
Pythonのコードは、ちょっとした工夫でテストしやすさが大きく変わります。
テストしやすいコードはバグが混入しにくく、リファクタリングもしやすく、チーム開発にも向いています。
本記事では、Pythonで「テストしやすいコード」を書くための設計原則15選と、Pythonならではのテクニック、そして既存コードを改善する実践パターンまで、図解とサンプルコードを交えながら詳しく解説します。
- テストしやすいPythonコードとは
- Pythonで意識したい設計原則15選
- 原則1 単一責任原則(SRP)で関数を小さく保つ
- 原則2 オープン・クローズド原則(OCP)で変更に強くする
- 原則3 依存関係逆転の原則(DIP)でテスト可能にする
- 原則4 インターフェイス分離原則(ISP)でモックを簡単にする
- 原則5 DRY原則でテストコードの重複も減らす
- 原則6 KISS原則でテストしやすいシンプルな設計にする
- 原則7 YAGNI原則で不要なテスト対象を増やさない
- 原則8 早期リターンで分岐とテストケースを整理する
- 原則9 副作用を減らし純粋関数を増やす
- 原則10 グローバル変数とシングルトンを避ける
- 原則11 小さなモジュールとパッケージに分割する
- 原則12 コンストラクタインジェクションで依存を差し替える
- 原則13 設定値とロジックを分離する
- 原則14 境界づけられたコンテキストで責務を分割する
- 原則15 エラーハンドリングを明示してテスト可能にする
- Pythonならではのテスト容易性テクニック
- テストしやすいコードを書くための実践パターン
- まとめ
テストしやすいPythonコードとは
「テストしやすいコード」の定義とメリット
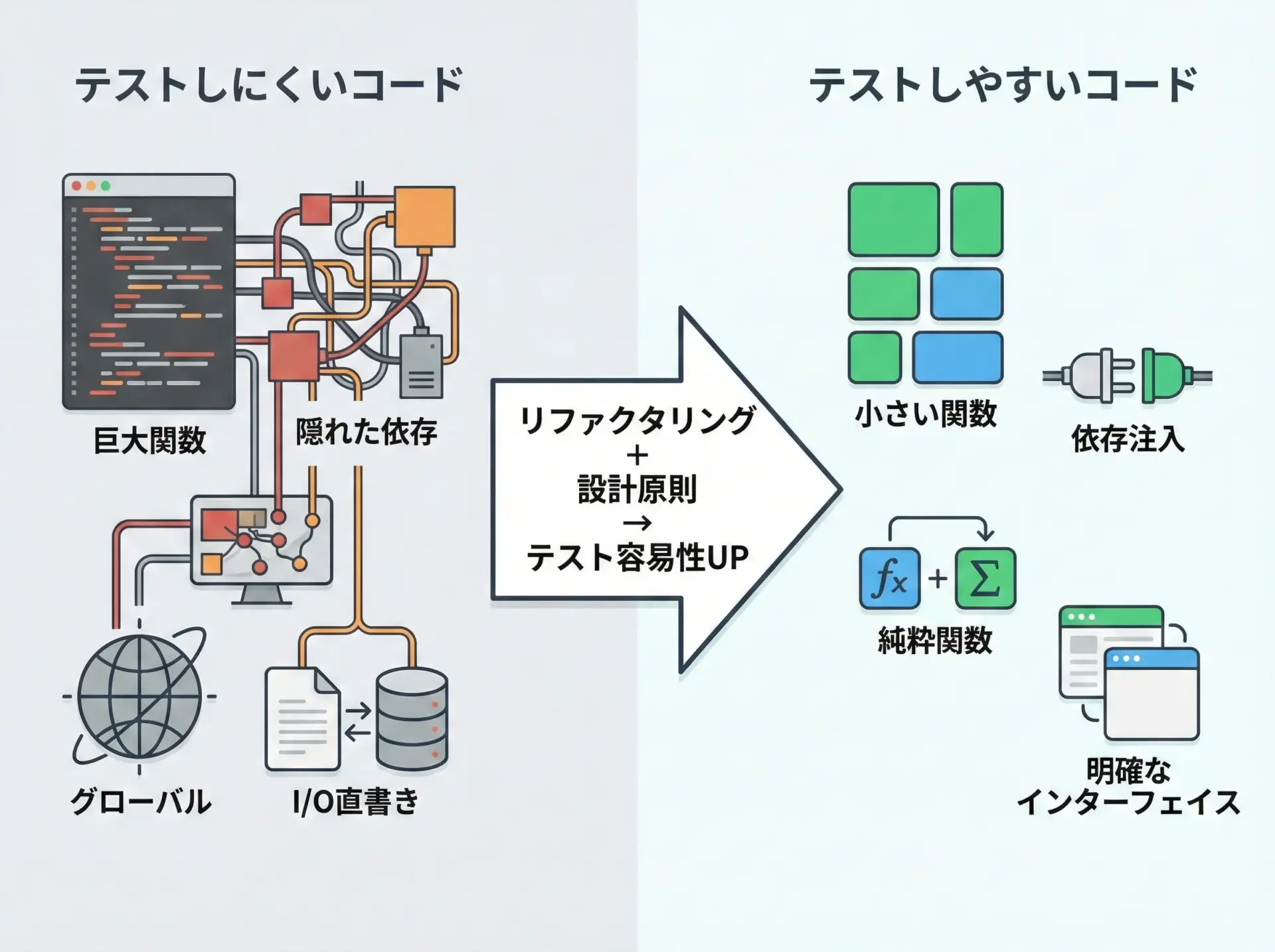
テストしやすいコードとは、簡単にユニットテストを書けて、かつテストの保守もしやすいコードのことです。
もう少し具体的に言うと、以下のような特徴を持つコードを指します。
- 関数やメソッドが小さく、入力と出力が明確であること
- 外部サービスやDBなどの依存を、差し替えしやすい形で扱っていること
- 副作用(ファイル書き込み、ネットワーク通信、グローバル状態の変更など)が最小限で、局所化されていること
- エラーハンドリングの方針が一貫しており、例外パターンもテストで確認しやすいこと
これらを満たしていると、以下のようなメリットが得られます。
- バグを早期に検出できる
- 仕様変更やリファクタリングを安心して行える
- テストコードも読みやすく・書きやすくなり、チーム全体の生産性が向上する
特に長く運用されるシステムほど、テストしやすさは開発スピードに直結します。
Pythonのユニットテストと設計原則の関係
Pythonではunittestやpytestといったテストフレームワークが広く使われていますが、フレームワーク自体はあくまで「テストを書くための道具」にすぎません。
テストが書きやすいかどうかは、次の順番で決まってきます。
- 設計原則が守られているかどうか
- その設計をコードにどう反映しているか
- それを前提に、どのテストフレームワークをどう使うか
設計が悪いコードに、どれだけ高機能なテストフレームワークを導入しても、テストはつらいままです。
そのため、本記事ではテストフレームワークの詳細よりも、テスト容易性を高める設計原則にフォーカスします。
テスト容易性を高める基本スタンス
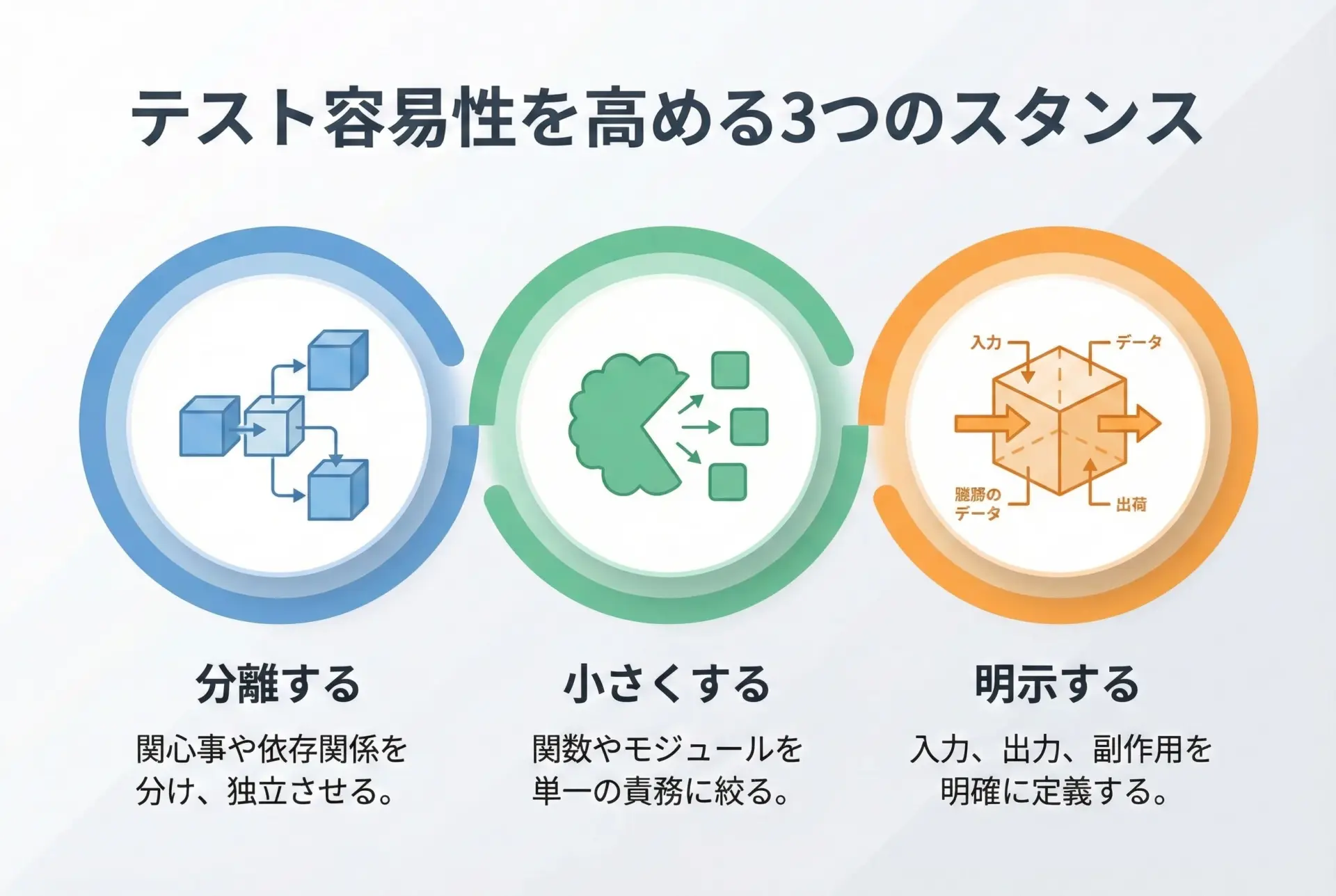
テストしやすいコードを書くためには、日常のコーディングで以下のスタンスを意識しておくと役立ちます。
1つ目は「分離する」ことです。
ビジネスロジックとI/O処理、設定値とロジック、外部サービスとの通信とドメインロジックなどを分けることで、それぞれを個別にテストできるようになります。
2つ目は「小さくする」ことです。
巨大な関数やクラスは、テストケースの組み合わせが爆発しやすくなります。
小さい単位に分解するほど、1つひとつのテストがシンプルになります。
3つ目は「明示する」ことです。
関数の入力・出力・例外・副作用・依存関係などを、暗黙ではなく明示することで、テストで何を確認すべきかが明確になります。
Pythonで意識したい設計原則15選
ここからは、テスト容易性に特に効いてくる設計原則を15個に整理して、Pythonの具体例とともに解説します。
原則1 単一責任原則(SRP)で関数を小さく保つ
単一責任原則(SRP)とは
単一責任原則(Single Responsibility Principle)とは、「モジュール(クラス・関数・ファイル)は、たった1つの理由でのみ変更されるべき」という原則です。
テスト容易性の観点では、1つの関数が1つのことだけを行っていると、テストケースの設計が簡単になります。
悪い例: 一つの関数が色々やりすぎ
def process_and_save_user(raw_data: dict, db):
# 1. バリデーション
if "name" not in raw_data or not raw_data["name"]:
raise ValueError("name is required")
if "age" not in raw_data or raw_data["age"] < 0:
raise ValueError("age must be non-negative")
# 2. ドメインロジック(年齢区分)
if raw_data["age"] >= 20:
category = "adult"
else:
category = "child"
# 3. DB保存
db.insert_user(name=raw_data["name"], age=raw_data["age"], category=category)
# 4. ログ出力
print(f"Saved user: {raw_data['name']} ({category})")この関数は、バリデーション、ドメインロジック、DB保存、ログ出力をすべて1つに詰め込んでいます。
テストを書くときも、正常系・異常系・DBエラー・ログ確認などが混ざり合い、テストが複雑になってしまいます。
良い例: 責務を分けてテスト対象を明確にする
from dataclasses import dataclass
@dataclass
class User:
name: str
age: int
category: str
def validate_user_data(raw_data: dict) -> None:
"""入力データのバリデーションのみを行う関数"""
if "name" not in raw_data or not raw_data["name"]:
raise ValueError("name is required")
if "age" not in raw_data or raw_data["age"] < 0:
raise ValueError("age must be non-negative")
def classify_user(age: int) -> str:
"""年齢からカテゴリーを判定する純粋関数"""
return "adult" if age >= 20 else "child"
def build_user(raw_data: dict) -> User:
"""バリデーションと分類を組み合わせてUserを生成する"""
validate_user_data(raw_data)
category = classify_user(raw_data["age"])
return User(
name=raw_data["name"],
age=raw_data["age"],
category=category,
)
def save_user(user: User, db) -> None:
"""DB保存のみを行う関数"""
db.insert_user(name=user.name, age=user.age, category=user.category)
def process_and_save_user(raw_data: dict, db) -> User:
"""オーケストレーション担当(高レベルの流れだけ)"""
user = build_user(raw_data)
save_user(user, db)
print(f"Saved user: {user.name} ({user.category})")
return userこのように分けることで、例えばclassify_userは純粋関数として、DBもログも関係なくテストできます。
SRPを意識して関数を小さく保つことは、テストしやすさに直結する最重要原則です。
原則2 オープン・クローズド原則(OCP)で変更に強くする
OCPとは何か
オープン・クローズド原則(Open/Closed Principle)は、「ソフトウェアのエンティティは拡張に対して開いており、修正に対して閉じているべき」と言われる原則です。
新しい機能を追加するとき、既存のコードを最小限しか変更しなくて済むように設計する、という考え方です。
if文だらけの分岐はテストがつらくなる
def calculate_discount(user_type: str, price: int) -> int:
if user_type == "normal":
return price
elif user_type == "member":
return int(price * 0.9)
elif user_type == "vip":
return int(price * 0.8)
# 新しい区分が増えるたびにここにelifを足す必要がある新しいユーザー区分が増えるたびにこの関数を修正する必要があります。
それに合わせてテストも更新しなければならず、変更の影響範囲が広がります。
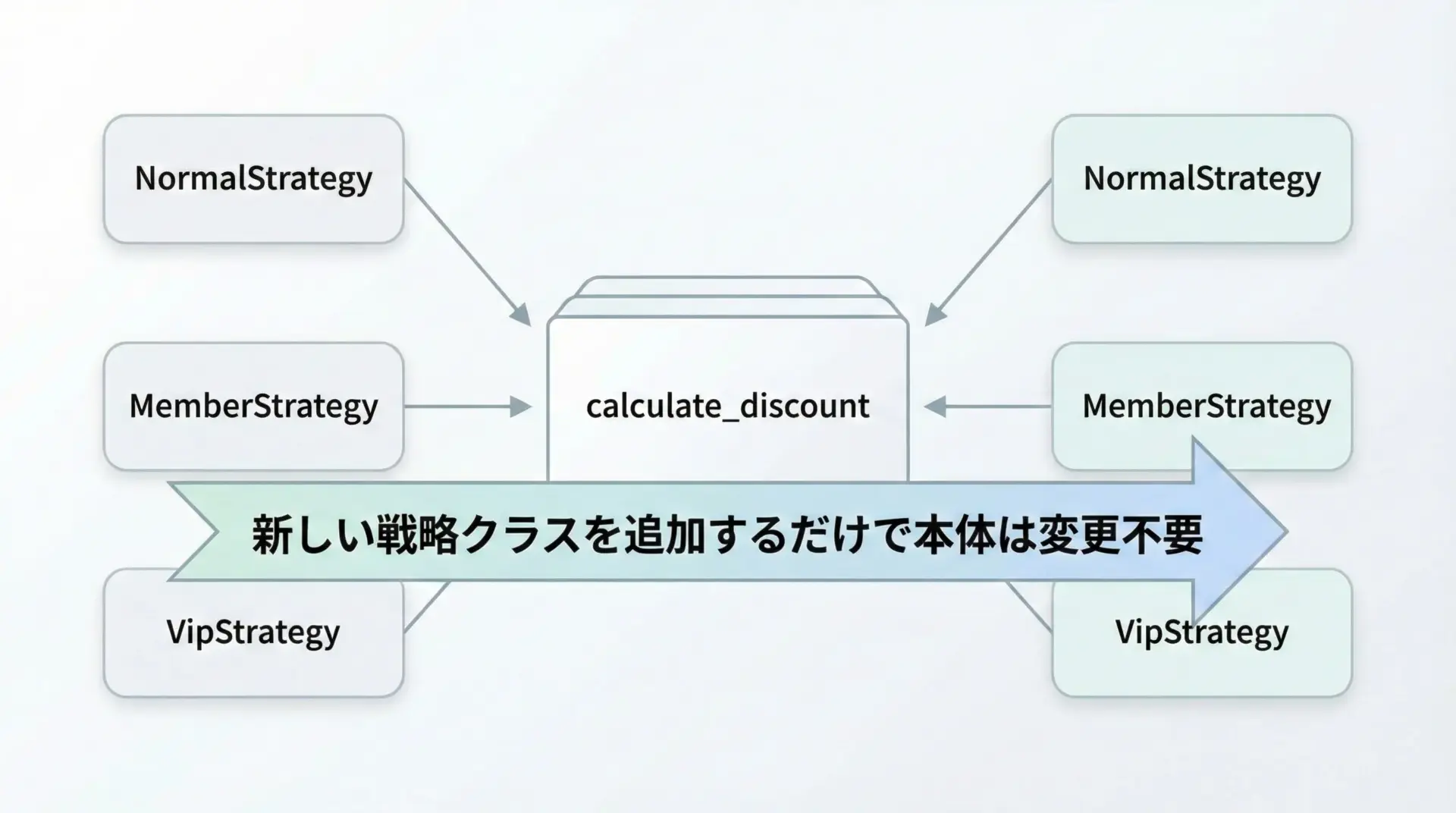
戦略パターンでOCPを満たす設計にする
from abc import ABC, abstractmethod
from typing import Protocol
class DiscountStrategy(Protocol):
def apply(self, price: int) -> int:
...
class NormalDiscount:
def apply(self, price: int) -> int:
return price
class MemberDiscount:
def apply(self, price: int) -> int:
return int(price * 0.9)
class VipDiscount:
def apply(self, price: int) -> int:
return int(price * 0.8)
def calculate_discount(price: int, strategy: DiscountStrategy) -> int:
"""戦略(依存)を注入することでOCPを満たす"""
return strategy.apply(price)この形にしておけば、新しい割引戦略を追加したいときは、新しいクラスを1つ追加するだけで済みます。
本体ロジック(ここではcalculate_discount)を変更しない設計は、テストの変更範囲も小さく抑えられるという意味で、テスト容易性に貢献します。
原則3 依存関係逆転の原則(DIP)でテスト可能にする
DIPのポイント
依存関係逆転の原則(Dependency Inversion Principle)は、「高レベルモジュールは低レベルモジュールに依存せず、抽象に依存すべき」という原則です。
テスト容易性において重要なのは、具体的な実装(例えば実際のDBクライアント)に直接依存するとテストが困難になるという点です。
悪い例: 具体クラスにべったり依存
import requests
def fetch_user_name(user_id: int) -> str:
# HTTPクライアントを直接呼び出している
resp = requests.get(f"https://api.example.com/users/{user_id}")
resp.raise_for_status()
return resp.json()["name"]この関数をテストしようとすると、実際のHTTP通信が発生してしまいます。
モンキーパッチやパッチデコレータでも対処はできますが、依存を注入した方がシンプルになります。
良い例: 抽象に依存して差し替え可能にする
from typing import Protocol
class HttpClient(Protocol):
def get(self, url: str) -> dict:
...
class RequestsHttpClient:
"""実運用時に使う実装"""
def get(self, url: str) -> dict:
import requests # 遅延インポートで依存を局所化
resp = requests.get(url)
resp.raise_for_status()
return resp.json()
def fetch_user_name(user_id: int, client: HttpClient) -> str:
"""抽象(Protocol)に依存させる"""
data = client.get(f"https://api.example.com/users/{user_id}")
return data["name"]テスト時には、HttpClientを満たすモッククラスを渡します。
class FakeHttpClient:
def __init__(self, responses: dict[int, dict]):
self._responses = responses
def get(self, url: str) -> dict:
# 非常に単純なURLパース(サンプルのため)
user_id = int(url.rstrip("/").split("/")[-1])
return self._responses[user_id]
def test_fetch_user_name():
client = FakeHttpClient({1: {"name": "Alice"}})
assert fetch_user_name(1, client) == "Alice"依存を抽象化し注入することで、外部サービスに依存しないユニットテストが書けるようになります。
原則4 インターフェイス分離原則(ISP)でモックを簡単にする
ISPとは
インターフェイス分離原則(Interface Segregation Principle)は、「クライアントは自分が利用しないメソッドへの依存を強制されるべきではない」という原則です。
Pythonではクラスのメソッドが多すぎると、テスト用のモックやスタブを書くときに不要なメソッドまで実装しなければならなくなり、テストが重くなります。
悪い例: 何でも入りの巨大リポジトリ
class UserRepository:
def find_by_id(self, user_id: int):
...
def find_all(self):
...
def save(self, user):
...
def delete(self, user_id: int):
...
def count(self):
...
# 他にも多数のメソッド...あるユースケースではfind_by_idしか使わないのに、テストでモックを作ろうとすると不要なメソッドも用意する必要が出てくるかもしれません。
良い例: 必要なメソッドだけを持つインターフェイスに分割
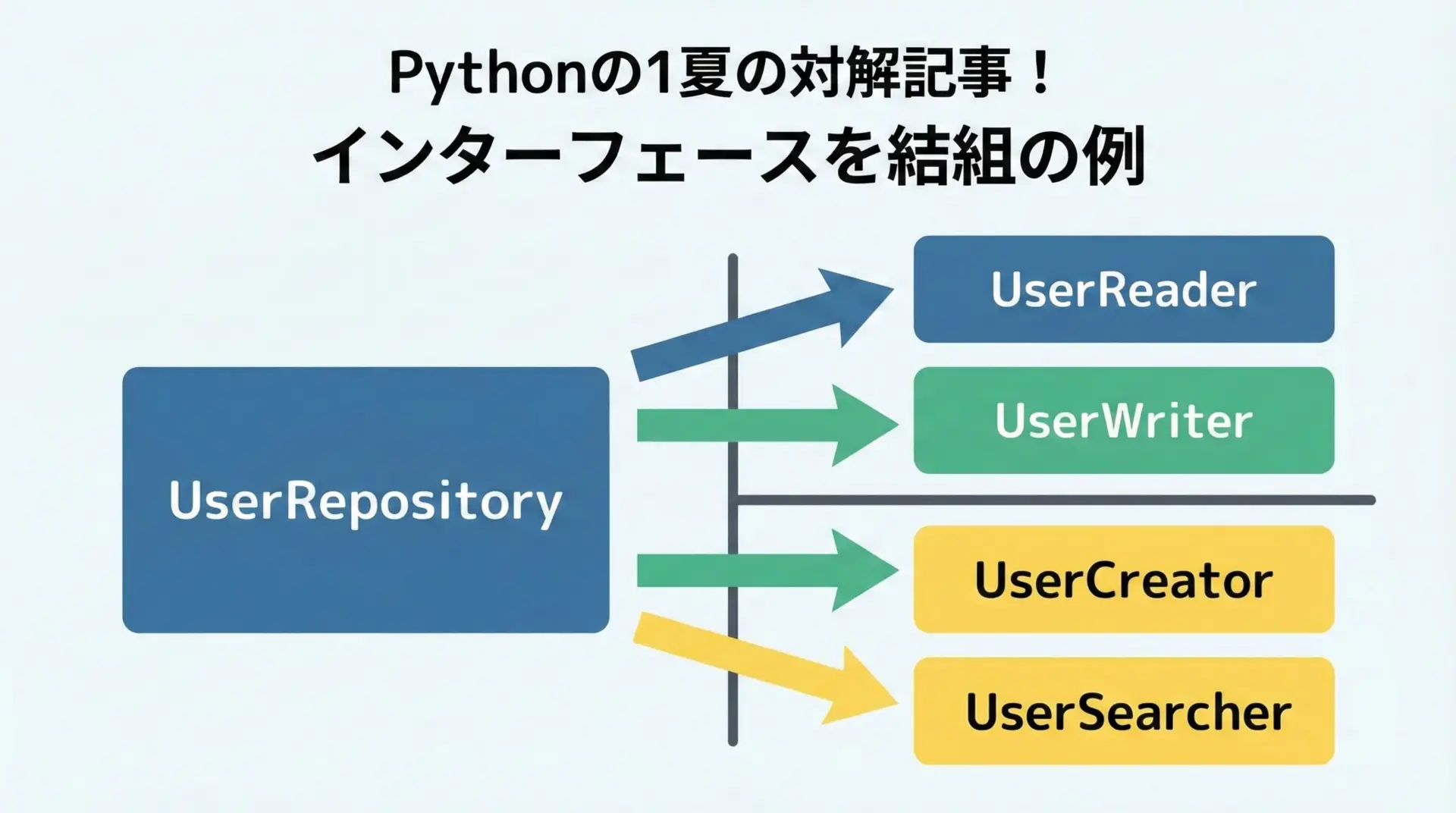
from typing import Protocol, Iterable
class UserReader(Protocol):
def find_by_id(self, user_id: int):
...
def find_all(self) -> Iterable:
...
class UserWriter(Protocol):
def save(self, user) -> None:
...
def delete(self, user_id: int) -> None:
...
class SqlUserRepository(UserReader, UserWriter):
"""実装クラスは複数のProtocolを実装してもよい"""
...読み取り専用のユースケースではUserReaderだけを依存として受け取り、書き込みユースケースではUserWriterだけを受け取ることで、モック実装も単純になります。
小さなインターフェイスは、小さなモックで済むため、テストの準備コードを大幅に削減できます。
原則5 DRY原則でテストコードの重複も減らす
DRY原則の対象はテストコードも含まれる
DRY(Don’t Repeat Yourself)原則は、「同じ知識を複数箇所に重複させない」という原則です。
本番コードだけでなく、テストコードにもDRYを適用することで、テストの保守性が高まります。
悪い例: 似たテストケースがコピペだらけ
def test_discount_normal():
price = 1000
result = calculate_discount("normal", price)
assert result == 1000
def test_discount_member():
price = 1000
result = calculate_discount("member", price)
assert result == 900
def test_discount_vip():
price = 1000
result = calculate_discount("vip", price)
assert result == 800入力パターンだけが違うテストがコピペされており、テストの意図が重複しています。
良い例: パラメタライズやヘルパーで知識を集約
import pytest
@pytest.mark.parametrize(
"user_type, price, expected",
[
("normal", 1000, 1000),
("member", 1000, 900),
("vip", 1000, 800),
],
)
def test_discount(user_type, price, expected):
assert calculate_discount(user_type, price) == expectedこのように1つのテスト関数でテーブル駆動テストにまとめると、仕様の一覧性が高まり、追加パターンにも強いテストになります。
原則6 KISS原則でテストしやすいシンプルな設計にする
KISS原則とは
KISS(Keep It Simple, Stupid)原則は、「設計は可能な限りシンプルであるべき」という原則です。
複雑な抽象化や汎用化は一見「かっこよく」見えますが、多くの場合テストを難しくします。
過剰な抽象化はテスト容易性を下げる
例えば、何でもかんでもメタプログラミングやリフレクションを多用したり、汎用すぎるフレームワーク的クラスを自作したりすると、テストが「内部構造依存」になりがちです。
Pythonではまずは素直な関数とデータクラスで書き、必要になったら抽象化を検討するスタイルの方が、テストもしやすく管理しやすいです。
原則7 YAGNI原則で不要なテスト対象を増やさない
YAGNI(You Aren’t Gonna Need It)は、「必要になるまで実装しない」という原則です。
将来必要になりそうだからといって先回りして機能を実装すると、その機能にもテストを書かねばならなくなり、テスト対象が増えてしまいます。
テスト容易性の観点では、今、必要な機能だけを実装し、そのテストだけを書くことが結果的に全体のシンプルさを保ちます。
不要な拡張ポイントや未使用のオプションを最初から仕込まないことが、大量のテストケース追加を防ぎます。
原則8 早期リターンで分岐とテストケースを整理する
ネストが深いとテストパターンが見えにくい
def process(value: int) -> int:
if value >= 0:
if value % 2 == 0:
# いろいろ処理...
return value * 2
else:
# 別の処理...
return value * 3
else:
# エラー処理...
raise ValueErrorifのネストが深くなると、どのパスをテストすべきかが一目で分かりにくくなります。
早期リターンでパスを分かりやすくする
def process(value: int) -> int:
if value < 0:
raise ValueError("value must be non-negative")
if value % 2 == 0:
return value * 2
return value * 3このように早期リターンを活用して分岐パスを平坦にすると、テストすべき分岐が目で追いやすくなり、テストケースの漏れも減ります。
原則9 副作用を減らし純粋関数を増やす

純粋関数とは、「同じ入力に対して必ず同じ出力を返し、副作用がない関数」のことです。
純粋関数は、テストにおいて次のような利点があります。
- 外部環境に依存せず、単純な入力と出力だけ確認すればよい
- 並列実行やプロパティベーステストとも相性が良い
- 失敗したときに原因を特定しやすい
可能な限りロジックを純粋関数として切り出し、外部I/Oは別の薄い層にまとめることで、テスト対象を明確に分離できます。
原則10 グローバル変数とシングルトンを避ける
グローバル変数やシングルトンは、テスト時に状態がテストケース間で共有されてしまうため、テストが順序依存になりがちです。
# 悪い例
cache = {}
def get_from_cache(key: str):
return cache.get(key)
def set_to_cache(key: str, value: str):
cache[key] = valueこの場合、あるテストがキャッシュを変更すると、別のテストに影響が出ます。
代わりに、状態を持つオブジェクトを作り、そのインスタンスを必要な箇所に渡す形にします。
class Cache:
def __init__(self):
self._data: dict[str, str] = {}
def get(self, key: str) -> str | None:
return self._data.get(key)
def set(self, key: str, value: str) -> None:
self._data[key] = valueテストではCache()をテストごとに新しく生成することで、テストの独立性を保てます。
原則11 小さなモジュールとパッケージに分割する
巨大な1ファイルに多くのクラスや関数が詰め込まれていると、どこをテストすべきか見通しが悪くなります。
Pythonではファイルとパッケージ単位で責務を分割し、テストも同じ構造で並行に配置すると理解しやすくなります。
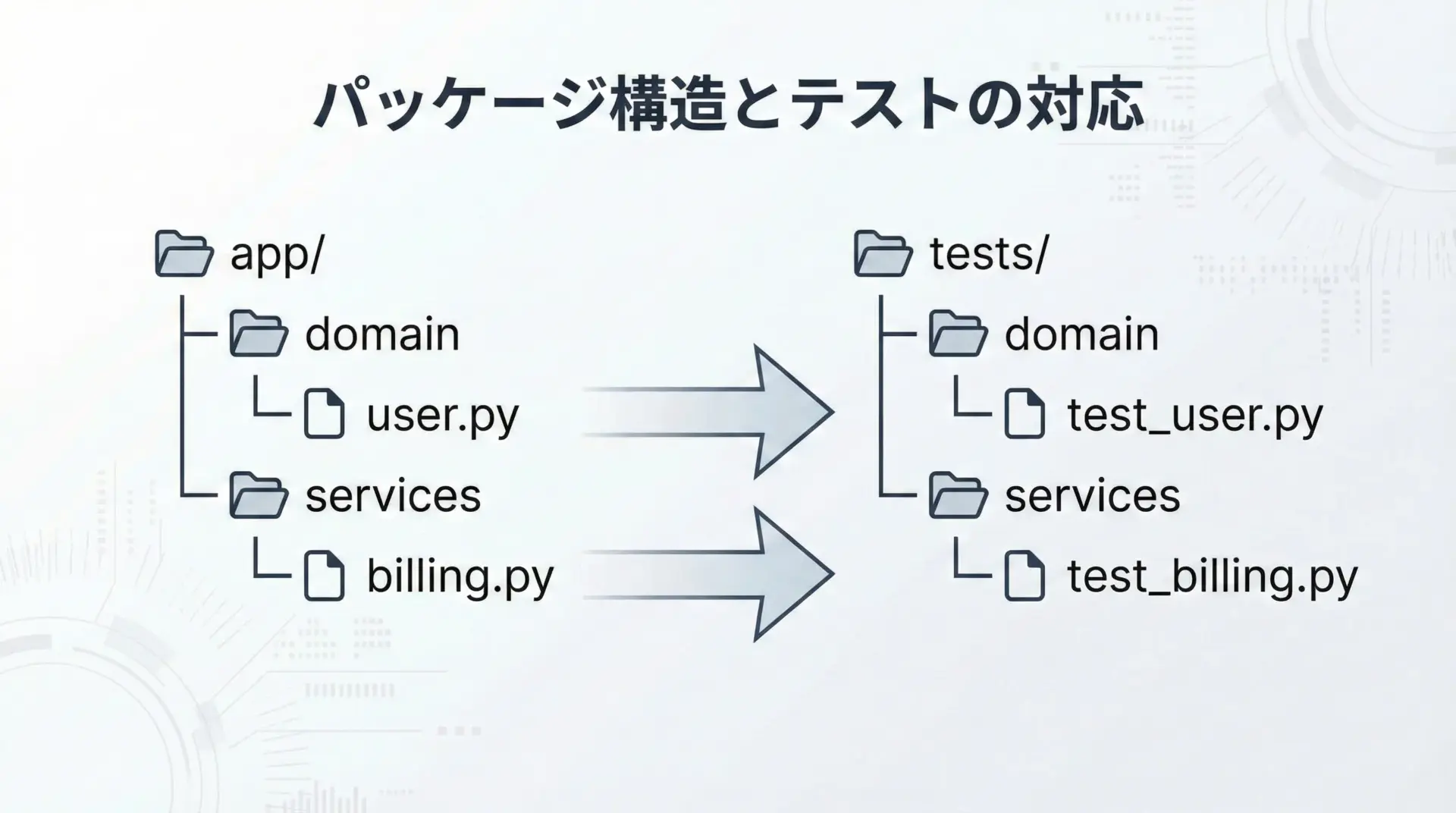
このようなミラー構造にしておくことで、あるモジュールのテストがどこにあるかを即座に見つけることができます。
原則12 コンストラクタインジェクションで依存を差し替える
コンストラクタインジェクションとは
コンストラクタインジェクションとは、クラスが必要とする依存オブジェクトを、コンストラクタの引数として受け取るやり方です。
Pythonでは__init__の引数で外部依存を渡す形を指します。
悪い例: 内部で依存を直接生成する
class UserService:
def __init__(self):
self._repo = SqlUserRepository() # ここで具象クラスを直接生成
def get_user_name(self, user_id: int) -> str:
user = self._repo.find_by_id(user_id)
return user.nameこの場合、SqlUserRepositoryをモックに差し替えるのが難しくなります。
良い例: 依存をコンストラクタで受け取る
from typing import Protocol
class UserRepository(Protocol):
def find_by_id(self, user_id: int):
...
class UserService:
def __init__(self, repo: UserRepository):
self._repo = repo
def get_user_name(self, user_id: int) -> str:
user = self._repo.find_by_id(user_id)
return user.nameテストでは、UserRepositoryを満たすフェイクを渡します。
class FakeUserRepository:
def __init__(self, users):
self._users = users
def find_by_id(self, user_id: int):
return self._users[user_id]
def test_get_user_name():
repo = FakeUserRepository({1: type("User", (), {"name": "Alice"})})
service = UserService(repo)
assert service.get_user_name(1) == "Alice"コンストラクタインジェクションは「依存を簡単に差し替えられる」という意味で、最も実用的なテスト容易性テクニックです。
原則13 設定値とロジックを分離する
ハードコーディングされた定数がロジックの中に散らばっていると、テストで異なる環境をシミュレートしにくくなります。
def send_report(email: str, content: str) -> None:
smtp_host = "smtp.example.com" # 直書き
...設定値は、環境変数・設定ファイル・DIコンテナなど、別レイヤーから注入可能にしておくと、テストで自由に差し替えられます。
@dataclass
class MailConfig:
smtp_host: str
smtp_port: int
def send_report(email: str, content: str, config: MailConfig) -> None:
# configから値を取得する
...テストではMailConfig("localhost", 1025)のようにテスト用設定を渡せば済みます。
原則14 境界づけられたコンテキストで責務を分割する
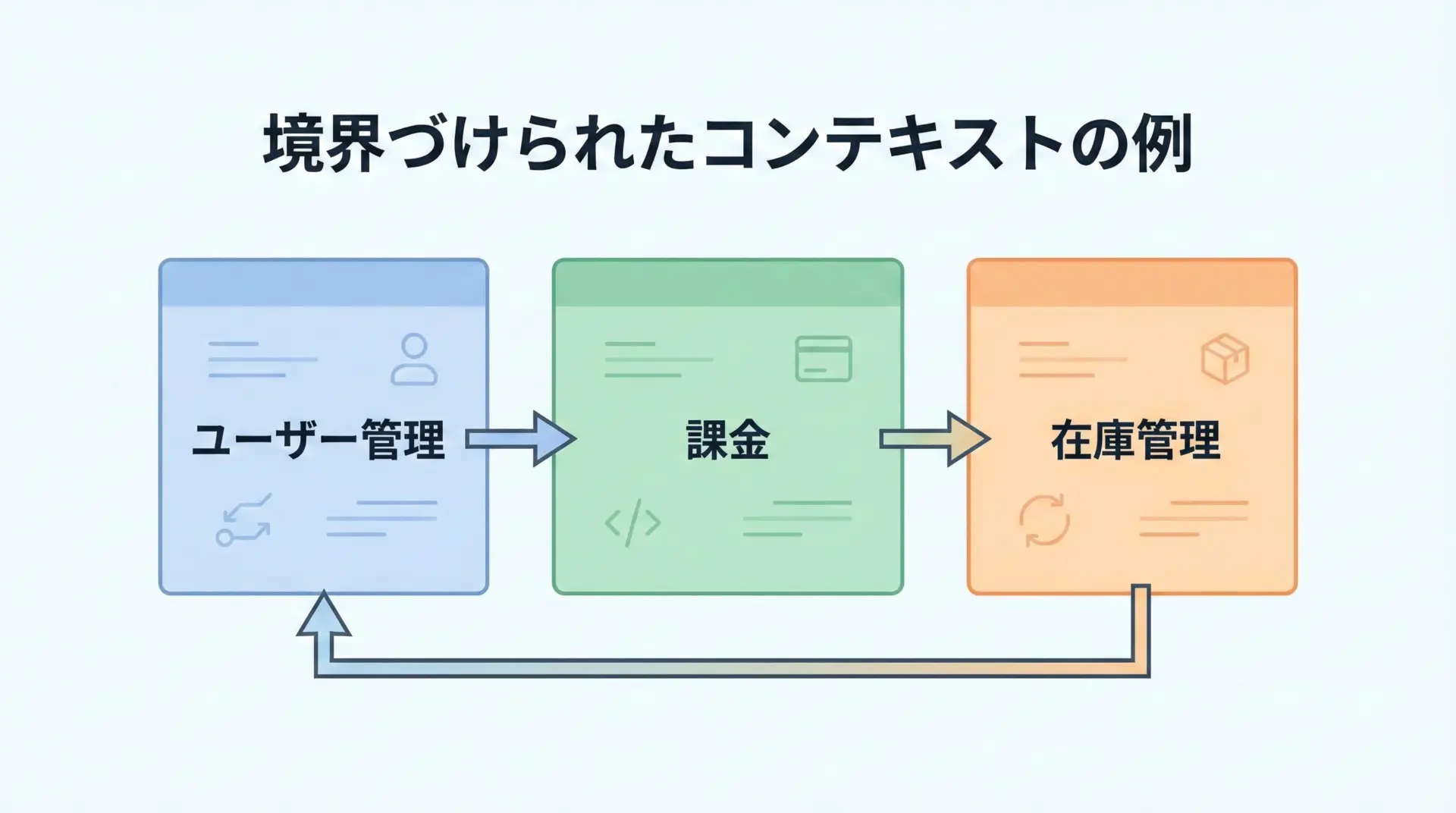
ドメイン駆動設計(DDD)でいう境界づけられたコンテキスト(Bounded Context)の考え方を取り入れると、テストの粒度も整理しやすくなります。
たとえば「課金」「在庫」「通知」といったコンテキストごとにモジュールを分け、テストもその単位で分けると、ある変更がどのテストに影響するかを把握しやすくなります。
原則15 エラーハンドリングを明示してテスト可能にする
曖昧なエラーハンドリングや、例外を握りつぶすコードはテストを書きにくくします。
def load_config(path: str) -> dict:
try:
with open(path) as f:
return json.load(f)
except Exception:
return {} # 何が起きたか分からないこのようなコードは、「どの失敗をどう扱うべきか」が不透明です。
よりよいのは、発生しうる例外を限定し、自分の例外としてラップすることです。
class ConfigLoadError(Exception):
pass
def load_config(path: str) -> dict:
try:
with open(path) as f:
return json.load(f)
except FileNotFoundError as e:
raise ConfigLoadError(f"config file not found: {path}") from e
except json.JSONDecodeError as e:
raise ConfigLoadError(f"invalid json: {path}") from eこれなら、テストでConfigLoadErrorのメッセージまで含めて確認できます。
def test_load_config_missing_file(tmp_path):
path = tmp_path / "missing.json"
with pytest.raises(ConfigLoadError) as excinfo:
load_config(str(path))
assert "not found" in str(excinfo.value)エラーが明示されていればいるほど、例外系テストも書きやすく、設計の意図も伝わりやすくなります。
Pythonならではのテスト容易性テクニック
型ヒント(type hints)でテストケース設計を明確にする
Pythonの型ヒントは、静的解析だけでなく、テストケースを考えるうえでも大きな助けになります。
引数や戻り値の型が明示されていると、「どのような入力パターンがありうるか」を洗い出しやすくなります。
from typing import Sequence
def average(values: Sequence[float]) -> float:
if not values:
raise ValueError("values must not be empty")
return sum(values) / len(values)この定義から、少なくとも次のようなテストが必要だと分かります。
- 正常系: 正の値・負の値を含むケース
- 境界: 要素数1のケース
- 異常系: 空シーケンスのケース
型がSequence[float]であることから、リストだけでなくタプルなども渡りうることも見えてきます。
プロトコル(protocol)と抽象基底クラス(ABC)でモックしやすくする
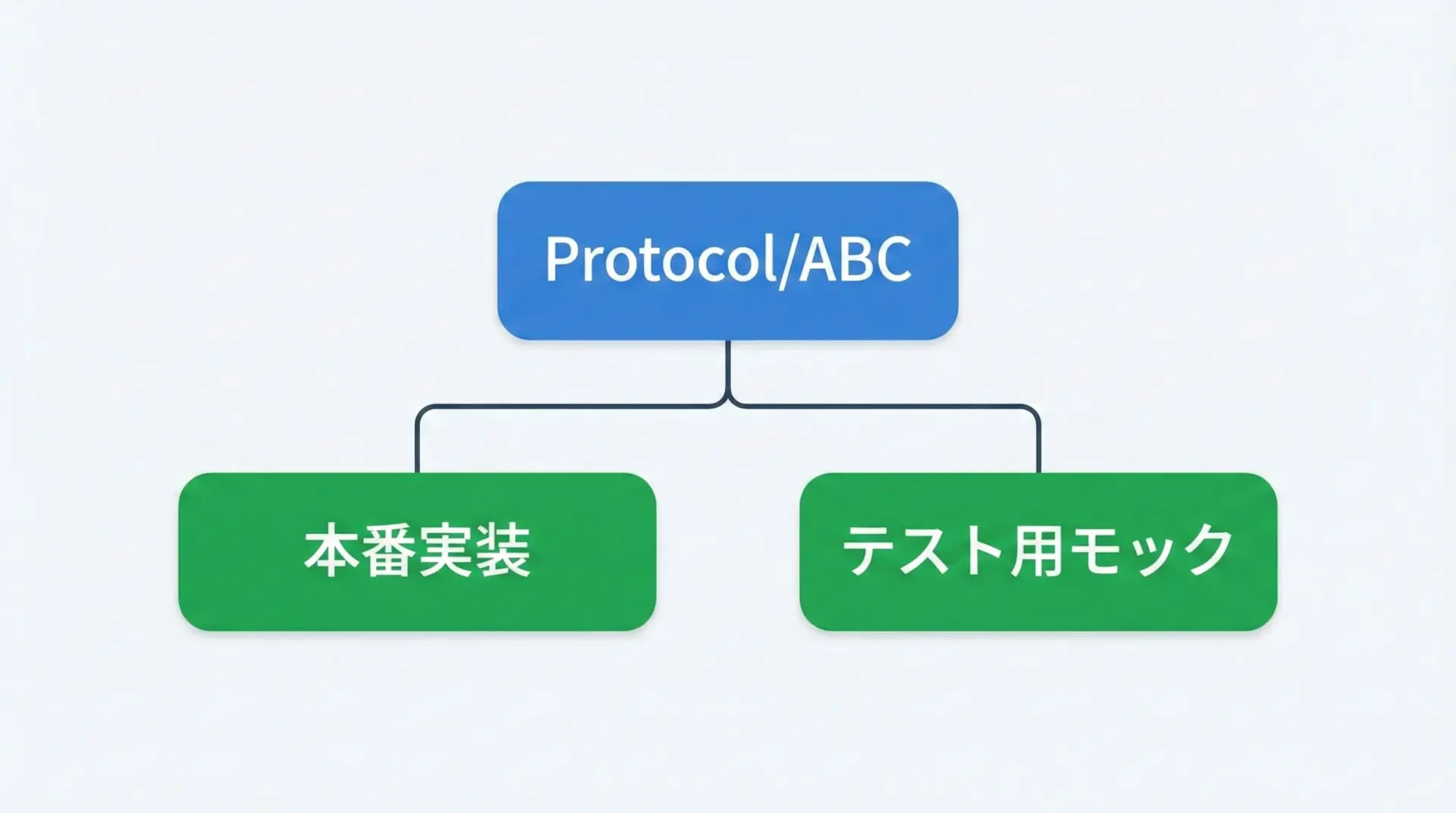
Pythonではtyping.Protocolやabc.ABCを使って抽象インターフェイスを定義できます。
これらを介して依存を注入しておくと、テスト時には簡単にモックを差し替えられます。
from typing import Protocol
from abc import ABC, abstractmethod
class PaymentGateway(Protocol):
def charge(self, amount: int) -> str:
...
class StripePaymentGateway(ABC):
@abstractmethod
def charge(self, amount: int) -> str:
...テストではPaymentGatewayを満たすフェイクリポジトリやフェイクゲートウェイを定義するだけで済みます。
class FakePaymentGateway:
def __init__(self):
self.charged_amounts: list[int] = []
def charge(self, amount: int) -> str:
self.charged_amounts.append(amount)
return "fake_tx_id"Protocol/ABCは「モックしやすい境界」を作る道具として活用すると便利です。
コンテキストマネージャでリソースの後始末を自動化する
ファイルやロック、トランザクションなどのリソースは、使い終わったら確実に後始末する必要があります。
Pythonのコンテキストマネージャ(with文)を使うと、後始末のロジックを1カ所に集約でき、テストでも状態をリセットしやすくなります。
from contextlib import contextmanager
@contextmanager
def transactional(session):
try:
yield
session.commit()
except Exception:
session.rollback()
raiseテストでは、トランザクションの中で例外が投げられたらロールバックされることを確認するだけで済みます。
非同期処理(asyncio)をテストしやすい形で設計する
非同期処理はテストが難しくなりがちですが、コルーチンを小さく保ち、副作用を分離することで対処しやすくなります。
import asyncio
from typing import Protocol
class AsyncUserRepo(Protocol):
async def find_by_id(self, user_id: int):
...
async def greet_user(user_id: int, repo: AsyncUserRepo) -> str:
user = await repo.find_by_id(user_id)
return f"Hello, {user.name}!"テストではpytest.mark.asyncioなどを使って、フェイクの非同期リポジトリを注入します。
class FakeAsyncUserRepo:
async def find_by_id(self, user_id: int):
await asyncio.sleep(0) # 文脈切り替え用(任意)
return type("User", (), {"name": "Bob"})
@pytest.mark.asyncio
async def test_greet_user():
repo = FakeAsyncUserRepo()
assert await greet_user(1, repo) == "Hello, Bob!"非同期関数でもインターフェイスと依存注入の原則は同じです。
テストしやすいコードを書くための実践パターン
ここまでの原則を、実際の関数・クラス・モジュール設計でどう活かすかをパターンとして整理します。
テスタビリティを意識した関数・メソッド設計パターン

関数レベルでは、次のようなパターンを意識するとテストがしやすくなります。
- 純粋関数として切り出せるロジックはできるだけ純粋関数にする
- I/Oや外部サービスとの接続部分は薄い関数に閉じ込める
- 上位の「オーケストレーション関数」は、純粋関数やI/O関数を組み合わせるだけにする
こうした分割により、ユニットテストの対象(純粋関数)と統合テストの対象(I/O層)を明確に分離できます。
テスタビリティを意識したクラス・モジュール設計パターン
クラスやモジュールの単位では、以下のようなパターンが効果的です。
- ドメインモデル(エンティティ・値オブジェクト)はできるだけ副作用なしで、ビジネスルールをカプセル化する
- アプリケーションサービスはユースケース単位で作り、リポジトリなどの抽象に依存する
- インフラ層では具体的なDB・外部API・メッセージングなどの実装を担当させる
Pythonでは、例えば次のような構成が考えられます。
app/
domain/
user.py # User, UserIdなど(純粋なドメインモデル)
services/
user_service.py # ユースケース(依存は抽象)
infra/
user_repo_sql.py # 実際のDB実装テスト側では、domainはユニットテスト、servicesはモックを使ったユースケーステスト、infraは統合テストといったレイヤごとのテスト戦略が立てやすくなります。
リファクタリングで既存コードをテストしやすくするコツ
最後に、すでに存在する「テストしにくいコード」を改善するためのリファクタリングのコツをまとめます。
- まず「外から観測できる振る舞い」を守るテストを追加し、リファクタリングの安全網を用意する
- 巨大関数を少しずつ分解し、純粋関数に切り出せる部分から切り出していく
- 直接生成している依存を、引数やコンストラクタ経由で渡すように変更する
- 設定値や環境依存部分を局所化し、テストで差し替えられるようにする
- モジュール構造やパッケージ構成を整理し、テストのファイル構造も揃える
いきなりすべての原則を適用しようとせず、影響範囲の小さな部分から一歩ずつ進めることが、現実的で安全なアプローチです。
まとめ
テストしやすいPythonコードは、単にテストツールの使い方を知っているだけでは実現できません。
単一責任原則や依存関係逆転原則といった設計原則をベースに、依存の注入・純粋関数の活用・設定値とロジックの分離などを組み合わせることで、初めてテスト容易性が高いコードになります。
本記事で紹介した15の原則とPythonならではのテクニックを少しずつ取り入れていけば、既存プロジェクトでも新規開発でも、テストが書きやすくメンテしやすいコードベースへと育てていくことができます。
