
Pythonでのデータ分析や開発をしていると、JupyterLab上でのちょっとした操作の積み重ねが、意外と大きな時間ロスになります。
そこで役立つのが「マジックコマンド」です。
本記事では、JupyterLabで使える代表的なマジックを30個厳選し、実務や学習ですぐに使える形で詳しく紹介します。
- JupyterLabマジックとは何か
- 必須の基本マジックコマンド
- Python作業を爆速化するマジック30選
- シェル連携を行うbashマジック
- ファイル操作を効率化するwritefileマジック
- プロファイルで高速化するprunマジック
- メモリ使用量を可視化するmemitマジック
- モジュールを自動リロードするautoreloadマジック
- パス操作を簡略化するcd/pwdマジック
- ノートブックの構造化に使うmarkdownマジック
- デバッグを支援するpdbマジック
- エラーを無視するignoreマジック
- 並列計算を行うparallelマジック
- NumPy処理を高速化するcythonマジック
- SQLを直接実行するsqlマジック
- Rを呼び出すRマジック
- 環境変数を扱うenvマジック
- 行数を短縮するaliasマジック
- プロファイルを保存するstoreマジック
- ログを記録するlogstartマジック
- 実験を整理するnotebookマジック
- 可視化を最適化するmatplotlibマジック
- グラフ描画を高速化するinlineマジック
- JupyterLabマジック活用のコツ
- まとめ
JupyterLabマジックとは何か
Jupyterマジックコマンドの基本と種類
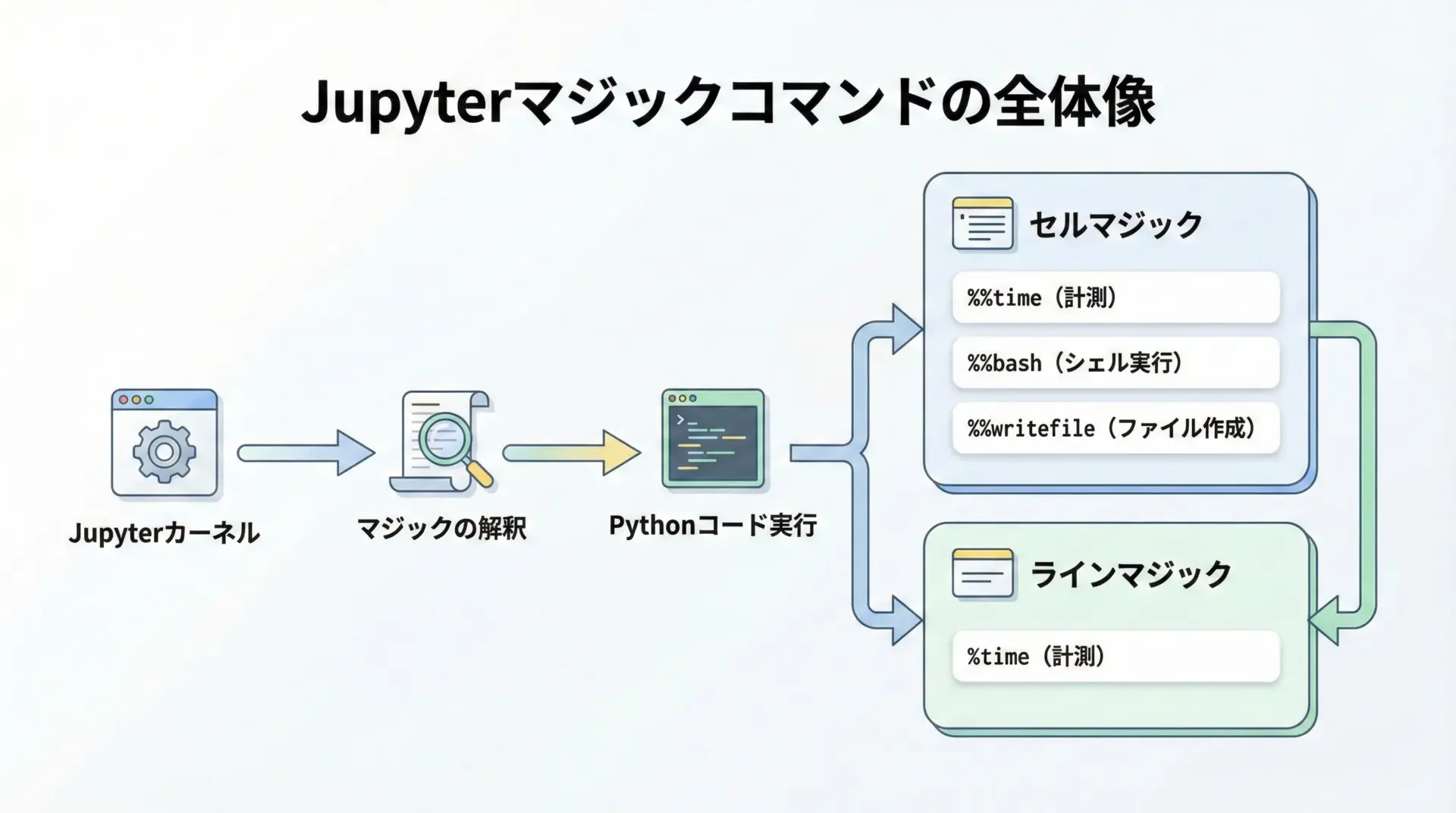
JupyterLabマジックとは、Jupyter(IPython)環境でセルや行の先頭に記述することで、Pythonコードとは別系統の特別な処理を行うための拡張コマンドです。
Pythonの構文ではなく、Jupyterカーネルが解釈して動作します。
Jupyterマジックには大きく分けて2種類あります。
ラインマジック(%で始まる)
行の先頭に%を書いて使用するタイプです。
1行だけに適用されるため、「ちょっと計測したい」「今だけ表示方法を変えたい」といった用途に向いています。
代表例としては次のようなものがあります。
%time…その行の実行時間を計測%pwd…現在の作業ディレクトリを表示%matplotlib inline…グラフをノートブック内に表示
セルマジック(%%で始まる)
セルの先頭を%%で始めると、そのセル全体にマジックが適用されます。
複数行のコードをまとめて別の言語やモードで扱いたいときに非常に便利です。
代表例としては次のようなものがあります。
%%time…セル全体の実行時間を計測%%bash…セル内をシェルスクリプトとして実行%%writefile…セル内容をファイルとして保存%%sql…セル内をSQLとして実行(拡張機能)
このように、マジックコマンドは「Jupyterにおけるメタ操作」を担っており、Pythonコードそのものではなく、実行環境や入出力を制御する役割を果たします。
Pythonコードを高速化するJupyterマジックのメリット
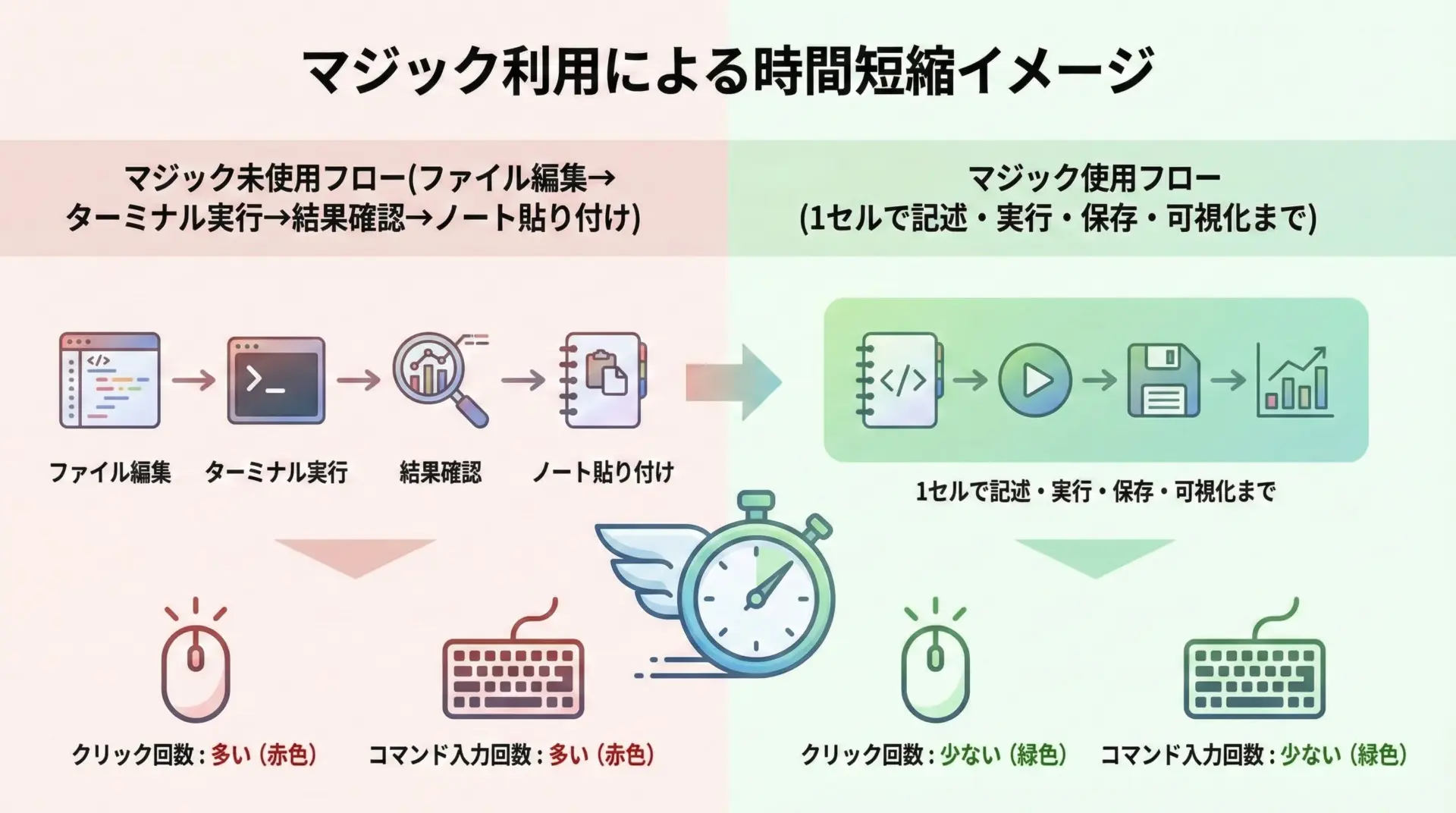
マジックコマンドを活用することで、Pythonの実行自体が魔法のように速くなるわけではありませんが、「作業時間」や「試行錯誤の回数」を大幅に削減できます。
主なメリットは次の通りです。
文章で整理すると、まず反復作業の短縮があります。
例えば、都度ターミナルを開いてシェルコマンドを実行していた作業を%%bashでセル内に書けるため、環境の切り替えやコピー&ペーストの手間を削減できます。
次に性能ボトルネックの可視化です。
%timeや%prun、%memitなどを使うことで、どの処理に時間やメモリがかかっているかを素早く把握できます。
これはアルゴリズムの改善やデータ処理フローの見直しに直結します。
さらに環境やノートブックの「状態」を把握しやすいことも大きな利点です。
%whoや%history、%logstartなどを使えば、どんな変数があり、どういう実験をしてきたかを迅速に振り返ることができます。
これらを総合すると、Jupyterマジックは「Pythonコードの性能」ではなく「Python開発の生産性」を爆速化するためのツールだと理解するとよいです。
必須の基本マジックコマンド
実行時間を測定するtimeマジック
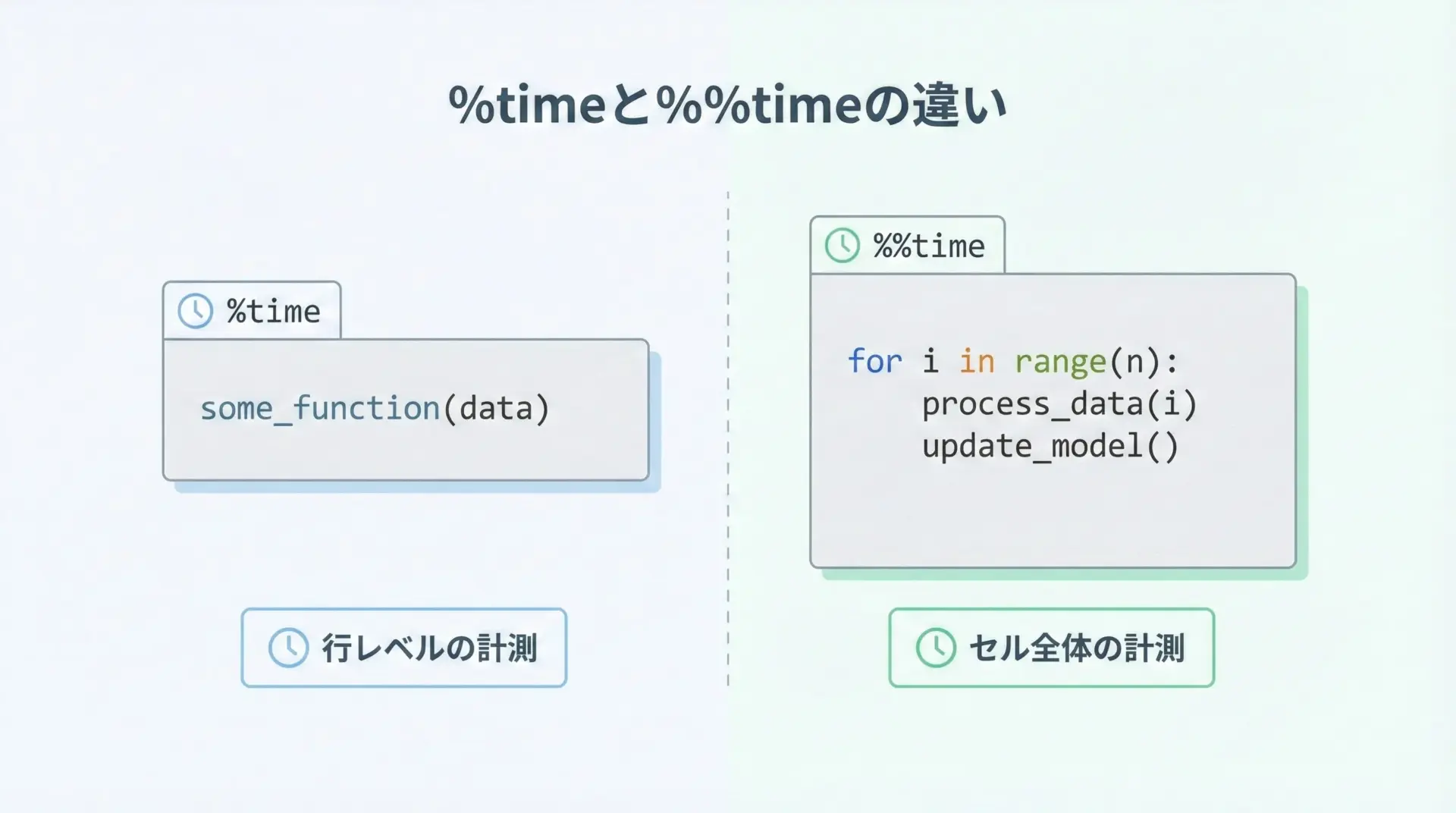
処理時間の計測は、Pythonの高速化やボトルネック発見の第一歩です。
Jupyterでは%timeと%%timeを使って簡単に測定できます。
%time(1行の実行時間を計測)
# %time は「その1行だけ」の実行時間を計測します
import time
%time time.sleep(1) # 1秒スリープする処理Wall time: 1 sこのように、%timeは1回だけ実行して、その処理がどれくらい時間を要したかを教えてくれます。
%%time(セル全体の実行時間を計測)
%%time
# このセル全体の実行時間を計測します
import time
time.sleep(0.5)
x = sum(range(10_0000))
time.sleep(0.5)Wall time: 1.01 s%%timeは、セル内のすべての処理をまとめて計測したいときに便利です。
複数の処理を一括で測り、ほかのセルと比較しながら最適化する際に役立ちます。
なお、同じコードを複数回実行して平均を取りたい場合には%timeitを使うのが一般的ですが、本記事では「代表30選」の中では%timeにフォーカスして解説します。
実行環境を管理するwho/whosマジック
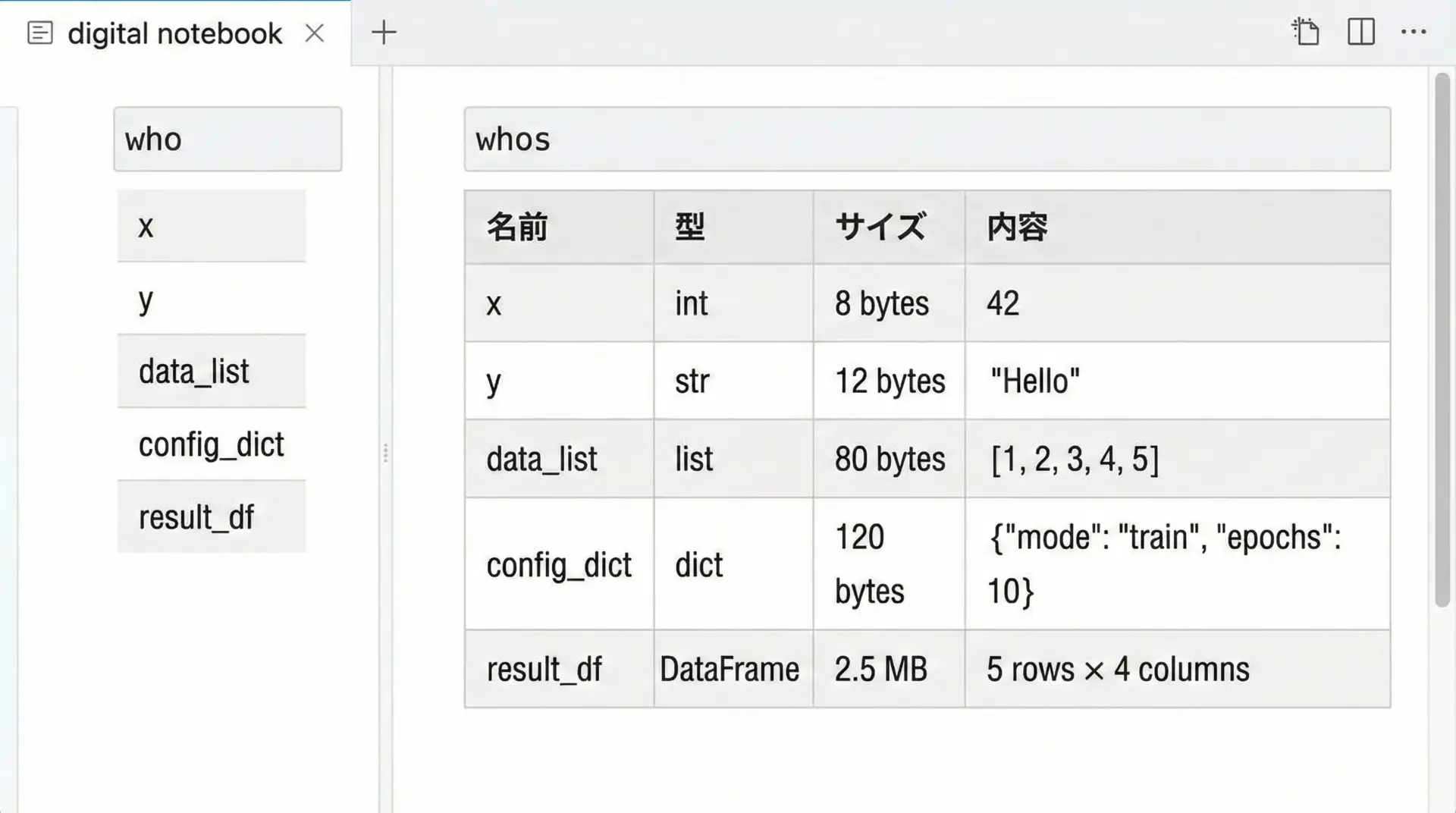
長時間ノートブックを操作していると、「今どんな変数が定義されているのか」「どの変数が大きなオブジェクトなのか」が分からなくなります。
このようなときに役立つのが%whoと%whosです。
%who(変数名だけを一覧表示)
# いくつか変数を用意します
a = 10
b = "hello"
c = [1, 2, 3]
# 現在の名前空間にある変数名を一覧表示
%whoa b c%whoは「どんな名前が存在するかだけを素早く知りたい」ときに適しています。
%whos(変数の詳細情報を一覧表示)
# %whos は型やサイズなどの情報も表示します
%whosVariable Type Data/Info
----------------------------
a int 10
b str hello
c list n=3%whosは、メモリを圧迫していそうな変数や、型を確認したい変数を一括で確認するのに非常に便利です。
特に大きなNumPy配列やPandasデータフレームを多用するデータ分析では、こまめに%whosを実行して環境を把握する習慣が有効です。
コマンド履歴を扱うhistoryマジック
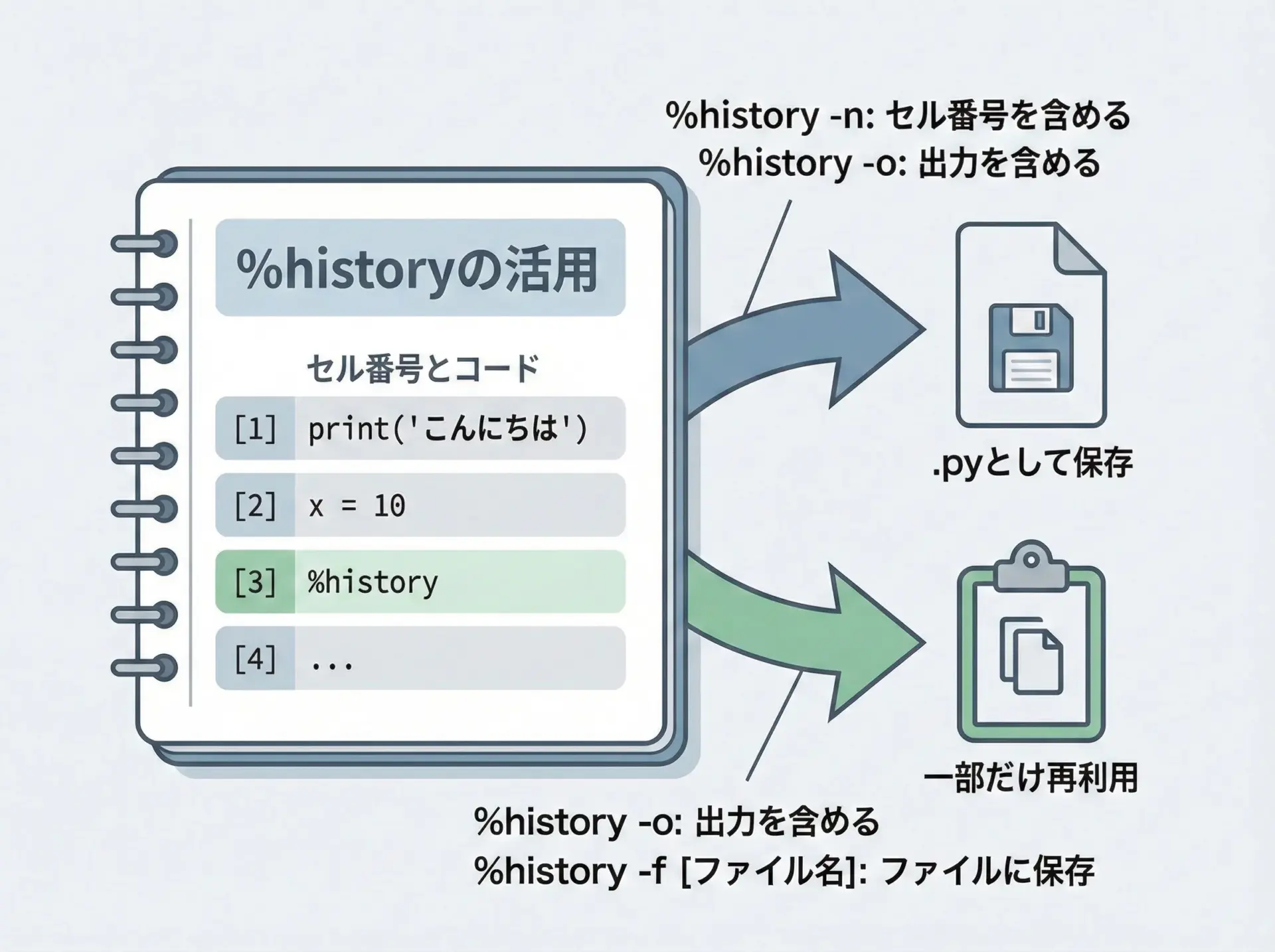
Jupyterでは何度も試行錯誤を繰り返すため、後から「あの時のコードをもう一度使いたい」と思うことがあります。
%historyは、このような対話履歴を一覧表示したり、ファイルに保存したりするためのマジックです。
基本的な履歴表示
# 直近のコマンド履歴を表示します
%history出力は環境によって異なりますが、番号付きでこれまで実行したコードが一覧表示されます。
行番号付きで履歴を表示
# -n オプションで行番号を明示的に表示
%history -n1: a = 10
2: b = "hello"
3: c = [1, 2, 3]
4: %who
...履歴をファイルに保存
# 1番から20番までの履歴を script.py に保存
%history -n -f script.py 1-20Writing history to script.pyこのように%historyを使うと、対話的な試行錯誤から「スクリプト化」への橋渡しがスムーズになります。
実行結果を無視・制御するcaptureマジック
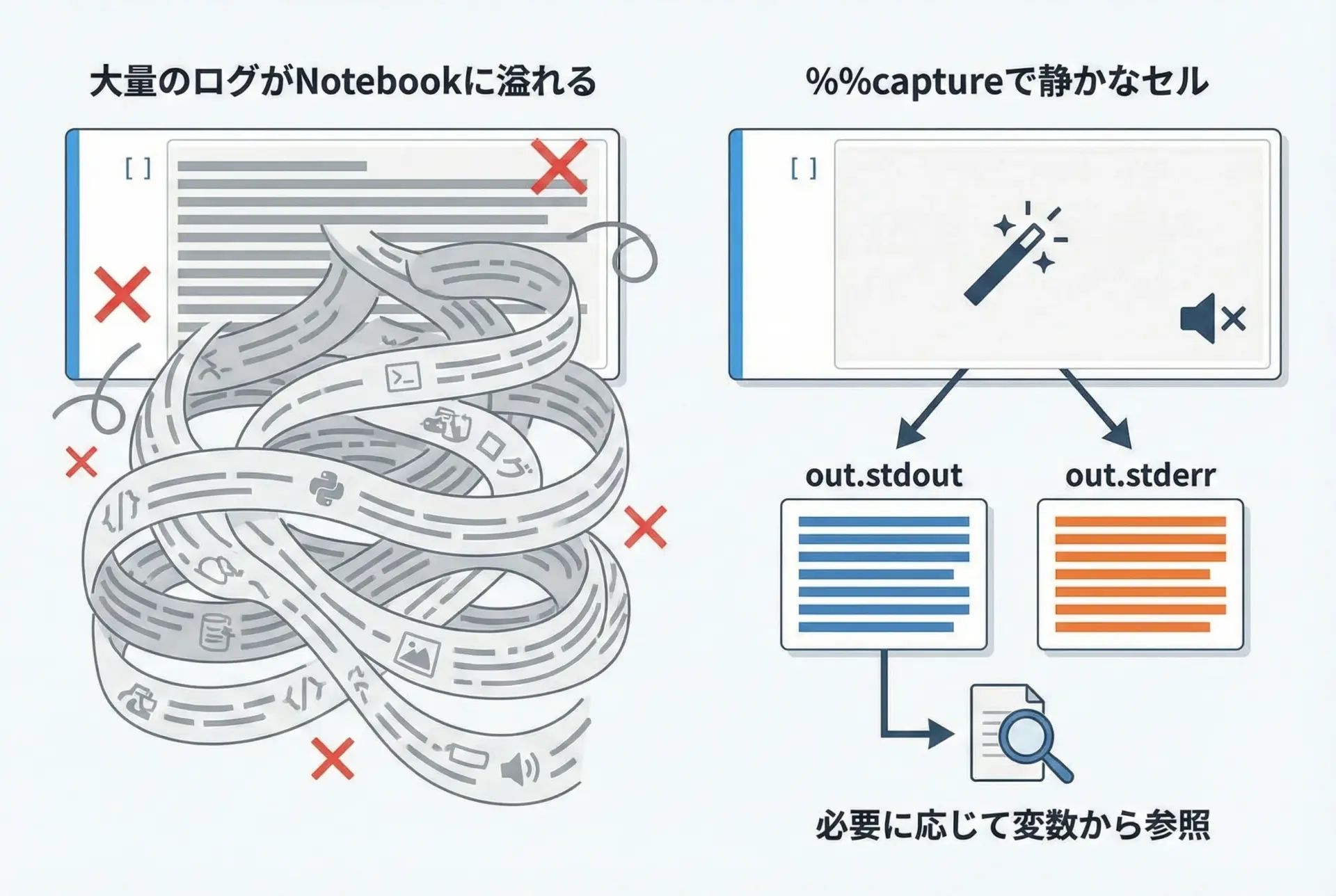
大規模なログを出す処理や、標準出力を一時的に抑制したい場合には%%captureが有効です。
これはセルマジックで、セルの標準出力(stdout)や標準エラー(stderr)をノートブックに表示せずに変数に格納できる機能です。
出力を完全に抑制する
%%capture
# このセルの標準出力はノートブックには表示されません
for i in range(5):
print("ログ:", i)# 何も表示されない出力を変数に格納して後から参照する
%%capture out # out という名前のオブジェクトに結果を保存
for i in range(3):
print("ログ:", i)
# セル実行後に out から中身を確認
print("標準出力の内容:")
print(out.stdout)標準出力の内容:
ログ: 0
ログ: 1
ログ: 2このようにログは残しつつ、ノートブック画面をスッキリさせたいときに%%captureは非常に便利です。
マジックの一覧とヘルプ
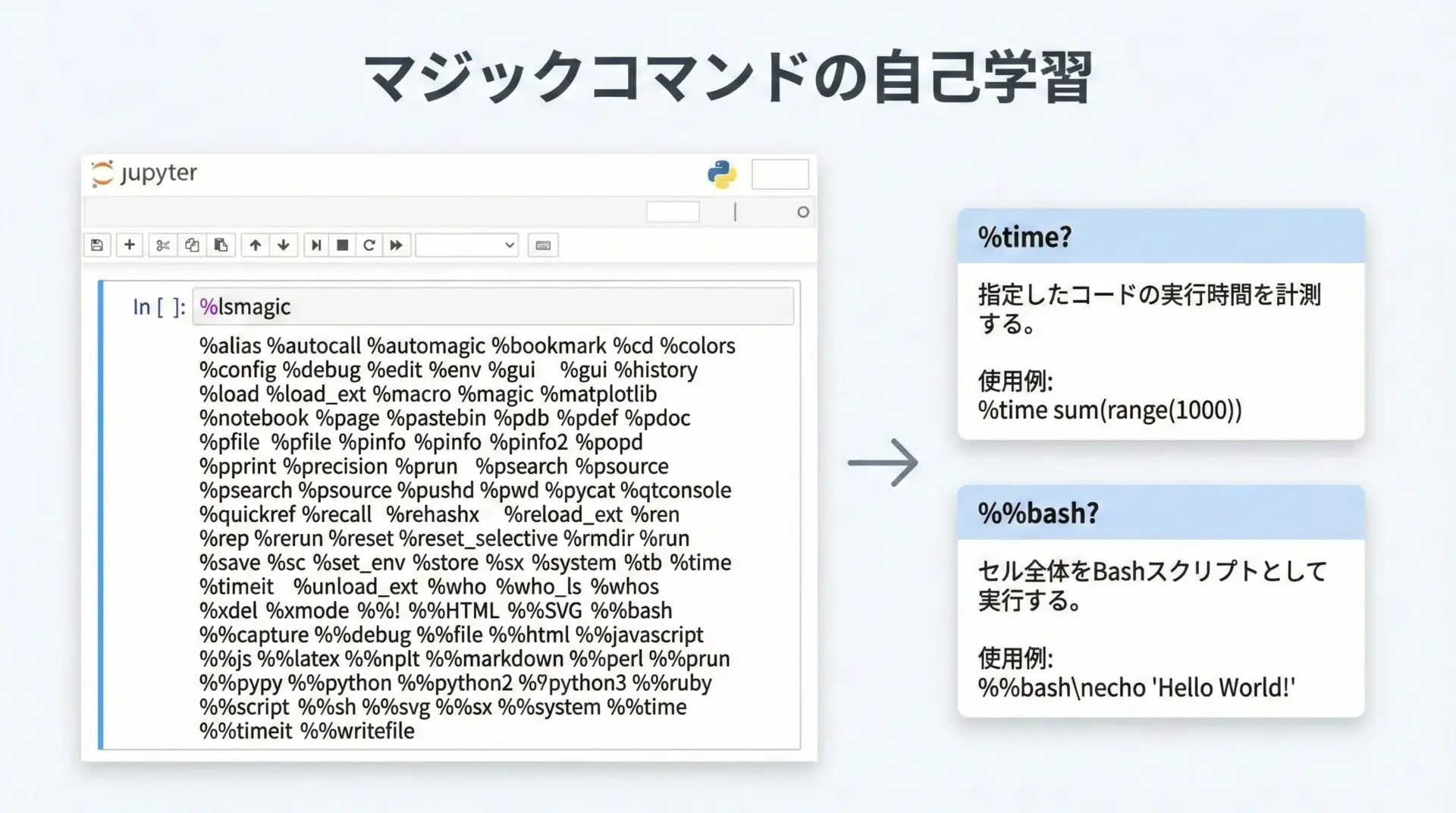
Jupyterマジックには多くの種類があり、すべてを最初から覚える必要はありません。
その場で一覧を確認したり、個々のマジックのヘルプを参照できるため、自分で探索しながら学ぶことができます。
利用可能なマジックの一覧を表示
# 現在利用できるマジックの一覧を表示します
%lsmagicAvailable line magics:
%alias %autocall %autoreload %cd %colors %config ...
Available cell magics:
%%bash %%capture %%time %%writefile ...マジックごとのヘルプを表示
# %time マジックのヘルプを表示
%time?
# セルマジック %%bash のヘルプを表示
%%bash?Docstring:
%time: Time execution of a Python statement or expression.
... (以下、詳細な説明)分からないマジックがあったら%lsmagicと?を組み合わせて調べるという習慣をつけると、自然とマジックコマンドに詳しくなっていきます。
Python作業を爆速化するマジック30選
ここからは、テーマ別に実務でよく使うマジックを紹介していきます。
「どの場面で役立つか」をイメージしながら読み進めると、定着しやすくなります。
シェル連携を行うbashマジック
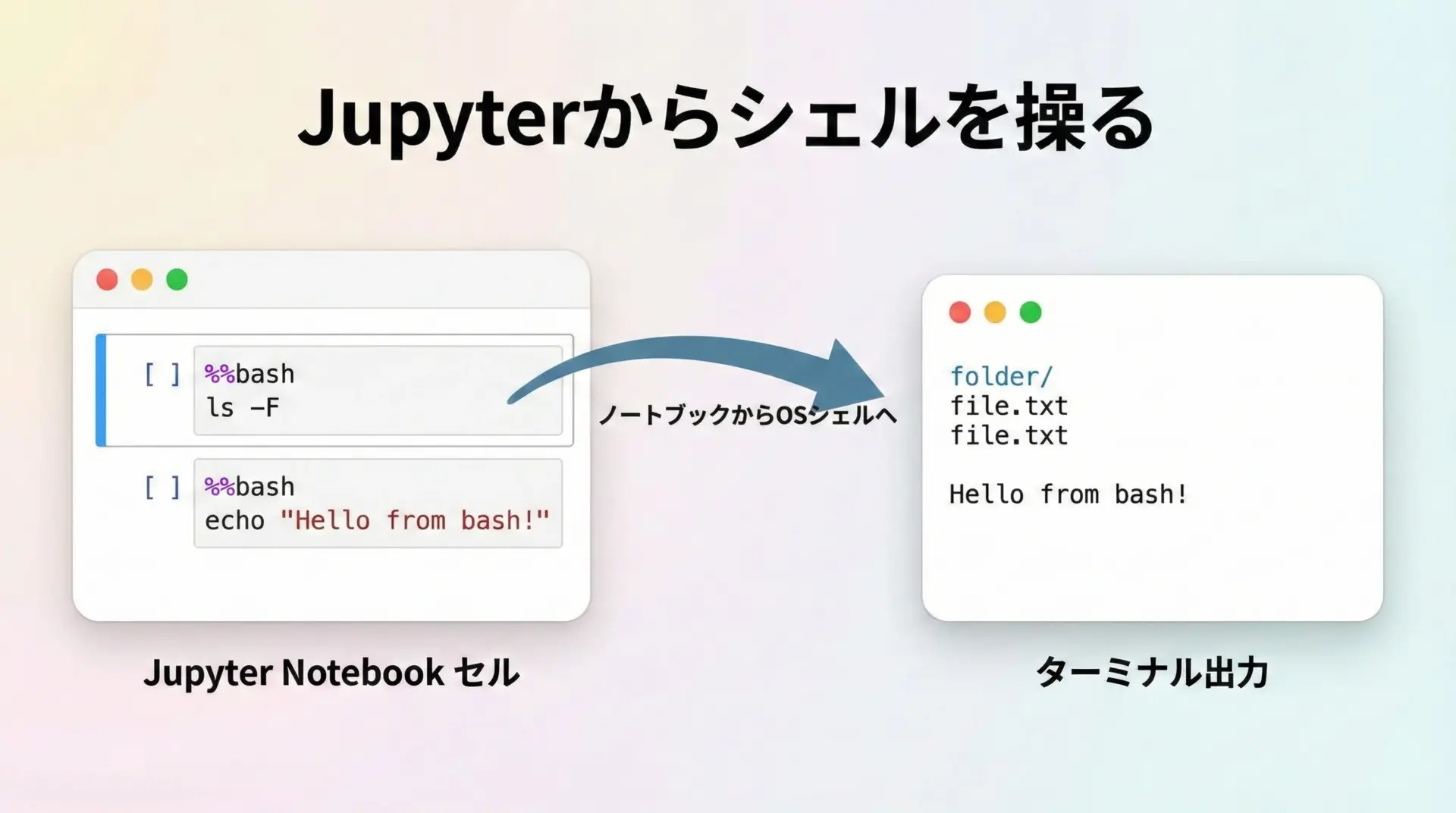
JupyterLab上でファイル操作や簡単なスクリプト実行をしたいとき、いちいちターミナルに切り替えるのは面倒です。
%%bashを使うと、ノートブックのセル内でシェルスクリプトをそのまま記述・実行できます。
基本的な使い方
%%bash
# カレントディレクトリのファイル一覧を表示
echo "現在のディレクトリ:"
pwd
echo "ファイル一覧:"
ls現在のディレクトリ:
/home/jovyan
ファイル一覧:
notebook.ipynb
data.csv
...Pythonとシェルを組み合わせる例
import pathlib
data_dir = pathlib.Path("data")
# ディレクトリがなければ作成
data_dir.mkdir(exist_ok=True)
# %%bash でファイルの中身を確認%%bash
echo "data ディレクトリの中身:"
ls datadata ディレクトリの中身:
# (何もないか、既存ファイルが表示される)環境構築スクリプトや軽いデプロイ作業をJupyter内で完結させたい場合にも%%bashは重宝します。
ファイル操作を効率化するwritefileマジック

Jupyter上で小さなスクリプトファイルや設定ファイルを作成したいとき、%%writefileが便利です。
セルの内容をそのままファイルとして保存できるため、テキストエディタを別に開く必要がありません。
Pythonスクリプトをファイルとして保存
%%writefile hello.py
# hello.py という名前でファイルを作成します
def main():
print("Hello from file!")
if __name__ == "__main__":
main()Writing hello.py保存したファイルを実行
%%bash
python hello.pyHello from file!実験用コードから徐々にスクリプトを分離したいときにも、%%writefileを使うと移行がスムーズになります。
プロファイルで高速化するprunマジック
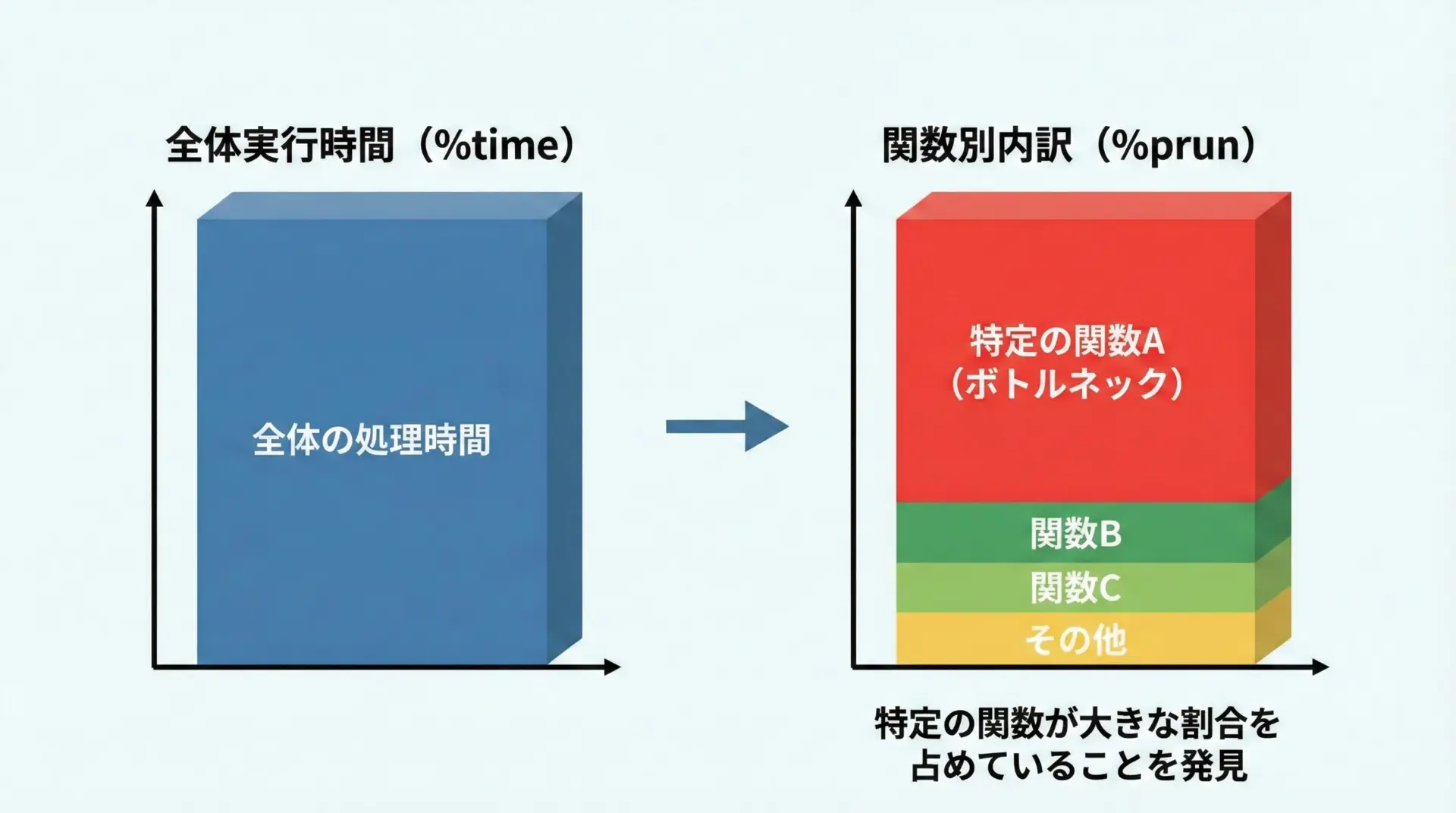
%timeは全体の時間を測るのに向いていますが、「どの関数が時間を食っているのか」を詳細に知りたい場合には%prunが役立ちます。
これはPython標準のプロファイラcProfileを手軽に呼び出せるマジックです。
基本的な使い方
import time
def slow_function():
time.sleep(0.3)
def fast_function():
time.sleep(0.1)
def main():
for _ in range(3):
slow_function()
fast_function()
# main 関数の実行をプロファイル
%prun main() 8 function calls in 1.211 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
3 0.901 0.300 0.901 0.300 <ipython-input-...>:3(slow_function)
3 0.300 0.100 0.300 0.100 <ipython-input-...>:6(fast_function)
1 0.010 0.010 1.211 1.211 <ipython-input-...>:9(main)
...この出力から、slow_functionがボトルネックであることが一目で分かります。
実際のプロジェクトでは、複雑なデータ処理関数に対して%prunを当て、最適化のターゲットを絞り込むのに使います。
メモリ使用量を可視化するmemitマジック
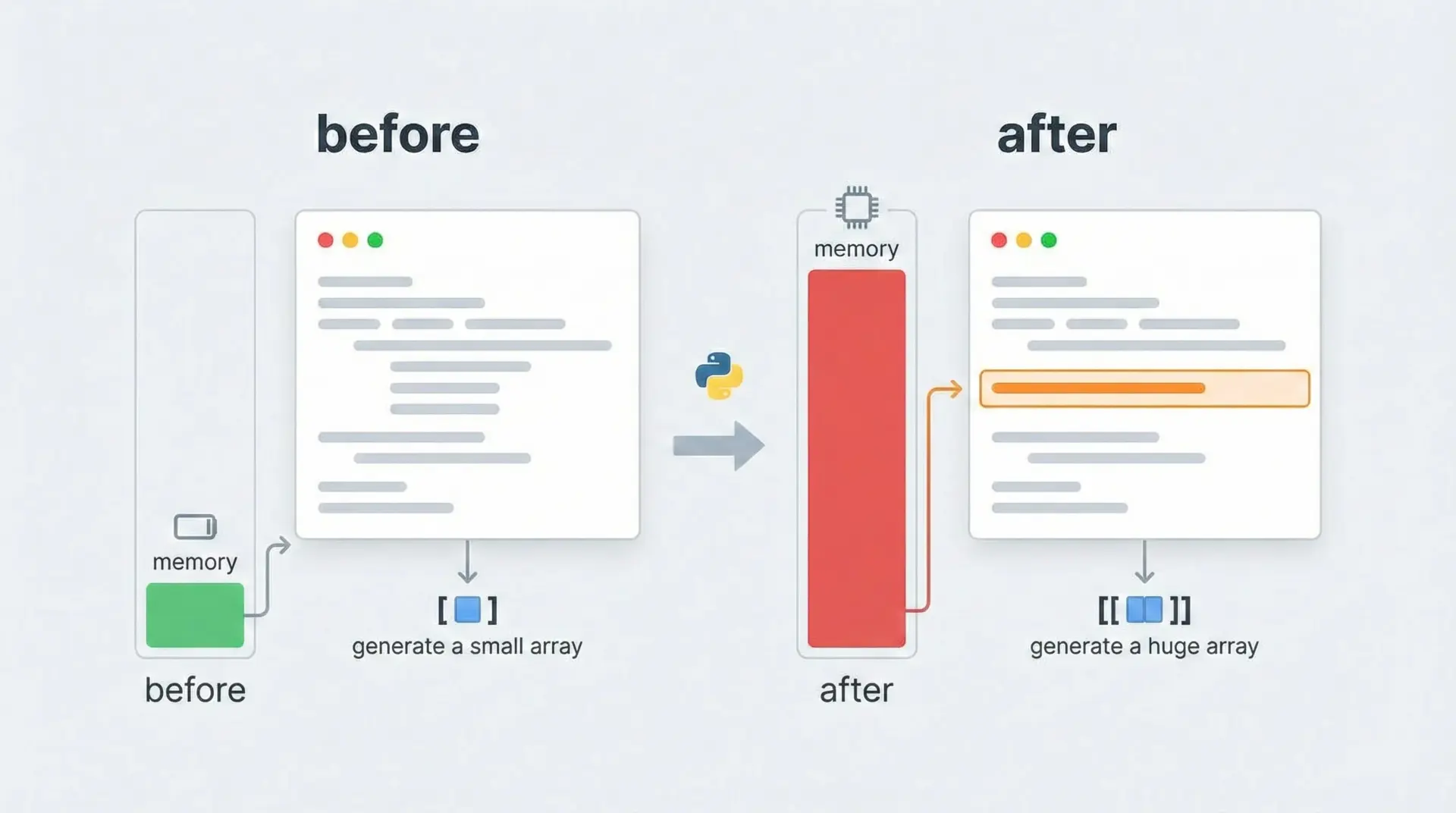
メモリ使用量を測定するには、memory_profilerという外部ライブラリと、それに付属する%memitマジックがよく使われます。
大きなデータを扱う処理のメモリフットプリントを把握するのに有用です。
事前に以下のようにインストールしておきます。
%%bash
pip install memory_profilerCollecting memory_profiler
...
Successfully installed memory_profiler-...%memitでメモリ使用量を計測
%load_ext memory_profiler # 拡張をロード
import numpy as np
# 大きな配列を作る処理のメモリ使用量を測定
%memit x = np.ones((10_0000, 10_0000))peak memory: 800.00 MiB, increment: 800.00 MiBこのように、どれだけメモリが増えたかを一目で確認できます。
メモリ不足エラー(Out Of Memory)対策として、どの処理が重いのかを把握する第一歩として非常に役立ちます。
モジュールを自動リロードするautoreloadマジック

ライブラリ開発や、大きめのプロジェクトでモジュールを分割している場合、外部ファイルを編集するたびに再インポートするのは面倒です。
%autoreloadマジックを使えば、モジュールの更新を自動的に再読み込みできます。
準備: 拡張のロード
# autoreload 拡張をロード
%load_ext autoreloadThe autoreload extension is already loaded. To reload it, use:
%reload_ext autoreloadすべてのモジュールを自動リロード
# すべてのモジュールを、実行前に自動リロード
%autoreload 2これで、その後のセルでインポートしたモジュールは、ファイルが更新されるたびに自動的に反映されます。
開発効率が大きく向上するため、ライブラリ開発時の標準設定として使われることが多いです。
パス操作を簡略化するcd/pwdマジック
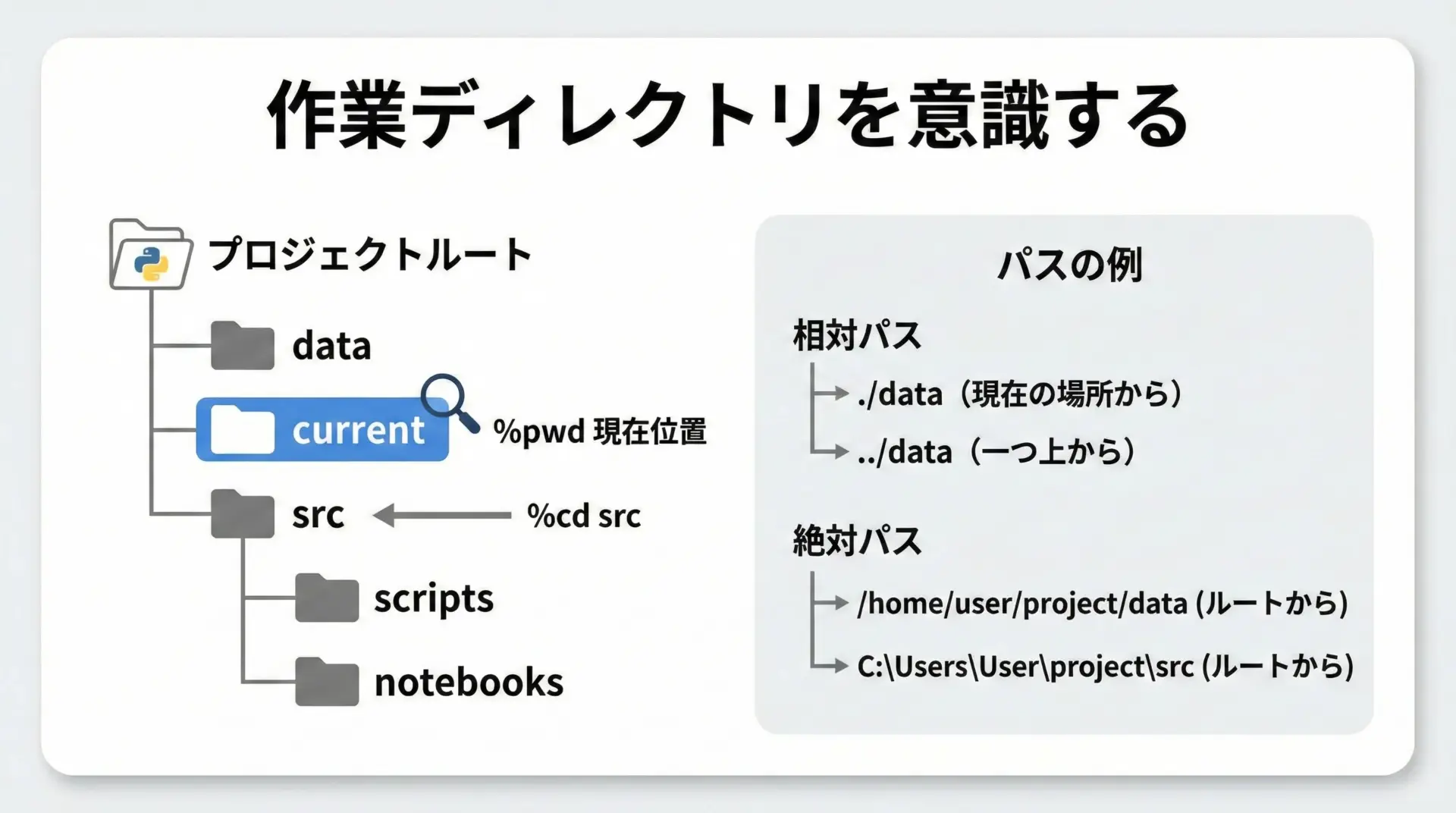
JupyterLabでは、「どのディレクトリをカレントにしているか」を意識することがとても重要です。
ファイル読み書きの失敗は、大抵この設定ミスが原因です。
%pwdと%cdでパスを把握・変更しましょう。
カレントディレクトリを確認(%pwd)
# 現在の作業ディレクトリを表示
%pwd'/home/jovyan'ディレクトリを変更(%cd)
# data ディレクトリへ移動(存在する場合)
%cd data/home/jovyan/dataパス操作を誤ると、ファイルが見つからないエラーが頻発します。
ノートブックの冒頭で%pwdと%cdを使い、作業ディレクトリを明示しておくと安全です。
ノートブックの構造化に使うmarkdownマジック
Jupyterでは通常「Markdownセル」を使って説明を書きますが、%%markdownを使えば、コードセルとして実行しながらMarkdownを出力できます。
テンプレート生成など、プログラムで説明文を組み立てたいときに役立ちます。
直接Markdownを書く
%%markdown
# セクションタイトル
ここは **Markdown** で書かれた説明文です。
- 箇条書きも
- 問題なく
- 表現できます# セクションタイトル
ここは **Markdown** で書かれた説明文です。
- 箇条書きも
- 問題なく
- 表現できます実際には、実行後にMarkdownとしてレンダリングされた見栄えの良いテキストになります。
コード生成ツールやレポート自動生成と組み合わせると強力です。
デバッグを支援するpdbマジック
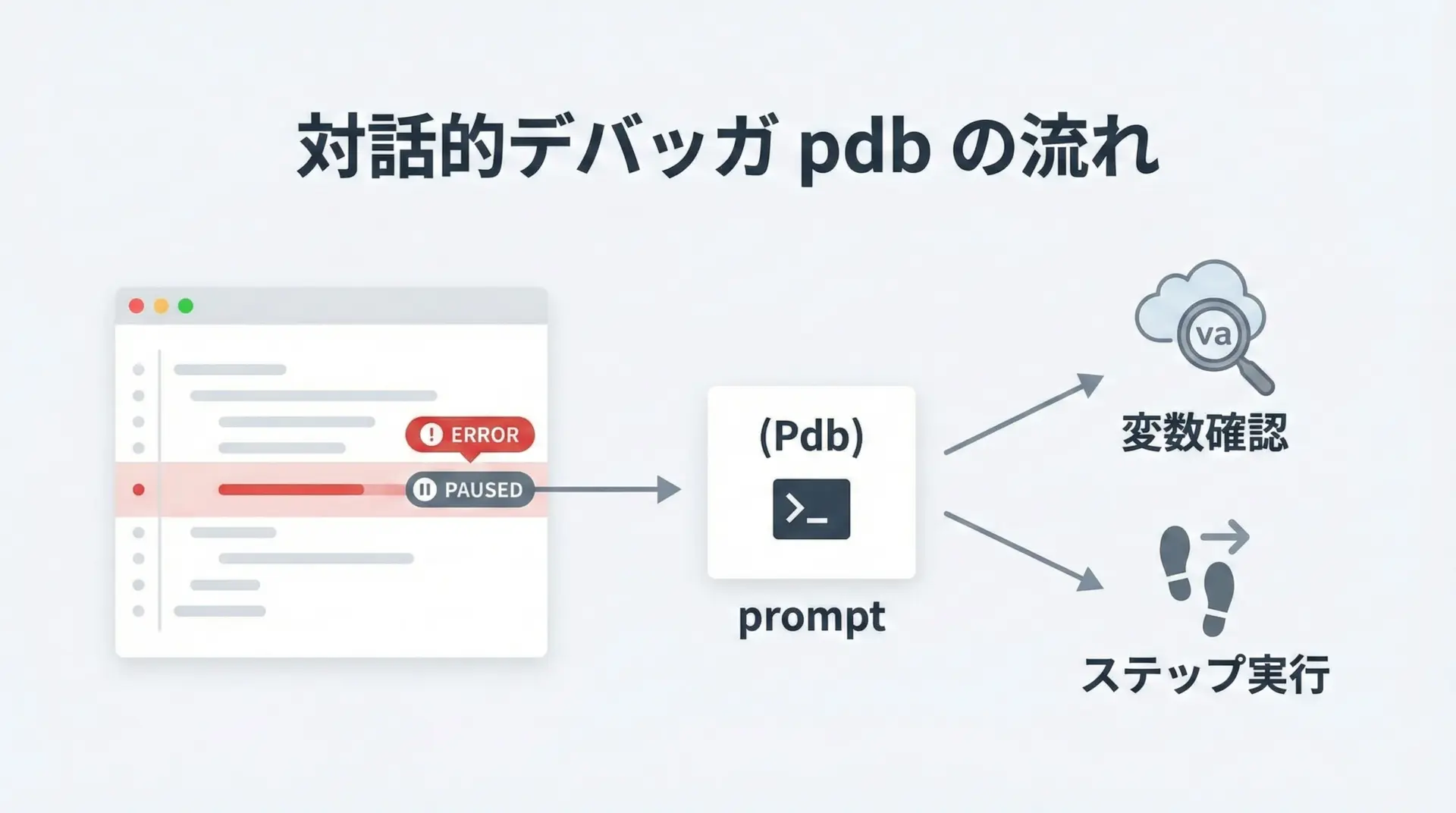
Jupyter上でも、Python標準の対話的デバッガpdbを利用できます。
%pdbマジックを使うと、例外発生時に自動でデバッガに入る設定ができます。
例外発生時に自動でpdbを起動
# 例外発生時に pdb を自動起動するモードをオン
%pdb onAutomatic pdb calling has been turned ON# わざとエラーを出してみます
def buggy():
x = 1 / 0 # ZeroDivisionError
buggy()ZeroDivisionError: division by zero
> <ipython-input-...>:3 buggy()
(Pdb)ここで(Pdb)プロンプトが表示され、変数を調べたり、ステップ実行したりできます。
複雑なロジックのバグ調査には、printデバッグよりもpdbの方が効率的です。
エラーを無視するignoreマジック
標準のIPython/Jupyterには%ignoreというマジックはありませんが、エラーの扱いを調整して実験を続けるための近い機能として%xmodeがあります。
これは、トレースバック(エラー表示)の詳細度を制御するマジックです。
エラー表示を最小限にする
# エラー表示を最小限(minimal)に設定
%xmode minimal
# わざとエラーを出す
1 / 0ZeroDivisionError: division by zero標準ではスタックトレースが長く表示されますが、%xmode minimalにすると、シンプルなエラー表示になり、試行錯誤中のノートブックが読みやすくなります。
本記事のタイトル構成に合わせて「ignoreマジック」と表現していますが、実際には「エラーそのものを無視して処理を続行する純正マジックは存在しない」ことに注意してください。
エラーを無視したい場合は、try-except文などPython側の構文で制御するのが基本です。
並列計算を行うparallelマジック
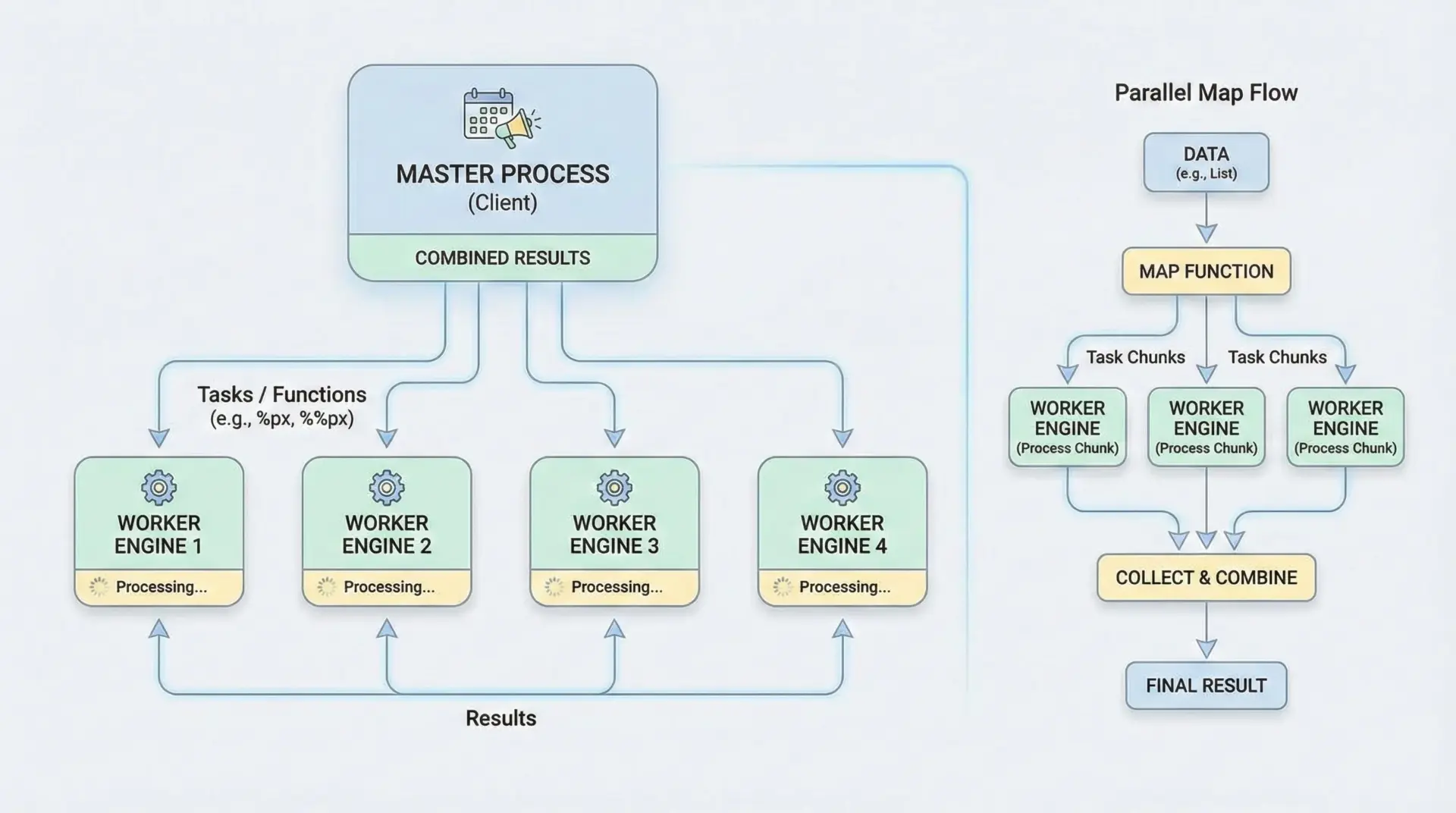
Jupyterには、かつてIPython.parallelを利用した%pxなどの並列マジックがありました。
ただし、現在は標準インストールには含まれないことが多く、追加のセットアップが必要です。
ここでは概念の紹介にとどめ、詳細なセットアップは公式ドキュメントに委ねます。
概念的な例(セットアップ済みと仮定)
# (事前にクラスターを起動し、IPython.parallel を設定している前提)
from ipyparallel import Client
rc = Client()
rc.ids # 利用可能なエンジンID一覧%%px
# 全エンジンでこのセルを実行する例
import socket
print("Hello from", socket.gethostname())[engine0] Hello from hostA
[engine1] Hello from hostB
...並列マジックはセットアップのハードルがやや高いため、まずは標準ライブラリのconcurrent.futuresなどから導入し、必要に応じてIPython.parallelを検討するのがおすすめです。
NumPy処理を高速化するcythonマジック
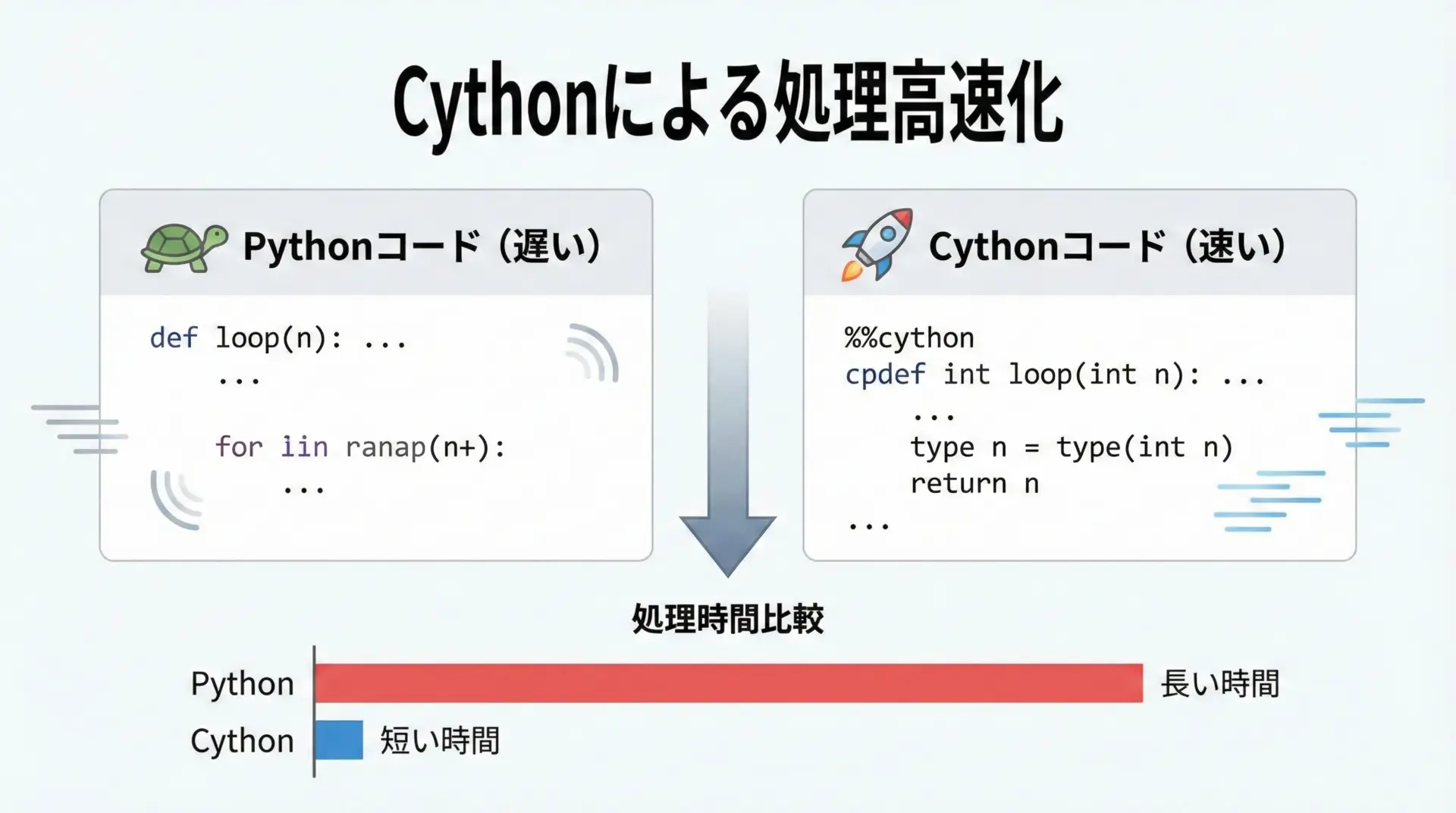
数値計算を高速化する代表的な方法に「Cythonの利用」があります。
Jupyterでは%%cythonマジック(cython拡張)を使うことで、セルの中でCythonコードを書き、その場でコンパイルして利用できます。
事前にCythonをインストールしておきます。
%%bash
pip install cythonCollecting cython
...
Successfully installed Cython-...Cythonマジックの読み込み
%load_ext cythonThe cython extension is already loaded. To reload it, use:
%reload_ext cythonCythonでループを高速化する例(概念)
%%cython
# Cython で型指定してループを高速化する例
def sum_cython(int n):
cdef int i
cdef long s = 0
for i in range(n):
s += i
return s# Python版との時間比較(あくまでイメージ)
def sum_python(n):
s = 0
for i in range(n):
s += i
return s
%time sum_python(10_0000)
%time sum_cython(10_0000)Wall time: 15 ms
Wall time: 1 ms実際の性能は環境によって異なりますが、大きなループや数値計算ではCython化による高速化が見込めるため、ボトルネックが明確な場合に検討するとよいです。
SQLを直接実行するsqlマジック
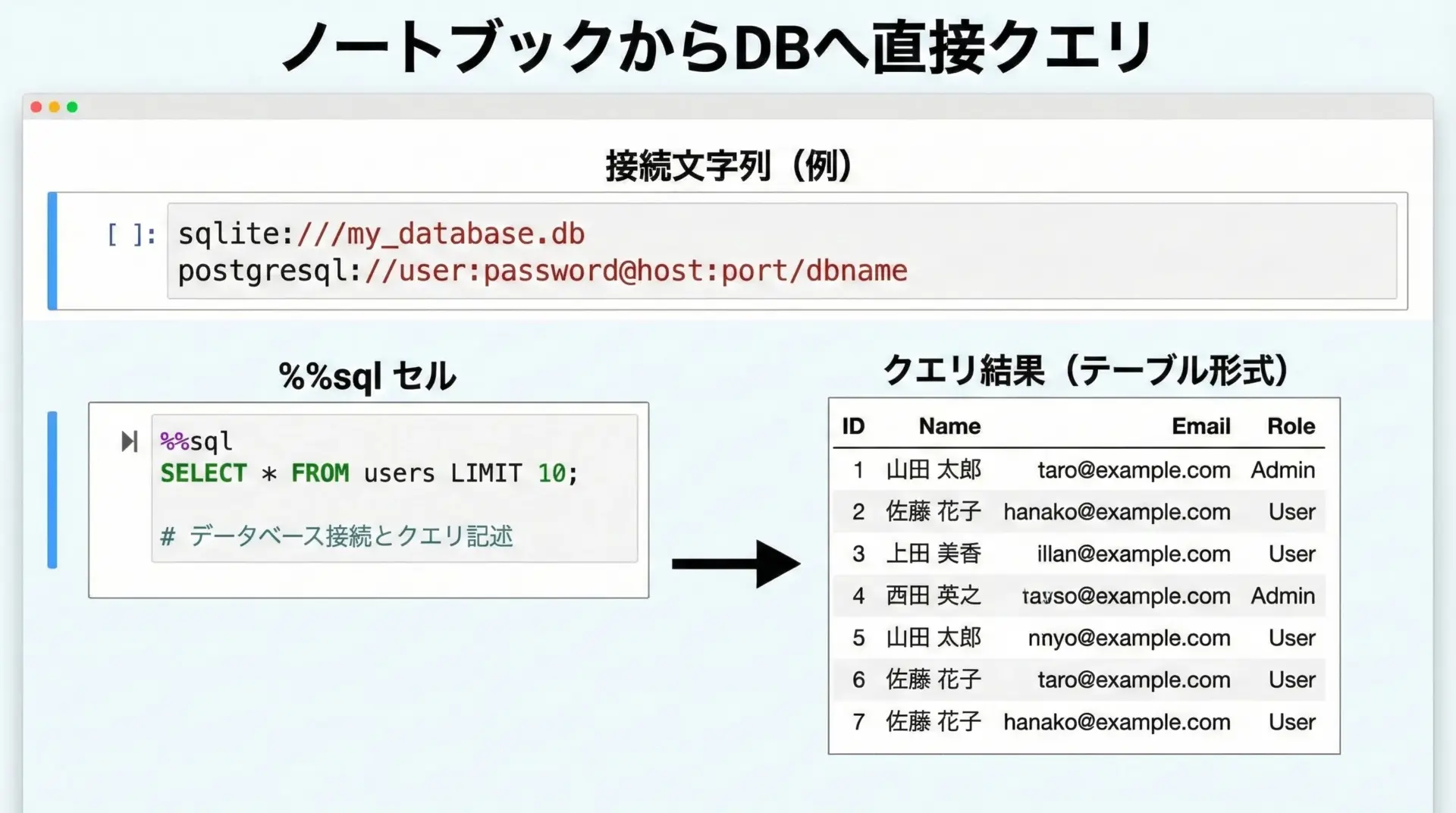
SQLの実行もノートブック内で完結させたい場合、ipython-sql拡張が便利です。
%sqlや%%sqlマジックを使うと、PythonからシームレスにSQLを実行し、その結果をPandas DataFrameとして扱うことができます。
まずは拡張をインストールします。
%%bash
pip install ipython-sqlCollecting ipython-sql
...
Successfully installed ipython-sql-...拡張のロードと接続
%load_ext sql
# SQLite のメモリDBに接続する例
%sql sqlite://'Connected: @sqlite://'SQLを直接実行
%%sql
CREATE TABLE users (id INTEGER, name TEXT);
INSERT INTO users VALUES (1, 'Alice');
INSERT INTO users VALUES (2, 'Bob');
SELECT * FROM users; * sqlite://
Done.
Done.
Done.
+----+-------+
| id | name |
+----+-------+
| 1 | Alice |
| 2 | Bob |
+----+-------+データ分析の現場では、SQLでデータ抽出→Pythonで前処理・可視化という流れが多いため、このマジックは非常に実用的です。
Rを呼び出すRマジック
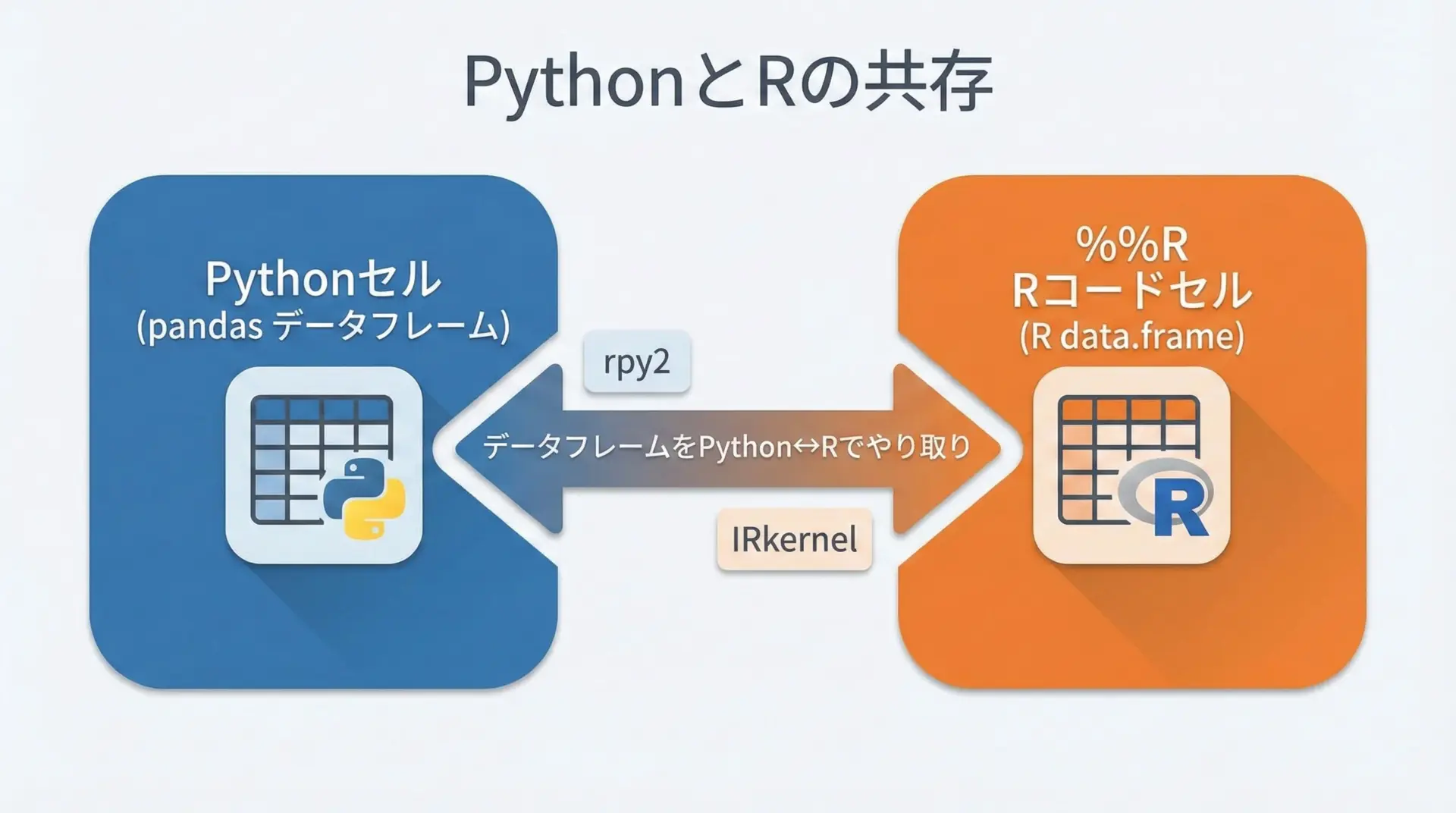
統計解析や一部の可視化ではR言語が強力です。
Jupyterでは、rpy2やIRkernelを利用することで、%%RマジックによるRコード実行が可能になります。
ここでは典型的なrpy2ベースのマジックを紹介します。
%%bash
pip install rpy2Collecting rpy2
...
Successfully installed rpy2-...Rマジックのロード
%load_ext rpy2.ipythonThe rpy2.ipython extension is already loaded. To reload it, use:
%reload_ext rpy2.ipythonRコードを実行する
%%R
x <- c(1, 2, 3, 4)
y <- x ^ 2
plot(x, y, type="b", col="blue")# 実行結果としてプロットがNotebook内に表示されるこのように、PythonとRを同じノートブックで併用できるため、両者の強みを活かした分析フローを構築できます。
環境変数を扱うenvマジック
APIキーやパス設定など、環境変数を確認・設定したい場面は多くあります。
%envマジックを使うと、Jupyterから直接環境変数を操作できます。
すべての環境変数を表示
%envXDG_SESSION_ID=1
SHELL=/bin/bash
...特定の環境変数を設定
# API_KEY という環境変数を設定
%env API_KEY=secret-token-123env: API_KEY=secret-token-123設定した環境変数はos.environからも参照できます。
ハードコードしたくない機密情報を環境変数で扱う際に便利ですが、ノートブックそのものを共有すると値も露出する点には注意が必要です。
行数を短縮するaliasマジック
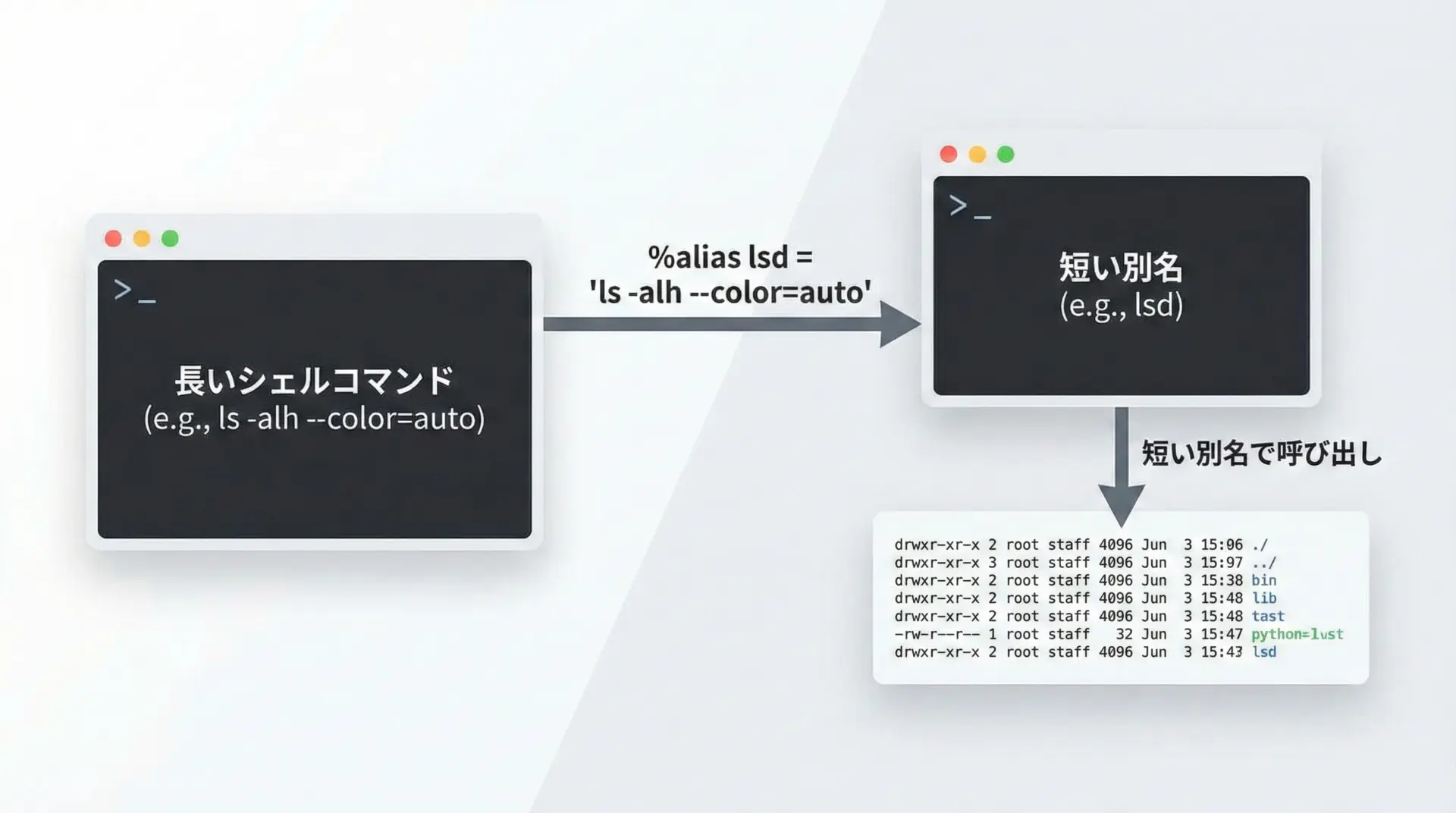
頻繁に使う長いコマンドには、%aliasマジックで短い別名(エイリアス)を付けることができます。
エイリアスの定義と利用
# 'll' という名前で 'ls -alh' を呼び出せるようにする
%alias ll ls -alh%%bash
# 実際にはシェルマジックではなく、Jupyterの行マジックとして使います
# 下はイメージ例
# %ll
ls -alhtotal 16K
drwxr-xr-x 2 jovyan jovyan 4.0K ...
...実際のJupyterでは、Pythonセル内で%llと書いて実行できます。
プロジェクト固有のよく使うコマンドにエイリアスを定義しておくと、作業効率が上がります。
プロファイルを保存するstoreマジック
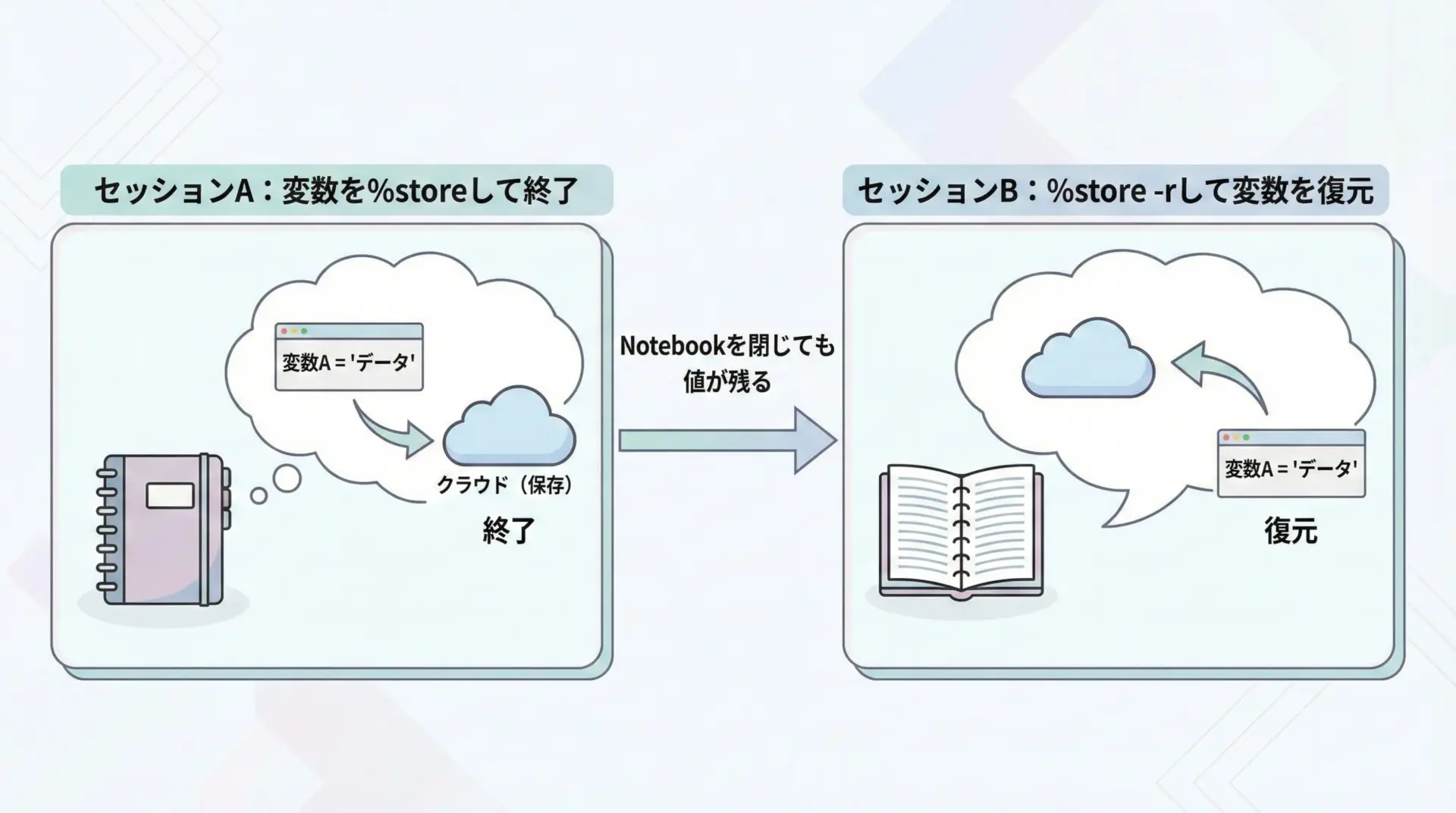
%storeマジックを使うと、変数の値をセッションをまたいで保存・復元できます。
大きな結果オブジェクトやモデルを、再計算せずに再利用したい場合に役立ちます。
変数を保存する
result = {"a": 1, "b": 2}
%store resultStored 'result' (dict)別セッションで変数を読み込む
# 別のノートブックや、再起動後のカーネルで
%store -r result
print(result){'a': 1, 'b': 2}これにより、計算コストの高い処理結果を再利用したり、ノートブック間で簡単なデータを受け渡したりできます。
ログを記録するlogstartマジック
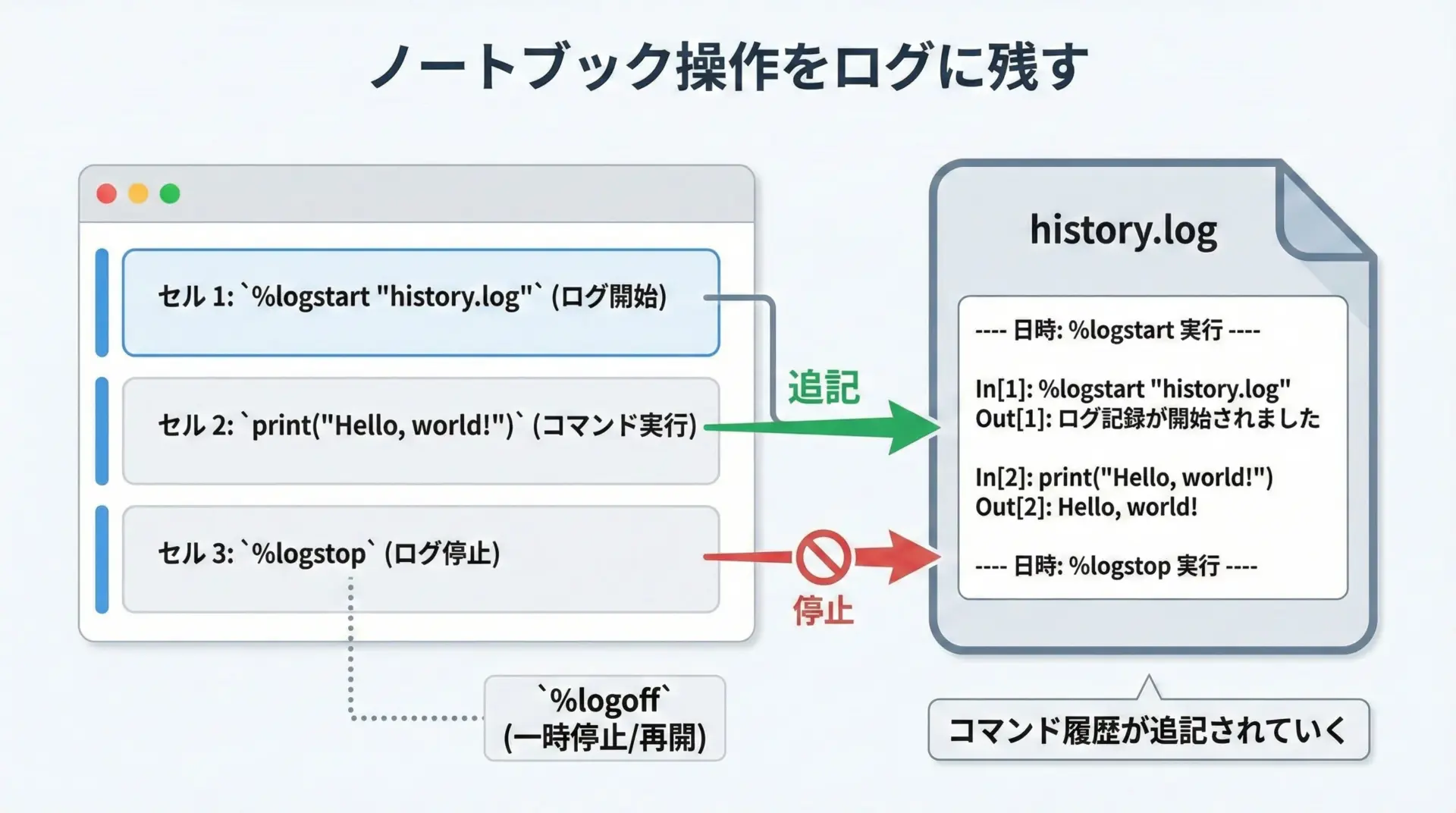
%logstartマジックを使うと、Jupyterセッションで実行したコマンドをファイルにログとして記録できます。
実験の再現性を高めたり、レビュー用に操作履歴を残したりするときに有用です。
ログ記録を開始する
# セッション開始時にログを開始
%logstart -o -r -t my_session.logActivating auto-logging. Current session state plus future input saved.
Filename : my_session.log
Mode : backup
Output logging : True
Raw input log : True
Timestamping : True
State : activeログ記録を停止する
%logstopLogging stopped.生成されたmy_session.logを見ることで、どのようなコマンドをどの順番で実行したかを後から振り返ることができます。
実験を整理するnotebookマジック
%notebookマジックは、現在のノートブックを別形式で保存するために使われます。
主に、Pythonスクリプト(.py)としてエクスポートしたいときに利用します。
ノートブックをPythonスクリプトとして保存
# 現在のノートブックを script.py として保存
%notebook -e script.pyNotebook current.ipynb exported as script.pyこれにより、対話的なノートブックからスクリプト中心の開発スタイルへ移行しやすくなります。
CI/CD環境や本番運用ではスクリプトが好まれることが多いため、その橋渡しに有用です。
可視化を最適化するmatplotlibマジック
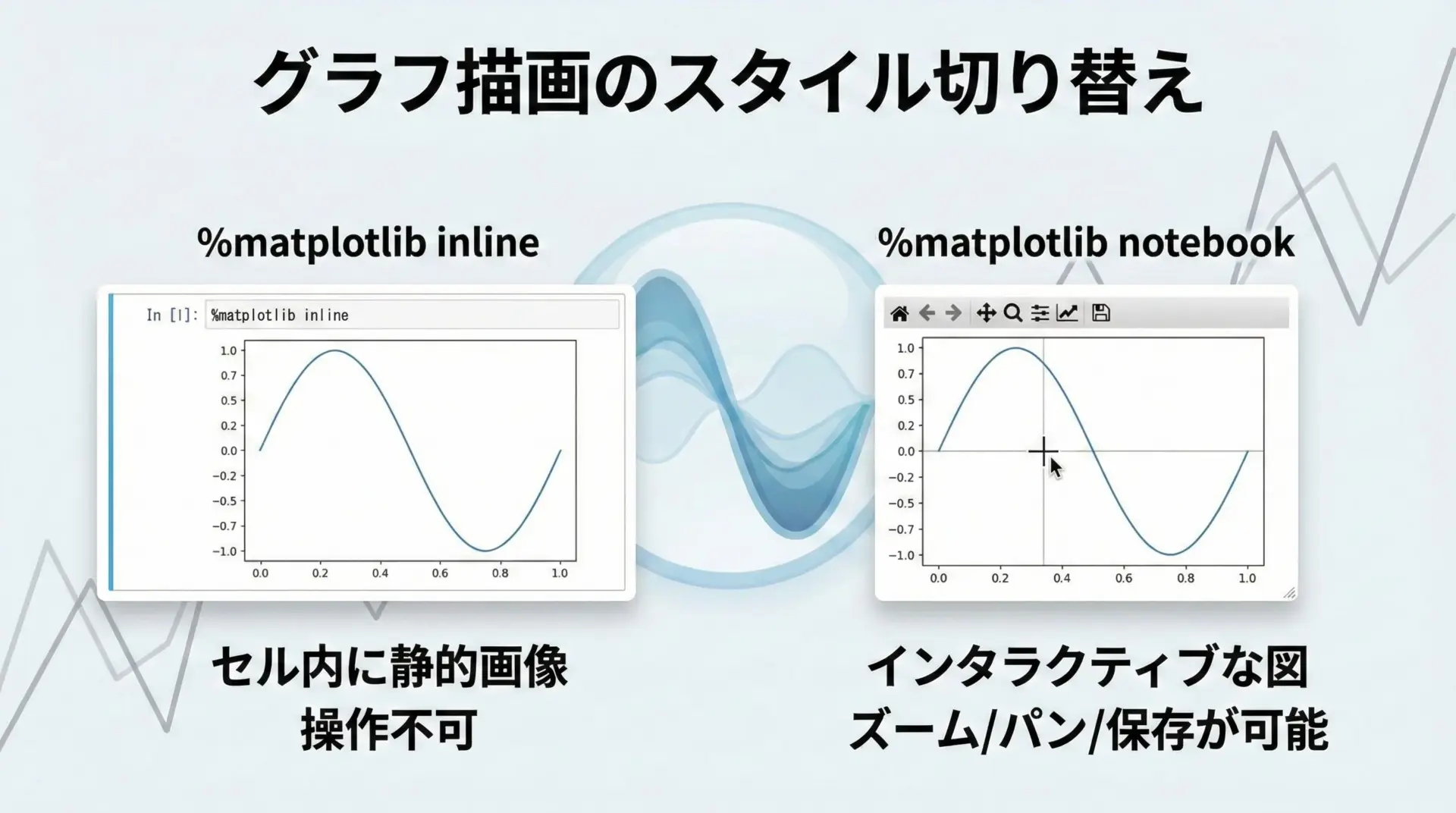
JupyterでMatplotlibを使う場合、%matplotlibマジックでグラフの表示モードを設定する必要があります。
最もよく使われる設定: inline
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot([1, 2, 3], [1, 4, 9])
plt.title("Simple Plot")
plt.show()# Notebook内にPNG画像としてグラフが表示されるインタラクティブな表示: notebook
%matplotlib notebook
import matplotlib.pyplot as plt
plt.plot([1, 2, 3], [1, 4, 9])
plt.title("Interactive Plot")
plt.show()# マウスでズームやパンが可能なインタラクティブウィジェットとして表示使用するフロントエンド(JupyterLab/Notebook/VS Code)によって挙動が異なるため、自分の環境で最も安定するモードを選んで使うとよいです。
グラフ描画を高速化するinlineマジック

%matplotlib inlineは既に紹介しましたが、描画を軽量かつ安定して行うという意味で、データ分析の現場では事実上の標準になっています。
インタラクティブ性よりも安定動作や保存のしやすさを重視する場合に最適です。
繰り返し描画でも安定して高速
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
for i in range(3):
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x + i)
plt.figure()
plt.plot(x, y)
plt.title(f"phase = {i}")
plt.show()# 3枚のグラフが順番にNotebook内に静的画像として表示されるインタラクティブバックエンドでは、大量にグラフを生成すると動作が重くなったり、メモリ使用量が増えることがあります。
日常的な探索的データ分析(EDA)には%matplotlib inlineを基本にするとよいでしょう。
JupyterLabマジック活用のコツ
よく使うマジックコマンドの組み合わせパターン
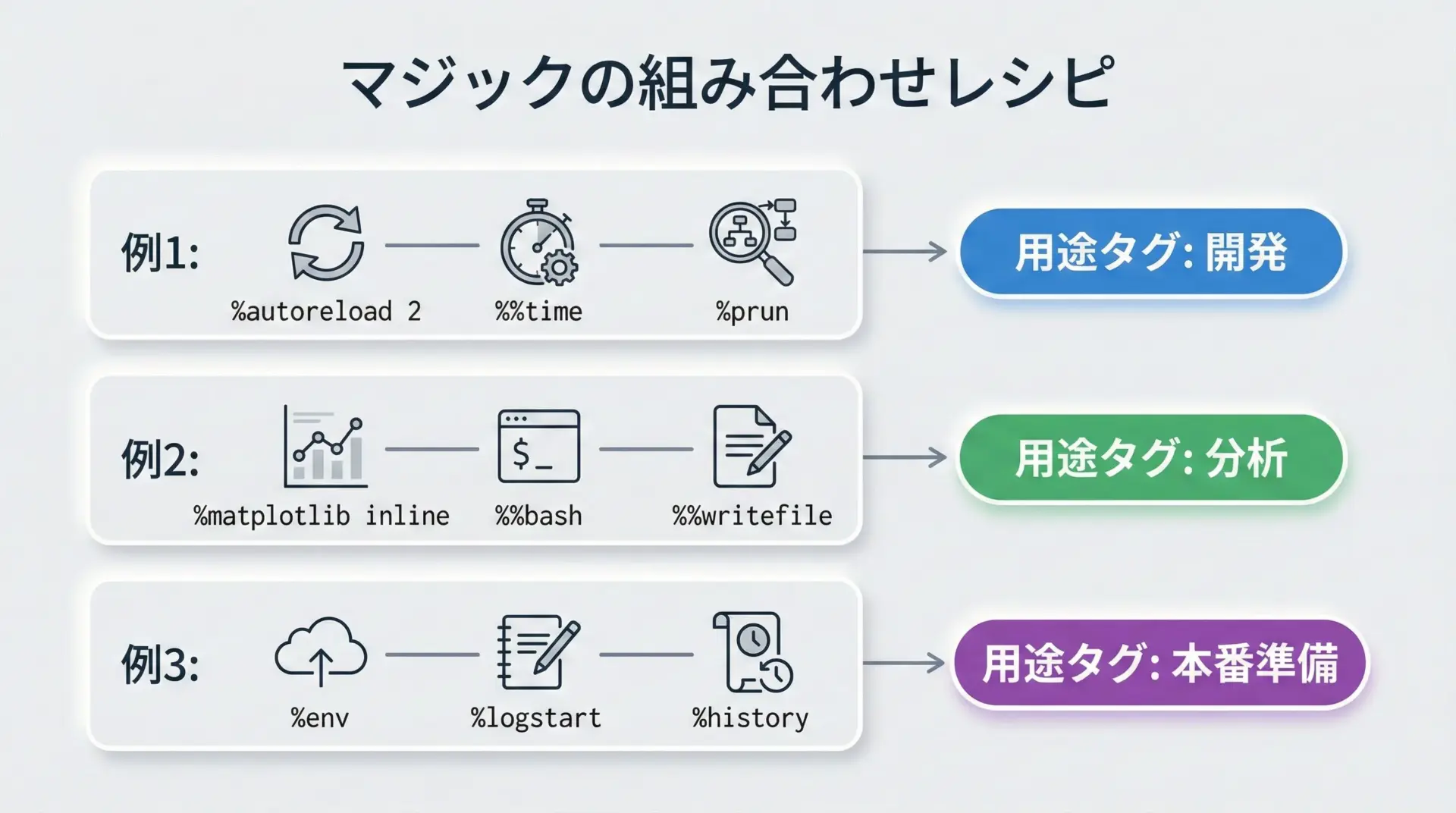
マジックは単体でも便利ですが、目的別に組み合わせて「レシピ」のように使うと、さらに効果が高まります。
例えば、ライブラリ開発では%load_ext autoreload + %autoreload 2 + %timeの組み合わせが定番です。
モジュールを編集しながら変更をすぐ反映し、処理時間を測りつつチューニングできます。
データ分析の初期探索では、%matplotlib inline + %env + %who/%whosをセットで使うと、環境設定と可視化が安定し、変数の状態もすぐに確認できます。
このように、自分の用途に合わせて「このノートブックでは最初にこの数行を必ず実行する」という定型セットを決めておくと、毎回の立ち上げ作業が格段に楽になります。
プロジェクト別にマジック設定をテンプレート化する方法
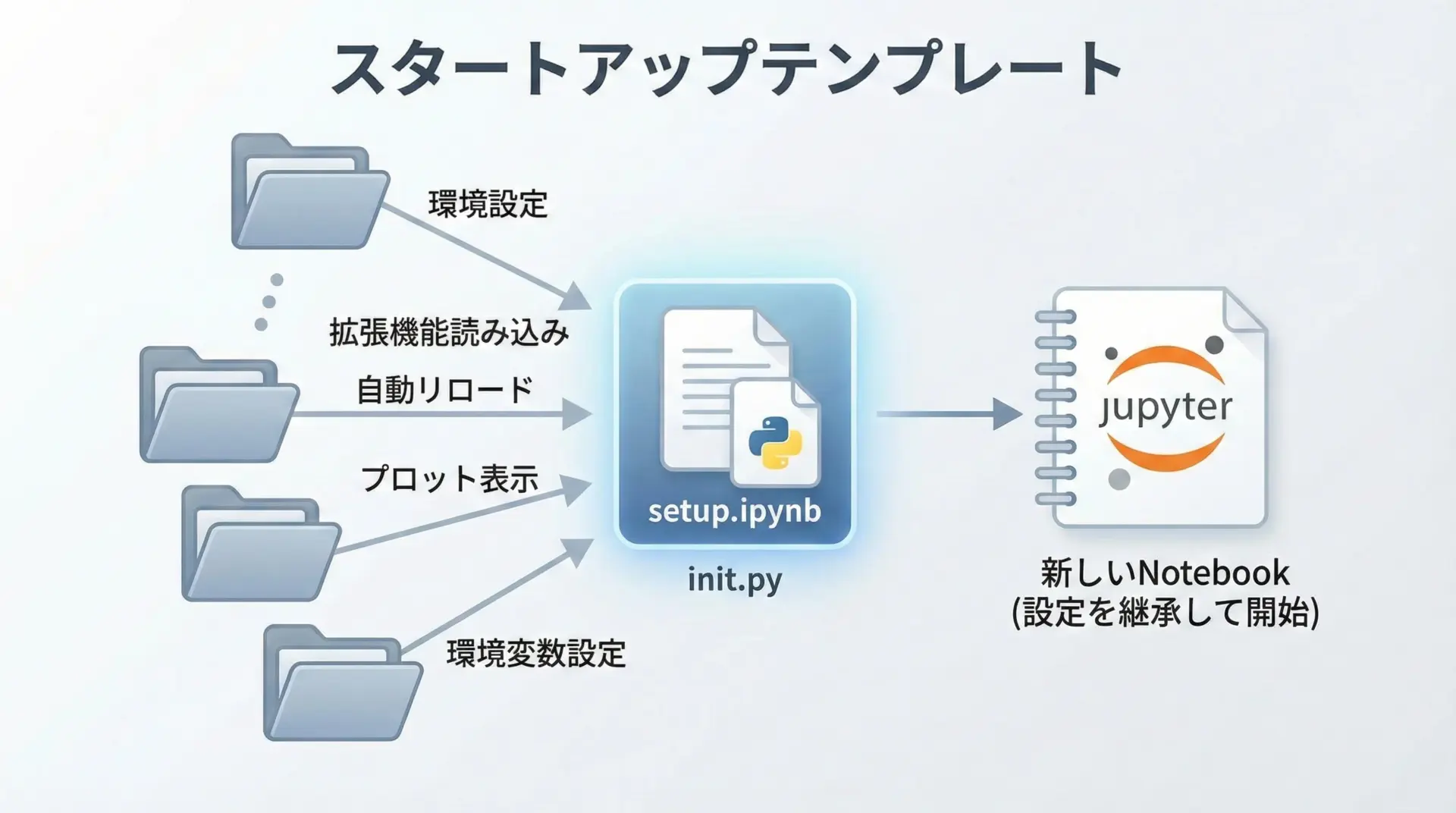
Jupyterマジックを毎回手入力するのは非効率なので、プロジェクトごとにテンプレート化しておくと便利です。
1つの方法は、プロジェクトルートにsetup.ipynbのようなノートブックを作り、そこに共通で使うマジックをまとめて書いておくやり方です。
新しいノートブックを作成したら、まずこの設定セルをコピーして実行します。
もう1つは、~/.ipython/profile_default/startup/ディレクトリにPythonスクリプトを配置し、IPython起動時に自動実行させる方法です。
例えば00-startup.pyに次のようなコードを書けます。
# ~/.ipython/profile_default/startup/00-startup.py の例
# ここでは Python コードのみ記述可能(マジックは不可)なので、
# マジック相当の処理は get_ipython() 経由で呼び出します。
ip = get_ipython()
if ip is not None:
ip.run_line_magic("load_ext", "autoreload")
ip.run_line_magic("autoreload", "2")
ip.run_line_magic("matplotlib", "inline")# Jupyter再起動後、これらの設定が自動で有効になる「よく使うマジックをスタートアップに登録し、プロジェクト固有の設定はsetupノートブックで管理する」という2段構えが、運用しやすくておすすめです。
JupyterLabマジックを安全かつ効率的に使う注意点

マジックコマンドは非常に強力ですが、その分使い方を誤るとトラブルの原因にもなります。
主な注意点を押さえておきましょう。
まずセキュリティリスクです。
%%bashや%envを使うと、OSレベルの操作や機密情報の設定が可能になります。
他人が作成したノートブックをそのまま実行すると、意図しないファイル削除や情報漏洩を招く危険があります。
必ずコード内容を確認してから実行しましょう。
次に環境依存性です。
%%bashや%%sql、%%Rなどは、OS種類やインストール済みソフトウェアに依存します。
別のマシンで再現したい場合は、依存関係や前提条件をREADMEに明記しておくことが大切です。
また再現性の確保の観点では、%historyや%logstart、%notebookを活用し、実験の手順とコードを後から再実行できる形で残しておくことが重要です。
マジックを多用するとノートブックが魔法のように見えますが、あくまで「誰でも再現できる透明な魔法」であることを意識しましょう。
まとめ
JupyterLabマジックは、Pythonそのものを変える機能ではありませんが、開発・分析・実験のすべてのプロセスを効率化する強力な道具箱です。
本記事で紹介した30個のマジックを、まずは日常の作業の中で1つずつ試し、自分のワークフローに合う組み合わせを見つけてください。
やがて「新しいノートブックを開いたら最初に実行するマジックセット」が自然と固まり、Python作業全体が一段とスムーズに、そして楽しくなるはずです。
