
Pythonでファイルやディレクトリを扱うとき、昔ながらのos.pathだけで頑張っていませんか。
path文字列を手書きでつなぎ、バックスラッシュやスラッシュに悩まされるコードから、そろそろ卒業してもよい頃かもしれません。
本記事では、標準ライブラリpathlibを使ったパス操作について、基本から実用的な書き換えパターンまでを丁寧に解説していきます。
今日からos.path中心の書き方をスッキリ刷新してみましょう。
pathlibとは?Pythonのパス操作をシンプルにする標準ライブラリ
[pathlibは、Python3.4以降で標準ライブラリに追加された、オブジェクト指向なパス操作用モジュールです。文字列として扱っていたパスを、Pathオブジェクトとして扱うことが最大の特徴です。]

pathlibを使うメリット
pathlibの利点は数多くありますが、実務で効いてくるポイントを中心に説明します。
まず、OS依存のパス区切りを意識しなくてよいことが大きなメリットです。
Windowsでは\、LinuxやmacOSでは/がパス区切りとして使われますが、pathlibは実行環境に応じて自動的に適切な区切り文字を選んでくれます。
コード上ではPath("dir") / "file.txt"のように、演算子/でパス結合できるため、OS差異を意識せずに書けます。
次に、パスが単なる文字列ではなく「Pathオブジェクト」になることで、直感的なメソッドが使える点も重要です。
たとえば、親ディレクトリはp.parent、拡張子はp.suffix、ファイル名はp.nameのように取得できます。
これにより、文字列のsplitやreplaceに頼らない、誤りにくいコードになります。
さらに、ファイルの存在確認、読み書き、削除、列挙など、ファイルシステム関連の操作をひとまとめで扱えることも魅力です。
従来はos、os.path、glob、shutilなどに分散していた関数群を、Pathオブジェクトのメソッドとして一元的に扱えるようになります。
Pathオブジェクトの基本
pathlibの中心となるのがPathクラスです。
通常はfrom pathlib import Pathでインポートして使用します。
Pythonでは、実行しているOSに応じて、内部的にPosixPathやWindowsPathといったサブクラスが自動で選ばれますが、開発者は基本的にPathとして意識すれば十分です。
Pathオブジェクトは、次のような特徴を持っています。
- 文字列から生成できる
/演算子でパス結合できる- プロパティ(
.name、.parent、.suffixなど)でパス情報を簡単に取り出せる .exists()や.is_file()などのメソッドで、ファイルシステムにアクセスできる
このように、パス文字列を直接操作せず、Pathオブジェクトに変換してから扱うことが、pathlibの基本スタイルです。
pathlibでできる主なファイル・ディレクトリ操作一覧
pathlibでは実に多くの操作が可能ですが、どのようなものがあるかをイメージしやすいよう、代表的な操作を一覧にまとめます。
| 分類 | 操作例 | メソッド・プロパティ |
|---|---|---|
| 生成 | パスの生成 | Path() |
| 結合 | サブパスの追加 | p / "subdir" / "file.txt" |
| 分解 | ファイル名取得 | p.name |
| 分解 | 親ディレクトリ取得 | p.parent、p.parents |
| 分解 | 拡張子取得 | p.suffix、p.suffixes |
| 情報 | 絶対パスへ変換 | p.resolve()、p.absolute() |
| 情報 | 存在チェック | p.exists() |
| 情報 | ファイル/ディレクトリ判定 | p.is_file()、p.is_dir() |
| 作成 | ディレクトリ作成 | p.mkdir() |
| 作成 | 親ディレクトリごと作成 | p.mkdir(parents=True) |
| 入出力 | テキスト読み書き | p.read_text()、p.write_text() |
| 入出力 | バイナリ読み書き | p.read_bytes()、p.write_bytes() |
| 列挙 | ファイル一覧取得 | p.iterdir() |
| 列挙 | パターンマッチ(glob) | p.glob(".txt")、p.rglob(".py") |
| 操作 | 削除 | p.unlink()、p.rmdir() |
| 操作 | リネーム/移動 | p.rename()、p.replace() |
この表に挙げたものをひと通り押さえておけば、日常的なパス操作のほとんどはカバーできます。
pathlib.Pathの基本的な使い方
ここからは、Pathオブジェクトの基本的な使い方を、サンプルコードとともに確認していきます。
Pathオブジェクトの生成
Pathオブジェクトの生成はとてもシンプルです。
文字列パスをPath()に渡すだけで、Pathインスタンスが得られます。
from pathlib import Path
# 文字列からPathオブジェクトを生成
p1 = Path("data/input.txt")
# 絶対パス(フルパス)から生成
p2 = Path("/usr/local/bin")
# Windows風のパス(Windows環境であれば正しく解釈されます)
p3 = Path("C:/Users/user/documents")
print(type(p1))
print(p1)
print(p2)
print(p3)<class 'pathlib.PosixPath'> # OSに応じてPosixPathやWindowsPathになる
data/input.txt
/usr/local/bin
C:/Users/user/documentsPathは複数の要素を引数として渡すこともできます。
このとき自動的に区切り文字を補ってくれるため、パス結合専用にos.path.joinを使う必要がなくなります。
from pathlib import Path
# 引数を分けて渡すと、OSに合わせてうまく結合される
p = Path("data", "images", "photo.jpg")
print(p)data/images/photo.jpg # Windowsなら data\images\photo.jpg のようになるパスの結合・分解
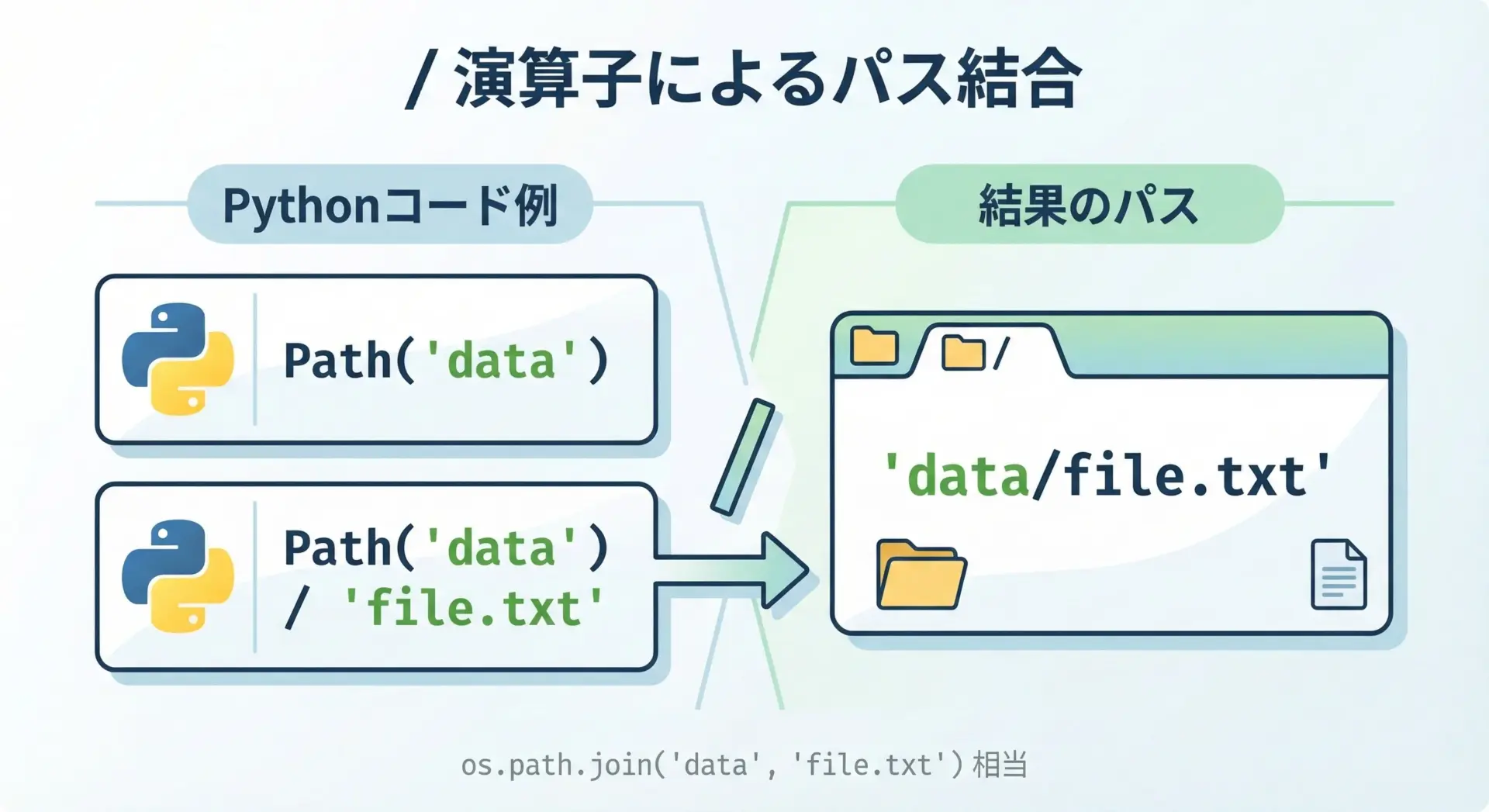
pathlibの特徴的な書き方として、/演算子によるパス結合があります。
文字列とPath、あるいはPath同士を/で結合することができます。
from pathlib import Path
base = Path("data")
# サブディレクトリやファイルを / でつなぐ
p1 = base / "images" / "photo.jpg"
p2 = base / "logs" / "app.log"
print(p1) # data/images/photo.jpg
print(p2) # data/logs/app.logdata/images/photo.jpg
data/logs/app.logパスの分解も、文字列操作ではなくプロパティで行えます。
たとえば、パスを親ディレクトリ・ファイル名・拡張子に分ける場合、次のように記述します。
from pathlib import Path
p = Path("data/images/photo.backup.jpg")
print("完全なパス:", p)
print("親ディレクトリ:", p.parent) # data/images
print("ファイル名:", p.name) # photo.backup.jpg
print("拡張子:", p.suffix) # .jpg
print("拡張子のリスト:", p.suffixes) # ['.backup', '.jpg']
print("拡張子なしの名前:", p.stem) # photo.backup完全なパス: data/images/photo.backup.jpg
親ディレクトリ: data/images
ファイル名: photo.backup.jpg
拡張子: .jpg
拡張子のリスト: ['.backup', '.jpg']
拡張子なしの名前: photo.backup複数の拡張子(例: .tar.gz)を扱う場合はsuffixesが便利で、最後の1つだけでよい場合はsuffix、ベース名だけ欲しい場合はstemを使うとよいです。
親ディレクトリ・拡張子の取得
親ディレクトリや拡張子の取得は、日常的によく行う操作です。
pathlibでは、これらをプロパティで簡潔に記述できます。
from pathlib import Path
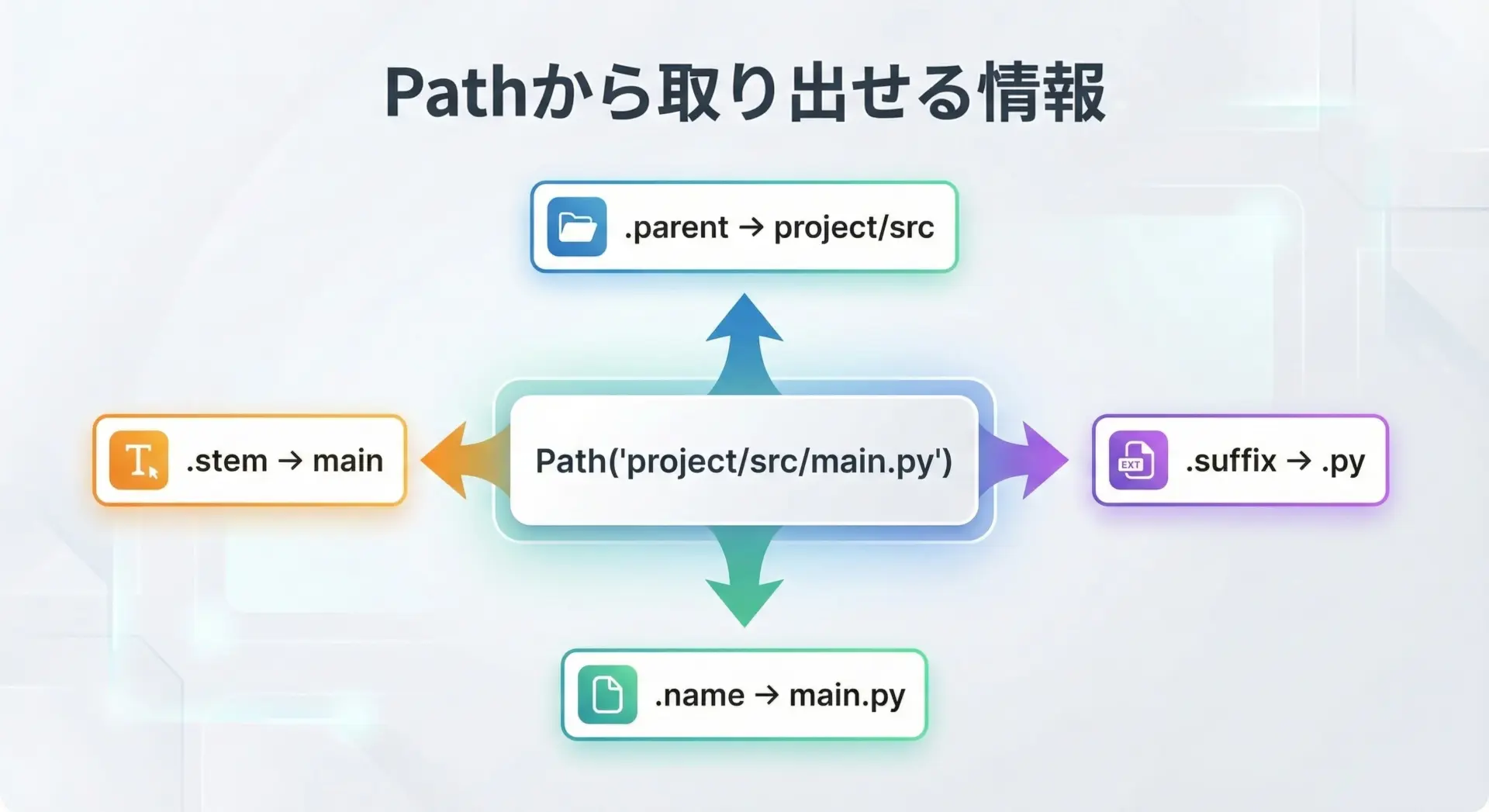
p = Path("project/src/main.py")
print("親ディレクトリ:", p.parent) # project/src
print("さらに上のディレクトリ:", p.parent.parent) # project
print("ファイル名:", p.name) # main.py
print("拡張子:", p.suffix) # .py
print("拡張子なしの名前:", p.stem) # main親ディレクトリ: project/src
さらに上のディレクトリ: project
ファイル名: main.py
拡張子: .py
拡張子なしの名前: main複数階層の親を扱う場合はparentsも便利です。
これはインデックスアクセスが可能なシーケンスです。
from pathlib import Path
p = Path("a/b/c/d.txt")
# parents[0] は parent と同じ
print(p.parents[0]) # a/b/c
print(p.parents[1]) # a/b
print(p.parents[2]) # aa/b/c
a/b
aカレントディレクトリ・ホームディレクトリ
pathlibでは、現在の作業ディレクトリ(カレントディレクトリ)や、ユーザーのホームディレクトリを簡単に取得できます。

from pathlib import Path
# カレントディレクトリ(現在の作業ディレクトリ)を取得
current = Path.cwd()
# ホームディレクトリ(ユーザーのホーム)を取得
home = Path.home()
print("カレントディレクトリ:", current)
print("ホームディレクトリ:", home)カレントディレクトリ: /path/to/current/dir
ホームディレクトリ: /home/username # OSにより異なるこれらを起点にして/演算子でサブディレクトリやファイルを指定すると、環境に依存しないコードを書きやすくなります。
from pathlib import Path
log_dir = Path.home() / "logs" / "myapp"
print(log_dir)/home/username/logs/myapp # 例ファイル・ディレクトリ操作をpathlibで書き換える
ここからは、実際にファイルやディレクトリを操作する場面で、pathlibをどのように使うかを見ていきます。
osやos.pathを使った従来のやり方と比較しながら解説します。
存在確認と種別チェック
ファイルやディレクトリが存在するかどうかを確認する場面は非常に多いです。
pathlibでは、exists()、is_file()、is_dir()といったメソッドを使います。

from pathlib import Path
p = Path("data/input.txt")
if p.exists():
print("存在します")
if p.is_file():
print("これはファイルです")
elif p.is_dir():
print("これはディレクトリです")
else:
print("ファイルでもディレクトリでもない特殊なパスです")
else:
print("存在しません")存在しません # ファイルがない場合の例シンボリックリンクを扱う場合など、より詳細な情報が必要な場合はis_symlink()などのメソッドも利用できます。
ディレクトリの作成
ディレクトリを作成するにはmkdir()を使います。
従来のos.makedirs()に相当する機能も、引数を指定することで簡単に行えます。
from pathlib import Path
# 単一のディレクトリを作成
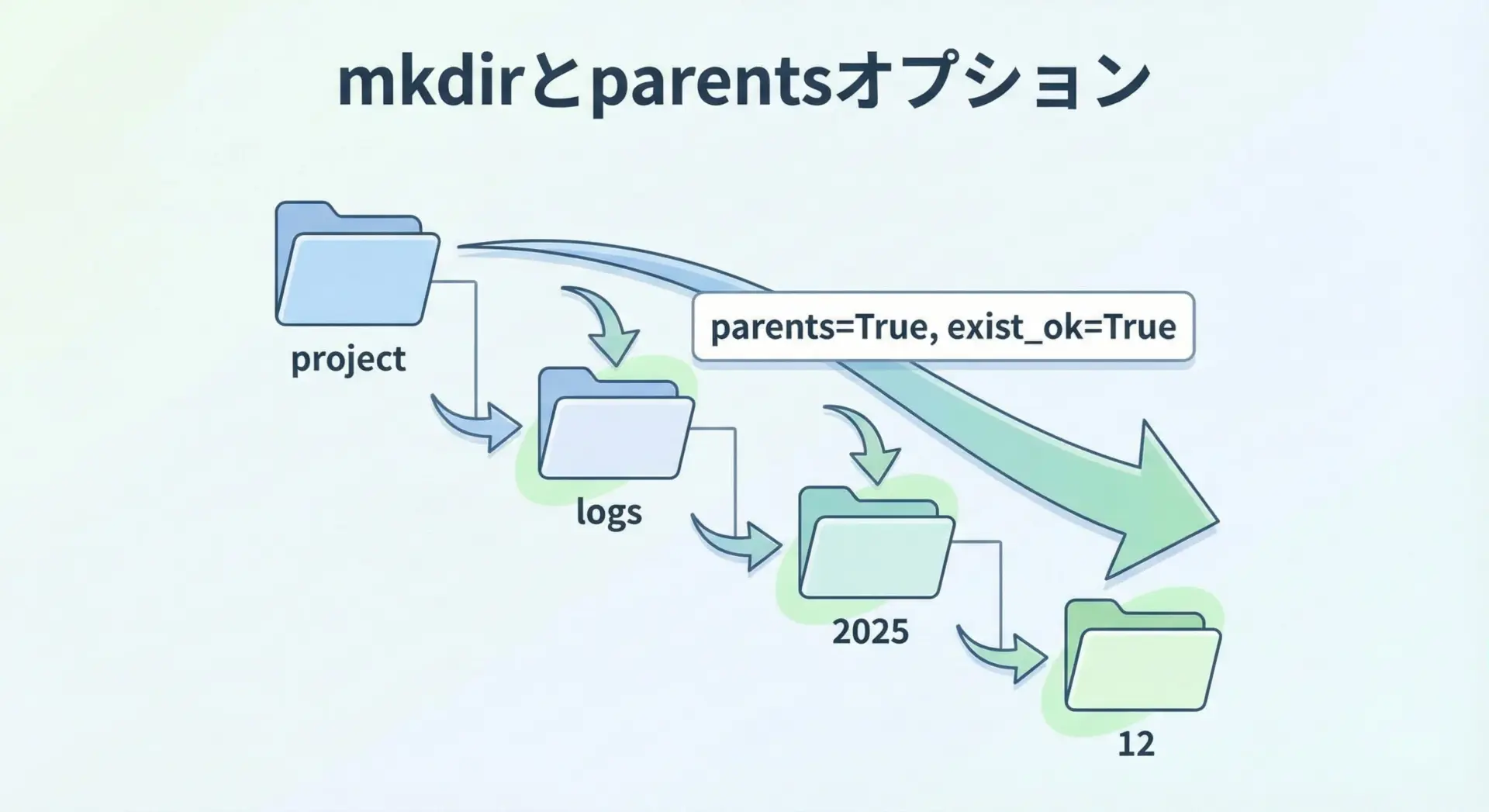
log_dir = Path("logs")
log_dir.mkdir(exist_ok=True) # すでにあってもエラーにしない
# 階層を含むディレクトリを一気に作成(必要な親ディレクトリも作る)
nested_dir = Path("output", "2025", "12")
nested_dir.mkdir(parents=True, exist_ok=True)
print("作成したディレクトリ:", nested_dir)作成したディレクトリ: output/2025/12parents=Trueを指定すると、中間ディレクトリが存在しない場合でも自動的に作成してくれます。
またexist_ok=Trueを指定すれば、すでに存在していても例外を出さずにスルーできます。
これにより、「ディレクトリが無いときだけ作成する」ための条件分岐をわざわざ書く必要がなくなります。
ファイルの読み書き
pathlibは、テキストファイルやバイナリファイルの読み書きを簡単に行えるメソッドも備えています。
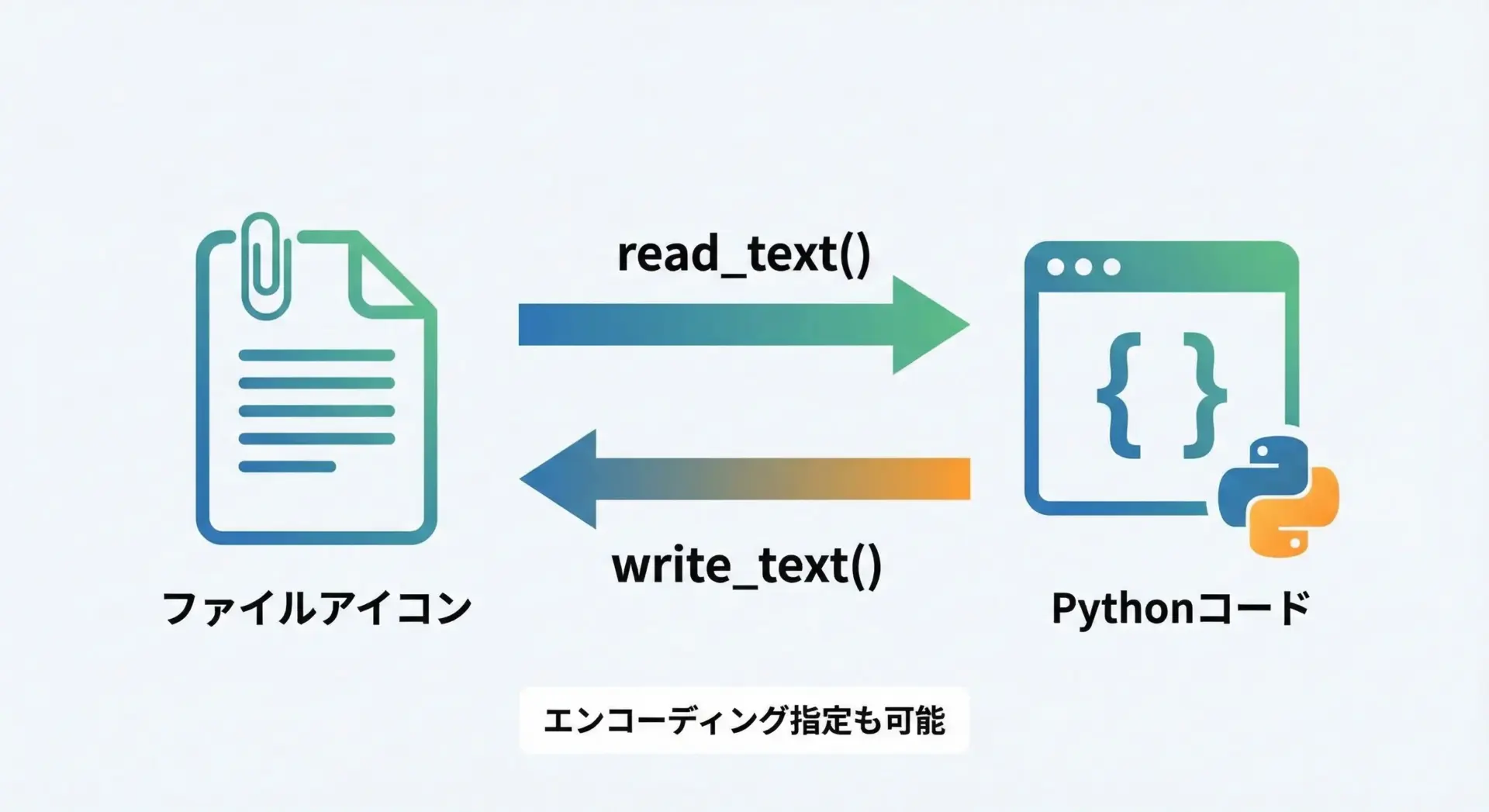
from pathlib import Path
p = Path("example.txt")
# テキストを書き込み(UTF-8で書き込む)
p.write_text("こんにちは、pathlib!\n2行目のテキストです。", encoding="utf-8")
# テキストを読み込み
content = p.read_text(encoding="utf-8")
print("読み込んだ内容:")
print(content)読み込んだ内容:
こんにちは、pathlib!
2行目のテキストです。バイナリデータを扱う場合は、read_bytes()とwrite_bytes()を使います。
from pathlib import Path
p = Path("image.bin")
# バイナリデータを書き込む
data = b"\x00\x01\x02\x03"
p.write_bytes(data)
# バイナリデータを読み込む
loaded = p.read_bytes()
print(loaded)b'\x00\x01\x02\x03'もちろん、従来通りopen()を使ってファイルオブジェクトを開くことも可能です。
Pathオブジェクトにはopen()メソッドがあり、with文と組み合わせて使えます。
from pathlib import Path
p = Path("numbers.txt")
# open()メソッドでファイルを開いて書き込み
with p.open("w", encoding="utf-8") as f:
for i in range(5):
f.write(f"{i}\n")
# 同じくopen()メソッドで読み込み
with p.open("r", encoding="utf-8") as f:
lines = [line.strip() for line in f]
print(lines)['0', '1', '2', '3', '4']ファイル・ディレクトリの列挙
ディレクトリ内のファイルを列挙するにはiterdir()を使います。
さらに、パターンマッチによる絞り込みにはglob()やrglob()が利用できます。
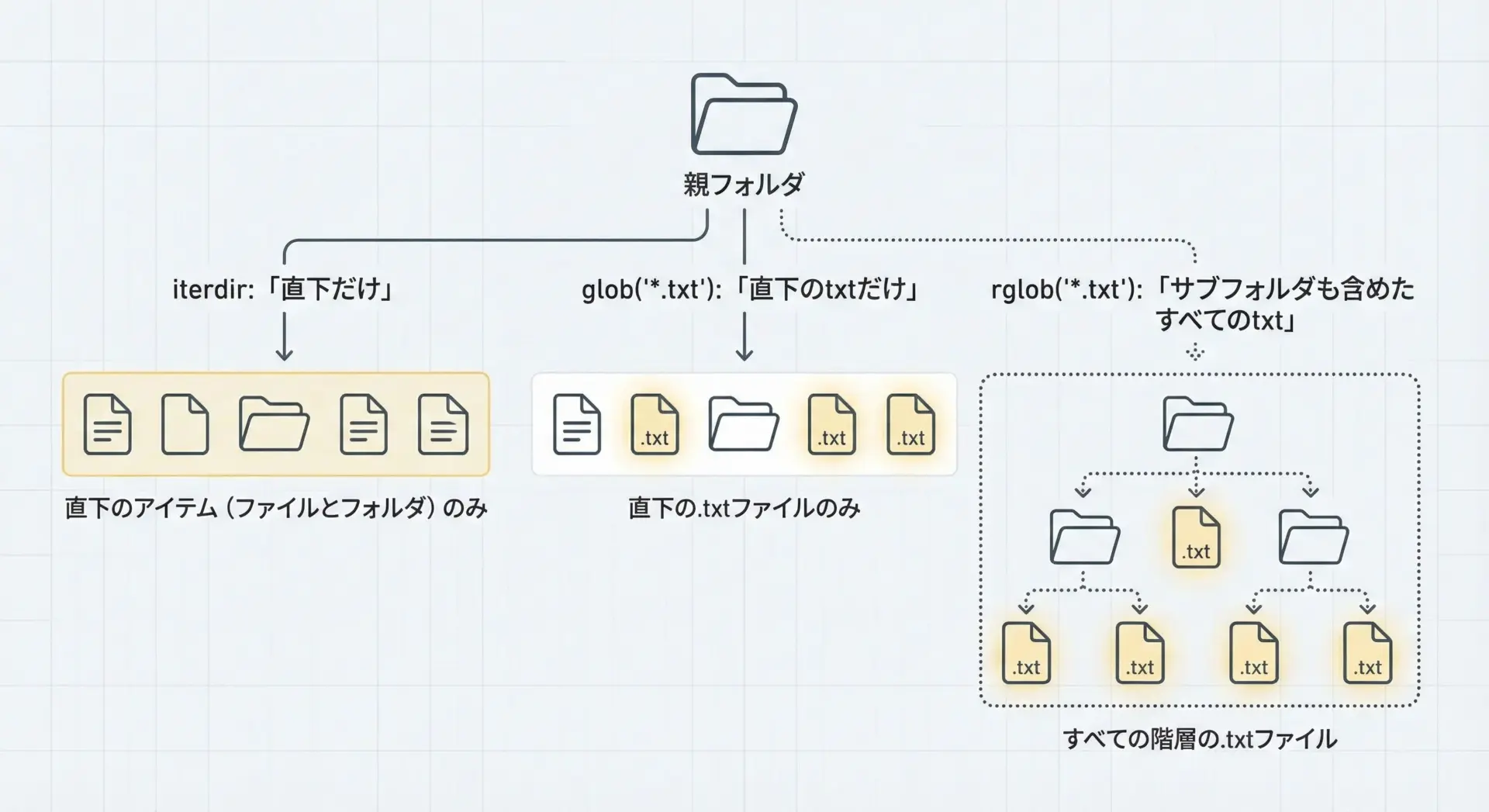
from pathlib import Path
root = Path("data")
# 直下のファイル・ディレクトリを列挙
print("=== iterdir() ===")
for p in root.iterdir():
print(p)
# 直下の*.txtだけを列挙
print("=== glob('*.txt') ===")
for p in root.glob("*.txt"):
print(p)
# サブディレクトリも含めて*.txtを再帰的に列挙
print("=== rglob('*.txt') ===")
for p in root.rglob("*.txt"):
print(p)=== iterdir() ===
data/file1.txt
data/file2.csv
data/images
=== glob('*.txt') ===
data/file1.txt
=== rglob('*.txt') ===
data/file1.txt
data/subdir/another.txtglobは直下のみ、rglobは再帰的にという違いを覚えておくと、意図した範囲のファイルを抽出しやすくなります。
ファイルのコピー・移動・削除
ファイルやディレクトリの削除はpathlibだけで完結しますが、コピーについてはshutilモジュールと組み合わせるのが基本です。
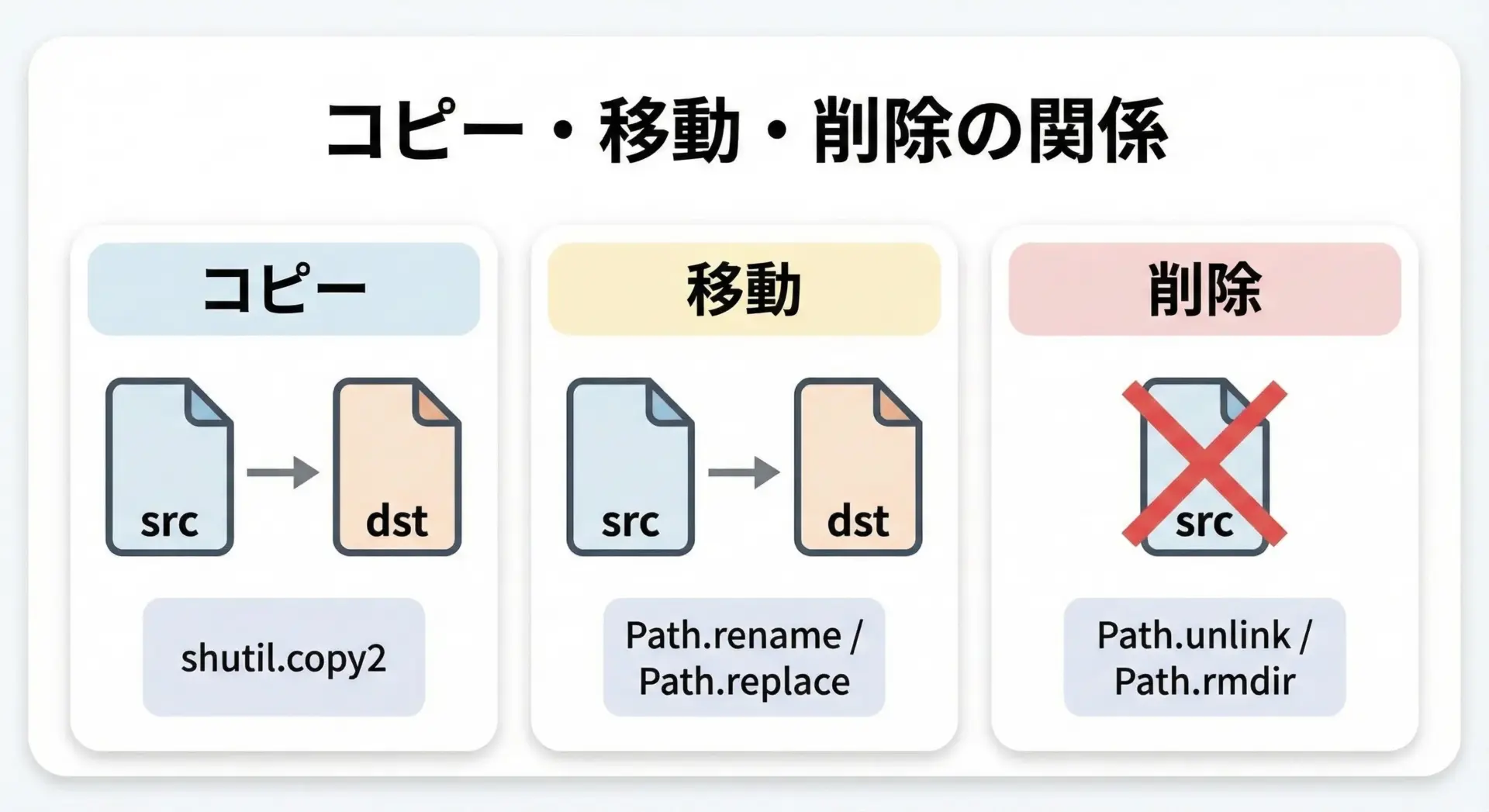
from pathlib import Path
import shutil
src = Path("data/input.txt")
dst = Path("backup/input_backup.txt")
# コピー(shutilを利用)
dst.parent.mkdir(parents=True, exist_ok=True) # コピー先のディレクトリを用意
shutil.copy2(src, dst) # メタデータも含めてコピー
# 移動(リネーム)
moved = Path("data/moved_input.txt")
src.rename(moved) # src → moved に名前変更(場所が変わることもある)
# 削除
moved.unlink() # ファイル削除
print("コピー元:", src)
print("コピー先:", dst)
print("移動後(削除済み):", moved)コピー元: data/input.txt
コピー先: backup/input_backup.txt
移動後(削除済み): data/moved_input.txtディレクトリの削除にはrmdir()を使いますが、空でないディレクトリは削除できない点に注意が必要です。
中身ごと削除したい場合はshutil.rmtree()を使います。
from pathlib import Path
import shutil
empty_dir = Path("tmp/empty")
non_empty_dir = Path("tmp/non_empty")
empty_dir.mkdir(parents=True, exist_ok=True)
(non_empty_dir / "file.txt").parent.mkdir(parents=True, exist_ok=True)
(non_empty_dir / "file.txt").write_text("test")
# 空ディレクトリはrmdirで削除可能
empty_dir.rmdir()
# 中身のあるディレクトリを削除するとエラーになるので、shutil.rmtreeを使う
shutil.rmtree(non_empty_dir.parent) # non_emptyの親ごと削除する例パスの正規化と解決
相対パスを絶対パスに変換したり、シンボリックリンクを解決して実体のパスを取得したい場合には、resolve()が役立ちます。
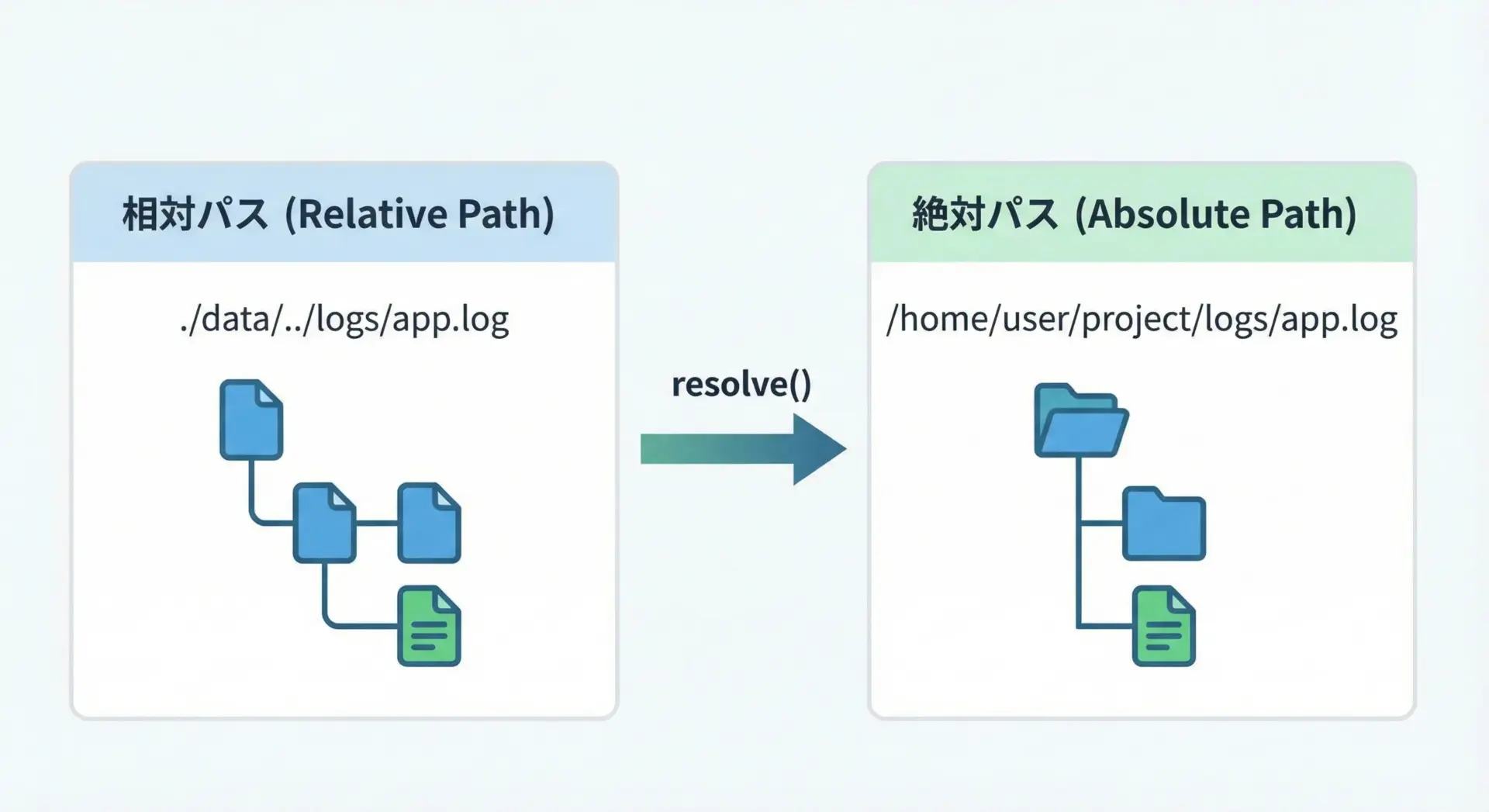
from pathlib import Path
# 相対パス
p = Path("./data/../logs/app.log")
print("元のパス:", p)
print("絶対パス:", p.absolute()) # カレントディレクトリ基準の絶対パスに変換
print("解決済みパス:", p.resolve()) # .. やシンボリックリンクを解決元のパス: data/../logs/app.log
絶対パス: /current/dir/data/../logs/app.log
解決済みパス: /current/dir/logs/app.logabsolute()は単にカレントディレクトリを前に足すだけなのに対し、resolve()は..を整理したりシンボリックリンクを解決したりする点が重要です。
特にログ出力などで「実際にどの場所を指しているのか」を明確にしたいときはresolve()を利用するとよいでしょう。
os.pathからpathlibへの書き換えパターン集
ここまででpathlibの基本を一通り見てきました。
ここからは、既存のos.pathベースのコードをpathlibに書き換えるときのパターンを具体的に紹介します。
よくあるos.pathコードをpathlibに置き換える
まずは、典型的なos.pathコードと、それをpathlibで書き換えた例を並べて比較します。

# 従来のos.pathを使ったコード例
import os
from glob import glob
base_dir = "data"
file_path = os.path.join(base_dir, "input.txt")
print("ファイル名:", os.path.basename(file_path))
print("ディレクトリ名:", os.path.dirname(file_path))
print("拡張子を除いた名前:", os.path.splitext(file_path)[0])
# txtファイルを列挙
for path in glob(os.path.join(base_dir, "*.txt")):
print(path)# pathlibで書き換えた例
from pathlib import Path
base_dir = Path("data")
file_path = base_dir / "input.txt"
print("ファイル名:", file_path.name)
print("ディレクトリ名:", file_path.parent)
print("拡張子を除いた名前:", file_path.stem)
# txtファイルを列挙
for p in base_dir.glob("*.txt"):
print(p)pathlib版では、パス操作が演算子とプロパティ中心になり、関数呼び出しがかなり少なくなっていることがわかります。
join, basename, dirname, splitextのpathlibでの書き方
os.pathの代表的な関数と、pathlibでの対応方法を整理しておきます。
| 機能 | os.path での書き方 | pathlib での書き方 |
|---|---|---|
| 結合 | os.path.join(a, b, c) | Path(a) / b / c |
| ファイル名 | os.path.basename(p) | Path(p).name |
| ディレクトリ | os.path.dirname(p) | Path(p).parent |
| 拡張子分離 | os.path.splitext(p) | (Path(p).stem, Path(p).suffix) |
少しまとめてサンプルコードにすると次のようになります。
import os
from pathlib import Path
path_str = "data/input.txt"
# os.path版
print("=== os.path版 ===")
print("join:", os.path.join("data", "input.txt"))
print("basename:", os.path.basename(path_str))
print("dirname:", os.path.dirname(path_str))
root, ext = os.path.splitext(path_str)
print("splitext:", root, ext)
# pathlib版
print("=== pathlib版 ===")
p = Path("data") / "input.txt"
print("join:", p)
print("basename:", p.name)
print("dirname:", p.parent)
print("splitext:", p.stem, p.suffix)=== os.path版 ===
join: data/input.txt
basename: input.txt
dirname: data
splitext: data/input .txt
=== pathlib版 ===
join: data/input.txt
basename: input.txt
dirname: data
splitext: input .txtsplitextとstem + suffixの違いとして、os.path版は「パス全体から拡張子を切り落とした文字列」を返しますが、pathlib版はstemが「ファイル名から拡張子を除いた部分のみ」を返します。
この違いに注意しつつ、必要に応じてp.with_suffix()なども活用するとよいです。
globモジュールからPath.glob, rglobへの移行
glob.glob()を使っていたコードは、Pathオブジェクトのglob()やrglob()で置き換えられます。

# globモジュール版
from glob import glob
import os
base_dir = "data"
print("=== globモジュール版 ===")
for path in glob(os.path.join(base_dir, "*.txt")):
print(path)# pathlib版
from pathlib import Path
base_dir = Path("data")
print("=== pathlib版(glob) ===")
for p in base_dir.glob("*.txt"):
print(p)
print("=== pathlib版(rglob) 再帰的検索 ===")
for p in base_dir.rglob("*.txt"):
print(p)パターンの書き方そのものはglobと同じですが、「どのディレクトリを基準に検索するか」をPathオブジェクトに持たせられる点がpathlibの利点です。
既存コードと共存させるコツ(str(Path)の使いどころ)
既存のライブラリやフレームワークの中には、引数として文字列パスのみを受け付けるものも少なくありません。
その場合は、Pathオブジェクトをstr()で文字列に変換してから渡します。

from pathlib import Path
import subprocess
# プロジェクト内のスクリプトを実行する例
script = Path("scripts") / "task.py"
# subprocess.runは文字列パスを想定していることが多いので、strに変換
result = subprocess.run(
["python", str(script)], # ここでstr()を使う
capture_output=True,
text=True,
check=True,
)
print(result.stdout)# scripts/task.py の実行結果がここに表示されるこのように、アプリケーション内部ではPathで統一し、外部との境界(ファイルパスを引数に取るライブラリなど)でのみstr()に変換する構成にすると、pathlibの恩恵を最大限活かしつつ、既存のエコシステムともスムーズに連携できます。
もうひとつのパターンとして、osやshutilなど標準ライブラリ関数にPathを渡したい場合があります。
多くの標準ライブラリ関数はPathオブジェクトも受け付けるようになっているため、実はstr()への変換すら不要な場合も多いです。
とはいえ、外部ライブラリではまだ文字列のみ対応のケースもあるため、str(path)は「最後の砦」として覚えておくと安心です。
まとめ
pathlibを使うことで、パスを単なる文字列ではなく「意味のあるオブジェクト」として扱えるようになり、OS差異を意識したり、文字列操作でパスをいじる煩雑さから解放されます。
Pathオブジェクトの生成、結合、分解、存在確認、読み書き、列挙といった基本を押さえ、よくあるos.pathコードとの対応関係を理解しておけば、既存プロジェクトも少しずつpathlibベースへ移行できます。
まずは新しく書くコードからPathを採用し、必要な場面だけstr(path)で互換性を保ちながら、段階的にos.path卒業を進めていきましょう。
