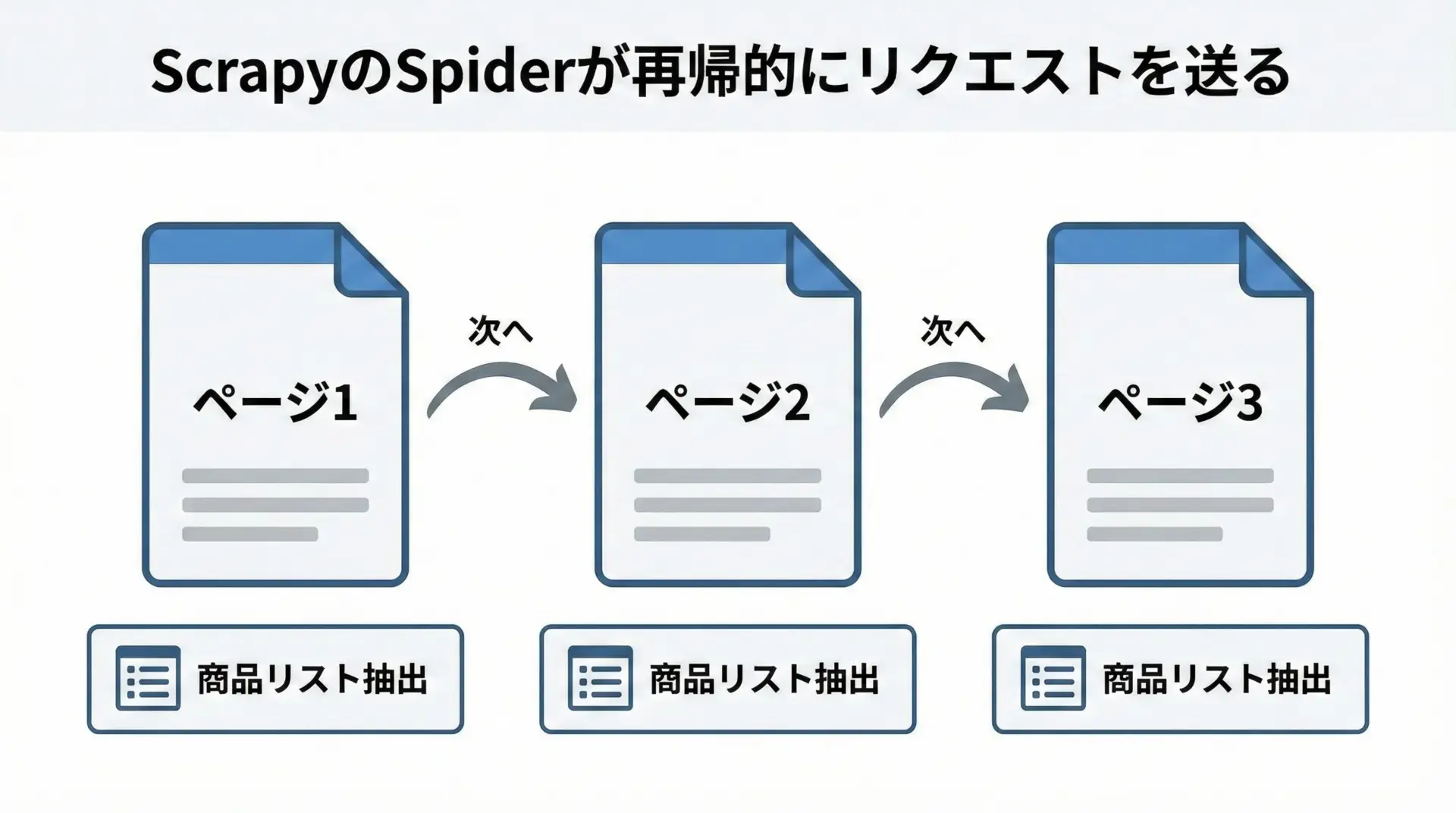
実用的なクローラーでは、1ページ分だけでなく、ページネーションを辿りながら複数ページを巡回する必要があります。
Scrapyでは、次ページのリンクを新しいリクエストとしてyieldすることで実現します。
次の例では、商品リストページを巡回し、各ページの商品のタイトルを取得しながら、ページ下部の「次へ」リンクをたどり続けるSpiderを示します。
# myproject/myproject/spiders/pagination_spider.py
import scrapy
class PaginationSpider(scrapy.Spider):
name = "pagination"
start_urls = [
"https://example.com/products?page=1"
]
def parse(self, response):
"""
商品リストを抽出しつつ、次ページがあればそこへリクエストを送るメソッドです。
"""
# 商品情報を1件ずつ抽出します
for product in response.css("div.product"):
title = product.css("h2.name::text").get()
price = product.css("span.price::text").get()
yield {
"title": title,
"price": price,
"page_url": response.url,
}
# 次ページへのリンクを探します(例: <a class="next" href="...?page=2">次へ)
next_page = response.css("a.next::attr(href)").get()
if next_page:
# 絶対URLに解決するにはresponse.followを利用します
yield response.follow(next_page, callback=self.parse)ポイントは、同じparseメソッドを再帰的に呼ぶようにcallback=self.parseを指定していることです。
これにより、ページネーションを自動で追跡し、最後のページまでクローリングが続きます。
実行結果のイメージ
{"title": "商品A", "price": "1000円", "page_url": "https://example.com/products?page=1"}
{"title": "商品B", "price": "2000円", "page_url": "https://example.com/products?page=1"}
{"title": "商品C", "price": "1500円", "page_url": "https://example.com/products?page=2"}
...リンクをたどるCrawlSpiderとRuleの使い方
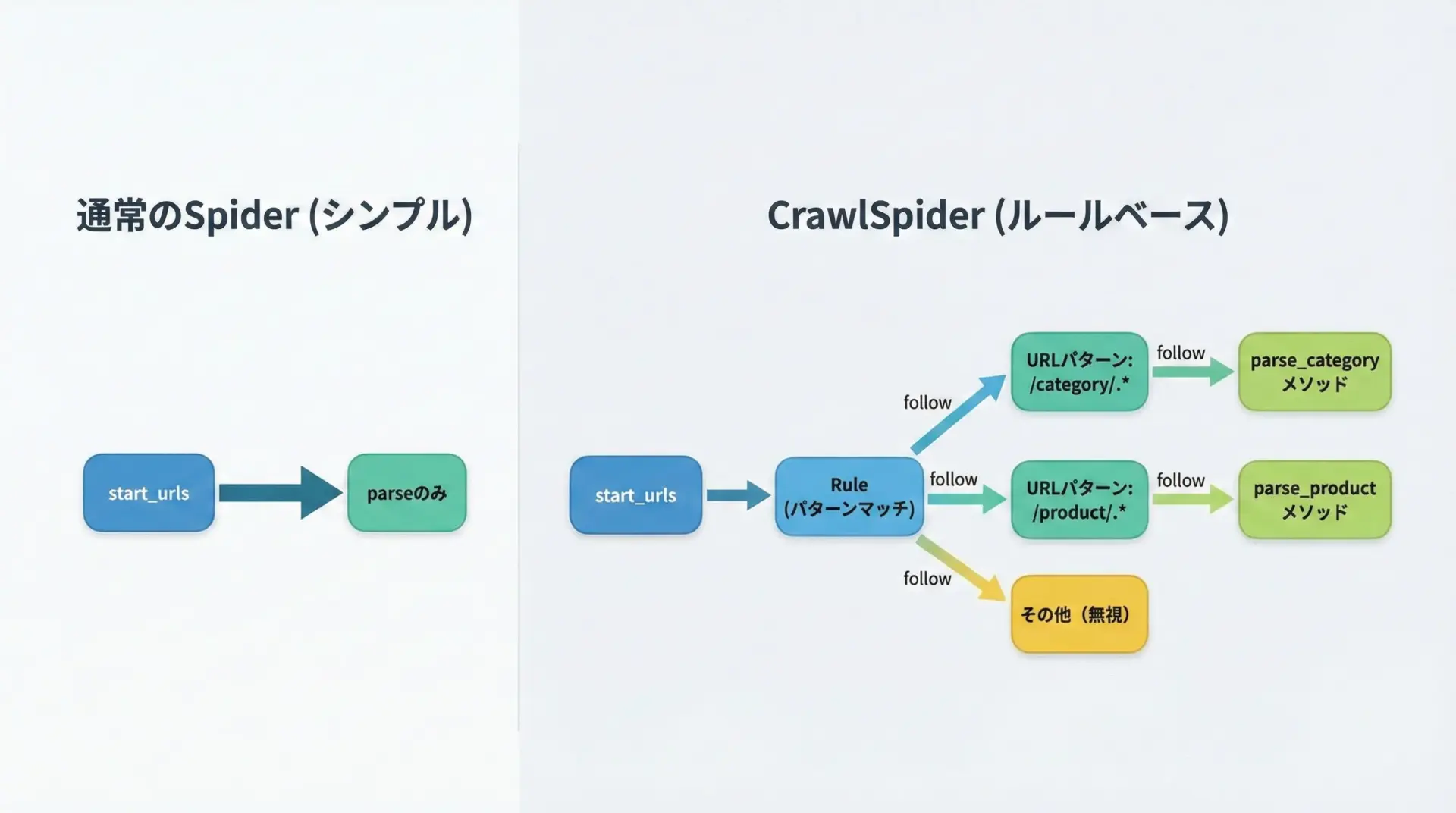
Scrapyには、サイト全体をパターンに従ってクロールするためのCrawlSpiderという便利なクラスが用意されています。
Ruleクラスを使って「どのURLをたどり、どのコールバックで処理するか」を定義できるため、リンク追跡を自分で実装する手間を省けます。
基本的なCrawlSpiderの例を示します。
# myproject/myproject/spiders/crawl_example_spider.py
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class CrawlExampleSpider(CrawlSpider):
name = "crawl_example"
allowed_domains = ["example.com"]
start_urls = [
"https://example.com/"
]
# Ruleのリストで、どのリンクをどのように処理するかを定義します
rules = (
# /category/ を含むURLをたどり、さらにリンクを追跡します
Rule(
LinkExtractor(allow=(r"/category/.*",)),
follow=True
),
# /product/ を含むURLを対象に、parse_productメソッドで処理します
Rule(
LinkExtractor(allow=(r"/product/.*",)),
callback="parse_product",
follow=False
),
)
def parse_product(self, response):
"""
商品詳細ページから情報を抽出するメソッドです。
"""
title = response.css("h1.product-title::text").get()
price = response.css("span.price::text").get()
yield {
"url": response.url,
"title": title,
"price": price,
}このSpiderでは、/category/を含むURLをたどり続け、/product/を含むURLではparse_productが呼び出されて商品情報を抽出します。
サイト構造がある程度ルール化されている場合、CrawlSpiderを使うとURL収集ロジックを簡潔に書けます。
Scrapy設定でクローラーを最適化する
DOWNLOAD_DELAYなどでアクセスマナーを守る

Scrapyは標準で高速なクローリングが可能ですが、そのままの設定で大量のリクエストを送ると、相手サーバーに負荷をかける恐れがあります。
DOWNLOAD_DELAYなどの設定を活用し、アクセスマナーを守ることが重要です。
代表的な設定項目をsettings.pyで調整してみましょう。
# myproject/myproject/settings.py
# ダウンロード間隔(秒)を設定します。例では1秒おきにリクエストを送ります。
DOWNLOAD_DELAY = 1.0
# 同時に開くリクエストの最大数です(全ドメイン合計)。
CONCURRENT_REQUESTS = 8
# 同一ドメインに対する同時リクエスト数です。
CONCURRENT_REQUESTS_PER_DOMAIN = 4
# 自動スロットリング機能を有効にすると、サーバーの応答速度に応じて
# リクエスト間隔を自動調整してくれます。
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 1.0
AUTOTHROTTLE_MAX_DELAY = 10.0
AUTOTHROTTLE_TARGET_CONCURRENCY = 2.0DOWNLOAD_DELAYを適切に設定し、必要に応じてAUTOTHROTTLEを有効にすることで、サーバーに優しいクローリングが可能になります。
アクセス過多によるブロックやトラブルを避けるためにも、これらの設定は意識的に調整しましょう。
USER_AGENTやROBOTSTXT_OBEYのおすすめ設定
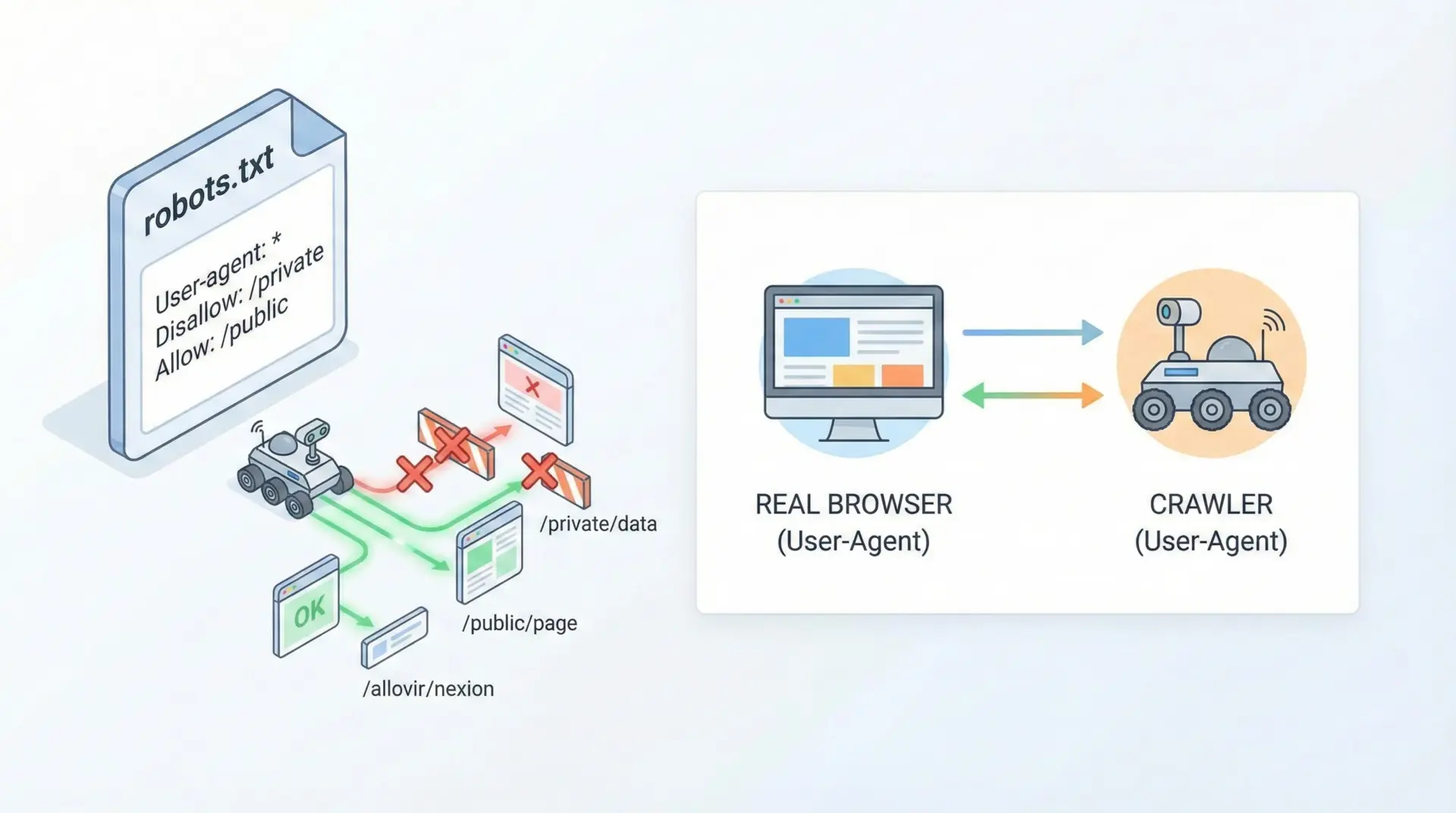
ScrapyはデフォルトでROBOTSTXT_OBEY = Trueになっており、robots.txtの指示に従う設定になっています。
これはマナーおよび法的リスクを考えても基本的に有効のままにすべきです。
# myproject/myproject/settings.py
# robots.txtのルールに従うかどうか
ROBOTSTXT_OBEY = Trueまた、USER_AGENTをデフォルトのままにしておくと、サイト側からはScrapyのクローラーであることが明確にわかります。
多くの場合でも問題ありませんが、自分のサイト名や連絡先を含んだUSER_AGENTを設定するのがより望ましいと言えます。
# myproject/myproject/settings.py
USER_AGENT = "MyScrapyBot/1.0 (+https://your-site.example.com/)"相手サイトの利用規約やrobots.txtを確認し、それに従った設定にすることが重要です。
無断での大量取得や禁止されたパスへのアクセスは避けなければなりません。
エラー対策とデバッグのコツ
HTTPエラー・タイムアウト時のリトライ設定
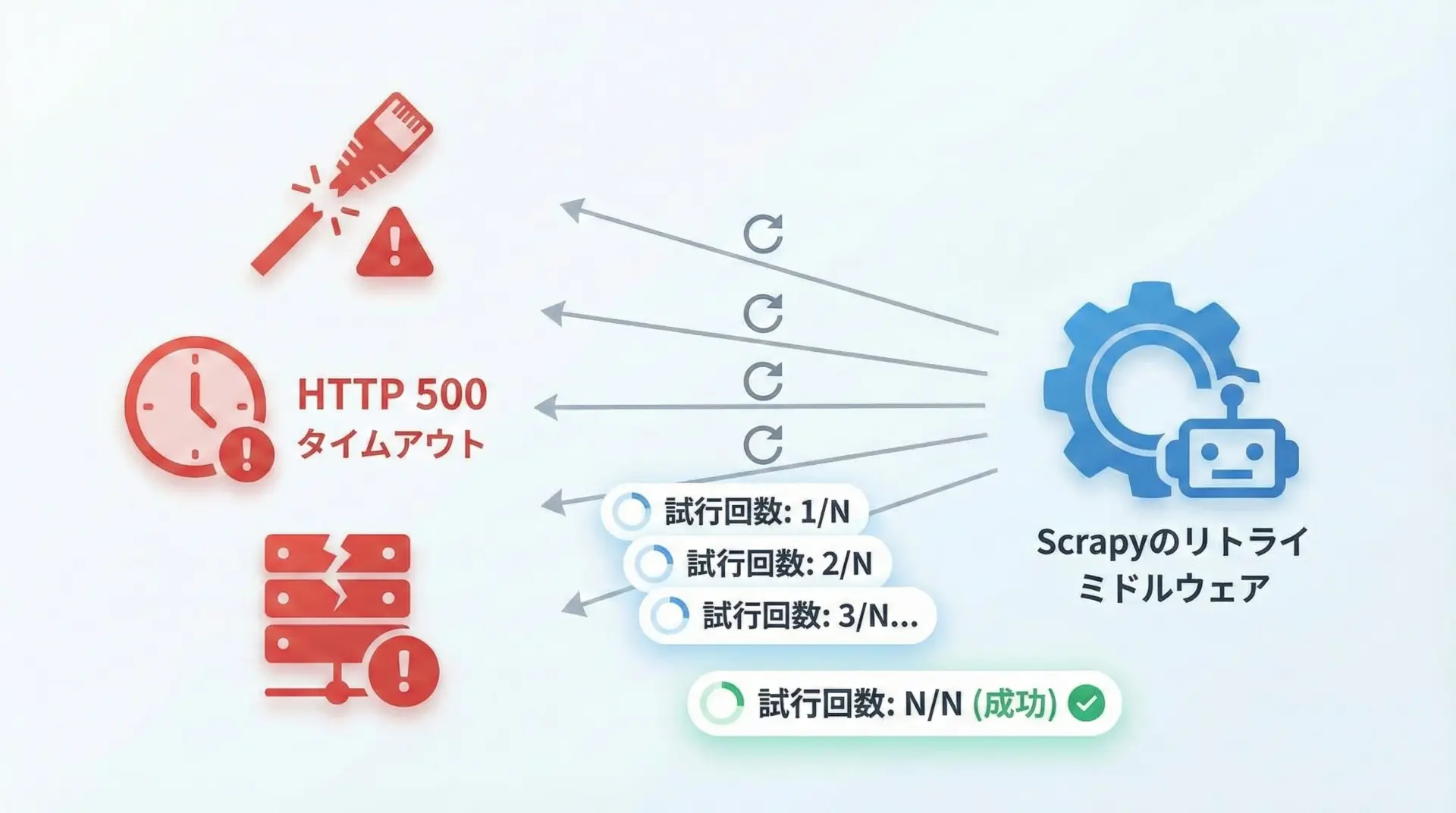
クローリングを行っていると、HTTP 500エラーやタイムアウトなど、さまざまなエラーに遭遇します。
ScrapyにはRetryMiddlewareという標準機能があり、自動的に再試行してくれますが、settings.pyで制御することもできます。
# myproject/myproject/settings.py
# リトライ回数(デフォルトは2回)を増やす
RETRY_TIMES = 3
# リトライ対象とするHTTPステータスコードの例
RETRY_HTTP_CODES = [500, 502, 503, 504, 522, 524, 408]
# ダウンロードタイムアウト時間(秒)の設定
DOWNLOAD_TIMEOUT = 15さらに、必要であれば自作のミドルウェアを追加し、特定のエラー時だけ別の処理を行うこともできます。
ただし、エラーが頻発する場合はサイト側に負荷がかかっている可能性もあるため、リトライ回数を極端に増やすのは避けるべきです。
scrapy shellでセレクタを素早く検証する
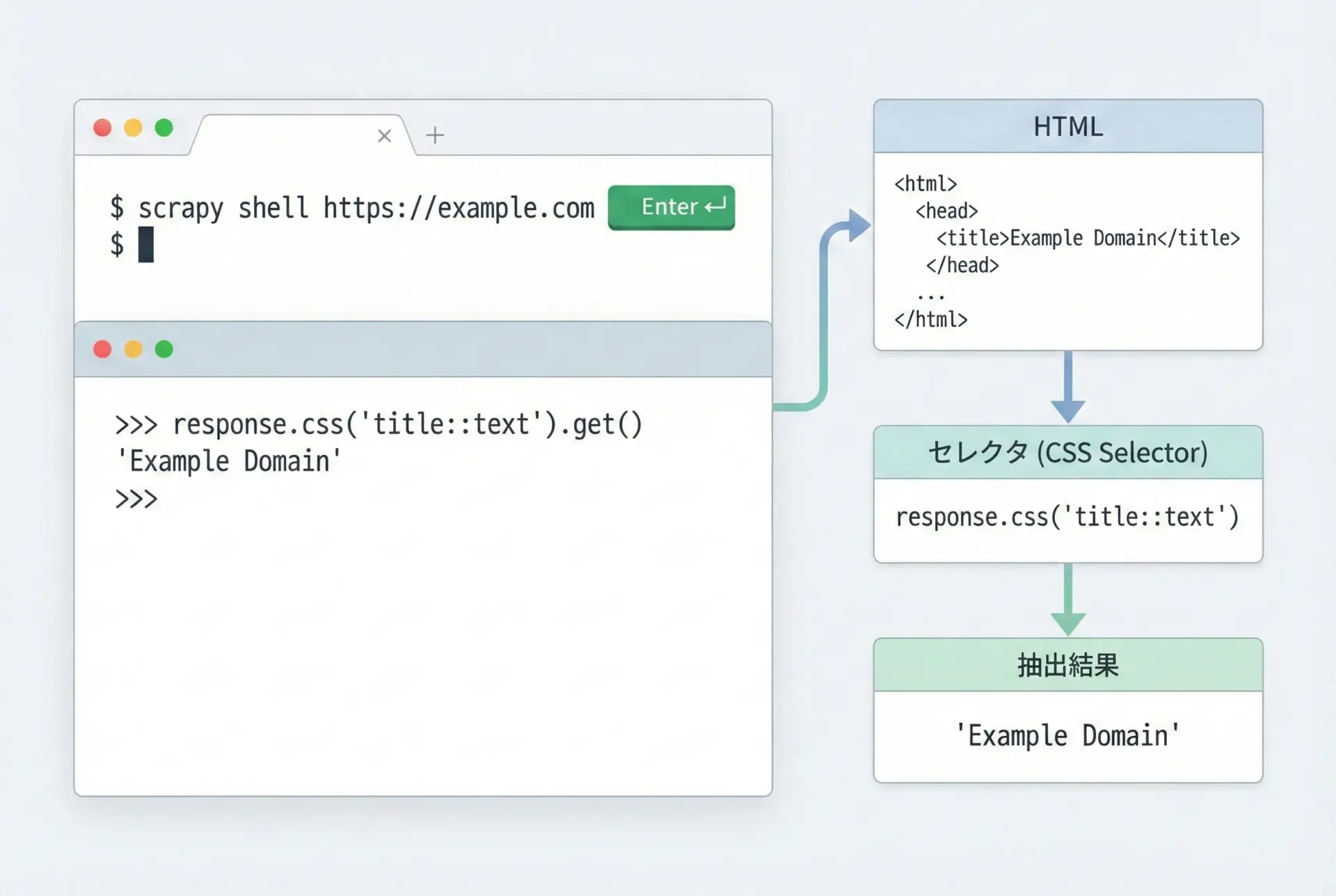
Spiderを書いているときに最もよく行う作業の1つが、「このCSSセレクタやXPathで本当に欲しい要素が取れるか?」の検証です。
Scrapyはscrapy shellという強力な対話型デバッグツールを提供しており、これを使うとブラウザの開発者ツール感覚でセレクタを試せます。
次のようにコマンドを実行します。
# 任意のURLでScrapyシェルを開く
scrapy shell "https://example.com/"シェルが立ち上がると、responseオブジェクトがすでに用意されています。
これに対してXPathやCSSセレクタを試してみます。
# ページタイトルの取得
response.xpath("//title/text()").get()
# 見出しリストを取得
response.css("h2::text").getall()
# 特定のクラスを持つ要素
response.css("div.article .summary::text").get()scrapy shellでセレクタを確かめてからSpiderに組み込むことで、試行錯誤の時間を大幅に短縮できます。
HTML構造を確認しながら、正しいパスやクラス名を使えているかを細かく検証しましょう。
まとめ
この記事では、PythonのScrapyフレームワークを使って最速で実用的なクローラーを構築するための基礎を解説しました。
インストールと仮想環境の準備から始まり、プロジェクト構造、Spiderクラスの基本、XPath・CSSセレクタによる要素抽出、JSON/CSV/SQLiteへの保存方法、ページネーションやCrawlSpiderによるリンク追跡、DOWNLOAD_DELAYなどのマナー設定、さらにリトライやscrapy shellを使ったデバッグまで、一通りの流れを押さえました。
あとは実際のターゲットサイトに合わせてSpiderを少しずつ改良していくことで、自分専用の強力なクローラーを育てていくことができます。
