
PythonでJSONを扱う場面では、デバッグのために中身を「きれいに整形して表示したい」と感じることが多いです。
標準ライブラリのjson.dumpsとindentオプションを使えば、複雑なJSONも見やすく整形できます。
本記事では、基本的な使い方から実践的なサンプルコード、日本語を含むJSONの注意点やパフォーマンス面まで、段階的に詳しく解説していきます。
PythonでJSONを整形出力する基本
json.dumpsとは
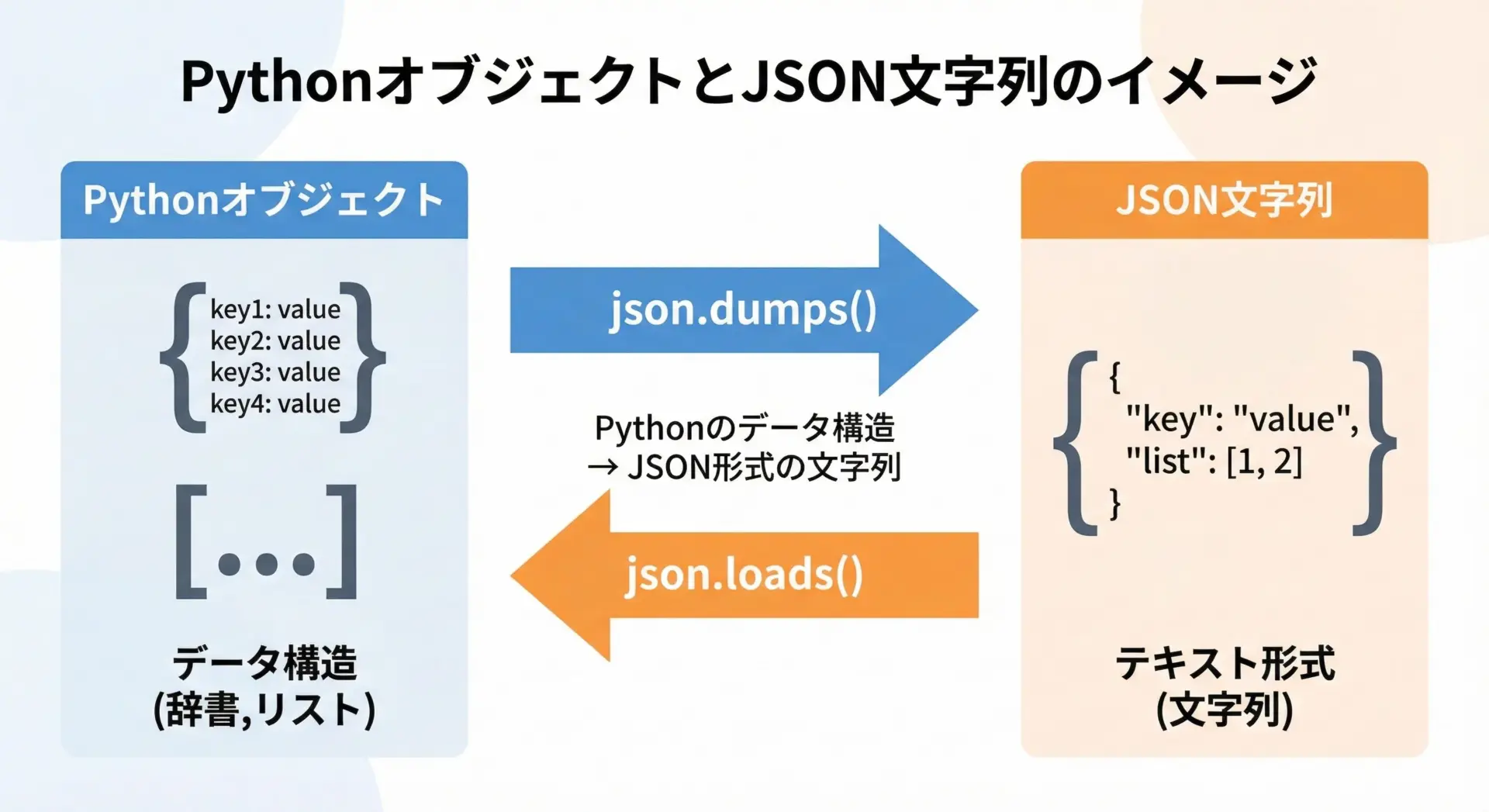
Pythonのjsonモジュールは、Pythonのデータ構造とJSON文字列を相互に変換するための標準ライブラリです。
その中でもjson.dumpsは、PythonオブジェクトをJSON形式の文字列に変換する関数です。
典型的には、辞書やリストなどのPythonオブジェクトをjson.dumpsに渡し、戻り値としてJSON文字列を得ます。
この文字列をそのまま画面に表示したり、ファイルに書き込んだり、APIのレスポンスとして返したりできます。
例えば、次のようなPythonオブジェクトをJSON文字列に変換できます。
import json
data = {
"name": "Taro",
"age": 30,
"languages": ["Python", "JavaScript"]
}
json_str = json.dumps(data)
print(json_str){"name": "Taro", "age": 30, "languages": ["Python", "JavaScript"]}このように、json.dumpsはデフォルトでは1行のコンパクトなJSON文字列を生成しますが、整形して読みやすくしたい場合に使うのがindentオプションです。
JSON整形に役立つ主な引数

json.dumpsには多くの引数がありますが、JSON整形に関係する代表的なものは次のとおりです。
データの見た目や読みやすさに関わる引数を、表形式で整理します。
| 引数名 | 役割の概要 |
|---|---|
indent | 行ごとのインデント幅を指定します。整形表示の中心となる引数です。 |
ensure_ascii | 非ASCII文字(日本語など)を\uXXXX形式にエスケープするかを制御します。 |
sort_keys | キーをアルファベット順に並び替えて出力するかどうかを指定します。 |
separators | カンマやコロンの後に入る空白の有無など、区切り文字の細かな形式を調整します。 |
特にindentとensure_asciiは、整形表示と日本語表示の両方に深く関わる重要な引数ですので、後のセクションで詳しく扱います。
json.dumpsでJSONをきれいに整形表示
indentパラメータの基本的な使い方

indentパラメータは、1階層ごとのインデント幅(スペース数)を指定する引数です。
整数値を指定するのが一般的で、たとえばindent=2とすると、ネストが1段深くなるごとに半角スペース2つ分の字下げが行われます。
具体的なコード例で確認します。
import json
data = {
"user": {
"name": "Taro",
"age": 30,
"skills": ["Python", "JavaScript"]
},
"active": True
}
# インデントなし(デフォルト)
print("=== indentなし ===")
print(json.dumps(data))
# インデントあり
print("\n=== indent=2 ===")
print(json.dumps(data, indent=2))
print("\n=== indent=4 ===")
print(json.dumps(data, indent=4))=== indentなし ===
{"user": {"name": "Taro", "age": 30, "skills": ["Python", "JavaScript"]}, "active": true}
=== indent=2 ===
{
"user": {
"name": "Taro",
"age": 30,
"skills": [
"Python",
"JavaScript"
]
},
"active": true
}
=== indent=4 ===
{
"user": {
"name": "Taro",
"age": 30,
"skills": [
"Python",
"JavaScript"
]
},
"active": true
}このように、indentを指定するだけでJSONが複数行に分割され、入れ子構造も視覚的に把握しやすくなります。
インデント幅(2や4)による見やすさの違い
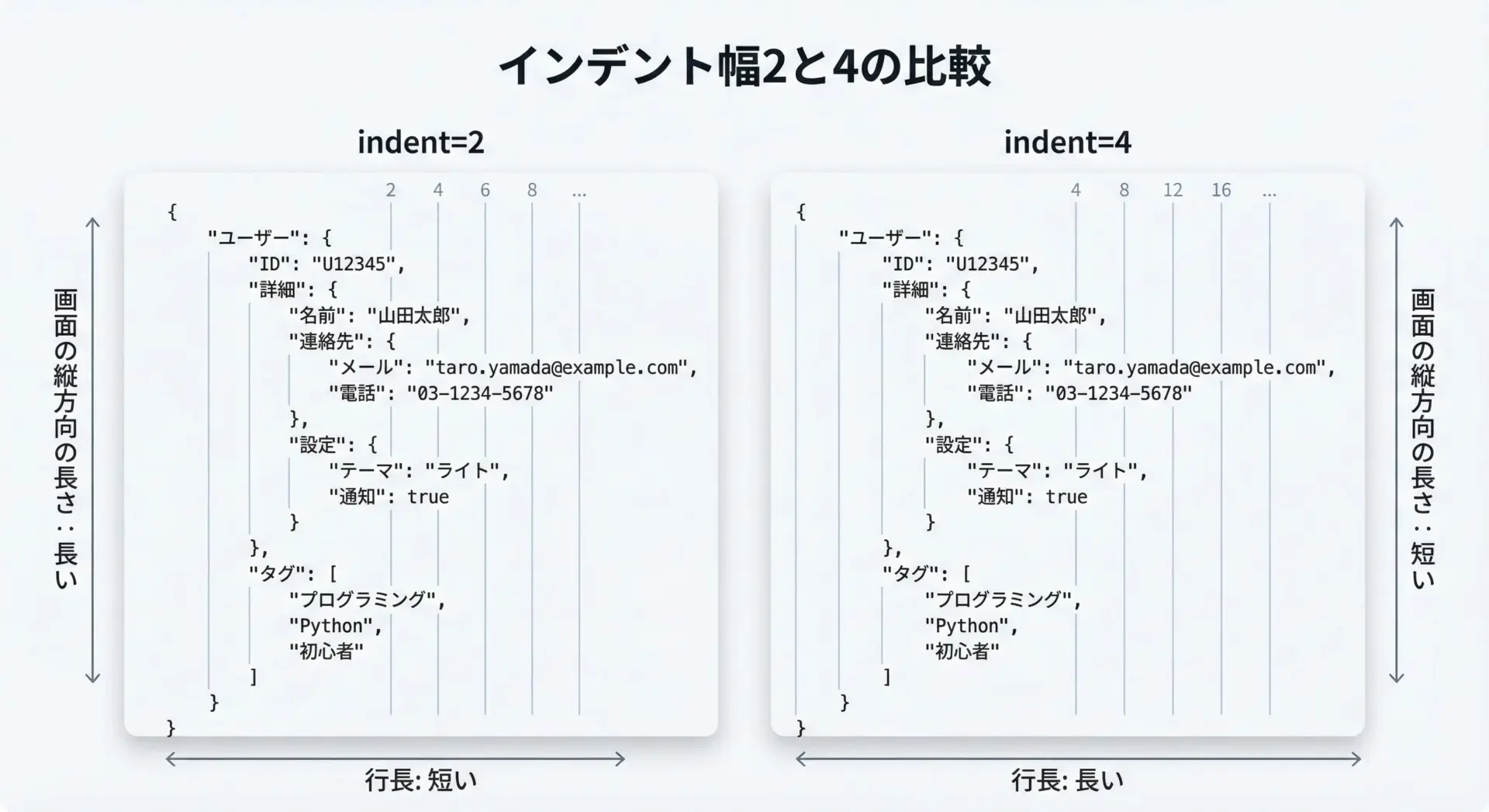
インデント幅としてよく使われるのは2または4です。
どちらが正解ということはありませんが、用途によって向き不向きがあります。
文章で違いを整理すると、次のような傾向があります。
| インデント幅 | 特徴と向いている場面 |
|---|---|
| 2 | 行の長さが比較的短く収まり、横幅の限られた画面でも表示しやすいです。APIレスポンスの確認や、狭いエディタ画面でのデバッグに向きます。 |
| 4 | 階層がよりはっきりと見えるため、ネストが深いデータ構造の解析に向きます。コードのインデント幅に合わせたい場合にも選ばれます。 |
「横方向の見やすさ」か「縦方向の見やすさ」かによって好みが分かれますが、チームで統一することも重要です。
ドキュメントやログなど、他の人も見るJSONについては、事前にルールを決めておくとよいでしょう。
ネストしたJSONを見やすく整形するポイント
ネストしたJSONを見やすく整形するには、単にindentを指定するだけでなく、いくつかのポイントを意識すると効果的です。
まず、インデントだけでなく、キーの順番も整えると構造が理解しやすくなります。
sort_keys=Trueを指定すると、キーがアルファベット順で並ぶため、同じような構造のデータを比較しやすくなります。
import json
data = {
"user": {
"profile": {
"address": {
"city": "Tokyo",
"zip": "100-0001"
},
"name": "Taro"
},
"id": 123
},
"active": True
}
print(json.dumps(data, indent=2, sort_keys=True)){
"active": true,
"user": {
"id": 123,
"profile": {
"address": {
"city": "Tokyo",
"zip": "100-0001"
},
"name": "Taro"
}
}
}また、リストの要素が多い場合は、1行あたりの情報量を意図的に抑えることが大切です。
JSON標準として「何文字で改行」というルールはありませんが、あまり長い行は目で追いにくくなります。
場合によっては、indentだけでなくseparatorsを調整して、不要なスペースを減らすことも検討します。
pretty printでJSONを読みやすくする実践例
辞書やリストを整形してprintするサンプルコード

Pythonの辞書やリストをそのままprintすると、Pythonのリテラル表現で出力されます。
これに対してjson.dumpsを使えば、JSON形式かつ整形済みの文字列として出力できます。
import json
data = {
"id": 1,
"name": "山田太郎",
"tags": ["python", "json", "pretty print"],
"profile": {
"country": "Japan",
"active": True
}
}
print("=== 通常のprint(data) ===")
print(data)
print("\n=== json.dumps + indentで整形 ===")
pretty = json.dumps(data, indent=2, ensure_ascii=False)
print(pretty)=== 通常のprint(data) ===
{'id': 1, 'name': '山田太郎', 'tags': ['python', 'json', 'pretty print'], 'profile': {'country': 'Japan', 'active': True}}
=== json.dumps + indentで整形 ===
{
"id": 1,
"name": "山田太郎",
"tags": [
"python",
"json",
"pretty print"
],
"profile": {
"country": "Japan",
"active": true
}
}ここでensure_ascii=Falseを指定している点が重要です。
これについては後ほど詳しく説明しますが、日本語をそのまま読みやすく出力したい場合には必須となります。
ファイル保存時に整形JSONを書き出す方法
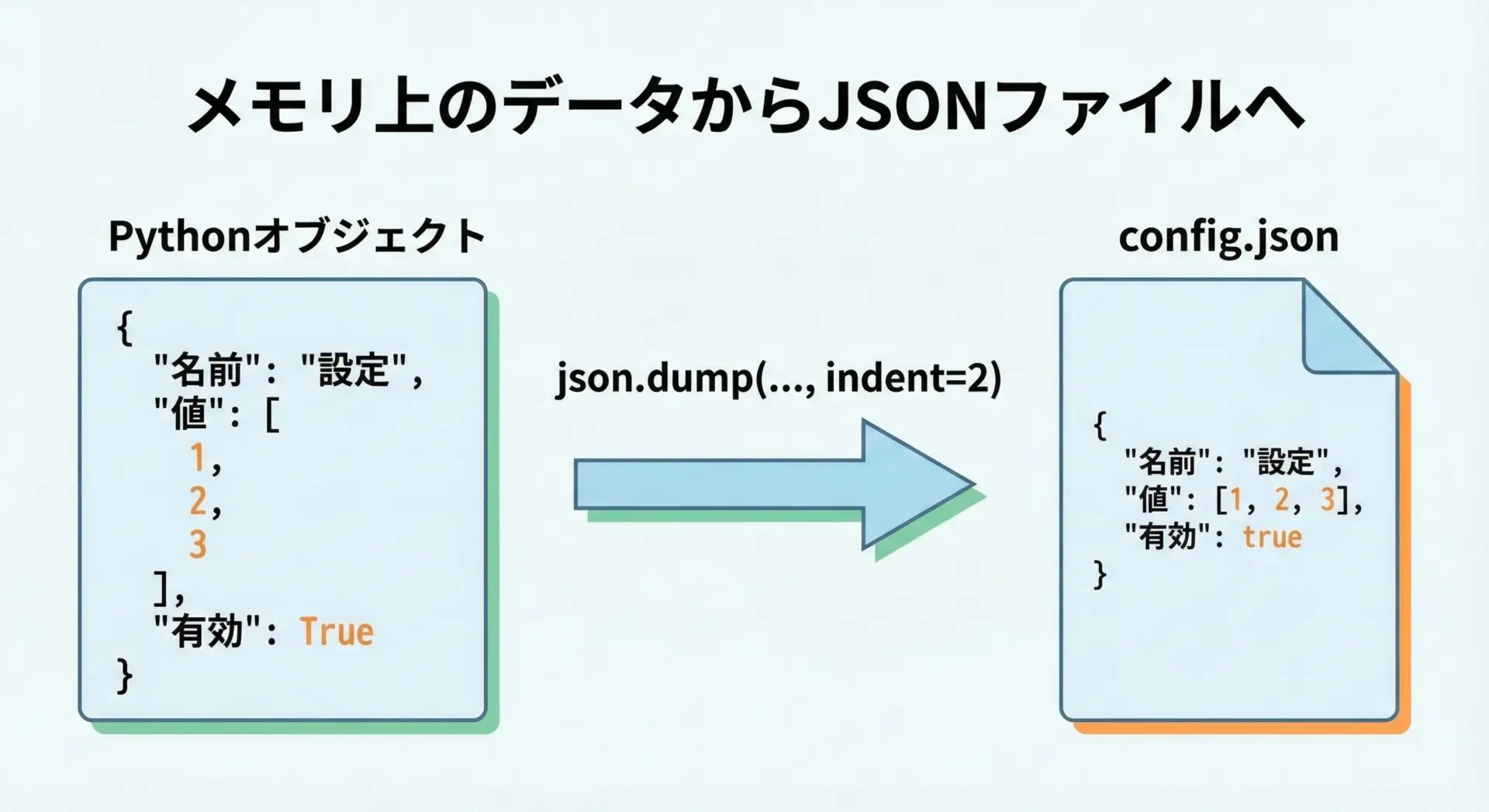
整形されたJSONは、ファイルに保存しておくと後で人間が読みやすく、設定ファイルやログとしても活用しやすくなります。
ファイル保存時には、文字列にしてから書き込む方法と、直接ファイルオブジェクトに書き込む方法の2通りがあります。
まずはjson.dumpsで文字列を作ってからファイルに書き込む例です。
import json
from pathlib import Path
data = {
"project": "sample-app",
"version": "1.0.0",
"features": ["login", "report", "analytics"]
}
json_str = json.dumps(data, indent=2, ensure_ascii=False)
# ファイルに書き込み
path = Path("config_pretty.json")
path.write_text(json_str, encoding="utf-8")次に、json.dumpを使って、ファイルオブジェクトに直接書き込む例です。
import json
data = {
"project": "sample-app",
"version": "1.0.0",
"features": ["login", "report", "analytics"]
}
with open("config_pretty.json", "w", encoding="utf-8") as f:
# json.dumpを使って直接整形JSONを書き込む
json.dump(data, f, indent=2, ensure_ascii=False)# config_pretty.json の中身イメージ
{
"project": "sample-app",
"version": "1.0.0",
"features": [
"login",
"report",
"analytics"
]
}人間が読む前提の設定ファイルやサンプルデータなどは、このようにindentを指定して保存しておくと、後からの保守性が高まります。
日本語を含むJSONを整形する時の注意点
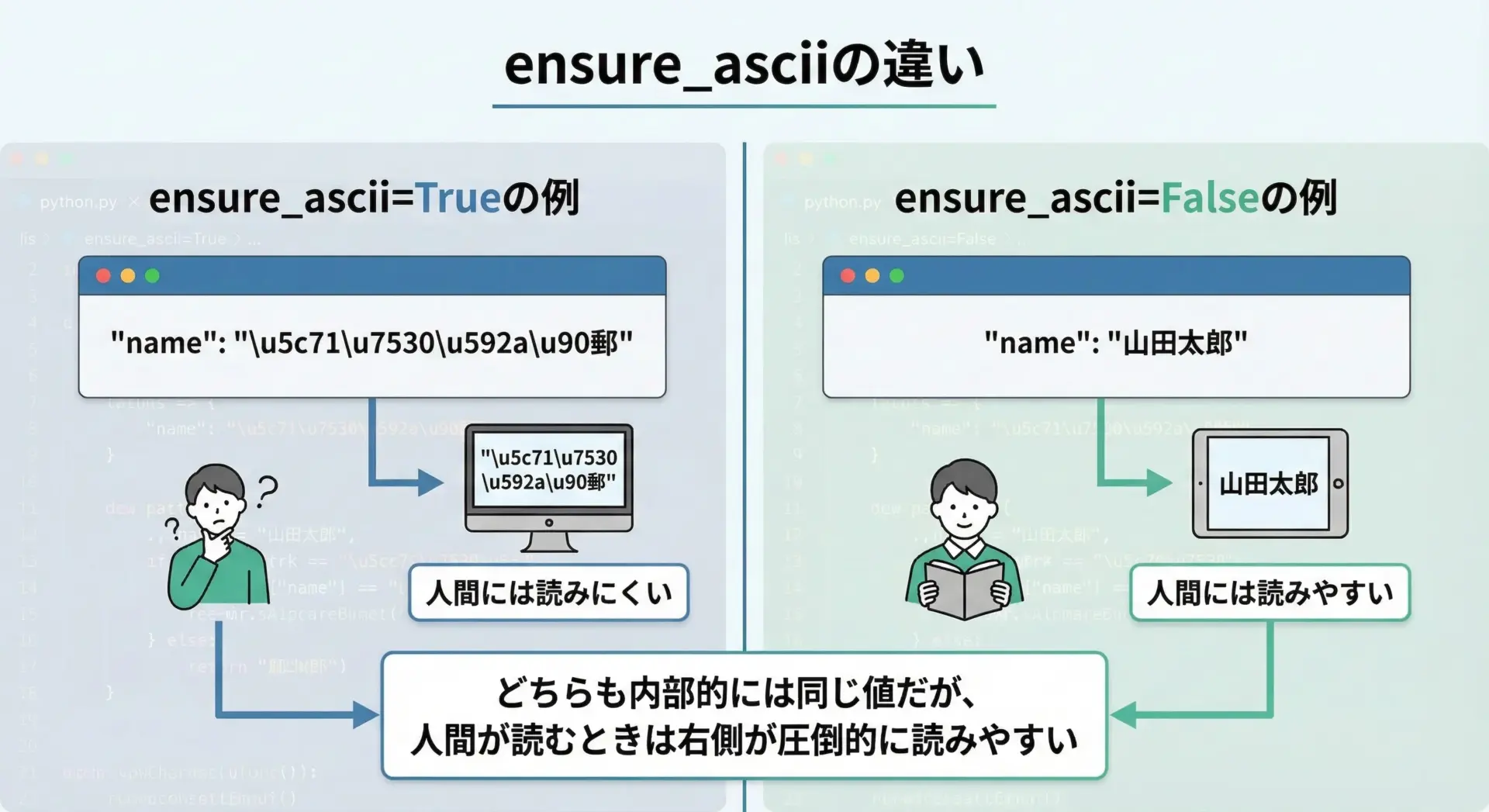
日本語を含むJSONを扱うときに重要なのがensure_asciiです。
デフォルトのensure_ascii=Trueでは、日本語などの非ASCII文字が\uXXXX形式に変換(エスケープ)されてしまうため、そのままでは読みにくくなります。
import json
data = {"name": "山田太郎", "city": "東京都"}
print("=== ensure_ascii=True (デフォルト) ===")
print(json.dumps(data, indent=2, ensure_ascii=True))
print("\n=== ensure_ascii=False ===")
print(json.dumps(data, indent=2, ensure_ascii=False))=== ensure_ascii=True (デフォルト) ===
{
"name": "\u5c71\u7530\u592a\u90ce",
"city": "\u6771\u4eac\u90fd"
}
=== ensure_ascii=False ===
{
"name": "山田太郎",
"city": "東京都"
}日本語を目視で確認したい場合は、必ずensure_ascii=Falseを指定するようにしてください。
また、ファイルに保存する際はencoding="utf-8"を指定し、エディタ側でもUTF-8として開くことで文字化けを防げます。
JSON整形で知っておきたい注意点とテクニック
デバッグ用と本番用でindentの使い分け
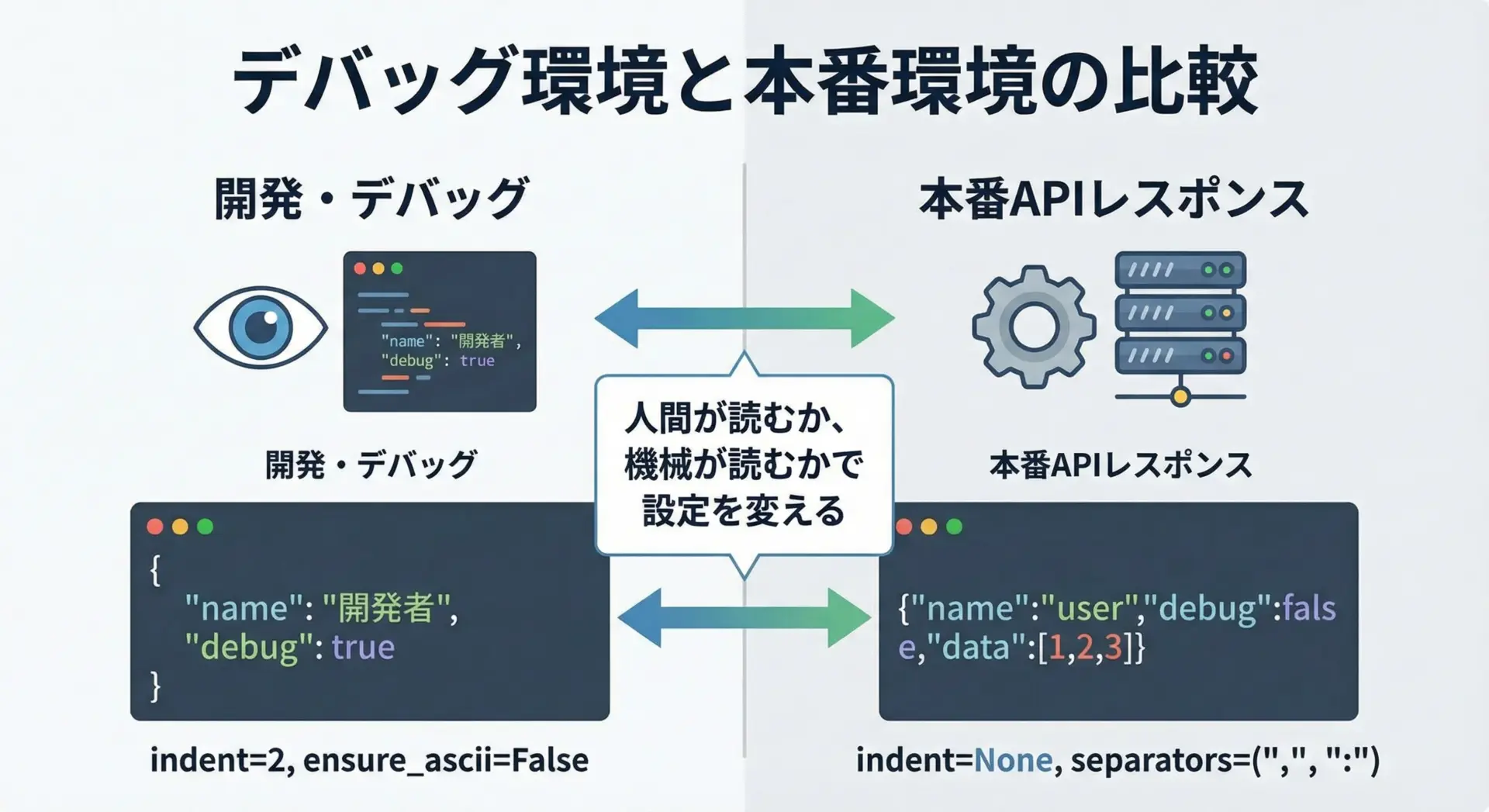
indentを付けるとJSONは非常に読みやすくなりますが、その分だけサイズは大きくなります。
そのため、次のような切り分けをしておくと効率的です。
開発・デバッグ用には、以下のような設定が向いています。
- indentを2または4に設定して構造を把握しやすくする
- ensure_ascii=Falseで日本語をそのまま表示する
- 場合によっては
sort_keys=Trueでキー順を固定する
一方、本番用のAPIレスポンスや大規模データの保存では、無駄な空白を極力省き、サイズを小さくするのが一般的です。
この場合は次のような方針が考えられます。
- indentを省略(またはNone)にして1行にまとめる
separators=(",", ":")のように指定し、カンマやコロンの後のスペースを削除する
import json
data = {
"id": 1,
"name": "山田太郎",
"active": True
}
# デバッグ用(読みやすさ重視)
debug_json = json.dumps(data, indent=2, ensure_ascii=False)
print("=== Debug用 ===")
print(debug_json)
# 本番用(サイズ重視)
prod_json = json.dumps(data, separators=(",", ":"), ensure_ascii=False)
print("\n=== 本番用(コンパクト) ===")
print(prod_json)=== Debug用 ===
{
"id": 1,
"name": "山田太郎",
"active": true
}
=== 本番用(コンパクト) ===
{"id":1,"name":"山田太郎","active":true}用途によって「人間が読むことを前提にするか」「機械が読むことを前提にするか」を意識して、indentの有無を使い分けるとよいです。
大量データのJSON整形によるサイズ増加とパフォーマンス
インデントは空白文字なので、技術的には「付けるだけ」ですが、データサイズと処理時間には確実に影響します。
特に、以下のようなケースでは注意が必要です。
- 数万件以上のレコードを含む大きなJSON
- ネストが深く、階層が多い構造
- ネットワーク帯域が限られている環境でのAPIレスポンス
インデントや改行を含めることで、JSONファイルのサイズは数十パーセント増加する場合があります。
1件あたりのオーバーヘッドは小さく見えても、レコード数が増えると無視できなくなります。
さらに、整形するためには余分な文字列操作が発生するため、生成にかかるCPU時間も増えます。
通常の開発規模では大きな問題にならないことが多いですが、リアルタイム性が求められるAPIや、リソース制約のある環境(組み込み機器など)では、本番ではindentを使わないことが推奨される場合もあります。
そのため、「整形は主にデバッグ・ログ・ドキュメント用、本番のデータ転送はコンパクトに」という方針を持っておくと安全です。
json.dumpsとjson.dumpの使い分け
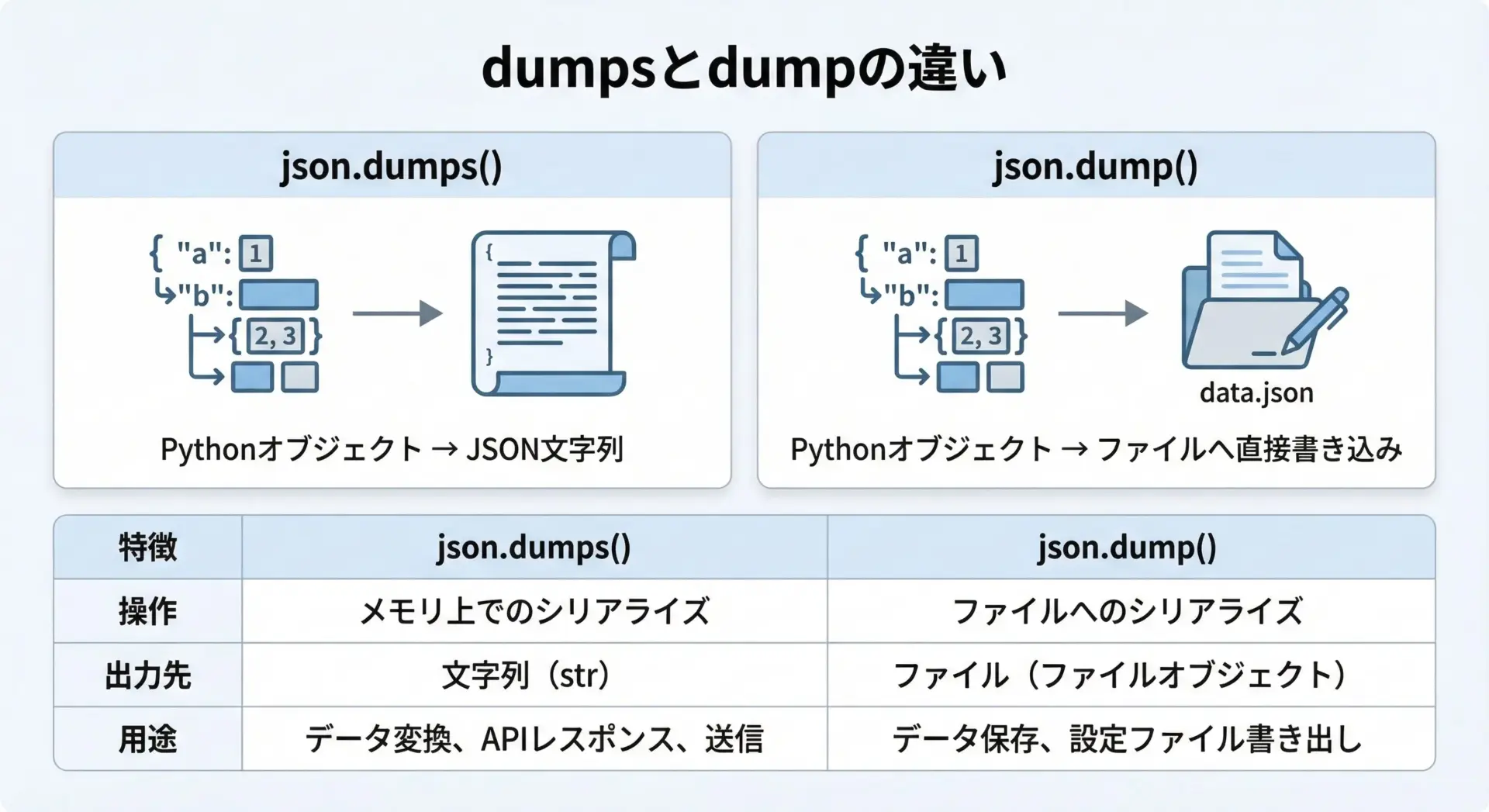
最後に、json.dumpsとjson.dumpの違いを整理しておきます。
どちらも整形にindentを使えるため混同しやすいですが、戻り値と用途が異なります。
| 関数名 | 主な用途 | 戻り値 |
|---|---|---|
json.dumps | Pythonオブジェクトを「文字列」として取得したいとき | JSON形式の文字列 |
json.dump | Pythonオブジェクトをファイルに直接書き込みたいとき | なし(ファイルに書き込むだけ) |
どちらもindentやensure_asciiなど、同じような引数を取ることができます。
使い分けのポイントは次のとおりです。
- 画面表示・ログ出力・テストコード内での比較には
json.dumps - 設定ファイル・サンプルデータ・キャッシュファイルの保存には
json.dump
簡単なサンプルで両方の使い方を示します。
import json
data = {"id": 1, "name": "Taro"}
# 1) dumpsで文字列として取得
json_str = json.dumps(data, indent=2, ensure_ascii=False)
print("=== dumpsの結果 ===")
print(json_str)
# 2) dumpでファイルに直接書き込み
with open("user.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=2, ensure_ascii=False)=== dumpsの結果 ===
{
"id": 1,
"name": "Taro"
}
# user.json には上と同じ内容が書き込まれているこのように、「文字列として扱いたいか」「ファイルに書き込みたいか」でdumpsとdumpを選ぶと覚えておくと迷いません。
まとめ
本記事では、Pythonのjson.dumpsとindentオプションを中心に、JSONをきれいに整形する方法を解説しました。
indentを指定することで階層構造が一目で分かるようになり、デバッグやレビューが大幅にしやすくなります。
さらにensure_ascii=Falseを組み合わせれば、日本語を含むJSONも読みやすい形で扱えます。
一方で、整形はサイズ増加やパフォーマンスへの影響もあるため、開発用にはインデント付き、本番用にはコンパクトという使い分けを意識することが重要です。
用途に応じてjson.dumpsとjson.dumpを使い分けながら、見やすく、扱いやすいJSON処理を実現していきましょう。
