
Pythonでのテスト自動化を効率化するうえで、pytestはとても強力なフレームワークです。
その中でもテストコードを劇的に簡略化してくれる機能が@pytest.mark.parametrizeです。
本記事では、基本から実践的なテクニック、注意点までを図解とサンプルコード付きで丁寧に解説し、明日からすぐ使える知識として身につけられるようにします。
pytest parametrizeとは何か
pytest parametrizeの基本機能

pytestのparametrizeは、1つのテスト関数に対して複数の入力値と期待値(テストケース群)を与え、同じテストロジックを繰り返し実行するための仕組みです。
通常であれば、入力と期待値の組み合わせごとに別々のテスト関数を書く必要がありますが、parametrizeを使うと、テストロジックを1カ所に集約し、データをテーブルのように列挙するだけで済むようになります。
この考え方は、いわゆる「テーブル駆動テスト」と呼ばれるスタイルに非常に近く、テスト対象の仕様変更やテストケース追加にも柔軟に対応しやすくなります。
unittestのテーブル駆動テストとの違い
Python標準ライブラリのunittestでも、工夫をすればテーブル駆動風のテストを書けますが、pytestのparametrizeとは以下のような違いがあります。
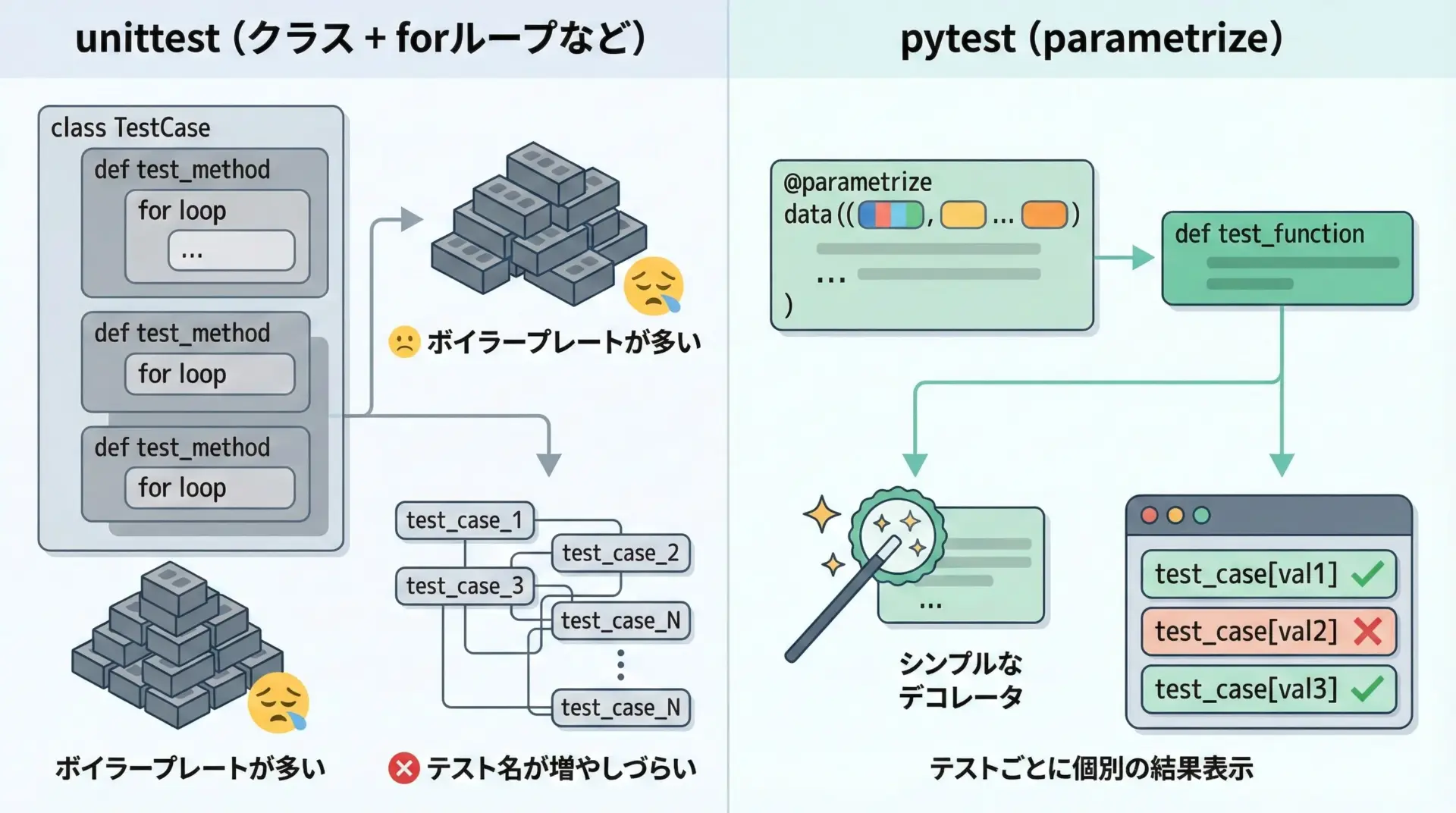
unittestでテーブル駆動テストをする場合、多くは以下のようなスタイルになります。
- ループでテストデータを回しながら
subTestを使う - メタクラスや動的関数生成でテストメソッドを量産する
- 共通テストメソッドに辞書やタプルのリストを渡してループする
これらはいずれもボイラープレートコードが多くなりやすく、テスト結果の表示もややわかりにくくなりがちです。
一方でpytestのparametrizeは@pytest.mark.parametrizeというデコレータ1つで表現でき、テストケースごとに独立したテストとしてレポートされるため、失敗したケースの特定も容易です。
テスト自動化にparametrizeが有効な理由
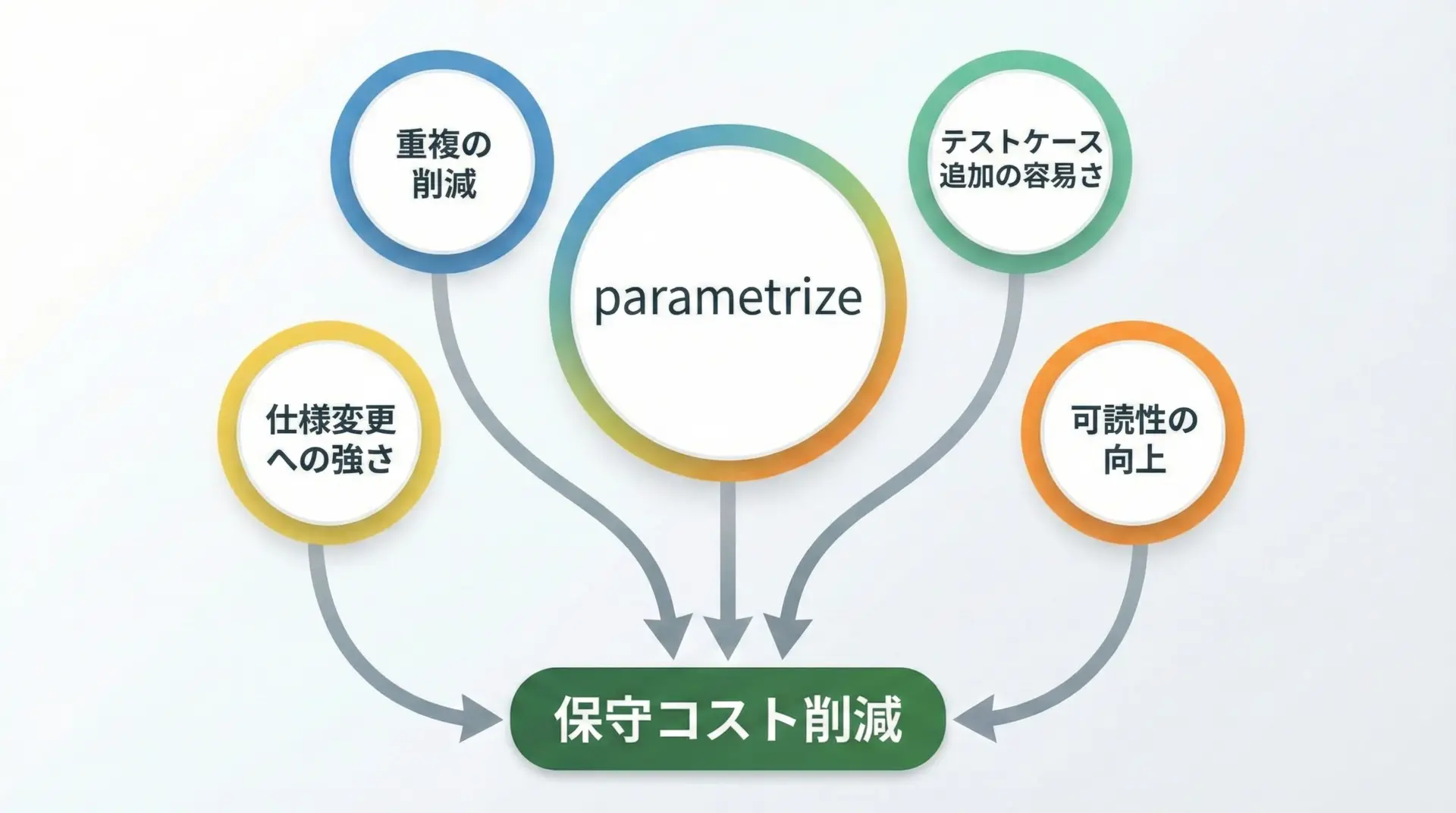
pytest parametrizeがテスト自動化に特に有効な理由は、単に「書く量が減る」以上の効果があるためです。
まず、ロジックとテストデータがきれいに分離されることで、テストケースの見落としに気づきやすくなります。
テーブルとして並んだパラメータを眺めることで、「この境界条件が足りない」「負の値のケースも必要だ」などの気づきが得やすくなります。
また、テストロジックが1カ所に集約されることで、仕様変更があったときはテスト関数側を、テストケースを追加・削除したいときはparametrizeのテーブル側を、というように役割分担が明確になり、保守性が高まります。
pytest parametrizeの基本的な書き方
@pytest.mark.parametrizeの構文と引数

@pytest.mark.parametrizeデコレータの基本的な構文は次のようになります。
@pytest.mark.parametrize(
"param1,param2,...", # テスト関数に渡す引数名(カンマ区切り文字列またはリスト)
[
(値1, 値2, ...), # 1つ目のテストケース
(値1, 値2, ...), # 2つ目のテストケース
# ...
],
ids=None, # (任意) テストケースごとのID(名前)
marks=None # (任意) テストケースごとのマーク(skip, xfailなど)
)
def test_xxx(param1, param2, ...):
...引数名リストは"a,b"のようなカンマ区切り文字列でも、["a", "b"]のようなリストでも構いません。
テストデータ部分にはリストやタプルだけでなく、ジェネレータや他の関数から生成したイテラブルも使えます。
単一引数のparametrizeサンプルコード
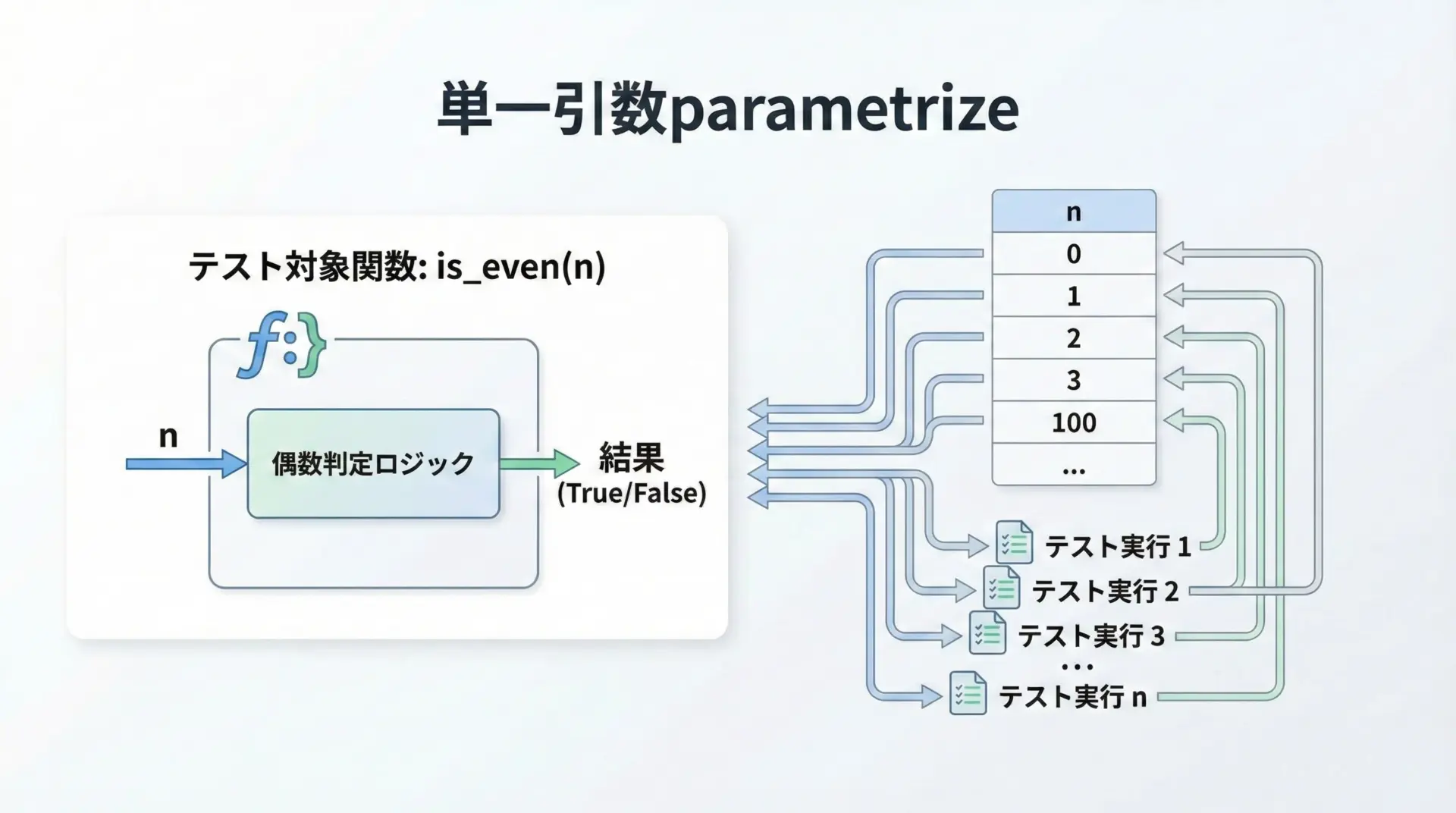
まずは最もシンプルな、1つの引数だけをparametrizeする例です。
偶数判定関数is_evenをテストするケースを考えます。
# file: test_is_even.py
import pytest
def is_even(n: int) -> bool:
"""nが偶数ならTrueを返す単純な関数"""
return n % 2 == 0
@pytest.mark.parametrize(
"value", # テスト関数に渡される引数名は1つだけ
[0, 1, 2, 3, 100, -2] # さまざまな整数をテストする
)
def test_is_even_basic(value: int) -> None:
"""偶数・奇数判定の基本的なテスト"""
# 実際の結果
result = is_even(value)
# 期待される結果(0を除き、2で割った余りが0なら偶数)
# 偶数かどうかの期待値を計算
expected = (value % 2 == 0)
# アサーション
assert result == expectedこのテストを実行すると、個々の値に対してテストが行われます。
$ pytest -q
......
6 passed in 0.02sここではテストケースごとのIDを明示していませんが、pytestは自動的にvalue0、value1といった形で識別して報告してくれます。
複数引数のparametrizeサンプルコード
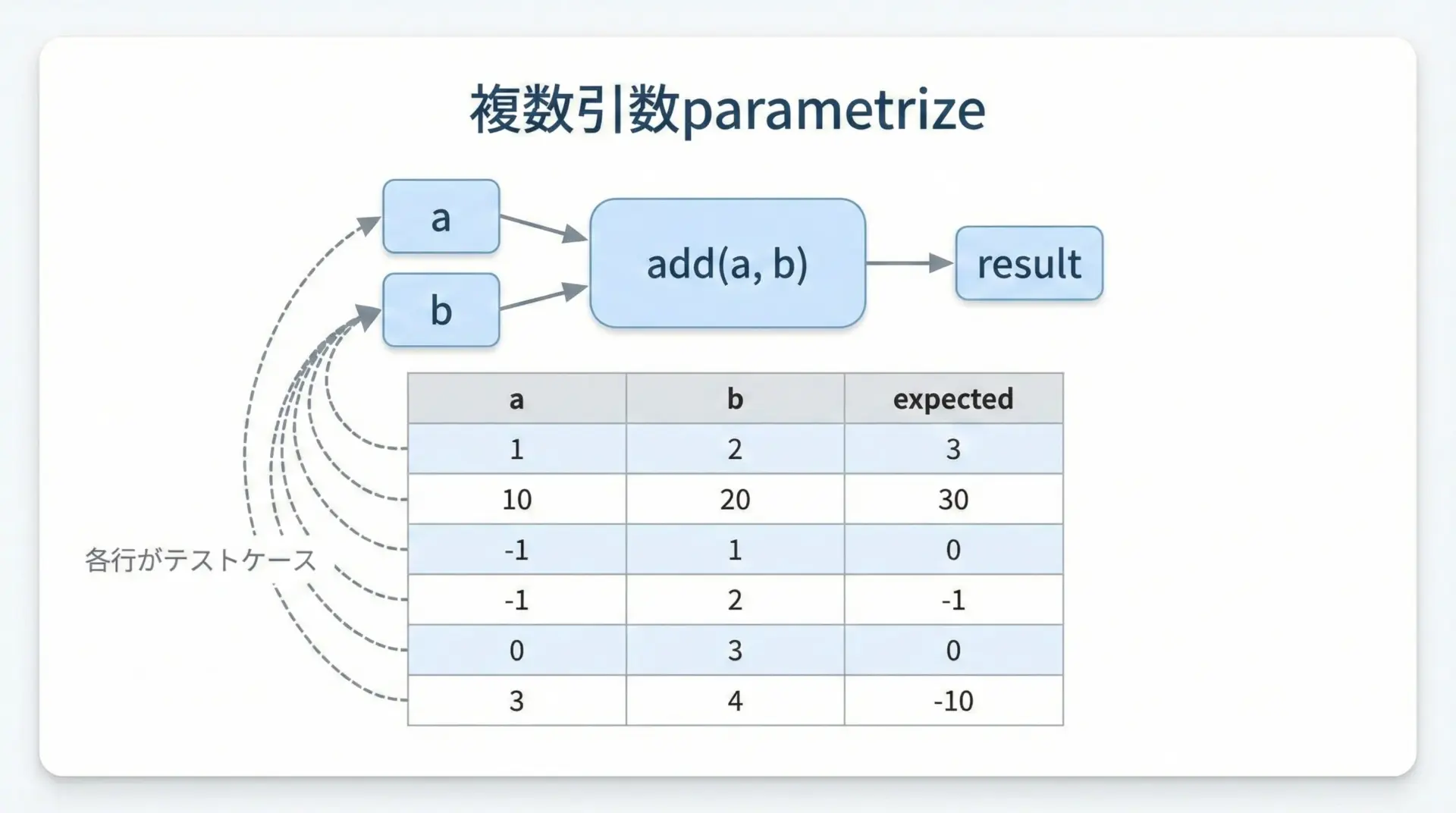
続いて、複数の引数を一度にparametrizeする例です。
ここでは単純な加算関数addをテストします。
# file: test_add.py
import pytest
def add(a: int, b: int) -> int:
"""2つの整数を足し合わせる関数"""
return a + b
@pytest.mark.parametrize(
"a,b,expected", # 3つの引数名を指定
[
(1, 2, 3), # 1 + 2 = 3
(0, 0, 0), # 0 + 0 = 0
(-1, 1, 0), # -1 + 1 = 0
(100, 200, 300), # 100 + 200 = 300
]
)
def test_add_basic(a: int, b: int, expected: int) -> None:
"""add関数の基本的な動作を確認するテスト"""
result = add(a, b)
assert result == expected$ pytest -q
....
4 passed in 0.01sこのように引数名の並びと、各テストケースのタプル内の順番を対応させることで、複数引数のテーブル駆動テストを簡単に記述できます。
テストケースの可読性を保つ命名と整理
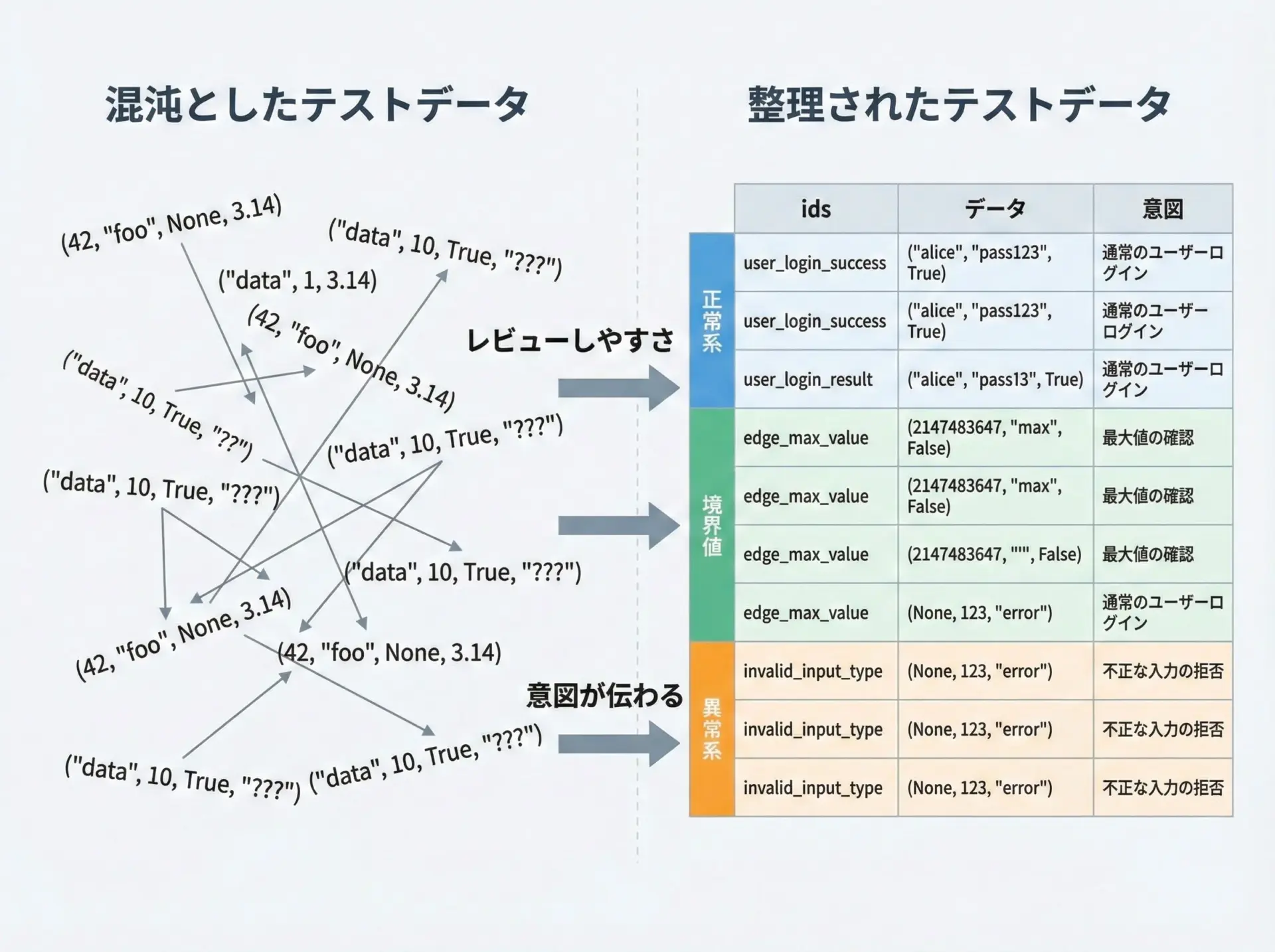
parametrizeを使うと、テストデータをどんどん追加できるため、気を抜くと「単なる数字の羅列」になってしまい、何をテストしているのか分かりにくくなります。
そのため、テストケースの可読性を保つ工夫が重要です。
例えば、以下のような工夫が考えられます。
- 正常系、境界値、異常系ごとにテーブルを分ける
- 行ごとにコメントを書き、意図を明示する
- 後述する
ids引数でテストケースに名前を付ける
@pytest.mark.parametrize(
"a,b,expected",
[
# 正常系
(1, 2, 3), # 代表的な正の整数
(0, 0, 0), # ゼロ同士
# 境界値
(10**9, 1, 10**9 + 1), # 大きな値に+1
# 異常系(仕様により例外を投げるなど)
# (None, 1, TypeError), のように別parametrizeにするなど
]
)
def test_add_readable(a, b, expected):
...「これはどんな条件をテストしているのか」が読み手に一目で伝わるように、テーブルを整理することが長期的な保守性につながります。
pytest parametrizeでテストコードを簡略化する実践テクニック
条件分岐の網羅テストをparametrizeで置き換える方法
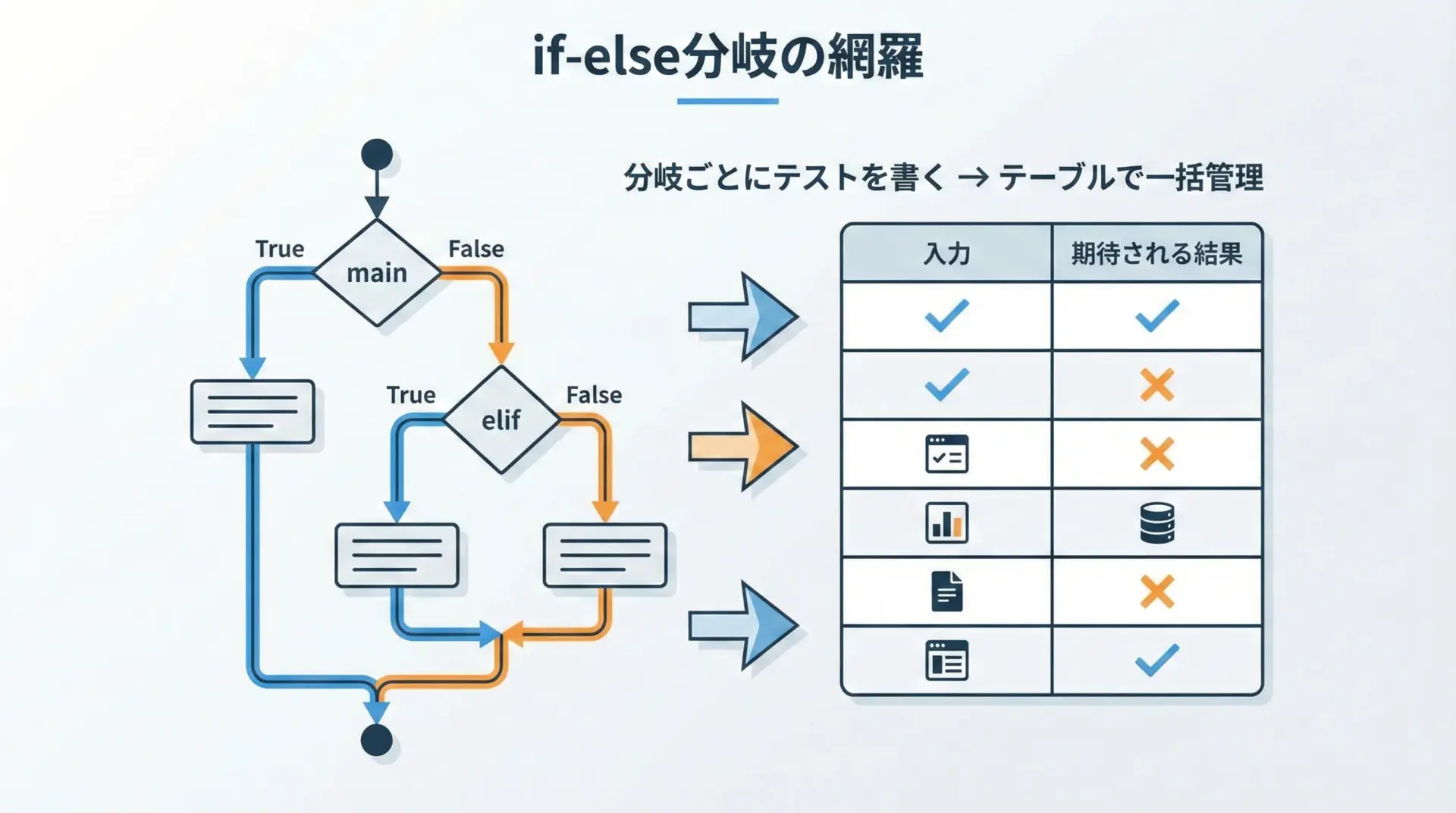
if文やelifが多い関数をテストする場合、各分岐ごとに別々のテスト関数を書いていくと、すぐに重複が増えてしまいます。
そうしたときにparametrizeを使うと、分岐条件をテストデータとしてテーブルにまとめ、一つのテスト関数で全分岐を網羅できます。
# file: test_classify_score.py
import pytest
def classify_score(score: int) -> str:
"""点数に応じてランクを返す関数"""
if score < 0:
return "invalid"
elif score < 60:
return "fail"
elif score < 80:
return "pass"
elif score <= 100:
return "excellent"
else:
return "invalid"
@pytest.mark.parametrize(
"score,expected",
[
# 無効値
(-1, "invalid"),
(101, "invalid"),
# 境界条件を中心に網羅
(0, "fail"),
(59, "fail"),
(60, "pass"),
(79, "pass"),
(80, "excellent"),
(100, "excellent"),
]
)
def test_classify_score(score: int, expected: str) -> None:
"""scoreの条件分岐をparametrizeで網羅的にテストする"""
assert classify_score(score) == expectedこのように、if-elseの境界にあたる値をテーブルとして並べることで、どの条件分岐も漏れなくテストできているかを目視で確認しやすくなります。
エッジケースをparametrizeでまとめて定義するコツ
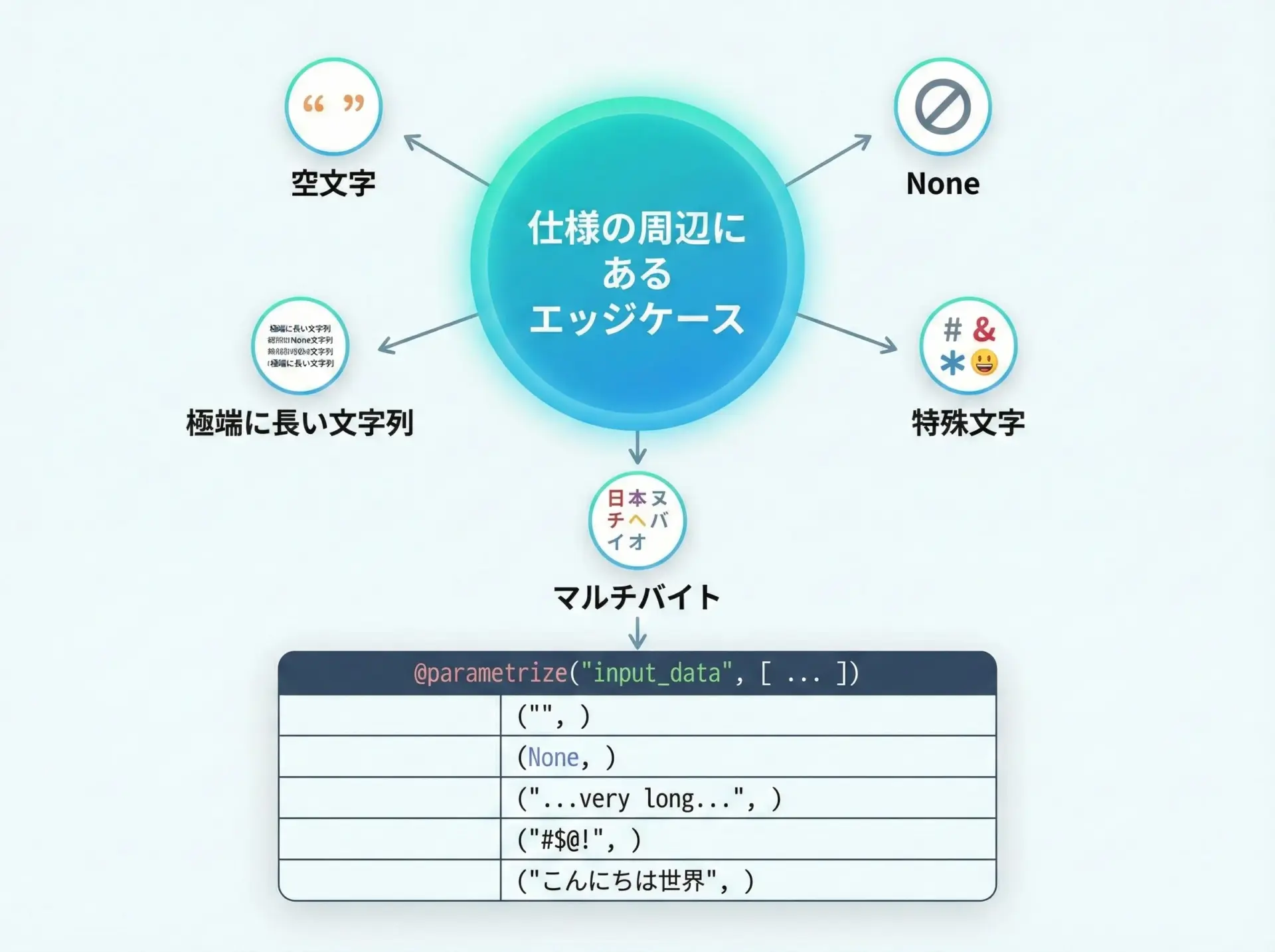
仕様の中心的なケースだけでなく、エッジケースもきちんとテストしておきたい場面は多いですが、1ケースずつ個別のテスト関数を書くと煩雑になります。
そこで、エッジケースを「まとまったセット」としてparametrizeに書き出すことで、見通しを良くできます。
# file: test_normalize_name.py
import pytest
def normalize_name(raw: str) -> str:
"""名前文字列をトリムし、連続スペースを1つにする簡単な関数"""
return " ".join(raw.strip().split())
@pytest.mark.parametrize(
"raw,expected",
[
# 代表的な正常系
("Alice", "Alice"),
(" Bob ", "Bob"),
# エッジケース群
("", ""), # 空文字
(" ", ""), # 空白のみ
("A B C", "A B C"), # 連続スペース
("太郎 花子", "太郎 花子"), # マルチバイト + スペース
]
)
def test_normalize_name_edge_cases(raw: str, expected: str) -> None:
"""名前文字列のエッジケースをparametrizeでまとめてテスト"""
assert normalize_name(raw) == expectedこのようにエッジケースを1つのテーブルに並べると、「どのような異常・特殊な入力を想定しているか」が一目でわかり、仕様レビューの材料としても活用しやすくなります。
fixtureとparametrizeを組み合わせるパターン
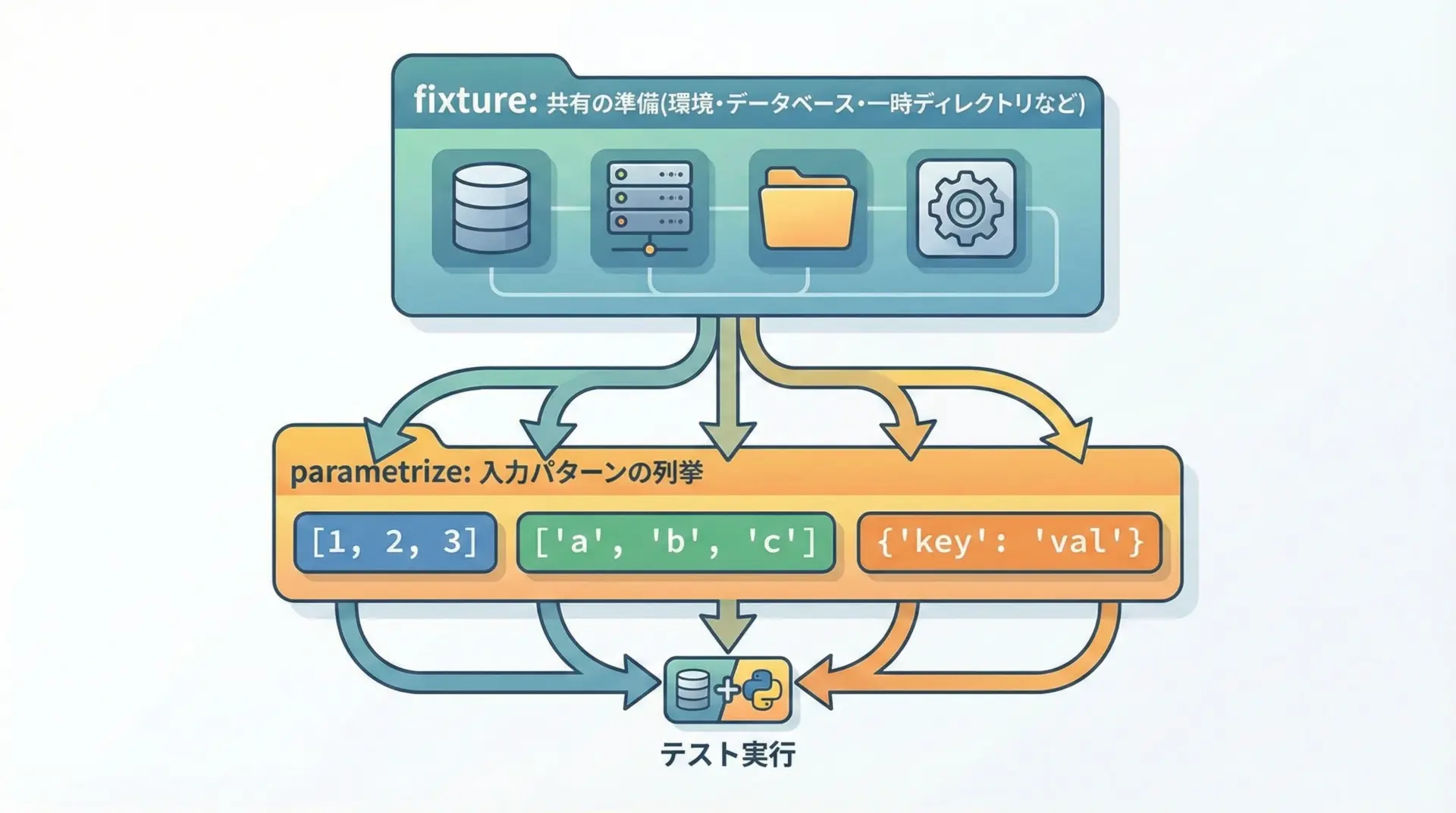
pytestの強みの1つであるfixtureとparametrizeを組み合わせると、共有の前処理を使い回しつつ、多数のテストデータで同じ環境をテストすることができます。
# file: test_with_fixture.py
import pytest
@pytest.fixture
def base_url() -> str:
"""APIテスト用のベースURLを提供するfixture"""
# 実際には設定ファイルから読んだり、テスト用サーバを起動したりする
return "https://api.example.com"
@pytest.mark.parametrize(
"path,expected_status",
[
("/health", 200),
("/not-found", 404),
]
)
def test_api_endpoints(base_url: str, path: str, expected_status: int) -> None:
"""ベースURLはfixtureから、パスと期待ステータスはparametrizeから受け取る"""
# 実際にはrequests.getなどを使うイメージ
# ここではデモ用に簡略化
url = base_url + path
# ダミーの振る舞い
if path == "/health":
status = 200
else:
status = 404
assert status == expected_statusこのように、fixtureで「共通の準備」を、parametrizeで「テストパターンの多様性」をそれぞれ担当させることで、テストコード全体の構造がすっきりします。
idパラメータでテストケース名をわかりやすくする

parametrizeにはidsという引数があり、これを使うと各テストケースに分かりやすい名前を付けることができます。
失敗したケースをログから瞬時に特定したいときに非常に役立ちます。
# file: test_add_with_ids.py
import pytest
def add(a: int, b: int) -> int:
return a + b
@pytest.mark.parametrize(
"a,b,expected",
[
(1, 2, 3), # normal
(0, 0, 0), # zero
(-1, 1, 0), # negative_plus_positive
],
ids=[
"normal_positive",
"both_zero",
"negative_and_positive",
]
)
def test_add_with_ids(a: int, b: int, expected: int) -> None:
"""idsを指定してテストケースに名前を付ける例"""
assert add(a, b) == expected実行すると、テスト名は次のように表示されます。
$ pytest -q
... [100%]
3 passed in 0.01s-vvオプションを付けると、個別のIDが見やすく表示されます。
$ pytest -q -vv
test_add_with_ids.py::test_add_with_ids[normal_positive] PASSED
test_add_with_ids.py::test_add_with_ids[both_zero] PASSED
test_add_with_ids.py::test_add_with_ids[negative_and_positive] PASSEDidsには関数も渡せるため、複雑なオブジェクトを含むテストケースでも、整形した文字列をIDとして利用できます。
マーク(xfail・skip)とparametrizeを組み合わせる

pytestは@pytest.mark.skipや@pytest.mark.xfailなどのマーク機能を持っていますが、parametrizeと組み合わせることで特定のテストケースだけをスキップ、あるいは期待される失敗として扱うことができます。
# file: test_divide.py
import pytest
def divide(a: int, b: int) -> float:
"""単純な除算関数(ゼロ除算は例外を投げる)"""
return a / b
skip_case = pytest.param(
1, 0, None,
marks=pytest.mark.xfail(reason="ZeroDivisionError is expected")
)
@pytest.mark.parametrize(
"a,b,expected",
[
(4, 2, 2.0),
(9, 3, 3.0),
skip_case, # xfailとして扱うケース
]
)
def test_divide(a: int, b: int, expected: float) -> None:
"""xfailを指定したテストケースを含むparametrize"""
result = divide(a, b)
if expected is not None:
assert result == expected上記では、pytest.paramを使って個別ケースにマークを付けています。
実行すると、ゼロ除算のケースは「xfail(期待通りの失敗)」としてカウントされます。
$ pytest -q
..x [100%]
2 passed, 1 xfailed in 0.01sこれにより、既知の不具合や仕様上の制約を「テストで見える化」しつつ、自動テスト全体はグリーンのまま保つといった運用も可能になります。
パラメータを外部ファイル(csv・json)から読み込む方法
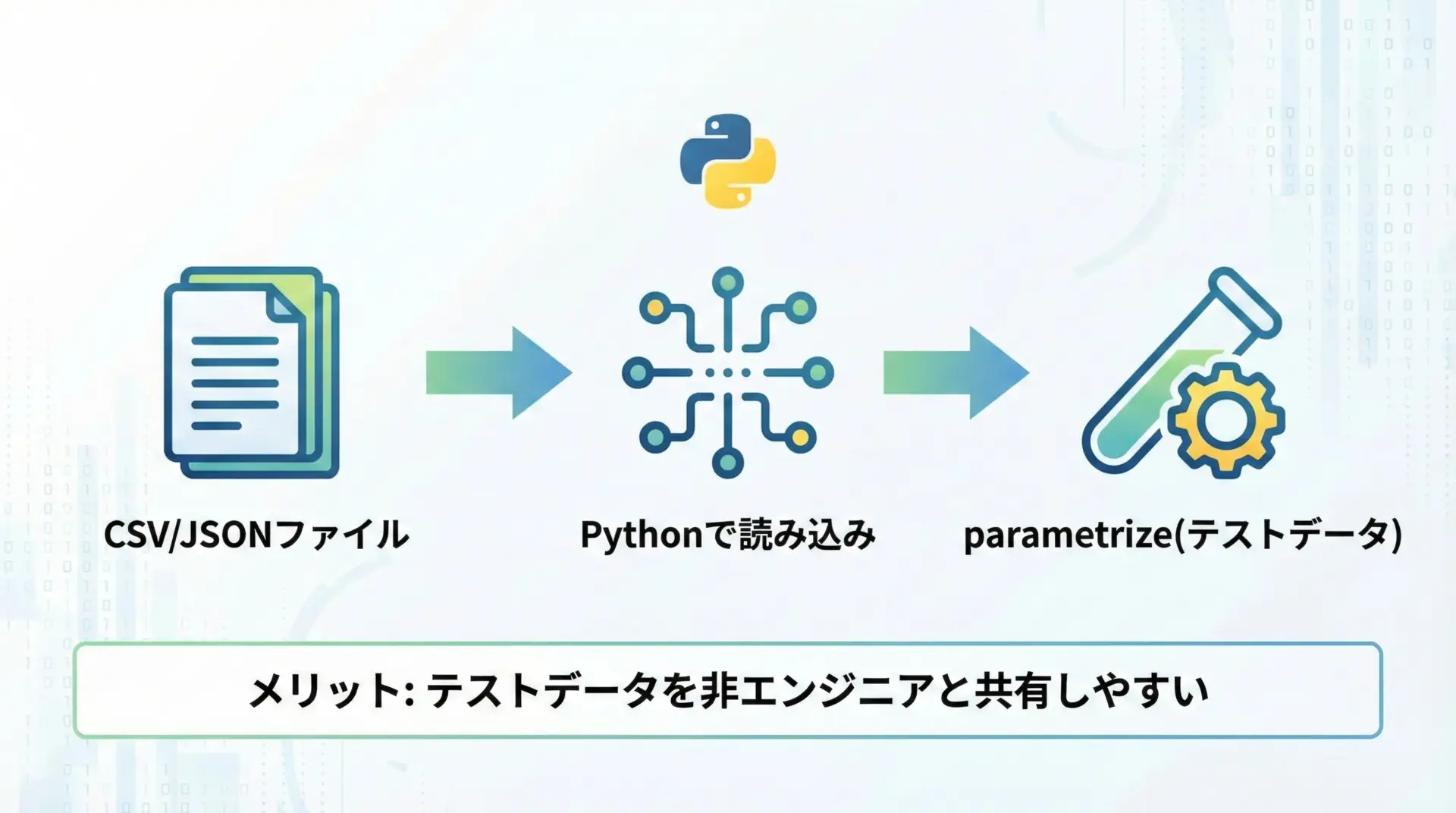
テストケースが非常に多くなってきた場合、テストデータ自体を外部ファイルで管理し、pytestから読み込んでparametrizeに渡すという方法が有効です。
ビジネス側の担当者とテスト条件を共有したいときなどにも便利です。
CSVファイルから読み込む例
# file: test_from_csv.py
import csv
import pathlib
import pytest
def multiply(a: int, b: int) -> int:
return a * b
def load_test_cases_from_csv():
"""CSVファイルからテストケースを読み込んで返す"""
csv_path = pathlib.Path(__file__).with_name("multiply_cases.csv")
cases = []
with csv_path.open() as f:
reader = csv.DictReader(f)
for row in reader:
a = int(row["a"])
b = int(row["b"])
expected = int(row["expected"])
cases.append((a, b, expected))
return cases
@pytest.mark.parametrize("a,b,expected", load_test_cases_from_csv())
def test_multiply_from_csv(a: int, b: int, expected: int) -> None:
"""CSVで定義したテストケースをparametrizeに流し込む"""
assert multiply(a, b) == expected# file: multiply_cases.csv
a,b,expected
1,2,2
3,4,12
-1,5,-5JSONファイルから読み込む例
# file: test_from_json.py
import json
import pathlib
import pytest
def multiply(a: int, b: int) -> int:
return a * b
def load_test_cases_from_json():
"""JSONファイルからテストケースを読み込んで返す"""
json_path = pathlib.Path(__file__).with_name("multiply_cases.json")
with json_path.open() as f:
data = json.load(f)
# data = [{"a": 1, "b": 2, "expected": 2}, ...] を想定
return [(case["a"], case["b"], case["expected"]) for case in data]
@pytest.mark.parametrize("a,b,expected", load_test_cases_from_json())
def test_multiply_from_json(a: int, b: int, expected: int) -> None:
"""JSONで定義したテストケースをparametrizeに流し込む"""
assert multiply(a, b) == expected// file: multiply_cases.json
[
{"a": 1, "b": 2, "expected": 2},
{"a": 3, "b": 4, "expected": 12},
{"a": -1, "b": 5, "expected": -5}
]このようにすることで、テストデータをコードから切り離し、Excelなどから変換して利用する運用も可能になります。
pytest parametrizeを使う際の注意点とベストプラクティス
パラメータ数が多くなりすぎる場合の分割方法
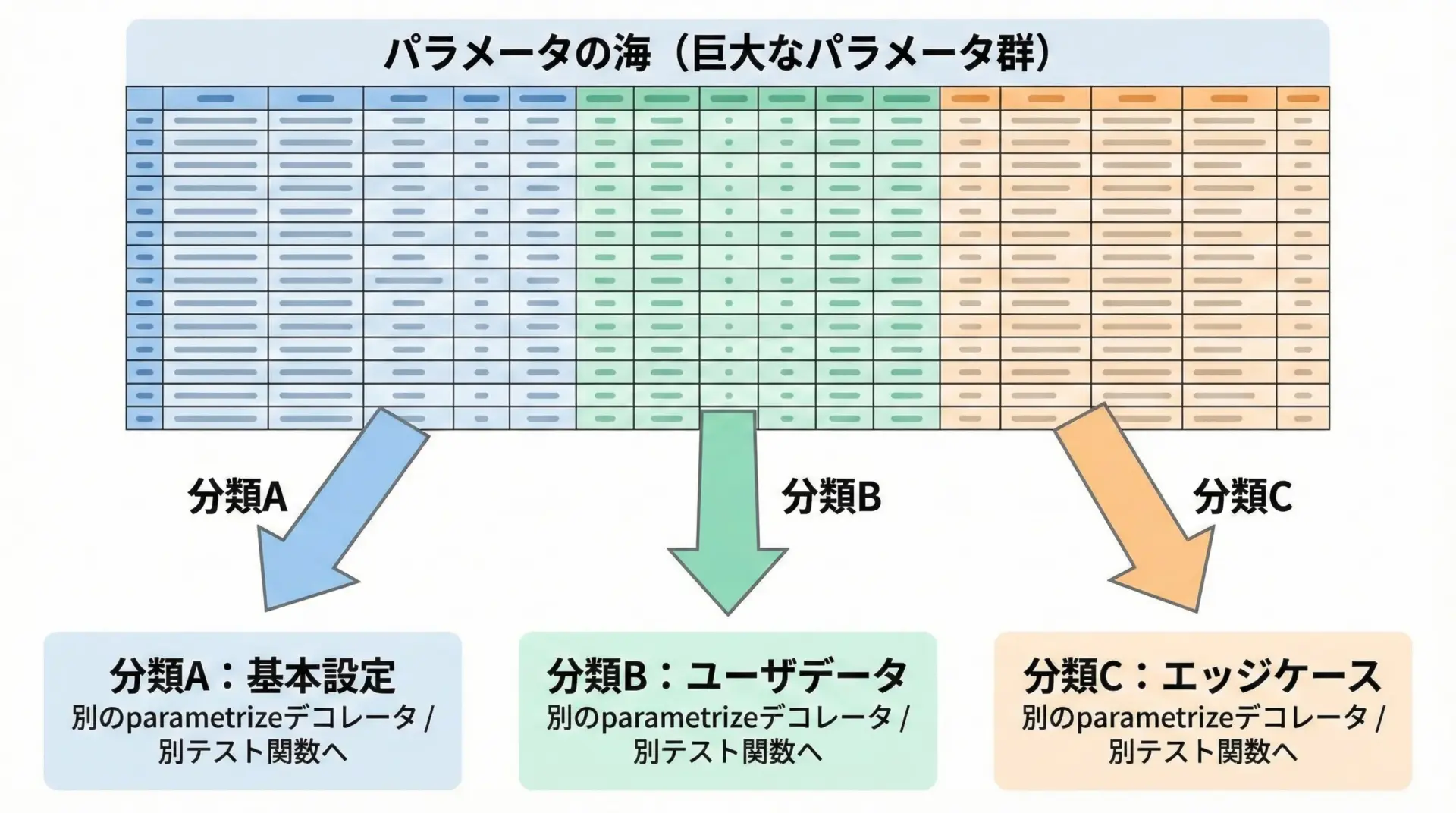
parametrizeは便利ですが、テストケースをどんどん追加していくと「1つのテスト関数に数百ケースがある巨大テーブル」になってしまうことがあります。
これでは失敗ケースの分析が難しくなるだけでなく、テスト実行時間も読みにくくなります。
パラメータ数が多くなってきたら、次のような分割を検討すると良いです。
- 正常系・境界値・異常系でテスト関数を分ける
- 機能単位やサブ仕様単位でテーブルを分ける
- 実行時間の長いケースと短いケースを分離し、マークで制御する
# 正常系だけをまとめたテスト
@pytest.mark.parametrize("a,b,expected", [...])
def test_add_normal(...):
...
# 異常系だけをまとめたテスト
@pytest.mark.parametrize("a,b,expected_exception", [...])
def test_add_error(...):
...「このテスト関数は何を検証しているのか」が明確になるように、テーブルを小さめに保つのがベストプラクティスです。
複雑な前処理が必要なケースとの切り分け
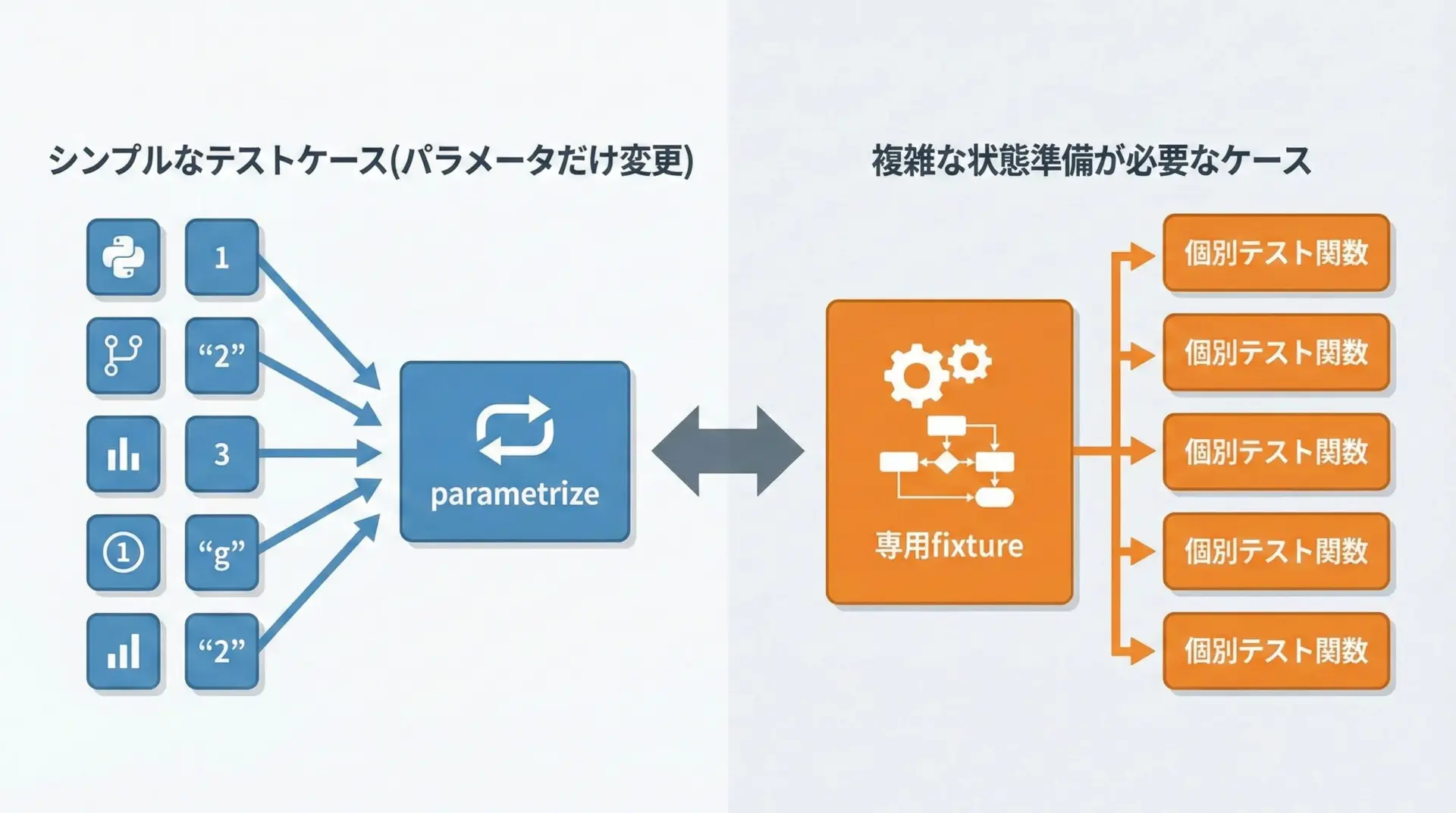
全てのテストをparametrizeで表現しようとすると、逆にコードが読みにくくなることがあります。
特に、テストケースごとに大きく異なる前処理やセットアップが必要な場合、テーブルにすべてを詰め込むのは得策ではありません。
そのような場合は、以下のような切り分けが有効です。
- シンプルに「入力と期待値」だけで表現できるケース → parametrize向き
- 大量のモック設定や複雑な前処理が必要なケース → 個別テスト関数や専用fixture
# シンプルにパラメータだけ変えればよいケース
@pytest.mark.parametrize("input,expected", [...])
def test_simple_case(...):
...
# 特殊な前処理が必要なケースは個別に書く
def test_complex_scenario(mock_service):
# 個別のモック設定やセットアップ
...「parametrizeはあくまでシンプルな繰り返しに使う」という原則を持っておくと、テストコード全体の見通しが良くなります。
テスト自動化プロジェクトでのparametrize導入ステップ
既存のテストコードベースにparametrizeを導入していく場合、いきなり大規模なリファクタリングを行うのではなく、段階的に進めるのがおすすめです。
1つの進め方の例を示します。
- まずは、同じようなアサーションがコピペされているテストを探します。例えば、入力値だけが異なる同型のテスト関数が並んでいる部分です。
- それらを1つのテスト関数にまとめ、
@pytest.mark.parametrizeで表現してみます。最初は数ケースから始めると安全です。 - 慣れてきたら、fixtureとの組み合わせや
idsの活用など、読みやすさと表現力を上げていきます。 - テストケースが増えて管理が大変になってきたら、CSVやJSONなど外部ファイルへの切り出しを検討します。
このように段階的に適用範囲を広げていくことで、既存プロジェクトにも無理なくparametrizeを浸透させることができます。
pytest parametrizeでテストコードを劇的に簡略化するためのまとめの指針
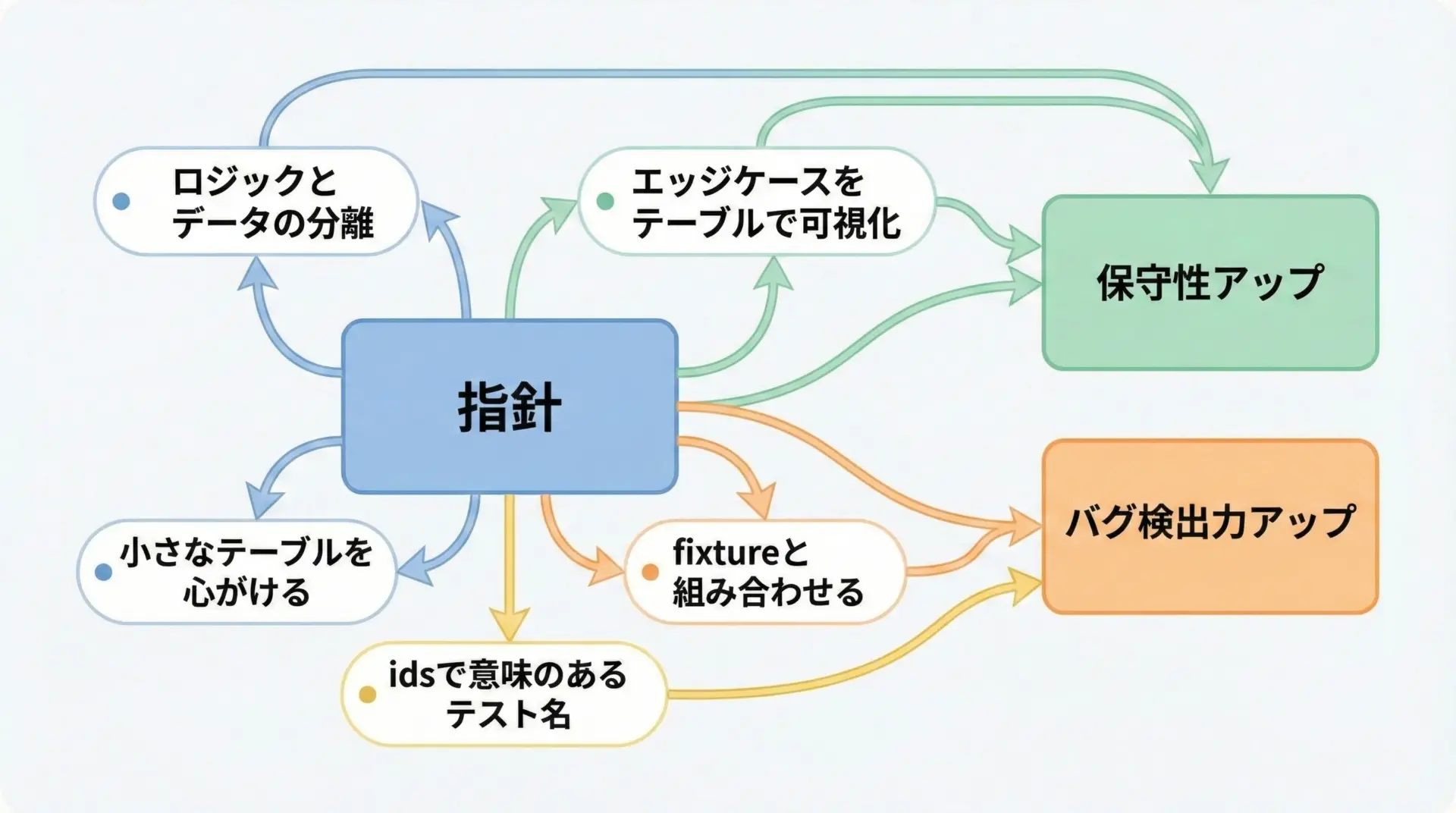
pytest parametrizeを使いこなすための指針を整理すると、次のようになります。
まず、ロジックとデータを分離し、テストデータをテーブルとして表現するという発想をベースにします。
これにより、仕様の網羅性やエッジケースの有無を目視で確認できるようになります。
次に、1つのparametrizeに詰め込みすぎず、小さなテーブルを保つことを意識します。
正常系・異常系・境界値など、意味のある単位でテーブルを分けることで、テストの意図がより明確になります。
さらに、fixtureやids、xfail・skipなどの機能と組み合わせることで、現実的な開発現場のニーズに即した、柔軟かつ読みやすいテストスイートを構築できます。
まとめ
pytestの@pytest.mark.parametrizeは、テストロジックを1カ所に集約し、テストデータをテーブルとして整理できる強力な仕組みです。
単一引数から複数引数、fixtureとの組み合わせ、idsによる命名、xfail・skipや外部ファイル連携まで活用範囲は広く、適切に使えばテストコードの重複を大きく減らし、仕様の網羅性も高められます。
まずは既存のテストから繰り返しパターンを見つけ、小さなparametrizeから導入していくことで、プロジェクト全体のテスト自動化を着実に効率化していけます。
