Pythonで軽量なデータ構造を扱う際に、クラスやdictだけでは物足りないと感じることはありませんか。
そうした場面で力を発揮するのがnamedtupleです。
この記事では、namedtupleの基本から実践的な活用パターン、注意点やdataclassとの比較までを、図解とコード例を交えながら丁寧に解説します。
namedtupleとは何か
namedtupleの概要と特徴

namedtupleは、Python標準ライブラリのcollectionsモジュールが提供する「名前付きタプル」機能です。
通常のタプルと同じくイミュータブル(変更不可)でありながら、各要素にフィールド名を付けてアクセスできるのが特徴です。
特徴を文章で整理すると、次のようになります。
namedtupleは、タプルと同様に軽量であり、要素数があらかじめ決まっているデータを扱うのに向いています。
また、dictのように文字列キーでアクセスしつつ、タプルのようにインデックスアクセスもできるため、読みやすさとパフォーマンスのバランスが良いデータ構造だといえます。
代表的な特徴を表にまとめます。
| 項目 | 内容 |
|---|---|
| 所属モジュール | collections |
| データ構造 | タプルを拡張した不変シーケンス |
| アクセス方法 | フィールド名、インデックス、アンパック |
| 変更可否 | 基本的に変更不可(イミュータブル) |
| 主な用途 | 軽量なレコード、関数戻り値、行データの表現など |
クラスとの違いと使い分け
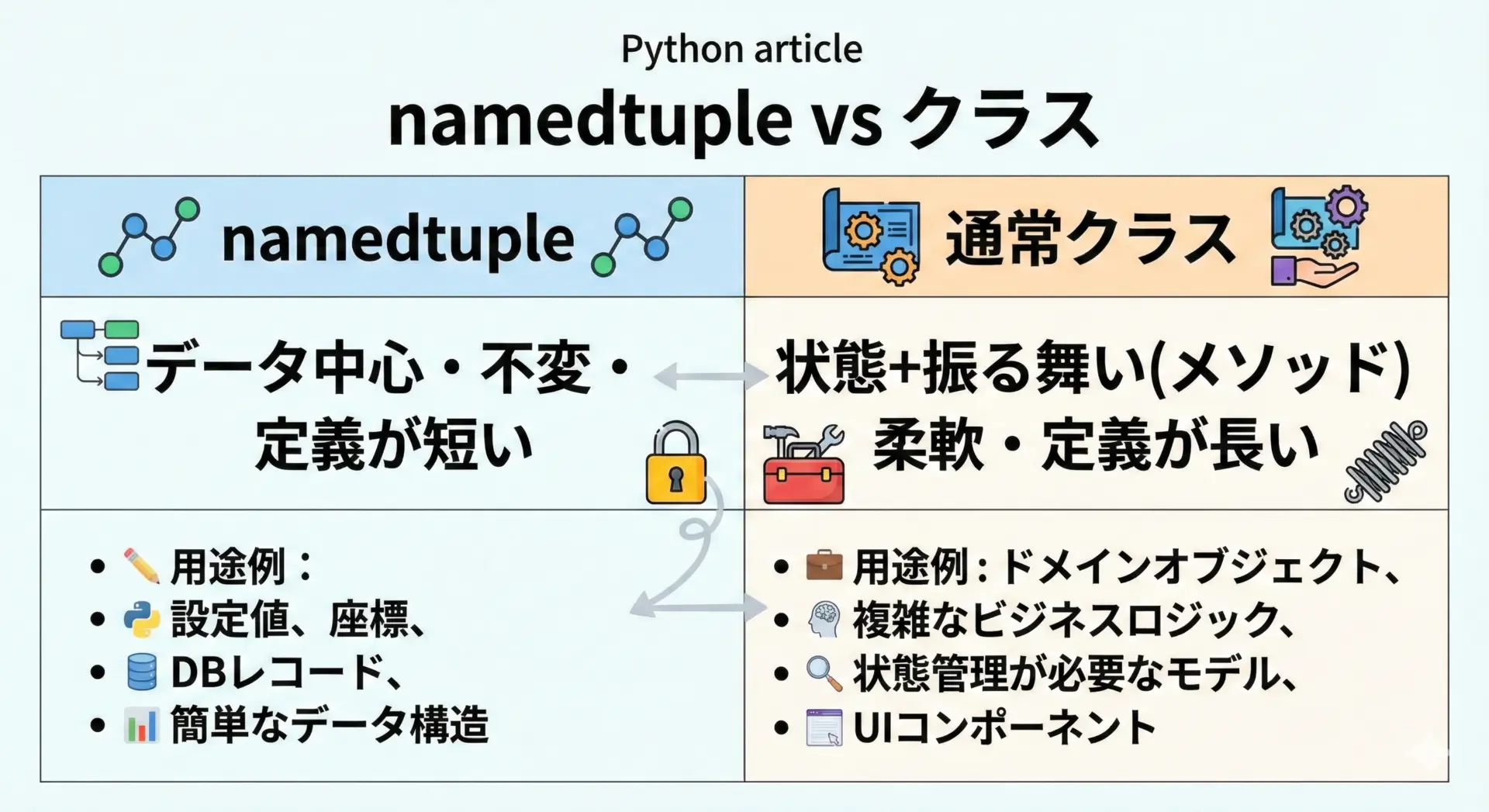
namedtupleと通常のクラスは、どちらも「属性名でアクセスできるオブジェクト」を提供しますが、目的と性質が異なります。
クラスはメソッドを持ち、状態と振る舞いをまとめて表現するのに向いています。
一方で、namedtupleは「ただのデータのまとまり」を表現することに特化しています。
メソッドを持つこともできますが、複雑なロジックを持たせるのには向きません。
使い分けの目安としては、次のように考えるとよいです。
「ロジックをあまり持たないデータの詰め合わせ」ならnamedtuple、「振る舞いも含めたオブジェクト」なら通常クラスを選ぶと理解しやすくなります。
dictとの違いと使いどころ
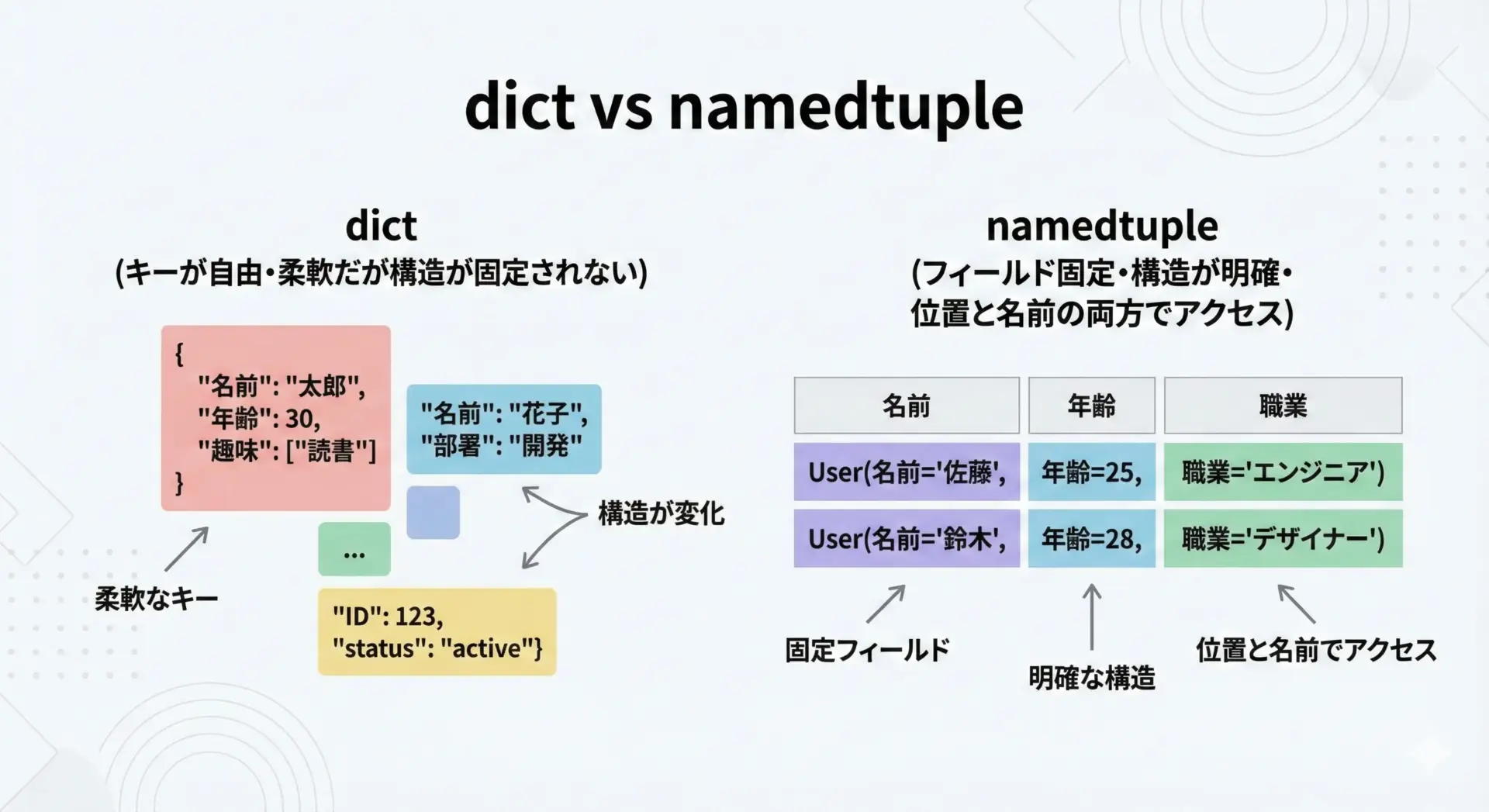
dictもキーでアクセスできるため、一見するとnamedtupleと似ています。
しかし、dictはキーの集合が変更可能であり、実行時に任意のキーを追加・削除しやすい柔軟性があります。
その一方で、データ構造が「ゆるい」ため、どのキーが存在するのかがコード上で明確になりにくいという側面もあります。
namedtupleは、定義時にフィールド名(キーに相当するもの)をすべて宣言するため、構造が固定されます。
これにより、次のような利点があります。
1つ目に、IDEやエディタの補完が効きやすくなり、タイプミスを減らせます。
2つ目に、コードを読む側にとって、どのようなデータ項目が存在するのかが明確になります。
3つ目に、タプル互換のため、ソートやアンパック、タプルを期待するAPIとの相性が良くなります。
一方で、フィールドを増減しづらいという制約もありますので、スキーマが比較的安定しているデータに使うことが重要です。
namedtupleの基本的な使い方
namedtupleの定義方法と命名ルール
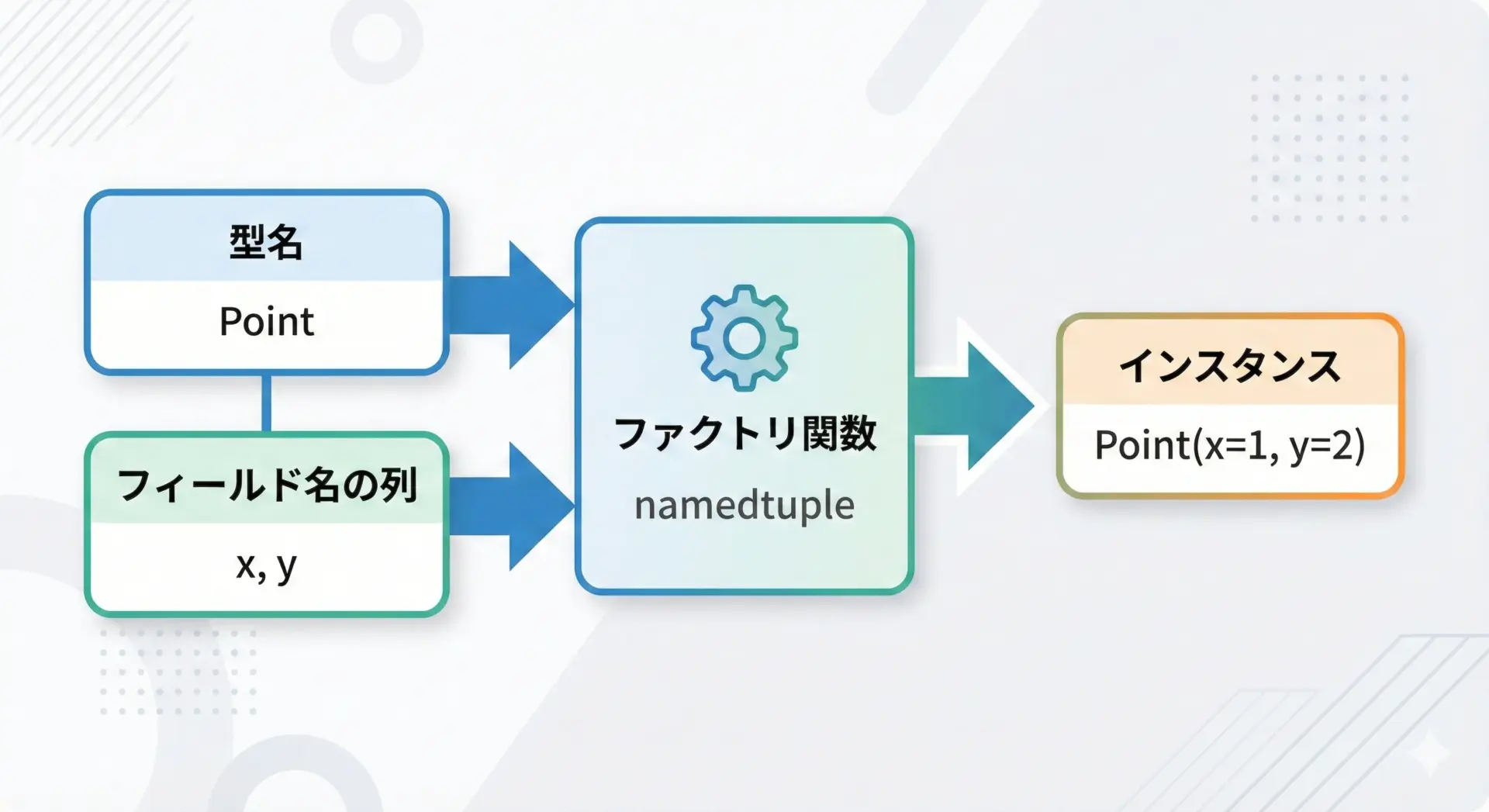
namedtupleはcollections.namedtuple関数を使って定義します。
この関数は「新しいクラスを生成するファクトリ関数」です。
つまり、namedtupleを定義すると、新しい型(クラス)が1つ作られ、その型からインスタンスを生成することになります。
基本的な定義方法
from collections import namedtuple
# Pointという名前のnamedtuple型を定義
# フィールドはxとyの2つ
Point = namedtuple("Point", ["x", "y"])
# インスタンス生成
p = Point(10, 20)
print(p) # Point(x=10, y=20)
print(p.x, p.y) # フィールド名でアクセスフィールド名の指定方法いろいろ
フィールド名は、リスト・タプル・スペース区切り文字列など、いくつかの方法で指定できます。
from collections import namedtuple
# 1. リストで指定
Point1 = namedtuple("Point1", ["x", "y"])
# 2. タプルで指定
Point2 = namedtuple("Point2", ("x", "y"))
# 3. スペース区切り文字列で指定
Point3 = namedtuple("Point3", "x y")
# 4. カンマ区切り文字列で指定
Point4 = namedtuple("Point4", "x, y")
p = Point1(1, 2)
print(p)命名ルールのポイント
namedtupleの型名は、通常のクラスと同様にアッパーキャメルケース(例: Point、UserInfo)で書きます。
フィールド名は変数名と同じスネークケース(例: x、user_id)で書くのが一般的です。
また、フィールド名には以下の制約があります。
| 制約内容 | 例 |
|---|---|
| 先頭は英字かアンダースコア | _hidden は可、1stは不可 |
| Pythonのキーワードは使用不可 | class、defなどは不可 |
| 重複フィールド名は不可 | ("x", "x") はエラー |
フィールド名が不正な場合、自動修正するオプションもありますが、基本的には明示的に正しい名前を付けることをおすすめします。
インスタンス生成と値の参照方法
namedtupleは、定義された型を「関数のように呼び出す」ことでインスタンスを生成します。
from collections import namedtuple
User = namedtuple("User", ["id", "name", "age"])
# 位置引数で生成
u1 = User(1, "Alice", 30)
# キーワード引数で生成
u2 = User(id=2, name="Bob", age=25)
print(u1)
print(u2)User(id=1, name='Alice', age=30)
User(id=2, name='Bob', age=25)アクセスは、タプルと同じくインデックス、あるいはフィールド名で行います。
print(u1[0]) # インデックスアクセス: 1
print(u1.id) # フィールド名アクセス: 1このとき、内部的には通常のタプルと同様に要素が並んでいるだけですが、ラッパーとしてフィールド名による属性アクセスが提供されています。
フィールド名によるアクセスとインデックスアクセス
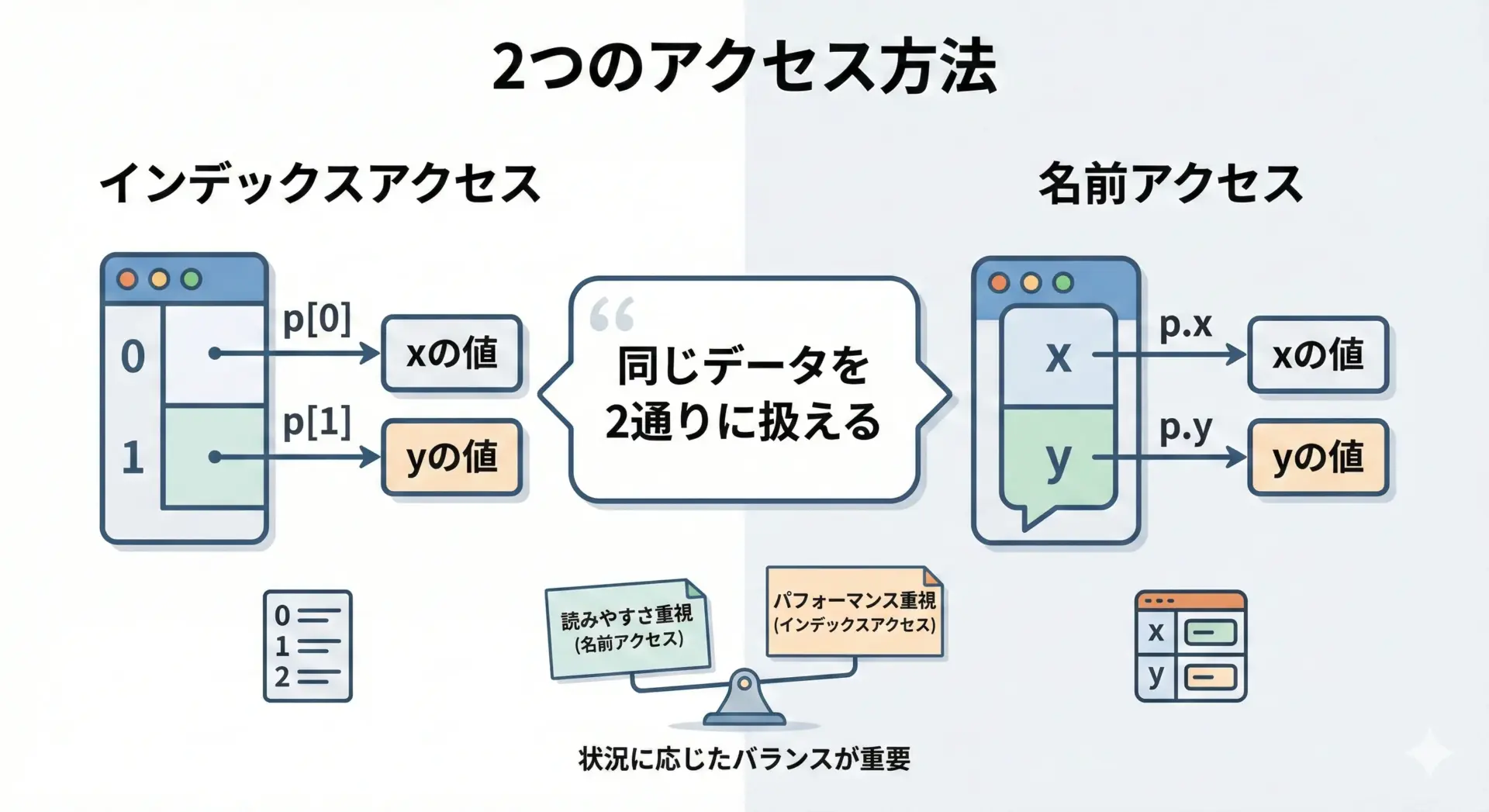
namedtupleは「タプル互換」であるため、インデックスでもアクセスできますが、日常的にはフィールド名によるアクセスが推奨されます。
なぜなら、コードの意図が明確になり、要素の順番を意識しなくてよくなるからです。
from collections import namedtuple
Point = namedtuple("Point", "x y")
p = Point(10, 20)
# フィールド名でアクセス
print("x =", p.x)
print("y =", p.y)
# インデックスでアクセス
print("x by index =", p[0])
print("y by index =", p[1])x = 10
y = 20
x by index = 10
y by index = 20インデックスアクセスは、例えばソートキーに使うなど「タプルとして扱う」場合に便利です。
一方、通常のビジネスロジックでは、フィールド名アクセスを優先した方が、後から読む人にとっても理解しやすくなります。
デフォルト値の設定と省略可能なフィールド
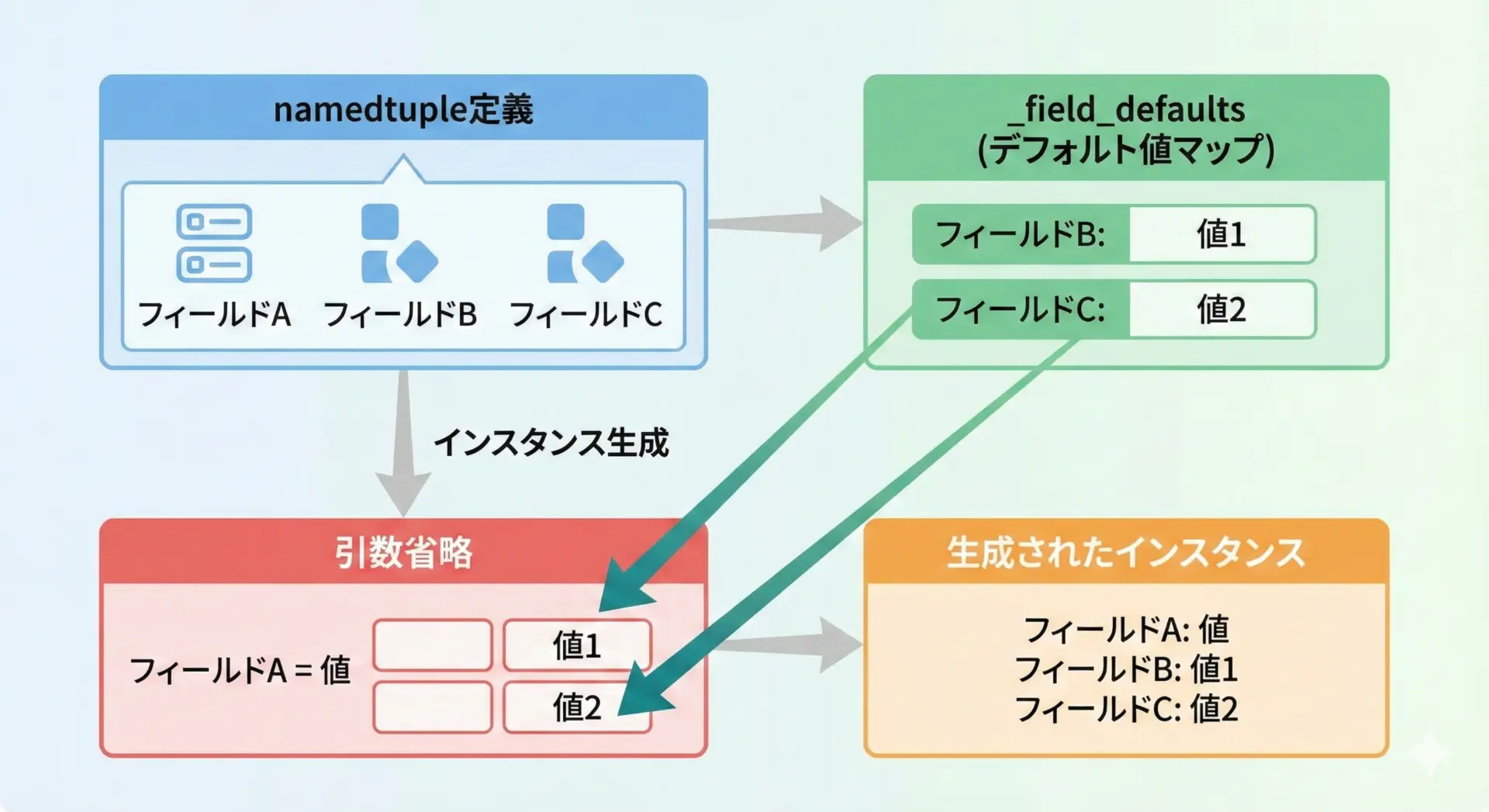
標準のnamedtupleは、そのままでは「途中までの省略」をサポートしていません。
つまり、定義された全フィールドに対して値を渡す必要があります。
しかし、_field_defaults属性を利用すると、一部のフィールドにデフォルト値を定義できます。
from collections import namedtuple
# User型を定義
User = namedtuple("User", ["id", "name", "age", "country"])
# _field_defaultsにデフォルト値を設定
User.__new__.__defaults__ = (None, "Japan") # 末尾2つのデフォルト値を設定
# または、Python3.7以降なら_field_defaultsを使うパターンも知られているが、
# 通常は__new__.__defaults__を直接触る方法がよく使われる
# 4フィールドすべて指定
u1 = User(1, "Alice", 30, "USA")
# 末尾2つを省略(デフォルト適用)
u2 = User(2, "Bob")
print(u1)
print(u2)User(id=1, name='Alice', age=30, country='USA')
User(id=2, name='Bob', age=None, country='Japan')このように、「末尾のフィールド」から順にデフォルトを設定する形になることに注意が必要です。
途中のフィールドだけを省略するような指定はできません。
デフォルト値を多用する場合は、後述するdataclassの方が自然な場合も多いため、「軽くデフォルトを指定したいとき」だけに留めるとよいです。
namedtupleの実践パターンと活用例
関数の戻り値をわかりやすくするパターン
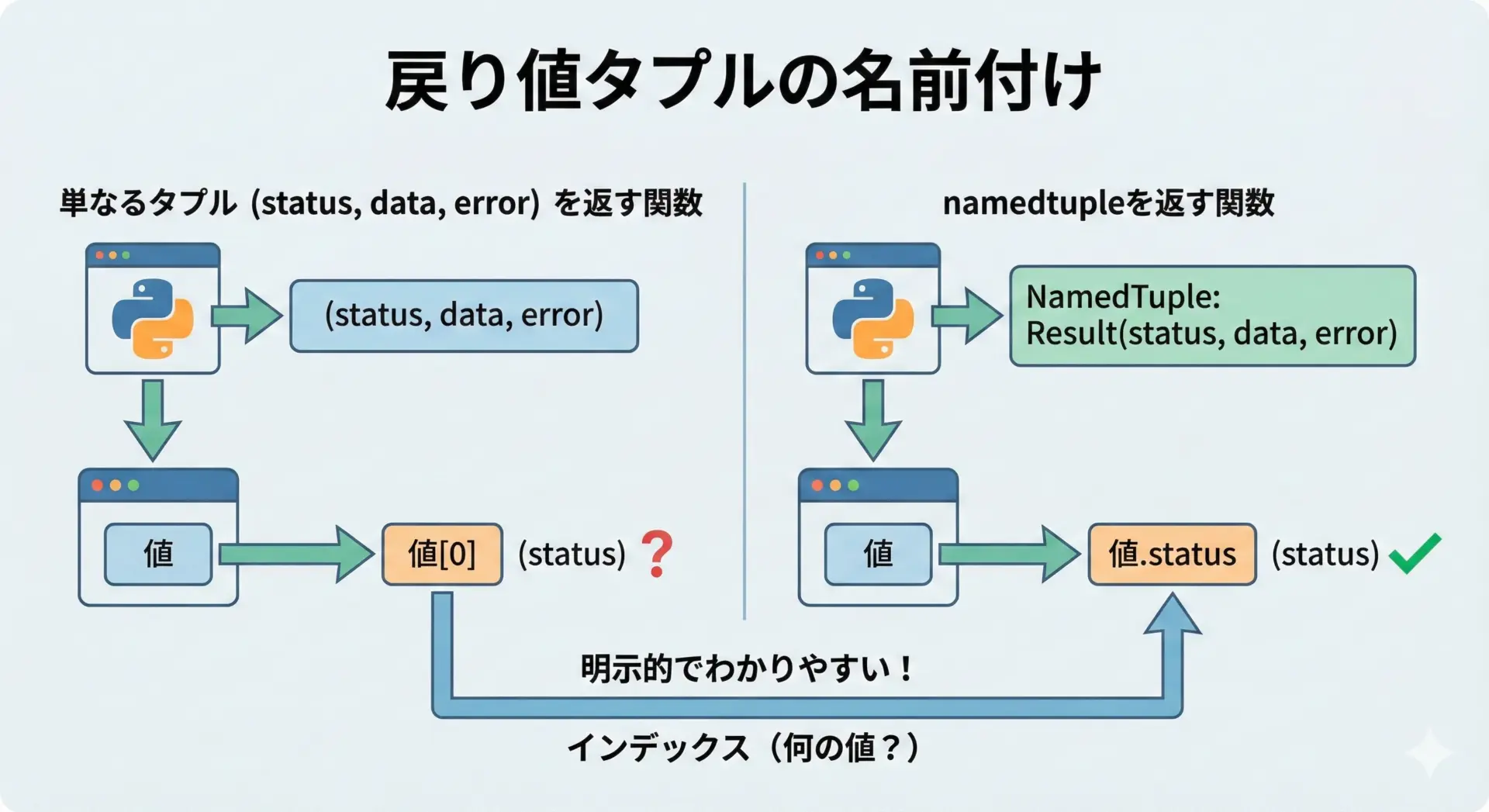
関数が複数の値を返したいとき、通常のタプルで返すと「どの要素が何を意味しているのか」が分かりにくくなります。
そこでnamedtupleを使うと、戻り値の各要素に名前を付けて明示的に表現できます。
from collections import namedtuple
# 関数の戻り値用namedtupleを定義
FetchResult = namedtuple("FetchResult", ["status_code", "body", "error"])
def fetch_data(url):
"""疑似的なHTTPリクエスト関数"""
# デモ用の適当な処理
if "ok" in url:
return FetchResult(status_code=200, body="OK", error=None)
else:
return FetchResult(status_code=500, body=None, error="Error occurred")
# 呼び出し側
result = fetch_data("https://example.com/ok")
print(result.status_code)
print(result.body)
print(result.error)200
OK
None通常のタプルだとresult[0]が何を表すかをコメントやドキュメントで補う必要がありますが、namedtupleならresult.status_codeと書くだけで意味が伝わります。
このように、「複数の戻り値にラベルを付けたいとき」は、namedtupleの典型的な出番です。
一時的なデータ構造として使うパターン
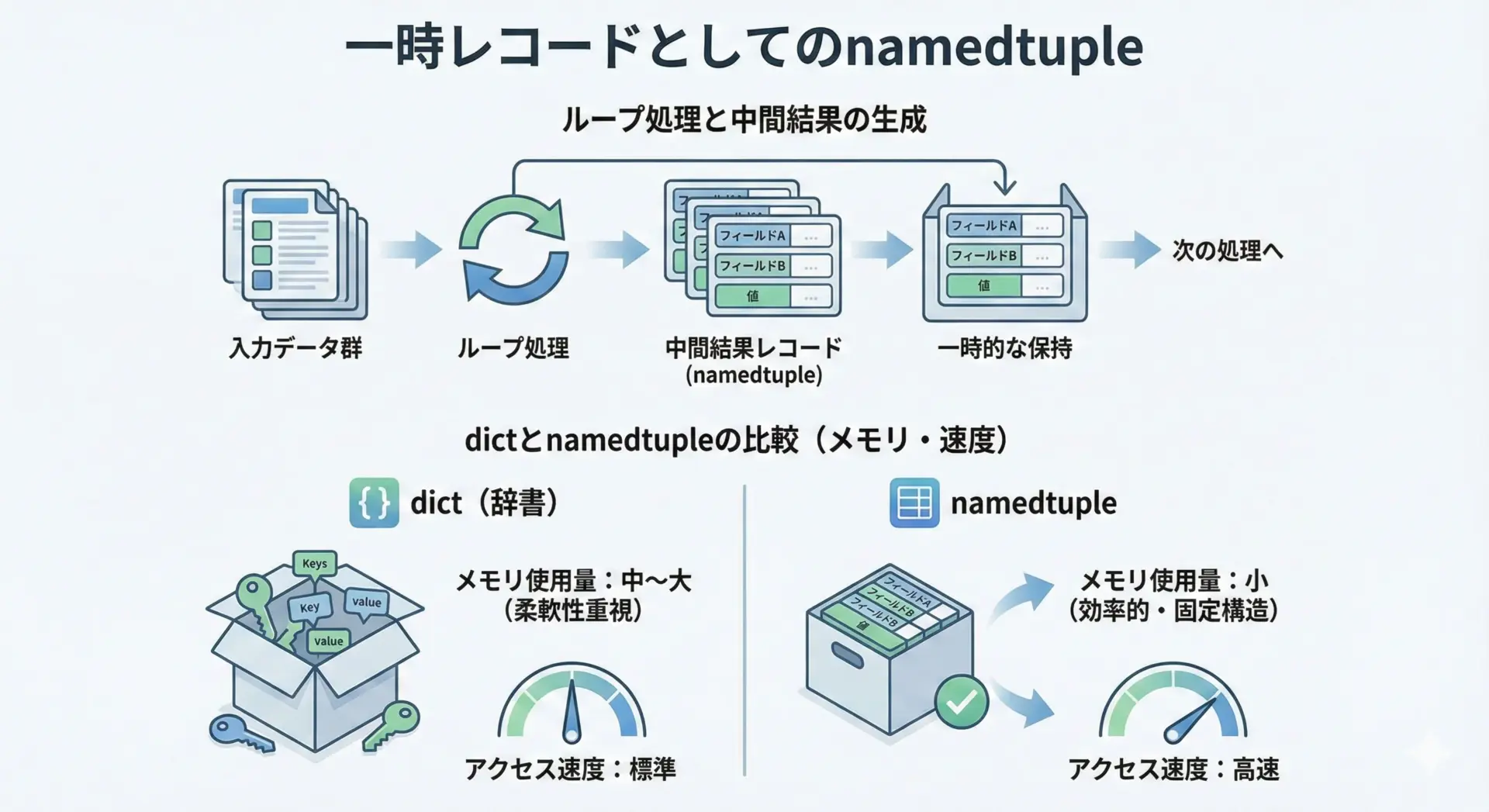
ちょっとした集計処理やフィルタリング処理の途中で、「一時的なレコード」を作りたいことがあります。
そのような場合、dictを使っても構いませんが、フィールドが固定されているならnamedtupleが適しています。
from collections import namedtuple
# 一時的な集計結果を表すnamedtuple
ItemSummary = namedtuple("ItemSummary", ["name", "price", "tax_included"])
def summarize_items(items):
"""
items: {"name": str, "price": int} のリストを想定
"""
summaries = []
for item in items:
tax_included = int(item["price"] * 1.1)
summary = ItemSummary(
name=item["name"],
price=item["price"],
tax_included=tax_included,
)
summaries.append(summary)
return summaries
items = [
{"name": "Apple", "price": 100},
{"name": "Banana", "price": 80},
]
for s in summarize_items(items):
print(s.name, s.price, s.tax_included)Apple 100 110
Banana 80 88このように、処理の中間結果に構造を与えることで、後から処理を見直す際にも意味が理解しやすくなります。
dictよりも軽量で、誤ったキー名に気付きやすいという利点もあります。
設定値や定数グループを表現するパターン
複数の関連する定数や設定値を、一つの固まりとしてまとめたい場合にもnamedtupleが使えます。
例えば、アプリケーションの設定をいくつかのグループに分けて管理したい場合です。
from collections import namedtuple
# データベース設定をまとめるnamedtuple
DbConfig = namedtuple("DbConfig", ["host", "port", "user", "password"])
# 本番用設定
PROD_DB_CONFIG = DbConfig(
host="db.example.com",
port=5432,
user="app_user",
password="secret",
)
# 開発用設定
DEV_DB_CONFIG = DbConfig(
host="localhost",
port=5432,
user="dev_user",
password="dev",
)
print(PROD_DB_CONFIG.host)
print(DEV_DB_CONFIG.user)db.example.com
dev_userこのように、関連する定数を1つのオブジェクトとしてまとめることで、コードの見通しがよくなり、設定値の受け渡しも簡潔になります。
クラスやdataclassを使うほどでもないが、dictだと「キー名のスペルミス」などが怖いという場面に向いています。
CSVやAPIレスポンスの行データに使うパターン
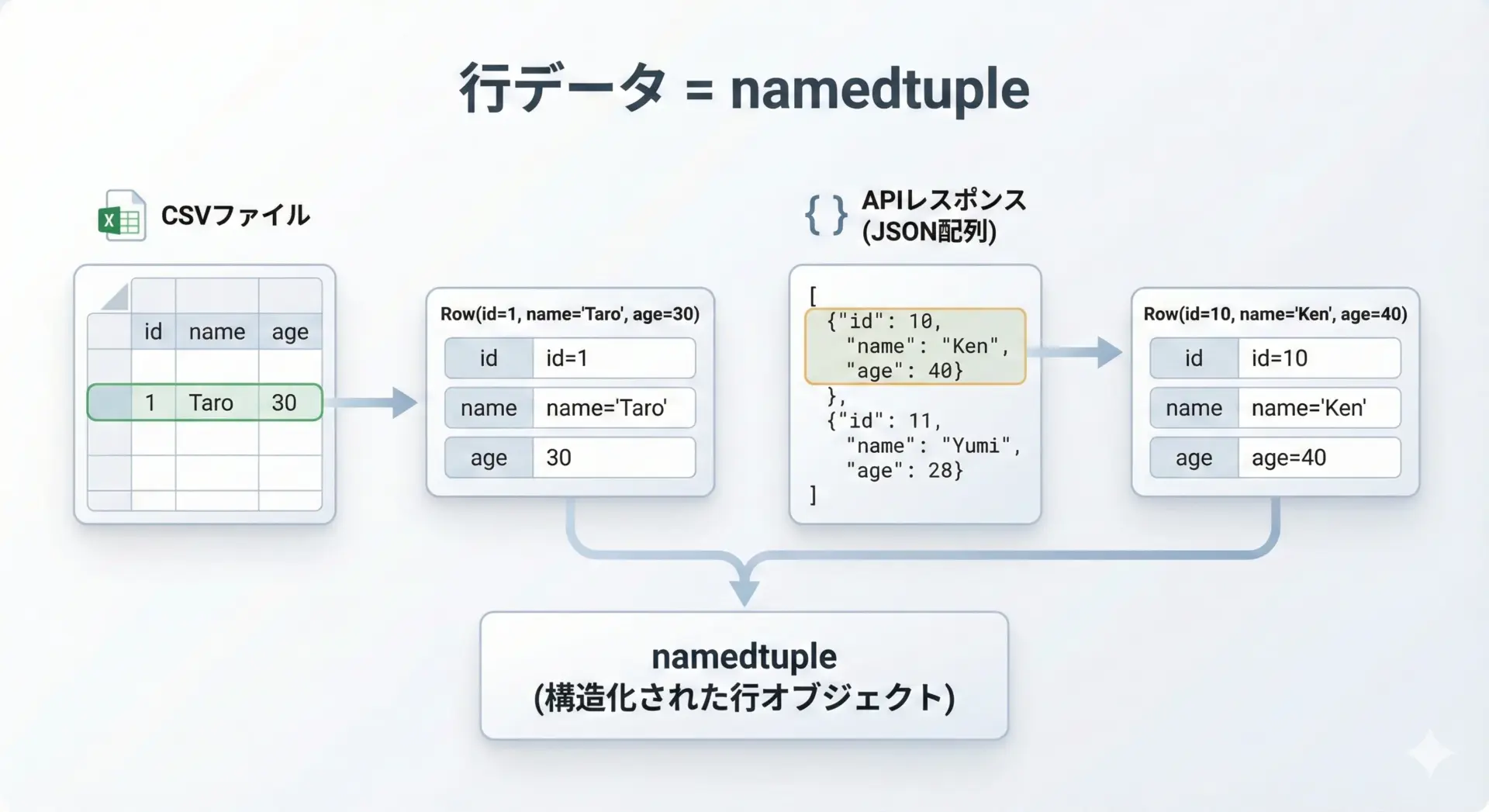
CSVやAPIレスポンスのように、「同じ構造のレコードが繰り返し出てくる」データにもnamedtupleはよく合います。
各行(レコード)をnamedtupleに変換しておくと、後段の処理が読みやすくなります。
CSV行をnamedtupleで表現する例
import csv
from collections import namedtuple
UserRow = namedtuple("UserRow", ["id", "name", "age"])
csv_data = """id,name,age
1,Alice,30
2,Bob,25
""".strip().splitlines()
reader = csv.DictReader(csv_data)
users = []
for row in reader:
# DictReaderはdictを返すので、必要な項目をnamedtupleに詰め替える
user = UserRow(
id=int(row["id"]),
name=row["name"],
age=int(row["age"]),
)
users.append(user)
for u in users:
print(u.id, u.name, u.age)1 Alice 30
2 Bob 25APIレスポンスの例
JSON APIから次のようなレスポンスを受け取るとします。
[
{"id": 1, "title": "First", "done": false},
{"id": 2, "title": "Second", "done": true}
]これをnamedtupleで扱うと、次のようなコードになります。
from collections import namedtuple
Todo = namedtuple("Todo", ["id", "title", "done"])
# 実際にはrequestsなどで取得するが、ここでは直接定義
raw_items = [
{"id": 1, "title": "First", "done": False},
{"id": 2, "title": "Second", "done": True},
]
todos = [Todo(**item) for item in raw_items]
for t in todos:
if not t.done:
print(f"{t.id}: {t.title} is not done")1: First is not doneこのように、「外部からの行データ」を型付きの構造として扱うことで、コードの安全性と読みやすさが向上します。
データクラス(dataclass)との比較と選び方
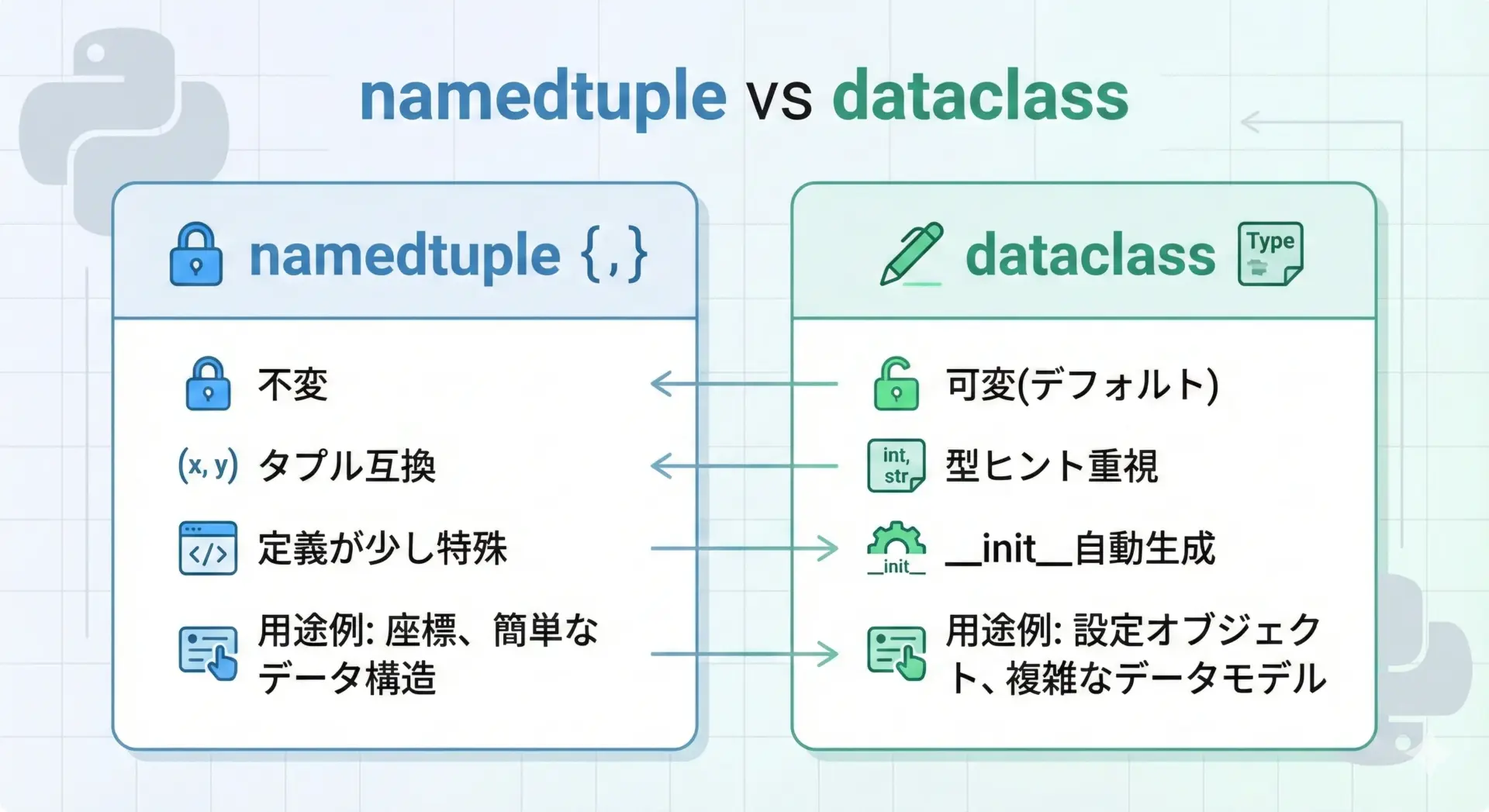
Python3.7以降ではdataclassesモジュールの@dataclassが登場し、「データ中心のクラス」を簡単に書く方法が広く使われるようになりました。
namedtupleとdataclassは似た用途を持つため、どちらを選べばよいか悩むことがあります。
簡単な比較は次の通りです。
| 項目 | namedtuple | dataclass |
|---|---|---|
| イミュータビリティ | デフォルトで不変 | デフォルトは可変、frozen=Trueで不変化 |
| 定義方法 | namedtuple("Name", "fields") | クラス+@dataclassデコレータ |
| 表現力 | シンプル、主にフィールドのみ | 型ヒント・デフォルト値・メソッドなどリッチ |
| タプル互換性 | あり(インデックスアクセス等) | なし(通常のクラス) |
| 速度・メモリ | 軽量・高速 | やや重いが十分高速 |
| 主な用途 | 軽量レコード、戻り値、多数インスタンス | ビジネスロジックを含むデータオブジェクト |
選び方の指針としては、次のように考えるとよいです。
まず、タプル互換性が必要かどうかを判断します。
タプル互換が必要であればnamedtuple一択です。
次に、フィールド数が多かったり、型ヒントやメソッドをしっかり定義したい場合はdataclassが適します。
最後に、「軽量でイミュータブルな値オブジェクトを大量に扱う」「既存のコードがタプル前提で書かれている」といった場合にはnamedtupleが活躍します。
namedtupleを使う際の注意点とアンチパターン
ミュータビリティ(変更不可)による制約
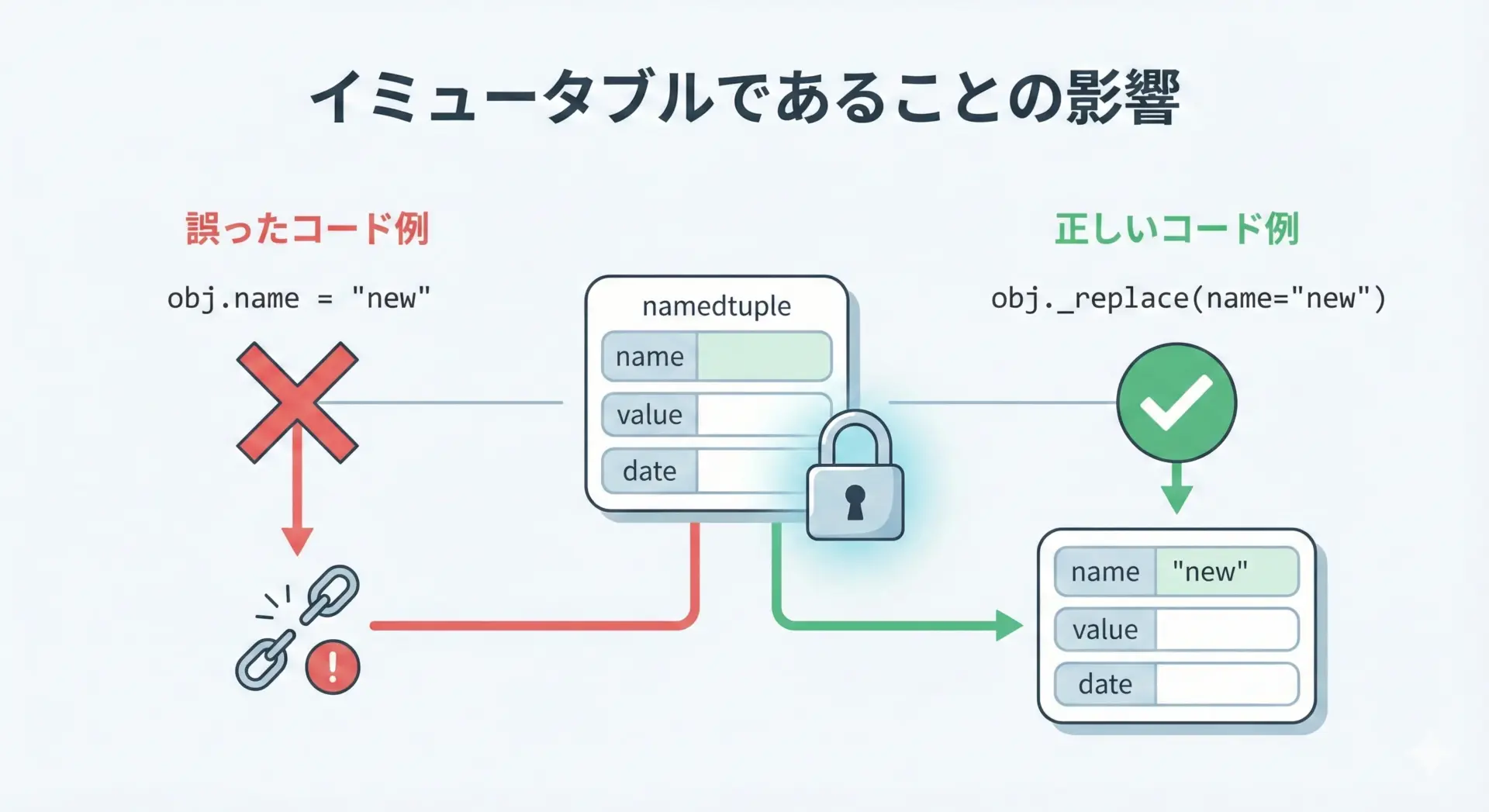
namedtupleはイミュータブル(不変)です。
これは、インスタンスを生成した後にフィールドの値を直接変更できないことを意味します。
from collections import namedtuple
User = namedtuple("User", ["id", "name"])
u = User(1, "Alice")
# これはエラーになる
try:
u.name = "Bob"
except AttributeError as e:
print("Error:", e)Error: can't set attribute値を変更したい場合は、_replaceメソッドを使って「新しいインスタンス」を作る必要があります。
u2 = u._replace(name="Bob")
print(u) # 元のインスタンスは変わらない
print(u2) # 新しいインスタンスが返るUser(id=1, name='Alice')
User(id=1, name='Bob')この性質は、スレッドセーフな設計やバグの予防には有利ですが、「オブジェクトの状態を更新しながら使う設計」には向きません。
そのような場合は、通常クラスやdataclass(可変)を用いることを検討すべきです。
フィールド追加・変更時の互換性問題
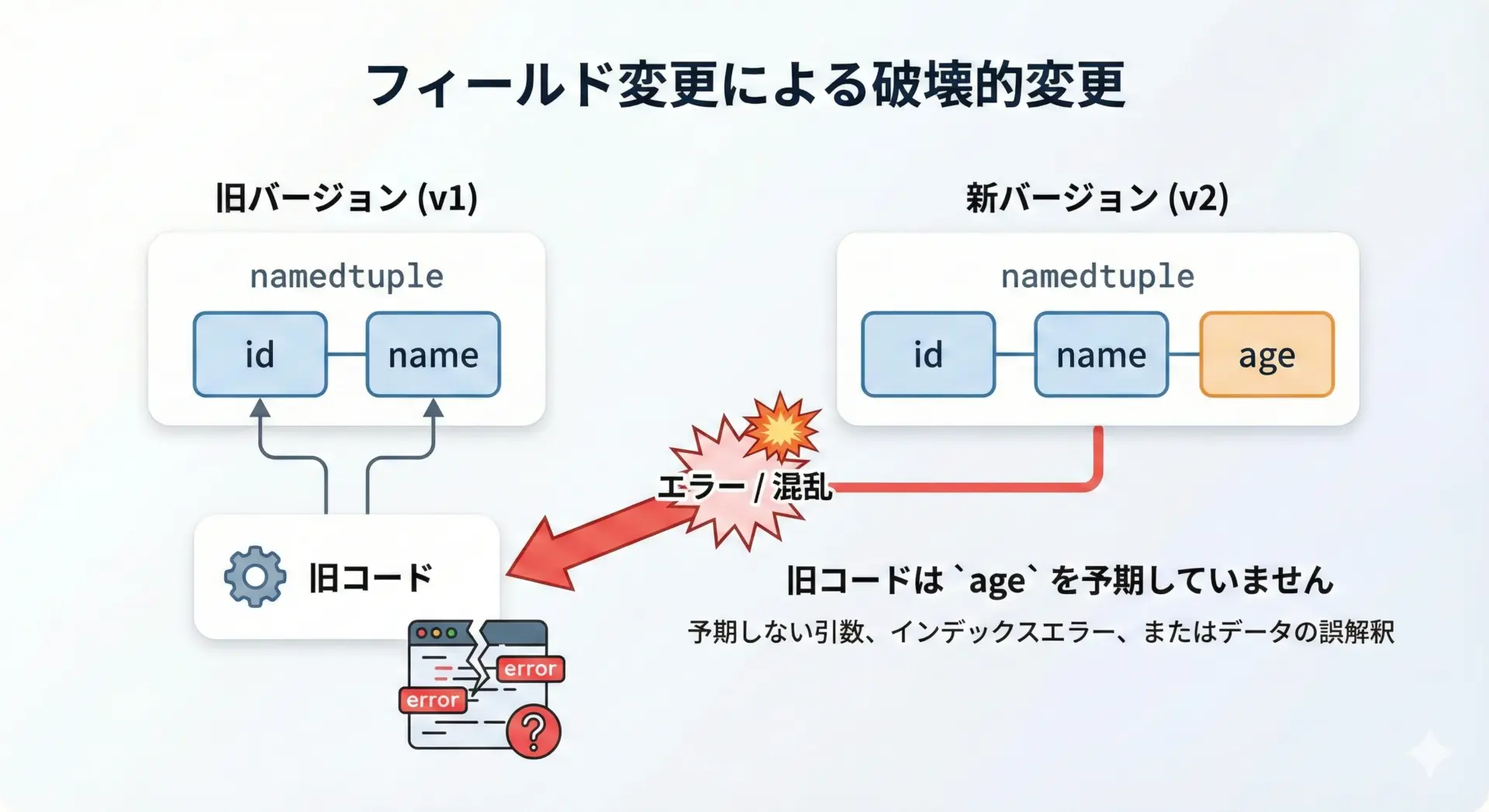
namedtupleのフィールドは固定されているため、後からフィールドを追加・削除・順番変更すると互換性に問題が生じやすいです。
特に、以下のようなケースに注意が必要です。
1つ目に、位置引数でインスタンスを生成しているコードがあると、フィールドの順番を変えたときに意味が入れ替わってしまいます。
2つ目に、既存のコードがタプルとしてアンパックしている場合、フィールド数の変更が即座にエラーにつながります。
3つ目に、別モジュールや別プロジェクト間でnamedtuple型を共有している場合、片方だけフィールドを変更すると整合性が崩れます。
この問題への対処策としては、次のようなものがあります。
まず、インスタンス生成は極力キーワード引数で行うようにします。
次に、フィールドを大きく変更したい場合は、UserV2のように新しい型名を定義する方法もよく使われます。
最後に、そもそも頻繁にスキーマ変更が想定されるデータであれば、namedtupleではなくdictやdataclassを選ぶことも選択肢になります。
大規模プロジェクトでのnamedtuple乱用を避けるコツ
namedtupleは手軽に使えるため、大規模プロジェクトでは「とりあえず何でもnamedtupleで定義してしまう」というアンチパターンが生じがちです。
これにより、どこにどの型があるのか分かりにくくなり、フィールド変更もしづらくなってしまいます。
乱用を避けるためのコツとしては、次のような指針を設けると効果的です。
1つ目に、namedtupleは「構造が単純で、寿命の短いデータ」に限定することです。
例えば、関数の戻り値や一時レコードなどに使い、永続的なドメインオブジェクトにはdataclassや通常クラスを使うようにします。
2つ目に、「公開APIで使うnamedtupleは最小限にし、文書化する」ことです。
3つ目に、プロジェクト内でnamedtupleの定義場所(モジュール)を整理し、無秩序に増加しないようにします。
また、型ヒントとの組み合わせにも注意が必要です。
namedtupleは型ヒントを付けにくいため、静的解析を重視するコードベースではdataclassやTypedDictなどのほうが適している場合も多くなります。
namedtupleからの移行先(通常クラス・dataclass)の検討ポイント
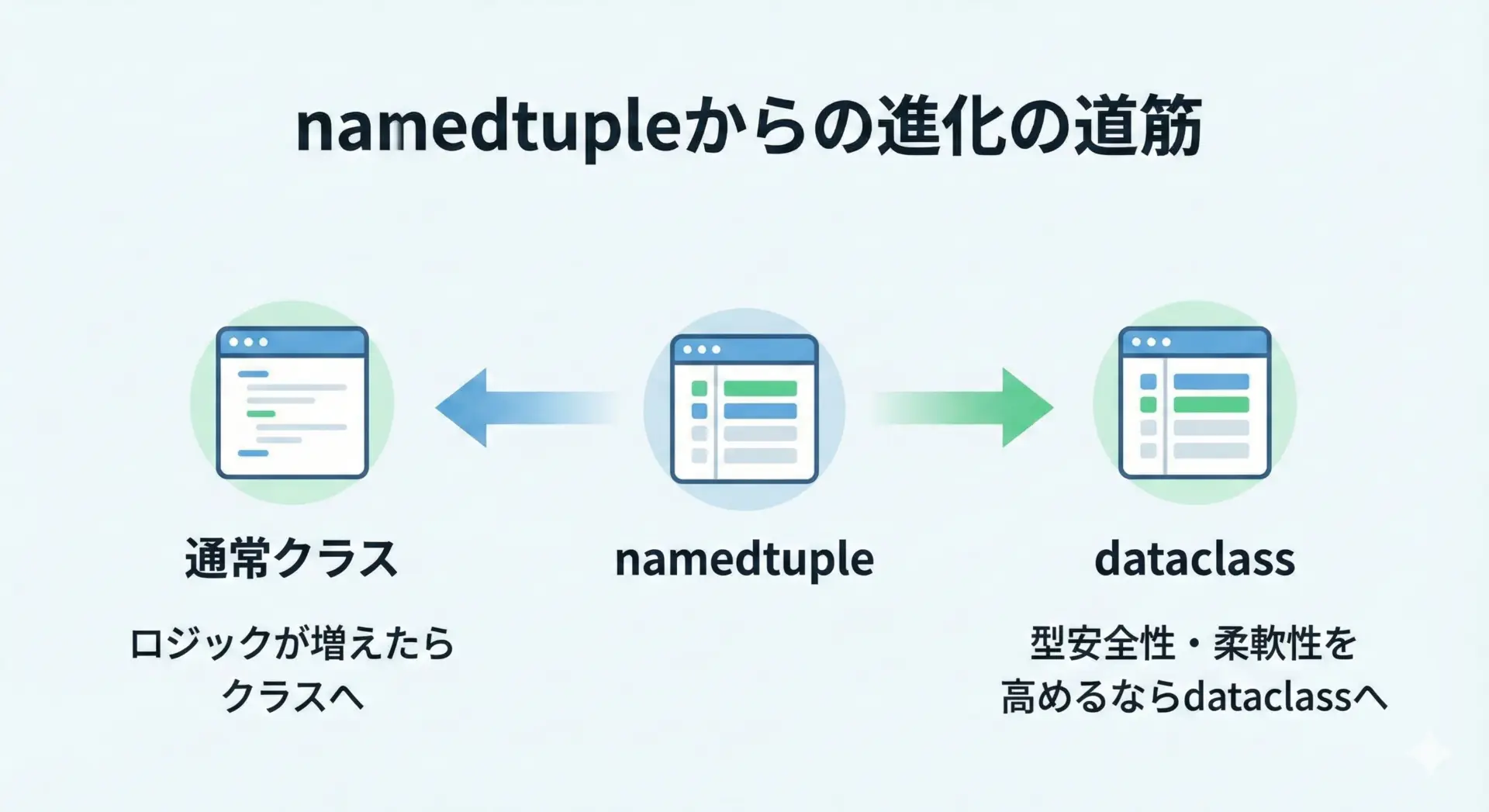
既存コードでnamedtupleを多用しており、次第に「もっと柔軟に扱いたい」「型ヒントやデフォルト値をきれいに書きたい」といったニーズが出てきた場合、通常クラスやdataclassへの移行を検討することになります。
移行先の選び方のポイントは次の通りです。
まず、業務ロジックやメソッドが増えてきて、単なるデータの入れ物ではなくなってきた場合は、通常クラスが適しています。
この場合、クラス定義の中で__init__を手書きし、必要なメソッドを定義していきます。
# namedtupleから通常クラスへ移行したイメージ例
class User:
def __init__(self, id, name, age):
self.id = id
self.name = name
self.age = age
def is_adult(self):
return self.age >= 20次に、フィールド定義に型ヒントを付けたい、デフォルト値を柔軟に扱いたいが、基本はデータ中心にしたい場合は、dataclassが有力です。
from dataclasses import dataclass
@dataclass
class User:
id: int
name: str
age: int = 0 # デフォルト値
def is_adult(self) -> bool:
return self.age >= 20このように、「その型がどの程度の責務を負うべきか」を基準に移行先を判断するとよいです。
なお、APIのインターフェースなど、外部との互換性が重要なケースでは、一気に置き換えずに「ラッパーを用意して段階的に移行」すると安全です。
まとめ
namedtupleは、タプルの軽さとdictの読みやすさを両立した、Python標準の強力なデータ構造です。
関数の戻り値や一時的なレコード、設定値や行データの表現など、「シンプルな値オブジェクト」を扱う場面で特に威力を発揮します。
一方で、イミュータブルであることやフィールド変更の難しさなどの制約もあるため、乱用は避け、スキーマが安定している箇所での利用に限定するのが賢明です。
dataclassや通常クラスとの役割分担を意識しつつ、場面に応じてnamedtupleを取り入れることで、コードの可読性と保守性を高めていくことができます。
