
Pythonで日本語を扱う時、Windows環境では今でもCP932(Shift_JIS)が絡んだ文字化けに悩まされることが多いです。
本記事では、CP932とUTF-8の違いから、文字化けが起こる典型パターン、完全に防ぐための設定とコード例、既存プロジェクトの直し方までを体系的に整理します。
実務でそのまま使えるサンプルと手順を中心に解説します。
CP932とは何か?文字コードの基本を押さえる
CP932(Shift_JIS)の概要と特徴
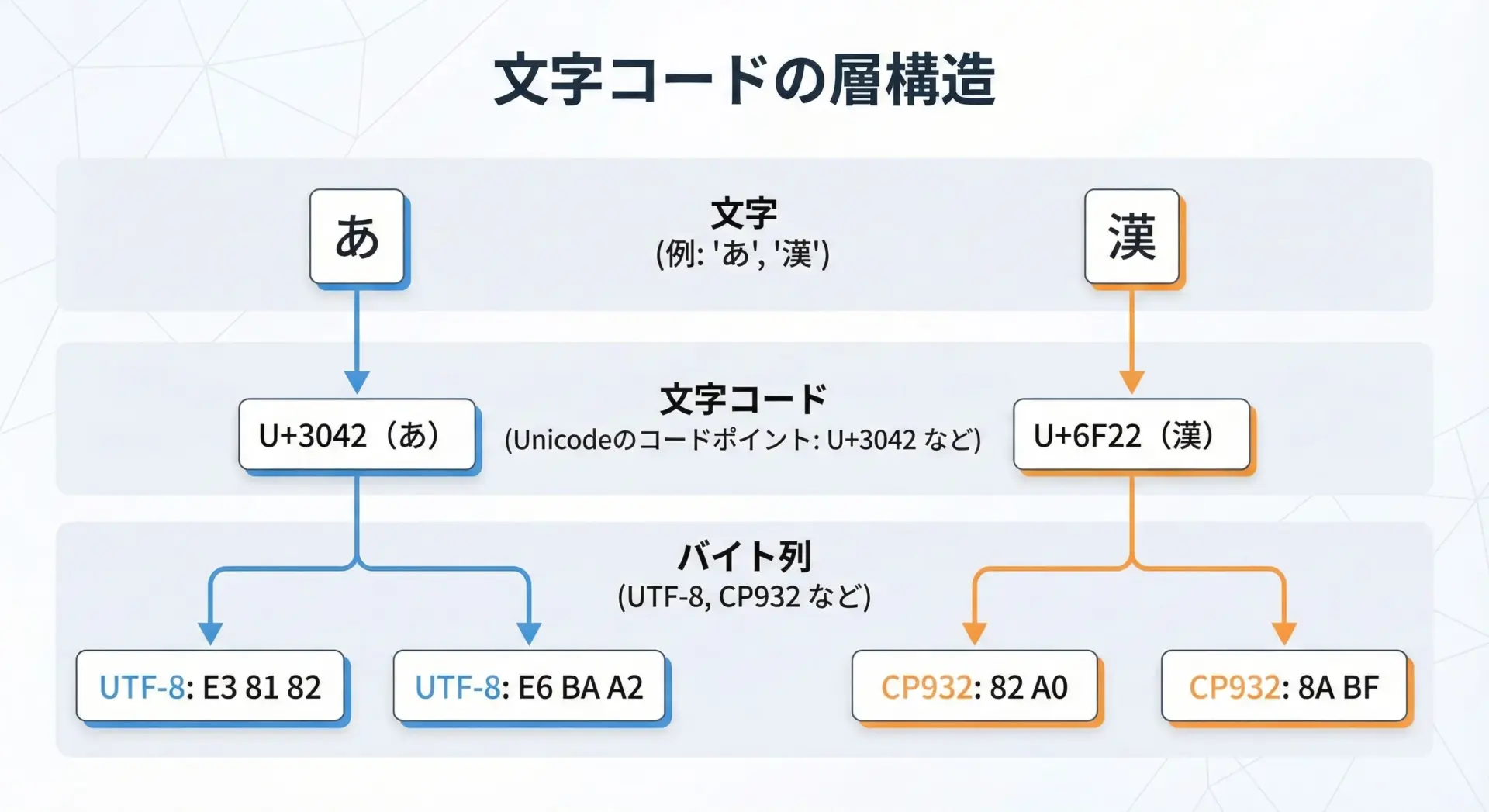
文字コードの話を始める前におさえておきたいのは、Python内部では文字はすべてUnicodeとして扱われているという点です。
画面に出したりファイルに保存するときに、初めて特定のエンコーディング(UTF-8やCP932など)に変換されます。
CP932は、Windows日本語環境で使われているシステム既定のエンコーディングで、便宜上cp932と呼ばれますが、中身としてはShift_JISを拡張したMicrosoft独自仕様です。
代表的なポイントを整理すると次の通りです。
- ベースはShift_JISだが、NEC選定IBM拡張文字やマイクロソフト拡張文字を含む
- 一部の文字がJISや他のShift_JIS変種と非互換(波ダッシュ、ローマ数字、一部記号など)
- Windowsの日本語版では、長年の互換性維持のため標準テキストエンコードとして使われ続けている
このため、「Shift_JISで保存したつもりのファイル」が、実際にはCP932として扱われることがよくあります。
逆に、他のShift_JIS系と微妙に違うため、環境をまたぐときに文字化けや変換エラーの原因になりやすいです。
UTF-8との違いと互換性の問題
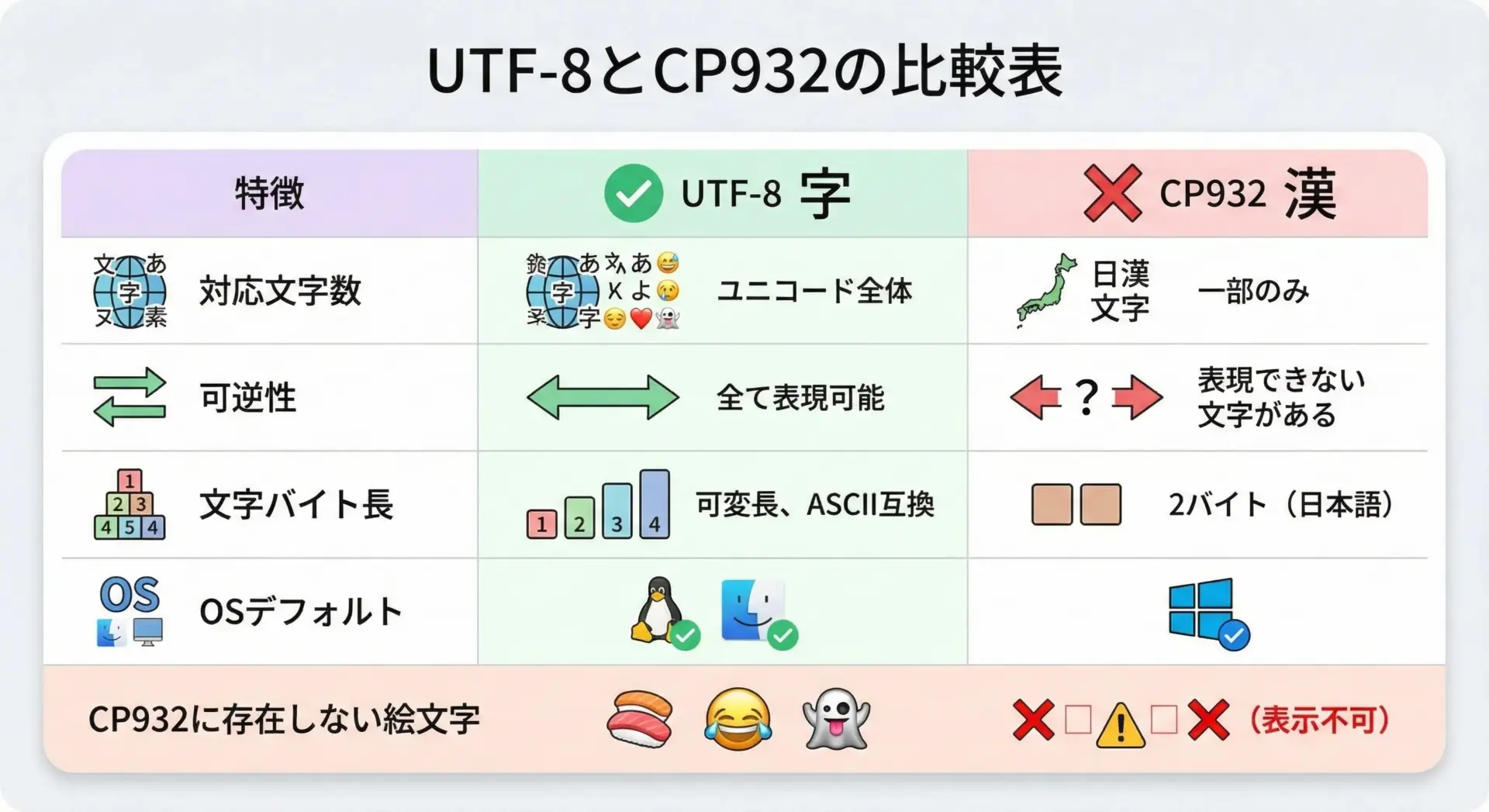
UTF-8とCP932の最大の違いは、「どこまでの文字を安全に扱えるか」と「環境間の互換性」です。
UTF-8はUnicodeの符号化方式であり、理論上Unicodeで定義されたほぼすべての文字を表現できます。
一方CP932は、Shift_JIS系の拡張であり、日本語と一部の記号に特化した有限の文字集合です。
この違いが次のような問題を生みます。
まず、CP932では表現できない文字が多数存在します。
具体的には以下のような文字です。
- 絵文字や多くの異体字、機種依存文字
- 一部の古い漢字や特殊記号
- Unicodeで新たに追加された文字
こうした文字をPython内部で扱うことはできますが、CP932にエンコードしようとした瞬間にUnicodeEncodeErrorが発生します。
逆に、CP932に特有のマイクロソフト拡張文字は、他の環境ではうまく解釈されないことがあります。
例えば、波ダッシュ〜や全角チルダ~など、見た目が似ていてもコードポイントが異なる文字があり、これが異なる文字に化けてしまうことがあります。
さらに、UTF-8とCP932は同じ日本語テキストでもバイト列が全く異なるため、「UTF-8のバイト列をCP932だと勘違いして読む」「その逆」といった状況で、いわゆる「文字化け」(読めない記号の羅列)が起きます。
Windows環境でCP932が使われる理由
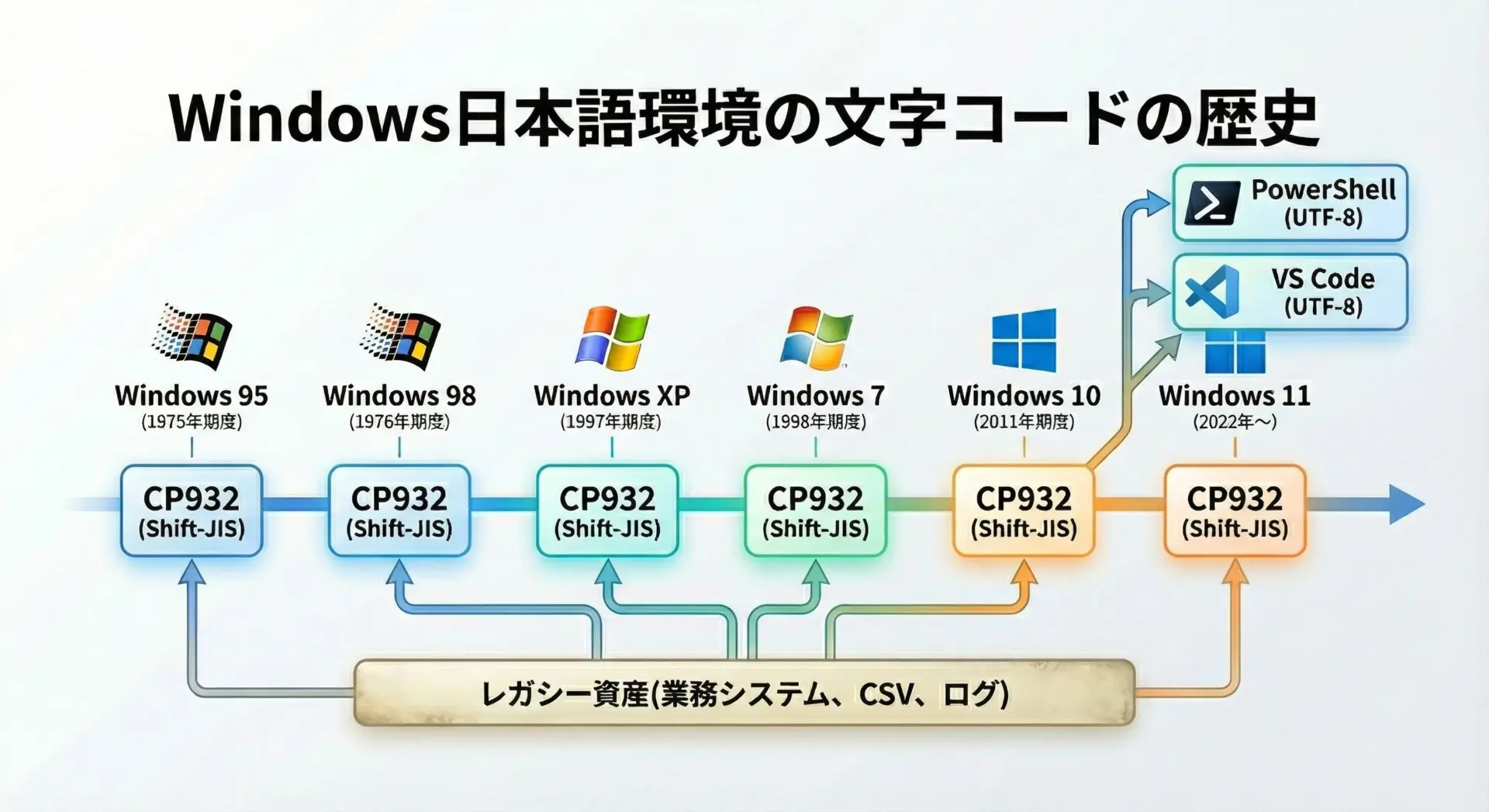
Windows日本語版でCP932が今なお多用される背景には、歴史的な経緯と互換性の問題があります。
日本語版Windowsでは長年、「システムロケールのANSIコードページ」としてCP932が採用されてきました。
その結果として、次のようなものがCP932前提で設計・実装されています。
- 社内システムや業務アプリケーションの出力するCSVやログファイル
- 古いバッチスクリプトやツール
- 一部の商用ソフトウェアの設定ファイル・レポート出力
さらに、Windowsのコマンドプロンプトや一部APIの既定エンコーディングがCP932であることも多く、「特に意識していないとCP932で動いている」という状態になりがちです。
最近はPowerShellやWindows Terminal、VS Codeなどを通じてUTF-8環境が広まりつつありますが、既存資産がCP932である以上、完全に無視することはできません。
このため、PythonでWindowsを扱う際は、UTF-8だけでなくCP932にも一定の理解が必要になります。
CP932文字化けが起こる典型パターン
ファイル読込時の文字化け
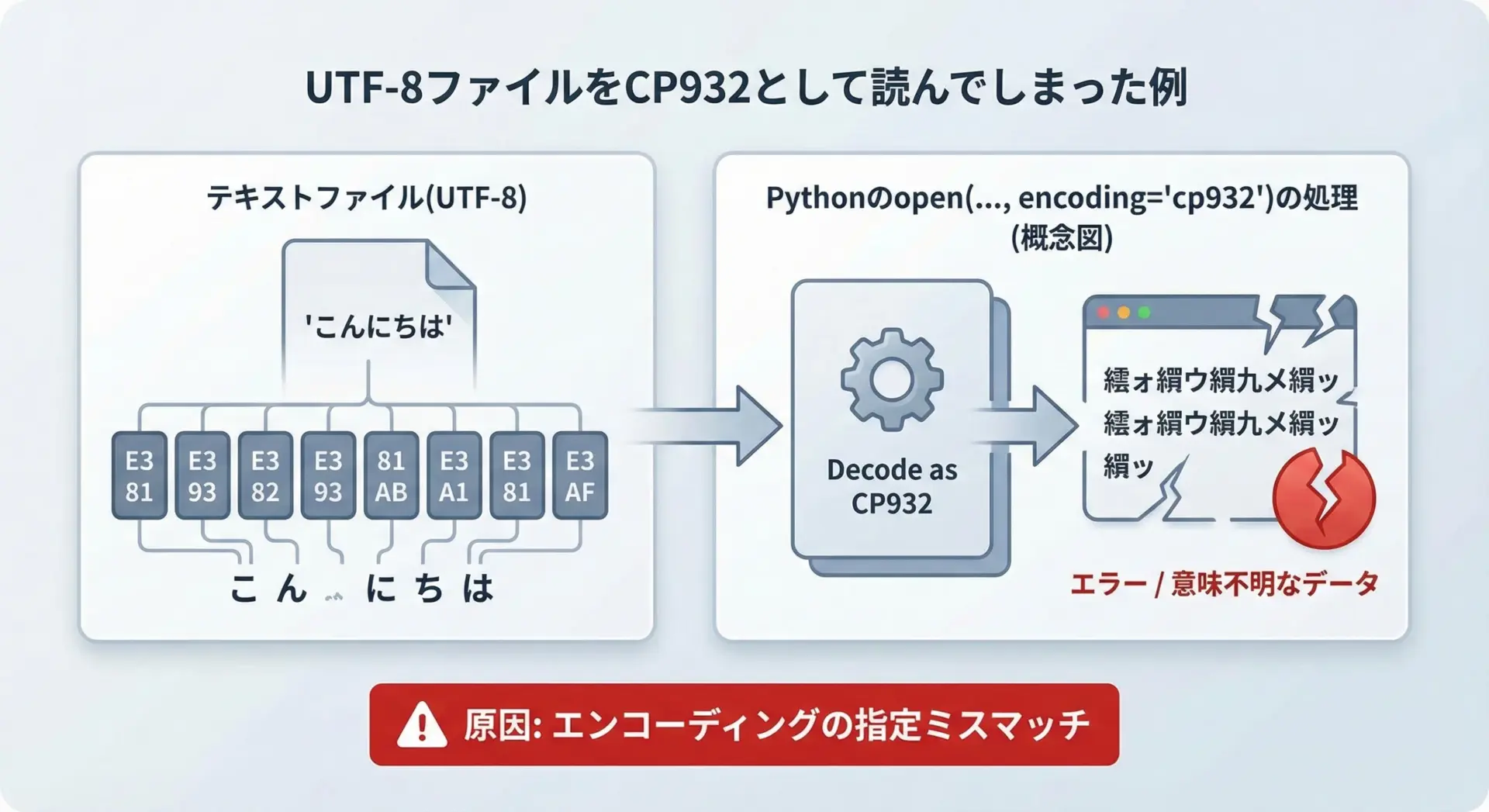
Pythonでファイルを開くとき、エンコーディングを明示しないと、環境依存の既定値が使われます。
Windows日本語環境ではここがCP932になっていることが多く、UTF-8で保存されたファイルを読むと文字化けが発生します。
例えば、UTF-8で保存されたdata.txtを次のように読んだ場合です。
# encoding を指定しない例 (Windows 日本語環境では cp932 になることが多い)
with open("data.txt", "r") as f:
text = f.read()
print(text)このとき、ファイルがUTF-8で保存されていれば、文字化けまたはUnicodeDecodeErrorが発生する可能性があります。
特に、マルチバイト文字の途中でバイト列が途切れたように見える場合、CP932として解釈できないためエラーになります。
「ファイルはUTF-8なのに、Python側はCP932で開いてしまっている」というミスマッチが典型的な原因です。
ファイル保存時の文字化け

ファイル保存時にも同様の問題があります。
たとえば、業務システムがUTF-8前提で作られているのに、Python側でCP932を指定してCSVを作成してしまうと、読み込む側のシステムで文字化けが発生します。
# CP932 でファイルを書き出してしまう例
data = "こんにちは、世界🌏" # 地球の絵文字が含まれている
with open("output.csv", "w", encoding="cp932") as f:
f.write(data)このコードは、実行時にUnicodeEncodeErrorを発生させる可能性があります。
理由は、CP932では絵文字など一部の文字を表現できないためです。
さらに、仮に表現可能な文字だけで構成されていても、保存されたCSVがUTF-8前提のツールで読まれると文字化けしてしまいます。
標準出力での文字化け

WindowsのコマンドプロンプトやPowerShellなどでは、コンソール自体の文字コード設定が絡んできます。
Pythonのprint()は、基本的にsys.stdout.encodingに従ってエンコードされるため、ここがCP932になっていると、UTF-8前提で作られたスクリプトとの間にギャップが生じます。
例えば、ターミナルエミュレータがUTF-8モードなのに、Python側はCP932で出力しようとすると、画面上で文字化けが起こります。
この場合、コンソールのコードページ(chcpコマンド)や、Python起動時の設定を見直す必要があります。
CSV・ログファイルでのCP932エラー・警告
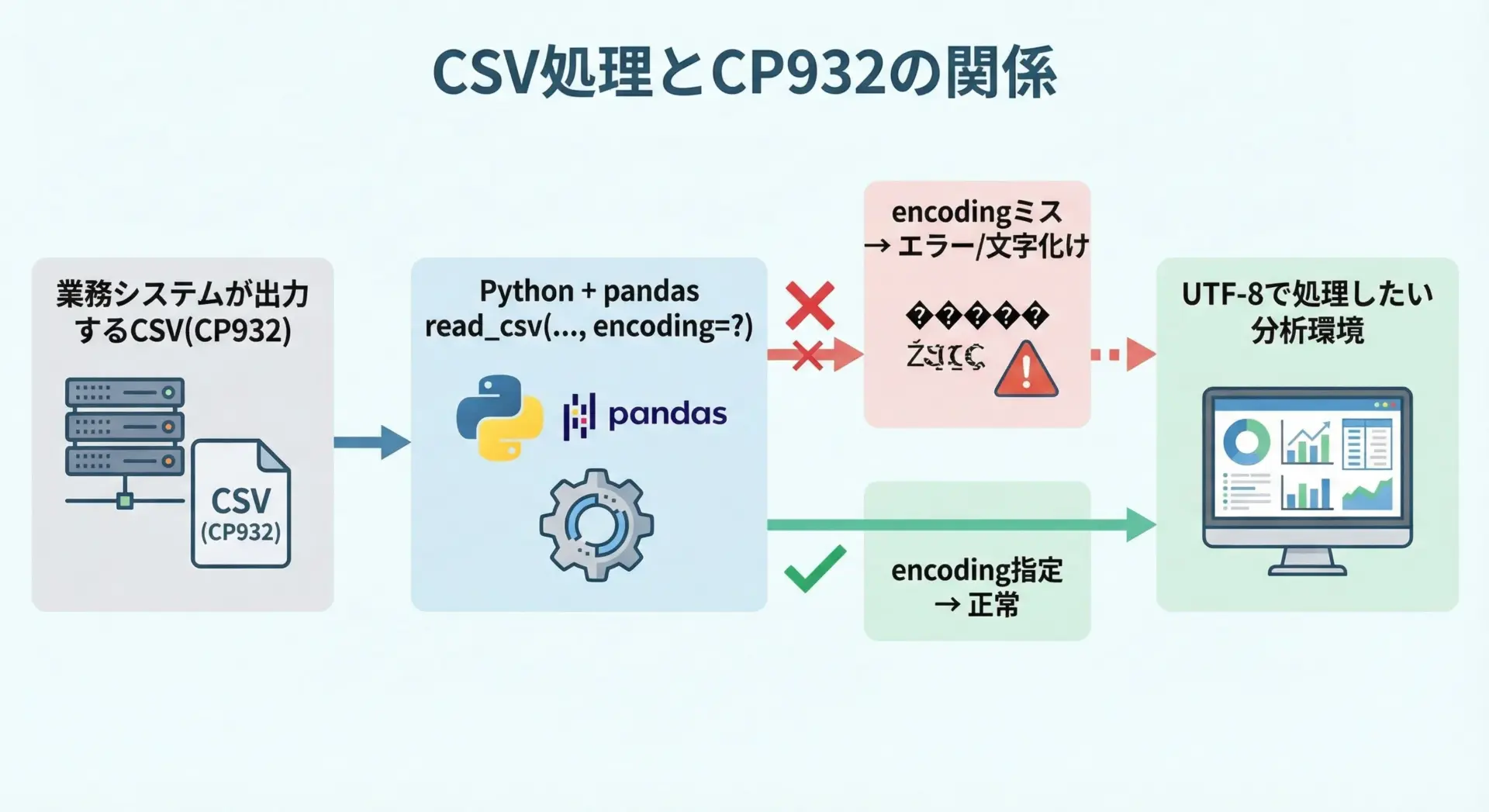
業務システムやExcelなどが出力するCSVは、日本語Windows環境ではCP932であることが一般的です。
これをPythonやpandasで処理する際に、encoding='utf-8'やencoding未指定で読み込むと、次のような問題が起きます。
- 文字化けした値がDataFrameに入る
- 中途半端な位置でデコードに失敗し
UnicodeDecodeErrorが発生 - 特定の列だけ途中で切れてしまうように見える
逆に、UTF-8で出力されたログファイルやCSVを、encoding='cp932'で読んでしまうと、同様に化けたりエラーになったりします。
「ファイルがどのエンコーディングで保存されているか」を必ず確認し、それに合わせたencodingを指定することが重要です。
cp932 codec can’t decode/encodeエラーの原因
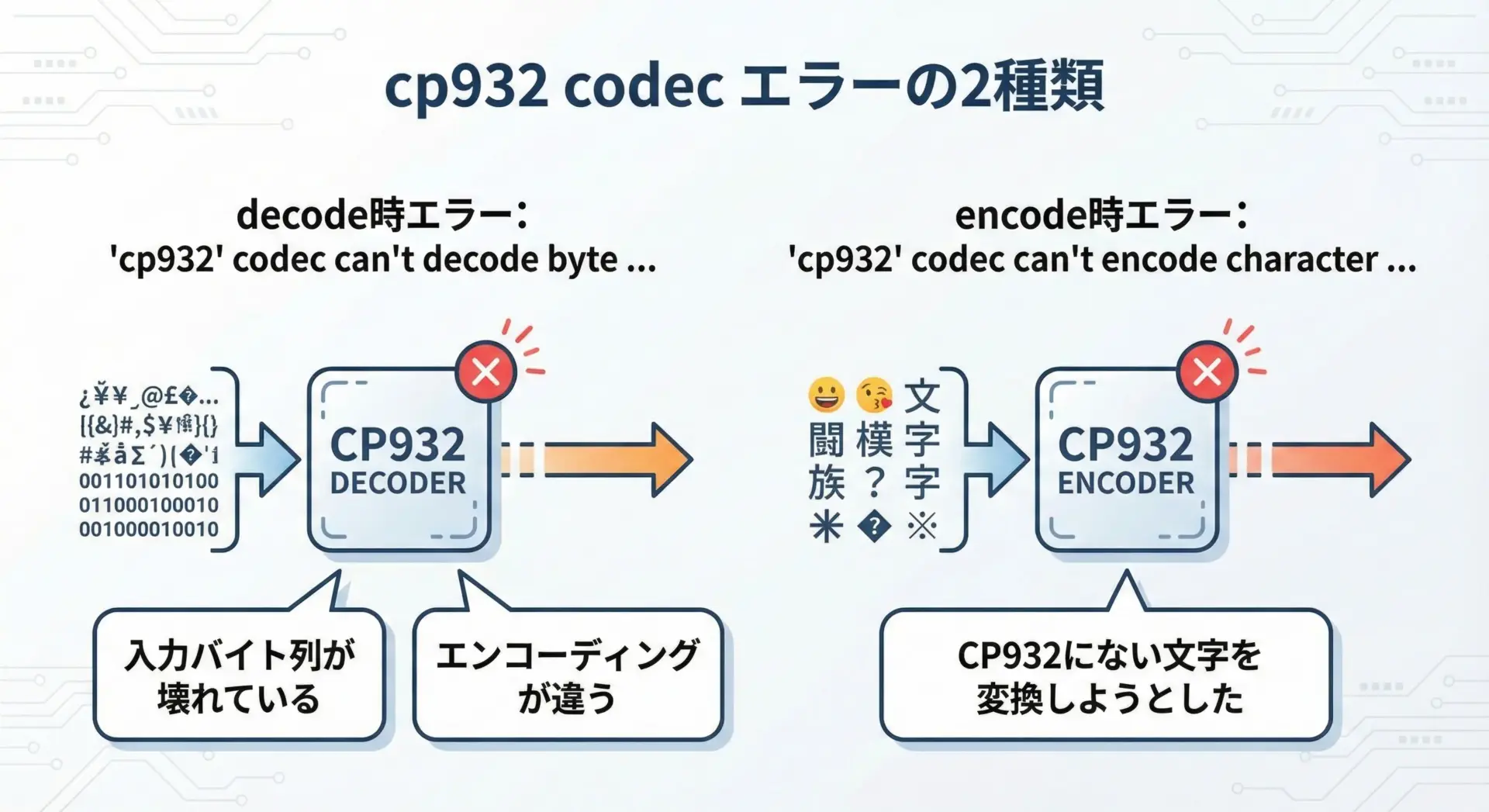
Pythonでよく見かけるのが、次の2種類のエラーです。
- デコードエラー:
'cp932' codec can't decode byte 0xXX in position N: illegal multibyte sequence
- エンコードエラー:
'cp932' codec can't encode character '\uXXXX' in position N: illegal multibyte sequence
前者は、「CP932として解釈できないバイト列をCP932でデコードしようとした」ときに発生します。
原因として多いのは、実際にはUTF-8や別のエンコーディングでエンコードされているファイルを、encoding='cp932'で読んでしまったケースです。
後者は、「Unicodeとしては存在するが、CP932には対応する文字がない」場合に、その文字をCP932に変換しようとした結果です。
絵文字や一部の記号・漢字などがこれに該当します。
どちらの場合も、「CP932を使うべき場面なのか」「そもそもUTF-8に統一できないのか」を一度立ち止まって検討することが、根本的な解決につながります。
CP932文字化けを完全に防ぐ設定とコード例
open関数でのencoding指定のベストプラクティス
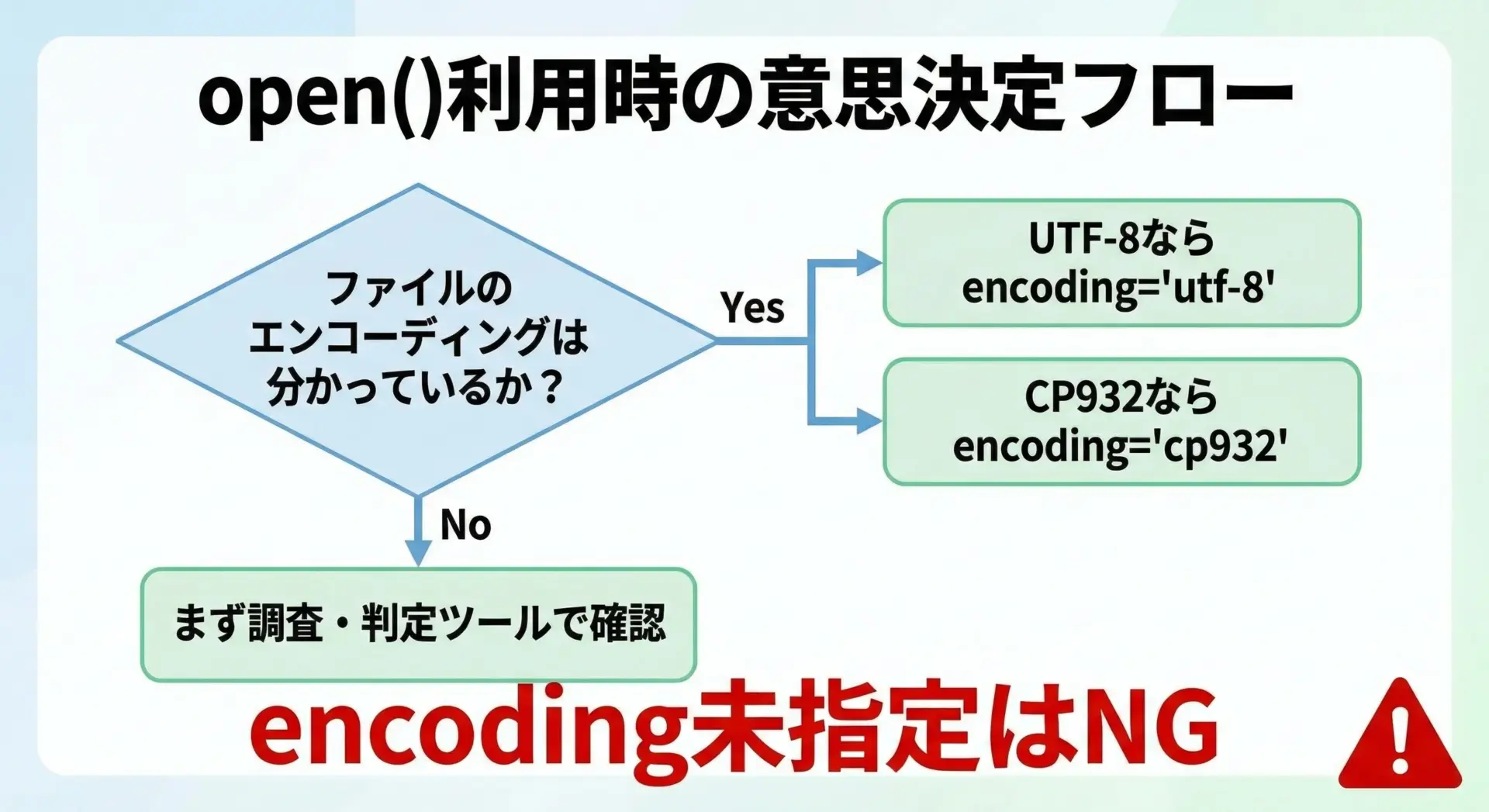
Pythonのopen()では、原則としてencodingを明示することが文字化け防止の最重要ポイントです。
特に、他者と共有するコードや、サーバ上で実行されるスクリプトでは必須と言えます。
代表的な書き方は次のようになります。
# UTF-8 のテキストファイルを安全に開く例
# 実務では UTF-8 を標準にするのがおすすめです
with open("input_utf8.txt", "r", encoding="utf-8") as f:
text = f.read()
with open("output_utf8.txt", "w", encoding="utf-8", newline="") as f:
f.write(text)CP932のファイルを扱う場合も、次のように必ず明示します。
# CP932 (Shift_JIS) のテキストファイルを開く例
with open("input_cp932.txt", "r", encoding="cp932") as f:
text = f.read()
with open("output_cp932.txt", "w", encoding="cp932", newline="") as f:
f.write(text)ポイントは、「ファイルのエンコーディングを把握し、それに合わせてencodingを指定する」ことです。
わからないまま開いてしまうと、環境依存の既定値に頼ることになり、文字化けやエラーの温床となります。
UTF-8で統一する場合の設定例
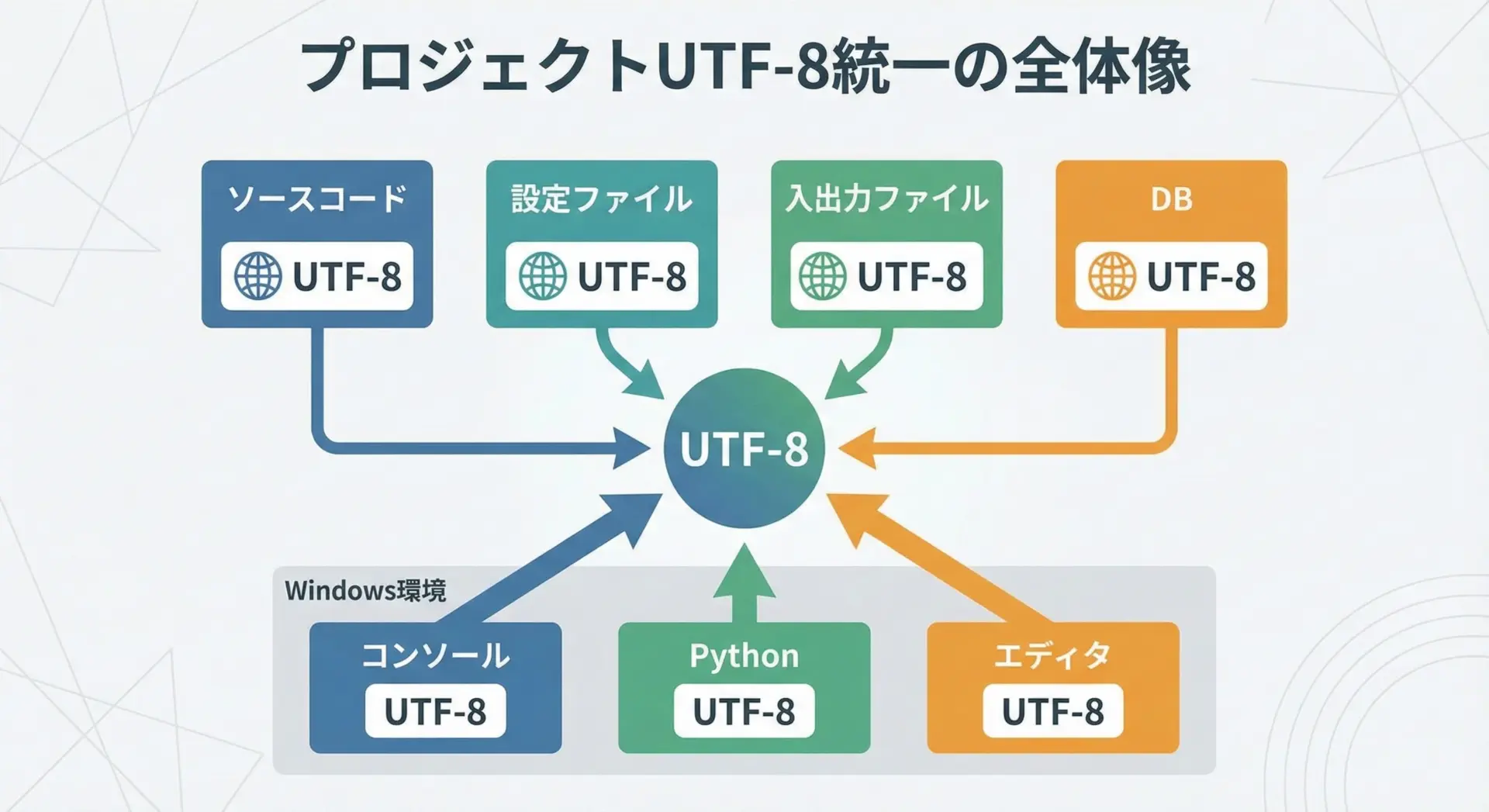
新規プロジェクトや、自分の管理下にあるシステムであれば、文字コードはUTF-8に統一するのが現代のベストプラクティスです。
その場合、次のような設定・習慣を徹底します。
1つ目は、Pythonファイル自体をUTF-8で保存することです。
最近のエディタやIDEは既定でUTF-8になっていることが多いですが、不安なら設定を確認し、明示的にUTF-8にしておきます。
2つ目は、ファイル入出力はすべてencoding='utf-8'を指定することです。
# プロジェクトを UTF-8 統一する場合の標準的な書き方
def read_text(path: str) -> str:
with open(path, "r", encoding="utf-8") as f:
return f.read()
def write_text(path: str, text: str) -> None:
with open(path, "w", encoding="utf-8", newline="") as f:
f.write(text)3つ目は、Windowsコンソールや環境設定をUTF-8モードに近づけることです。
これについては後述の「Windowsコンソールの文字コード設定」で詳しく扱います。
あえてCP932で扱う場合の安全な書き方
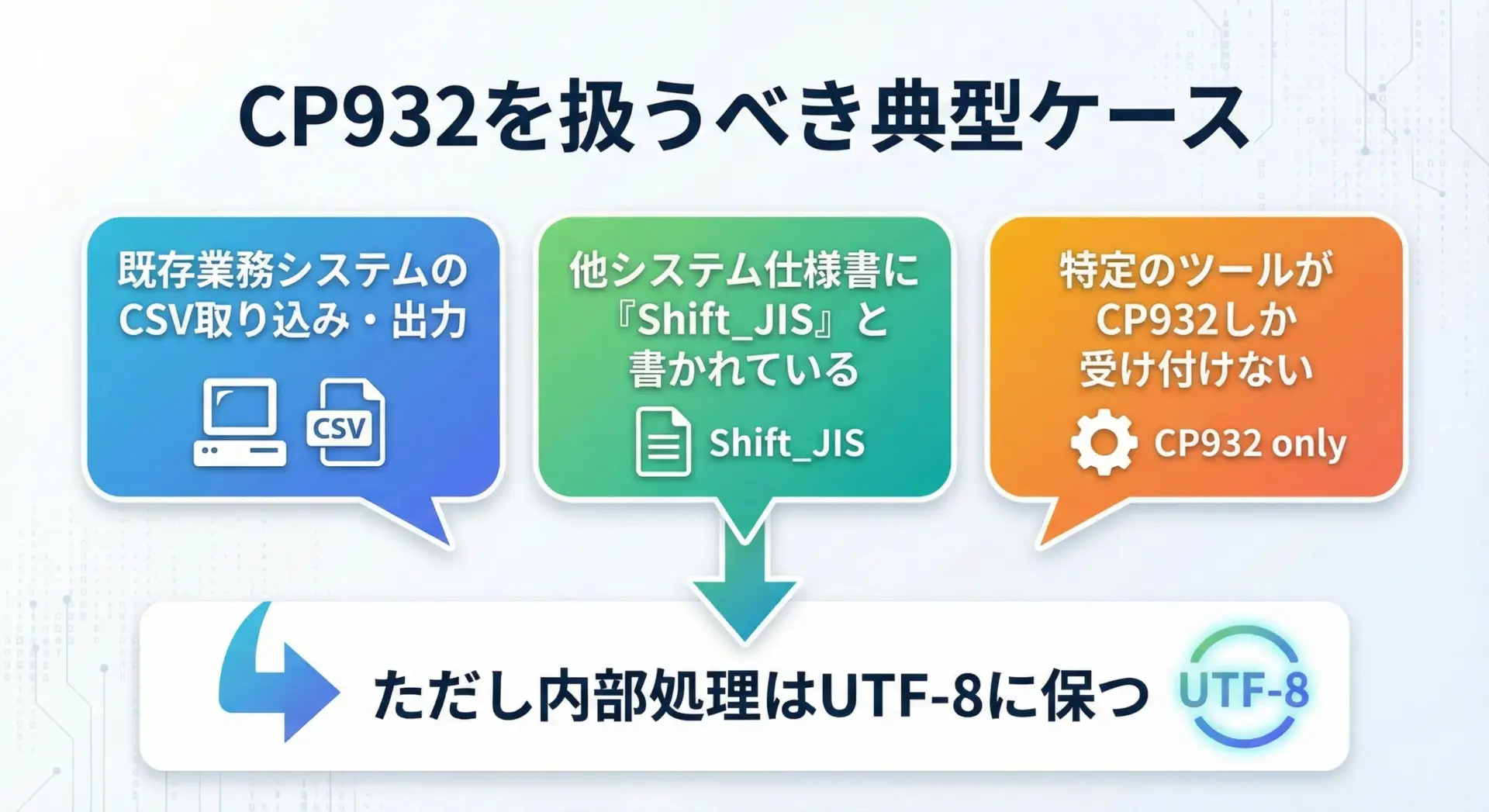
どうしてもCP932を扱わざるを得ないケースもあります。
その際の安全な方針は、「入出力だけCP932にし、内部ではUnicode(UTF-8想定)で処理する」ことです。
def read_cp932(path: str) -> str:
"""CP932 のファイルを読み込み、Python 内部の Unicode 文字列として返す"""
with open(path, "r", encoding="cp932", errors="strict") as f:
return f.read()
def write_cp932(path: str, text: str) -> None:
"""Python の文字列を CP932 で保存する (表現できない文字は ? に置き換え)"""
with open(path, "w", encoding="cp932", errors="replace", newline="") as f:
f.write(text)読み込み時は、エラーを検知できるerrors="strict"を使うことで、想定と異なるバイト列が混入していないかチェックできます。
書き込み時には、どうしてもCP932にない文字が含まれる可能性がある場合errors="replace"を使い、失敗しないようにする選択肢もあります(ただし、文字が?に置き換わるので注意が必要です)。
エンコードエラー時のerrorsパラメータ活用
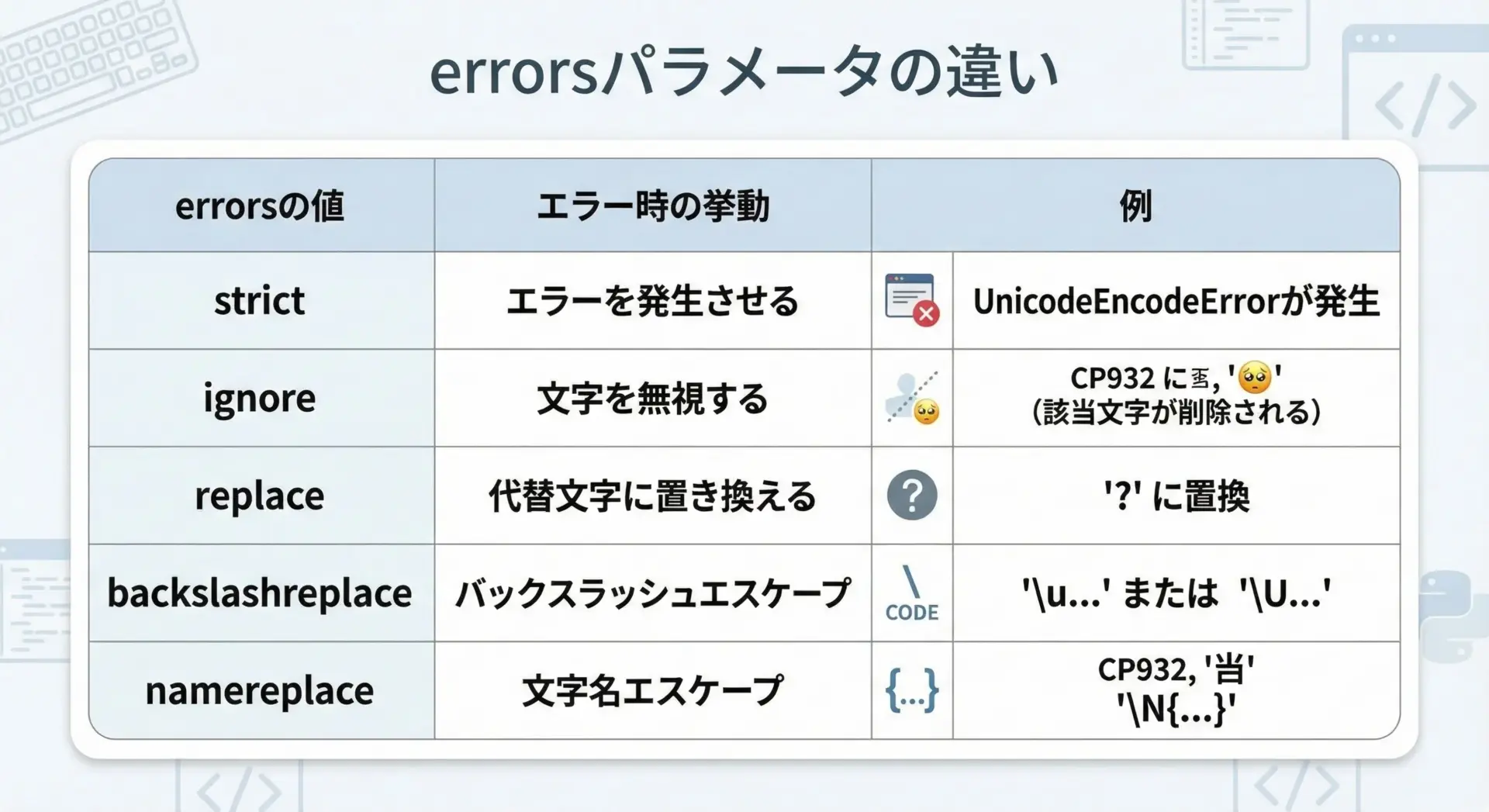
open()やstr.encode()、bytes.decode()にはerrorsパラメータがあり、エンコード/デコードエラー発生時の挙動を制御できます。
代表的な値は次の通りです。
| errors値 | 動作 | 用途の目安 |
|---|---|---|
| strict | エラー時に例外を投げる | データ品質を厳密に担保したいときの基本設定 |
| ignore | 問題の文字を無視する | ログ解析など、「多少欠けてもいいが止まってほしくない」処理 |
| replace | 代替文字(通常?)に置換 | レポート出力など、「とにかく処理を完走させたい」場合 |
| backslashreplace | \uXXXXなどのエスケープ表記にする | デバッグや、不正文字の位置を特定したいとき |
| namereplace | \N{...}表記にする | Unicode名を保ちたい特殊用途 |
例えば、CP932にない文字を含むテキストをログとして書き出したい場面では、次のような書き方が考えられます。
log_text = "処理結果: OK ✅" # チェックマークの絵文字は CP932 では表現できない
# 1. 厳密に検査し、問題があればエラーにする
with open("log_strict.txt", "w", encoding="cp932", errors="strict") as f:
f.write(log_text)
# 2. どうしても止めたくないので、表現できない文字は ? に置換
with open("log_replace.txt", "w", encoding="cp932", errors="replace") as f:
f.write(log_text)
# 3. どの位置に問題があるか調べたいとき (例: デバッグ用)
with open("log_debug.txt", "w", encoding="cp932", errors="backslashreplace") as f:
f.write(log_text)本番処理ではstrictで早期発見、例外キャッチの上でreplaceなどに切り替えるといった運用も有効です。
pandas・CSV処理でのencoding指定
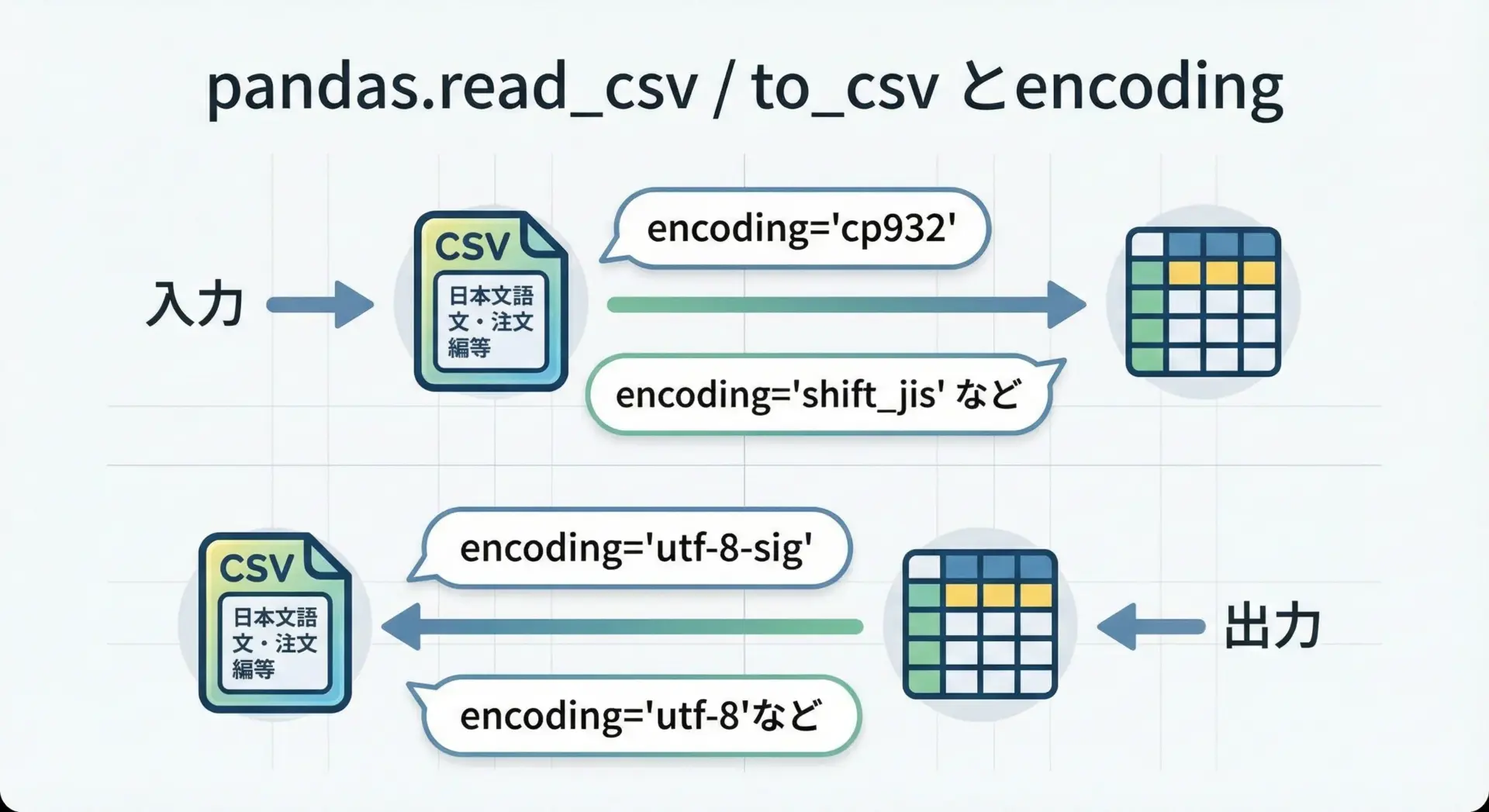
CSVやTSVの処理では、pandasを使うケースが多いと思います。
ここでもencodingを明示する習慣が重要です。
import pandas as pd
# CP932 の CSV を読み込む
df = pd.read_csv("input_cp932.csv", encoding="cp932")
# 分析結果を UTF-8 (BOM 付き) で出力し、Excel でも開きやすくする例
df.to_csv("output_utf8.csv", index=False, encoding="utf-8-sig")Excel互換性を重視する場合、encoding="utf-8-sig"を使うと、UTF-8でありながらBOM付きのため、古いExcelでも文字化けしにくくなるという利点があります。
逆に、業務システムが「Shift_JIS(実質CP932)」と仕様に明記している場合には、次のようにします。
# 業務システムが期待する CP932 で出力
df.to_csv("for_legacy_system.csv", index=False, encoding="cp932")「どのファイルを誰(どのシステム)が読むのか」を意識し、それに合わせてencodingを選ぶことで、CP932に関するトラブルを大幅に減らすことができます。
既存コード・環境のCP932問題を直す手順
文字コードの判定方法(chardetなど)と確認ポイント
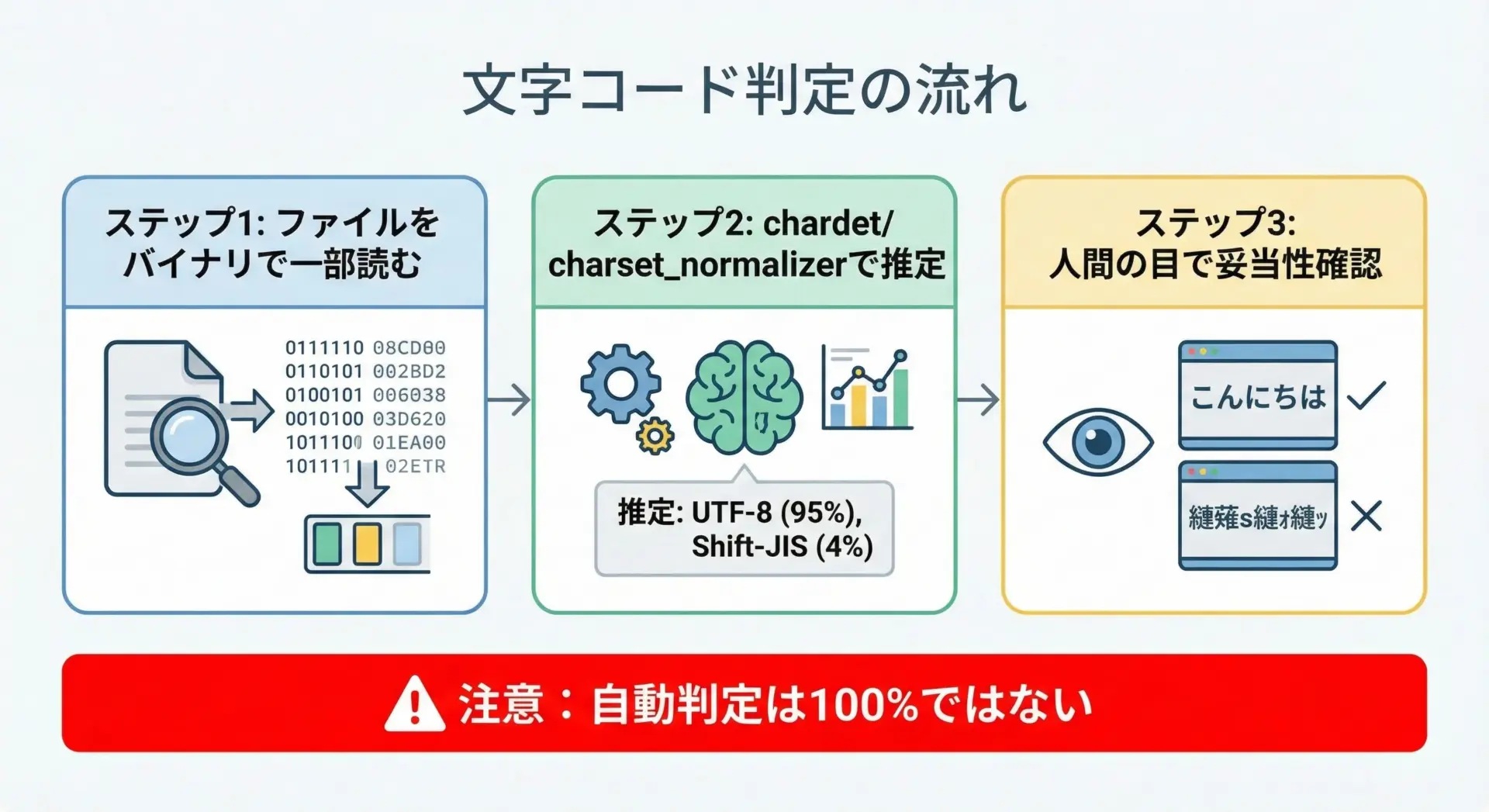
既存ファイルの文字コードが不明な場合、自動判定ツールを補助的に使いつつ、人間の確認で確定するのが現実的なアプローチです。
Pythonで使える代表的なライブラリはchardetやcharset-normalizerです。
# chardet を使ってファイルの文字コードを推定する例
import chardet
def detect_encoding(path: str, sample_size: int = 1024) -> None:
with open(path, "rb") as f:
raw = f.read(sample_size) # 先頭からサンプルを取得
result = chardet.detect(raw)
print(result)
# 実行例
detect_encoding("mystery.csv"){'encoding': 'SHIFT_JIS', 'confidence': 0.99, 'language': 'Japanese'}ここでencodingが"SHIFT_JIS"と出た場合、Windows環境では実質的に「CP932の可能性が高い」と判断できます。
ただし、自動判定は完全ではないため、実際にそのエンコーディングで開いて日本語が正しく読めるかを確認することが重要です。
スクリプト・設定ファイルのUTF-8化手順
既存のPythonスクリプトや設定ファイルがCP932(またはShift_JIS)で保存されている場合、まずはソースコード自体をUTF-8に変換するのが将来的なトラブル回避に有効です。
一般的な手順は次のようになります。
- 元ファイルのバックアップを取る
- 文字コードを意識できるエディタ(例: VS Code, Notepad++, Sakura Editor など)でファイルを開く
- 現在の文字コードがCP932/Shift_JISであることを確認
- エディタの「名前を付けて保存」や「別のエンコーディングで保存」機能を使い、UTF-8で保存
- Pythonで実際にスクリプトを実行し、問題なく動くことを確認
Python3では、ソースファイルがUTF-8であることを前提としていますので、現代的な環境ではUTF-8化が最も自然な状態です。
もし、ソース内に特定の文字コードを示すマジックコメント(例: # -- coding: cp932 --)がある場合は、UTF-8に変換した後でその記述を削除するか、utf-8に書き換えてください。
Windowsコンソールの文字コード設定

WindowsでPythonスクリプトを実行する際、コンソールのコードページがCP932のままだと、printの出力や標準入力との間で文字化けすることがあります。
対策として、コンソールをUTF-8モードに切り替える方法があります。
一時的にUTF-8にするには、コマンドプロンプトで次のコマンドを実行します。
chcp 65001これにより、現在のコンソールセッションのコードページがUTF-8(65001)になります。
その上で、PythonスクリプトをUTF-8前提で動かすと、表示の文字化けが減ります。
また、Windows 10以降では「ベータ版: Unicode UTF-8を使用」というシステムロケール設定があります。
これを有効にすると、多くのレガシーAPIもUTF-8ベースで動作するようになりますが、一部の古いアプリケーションが動作不良を起こす可能性もあるため、業務環境では慎重に検討してください。
よりモダンな選択肢として、PowerShellやWindows Terminalを利用し、プロファイルでUTF-8を前提にする方法もあります。
これらはVS Codeとの連携も良く、開発環境をUTF-8中心にまとめやすくなっています。
混在環境(CP932とUTF-8)での移行戦略と注意点

現実の現場では、CP932とUTF-8が混在していることが多く、一気にすべてUTF-8に移行するのは難しいことがあります。
そのような場合は、「変換ポイント」を明確に設けるのが有効です。
具体的には、次のような戦略が考えられます。
1つは、レガシーシステムとのインターフェイス層でのみCP932を扱い、それ以外の内部処理・保存はUTF-8に統一する方法です。
CSVやログを受け取る部分でencoding="cp932"を指定してデータを読み込み、内部では標準のUnicode文字列として扱います。
逆に外部へ出力する際には、指定された形式(CP932など)に変換して書き出します。
def legacy_input(path: str) -> str:
# レガシー(CP932)→内部(UTF-8/Unicode)
with open(path, "r", encoding="cp932", errors="strict") as f:
return f.read()
def legacy_output(path: str, text: str) -> None:
# 内部(Unicode)→レガシー(CP932)
with open(path, "w", encoding="cp932", errors="replace", newline="") as f:
f.write(text)こうすることで、CP932に関する注意を払う必要がある場所を限定できるため、システム全体の複雑さを抑えられます。
もう1つ重要なのは、「Shift_JIS」「シフトJIS」とだけ書かれた仕様書は、実際にはCP932を意味していることが多いという点です。
UNIX系のshift_jisや他の亜種とは微妙に異なる場合があり、互換性問題を引き起こします。
可能であれば、実際にサンプルファイルを受け取り、どのエンコーディングで正しく読めるかを確認してから実装に入ることをおすすめします。
まとめ
CP932(Shift_JIS系)は、Windows日本語環境で長く使われてきたため、今もなおCSVやログ、既存システムとの連携で避けて通れません。
ただし、Python内部はUnicodeであり、UTF-8を標準とする設計にしておくことで、文字化けやcp932 codecエラーの大半は防げます。
重要なのは「ファイルやコンソールのエンコーディングを正しく把握し、encodingを明示する」「CP932は入出力の境界だけで扱い、内部はUTF-8で統一する」という方針です。
本記事の手順とサンプルコードを参考に、段階的に環境を整備し、CP932由来のトラブルから解放される運用を目指してください。
