PythonでCSVファイルを扱えるようになると、データ集計やログ分析、業務レポート作成など多くの作業を効率化できます。
本記事では、Python標準のcsvモジュールとPandasの両方を使いながら、初心者でも実務で通用するCSV読み書きの基礎から応用までを丁寧に解説していきます。
PythonでCSVを扱う基本
CSVとは何かとPythonでのメリット

CSVとは、Comma Separated Valuesの略で、カンマなどの区切り文字で表形式のデータを並べたテキストファイル形式です。
Excelファイルのような複雑な書式を持たず、1行が1レコード、カンマ区切りでカラムが並ぶだけの非常にシンプルな構造になっています。
たとえば次のような内容が典型的なCSVです。
name,age,department
山田太郎,30,営業
佐藤花子,28,開発PythonからCSVを扱うメリットは大きく分けて次のようになります。
まず、ほとんどのシステムがCSVでの入出力に対応しているため、社内システムや外部サービスとのデータ連携がしやすい点が挙げられます。
また、テキストベースなのでファイルサイズが比較的小さく、Gitなどのバージョン管理もしやすくなります。
Pythonには標準でcsvモジュールが組み込まれているため、追加インストールなしで読み書きが可能です。
さらに、データ分析の定番ライブラリであるPandasを使えば、数万〜数百万行のデータでも効率的に加工・集計できます。
この2つを場面に応じて使い分けることが、実務でのCSV処理では重要になります。
csvモジュールとPandasの違いと使い分け
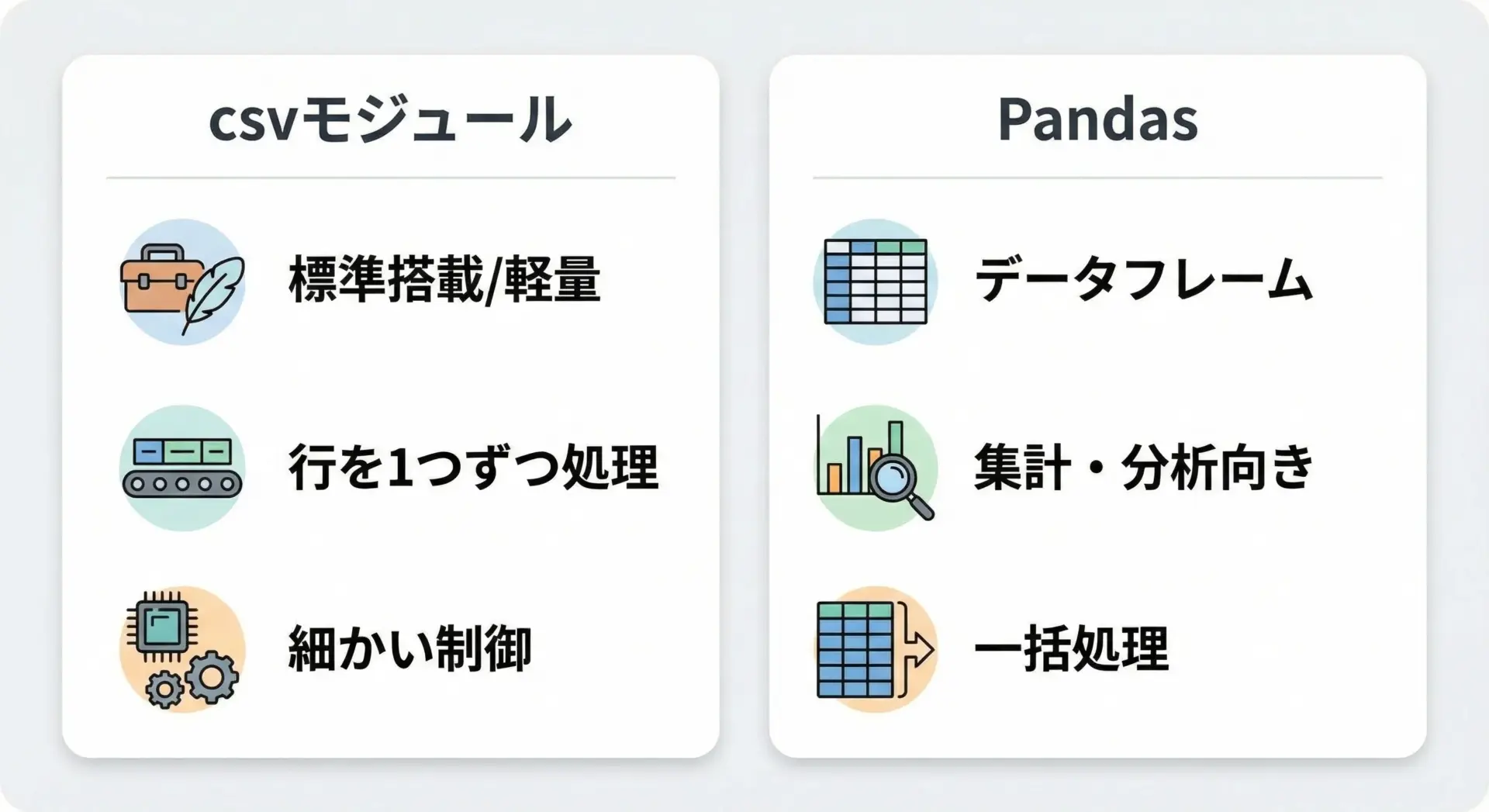
PythonでCSVを扱う代表的なアプローチは、標準ライブラリのcsvモジュールと、外部ライブラリのpandasを使う方法です。
両者の違いと使い分けのイメージを文章で整理しておきます。
csvモジュールは、Pythonに標準で組み込まれている低レベルなCSV処理用モジュールです。
特徴としては、行を1件ずつ順番に読んだり書いたりする処理に向いており、メモリ使用量を抑えやすいこと、細かい区切り文字やクオートの設定がしやすいことなどが挙げられます。
ログのストリーミング処理や、数十行〜数千行程度の軽い入出力には十分です。
一方でPandasは、データフレーム(DataFrame)という表形式データ構造を提供する強力なライブラリで、統計処理や分析に適しています。
CSVを読み込むと、すぐにカラムごとの集計やフィルタリング、グルーピングといった高度な操作が可能です。
ただし、一般的にはファイル全体をメモリに読み込むため、データ量が極端に多い場合は注意が必要です。
実務では、次のような使い分けがよく行われます。
まず、単純変換やシンプルな入出力にはcsvモジュール、そして集計・分析・レポート作成にはPandasという組み合わせです。
後半の章では、この使い分けをさらに具体的に解説していきます。
環境準備
PythonでCSVを扱うための環境準備は、それほど難しくありません。
標準のcsvモジュールはPythonに最初から含まれているため、Python本体さえインストールされていれば追加のセットアップは不要です。
まずPythonがインストールされているかを確認します。
ターミナル(またはコマンドプロンプト)で次のコマンドを実行します。
python --versionPythonのバージョンが表示されればOKです。
3.x系であれば、この記事の内容はそのまま利用できます。
もしPythonがインストールされていない場合は、公式サイトからダウンロードし、インストールしてください。
Pandasを使う場合は、別途インストールが必要です。
ターミナルで次のコマンドを実行します。
pip install pandasバージョン確認は次のように行います。
python -c "import pandas as pd; print(pd.__version__)"これで、csvモジュールとPandasの両方を使ったCSV処理の準備が整います。
エディタとしては、VS CodeやPyCharm、Jupyter Notebookなど、任意のPython対応エディタを使って問題ありません。
Python標準csvモジュールでのCSV読み書き
csv.readerでCSVを読み込む基本
まずは、Python標準のcsvモジュールを使ってCSVを読み込む最も基本的な方法から説明します。
ここでは、次のようなsample.csvファイルを用意しているとします。
name,age,city
山田太郎,30,東京
佐藤花子,28,大阪このCSVをcsv.readerで読み込むサンプルコードは次の通りです。
import csv
# sample.csv を読み込む基本例
with open("sample.csv", mode="r", encoding="utf-8", newline="") as f:
reader = csv.reader(f) # csv.reader は行ごとにリストを返すイテレータ
for row in reader:
# row は ["name", "age", "city"] のようなリストになります
print(row)実行結果のイメージは次のようになります。
['name', 'age', 'city']
['山田太郎', '30', '東京']
['佐藤花子', '28', '大阪']ここで重要なのは、csv.readerが返すのは文字列のリストであり、数値も最初は文字列として扱われるという点です。
年齢などを数値として扱いたい場合は、自分でint(row[1])などに変換する必要があります。
また、ファイルを開くときはnewline=""を指定することが推奨されています。
これは、csvモジュールが改行コードを正しく処理しやすくするための設定です。
Windows環境などでも、意図しない空行が入るのを防ぐ効果があります。
ヘッダー行付きCSVの扱い
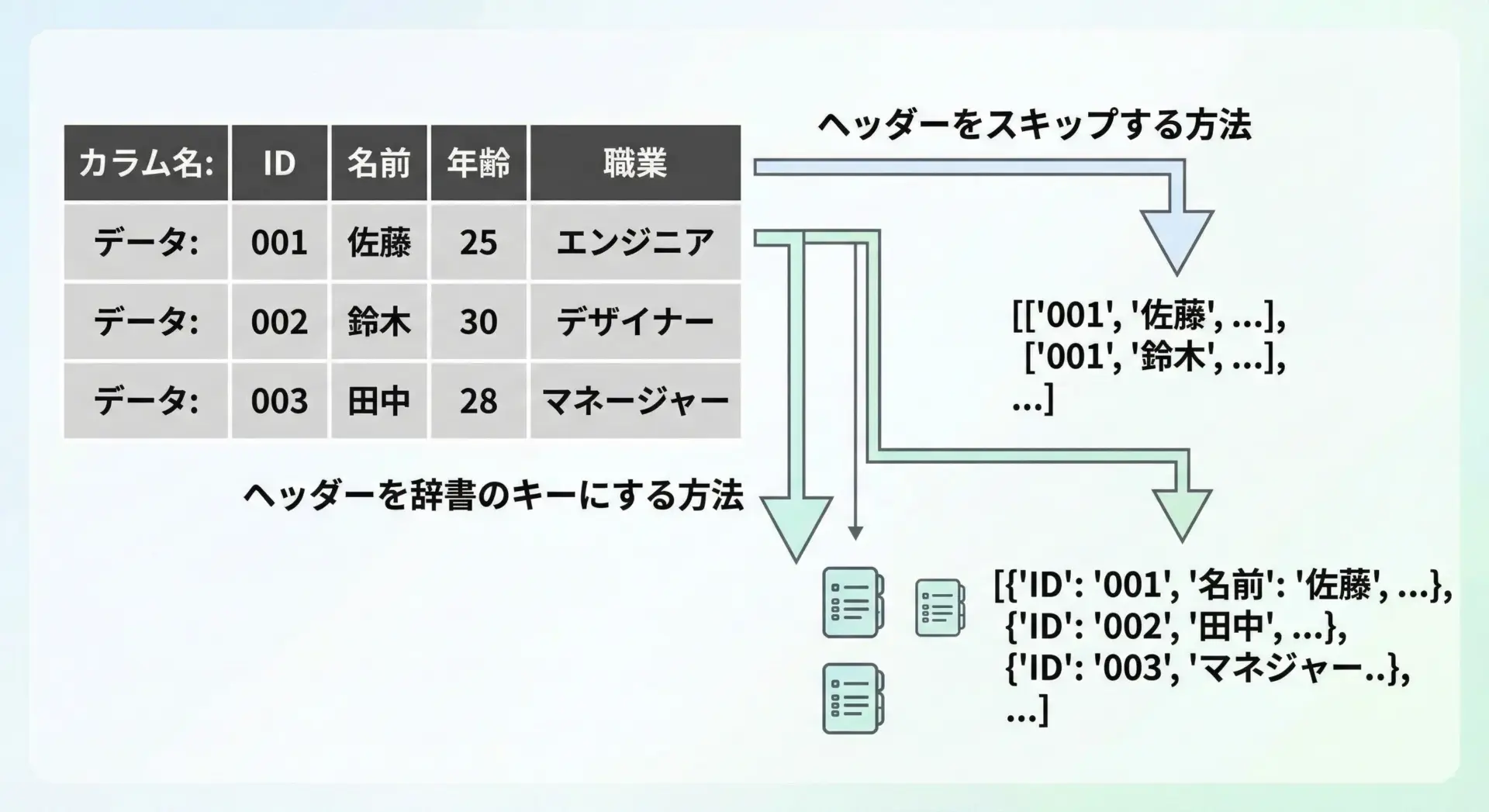
実務のCSVファイルには、多くの場合1行目にカラム名(ヘッダー行)が含まれています。
このヘッダーをどのように扱うかで、コードの書きやすさが変わってきます。
ヘッダー行を単純にスキップする
最も単純な方法は、next()を使って1行だけ読み飛ばす方法です。
import csv
with open("sample.csv", mode="r", encoding="utf-8", newline="") as f:
reader = csv.reader(f)
header = next(reader) # 最初の1行(ヘッダー)だけ取得してスキップ
print("ヘッダー:", header)
for row in reader:
# ここからはデータ行のみが処理されます
print("名前:", row[0], "年齢:", row[1])出力結果(イメージ):
ヘッダー: ['name', 'age', 'city']
名前: 山田太郎 年齢: 30
名前: 佐藤花子 年齢: 28この方法はシンプルですが、カラムの位置をインデックスで直接指定する必要があるため、列の順序が変わるとコードも修正しなければならないという弱点があります。
DictReaderでカラム名をキーにして扱う
そこで便利なのがcsv.DictReaderです。
これは、各行を辞書(dict)として返してくれるクラスで、カラム名をキーとして扱えるようになります。
import csv
with open("sample.csv", mode="r", encoding="utf-8", newline="") as f:
reader = csv.DictReader(f) # ヘッダー行から自動的にカラム名を取得
for row in reader:
# row は {"name": "山田太郎", "age": "30", "city": "東京"} のような辞書
print("名前:", row["name"], "年齢:", row["age"])出力結果(イメージ):
名前: 山田太郎 年齢: 30
名前: 佐藤花子 年齢: 28このように、DictReaderを使うと、カラム名を指定して値を取得できるため、列の順序が変わってもコードが壊れにくくなります。
実務ではDictReaderを使うケースが非常に多くなります。
csv.writerでCSVを書き出す基本
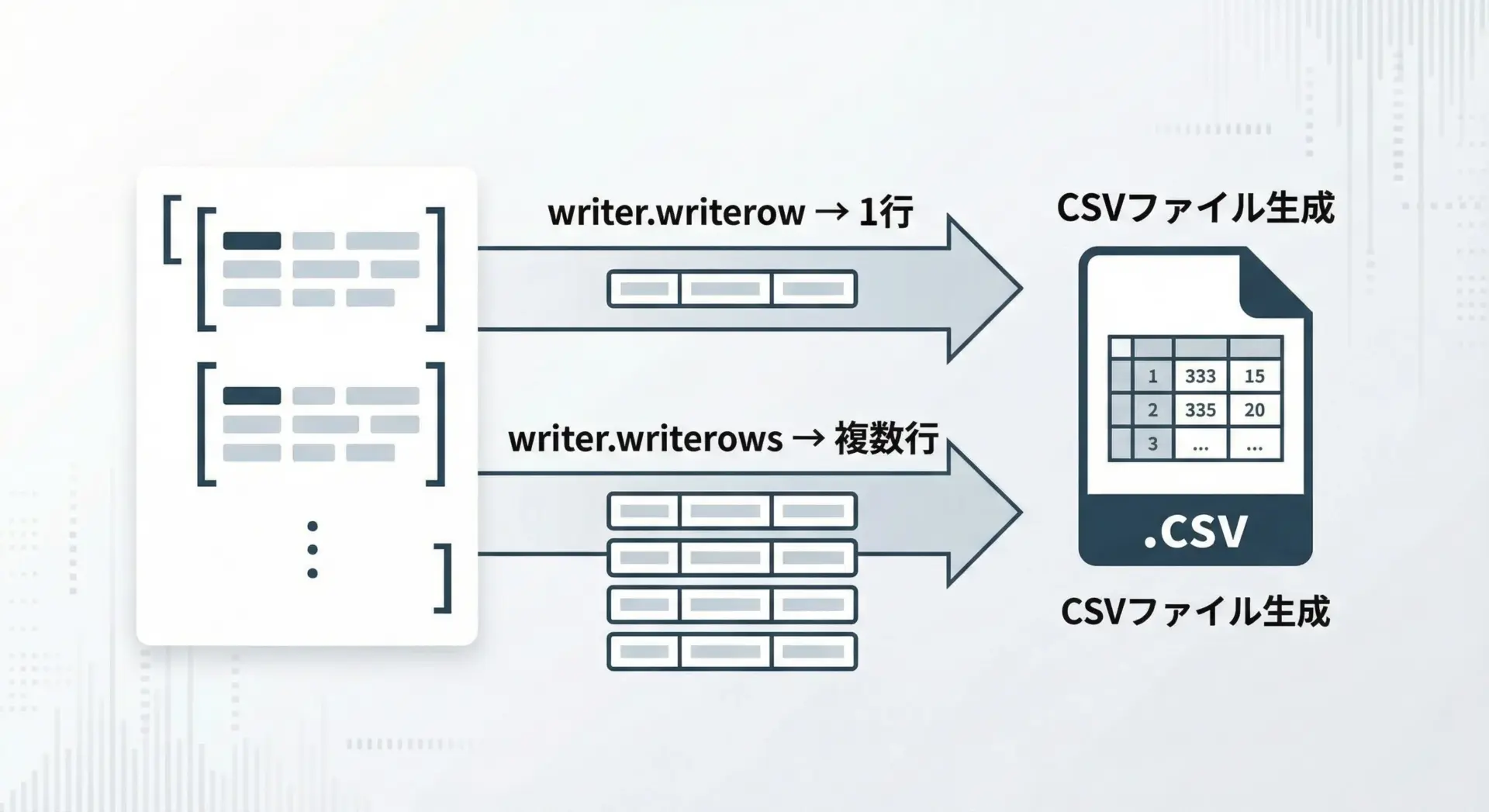
次に、csvモジュールを使ってCSVを書き出す方法を解説します。
最も基本的なクラスはcsv.writerです。
1行ずつ書き出す基本
import csv
# 出力するデータ(リストのリスト)
rows = [
["name", "age", "city"], # ヘッダー行
["山田太郎", 30, "東京"],
["佐藤花子", 28, "大阪"],
]
with open("output.csv", mode="w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
for row in rows:
# writerow で1行ずつ書き込みます
writer.writerow(row)このコードを実行すると、output.csvには次のような内容が書き出されます。
name,age,city
山田太郎,30,東京
佐藤花子,28,大阪ここでも、ファイルオープン時のnewline=""指定が重要です。
これを忘れると、特にWindows環境で余分な空行が挿入されてしまうことがあります。
複数行をまとめて書くwriterows
複数行のデータが既にリストとして用意されている場合、writerowsを使うと簡潔に書き出せます。
import csv
rows = [
["name", "age", "city"],
["山田太郎", 30, "東京"],
["佐藤花子", 28, "大阪"],
]
with open("output2.csv", mode="w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerows(rows) # まとめて書き込み結果として、先ほどと同様のCSVが生成されます。
ループを自分で回す必要がないため、コードが短く読みやすくなります。
DictWriterで辞書から書き出す
DictReaderと同様に、csv.DictWriterを使うと、辞書型のデータをカラム名付きでCSV出力できます。
import csv
# 出力するデータ(辞書のリスト)
rows = [
{"name": "山田太郎", "age": 30, "city": "東京"},
{"name": "佐藤花子", "age": 28, "city": "大阪"},
]
fieldnames = ["name", "age", "city"] # カラムの順序を明示
with open("output_dict.csv", mode="w", encoding="utf-8", newline="") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader() # ヘッダー行の書き出し
writer.writerows(rows) # 辞書のリストを書き出し生成されるCSV:
name,age,city
山田太郎,30,東京
佐藤花子,28,大阪このように、アプリ内では辞書で扱い、入出力だけDictReader/DictWriterに任せる構成は、実務で非常によく使われるパターンです。
文字コード(UTF-8/Shift_JIS)と改行コードの注意点
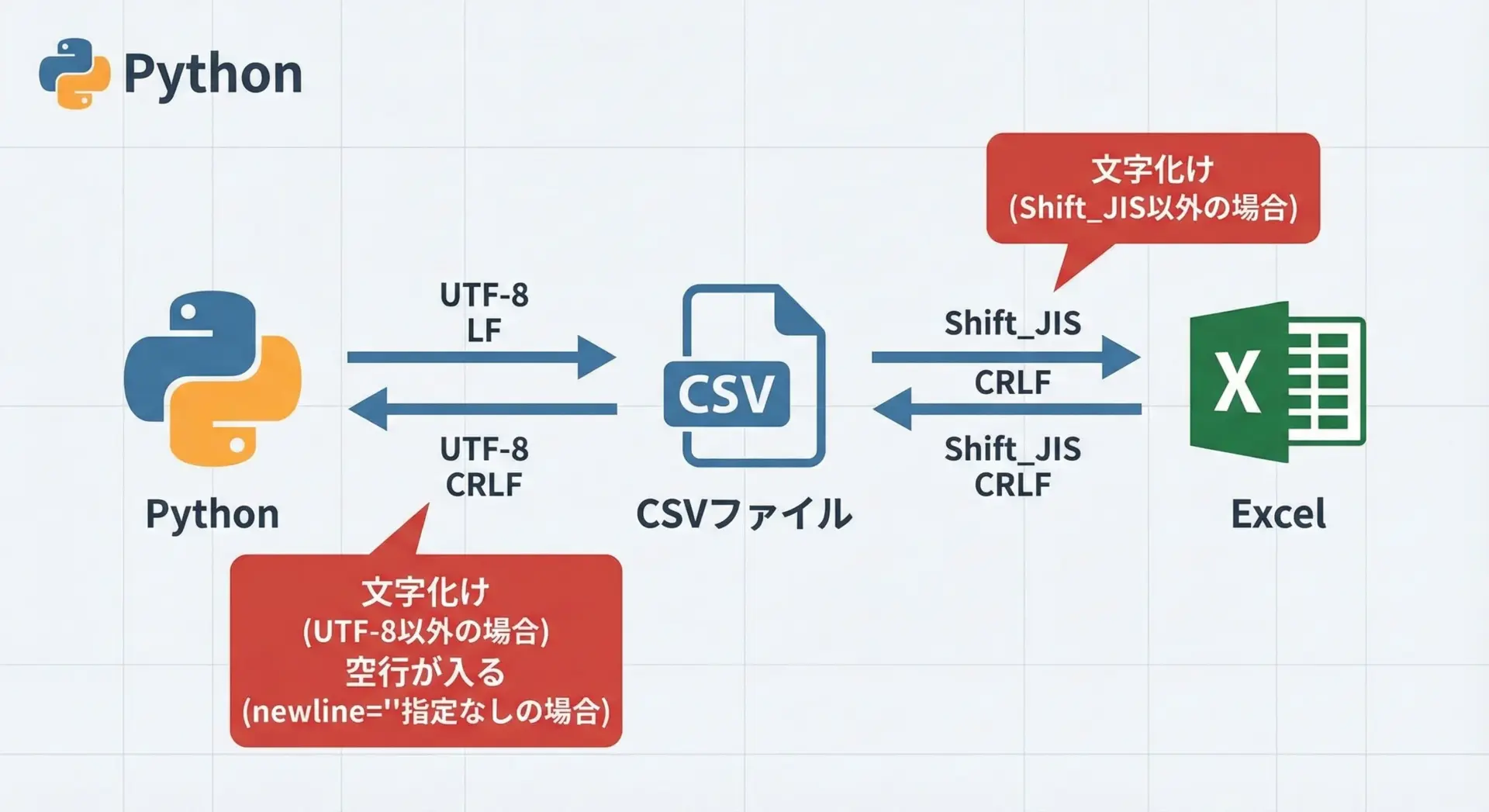
日本語を含むCSVでは、文字コードと改行コードの扱いが重要です。
ここでは主に、UTF-8とShift_JIS、および改行コードのポイントを整理します。
まず文字コードについてですが、Pythonではencoding="utf-8"を使うのが基本です。
UTF-8は国際的にも標準的な文字コードであり、多くのツールが対応しています。
ただし、古いWindowsのExcelや一部の日本向けソフトはShift_JISを前提としており、そのままUTF-8のCSVを開くと文字化けすることがあります。
Excel用にShift_JISで書き出す例は次の通りです。
import csv
rows = [
["name", "age", "city"],
["山田太郎", 30, "東京"],
]
# Excel(日本語版)向けに Shift_JIS で出力する例
with open("excel_compatible.csv", mode="w", encoding="cp932", newline="") as f:
writer = csv.writer(f)
writer.writerows(rows)ここではencoding="cp932"を指定しています。
これはWindows日本語環境のShift_JIS互換コードで、Excelとの相性が良い設定です。
次に改行コードですが、OSによって標準の改行コードが異なります。
WindowsはCRLF、LinuxやmacOSはLFを使います。
Pythonのcsvモジュールでは、ファイルを開くときにnewline=""を指定し、改行コードの処理をcsvモジュールに任せることが推奨されています。
これにより、OSに依存しない安定したCSV出力が可能になります。
もしnewline=""を指定しなかった場合、とくにWindowsで、行間に空行が挟まってしまうといったトラブルが起こりやすくなります。
実務では、この指定をテンプレートとして覚えてしまうのがおすすめです。
区切り文字・クオート・エスケープの設定方法
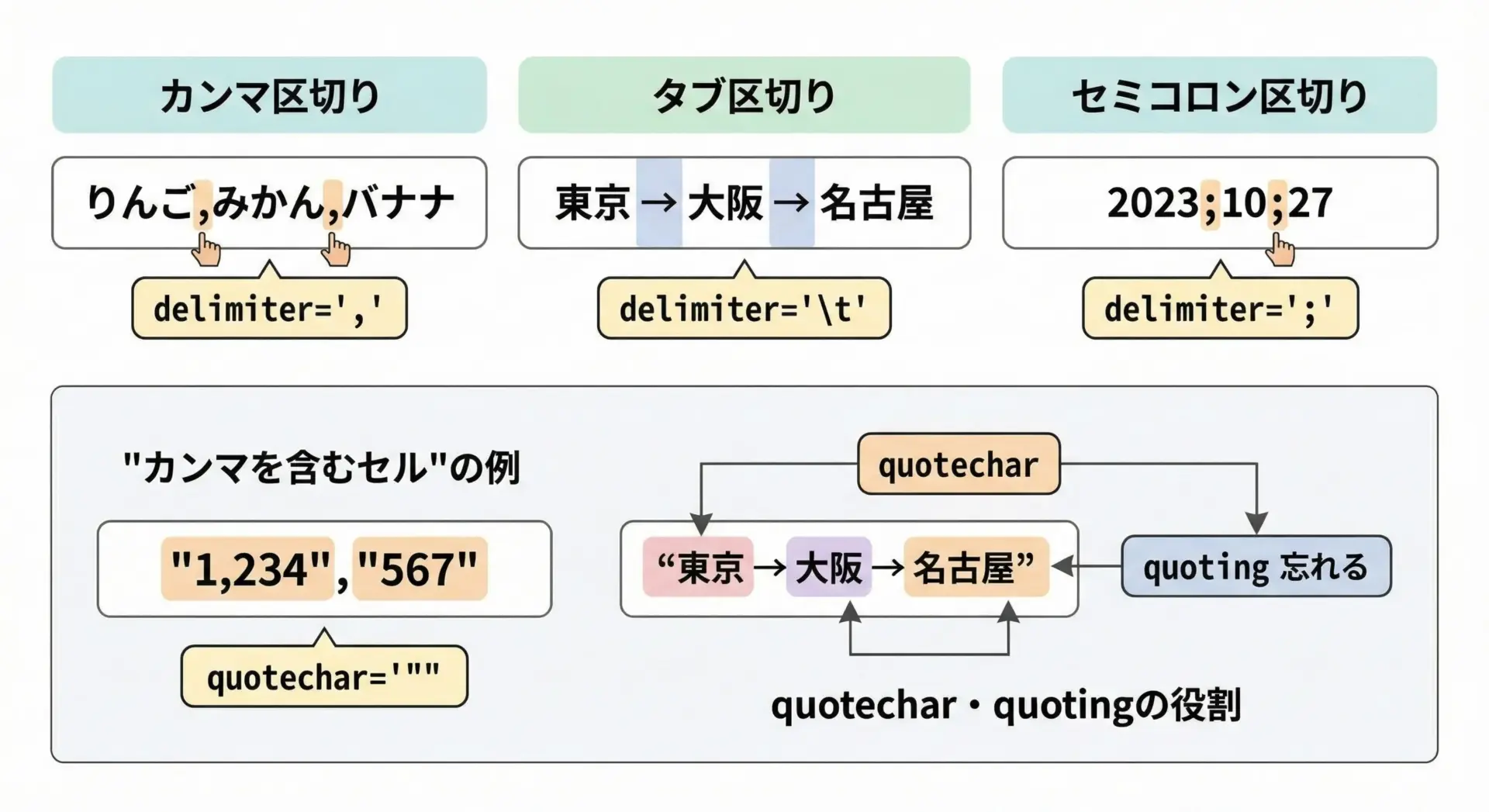
CSVといっても、実際にはカンマ以外の区切り文字を使うファイルも多く存在します。
たとえばタブ区切りのTSV、セミコロン区切りのファイルなどです。
また、カンマを含む文字列や改行を含むセルを安全に扱うためには、クオート(引用符)やエスケープの設定もポイントになります。
csv.reader / csv.writerでは、次のようなオプションを指定できます。
delimiter: 区切り文字(デフォルトは',')quotechar: 値を囲む引用符(デフォルトは'"')quoting: どのような場合にクオートするかescapechar: クオートをエスケープする文字
タブ区切りファイルの読み書き
import csv
# 読み込み(タブ区切り)
with open("data.tsv", mode="r", encoding="utf-8", newline="") as f:
reader = csv.reader(f, delimiter="\t")
for row in reader:
print(row)
# 書き込み(タブ区切り)
rows = [
["id", "value"],
[1, "hello"],
]
with open("output.tsv", mode="w", encoding="utf-8", newline="") as f:
writer = csv.writer(f, delimiter="\t")
writer.writerows(rows)カンマを含む値を安全に扱う
値の中にカンマや改行が含まれる場合、クオートしておかないと正しく読み書きできません。
csv.writerはデフォルトでquoting=csv.QUOTE_MINIMALとなっており、必要な場合だけ自動的に引用符を付けてくれます。
import csv
rows = [
["name", "comment"],
["山田太郎", "お世話になっております, 今回の件ですが…"],
]
with open("quoted.csv", mode="w", encoding="utf-8", newline="") as f:
writer = csv.writer(f, quoting=csv.QUOTE_MINIMAL)
writer.writerows(rows)生成されるCSV(イメージ):
name,comment
山田太郎,"お世話になっております, 今回の件ですが…"このように、カンマや改行を含む値は引用符で囲まれるため、安全にCSVとして扱えます。
引用符そのものが値に含まれる場合は、escapecharやdoublequoteオプションを調整することで、さらに細かく制御できます。
PandasでのCSV読み書き
read_csvでCSVを読む基本とよく使う引数
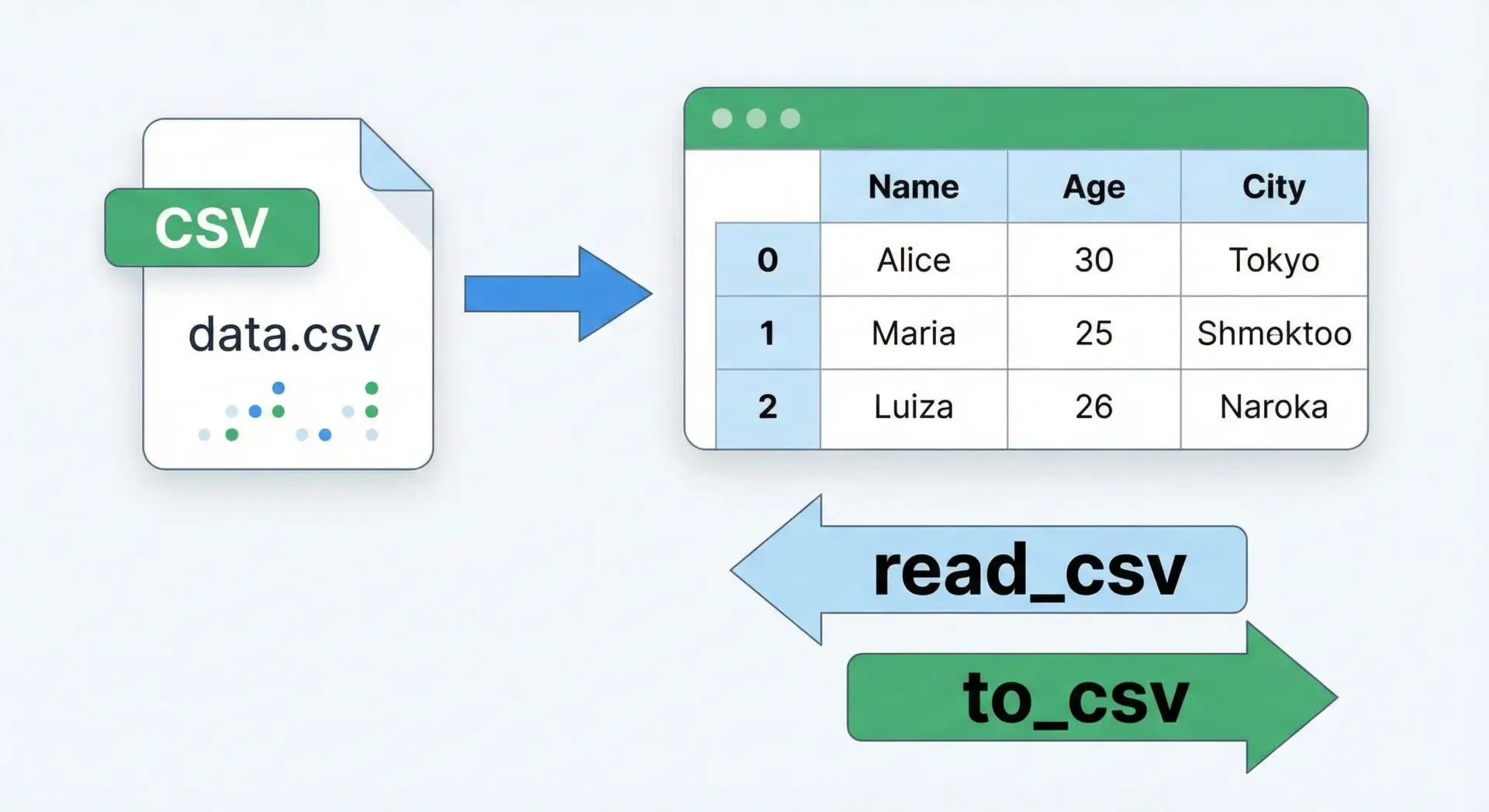
Pandasを使うと、CSVの読み込みと同時に、表形式のデータとしてすぐに分析や加工ができる状態になります。
基本となる関数はpandas.read_csvです。
import pandas as pd
# 基本的な read_csv の使い方
df = pd.read_csv("sample.csv", encoding="utf-8")
print(df)
print(type(df)) # <class 'pandas.core.frame.DataFrame'> name age city
0 山田太郎 30 東京
1 佐藤花子 28 大阪
<class 'pandas.core.frame.DataFrame'>Pandasのread_csvには非常に多くの引数がありますが、日常的によく使うものを文章でまとめると次のようになります。
まずencodingは文字コードを指定する引数で、日本語CSVでは"utf-8"や"cp932"を使います。
次にsepは区切り文字を指定する引数で、タブ区切りのTSVの場合はsep="\t"とします。
またheaderはヘッダー行の位置を指定するもので、1行目がヘッダーであればデフォルトのままで構いませんが、ヘッダーがない場合はheader=Noneを指定します。
行の一部だけを読みたい場合はusecols、最初の数行だけで良い場合はnrowsといった引数も便利です。
これらを組み合わせることで、必要なデータだけを効率的に読み込むことができます。
カラム名・インデックス・データ型の指定
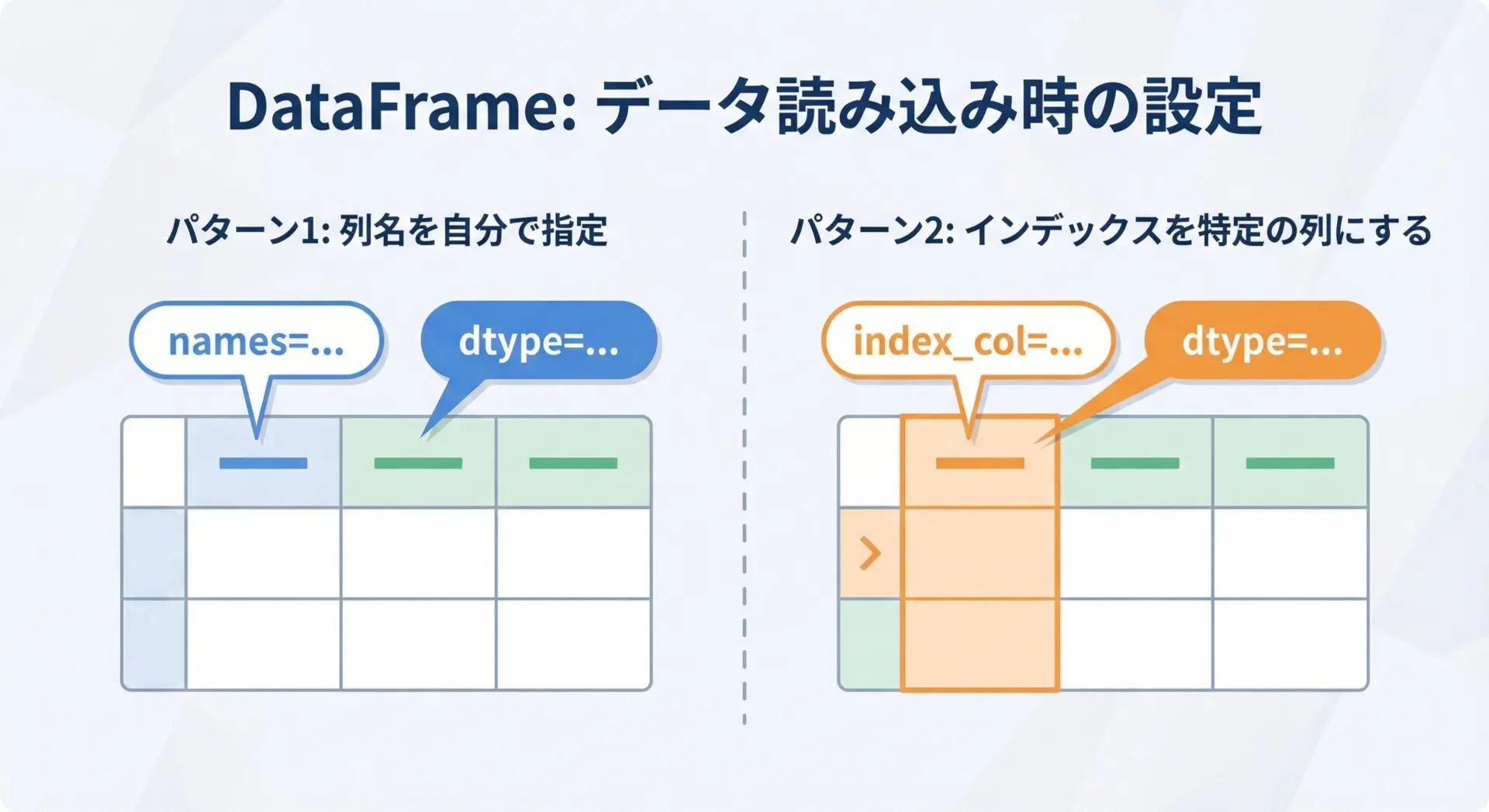
Pandasでは、CSV読み込み時にカラム名やインデックス(行ラベル)、データ型を細かく制御できます。
これにより、読み込み直後から扱いやすいデータ構造を用意できます。
カラム名を自分で指定する
ヘッダー行がないCSVや、ヘッダーを無視して新しいカラム名を付けたい場合は、names引数を使います。
import pandas as pd
# ヘッダーなしCSVを読み込んで列名を付ける例
df = pd.read_csv(
"no_header.csv",
header=None, # 既存のヘッダー行はない
names=["name", "age", "city"], # 新しく付けるカラム名
encoding="utf-8",
)
print(df.head())特定の列をインデックスにする
ある列を行ラベルとして扱いたい場合は、index_colを指定します。
import pandas as pd
df = pd.read_csv(
"sample.csv",
encoding="utf-8",
index_col="name", # name 列をインデックスにする
)
print(df) age city
name
山田太郎 30 東京
佐藤花子 28 大阪このように、名前をキーにして行を参照したい場合などに便利です。
データ型(dtype)を明示する
Pandasは自動的にデータ型を推測しますが、明示的に指定した方が安全な場合もあります。
たとえばIDを数値としてではなく文字列として扱いたい場合などです。
import pandas as pd
df = pd.read_csv(
"users.csv",
encoding="utf-8",
dtype={
"user_id": "string", # 数値っぽく見えても文字列として扱う
"age": "Int64", # 欠損値を許容する整数型
},
)
print(df.dtypes)このようにdtype引数を使うと、後続処理での型エラーや意図しない型変換を防ぎやすくなります。
日本語CSV・日付データの読み込み
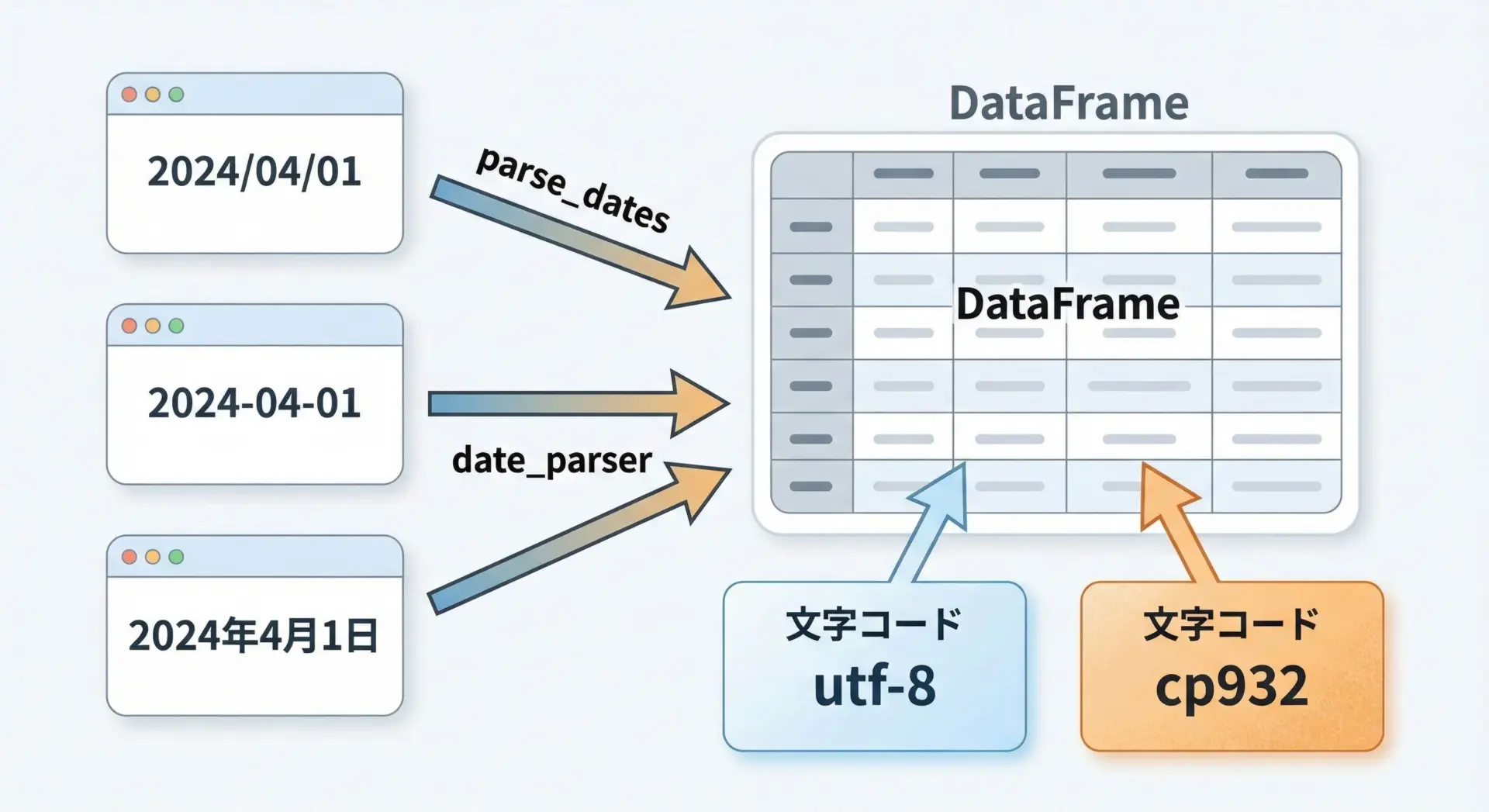
日本語CSVでは文字コードの他に、日付型の扱いがよく問題になります。
まず文字コードについては、基本的にはencoding="utf-8"を指定しますが、Excelで保存されたShift_JIS系のCSVでは"cp932"を使うと良いことが多いです。
import pandas as pd
# Excel起点の日本語CSVを読み込む例
df = pd.read_csv("excel_export.csv", encoding="cp932")次に日付ですが、単にCSVを読み込むだけだと日付が文字列として扱われます。
Pandasにはparse_dates引数があり、読み込み時に特定の列を日付型に変換できます。
import pandas as pd
# order_date 列を日付として解釈して読み込む
df = pd.read_csv(
"orders.csv",
encoding="utf-8",
parse_dates=["order_date"], # 日付として解釈する列名を指定
)
print(df["order_date"].dtype)
print(df.head())出力例(型):
datetime64[ns]もし日付の形式が特殊で、Pandasが自動認識できない場合は、date_parserに自前の関数を渡して変換することもできます。
ただし、近年のPandasではこのパラメータは推奨されない場合もあるため、可能ならto_datetimeを後から適用する方法も検討します。
import pandas as pd
df = pd.read_csv("orders_jp.csv", encoding="utf-8")
# "2024年4月1日" のような形式を後から日付に変換する例
df["order_date"] = pd.to_datetime(df["order_date"], format="%Y年%m月%d日")
print(df.dtypes)このようにして、日本語環境固有のフォーマットにも柔軟に対応できます。
to_csvでのCSV書き出しとエンコーディング設定
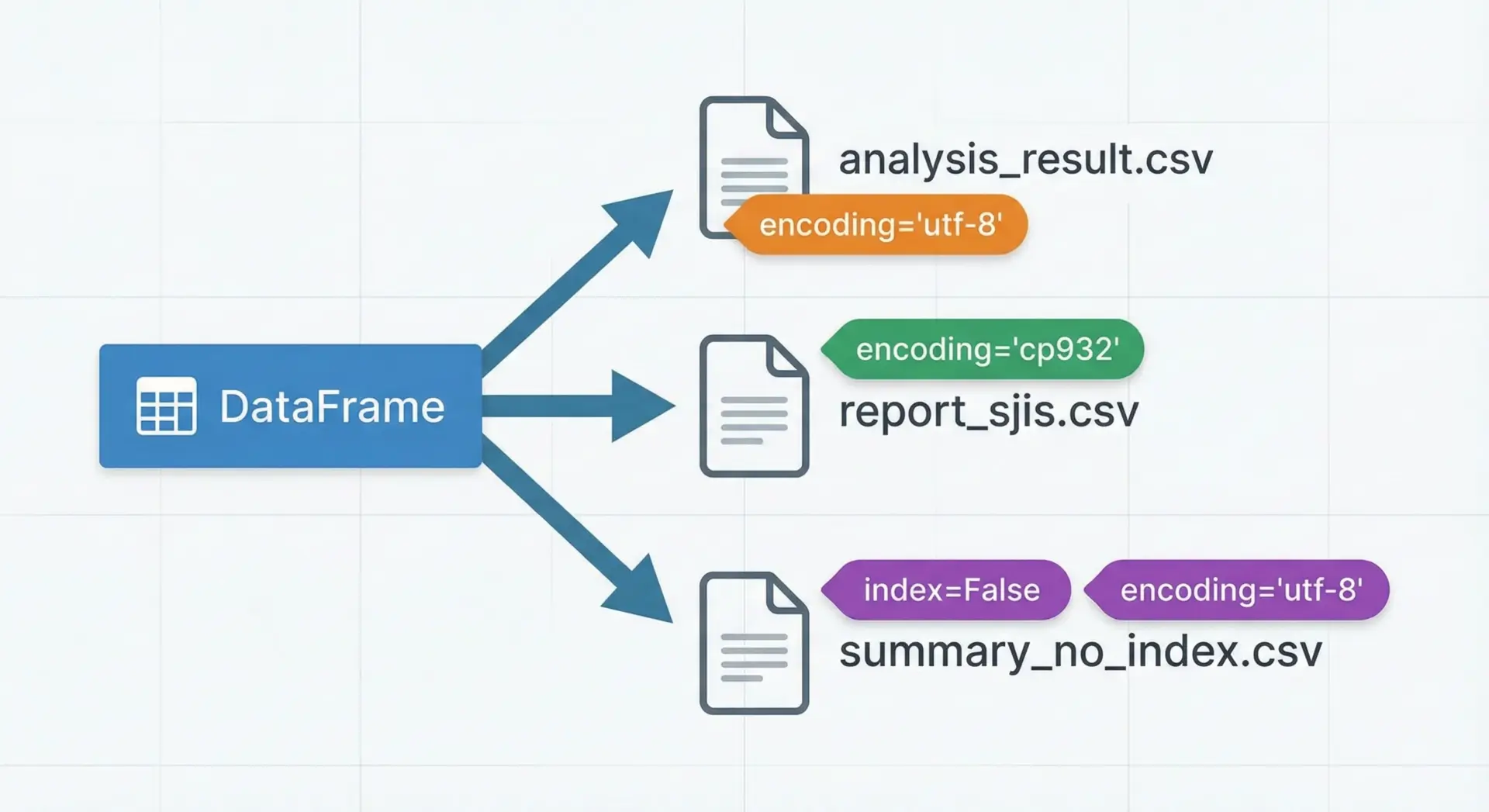
Pandasのto_csvメソッドを使うと、DataFrameをそのままCSVファイルとして保存できます。
エンコーディングやインデックスの有無も柔軟に制御できます。
import pandas as pd
df = pd.DataFrame(
{
"name": ["山田太郎", "佐藤花子"],
"age": [30, 28],
"city": ["東京", "大阪"],
}
)
# 分析用: UTF-8、インデックス列なし
df.to_csv("analysis_result.csv", encoding="utf-8", index=False)
# Excel共有用: Shift_JIS系、インデックス列も含める
df.to_csv("report_sjis.csv", encoding="cp932", index=True)生成されるanalysis_result.csv(イメージ):
name,age,city
山田太郎,30,東京
佐藤花子,28,大阪Pandasのto_csvには、他にも多くのオプションがあります。
たとえばsepで区切り文字を変更したり、na_repで欠損値を特定の文字列に置き換えたりできます。
これにより、外部システムが期待するフォーマットに合わせた出力が可能になります。
大量データの高速処理
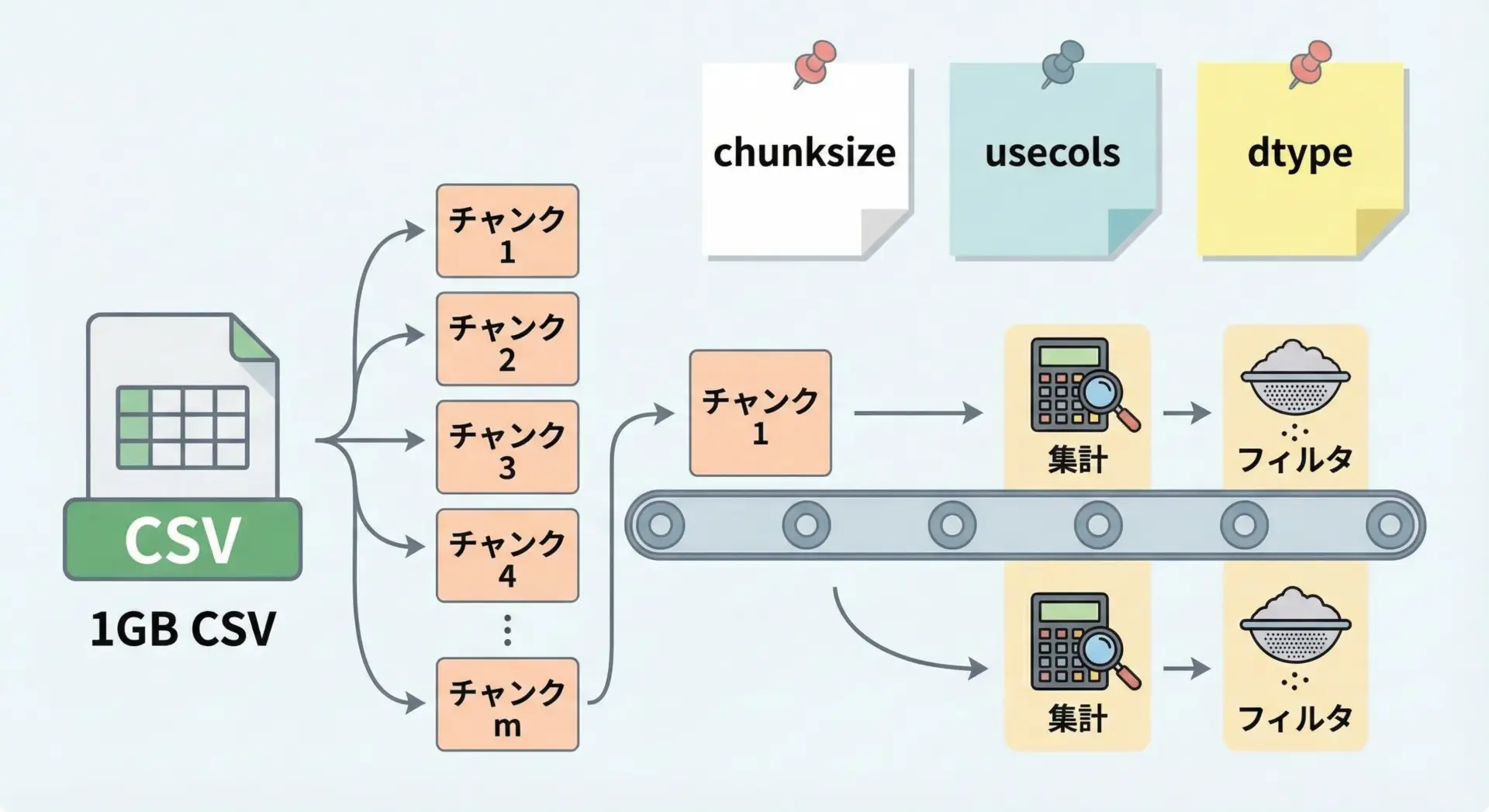
Pandasはメモリ上での処理が基本ですが、数百万行を超えるような巨大CSVを扱うと、メモリ不足に陥る可能性があります。
そのような場合は、いくつかのテクニックを組み合わせて対応します。
1つはchunksizeを使う方法です。
これは、CSVを一定行数ごとのチャンク(塊)に分割して順次処理する仕組みで、メモリ使用量を抑えながら全体を処理できます。
import pandas as pd
total = 0
# 10000行ずつチャンクとして読み込んで集計する例
for chunk in pd.read_csv("bigdata.csv", encoding="utf-8", chunksize=10_000):
total += chunk["amount"].sum()
print("合計金額:", total)また、usecolsで本当に必要なカラムだけを読み込んだり、dtypeを指定してメモリ効率の良い型を使うことも重要です。
これらを組み合わせることで、Pandasでも数千万行規模まで実用的に扱えるケースが多くなります。
さらに巨大なデータを扱う場合は、SQLiteやParquet形式への変換、DaskやPolarsといった別のツールの利用も検討されますが、まずはPandasのchunksizeとusecolsを押さえておくと良いでしょう。
実務で役立つCSV処理テクニック
CSVデータの前処理
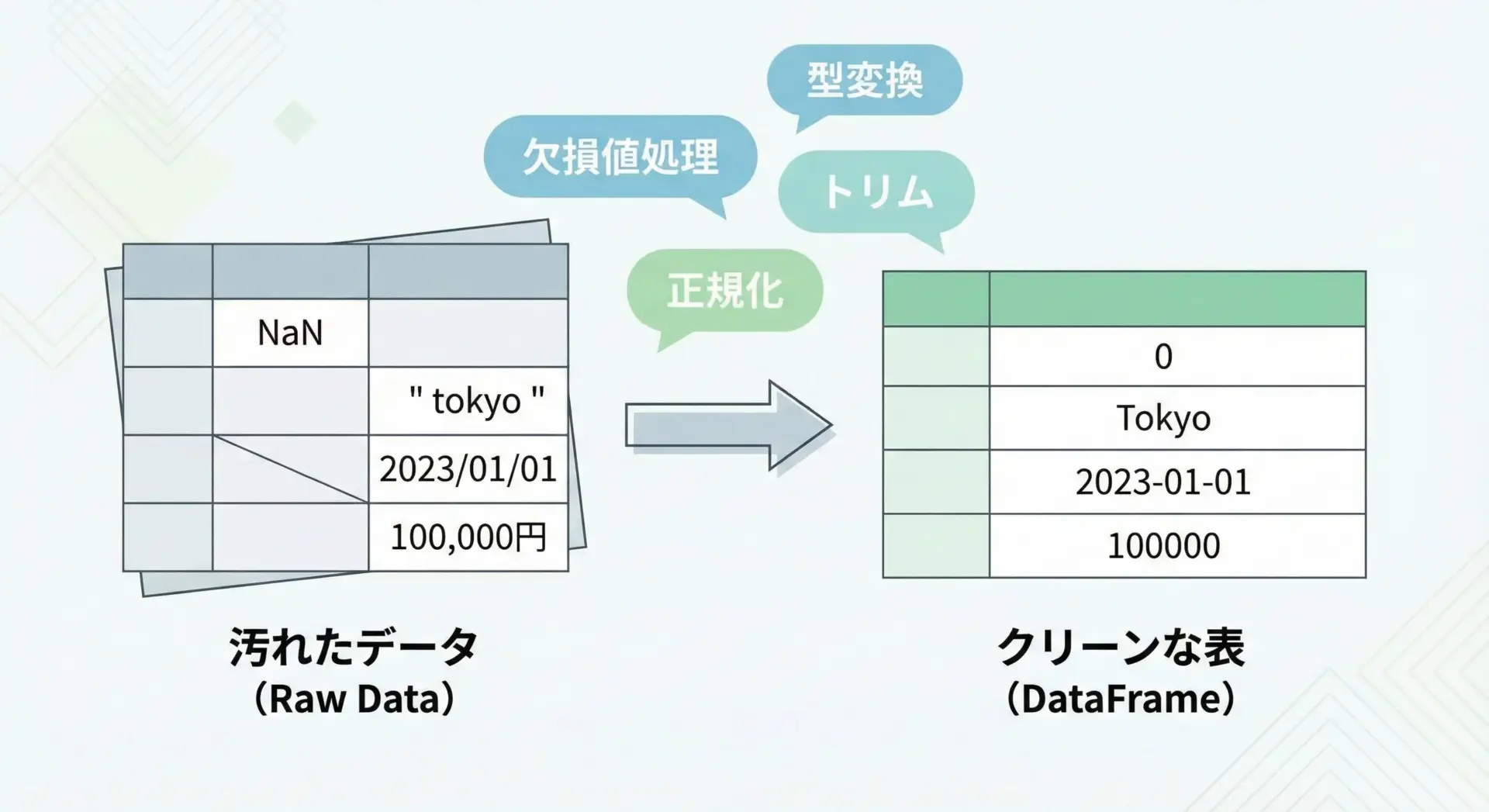
実務で受け取るCSVは、理想的な状態とは限りません。
欠損値があったり、表記ゆれがあったり、数字が文字列として入っていたりといった問題が頻繁に発生します。
こうしたデータを使いやすい形に整える前処理が、分析やレポートの品質を大きく左右します。
Pandasを前提に、代表的な前処理例を紹介します。
import pandas as pd
df = pd.read_csv("raw_data.csv", encoding="utf-8")
# 1. 文字列の前後の空白を削除
str_cols = ["name", "city"]
for col in str_cols:
df[col] = df[col].str.strip()
# 2. 数値列を適切な型に変換(変換できないものはNaNに)
df["age"] = pd.to_numeric(df["age"], errors="coerce")
# 3. 欠損値を補完または除去
df["age"] = df["age"].fillna(df["age"].median()) # 年齢の欠損を中央値で埋める
# 4. カテゴリ値の統一(表記ゆれ対応)
df["city"] = df["city"].replace({"東京市": "東京", "TOKYO": "東京"})
print(df.head())このように、前処理パターンをテンプレート化しておくと、新しいCSVに対しても素早くクリーンアップを適用できるようになります。
csvモジュールでも同様の処理は可能ですが、行ごとに自前でロジックを書く必要があるため、複雑な前処理にはPandasの方が向いています。
複数CSVの結合と集計処理
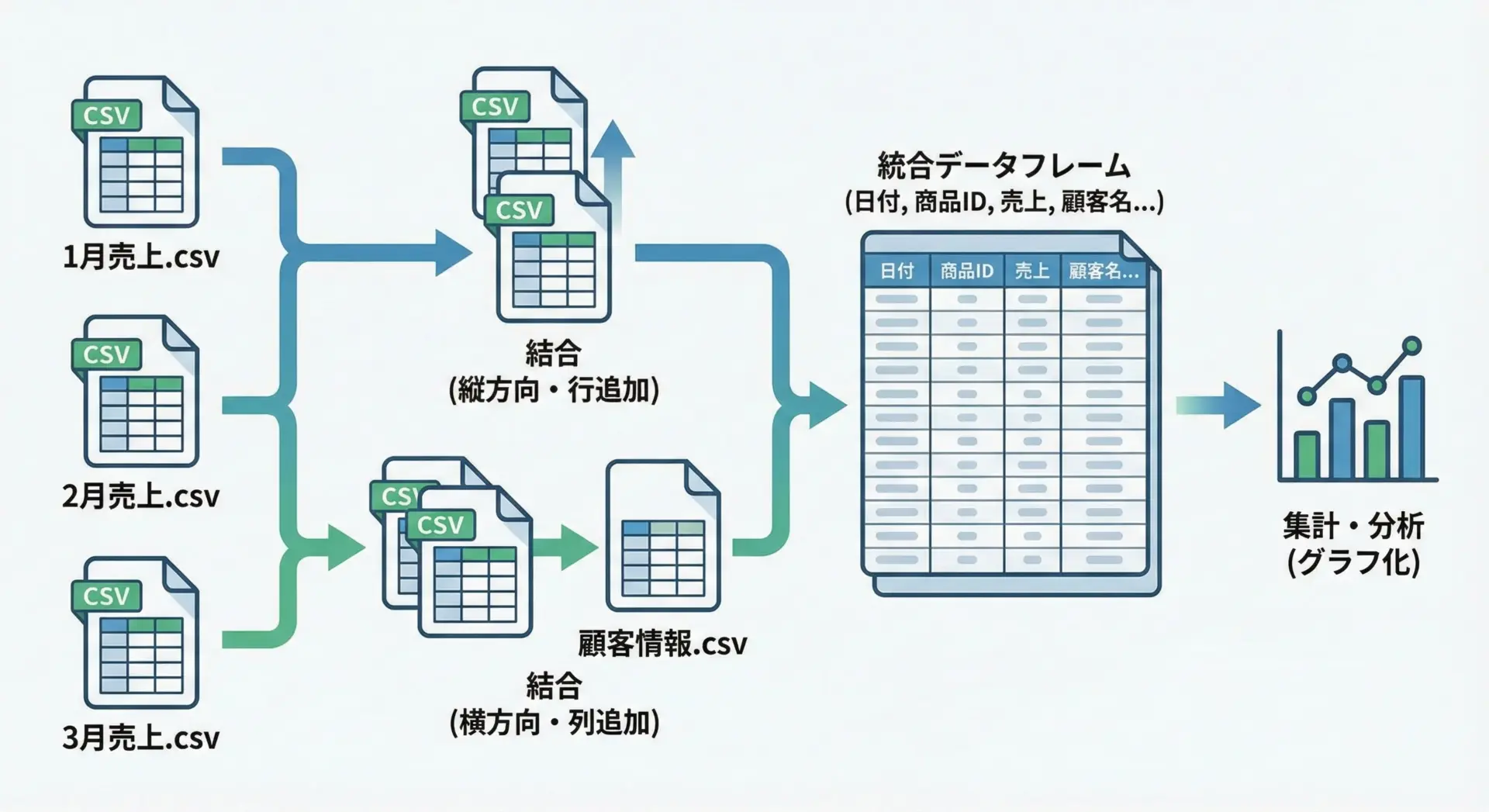
実務では、複数のCSVを結合して1つのデータセットにまとめるケースがよくあります。
たとえば月次売上データを1年分まとめたり、マスタデータとトランザクションデータを結合したりする場面です。
同じ形式のCSVを縦に結合する
複数のファイルが同じカラム構成であれば、pd.concatで縦方向に結合できます。
import pandas as pd
from pathlib import Path
csv_dir = Path("sales_monthly")
files = sorted(csv_dir.glob("sales_*.csv")) # sales_2024-01.csv など
dfs = []
for f in files:
df = pd.read_csv(f, encoding="utf-8")
dfs.append(df)
# 縦方向に結合
all_sales = pd.concat(dfs, ignore_index=True)
print(all_sales.head())結合したデータに対して、さらにグループ集計を行うことも簡単です。
# 店舗ごとの売上合計を集計
summary = all_sales.groupby("store")["amount"].sum().reset_index()
print(summary)キーを使って横に結合する(マージ)
別々のCSVに分かれたデータを、共通のキーで横方向に結合することもよくあります。
Pandasではmergeを使います。
import pandas as pd
# 顧客マスタ
customers = pd.read_csv("customers.csv", encoding="utf-8") # customer_id, name, city
# 注文データ
orders = pd.read_csv("orders.csv", encoding="utf-8") # order_id, customer_id, amount
# customer_id をキーに横結合
merged = pd.merge(orders, customers, on="customer_id", how="left")
print(merged.head())このように、複数CSVを統合してから集計・分析するのが、Pandasによる実務データ処理の王道パターンです。
ログ・レポートをCSV出力するパターン
Pythonで業務スクリプトやバッチ処理を作成する際、処理結果やログをCSVとして出力すると、後からExcelで確認したり、他のシステムに渡したりしやすくなります。
ここでは、csvモジュールを使って処理ログを行ごとに追記していくシンプルな例を示します。
import csv
from datetime import datetime
LOG_FILE = "process_log.csv"
# ログファイルのヘッダーを書き出す(初回のみ)
def init_log():
with open(LOG_FILE, mode="w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow(["timestamp", "level", "message"])
# ログを1行追記する
def write_log(level, message):
with open(LOG_FILE, mode="a", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow([datetime.now().isoformat(), level, message])
if __name__ == "__main__":
init_log()
write_log("INFO", "処理開始")
# ここで何らかの処理を行う
write_log("INFO", "処理終了")生成されるprocess_log.csv(イメージ):
timestamp,level,message
2025-01-01T10:00:00,INFO,処理開始
2025-01-01T10:00:05,INFO,処理終了このような形式にしておくと、後からPandasで読み込んで集計・可視化することも容易になります。
また、定期レポートをPandasで集計してto_csvで出力し、それをメール添付や共有フォルダに配置する、といった運用もよく行われます。
実務でのcsvモジュールとPandasの使い分け指針

ここまで見てきた通り、csvモジュールとPandasにはそれぞれ得意分野があります。
実務での使い分け指針を文章で整理しておきます。
まず、csvモジュールは標準ライブラリのみで完結させたい場合や、行単位で順次処理したいストリーミング型の処理に向いています。
たとえば、ログを1行ずつ追記したり、巨大CSVを行ごとに読み込んで早期にフィルタリングして捨ててしまうようなケースです。
また、外部依存を避けたい小さなスクリプトや、組み込み環境などでも有利です。
一方でPandasは、データをある程度まとめてメモリに載せられる環境で、集計・分析・前処理・レポート作成を行う場面に最適です。
複数CSVの結合やピボットテーブルのような集計、グラフ作成といった処理は、Pandasを使うことで大幅にコード量を減らせます。
実際のプロジェクトでは、両者を組み合わせることもあります。
たとえば、最初の段階でcsvモジュールを使って大まかなフィルタリングを行い、その結果をPandasで精緻に分析するといったパターンです。
こうしたハイブリッド構成により、パフォーマンスと開発生産性のバランスを取ることができます。
最後に、チーム開発では「どの処理はcsvモジュール」「どの処理はPandas」とあらかじめ役割分担を決めておくと、コードベースが混乱しにくくなります。
まとめ
PythonでのCSV読み書きは、標準のcsvモジュールとPandasを理解しておくことで、業務に直結する強力なスキルになります。
csvモジュールはシンプルな入出力や行単位の処理に、Pandasは集計・前処理・レポート作成にそれぞれ適しており、目的に応じて使い分けることが重要です。
文字コードや改行コード、区切り文字、日付や日本語の扱いといった実務的な注意点も押さえておくことで、さまざまなCSVデータを安全かつ効率的に扱えるようになります。
この記事の内容をベースに、自分の業務や学習プロジェクトで少しずつ実践してみてください。
