Jupyter Notebookでコードを書いていると、どんなに注意していてもエラーは必ず発生します。
そのたびにプリントデバッグを繰り返していると、時間も集中力も奪われてしまいます。
そこで頼りになるのが%debugマジックコマンドです。
エラー直後の状態に飛び込んで、原因をその場で洗い出せる強力な武器を、この記事では図解と実例で丁寧に解説していきます。
Jupyterの%debugとは?基本と特徴
%debugマジックコマンドの役割

Jupyter Notebookの%debugは、Python標準ライブラリのpdbというデバッガを、Notebook上で簡単に呼び出せるマジックコマンドです。
役割を一言でまとめると、「エラー直後のプログラムの内部状態を、その場で対話的に調べるための入口」になります。
通常、プログラムがエラーで止まってしまうと、表示されるのはスタックトレースだけで、その先は「printで追加調査」くらいしかできません。
しかし%debugを使えば、エラーが起きた瞬間の関数や変数、実行位置に入り込み、Python対話シェルのようにコマンドを打ちながら原因を探ることができます。
ここで押さえておきたいポイントは次の3つです。
まず1つ目は、エラーが起きた後からでもデバッグに入れることです。
2つ目は、通常のセル実行とは異なる、(Pdb)と表示される専用の対話モードに入ることです。
3つ目は、そこで使えるコマンド体系はほぼ標準のpdbと同じということです。
このように、Jupyterの%debugは、Notebook上で手軽にpdbを呼び出すための「マジックなショートカット」と考えると理解しやすくなります。
事後デバッグ(post-mortem)の仕組み
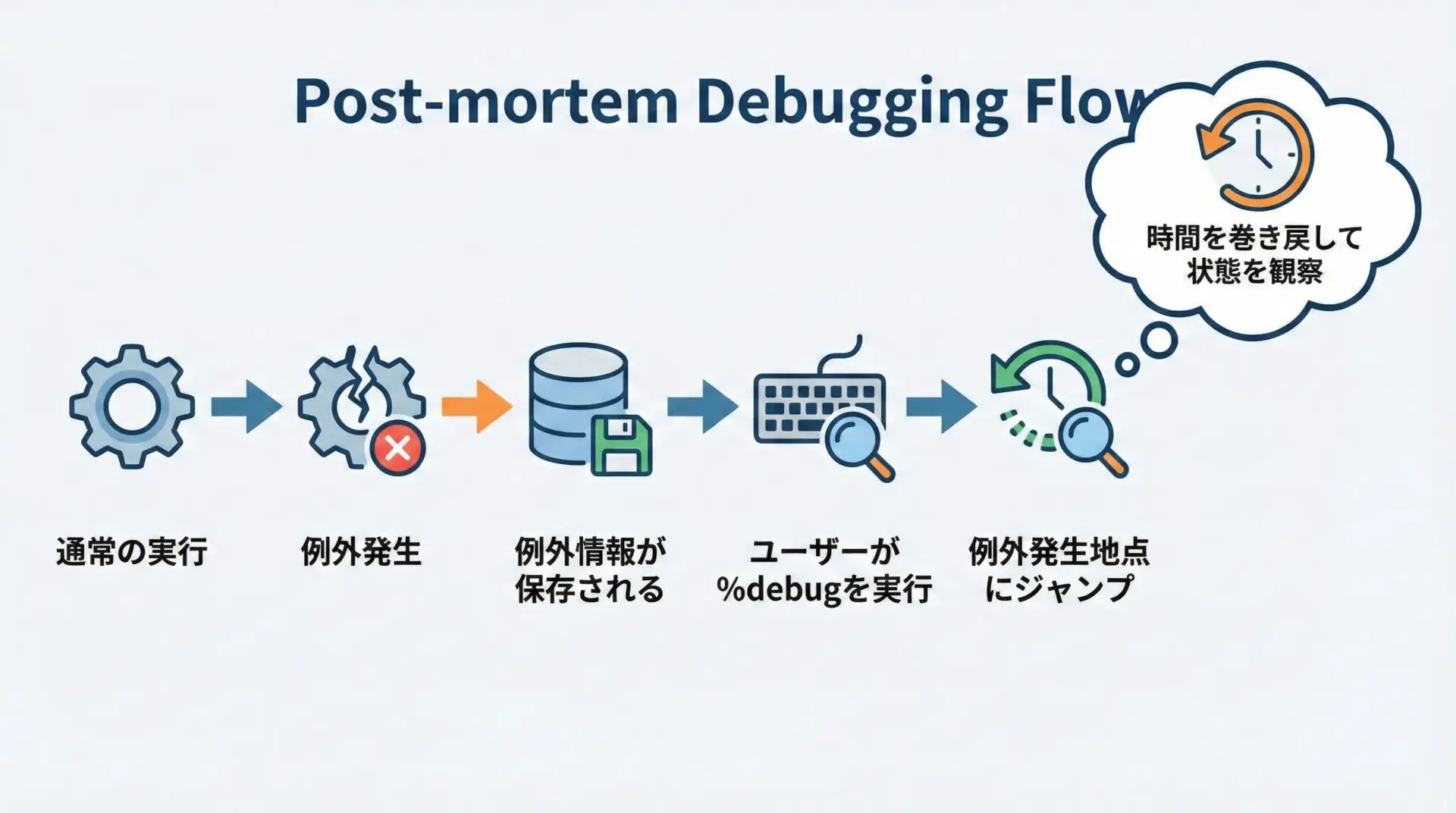
%debugが提供するのは、いわゆる事後デバッグ(post-mortem debugging)です。
これは、プログラムがクラッシュした「後」から、その時点の状態を再現して追跡するデバッグスタイルを指します。
Pythonでは、未処理の例外が発生するとsys.last_type、sys.last_value、sys.last_tracebackといった変数に、次の情報が一時的に退避されます。
- どんな種類の例外か(type)
- 例外インスタンスそのもの(value)
- 例外がどの位置で発生したかという履歴(traceback)
Jupyterの%debugは、この保存された情報を利用してエラー発生地点のフレーム(実行環境)を復元し、その中にpdbとして潜り込んでくれます。
つまり、実行中のプログラムそのものを巻き戻しているわけではなく、エラー発生時点で凍結された「状態のスナップショット」に入り込むイメージです。
この仕組みのおかげで、エラーが出た後にNotebookをスクロールしながら「なんで?」と思った時点からでも、すぐに詳細調査モードに切り替えられるようになっています。
%pdbとの違いと使い分け
%debugとよくセットで話題になるのが%pdbです。
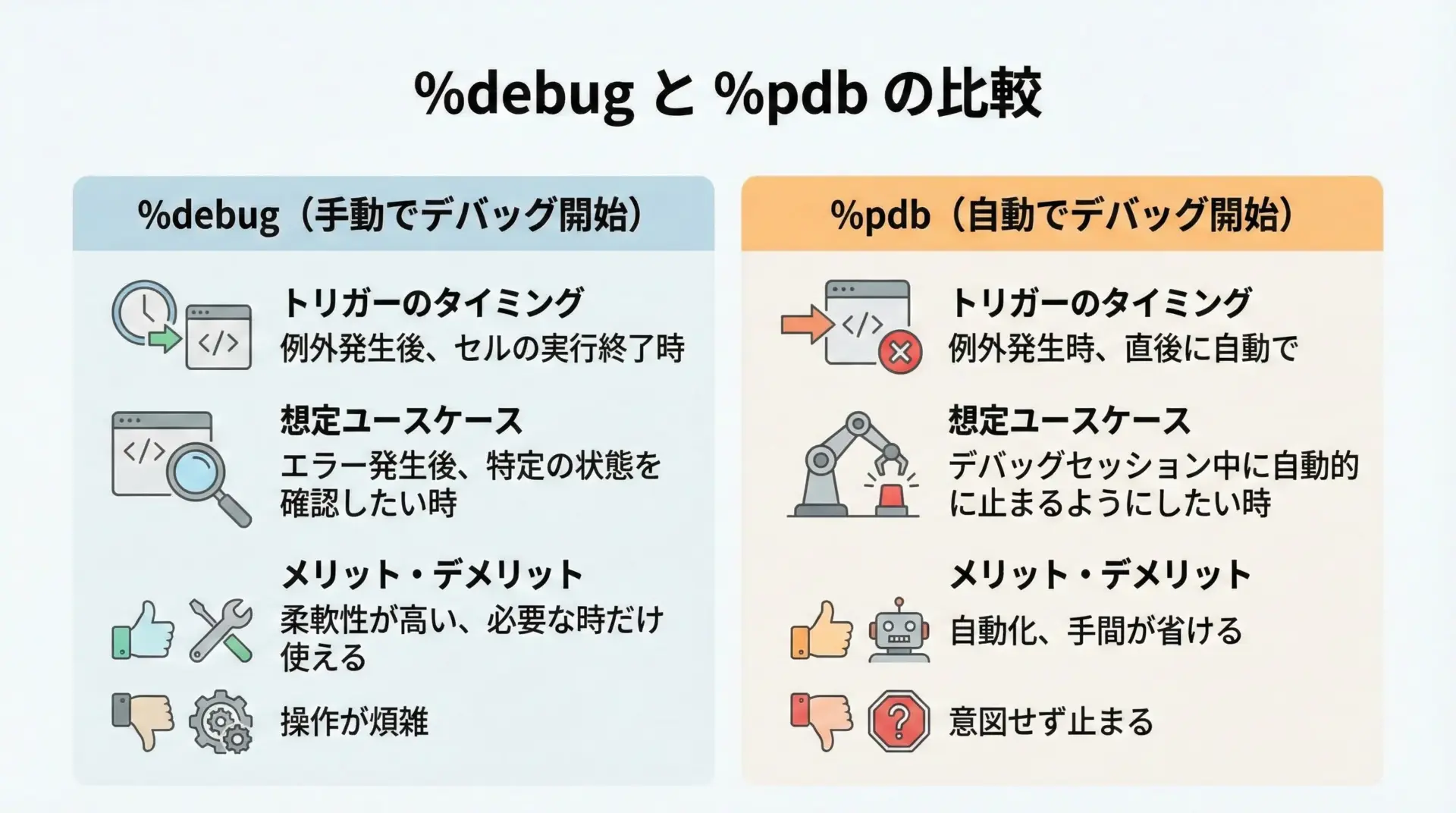
両者は似ていますが、「いつデバッガに入るか」という点が決定的に違います。
%debugは、エラーが出た「後」で、ユーザーが明示的に実行してデバッガに入ります。
一方%pdbは、エラーが発生した瞬間に自動的にpdbを起動するスイッチです。
代表的な違いを表にまとめます。
| 項目 | %debug | %pdb |
|---|---|---|
| 起動タイミング | 例外発生後に、ユーザーが入力して起動 | 例外発生時に自動で起動 |
| 設定方法 | エラー後のセルで%debugを実行 | 一度%pdb onでONにしておく |
| 向いている場面 | たまに発生するエラーを、その都度調べたいとき | 多くのセルで頻繁にデバッグしながら開発するとき |
| 使い心地 | 必要な時だけ入れるので邪魔になりにくい | 予期しないエラーでもすぐに原因を調べられる |
日常的な開発では、まず%debugを基本ツールとして使い、デバッグフェーズに入ったら%pdbをオンにして自動で落ちるようにするという使い分けが実用的です。
%debugの基本的な使い方
エラー発生後に%debugを実行する手順
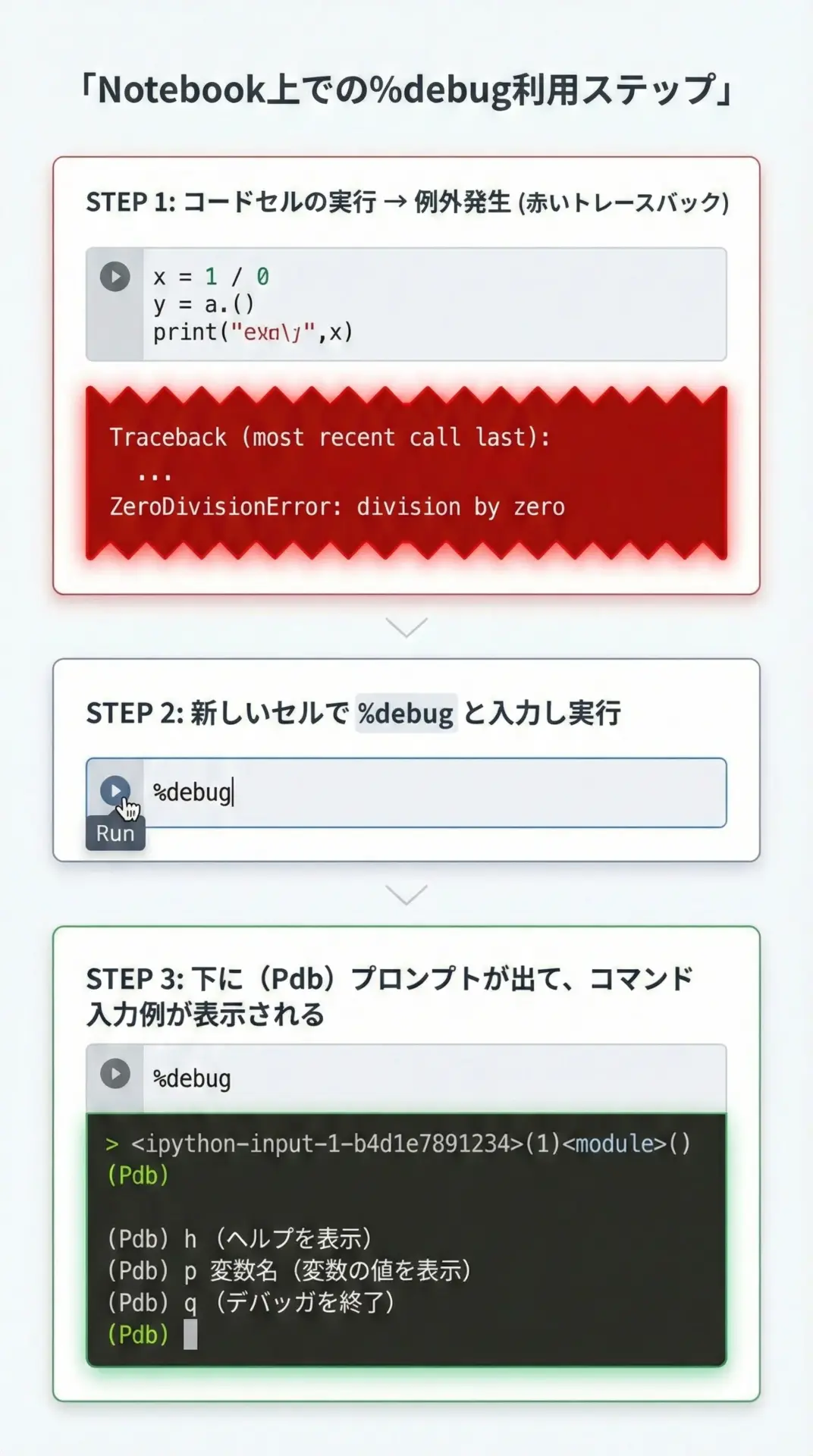
まずは、一連の流れを通して見てみます。
わざとエラーになる簡単なコードを書き、そこから%debugを使う例を示します。
# エラーを起こすサンプルコード
def divide(a, b):
# b が 0 のときに ZeroDivisionError が発生します
return a / b
x = 10
y = 0 # 敢えて 0 を代入
result = divide(x, y) # ここで ZeroDivisionError
print(result)上のセルを実行すると、ZeroDivisionErrorのトレースバックが表示されます。
この直後に、新しいセルを1つ作成し、次のように入力して実行します。
%debugこれを実行すると、Notebookの出力部分に(Pdb)というプロンプトが現れ、デバッガモードに入ります。
> <ipython-input-1-xxxxxxxxx>(4)divide()
3 # b が 0 のときに ZeroDivisionError が発生します
----> 4 return a / b
5
ipdb>
# 実際の表示例では "ipdb>" または "(Pdb)" などと表示されますこの状態になったら、キーボードからpdbコマンドやPython式をどんどん入力して、エラーの原因を調べていきます。
代表的なコマンド一覧
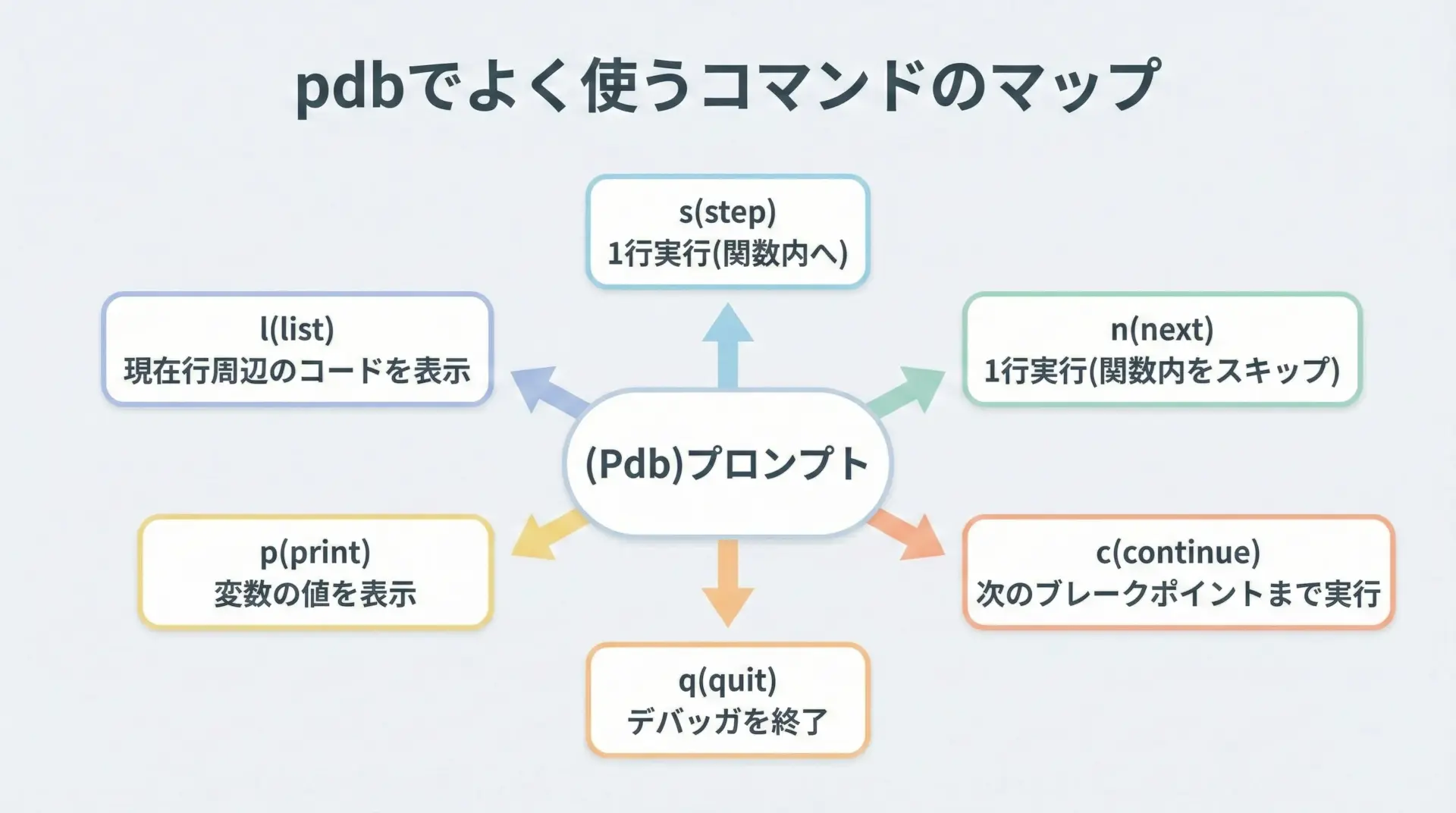
%debugで入るデバッガは、基本的にpdb互換のコマンドを受け付けます。
すべてを暗記する必要はありませんが、よく使うものだけ押さえておくと一気に効率が上がります。
| コマンド | 意味 | 典型的な用途 |
|---|---|---|
| c | continue。次のブレークポイントまたは終了まで実行 | 一時停止から一気に先へ進める |
| n | next。現在の行を実行し、同じ関数内の次の行で停止 | 同じ関数内を1行ずつ追う |
| s | step。関数呼び出しの中に入って詳細を追う | 呼び出し先の関数の中身を見たいとき |
| l | list。現在位置周辺のソースコードを表示 | どの行で止まっているかを確認 |
| p 式 | print。任意の式を評価して結果を表示 | 変数の値や式の結果を素早く確認 |
| q | quit。デバッガを終了してNotebookのプロンプトに戻る | 調査を終えたとき |
例えば、次のような対話になります。
ipdb> l
1 def divide(a, b):
2 # b が 0 のときに ZeroDivisionError が発生します
3 return a / b
ipdb> p a
10
ipdb> p b
0
ipdb> qこのように、「今どの行にいるのか」と「その時点で変数がどうなっているか」を確認するだけでも、かなりのバグは特定できます。
変数の中身を調べる方法
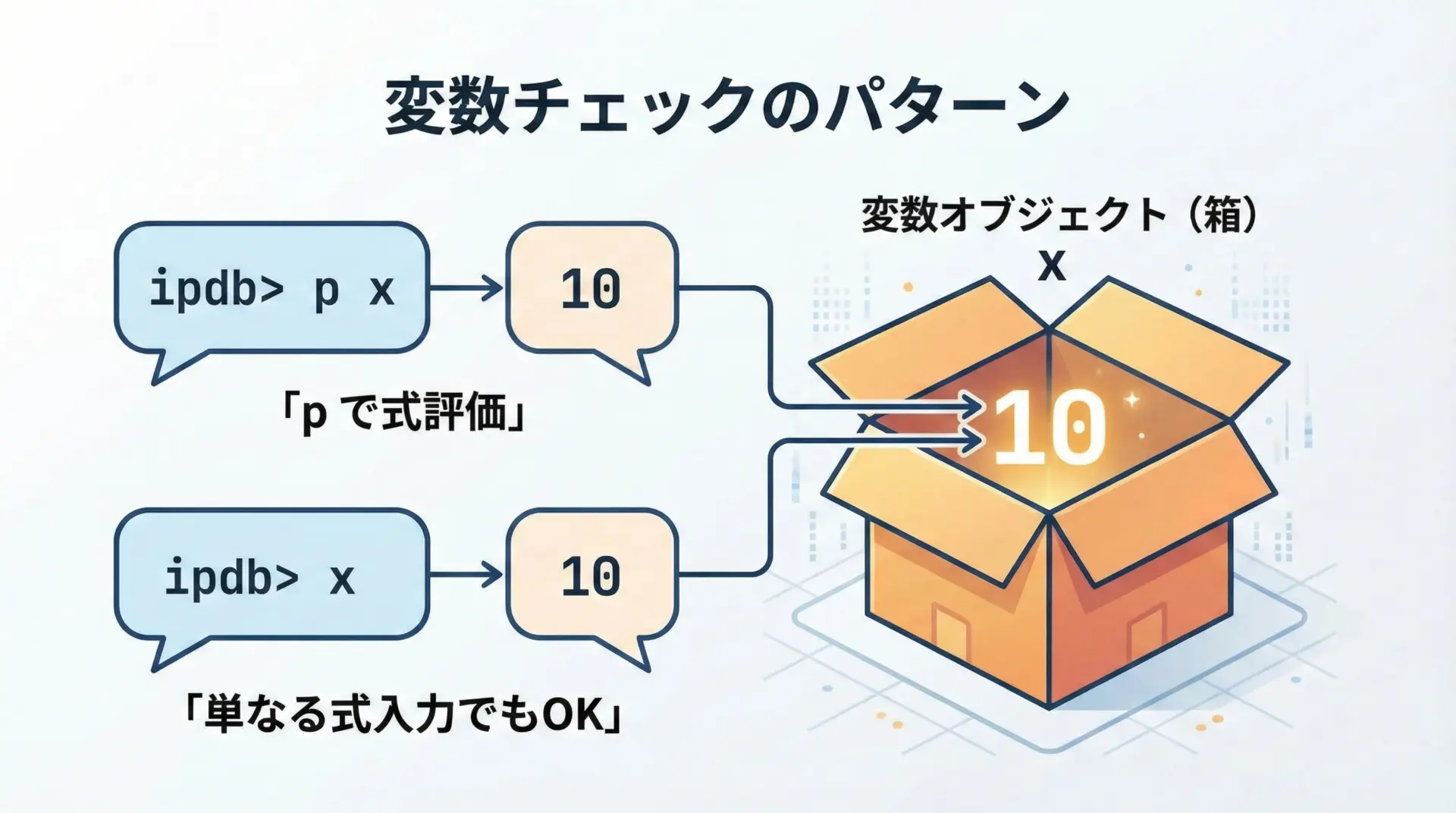
デバッグ中に最もよく行う操作は、変数の中身を確認することです。
pdbでは主にpコマンドを使いますが、実はpを付けずにそのまま式を書いても評価されます。
ipdb> p a # 変数 a の値を表示
10
ipdb> p b
0
ipdb> a + 5 # 単に式を書いても OK
15
ipdb> type(a)
<class 'int'>もう少し複雑なオブジェクトでも、基本は同じです。
ipdb> p my_list
[1, 2, 3, 4]
ipdb> len(my_list)
4
ipdb> my_list[2]
3このように、pdbの中でもほぼ通常のPython REPLと同じ感覚で操作できるため、辞書やクラスインスタンス、PandasのDataFrameなど、どんなオブジェクトでも一貫した手つきで調査可能です。
関数の呼び出し履歴(スタックトレース)の確認方法
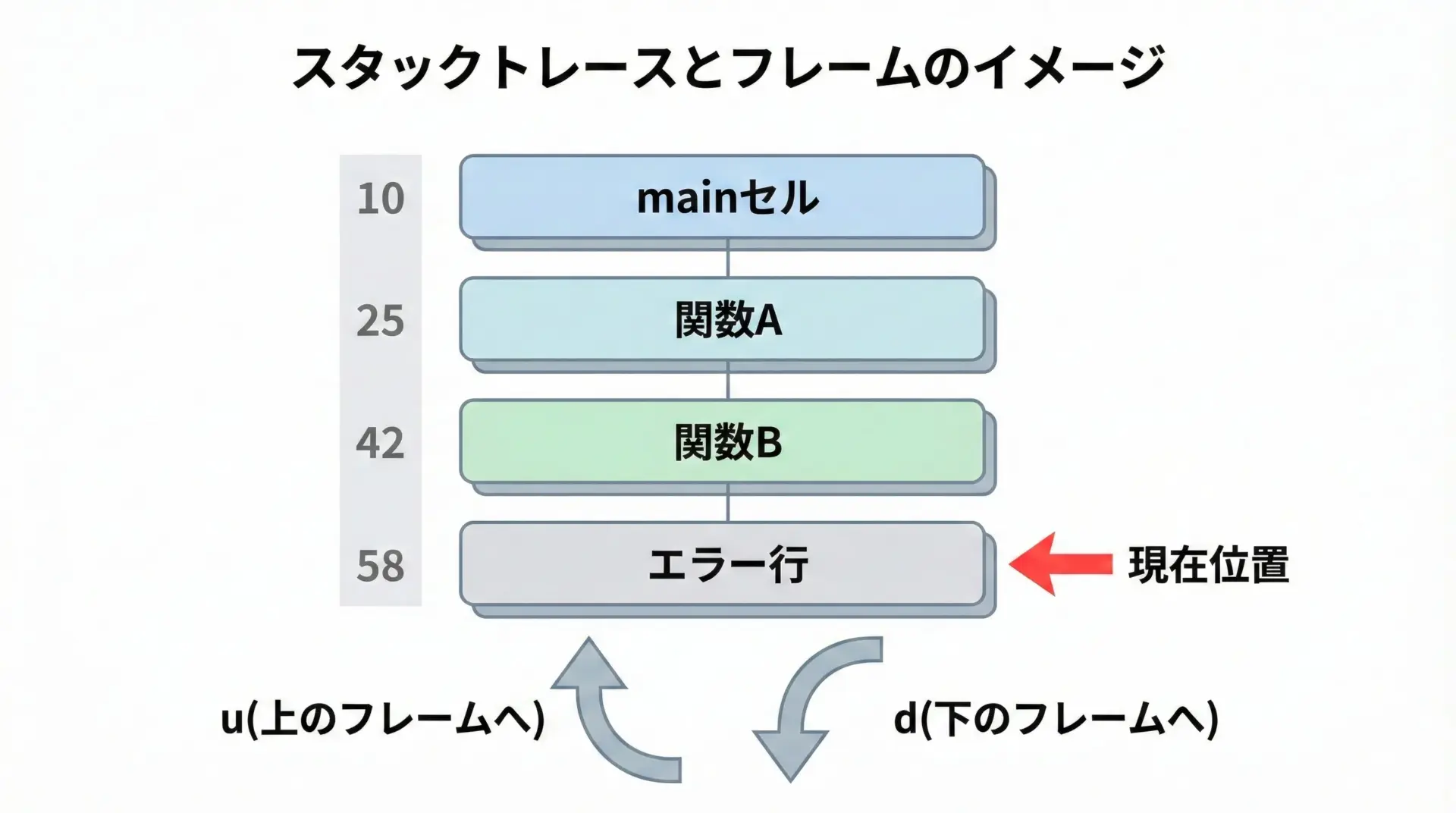
バグの原因が複数の関数をまたいでいる場合、「どの関数からどの関数が呼ばれて、最終的にどこで落ちたのか」という呼び出し履歴を追う必要があります。
pdbではwhereまたはwコマンドで、現在のスタックトレースを確認できます。
ipdb> w
File "<ipython-input-2-aaaa>", line 10, in <module>
main()
File "<ipython-input-2-aaaa>", line 6, in main
calc()
File "<ipython-input-2-aaaa>", line 3, in calc
return 1 / 0
ZeroDivisionError: division by zeroさらに、u(up)、d(down)で、フレームと呼ばれる各呼び出しレベルを移動できます。
上位の関数のローカル変数を確認したい場合には、次のような操作をします。
ipdb> w # まずはスタック全体を確認
ipdb> u # 1つ上のフレーム(呼び出し元)へ
ipdb> l # そのフレームでのソースを表示
ipdb> p some_var # 呼び出し元の変数を確認このように、「どのレイヤーの関数で何が起きているか」を上下に移動しながら見ることで、複雑なバグでも全体像を掴みやすくなります。
%debugを使った効率的なバグ特定テクニック
バグ箇所を一発特定するための視点
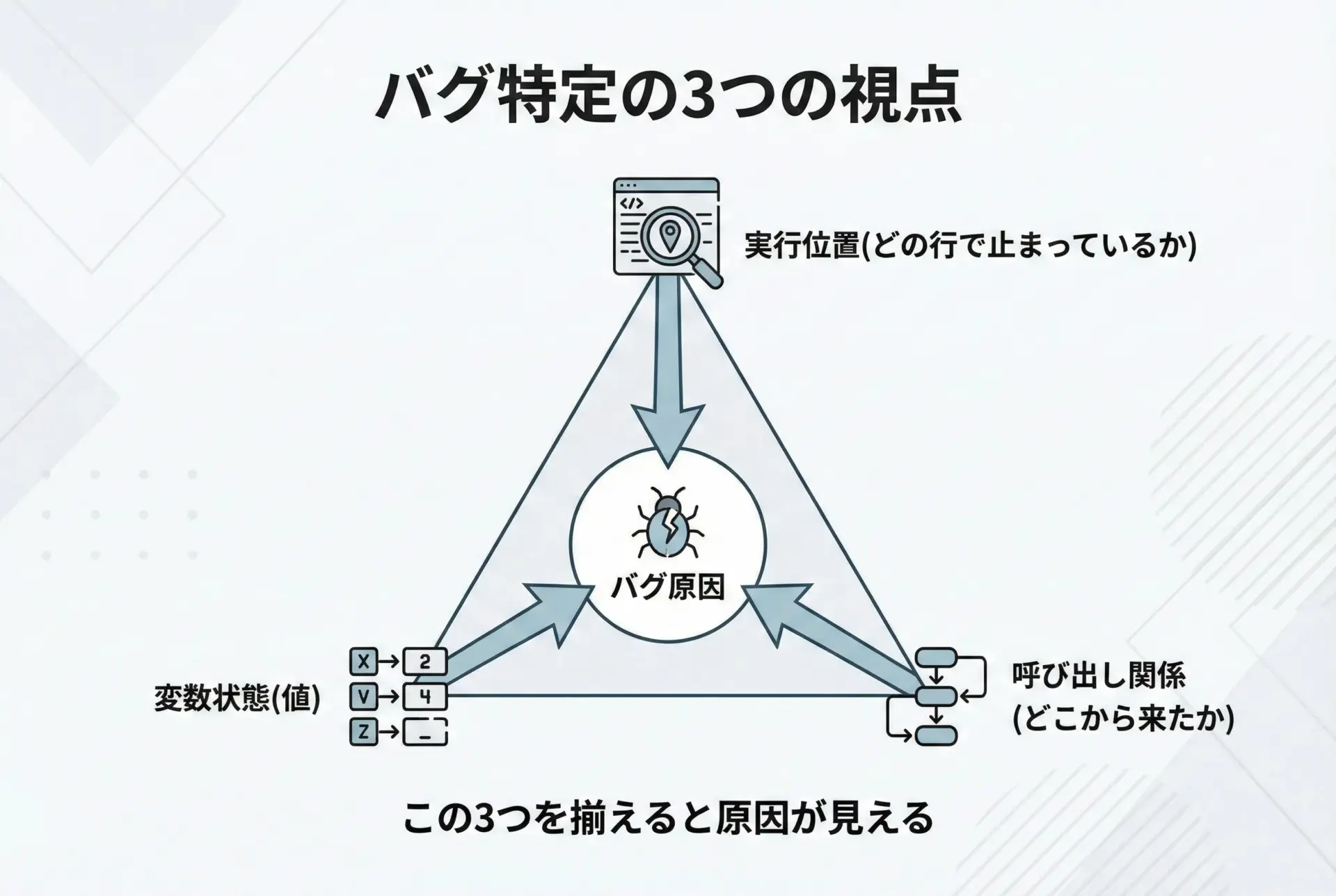
%debugに入ったら、闇雲にコマンドを打つのではなく、「3つの視点」を意識すると一発でバグ箇所に辿り着きやすくなります。
1つ目は「どの行で止まっているか」というlコマンドによるソースの確認です。
2つ目は「その行で使っている変数が、どんな値になっているか」というpコマンドや式評価による確認です。
3つ目は「この関数がどこから呼ばれた結果ここに来ているか」というw、u、dによる呼び出し関係の確認です。
例えば、次のようなデバッグ手順が典型的です。
ipdb> l # 現在位置を確認
ipdb> p data # 問題箇所で使っている変数を確認
ipdb> p len(data)
ipdb> w # どこからこの関数に来たのかを確認
ipdb> u # 呼び出し元のフレームに移動
ipdb> p other # 呼び出し元の変数も確認このとき「本来どんな値・流れになってほしかったか」という期待と、実際の状態のギャップを、常に頭の中で比較できるようにしておくと、バグの原因にすばやく気付けます。
ループや条件分岐の中を丁寧に追うコツ
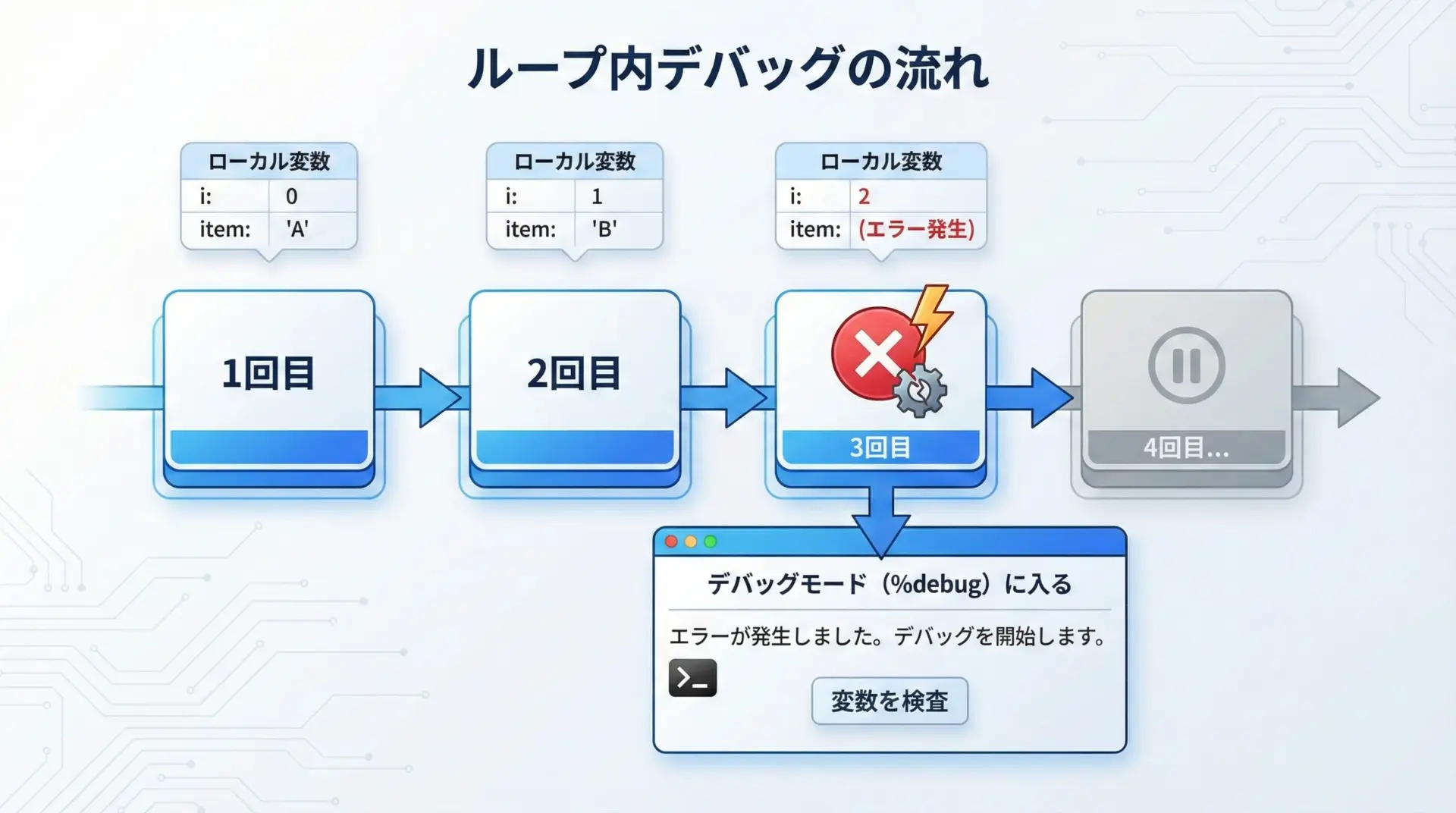
ループや条件分岐の中でバグが起きている場合、「どの反復(どのケース)でおかしくなっているか」をピンポイントで知ることが重要です。
%debugを使えば、問題が起きたその反復の状態に入ることができます。
例として、リスト内の要素を処理する関数を考えてみます。
def process_items(items):
total = 0
for i, item in enumerate(items):
# item が数値でない場合にエラーが出る可能性があります
total += int(item)
return total
data = [1, 2, "A", 4]
process_items(data) # "A" で ValueError が発生エラー後に%debugを実行し、ループ内の状態を確認してみます。
ipdb> l
1 def process_items(items):
2 total = 0
3 for i, item in enumerate(items):
4 # item が数値でない場合にエラーが出る可能性があります
5 -> total += int(item)
6 return total
ipdb> p i
2
ipdb> p item
'A'
ipdb> p items
[1, 2, 'A', 4]このように、「どのインデックス(i)で、どんな値(item)が来ていたのか」をその場で確認できるため、エラー条件の特定が非常に楽になります。
条件分岐の場合も同様に、条件式に使っている変数の値を1つずつチェックすることで、「想定外の条件でこの分岐に入ってしまった」ことに気づけます。
DataFrameや配列(Numpy/Pandas)を確認するワザ

Numpy配列やPandasのDataFrameが絡んだ不具合では、「どの要素やどの行におかしな値が紛れ込んでいるか」を見つける必要があります。
%debugの中でも、普段のNotebookと同じようにheadやdescribeなどを使えます。
次のようなコードを例に考えてみます。
import pandas as pd
df = pd.DataFrame({
"value": [1, 2, 3, None, 5],
})
mean = df["value"].mean() # None が混じっていることで想定外の結果に
print(mean)ここではエラーにはなりませんが、想定より小さい平均値が出たとします。
こうした場合にも%debugを使って詳細を見たいことがあります。
少し工夫して、mean計算の前にわざと例外を発生させ、そこに入ることで状態を観察できます。
import pandas as pd
df = pd.DataFrame({
"value": [1, 2, 3, None, 5],
})
# 意図的に例外を発生させる
raise RuntimeError("Debug here")
mean = df["value"].mean()
print(mean)エラー後に%debugを実行したら、次のようにDataFrameを直接確認できます。
ipdb> p df.head()
value
0 1.0
1 2.0
2 3.0
3 NaN
4 5.0
ipdb> df["value"].isna().sum()
1
ipdb> df["value"].describe()Numpy配列であれば、shapeやdtype、統計量などを順に確認していくのが定石です。
ipdb> p arr.shape
(100, 5)
ipdb> p arr.dtype
float64
ipdb> arr[:5]
array([[...], ...])このように、「Notebookで普段やっている調査作業を、そのままエラー直後の状態で行える」ことが、%debugの大きな強みです。
Notebookとテキストエディタを併用するワークフロー
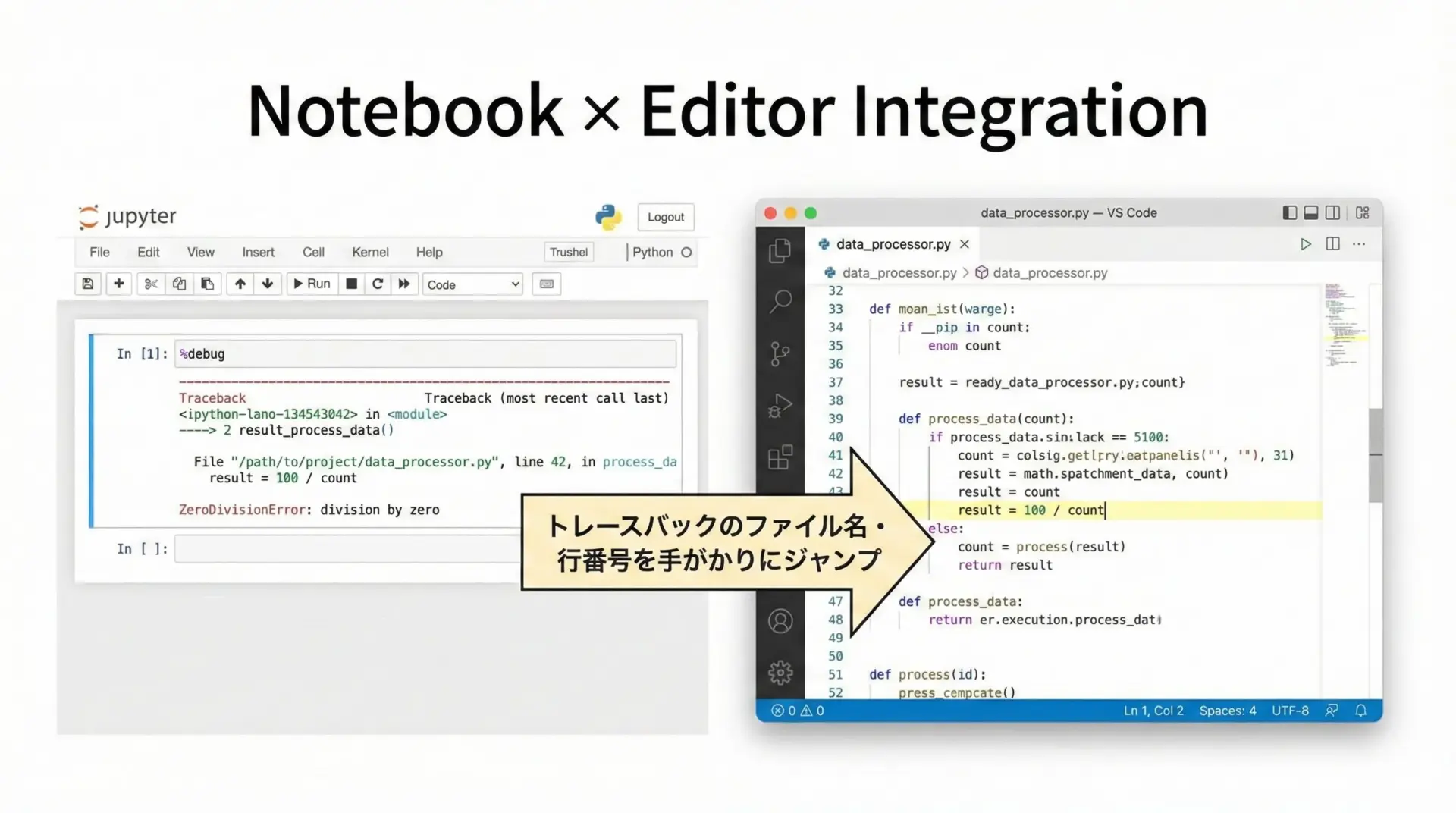
%eebugはNotebook内のコードだけでなく、外部ファイルに定義したモジュールのデバッグにも有効です。
実務では、ライブラリ的なコードは.pyファイルで管理し、それをNotebookから呼び出す構成が一般的です。
この場合の典型的なワークフローは、次のようになります。
1つ目として、テキストエディタ(またはIDE)でライブラリコードを編集し、Notebookからimportして呼び出します。
2つ目として、Notebookで実行中にエラーが出たら%debugに入り、wコマンドでスタックトレースを確認します。
3つ目として、トレースバックに表示されたファイル名と行番号を手がかりに、エディタ側で対応箇所へジャンプし、コードを修正します。
4つ目として、Notebookに戻って再実行し、必要なら再度%cst-code>%debugで検証します。
このようにNotebookを「実験場」、テキストエディタを「コードの本体編集環境」と割り切り、%debugで見つけた情報を即座にエディタに反映することで、快適な開発サイクルを回すことができます。
%debugを使いこなすための応用Tips
自動デバッグ%pdbとの組み合わせ活用
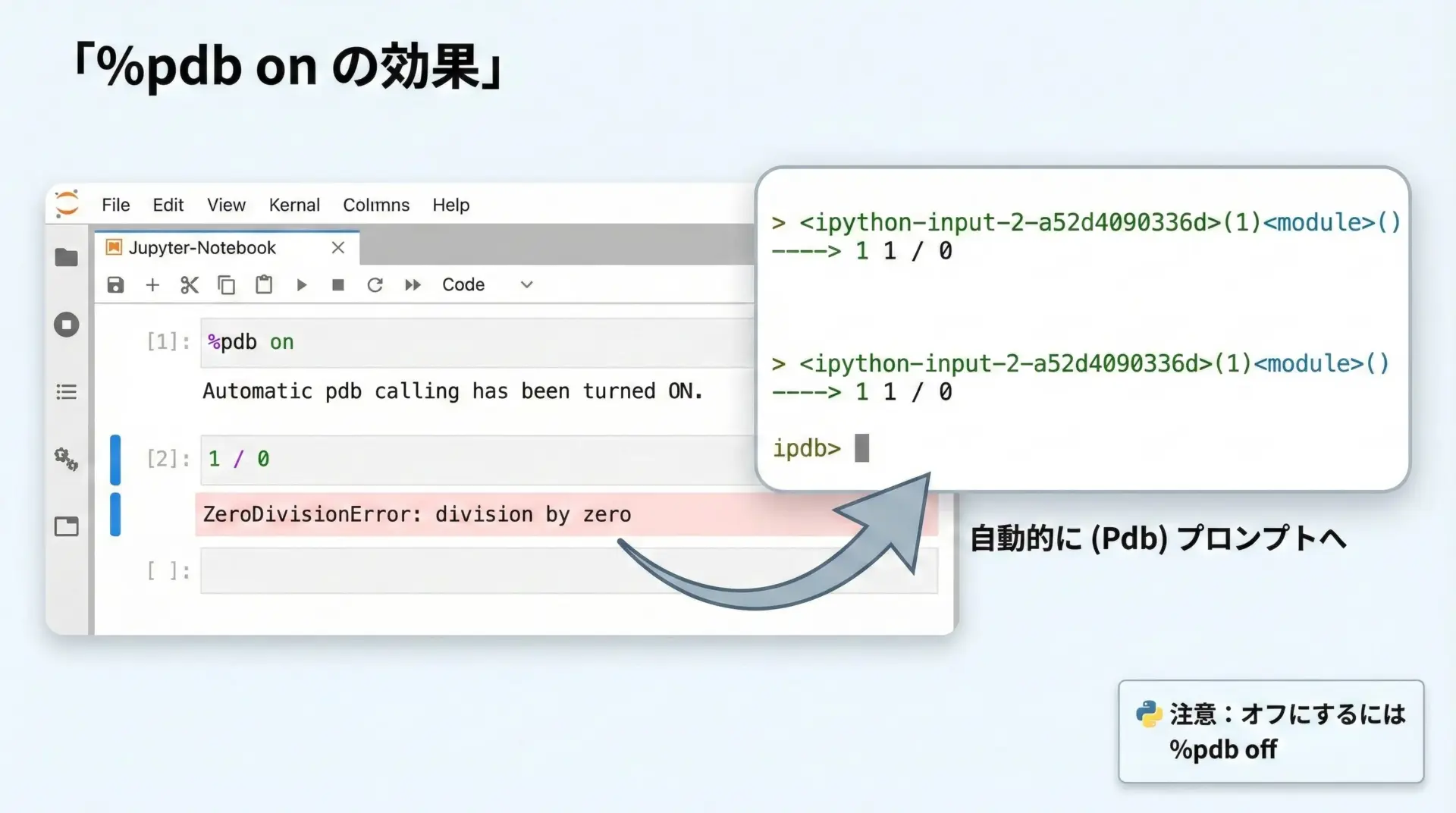
%pdbは、「エラーが発生したら必ずデバッガに落ちる」という自動デバッグモードをON/OFFするマジックコマンドです。
長時間の開発セッションでは、次のように最初のセルで有効化しておくのがおすすめです。
%pdb on # 自動デバッグを有効化この設定をした状態でエラーが発生すると、ユーザーが%debugを実行しなくても、自動でpdbに入ります。
「とにかくどんなエラーも即座に調査したいフェーズ」では、とても有効です。
不要になったときは、次のようにオフに戻します。
%pdb off # 自動デバッグを無効化%debugと%pdbを組み合わせる考え方としては、普段は%debugで手動デバッグし、難しいバグの調査中や頻繁にエラーが出るフェーズでは一時的に%pdb onにスイッチする、というスタイルが現実的です。
他のデバッグツール(%run -d/ipdb)との比較
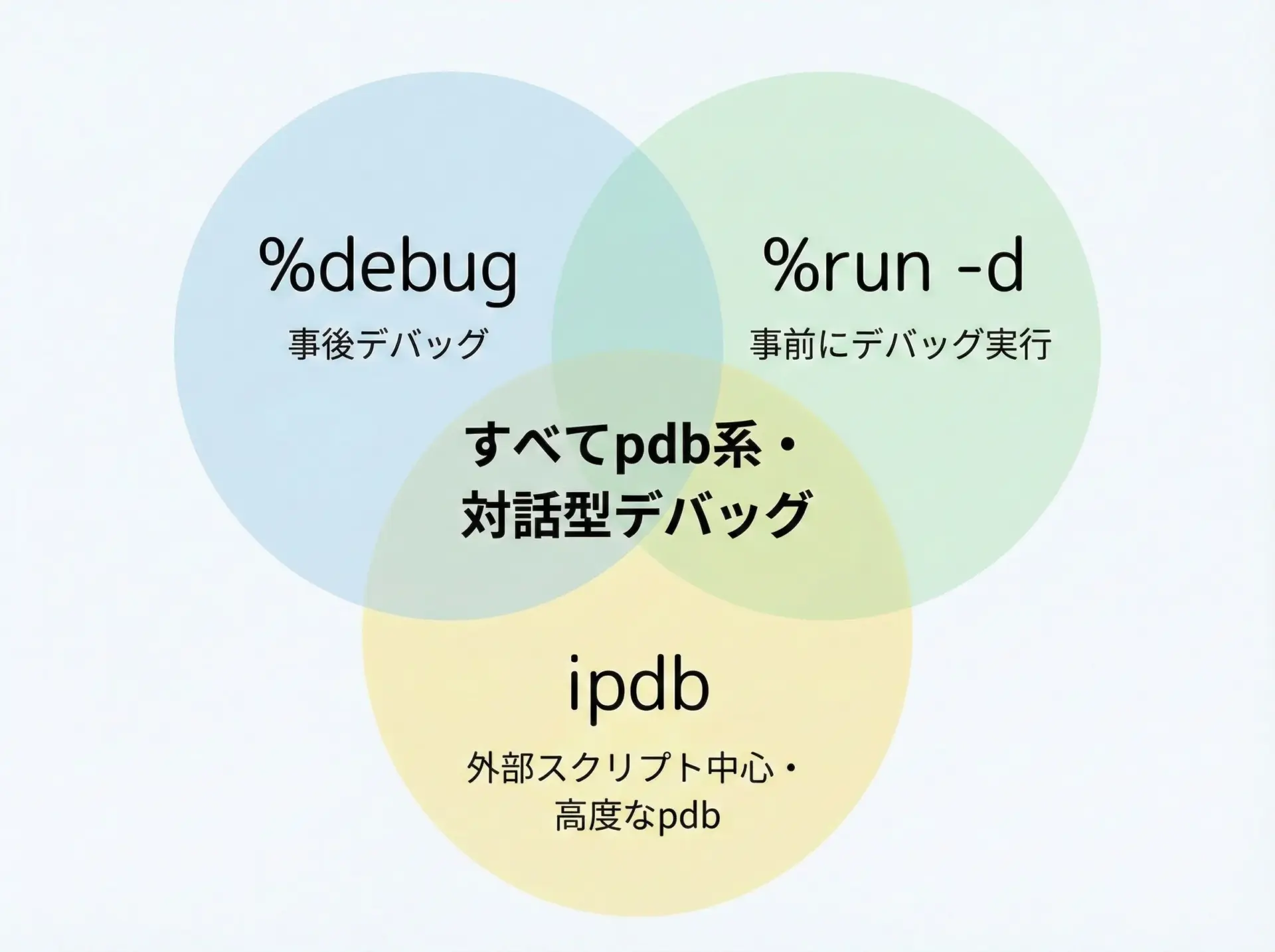
Jupyterでは%debug以外にもpdb系のツールがいくつか存在します。
それぞれに得意分野があるので、目的に応じて使い分けると便利です。
1つ目は%run -dです。
これはスクリプトファイルを最初からデバッガ付きで実行するためのコマンドです。
%run -d my_script.pyこのように起動すると、プログラム開始直後からpdbモードになり、ブレークポイントを設定しながら進められます。
事前に「どの辺りを追いたいか」がわかっている場合に向いています。
2つ目はipdbです。
これはpdbを拡張したサードパーティライブラリで、カラフルな表示や補完機能などが追加されています。
Notebook上でもimport ipdb; ipdb.set_trace()のようにしてブレークポイントを仕込めます。
import ipdb
def some_func(x):
ipdb.set_trace() # ここで一時停止してデバッグ開始
return x * 2これらと%debugの違いをまとめると、次のようになります。
| ツール | タイミング | 主な用途 |
|---|---|---|
| %debug | 事後(エラー発生後) | 想定外の例外原因をその場で調査 |
| %run -d | 事前(スクリプト実行時) | 最初から追跡したいバグの解析 |
| ipdb.set_trace() | 任意の行で停止 | 特定の箇所をブレークポイントとして詳細調査 |
Notebookでの開発では、まず%debugを基本にし、必要になったときに%run -dやipdbを補助的に使う、というスタンスが扱いやすいです。
よくあるつまずきポイントと対処法
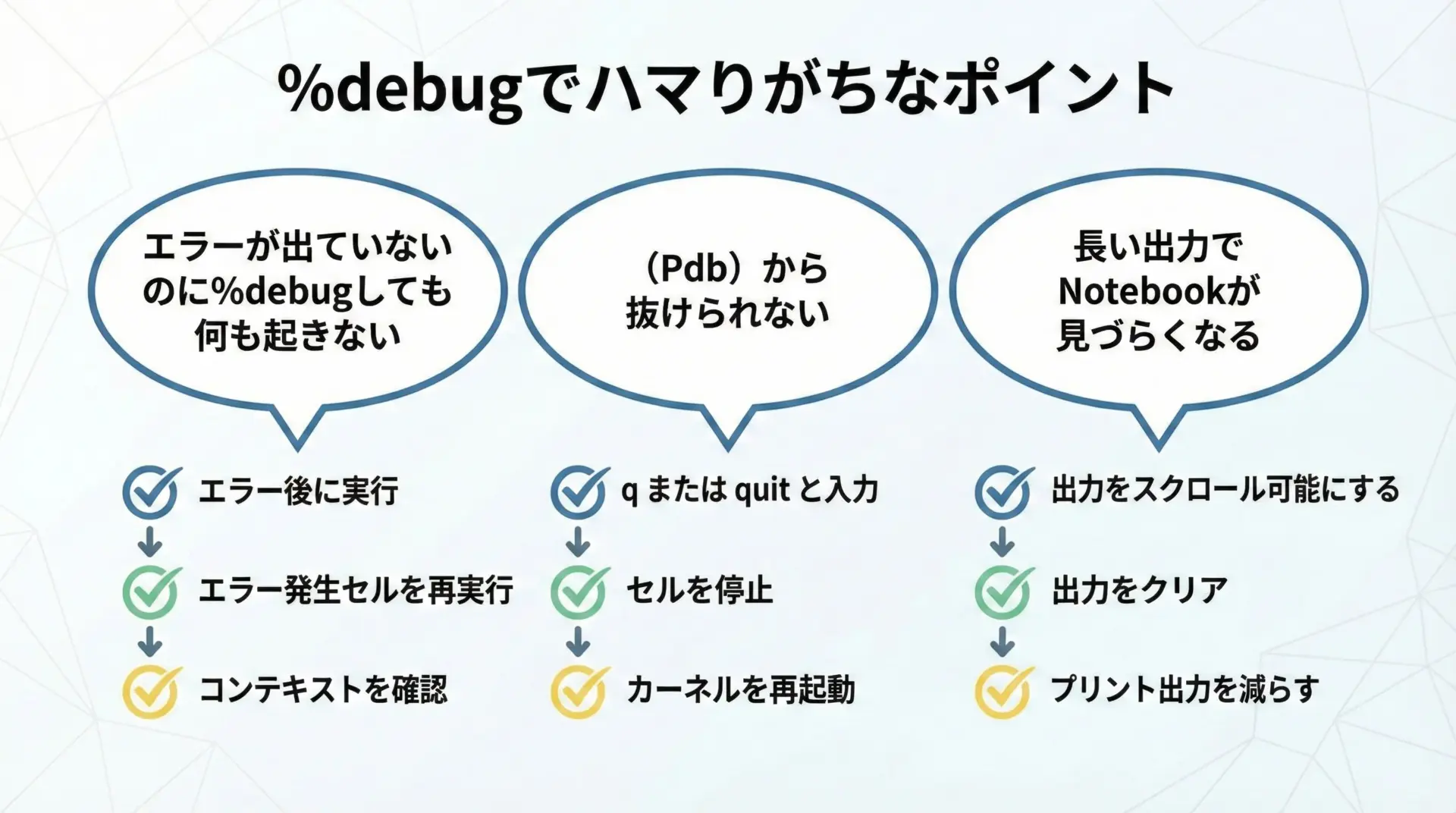
%cst-code>%debugは便利ですが、初めて使うときにいくつかつまずきやすいポイントがあります。
代表的なものと対処法を整理します。
1つ目は「エラーが出ていないのに%debugを実行しても、何も起きない」ケースです。
%debugは直前のセルで発生した例外情報を使うため、直前にエラーが発生していないと、有効なトレースバックが存在しません。
この場合は、まず問題のセルを実行してエラーを再現し、それから続けて%cst-code>%debugを実行するようにしてください。
2つ目は「(Pdb)からどうやって抜ければいいかわからない」という問題です。
pdbから抜けるにはqコマンドを使います。
ipdb> qこれでNotebookの通常のプロンプトに戻れます。
もし誤ってEnterを連打してしまい、どんどん進んでしまった場合でも、慌てずqと打てば抜けられます。
3つ目は、「lやpで膨大な量の出力をしてしまい、Notebookがスクロールだらけになる」という問題です。
これを避けるには、表示する行数や要素数を絞ることが有効です。
例えば、リスト全体ではなく先頭の数件だけを見る、DataFrameは.head()で一部だけ表示する、といった工夫です。
ipdb> p big_list[:10] # 先頭 10 要素だけ
ipdb> p df.head(5) # 先頭 5 行だけ
ipdb> l 10, 30 # 10 〜 30 行だけ表示このようなテクニックを覚えておくと、Notebookの見通しを保ちつつ、効率よくデバッグ作業を進めることができます。
まとめ
Jupyterの%debugマジックコマンドは、エラーが出た直後の世界に飛び込んで、コードの流れや変数の状態を対話的に調べられる強力なデバッグ手段です。
エラー発生後に%debugでpdbに入り、l・p・w・uといった基本コマンドで「どの行で」「どんな値で」「どこから来て」止まったのかを確認するだけでも、多くのバグは素早く特定できます。
さらに%pdbで自動デバッグを有効化したり、%run -dやipdbと組み合わせたりすることで、Notebookと外部ファイルを跨いだ本格的なデバッグも可能になります。
プリントデバッグに頼りきりだった作業を一歩進めるために、ぜひ日常的な開発フローの中へ%debugを取り入れてみてください。
